引言
书接上回, 我们在 OpenClaw 上手实践: 使用 Docker 从构建到可用全流程指南 介绍了, 如果通过 Docker 来快速部署 OpenClaw。
其实呢, 这边想要借助 OpenClaw 在 昆仑虚 搭一个个人的 AI 应用, 这里希望整体架构如下:
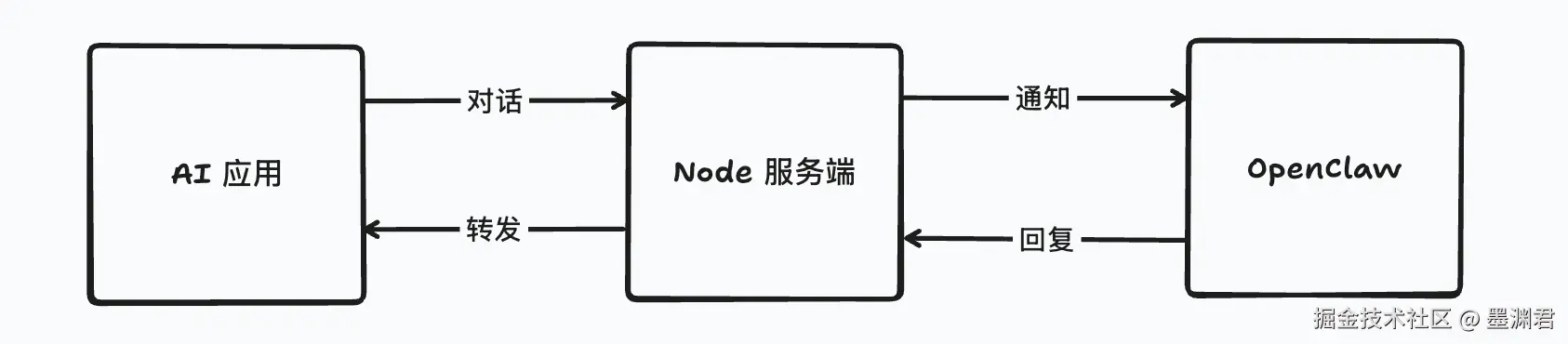
这边 Node 服务端就是做了中间层的转发, 但是这么做有什么好处呢?
- 权限: 可以进行很好的权限管理,
OpenClaw 仅运行 Node 服务进行访问, 不对外开放
- 多用户: 可以将
session、agent、message 等内容按用户进行隔离, 甚至可以一个用户分配一个独立隔离的 OpenClaw(容器)
- 定制化: 要想做应用, 必然会有很对定制信息, 比如设置
Agent 的头像等。这边我们只需要 OpenClaw 调度大模型的能力, 其他的就希望完全定制。
所以接下来最重要的就是, 在 Node 服务端要如何和 OpenClaw 进行协作(通信), 这也正是接下来我们要聊的....
一、OpenClaw 架构
如图, 是 OpenClaw 的整体架构
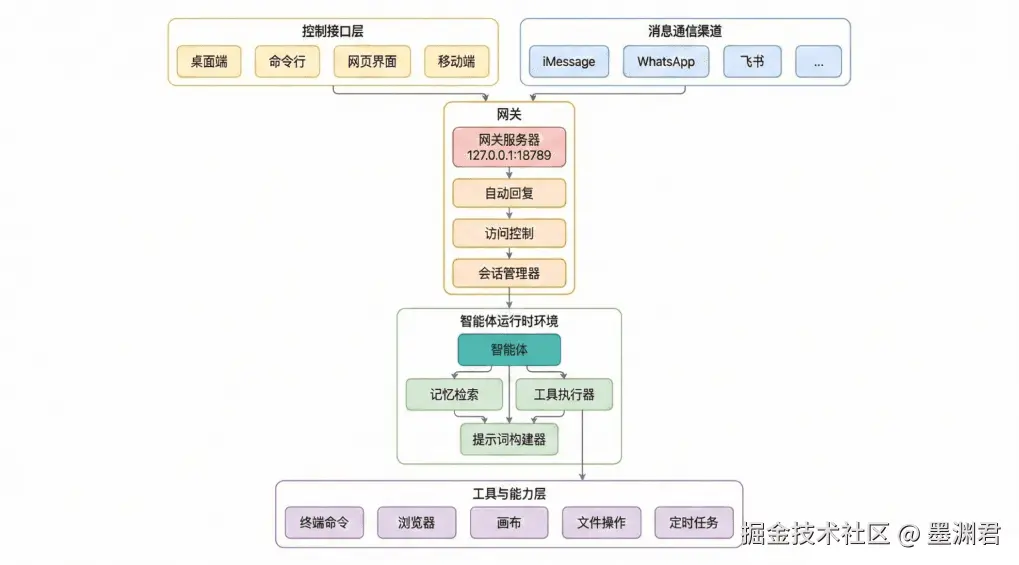
1.1 智能体运行时环境
这里是整个核心, 是真正干活的核心引擎, 也是我想要的核心能力, 这边主要就是:
- 负责拼装
prompt、context
- 调度各种大模型
- 协调各种
Agent、Skill、Tools 的执行
- 保存各种配置、回话记录
当然这边其实没这么简单, 只是想说明这边主要就是核心干活的地方
1.2 网关层
外界各个应用、服务、IM 如何通知引擎部分让 Agent 开始干活? 而引擎部分又如何告知外界 Agent 处理的结果? 而它们之间又是怎么鉴权的? 怎么通信的? 这都是网关层进行控制的。
OpenClaw 通过 WebSocket 并定义了一套协议, 来链接 "外界" 和 "引擎"
如下所示, 是外界通过 ws 连接到 OpenClaw 网关, 并约定好的参数(协议)来调用 "引擎" 干活:
import WebSocket from 'ws';
const ws = new WebSocket('ws://127.0.0.1:18789');
ws.send(JSON.stringify({
type: 'req', // 请求类型,固定为 req
id: '任意唯一ID', // 请求 ID
method: 'chat.send', // 请求内容
params: {}, // 请求参数,根据不同 method 定义不同的参数结构
}));
同时, 外界也是通过 ws 来监听网关发来的消息, 来获取 "引擎" 广播的消息:
// 监听 OpenClaw 广播的消息
ws.on('message', (data) => {
});
// 可能数据如下
{
"type": "event",
"event": "chat",
"payload": {
"runId": "同一个 runId",
"sessionKey": "main",
"seq": 1,
"state": "delta",
"message": {
"role": "assistant",
"content": [
{ "type": "text", "text": "正在生成中的文本" }
],
"timestamp": 1710000000000
}
}
}
我们可能习惯性通过 REST API 来调用第三方服务提供的接口来获取数据、修改数据, 但这边则全部走 WebSocket 并通过约定好的协议来完成所有事情
// 拉历史
ws.send(JSON.stringify({
type: "req",
id: "history-1", // 自定义请求 AI
method: "chat.history", // 具体请求方法
params: {} // 参数
}));
// 拉 agent 列表
ws.send(JSON.stringify({
type: "req",
id: "agents-1", // 自定义请求 AI
method: "agents.list", // 具体请求方法
params: {} // 参数
}));
1.3 其他层
-
工具与能力层: 本质上大模型是不具备各种调用工具的能力的, 所有工具的调用都是在本地完成, 并将调用结果告诉大模型。大模型再进行决策, 而这边工具与能力层就是提供各种工具能力, 来供 OpenClaw 来调度, 在需要时 OpenClaw 会调用相关工具来完成各类工作, 并将工具调用结果返回给大模型
-
接口控制层、消息通讯渠道: 这边其实就是针对各种场景、IM, 来做一些兼容处理, 使得能够顺利接入网关。
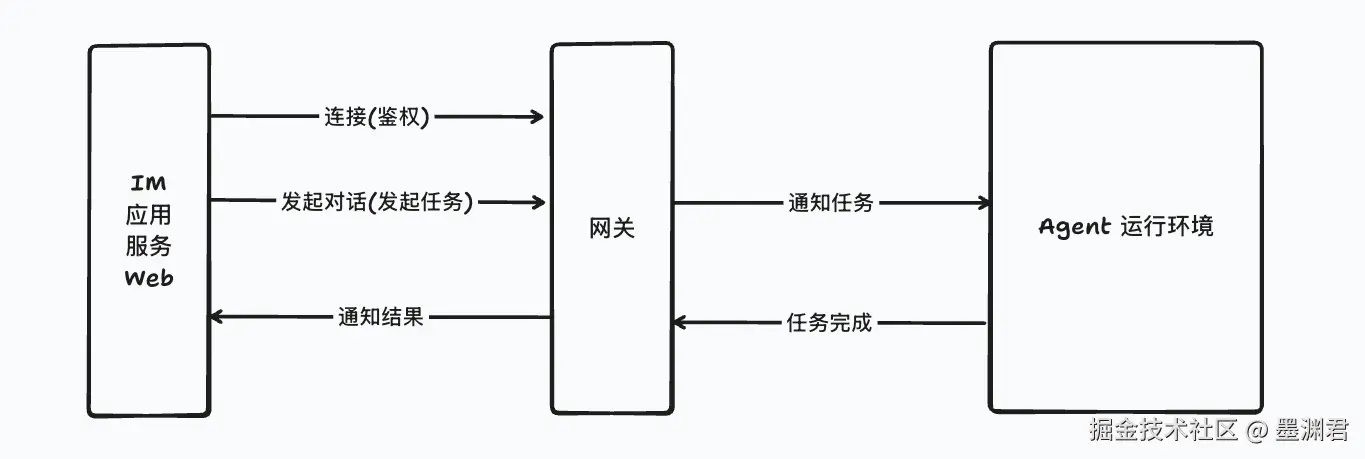
二、握手流程
参考文档: Gateway 网关协议 - 握手
如下图所示:
- 当客户端与
OpenClaw 网关连接建立后
- 网关会立刻发送
connect.challenge 事件(消息)
- 客户端需要紧接着发送
connect 请求(含鉴权信息)
- 网关层鉴权成功则返回
hello-ok 响应, 否则则关闭连接

如下代码所示, 是一个最简化的 DEMO:
import WebSocket from 'ws';
// 1. 建立连接
const ws = new WebSocket('ws://127.0.0.1:18789');
ws.on('message', (data) => {
const msg = JSON.parse(data.toString());
// 2. 网关发送 connect.challenge 事件(消息)
if (msg.type === 'event' && msg.event === 'connect.challenge') {
console.log('🔐 receive challenge');
// 3. 客户端紧接着发送 connect 请求(含鉴权信息)
ws.send(JSON.stringify({
id: '1', // 唯一 ID 客户端自己随便写即可
type: 'req',
method: 'connect',
params: {
minProtocol: 3,
maxProtocol: 3,
client: {
id: 'cli',
version: '1.0.0',
platform: 'node',
mode: 'node',
},
role: 'operator',
scopes: [
'operator.read',
'operator.write',
'operator.admin',
'operator.approvals',
'operator.pairing',
],
auth: { token: '9e1a21f5555asdsads555666666666df3f81' }, // 换成你自己的 OpenClaw 登陆 Token
},
}));
}
// 4. 网关层鉴权成功则返回 hello-ok 响应
if msg.payload?.type === 'hello-ok') {
console.log('🎉 connected success');
}
});
// 其他事件
ws.on('open', () => console.log('✅ connected'));
ws.on('close', () => console.log('✅ connected'));
使用 Node 运行结果如下:

三、简单通信
上面我们简单演示了和 OpenClaw 网关建立握手连接, 但是实际上还缺了设备鉴权、授权这部分内容, 如果想要调用一些操作就需要把这部分补全...
3.1 设备身份鉴权
这边其实就是:
- 根据
OpenClaw 自己的一套加密方式, 在客户端生成唯一设备 ID、公钥、私钥
- 在握手阶段认证阶段, 需要按
OpenClaw 定义的规则, 生成相关的签名、设备信息, 一同传给网关层
- 并且在首次设备连接时, 需要在
OpenClaw 进行设备的授权
- 需要注意的是: 我们生成的设备
ID、公钥、私钥, 应该是固定不变的, 不应该每次都动态生成(实际场景中, 我们需要进行缓存, 或者加到服务配置中)
下面是一份完整的设备信息、签名生成代码:
import crypto from 'node:crypto';
import fs from 'fs';
const ED25519_SPKI_PREFIX = Buffer.from('302a300506032b6570032100', 'hex');
// base64url 编码
const base64UrlEncode = (buf) => buf.toString('base64').replaceAll('+', '-')
.replaceAll('/', '_')
.replace(/=+$/g, '');
// 从 PEM 格式的公钥中提取原始公钥数据,并进行 base64url 编码
const derivePublicKeyRaw = (publicKeyPem) => {
const key = crypto.createPublicKey(publicKeyPem);
const spki = key.export({ type: 'spki', format: 'der' });
if (
spki.length === ED25519_SPKI_PREFIX.length + 32 &&
spki.subarray(0, ED25519_SPKI_PREFIX.length).equals(ED25519_SPKI_PREFIX)
) {
return base64UrlEncode(spki.subarray(ED25519_SPKI_PREFIX.length));
}
return base64UrlEncode(spki);
};
// 从原始公钥数据派生设备 ID,通常是公钥的 SHA-256 哈希值
const deriveDeviceIdFromPublicKey = (publicKeyRawBase64Url) => crypto
.createHash('sha256')
.update(Buffer.from(publicKeyRawBase64Url, 'base64url'))
.digest('hex');
// 创建网关设备身份,包括生成密钥对和设备 ID
const createGatewayDeviceIdentity = () => {
// 如果已经存在设备身份文件,则直接读取并返回
if (fs.existsSync('./device_identity.json')) {
const content = fs.readFileSync('./device_identity.json', 'utf-8');
return JSON.parse(content);
}
const { privateKey, publicKey } = crypto.generateKeyPairSync('ed25519');
const privateKeyPem = privateKey.export({ type: 'pkcs8', format: 'pem' }).toString();
const publicKeyPem = publicKey.export({ type: 'spki', format: 'pem' }).toString();
const publicKeyRaw = derivePublicKeyRaw(publicKeyPem);
const deviceId = deriveDeviceIdFromPublicKey(publicKeyRaw);
const identity = {
deviceId,
privateKeyPem,
publicKeyPem,
publicKeyRaw,
};
// 将生成的设备身份信息保存到文件中,供后续使用
fs.writeFileSync('./device_identity.json', JSON.stringify(identity, null, 2), 'utf-8');
return identity;
};
// 构建设备认证信息,包括生成签名等
export const buildDeviceAuthPayloadV3 = (params) => [
'v3',
params.deviceId,
params.clientId,
params.clientMode,
params.role,
params.scopes.join(','),
String(params.signedAtMs),
params.token ?? '',
params.nonce,
params.platform ?? '',
params.deviceFamily ?? '',
].join('|');
// 使用设备的私钥对认证负载进行签名,生成 base64url 编码的签名字符串
export const signDevicePayload = (privateKeyPem, payload) => crypto.sign(null, Buffer.from(payload, 'utf8'), privateKeyPem).toString('base64url');
// 构建网关设备认证信息,供连接网关时使用
export const buildGatewayDeviceAuth = (params) => {
const signedAt = Date.now();
const identity = createGatewayDeviceIdentity();
const payload = buildDeviceAuthPayloadV3({
deviceId: identity.deviceId,
clientId: params.clientId,
clientMode: params.clientMode,
role: params.role,
scopes: params.scopes,
signedAtMs: signedAt,
token: params.token,
nonce: params.nonce,
platform: params.platform,
deviceFamily: params.deviceFamily,
});
const signature = signDevicePayload(identity.privateKeyPem, payload);
return {
signedAt,
signature,
nonce: params.nonce,
id: identity.deviceId,
publicKey: identity.publicKeyRaw,
};
};
下面是完整连接 OpenClaw 网关代码, 这边调用 buildGatewayDeviceAuth 来生成设备签名等信息:
import WebSocket from 'ws';
import { buildGatewayDeviceAuth } from './device.mjs';
const REQUESTED_SCOPES = ['operator.admin'];
const CLIENT = {
id: 'cli',
version: '1.0.0',
platform: 'node',
mode: 'node',
deviceFamily: 'desktop',
};
const GATEWAY_TOKEN = 'your-real-token';
const ws = new WebSocket('ws://127.0.0.1:18789');
ws.on('message', (data) => {
const msg = JSON.parse(data.toString());
// 1️⃣ 先接 challenge
if (msg.type === 'event' && msg.event === 'connect.challenge') {
console.log('🔐 receive challenge', msg.payload);
const device = buildGatewayDeviceAuth({
role: 'operator',
nonce: msg.payload?.nonce ?? '',
token: GATEWAY_TOKEN,
clientId: CLIENT.id,
clientMode: CLIENT.mode,
scopes: REQUESTED_SCOPES,
platform: CLIENT.platform,
deviceFamily: CLIENT.deviceFamily,
});
ws.send(JSON.stringify({
type: 'req',
id: '1',
method: 'connect',
params: {
device,
minProtocol: 3,
maxProtocol: 3,
client: CLIENT,
role: 'operator',
scopes: REQUESTED_SCOPES,
auth: { token: GATEWAY_TOKEN },
},
}));
}
// 2️⃣ connect 成功
if (msg.payload?.type === 'hello-ok') {
console.log('🎉 connected success');
}
console.log('👀 receive message', msg);
});
// 其他事件
ws.on('open', () => console.log('✅ connected'));
ws.on('close', () => console.log('✅ connected'));
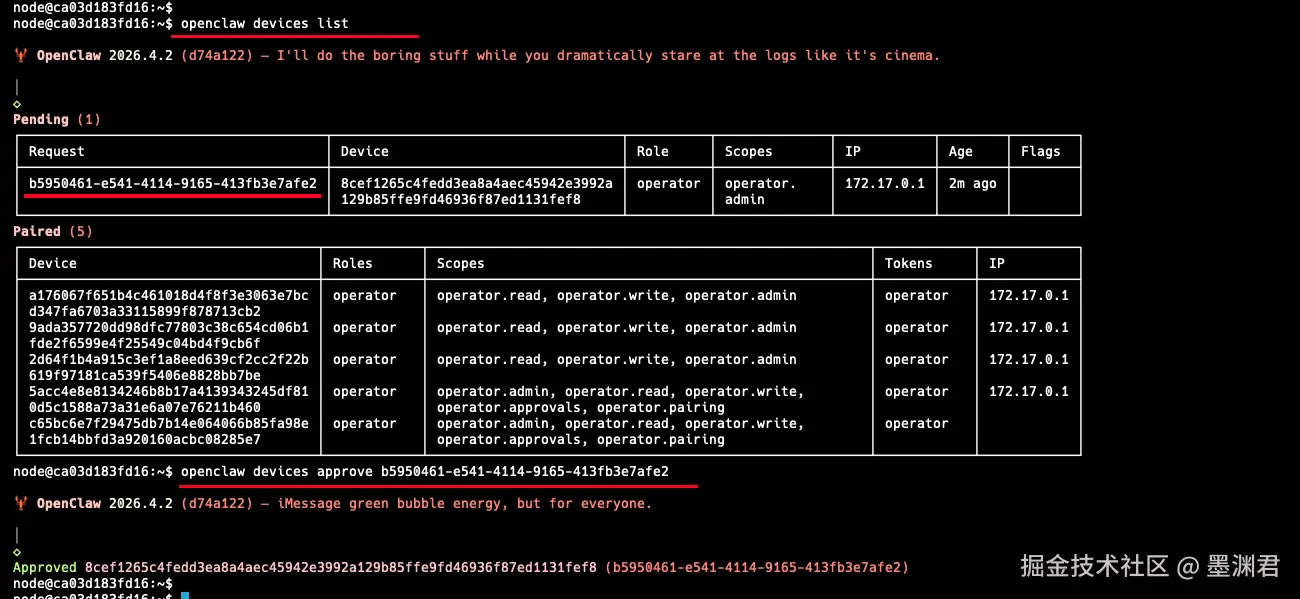
执行上面连接 OpenClaw 脚本, 连接能够成功, 同时还会提示需要配对:
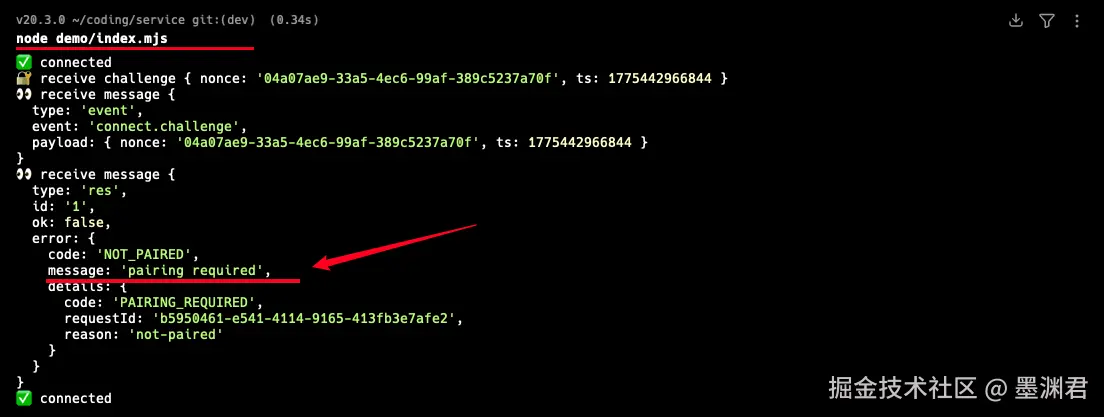
进入 OpenClaw 容器内部, 进行设备授权:
docker exec -it openclaw bash # 进入 openclaw 容器
openclaw devices list # 查看当前设备连接情况
openclaw devices approve b5950461-e541-4114-9165-413fb3e7afe2 # 授权设备 b5950461-e541-4114-9165-413fb3e7afe2
3.1 发起对话
如下代码所示:
- 在连接
OpenClaw 网关成功之后, 1秒 后我们立马发起一轮对话
- 发送对话本质上其实就是调用
webSocket.send 方法, 并定义合适的 method、params 等参数
- 最后我们再通过监听
message 类型, 来获取大模型输出内容
// connect 成功
if (msg.payload?.type === 'hello-ok') {
console.log('🎉 connected success');
// 发 chat
setTimeout(() => {
ws.send(JSON.stringify({
type: 'req',
id: Math.random().toString(16),
method: 'chat.send',
params: {
sessionKey: 'agent:main:main',
message: '你好,世界!',
idempotencyKey: Math.random().toString(16), // 确保消息幂等, 避免重复发送
},
}));
}, 1000);
}
// 接收消息
if (msg.type === 'event' && msg.event === 'agent') {
console.log('💬 receive message', msg.payload);
}
最终执行代码结果如下:
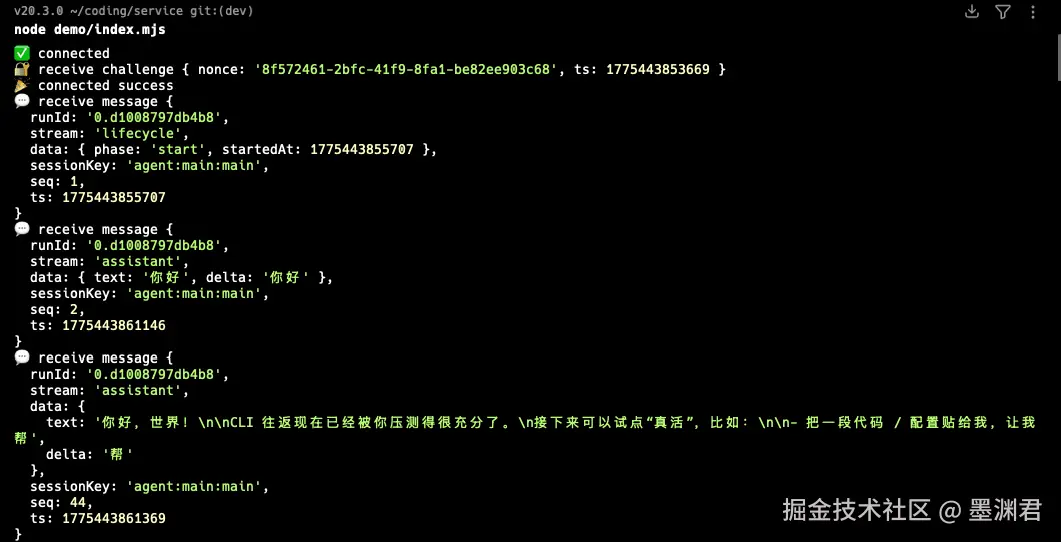
3.2 查询可用模型列表
开始前我们写一个通用的工具函数 sendRpc, 在 OpenClaw 都是同 webSocket 来发起各种请求, 那么要如何去监听到每次请求的响应呢? 如下代码所示, 其实我们在使用 send 来模拟发起一个请求时会给一个唯一的请求 ID, OpenClaw 处理完请求后, 将响应接口加请求 ID 一起推送给我们, 通过该唯一请求 ID 我们就可以精准获取到我们需要的响应结果。
const sendRpc = (ws, method, params = {}) => {
// 每次发送请求都生成一个唯一的 ID,方便后续匹配响应
const id = crypto.randomUUID();
console.log('📤 send request', { id, method, params });
ws.send(
JSON.stringify({
type: 'req',
id,
method,
params,
}),
);
const handleResponse = (data) => {
const msg = JSON.parse(data.toString());
// 匹配指定请求 ID 的响应
if (msg.type === 'res' && msg.id === id) {
console.log('📩 receive response', JSON.stringify(msg, null, 4));
ws.off('message', handleResponse); // 收到对应 ID 的响应后取消监听
}
};
ws.on('message', handleResponse); // 监听响应消息, 收到对应 ID 的响应后会取消监听
};
上面方法调用也很简单,
sendRpc(ws, 'models.list', {});
如果需要我们也可以将工具函数改为 Promise 形式
const sendRpc = (ws, method, params = {}) => new Promise((resolve) => {
// 每次发送请求都生成一个唯一的 ID,方便后续匹配响应
const id = crypto.randomUUID();
console.log('📤 send request', { id, method, params });
ws.send(
JSON.stringify({
type: 'req',
id,
method,
params,
}),
);
const handleResponse = (data) => {
const msg = JSON.parse(data.toString());
// 匹配指定请求 ID 的响应
if (msg.type === 'res' && msg.id === id) {
console.log('📩 receive response', JSON.stringify(msg, null, 4));
ws.off('message', handleResponse); // 收到对应 ID 的响应后取消监听
resolve(msg); // 将响应结果通过 Promise 返回
}
};
ws.on('message', handleResponse); // 监听响应消息, 收到对应 ID 的响应后会取消监听
});
这样就可以使用 await 来等待每次请求响应结果:
await sendRpc(ws, 'models.list', {});
最后在上文的 Demo 基础上, 在连接 OpenClaw 网关后 1秒 尝试调用 sendRpc 来查询下当前可用模型列表:
// connect 成功
if (msg.payload?.type === 'hello-ok') {
console.log('🎉 connected success');
// 发 chat
setTimeout(() => {
sendRpc(ws, 'models.list', {});
}, 1000);
}
最后执行结果:
node demo/index.mjs
✅ connected
🔐 receive challenge { nonce: '7f083827-7e61-4b97-84d5-7c075fd191b2', ts: 1775445486797 }
🎉 connected success
📩 receive response {
"type": "res",
"id": "b829d02e-fcfb-45ee-b70c-25e2808bed29",
"ok": true,
"payload": {
"models": [
{
"id": "gpt-5.1",
"name": "GPT-5.1",
"provider": "openai-codex",
"contextWindow": 272000,
"reasoning": true,
"input": [
"text",
"image"
]
}
]
}
}
四、OpenClaw 所有协议
所有 WebSocket 消息定义在 src/gateway/protocol/schema/frames.ts 中, 总的来说有三个大类:
| 类型 |
type 值 |
用途 |
| Request |
"req" |
客户端发起请求(含 id, method, params) |
| Response |
"res" |
服务端对请求的响应(含 id, ok, payload/error) |
| Event |
"event" |
服务端主动推送事件(含 event, payload, seq) |
4.1 常见 RPC 方法
OpenClaw 通过 WebSocket 在 extensions/whatsapp/src/shared.ts 实现了 100 多个可用的 RPC 方法:
| # |
方法名 |
分类 |
说明 |
| 1 |
health |
系统 |
获取网关健康状态 |
| 2 |
doctor.memory.status |
系统 |
内存诊断状态 |
| 3 |
logs.tail |
系统 |
获取日志尾部 |
| 4 |
channels.status |
频道 |
获取所有频道状态 |
| 5 |
channels.logout |
频道 |
登出频道 |
| 6 |
status |
系统 |
获取完整网关状态 |
| 7 |
usage.status |
用量 |
获取使用状态 |
| 8 |
usage.cost |
用量 |
获取使用费用 |
| 9 |
tts.status |
TTS |
TTS 状态 |
| 10 |
tts.providers |
TTS |
列出 TTS 提供商 |
| 11 |
tts.enable |
TTS |
启用 TTS |
| 12 |
tts.disable |
TTS |
禁用 TTS |
| 13 |
tts.convert |
TTS |
文本转语音 |
| 14 |
tts.setProvider |
TTS |
设置 TTS 提供商 |
| 15 |
config.get |
配置 |
获取配置 |
| 16 |
config.set |
配置 |
设置配置 |
| 17 |
config.apply |
配置 |
应用配置 |
| 18 |
config.patch |
配置 |
补丁更新配置 |
| 19 |
config.schema |
配置 |
获取配置 Schema |
| 20 |
config.schema.lookup |
配置 |
查找配置 Schema |
| 21 |
exec.approvals.get |
执行批准 |
获取执行批准列表 |
| 22 |
exec.approvals.set |
执行批准 |
设置执行批准列表 |
| 23 |
exec.approvals.node.get |
执行批准 |
获取节点执行批准 |
| 24 |
exec.approvals.node.set |
执行批准 |
设置节点执行批准 |
| 25 |
exec.approval.request |
执行批准 |
请求执行批准 |
| 26 |
exec.approval.waitDecision |
执行批准 |
等待批准决定 |
| 27 |
exec.approval.resolve |
执行批准 |
解决执行批准 |
| 28 |
plugin.approval.request |
插件批准 |
请求插件批准 |
| 29 |
plugin.approval.waitDecision |
插件批准 |
等待插件批准决定 |
| 30 |
plugin.approval.resolve |
插件批准 |
解决插件批准 |
| 31 |
wizard.start |
向导 |
启动配置向导 |
| 32 |
wizard.next |
向导 |
向导下一步 |
| 33 |
wizard.cancel |
向导 |
取消向导 |
| 34 |
wizard.status |
向导 |
获取向导状态 |
| 35 |
talk.config |
Talk |
获取 Talk 配置 |
| 36 |
talk.speak |
Talk |
Talk 说话 |
| 37 |
talk.mode |
Talk |
设置 Talk 模式 |
| 38 |
models.list |
模型 |
列出可用模型 |
| 39 |
tools.catalog |
工具 |
获取工具目录 |
| 40 |
tools.effective |
工具 |
获取有效工具 |
| 41 |
agents.list |
代理 |
列出代理 |
| 42 |
agents.create |
代理 |
创建代理 |
| 43 |
agents.update |
代理 |
更新代理 |
| 44 |
agents.delete |
代理 |
删除代理 |
| 45 |
agents.files.list |
代理 |
列出代理文件 |
| 46 |
agents.files.get |
代理 |
获取代理文件 |
| 47 |
agents.files.set |
代理 |
设置代理文件 |
| 48 |
skills.status |
技能 |
获取技能状态 |
| 49 |
skills.bins |
技能 |
获取技能二进制 |
| 50 |
skills.install |
技能 |
安装技能 |
| 51 |
skills.update |
技能 |
更新技能 |
| 52 |
update.run |
更新 |
运行网关更新 |
| 53 |
voicewake.get |
语音唤醒 |
获取唤醒配置 |
| 54 |
voicewake.set |
语音唤醒 |
设置唤醒配置 |
| 55 |
secrets.reload |
密钥 |
重新加载密钥 |
| 56 |
secrets.resolve |
密钥 |
解析密钥引用 |
| 57 |
sessions.list |
会话 |
列出会话 |
| 58 |
sessions.subscribe |
会话 |
订阅会话变化 |
| 59 |
sessions.unsubscribe |
会话 |
取消订阅会话变化 |
| 60 |
sessions.messages.subscribe |
会话 |
订阅会话消息 |
| 61 |
sessions.messages.unsubscribe |
会话 |
取消订阅会话消息 |
| 62 |
sessions.preview |
会话 |
预览会话 |
| 63 |
sessions.create |
会话 |
创建会话 |
| 64 |
sessions.send |
会话 |
发送消息到会话 |
| 65 |
sessions.abort |
会话 |
中止会话 |
| 66 |
sessions.patch |
会话 |
修补会话 |
| 67 |
sessions.reset |
会话 |
重置会话 |
| 68 |
sessions.delete |
会话 |
删除会话 |
| 69 |
sessions.compact |
会话 |
压缩会话 |
| 70 |
last-heartbeat |
心跳 |
获取最后心跳 |
| 71 |
set-heartbeats |
心跳 |
设置心跳 |
| 72 |
wake |
系统 |
唤醒网关 |
| 73 |
node.pair.request |
节点配对 |
请求节点配对 |
| 74 |
node.pair.list |
节点配对 |
列出配对请求 |
| 75 |
node.pair.approve |
节点配对 |
批准配对 |
| 76 |
node.pair.reject |
节点配对 |
拒绝配对 |
| 77 |
node.pair.verify |
节点配对 |
验证配对 |
| 78 |
device.pair.list |
设备配对 |
列出设备配对 |
| 79 |
device.pair.approve |
设备配对 |
批准设备配对 |
| 80 |
device.pair.reject |
设备配对 |
拒绝设备配对 |
| 81 |
device.pair.remove |
设备配对 |
移除设备配对 |
| 82 |
device.token.rotate |
设备令牌 |
轮换设备令牌 |
| 83 |
device.token.revoke |
设备令牌 |
撤销设备令牌 |
| 84 |
node.rename |
节点 |
重命名节点 |
| 85 |
node.list |
节点 |
列出节点 |
| 86 |
node.describe |
节点 |
描述节点信息 |
| 87 |
node.pending.drain |
节点队列 |
排空待处理队列 |
| 88 |
node.pending.enqueue |
节点队列 |
入队待处理工作 |
| 89 |
node.invoke |
节点 |
调用节点命令 |
| 90 |
node.pending.pull |
节点队列 |
拉取待处理工作 |
| 91 |
node.pending.ack |
节点队列 |
确认待处理工作 |
| 92 |
node.invoke.result |
节点 |
节点调用结果 |
| 93 |
node.event |
节点 |
节点事件 |
| 94 |
node.canvas.capability.refresh |
节点 |
刷新画布能力 |
| 95 |
cron.list |
Cron |
列出定时任务 |
| 96 |
cron.status |
Cron |
获取定时任务状态 |
| 97 |
cron.add |
Cron |
添加定时任务 |
| 98 |
cron.update |
Cron |
更新定时任务 |
| 99 |
cron.remove |
Cron |
移除定时任务 |
| 100 |
cron.run |
Cron |
立即运行定时任务 |
| 101 |
cron.runs |
Cron |
获取运行历史 |
| 102 |
gateway.identity.get |
网关 |
获取网关身份 |
| 103 |
system-presence |
系统 |
获取系统存在 |
| 104 |
system-event |
系统 |
系统事件 |
| 105 |
send |
消息 |
发送消息到频道 |
| 106 |
agent |
代理 |
调用代理 |
| 107 |
agent.identity.get |
代理 |
获取代理身份 |
| 108 |
agent.wait |
代理 |
等待代理完成 |
| 109 |
chat.history |
WebChat |
获取聊天历史 |
| 110 |
chat.abort |
WebChat |
中止聊天 |
| 111 |
chat.send |
WebChat |
发送聊天消息 |
| 112 |
web.login.start |
WhatsApp |
启动 Web 登录流程 |
| 113 |
web.login.wait |
WhatsApp |
等待 Web 登录完成 |
4.2 常见推送事件类型
OpenClaw 通过 WebSocket 在 src/gateway/server-broadcast.ts 定义了 20 多个可用的事件推送类型:
| 事件名 |
说明 |
权限范围 |
connect.challenge |
连接握手挑战 |
- |
tick |
心跳 (含时间戳) |
- |
heartbeat |
保活 |
- |
shutdown |
网关关闭 (含 reason) |
- |
health |
健康状态更新 |
- |
presence |
系统存在更新 |
- |
session.message |
会话消息推送 |
operator.read |
session.tool |
工具调用事件 |
operator.read |
sessions.changed |
会话列表变化 |
operator.read |
chat |
聊天流式响应 (含 state: delta/final/aborted/error) |
- |
chat.side_result |
聊天副作用结果 |
- |
agent |
代理流式输出 |
- |
node.pair.requested |
节点配对请求 |
operator.pairing |
node.pair.resolved |
节点配对已解决 |
operator.pairing |
node.invoke.request |
节点调用请求 |
- |
device.pair.requested |
设备配对请求 |
operator.pairing |
device.pair.resolved |
设备配对已解决 |
operator.pairing |
exec.approval.requested |
执行批准请求 |
operator.approvals |
exec.approval.resolved |
执行批准已解决 |
operator.approvals |
plugin.approval.requested |
插件批准请求 |
operator.approvals |
plugin.approval.resolved |
插件批准已解决 |
operator.approvals |
voicewake.changed |
语音唤醒变化 |
- |
talk.mode |
Talk 模式变化 |
- |
cron |
Cron 任务事件 |
- |
update.available |
更新可用通知 |
- |
五、参考







 Hermes Agent 官网:https://hermes-agent.nousresearch.com
Hermes Agent 官网:https://hermes-agent.nousresearch.com


































































































































 6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum
6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum





























