英伟达回应与 OpenAI 合作:仍将以所有客户为优先
OpenAI、甲骨文与软银宣布在美国新建五大 AI 数据中心
卢伟冰:小米17 Pro Max 有「2K级」的显示效果
1998 元起,大疆发布 Osmo Nano 自由视角穿戴相机
支持 8K 拍摄,GoPro MAX 2 全景运动相机发布
特斯拉简化版 Model Y 被曝光,配置大幅精简
苹果已关闭 iOS 18 降级通道
苹果固件网站 ipsw.me 显示,苹果已停止对 iOS 18.6.2 进行签署验证,这意味着一旦设备升级至 iOS 26,将无法回退至 iOS 18 系列版本。
所谓「签署」,是指系统在安装过程中需通过苹果服务器的验证检查,未通过验证的固件无法安装。
停止签署后,用户将无法降级至旧版。
目前,用户仍可继续使用 iOS 18,但一旦升级至 iOS 26,就无法降级。
此外,苹果还停止签署了 iPadOS 18.6.2 和 tvOS 18.6,iPad 同样无法回退至旧版本。
据悉,苹果在 iOS 26 上引入了全新的「Liquid Glass」设计语言,并带来多项功能更新。
此外,苹果还在昨天推送了 iOS 26.1 Developer Beta 版本。
「拴 Q」,台风前夕腾讯把企鹅拴住了
9 月 23 日下午,广东地区在台风来临前夕出现了颇具网络话题性的「拴 Q」事件。
腾讯方面在微信公众号发布文章《拴好自己,大家注意安全!》,配图为企鹅形象被「拴住」,并配文提示「赶紧把自己绑好,不然飞走了就真的拴 Q very much」,呼吁用户注意安全。
广东多地气象部门此前已发布台风黄色预警,建议居民加固门窗、收纳室外物品,并避免在强风暴雨期间外出。
上市公司紧急回应「汽车热失控自动弹出电池」视频
据红星新闻报道,近日,一段展示「汽车电池热失控时自动弹出」的演示视频在网络热传。
视频显示,9 月 19 日,一辆车身贴有「中国碰撞维修技术中心」标识的车辆,在模拟电池热失控场景时,将电池抛出车身约 3-6 米,实现车电分离。
视频信息称,该技术由「中国碰撞维修技术中心」与均胜电子联合推出。
然而,该演示迅速引发争议,有网友质疑「把活命留给自己,把灾难弹射给众人」,甚至用「死道友不死贫道」形容。
9 月 22 日,均胜电子向媒体回应称,公司与「中国碰撞维修技术中心」不存在任何形式的合作开发协议。
公开资料显示,宁波均胜电子股份有限公司是一家全球智能汽车科技解决方案提供商,业务涵盖智能座舱、智能网联、智能驾驶、新能源管理及汽车安全系统等领域,在全球设有 19 个研发中心和超过 50 个生产基地。
据知情人士透露,「中国碰撞维修技术中心」隶属于麦特集团,该集团成立于 1992 年,主营汽车后市场业务,旗下拥有威力狮(Welion)、奔腾(BANTAM)、MAXIMA 等品牌。
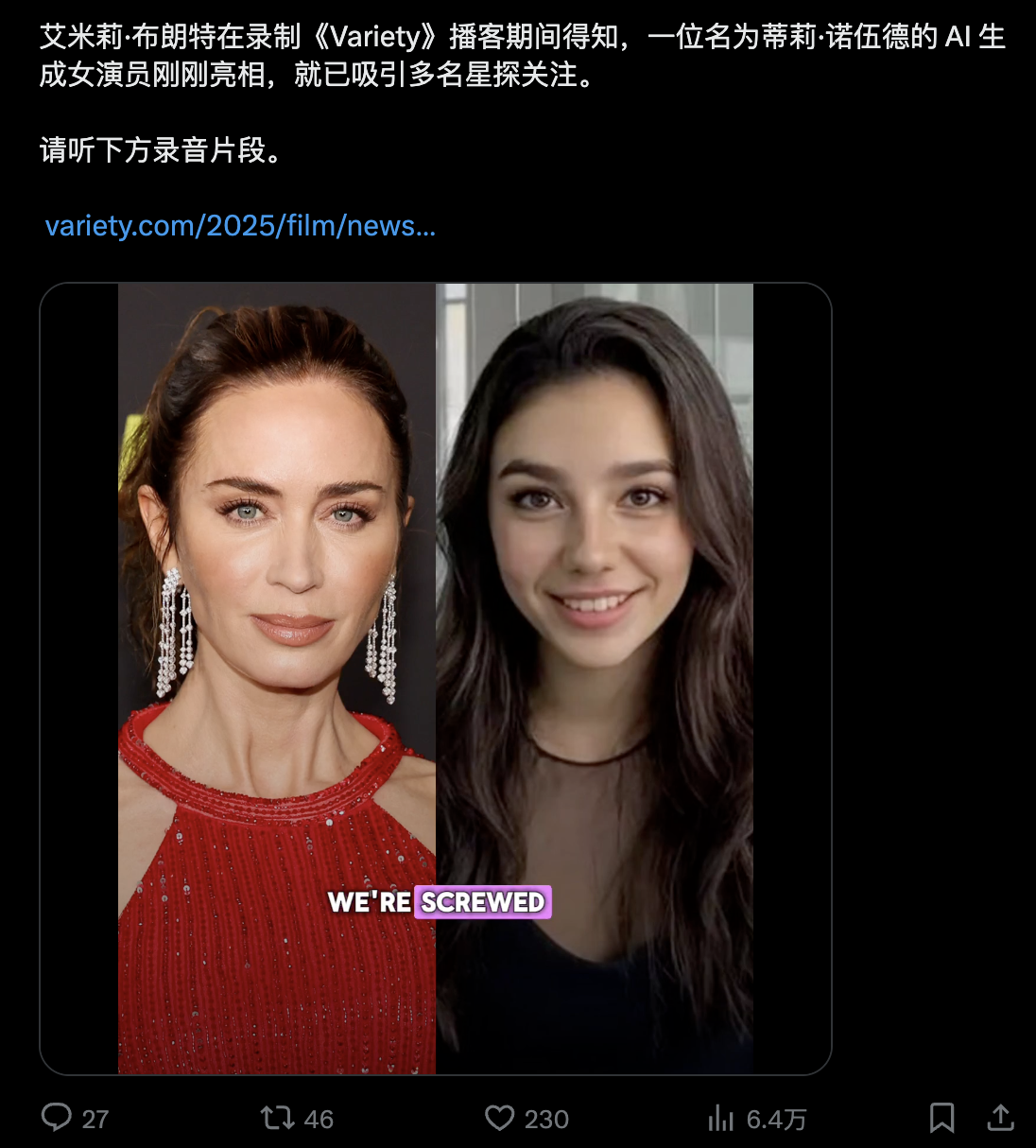
英伟达回应与 OpenAI 合作:仍将以所有客户为优先
据彭博社报道,英伟达在昨天发布声明称,其与 OpenAI 达成的 1000 亿美元 AI 基础设施合作意向,不会影响对其他客户的供货与支持。
英伟达强调:「我们的投资不会改变关注重点或影响对其他客户的供应,我们将继续让每一位客户保持最高优先级,无论是否存在股权关系。」
当天早些时候,英伟达与 OpenAI 宣布已签署合作意向书,计划建设配备英伟达芯片的数据中心,总功率至少达到 10 吉瓦,用于开发和运行人工智能模型。
近年来,英伟达芯片在硅谷成为最抢手的硬件资源,数据中心运营商争相采购,推动公司销售额与股价持续飙升,市值已接近 4.5 万亿美元。
尽管如此,英伟达的营收仍高度依赖微软、Meta、亚马逊和 Alphabet 等少数大型客户,这些公司正加速自研或部署替代组件,以降低对英伟达的依赖。
20 周年 iPhone 或将搭载更亮的屏幕
据 MacRumors,有产业链人士透露,苹果计划在 20 周年纪念版 iPhone 上引入由三星供应的全新 OLED 技术 COE(Color Filter on Encapsulation),以实现更高亮度和更纤薄的机身设计。
据悉,传统 OLED 面板在显示层上方会增加一层偏光片,用于减少反射、提升对比度,但该结构会吸收部分自发光,降低亮度与能效。
COE 技术则直接将彩色滤光层覆盖在封装保护层上,取消偏光片,从而减少显示堆叠厚度,让更多光线透出,在不增加功耗的情况下提升亮度。
业内分析指出,去除偏光片后,屏幕在户外的反射与眩光控制将更具挑战,苹果预计会采用先进镀膜与像素级材料优化可视效果。
另有消息称,苹果正考虑为 20 周年纪念版打造四边曲面、无边框的全新外观设计,并在 2026 年率先推出首款可折叠 iPhone。
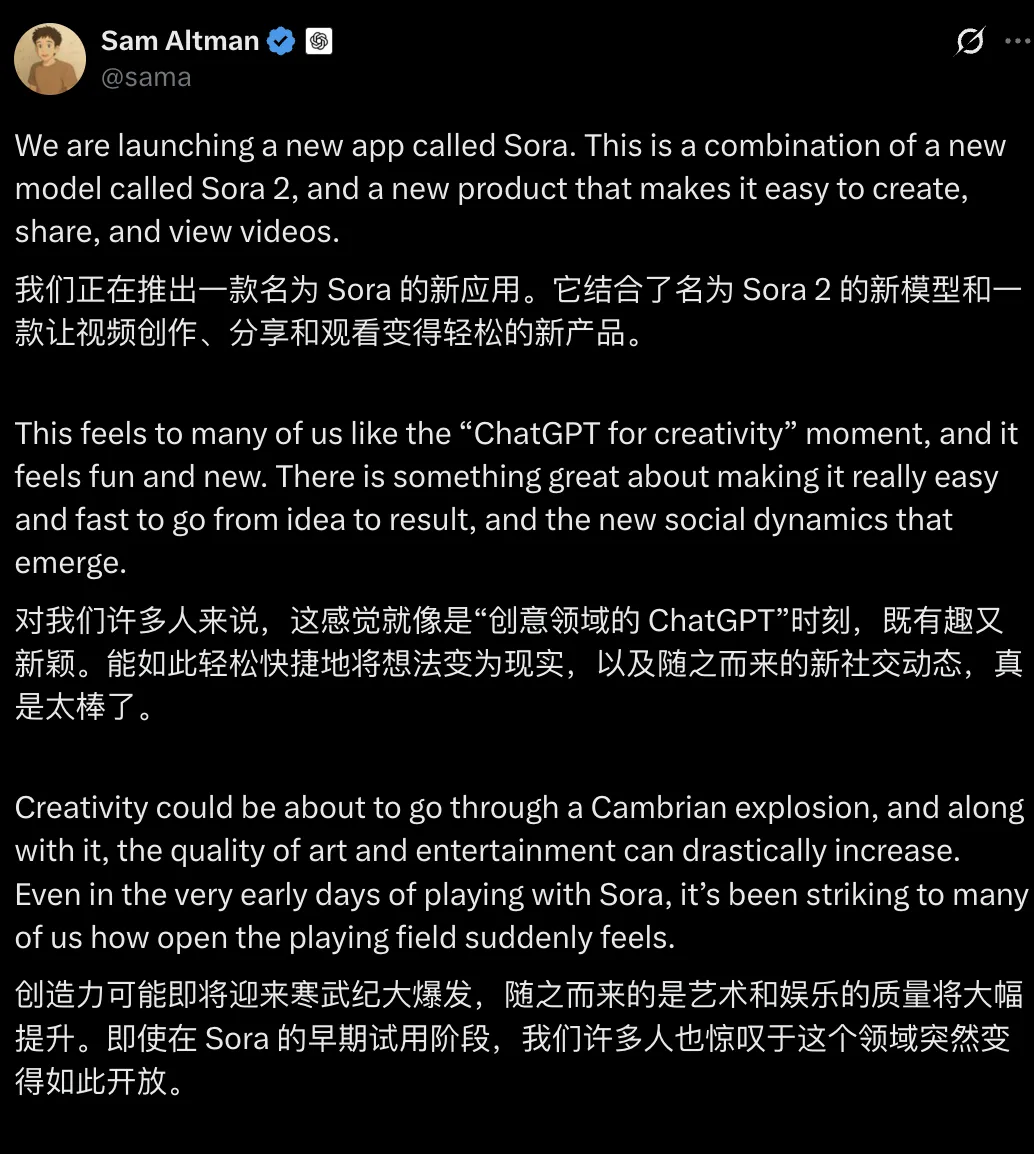
OpenAI、甲骨文与软银宣布在美国新建五大 AI 数据中心
今天凌晨,OpenAI 在官网发布新闻稿,称 OpenAI、甲骨文与软银将联合,在美国新建五个 AI 数据中心站点,进一步扩展「星际之门(Stargate)」基础设施平台。
随着这些新站点的加入,Stargate 的规划总容量已接近 7 吉瓦,相关投资规模超过 4000 亿美元,预计将在 2025 年底前实现最初提出的 5000 亿美元、10 吉瓦目标。
根据官方信息,此次公布的五个新站点分布在德克萨斯州 Shackelford 县、新墨西哥州 Doña Ana 县、中西部某地(尚未公布)、俄亥俄州 Lordstown,以及德克萨斯州 Milam 县。
其中,部分站点由甲骨文主导建设,另有两个站点由软银及其旗下 SB Energy 参与开发。
OpenAI 首席执行官 Sam Altman 表示:「AI 的潜力能否实现,取决于是否具备足够的算力支撑。星际之门正在为这一目标奠定基础,并推动下一阶段的突破。」
甲骨文首席执行官 Clay Magouyrk 称:「我们正在以前所未有的速度扩展 OCI 的布局,以满足快速增长的 AI 训练与推理需求。」
软银集团董事长兼首席执行官孙正义则指出:「Stargate 正在结合软银的数据中心设计与能源优势,为 AI 的未来提供可扩展的算力。」
据悉,Stargate 计划自今年 1 月启动以来,已吸引超过 30 个州、300 余份提案参与竞争。此次公布的五个站点为首批入选项目,后续仍将有更多地点加入整体投资计划。
全国餐饮商家可免费入驻高德
高德昨天宣布,现在全国餐饮商家可免费入驻平台,并享受为期一年的入驻年费全免政策。
官方表示,此次举措旨在帮助餐饮行业「多来客、好经营」,并同步推出流量扶持、专属客服、智能收银等多项配套服务。
高德方面指出,未来将持续倾听商家反馈,优化平台功能与服务体验,助力餐饮商家提升运营效率与顾客满意度。
商家可通过高德地图 APP 搜索「免费入驻」或拨打 400-9039-658 了解详情并快速办理入驻手续。
OpenAI 在印尼推出 ChatGPT Go
TechCrunch 报道,继在印度上线后,OpenAI 将其面向大众的 ChatGPT Go 订阅计划扩展至印度尼西亚市场。
该计划定价为 75,000 印尼盾/月(约 32 元人民币),定位介于免费版与每月 140 元的 ChatGPT Plus 之间。
据介绍,ChatGPT Go 用户可获得比免费版高 10 倍的使用额度,用于发送提问或提示、生成图片以及上传文件。
同时,该计划支持更好地记忆过往对话,从而在长期使用中提供更具个性化的回应。
OpenAI ChatGPT 产品负责人 Nick Turley 表示,自印度推出该计划以来,付费用户数量已超过两倍增长。
此次扩展也使 OpenAI 在印尼市场直接对标 Google。
本月早些时候,Google 推出了价格相近的 AI Plus 订阅服务,提供 Gemini 2.5 Pro 聊天机器人,以及 Flow、Whisk、Veo 3 Fast 等图像与视频创作工具。
雷军谈年度演讲推迟至本月:内容太多
在今年第 6 次年度演讲开始前,雷军在微博发布短视频,回应了外界关心的多个问题。
他表示,世界变化很快,小米也在快速变化,「每年办一次年度演讲,就像做一次年度总结,挺有趣的」。
对于今年演讲比往年晚的原因,雷军透露,原计划是 6 月与小米 YU7 发布会同步举行,但由于发布会内容过多、时长过长,临时推迟到 9 月,与小米 17 系列年度旗舰一同发布。
谈及为何有如此多观众愿意听他的演讲,雷军坦言「其实我自己也不知道」,并感谢所有朋友的捧场,欢迎大家在评论区留言分享原因。
据悉,今年雷军年度演讲的主题为「改变」。
视频中,雷军认为人的命运并非命中注定,「别人觉得你行不行不重要,关键是你自己有没有勇气、有没有决心去试一试」。他强调,只要不断尝试、努力、成长,就有机会「逆天改命」。
在被问及近几年自身最大的变化时,雷军表示是「认知」的提升和改变,「过去几年小米发生了翻天覆地的变化,本质就是我们的认知发生了变化」,并计划在年度演讲中与大家深入探讨这一话题。
美宜佳首款鸿蒙「碰一下」智慧收银机亮相
支付宝开放平台昨日宣布,美宜佳近日与华为云、支付宝在上海签署联创合作协议,三方将整合优势资源,共同打造智慧零售标杆解决方案。
作为合作的重要成果,美宜佳率先推出首台搭载「碰一下」交互技术的鸿蒙智慧收银机,并计划陆续在全国多家门店投入使用。
根据协议,美宜佳将依托全国超 40000 家门店网络,结合华为鸿蒙系统及生态技术支持,以及支付宝在数字经营与支付领域的成熟能力 —— 包括「碰一下」等创新交互技术,推进全店智能运营体系建设,实现消费者体验与门店效率的双提升。
「碰一下」是支付宝于 2024 年推出的创新交互方式,用户无需打开 App,解锁手机后轻触设备或贴纸即可完成支付或获取服务。
三方表示,未来将分阶段推动智能设备升级、账号体系互通与会员运营优化,并探索支付、广告等多场景的智能化创新,打造可规模化复制的智慧门店样板,推动行业数字化加速。
芬兰智能戒指厂商 Oura 将融资近 9 亿美元
据彭博社报道,芬兰健康科技公司 Oura Health Oy 近日正在进行新一轮融资,预计将筹集约 8.75 亿美元,投后估值约为 109 亿美元。
据知情人士透露,本轮融资为 E 轮,估值较去年 11 月 D 轮的 50 亿美元几乎翻倍,最终融资额或超过 9 亿美元。
Oura 计划将资金用于扩大产能、加大研发投入并加速国际市场布局。
今年以来,该公司已在日本和德国推出最新款 Oura Ring 4,并计划进一步拓展全球销售网络。
公司 CEO Tom Hale 在接受采访时表示,Oura 业务增长「如同火箭般迅速」,并称这是其 130 个季度商业生涯中「最强劲的一个季度」。
他预计 2025 年营收将超过 10 亿美元,较 2024 年的 5 亿美元翻倍,2026 年有望突破 15 亿美元。
除融资外,Oura 还与包括美国银行、富国银行、摩根大通、高盛、花旗和巴克莱在内的多家银行签署了 2.5 亿美元循环信贷协议。
在智能戒指市场,Oura 仍是领先者,但竞争正逐步加剧。
三星去年推出 Galaxy Ring 反响平平,Amazfit、Velia、Ultrahuman 等初创公司也已入局。
Hale 表示,戒指将继续作为公司核心产品形态,并称其在「佩戴舒适度、时尚性与精确度」方面具备优势。
货拉拉回应被约谈
昨天,市场监管总局约谈货拉拉,要求其严格遵守《中华人民共和国反垄断法》等法律规定,落实反垄断合规主体责任,及时规范经营行为,公平参与市场竞争,维护货车司机、消费者等相关主体合法权益。
监管部门指出,平台需推动规则与算法公平、公正、公开、透明,确保行业健康有序发展。
当天晚间,货拉拉对此事进行了回复,表示将全面接受并落实约谈要求,立即启动整改,提升反垄断合规管理水平,依法合规经营,公平参与市场竞争。
广汽法务部:坚决追究造谣者法律责任
多部门近日联合发布《关于开展汽车行业网络乱象专项整治行动的通知》,决定在全国范围内开展为期 3 个月的专项整治行动。
广汽集团法务部昨天在微博发文表示,近期网络上有部分未经证实的信息传播,影响品牌形象并扰乱正常网络秩序,广汽集团已固定相关证据,将视情节依法向公安机关报案,并「坚决追究造谣者的法律责任」,以维护合法权益。
罗永浩:将评测预制菜
罗永浩在社交平台发文称已回到上海,并表示「我爱上海」,同时回应外界「跑路」猜测,称此次只是正常出差。
当天,他晒出餐厅用餐照片,再次谈及预制菜话题,称商场连锁餐厅也可以有现炒菜,并表示将评测市面在售的大部分预制菜。
此前,罗永浩因批评西贝使用预制菜未告知消费者且定价虚高,被西贝创始人贾国龙起诉「损害商誉」,双方争论引发舆论关注。
有网友发现其微博 IP 属地曾在 9 月中旬变为「中国香港」和「日本」,引发「避险跑路」猜测。罗永浩转发相关言论并回复「我来,赌什么?」
像素蛋糕宣布基础调色与手动工具永久免费
日前,AI 修图软件「像素蛋糕」官方宣布,旗下像素系列产品的基础调色功能与手动工具将改为永久免费开放,用户无需额外付费即可使用。
据介绍,此次调整涵盖基础色彩校正、亮度与对比度调节等常用功能,同时保留原有的手动修图工具集。
官方表示,此举旨在降低创作者的使用门槛,并提升整体创作体验。
YouTube CEO:AI 是「下一次大爆炸」
据 Wired 报道,YouTube 在成立 20 周年之际宣布全面拥抱人工智能技术,推出多项面向创作者的 AI 功能。
官方表示,这些工具将帮助用户通过提示词生成视频内容,并可自动为播客音频生成匹配的视觉画面。
YouTube CEO Neal Mohan 在接受采访时回顾了平台的成长历程,并强调 AI 是延续「让更多人发声」这一核心使命的最新技术手段。
当 YouTube 诞生时,技术让更多人能够被听到;如今 AI 也是同样的原则 —— 用技术来让创作更普惠。
据悉,部分新功能基于 Google DeepMind 的 Veo 3 技术,支持即时生成复杂场景视频,例如「在月球上的 100 位印尼舞者」。
平台将对 AI 生成内容进行标注,但目前没有提供过滤选项。Mohan 认为,AI 视频的价值取决于创作者的原创性和创意,而非生成比例。
OPPO Find X9 外观公布
OPPO Find 系列产品负责人周意保昨天在微博正式公布了 Find X9 系列的完整外观与核心设计亮点。
周意保表示,该机定位顶级旗舰,重点在于质感升级与细节优化:
- 全新「绒砂工艺」:采用微米级精度控制,让玻璃呈现高级内敛的绒感金属光泽,并带来细腻亲肤的触感;
- 冷雕工艺消除拼接感:镜头模组与背板通过超精密冷雕工艺实现无缝衔接,整体观感更自然;
- 黄金握持尺寸直屏:延续 6.59 英寸与 6.78 英寸直屏设计,并采用超大弧度边框,提升握持舒适度;
- 极窄四等边 + 全场景 1nit 明眸护眼屏:物理四等边黑边进一步收窄,搭配新一代护眼屏,视觉效果更沉浸;
- 轻薄机身兼顾影像与续航:全系搭载哈苏四摄影像系统,方形镜组在控制凸起的同时提升进光量。
电池容量方面,标准版为 7025mAh,Pro 版达 7500mAh,并保持均衡配重。
配色方面,Find X9 提供「绒光钛」「霜白」「雾黑」,Find X9 Pro 提供「绒砂钛」「霜白」,另有一款特别配色尚未公布。
官方此前公布,该系列将于 10 月 16 日正式发布。
卢伟冰:小米17 Pro Max 有「2K级」的显示效果
小米集团总裁卢伟冰昨天在社交平台透露,小米 17 Pro Max 首次采用「超级像素排列」技术。
他介绍道,该方案为每颗像素配备独立的红、绿、蓝三色子像素,相比传统 OLED 无需借用相邻子像素。虽然屏幕分辨率在数值上未达到 2K,但子像素总量高达 938 万,与 2K 水准相当。
卢伟冰指出,内部曾对这一方案存在较大争议。2K 屏幕已在市场存在十年,是超清显示的代名词,放弃 2K 在数值上意味着「回退」。
此外,昨天下午,小米官方还在微博发布小米 17 系列宣传海报,称小米 17 系列全面兼容 100W PPS 通用充电协议。
据此前报道,小米 17 系列将全球首发第五代骁龙 8 至尊版移动平台,小米 17 Pro 和 Pro Max 将配备 5000 万像素徕卡超大底后置三摄和全新背屏设计。
尚界 H5 与全新问界 M7 同台亮相
9 月 23 日晚,华为在秋季新品发布会上推出两款智能汽车新品 —— 尚界 H5 与全新问界 M7,进一步丰富鸿蒙智行产品矩阵,覆盖从十几万元到三十万元以上的市场区间。
据介绍,尚界 H5 是华为与上汽集团合作打造的「尚界」品牌首款车型,起售价 15.98 万元,定位 20 万元以下智能汽车市场。
全新问界 M7 则在外观、座舱、性能与安全方面全面升级,提供增程与纯电两种动力版本,售价分别为 27.98 万元起与 31.98 万元起。
尚界 H5 主要配置:
- 搭载乾崑智驾 ADS 4 系统,全系标配 3 颗 4D 毫米波雷达、192 线激光雷达
- 鸿蒙座舱,支持主驾迎宾、3D 人脸识别、电子萌宠、超流畅导航
- 支持手表控车与星闪车钥匙
- 无麦 K 歌 2.0、HUAWEI MagLink 车载屏、天生绘画功能
- 首次引入车位到车位领航辅助功能
- 601L 后备箱,二排座椅可放倒形成「大床模式」
- 纯电版最长续航 655 km,增程版综合续航 1360 km
全新问界 M7 主要配置:
- 搭载乾崑智驾 ADS 4、途灵平台、巨鲸电池平台
- 全维防碰撞系统 4.0、激光雷达方案
- 主驾零重力座椅可联动方向盘自动调节
- 副驾准零重力座椅支持 70° 腿托、靠背调节、按摩、通风、加热
- 星环双翼大灯、贯穿式星翼尾灯
- 16.1 英寸 3K 悬浮屏 + 17.3 英寸后排娱乐屏
- 全车屏幕支持三指滑动多屏流转
- 增程版最高综合续航 1600+ km,纯电版最长续航 700+km
发布会上,华为方面还公布了鸿蒙智行其他车型的最新交付数据,并强调「安全是最大的豪华」,将安全能力视为全系标配。
相关阅读:鸿蒙智行上新,尚界 H5 只卖 15.98 万元!
1998 元起,大疆发布 Osmo Nano 自由视角穿戴相机
大疆于昨天正式推出新款 Osmo Nano 自由视角穿戴相机,定位轻量化便携拍摄设备,面向运动记录、旅行 vlog 及日常生活场景。
据悉,该产品采用可穿戴设计,支持多角度拍摄,并在机身尺寸与重量上进行了优化,以提升长时间佩戴的舒适度。
主要硬件与功能亮点:
- 机身重量约 80 克,支持长时间佩戴
- 搭载 1/1.3 英寸 CMOS 传感器,支持 4K 60 帧视频录制
- 内置三轴防抖系统,提升动态拍摄稳定性
- 支持蓝牙与 Wi-Fi 连接,可与手机应用实时同步画面
- 续航时间约 120 分钟,支持快充功能
- 防水等级 IPX4,可应对日常防泼溅需求
Osmo Nano 目前已上架购物平台,64GB 标准套装 1998 元起。
支持 8K 拍摄,GoPro MAX 2 全景运动相机发布
运动相机品牌 GoPro 今日正式推出最新旗舰产品 MAX 2,主打原生 8K 全景拍摄能力。
通过双镜头 360° 全景模式,MAX 2 可呈现高达 3500 万像素画质,带来「真正的」8K 分辨率 360° 视频,据官方介绍,有效分辨率较同类产品提升约 21%。
MAX 2 的硬件配置较前代有显著提升,主要包括:
- 原生 8K 分辨率 360° 全景视频拍摄,画质可达 3500 万像素,支持 5.6K60 与 8K30 高画质高帧率拍摄模式和 3 倍慢动作拍摄(4K 100 帧)
- 10-Bit 色深与 GP-Log 模式,最高 300Mbps 比特率
- 2900 万像素 360° 照片拍摄,支持后期自由构图
- 双镜头支持 4K 60 帧 180° 超广视角视频,视角范围超过传统 170°
- 可替换式镜头设计
- 升级的 6 麦克风阵列,支持 360° 立体声与降风噪
- 1960mAh 电池
- 5 米防水、地平线锁定防抖、AI 智能追踪等功能
配件方面,官方同步推出 1 米碳纤维杆、80cm 漂浮式延长杆、带锁 1/4-20 安装卡扣、碳纤维延长套装及 MAX2 USB 传输转口等。
GoPro MAX 2 已在海外官网开售,售价为 499.99 美元(约合人民币 3557 元),国行版售价与上市时间暂未公布。
爱范儿也在第一时间推出了两款运动相机新品的对比体验,可点击下方链接了解更多。
相关阅读:大疆 vs 影石:1998 元起,最强拇指相机对决
iQOO 15 举办电竞性能技术沟通会
在 iQOO 15 正式发布前,iQOO 举办了一场以电竞性能为主题的技术沟通会,公布了多项核心硬件与功能细节。
官方表示,新机在屏幕、图像处理以及游戏引擎方面进行了针对性优化,旨在满足高强度移动电竞的需求。
主要硬件与功能参数如下:
- 搭载 6.85 英寸 2K 直屏,全球首发「M14 发光材料」,支持硬件级游戏护眼与 8T LTPO 技术
- 内置自研电竞芯片「Q3」,提供「显卡级」游戏视效处理能力
- 配备「Monster 超核引擎」,包含「先知调度器」与「闪电加速器」
- 首批机型包括 iQOO 15 与 iQOO Neo 11
- 搭载潜望长焦、无线充电功能以及全新线性马达
此次沟通会的内容显示,厂商在屏幕材料、图像处理芯片以及游戏引擎方面均有新尝试,意在为移动电竞用户提供更接近 PC 端的视觉与操作体验。
阿里云发布首个端到端全模态 AI 模型
昨天,阿里云正式发布并开源全新的 Qwen3-Omni、Qwen3-TTS,以及对标谷歌 Nano Banana 图像编辑工具的 Qwen-Image-Edit-2509。
据介绍,Qwen3-Omni 是业界首个原生端到端全模态 AI 模型,支持文本、图像、音频和视频多类型输入,并可通过文本与自然语音实时流式输出结果,解决了多模态模型在不同能力间权衡取舍的长期难题。
核心特性包括:
- 跨模态先进表现:在 36 项音频 / 视频基准测试中,22 项达到最新水平,32 项在开源范围内领先;在自动语音识别、音频理解与语音对话方面可与 Gemini 2.5 Pro 相当。
- 多语言支持:涵盖 119 种文本语言、19 种语音输入语言及 10 种语音输出语言。
- 创新架构:基于 MoE「专家混合」的「思考者–表达者」设计,结合 AuT 预训练与多码本方案,降低延迟。
- 实时交互:低延迟流式音频 / 视频交互,支持自然轮流对话与即时响应。
- 精细音频描述:已开源 Qwen3-Omni-30B-A3B-Captioner,填补开源社区在通用型音频描述领域的空白。
同时亮相的 Qwen3-TTS 支持 17 种音色选择,每种音色均支持 10 种语言,并覆盖闽南语、吴语、粤语、四川话等多种中国方言。
Qwen3-TTS-Flash 在语音稳定性与音色相似度方面超越 SeedTTS、MiniMax、GPT-4o-Audio-Preview、Elevenlabs。
Qwen-Image-Edit-2509 则是 Qwen-Image 月度迭代版本,提升了单图与多图编辑一致性,支持人像、产品、文字等多类型编辑,并原生支持 ControlNet。
此外,Qwen3-Next-80B-A3B-Instruct-FP8 与 Qwen3-Next-80B-A3B-Thinking-FP8 也已同步开源。
特斯拉简化版 Model Y 被曝光,配置大幅精简
近日,一名叫 @greentheonly 的用户在 X 上称,在特斯拉官方固件中发现代号为「E41」的 Model Y 简化版本,该车被认为是即将推出的低价版 Model Y。整体策略可用一句话概括 ——「能砍的都砍了」。
据其爆料,主要减配内容包括:
- 车顶:取消全景玻璃天窗
- 悬挂:降级版悬挂系统
- 座椅:多向调节降级为单轴调节
- 空调:简化出风口
- 后视镜:取消电动折叠功能
- 摄像头:后视摄像头取消加热功能
- 车内屏幕:取消第二排显示屏
- 音响系统:降级为「Essential」基础版或「经过改进的基础版」
- 内饰:车顶内衬简化为玻璃纤维,取消氛围灯和迎宾灯
- 轮毂:缩减为 18 英寸规格
- 其他:取消胎压监测系统
据悉,「E41」将提供后驱与全驱两种版本,均采用特殊电机配置,但具体参数尚未公布。
部分网友甚至认为取消全景天窗是「升级」,因为夏季行车不再暴晒头顶。
相关阅读:各种减配!特斯拉的「Model Y 廉价版」被扒光了
可口可乐或继续掌控 Costa 即饮业务
英国天空新闻援引消息人士称,可口可乐公司已向潜在收购方明确表示,将保留对 Costa 咖啡即饮产品的控制权。这意味着,若交易成真,出售范围或仅限于门店业务。
报道称,阿波罗全球管理公司曾考虑竞购 Costa,但在上周报价截止前决定不参与。其他竞标方包括 TDR Capital,不过投标数量低于预期。
据悉,可口可乐在超市及杂货渠道销售的 Costa 即饮系列将继续由其掌控。
资料显示,Costa 于 2020 年初进入中国即饮市场,依托中粮可口可乐与太古可口可乐的分销网络,迅速覆盖商超、便利店及电商渠道。
过去 5 年,该品牌已跻身中国即饮咖啡市场前三。其定价策略介于康师傅、雀巢等零售咖啡品牌与星巴克瓶装咖啡之间,每百毫升售价约 2.33 元。
可口可乐方面未正式确认出售 Costa 门店业务的计划,但高管此前强调,所有并购交易的核心是为体系、客户与消费者创造整体价值。
盒马最难吃的甜品被台风「选出」
据南方都市报报道,近日,台风「桦加沙」来势汹汹,广东多地市民提前囤货应对,青菜、粮油等食材补货频率明显提升。
不过,这波「台风严选」也意外揭示了当地消费者的口味偏好 —— 部分甜品、方便面、水果、蔬菜在抢购潮中被冷落,其中一款榴莲大福尤为显眼。
有网友调侃「广东人宁可饿着也不向味蕾妥协」,而榴莲大福则成为被剩下最多的甜品。
对此,盒马客服回应称,榴莲大福库存充足,非因滞销导致剩货,并表示后续将根据消费者反馈对商品配方进行调整,以满足更多人的喜好。同时提醒广东消费者尽量减少外出,注意安全。
卖婴儿纸尿裤的尤妮佳在华转向宠物食品
据日本经济新闻此前报道,日本日用品企业尤妮佳(Unicharm)在中国的首家宠物食品工厂已于今年正式投入运营。
该工厂位于江苏省,由尤妮佳与吉家宠物(JIA PETS)合作建设,尤妮佳持股比例超过 40%,总投资额超过 100 亿日元(约人民币 4.8 亿元)。
尤妮佳表示,此举旨在通过本土化生产实现稳定供给与快速销售,降低成本,并计划到 2030 年将宠物相关产品在中国业务销售额中的占比从目前的 1% 提升至 20%。
公开资料显示,吉家宠物在江苏徐州新沂经济开发区建设的宠物食品项目一期已全面投产,年产能可达 20 万吨,预计年产值超 40 亿元。
业内数据显示,中国是全球第二大宠物消费市场,2024 年犬猫数量预计达 1.87 亿只,宠物食品市场规模突破 3000 亿元,且保持稳定增长。
尤妮佳认为,随着年轻群体养宠比例提升,本土化生产将加速新品研发与上市,宠物用品有望成为继卫生巾和纸尿裤之后的重要营收来源。
抹茶秋季热度再攀高,茶饮品牌集中上新「浓郁系」新品
FoodTalks 近日发布文章称,今年秋季,抹茶在饮品市场的热度持续升温。
自 9 月以来,古茗、奈雪、茶百道、沪上阿姨等多家头部品牌密集推出抹茶新品,口味从春季的清爽风格转向更适合秋冬的「浓郁系」搭配。
9 月 3 日,沪上阿姨推出「千目抹茶芝芝米麻薯」与「千目抹茶生椰大福」,将抹茶与米麻薯、芝士奶盖、生椰乳等食材结合,带来层次丰富的口感。
9 月 5 日,奈雪上新「浓抹干酪米布布鲜奶茶」,以干酪中和抹茶微苦,获得不少消费者好评。
古茗则在 9 月 11 日推出「生椰抹茶麻薯」「抹茶开心椰」,并于 19 日加码「双重芝士抹茶」。
茶百道在 9 月 16 日推出「千目咸法酪」,以超千目径山抹茶搭配咸香法酪,迅速在社交平台走红。
文章指出,本轮抹茶热潮呈现三大变化:
- 搭配更浓郁——米麻薯、干酪、芝士等食材成为抹茶新品的常见组合,满足秋冬消费者对温暖、饱满口感的需求。
- 强调「千目」品质——多家品牌在新品命名与宣传中突出「千目研磨」概念,强化抹茶细腻粉质与高端定位。
- 应用更多元——抹茶不再局限于饮品基底,还被广泛用于奶盖、小料及水果搭配,展现出极高的风味兼容度。
业内分析认为,抹茶与牛乳、芝士等浓郁食材的适配性,使其突破了「春夏限定」的认知边界,秋冬市场潜力巨大。未来,香气创新与视觉突破或将成为抹茶产品持续吸引消费者的关键方向。
《毕正明的证明》预售开启
动作 / 剧情片《毕正明的证明》于昨日正式开启全国预售,并同步发布「请看管好随身财物」版预告。
影片由佟志坚执导,王安宇、张天爱、王彦霖领衔主演,聂远特别出演,冯兵、邬家楷、孔令美主演,将于 10 月 1 日登陆全国院线。
影片故事讲述毕正明从小立志当警察,却在报到首日意外致残,沦为「一日警察」。
为证明自己,他孤身潜入盗贼团伙「荣门」,在危机四伏中坚持初心。片中大量火车场景不仅贴近节日出行生活,也折射时代变迁:从绿皮火车盗贼猖獗到高铁时代秩序井然,「安全」成为全民共感的关键词。
死亡搁浅系列首部动画电影项目《MOSQUITO》正式公布
小岛工作室宣布,作为游戏《死亡搁浅》系列的延伸,将启动全新动画电影项目《MOSQUITO(暂定名)》,并同步公开先导影像。
该片将与好莱坞联合制作,由株式会社 ABC ANIMATION 导演宫本浩史执导,Aaron Guzikowski 担任编剧。
据悉,《MOSQUITO》是小岛工作室首次尝试长篇动画电影制作,动画部分由 ABC ANIMATION 独立负责,这也是该公司首次完全参与大型动画电影项目。
宫本浩史曾执导《拥抱!光之美少女♡光之美少女 All Stars Memories》等作品,编剧 Aaron Guzikowski 代表作包括《异星灾变》与,《红番血路》。
官方尚未公布上映日期及更多剧情细节,但从先导影像来看,影片延续了《死亡搁浅》系列的独特世界观与视觉风格,预计将为粉丝带来全新的叙事体验。
《浪浪人生》开启预售
电影《浪浪人生》今日发布「全家一起上」版预告及「这一家子不好惹」版海报,并宣布全国预售正式开启。
影片改编自蔡崇达畅销书《皮囊》,由韩寒监制,马林执导,周运海编剧,黄渤、范丞丞、殷桃领衔主演,将于 9 月 30 日上映。
据片方介绍,《浪浪人生》不仅有「疯」力十足的喜剧元素,还传递出家人之间彼此关心与托举的温暖情感,适合观众在国庆假期与亲友一同观影。影片预售现已开启。
小岛恐怖游戏新作《OD – KNOCK》发布先导预告片
在今日举行的小岛工作室成立 10 周年纪念活动「Beyond The Strand(超越羈絆)」上,知名游戏制作人小岛秀夫正式发布与 Xbox Game Studios 合作开发的恐怖新作《OD》最新前导预告片「KNOCK」。
《OD》最早于 2023 年底的 The Game Awards 首次亮相,采用最新虚幻引擎打造,并邀请《牠》演员苏菲亚·莉莉丝(Sophia Lillis)、《高校十八禁》演员杭特·薛佛(Hunter Schafer)以及曾饰演《红色警戒 2》角色「尤里」的乌多·基尔(Udo Kier)参演。
与此前仅展示 3D CG 面部演出的首支预告不同,本次影片完整呈现了由游戏引擎驱动的高度写实室内场景,以及苏菲亚·莉莉丝饰演的主要角色的生动表演,营造出令人屏息的恐怖氛围。
目前,官方尚未公布《OD》的具体上市时间。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博