2026五一档新片票房破4亿
据猫眼专业版数据,2026年五一档新片总票房破4亿,《消失的人》《寒战1994》《穿普拉达的女王2》暂列五一档新片票房榜前三位。

中国机器人公司火,已经不只是在国内了。一家具身智能公司,近期已经把发布会开到了硅谷。
美西时间 4 月 28 日,魔法原子 MagicLab 在硅谷举办全球首届具身智能创新大会 GEIS。
魔法原子在会上推出了新一代人形机器人 MagicBot X1 和灵巧手 MagicHand H01,而且第一次把其世界模型 Magic-Mix、数据生成与训练反馈闭环,作为一套完整的具身智能底层能力集中展示出来。
过去,魔法原子最先进入外界视野,靠的是硬件实力和高辨识度场景:从苏超近 300 台机器人开场秀,春晚舞台上的机器人表演,到首届国际人形机器人运动会上获得跳高铜牌的 MagicBot Z1,都让这家公司建立起鲜明的本体能力标签。按照公司披露,其硬件自研比例已经超过 90%。
而这次在硅谷 GEIS 上,除了连发两款产品外,首次发布了「世界模型」Magic-Mix。Magic-Mix 试图回答的是更底层的问题:机器人如何理解物理环境,如何进行空间推演和动作决策,又如何通过数据生成、模型训练、结果反馈和数据再生成,形成持续迭代的闭环。
从官方发布的信息来看, Magic-Mix Creator,指向的是具身智能行业核心瓶颈——数据。按照魔法原子的说法,公司已经搭建机器人训练数据池,日均采集约 16000 条数据,高质量数据规模超过 100 万小时,并通过数据合成实现 1 万倍的数据体量扩展。
本届 GEIS 上,魔法原子总裁顾诗韬首次对外披露魔法原子的长期营收目标:到 2036 年,公司将向 140 亿美元营收规模迈进。
这个目标仍需要长期交付验证,但此次发布后,魔法原子的命题变得十分清晰:要做一个具备世界模型、硬件平台、数据闭环和海外生态组织能力的具身智能平台公司。
01
Magic-Mix:
魔法原子世界模型的技术路线成型
在本届大会上,魔法原子发布自研世界模型 Magic-Mix。这也是此次 GEIS 最核心的技术发布之一。
过去一段时间,VLA 是具身智能行业的重要路线。它让机器人可以把视觉、语言和动作连接起来,完成从感知到执行的任务链条。但当机器人真正走出实验室,进入工厂、商业服务、家庭健康等复杂环境时,环境细微变化、物体状态差异、动作链条拉长,都可能带来泛化不足和执行不稳定。
而魔法原子世界模型想补上的,正是这一层能力:机器人不只是识别眼前画面、执行下一步动作,而是要理解物理环境,预测未来变化,并基于更接近物理常识的判断做出动作决策。
这也是开年以来,机器人领域最热的方向。
按照魔法原子的介绍,Magic-Mix 由两个核心引擎构成。其中,Magic-Mix WAM 负责物理环境理解、空间推演与动作决策;Magic-Mix Creator 则作为离线数据生成引擎,用于生成大批量训练样本,持续驱动模型训练和能力迭代。也就是说,Magic-Mix 不是一个静态模型,而是一套动态系统:它试图通过「数据生成—模型训练—训练结果反馈—数据再生成」的闭环,让机器人在真实场景和模拟环境中持续学习、不断修正。
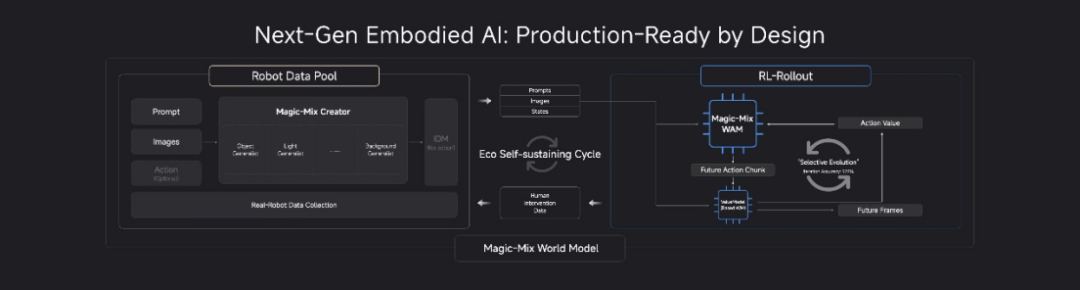
这一路线的价值,在于回应具身智能商业化中最难的一类问题:机器人要进入真实世界,不能只依赖少量示范任务。它需要在开放环境中处理长线程任务、物体变化、动作误差累积和物理常识偏移。为此,Magic-Mix 采用视频动作双专家协同训练模式,并引入共享信息梯度隔离、目标图像约束、失败图像特征输入等设计,试图同时增强机器人「思考」和「行动」的能力。
02
从数据到场景
机器人「能思考」也要会「真干活」
与世界模型配合的是,魔法原子更系统地构建数据飞轮。
前面已经提到,Magic-Mix Creator 的核心价值,是通过大批量合成数据,降低模型训练对真机数据采集的依赖,为世界模型提供持续稳定的数据供给。
不过,仅有合成数据还不够。对具身智能来说,真正有价值的数据仍然来自真实任务和真实用户。
按照公司披露,魔法原子已经搭建机器人训练数据池,日均采集约 16000 条数据,高质量数据规模超过 100 万小时,并通过数据合成实现 1 万倍的数据体量扩展。
除此之外,魔法原子还试图用「全场景」落地的方式推动数据循环。公司此前曾提出「1+2+N」框架:以全栈自研能力为底座,以人形机器人和四足机器人两条产品线承接场景,再延伸到 N 个垂直应用。
目前,其布局已经覆盖工业柔性生产、巡检安防、智慧导览、公共安全、智慧物流、赛事文娱、科研教育、家庭生活、大健康等九大场景。

这种全场景布局有两层含义。短期看,它是产品能力的验证:不同场景有不同付费能力和落地节奏,导览、文娱、科研教育、公共安全等场景可以更快形成项目和订单;非标准化场景则对应更长期、更高价值的应用空间。只有进入更多场景,机器人在越多场景中被部署,就越有机会获得更多任务数据、环境数据、交互数据和失败案例,再反向推动模型、控制和硬件迭代。
4 月,魔法原子刚刚签订了一笔 1.5 亿元订单,聚焦家庭健康管理与智能陪护,计划覆盖 1 万名高净值家庭用户,提供定制化智能硬件和一体化服务方案。
家庭场景对机器人尤其困难。每个家庭的空间布局、成员结构、生活习惯、健康需求都不同,机器人需要处理的不只是导航和动作,还包括陪护、健康管理、人机交互和长期服务可靠性。如果这类订单能够真正落地,它带来的不只是硬件交付,更可能是持续的用户行为、家庭环境和服务反馈数据。
不止是成功数据能够训练机器人,失败的数据甚至更为重要。Magic-Mix 在训练机制中引入失败图像特征输入,试图把机器人在开放环境中的失败状态纳入训练反馈,用失败样本修正长线程任务中的误差累积和物理常识偏移。正因如此,开放世界的数据,将更能决定模型能否从「能完成一次任务」走向「能在复杂场景中稳定工作」。
如果这个循环能够跑通,魔法原子就不只是拥有多个场景订单,而是在用场景反哺模型,用模型提升产品,再用产品进入更多场景。
也就是说,订单的意义不止是收入,场景的意义也不止是展示;它们共同构成数据飞轮启动的前提,这才是更长期的价值所在。
03
中国硬科技代表迈向全球
这次发布会很有趣的一点,是它设置在了硅谷。
更有趣的是,从 GEIS 的议程设置来看,它并不只是把一场本该开在中国的发布会搬到硅谷,而是在尝试把发布会做成一个具身智能产业大会。
大会邀请了图灵奖得主 Martin Hellman、旧金山前市长 Willie Brown,也邀请了英伟达 GEAR Lab 高级研究科学家 Zhengyi Luo、亚马逊前沿 AI 与机器人研究院科学家 Haozhi Qi、OpenMind 创始人 Jan Liphardt、Chestnut Robotics 创始人 Evan Tao、XGSynBot CEO Zizheng Li 等海外机器人与 AI 领域的研究者、创业者和产业人士参与讨论。议程也不只是新品发布,而是围绕「具身智能本体演进」「具身智能大脑革命」「生态伙伴演讲」等主题展开。

看似意外,也很合理。
硅谷恰好适合承担这样的角色。这里聚集着全球 AI 开发者、机器人创业公司、产业资本和场景创新资源。更现实地看,北美、欧洲等市场在劳动力成本、服务供给、老龄化、工业自动化和家庭健康管理等方面,都存在明确需求;而中国机器人企业在硬件工程、供应链效率、产品迭代和成本控制上,又有自己的优势。
魔法原子选择硅谷,正是在尝试把这两端接起来:一端是中国智造和具身智能技术能力,另一端是海外丰富的场景、开发者和产业资源。

这也是此次发布会提出 10 亿美元生态投入和「千景共创」计划的含义。魔法原子试图向外部伙伴开放硬件样机、开发资金、核心技术、项目导流和品牌资源,不只是降低单个场景的开发门槛,更是希望以开放协作的方式,推动开发者、场景方与产业伙伴共同验证应用价值,扩大具身智能在真实世界中的产业半径。
过去,中国机器人企业更多被看作高效率的产品制造者和快速迭代者;而这一次,魔法原子试图以全球创新大会的形式,把自己的技术路线、硬件平台和生态计划放到硅谷讨论。
它正在传递一个新的信号:中国智造在具身智能这样的前沿科技领域,已经不只是跟随者,而正在成为能够参与全球议题、连接全球资源、输出技术方案的重要力量。




5 月 2 日消息,在 2026 世界超级摩托车锦标赛(WSBK)匈牙利站 WorldSSP 组别第一回合正赛中,中国摩托车制造商「张雪机车」的法国车手瓦伦丁·德比斯夺得冠军。这也是他与「张雪机车」的第三冠。
凭借本场胜利,德比斯以 97 分在车手积分榜上升到第三位;「张雪机车」积 99 分,在制造商积分榜上同样排名第三。
德比斯在 1 日的本站超级杆位赛中第六位冲线。由于排名第三的意大利车手费拉里被罚退三个发车位,从第三位降至第六位,德比斯在第一回合正赛中得以第五位发车。
驾驶雅马哈赛车的阿雷纳斯、恩居分获第二、三名。「张雪机车」的另一名车手卡里卡苏洛第 15 位完赛,钱江摩托车手德罗萨位列第 16。
「我知道这条赛道对我们来说会很困难。车队整个周末都在告诉我要保持耐心,我们会找到办法。今天早上我对赛车还是不太满意,不过比赛开始前车队帮我做了一些调整,我感觉舒服多了。」德比斯赛后说。(消息来源:新华网)

5 月 2 日消息,据科技媒体 Quartz 今天报道,监管文件显示,特斯拉 CEO 埃隆 · 马斯克去年总薪酬约为 1583 亿美元。但公司指出,该数字并不能反映马斯克收到的真实现金。
据报道,这 1583 亿美元中大部分是会计估值,与 2025 年 CEO 绩效奖励(特斯拉董事会去年批准的股票激励计划)息息相关。截至文件披露日期,该奖励的任何股份都未有归属,并且所有股份都需要按每股 334.09 美元(现汇率约合 2284 元人民币)的价格抵扣,除非马斯克选择用现金支付。
事实上,马斯克 2025 年的真实薪酬为零,他带领的特斯拉并未达成任何市场价值或运营目标,并且他多年来也没拿过公司薪水。
特斯拉在文件中承认,报告的薪酬数字与马斯克最终实际获得薪酬可能存在显著差距。公司指出,这些数字依赖会计规则的假设和预测,并不能完全反映价值。
作为参考,特斯拉员工总薪酬中位数为 62786 美元,这意味着薪酬比率达到 2522203:1。(消息来源:IT 之家)

5 月 2 日,奥特曼在 X 宣布,「您现在可以用您的 Chatgpt 账号登录 OpenClaw 并在那里使用您的订阅!祝您捕龙虾愉快。」在此之前,用户在 OpenClaw 中使用 GPT-4/5 模型通常需要绑定 OpenAI API Key,现在可直接使用 ChatGPT 订阅(Plus/Pro)登录,并在 OpenClaw 中使用自己的 ChatGPT 订阅额度。
对于开发者特别是「养虾族」来说,主要好处除了简单方便外,还有 Token 整体成本更低。
以前用 API 运行一个「全天候监控邮件并回复」的任务,可能每个月会产生数百美金的账单;现在,广大 Chatgpt Plus 或 Pro 级的订阅者无需再额外购买大量 API Token,只需要使用原来的订阅,就能在 OpenClaw 中调用同级别的 GPT 模型,包括 GPT-5.5 的 Terminal-Bench 2.0(命令行工作流理解)、GDPval(知识工作指数)等智能体核心模型能力。
OpenClaw 是知名独立开发者 Peter Steinberger 创建的开源 AI 智能体项目,主打让 AI 接管用户的日常任务——处理邮箱、编写代码、预订航班、操作硬件甚至是运行银行接口操作相关事务。而 GPT-5.5 主打强调其智能体能力。
有意思的是,今年 4 月初,OpenAI的最大竞争对手、由前 OpenAI 成员创立的 Anthropic(A 社)突然宣布了与 OpenAI 相反的策略:封杀 OpenClaw。自 2026 年 4 月 4 日起,订阅用户将无法再使用 Claude 订阅额度通过 OpenClaw 等第三方集成工具访问其大模型。如果用户要继续让 OpenClaw 调用 Claude,则必须采用常规 API 按量付费。(消息来源:IT 之家)
5 月 2 日,投资界的年度盛会——伯克希尔-哈撒韦股东大会在美国内布拉斯加州奥马哈市拉开帷幕。
这是伯克希尔自巴菲特退休后首次股东年会,也是巴菲特「接班人」格雷格·阿贝尔(Greg Abel)的首场股东大会。本次大会的主题是「传承延续」。以此为标志,伯克希尔-哈撒韦进入「后巴菲特时代」。
自去年 5 月巴菲特宣布退休以来,伯克希尔 A 类股表现落后同期标普 500 指数。股东们希望了解,手握 3973 亿美元现金,伯克希尔如何在格雷格·阿贝尔的带领下重振。
伯克希尔-哈撒韦发布的 2026 财年年一季报显示,一季度公司实现归属于股东的净利润 101.06 亿美元,上年同期为 46.03 亿美元,同比增长近 120%。同期,公司投资净亏损 12.40 亿美元,上年同期为净亏损 50.38 亿美元。伯克希尔表示,经营业绩可能会受到未来期间持续的宏观经济和地缘政治冲突及事件影响,仍然具有不确定性。
财报数据还显示,截至 2026 年 3 月 31 日,公司现金储备合计 3973.8 亿美元(约合人民币 2.7 万亿元),其中现金与短期国债合计约 3907 亿美元,铁路及公用事业板块另持有现金 66.44 亿美元。与上次披露时约 3700 亿美元相比,一季度末伯克希尔的现金储备再创历史新高。
95 岁的沃伦·巴菲特在人引领下入座董事席前排,全场给予热烈的掌声。巴菲特在座位上接过麦克风,再度盛赞阿贝尔。「他就是那个对的人。」
苹果 CEO 蒂姆·库克同时也现身了股东大会。巴菲特谈到了蒂姆·库克从苹果创始人史蒂夫·乔布斯手中接过苹果大权所面临的压力,以及他如何克服重重压力并取得成功的。「试想,你要怎么接手史蒂夫·乔布斯的衣钵、延续他创下的辉煌成就。这堪称美国企业管理史上的一大奇迹⋯⋯谢谢你,蒂姆。」巴菲特说道。(消息来源:每日经济新闻)

当其他大型科技公司竞相在资本支出上投入数千亿美元时,苹果一直处于旁观状态——通过股票回购和分红将资金返还给股东。不过,苹果可能很快就会加入这场游戏。在周四的第二季度财报电话会议上,苹果表示将放弃其长期持有的净现金中性目标。
早在 2018 年,苹果就开始缩减其庞大的现金储备,目标是保持现金和债务水平相当,但苹果表示,未来将分别评估这两个指标。首席财务官凯文·帕雷克表示,这一决定将帮助公司「在如何最优地利用我们的债务和现金组合来支持业务方面,做出更优的经济决策」。
Wedbush 分析师丹·艾夫斯在电子邮件中表示:「我们认为,随着新 CEO 的上任,苹果的领导层更迭预示着未来的收购,这对投资者来说是一个令人欣慰的消息。」
关于潜在收购的传闻已经流传了数月。Wedbush 的艾夫斯表示,苹果的并购策略「很可能包括 AI 领域的公司,而 Perplexity 在我们看来是一个潜在的候选对象」。
苹果在今年早些时候已经宣布了一笔令人意外的收购,收购了神秘的 AI 音频初创公司 Q.ai。虽然未披露收购价格,但媒体报道称,这笔交易估值达到 20 亿美元——这将使其成为苹果历史上第二大收购案,仅次于 2014 年以 30 亿美元收购 Beats Electronics。(消息来源:环球市场播报)

5 月 2 日消息,据《财富》杂志报道,Meta 第一季度业绩本身并不差,净利润和营收都超过市场预期,然而在当地时间周四,其股价却大跌近 9%。投资者担心的重点,是用户减少 2000 万,以及 AI 资本开支继续大幅上升。
与此同时,Meta 仍在向元宇宙和虚拟现实部门 Reality Labs 投入数十亿美元。Meta 第一季度净利润为 268 亿美元(IT 之家注:现汇率约合 1832.4 亿元人民币),营收为 563 亿美元,双双高于分析师预期。净利润中包含一次性 80 亿美元税收收益。营收同比增长 33%,也是 Meta 过去 5 年来最大同比增幅。
该季度,Meta 旗下应用家族全球用户数较上一季度减少 2000 万。Meta CFO 苏珊 · 李把这一变化归因于伊朗的互联网中断,以及俄罗斯对 WhatsApp 访问的限制。
Meta 仍在为元宇宙买单。第一季度,负责 Meta 元宇宙和虚拟现实业务的 Reality Labs 录得 40.3 亿美元营业亏损。讽刺的是,公司一边继续投入,一边也在 2026 年多轮裁员,其中包括裁掉 Reality Labs 约 1.5 万名员工中的 10%。自 2020 年底开始单独披露 Reality Labs 业绩以来,Meta 在该部门累计亏损超 800 亿美元。(消息来源:IT 之家)
五一假期第一天,全国第一个成建制的交管机器人中队在杭州正式上岗,一共 15 台,名字叫杭警智行,五一假期一亮相就成了街头顶流。这批机器人主要部署在西湖景区周边、湖滨商圈还有城区主干道的重点路口,和真人交警一起配合维护交通秩序。
它们的任务很明确,帮游客指路、劝导非机动车和行人违法、协助指挥交通,刚好能分担五一期间警力最忙的工作。
因为接入了大语言模型,机器人回答问题特别快。游客问路直接开口说,机器人能秒回,屏幕上还会弹出路线指引。像断桥、动物园这些热门点位,问路需求最大,现在基本都由机器人接手,帮警力省了不少事。
在路口执勤时,机器人也很管用。遇到行人或非机动车越线停车,它会温和提醒,当事人听到后一般都会马上配合。现场民警说,机器人提醒的效果反而很好,大家更愿意听。

5 月 2 日消息,根据中国移动今年 3 月发布的公告,因产品运营策略调整,和生活、农信通、Mobile Market、12590 (语音杂志)、梦网全网短彩业务 5 款产品,将于 2026 年 4 月 30 日 24:00 正式下线并停止相关服务。
梦网全网短彩业务,隶属于中国移动在 2000 年推出的移动数据业务品牌「移动梦网」。移动梦网(Monternet)意为「Mobile+Internet」,是中国移动向客户提供的移动数据业务的统一品牌,囊括了短信、彩信、手机上网(WAP)、手机游戏等多种信息服务。
至 2009 年,移动梦网用户规模达到每月 9000 万。然而随着智能手机和 4G 网络的普及,传统 WAP 门户逐渐被原生 App 取代。2019 年 12 月 20 日,移动梦网热点资讯服务正式停止运营。2025 年 8 月 31 日起,部分 SP 公司提供的移动梦网短彩信业务服务停止。(消息来源:IT 之家)

5 月 2 日消息,追觅科技创始人俞浩直接放出了自家模块化手机的真机视频,这款手机的设计非常有看点,镜头和后盖都能单独拆卸,可玩性很高。
这款手机用的是白色后盖,整体外观简洁。最特别的是它的后置圆形镜头模组,可以直接取下来,依靠磁吸和触点连接,拆装都很方便。手机正面采用居中前置摄像头,不过屏幕暂时没有点亮,具体显示效果和细节还不清楚。
其实追觅做模块化手机早就有消息了。今年 1 月份,追觅手机团队就在西南欧经销商大会上,展示过高奢系列和旗舰模块化系列产品,当时就透露模块化版本会搭配丰富的拓展配件。(消息来源:快科技)

5 月 3 日消息,5 月新机大战将至,多家厂商新品蓄势待发。
日前,博主「数码闲聊站」汇总了部分 5 月将发布的新机,包括 OPPO Reno16 系列、荣耀 600 系列、iQOO 15T 以及小米 17 系列新机,vivo S60 系列发布时间仍未确定。
从目前信息来看,小米 17 系列新机或为此前多次曝光的小米 17 Max。该机已获得入网许可,型号为 2605EPN8EC,定位全能大屏旗舰。
与小米 17 Pro 系列不同,小米 17 Max 取消了标志性的背屏设计,将内部空间更多用于提升电池容量。
此前爆料显示,其电池容量达到 8000mAh,成为小米史上电池最大的手机,同时维持 100W 有线快充与 50W 无线快充的组合。
核心配置上,新机预计配备 6.9 英寸 1.5K 四等窄边直屏,搭载 2 亿像素主摄与 5000 万像素长焦微距镜头,采用第五代骁龙 8 至尊版。(消息来源:快科技)

距离国行 Nintendo Switch 网络功能彻底关停,已经只剩最后 15 天。国行 Nintendo Switch 网络服务将于 2026 年 5 月 15 日 22 点正式停止。
届时,这台曾承载着无数玩家期望的游戏机,将永久性地沦为单机设备。不仅 e 商店将彻底关闭,下载服务与兑换码兑换功能也将同步失效。在那之后,即便是你花钱购买过的游戏,一旦从机器里删除,也将永远无法找回。系统更新与游戏补丁下载也将于 5 月 15 日后终止服务。
根据官方计划,国行 Switch 及相关配件的维修服务,将于 2026 年 12 月 31 日正式终止。届时,无论是主机还是 Joy-Con 手柄坏了,都可能面临无处可修的尴尬境地。
为了能把它当一个纯粹单机设备,继续在国行 Switch 玩游戏,建议大家做好以下操作:
兑换全部兑换码:无论是免费补偿拿到的,还是在别处购买的,所有未用的游戏兑换码必须在 5 月 15 日前用完,过期即作废。
立即执行高强度下载:将游戏库中所有数字版游戏以及 DLC 内容,全部下载到机身存储或额外的 microSD 卡中。如果存储空间不够,现在就得去配一张大容量存储卡。
严防死守本地数据:永远不要删除已安装的游戏,也谨慎对机器执行「初始化」操作。
固定硬件与账号:提前设置好「常用主机」,绑定微信账号,不要轻易删除关联账户。
物理数据备份:重要的游戏截图、视频等资料,请尽快备份到电脑中,以防主机故障无法维修导致数据全无。(消息来源:游民星空)
给定两个字符串, s 和 goal。如果在若干次旋转操作之后,s 能变成 goal ,那么返回 true 。
s 的 旋转操作 就是将 s 最左边的字符移动到最右边。
s = 'abcde',在旋转一次之后结果就是'bcdea' 。
示例 1:
输入: s = "abcde", goal = "cdeab" 输出: true
示例 2:
输入: s = "abcde", goal = "abced" 输出: false
提示:
1 <= s.length, goal.length <= 100s 和 goal 由小写英文字母组成你写了测试,覆盖率100%,感觉稳了。结果上线后,用户点了个按钮,页面直接白屏。你纳闷:覆盖率不是100%吗?因为你测的都是“天气好不好”,没测“会不会地震”。今天我们就来聊聊前端测试的正确姿势——怎么测才能真的有用,而不是为了指标好看写一堆废话。
前端测试常走两个极端:要么完全不测,上线随缘;要么为了覆盖率,测了等于没测(比如测个1 + 1 = 2)。真正有效的测试,不是越多越好,而是该测的测,不该测的别浪费生命。
今天我们用“测试金字塔”模型,帮你理清单元测试、组件测试、E2E测试的分工。看完你会知道:哪部分代码必须测,哪部分可以跳过,哪部分用哪个工具。
/\
/E2E\ ← 少而精,关键路径
/------\
/集成测试\ ← 中等,组件间交互
/----------\
/ 单元测试 \ ← 多而快,纯逻辑
/--------------\
比例大概是:单元测试占70%,集成测试20%,E2E 10%。不是死规定,但原则:底层测试成本低,多写;顶层测试维护成本高,只写关键路径。
单元测试的目标:给定输入,输出是否正确。不关心函数内部怎么实现的,只关心结果。
适合测的:
calculateDiscount(price, level))。formatDate、parseQuery)。不适合测的(测了也白测):
工具:Jest + Vitest(Vite项目推荐Vitest)。
例子:
// 要测的函数
function formatPrice(price, currency = '¥') {
return `${currency}${price.toFixed(2)}`;
}
// 测试
test('格式化价格', () => {
expect(formatPrice(10.5)).toBe('¥10.50');
expect(formatPrice(10.5, '$')).toBe('$10.50');
});
黄金法则:如果重构代码不破坏测试,说明你测的是行为,不是实现。
组件测试(React Testing Library / Vue Test Utils)的目标:模拟用户行为,检查组件渲染和交互是否正确。不关心DOM结构细节,只关心用户能看到什么、能做什么。
适合测的:
不适合测的:
工具:React Testing Library + Jest(官方推荐),Vue Test Utils + Vitest。
例子(React Testing Library):
import { render, screen, fireEvent } from '@testing-library/react';
import Counter from './Counter';
test('点击按钮增加计数', () => {
render(<Counter />);
const button = screen.getByText('增加');
fireEvent.click(button);
expect(screen.getByText('计数: 1')).toBeInTheDocument();
});
原则:测用户能看到的东西,不要测内部实现。
E2E测试模拟真实浏览器,跑完整的用户流程。它最像真实用户,但也最慢、最脆弱(网络波动、页面改动容易挂)。
适合测的(3-5个核心流程):
不适合测的:
工具:Cypress(最友好)、Playwright(更可靠)、Puppeteer(较底层)。
例子(Cypress):
describe('用户登录', () => {
it('输入正确账号密码后跳转到首页', () => {
cy.visit('/login');
cy.get('[data-cy=username]').type('user@example.com');
cy.get('[data-cy=password]').type('password123');
cy.get('[data-cy=submit]').click();
cy.url().should('include', '/dashboard');
cy.contains('欢迎回来', { timeout: 10000 });
});
});
维护技巧:给关键元素加上data-cy属性,避免改样式或文本时测试挂掉。
很多团队追求100%覆盖率,结果工程师花大量时间测无关紧要的代码(比如测Redux的action creator是个纯对象)。覆盖率工具(Istanbul)只能告诉你“哪些代码没执行过”,不能告诉你“没测到的重要逻辑”。有时100%覆盖率,却漏掉了一个关键的空值判断。
正确的覆盖率指标:
日常开发:单元测试 + 组件测试在CI里跑(每次push)。E2E测试单独流水线,部署前跑一次(因为慢)。
测试是手段,不是目的。目的是信心:当你改完代码,测试全绿,你能放心上线。
别买一大堆没用的险,也别裸奔。
用 AI 写代码一段时间后,我发现一个很反直觉的问题:我们其实已经有一些“最佳实践”,但它们无法复用:
既然代码可以用 Git 管理、用 NPM 分发,为什么 AI 规范还停留在“复制粘贴”?
本质问题是:我一直把规则当“文本”,而不是“代码”。
如果把 AI 规则当作代码,它应该具备三个能力:
否则它就不是工程资产,而只是碎片化经验沉淀。一个规范,如果不能被 install,那它本质上只是不成体系的经验。
那问题来了:一个“可安装的 AI 规范”,在工程上到底长什么样?
最小结构其实非常简单:
my-skill/
├── SKILL.md
├── rules/
├── package.json
但真正的关键不是结构,而是它解决的问题。
传统方式是把所有规则写在一个 prompt 里,但这会导致:
上下文污染 + 规则冲突 + AI 记忆漂移
拆分之后:
AI 不再“理解一坨规则”,而是按职责加载规则上下文
AI 最大的问题不是不会写代码,而是:
不知道当前约束体系是什么
SKILL.md 本质是一个“运行时契约”:
name: project-core-standards
description: 项目的核心代码规范、行为准则与架构要求
version: 1.0.0
author: Admin
它定义的不是规则内容,而是:规则系统的身份边界
一旦进入 npm 体系,规则就发生了本质变化: 从“文档”变成“可安装能力”
这套自定义的skills最终是这样被使用的:
npx project-core-standards init
执行后,会进入一个交互式初始化流程:
Welcome to Project Core Standards Setup
Please select the IDEs you want to generate rules for:
[1] Cursor (.cursorrules)
[2] Windsurf (.windsurfrules)
[3] Antigravity / Gemini (GEMINI.md)
[4] GitHub Copilot (.github/copilot-instructions.md)
[5] Cline / Roo Code (.clinerules)
[6] Codex (.codexrules)
[A] All of the above
Enter your choices (e.g., 1,3 or A):
这一步的意义非常关键:同一套规则,可以适配所有主流 AI 编程环境**
也就是说:不再是“适配工具”,而是“统一规则源”
最终,我把这套系统封装成了一个 npm 包: project-core-standards
它的核心结构如下:
---
name: project-core-standards
description: 项目的核心代码规范、行为准则与架构要求。适用于所有需要编写代码、重构或进行代码审查的场景。
version: "1.0.0"
author: "Admin"
---
两个核心规则(真正落地的部分),Skill 的真正价值,不是结构,而是规则本身。
涵盖核心开发底线:
- commit 规范化(Conventional Commits)
- pnpm 作为唯一包管理方式
- Vue 项目结构约束
- TypeScript 强制类型约束
- 数据库变更必须可追踪
- 组件必须可复用、不可重复造轮子
这个规则解决的是:AI 写代码“失控”的问题
核心目标:保持功能不变的前提下优化代码质量
原则包括:
- 优先简化逻辑,而不是增加抽象
- 删除重复代码,而不是复制模式
- 提升可读性优先于“设计模式正确性”
- 避免过度工程化
- 保持结构一致性
这个规则解决的是: AI 过度设计 / 复杂化代码的问题
分发不是问题,问题是: 如何更新规则,而不破坏项目已有定制? 这里的设计核心是 Marker:
<!-- BEGIN: project-core-standards -->
<!-- END: project-core-standards -->
同步逻辑:
本质是: 局部 patch,而不是文件 overwrite
工程实现关键点,在 CLI 层:
INIT_CWD 定位真实项目路径核心思想是:把 Git 的 diff 能力,搬进 AI 规则系统**
引入 project-core-standards 后,开发流程变成:
以前:
新项目 → prompt 调教 → 规则迁移 → 人工同步
现在:
npx init → 自动生成规则体系
当 AI 成为开发流程的一部分,一个新的层级出现了:
而 Skill 的意义是: 让 AI 行为本身,变成可工程化管理的资产
未来可能会变成这样:不再“调教 AI”, 而是“安装开发规范”。想了解详细的规则内容可以点击这里查看。
上个月,我接手了一个"Uniswap 精简版"项目——一个支持 Ethereum、Polygon、Arbitrum 三条链的 DEX 前端。项目用 wagmi v2 + RainbowKit 做钱包连接,React + Vite 开发。需求听起来很简单:用户连接钱包后,能选择任意一条链进行交易,并且钱包会自动切换到对应链。
我当时想,wagmi 不是有 useSwitchChain 和 useAccount 吗?直接调用就完事了。结果呢?我花了整整三天,经历了无数个"为什么钱包没反应"、"为什么链没切换但页面状态变了"的抓狂时刻。这篇文章,就是把我踩过的坑和最终的解决方案完整记录下来。
一开始,我的思路很直接:用 useAccount 获取当前链 ID,用 useSwitchChain 切换链。代码大概长这样:
// 我最初的错误写法
const { chain } = useAccount();
const { switchChain } = useSwitchChain();
const handleChainChange = (targetChainId: number) => {
if (chain?.id !== targetChainId) {
switchChain({ chainId: targetChainId });
}
};
看起来没问题对吧?但实际运行时,问题来了:
问题 1: 在 MetaMask 上切换链后,useAccount 返回的 chain 更新了,但 UI 上的交易对信息没有更新。我明明用了 useEffect 监听 chain 变化,但页面就是不刷新。
问题 2: 切换到一条不支持的链(比如用户自己添加了 BSC)时,useSwitchChain 会报错,但错误信息非常不友好,而且 chain 状态会被污染。
问题 3: 最诡异的是——当用户手动在钱包里切换链,而不是通过我写的按钮切换时,useSwitchChain 根本不会触发,但 useAccount 的 chain 变了。这就导致我的代码里有两套"当前链":一套来自按钮操作,一套来自钱包事件,它们经常不同步。
排查了两天,我翻遍了 wagmi 的文档和 GitHub Issues,终于发现了关键点:wagmi v2 中 useAccount 的 chain 是只读的,它只反映钱包当前连接的链,不会触发 React 组件的重新渲染(至少在特定场景下)。而 useSwitchChain 返回的 isSuccess 状态才是可靠的切换完成标志。
我做的第一件事,是抛弃了"用 useAccount 驱动 UI"的思维。wagmi v2 推荐的做法是:用 useChainId 获取当前链 ID,用 useSwitchChain 处理切换,用 useEffect 监听切换完成事件。
这里有个坑:useChainId 返回的是 wagmi 配置中的当前链 ID,而不是钱包实际连接的链 ID。如果用户手动在钱包里切换,useChainId 不会自动更新!所以,我最终决定自己维护一个"同步的链状态"。
我创建了一个自定义 hook useSyncedChain:
// hooks/useSyncedChain.ts
import { useChainId, useSwitchChain, useAccount, usePublicClient } from 'wagmi';
import { useEffect, useState, useCallback } from 'react';
export function useSyncedChain() {
// 从 wagmi 获取基础状态
const configChainId = useChainId(); // wagmi 配置中的链 ID
const { chain: accountChain, isConnected } = useAccount(); // 钱包实际连接的链
const { switchChain, isPending, error } = useSwitchChain();
const publicClient = usePublicClient(); // 用来做链验证
// 我们自己的"权威"链 ID
const [activeChainId, setActiveChainId] = useState<number>(configChainId);
// 核心逻辑:同步钱包状态和配置状态
useEffect(() => {
if (!isConnected || !accountChain) {
// 未连接时,使用配置默认链
setActiveChainId(configChainId);
return;
}
// 如果钱包连接的链和配置链不同,说明用户手动切换了
if (accountChain.id !== configChainId) {
// 这里有个坑:不要直接 setActiveChainId,因为配置链可能不支持
// 应该检查 accountChain 是否在我们支持的链列表中
const supportedChains = [1, 137, 42161]; // Ethereum, Polygon, Arbitrum
if (supportedChains.includes(accountChain.id)) {
setActiveChainId(accountChain.id);
} else {
// 不支持的话,尝试切回默认链
switchChain({ chainId: configChainId });
}
} else {
setActiveChainId(configChainId);
}
}, [configChainId, accountChain, isConnected, switchChain]);
// 封装的切换函数
const switchToChain = useCallback(async (targetChainId: number) => {
try {
await switchChain({ chainId: targetChainId });
// switchChain 成功后,wagmi 会自动更新 configChainId
// 但为了保险,我们手动更新
setActiveChainId(targetChainId);
} catch (err) {
console.error('切换链失败:', err);
throw err;
}
}, [switchChain]);
return {
activeChainId,
switchToChain,
isSwitching: isPending,
error,
};
}
这个 hook 的核心思路是:不要信任任何一个单一来源,而是用钱包状态、配置状态、用户操作事件三者做交叉验证。
链切换后,我们需要重新获取交易对数据、用户余额等。一开始我用 useEffect 监听 activeChainId,但发现会触发两次:一次是状态更新,一次是钱包实际切换完成。
后来我用了 wagmi 的 useWatchChainId 来做精细控制:
// hooks/useChainDataRefresh.ts
import { useEffect, useRef } from 'react';
import { useChainId } from 'wagmi';
export function useChainDataRefresh(callback: (chainId: number) => void) {
const chainId = useChainId();
const prevChainIdRef = useRef(chainId);
useEffect(() => {
// 只在链真正变化时触发,避免初始化时的重复调用
if (prevChainIdRef.current !== chainId) {
console.log(`链已切换: ${prevChainIdRef.current} -> ${chainId}`);
callback(chainId);
prevChainIdRef.current = chainId;
}
}, [chainId, callback]);
}
然后在组件中使用:
// 在 Swap 组件中
const { activeChainId, switchToChain, isSwitching } = useSyncedChain();
const { data: pairData, refetch: refetchPair } = useQuery({
queryKey: ['pair', activeChainId, tokenA, tokenB],
queryFn: () => fetchPairData(activeChainId, tokenA, tokenB),
enabled: !!activeChainId && !!tokenA && !!tokenB,
});
useChainDataRefresh((newChainId) => {
// 链切换后,重新获取数据
refetchPair();
// 同时重置用户输入状态
setTokenA('');
setTokenB('');
});
最头疼的是用户手动在 MetaMask 里切换链。wagmi v2 的 useAccount 会更新,但 useChainId 不会。我之前的 useSyncedChain hook 已经通过 accountChain 处理了这种情况,但还有一个细节:切换完成后,需要等待钱包确认,期间 UI 应该显示加载状态。
我添加了一个"切换中"的状态管理:
// 在 useSyncedChain 中增加 pendingChainId
const [pendingChainId, setPendingChainId] = useState<number | null>(null);
const switchToChain = useCallback(async (targetChainId: number) => {
setPendingChainId(targetChainId);
try {
await switchChain({ chainId: targetChainId });
setPendingChainId(null);
setActiveChainId(targetChainId);
} catch (err) {
setPendingChainId(null);
throw err;
}
}, [switchChain]);
// 在 UI 中显示加载
const isLoading = isSwitching || pendingChainId !== null;
把所有逻辑整合到一个组件中:
// components/ChainSwitcher.tsx
import { useSyncedChain } from '../hooks/useSyncedChain';
import { useChainDataRefresh } from '../hooks/useChainDataRefresh';
import { useQuery } from '@tanstack/react-query';
import { useEffect } from 'react';
const SUPPORTED_CHAINS = [
{ id: 1, name: 'Ethereum', nativeCurrency: 'ETH' },
{ id: 137, name: 'Polygon', nativeCurrency: 'MATIC' },
{ id: 42161, name: 'Arbitrum', nativeCurrency: 'ETH' },
];
export function ChainSwitcher() {
const { activeChainId, switchToChain, isSwitching, error } = useSyncedChain();
// 链切换后刷新数据
useChainDataRefresh((chainId) => {
console.log('链已切换,刷新数据');
// 这里可以触发其他数据获取
});
const handleChainClick = async (chainId: number) => {
if (chainId === activeChainId) return;
try {
await switchToChain(chainId);
// 切换成功后,UI 会自动更新,因为 activeChainId 变了
} catch (err) {
// 显示错误 toast
alert(`切换失败: ${(err as Error).message}`);
}
};
return (
<div>
<h2>选择链</h2>
{SUPPORTED_CHAINS.map((chain) => (
<button
key={chain.id}
onClick={() => handleChainClick(chain.id)}
disabled={isSwitching}
style={{
fontWeight: chain.id === activeChainId ? 'bold' : 'normal',
opacity: isSwitching ? 0.5 : 1,
}}
>
{chain.name} ({chain.nativeCurrency})
{isSwitching && ' 切换中...'}
</button>
))}
{error && <p style={{ color: 'red' }}>错误: {error.message}</p>}
</div>
);
}
我把所有代码整合到一个可运行的示例中。假设你使用 Vite + React + TypeScript,安装依赖:
npm install wagmi viem @tanstack/react-query react
// main.tsx - 入口文件
import { WagmiProvider, createConfig, http } from 'wagmi';
import { mainnet, polygon, arbitrum } from 'wagmi/chains';
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
import { RainbowKitProvider, getDefaultConfig } from '@rainbow-me/rainbowkit';
import { ChainSwitcher } from './components/ChainSwitcher';
const config = createConfig({
chains: [mainnet, polygon, arbitrum],
transports: {
[mainnet.id]: http(),
[polygon.id]: http(),
[arbitrum.id]: http(),
},
});
const queryClient = new QueryClient();
function App() {
return (
<WagmiProvider config={config}>
<QueryClientProvider client={queryClient}>
<RainbowKitProvider>
<ChainSwitcher />
</RainbowKitProvider>
</QueryClientProvider>
</WagmiProvider>
);
}
export default App;
// hooks/useSyncedChain.ts - 上面已给出完整代码
// hooks/useChainDataRefresh.ts - 上面已给出完整代码
// components/ChainSwitcher.tsx - 上面已给出完整代码
坑 1:useAccount 的 chain 在切换后不会立即更新
现象:调用 switchChain 后,useAccount 返回的 chain 还是旧的,导致 UI 显示错误。解决:用 useChainId 配合 useEffect 监听,而不是依赖 useAccount 的 chain。
坑 2:useSwitchChain 的 isSuccess 有时为 false
现象:钱包已经切换成功,但 isSuccess 一直是 false。原因:wagmi v2 中 isSuccess 只在第一次成功时为 true,后续切换不会重置。解决:用 error 和 isPending 做判断,或者自己维护状态。
坑 3:在非浏览器环境(如测试时)调用 switchChain 会报错
现象:在 Node.js 或 React Native 中,window.ethereum 不存在,导致切换失败。解决:用 try-catch 包裹,并在错误时回退到配置默认链。
坑 4:链切换后,之前订阅的事件没有清理
现象:切换到 Polygon 后,Ethereum 上的事件监听还在运行,导致内存泄漏。解决:在 useEffect 中返回清理函数,或者用 wagmi 的 watchContractEvent 自动管理。
多链切换的核心不是调用 switchChain,而是同步钱包状态、配置状态和用户操作状态。wagmi v2 提供了基础工具,但需要自己组合成可靠的解决方案。如果你也遇到类似问题,可以试试我写的 useSyncedChain hook,或者深入看看 wagmi 的源码——里面有很多有趣的细节。
接下来,你可以探索如何用 wagmi 的 watchChainId 做更精细的控制,或者结合 viem 的 publicClient 做链验证。
这篇只讲本项目里“PDF拆分”工具的功能层 JavaScript 实现。主流程可以概括为:
选择 PDF -> 读取页数 -> 生成拆分页组 -> 复制指定页面 -> 生成多个 PDF -> 单文件下载或 ZIP 打包下载
工具基于 Vue 组织交互状态,核心 PDF 操作使用 pdf-lib,多文件结果打包使用 JSZip,页面预览和书签读取由 pdfjs-dist 辅助完成。
在线工具网址:see-tool.com/pdf-split
工具截图:
文件选择和拖拽上传共用同一套入口。真正加载前,先判断文件类型:
export function isPdfSplitFile(file) {
if (!file) {
return false;
}
var fileType = String(file.type || "").toLowerCase();
var fileName = String(file.name || "");
return fileType === "application/pdf" || /\.pdf$/i.test(fileName);
}
这里同时判断 MIME 和文件后缀,是因为部分浏览器环境下 file.type 可能为空,只依赖 MIME 会误拦正常 PDF。
加载文件时,会把同一份原始字节切成两份用途:
var rawBytes = await file.arrayBuffer();
var splitBytes = rawBytes.slice(0);
var previewBytes = rawBytes.slice(0);
var sourceDoc = await PDFDocument.load(splitBytes);
splitBytes 用于后续拆分,previewBytes 用于预览和书签读取。这样拆分主链路和辅助信息链路互不影响。
拆分逻辑不是直接处理输入框字符串,而是先转成统一结构:
{
label: "1-3",
indices: [0, 1, 2]
}
label 用于文件命名,indices 是 pdf-lib 需要的零基页码数组。
页码范围解析支持逗号分隔,也支持倒序区间:
function buildPageIndices(start, end) {
var indices = [];
var page;
if (start <= end) {
for (page = start; page <= end; page += 1) {
indices.push(page - 1);
}
return indices;
}
for (page = start; page >= end; page -= 1) {
indices.push(page - 1);
}
return indices;
}
所以用户输入 1-3,5,8-6 时,会生成三个输出段:第 1 到 3 页、第 5 页、第 8 到 6 页。
工具支持按页码范围、每 N 页、每页单独、奇偶页、可视化选择、书签、平均拆成 N 份。虽然入口不同,但最终都会变成 groups:
buildSplitGroups: function () {
if (this.splitMode === "ranges") {
return parsePdfSplitRangeGroups(this.rangeInput, this.totalPages);
}
if (this.splitMode === "everyN") {
return buildPdfSplitCountGroups(
this.totalPages,
parsePdfSplitPositiveInt(this.everyNInput),
);
}
if (this.splitMode === "everyPage") {
return buildPdfSplitEveryPageGroups(this.totalPages);
}
if (this.splitMode === "evenOdd") {
return buildPdfSplitEvenOddGroups(this.totalPages, this.evenOddMode);
}
if (this.splitMode === "visual") {
return buildPdfSplitVisualGroups(this.selectedPages);
}
if (this.splitMode === "bookmarks") {
return buildPdfSplitBookmarkGroups(this.bookmarkItems, this.totalPages);
}
if (this.splitMode === "nTimes") {
return buildPdfSplitNPartsGroups(
this.totalPages,
parsePdfSplitPositiveInt(this.nTimesInput),
);
}
return [];
}
这个设计的好处是,真正拆分 PDF 时不关心用户选择了哪种模式,只消费统一的页码分组。
可视化模式下,用户点选的是离散页码。工具会先排序、去重,再把连续页合并成一个输出段:
export function buildPdfSplitVisualGroups(selectedPages) {
var uniquePages = Array.isArray(selectedPages)
? selectedPages
.map(function (page) {
return Number(page);
})
.filter(function (page) {
return Number.isInteger(page) && page > 0;
})
.sort(function (left, right) {
return left - right;
})
.filter(function (page, index, source) {
return index === 0 || page !== source[index - 1];
})
: [];
if (!uniquePages.length) {
throw createPdfSplitInputError("emptySelection");
}
var groups = [];
var start = uniquePages[0];
var end = uniquePages[0];
for (var i = 1; i < uniquePages.length; i += 1) {
if (uniquePages[i] === end + 1) {
end = uniquePages[i];
continue;
}
pushMergedSelectionGroup(groups, start, end);
start = uniquePages[i];
end = uniquePages[i];
}
pushMergedSelectionGroup(groups, start, end);
return groups;
}
比如选择 1、2、3、7、9、10,结果会拆成 1-3、7、9-10 三个文件。
书签模式先读取 PDF 的 outline,再把书签所在页转换成拆分区间。核心逻辑是:当前书签页作为开始页,下一个书签前一页作为结束页。
export function buildPdfSplitBookmarkGroups(bookmarks, totalPages) {
var normalizedBookmarks = Array.isArray(bookmarks)
? bookmarks
.filter(function (item) {
return (
item &&
Number.isInteger(Number(item.pageNumber)) &&
Number(item.pageNumber) >= 1 &&
Number(item.pageNumber) <= totalPages
);
})
.map(function (item) {
return {
title: String(item.title || "").trim() || "bookmark",
pageNumber: Number(item.pageNumber),
};
})
.sort(function (left, right) {
return left.pageNumber - right.pageNumber;
})
: [];
var groups = [];
if (normalizedBookmarks[0].pageNumber > 1) {
groups.push({
label: "preface",
indices: buildPageIndices(1, normalizedBookmarks[0].pageNumber - 1),
title: "preface",
});
}
for (var index = 0; index < normalizedBookmarks.length; index += 1) {
var current = normalizedBookmarks[index];
var next = normalizedBookmarks[index + 1];
var start = current.pageNumber;
var end = next ? next.pageNumber - 1 : totalPages;
groups.push({
label: current.title,
indices: buildPageIndices(start, end),
title: current.title,
});
}
return groups;
}
如果第一个书签不在第一页,前面的内容会单独生成一个 preface 分段。
拆分主函数先构建 groups,然后每个分组创建一个新的 PDF:
for (index = 0; index < groups.length; index += 1) {
var group = groups[index];
var outputDoc = await PDFDocument.create();
var copiedPages = await outputDoc.copyPages(
this.sourceDoc,
group.indices,
);
copiedPages.forEach(function (page) {
outputDoc.addPage(page);
});
var outputBytes = await outputDoc.save();
var outputBlob = new Blob([outputBytes], {
type: "application/pdf",
});
nextOutputs.push({
name: this.buildOutputName(group, index, groups.length),
blob: outputBlob,
size: outputBlob.size,
});
}
这里不是修改原 PDF,也不是切割二进制文件,而是把源文档里的指定页面复制到一个新文档。group.indices 决定当前输出文件包含哪些页。
文件名会先清理原 PDF 名称,再结合模式和页码标签生成:
export function buildPdfSplitOutputName(options) {
var config = options || {};
var baseName = safePdfSplitBaseName(config.baseName);
var index = Number(config.index) || 0;
var total = Number(config.total) || 0;
var label = String(config.label || "");
var mode = String(config.mode || "ranges");
var sequence = String(index + 1).padStart(3, "0");
var safeLabel = sanitizePdfSplitFileLabel(label) || sequence;
if (mode === "everyPage") {
return baseName + "_page_" + safeLabel + ".pdf";
}
if (mode === "bookmarks") {
return baseName + "_" + sequence + "_" + safeLabel + ".pdf";
}
if (total === 1) {
return baseName + "_split.pdf";
}
return baseName + "_split_" + sequence + "_p" + safeLabel + ".pdf";
}
这样拆出多个文件时,用户能从文件名看出顺序和页码范围。
导出时先判断结果数量。只有一个 PDF 时直接下载;多个 PDF 时放进 ZIP:
downloadResult: async function () {
if (!this.outputs.length) {
return;
}
if (this.outputs.length === 1) {
this.downloadOutput(this.outputs[0]);
return;
}
var zip = new JSZip();
this.outputs.forEach(function (item) {
zip.file(item.name, item.blob);
});
var zipBlob = await zip.generateAsync({
type: "blob",
compression: "DEFLATE",
compressionOptions: {
level: 6,
},
});
this.downloadBlob(zipBlob, "split_result.zip");
}
浏览器下载统一通过 Blob 和临时 a 标签完成:
downloadBlob: function (blob, filename) {
var url = URL.createObjectURL(blob);
var link = document.createElement("a");
link.href = url;
link.download = filename;
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
URL.revokeObjectURL(url);
}
整个 PDF 拆分功能的核心,就是把不同输入方式都转换成稳定的页码分组,再用 pdf-lib 复制页面生成新文档,最后根据结果数量决定直接下载还是打包下载。
pathfinding3d 。好久不见,今天为大家带来的是,JavaScript目前最快的三维寻路库:pathfinding3d。性能是目前three-pathfinding和three-pathfinding-3d)的10-20倍 它不是仅限 Three.js 的插件,而是通用的 WASM 三维寻路引擎。只要你的 JavaScript 三维引擎能提供网格顶点与索引数据,就可以用本库构建导航区域、查询分组并搜索路径。
three-pathfinding-3d 的 10-20 倍量级。Float32Array,减少对象分配与 GC 压力。wasm-pack 打包,适用于 Web、Electron、Node.js 等 JavaScript 环境。three-pathfinding-3d 更快的项目本文从性能特征、底层模块实现与三维引擎兼容性三方面,说明 pathfinding3d 中 NavMesh 式三维寻路的算法结构与工程取舍。实现语言为 Rust,通过 WebAssembly 暴露给 JavaScript/TypeScript。
库采用经典的 导航网格(NavMesh) 工作流:将可走区域表示为三角面片及其邻接图,在图上做 A* 搜索得到多边形序列,再用 漏斗算法(String Pulling / Funnel) 把多边形通道拉直为空间折线。
flowchart LR
subgraph build [构建阶段]
Mesh[顶点 positions + 索引 indices]
Weld[容差焊接顶点]
Tri[三角面与邻接/Portal]
Group[连通分量分组]
Idx[GroupData + KD 树 + AABB]
Mesh --> Weld --> Tri --> Group --> Idx
end
subgraph query [查询阶段]
Pos[世界坐标]
KD1[KD 最近邻 + 可选多边形判定]
Astar[A* 在分组内图上搜索]
Portals[Portal 序列]
Funnel[3D 漏斗拉直]
Out[Float32Array 路径点]
Pos --> KD1 --> Astar --> Portals --> Funnel --> Out
end
Idx --> query
同一 Zone 内可能包含多个 Group(互不相连的三角面子图);get_group 决定点落在哪一组,find_path 仅在给定 group_id 内寻路。
three-pathfinding-3d 的对比属于同量级场景下的经验性描述;具体倍数随网格规模、图密度与硬件变化,应以实际基准测试为准。f64(glam::DVec3)做几何与搜索,与 JS 侧 number 精度衔接自然;输出写入 Float32Array 时再做 f32 截断,减小返回路径的内存与带宽。AstarScratch(开放表、closed、g/h、父指针、touched 用于增量清空)与 PathScratch(Portal 缓冲、路径点、flat_points)。单次查询主要在这些缓冲上读写,避免每次 find_path 在堆上大量分配小对象。reset:通过 touched 只恢复本次搜索访问过的节点,在图较大但搜索范围局部时,比整表 memset 更省。h_score + h_seen 对每个节点到终点的欧氏距离只算一次,重复入堆时复用。| 环节 | 典型结构 | 说明 |
|---|---|---|
| 最近三角形 / 分组 | 三维 KD 树 + AABB 剪枝 | 最近邻平均接近 (O(\log n)),predicate 会过滤无效候选 |
| A* | 二叉堆 + 邻接表 | 与展开节点数相关;边数约为三角网格邻接规模 |
| 漏斗 | 线性于 Portal 数量 | 对每个 Portal 常数次方向与交点判断 |
以下按源码模块对应说明(路径相对于仓库根目录 src/)。
builder.rs:从原始网格到 Zonepositions 长度为 3 的倍数,indices 为三角形索引三元组,且索引不越界。tolerance 将顶点量化到整数格点 (x/tol, y/tol, z/tol),合并近似重合顶点,得到压缩后的 vertices 与 remapped_indices。vertex_indices、质心 center、neighbours、portals(共享边上的两个顶点索引)。HashMap<(min,max), tri_idx>,若同一条边被两个三角形使用则 bind_neighbour,双向记录邻接三角形 id 与共享边的顶点对。group_id == -1 的三角形做 BFS(VecDeque)扩散,将连通分量标为 0..G-1,再按 group_id 聚合成 ZoneInput.groups。impls.rs:分组内图结构 GroupData
PolygonInput.id(构建时的三角形序号)映射到分组内的紧凑下标 id_to_index。neighbours_by_index 存储 NeighborLink { index, portal },供 A* 枚举邻居与后续取 相邻三角形之间的 Portal 边。pathfinding.rs:运行时索引与查询编排GroupSpatialData:每个分组维护全体三角形 AABB、每个三角形的 AABB、以三角形 质心 为点集的 KD 树(项为分组内下标)。node_tree:所有分组的 (group_idx, node_idx) 挂在同一棵 KD 树上,用于跨分组挑选最近三角形(如 get_group)。compute_group:
check_polygon == true:在最大距离平方阈值内,KD 搜索 + AABB + 到三角形平面距离 + 点是否在三角形内(math 模块)。get_closest_node_index:分组内 KD + AABB 距离剪枝;可选 is_vector_in_polygon(带 y 方向条带 + 三角形内测试)判定是否落在当前三角形上。compute_path_points:
astar_search 得到中间三角形序列;Portal3 列表:起点到第一段若有合法 Portal 则加入;相邻三角形间用 portal_between_indices 取共享边两端世界坐标;最后以目标点闭合通道;judge_dir(叉积的 y 分量)统一 Portal 左右顺序;funnel3d_into 生成平滑折线到 path_scratch.points;write_path_to_output 跳过第一个点(起点),将后续点写入调用方 Float32Array。astar.rs:分组内 A*BinaryHeap 按 f = g + h 最大堆反转实现最小 f;HeapNode 在 f 相等时用 idx 打破平局,保证次序稳定。g 的增量为当前与邻居三角形 质心间距离平方之和。h 为邻居三角形质心到 终点三角形质心 的 欧氏距离(非平方),并对每个节点缓存。parent 链从终点回到起点,再 reverse 得到从起点侧到终点侧的三角形序列(注意与 path 向量填充顺序一致)。channel.rs:三维漏斗与辅助插点funnel3d_into:在 Portal 序列上维护 apex、左右边界点与索引,用 judge_dir 判断“右转/左转”约束;必要时 insert 在一段 Portal 间按 线段最近点 在边上插值(distance_sq_segment_to_segment),并在 xz 平面上算交点参数 segment_fraction_xz,再 lerp 出三维点,减少拐角处路径贴边生硬的问题。math.rs:几何原语is_vector_in_polygon:先限制查询点 y 在三角形 y 范围加 ±0.5,再调用 is_point_in_triangle。point_to_plane_distance:点到三角形所在平面的有符号距离,用于分组时“落在面上”的数值容差(如 0.01)。distance_sq_segment_to_segment:两线段最近距离的平方及最近点,供漏斗 insert 使用。kdtree.rs:三维 KD 树x → y → z,对当前点集按该维排序,取中位点建节点,递归左右子树。nearest_matching:标准 KD 最近邻遍历,维护 best_distance;仅在 distance < best_distance 且 谓词为真时更新最优;利用 delta² < best_distance 决定是否搜索远侧子树。utils.rs / lib.rs
lib.rs 仅 pub use pathfinding::PathfindingWasm,JS 通过 wasm-bindgen 调用。本库 不依赖任何渲染引擎对象(无 THREE.Mesh、无场景图),只要求调用方提供:
positions:[x,y,z, ...] 的 f32 扁平数组(与 WebGL 属性布局一致即可)。indices:三角形索引 u32,每三个一组。因此只要引擎能导出或拼接 世界空间 下的顶点与索引(Three.js、Babylon.js、PlayCanvas、Cesium、自研 WebGL/WebGPU 等),即可使用;坐标系与单位由数据决定,库内部不做左手/右手或 Y-up/Z-up 的强制转换。
集成时注意:
group_id,跨组需业务层处理(如传送或桥接网格)。judge_dir 与部分点在三角形内判定依赖 y 轴 与水平投影习惯;若可走面为任意朝向的陡坡,需在业务上评估是否适用或是否应预处理网格。find_path 返回的点数对应 output 中写入的三元组个数;若缓冲区不足,返回值表示所需长度(见 README API 说明),需调用方扩容后重试。pathfinding3d 将 NavMesh 构建(焊接、邻接、连通分组)、KD 树空间查询、质心图上 A* 与 带 Portal 的三维漏斗拉直 集中在 Rust/WASM 中,并通过 复用搜索缓冲区 与 Float32Array 直写 控制 JS 侧开销,从而在浏览器与 Node 中提供通用的三维寻路后端;与具体三维引擎的耦合点仅有 网格顶点与索引的序列化格式。
你是否也和我一样,最初被 Cursor 的 Agent 模式惊艳到,感觉拥有了一个不知疲倦的编程助手?但用了一段时间后,可能会陷入一个瓶颈:除了打开 Cmd+I 让 Agent 写代码,似乎挖掘不出它更多的潜力了。
其实,Agent 只是 Cursor 强大能力的冰山一角。当你把它从一个“代码生成器”视为一个“AI 开发团队”时,才能真正释放它的生产力。今天,我们就来深入挖掘 Cursor 那些被低估的进阶技巧,让你从“会用”到“精通”。
很多效率问题,根源在于用错了模式。Cursor 提供了三种核心交互模式,理解它们的定位是高效使用的第一步。
Ask 模式:你的技术顾问
当你面对一个陌生的代码库,或者需要探索技术方案时,Ask 模式是你的最佳选择。它的核心价值在于探索、学习和理解,而不是直接修改代码。
典型场景:
@file src/utils/auth.ts 中的 validateUser 函数是如何工作的?”next-intl 和 react-i18next 哪个更合适?”黄金法则:在不确定的情况下,永远先用 Ask 模式探索,明确方案后再切换到 Agent 执行。宁可多问几轮,也别让 Agent 盲目修改代码。
Agent 模式:你的执行工程师
当你有了明确的目标和方案后,就该 Agent 上场了。它能理解你的意图,自主搜索代码、修改文件、执行命令,直到完成任务。
高效提示词原则:
说“做什么”,而非“怎么做” :
提供可验证的目标:例如,要求 Agent 遵循项目中已有的测试模式来编写新的测试用例,这给了它一个客观的成功标准。
Plan 模式:你的架构师
面对涉及多个文件、有数据库变更或核心逻辑修改的复杂需求时,直接丢给 Agent 风险极高。Plan 模式的价值在于“磨刀不误砍柴工”。
工作流程:
何时必须用 Plan?
AI 输出质量的高低,很大程度上取决于你喂给它什么上下文。塞太多无关信息会稀释它的注意力,导致输出“牛头不对马嘴”。Cursor 的 @ 引用体系就是为了解决这个问题。
@文件名:精确注入单个文件内容。当你需要修改或分析特定文件时,这是最直接的方式。@文件夹名:注入整个目录的结构信息,适合让 AI 分析某个模块的整体情况。@codebase:触发语义搜索,让 Agent 自己在整个项目中寻找相关代码。当你不确定代码在哪时,用它来探索。@doc:引入已索引的第三方文档,例如 React 或 Next.js 的官方文档,让 AI 的回答更权威。@git:引用 Git 历史或 diff,方便进行代码审查或追溯变更。使用建议:遵循“先精确,后宽泛”的原则。知道文件名就直接 @文件名,不确定时再用 @codebase。
你是否厌倦了每次开新会话都要跟 AI 重复解释项目规范?“我们用 Tailwind,别用 styled-components”、“API 统一放 src/api/ 目录”……
Rules 功能可以将你的编码规范、架构决策固化为 AI 的“持久记忆”。配置一次,永久生效。
.cursor/rules/ 目录下,与项目代码一起提交到 Git,团队成员共享。最佳实践:
这是 Cursor 最具颠覆性的能力之一,将 AI 从“实时交互”解放为“后台自动化”。
Cloud Agents:你的后台任务执行者
对于耗时较长、不需要实时干预的任务,可以交给 Cloud Agent。它会在独立的云端沙盒环境中执行,完成后通过 Pull Request 的形式交付成果。
适用场景:
你可以从 Cursor 的网页界面、Slack、Linear 甚至 GitHub Issue 的评论中触发 Cloud Agent,然后安心地去处理其他工作,回来验收即可。
Automations:事件驱动的自动化流程
如果说 Cloud Agent 是你手动触发的,那么 Automations 就是为 AI 配置了“触发器”,满足条件就自动运行。
触发方式:
还在等待同事进行 Code Review?Bugbot 可以作为全自动的后台守卫,在你推送 PR 后自动运行,在代码行内直接留下评论。
它能帮你发现:
你还可以在项目的 .cursor/BUGBOT.md 文件中配置项目特有的检查规则,例如“所有 API 入参必须经过 zod 校验”,让审查标准与团队规范保持一致。
Cursor 已经远远超越了一个简单的 AI 代码编辑器。通过灵活运用 Ask、Agent、Plan 三种模式,精准管理上下文,用 Rules 固化规范,并借助 Cloud Agents、Automations 和 Bugbot 实现自动化,你实际上是在指挥一个分工明确、7x24 小时待命的 AI 开发团队。
希望这些技巧能帮助你打破使用瓶颈,将开发效率提升到新的层次。
同一个 Mobile 项目,
expo start --web跑得好好的,真机扫码后 AI 对话一直转圈,Vercel 线上日志一条都没有。请求根本没到服务端,但原因远不止"网络不通"这么简单。这篇文章从一次真机调试讲起,把 Vercel 路由冲突、Edge Runtime 识别、SSE 平台分流、环境变量管理、国内网络限制五个层面的问题一次性讲清楚。
我的项目是一个 AI 原生的类 Notion 应用,Web 端和 Mobile 端共享同一套 AI 请求逻辑。某天我在真机上测试 Mobile 端的 AI 对话功能,发送消息后一直转圈,最终走到 onError 回调。
切到 Web 端(expo start --web),同样的代码、同样的 AI 服务地址,一切正常。
更诡异的是——Vercel 线上日志里一条请求记录都没有。请求像凭空消失了一样。
"线上没日志"意味着两种可能:请求根本没到服务端,或者请求到了但没进入业务代码。 这个判断成了后续排查的分水岭。
在讲问题之前,先交代一下项目的 AI 请求链路,因为后面的每个问题都和这个架构有关。
My-Notion/
├── apps/
│ ├── web/ # Next.js Web 应用
│ └── mobile/ # Expo React Native 应用
├── packages/
│ ├── ai/ # AI 核心逻辑(共享)
│ ├── business/ # 业务状态(共享)
│ └── convex/ # 数据库逻辑(共享)
└── services/
└── ai/ # AI 网关(独立部署到 Vercel)
├── api/
│ ├── chat.ts # /api/chat 入口
│ └── [[...route]].js # catch-all 路由
└── src/
└── index.ts # Hono 主应用
Mobile App
└─ fetch("https://my-notion-ai.vercel.app/api/chat")
└─ Vercel (services/ai)
└─ DashScope (阿里云 AI 服务)
Mobile 端直接请求 services/ai 部署在 Vercel 上的 API,不经过 Web 端的 Next.js。这是因为 Expo React Native 不走 Next.js 的 API Route,需要独立的 AI 服务入口。
AI 对话使用 SSE(Server-Sent Events)实现流式输出。但 React Native 对 ReadableStream 的支持不完整,需要按平台分流:
if (Platform.OS === "web") {
// Web 端:ReadableStream 逐块读取,实现真正的流式
const reader = response.body?.getReader();
// ...
} else {
// Native 端:response.text() 一次性读取
const text = await response.text();
processSSEBuffer(text + "\n", callbacks);
}
Web 端能实时看到 AI 逐字输出,Native 端则是等 DashScope 完全响应后一次性显示——不流式,但能用。
services/ai/api/ 目录下有两个文件:
api/chat.ts — Hono 格式,声明了 export const runtime = "edge" 和 export default app
api/[[...route]].js — Serverless catch-all,内容是:const { handle } = require("@hono/node-server/vercel");
const app = require("../dist/services/ai/src/index.js").default;
module.exports = handle(app);
Vercel 的路由解析规则是:catch-all [[...route]] 会匹配所有 /api/* 请求,包括 /api/chat。
这意味着,即使 chat.ts 声明了 export const runtime = "edge",Vercel 也不会把它当作独立的 Edge Function——因为 [[...route]].js 已经接管了 /api/chat 这个路由。
Web 端有自己的 Next.js Route Handler 处理 /api/chat,根本不走 services/ai 的 Vercel 部署。所以 Web 端从来没触发过这个路由冲突。
[[...route]].js 是 Node.js Serverless 函数,它 require("../dist/services/ai/src/index.js")。而 src/index.ts 使用了:
import "dotenv/config";
import { randomUUID } from "crypto";
这些是 Node.js 专用模块。在 Serverless Runtime 中:
dist/ 没有正确构建,require 直接失败 → 请求 500/502dist/ 存在,Serverless 函数到 DashScope 国内节点的网络不稳定,可能超时无论哪种情况,请求都不会进入 chat.ts 的业务代码,所以 Vercel 日志里看不到你的业务日志。
删除 api/[[...route]].js,让 api/chat.ts 作为独立 Edge Function 被 Vercel 识别。
同时将 api/chat.ts 从 Hono 格式改为 Vercel 原生 Edge Function 格式:
// 之前:Hono 格式
import { Hono } from "hono";
import { streamSSE } from "hono/streaming";
const app = new Hono().basePath("/api");
app.post("/chat", async (c) => { ... });
export default app;
// 之后:Vercel 原生 Edge Function
export const runtime = "edge";
export async function POST(request: Request): Promise<Response> { ... }
关键区别:
| Hono 格式 | Vercel 原生格式 | |
|---|---|---|
| 入口 | export default app |
export async function POST |
| Runtime 识别 | 可能被 catch-all 劫持 | Vercel 直接识别为 Edge Function |
| SSE 输出 |
streamSSE() (Hono API) |
new ReadableStream() (Web 标准) |
| CORS | app.use("*", cors()) |
手动处理 OPTIONS + 响应头 |
Hono 的 streamSSE 输出格式:
event: content
data: {"type":"content","text":"..."}
原生 ReadableStream 手动编码的格式:
event: content
data: {"type":"content","text":"..."}
格式完全一致——客户端的 processSSEBuffer 按 data: 前缀解析,忽略 event: 行,解析 JSON 里的 type 字段来分发。客户端代码无需任何修改。
检查 .env 发现:
EXPO_PUBLIC_AI_SERVICE_URL=https://my-notion-ai.vercel.app
本地开发时 AI 请求直接打到 Vercel 线上服务,而不是本地 services/ai 源码。如果改了 AI 逻辑想验证,必须先推代码等 Vercel 部署——开发效率极低。
Expo 遵循 .env.local > .env.production > .env 的优先级。之前踩过的坑:
.env.local 覆盖 .env,导致本地开发走线上地址.env.production 在 --no-dev 模式下覆盖 .env
localhost 在真机上指向手机自身,必须用局域网 IP.env 保持线上域名作为默认值,通过启动命令行内覆盖为本地地址:
{
"scripts": {
"dev": "expo start",
"dev:local": "EXPO_PUBLIC_AI_SERVICE_URL=http://localhost:3001 expo start",
"dev:all": "concurrently \"pnpm run dev\" \"pnpm run dev:convex\"",
"dev:all:local": "concurrently \"pnpm run dev:local\" \"pnpm run dev:convex\""
}
}
Expo 的优先级是 process.env(行内设置)> .env 文件,所以 dev:local 的行内变量会覆盖 .env 的值。
| 命令 | AI 地址 | 场景 |
|---|---|---|
pnpm dev |
https://my-notion-ai.vercel.app(读 .env) |
默认走线上 |
pnpm dev:local |
http://localhost:3001(行内覆盖) |
走本地 AI 源码 |
真机调试时把 localhost:3001 换成局域网 IP 即可。
.env 在 .gitignore 中,EAS 云端构建时无法读取。EXPO_PUBLIC_ 变量必须在 eas.json 的 env 字段中显式声明:
{
"build": {
"preview": {
"env": {
"EXPO_PUBLIC_AI_SERVICE_URL": "https://my-notion-ai.vercel.app"
}
},
"production": {
"env": {
"EXPO_PUBLIC_AI_SERVICE_URL": "https://my-notion-ai.vercel.app"
}
}
}
}
路由冲突修复后,重新部署 services/ai 到 Vercel,真机测试——还是不行。
仔细一想:我的手机没开代理。
.vercel.app 域名在国内被 DNS 污染/网关拦截,请求根本出不去。这就是为什么 Vercel 线上日志一条都没有——请求从手机发出后,在网络层就被拦截了,根本没到 Vercel。
Web 端没问题是因为电脑开了代理。
这不是代码问题,而是基础设施问题。在国内使用 Vercel 部署的服务,移动端用户大概率会遇到:
.vercel.app 域名被 DNS 污染,解析失败fetch 超时或 Network request failed,没有任何服务端日志| 方案 | 复杂度 | 效果 |
|---|---|---|
给 services/ai 绑自定义域名 + Cloudflare CDN |
中 | 完全解决 |
在 eas.json 中指向国内可达的代理地址 |
低 | 部分解决 |
| 自建国内服务器部署 AI 服务 | 高 | 完全解决 |
当前阶段,开发测试时开手机代理即可。后续上线需要绑定自定义域名。
React Native 对 ReadableStream 的支持不完整。Web 端 response.body.getReader() 正常工作,但 Native 端可能导致 SSE 流读取卡住,AI 请求一直转圈。
async function parseSSEStream(
response: Response,
callbacks: StreamCallbacks,
): Promise<void> {
if (Platform.OS === "web") {
await parseSSEStreamWeb(response, callbacks); // ReadableStream 逐块读取
} else {
await parseSSEStreamNative(response, callbacks); // response.text() 一次性读取
}
}
Web 端保持流式体验,Native 端牺牲流式效果换取稳定性。等 React Native 对 ReadableStream 的支持完善后,可以统一为流式方案。
response.text() 会等整个响应完成后才返回。这意味着:
这是当前方案的已知限制,后续可以通过引入 react-native-sse 等第三方库实现原生端的流式体验。
将 api/chat.ts 改为 Vercel 原生 Edge Function 格式后,使用了 request.json()、new Response() 等 Web 标准 API。但 tsconfig.json 的 lib 只有 ["ES2022"],缺少 "WebWorker"。
TypeScript 不认识 Edge 环境下的 Request、Response、crypto.randomUUID() 等全局类型,编译报错。
{
"compilerOptions": {
"lib": ["ES2022", "WebWorker"]
},
"include": [
"api/**/*",
"src/**/*",
...
]
}
WebWorker lib 提供了 Edge Runtime 环境下的类型定义。同时 include 中加入 "api/**/*",确保 api/chat.ts 被 TypeScript 编译器覆盖。
之前 api/chat.ts 使用 Hono 格式,c.req.json() 是 Hono 的方法,类型由 Hono 自己提供。改成原生 request.json() 后,类型来源从 Hono 切换到了 Web 标准 API,才触发了这个问题。
{
"version": 2,
"buildCommand": "pnpm build",
"functions": {
"api/[[...route]].js": {
"memory": 1024,
"maxDuration": 60
}
}
}
functions 配置的是已删除的 [[...route]].js,Edge Function 不需要在这里声明。
{
"buildCommand": "pnpm build"
}
Edge Function 由 Vercel 自动识别(通过 export const runtime = "edge" 声明),不需要在 vercel.json 中额外配置。
| 文件 | 改动 | 解决的问题 |
|---|---|---|
services/ai/api/chat.ts |
Hono 格式 → Vercel 原生 Edge Function | 路由冲突 + Runtime 识别 |
services/ai/api/[[...route]].js |
删除 | 消除 catch-all 路由劫持 |
services/ai/vercel.json |
移除 Serverless 函数配置 | 配套 catch-all 删除 |
services/ai/tsconfig.json |
加 WebWorker lib + api include |
Edge 环境类型定义 |
apps/mobile/package.json |
加 dev:local / dev:all:local 命令 |
本地开发走本地 AI |
apps/mobile/.env |
AI 地址保持线上域名 | 默认走线上,本地开发用命令覆盖 |
这次调试涉及四个层面的问题,每个层面的排查思路不同:
| 层面 | 现象 | 排查方法 | 根因类型 |
|---|---|---|---|
| 路由层 | 线上无业务日志 | 检查 Vercel 路由文件是否冲突 | 架构设计 |
| 环境变量 | 本地开发走线上 | 检查 .env 优先级和实际值 |
配置管理 |
| 网络层 | 请求超时/无响应 | 确认客户端网络环境(代理/DNS) | 基础设施 |
| 运行时 | SSE 解析卡住 | 检查平台 API 兼容性 | 平台差异 |
关键经验:
ReadableStream、CORS、网络环境都有平台差异.env.local 覆盖 .env 这种行为,不看文档根本想不到export const runtime = "edge"
.vercel.app 域名在国内不可达是基础设施问题,不是代码 Bug这次调试反复涉及 Vercel 的两种运行时,最后做一个对比:
| Edge Runtime | Serverless Runtime | |
|---|---|---|
| 运行环境 | V8 isolate(类似 Cloudflare Workers) | Node.js(AWS Lambda) |
| 冷启动 | < 1ms | 数百 ms 到数秒 |
| 最大执行时间 | 30s(免费)/ 60s(Pro) | 10s(默认)/ 60s(Pro)/ 300s(Enterprise) |
| 网络稳定性 | 边缘节点,全球分布 | 集中式,受区域网络影响 |
| Node.js API | 不支持(无 fs、crypto 等) | 完整支持 |
| 适合场景 | AI 流式响应、API 代理、短请求 | 长耗时任务、需要 Node.js API 的场景 |
AI 对话场景选择 Edge Runtime 的原因:
hkg1 香港)到国内网络更稳定但 RAG 相关路由因为依赖 convex 和 @langchain(使用 Node.js API),仍需保留在 Serverless Runtime。
本文基于 My-Notion 项目的真实调试经历撰写——一个 AI 原生的个人版 Notion,采用 pnpm workspace Monorepo 架构,Web + Mobile 双端。欢迎 Star ⭐
无论 $s$ 如何旋转,旋转后的字符串一定是 $s+s$ 的子串。
例如 $s=\texttt{abcde}$ 旋转若干次后得到 $t=\texttt{cdeab}$,这是 $s+s=\texttt{abcdeabcde}$ 的子串。
所以问题等价于:
注意题目没有保证 $s$ 和 $\textit{goal}$ 长度相等,如果不等,直接返回 $\texttt{false}$。
class Solution:
def rotateString(self, s: str, goal: str) -> bool:
return len(s) == len(goal) and goal in s + s
class Solution {
public boolean rotateString(String s, String goal) {
return s.length() == goal.length() && (s + s).contains(goal);
}
}
class Solution {
public:
bool rotateString(string s, string goal) {
return s.size() == goal.size() && (s + s).contains(goal);
}
};
func rotateString(s, goal string) bool {
return len(s) == len(goal) && strings.Contains(s+s, goal)
}
用 KMP、Z 函数、字符串哈希等算法,都可以 $\mathcal{O}(n)$ 判断 $s+s$ 是否包含 $\textit{goal}$。
下面用的 KMP 算法,原理见 KMP 算法讲解。
# 下面是 KMP 模板。对于本题来说,找到一个就可以返回了。为方便大家使用,我保留了完整的模板。
# 在文本串 text 中查找模式串 pattern,返回所有成功匹配的位置(pattern[0] 在 text 中的下标)
def kmp_search(text: str, pattern: str) -> List[int]:
m = len(pattern)
pi = [0] * m
cnt = 0
for i in range(1, m):
b = pattern[i]
while cnt and pattern[cnt] != b:
cnt = pi[cnt - 1]
if pattern[cnt] == b:
cnt += 1
pi[i] = cnt
pos = []
cnt = 0
for i, b in enumerate(text):
while cnt and pattern[cnt] != b:
cnt = pi[cnt - 1]
if pattern[cnt] == b:
cnt += 1
if cnt == len(pattern):
pos.append(i - m + 1)
cnt = pi[cnt - 1]
return pos
class Solution:
def rotateString(self, s: str, goal: str) -> bool:
return len(s) == len(goal) and len(kmp_search(s + s, goal)) > 0
class Solution {
public boolean rotateString(String s, String goal) {
return s.length() == goal.length() &&
!kmpSearch((s + s).toCharArray(), goal.toCharArray()).isEmpty();
}
// 下面是 KMP 模板。对于本题来说,找到一个就可以返回了。为方便大家使用,我保留了完整的模板。
// 在文本串 text 中查找模式串 pattern,返回所有成功匹配的位置(pattern[0] 在 text 中的下标)
private List<Integer> kmpSearch(char[] text, char[] pattern) {
int m = pattern.length;
int[] pi = new int[m];
int cnt = 0;
for (int i = 1; i < m; i++) {
char b = pattern[i];
while (cnt > 0 && pattern[cnt] != b) {
cnt = pi[cnt - 1];
}
if (pattern[cnt] == b) {
cnt++;
}
pi[i] = cnt;
}
List<Integer> pos = new ArrayList<>();
cnt = 0;
for (int i = 0; i < text.length; i++) {
char b = text[i];
while (cnt > 0 && pattern[cnt] != b) {
cnt = pi[cnt - 1];
}
if (pattern[cnt] == b) {
cnt++;
}
if (cnt == m) {
pos.add(i - m + 1);
cnt = pi[cnt - 1];
}
}
return pos;
}
}
class Solution {
// 下面是 KMP 模板。对于本题来说,找到一个就可以返回了。为方便大家使用,我保留了完整的模板。
// 在文本串 text 中查找模式串 pattern,返回所有成功匹配的位置(pattern[0] 在 text 中的下标)
vector<int> kmp_search(const string& text, const string& pattern) {
int m = pattern.size();
vector<int> pi(m);
int cnt = 0;
for (int i = 1; i < m; i++) {
char b = pattern[i];
while (cnt && pattern[cnt] != b) {
cnt = pi[cnt - 1];
}
if (pattern[cnt] == b) {
cnt++;
}
pi[i] = cnt;
}
vector<int> pos;
cnt = 0;
for (int i = 0; i < text.size(); i++) {
char b = text[i];
while (cnt && pattern[cnt] != b) {
cnt = pi[cnt - 1];
}
if (pattern[cnt] == b) {
cnt++;
}
if (cnt == m) {
pos.push_back(i - m + 1);
cnt = pi[cnt - 1];
}
}
return pos;
}
public:
bool rotateString(string s, string goal) {
return s.size() == goal.size() && !kmp_search(s + s, goal).empty();
}
};
// 下面是 KMP 模板。对于本题来说,找到一个就可以返回了。为方便大家使用,我保留了完整的模板。
// 在文本串 text 中查找模式串 pattern,返回所有成功匹配的位置(pattern[0] 在 text 中的下标)
func kmpSearch(text, pattern string) (pos []int) {
m := len(pattern)
pi := make([]int, m)
cnt := 0
for i := 1; i < m; i++ {
b := pattern[i]
for cnt > 0 && pattern[cnt] != b {
cnt = pi[cnt-1]
}
if pattern[cnt] == b {
cnt++
}
pi[i] = cnt
}
cnt = 0
for i, b := range text {
for cnt > 0 && pattern[cnt] != byte(b) {
cnt = pi[cnt-1]
}
if pattern[cnt] == byte(b) {
cnt++
}
if cnt == m {
pos = append(pos, i-m+1)
cnt = pi[cnt-1]
}
}
return
}
func rotateString(s, goal string) bool {
return len(s) == len(goal) && kmpSearch(s+s, goal) != nil
}
见下面字符串题单的「一、KMP」。
欢迎关注 B站@灵茶山艾府
Neo 框架连载 · AI 辅助撰写
在 AI 编程工具快速普及的今天,产品的试错成本大幅降低——把 IDEA 尽可能快地做出来才是最重要的,人工打磨细节和文章的 ROI 已经不高了。本系列文章均为人指导、AI 生成的内容,核心思路和设计决策来自人的判断,AI 负责快速落地。
在鸿蒙应用开发过程中,工作内容远不止写代码。需求评审、三方 SDK 对接(鸿蒙化进度不受控时需要兜底方案)、功能测试、自动化测试、稳定性测试、CI/CD 部署……这些都是日常。
这些环节的质量,很大程度上取决于系统的初始设计。
一般来说,组织沟通方式会通过系统设计表达出来——康威定律。基于 Spring 的微服务是特例,技术栈自带局部架构。但客户端不一样,尤其是鸿蒙客户端——技术栈太新,没有"自带架构"的框架可用。
没有明确设计的系统,功能基本是平铺开发,整体结构不超过三层:
项目像一个穿着"百衲衣"的大胖子,某处破裂贴上胶布继续凑合用。按照 Martin Fowler 在《企业应用架构模式》中的观点:随着领域逻辑复杂度的提升,领域建模程度较低的项目,增加的工作量是近似指数级的。
三个客观现实:
前些年很火的 DDD(领域驱动建模),在中小团队中培训成本高到不可能落地。但我认为最适合领域建模的软件产品是客户端而非服务器——客户端所有代码跑在同一个进程里,没有网络边界作为天然屏障,一个烂模块会影响整个应用。
面对以上问题,我提出两种约束——不是"最佳实践",而是划定底线:
这两种约束的具体落地就是 Neo 框架。下面展开约束一。
┌─────────────────────────────────────┐
│ entry(应用入口) │
│ 页面入口 / 路由 / 一多方案适配 │
├─────────────────────────────────────┤
│ features(功能页面层) │
│ 只处理页面交互,不处理数据逻辑 │
├─────────────────────────────────────┤
│ domains(领域建模层) │
│ 数据获取、业务逻辑、跨功能服务 │
├─────────────────────────────────────┤
│ infra(基础设施层) │
│ 无状态,可迁移,三方 SDK │
└─────────────────────────────────────┘
功能聚集层。入口页面、路由、一多方案适配,既是所有页面和功能的门面,也是构建的集合。按照项目实际情况可以选择一多方案适配或多端独立方式适配。
通过领域建模获取数据,自身只处理页面交互逻辑,不处理服务器、硬盘的数据。上层页面是相对抽象的,聚合内部功能的;下层负责具体功能。
这里并不一定要使用领域驱动建模的概念。具体业务领域是容易区分的,但公共能力很容易渗透到全局。上层的责任是编排各个领域,而非公共能力。
例如用户鉴权,很容易被拆分成用户数据结构在最下层、登录逻辑在上层。而更合理的情况是:上层有自己的值对象,登录鉴权的逻辑和数据结构内聚,完成这个过程后通知全局,自上而下分发状态。
最简单的理解就是当做二方和三方,尽可能按照可迁移到其他项目的思路设计。重点考虑无状态和可迁移——不是真的要迁移,而是最干净的基础设施是完全无状态的。
状态指的是由使用、登录获取的数据及其传递依赖。例如从个人登录信息 → 登录会议 SDK → 处理会议数据,这里就是状态的传递。无状态的模块不可以主动获取状态,需要数据应由调用方传入。
企业的最初和最终的目的是盈利,项目最初和最终的定位是工具。设计原则不管是 SOLID 还是七原则,都是局部"术"的层面,而真实的世界是混沌的。各层之间的设计都应考虑层级边界渗透的情况。
页面是相对抽象的,聚合内部功能的,主要是整体页面框架、路由、一多适配。与下层的边界较好区分。
features → domains:页面逻辑还是业务逻辑?通常的经验是页面操作驱动业务逻辑,业务数据驱动页面逻辑。例如网络通话场景,通话状态的转移是 SDK 数据的变化,页面也会根据这个数据变化。但页面不存在通话就不存在了吗?现在的大部分通话场景都已支持悬浮窗,通话的数据要独立在自己的领域建模中。
features → infra:具体功能页面还是组件?某个组件是否需要复用,复用即在下层。
渗透的重灾区。在没有建模的项目中,事实上的基础模块很多都是带业务状态的。这种很难改——改完容易出错,出错容易背锅,写的越多越错。逻辑的编排需要分清是通用逻辑还是业务逻辑,这部分可以适当用一些设计模式。
以 Neo 的 SoulApp 示例为例:
entry/src/main/ets/
├── pages/ # features — 页面交互
│ ├── IndexPage.ets # 首页
│ ├── ChatPage.ets # 聊天
│ ├── ExplorePage.ets # 发现
│ └── ...
├── services/ # domains — 领域服务
│ ├── business/ # 核心业务 (12个)
│ │ ├── AuthService # 认证
│ │ ├── ChatService # 聊天
│ │ └── ...
│ ├── feature/ # 功能服务 (5个)
│ └── lazy/ # 非关键服务 (2个)
├── services/infra/ # infra — 基础设施 (8个)
│ ├── NetworkService
│ ├── DatabaseService
│ ├── CacheService
│ └── ...
├── modules/ # entry — 模块注册
│ └── AppModule.ets # 所有 Service 的编排入口
└── data/ # 跨层数据模型
├── Models.ets
└── MockData.ets
下一篇将展开约束二:Service、NeoModule、ServiceManager 和 Phase 如何实现模块化服务编排与渐进式启动。
在LeetCode中等难度题目中,「交错字符串」是一道经典的动态规划应用题。它的核心是判断一个字符串是否能由另外两个字符串“交错”组成,看似简单却容易陷入思维误区,今天我们就来一步步拆解这道题,从题目理解到代码实现,把每一个细节讲透。
先明确题目要求:给定三个字符串s1、s2、s3,验证s3是否是由s1和s2交错组成的。这里的「交错」有严格定义,我们用通俗的话翻译一下:
将s1分割成若干个非空子串(比如s1 = a + b + c),s2分割成若干个非空子串(比如s2 = x + y);
分割后两个字符串的子串数量相差不超过1(|n - m| ≤ 1);
把这两组子串交替拼接,要么是「s1子串在前、s2子串在后」(a+x + b+y + c),要么是「s2子串在前、s1子串在后」(x+a + y+b),最终拼接结果等于s3。
举个例子:s1 = "aabcc",s2 = "dbbca",s3 = "aadbbcbcac",就是一个合法的交错组合——s1分割为"aa"+"bc"+"c",s2分割为"dbbc"+"a",交替拼接后得到"aa"+"dbbc"+"bc"+"a"+"c",正好等于s3。
而如果s3的长度不等于s1+s2的长度,那直接可以判定为false,这是最基础的边界条件。
拿到这道题,首先会想到暴力解法——枚举s1和s2的所有分割方式,再判断拼接后是否等于s3。但这种方法的时间复杂度极高,因为分割方式的数量是指数级的,对于稍长的字符串完全不适用。
这时候就需要动态规划(DP)来优化。动态规划的核心是「状态定义+状态转移」,我们可以通过定义一个DP数组,记录“用s1的前i个字符和s2的前j个字符,能否组成s3的前i+j个字符”,这样就能把大问题拆解成小问题,逐步递推求解。
定义dp[i][j]:表示s1的前i个字符(s1[0..i-1])和s2的前j个字符(s2[0..j-1]),能否交错组成s3的前i+j个字符(s3[0..i+j-1])。
这里要注意下标细节:i和j从0开始,当i=0时,意味着不使用s1的任何字符,只使用s2的前j个字符;当j=0时,意味着不使用s2的任何字符,只使用s1的前i个字符。
初始化的核心是处理“只使用s1”或“只使用s2”的情况:
dp[0][0] = true:s1的前0个字符(空字符串)和s2的前0个字符(空字符串),能组成s3的前0个字符(空字符串),这是基础条件。
当i>0、j=0时:dp[i][0] = dp[i-1][0] && s1[i-1] === s3[i-1]。也就是说,只有前i-1个字符能组成s3的前i-1个字符,且s1的第i个字符(s1[i-1])等于s3的第i个字符(s3[i-1]),才能满足条件。
当j>0、i=0时:类似上面,dp[0][j] = dp[0][j-1] && s2[j-1] === s3[j-1]。
对于任意i>0、j>0的情况,dp[i][j]的取值有两种可能,只要满足其中一种,就为true:
最后一个字符来自s1:此时需要满足「s1的前i-1个字符和s2的前j个字符能组成s3的前i+j-1个字符」(即dp[i-1][j]为true),并且s1的第i个字符(s1[i-1])等于s3的第i+j个字符(s3[i+j-1])。
最后一个字符来自s2:此时需要满足「s1的前i个字符和s2的前j-1个字符能组成s3的前i+j-1个字符」(即dp[i][j-1]为true),并且s2的第j个字符(s2[j-1])等于s3的第i+j个字符(s3[i+j-1])。
因此,状态转移方程可以写成:
dp[i][j] = (dp[i-1][j] && s1[i-1] === s3[i+j-1]) || (dp[i][j-1] && s2[j-1] === s3[i+j-1])
dp[s1.length][s2.length] 就是我们要的答案——表示s1的全部字符和s2的全部字符,能否交错组成s3的全部字符。
下面是完整的TypeScript代码,结合上面的思路,逐行解读每一步的作用:
function isInterleave(s1: string, s2: string, s3: string): boolean {
// 1. 边界条件:s3长度不等于s1+s2长度,直接返回false
const l1: number = s1.length;
const l2: number = s2.length;
const l3: number = s3.length;
if (l1 + l2 != l3) {
return false;
}
// 2. 初始化DP数组:dp[i][j]表示s1前i个、s2前j个能否组成s3前i+j个
const dp: boolean[][] = Array.from({ length: l1 + 1 }, () => new Array(l2 + 1).fill(false))
dp[0][0] = true; // 空字符组成空字符,基础条件
// 3. 填充DP数组:双重循环遍历所有i和j的组合
for (let i = 0; i <= l1; i++) {
for (let j = 0; j <= l2; j++) {
const p = i + j - 1; // s3当前对应的下标(前i+j个字符的最后一个下标)
// 情况1:最后一个字符来自s1(i>0才有可能)
if (i > 0) {
dp[i][j] = (dp[i - 1][j] && s1[i - 1] === s3[p]) || dp[i][j];
}
// 情况2:最后一个字符来自s2(j>0才有可能)
if (j > 0) {
dp[i][j] = (dp[i][j - 1] && s2[j - 1] === s3[p]) || dp[i][j];
}
}
}
// 4. 返回最终结果:s1全部和s2全部能否组成s3全部
return dp[l1][l2];
};
一定要注意:s1的第i个字符对应的下标是i-1,s2的第j个字符对应的下标是j-1,s3的前i+j个字符的最后一个下标是i+j-1(即变量p)。很多人会在这里混淆下标,导致代码出错。
上面的代码使用了二维DP数组,空间复杂度是O(l1*l2)。但观察状态转移方程可以发现,dp[i][j]只依赖于dp[i-1][j](上一行)和dp[i][j-1](同一行前一列),因此可以优化为一维DP数组,将空间复杂度降低到O(min(l1, l2))。
优化思路:用一个一维数组dp[j],每次遍历i时,更新dp[j]的值,具体可以自行尝试(提示:遍历i时,dp[j]的更新需要注意顺序,避免覆盖未使用的值)。
提交代码前,建议测试以下几个特殊用例,避免边界漏洞:
s1、s2均为空:s3也为空 → 返回true;s3非空 → 返回false。
其中一个字符串为空:比如s1为空,判断s2是否等于s3;反之亦然。
字符重复场景:比如s1="aabcc",s2="dbbca",s3="aadbbbaccc" → 返回false(最后一个c的来源不匹配)。
「交错字符串」的核心是用动态规划将“分割拼接”的复杂问题,转化为“逐步判断字符匹配”的子问题。关键在于正确定义DP状态,理清状态转移的两种情况,同时注意下标细节。
这道题的DP思路具有通用性,类似“两个字符串拼接成第三个字符串”的问题,都可以尝试用类似的状态定义来解决。掌握了这道题,也能加深对动态规划“递推思想”的理解。
由于每次旋转操作都是将最左侧字符移动到最右侧,因此如果 goal 可由 s 经过多步旋转而来,那么 goal 必然会出现在 s + s 中,即满足 (s + s).contains(goal),同时为了 s 本身过长导致的结果成立,我们需要先确保两字符串长度相等。
代码:
###Java
class Solution {
public boolean rotateString(String s, String goal) {
return s.length() == goal.length() && (s + s).contains(goal);
}
}
contains 操作的复杂度说明看到不少同学对 contains 的复杂度写成 $O(n)$ 有疑问。
在 Java 中,contains 实际最终是通过 indexOf(char[] source, int sourceOffset, int sourceCount, char[] target, int targetOffset, int targetCount, int fromIndex) 来拿到子串在原串的下标,通过判断下标是否为 $-1$ 来得知子串是否在原串出现过。
我们知道一个较为普通的子串匹配算法的复杂度通为 $O(n*k)$,其中 $n$ 和 $k$ 分别是原串和子串的长度,而一些复杂度上较为优秀的算法可以做到 $O(n + k)$,例如 KMP。
从复杂度上来看 KMP 似乎要更好,但实际上对于 indexOf 这一高频操作而言,KMP 的预处理逻辑和空间开销都是不可接受的。
因此在 OpenJDK 中的 indexOf 源码中,你看不到诸如 KMP 这一类「最坏情况下仍为线性复杂度」的算法实现。
但是 contains 的复杂度真的就是 $O(n * k)$ 吗?
其实并不是,这取决于 JVM 是否有针对 indexOf 的优化,在最为流行 HotSpot VM 中,就有对 indexOf 的优化。
使用以下两行命令执行 Main.java,会得到不同的用时。
###Java
// Main.java
import java.util.*;
class Main {
static String ss = "1900216589537958049456207450268985232242852754963049829410964867980510717200606495004259179775210762723370289106970649635773837906542900276476226929871813370344374628795427969854262816333971458418647697497933767559786473164055741512717436542961770628985635269208255141092673831132865";
static String pp = "830411595466023844647269831101019568881117264597716557501027220546437084223034983361631430958163646150071031688420479928498493050624766427709034028819288384316713084883575266906600102801186671777455503932259958027055697399984336592981698127456301551509241";
static int cnt = (int) 1e8;
static public void main(String[] args) {
long start = System.currentTimeMillis();
while (cnt-- > 0) ss.contains(pp);
System.out.println(System.currentTimeMillis() - start);
}
}
环境说明:
###Shell
➜ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
先执行 javac Main.java 进行编译后:
indexOf 实现进行匹配(执行多次,平均耗时为基准值 $X$):java -XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_indexOf Main
indexOf 进行匹配(执行多次,平均耗时为基准值 $X$ 的 $[0.55, 0.65]$ 之间):java Main
因此实际运行的 contains 操作的复杂度为多少并不好确定,但可以确定是要优于 $O(n * k)$ 的。
今日份加餐 :【面试高频题】难度 2/5,结合二分的序列 DP 运用题 🍭🍭🍭🍭
或是考虑加练如下「模拟」题 🍭🍭🍭
| 题目 | 题解 | 难度 | 推荐指数 |
|---|---|---|---|
| 6. Z 字形变换 | LeetCode 题解链接 | 中等 | 🤩🤩🤩 |
| 8. 字符串转换整数 (atoi) | LeetCode 题解链接 | 中等 | 🤩🤩🤩 |
| 12. 整数转罗马数字 | LeetCode 题解链接 | 中等 | 🤩🤩 |
| 59. 螺旋矩阵 II | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 65. 有效数字 | LeetCode 题解链接 | 困难 | 🤩🤩🤩 |
| 73. 矩阵置零 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 89. 格雷编码 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 166. 分数到小数 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 260. 只出现一次的数字 III | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 414. 第三大的数 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 419. 甲板上的战舰 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 443. 压缩字符串 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 457. 环形数组是否存在循环 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 528. 按权重随机选择 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 539. 最小时间差 | LeetCode 题解链接 | 中等 | 🤩🤩🤩🤩 |
| 726. 原子的数量 | LeetCode 题解链接 | 困难 | 🤩🤩🤩🤩 |
注:以上目录整理来自 wiki,任何形式的转载引用请保留出处。
如果有帮助到你,请给题解点个赞和收藏,让更多的人看到 ~ ("▔□▔)/
也欢迎你 关注我 和 加入我们的「组队打卡」小群 ,提供写「证明」&「思路」的高质量题解。
所有题解已经加入 刷题指南,欢迎 star 哦 ~
思路
首先,如果 $s$ 和 $\textit{goal}$ 的长度不一样,那么无论怎么旋转,$s$ 都不能得到 $\textit{goal}$,返回 $\text{false}$。在长度一样(都为 $n$)的前提下,假设 $s$ 旋转 $i$ 位,则与 $\textit{goal}$ 中的某一位字符 $\textit{goal}[j]$ 对应的原 $s$ 中的字符应该为 $s[(i+j) \bmod n]$。在固定 $i$ 的情况下,遍历所有 $j$,若对应字符都相同,则返回 $\text{true}$。否则,继续遍历其他候选的 $i$。若所有的 $i$ 都不能使 $s$ 变成 $\textit{goal}$,则返回 $\text{false}$。
代码
###Python
class Solution:
def rotateString(self, s: str, goal: str) -> bool:
m, n = len(s), len(goal)
if m != n:
return False
for i in range(n):
for j in range(n):
if s[(i + j) % n] != goal[j]:
break
else:
return True
return False
###Java
class Solution {
public boolean rotateString(String s, String goal) {
int m = s.length(), n = goal.length();
if (m != n) {
return false;
}
for (int i = 0; i < n; i++) {
boolean flag = true;
for (int j = 0; j < n; j++) {
if (s.charAt((i + j) % n) != goal.charAt(j)) {
flag = false;
break;
}
}
if (flag) {
return true;
}
}
return false;
}
}
###C#
public class Solution {
public bool rotateString(string s, string goal) {
int m = s.Length, n = goal.Length;
if (m != n) {
return false;
}
for (int i = 0; i < n; i++) {
bool flag = true;
for (int j = 0; j < n; j++) {
if (s[(i + j) % n] != goal[j]) {
flag = false;
break;
}
}
if (flag) {
return true;
}
}
return false;
}
}
###C++
class Solution {
public:
bool rotateString(string s, string goal) {
int m = s.size(), n = goal.size();
if (m != n) {
return false;
}
for (int i = 0; i < n; i++) {
bool flag = true;
for (int j = 0; j < n; j++) {
if (s[(i + j) % n] != goal[j]) {
flag = false;
break;
}
}
if (flag) {
return true;
}
}
return false;
}
};
###C
bool rotateString(char * s, char * goal){
int m = strlen(s), n = strlen(goal);
if (m != n) {
return false;
}
for (int i = 0; i < n; i++) {
bool flag = true;
for (int j = 0; j < n; j++) {
if (s[(i + j) % n] != goal[j]) {
flag = false;
break;
}
}
if (flag) {
return true;
}
}
return false;
}
###JavaScript
var rotateString = function(s, goal) {
const m = s.length, n = goal.length;
if (m !== n) {
return false;
}
for (let i = 0; i < n; i++) {
let flag = true;
for (let j = 0; j < n; j++) {
if (s[(i + j) % n] !== goal[j]) {
flag = false;
break;
}
}
if (flag) {
return true;
}
}
return false;
};
###go
func rotateString(s, goal string) bool {
n := len(s)
if n != len(goal) {
return false
}
next:
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
if s[(i+j)%n] != goal[j] {
continue next
}
}
return true
}
return false
}
复杂度分析
时间复杂度:$O(n^2)$,其中 $n$ 是字符串 $s$ 的长度。我们需要双重循环来判断。
空间复杂度:$O(1)$。仅使用常数空间。
思路
首先,如果 $s$ 和 $\textit{goal}$ 的长度不一样,那么无论怎么旋转,$s$ 都不能得到 $\textit{goal}$,返回 $\text{false}$。字符串 $s + s$ 包含了所有 $s$ 可以通过旋转操作得到的字符串,只需要检查 $\textit{goal}$ 是否为 $s + s$ 的子字符串即可。具体可以参考「28. 实现 strStr() 的官方题解」的实现代码,本题解中采用直接调用库函数的方法。
代码
###Python
class Solution:
def rotateString(self, s: str, goal: str) -> bool:
return len(s) == len(goal) and goal in s + s
###Java
class Solution {
public boolean rotateString(String s, String goal) {
return s.length() == goal.length() && (s + s).contains(goal);
}
}
###C#
public class Solution {
public bool rotateString(string s, string goal) {
return s.Length == goal.Length && (s + s).Contains(goal);
}
}
###C++
class Solution {
public:
bool rotateString(string s, string goal) {
return s.size() == goal.size() && (s + s).find(goal) != string::npos;
}
};
###C
bool rotateString(char * s, char * goal){
int m = strlen(s), n = strlen(goal);
if (m != n) {
return false;
}
char * str = (char *)malloc(sizeof(char) * (m + n + 1));
sprintf(str, "%s%s", goal, goal);
return strstr(str, s) != NULL;
}
###JavaScript
var rotateString = function(s, goal) {
return s.length === goal.length && (s + s).indexOf(goal) !== -1;
};
###go
func rotateString(s, goal string) bool {
return len(s) == len(goal) && strings.Contains(s+s, goal)
}
复杂度分析
时间复杂度:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。$\text{KMP}$ 算法搜索子字符串的时间复杂度为 $O(n)$,其他搜索子字符串的方法会略有差异。
空间复杂度:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。$\text{KMP}$ 算法搜索子字符串的空间复杂度为 $O(n)$,其他搜索子字符串的方法会略有差异。
在2026世界超级摩托车锦标赛(WSBK)匈牙利站WorldSSP组别第一回合正赛中,中国摩托车制造商张雪机车的法国车手瓦伦丁·德比斯通过最后时刻的反超绝杀夺得冠军。赛后,荣耀CEO李健发文祝贺,并宣布作为张雪机车WSBK的首席战略合作品牌,荣耀将推出双方的冠军联名款手表,以庆祝这一夺冠时刻。 此前在4月初,荣耀已正式成为张雪机车WSBK首席战略合作品牌。荣耀首席营销官关海涛曾代表品牌向车队赠送荣耀WIN系列手机及荣耀WIN游戏本,寄望该系列产品能为车手带来胜利。荣耀此次通过与冠军联名,旨在借助国际赛事热度与效应,进一步提升品牌在年轻用户群体及运动场景中的影响力。 5月2日消息,在刚刚结束的2026世界超级摩托车锦标赛(WSBK)匈牙利站WorldSSP组别第一回合正赛中,中国摩托车制造商张雪机车的法国车手瓦伦丁·德比斯,最后时刻反超绝杀,强势夺冠。 赛后,荣耀CEO李健发文祝贺张雪机车夺冠,称这是一场“让所有观众都无比骄傲的比赛”。 与此同时,李健还宣布,作为张雪机车WSBK的首席战略合作品牌,荣耀将推出与张雪机车的冠军联名款手表,来庆祝这个历史性的夺冠时刻。
官方图片
今年4月初,荣耀已正式成为张雪机车WSBK首席战略合作品牌。 荣耀首席营销官关海涛当时还代表品牌向车队赠送荣耀WIN系列手机及荣耀WIN游戏本。 关海涛表示,希望荣耀WIN系列能为车手带来胜利(WIN)。 借助国际赛事热度与冠军效应,荣耀此番联名动作有望进一步提升品牌在年轻用户与运动场景中的影响力。
官方图片


{kind=link}