意大利央行下调未来三年经济增长预期
当地时间4月3日,意大利央行发布最新宏观经济预测报告,下调了该国未来三年的经济增长预期。报告预测意大利2026年的国内生产总值增长为0.5%,低于此前预测的0.6%;2027年的经济增长预期从0.8%下调至0.5%,2028年的预期从0.9%下调至0.8%。(央视新闻)


曝苹果「天价扫货」DRAM,阻止竞争对手获取

小米手机官宣涨价,卢伟冰:内存涨价远超预期

充电宝迎史上最严国标,明年强制实施

福特刷新纽北美系纪录,小米排名下滑、雷军发文祝贺

Slack 切断大中华区服务,执行方式引发用户强烈反弹

工信部预警:iOS 13 至 17.2.1 存在严重漏洞,建议尽快升级

Vibe Coding 应用 Anything 被苹果下架后重新上架

阿里千问 3.6 登顶国产 AI 编程榜

曝 R 星母公司解散 AI 团队,七年研发成果戛然而止

麦肯锡高级合伙人:AI 正在「压扁」你的公司,管理层级将大幅削减

39 元/月起,小米 MiMo 推出订阅制 Token 套餐

三大外卖平台被约谈,6 月 1 日前落实食品安全新规

滴滴开放打车 Skill,支持「龙虾」打车

告别「抽卡」,阿里发布 Wan2.7-Video,可一句话修改视频

蚂蚁数科发布专业 AI 智能体 DTClaw

Manner 咖啡涨价

AI 短剧《桃花簪》因 AI 换脸全面下架,播放量曾破 4000 万
 周末也值得一看的新闻
周末也值得一看的新闻
据消息源「Jukan」发布的爆料,苹果以极高的溢价,在市场上几乎「扫光了市场上所有可取得的移动 DRAM」,甚至愿意为此承受营业利润率受损的代价。
该消息人士强调,苹果此举并非单纯为了满足自身的常规备货需求,而是旨在通过人为抬高 DRAM 市场价格,阻止其他智能手机厂商获取足够的内存芯片。
而分析师郭明錤此前曾发布研报指出,苹果正凭借其供应链话语权在存储芯片涨价周期中强力锁定产能,并计划通过吸收成本压力以换取更大的市场份额。
尽管内存成本攀升将不可避免地挤压 iPhone 的毛利率,但郭明錤指出,苹果的核心策略是利用市场动荡期锁定芯片、吸收成本并抢占份额,后续再通过服务业务的增长进行利润回补。
此外,为利于市场营销,苹果目前计划在 2026 年下半年发布的 iPhone 18 系列上尽量维持起售价不变。

小米手机昨日正式宣布,受全球存储芯片等关键零部件价格持续大幅上涨影响,将于 4 月 11 日起调整部分在售产品的建议零售价。
此次调价涉及 3 款 REDMI 机型:REDMI K90 Pro Max 建议零售价上调 200 元;REDMI Turbo 5 取消新春特惠,512 GB 大内存版本继续保留 200 元补贴;REDMI Turbo 5 Max 同步取消新春特惠,512 GB 版本同样维持 200 元补贴。
对此,小米集团合伙人、总裁卢伟冰在微博发文回应称,「本轮内存涨价的力度确实远超预期,同版本内存价格相比去年 Q1 飙升近 4 倍……我们不得不对部分机型的零售价格做出小幅上涨或者恢复原价,还望大家理解。」
小米中国区市场部总经理魏思琪亦表示,公司此前一直全力抑制内存涨价对终端售价的影响,但本轮涨价的速度和幅度均超出预期,为保障产品正常供应与品质稳定,最终决定对部分产品进行调价。
另据《财经》杂志报道,小米内部预计今年手机业务销量将下滑 13%,正着手调整线下门店策略,将营收重心转向大家电业务,同时停止线下门店扩张。

据央视新闻报道,由工业和信息化部组织制定的强制性国家标准 GB 47372-2026《移动电源安全技术规范》已于昨天(4 月 3 日)正式发布,将于明年 4 月 1 日起正式实施。
新国标覆盖「充电宝」和「户外电源」两类产品。
安全性方面,标准引入针刺试验,明确提升移动电源在高温、过度充电、挤压等极端场景下的安全防护能力;同时新增循环老化检测,以降低长期使用后的内部短路风险,并要求产品标明建议安全使用年限,提醒消费者及时更换老化产品。
此外,新国标推行产品唯一性编码管理,消费者可通过编码查询电池品牌等核心信息;在生产制造流程方面,明确提出原材料及生产过程管控要求,从源头提升安全水平。
专家表示,新国标实施后,此前已购买并通过旧 3C 认证的充电宝,只要符合民航现行相关规定,仍可正常携带乘机。
本次新国标的主要起草单位阵容庞大,涵盖中国电子技术标准化研究院、宁德新能源科技、华为终端、欣旺达、安克创新、小米、OPPO 广东移动通信、比亚迪锂电池、联想、公牛集团等逾 30 家企业与学术机构。

4 月 3 日,福特中国宣布福特 GT Mk IV 在纽北赛道刷新圈速纪录,成绩为 6:15.977,创下美系厂商纽北最快圈速。
对此,小米 CEO 雷军随即在微博上转发并留言「祝贺福特」,还附上点赞表情。雷军在评论中补充称,小米 SU7 Ultra 目前位列纽北官方圈速榜全球第 4,「也不丢人」。
此前,小米 SU7 Ultra 曾凭借纽北圈速成绩引发广泛关注。此番福特 GT Mk IV 刷新纪录后,小米在该榜单上的排名相应下降一位。

据 The Information 报道,Slack 于近日正式停用了账单地址位于中国大陆、中国香港及中国澳门地区的所有 Workspace,付费用户与免费用户均受影响。
停用后,用户无法访问历史消息、文件、频道及工作流,Slack 同时启动了 90 天数据删除倒计时。经核查,爱范儿自己的 Slack Workspace 也已被停用。
去年 11 月,The Information 率先报道 Slack 已向受影响地区用户发送通知,要求其在今年 2 月前将账户迁移至阿里云,否则订阅将不予续期。
然而,实际执行方式引发了大量用户的强烈不满。Reddit 上多名中国香港用户反映,他们从未收到任何事先通知,或通知邮件被系统归入垃圾邮件文件夹。
一名用户写道:「我们完全被锁在外面,无法访问任何文件、客户沟通记录和历史数据。Slack 的处理方式感觉就像是勒索——他们切断了我们的访问,却不给我们任何导出数据的时间窗口。」
Slack Support 对此给出的是统一模板回复,确认「Workspace 已受到此前已告知的服务变更影响」,但未提供具体的数据导出流程或时间表。
通知本身也存在明显的差异化处理:较大的付费客户收到了阿里云迁移指引,而规模较小的团队则直接收到服务终止通知,未获提供迁移选项。
据界面新闻报道,工信部网络安全威胁和漏洞信息共享平台(NVDB)近日监测发现,有攻击者正在利用针对苹果终端产品的漏洞利用工具实施网络攻击活动,可导致信息窃取、系统受控等严重危害。受影响范围涵盖运行 iOS 13.0 至 17.2.1 版本的 iPhone、iPad 等苹果终端产品。
工信部建议相关用户尽快完成风险排查,通过升级系统版本或安装补丁的方式修复漏洞,并参考苹果官方安全更新公告。

Vibe Coding App「Anything」官方账号刚刚发文确认,苹果已将此前下架的 Vibe Coding 工具 Anything 重新上架 App Store。为庆祝此次重新上架,Anything 宣布发起一场 5000 美元的周末黑客马拉松活动,并附赠 2 万 Credits。
此前,苹果以违反 App Store 审核指南第 2.5.2 条款为由,将 Anything 彻底下架。
该条款规定,App 应自包含在自己的套装中,不得下载、安装或执行会引入或更改 App 特性或功能的代码。Anything 支持用户在 iPhone 上通过自然语言描述需求、由 AI 实时生成代码并在设备上运行,与该条款直接冲突。
对于此次下架,Anything 官方曾在 X 平台发文反击:「重磅:苹果对 Vibe Coding 感到恐慌,把 Anything 从 App Store 下架了,所以我们把应用开发转移到了 iMessage。祝苹果顺利移除这个。」
值得注意的是,苹果本身并不反对 AI 辅助编程——今年 2 月推出的 Xcode 26.3 已将 Claude Agent 与 OpenAI Codex 集成其中。
苹果真正抵制的,是用户通过第三方 App 在商店审核之外生成并执行新代码,这场风波本质上是一场平台控制权之争。

4 月 2 日,阿里巴巴发布新一代大语言模型 Qwen 3.6-Plus,发布次日,该模型即在全球知名大模型盲测平台 LMArena 旗下的 Code Arena 榜单 React 专项中以 1452 分位列全球第二,成为该榜单排名最高的国产大模型。
榜单数据显示,Qwen 3.6-Plus 以 1452 分位列第二,仅次于 Anthropic 旗下的 Claude-Opus-4.6-Thinking(1540 分),以 4 分优势领先 GPT-5.0-High(1448 分),并以 12 分差距超越 Gemini 3.1 Pro Preview(1440 分)。
在综合评估 AI 编程能力的 Code Arena 全榜中,Qwen 3.6-Plus 同样位居国产模型首位。凭借上述成绩,阿里在全球 AI 实验室排名中升至第四,仅次于 Anthropic、OpenAI 和 Google。
LMArena 采用真实用户盲测、实时对抗排名机制,被视为 AI 领域较具公信力的性能评测平台。
据 Insider Gaming 报道,GTA 6 开发商 Rockstar 的母公司 Take-Two Interactive 昨天对旗下 AI 部门进行了重大调整,裁撤了包括 AI 负责人在内的不明数量员工。
Take-Two 前 AI 负责人 Luke Dicken 在 LinkedIn 上发文证实了这一消息:「很遗憾,我不得不告诉大家,我和我的团队在 T2 的工作丢了。」
他表示将在一周后发布更详细的回顾文章,并呼吁业界人士帮助团队成员寻找新工作,称这些人「用 7 年时间开发了前沿技术,擅长将创新与产品设计结合,打造出能赋能整个开发流程的系统」。
目前 Take-Two 尚未公开说明此次裁员的具体规模和原因,但外界普遍将此解读为游戏行业在 AI 研发投入上有所收缩的信号。值得注意的是,Take-Two CEO Strauss Zelnick 此前曾公开表态,AI「永远」无法制作出 GTA 6 这样的游戏,并长期为人工开发模式背书。
这并非 Take-Two 近年来首次大规模裁员。2024 年,该公司曾裁减约 5% 的员工,并取消多个开发中的项目,以提升财务效率。此次 AI 部门的调整发生在 GTA 6 发售前数月,时间节点颇为敏感。

日前,荣耀与京东签订战略合作协议,建立全方位战略合作伙伴关系。根据协议,双方将围绕产品共创、用户共营、生态共享三大核心领域展开深度合作,并设定三年累计规模超 1000 亿元的全领域合作目标。
产品共创层面,双方将覆盖手机、全场景、AIoT 及机器人等多品类产品的全生命周期。合作内容包括战略新品首发、联合 IP 与 C2M 定制项目,以及针对外卖骑手、快递员、游戏玩家等特定人群的场景化产品共创。
用户共营层面,双方将整合全链路营销资源,通过联合会员运营与精准人群触达提升用户体验,并在电竞、运动健康等场景展开深度合作。
生态共享层面,双方将基于荣耀端侧大模型能力与京东 JoyAI 大模型、JoyInside 等 AI 生态,共同打造商品导购、生活服务、金融理财等场景的创新体验。
在机器人领域,京东线下门店将试点部署荣耀机器人用于引流导购。此外,双方还将依托荣耀终端产品与京东 Joybuy 平台协同拓展海外市场,并在全渠道 O2O、即时零售、科技金融保险等领域进一步深化合作。

上海交通大学人工智能学院与蚂蚁健康近日在上海签署合作协议,双方将共同发起成立「AI4HealthCare 联合实验室」,围绕医疗领域专科智能体的研发与临床适配应用展开联合攻坚。
联合实验室将依托上海交大在基础研究、算法模型与学术创新方面的领先优势,结合蚂蚁健康在医疗健康领域积累的场景资源、技术能力与产业资源,共同探索 AI 在疾病预防、健康管理、辅助诊疗等环节的创新应用模式。
双方还将联动人工智能学科与各附属医院临床专科,重点推进医疗专科智能体与临床应用的关键技术研发。相关成果将率先落地于蚂蚁阿福 App。
麦肯锡高级合伙人:AI 正在「压扁」你的公司,管理层级将大幅削减
据《商业内幕》报道,麦肯锡高级合伙人 Alexis Krivkovich 近日在《The McKinsey Podcast》中表示,AI 正在赋予企业领导者「超人般的管理能力」,使其得以统筹更大规模的团队,从而推动企业组织架构走向扁平化。
Krivkovich 指出,过去十年间,企业在 CEO 与一线员工之间平均新增了至少一至三个管理层级。这不仅带来高昂的人力成本,更拖慢了决策效率——每一个层级,都意味着多一道需要「签字放行」的关卡。
而 AI Agent 的介入,正在替代这些中间节点,直接承担决策辅助与信息传递的职能。
AI 原生软件开发平台 Factory 的联合创始人兼 CTO Eno Reyes 今年 3 月对《商业内幕》表示:「你的组织架构图很可能会开始横向压缩,变得更加扁平。」
Factory 目前已为毕马威等咨询公司及英伟达、Adobe 等科技企业部署自主编程智能体。
IBM 方面同样在推进类似布局。该公司高级副总裁 Mohamed Ali 透露,IBM 计划将「数字员工」与旗下 15 万名人类顾问协同部署,并预判未来管理 AI 的方式将与管理人类员工截然不同。
会有专门的系统来管理这些东西,会有专门的系统来设定护栏。

昨天,小米正式发布了 Xiaomi MiMo Token Plan,面向全球开发者和 AI 用户推出订阅制 Token 套餐服务。套餐共分四档:
在工具兼容性方面,MiMo Token Plan 已针对 Claude Code、Cline、Kilo Code、OpenCode、Hermes Agent、CodeBuddy Code 等主流 AI 编程工具和开发平台完成适配。小米表示,自动续费及更灵活的用量管理功能正在开发中。
据央视新闻报道,市场监管总局近日在北京召开外卖平台企业行政指导会,要求美团、淘宝闪购、京东 3 家平台企业尽快开展自查整改,严格落实即将实施的《网络餐饮服务经营者落实食品安全主体责任监督管理规定》。
会议要求各平台逐条对标《规定》,从资质审查、管理保障、社会公开、应急管理、协同监管 5 个维度全面履行平台主体责任。
同时,以《规定》正式实施的 6 月 1 日为节点,倒排工期,全面梳理现有制度、流程、人员配备及技术保障等环节。
监管层还强调,三大平台须严把审查关、管理关、配送关,借助技术手段强化管理能力,主动融入政府监管体系,从「被动应付」转向「主动对接」。
具体措施包括推动「互联网 + 明厨亮灶」落地,以及鼓励外卖骑手参与食品安全监督,共建食品安全社会共治格局。

滴滴出行昨日宣布,正式开放旗下打车 Skill「didi-ride-skill」,面向「龙虾」(OpenClaw) 用户提供完整的出行服务能力接入。
didi-ride-skill 将滴滴多年积累的底层出行能力打包开放,涵盖地址解析、价格预估、路线规划、司机匹配、订单追踪与周边搜索等功能。
安装后,可直接在龙虾对话框中以自然语言发起打车需求,无需切换至独立 App,全程由 Skill 完成地址确认、车型选择、下单及订单状态回查等操作。
didi-ride-skill 还支持记忆用户偏好,例如「上班打快车,下班打特惠」或将「回家」绑定为固定地址,以便在后续请求中更快响应。
滴滴同步披露了 AI 叫车的使用数据:最近一周,使用滴滴 AI 打车的用户数量相比年初增加了 37 倍,其中 00 后用户占比超过 40%,是当前 AI 出行功能的主力用户群体。
 GitHub: github.com/didi/didi-ride-skill
GitHub: github.com/didi/didi-ride-skill

4 月 3 日,阿里通义实验室官宣发布 Wan2.7-Video 视频生成系列模型,涵盖文生视频(Wan2.7-t2v)、图生视频(Wan2.7-i2v)、参考生视频(Wan2.7-r2v)和视频编辑(Wan2.7-videoedit)四个专业子模型。

蚂蚁数科昨天正式宣布,旗下专业 AI 智能体产品 DTClaw 开启内测阶段,这款产品的定位是「专业虾」,面向金融专家、营销专家、数据专家等专业人群,提供 7 × 24 小时在线的专属 AI 智能体服务。
据介绍,DTClaw 主打「出生即专家」,内置上百种专业 skills 技能,覆盖理财、投资、数据分析、研发与测试等高价值场景,并深度集成企业办公、财务、销售、营销系统,支持工作流程自动化。
官方称,用户一键部署即可上手,无需从零配置,可节省 50% 的 Token 消耗量。
安全方面,DTClaw 独创了 CARLI 安全模型,通过为 AI 配备「刹车」和「黑匣子」机制,为智能体运行建立安全护栏。

据界面新闻报道,Manner Coffee 近期在其官方点单小程序发布价格调整公告,宣布将于 4 月 7 日起对门店单品豆 SOE 咖啡每杯上调 5 元、门店热门产品「绿野仙踪」售价同步上涨 5 元。
Manner Coffee 方面表示,全国门店价格同步上调,核心原因是将选用品质更优的咖啡豆,以为消费者提供更出色的风味体验。公司同时强调,门店长期推行的「自带杯减 5 元」优惠政策保持不变。

昨天,字节跳动旗下红果短剧宣布全面下架短剧《桃花簪》,并暂停该出品方上传所有剧集 15 天。
事件起源于 3 月 30 日晚,汉服妆造博主「白菜汉服妆造」在社交平台公开指控,《桃花簪》出品方未经其授权,擅自使用其个人照片,通过 AI 技术生成角色形象,且将角色塑造为「贪财好色」的负面形象。
据凤凰网科技报道,《桃花簪》为 AI 生成古风短剧,相关平台播放量曾突破 4000 万,超 2.8 万人收藏。
4 月 2 日,中国广播电视社会组织联合会演员委员会发布声明,直指当前 AI 换脸合成、声纹克隆复刻等侵权乱象,要求网络平台严格落实内容审核主体责任,建立 AI 演艺内容授权核验长效机制。
红果短剧在声明中表示,平台收到投诉后第一时间启动对出品方相关信息与材料的梳理审核。经细致比对核查,平台认定出品方违反相关内容合规使用规定,构成违规违约,遂作出下架及暂停上传的处理决定。
声明还指出,对于违规违约出品方,平台将视情节采取包括内容下架、停止合作、相关法律追责等措施。

乐高集团昨日宣布与克里斯蒂亚诺·罗纳尔多、基利安·姆巴佩、利昂内尔·梅西及维尼修斯·儒尼奥尔达成合作,推出全新乐高® Editions 系列套装,以迎接今年的 2026 FIFA 世界杯。
此次发布共涵盖「经典进球瞬间」「足球传奇」「梅西的庆祝时刻」三类产品线:

由梁乐民执导的犯罪动作电影《寒战 1994》正式官宣定档五一,并同步发布定档预告及海报。这是《寒战》系列时隔十年的回归之作。
影片汇集了周润发、郭富城、梁家辉等「寒战宇宙」原班人马强势回归,古天乐特别出演,吴彦祖、刘俊谦、吴慷仁、谢君豪领衔主演,王丹妮、廖子妤、艾丹·吉伦及休·博纳维尔主演,阵容规模堪称近年港产警匪片之最。
剧情上,《寒战 1994》采用双时间线叙事结构,以「2017 年」与「1994 年」交织推进。2017 年线索中,前警务处行动副处长李文彬(梁家辉 饰)意外遇袭失踪,警务处处长刘杰辉(郭富城 饰)随即向资深大律师简奥伟(周润发 饰)寻求协助,两人共同开启一份尘封的 1994 年神秘档案。
 是周末啊!
是周末啊!
据鞭牛士报道,近日有网友在 GitHub 上发现一个名为「colleague-skill」的开源项目,可将员工的工作数据、文档及聊天记录等信息训练成 AI 模型,在员工离职后,由 AI 「数字人分身」继续承担部分工作,实现「赛博永生」。
目前已有网友反映,自己的离职同事被公司以上述方式「炼化」成数字人。公司将离职员工的聊天记录与工作文档用于训练 AI 并自动生成该员工的 AI 分身。
该分身不仅能模仿离职员工的语气与工作习惯,还可向在职员工发送消息,基于其在职期间留存的文档完成工作交接、回答业务问题。

《我,许可》已于昨天正式上映,由杨荔钠执导,游晓颖编剧,文淇、秦海璐领衔主演,白客、李雪琴、牛莉等联合出演。
影片聚焦「00 后」「母单」女孩许可(文淇 饰),她因一场迫在眉睫的妇科手术而陷入困境,却被妈妈胡春蓉(秦海璐 饰)的突袭式造访彻底打乱计划。
母女同居后冲突频发,在新旧观念的摩擦中,女儿对妈妈展开一轮又一轮「反向教育」——以蹦迪代替谈心,以实物代替生理课。影片以许可能否顺利完成手术、胡春蓉能否开启新生活为双线收束,试图在笑点与泪点并行中重塑母女关系。

《海边的小院》是作家阿禾创作的非虚构作品,全书以一座濒临拆除的海边小院为叙事原点,记录了这个家族近半个世纪的谋生往事。
1962 年冬天,流离失所多年的外公外婆徒手从海滩刨出海泥,填平河湾旁的烂泥地,用芦苇和稻草搭起窝棚,建成这座能抵御台风的小院。此后数十年,它成为整个家族与命运周旋、在困顿中喘息、一次次重振旗鼓的根据地。
书中刻画了一系列鲜活的人物群像:不识字却敢于蹚出生意路的母亲,从挖弹涂鱼到开鞋店、开厂,几经起落;有天才般艺术直觉却因做倒爷而瘫痪的舅舅,在轮椅上编织新的活法;被称作「小刘德华」却在 18 岁破相的堂哥……
作者本人的经历同样充满曲折——她分别在高中和大学两次退学,第二次离开的甚至是众人向往的名牌大学,只为寻找「人生的意义是什么」的答案。

《Stray》是由法国独立工作室 BlueTwelve Studio 开发的第三人称冒险游戏,玩家扮演一只流浪橘猫,迷失于一座被人类遗弃、仅剩机器人居民的赛博朋克地下城市,途中唤醒微型无人机伙伴 B-12,共同寻找通往地面的出路。
游戏美学深受香港九龙城寨影响,项目最初以「HK_Project」为名于 2015 年启动,历时七年完成开发。
评分方面,Metacritic 综合评分为 82~83 分,OpenCritic 推荐率 86%。IGN 给出 8/10,GameSpot 给出 9/10,《卫报》与 VG247 均给出满分。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
适合人群:
git地址在这里:https://gitee.com/mslimyjj/old-ling-python/tree/master/python-cheatsheet-demos
建议在 python-cheatsheet-demos/ 目录中运行命令(相对路径/生成文件最直观)。
python 01_basics.py
如果你的环境里 python 命令不可用,可以使用 Python 官方“嵌入式版本”(无需安装、不污染系统环境)。
在 python-cheatsheet-demos/ 目录执行:
$ver='3.11.8'
$zip="python-$ver-embed-amd64.zip"
$url="https://www.python.org/ftp/python/$ver/$zip"
$dest="..\.python-embed"
New-Item -ItemType Directory -Force -Path $dest | Out-Null
Invoke-WebRequest -Uri $url -OutFile "$dest\$zip"
Expand-Archive -Force -Path "$dest\$zip" -DestinationPath $dest
& "$dest\python.exe" 01_basics.py
后续统一用它运行 demo:
& "..\.python-embed\python.exe" 05_requests_demo.py
如果你用系统 Python:
pip install -r requirements.txt
如果你用嵌入式 Python:
& "..\.python-embed\python.exe" -m pip install -r requirements.txt
文件:01_basics.py
name = "张三" # str
age = 20 # int
is_ok = True # bool
arr = [1, 2, 3] # list = JS Array
obj = {"a": 1} # dict = JS Object
print(name, age, is_ok, arr, obj)
if age > 18:
print("成年")
elif age == 18:
print("刚成年")
else:
print("未成年")
for item in [1, 2, 3]:
print("item:", item)
for i in range(10):
print("i:", i)
def add(a, b):
return a + b
res = add(1, 2)
print("add:", res)
运行:
& "..\.python-embed\python.exe" 01_basics.py
文件:02_list_dict.py
arr = [1, 2, 3]
arr.append(4)
last = arr.pop()
print(arr, "popped:", last)
print("len:", len(arr))
print("first:", arr[0])
user = {
"name": "tom",
"age": 20,
}
print("name1:", user["name"])
print("name2:", user.get("name"))
print("missing:", user.get("addr"))
user["addr"] = "北京"
print(user)
你可以把 list 当成 JS 的数组,把 dict 当成 JS 的对象。
运行:
& "..\.python-embed\python.exe" 02_list_dict.py
文件:03_json_demo.py
import json
data = json.loads('{"name":"tom","age":20}')
print(data, type(data))
str_data = json.dumps(data, ensure_ascii=False)
print(str_data, type(str_data))
json.loads:字符串 -> 对象json.dumps:对象 -> 字符串运行:
& "..\.python-embed\python.exe" 03_json_demo.py
文件:04_file_io.py
import json
with open("test.txt", "w", encoding="utf-8") as f:
f.write("hello\n")
with open("test.txt", "r", encoding="utf-8") as f:
content = f.read()
print("content:", content)
payload = {"name": "tom", "age": 20}
with open("data.json", "w", encoding="utf-8") as f:
json.dump(payload, f, ensure_ascii=False, indent=2)
with open("data.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("json:", data)
运行:
& "..\.python-embed\python.exe" 04_file_io.py
输出会读写当前目录的:
test.txtdata.json文件:05_requests_demo.py
import requests
res = requests.get("https://httpbin.org/get", params={"q": "test"}, timeout=10)
print("get status:", res.status_code)
print(res.json()["args"])
res = requests.post("https://httpbin.org/post", json={"username": "admin"}, timeout=10)
print("post status:", res.status_code)
print(res.json()["json"])
这个 demo 用 https://httpbin.org 作为测试服务,演示 GET/POST JSON。
运行:
& "..\.python-embed\python.exe" 05_requests_demo.py
文件:06_fastapi_main.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/api/user")
def get_user():
return {"name": "tom", "age": 20}
安装依赖(如果还没装):
pip install fastapi uvicorn
运行:
uvicorn 06_fastapi_main:app --reload
访问:
http://localhost:8000/api/userhttp://localhost:8000/docs文件:07_scripts_os.py
import os
for file in os.listdir("./"):
print(file)
imgs_dir = "./imgs"
if os.path.isdir(imgs_dir):
for i, file in enumerate(os.listdir(imgs_dir)):
src = os.path.join(imgs_dir, file)
dst = os.path.join(imgs_dir, f"img{i}.png")
if os.path.isfile(src):
os.rename(src, dst)
print("renamed:", src, "->", dst)
运行:
& "..\.python-embed\python.exe" 07_scripts_os.py
注意:批量重命名会操作 ./imgs 目录下文件名,运行前确认目录存在并且文件可改名。
文件:08_ai_call.py
import requests
def call_ai(prompt: str):
res = requests.post(
"http://localhost:8000/ai",
json={"prompt": prompt},
timeout=30,
)
res.raise_for_status()
return res.json()
code = call_ai("生成一个Vue3按钮组件")
print(code)
这个 demo 会调用:POST http://localhost:8000/ai
如果你本地没有启动这个服务,会出现连接被拒绝(这属于正常现象)。
运行:
& "..\.python-embed\python.exe" 08_ai_call.py
文件:09_capture_requests.py
import argparse
import re
import sys
from urllib.parse import urlparse
def _normalize_url(u: str) -> str:
try:
p = urlparse(u)
if not p.scheme or not p.netloc:
return u
return p._replace(fragment="").geturl()
except Exception:
return u
def _looks_like_api(u: str) -> bool:
low = u.lower()
if any(x in low for x in ("/api", "/graphql", "/v1/", "/v2/", "/rpc")):
return True
if any(low.endswith(x) for x in (".json", ".xml")):
return True
return False
def _capture_with_playwright(url: str, timeout_ms: int, only_api: bool) -> list[str]:
try:
from playwright.sync_api import sync_playwright # type: ignore
except Exception as e:
raise RuntimeError("missing_playwright") from e
seen: set[str] = set()
out: list[str] = []
def on_request(req):
u = _normalize_url(req.url)
if only_api and (not _looks_like_api(u)):
return
if u not in seen:
seen.add(u)
out.append(u)
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
page.on("request", on_request)
page.goto(url, wait_until="networkidle", timeout=timeout_ms)
try:
page.wait_for_timeout(1500)
except Exception:
pass
context.close()
browser.close()
return out
def _extract_from_html(url: str, timeout_sec: int, only_api: bool) -> list[str]:
import requests
html = requests.get(url, timeout=timeout_sec).text
candidates = set(re.findall(r"https?://[^\s\"'>]+", html))
cleaned = [_normalize_url(u) for u in candidates]
if only_api:
cleaned = [u for u in cleaned if _looks_like_api(u)]
cleaned.sort()
return cleaned
def main(argv: list[str]) -> int:
parser = argparse.ArgumentParser()
parser.add_argument("url")
parser.add_argument("--out", default="send.txt")
parser.add_argument("--timeout", type=int, default=30)
parser.add_argument("--only-api", action="store_true")
parser.add_argument("--mode", choices=["auto", "playwright", "html"], default="auto")
args = parser.parse_args(argv)
url = args.url
out_path = args.out
timeout_sec = args.timeout
only_api = bool(args.only_api)
mode = args.mode
urls: list[str] = []
if mode in ("auto", "playwright"):
try:
urls = _capture_with_playwright(url, timeout_sec * 1000, only_api)
except RuntimeError as e:
if str(e) != "missing_playwright" or mode == "playwright":
raise
urls = []
if (not urls) and mode in ("auto", "html"):
urls = _extract_from_html(url, timeout_sec, only_api)
with open(out_path, "w", encoding="utf-8") as f:
for u in urls:
f.write(u + "\n")
print(f"saved {len(urls)} urls -> {out_path}")
return 0
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))
目标:给一个网页 URL,把它“页面里出现的 URL / 或页面运行时发出的请求”抓出来,写到 send.txt。
安装:
pip install playwright
python -m playwright install chromium
运行(只保留更像接口的 URL):
python 09_capture_requests.py https://example.com --only-api --out send.txt
如果你不安装 Playwright,脚本会自动降级为“从 HTML 源码中提取 URL”。
你也可以强制:
python 09_capture_requests.py https://example.com --mode html --out send.txt
参数速记:
--mode playwright:强制用浏览器抓--mode html:只解析 HTML--only-api:只保留更像接口的 URL(包含 /api、/graphql、/v1/、/v2/、.json 等)文件:10_sleep_print.py
import time
from pynput.keyboard import Controller
time.sleep(3)
Controller().type("Helloween")
这个 demo 用 pynput 控制键盘:
Helloween
使用方法:先把光标点到你想输入的位置(例如记事本/浏览器输入框),再运行脚本。
运行:
& "..\.python-embed\python.exe" 10_sleep_print.py
文件:11_generate_user_excel.py
import os
import random
from openpyxl import Workbook
def random_cn_name() -> str:
surnames = list("赵钱孙李周吴郑王冯陈褚卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜戚谢邹喻柏水窦章云苏潘葛范彭郎鲁韦昌马苗凤花方俞任袁柳酆鲍史唐费廉岑薛雷贺倪汤滕殷罗毕郝邬安常乐于时傅皮卞齐康伍余元卜顾孟平黄和穆萧尹姚邵湛汪祁毛禹狄米贝明臧计伏成戴谈宋茅庞熊纪舒屈项祝董梁杜阮蓝闵席季麻强贾路娄危江童颜郭梅盛林刁钟徐邱骆高夏蔡田樊胡凌霍虞万支柯昝管卢莫经房裘缪干解应宗丁宣贲邓郁单杭洪包诸左石崔吉钮龚程嵇邢滑裴陆荣翁荀羊於惠甄曲家封芮羿储靳汲邴糜松井段富巫乌焦巴弓牧隗山谷车侯宓蓬全郗班仰秋仲伊宫宁仇栾暴甘钭厉戎祖武符刘景詹束龙叶幸司韶郜黎蓟薄印宿白怀蒲邰从鄂索咸籍赖卓蔺屠蒙池乔阴郁胥能苍双闻莘党翟谭贡劳逄姬申扶堵冉宰郦雍却璩桑桂濮牛寿通边扈燕冀郏浦尚农温别庄晏柴瞿阎充慕连茹习宦艾鱼容向古易慎戈廖庾终暨居衡步都耿满弘匡国文寇广禄阙东欧殳沃利蔚越夔隆师巩厍聂晁勾敖融冷訾辛阚那简饶空曾毋沙乜养鞠须丰巢关蒯相查后荆红游竺权逯盖益桓公万俟司马上官欧阳夏侯诸葛闻人东方赫连皇甫尉迟公羊澹台公冶宗政濮阳淳于单于太叔申屠公孙仲孙轩辕令狐钟离宇文长孙慕容司徒司空")
given_chars = list("一乙二十丁厂七卜人入八九几儿了力乃刀又三于干亏士工土才下寸大丈与万上小口山巾千乞川亿个夕久么勺丸凡及广亡门义之尸弓己已子卫也女飞刃习叉马乡丰王井开夫天元无云专扎艺木五支厅不太犬区历尤友匹车巨牙屯比互切瓦止少日中贝内水冈见手午牛毛气升长仁什片仆化仇币仍仅斤爪反介父从今凶分乏公仓月氏勿欠风丹匀乌凤勾文六方火为斗忆计订户认心尺引丑巴孔队办以允予劝双书幻玉刊末未示击打巧正扑扒功扔去甘世古节本术可丙左厉右石布龙平灭轧东卡北占业旧帅归且旦目叶甲申叮电号田由史只央兄叼叫另叨叹四生失禾丘付仗代仙们仪白仔他斥瓜乎丛令用甩印乐句匆册犯外处冬鸟务包饥主市立闪兰半汁汇头汉宁它讨写让礼训必议讯记永司尼民出辽奶奴召加皮边发孕圣对台矛纠母幼丝式刑动扛寺吉扣考托老执巩圾扩扫地扬场耳共芒亚芝朽朴机权过臣再协西压厌在有百存而页匠夸夺灰达列死成夹轨邪划迈毕至此贞师尘尖劣光当早吐吓虫曲团同吊吃因吸吗屿帆岁回岂则刚网肉年朱先丢舌竹迁乔伟传乒乓休伍伏优伐延件任伤价伦份华仰仿伙伪自伊血向似后行舟全会杀合兆企众爷伞创肌朵杂危旬旨负各名多争色壮冲妆冰庄庆亦刘齐交次衣产决充妄闭问闯羊并关米灯州汗污江池汤忙兴宇守宅字安讲军许论农讽设访那迅尽导异孙阵阳收阶阴防如妇好她妈戏羽观欢买红驮纤级约纪驰巡")
surname = random.choice(surnames)
given_len = random.choice([1, 2])
given = "".join(random.choice(given_chars) for _ in range(given_len))
return surname + given
def main():
wb = Workbook()
ws = wb.active
ws.title = "user"
ws.append(["id", "name"])
for i in range(1, 11):
ws.append([i, random_cn_name()])
out_path = os.path.join(os.path.dirname(__file__), "user.xlsx")
wb.save(out_path)
print("saved ->", out_path)
if __name__ == "__main__":
main()
这个 demo 用 openpyxl 生成 Excel:
user.xlsx
user
id、name
运行:
& "..\.python-embed\python.exe" 11_generate_user_excel.py
with open(...) / requests.get(...) 直接回来抄给你一个 m x n 的网格图,其中 (0, 0) 是最左上角的格子,(m - 1, n - 1) 是最右下角的格子。给你一个整数数组 startPos ,startPos = [startrow, startcol] 表示 初始 有一个 机器人 在格子 (startrow, startcol) 处。同时给你一个整数数组 homePos ,homePos = [homerow, homecol] 表示机器人的 家 在格子 (homerow, homecol) 处。
机器人需要回家。每一步它可以往四个方向移动:上,下,左,右,同时机器人不能移出边界。每一步移动都有一定代价。再给你两个下标从 0 开始的额整数数组:长度为 m 的数组 rowCosts 和长度为 n 的数组 colCosts 。
r 行 的格子,那么代价为 rowCosts[r] 。c 列 的格子,那么代价为 colCosts[c] 。请你返回机器人回家需要的 最小总代价 。
示例 1:
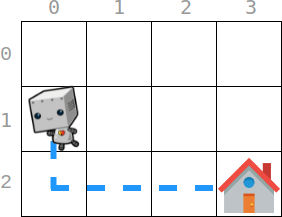
输入:startPos = [1, 0], homePos = [2, 3], rowCosts = [5, 4, 3], colCosts = [8, 2, 6, 7] 输出:18 解释:一个最优路径为: 从 (1, 0) 开始 -> 往下走到 (2, 0) 。代价为 rowCosts[2] = 3 。 -> 往右走到 (2, 1) 。代价为 colCosts[1] = 2 。 -> 往右走到 (2, 2) 。代价为 colCosts[2] = 6 。 -> 往右走到 (2, 3) 。代价为 colCosts[3] = 7 。 总代价为 3 + 2 + 6 + 7 = 18
示例 2:
输入:startPos = [0, 0], homePos = [0, 0], rowCosts = [5], colCosts = [26] 输出:0 解释:机器人已经在家了,所以不需要移动。总代价为 0 。
提示:
m == rowCosts.lengthn == colCosts.length1 <= m, n <= 1050 <= rowCosts[r], colCosts[c] <= 104startPos.length == 2homePos.length == 20 <= startrow, homerow < m0 <= startcol, homecol < n一看到题目第一感觉是用dp,但是我dp一点都没看过呀,觉得一定做不出来,遂准备放弃。突然灵光一闪,好像只要讨论四个方向的情况回家就行(以startPos为原点)😂
这里是以homePos坐标减去startPos坐标得到:
/**
* @param {number[]} startPos
* @param {number[]} homePos
* @param {number[]} rowCosts
* @param {number[]} colCosts
* @return {number}
*/
var minCost = function(startPos, homePos, rowCosts, colCosts) {
let res = 0;
if (startPos[0] === homePos[0] && startPos[1] === homePos[1]) {
return 0;
}
let row = homePos[0] - startPos[0]; // 行差
let col = homePos[1] - startPos[1]; // 列差
if (row >= 0 && col >= 0) {
for (let i = 0; i < row; i++) {
res += rowCosts[startPos[0] + i + 1];
}
for (let j = 0; j < col; j++) {
res += colCosts[startPos[1] + j + 1];
}
} else if (row >= 0 && col < 0) {
for (let i = 0; i < row; i++) {
res += rowCosts[startPos[0] + i + 1];
}
for (let j = 0; j < Math.abs(col); j++) {
res += colCosts[startPos[1] - j -1];
}
} else if (row < 0 && col >= 0) {
for (let i = 0; i < Math.abs(row); i++) {
res += rowCosts[startPos[0] - i - 1];
}
for (let j = 0; j < col; j++) {
res += colCosts[startPos[1] + j + 1];
}
} else {
for (let i = 0; i < Math.abs(row); i++) {
res += rowCosts[startPos[0] - i - 1];
}
for (let j = 0; j < Math.abs(col); j++) {
res += colCosts[startPos[1] - j -1];
}
}
return res;
};
思路:
例子:
机器人在[1,0]这个位置,家在[2,3]这个位置
计算出机器人在家的左上方,所以机器人需要向朝着回家的方向走,即
###java
class Solution {
public int minCost(int[] startPos, int[] homePos, int[] rowCosts, int[] colCosts) {
// 计算机器人到家的纵向和横向距离
int disX = startPos[0] - homePos[0]; // 纵向距离
int disY = startPos[1] - homePos[1]; // 横向距离
int ans = 0;
// 计算纵向距离的代价
if(disX < 0){
for(int i=startPos[0]+1;i<=homePos[0];i++){
ans += rowCosts[i];
}
}
else{
for(int i=startPos[0]-1;i>=homePos[0];i--){
ans += rowCosts[i];
}
}
// 计算横向距离的代价
if(disY < 0){
for(int j=startPos[1]+1;j<=homePos[1];j++){
ans += colCosts[j];
}
}
else{
for(int j=startPos[1]-1;j>=homePos[1];j--){
ans += colCosts[j];
}
}
return ans;
}
}
脑筋急转弯:由于题目保证代价均为非负数,所以除了径直走以外,其它弯弯绕绕的策略都不可能更优,那么直接统计径直走的代价即可。
设起点为 $(x_0,y_0)$,终点为 $(x_1,y_1)$。
分别计算上下移动的代价,左右移动的代价,二者之和就是总代价。
代码实现时,不需要根据 $x_0$ 和 $x_1$ 的大小关系分情况讨论,而是计算 $\textit{rowCosts}$ 的子数组 $[\min(x_0,x_1), \max(x_0,x_1)]$ 的元素和,再减去多算的起点代价 $\textit{rowCosts}[x_0]$。对于 $y_0$ 和 $y_1$ 同理。
class Solution:
def minCost(self, startPos: List[int], homePos: List[int], rowCosts: List[int], colCosts: List[int]) -> int:
x0, y0 = startPos
x1, y1 = homePos
# 起点的代价不计入,先减去
ans = -rowCosts[x0] - colCosts[y0]
# 累加代价(包含起点)
ans += sum(rowCosts[min(x0, x1): max(x0, x1) + 1])
ans += sum(colCosts[min(y0, y1): max(y0, y1) + 1])
return ans
class Solution {
public int minCost(int[] startPos, int[] homePos, int[] rowCosts, int[] colCosts) {
int x0 = startPos[0], y0 = startPos[1];
int x1 = homePos[0], y1 = homePos[1];
// 起点的代价不计入,先减去
int ans = -rowCosts[x0] - colCosts[y0];
// 累加代价(包含起点)
int l1 = Math.min(x0, x1), r1 = Math.max(x0, x1);
for (int i = l1; i <= r1; i++) {
ans += rowCosts[i];
}
int l2 = Math.min(y0, y1), r2 = Math.max(y0, y1);
for (int i = l2; i <= r2; i++) {
ans += colCosts[i];
}
return ans;
}
}
class Solution {
public:
int minCost(vector<int>& startPos, vector<int>& homePos, vector<int>& rowCosts, vector<int>& colCosts) {
int x0 = startPos[0], y0 = startPos[1];
int x1 = homePos[0], y1 = homePos[1];
// 起点的代价不计入,先减去
int ans = -rowCosts[x0] - colCosts[y0];
// 累加代价(包含起点)
ans += reduce(rowCosts.begin() + min(x0, x1), rowCosts.begin() + max(x0, x1) + 1, 0);
ans += reduce(colCosts.begin() + min(y0, y1), colCosts.begin() + max(y0, y1) + 1, 0);
return ans;
}
};
#define MIN(a, b) ((b) < (a) ? (b) : (a))
#define MAX(a, b) ((b) > (a) ? (b) : (a))
int minCost(int* startPos, int startPosSize, int* homePos, int homePosSize, int* rowCosts, int rowCostsSize, int* colCosts, int colCostsSize) {
int x0 = startPos[0], y0 = startPos[1];
int x1 = homePos[0], y1 = homePos[1];
// 起点的代价不计入,先减去
int ans = -rowCosts[x0] - colCosts[y0];
// 累加代价(包含起点)
int l1 = MIN(x0, x1), r1 = MAX(x0, x1);
for (int i = l1; i <= r1; i++) {
ans += rowCosts[i];
}
int l2 = MIN(y0, y1), r2 = MAX(y0, y1);
for (int i = l2; i <= r2; i++) {
ans += colCosts[i];
}
return ans;
}
func minCost(startPos, homePos, rowCosts, colCosts []int) int {
x0, y0 := startPos[0], startPos[1]
x1, y1 := homePos[0], homePos[1]
// 起点的代价不计入,先减去
ans := -rowCosts[x0] - colCosts[y0]
// 累加代价(包含起点)
for _, cost := range rowCosts[min(x0, x1) : max(x0, x1)+1] {
ans += cost
}
for _, cost := range colCosts[min(y0, y1) : max(y0, y1)+1] {
ans += cost
}
return ans
}
var minCost = function(startPos, homePos, rowCosts, colCosts) {
const [x0, y0] = startPos;
const [x1, y1] = homePos;
// 起点的代价不计入,先减去
let ans = -rowCosts[x0] - colCosts[y0];
// 累加代价(包含起点)
ans += _.sum(rowCosts.slice(Math.min(x0, x1), Math.max(x0, x1) + 1));
ans += _.sum(colCosts.slice(Math.min(y0, y1), Math.max(y0, y1) + 1));
return ans;
};
impl Solution {
pub fn min_cost(start_pos: Vec<i32>, home_pos: Vec<i32>, row_costs: Vec<i32>, col_costs: Vec<i32>) -> i32 {
let x0 = start_pos[0] as usize;
let y0 = start_pos[1] as usize;
let x1 = home_pos[0] as usize;
let y1 = home_pos[1] as usize;
// 起点的代价不计入,先减去
let mut ans = -row_costs[x0] - col_costs[y0];
// 累加代价(包含起点)
ans += row_costs[x0.min(x1)..=x0.max(x1)].iter().sum::<i32>();
ans += col_costs[y0.min(y1)..=y0.max(y1)].iter().sum::<i32>();
ans
}
}
本题是图论中的最短路问题。在有负数边权的情况下,可以用 Bellman-Ford 算法解决。需要注意的是,如果有负环,则最小代价为 $-\infty$。
见下面贪心与思维题单的「§5.2 脑筋急转弯」。
欢迎关注 B站@灵茶山艾府
国家地名信息库链接: dmfw.mca.gov.cn
接口服务文档:dmfw.mca.gov.cn/interface.h…
正常程序中使用时,将数据缓存起来存入文件或者数据库,比调用接口更稳定。
//直接在浏览器控制台执行,可以测试接口结果
/* 接口说明
code不填时获取省级,填了时获取对应的区划和下级数据
maxLevel=1只获取一级数据 maxLevel=2获取两级数据 maxLevel=3获取三级数据
*/
//获取全国省市区三级,将近300KB数据接口会比较慢
var response=await fetch("https://dmfw.mca.gov.cn/9095/xzqh/getList?code=&maxLevel=3");
var data=await response.json();
console.log(data);
//只获取获取省级数据,速度比较快
var response=await fetch("https://dmfw.mca.gov.cn/9095/xzqh/getList?code=&maxLevel=1");
var data=await response.json();
console.log(data);
//获取湖北省 省、市、区 三级
var response=await fetch("https://dmfw.mca.gov.cn/9095/xzqh/getList?code=420000000000&maxLevel=3");
var data=await response.json();
console.log(data);
//获取武汉市 市、区县、乡镇街道 三级
var response=await fetch("https://dmfw.mca.gov.cn/9095/xzqh/getList?code=420100000000&maxLevel=3");
var data=await response.json();
console.log(data);
注意:当直接获取省市区三级数据时,以下城市只有两级:
其他省市都有三级结构。
统计局自2024年下半年起就不再公开统计用区划代码,改用国家地名信息库数据。
民政部公告相关链接:www.mca.gov.cn/n156/n186/i…
摘自民政部的公告:自2026年起,本栏目不再公布行政区划代码相关信息。请前往民政部门户网站首页的国家地名信息库版块查询相关信息。
已整合的开源库:github.com/xiangyuecn/…
开源库:已将四级数据整合到了单个csv文件中,同时提供标注拼音、坐标和四级边界范围。提供工具生成多级联动数据和代码,也支持将数据导入MySQL、MSSQL、PgSQL、Oracle等数据库中
【2026-04-03】国家地名信息库行政区划数据截止日期为2025年12月31日。
✨文章摘要(AI生成)
笔者分享了将 Harness Engineering 知识提炼为可复用 Agent Skill 的经验。在系统阅读了 Anthropic、OpenAI、Martin Fowler、LangChain 等来源的文章后,提炼出 Harness 设计的七个核心层:项目搭建、上下文工程、约束与防护、多 Agent 架构、评估与反馈、长时间任务、诊断。最终产出的 harness-engineering 技能覆盖三大场景——新项目搭建、Agent 行为诊断、持续改进,采用渐进式披露架构。定量评估显示有技能时断言通过率 100%,无技能时 83%。核心洞察:Agent 表现不好,80% 的原因不在模型,在 Harness。
最近两年,笔者在使用各种AI编码助手(Claude Code、Cursor、Copilot等)的过程中,反复遇到一个问题:Agent时好时坏,虽然整体来说随着模型能力进步是向好的,但是向好的过程是曲折波动的。
有时候它写的代码完美契合项目风格,有时候它像个第一天入职的实习生——不知道项目结构、不遵守约定、还把之前商量好的决策忘得一干二净。
然后开始从 Prompt Engineering 中使用结构化、few shot、few example 等技巧,来让 AI 的输出更加稳定。 后面又使用 Context Engineering 来让 Agent 的上下文更加丰富,来让 Agent 的表现更加稳定。
最近几周,一个更系统的词汇出现了:Harness Engineering。
Agent表现不好,80%的原因不在模型,在Harness。 - Anthropic
什么是Harness?简单说:
你不会指望一个CPU在没有操作系统的裸机上高效运行。同理,你也不该指望一个模型在没有Harness的项目里稳定输出。
笔者系统阅读了以下来源的文章:
读完之后,我发现这些文章虽然角度各异,但核心思想收敛到了七个层:
| 层级 | 解决什么问题 | 一句话总结 |
|---|---|---|
| 项目搭建 | Agent不知道项目是什么 | AGENTS.md是目录,不是百科全书 |
| 上下文工程 | Agent看到的信息不对 | 给地图,不给手册 |
| 约束与防护 | Agent犯重复的错 | 每犯一次错,加一条规则 |
| 多Agent架构 | 单Agent搞不定复杂任务 | 分工明确,协议清晰 |
| 评估与反馈 | 不知道Agent做得好不好 | 让AI检查AI |
| 长时间任务 | Agent跑着跑着就走偏了 | 进度文件 + 上下文重置 |
| 诊断 | 用户骂Agent不好用 | 问题在Harness,不在模型 |
读完这些文章,笔者意识到这些模式完全是可复用的。不管你的项目是React前端、Python后端还是Rust CLI工具——Harness的设计原则是通用的。
于是我把这些知识提炼成了一个 Agent Skill,名叫 harness-engineering。
这个技能有三个核心使用场景:
场景一:新项目搭建
当你启动一个新项目,告诉Agent"帮我搭建Harness工程",它会:
AGENTS.md(表of目录式的Agent导航文件)docs/ 目录(架构、约定、数据模型等)场景二:Agent表现不佳时的诊断
这是最有意思的场景。当你开始抱怨——
这个技能会被触发,引导Agent去诊断Harness层的缺失,而不是怪模型:
| 你的抱怨 | 大概率原因 | 修复方式 |
|---|---|---|
| 总犯同一个错 | 没有约束阻止它 | 加一条lint规则 |
| 不遵守约定 | 约定没写下来或Agent找不到 | 写入docs/,在AGENTS.md中引用 |
| 忘记之前的决定 | 跨会话上下文未持久化 | 用progress.md记录决策 |
| 代码质量差 | 没有好代码的示例 | 在DESIGN_NOTES.md中加示例 |
场景三:持续改进
每次发现新的可复用Harness模式,更新到技能中,让它在其他项目中也能受益。
技能采用渐进式加载架构:
harness-engineering/
├── SKILL.md # 入口文件(<60行),路由到具体参考文档
└── references/
├── 01-project-setup.md # 项目搭建
├── 02-context-engineering.md # 上下文工程
├── 03-constraints.md # 约束与防护
├── 04-multi-agent.md # 多Agent架构
├── 05-eval-feedback.md # 评估与反馈
├── 06-long-running.md # 长时间任务
└── 07-diagnosis.md # 诊断
SKILL.md本身非常精简——它就像一个路由器,根据当前场景指引Agent去读对应的参考文档。这遵循了Harness Engineering本身的原则:渐进式披露,按需加载。
有几个模式特别触动笔者,感同身受,这里单独拿出来聊聊。
这个观点从推文中看到。传统做法是给Agent写详细的分步指令(手册),但这让Agent变得脆弱——任何偏差都会导致它不知所措。
更好的做法是给Agent一张地图:
# 不好的写法(手册)
Step 1: 打开 src/auth/login.ts
Step 2: 找到 handleLogin 函数
Step 3: 在第42行添加...
# 好的写法(地图)
Auth系统在 src/auth/。登录流程:login.ts → validate.ts → session.ts。
限流中间件在 src/middleware/rateLimit.ts——参考它的模式。
每次修改auth都要在 src/auth/__tests__/ 里加测试。
地图让Agent能自主导航,手册让它成为脆弱的执行机器。
这个模式来自多篇文章的交叉验证。核心思想:
这条规则可以是lint规则、类型约束、测试用例,或者只是文档中的一条约定。随着时间推移,Harness积累了越来越多的规则,Agent的错误率对已知模式趋近于零。
这其实就是Martin Fowler说的 "Relocating Rigor"——把人类通过Code Review、经验、直觉实施的质量把关,迁移到自动化检查中。Agent在被检查的边界内自由运行。
这个观点来自Anthropic。每次Agent交互都是一个训练信号:
这些痕迹(traces)就是你的竞争优势。它们是让你的Harness随时间越来越好的数据——不是微调模型,而是优化操作系统。
笔者遵循skill-creator的流程,对这个技能做了定量评估。设计了3组测试场景,每组跑with-skill和without-skill两个版本:
| 测试场景 | 有技能 | 无技能 |
|---|---|---|
| 新项目搭建 | 6/6 ✅ | 4/6 |
| Agent行为诊断 | 6/6 ✅ | 5/6 |
| 跨模块依赖问题 | 6/6 ✅ | 6/6 |
| 合计 | 18/18 (100%) | 15/18 (83%) |
有技能的版本在所有场景下都通过了全部断言。无技能的版本在"新项目搭建"场景下缺失较多——它不知道要创建AGENTS.md、不知道docs/应该怎么组织、不会设置渐进式披露的上下文架构。
当然,17%的差距不算巨大。但关键是:有技能时Agent的输出一致且完整,无技能时看运气。对于一个工程实践类技能来说,一致性比偶尔的惊艳更有价值。
这个技能可通过 GitHub 安装:
npx skills add 10xChengTu/harness-engineering
安装后,当你在Claude Code、OpenCode或其他支持Skills的Agent中工作时:
Harness Engineering目前还是一个非常早期的领域。模型在变强,今天需要的约束明天可能就多余了——所以这个技能本身也遵循一个核心原则:为删除而构建。
如果你也在用AI Agent做开发,不妨试试给你的项目加上Harness。从最简单的开始——一个AGENTS.md文件、几条lint规则、一个progress.md。然后观察Agent的表现变化。
你大概率会和笔者有同样的感受:不是模型不行,是我们没给它一个好的工作环境。
本文涉及的所有参考文章和完整技能源码,均可在GitHub 仓库中找到。
Debian 13, codenamed “Trixie”, was released on August 9, 2025. It ships with Linux kernel 6.12 LTS, GNOME 48, KDE Plasma 6, GCC 14.2, Python 3.13, and over 14,100 new packages. Debian 13 will receive full support until August 2028, with Long Term Support (LTS) extending to June 2030.
This guide walks you through upgrading Debian 12 “Bookworm” to Debian 13 “Trixie” via the command line.
You need to be logged in as root or a user with sudo privileges to perform the upgrade. You can only upgrade to Debian 13 from Debian 12. If you are running an older Debian version, upgrade to Debian 12 first.
Before starting a major version upgrade, make sure you have a complete backup of your data. If you are running Debian on a virtual machine, take a full system snapshot so you can restore quickly if anything goes wrong.
Before changing the source repositories, bring your existing Debian 12 system fully up to date.
Check whether any packages are marked as held back, which could interfere with the upgrade:
sudo apt-mark showholdIf there are held packages, either unhold them with sudo apt-mark unhold package_name or make sure they will not cause issues during the upgrade.
Refresh the package index and upgrade all installed packages:
sudo apt update
sudo apt upgradePerform a major version upgrade of the installed packages:
sudo apt full-upgradeRemove automatically installed dependencies that are no longer needed:
sudo apt autoremoveThe upgrade works by pointing your APT repositories from bookworm to trixie.
Open /etc/apt/sources.list with your text editor
and replace every instance of bookworm with trixie. You can also do this with a single sed
command:
sudo sed -i 's/bookworm/trixie/g' /etc/apt/sources.listIf you have third-party repository files under /etc/apt/sources.list.d/, disable them before the upgrade. They may not be compatible with Debian 13 and can cause errors.
bookworm-backports entries from your sources files before upgrading. You can add trixie-backports after the upgrade is complete.After editing, your /etc/apt/sources.list should look similar to this:
deb https://deb.debian.org/debian/ trixie main contrib non-free non-free-firmware
# deb-src https://deb.debian.org/debian/ trixie main contrib non-free non-free-firmware
deb https://deb.debian.org/debian/ trixie-updates main contrib non-free non-free-firmware
# deb-src https://deb.debian.org/debian/ trixie-updates main contrib non-free non-free-firmware
deb https://security.debian.org/debian-security/ trixie-security main contrib non-free non-free-firmware
# deb-src https://security.debian.org/debian-security/ trixie-security main contrib non-free non-free-firmwareYou can find a full list of Debian mirror addresses on the official mirrors page .
Set the terminal output to English to make it easier to follow any prompts:
export LC_ALL=CUpdate the package index with the new Trixie repositories:
sudo apt updateIf you see errors related to third-party repositories, fix or disable them before continuing.
Run the initial upgrade. This upgrades packages that do not require installing or removing other packages:
sudo apt upgrade --without-new-pkgsDuring the upgrade, you may be asked whether services should be automatically restarted:
Restart services during package upgrades without asking?You may also see prompts about configuration files. If you have not made custom changes to a file, it is safe to accept the package maintainer’s version. If you have made changes, keep the current version to avoid losing your customizations.
Once the initial upgrade finishes, run the full upgrade. This installs new packages, removes obsolete ones, and resolves any remaining dependency changes between Debian 12 and 13:
sudo apt full-upgradeThe upgrade may take some time depending on the number of packages, your hardware, and your internet speed.
When it completes, clean up packages that are no longer needed:
sudo apt autoremoveReboot your system to load the new kernel:
sudo systemctl rebootAfter the system boots, log in and check the Debian version :
lsb_release -aNo LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 13 (trixie)
Release: 13
Codename: trixieYou can also verify the kernel version:
uname -rThe output should show a 6.12.x kernel.
Third-party repository errors during apt update
Disable any third-party sources under /etc/apt/sources.list.d/ before the upgrade. Re-enable them one by one after the upgrade completes, checking that each repository supports Debian 13.
“Packages have been kept back” during upgrade
This is normal during the initial apt upgrade --without-new-pkgs step. The subsequent apt full-upgrade resolves these held-back packages by installing new dependencies or removing conflicting ones.
Services fail to start after reboot
Check the service logs with journalctl -xe and the service status with systemctl status service_name. Configuration file format changes between major versions are a common cause. Compare your config with the package maintainer’s version in /etc/*.dpkg-dist files.
Your system is now running Debian 13 Trixie. Re-enable any third-party repositories you disabled, verify that your critical services are running, and consider adding trixie-backports to your sources if you need newer package versions. For a full list of known issues and detailed upgrade notes, see the official Debian 13 release notes
.

 相关阅读:
相关阅读: