Ilya 罕见发声:Scaling 时代已结束,我们对 AGI 的定义可能全错了
修个 bug 可以来回把同一个错误引回来,写代码能绕一圈又走回原地。
但几乎所有 AI 公司都坚信,只要把模型做大、把数据堆满、把算力扔进去,智能就会自动涌现。这套规模定律(Scaling Law)曾经是硅谷最坚定的信仰。
![]()
在隐退许久并创立新公司 SSI(Safe Superintelligence)后,前 OpenAI 首席科学家 Ilya Sutskever 用一种极其冷静的语调,宣告「Scaling 的时代结束了,我们重新回到了研究时代。」
最近一场 Ilya 与 Dwarkesh Patel 的深度对话中,他不仅给出了,对于 AI 未来的技术路线图,更重要的是,他深刻地回答了,为什么现在的 AI 即使再强,也依然不像人。
![]() 播客链接:https://x.com/dwarkesh_sp/status/1993371363026125147
播客链接:https://x.com/dwarkesh_sp/status/1993371363026125147
为什么 AI 是个高分低能的优等生
我们总觉得现在的 AI 很强,它们能在编程竞赛、数学竞赛、各种榜单上拿金牌,每次有新的模型发布,也是一次次刷新着各种 benchmark。但 Ilya 指出了一个让他感到困惑的现象。
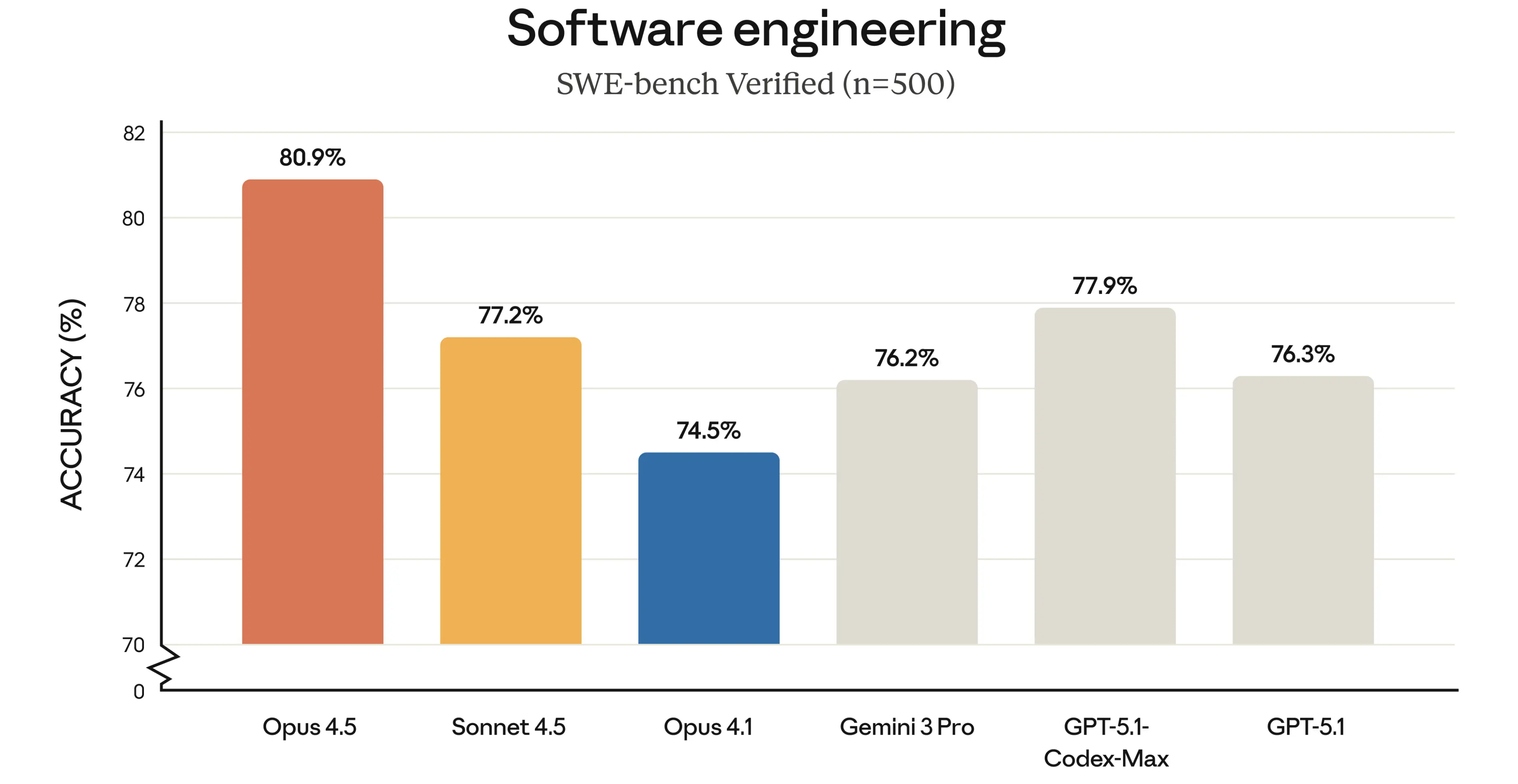
▲ 最新发布的 Claude 4.5 Opus 模型,在编程相关的榜单,已经拿到了 80.9 分
他说我们在用 vibe coding,要 AI 写代码时,AI 可能写到某个地方,出现了一个 Bug。我们直接告诉它:「这儿有个错误。」AI 会说:「天呐你是对的,我马上改。」 然后它解决了这个 Bug,又引入了另一个 Bug。 你再指出,它又改回了第一个 Bug。 它就在这两个 Bug 之间无限循环,显得极其笨拙。
他的解释提到了这说明 AI 的「泛化能力(Generalization)」出了问题。为了解释这个词,Ilya 用不同的学生打了一个比方。
![]()
想象两个学生都在学编程,学生 A 代表 AI, 极其刻苦,练了 10000 个小时。他背下了所有的题库,记住了所有的解题套路。考试时,只要见过类似的题,他就能拿满分。
学生 B 代表人类,他只是觉得编程竞赛很酷,花了 100 个小时联系,但他真正理解了编程的逻辑,拥有了某种直觉,也能做得很好。长期来看,谁会在职业生涯中走得更远?他说一定是学生 B。
而现在的 AI 就像学生 A。所谓的智能,很大程度上是靠海量数据强行记忆出来的;它们在特定问题的庞大、增强数据集上过度训练,使它们在任务上表现出色,但不一定擅长泛化到其他领域。
一旦遇到训练数据之外的微小变动,比如修复一个重复出现的 Bug,它缺乏那种举一反三的泛化能力。
从堆算力回归拼创意
但这种海量数据的训练方式也不是完全没有用。在过去五年里,AI 行业的发展基本上都是遵循着所谓的「规模定律 Scaling Law」,从一开始的还是以百万参数来衡量的大模型,现在都来到了万亿参数。GPU 显卡算力的消耗,规模更是未雨绸缪,要卷上天际。
这种把一定量的算力,和一定量的数据混合进一个神经网络里的方案,也成了所有大模型开发的必备流程,即预训练。在预训练阶段,不需要思考用什么数据,因为答案是所有数据,它是人类投射到文本上的整个世界。
而 Ilya 认为,「Scaling」这个词,本身就固定了我们的思维。它暗示着我们只需要做一件事:加算力,加数据,保持配方不变,把锅搞大一点,就能做出好菜。
他说这样的法则,让大公司很舒服,因为这是一种「低风险」的投资。相比于需要灵感和运气的研究,大公司不需要雇佣科学家去苦思冥想,只需要「加数据、加算力」,而模型变强的结果是可预测的。
但现在,瓶颈来了。数据不够了,预训练数据,我们的互联网文本语料是有限的,而且已经快被用光了;有专门的研究结构统计过,现在互联网上 AI 内容的比例,已经是超过我们人类输出的内容。
其次是边际效应,把模型再做大 100 倍,也许会有提升,但不会带来质变。
Ilya 也提到了最近在 X 上,有人说 Gemini 3 似乎解决了预训练的一些问题。而此前 The Information 也曾报道奥特曼担心 Google 的发展会影响 OpenAI,甚至已经让他感受到压力。
其中一部分的原因,正是 GPT-5 的推出,遇到了预训练上的问题,即随着预训练数据的增加,模型并没有像之前一样表现出智能的提升。反而 Gemini 确找到了突破的方法,奥特曼在内部备忘录里说,OpenAI 也必须解决预训练的问题,或许才能再次超过 Google。
![]()
▲ Google DeepMind 研究副总裁 Oriol Vinyals 提到 Gemini 3 的秘密,是解决了预训练的问题
我们回到了研究时代。只不过这一次,我们有了更大的计算机。
Ilya 把过去这段时间的研究,分成了两个阶段。2012 年到 2020 年是研究时代,大家都在试错,寻找新方法。而 2020 年到 2025 年,是扩展时代,大家都在盲目扩建,算力在扩建,越来越多的 AI 公司在出现。
而现在,单纯的大力出奇迹已经行不通了,或者说单纯靠 Scaling 的红利吃尽了,我们又回到了研究时代。只不过这一次,我们是在用 Scaling 时代建立起来的巨型计算机来做研究,这是一个有着大型算力的研究时代。
总的来说,Ilya 并没有否认预训练和 Scaling 的巨大成功,但他认为这是一种用钱换智能的,低风险暴力美学,而现在这种模式已经触到了天花板,AI 行业必须回归到拼想法、拼直觉、拼创新的硬核研究阶段。
寻找直觉:AI 缺失的那块拼图
如果单纯的数据堆叠无法产生真正的智能,那人类的秘诀是什么?Ilya 给出的答案是:情感(Emotions)。
他提到了一个脑损伤患者的案例,这个人失去了情感能力,虽然智商正常、能言善辩,却连穿哪双袜子都要纠结几个小时。 这说明情感不仅是情绪,它本质上是一个价值函数(Value Function)。
不过 Ilya 说目前没有找到很合适的概念,来类比情绪在机器学习中的角色,所以用价值函数来替代。
为了解释什么是价值函数,Ilya 提到了少年学开车的例子, 一个青少年,可能只需要练 10 个小时甚至更少,就能学会开车上路。他不需要像现在的自动驾驶 AI 那样,在模拟器里撞车几百万次才能学会避让。
为什么?因为人类自带了一个极其强大的价值函数,这个价值函数就像一个内置评价器,一旦偏离车道,我们人类会感到紧张,而这相当于一种负反馈。
那么依赖情绪的价值函数,和我们之前一直听到的强化学习,区别又是什么呢?
Ilya 说在没有中间价值函数的强化学习里,通常要等到任务彻底结束,AI 才知道自己是赢了还是输了;但价值函数就像是我们的直觉或内心评分系统。当我们下棋丢了一个子,不需要等到这盘棋下完,我们心里立马会「咯噔」一下,这步棋下错了。
那个学开车的少年,不用等到真的压线丢分了才会改正,而是只要开得稍微偏离车道,他立刻会感到紧张或不自信。这种实时的、内在的反馈机制,让他能极其高效地从少量经验中学习。
对于传统的强化学习,他的看法是这是一种天真且低效率做法。在传统的强化学习中,模型需要尝试成千上万次动作或思考步骤,直到产出一个最终的解决方案,然后根据这个最终结果的好坏获得一个评分,即训练信号。
这意味着在得出最终解之前,模型完全没有进行任何学习。这种方法需要消耗大量的计算资源来进行漫长的推演,但每次推演带来的学习量却相对较少。
而价值函数不需要等到最后,它能提供中间过程的评价;在每一步都给出信号,指引方向,从而极大地压缩了搜索空间,提高了学习速度。
目前的 AI 缺乏这种高效的内心评分系统。如果我们能让 AI,拥有类似人类情感或本能的价值判断能力,它就能摆脱对海量数据的依赖,真正像人一样高效学习。
Ilya 的下一步是直通超级智能
既然认定了拼算力的时代已经过去,而强大的价值函数或许又会成为新的 AI 方法,那 Ilya 的新公司 SSI(Safe Superintelligence)打算怎么做?
他的答案带着一种极其理想主义的色彩,直通超智能,他们选择去攻克那个最根本的难题,实现可靠的泛化。
![]()
Ilya 直言,现在的 AI 行业陷入了一场老鼠赛跑。为了在市场竞争中存活,公司被迫不断发布半成品,被迫在产品体验和安全性之间做艰难的权衡。SSI 想要做的是从这种商业噪音中抽离出来,闭门造车,直到造出真正的超级智能。
但有趣的是,Ilya 这种「闭关修炼」的想法正在发生动摇。他开始意识到,渐进式发布可能才是安全的必经之路。
为什么?因为人类的想象力是贫瘠的。如果你只是写文章、发论文告诉大家AI 会很强,大家只会觉得这是科幻小说。只有当人们亲眼看到 AI 展现出某种令人不安的力量时,所有人、包括竞争对手,才会真正感到害怕,从而变得更加关注安全 。

Ilya 预言,随着 AI 变得越来越强,现在打得不可开交的科技巨头们,最终会在 AI 安全策略上走向趋同。
播客里他也提到了,SSI 与 OpenAI、Google 那些大型实验室相比,虽然筹集的资金较少,但用于纯研究的计算能力比表面上看是更多的。他说那些大公司将大量的计算资源用于产品推理,并拥有庞大的工程和销售团队,导致其资源分散。Ilya 认为 SSI 拥有足够的计算能力,来证明其想法是正确的。
当被问及盈利模式时,Ilya 只是淡淡地说,我们只专注于研究,赚钱的问题以后自然会有答案。主持也提到了之前 SSI 的前 CEO(联合创始人)选择了离开,然后加入 Meta,在 Meta 希望收购 SSI 时。
Ilya 特意澄清,「他是唯一一个去 Meta 的人。」 他建立 SSI 不是为了在商业市场上套现,而是为了那个唯一的、纯粹的目标,在那个不可逆转的奇点到来之前,把安全的超级智能造出来。
重新定义 AGI,一个 15 岁的少年
那我们距离 AGI 还有多远?Ilya 给出的预测是 5 到 20 年。
但他提醒我们要警惕「AGI」这个词。因为预训练模型让我们产生了一种错觉,以为 AGI 就是一个什么都懂的百科全书。但 Ilya 心目中的超级智能,更像是一个绝顶聪明的 15 岁少年。
这个少年可能还没学过法律或医学,但他拥有极致的学习效率。你让他去学医,他可能几天就能读完人类所有的医学文献,并开始做手术。
而在这一愿景中,最让人细思极恐的概念是融合(Amalgamation)。

人类的悲哀在于知识无法直接复制。这个人学会了开车,另一个人还是得从头练起,但 AI 不一样。Ilya 描述了一个场景,数百万个 AI 分身在经济体的不同角落工作,有的在写代码,有的在打官司。它们在各自学习,然后将所有的经验融合进同一个大脑。
这种集体进化的速度,才是他所认为的 AGI。
面对这样一个能够瞬间融合万千经验的超级大脑,人类又该何去何从?
![]()
Ilya 给出了两个层面的思考。首先是给 AI 的设定。不要只让它爱人类,因为这太狭隘了。未来的 AI 自己也将是有知觉的生命体,应该利用同理心的原理,让它关爱所有有知觉的生命,可能是比代码更稳固的安全防线。
其次是人类的退路。如果每个人都有一个比自己聪明百倍的 AI 智能体,人类会不会沦为历史的旁观者?Ilya 给出了一个他坦言「自己并不喜欢,但可能是唯一解」的答案:脑机接口(Neuralink)。
只有当人类选择与 AI 融合,让 AI 的理解直接变成我们的理解,我们才能在那个奇点之后,依然是这个世界的主角。
播客的最后,Dwarkesh 问了那个所有人都想问的问题:作为 AI 领域的传奇,你是如何一次次押对方向的?
Ilya 的回答很像个艺术家:「寻找美感。」
在那些数据都不支持你的至暗时刻,唯有对美、简洁和生物学合理性的自上而下的信念,能支撑你走下去。因为神经网络模仿了大脑,而大脑是美的,所以它一定是通往智能的正确道路。
这或许就是 Ilya 所说的「研究时代」最需要的品质:在算力之外,保留一份对智能本质的诗意直觉。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。