前言
在上一篇文章juejin.cn/post/762508… 中,介绍了 TypeScript 系统中的基础类型及其用法,本篇我们将进击 TypeScript 中一些高级类型,学完本篇,就能对 TypeScript 系统中的各大类型有个比较全面的理解了。
泛型
泛型可以理解为类型参数或类型变量,在定义类型别名、接口、类、函数参数时都会用到。在上一篇文章中我们已经介绍过了,下边来看与它相关联的一些场景。
extends 约束
extends 关键字主要用于泛型约束中,例如:
type IsNumber<T> = T extends number ? T : never
IsNumber 类型接收泛型 T 作为类型参数,随后使用 extends 关键字
-
T extends number:表示 T 能赋值于 number,extends 表示 赋值于
-
T extends number ? T : never:这里运用条件类型(类似 js 的三元表达式),意思是,T 如果能赋值于 number 类型,那么返回结果就是 T 类型,反之就返回 never 忽略类型。
那上边这个例子就很好理解,主要使用 extends 关键字来约束泛型在满足 number 类型时再返回它。
内置工具约束
在了解了泛型、extends 和基本的条件类型,我们可以来看 TypeScript 提供的一些内置工具,主要用于约束泛型,比如 Partial<T>、Required<T>,都是工具名称 + <T> 的组合,专为约束泛型 T 而生。
Partial
Partial 允许我们将传入泛型中的所有属性变为可选的属性,例如:
type Person = {
name: string,
age: number
}
type MyPartialProperties = Partial<Person>

所有属性名旁边都加上了 ? 符号,表示可选属性。
Required
Required 将传入类型中的所有属性变为必传的属性,例如:
type Person = {
name?: string,
age: number
}
type MyRequiredProperties = Required<Person> // Person 上的所有属性都是必须的,? 会去掉
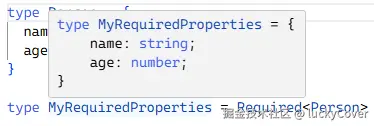
可以看到原本可选 name 属性旁边的 ? 被去掉了,变成了必须项。
ReadOnly
ReadOnly 可以将类型上的属性指定为只读的:
type Person = {
name?: string,
age: number
}
type MyReadOnlyProperties = Readonly<Person> // Person 上的所有属性前边会加上 readonly 表示只读属性
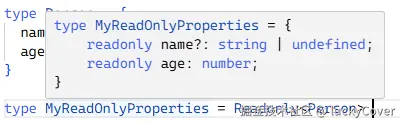
所有属性前边都加上了 readonly 描述符,表示属性是只读的。
Pick
Pick 可以从类型中筛选出某个属性:
type Person = {
name: string,
age: number
}
type MyPickProperties = Pick<Person, "name"> // 仅筛选出 Person 中为 name 的那个属性

从泛型 Person 中取出了 name 属性作为新类型,如上图 MyPickProperties 只剩下 name 属性。
Omit
可以从对象类型中排除掉不需要的属性,支持传联合类型用于同时排除多个属性:
type Person = {
name: string,
age: number,
sex: string
}
type MyOmitProperties1 = Omit<Person, "name"> // 排除掉 Person 类型中的 name 属性
type MyOmitProperties2 = Omit<Person, "name" | "age"> // 排除掉 Person 类型中的 name 和 age 属性
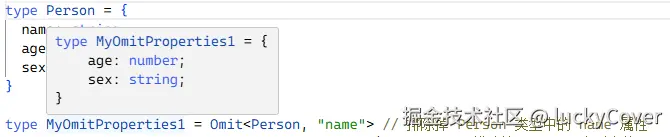
将泛型 Person 中的 name 属性排除掉了。

通过联合类型将泛型 Person 中的 name 和 age 属性一块排除掉。
Record
可以创建一个新的对象类型,这个新对象类型是由某个指定类型中的属性组成的,同时可以指定新类型上的属性类型:
type Example = 'name' | 'age' | 'sex'
type MyRecord = Record<Example, string> // 新类型中属性由 Example 中组成,同时新类型上属性类型指定为 string
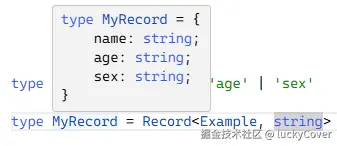
由 Example 类型中的所有属性组成的新类型 MyRecord,并且指定新类型中属性的类型为 string。
ReturnType
ReturnType 用于提取函数类型的返回值类型,而可以不用手动指定函数的返回值类型:
function testExample(a: number, b: number) {
return a + b
}
type GetFuncReturnType = ReturnType<typeof testExample> // number
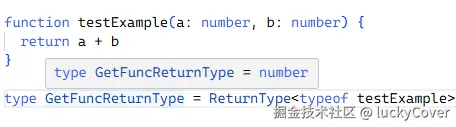
提取 testExample 函数的返回值类型于新类型 GetFuncReturnType 中。
Extract
Extract 用于从两个类型中取出相互兼容的部分,其实就是取交集:
type A = string | number
type B = boolean | number
type ExtractAB = Extract<A, B> // number(相交的部分就是 number)
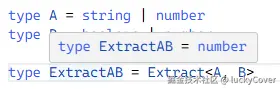
类型 A 和类型 B 共有的部分就是 number,自然取到的交集就是 number,作为 ExtractAB 的新类型。
Exclude
Exclude 主要用于从联合类型中排除掉不需要的属性:
type Example = string | number | boolean
type ExcludeString = Exclude<Example, string> // ExcludeString 剩下 number | boolean

从 Example 类型中排除掉 string 类型,剩下的 number 和 boolean 就作为 ExcludeString 的类型。
type Example1 = "dog" | "cat"
type Example2 = "cat"
type ExcludeCat = Exclude<Example1, Example2>
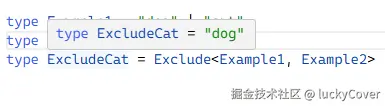
上边这个例子可以看出,Exclude 会排除掉 Example1 中和 Example2 相同那一部分,Example1 中和 Example2 相同的那部分是 cat,故排除掉 Example1 中的 cat。
我们可以发现,Extract 和 Exclude 的操作刚好相反,Extract 是取两个泛型相交的部分,而 Exclude 是从第一个泛型中排除掉和第二个泛型相同(相交)的那部分。Extract 是取,而 Exclude 是排,两者都是取交集。
NonNullable
NonNullable 用于排除类型中为 null 或 undefined 的部分,返回一个新类型:
type Example = number | undefined | null
type NotNullAndUndefined = NonNullable<Example> // 排除类型 C 中为 null 和 undefined 的部分
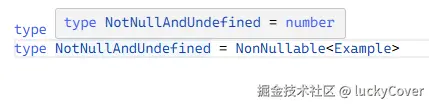
NonNullable 可以排除 Example 类型中的 null 和 undefined。
条件类型
条件类型我们在开篇泛型那里就见过了,ts 中的条件类型类似于 js 中的三元运算符,一般配合 extends 一起使用,如:T extends U ? U : never。下面我们来看下分布式条件类型。
分布式条件类型
当条件类型作用于泛型类型参数时,如果该类型是联合类型(注意是联合类型),则条件会分布到每一个联合成员上,分别计算,再将结果合并成一个新的联合类型,我们来举例看下:
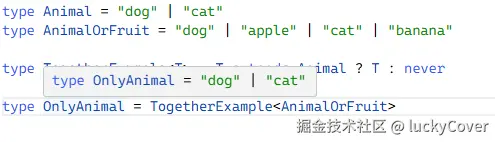
type Animal = "dog" | "cat"
type AnimalOrFruit = "dog" | "apple" | "cat" | "banana"
type TogetherExample<T> = T extends Animal ? T : never
type OnlyAnimal = TogetherExample<AnimalOrFruit>
-
T extends Animal:T 能否赋值于 Animal 类型(Animal 类型中包含 dog 和 cat,也就是 T 是否为 dog 或 cat)。
-
T extends Animal ? T : never:接收的泛型 T 如果能赋值于 Animal(dog 和 cat),那么就取这个 T,反之就用 never 来忽略类型。
-
TogetherExample<AnimalOrFruit>:AnimalOrFruit 类型中为 dog 和 cat 的就正常收集到新类型 OnlyAnimal 中,其他的 apple 和 banana 由于不能赋值于 Animal,被使用 never 类型忽略了。故最终新类型 OnlyAnimal 中仅包含 dog 和 cat。
从上边例子也能看出来,所谓分布式条件类型,就是当接收的泛型参数为联合类型时,会将条件作用于每个类型中。
infer
infer 关键字的作用是延时推导,它会在类型未推导时进行占位,等到真正推导出来后,它能返回准确的类型:
type Example<T> = T extends (...args: any) => infer R ? R : never
type ExampleFunc = (a: number, b: number) => number
type TestGetFuncReturnExample = Example<ExampleFunc> // number
-
T extends (...args: any) => infer R ? R : never:判断 T 是否为一个函数类型
-
(...args: any) => infer R:args 为函数入参,infer R 为返回值类型的占位操作
整个意思就是,T 是函数类型的话,能推导出它的返回值类型 R;反之,就返回 never。代入上边例子,ExampleFunc 是一个函数类型,先使用 infer R 占位返回值类型,等到真正推导出函数的返回值类型为 number 时,它能准确返回类型。
映射类型
映射类型可以基于现有的类型来修改某个属性或通过排除属性来生成新的类型,修改属性包括把属性映射为只读、可选、属性名添加前缀等操作。排除属性主要就是将不符合条件的属性映射为 never。我们逐个举例来看下:
interface Person {
name: string,
age: number,
}
type MyReadOnlyProperties<T> = {
readonly [P in keyof T]: T[P] // 通过 readonly 关键字将属性映射为只读
}
type ReadOnlyPerson = MyReadOnlyProperties<Person>

interface Person {
name: string,
age: number,
}
type MyPartialProperties<T> = {
[P in keyof T]?: T[P] // 通过 ? 符号将属性映射为可选
}
type PartialPerson = MyPartialProperties<Person>

interface Person {
name: string,
age: number,
}
type MyPrefixProperties<T> = {
[P in keyof T as `prefix_${string & P}`]: T[P]
}
type PrefixProperties = MyPrefixProperties<Person>

1、首先使用 P in keyof T 将枚举出 T 类型中的每个属性
2、使用 as 来将每个属性重命名为 prefix_${string & P},即加上 prefix_ 这个前缀,如 name 就会变成 prefix_name,这里的 string & P 作用就是确保 P 类型是一个字符串。
3、T[P]:属性的值就正常映射为 P 属性在 T 上的原有类型
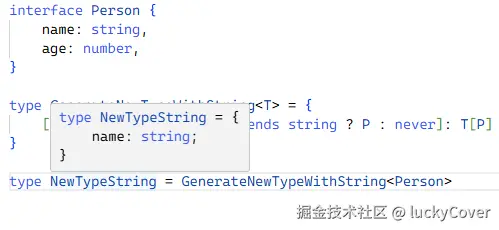
interface Person {
name: string,
age: number,
}
type GenerateNewTypeWithString<T> = {
[P in keyof T as T[P] extends string ? P : never]: T[P] // 仅映射出类型为 string 的属性
}
type NewTypeString = GenerateNewTypeWithString<Person> // 仅包含 string 类型的属性,即 name
索引类型
索引类型可以通过属性名直接访问某个属性的具体类型,主要使用中括号 [],例如:
interface Person {
name: string
age: number
}
type PersonOfAge = Person["age"]

如上访问 Person 上的 age 属性,其类型就是 number。
还可以获取类型中所有属性的联合类型,如下:
interface Person {
name: string
age: number
}
type PersonOfValue = Person[keyof Person]

使用 keyof 遍历出 Person 上所有的属性,相当于:
Person["name"] | Person["age"]- 那结果就是
string | age
类型守卫
类型守卫可以根据条件来细化变量的具体类型,从而使代码在运行时更加安全和可维护,主要通过几种方式来实现,包括 typeof、instanceof、in、自定义类型函数,我们逐个来看看。
type A = string | number | boolean
function logInfo(a: A): void {
if(typeof a === 'string') {
// 当 a 为 string 时执行某些操作...
console.log(`variable ${a} is a string`)
}
}
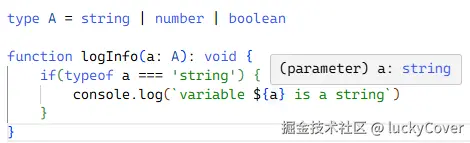
logInfo 函数接收形参 a,用类型 A 约束,类型 A 是个联合类型,也就是说形参 a 的类型可能是 string、number、boolean 中的一个,在函数体内通过 typeof 来判断 a 为 string 类型,那么在该条件分支内,ts 就能确定 a 的类型为 string 了,这也很好的避免由于类型不确定导致的意外操作。
class Person {
speak() {
console.log('people can speak')
}
}
class Animal {
fly() {
console.log('some animals can fly')
}
}
const p1 = new Person()
const a1 = new Animal()
function personOrAnimal(a: Person | Animal) {
if(a instanceof Person) {
a.speak()
} else if(a instanceof Animal) {
a.fly()
}
}
personOrAnimal(a1) // people can speak
使用 instanceof 能够检查变量是否属于某个类的实例,这样在对应条件分支内 ts 编译器就能确定该实例所属类,从而能给予我们该实例上能调用的方法和属性的提示,这也很好保证了运行时的准确性。
interface Person {
write(): void
}
interface Animal {
eat(): void
fly(): void
}
class A implements Animal {
eat() {
console.log('animal can eat')
}
fly() {
console.log('animal can fly')
}
}
function getInfo(a: Person | Animal) {
if('write' in a) {
a.write()
} else if('fly' in a) {
a.fly()
a.eat()
}
}
上边 getInfo 函数接收一个实例,通过 in 来判断属性是否存在于实例上,如果存在就能直接使用,而且该属性所属类上的其他属性也能直接访问,比如判断 a 上如果存在 fly 属性。那么 fly 属性所属类上的 eat 也能访问了。
function isString(str: any) {
return typeof str === 'string'
}
function getInfo(a: any) {
if(isString(a)) {
console.log('the operation of string a')
}
}
通过使用自定义的 isString 函数来判断某个变量是否为特定的类型,满足就能在条件分支内对该类型变量进行一些操作。
类
类是面向对象的核心概念,它主要封装了对象的状态和行为,也就对应着属性和方法,ts 为类提供了类型检查功能。为此我们可以在类中为属性或方法定义类型,如下例子:
class Animal {
name: string
constructor(name: string) {
this.name = name
}
say(): void {
console.log('动物发出声音')
}
}
继承
在 ts 中实现类的继承和 js 中是一致的,如下示例:
class Dog extends Animal {
constructor(name: string) {
super(name) // 调用父类构造函数初始化
}
say(): void { // 重写父类方法
console.log("wang wang~")
}
}
const d1 = new Dog("哈士奇")
console.log(d1.name) // 哈士奇
super
super 主要用于调用父类的构造函数,将子类构造函数接收的参数传给父类构造函数,由父类构造函数来做初始化,这样也省去了在子类构造函数中重复声明初始化的操作。
class Dog extends Animal {
constructor(name: string) {
super(name) // 调用父类构造函数初始化
// this.name = name // 相当于
// this.xxx = xxx // 更多参数
}
say(): void { // 重写父类方法
console.log("wang wang~")
}
}
修饰符
- public:可在任何地方访问
- private:仅可在类内部访问,子类也不允许访问
- protected:仅可在类内部、子类中访问
下边我们举例来理解这三个修饰符:
class Person {
public name: string // 公共属性
private age: number // 私有属性
protected sex: string // 保护属性
constructor(name: string, age: number, sex: string) {
this.name = name
this.age = age
this.sex = sex
}
getPersonAge(): number {
return this.age // 私有属性,仅在当前类能访问
}
}
const p1 = new Person("man", 11, 'male')
console.log(p1.name) // man
console.log(p1.age) // 编译报错,age 是类私有属性
console.log(p1.sex) // 编译报错,sex 是类的保护属性,仅可子类中访问
- 子类访问:可以访问公有属性(public)和保护属性(protected)
class Student extends Person {
constructor(name: string, age: number, sex: string) {
super(name, age, sex)
}
getStudentName(): string {
return this.name // 正常
}
getStudentSex(): string {
return this.sex // 正常
}
getStudentAge(): number {
return this.age // 编译报错,age 是私有属性,仅能声明类自身访问
}
}
抽象类与接口
抽象类就是使用 abstract 修饰的类,抽象类中可以定义抽象、也可以定义具体方法,继承抽象类的子类必须实现抽象类中定义的抽象方法,同时也可以重写抽象类中的具体方法,我们看下边例子就知道了:
abstract class Person {
abstract myHobby(): void // 抽象方法
walk(): void {
console.log('people walking')
}
}
class Student extends Person {
myHobby(): void { // 子类必须实现父类的抽象方法
console.log('music')
}
walk(): void { // 重写父类的方法
console.log('student walking')
}
}
const s1 = new Student()
s1.myHobby() // music
s1.walk() // student walking
再来看看接口:
定义一组规范,不提供具体的实现,仅包含函数的签名
interface Play {
games(): void // 函数签名
}
由实现类来完成函数体:
class Student extends Person implements Play {
// 实现接口中的函数签名
games() {
console.log('lol')
}
myHobby(): void {
console.log('music')
}
walk(): void {
console.log('student walking')
}
}
const s1 = new Student()
s1.games() // lol
为此,我们可以得出抽象类和接口的区别:
相同点:都用于定义行为规范,抽象类的抽象方法和接口中的函数签名都必须在子类中实现。
不同点:抽象类中可以包含具体方法的实现,而接口仅含函数签名或属性签名,不包含具体方法的实现。抽象类不能直接实例化,只能作为基类通过子类来继承;而接口可以被类实现,一个类可以同时实现多个接口,使用 implements 关键字。
总结
本篇文章主要围绕 TypeScript 中的高级类型展开介绍,从泛型开始,扩展来看它的一些场景,包括泛型约束、ts 中的内置工具类型。然后就是常用的条件类型、映射类型、索引类型、类型守卫,以及我们常用的类,最后对比了抽象类与接口的区别。
我是 luckyCover,我正在持续更新 TypeScript 学习系列的文章,欢迎大家一起讨论学习呀~