1. 前言
OpenClaw 与其他 AI Agent 最本质的区别是什么?首先,OpenClaw 本身也是一个 AI Agent,但关键在于它能连接多种 IM 渠道,并利用这些 IM 工具提供的开发能力来调用自身的 Agent——这种能力被称为“网关”。因此,有后端的技术大咖将 OpenClaw 总结为:OpenClaw = 高权限 AI Agent + 网关。
所以只有理解了 OpenClaw 的本质之后,我们才可以实现一个 Mini OpenClaw。
首先我们要实现一个网关,那么网关是什么呢?
网关对于后端的同学来说,肯定不陌生。在 Spring Boot 微服务架构中,API 网关已成为标准的基础设施组件,其核心作用与 OpenClaw 中的“网关”如出一辙:对外隐藏后端的实现细节(服务地址、版本、熔断等),对内统一通信协议,并提供横切能力(如鉴权、限流、日志等) 。两者的区别仅在于作用对象不同——OpenClaw 的网关面向 IM 渠道(消息协议适配),而后端网关面向 HTTP/RPC 调用(协议转换与流量管理)。
所以 OpenClaw 的所谓网关就是一个消息协议适配器。
所以我们先要实现网关最核心的功能:协议适配。这是网关最本质的能力——对外讲 IM 的方言,对内统一说普通话。
2. 网关核心功能:协议适配
不同 IM(飞书、微信 等)的消息格式千差万别:有的用 user_id,有的用 from 字段,有的消息正文可能嵌套在 text 或 message 对象中。我们可以通过设计一个消息协议将这些差异全部“抹平”,这样本地 AI Agent 就只依赖这标准消息协议,无需关心消息来自哪个渠道。
设计一个入站的消息对象 InboundMessage:
# events.py
from dataclasses import dataclass, field
from datetime import datetime
@dataclass
class InboundMessage:
"""从聊天频道接收到的消息"""
channel: str # 用于区分来源,后续发送回复时需要知道应该调用哪个 IM 的 API(feishu、wechat)
sender_id: str # 用户标识符
chat_id: str # 聊天/频道标识符
content: str # 消息文本
timestamp: datetime = field(default_factory=datetime.now) # 消息时间
这样新增一个 IM 渠道时,只需要写一个适配器将私有消息转换成 InboundMessage 即可,其余代码零改动。
简而言之:设计 InboundMessage 就是为了让网关“对外讲方言,对内讲普通话”,所有渠道的消息到达网关后立刻被标准化,Agent 只需处理这一种标准格式。
同样地不同 IM 的发送接口千差万别:飞书需要 receive_id,微信需要 touser,Telegram 需要 chat_id。通过设计一个 OutboundMessage 消息对象,这样 Agent 只需要产出 channel、chat_id、content 三个核心字段,网关再根据 channel 值调用对应的 IM 适配器,由适配器负责转换成目标 IM 的私有请求格式即可。
OutboundMessage 消息对象的字段设计如下:
# events.py
@dataclass
class OutboundMessage:
"""要发送到聊天频道的消息"""
channel: str
chat_id: str
content: str
reply_to: str | None = None # 支持引用回复,用于指明当前回复的是哪一条历史消息
网关的输入是 InboundMessage,输出是 OutboundMessage,这样本地 AI Agent 核心只处理这两种标准格式信息,完全不依赖任何 IM 私有 API。这使得添加新 IM 渠道变得非常简单:只需要写一个适配器,将 InboundMessage 解析出来,并将 OutboundMessage 转换成该 IM 的发送请求即可。因为本地 AI Agent 完全不知道自己在和谁在交互,它只看到 InboundMessage/OutboundMessage,这正是网关隐藏后端实现细节的精髓,也是网关本质的体现。
3. 网关内部路由:统一通信总线
根据前面的设计,我们已经将各个 IM 渠道的消息统一成了 InboundMessage,并将 Agent 的回复统一成了 OutboundMessage。但仅仅统一格式还不够,还需要解决一个核心问题:多个渠道的消息并发涌入,而 Agent 的处理可能是同步/半异步的,如何让它们有序、可靠、不互相阻塞?
这就需要一个统一通信总线——本质上是一个轻量级的内部消息路由。而最经典、最可靠的实现方式就是双队列解耦:
入站异步队列: 渠道 → Agent
出站异步队列: Agent → 渠道
通过双队列把网关内部的“消息流动”标准化为两个 FIFO 管道:
-
入站异步队列:所有 IM 渠道的消息汇聚点,Agent 从这头取“原材料”。
-
出站异步队列:所有回复的汇聚点,分发器从这头取“成品”并发送。
为什么需要这样设计?
每个 IM 渠道(飞书、微信等)都有自己的 Webhook 或长连接,当瞬间收到大量消息(例如群聊刷屏)时,如果直接在回调中同步调用 Agent,Agent 处理耗时较长,会导致 Webhook 超时、连接堆积,甚至被 IM 服务器屏蔽。
我们让每个渠道适配器只做最轻量的事情,每当接收到消息时,就只需要解析消息、封装成上述设计的 InboundMessage,然后立即推送到入站异步队列中,马上返回返回即可。而 Agent 的处理则由一个独立的后台协程从入站异步队列中拉取,这样生产者和消费者的速度完全解耦。即使 Agent 处理得慢,队列也能起到“缓冲”作用,不会丢消息。
同时 Agent 只产出上述设计的 OutboundMessage 的数据并推送到出站异步队列中。另一个独立的分发器协程从出站异步队列中取出消息,找到对应的渠道适配器,调用该适配器的发送方法进行发送消息。这样一来,Agent 完全不需要知道消息要发往哪里、怎么发,路由逻辑全封装在网关内部。
统一通信总线代码实现如下:
# message_bus.py
"""用于解耦频道与智能体通信的异步消息队列"""
import asyncio
from loguru import logger
from events import InboundMessage, OutboundMessage
class MessageBus:
"""
异步消息总线,用于将聊天频道与智能体核心解耦。
频道将消息推送到入站队列,智能体处理它们并将响应推送到出站队列。
"""
def __init__(self):
# 入站异步队列
self.inbound: asyncio.Queue[InboundMessage] = asyncio.Queue()
# 出站异步队列
self.outbound: asyncio.Queue[OutboundMessage] = asyncio.Queue()
async def publish_inbound(self, msg: InboundMessage) -> None:
"""将来自频道的消息发布给智能体"""
await self.inbound.put(msg)
async def consume_inbound(self) -> InboundMessage:
"""消费下一条入站消息(阻塞直到有消息可用)"""
return await self.inbound.get()
async def publish_outbound(self, msg: OutboundMessage) -> None:
"""将智能体的响应发布给频道"""
await self.outbound.put(msg)
async def consume_outbound(self) -> OutboundMessage:
"""消费下一条出站消息(阻塞直到有消息可用)"""
return await self.outbound.get()
同时入站异步队列和出站异步队列通过 asyncio.Queue 提供。asyncio.Queue 是异步编程中实现生产者-消费者模式的标准工具,它让不同协程之间可以安全、非阻塞地交换数据。在我们上述网关的设计中,正是依赖它实现了入站/出站双队列解耦,从而让多个 IM 渠道可以并发接收消息,同时 Agent 通过并发处理消息,实现效率提高。没有它,你就得自己用锁和条件变量实现类似功能,既复杂又容易出错。
接着我们修改上一篇文章《如何使用飞书机器人连接本地 AI Agent》中实现的飞书连接本地 AI Agent 的飞书频道,实现将来自飞书的消息转发到通信总线。
# feishu.py
+ from events import InboundMessage
+ from message_bus import MessageBus
class FeishuChannel:
"""极简版飞书 WebSocket 长连接机器人"""
+ name = "feishu"
def __init__(self, config: FeishuConfig, bus: MessageBus):
self.config = config
self.bus = bus
# 省略...
async def start(self) -> None:
# 省略...
- def _on_message(self, data: P2ImMessageReceiveV1) -> None:
+ async def _on_message(self, data: P2ImMessageReceiveV1) -> None:
"""接收到消息时的回调"""
msg = data.event.message
+ sender = data.event.sender
# 只处理用户发送的纯文本消息
if data.event.sender.sender_type == "bot" or msg.message_type != "text":
return
content = json.loads(msg.content).get("text", "")
if not content:
return
+ # 提取发送者信息
+ sender_id = sender.sender_id.open_id if sender.sender_id else "unknown"
+ # 获取用于回复的 chat_id
+ chat_id = msg.chat_id
+ chat_type = msg.chat_type # "p2p" 或 "group"
+ reply_to = chat_id if chat_type == "group" else sender_id
+ # 将消息转发到总线
+ await self._handle_message(
+ sender_id=sender_id,
+ chat_id=reply_to,
+ content=content,
+ )
- # 启动独立线程处理 AI 逻辑并回复,防止阻塞 WebSocket 接收循环
- # threading.Thread(
- # target=self._process_and_reply,
- # args=(msg.chat_id, content)
- # ).start()
+ async def _handle_message(
+ self,
+ sender_id: str,
+ chat_id: str,
+ content: str,
+ ) -> None:
+ """
+ 处理来自聊天平台的传入消息。
+ 此方法将消息转发到总线。
+ 参数:
+ sender_id: 发送者的标识符。
+ chat_id: 聊天/通道的标识符。
+ content: 消息文本内容。
+ """
+ msg = InboundMessage(
+ channel=self.name,
+ sender_id=str(sender_id),
+ chat_id=str(chat_id),
+ content=content
+ )
+ await self.bus.publish_inbound(msg)
现在我们已经将飞书发过来的消息推送到通信总线中了,接着我们需要在 Agent 异步处理协程中循环读取总线中的消息进行处理了。
4. 实现并发 Agent Loop
我们上文讲到了通过 asyncio.Queue 实现了入站/出站双队列解耦,从而让多个 IM 渠道可以并发接收消息,同时 Agent 通过并发处理消息,实现效率提高。
但我们前面实现的 Agent Loop 的同步处理数据,所以我们需要重新设计并实现我们的 Agent Loop。
首先我们这个 Agent Loop 需要具备以下功能点:
-
持续运行:只要网关没有关闭,Agent Loop 就要一直工作,不能退出。
-
响应及时:当有新消息到达时,应尽快开始处理,避免不必要的延迟。
-
可优雅停止:外部可以调用
stop() 方法,让循环在安全时机退出,而不是强制杀死协程。
-
容错性:单条消息处理失败不应导致整个循环崩溃,并且要能告知用户出错。
那么第一个功能点持续运行,我们可以通过使用一个布尔标志控制循环是否继续。
self._running = True
while self._running:
# 只要 self._running = True 就一直循环读取通讯总线中的消息进行处理
这样只要 self._running = True 就一直循环读取通讯总线中的消息进行处理。同时我们设计一个 stop() 方法设置 self._running = False,这样外部协程就可以调用 stop() 使得循环将在下一次条件判断时退出。
在读取通讯总线中的消息时,我们需要通过 asyncio.wait_for 实现可中断阻塞读取。即如下实现:
self._running = True
while self._running:
# 只要 self._running = True 就一直循环读取通讯总线中的消息进行处理
msg = await asyncio.wait_for(
self.bus.consume_inbound(), # 本质是 await inbound_queue.get()
timeout=1.0,
)
如果不使用 asyncio.wait_for 而是直接使用 await self.bus.consume_inbound() 的话,没有消息就一直等着,那么循环永远不会走到 while self._running 的条件判断。此时调用 stop() 设置 self._running = False 是无效的,因为协程卡在 get() 上,永远没有机会检查 self._running 标志。
而使用 asyncio.wait_for 并设置超时为 1 秒,也就是如果 1 秒内返回了消息,就正常得到 msg。如果 1 秒后队列仍为空,wait_for 会抛出 asyncio.TimeoutError。这样,协程最多阻塞 1 秒就会醒来一次,重新检查 while self._running。因此,即使没有消息,循环也能每秒检查一次退出标志,实现可中断的阻塞读取。
根据上述设计我们初步实现 Agent Loop 如下:
import asyncio
import json
import os
from typing import Any
from dotenv import load_dotenv
from loguru import logger
from openai import AsyncOpenAI
from events import InboundMessage, OutboundMessage
from message_bus import MessageBus
load_dotenv()
class AgentLoop:
def __init__(
self,
bus: MessageBus,
max_iterations: int = 200,
api_key: str | None = None,
base_url: str = "https://api.deepseek.com",
model: str = "deepseek-chat",
):
self.bus = bus
# 最大工具调用轮次,防止死循环
self.max_iterations = max_iterations
self.model = model
self._running = False
# 初始化 OpenAI异步客户端 兼容客户端(如 DeepSeek)
self.client = AsyncOpenAI(
api_key=api_key or os.getenv("DEEPSEEK_API_KEY"),
base_url=base_url,
)
# ------------------------------------------------------------------
# 主循环:持续消费 入站异步队列
# ------------------------------------------------------------------
async def run(self) -> None:
"""运行智能体循环,处理来自总线的消息。"""
self._running = True
logger.info("Agent loop started")
while self._running:
try:
# 从入站队列消费下一条消息,设置超时以便能定期检查 _running 标志
msg = await asyncio.wait_for(
self.bus.consume_inbound(),
timeout=1.0,
)
try:
# 处理消息并获取响应
response = await self._process_message(msg)
if response:
# 将响应发布到出站队列
await self.bus.publish_outbound(response)
except Exception as e:
logger.error(f"Error processing message: {e}")
await self.bus.publish_outbound(
OutboundMessage(
channel=msg.channel,
chat_id=msg.chat_id,
content=f"抱歉,处理消息时出错:{e}",
)
)
except asyncio.TimeoutError:
continue
def stop(self) -> None:
"""停止智能体循环。"""
self._running = False
logger.info("Agent loop stopping")
上述的 run 方法需要在一开始就启动,这样才可以实现一有消息就马上处理,而不会漏消息。我们把上一篇讲解实现飞书接入本地 AI Agent 的启动文件 test_feishu.py 重命名为 gateway.py,也就是网关的意思,并且修改其中的启动代码:
+ from message_bus import MessageBus
+ from loop import AgentLoop
async def main():
# 1. 填入你的飞书机器人凭证
config = FeishuConfig(
app_id="xxx", # 替换为真实的 App ID
app_secret="xxx", # 替换为真实的 App Secret
encrypt_key="", # 如果飞书后台配置了 Encrypt Key 则填入,否则留空
verification_token="" # 如果配置了 Verification Token 则填入,否则留空
)
+ deepseek_key = os.getenv("DEEPSEEK_API_KEY", "")
+ bus = MessageBus()
+ agent = AgentLoop(
+ bus=bus,
+ api_key=deepseek_key,
+ base_url="https://api.deepseek.com",
+ model="deepseek-chat",
+ max_iterations=20,
+ )
# 2. 初始化频道并启动长连接
- channel = FeishuChannel(config=config)
+channel = FeishuChannel(config=config, bus=bus)
logger.info("正在启动飞书机器人长连接...")
- # 3. 启动并保持运行
+ # 3. 并发运行
try:
- await channel.start()
+ await asyncio.gather(
+ agent.run(), # 持续消费 inbound 队列,调用 LLM
+ channel.start(), # 飞书启动
+ )
except KeyboardInterrupt:
logger.info("收到退出信号,正在关闭...")
if __name__ == "__main__":
import asyncio
asyncio.run(main())
通过上述修改我们就实现了 Agent 和飞书频道在初始化的时候并发运行,从而实现了一开始就监听入站异步队列的消息。
上述 Agent Loop 的 self._process_message 方法是还没实现的,所以我们继续实现 Agent 对消息的处理。本质就是实现大模型的工具调用循环。
在实现 Agent 对消息的处理之前,我们先要重新设计一下会话历史。
5. 会话历史设计
在前面的文章中我们的会话历史就是一个数组,结构如下:
history = [
{"role": "system", "content": getattr(agent, "SYSTEM", "你是一个助手")},
{"role": "user", "content": content}
]
后续如果继续有消息就根据角色往数组 history 中追加用户消息和助手消息即可。
但在 OpenClaw 中需要保证不同渠道、不同群、不同用户的历史会话完全隔离。我们可以使用 dict[str, list[dict]] 作为存储结构,相当于在 JavaScript 中设置一个对象,然后通过 key 作为唯一标识进行会话隔离。
key 设计:
这个 key 我们可以设置由 channel + chat_id 组合而成,例如 "feishu:oc_xxx"。然后我们在之前设计的 InboundMessage 对象中设置一个 session_key 方法用于返回会话唯一标识。设置如下:
@dataclass
class InboundMessage:
# 省略...
+ @property
+ def session_key(self) -> str:
+ """用于会话标识的唯一键"""
+ return f"{self.channel}:{self.chat_id}"
value 设计:
value 其实就是上述的历史会话数组,即:
[
{"role": "system", "content": getattr(agent, "SYSTEM", "你是一个助手")},
{"role": "user", "content": content}
]
同时我们设计一个 _get_history 的函数来实现对会话历史的懒加载,如果 session_key 不存在,自动创建新列表并插入 system prompt,如果 session_key 存在则返回内部列表的直接引用,调用方可以修改它,即追加消息。这样设计可以避免拷贝带来的性能开销。
实现如下:
# ---------- 会话历史管理(按 session_key 隔离) ----------
# 全局字典:存储所有会话的对话历史
# - Key: session_key,用于唯一标识一个会话(例如 "feishu:chat_id")
# - Value: 消息列表,每个元素是 OpenAI API 兼容的消息字典(包含 role, content 等字段)
_sessions: dict[str, list[dict]] = {}
# 系统提示词:定义 AI 助手的角色、能力和行为准则
SYSTEM_PROMPT = (
"你是一个智能助手,可以通过工具帮助用户完成任务。"
"请简洁、准确地回答用户问题。"
)
# 获取会话历史
def _get_history(session_key: str) -> list[dict]:
# 若为新会话,自动初始化一条包含 system prompt 的消息
if session_key not in _sessions:
_sessions[session_key] = [{"role": "system", "content": SYSTEM_PROMPT}]
# 返回该会话的历史列表(引用,允许外部修改)
return _sessions[session_key]
6. Agent Loop 的核心:消息处理
在完成了会话历史管理和主循环的可中断阻塞读取之后,Agent Loop 最核心的部分就是 单条消息的处理逻辑——即 _process_message 方法。该方法实现了 ReAct(推理+行动)模式:调用 LLM → 若需要工具则执行工具 → 将结果返回 LLM → 重复直到得到最终答案。下面详细解析其实现:
class AgentLoop:
# 省略...
# ------------------------------------------------------------------
# 单条消息处理:tool-call 循环
# ------------------------------------------------------------------
async def _process_message(self, msg: InboundMessage) -> OutboundMessage | None:
# 1. 获取当前会话的历史,并追加用户消息
messages = _get_history(msg.session_key)
messages.append({"role": "user", "content": msg.content})
final_content: str | None = None
# 2. 进入工具调用循环(最多 max_iterations 次)
for iteration in range(self.max_iterations):
# 3. 调用 LLM(异步非阻塞)
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=TOOLS,
tool_choice="auto",
)
assistant_msg = response.choices[0].message
# 将助手消息追加到历史
messages.append(assistant_msg)
# 4. 如果没有 tool_calls,说明任务完成
if not assistant_msg.tool_calls:
final_content = assistant_msg.content or ""
break
# 5. 执行所有工具调用,并将结果以 role=tool 追加到历史记录
for tool_call in assistant_msg.tool_calls:
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
logger.debug(f"Executing tool: {name}, args: {args}")
result = _execute_tool(name, args)
logger.debug(f"Tool result: {result[:100]}")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": name,
"content": result,
}
)
else:
# 达到最大迭代次数
final_content = "已达到最大处理轮次,无法给出最终答案。"
if final_content is None:
final_content = "处理完成,但没有内容返回。"
# 6. 构造出站消息返回给用户
return OutboundMessage(
channel=msg.channel,
chat_id=msg.chat_id,
content=final_content,
)
上述代码的实现跟我们前面文章实现 Agent Loop 是一样的,所以大家还有不懂的话,可以回看前面文章的详细解析。最最重要的就是最后返回了构造了 OutboundMessage 格式的出站消息,然后在 run 方法中通过 self.bus.publish_outbound(response) 将消息发布到出站队列。
其中工具定义实现如下:
# ---------- 内置工具定义 ----------
TOOLS: list[dict] = [
{
"type": "function",
"function": {
"name": "read_file",
"description": "读取本地文本文件内容。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"},
"encoding": {
"type": "string",
"enum": ["utf-8", "gbk"],
"description": "文件编码,默认 utf-8",
},
},
"required": ["path"],
},
},
}
]
def _execute_tool(name: str, arguments: dict) -> str:
"""同步执行内置工具,返回字符串结果。"""
if name == "read_file":
from pathlib import Path
path = arguments.get("path", "")
encoding = arguments.get("encoding", "utf-8")
try:
p = Path(path).expanduser()
if not p.exists():
return f"❌ 文件不存在: {path}"
return p.read_text(encoding=encoding)
except Exception as e:
return f"❌ 读取失败: {e}"
return f"❌ 未知工具: {name}"
我们这里先只实现一个读取文件内容的工具,后续再实现更多的工具。
7. 构建网关的渠道层
7.1 为什么需要渠道层?
在上一小节中,我们实现在 Agent 中构造了 OutboundMessage 格式的出站消息,然后将消息发布到出站队列中。但还缺少关键的一环:出站异步队列中的消息由谁来消费?如何将 Agent 的回复正确地发送回原来的聊天频道?
我们知道每个即时通讯平台都有自己独特的 API 协议,如果让 Agent 直接处理这些差异,会导致 Agent 逻辑中混杂大量渠道特定代码,每增加一个渠道就要修改 Agent 核心逻辑,这会造成维护噩耗。
所以我们需要构建一个 渠道管理器(ChannelManager),作为网关的出站交通枢纽,负责管理所有 IM 适配器的生命周期,并将出站消息路由到正确的渠道。具体需要实现以下功能:
-
注册与管理渠道实例
- 运行时动态注册各个渠道
- 维护渠道状态信息
- 提供统一的渠道访问接口
-
协调启动与停止流程
- 控制渠道启动顺序,避免竞态条件
- 实现优雅停止,防止消息丢失
- 处理异常情况下的资源清理
-
消息路由与派发
- 根据消息的 channel 字段路由到正确渠道
- 调用渠道的发送方法
- 实现错误隔离和重试机制
7.2 渠道层的设计与实现
如果把整个网关系统比作一个繁忙的交通枢纽,那么渠道层就是站在十字路口中央的交警。它不亲自运送货物,但指挥着所有运输车辆有序通行。
具体来说,渠道层连接着:
-
上游:内部消息总线(MessageBus),接收标准化的出站消息
-
下游:各个 IM 渠道适配器(FeishuChannel、WechatChannel 等)
我们先实现一个 ChannelManager 类,并实现数据结构与初始化。代码如下:
import asyncio
from loguru import logger
from message_bus import MessageBus
from feishu import FeishuChannel
class ChannelManager:
def __init__(self, bus: MessageBus):
self.bus = bus
# 存储已注册的渠道适配器,key 为渠道名称(如 "feishu")
self.channels: dict[str, FeishuChannel] = {}
# 出站分发器的任务句柄,用于优雅停止
self._dispatch_task: asyncio.Task | None = None
ChannelManager 的核心数据结构 channels 是一个字典: channel_name → 适配器实例 。
- Key = 渠道名称(如 "feishu"、"wechat")
- Value = 渠道实例对象
这个设计实现了运行时动态注册,可以在不重启服务的情况下添加新渠道。
接着我们来实现注册渠道功能:
class ChannelManager:
def __init__(self, bus: MessageBus):
# 省略...
def register(self, channel: FeishuChannel) -> None:
"""注册一个渠道适配器。要求该适配器必须有 name 属性和 send 方法。"""
self.channels[channel.name] = channel
logger.info(f"Channel registered: {channel.name}")
上述注册渠道的代码实现看起很简单,其实背后的设计原理一点也不简单。它应用了工厂模式 + 依赖注入的设计模式。
-
工厂模式体现在:渠道的创建由外部完成,ChannelManager 只负责使用
-
依赖注入体现在:渠道实例通过 register() 方法注入,而非在 ChannelManager 内部创建
我们已经实现了一个飞书渠道 FeishuChannel,所以现在需要通过以下方式进行注册飞书渠道:
manager.register(FeishuChannel(...))
同时将来如果我们想新增一个微信渠道,就可以这样实现了,先实现一个 WechatChannel,然后:
manager.register(WechatChannel(...))
这样网关核心代码零改动,真正实现了"开闭原则":对扩展开放,对修改关闭。
接着实现启动所有已注册的频道以及出站分发器。
代码实现如下:
class ChannelManager:
def __init__(self, bus: MessageBus):
# 省略...
def register(self, channel: FeishuChannel) -> None:
# 省略...
async def start_all(self) -> None:
"""启动所有已注册的频道以及出站分发器。"""
if not self.channels:
logger.warning("No channels registered")
return
# 先启动出站分发器协程(确保一有出站消息就能被处理)
self._dispatch_task = asyncio.create_task(self._dispatch_outbound())
# 并发启动所有渠道(每个渠道的 start 方法负责建立长连接或监听 Webhook)
tasks = []
for name, channel in self.channels.items():
logger.info(f"Starting {name} channel...")
tasks.append(asyncio.create_task(channel.start()))
# 注意:通常渠道的 start 会永久阻塞(如 WebSocket 循环),因此 gather 不会返回
await asyncio.gather(*tasks, return_exceptions=True)
我们上述的代码实现了一个看似简单却至关重要的设计决策,就是先启动分发器再启动渠道。那么为什么先启动分发器再启动渠道呢?
主要是为了防止消息丢失与响应延迟。让我们分析两种启动顺序的后果:
场景 A:先启动渠道,后启动分发器
时间线:
- 飞书渠道启动成功 ✓
- 用户立即发送消息:"你好"
- Agent 快速处理,生成回复:"你好!我是AI助手"
- 回复进入出站队列...
- 但是!分发器还没启动 ❌
- 回复消息在队列中堆积
- 用户等待...等待...(用户体验差)
场景 B:先启动分发器,后启动渠道(我们采用的方式)
时间线:
- 分发器启动,开始监听出站队列 ✓
- 飞书渠道启动成功 ✓
- 用户发送消息:"你好"
- Agent 处理,生成回复:"你好!我是AI助手"
- 回复进入出站队列
- 分发器立即发现新消息 ✓
- 路由到飞书渠道,立即发送 ✓
- 用户秒级收到回复(体验流畅)
在实际的生产环境经验中,"空转等待"比"忙中丢消息"要好得多。分发器提前就位,就像快递员提前在仓库门口等待,包裹一出来就能立即配送。
接着我们实现出站消息分发器。
代码实现如下:
class ChannelManager:
def __init__(self, bus: MessageBus):
# 省略...
def register(self, channel: FeishuChannel) -> None:
# 省略...
async def start_all(self) -> None:
# 省略...
async def _dispatch_outbound(self) -> None:
"""
出站分发器:持续消费 outbound 队列,将消息发送到对应的渠道。
这是一个后台协程,在 start_all 时启动。
"""
logger.info("Outbound dispatcher started")
while True:
try:
# 可中断阻塞读取,每隔1秒检查一次取消信号
msg = await asyncio.wait_for(
self.bus.consume_outbound(),
timeout=1.0,
)
# 根据消息中的 channel 字段找到对应的适配器
channel = self.channels.get(msg.channel)
if channel:
try:
# 调用适配器的 send 方法(各渠道自己实现转换和发送逻辑)
await channel.send(msg)
except Exception as e:
logger.error(f"Error sending to {msg.channel}: {e}")
else:
logger.warning(f"Unknown channel: {msg.channel}")
except asyncio.TimeoutError:
# 超时不是错误,只是没有消息,继续循环
continue
except asyncio.CancelledError:
break
我们上一小节中所说的先启动分发器,本质就是通过 while True 不断循环使用 asyncio.wait_for 消费 outbound 队列,然后根据 msg.channel 路由并调用 send 方法。
设计亮点:
-
拉模式(Pull)而非推模式(Push)
- 主动从消息队列拉取消息,控制权在自己手中
- 相比回调式的推模式,更容易控制消费速率和错误处理
-
可中断的事件循环
- timeout=1.0 让循环能定期"抬头看路",检查是否有停止信号
- 没有这个超时,任务会一直阻塞在 consume_outbound() 上,难以优雅停止
接着我们继续实现渠道的发送方法,这是协议翻译的最后一步。
为了让 ChannelManager 能够统一管理,每个 IM 适配器必须实现以下两个成员:
-
name: str:渠道唯一标识(如 "feishu")。
-
async send(msg: OutboundMessage) -> None:发送回复的方法。
以飞书适配器为例,我们之前已经定义了 name = "feishu",现在补充 send 方法的实现:
class FeishuChannel:
# 省略...
async def send(self, msg: OutboundMessage) -> None:
"""通过飞书发送消息。"""
if not self._client:
logger.warning("飞书客户端未初始化")
return
try:
# 根据 chat_id 格式确定 receive_id_type
# open_id 以 "ou_" 开头,chat_id 以 "oc_" 开头
if msg.chat_id.startswith("oc_"):
receive_id_type = "chat_id"
else:
receive_id_type = "open_id"
# 构建文本消息内容
content = json.dumps({"text": msg.content})
request = CreateMessageRequest.builder() \
.receive_id_type(receive_id_type) \
.request_body(
CreateMessageRequestBody.builder()
.receive_id(msg.chat_id)
.msg_type("text")
.content(content)
.build()
).build()
# OpenAPI 调用是同步的,在线程中运行以避免阻塞
response = await asyncio.to_thread(
self._client.im.v1.message.create, request
)
if not response.success():
logger.error(
f"发送飞书消息失败:code={response.code}, "
f"msg={response.msg}, log_id={response.get_log_id()}"
)
else:
logger.debug(f"飞书消息已发送至 {msg.chat_id}")
except Exception as e:
logger.error(f"发送飞书消息时出错:{e}")
本质是就是将我们上一篇文章中的 FeishuChannel 类中 _process_and_reply 方法改成 send 方法即可。这样,ChannelManager 就可以统一调用 await channel.send(msg),完全不需要关心飞书 API 的具体细节。
8. 集成到网关启动入口
现在,我们将 MessageBus、AgentLoop、FeishuChannel 和 ChannelManager 全部串联起来。实现如下:
# gateway.py
import os
from loguru import logger
from feishu import FeishuChannel, FeishuConfig
from message_bus import MessageBus
from loop import AgentLoop
from manager import ChannelManager
async def main():
# 1. 填入你的飞书机器人凭证
config = FeishuConfig(
app_id="xxx", # 替换为真实的 App ID
app_secret="xxx", # 替换为真实的 App Secret
encrypt_key="", # 如果飞书后台配置了 Encrypt Key 则填入,否则留空
verification_token="" # 如果配置了 Verification Token 则填入,否则留空
)
deepseek_key = os.getenv("DEEPSEEK_API_KEY", "")
# 2. 创建总线
bus = MessageBus()
# 3. 创建 Agent 循环
agent = AgentLoop(
bus=bus,
api_key=deepseek_key,
base_url="https://api.deepseek.com",
model="deepseek-chat",
max_iterations=20,
)
# 4. 创建飞书渠道(传入总线,以便它 publish_inbound)
feishu_channel = FeishuChannel(config=config, bus=bus)
# 5. 创建渠道管理器,并注册飞书渠道
channels = ChannelManager(bus=bus)
channels.register(feishu_channel)
logger.info("正在启动 Mini OpenClaw 网关...")
# 6. 并发运行
try:
await asyncio.gather(
agent.run(), # 持续消费 inbound 队列,调用 LLM
channels.start_all(), # 飞书长连接 + 出向派发器
)
except KeyboardInterrupt:
pass
finally:
logger.info("收到退出信号,正在关闭...")
agent.stop()
await channels.stop_all()
if __name__ == "__main__":
import asyncio
asyncio.run(main())
至此整个网关的运行流程如下:
1. 网关“通电”
- 我们启动
manager.start_all(),它立刻做了两件事:
- 先派一个“快递员”(
_dispatch_outbound 后台任务)守在 发件箱(outbound 队列) 旁边,随时准备把回复送出去。
- 然后接通 飞书这个“电话线”(
feishu_channel.start()),开始等待用户发消息。
2. 用户发来消息
- 用户在飞书群里说了一句“帮我读一下 /tmp/note.txt”。
- 飞书适配器收到这条“方言消息”,立即翻译成网关内部的 普通话(InboundMessage),然后丢进 收件箱(inbound 队列)。
3. Agent 大脑开始思考
-
agent.run() 一直在盯着 收件箱,一看到有新消息就取出来。
- 它调用大模型并可能执行工具(比如读取文件),最终生成一段回复文本。
- 然后把回复包装成 标准包裹(OutboundMessage),扔进 发件箱(outbound 队列)。
4. 快递员送货
- 守在 发件箱 旁边的快递员(
_dispatch_outbound)发现新包裹,看看上面写的“收件渠道”是 feishu。
- 他马上找到飞书适配器,把包裹交给它:“请发到这个
chat_id 的群里”。
- 飞书适配器又把回复从 普通话 翻译回 飞书的方言,调用飞书 API 发回群里。
5. 用户看到回复
我们上述的 channels.start_all() 方法是还没实现的,我们实现一下:
class ChannelManager:
def __init__(self, bus: MessageBus):
# 省略...
async def start_all(self) -> None:
# 省略...
async def stop_all(self) -> None:
"""优雅停止所有渠道和出站分发器。"""
logger.info("Stopping all channels...")
# 第一阶段:取消出站分发器任务
if self._dispatch_task:
self._dispatch_task.cancel()
try:
await self._dispatch_task
except asyncio.CancelledError:
pass
# 第二阶段:逐个停止渠道(每个渠道的 stop 方法应关闭连接、释放资源)
for name, channel in self.channels.items():
try:
await channel.stop()
logger.info(f"Stopped {name} channel")
except Exception as e:
logger.error(f"Error stopping {name}: {e}")
实现也很简单,首先停止出站分发器的任务,再逐个停止渠道的连接,释放资源。
接着我们启动网关:
python gateway.py
启动结果如下:
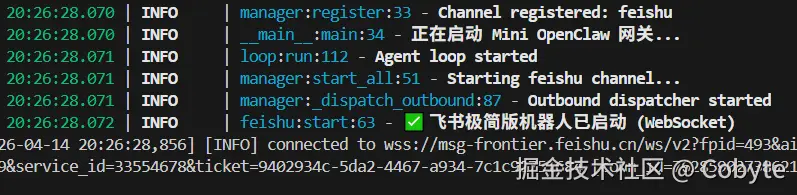
然后我们接着在上一篇文章中设置了的飞书机器人中进行发消息。
然后我们发现报错了:

报错原因是因为飞书 SDK 的 register_p2_im_message_receive_v1 要求注册一个同步回调函数(不能是 async def),但消息处理逻辑(如解析内容、发布到 MessageBus)是异步的。因此,我们需要实现一个跨线程调度适配器,用于将飞书 WebSocket 线程中的同步回调安全地桥接到 asyncio 主事件循环。
9. 跨线程调度适配器
首先我们需要保存主事件循环对象,我们是在网关启动文件 gateway.py 中通过 asyncio.run(main()) 启动的主循环。因为飞书 WebSocket 客户端运行在一个独立的后台线程中(见 threading.Thread(target=run_ws, daemon=True).start()),它的回调需要一个同步函数,但真正的消息处理逻辑 _on_message 是一个异步协程,需要被提交到主事件循环中执行,因为 MessageBus 等组件是绑定到主循环的。为了从另一个线程安全地将协程投递到主事件循环,就需要持有主事件循环的引用。
先保存主事件循环对象:
class FeishuChannel:
def __init__(self, config: FeishuConfig, bus: MessageBus):
self.config = config
self.bus = bus
+ self._loop = None
self._client = lark.Client.builder() \
.app_id(config.app_id) \
.app_secret(config.app_secret) \
.build()
async def start(self) -> None:
# 省略...
+ # 保存主事件循环对象
+ self._loop = asyncio.get_running_loop()
def run_ws():
# 省略...
接着我们创建了一个同步函数 _on_message_sync 作为 register_p2_im_message_receive_v1 的实际回调,然后在 _on_message_sync 中将真正异步的处理函数 _on_message 调度到主事件循环中执行。实现如下:
def _on_message_sync(self, data: "P2ImMessageReceiveV1") -> None:
try:
if self._loop and self._loop.is_running():
# 将异步处理函数调度到主事件循环
asyncio.run_coroutine_threadsafe(
self._on_message(data),
self._loop
)
else:
# 备用方案:在新事件循环中运行
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
loop.run_until_complete(self._on_message(data))
finally:
loop.close()
except Exception as e: logger.error(f"处理飞书消息时出错:{e}")
接着我们修改 register_p2_im_message_receive_v1 的实际回调函数为上述我们实现的 _on_message_sync。
class FeishuChannel:
def __init__(self, config: FeishuConfig, bus: MessageBus):
# 省略...
async def start(self) -> None:
# 省略...
# 注册接收消息事件处理函数 im.message.receive_v1
- handler = builder.register_p2_im_message_receive_v1(self._on_message).build()
+ handler = builder.register_p2_im_message_receive_v1(self._on_message_sync).build()
# 保存主事件循环对象
self._loop = asyncio.get_running_loop()
总的来说就是在主事件循环中“记住”主循环对象,供后续其他线程通过 asyncio.run_coroutine_threadsafe 将协程调度回主循环执行,是实现跨线程异步任务调度。
同时当主事件循环不存在时创建一个全新的临时事件循环,在当前线程(WebSocket 线程)中同步运行 self._on_message(data),执行完毕后关闭循环。
经过上述迭代后,我们再次启动我们的程序:python gateway.py。
然我们再在飞书设置的 AI 机器人上跟我们的 Mini OpenClaw 进行对话,结果如下:
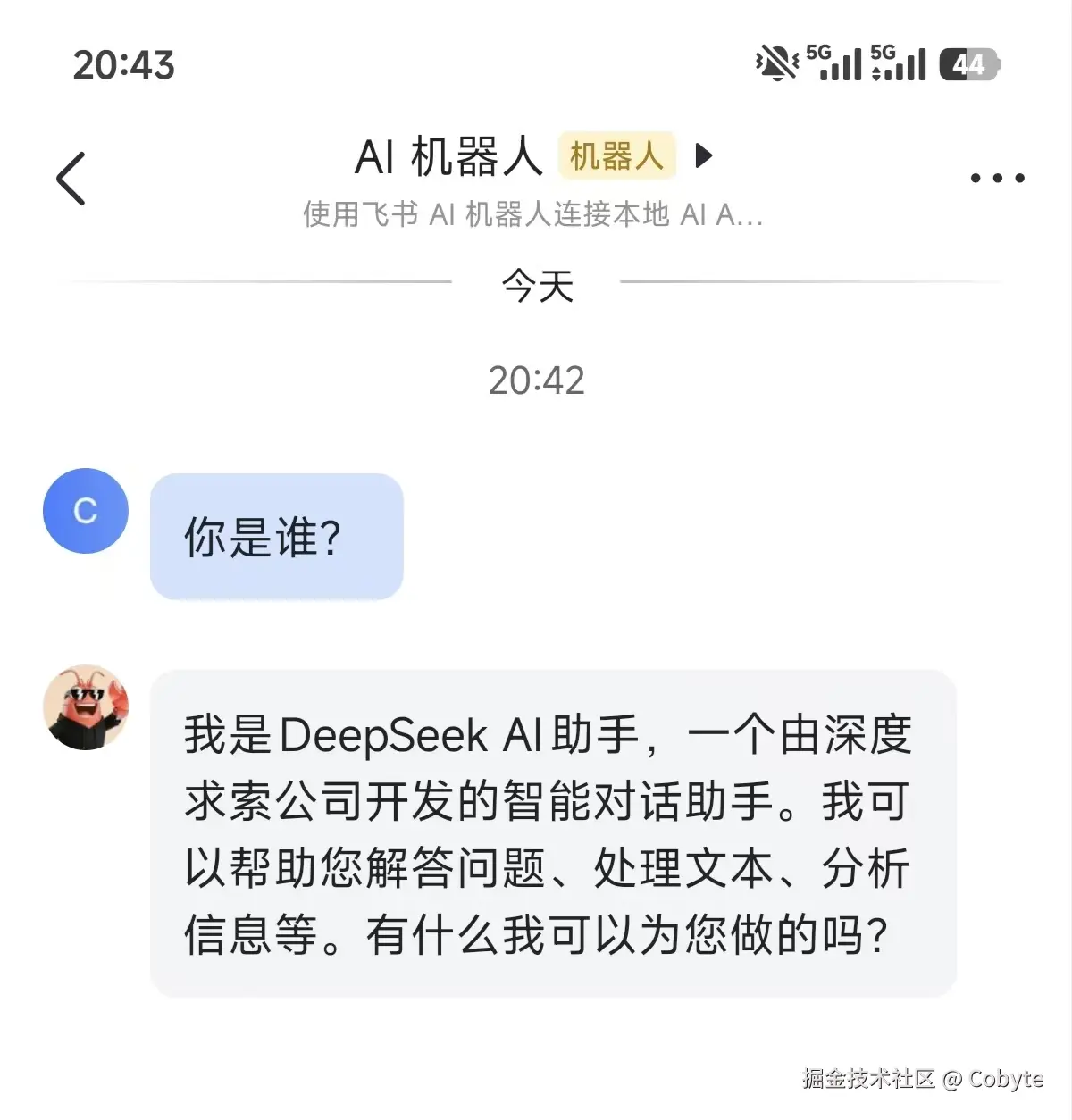
然后我们再根目录下创建一个 test.txt 文件,内容为:“从网关的角度理解并实现一个 Mini OpenClaw”,然后在飞书设置的 AI 机器人输入:“帮我读取 test.txt 文件”,结果如下:

至此我们的 Mini OpenClaw 就实现了。
10. 总结
经过上述文章我们可以更加透彻地理解为什么说 OpenClaw 可以简单总结为“高级 Agent + 网关”了。它把飞书、微信这些聊天软件的“方言消息”统一通过一个网关转成内部能听懂的“普通话”(InboundMessage),Agent 只处理这种标准消息。
为了防止消息太多堵死系统,用了两个队列(入站异步队列和出站异步队列,相当于收信箱和发件箱)把接收和回复解耦开,像流水线一样互不干扰。Agent 处理完后把回复扔进发件箱,再由分发器根据渠道标签(feishu、wechat)转回对应平台的格式发回去。
这样一来,添加新平台就像加个翻译插件,核心代码完全不用动。最后用跨线程调度解决了飞书回调异步的问题。整个网关跑起来就是:用户发消息 → 标准化 → 入站队列 → Agent 思考(可调用工具)→ 出站队列 → 翻译回原平台 → 用户收到回复。
上述实现也是港大开源的 Nanobot 的核心实现,Nanobot 可以说是 Python 版的 OpenClaw,是学习研究场景的轻量选择。
我是程序员Cobyte,欢迎添加 v: icobyte,学习交流 AI Agent 应用开发。
