中国 AI 视频赛道最大单笔融资,为什么给了爱诗科技
![]()
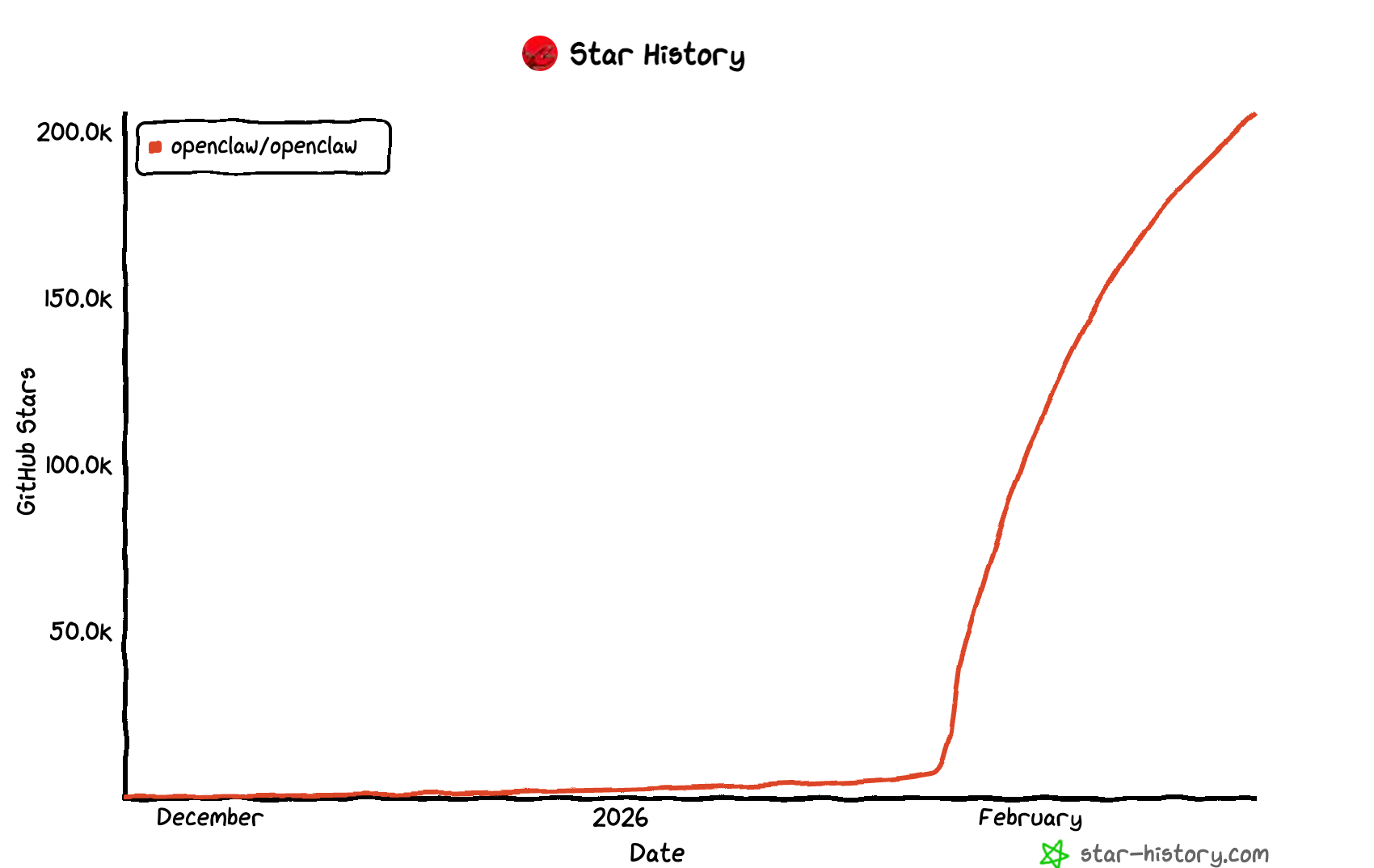
APPSO 获悉,爱诗科技近日完成 3 亿美元 C 轮融资,创下国内 AI 视频生成赛道单笔融资的最高纪录。
领投方鼎晖香港基金联合鼎晖 VGC、鼎晖百孚重金押注;产业资本中国儒意、三七互娱紧随入场;国内政府引导基金、险资、家族办公室,还有 UOB Venture Management、Lion X 基金。参投名单横跨两个半球,不同领域的资本默契涌向了同一个方向。
3 亿美元融资放在当下 AI 行业似乎没有什么好惊讶的,这还不到 OpenAI 融资的零头。但你得把这个数字放进 AI 视频赛道的坐标系里看:成立于 2018 年的 Runway,花了七年才在上个月完成 3.15 亿美元的 E 轮融资。而爱诗科技从种子轮走到同等量级的 C 轮,只用了不到三年。
A 轮,达晨财智领投,蚂蚁集团跟进;B 轮,阿里巴巴领投逾 6000 万美元,彼时已是国内视频生成赛道最大的一笔钱;C 轮,3 亿美元,纪录再次被自己改写。
每一轮都有新的顶级机构首次入场,每一轮金额都在翻倍。节奏越来越快,筹码越押越重。
实际上,这笔融资反映出的信号大于数字本身:AI 视频不再是大模型叙事的配角,资本已经把它当作一条独立的、值得重仓的赛道来押注。
爱诗科技创始人王长虎曾在 2024 年表示,视频生成一定是被低估的。爱诗科技用不到三年时间,将这个非共识变成了资本共识。
非共识的起点:2023 年,为什么是视频
「我不会创业,但没关系,创业就是边做边学。」2023 年 4 月,爱诗科技创始人王长虎决定创业时,就是带着这句话出门的。
2023 年 4 月,爱诗科技创始人王长虎带着一个在当时看起来相当「偏科」的判断出来:当所有人都在追大语言模型,他要押注视频生成。
要知道一年之后 OpenAI 的 Sora 才正式亮相,可以想象当时王长虎这个选择有多么反常识。
在微软亚洲研究院待了 8 年、在字节跳动做了 4 年 AI Lab 总监之后,王长虎比大多数人更清楚视频 AI 的技术节奏。「2023 年初很多人都不认同做视频这件事,大家都在看大语言模型,」他后来回忆,「但这就有了非共识:我们觉得视频生成是大事,而我们过去在视频和 AI 方面有经验,能赢在全球。」
这个判断在当时要承受不小的压力。相比语言模型,视频生成的算力消耗更大,生成质量更难控制,产品化路径也更模糊。早期的投资人需要相信的,不是现在能看到什么,而是三年后那张尚未成型的蓝图。
2024 年 3 月,达晨财智率先领投 A1 轮,完成了第一次押注。随后一个月,蚂蚁集团以逾 1 亿元人民币跟投,是彼时国内 AI 视频领域单笔最大机构投资。至此,爱诗科技基本完成了从「技术方向」到「资本方向」的验证。
王长虎在创业之初就明确了愿景:「帮助每个人成为生活的导演」。海外产品 PixVerse 和国内产品拍我 AI,都是在这个方向上的落地——前者于 2024 年 1 月上线,后者于 2025 年 6 月推出,两款产品针对不同市场独立运营。
![]()
DiT 架构:那个没人看好的选择
要理解这笔 3 亿美元的 C 轮,需要先看懂爱诗科技的技术路线。
把爱诗科技的技术路线从头捋一遍,会发现 DiT(Diffusion Transformer)架构这个选择,是整个故事的原点,也是很多结果的前提。
2023 年,国内主流视频生成方案普遍采用 U-Net 架构。这也没问题,U-Net 经过了图像生成领域多年实践的充分验证,稳定、成熟,调参经验相对成熟,可以较快地跑出效果。对大多数想先做出来再说的团队,这是理所当然的选择。
可以爱诗科技选了 DiT,成为国内首家将这一架构用于视频生成的创业公司。
DiT 是 Diffusion(扩散模型)与 Transformer 的组合架构。Transformer 的核心优势在于注意力机制(Attention Mechanism)——它让模型在处理数据时,能够同时「感知」序列中任意位置的信息,而不是像卷积网络那样只能处理局部区域。
对于视频生成这个任务来说,这种能力的价值是决定性的:视频的本质是时间轴上的连续帧,每一帧的内容与上下帧存在复杂的时空依赖关系。人物的动作要连贯,物体的运动轨迹要符合物理规律,光影变化要在跨帧时保持一致——这些要求,需要模型能够捕捉「跨帧的长程时空关联」,而这正是 Transformer 天然擅长的事。
![]()
但这个选择在 2023 年要付出不小代价:DiT 在训练初期对算力和数据量的要求更高,起步阶段几乎必然要经历「效果不如成熟 U-Net」的阵痛期。对一家刚起步的创业公司,这是不小的风险,钱可能在效果变好之前就烧完了。
事实证明,这个判断是对的。2024 年 Sora 发布时,OpenAI 公开的技术路线正是 DiT。在视频生成这个方向上,DiT 架构确实是更接近正确答案的那条路。
当 Sora 发布时,爱诗已经在 DiT 架构上积累了一年多的训练经验、数据处理流程、工程优化方案。这种时间差,在技术迭代速度极快的 AI 领域,十分关键。
模型产品两手抓,被低估的核心逻辑
在 AI 视频领域,大多数公司的做法是先把模型训练好,再去想产品怎么做。这是一条看起来稳妥的路,模型成熟了,产品化的风险就小得多。
但这种路线有个致命问题:等模型「训练好」的时候,你已经错过了最关键的反馈窗口。用户真正需要什么样的生成效果?哪些场景的需求最强烈?模型应该在哪些维度上优先优化?这些问题,只有产品跑起来、用户用起来,才能得到真实答案。
爱诗从一开始就把模型训练和产品迭代放在同一个循环里。
PixVerse 网页版 2024 年 1 月上线时,模型还远未到「完美」状态,但产品已经可以让用户生成视频、给出反馈。每一个版本的模型升级,都直接来自上一个版本用户的真实使用数据,哪些 Prompt 成功率低、哪些特效最受欢迎、哪些场景容易出错,这些信号实时回流到训练流程,指导下一轮模型优化的方向。
更重要的是,这种模型-产品的协同进化,会随着时间推移形成复利效应:用户越多,反馈越密集,模型优化越精准,产品体验越好,又吸引更多用户——这是一个正向飞轮,而不是单向的技术推进。
「这就是创业公司的优势所在,没那么复杂,所以效率高,」爱诗联合创始人谢旭璋说。这句话听起来轻描淡写,但背后是对技术路线、产品节奏、组织能力的高度整合。大厂可以投入更多算力、更大团队,但很难做到这种模型与产品的深度结合,流程太长,部门太多,反馈链条一旦拉长,速度优势就会被稀释。
这种效率优势最终体现在成本结构上。谢旭璋在接受晚点采访时透露,爱诗「平均每月用的训练资源不到千卡,成本大概只有同行的 10%」。
这是一种结构性的成本优势,而不是靠压缩预算换来的短期节省。用谢旭璋的话说,是模型架构、算法、工程、产品能力的综合优势。
当模型优化方向始终贴着真实需求在走,就能减少在错误的方向上浪费算力;产品反馈能实时指导训练策略,每一次迭代的投入产出比都会更高。
从 2024 年 1 月 PixVerse 网页版正式上线,到 2026 年初 V5.6 发布,爱诗科技连续更新 8 个主要版本,平均每两个月就有一次大的模型升级。
这种迭代密度的背后,正是模型与产品一起训练的方法论在起作用:
- V2(2024 年 7 月):多段视频生成与局部重绘笔刷上线,用户从单纯「生成一段」开始走向「编辑与创作」;
- V3(2024 年 10 月):特效模式上线,「抽卡概率」从随机提升至接近确定性,这是 PixVerse 从创作工具迈向大众产品的真正节点;
- V3.5(2024 年 12 月):生成时间压缩至 10 秒内,极大降低用户等待成本;
- V4(2025 年初):「准实时生成」能力出现,5-7 秒生成 5 秒视频;
- V4.5(2025 年 5 月):参数量与训练数据集指数级扩张,全球用户达 6000 万;
- 拍我AI (2025 年 6 月):PixVerse 国内版「拍我AI」发布,同步上线网页端及移动端应用;
- V5(2025 年 8 月):Agent 创作助手上线,用户不再需要学习 Prompt 语法,口语化意图自动转化为模型指令,API 生态同步开放;
- V5.5(2025 年 12 月):「分镜 + 音频」一键生成,国内首次实现画面与声音的同步协同,完整叙事能力成型;
- V5.6 (2026 年 1 月 26 日 ):模态大模型,支持分镜和音画同步生成。
在权威 AI 评估机构 Artificial Analysis 最新发布的视频生成模型排行榜中, PixVerse V5.6 位列全球第 2 位,持续领跑全球视频生成模型第一梯队。
![]()
![]()
这种迭代密度在 AI 视频行业里相当罕见,爱诗跟很多同类产品的策略不同:持续往前推,每一版解决真实用户在当下遇到的真实问题,同时在架构层面为下一次跃升保留余量。
背后的可行性,恰恰是 DiT 架构的可扩展性所赋予的,每次模型升级,不需要推倒底层重来,而是在既有基础上加宽加深。
3 亿美元,押注不只是 AI 视频
但鼎晖最终决定领投这次 C 轮,押注的不只是 V5 的榜单排名,可能还有 2026 年 1 月刚刚发布的 PixVerse R1。
R1 可以说是爱诗科技迄今最激进的一次产品技术迭代。
![]()
过去的视频生成,无论做得多精致,本质上都是「把指令翻译成一段视频文件」,是一次性的、离线的渲染过程。用户输入指令,等待生成,拿走一段固定的视频文件。这像是在冲洗胶卷,你拍完就拍完了,要等冲洗出来才能看,看完也无法再改。
R1 不是这个逻辑,它不再只是「生成一段视频」,是一个能实时响应用户交互指令的「世界模型」:用户可以在视频播放中输入指令,改变光影、替换背景、控制角色走向,系统响应延迟约 2 秒,输出为 1080P 超高清实时视频流。
背后依赖的是爱诗自研的「瞬时响应引擎(IRE)」,它将计算步骤从数十步压缩至 1-4 步,实现从「离线渲染」到「实时交互」的重要升级。
谢旭璋判断,未来视频和游戏的边界一定会越来越模糊。一旦视频变得能交互了,全新的内容、用户和创作机会就会涌现。
谢旭璋在采访中透露,R1 发布后,游戏行业的 B 端客户来得最多,「以后的游戏开发不用再像过去那样熬漫长的大周期了,无论是玩法、画面还是剧情,AI 都能让它变得更轻量、更具想象力。更重要的是,它能帮那些不懂代码但有创意的人,把点子变成真正的游戏。」
R1 的潜在价值,已经超出了「更好的视频生成工具」这个范畴。如果说 PixVerse V5 是在争视频生成工具的头部位置,R1 是在定义是一个完全不同的品类——实时交互式内容体验的操作系统。它的竞争对手,不再是 Runway 或可灵,是 Unity、Unreal Engine,甚至是尚未出现的内容消费形态。
![]()
回看爱诗科技这笔 C 轮的投资人结构,其实本身就是一个信号。
鼎晖三支基金联合领投,背后是对这家公司进入规模化阶段的系统性判断。产业资本中国儒意(影视内容)和三七互娱(游戏)的入场,指向了 R1 要重构两个行业:互动影视制作和 AI 原生游戏开发。
进入 2026 年,整个 AI 视频赛道也在加速进入下半场。前有 Seedance 2.0 风靡全球,现在爱诗科技成为新的独角兽。
目前,PixVerse 全球注册用户突破 1 亿,MAU 超过 1600 万;国内版拍我 AI 与 PixVerse 形成双轨并行格局;爱诗科技也是 2025 年联合国「人工智能向善全球峰会」上唯一入选的中国 AI 视频应用,并于同年正式加入联合国大学全球人工智能网络。
![]()
这笔 3 亿美元融资,可以理解为资本对一个即将到来的时代的投票。AI 视频的下一个战场,不在参数量,不在榜单排名,关键在于谁先把视频从一个「消费品」变成一个「交互界面」。
不过,知道技术路线在哪里会拐弯,和相信这条路最终走得通,是两件事。
在 AI 这个行业,「选对了方向」本身并不稀缺。稀缺的是,在方向被主流认可之前那段空白期里,有没有足够具体、足够扎实的东西,支撑你不摇摆。
三年里爱诗科技在这条路线没有在中途断裂,很难说是提前预见了终点的全知视角,而是每走一步,下一步的方向都从上一步的技术现实中自然长出来。
视频正在从被观看的内容,变成被触碰的世界。因此,这三亿美元所押注,远不止 AI 视频的未来,而是那个「」万物皆可交互」的时代。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。