一、背景
事情是这样的,之前对 AI 编程一直是观望态度,但是部门最近在做 AI 辅助编程 POC,有幸成为 POC 用户,用上了自己舍不得买的高级编程模型 (感谢公司)。尽管我自认为是一个在代码上很挑剔的人,但是试了下感觉居然还可以 (Go、React)!只能说还得是谷歌,调整重心略微发力,Gemini 3 表现确实很不错。既然尝到甜头了,觉得自己是时候好好地琢磨琢磨,研究研究,沉淀一套自己的工作流、方法论,解放自己的生产力,顺应潮流努力成为 AI 时代的受益者,而不是被淘汰的人!
新的开发范式需要搭建新的开发环境和匹配自己开发习惯的工作流,这就像刚学编程那会,需要挑一个自己喜欢的 IDE、熟悉 IDE 快捷键和优化 IDE 设置一样。过程中间肯定有阵痛,Java 开发者们回忆一下多年之前从 Eclipse 转 IDEA 那会的阵痛吧,但是磨刀不误砍柴工,阵痛之后一定是生产力提升。借本文分享下我摸索后的方案,供大家参考。
二、工具选型
目前 AI 辅助编程领域热火朝天,各种 GUI 工具、TUI 工具如雨后春笋让人目不暇接,这对于花心的强迫症选手(比如我)来说选型很困难。但是我觉得有两个基础认知可以帮助我们更好地做决定:
(一)AI 辅助编程工具由脑和手两部分组成。脑是外接的大模型 API,手是各个产品调教的提示词和内部工作流。按我理解,【脑】决定了工具的上限,【手】决定了工具的下限。在这个场景里,大模型就像是汽车里的发动机,而且所有型号的汽车支持的【发动机】规格都是通用的、统一的、标准化的。有了这个基础,我们可以随便选一个趁手的工具,然后自行按场景选配【合适】的【发动机】。
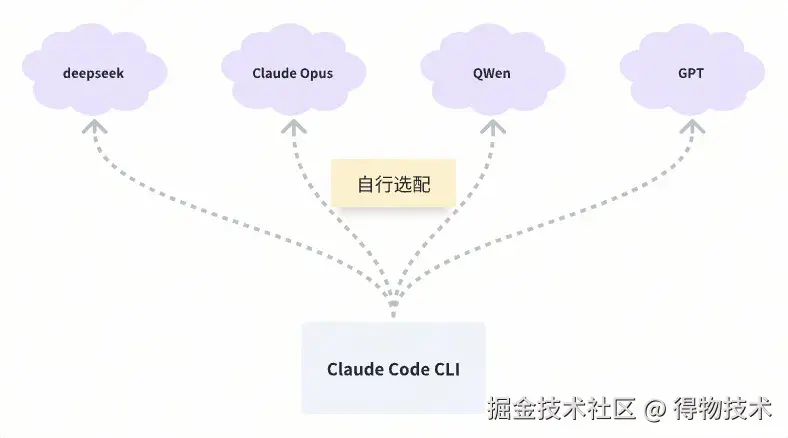
(二)AI 辅助编程当前是一个【千帆竞发】的热门领域,而且单纯就【工具】来说,这个领域【没有技术壁垒】。A 产品抛出的杀手级特性,不出半个月一定会有 B 产品跟进。毕竟现在软件迭代的速度借助 AI 提升了很多,A 产品验证过的想法,B 产品可以很快地跟进和实现。Claude Code CLI 的开发者就使用 Claude Code CLI 迭代 Claude Code CLI,有点绕口,大概就是【工具自举】的意思吧。
Claude Code CLI
综上,其实没啥纠结的,我们照着这两点来选型就好:1. 这个工具一定得便捷地支持模型插拔,就是我随时可以根据场景换一个更适合的、更便宜的、表现更好的大模型。而且这种插拔一定要简单。 2. 这个工具一定要有积极的维护者,不断地迭代、优化它的工作流、提示词。最好是一个商业化产品,因为商业化产品出于其商业目标,一定会投入资源积极进行迭代。
当前满足这两个条件的,我想也就是 Claude Code CLI 了: 1. Claude Code CLI 是一个商业化产品,有专门的技术团队在不停地更新、迭代。 2. Claude Code CLI 可以非常便捷地支持大模型插拔,我可以随时根据成本、效率、体验来切换合适的大模型。因此,这个环节我选 【Claude Code CLI】。
后文以CC代指Claude Code CLI。
快速切换模型
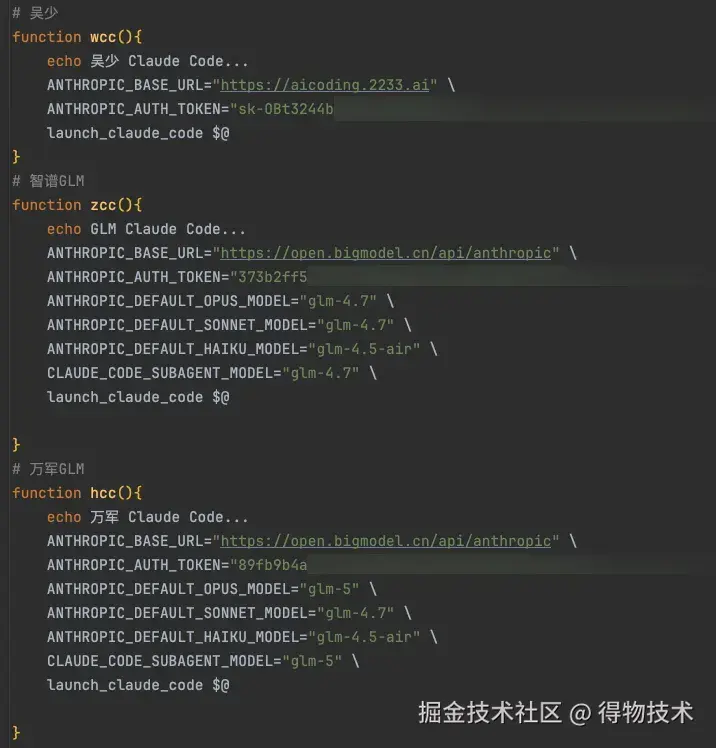
我通过自定义 Shell 函数来实现便捷的模型切换,不同的场景、不同的任务使用不同的模型。基本原理就是,CC 支持环境变量注入 LLM 配置信息,因此我只需要按场景注入【行内临时环境变量】即可。

详见:Bash - 行内环境变量,Bash 是标准的 Shell 实现,其他 Shell 如 Zsh 都兼容其行为。
Shell配置
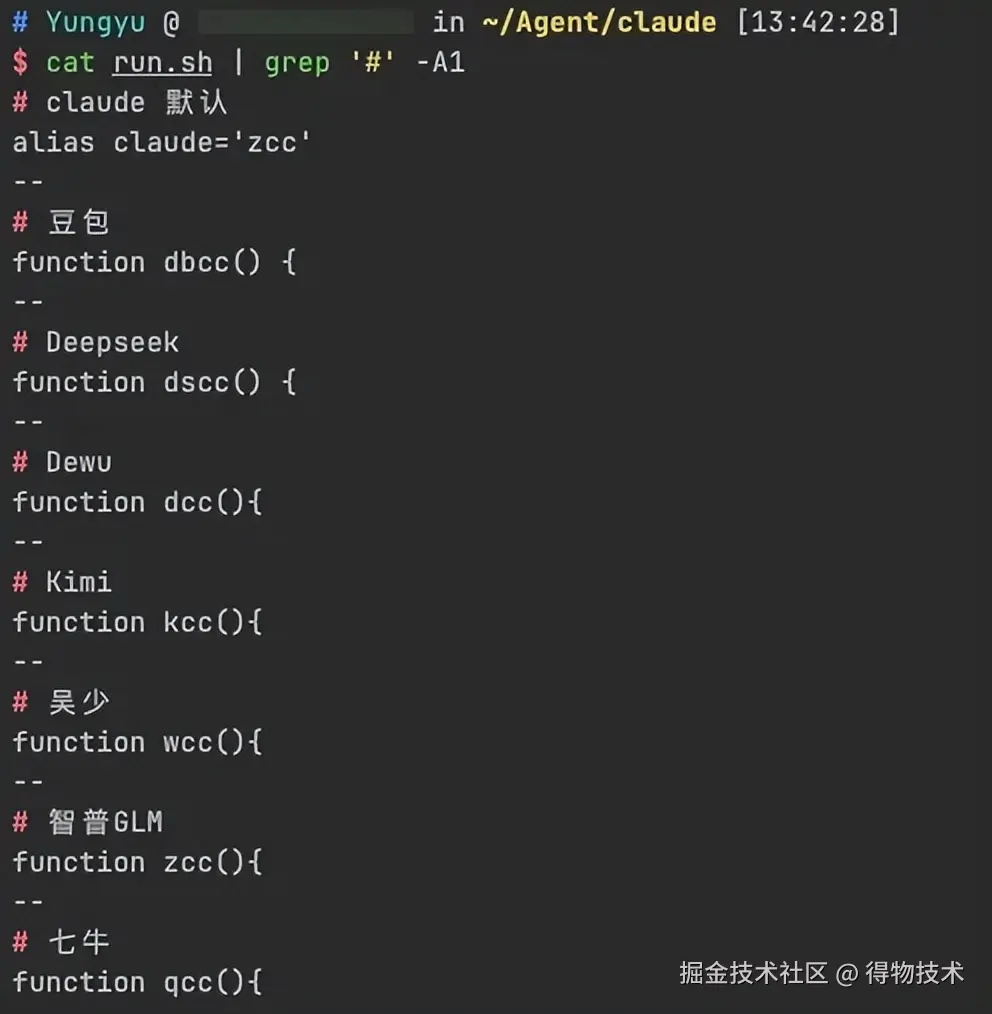
我到处弄了一堆免费的、收费的模型用,然后给他们取了我记得住的别名:
使用效果
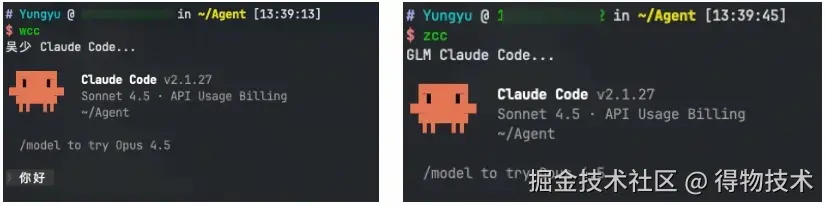
为了兼容,设置了一个 claude 别名:
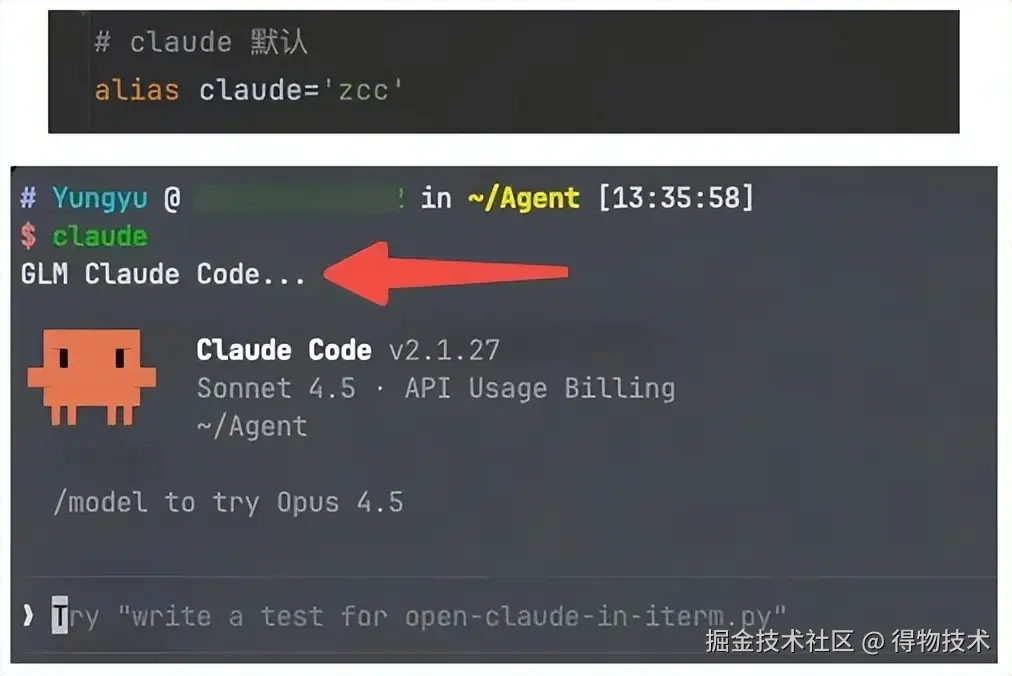
这样输入claude 时,默认使用智谱 GLM 模型。
脚本源码
Shell 脚本大概这样,可以修改后配置到自己的 ~/.zshrc 中。如果不熟悉 Shell,嫌麻烦也可以试试这个开源工具:farion1231/cc-switch。
# claude 默认
alias claude='zcc'
# Kimi
function kcc(){
echo Kimi Claude Code...
local model="kimi-k2.5"
ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic" \
ANTHROPIC_AUTH_TOKEN="sk-xxxxxxxxx" \
ANTHROPIC_SMALL_FAST_MODEL="$model" \
ANTHROPIC_DEFAULT_OPUS_MODEL="$model" \
ANTHROPIC_DEFAULT_SONNET_MODEL="$model" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="$model" \
CLAUDE_CODE_SUBAGENT_MODEL="$model" \
launch_claude_code $@
}
# 智谱GLM
function zcc(){
echo GLM Claude Code...
ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic" \
ANTHROPIC_AUTH_TOKEN="sk-xxxxxxxxx" \
launch_claude_code $@
}
# 七牛
function qcc(){
echo QiNiu Claude Code...
local model="minimax/minimax-m2.1"
ANTHROPIC_BASE_URL="https://api.qnaigc.com" \
ANTHROPIC_AUTH_TOKEN="sk-xxxxxxxxx" \
ANTHROPIC_SMALL_FAST_MODEL="$model" \
ANTHROPIC_DEFAULT_OPUS_MODEL="$model" \
ANTHROPIC_DEFAULT_SONNET_MODEL="$model" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="$model" \
CLAUDE_CODE_SUBAGENT_MODEL="$model" \
launch_claude_code $@
}
function launch_claude_code(){
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 \
# clear
command claude $@
}
三、开发环境
在当前的气氛下,我想我算是一个【古板】的开发者,我做不到【fire and forget】,或者说完全靠黑盒的自然语言对话来完成代码开发。
我还是只将 AI 当助手,还是想要白盒的掌控 AI 写的代码,还是希望最终交付的代码有我的风格、我的审美、我的品味。毕竟 AI 也只能帮我写代码,并不能帮我背锅。尽管我选择了 TUI 工具 Claude Code CLI,但是我还做不到全程只在终端操作,我还是习惯 JetBrains 特色的双栏 diff。
因此,当前我开发流程的起点还是传统的 IDE,比如我最喜欢的 JetBrains。每天上班第一件事是接水,第二件事就是打开 IDE。所以我需要想办法来将 GUI 工具和 TUI 工具流畅的衔接起来,减少代码开发时的频繁切换产生的割裂感!
多屏协作

如上图,我有 3 个显示器,我的构想是这样的:
- MacBook 内置显示器 —— 常驻两个空间:一个用来打开浏览器,还有 VPN、网易云音乐、Finder 软件,用来承接各种临时的操作。一个用来打开飞书,用来沟通、协作。
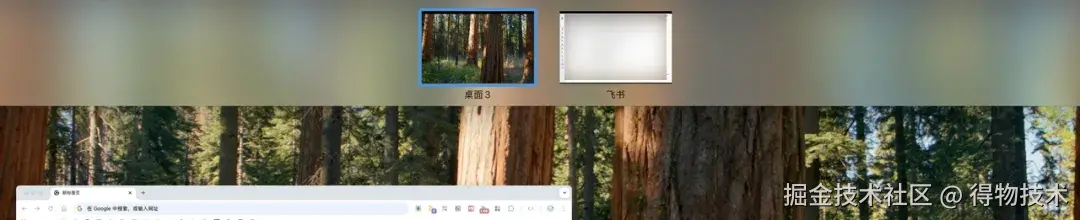
- 中间主屏 —— 常驻两个空间:一个用来打开浏览器,用来做各种【输出】。一个用来打开 IDE,专注于写代码、看代码,用标签页打开多个 Project。
- 左边竖屏 —— 常驻两个空间:一个用来打开浏览器,用于看文档、查资料等各种【输入】。一个用来打开 TUI 工具,进行辅助编程!
GUI/TUI衔接
现在问题来了,我希望我的开发工作的【主轴】是 IDE,流程的起点是 IDE。但是我的 IDE 在中间屏幕,终端在左边屏幕,它俩是独立软件,没法协作、自动跟随切换 Project 的工作目录。我希望有个【自动化流程】,当我在 IDE 里切换项目的时候,CC 自动跟随切换!
衔接流程
我期待的流程是这样的:
因为某个原因,我在 IDE 里打开了一个项目 A → 准备写代码了,点击 IDE 里的某个【按钮】,左边屏幕自动【新建】一个项目 A 的 CC 会话终端并激活到前台显示 → 我跟左边的 CC 对话,让他干活 → 我在中间的 IDE 里评审、调试、诊断 → 因为某些原因我又要在 IDE 打开一个别的项目 B → 我再次点击那个【按钮】,左边屏幕自动【新建】一个项目 B 的 CC 会话终端并激活到前台显示 → 我在 IDE 里又切回了项目 A,我又点击了那个【按钮】,左边屏幕自动【切换】到 A 的 CC 会话终端并激活到前台显示。
好的想法已经有了,AI 时代就怕你没有想法,有想法就一定有办法实现!
代码实现
-
macOS 上的原生软件,大部分支持 AppleScript 自动化,也就是说我们可以写脚本驱动软件的行为、模拟人机交互,比如打开软件、新建 tab、点击按钮等。
-
JetBrains IDE 支持集成外部命令,也就是说:可以在 IDE 里点击一个按钮,自动执行一个 Shell 脚本或者别的可执行文件。
产品需求清晰了,接下来开始让 AI 干活!一顿沟通和调试之后,我们有了一个【自动化】创建 iTerm2 新标签的可执行脚本!
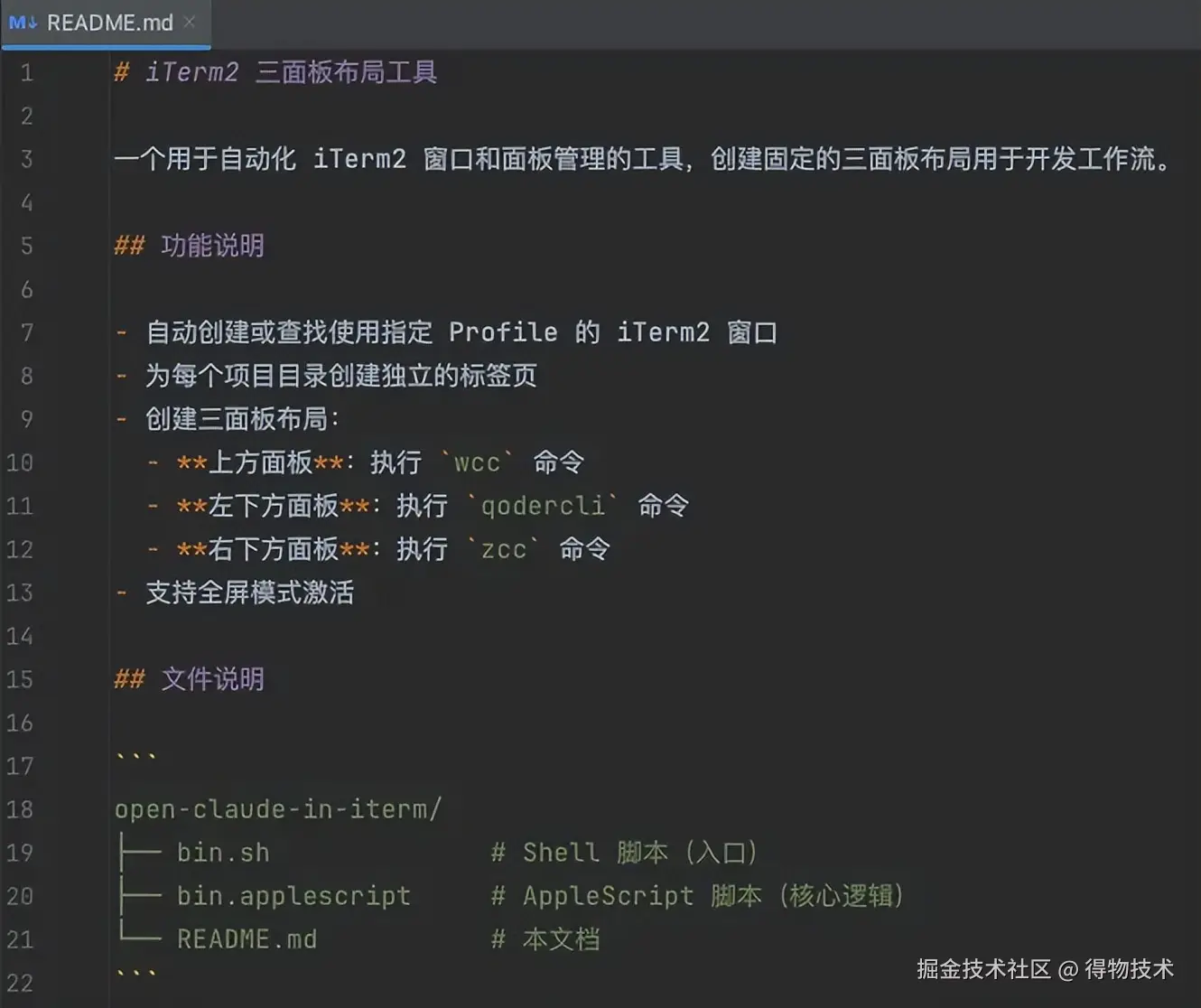
这是给大模型的需求提示词,大家可以按需选用,做个性化的调整:
## 📌 工具功能说明
请帮我创建一个 macOS 上的 iTerm2 自动化工具,主要功能包括:
### 核心需求
1. **智能窗口管理**:自动使用或创建 iTerm2 窗口
2. **项目标签管理**:为每个项目目录维护独立的标签页,支持标签复用
3. **三面板布局**:自动创建固定的三面板布局(上方一个全宽面板,下方两个并排面板)
4. **命令自动执行**:在每个面板中自动切换到项目目录并执行预定义的命令
### 使用场景
```bash
# 基本用法:在当前目录打开
./open-claude-in-iterm.sh
# 指定项目目录
./open-claude-in-iterm.sh /path/to/project
```
---
## 🎯 技术架构要求
### 技术栈
- **Shell 脚本** (open-claude-in-iterm.sh):参数处理、路径规范化、日志管理
- **AppleScript** (open-claude-in-iterm.applescript):iTerm2 自动化核心逻辑
- **依赖**:macOS、iTerm2、Bash
---
## 📋 详细功能规格
### 1. Shell 脚本 (open-claude-in-iterm.sh)
#### 参数处理
- **参数1**:项目目录(可选,默认当前目录)
- **自动处理**:相对路径转绝对路径
#### 面板命令配置
```bash
PAN1_CMD="claude" # 上方面板命令
PAN2_CMD="claude" # 左下面板命令
PAN3_CMD="claude" # 右下面板命令
```
### 2. AppleScript (open-claude-in-iterm.applescript)
#### 主要流程
**步骤1:窗口管理**
- 检查 iTerm2 是否运行(未运行则自动启动)
- 使用当前激活的 iTerm2 窗口,如果没有则创建新窗口
**步骤2:标签管理(关键逻辑)**
- 在找到的窗口中,查找 `session.path` 变量等于项目目录的标签
- **复用逻辑**:如果找到现有标签 且 窗口不是新创建的 → 直接切换标签并返回
- **创建逻辑**:如果未找到标签 或 窗口是新创建的 → 创建新标签和布局
**步骤3:三面板布局创建**
```
布局示意图:
┌─────────────────────────┐
│ 上方面板 (全宽) │
│ 执行: PAN1_CMD │
├──────────────┬──────────┤
│ 左下面板 │ 右下面板 │
│ PAN2_CMD │ PAN3_CMD │
└──────────────┴──────────┘
```
**分割顺序(重要)**:
1. 初始状态:一个全屏 session(上方面板)
2. 第一次分割:对上方 session 执行**水平分割**,创建下方面板
3. 第二次分割:对下方 session 执行**垂直分割**,创建右下面板
**步骤4:命令执行**
在每个面板中依次执行:
1. 切换到项目目录:`cd "/path/to/project"`
2. 清屏:`clear`
3. 等待 0.3 秒(确保目录切换完成)
4. 执行命令:`PAN_CMD`
5. 等待 0.5 秒(确保命令启动)
## ⚠️ 常见错误
- ❌ 符号链接未处理,导致找不到 AppleScript 文件
- ❌ 分割顺序错误,导致布局不正确
- ❌ 缺少 delay,导致命令执行失败或在错误目录执行
- ❌ 新窗口处理错误,导致多余空白标签
- ❌ 标签复用逻辑错误,导致同一项目创建多个标签
- ❌ 路径未引用,导致包含空格的路径失败
IDE配置
创建外部工具
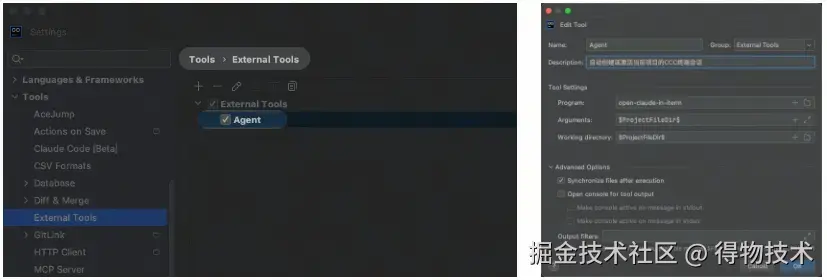
添加到工具栏

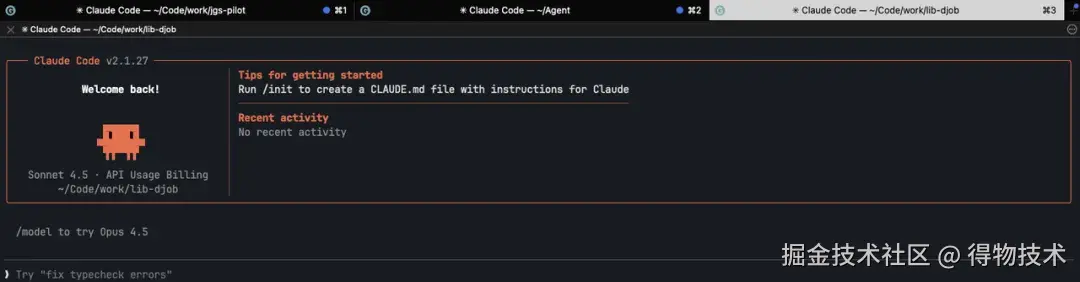
使用效果
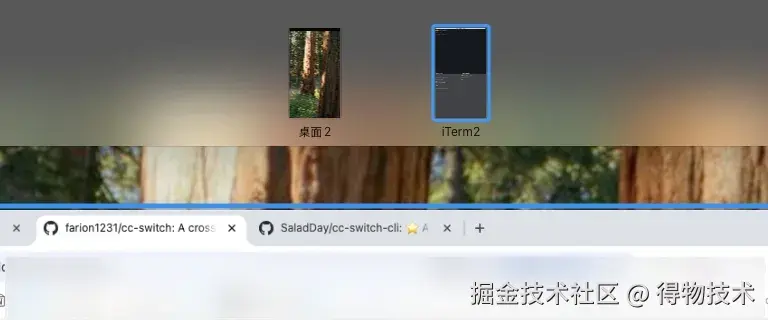
点击工具栏按钮后,自动在全屏的 iTerm2 窗口新建或激活项目目录下的 CC 会话,下图里就是 3 个项目。
四、多Agent协作
会的越多,让你干的就越多。既然 AI 那么牛,一个 CC 会话已经满足不了我膨胀的想法和需求了。我希望我可以同时支配多个 AI 开发工程师,而我变成 PM!所以参考酒米的思路,我给每个项目的终端,自动化的划分了 3 个子窗口,每个子窗口都是一个 CC 会话。效果大概这样:
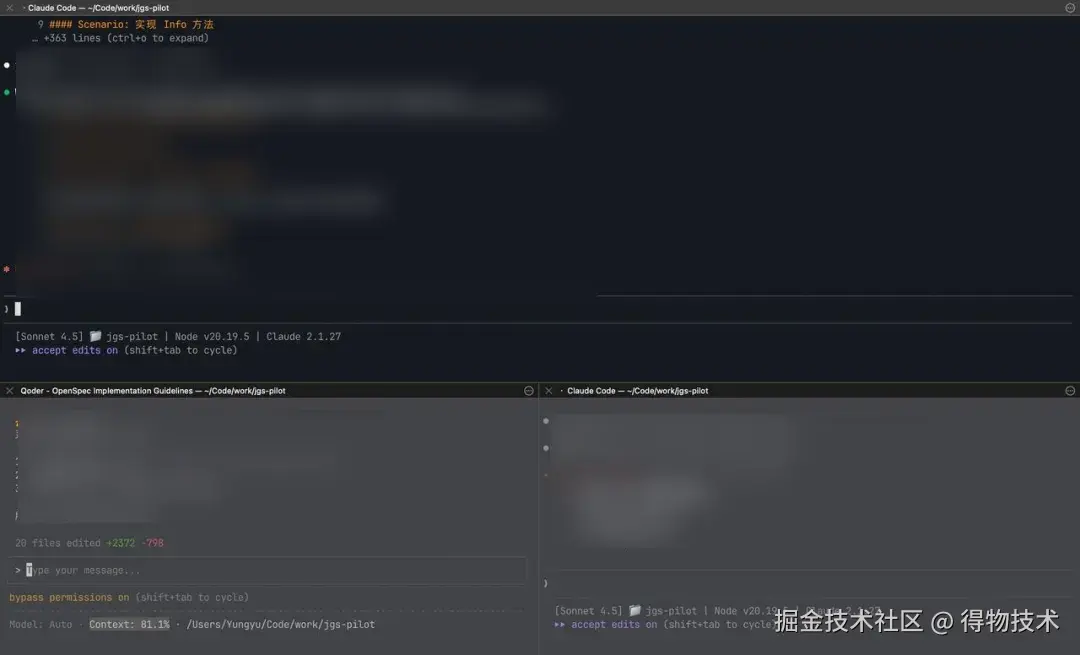
主从架构
每个项目自动打开 3 个常驻的 AI 会话,我设想的工作流是这样的:
【架构师】上面的大屏,用贵的模型!专门用来跟我聊需求、对方案、产出任务列表。
【开发者】下面的两个小屏,用领域特定的模型,专门用来落地大屏架构师产出的方案和任务。比如前端需求用前端效果好的模型,后端需求用后端效果好的模型。
知人善用才是好 PM!这个模式也很匹配现实中的组织架构和成本取舍,现实中每个需求一般也都是由一个架构师和多个中高级开发者来协作完成!感谢热心市民无声雨,给我们小组共享了自己采购的纯血 Claude 模型,所以目前我用 Claude 模型来对方案,用 GLM 或者 MiniMax 来实施方案!
规范驱动开发(SDD)
主从智能体的协作很重要,我跟【架构师】聊了半天确定的方案和设计,需要有一个清晰的、对大模型友好的方案和任务文档作为【开发者】的输入。这就很巧,刚好最近在流行 SDD,规范驱动开发。大致就是模拟现实中的软件开发流程将开发生命周期拆分为 3 个阶段:
- 【proposal】需求对齐、方案设计、【任务细化】;
- 【apply】开发任务实施;
- 【archive】功能验收、文档沉淀
围绕这个流程,开源社区设计和研发了一系列对大模型非常友好的工具和提示词(比如 OpenSpec),【阶段 1】和【阶段 2】中间通过格式设计良好的【设计文档和任务文档】来进行上下文交接。
也就是说,我可以在上述的 3 窗口环境中,按照 SDD 流程来:【proposal】跟【架构师】交互,对齐需求、设计和任务 A → 【apply】让【开发者 1】着手完成任务 A → 【proposal】继续跟【架构师】交互,对齐需求、设计和任务 B → 【apply】让【开发者 2】着手完成任务 B → 【proposal】继续跟【架构师】交互,对齐需求、设计和任务 C → 【apply】让【开发者 1】着手完成任务 C → ……
五、CC拓展
CC 当然很厉害,但它本质上也就是一个朴素的 ReAct 模式智能体。
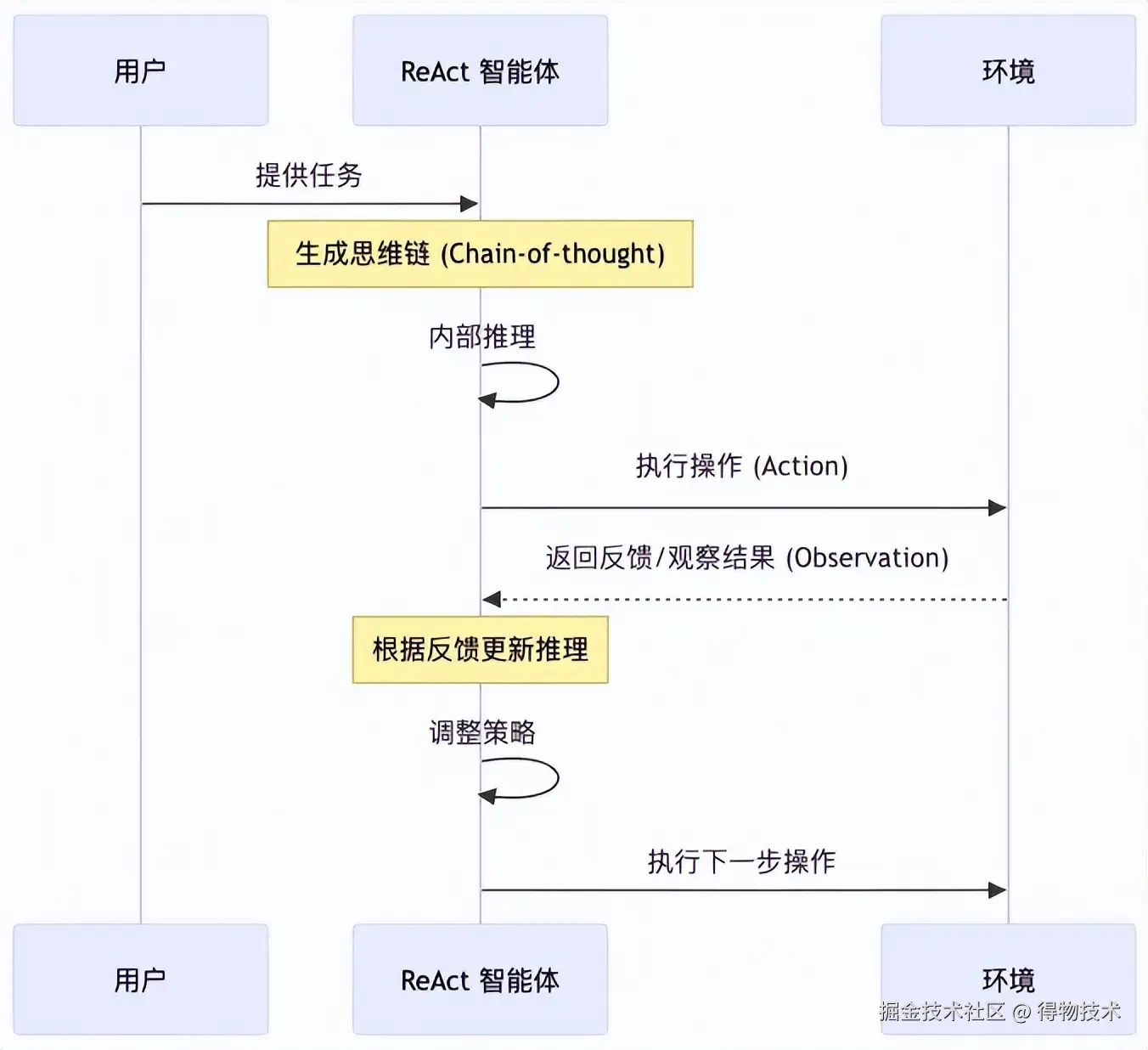
ReAct 这么火,大家肯定也都耳熟能详了,我们也就不说太多。当然 CC 团队围绕编程这个课题做了很多细致的提示词调优和内置工作流设计,这个我们黑盒的用就好了,也没必要关注太多。我们最需要关注的,是 CC 提供给我们使用者的【拓展点】,那些允许我们个性化设置的东西。
命令(command)
命令的本质就是预定义的提示词模板。目的是为了省事,不用每次都重复的输入类似的提示词。比如想让 CC 帮我提交代码,每次我们可能都要交代一大堆字,比如:
请调用 git diff --cached 获取当前暂存区的代码变动。
忽略所有的 node_modules 或二进制文件。
基于变动内容,判断这是一个 feat (新功能), fix (修复) 还是 chore (杂务)。
生成一个不超过 50 字符的标题,并在正文详细列出影响的文件。
由我确认后执行 git commit。”
就像写代码的时候将重复代码提取为一个独立方法一样,我们可以把这些可以复用的提示词固定成一个【命令】,后续使用的时候,直接输入命令名字就好。斜杠命令是一段提示词的快捷方式。
技能(skill)
技能和命令最大的差别就是:命令是用户主动提交的提示词,而技能是 Agent 自己决策后自动导入的提示词。当然技能包里除了提示词,一般还会携带一些配套的工具、脚本、命令或者文档。
比如,我安装了一个【html 转 pdf 的技能包】,这只能提示 CC 可以使用这个技能,但是具体用不用、什么时候用、怎么用都是 CC 自己规划、决策的。
子代理(subAgent)
SubAgents 是可以并行处理任务的独立 AI 代理,每个子代理拥有独立的上下文窗口,可以分配不同任务以提高效率。【主代理】的上下文窗口中包含有【子代理】的【简短】描述信息,可以基于这个描述信息规划、决策使用哪个子代理。
{
"agents":{
"code-reviewer":{
"description":"专门负责代码审查的子代理",
"model":"claude-opus-4-5",
"instructions":"你是一个专业的代码审查专家,专注于检查代码质量、安全漏洞和性能问题。",
"tools":["read","search","git"],
"permissions":{
"allowWrite":false
}
},
"test-writer":{
"description":"专门负责编写测试的子代理",
"model":"claude-sonnet-4-5",
"instructions":"你是一个测试工程师,专注于编写全面的单元测试和集成测试。",
"tools":["read","write","bash"]
},
"doc-generator":{
"description":"专门负责生成文档的子代理",
"model":"claude-sonnet-4-5",
"instructions":"你是一个技术文档专家,专注于生成清晰、准确的技术文档。",
"tools":["read","write"]
}
}
}
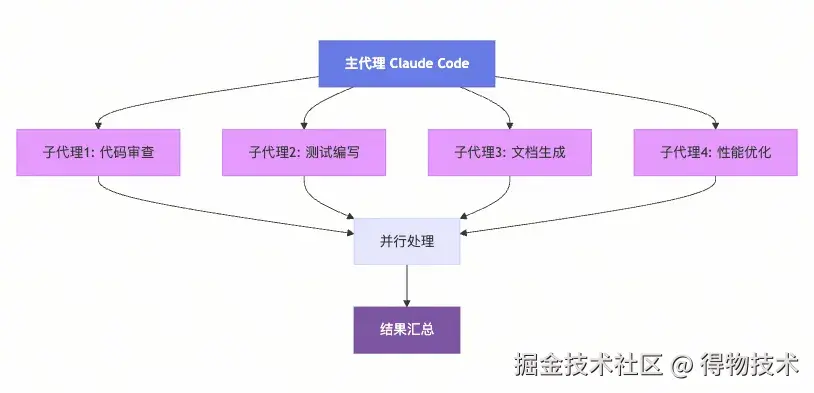
独立上下文窗口的好处是:避免上下文污染和占用。比如我要在代码里找一个接口的所有实现类,这个就很适合子代理来做。主代理只需要交代给子代理接口名,然后就等子代理返回实现类列表。
这样在主代理的上下文窗口里,只会有子代理的输入和输出(几个类文件路径),而子代理在搜索过程中遍历文件、目录、读取文件内容产生的临时 token,不会对主代理产生影响。我目前认为 SubAgent 和 Skill 差不太多。不过我不确认 Skill 是不是在独立的上下文中执行。
MCP
MCP 和技能一样,都是由 CC 自主规划、决策使用的。差别有两个:
-
MCP 工具的说明信息占用的上下文太多了!不管是否被使用,每次都需要一口气提交所有工具的完整元信息(使用说明 + 出入参 Schema)供大模型规划、决策,占用大量上下文。而【技能】选择了【渐进式披露】,先向大模型提供少量关键信息,只有在大模型选择了使用技能时,才告诉大模型更多关于技能的补充说明信息,让大模型进一步推理、决策。
-
MCP 工具更多的偏向【远程 RPC】,基于网络来实现原子化的远程能力调用。而【技能】更多的偏向【本地 IPC】,具体能力更多通过【编排】本地脚本、本地命令来实现,有点像 stdio 模式下的 MCP。
钩子(hook)
hook 是在特定事件触发时自动执行的脚本,用于自定义工作流、拦截危险操作、自动格式化代码等。就类似 Linux NetFilter,CC 在很多地方植入了流程执行的劫持点,将流程上下文交给用户开发的脚本或者命令。

插件(plugin)
plugin 就是上述各种拓展打包、分发、安装的一种格式。你可以把它想象成 npm 包、pip 包、apk 包等我们比较熟悉的概念。然后我们可以按流程和格式建设插件市场,类似 pip-index、npm-index 等。
我没有细看流程和格式,但是大概也就是一个特定文件布局的 zip 文件包,里面有插件描述信息和各类拓展,比如可以包含:
- 5 个 Skills;
- 10 个斜杠命令;
- 3 个 MCP 服务器配置;
- 2 个 SubAgent 定义;
- 若干 Hooks。
六、CC技巧
飞书MCP
飞书官方提供了 MCP,我主要用它来读写飞书文档,蛮好用的,大家可以试试。比如我每周都要在固定目录下创建固定标题格式的【系统巡检文档】,所以我借助飞书 MCP 整了个自定义 Command 帮我自动创建这些文档去除重复劳动,感觉真香!之前每次都要手动建 3 个文档、选目录、改名字!
@模糊搜索
有时候我们需要精确的告诉 CC,哪个文件需要读或者改,其实不用从 IDE 里复制文件路径,直接在终端里模糊搜索就好了。
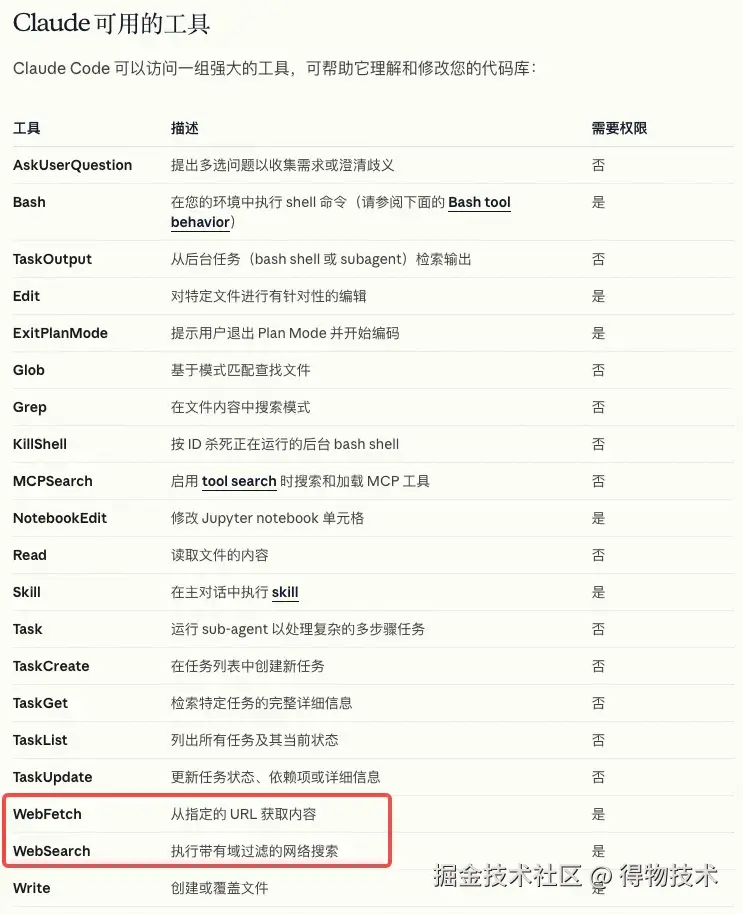
WebFetch
CC 默认集成了 WebFetch 命令,就是指定 URL 读取网页内容,这个理论上就是一个本地执行的 curl 命令,没有云端成本,不需要云端协作。但是有个问题:(一)CC 在访问地址之前,会先调用 anthropic.com 的一个风控接口,判断这个网络地址是否有安全风险。(二)政策原因,anthropic.com 会拒绝所有来自中国大陆、香港的请求,风控接口返回 404 或者其他。(三)风控不通过,WebFetch 失败。

在 ~/.claude/settings.json 中添加如下配置,禁用 WebFetch 工具前置的风控检查就好了。
{
"skipWebFetchPreflight":true,
}
详见:linux.do/t/topic/114…
WebSearch
WebSearch 是需要云端协作的,需要有个搜索引擎服务提供能力。因为我们没有用官方的付费订阅,所以默认的 WebSearch 工具我们用不了,调用 WebSearch 工具得到的结果都是 0。
办法是去找一个免费或者收费的 MCP 服务。免费的我看大家都推荐 Brave<brave.com>,大家也可以找找别的。收费的也有很多,我看智谱的套餐里限量提供了 <联网搜索 MCP - 智谱 AI 开放文档>。也有很多按量付费的,大概几分钱一次,有需要的可以找找。
添加了 MCP 搜索工具后,建议禁用 CC 自带的 WebSearch 工具,不然每次跟大模型交互时,工具信息还会带给大模型,产生额外的 token 开销和推理误判。在 ~/.claude/settings.json 中添加如下配置:
{
"permissions":{
"deny":[
"WebSearch"
]
}
}
iTerm2通知
终端上的任务需要我们输入的时候,可以配置下,让 iTerm2 发出声音和通知。这样我们就不会因为忘记确认操作而阻塞进度。
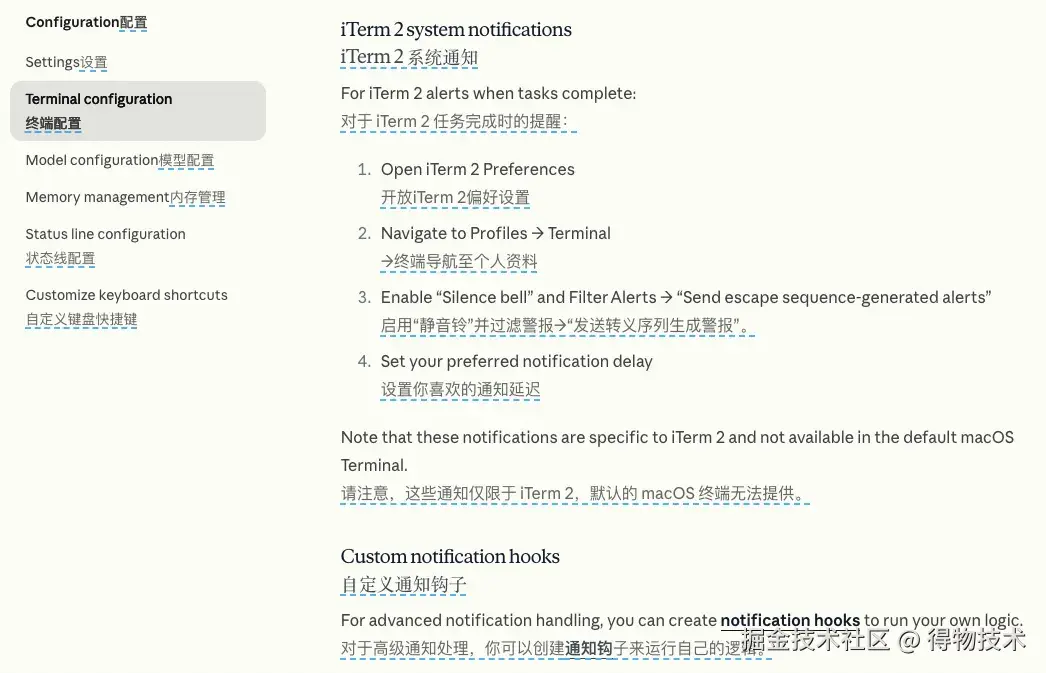
详见:Optimize your terminal setup - Claude Code Docs
清空上下文
因为我们每个项目都复用一屏内的 3 个子窗口,一般不会重开。为了避免上下文溢出或者之前对话对新任务产生干扰,当我们完成一个任务时,需要及时的执行 /clear 命令,清空上下文,从 0 开始新对话。
如果任务没有完成,但是又不得不 clear,那么可以维护一个自定义命令,在 clear 后提示大模型根据 git status 看到的文件变更快速找回上下文。把 git 状态当作 AI 的 “短期记忆快照”,/clear 只清上下文,不清工作进度。
# Context Catch-up
当前对话已被 `/clear`,请通过 git 状态恢复上下文。
使用方式:
1. 阅读 `git status`(必要时结合 `git diff`)
2. 仅基于文件变更推断正在进行的任务
3. 延续现有实现思路,不要假设额外背景
4. 在未收到明确指令前,先给出你对当前上下文的判断
目标:
- 快速找回任务状态
- 避免旧对话或错误假设干扰新任务
注意力哨兵
在记忆文件里要求大模型扮演一个特别的角色,如果聊着聊着角色行为丢失了,说明大模型注意力失焦了,已经丢掉了你最开始的要求。这时候就该 clear 一下重开会话了。

拓展市场
为了便于相关个性化拓展物料的分发、便于大家搜索、安装,市面上已经有了相关的分发平台和便捷安装命令了。
- skills.sh

- www.aitmpl.com

状态行个性化

状态行显示在 Claude Code 会话界面底部,可以自定义显示的内容,比如git分支名、目录名、模型名等。推荐使github开源项目:claude-code-statusline-pro-aicodeditor,效果如下:

详见:github.com/HorizonWing…
七、总结
差生文具多,尽管我暂时还没有使用 CC 产出啥说得上来的东西,但是确实花了很多时间琢磨怎么让它用起来更顺手。一些不成熟的想法,希望可以给到大家启发。
参考:
- www.ginonotes.com/posts/how-i…
- www.cnblogs.com/knqiufan/p/…
往期回顾
1.AI编程能力边界探索:基于 Claude Code 的 Spec Coding 项目实战|得物技术
2.搜索 C++ 引擎回归能力建设:从自测到工程化准出|得物技术
3.得物社区搜推公式融合调参框架-加乘树3.0实战
4.深入剖析Spark UI界面:参数与界面详解|得物技术
5.Sentinel Java客户端限流原理解析|得物技术
文 /羊羽
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。






































 Hermes Agent 官网:https://hermes-agent.nousresearch.com
Hermes Agent 官网:https://hermes-agent.nousresearch.com
















































