前言
最近与前同事深入交流,他现为字节某组的 TL(组长),团队规模近 10 人。在讨论他们团队的 AI 工作流实践中,也得到一些八卦信息。
第一个是: 人才储备变化
他们团队已基本停止招聘实习生,今年仅招一人
个人解读: AI 协作模式下,新人的边际效应大幅下降
第二个是:组织预期转变
业内多位跟他同级的 Leader 私下评估:今年可能出现大规模调整
个人解读: 生成式 AI 在降本增效上的潜力被普遍看好,提前做好裁员准备
第三个是:开发方法论的周期性
- 层出不穷的新概念:Vibe Coding、SDD 规范、Harness Engineering……
- 理性看待:这些都是过渡阶段产物,随着大模型升级,这些方法论的生命周期可能只有几个月
个人建议: 不必投入过多精力去追赶,因为等你熟练一种方法论后,可能用不了多久就被淘汰了
第四个是:招聘标准演变
前端岗位招聘标准很多 JD 上开始冠以"全栈开发" 的名义招聘了
实际面试:侧重前端能力考察,但开始要求一些后端基础能力了
个人解读: AI 协作工具提效下,企业希望前端承担更多职能
好了,八卦之后,关于他们的 ai 工作流的核心如下:
你得教 AI,不断沉淀并固化它的规范
具体实践方法:
- 识别问题:第一次遇到某类问题,AI 执行效果不理想
- 人工介入:手动处理并解决问题
- 规则沉淀:将解决方案固化为规则或 Skill
- 迭代积累:问题解决越多,效率提升越明显,也就是后期 ai 执行的只要不是新的场景和复杂业务,基本不会出错
本质: 通过持续的反馈循环来训练和优化 AI 的工作能力,而不是一开始就寻求完美的工作流
这个理念在字节技术专家杨晨的全软软件开发大会分享中也提出过:Prompt = 可训练资产(像模型一样优化)
让后我个人抽象了这个单 Agent 的工作流程图如下:
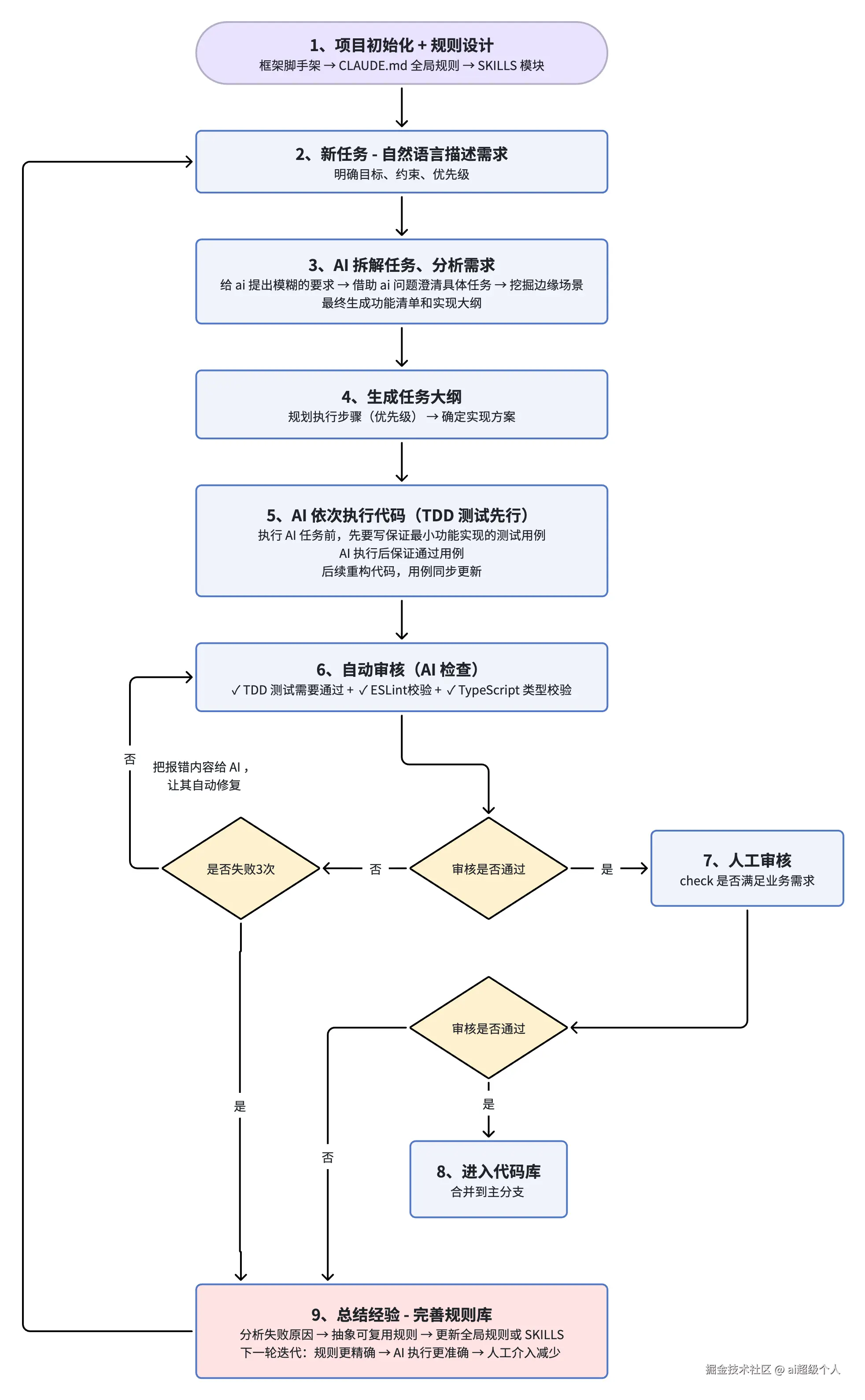
接下来我会解释每个步骤的思路和如何落地:
步骤 1:项目初始化 + 全局规则设计
项目初始化是指,大多数现代框架都提供了开箱即用的脚手架工具,例如:
# Vue/React 生态
npm create vite@latest
# Nest.js
nest new project-name
# Hono.js
pnpm create hono@latest
初始化完成后,立即在根目录创建规则文件,通常命名为 CLAUDE.md 或 AGENTS.md。
这个文件是 AI 协作的宪法,应包含例如项目定位,技术栈清单,核心哲学(例如测试先行,采用 TDD 测试方案),项目结构示例,AI 协作原则等等内容。有兴趣的同学可以找我要这个项目的全局规则。
两个关键注意事项
✅ 动态迭代
规则文件不是一成不变的。当发现 AI 写的代码不规范时,要想到如何抽离抽象的规则来约束,而不是一味手动修改
✅ SKILL 机制(规则的模块化)
当规则内容过多时,抽象可复用的 Skill 文件。好处是 AI 按需加载,不会每次都把全局规则加入上下文,大大减少 token 用量
规则中引用 SKILL 的示例:
## 3. 核心哲学:测试先行 (TDD)
参考 `.trae/skills/tdd-first/SKILL.md` 中的测试驱动开发规范。
所有新功能开发或 Bug 修复必须遵循 **「红-绿-重构」** 循环。**严禁**在没有对应测试用例的情况下提交业务逻辑代码。
---
## 4. 响应格式
参考 `.trae/skills/response-standard/SKILL.md` 中的响应格式规范。
**[强制]** 所有接口统一返回 JSON,使用 `@/utils/response` 中的工具函数生成响应。
---
步骤 2:需求分析
如果你很清楚自己要做什么,可以直接下发任务。但如果只有模糊想法,建议先和 AI 一起做需求分析。
推荐提示词
你好!现在的任务是:我们要从零开始设计并实现 `hono.js boilerplate`。
你现在是资深的 Node.js 工程师。我有一个初步的想法,需要你通过向我提问,帮助我澄清需求、挖掘边缘场景,最终目标是理清我做一个通用后端功能的脚手架需要实现哪些功能。并按顺序输出一个实现这些功能的大纲。
请开始你的提问。
效果: Claude 会像资深 PM 一样向你提问,你逐一回答这些问题后,AI 会生成一份完整的功能清单文档。
步骤 3:测试先行 + AI 执行代码
这是整个工作流的核心环节,必须让 AI 严格按照 TDD 测试方案执行代码。
执行策略
-
任务拆解 → 将需求拆分为最小可测试单元
-
红阶段 → 先编写测试用例(此时测试应当失败)
-
绿阶段 → 编写最小化实现代码,使测试通过
-
重构阶段 → 在测试通过的基础上,优化代码结构和性能
关键约束
在全局规则中强制要求 AI:
- ✅ 任何业务代码提交前,必须有对应的单元测试覆盖
- ✅ 测试用例需包含正常场景 + 边界场景 + 异常场景
- ✅ 测试执行必须通过,覆盖率不低于 80%
- ✅ 严禁为了赶进度而跳过测试环节
步骤 4:代码审核 + 规则反馈循环
AI 执行代码后,进入审核阶段,分为 AI 自动审核和人工审核两部分。
AI 自动审核
AI 每次完成任务时,需要自动进行:
- Eslint 校验
- TypeScript 类型校验
如果报错,AI 自己修复直到通过(可以限制修复次数,避免死循环)
人工审核
前期必须进行人工审核,一旦发现问题,思考如何抽象成规则或 Skill,避免 AI 再次犯错。
核心发现: 你会发现后期 AI 执行的效果会越来越好。对于 CRUD 场景,基本不需要人审核了,大概看一下产出代码就知道没问题。
步骤 5:持续迭代与精准化
随着迭代轮次增加,形成正向循环:
迭代轮数 ↑
↓
规则精确度 ↑ → AI 执行准确率 ↑
↓
处理边界场景的能力 ↑
↓
人工介入频率 ↓
↓
开发效率 ↑
这就是 AI 时代的竞争力所在: 不是盲目信任 AI,而是通过不断的反馈循环来「教」AI,逐步固化和优化工作规范。
我举个自己实践中的迭代案例:
- 例如我让 ai 实现超时中间件的时候,ai 是自己原生实现的,然后我感觉这种很常用的功能一般都有现成的库,就查了一下,果然是有 'hono/timeout' 这个库,然后就在全局规则加入了类似:”优先使用社区成熟,稳定的库解决问题“。
- 例如我在设计后端的 url 的时候,突然想起 K8s 有一个类似的 url 设计规范,可以跟权限结合起来,例如,/api/v1/roles/{roleId},其中 roles 代表就是资源,roleId 代表的是子资源。
resources: ["roles"] # 操作的资源
verbs: ["get"] # 操作类型,增删改查
resourceNames: ["{roleId}"] # 可选(精确到某个子资源)
简单就是说一个 url 代表对什么资源的什么操作。
| HTTP 请求 |
RBAC |
| GET /roles/{id} |
verbs: ["get"] |
| GET /roles |
verbs: ["list"] |
| POST /roles |
verbs: ["create"] |
| DELETE /roles/{id} |
verbs: ["delete"] |
然后就可以结合我们的 rbac 模型(权限模型),用来标识一个权限是什么,简单来说就是资源名 + 操作,就能标识一个权限。
然后我干脆让 ai 把这个 url 规范抽象为一个 skill,下次 ai 定义 url 的时候就会调用这个规则。
需要注意的是,字节内部的复杂度是更高的,我们后期也会探索,例如字节内部还有:
- 多 Agent 系统,比如主 Agent 来负责 plan 的制定,有 Coder Agent 负责编码,还有测试 Agent, test Agent 等等,这种多 Agent 协作,我个人估计字节迟早会推出一个开源库让我们使用的,所以不必着急。
- 评测体系,会对 AI 输出质量进行打分,也就是评测 AI 的输出质量,这条我们目前这一版是靠人工来识别,但我觉得还好,前期人工介入,后期规则越来越好,模型能力越来越强,就可以进入 AI 自我评测阶段了。
- 可观测性体系:就是对于 AI 写错的地方,是否能知道哪一步错了,然后根据这个让 AI 自动修正 Prompt,然后自动修正全局规则或者抽象为 SKILL。
上面要这么玩,目前个人还是很难的,需要大的平台支持,本文主要是先走通一个小循环,也欢迎大家一起交流(如果觉得不错,感谢点赞关注哦,欢迎入群交流~)。
项目实战:通用后端脚手架
技术栈: Hono.js + Drizzle ORM + PostgreSQL 数据库
前置声明: 整个工作流仅使用免费版工具(Trace + GLM5/豆包模型)即可高质量完成,充分说明该方法论的实际效果令人满意,而非纸上谈兵。
源码获取: 因外链限流问题,需要的朋友可以联系我获取完整代码(github)
脚手架目前的架构图如下:
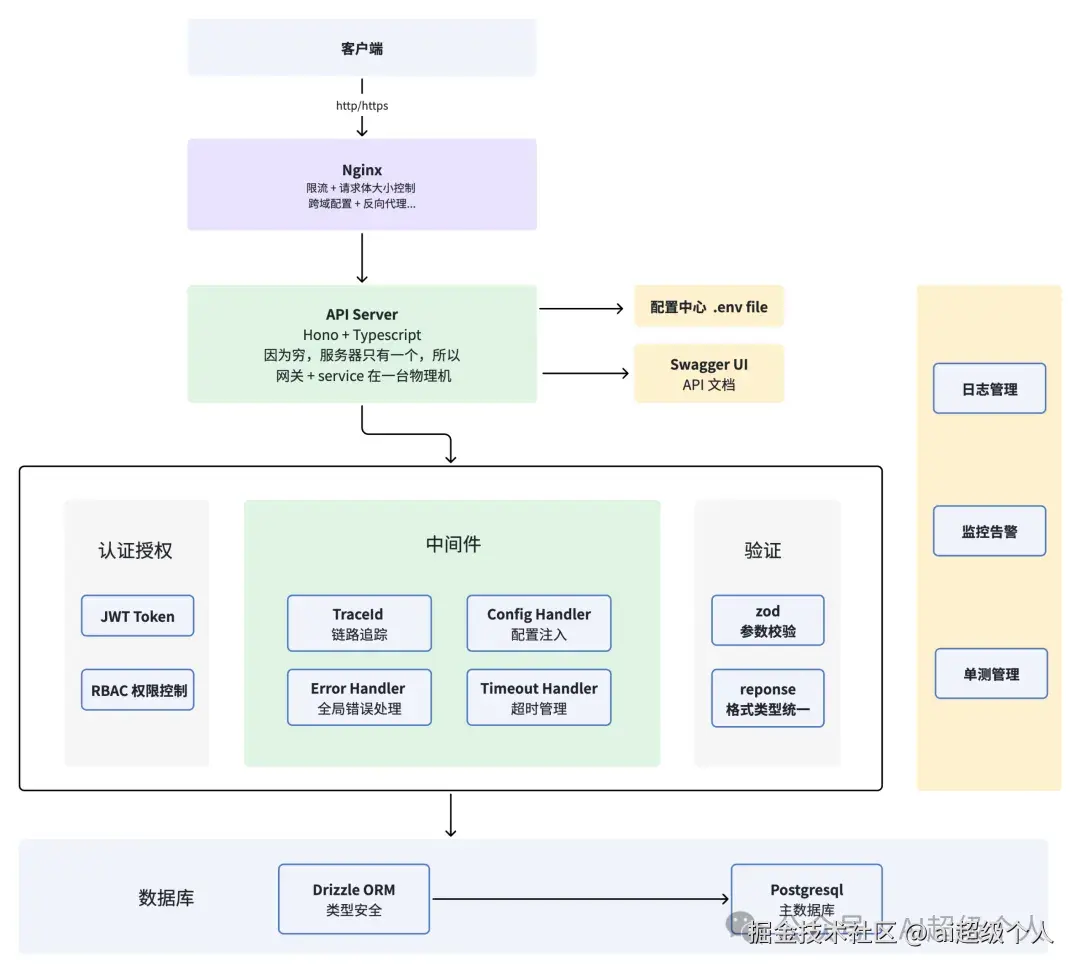
第二部分:企业级技术要点
分享上述实战过程中,网上 Node.js 教程很少提及的企业级最佳实践。
优雅关闭(Graceful Shutdown)
无论部署在 Kubernetes、Docker Compose 还是物理机,都需要实现优雅关闭逻辑。
为什么重要?
当应用报错或升级时,容器编排系统会执行关闭流程:
应用故障/升级 → 容器启动关闭流程
↓
向 PID 1 进程发送 SIGTERM 信号
↓
开启倒计时(默认 10 秒)
↓
如果 10 秒后进程未退出,发送 SIGKILL(强制杀死)
问题场景
例:电商扣款业务
1. 扣除用户余额 ✅
2. Docker 信号来了,进程被强杀 🔥
3. 积分增加 ❌(未执行)
结果:用户钱扣了但没到账,投诉炸裂。
问题根源: Docker 强杀是瞬间的,Node.js 无法执行完事件循环中的剩余回调。
解决方案
优雅关闭可以让你在收到信号后,停止接收新请求,但把内存中已排队的写操作执行完。同时及时释放系统资源(如数据库连接),避免占满最大连接数。
链路追踪(TraceId)
TraceId 是请求在系统中的唯一标识符,从进入系统到返回响应,始终伴随整个生命周期。
为什么需要?
场景:前端用户报错
用户说:"我提交表单后,收到错误 ID:abc123def456"
后端排查:
❌ 日志有 1000 条,怎么找到那条错误?
✅ 按 traceId = abc123def456 过滤,立即定位问题
Node.js 的特殊性
与 Java/Go 等多线程模型相比,Node.js 的单进程模型在处理 TraceId 时有本质区别:
| 语言 |
模型 |
上下文隔离方案 |
难度 |
| Java/Go |
多线程/协程 |
ThreadLocal |
⭐ 简单 |
| Node.js |
单进程 |
AsyncLocalStorage |
⭐⭐⭐ 复杂 |
错误做法
❌ 方案 1:全局变量
let traceId; // 全局变量
app.use((req, res, next) => {
traceId = generateId(); // 请求 A 的 traceId
next();
});
// 问题:请求 B 来了,traceId 被覆盖,日志全乱
❌ 方案 2:函数传参
// controller → service → dao,每层都要传 traceId
// 代码极其丑陋,难以维护
async function getUserOrder(traceId, userId) {
const user = await getUser(traceId, userId);
const order = await getOrder(traceId, user.id);
return { user, order };
}
正确方案:AsyncLocalStorage
Node.js 官方在 async_hooks 基础上,封装了更高级、性能更优的 API:
import { AsyncLocalStorage } from 'async_hooks';
const traceIdStorage = new AsyncLocalStorage();
// 在请求中间件中创建隔离上下文
app.use((req, res, next) => {
const traceId = generateId();
// 在当前上下文中存储 traceId(自动隔离)
traceIdStorage.run(traceId, () => {
next();
});
});
// 任何地方都可以取,不用传参
function getTraceId() {
return traceIdStorage.getStore();
}
// 使用示例
async function getUserOrder(userId) {
const traceId = getTraceId(); // 直接取,无需传参
logger.info(`[${traceId}] Fetching user`, { userId });
const user = await getUser(userId);
logger.info(`[${traceId}] User fetched`, { userId: user.id });
return user;
}
日志集成
const logger = createLogger((level, msg, meta) => {
const traceId = getTraceId();
const logEntry = {
timestamp: new Date().toISOString(),
level,
traceId, // 自动注入
message: msg,
...meta,
};
console.log(JSON.stringify(logEntry));
});
TDD 测试驱动开发
TDD 是企业级后端项目的核心质量保障手段,在 AI 协作开发模式下更是确保代码质量的关键。
核心流程:红-绿-重构
-
红阶段 → 编写测试用例,预期会失败(功能未实现)
-
绿阶段 → 实现最小化代码,使测试通过
-
重构阶段 → 优化代码结构,保持测试通过
Hono.js 项目中的实践
采用 Hono 原生集成测试方案,结合 Vitest 测试框架:
// test/user.test.ts
import { describe, it, expect } from 'vitest';
import app from '../src/app';
describe('User API', () => {
it('should return 404 for non-existent user', async () => {
const res = await app.request('/api/users/9999', {
method: 'GET'
});
expect(res.status).toBe(404);
const data = await res.json();
expect(data.code).toBe(0);
expect(data.message).toBe('User not found');
});
it('should create a new user', async () => {
const res = await app.request('/api/users', {
method: 'POST',
body: JSON.stringify({
name: '测试用户',
email: 'test@example.com',
password: 'password123'
}),
headers: {
'Content-Type': 'application/json'
}
});
expect(res.status).toBe(200);
const data = await res.json();
expect(data.code).toBe(1);
expect(data.data.name).toBe('测试用户');
});
});
表格驱动测试
对于多分支逻辑和边界情况,采用表格驱动测试风格:
describe('User Validation', () => {
const testCases = [
{
desc: '缺少必填字段',
body: { name: '测试用户' },
expectedStatus: 400,
expectedMessage: 'Email is required'
},
{
desc: '邮箱格式错误',
body: { name: '测试用户', email: 'invalid-email' },
expectedStatus: 400,
expectedMessage: 'Invalid email format'
},
{
desc: '密码长度不足',
body: { name: '测试用户', email: 'test@example.com', password: '123' },
expectedStatus: 400,
expectedMessage: 'Password must be at least 6 characters'
}
];
test.each(testCases)('$desc', async ({ body, expectedStatus, expectedMessage }) => {
const res = await app.request('/api/users', {
method: 'POST',
body: JSON.stringify(body),
headers: { 'Content-Type': 'application/json' }
});
expect(res.status).toBe(expectedStatus);
const data = await res.json();
expect(data.message).toBe(expectedMessage);
});
});
请求超时处理
请求超时处理是后端服务稳定性的重要保障,可以防止长时间运行的请求占用系统资源。
为什么需要?
- 保护用户体验:与其让用户等待 30 秒,不如在 5 秒内返回"请求超时"
- 防止系统雪崩:大量超时请求堆积会导致 CPU/内存被迅速耗尽
API 接口级超时
利用 Hono 自带的 timeout 中间件:
import { timeout } from 'hono/timeout'
// 1. 全局配置:所有请求默认 5 秒超时
app.use('/api/*', timeout(5000))
// 2. 局部配置:针对耗时操作,允许更长时间
app.get('/api/export', timeout(30000), async (c) => {
// 执行耗时操作...
return c.json({ success: true })
})
// 3. 自定义超时后的逻辑
const customTimeout = timeout(5000, {
onTimeout: (c) => {
return c.json({ code: 0, message: '服务器繁忙,请稍后再试' }, 408)
}
})
数据库级超时
API 层超时只是"切断了回传给用户的路",但数据库内部的任务可能仍在运行。需要更细粒度的控制:
// Drizzle ORM 配置:通过底层驱动设置超时
import { drizzle } from 'drizzle-orm/postgres-js'
import postgres from 'postgres'
const queryClient = postgres(process.env.DATABASE_URL, {
timeout: 5, // 建立连接超时 (秒)
idle_timeout: 20, // 空闲连接释放
max_lifetime: 60 * 30 // 连接存活最大时间
})
// 在业务代码中手动控制单次查询超时
async function getSlowData() {
return await db.select().from(users).execute();
}
全局错误处理
在复杂的后端系统中,错误可能来自业务逻辑、数据库约束、第三方 API 失败或语法错误。没有统一处理的话,返回给前端的可能是难看的堆栈信息。
设计原则
-
收口原则 → 业务代码通过 throw 抛出错误,由顶层中间件统一拦截处理
-
分类分级 → 区分"预期内错误"和"预期外错误"
-
安全性 → 生产环境下严禁将详细 Stack 返回给客户端
实现方案
步骤 1:定义标准错误类
// src/utils/errors.ts
export class AppError extends Error {
constructor(
public statusCode: number,
public message: string,
public code: number = 0 // 自定义业务状态码
) {
super(message);
this.name = 'AppError';
}
}
步骤 2:配置全局捕获钩子
import { Hono } from 'hono';
import { AppError } from './utils/errors';
const app = new Hono();
app.onError((err, c) => {
const traceId = c.get('traceId') || 'unknown';
// 1. 处理已知业务异常
if (err instanceof AppError) {
return c.json({
code: err.code,
message: err.message,
traceId
}, err.statusCode as any);
}
// 2. 处理参数校验错误
if (err.name === 'ZodError') {
return c.json({
code: 400,
message: '参数验证失败',
details: err,
traceId
}, 400);
}
// 3. 处理未知错误
console.error(`[Fatal Error] [${traceId}]:`, err);
return c.json({
code: 500,
message: process.env.NODE_ENV === 'production'
? '服务器内部错误'
: err.message,
traceId
}, 500);
});
步骤 3:业务层使用
export async function deleteUser(id: string) {
const user = await db.findUser(id);
if (!user) {
throw new AppError(404, '用户不存在', 10001);
}
return db.delete(id);
}
RBAC 权限控制
RBAC(基于角色的访问控制)是中后台系统最通用的权限模型。通过"用户-角色-权限"的关联,实现权限的解耦。
为什么不直接判断角色?
如果代码里写 if (user.role === 'admin'),当新增一个"超级编辑"角色也需要此权限时,得修改所有代码。判断权限点(Permission)而非角色名,才是系统扩展性的关键。
核心概念
-
用户 (User) → 拥有一个或多个角色
-
角色 (Role) → 如 Admin、Editor、Viewer
-
权限 (Permission) → 如 user:create、order:delete
实现方案
步骤 1:定义数据模型
// 简化版 schema
export const users = pgTable('users', {
id: serial('id').primaryKey(),
role: text('role').default('viewer'),
});
// 权限映射表
const ROLE_PERMISSIONS = {
admin: ['user:all', 'post:all'],
editor: ['post:edit', 'post:create'],
viewer: ['post:read'],
} as const;
步骤 2:实现 RBAC 中间件
// middleware/rbac.ts
import { createMiddleware } from 'hono/factory';
import { AppError } from '../utils/errors';
export const checkPermission = (requiredPermission: string) => {
return createMiddleware(async (c, next) => {
const user = c.get('user');
if (!user) {
throw new AppError(401, '未授权访问');
}
const userPermissions = ROLE_PERMISSIONS[user.role] || [];
// 支持通配符或精确匹配
const hasPermission = userPermissions.some(p =>
p === requiredPermission || p === `${requiredPermission.split(':')[0]}:all`
);
if (!hasPermission) {
throw new AppError(403, '权限不足,无法执行此操作');
}
await next();
});
};
步骤 3:在路由层应用
const api = new Hono();
// 只有拥有 post:create 权限的角色才能访问
api.post('/posts', checkPermission('post:create'), async (c) => {
return c.json({ message: '发布成功' });
});
// 管理员专属接口
api.get('/admin/stats', checkPermission('user:all'), async (c) => {
return c.json({ stats: '...' });
});
日志轮转
在生产环境中,如果所有日志都无限制地写入同一个文件,最终会导致磁盘爆满和日志文件难以打开。
核心目的
- 防止单个文件过大(难以检索、占用磁盘空间)
- 自动化归档(按日期分类)
- 过期清理(例如只保留最近 14 天的日志)
实现方案:Winston + Daily Rotate File
import winston from 'winston';
import 'winston-daily-rotate-file';
const transport = new winston.transports.DailyRotateFile({
filename: 'logs/application-%DATE%.log',
datePattern: 'YYYY-MM-DD',
zippedArchive: true, // 历史日志压缩
maxSize: '20m', // 单个文件超过 20MB 也会切分
maxFiles: '14d', // 只保留最近 14 天的日志
level: 'info',
});
const logger = winston.createLogger({
transports: [
transport,
new winston.transports.Console()
]
});
应对 DDoS 攻击
DDoS 攻击的本质是发大量垃圾请求,导致带宽占满、CPU/内存耗尽、连接数耗尽。
现实: 普通企业很难防住大规模 DDoS,目的是提高攻击成本。
限流
在接入层(Nginx)—— 粗筛
性能极高,在流量进入 Node.js 之前就拦截:
limit_req_zone $binary_remote_addr zone=api:10m rate=10r/s;
limit_req zone=api burst=20;
在应用层(Middleware)—— 精滤
灵活度高,根据业务维度限流:
// 限制某个登录用户每分钟只能发 5 条评论
app.use(rateLimit({
windowMs: 60 * 1000,
max: 5,
keyGenerator: (c) => c.get('user').id
}));
限制请求体大小
防止内存溢出 (OOM):
// 攻击场景:发送 2GB 垃圾字符的 JSON POST 请求
// 后果:Node.js 进程尝试分配 2GB 内存,很快就 Out of Memory
// 解决:在 Nginx 层配置
client_max_body_size 1m;
Helmet 安全头
Helmet 通过设置各种 HTTP 响应头,自动防御常见的 Web 漏洞(XSS、点击劫持、MIME 类型嗅探等)。
性价比最高的安全加固方案。
Hono.js 官方支持 hono/helmet 中间件,在入口文件 src/app.ts 中引入即可:
import { helmet } from 'hono/helmet';
app.use(helmet());
告警机制
告警机制是"及时发现问题"的关键,通过监控关键指标,在异常情况下主动通知相关人员。
告警规则设计
根据应用的 SLA,定义不同严重等级:
export const alertRules = [
{
name: 'High Error Rate',
condition: 'error_rate > 5%',
severity: 'critical',
duration: '5m',
action: 'page_oncall', // 立即电话/Slack 通知
},
{
name: 'High Response Latency',
condition: 'p95_latency > 1000ms',
severity: 'warning',
duration: '10m',
action: 'send_to_slack',
},
{
name: 'Database Connection Pool Exhausted',
condition: 'db_connections > 90%',
severity: 'critical',
duration: '1m',
action: 'page_oncall',
}
];
与监控系统集成
使用 Prometheus + Alertmanager:
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'hono-app'
static_configs:
- targets: ['localhost:3000']
metrics_path: '/metrics'
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
多渠道通知
export async function sendAlert(
title: string,
message: string,
severity: 'critical' | 'warning' | 'info'
) {
const timestamp = new Date().toISOString();
// 1. Slack 通知
if (severity === 'critical' || severity === 'warning') {
await axios.post(process.env.SLACK_WEBHOOK_URL, {
text: `[${severity.toUpperCase()}] ${title}`,
attachments: [{
color: severity === 'critical' ? 'danger' : 'warning',
text: message,
ts: Math.floor(new Date().getTime() / 1000),
}],
});
}
// 2. 邮件通知(仅限 critical)
if (severity === 'critical') {
await sendEmail({
to: process.env.ALERT_EMAIL,
subject: `🚨 CRITICAL: ${title}`,
html: `<h2>${title}</h2><p>${message}</p><p>${timestamp}</p>`,
});
}
// 3. 记录到数据库
await db.insert(alerts).values({
title,
message,
severity,
createdAt: new Date(),
});
}
性能测试
性能测试是确保应用在生产环境中稳定运行的最后一道防线。
基准测试(Benchmarking)
使用 Autocannon 进行简单的吞吐量和延迟测试:
# 安装 Autocannon
npm install -g autocannon
# 基准测试:100 并发,持续 30 秒
autocannon -c 100 -d 30 http://localhost:3000/api/users
# 输出示例
# Req/Sec: 1234
# Latency: { mean: 45.2, p50: 42, p95: 78, p99: 120 }
压力测试(Load Testing)
使用 K6 模拟真实用户行为:
// load-test.js
import http from 'k6/http';
import { check, sleep, group } from 'k6';
export const options = {
stages: [
{ duration: '2m', target: 100 },
{ duration: '5m', target: 100 },
{ duration: '2m', target: 200 },
{ duration: '5m', target: 200 },
{ duration: '2m', target: 0 },
],
};
export default function () {
group('User API', () => {
// 测试获取用户列表
let listRes = http.get('http://localhost:3000/api/users');
check(listRes, {
'list status is 200': (r) => r.status === 200,
'list response time < 100ms': (r) => r.timings.duration < 100,
});
// 测试创建用户
let createRes = http.post('http://localhost:3000/api/users', {
name: `user-${__VU}-${__ITER}`,
email: `user-${__VU}-${__ITER}@example.com`,
password: 'password123',
});
check(createRes, {
'create status is 200': (r) => r.status === 200,
});
sleep(1);
});
}
运行压力测试:
# 安装 K6
npm install -g k6
# 执行测试
k6 run load-test.js
数据库性能测试
// src/tests/db-performance.test.ts
import { describe, it, expect } from 'vitest';
import { db } from '../db';
describe('Database Performance', () => {
it('should query 10k users in < 500ms', async () => {
const start = performance.now();
const users = await db.query.users.findMany({ limit: 10000 });
const duration = performance.now() - start;
expect(users.length).toBe(10000);
expect(duration).toBeLessThan(500);
});
it('should create 1k users in batch < 2s', async () => {
const data = Array.from({ length: 1000 }, (_, i) => ({
name: `user-${i}`,
email: `user-${i}@example.com`,
password: 'hashed-password',
}));
const start = performance.now();
await db.insert(users).values(data);
const duration = performance.now() - start;
expect(duration).toBeLessThan(2000);
});
});
数据持久化与备份
数据持久化本质上解决的是:当系统崩溃、误操作、甚至被攻击时,数据还能不能恢复?
重要认知: 数据库 ≠ 数据安全。数据库只是"存储",而备份 + 恢复能力才是安全的核心。
备份脚本示例
#!/bin/bash
set -o pipefail # 核心:捕获管道中任何一步的错误
DB_NAME="your_db"
BACKUP_FILE="/data/backups/db_$(date +%Y%m%d).sql.gz"
# 执行备份
pg_dump -U admin -d $DB_NAME | gzip -1 > $BACKUP_FILE
# 检查备份是否成功
if [ $? -ne 0 ]; then
echo "❌ 备份失败!清理空文件..."
rm -f $BACKUP_FILE
# 调用告警机制
# sendAlert "Database Backup Failed" "pg_dump connection error" "critical"
exit 1
else
echo "✅ 备份成功"
fi
可观测性(Observability)
可观测性与监控的区别:
-
监控 → 告诉你"系统出了问题"(基于预定义的指标和阈值)
-
可观测性 → 告诉你"系统为什么出了问题"(通过日志、指标、链路追踪)
可观测性的三大支柱
支柱 1:结构化日志
// src/utils/logger.ts
import winston from 'winston';
const logger = winston.createLogger({
format: winston.format.combine(
winston.format.timestamp({ format: 'YYYY-MM-DD HH:mm:ss' }),
winston.format.errors({ stack: true }),
// 自定义格式化,确保输出为结构化 JSON
winston.format.printf(({ timestamp, level, message, ...meta }) => {
return JSON.stringify({
timestamp,
level,
traceId,
message,
...meta,
});
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'logs/error.log', level: 'error' }),
new winston.transports.File({ filename: 'logs/combined.log' }),
],
});
支柱 2:指标收集(Metrics)
使用 Prometheus 收集性能指标:
// src/utils/metrics.ts
import promClient from 'prom-client';
// 创建指标
export const httpRequestDuration = new promClient.Histogram({
name: 'http_request_duration_seconds',
help: 'HTTP request latency',
labelNames: ['method', 'route', 'status_code'],
buckets: [0.1, 0.5, 1, 2, 5],
});
export const dbQueryDuration = new promClient.Histogram({
name: 'db_query_duration_seconds',
help: 'Database query latency',
labelNames: ['operation', 'table'],
buckets: [0.01, 0.05, 0.1, 0.5, 1],
});
// 暴露 Prometheus 指标端点
export function registerMetricsRoute(app: Hono) {
app.get('/metrics', (c) => {
return c.text(promClient.register.metrics());
});
}
支柱 3:链路追踪(Traces)
已在前面的 TraceId 部分详细说明。
最后
这套工作流的核心理念就是 持续反馈、不断优化。感谢您的阅读,建议点赞收藏,我们下期再见!