三百多万人围观的 AI 油画视频,是技术的神作,还是没有灵魂的电子垃圾
「比蒙娜丽莎更美的,就是正在燃烧的蒙娜丽莎」,这是多年前一档辩论节目里,大家对于艺术价值的不同理解方式,那时听到可能觉得挺激进,笑一笑便过了。
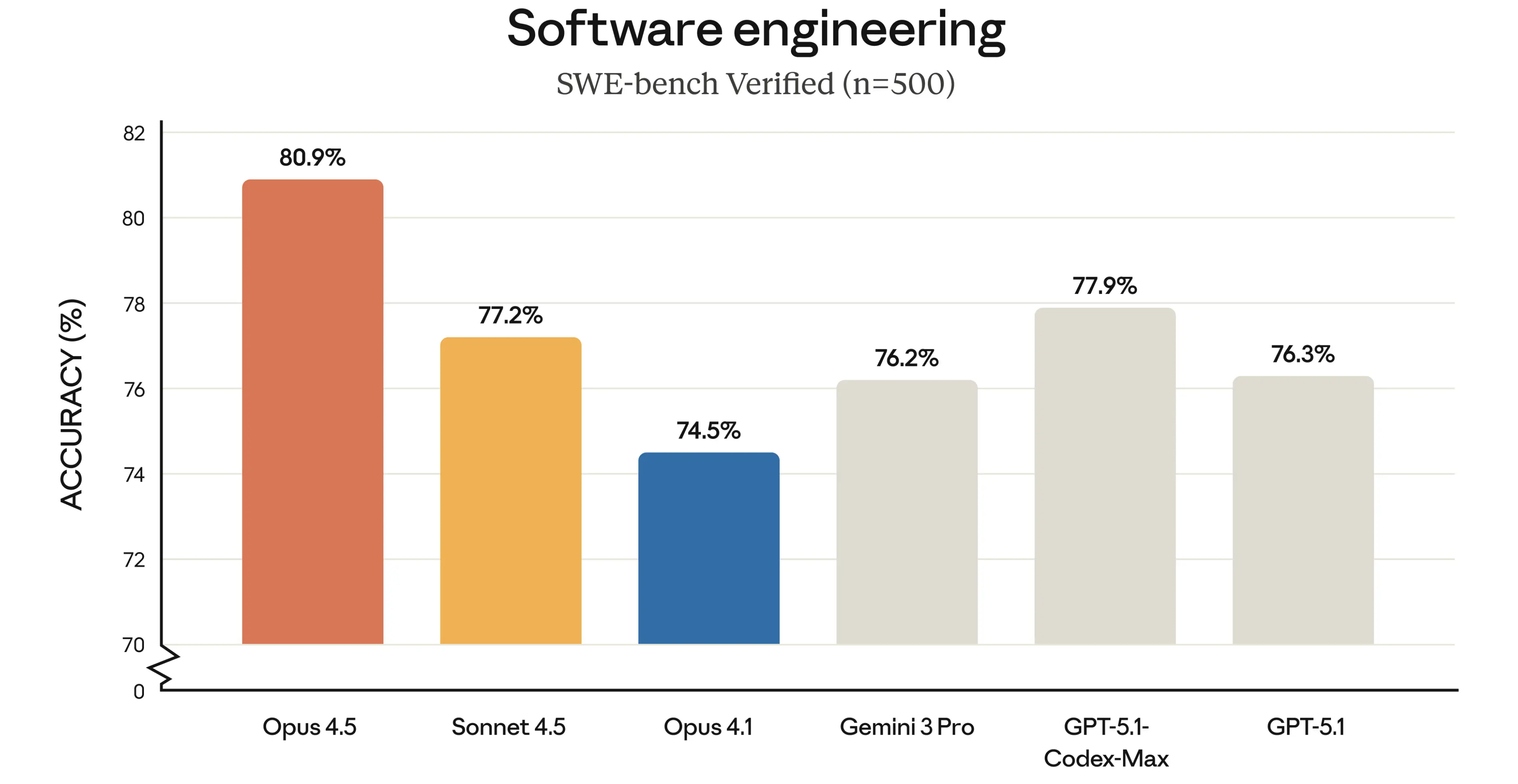
最近一段把几幅经典油画「复活」的 AI 视频,在 X 上引起了巨大的争议,视频刷到 300 多万播放,被不少人称之为栩栩如生的艺术;比经典油画作品更好看的,是会流动的油画?AI 做的东西是不是没有任何艺术价值?

网友分享的油画视频里,经典的油画元素不再静止,颜料开始流动,天空的云朵、火山的喷发、还有海浪的汹涌都变得生动自然,仿佛那些存在几百年前的画布,突然拥有了生命一样。
乍看之下,这就是一场视觉盛宴的享受;如果不是其中几个视频,忘了去掉右下角 Google Veo 视频生成的水印,甚至会觉得完全是用 CG 特效制作实现,毕竟对油画风格来说,没有很明显的「AI 味」。
但是点开评论区之后,发现网友们撕成了两派,有人说,这就是新时代的艺术,是全新的审美体验;有人就不买单,用 AI 时代最刻薄的词汇——Slop(垃圾/泔水)一言蔽之,说等到 AI 有意识了,再来谈配不配成为艺术。
同样的一条 AI 视频,让人看到了艺术、技术、恐惧、愤怒、敬畏、厌烦,还有时代变化。
如果不说这是 AI,你的第一反应是
X 网友发布的这则视频,其实并不是他本人的原创,在评论区有人指出来,说他没有标注视频来源,也没说明使用了 AI,只是单纯地为了赚取流量。现在这波流量,也确实是被他赚到了。
![]()
视频最早是出现 YouTube 上,一位有着 2000 多粉丝的博主@bandyquantguy,他是宾夕法尼亚州立大学艺术与建筑学院的一名助理教学教授。频道内发布的内容,基本上都是不同油画的动态视频作品,长度在一分半到 3 分钟不等。
而那条被转发到 X 上的视频,并收获了三百多万的观看,是他将近一个月之前的作品。
当我看着满屏的动态油画时,说实话,根本没想到这是否通过 AI 生成。一方面是对油画艺术的不了解,是否有相关的技术,或者爱好者在专门做类似的工作。另一方面,大多数时候,我们所说的 AI 味,主要是在制作一些写实的画面,像现实世界、真人版等。而这种风格化本身就足够突出的内容,AI 的处理反而不会太突兀。
有网友评价,这是他见过最原汁原味的 AI 艺术作品之一,因为视频没有生硬地模仿现实,而是创造了一种介于梦境,与现实之间的流体美感。
第一眼都是觉得「震撼」,而这种迎面而来的视觉冲击,在知道它是 AI 生成的之后,也变成了争议的起点。大多数的人会觉得,这样的作品很棒;但对剩下一部分人来说,如果光靠 AI 就能得到原本属于「艺术」的内容,那该有多可怕。
Slop,AI 是原罪
所以,打压和看衰,成了评论区的另一种态度,Slop 就是代表性的关键词。
在 AI 语境下,Slop 指的是通过 AI 大量生成的、看似有内容实则空洞的劣质品。像是之前奥特曼推出 Sora,就有人犀利的丢下断言,Sora 生成的视频,全部都是 AI Slop。
这次,也有网友说,这样的油画视频,不应该放在社交媒体上,Sora 才是他最好的归宿,那里都是同样的 AI 垃圾。为什么画面如此精美的视频,会被称为 Slop?反而一些 AI 味明显的视频,激不起大家这么热烈的反馈。
因为它是机器盲目的困境。
反对者认为,AI 生成的内容,是缺乏意义,就像是一台机器盲目的梦境,它甚至不知道自己正在做梦。
他们的观点是,艺术不仅仅是停留在好看,那只是媚俗。艺术需要人类的意图、深度和复杂性。在这个视频里,原本油画的笔触,变成了毫无逻辑的像素流动,就像是单纯地为了展示「我能动」而动,没有任何节奏、理由或概念支撑这个视频的内容。
对他们来说,AI 最大的问题从来不是不够好看,而是「不够人」。
AI 的每一次选择,只不过是概率。而人类创作一个作品,画一幅油画,背后包含的是对人生、对世界的思考和回应;有情感、时间、技巧、犹豫和失败等经历。
支持者觉得,现在的 AI,就像相机刚被发明时一样,不是在替代传统,而是在扩张想象力。甚至有网友说,「我想艺术家们在作画前,脑海中可能就有这样的画面,现在我们也能走进他们的灵感了。」
是结果,还是过程重要
如果这个视频是一个人类艺术家,花费 1000 个小时,一帧一帧手绘出来的,评论区又会发生什么。除了震撼,大概还是一样,会有人说,这视频顶多用来作为我的手机屏保,除了好看也就仅此而已了。
艺术是主观觉得还是客观认定呢,其实都没有明确的界定。网友的期待,大概是希望,艺术应该是需要「努力」才能抵达的地方,而 AI 正在稀释「努力」在艺术中的价值。
前段时间,一幅名为《太空歌剧院》的画作,拿到了艺术比赛的头奖,还有 AI 画作甚至在拍卖市场,以十万、百万的价格被拍走。
我们在一个输入提示词就能生成图像的世界里,任何一个人不需要复杂的技巧,也不需要付出多少汗水,都有机会创作自己的作品,作品的意义也不再靠时间来定义。
![]()
▲提示词:将油画纹理动画化为粘稠流体模拟,厚重的颜料笔触融化并流动。旋转的天空、粘稠的黄色光芒、翻腾的蓝色云朵。
当 AI 把时间成本压缩到几秒钟,这种神圣感瞬间崩塌,剩下的就只有廉价。「这不难做吧」、「我用 Veo 3 也能生成」,这样的东西,自然就成不了艺术了。
更有趣的是,有网友提到,这是一种很明显的社会心理学现象,巴浦洛夫的狗。现在我们只要看到 AI 的标签,就有了条件反射,瞬间进入狂怒模式,无论作品本身好坏,一律打成 Slop。
![]()
具体来说,就是眼睛告诉我,这个视频还不错,但大脑告诉我,这是 AI,AI 做的都是不好的,为了调和这种矛盾,我就必须强行说服自己,它看起来很糟糕。
心理效应是存在,更多的我想其实还是,AI 内容的泛滥,正在把我们的审美阈值无限拔高。
没有 AI 的时候,让一幅油画像这样动起来,可以说是「魔法」一样的存在。现在如果这些作品没有极强的故事性,或情感内核,仅仅是视觉特效,已经很难打动被各种 AI 效果喂饱的我们。

▲ YouTube 上该博主的其他油画视频
无论评论区吵得多么不可开交,一个事实是无法改变:AI 不会消失,艺术也不会因为 AI 的出现而消失。
就像一些网友说的,「电力曾让蜡烛工厂破产,但人类具有适应性」。现在的混乱,也许只是新旧审美体系,交替时发生的阵痛。
如果在 100 年前我们按一下播放键,就能听到录好的歌,大概也会有人觉得,只有黑胶唱片出来的声音才是真音乐;现在我们只是习惯了,现场、黑胶、手机、音响都有好音乐。
艺术,从来看的是最终的愿景,是我想让你看到什么,而不是用了什么工具,我花了多久才做出来。一个活过来的 AI 艺术,就算是简单的几行提示词,一样倾注了真正属于创作者的叙事、情感与意图。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。