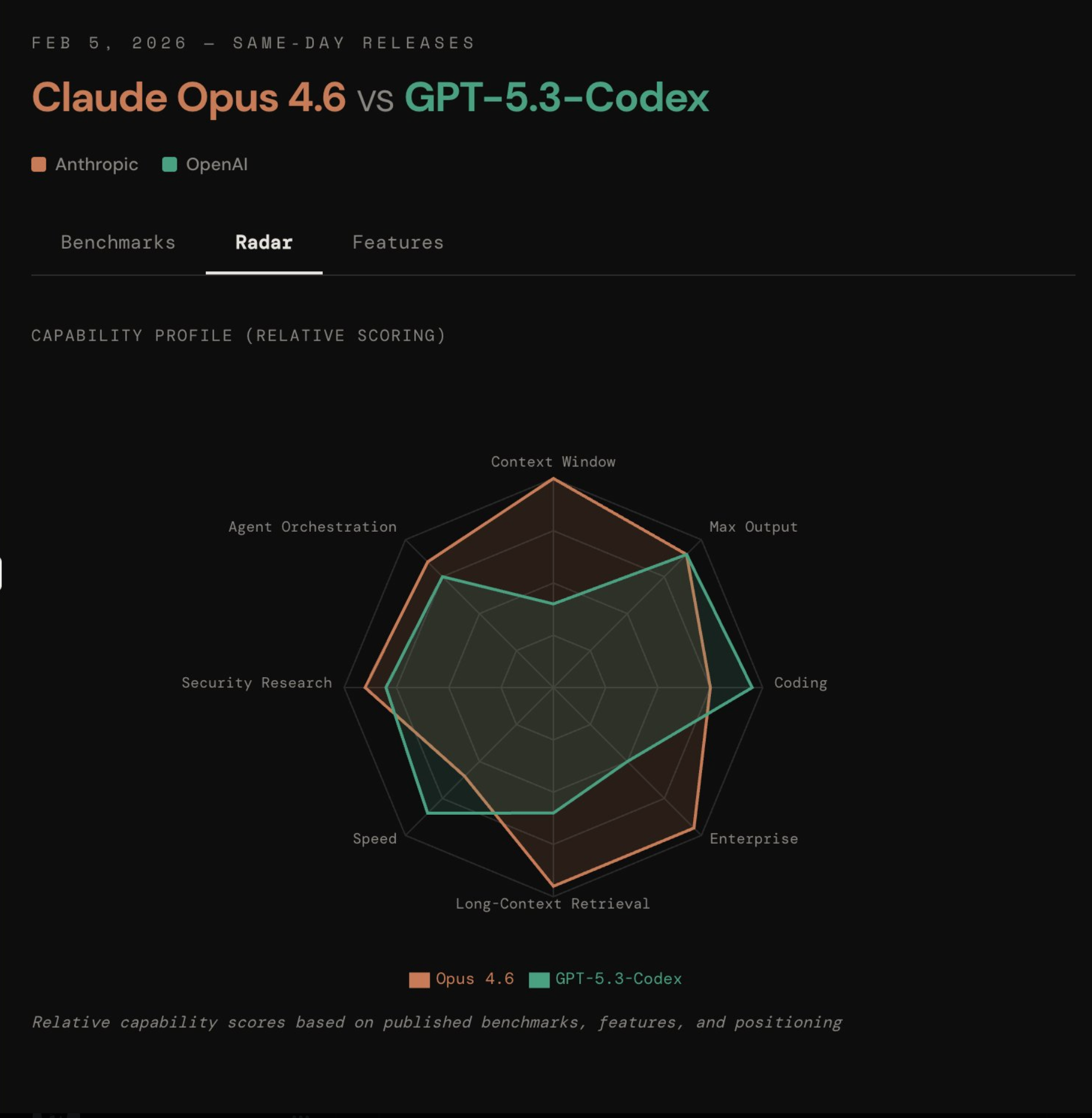
Nano Banana 2 的 5 个神级玩法,还是 AI 生图的神,建议收藏(附提示词)
![]()
「2.0 比不上 1.0 Pro,真正的升级还得看 Nano Banana 2 Pro。」
这是不少网友在昨天 Nano Banana 2 推出后,体验完的明显感受。一方面部分场景下的生成速度有所提升,还有文本渲染的表现也更稳定,但是图片的美学表现,却似乎还不如之前的 Pro 版本。
![]()
▲Nana Banana Pro 模型的描述,竟然还是 SOTA
在 AI Studio 上能看到两款模型的具体情况,世界知识的截止日期都是今年 1 月,不同的是价格方面和背后采用的模型。Nano Banana 2 使用 Gemini 3.1 Flash,而 Pro 则是 Gemini 3 Pro。
APPSO 第一时间的实测也发现,Nano Banana 2 的生成的质量效果和速度,并未得到肉眼可见的提升,最大的变化还是在于把价格打下来了。
不过更便宜,也意味着消耗同样的 Token,我们能生成更多的图片了。像这种九宫格大头贴的照片,先生成一张总的,直接再要 Nano Banana 2 逐一分割生成。
![]()
▲提示词:生成马斯克的九宫格大头贴照片,背景是在拍大头贴的房间内,一只手拿着这张九宫格照片,每个宫格都是不同的动作和表情,有高兴的也有悲伤的,凸显出他的年轻活泼和搞怪爱玩
还有这种一次性就能给我们把海报翻译成不同语言的用法,直接就生成多个地区的广告图片。
![]()
让更多的人可以用到,本身就是一项大的升级。我们这次汇总了一波新发布的 Nana Banana 2 玩法,对比之前的 Nano Banana Pro,在这些场景表现很不错。
玩法一:海报全球化推广
例如这个在 AI Studio 内的官方应用,就是用 Nano Banana 2 搭建了一个「Global Kit Generator 全球包生成器」。顾名思义,专门用来给自己的广告做全球化推广的。
![]()
▲体验地址:https://aistudio.google.com/apps/bundled/global_kit_generator
我们输入了一张之前 AIDONE 的活动海报,然后在目标市场里面选择了使用不同语言文字的几个地区,这个 Demo 会直接一次性生成对应市场的海报。
翻译的效果跟 PS 等传统工具比,一眼看去几乎找不到明显差别。我们也给它一张简体中文的《星际穿越》电影海报,进行全球化推广。
![]()
这里我们选择了韩语、日语、繁体中文和英语四个市场,让我惊喜地除了它对字体的保持,还有翻译。因为《星际穿越》在台湾上映使用的译名,就叫做《星际效应》,Nano Banana 2 没有粗暴的把星际穿越转译成「星際穿越」。
这个小工具对于要做多种语言海报的设计师来说,会是一个相当称手的快速预览工具。
我们也从 Demo 项目的源代码里,提取到了 Google 所使用的提示词,大家可以复制,在 Gemini 内使用。
Translate all text in this advertisement image to the language of ${market}. ONLY translate the text – do not add any cultural imagery, flags, national symbols, or stereotypical visual elements. Keep the image, composition, styling, colors, and all visual elements exactly the same as the original. The only change should be the language of the text.
![]()
▲使用上述提示词,左图为使用 Nano Banana Pro 生成,可以看到区别在「经典作品」的转译,Nano Banana 更准确;而最右边是 Seedream 5.0 Lite,从多张结果里选择了这张表现最好的,但还有很多文字无法被正确渲染
玩法二:从世界上的某一扇窗看城市天气
Google 官方针对 Nano Banana 2 的发布,还提供了另一个热门的小工具,「Window Seat 窗户边的座位」,这个 Demo 可以让我们在输入城市名字,具体的景点之后,调用获取天气的工具,自动生成一张从窗户外预览风景的照片。
![]()
▲体验地址:https://aistudio.google.com/apps/bundled/window_seat
我们这里生成了多张国内城市的窗外照片,天气、风景和你所在的地方是一样吗。
![]()
![]()
![]()
![]()
![]()
![]()
Demo 背后的提示词,我们也放在这里,方便大家复制到 Gemini 内使用。在我们的测试中,如果是将下面的英文提示词翻译成中文输入给模型,Nano Banana 的表现,会在文字的渲染上大打折扣。
因为中文的显示,当模型没有参考时,通常会以统一的字体进行渲染,而英文字体的样式,适配会更丰富。
Generate a photorealistic window view poster based on the following data:
location: ${location name},
specific_view: ${view name},
Weather: ${weather},
aspect_ratio: ${16:9/21:9……}– Use Image Search to search for an image of the specified place. Use keywords to search for the place.
– Keep the location and the view as close to the real reference as possible.
– If the location or view is unrealistic or fictional, create a composition blending both the location and the view into a single scene.
– Choose ONE specific image for the location and ONE specific image for the view to work with, don’t use multiple images.
– Choose an an appropriate window frame style for the location, keep the view consistent to the aspect ratio, rather than creating a collage.
– Reason about how current the time of day, and the weather each affect the view, and add details to the scene.
– Create an image which includes location name text, and a brief summary of the weather, using graphic design that matches the theme. Don’t add any other text.
我们用这套提示词在 AI Studio 内使用 Nano Banana Pro 和 Nana Banana 2 都生成了几张图片。
![]()
![]()
▲提示词仅需修改前面部分:location: Hong Kong, specific_view: Vitoria Harbour, Weather: Sunny, aspect_ratio: 21:9.
你能分辨出哪张是来自 Nano Banana 2 吗。
其实在这个提示词里面,有一个「Image search」的选项,这个功能目前是只有 Nano Banana 2 才能启用,如果是初代的 Pro 版本,只有 Google Search 这一个工具。
![]()
这也意味着当我们在图片生成或者编辑时,如果不仅仅是用到 Google 搜索的知识,还需要图片搜索,Nano Banana 2 的表现,或许会比初代 Pro 更准确。
社交媒体上,也有大量网友分享了 Nano Banana 2 的玩法。因为价格更低,有网友写了一个 Skill,在 Claude Code 里就能使用 Gemini API,批量生成各种图片。
![]()
▲地址:https://x.com/KingBootoshi/status/2027138938335637914
玩法三:创意生成,电影票根、PS 游戏盒
之前的手办玩法,又新增了 PlayStation 游戏盒,让 Nano Banana 生成一张电影改编的游戏盒照片。
Playstation 1 game case with a movie tie-in game that seems like a real game you may have played back in the day.

▲左边为 Nano Banana Pro 生成,右边是 2;在我看来,初代 Pro 版本的真实感会更强|提示词来源:X@cfryant
还有日式风格明显的电影票根纪念。

▲图片来源:X@vamsibatchuk|提示词来源:X@TechieBySA
A single vintage postage stamp displayed on a flat matte black background (#0a0a0a), centered in a 16:9 canvas with small black borders visible on all sides. The stamp itself is an ultrawide horizontal rectangle at approximately 3:1 aspect ratio. The stamp has serrated/perforated zigzag edges on all four sides, like a real postage stamp, with clean white perforation teeth.
The movie this stamp is based on is [MOVIE]. Every visual and textual element of this stamp must be automatically derived from and tailored to this movie — including illustration subjects, kanji, location, year, and country.
The stamp’s background fill color is [COLOR] — muted, desaturated, dusty, vintage-toned, completely flat. No gradients, no shading. The illustration engraving lines must be a significantly darker shade of [COLOR], dark enough to stand out clearly and crisply against the background at high contrast.
Inside the stamp, the entire surface is filled with monochrome dark illustrations etched into the background like fine engraving. The illustrations must depict 5–8 of the most universally iconic and recognizable objects, characters, vehicles, symbols, and locations from [MOVIE] — chosen specifically because anyone who has seen the film would instantly recognize them. All arranged loosely across the full width of the stamp with generous spacing. Detailed technical engraving style — only outlines and fine internal linework, no fills, high contrast against the background.
The stamp has a thin dark inner border line just inside the perforations, framing all content. Below this inner border line, there is a flat white horizontal strip spanning the full bottom width of the stamp, sitting inside the perforated edge. In the bottom-left of this white strip: the movie title in large heavy bold grotesque sans-serif font (similar to Franklin Gothic), in solid black. In the bottom-right of this white strip: the most accurate and natural Japanese kanji translation of the title or central theme of the movie in large bold black text, with small text above it reading “NIPPON 郵便”, and two lines of tiny black text below it — the first line showing the most iconic or recognizable location from the movie in all caps, and the second line showing the country where the movie was produced followed by a · and the year the movie was released — all right-aligned.
Flat graphic design, vintage retro
玩法四:8:1 超长图,无限拓展的画布
作为对比,Nano Banana 2 还带来了 1:4、4:1、1:8、8:1 长宽比图片生成,这是之前的 Pro 模型所不能做到的。
![]()
▲提示词:清明上河图长卷
![]()
▲提示词:太阳系
![]()
▲提示词:银河系
这类 8:1 的图片,会特别适合用来作为网页顶部的横幅图片,直接经过 AI 生成的效果,也比裁剪后要在内容上更完整。
当我们选择 4K 分辨率时,Nano Banana 2 生成的图片大小会高达 20 MB 一张。
![]()
▲提示词:万米深潜。画面构想:这是一场向海洋极深处的坠落。最上方是波光粼粼的海面和一艘小船;往下是游动着巨大蓝鲸;继续往下光线急剧变暗,出现沉船和发光水母;到了画面的最底部,是一个几乎占据整个屏幕宽度的、潜伏在海沟里的不可名状的克苏鲁巨兽张开的深渊巨口,而上方正有一个极小的潜水员在缓缓下落。
![]()
▲图片来源:X@DerekNee
1:4 和 4:1 的尺寸,同样适合用来生成各种特定物体的图片。
![]()
▲ 流浪地球的太空电梯
以及群像图片。
![]()
▲提示词:生成一张包含所有硅谷 AI 大佬的群像
玩法五:P 图大师上线,能秒了 PS
还有网友发现,现在的 Nano Banana 2 在文字处理上,能直接复制我们的笔迹。

▲图片来源:https://x.com/Prathkum/status/2027069198091071664/photo/2
不得不承认,Google 团队在训练 Nano Banana 的路线上,采用「文字渲染」作为一项重要指标,是很成功的选择。之前团队在技术分享播客上就曾提到,如果能把图片上的文字准确地生成,那么整个图片生成也会没有太大的问题。
各种信息图和海报设计,现在基本上初稿都可以交给 Nano Banana。之前难倒一众 AI 的「我想洗车。洗车店距离50米。我应该步行还是开车?」热门问题,直接丢给 Nano Banana 2,它会生成一个详细的说明信息图。
![]()
▲提示词:I want to wash my car. The car wash is 50 meters away. Should I walk or drive?|图片来源:X@Google
而像是台词拼接、手机截图美化、图片拼接、局部模糊、去掉不想要的内容、换脸、和不同的明星合照等等操作,现在对 Nano Banana 来说,都是手拿把掐。

▲图片来源:X@munou_ac
task: “edit-image: add widened torn-paper layered effect”
base_image:
use_reference_image: true
preserve_everything:
– character identity
– facial features and expression
– hairstyle and anatomy
– outfit design and colors
– background, lighting, composition
– overall art stylerules:
– Only modify the torn-paper interior areas.
– Do not change pose, anatomy, proportions, clothing details, shading, or scene elements.effects:
– effect: “torn-paper-reveal”
placement: “across chest height”
description:
– Add a wide, natural horizontal tear across the chest area.
– The torn interior uses the style defined in interior_style.– effect: “torn-paper-reveal”
placement: “lower abdomen height”
description:
– Add a wide horizontal tear across the lower abdomen.
– The torn interior uses the style defined in interior_style.interior_style:
mode: “line-art”style_settings:
line-art:
palette: “monochrome”
line_quality: “clean, crisp”
paper: “notebook paper with subtle ruled lines”sumi-e:
palette: “black ink tones”
brush_texture: “soft bleeding edges”
paper: “plain textured paper”figure-render:
material: “PVC-like”
shading: “semi-realistic highlights”
paper: “plain smooth surface”colored-pencil:
stroke_texture: “visible pencil grain”
palette: “soft layered hues”
paper: “rough sketchbook paper”watercolor:
palette: “soft transparent pigments”
blending: “smooth bleeding”
edges: “soft contours”
paper: “watercolor paper texture”pencil-drawing:
graphite_texture: “visible pencil grain”
shading: “smooth gradients”
line_quality: “mixed sharp and soft”
tone: “gray-scale”
paper: “notebook paper with faint ruled lines”
总的来说,Nano Banana 2 给了我们更低的价格,也有了图片搜索和更丰富比例选择,1:4 和 1:8 这些尺寸,几乎是生图模型里独一档的存在。
之前很多 Nano Banana Pro 的玩法,现在也能花更少的钱,得到更稳定的输出。
模型的能力在变化,Gemini 在软件层面也给我们带来了更好的生图体验。新增的这些风格,让我想到了之前在 Google Labs 里面的 Whisk 工具,上传参考图片,一键复制风格。而现在是,选择对应的风格,简单输入提示词,就能得到一种理想的图片。
![]()
▲使用 Enamel Pin
前几天,Google 还更新了旗下的视频生成平台 Flow,实验室产品图像生成工具 Whisk 和 ImageFX 被正式整合进 Flow,不再独立存在。
同时,在 Flow 内置 Nano Banana 这一高保真图像模型,支持直接生图并作为视频生成的关键帧素材。我们在 Flow 平台,也能使用最新的 Nano Banana 2 模型。
![]()
新版 Flow 也引入了类似 Photoshop 的套索工具,我们可以圈选视频里的某一块区域,然后直接告诉 AI,「把这个人移走」或者「水里加几条锦鲤」等更精细化的控制
曾经的 Nano Banana 一举之力把 Gemini 送上了排行榜前列,到现在与 OpenAI 的 ChatGPT 抗衡。这次的更新虽然没有之前的轰动,但 Google 这一系列在创意工具上的操作,显然还在继续加速。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。