大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于 Tiptap 的富文本编辑、NestJS 后端服务、实时协作与智能化工作流等核心模块。
在这个项目的持续打磨过程中,我积累了不少实战经验,不只是 Tiptap 的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。
如果你对 AI 全栈开发、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信 yunmz777 一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐

企业级前端工程化的本质,是把"人肉重复、靠经验兜底"的开发方式,收敛成可复用、可度量、可演进的一套体系。从零搭建前端时,先想清楚要解决什么、要什么结果,再选工具和流程,会少走很多弯路。
工程化主要针对三类问题:

把这三块从"人治"变成"机制",工程化才算真正落地。
落到团队层面,能带来几件事。流程上,标准化、能自动化的尽量自动化,关键环节可以借 AI 提效,结果上,开发成本下来、迭代速度上去,代码质量和可维护性提高,bug 和线上风险更容易被提前拦住。这些都不是单点工具能完成的,需要从需求到上线的整条链路一起设计。
接下来我们按常见阶段展开,依次是需求与规范、开发与联调、测试与优化、构建与部署、运维与监控。每个阶段会写目标、推荐流程、常用工具、典型场景,以及适合用 AI 或自动化做得更好的地方。
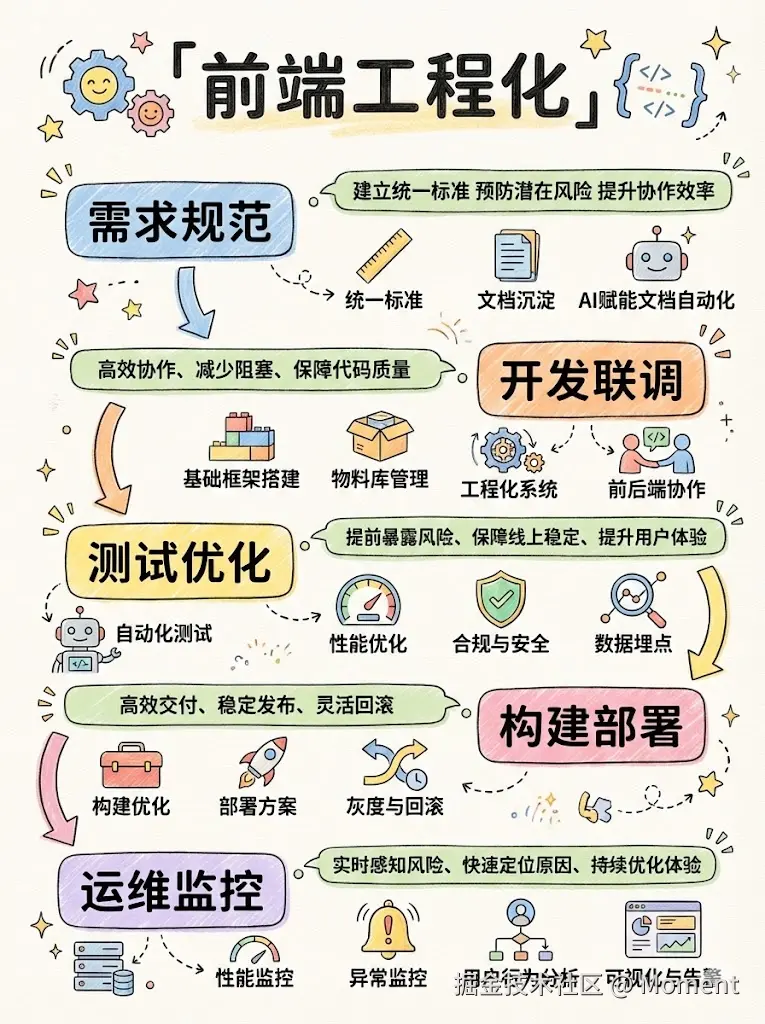
前端工程化总览
整条链路可以概括为五个阶段,从需求规范到运维监控依次串联。整体追求三个结果,稳(高可用、可回滚)、快(敏捷交付、自动化流水线)、省(低成本工具链、资源复用),下面用一张流程图把阶段关系画清楚。

各阶段侧重不同。需求规范阶段重在建立统一标准、预防潜在风险、提升协作效率,常见动作包括需求与接口规范、文档沉淀与知识库、以及用 AI 做文档自动化。开发联调阶段和测试优化阶段共同指向高效协作、减少阻塞、保障代码质量,前者覆盖基础框架与脚手架、组件与物料库管理、工程化工具链、前后端接口联调与 Mock,后者覆盖单元与 E2E 自动化测试、性能与体积优化、合规与安全扫描、埋点与数据上报。构建部署阶段和运维监控阶段则共同强调高效交付、稳定发布、灵活回滚,构建部署侧重构建与打包优化、CI/CD 部署方案、灰度发布与一键回滚,运维监控侧重性能与可用性监控、异常与错误追踪、用户行为与转化分析、大屏可视化与告警,目标是实时感知风险、快速定位原因、持续优化体验。
下图是同一套阶段与目标的示意,便于对照查阅。
需求规范阶段
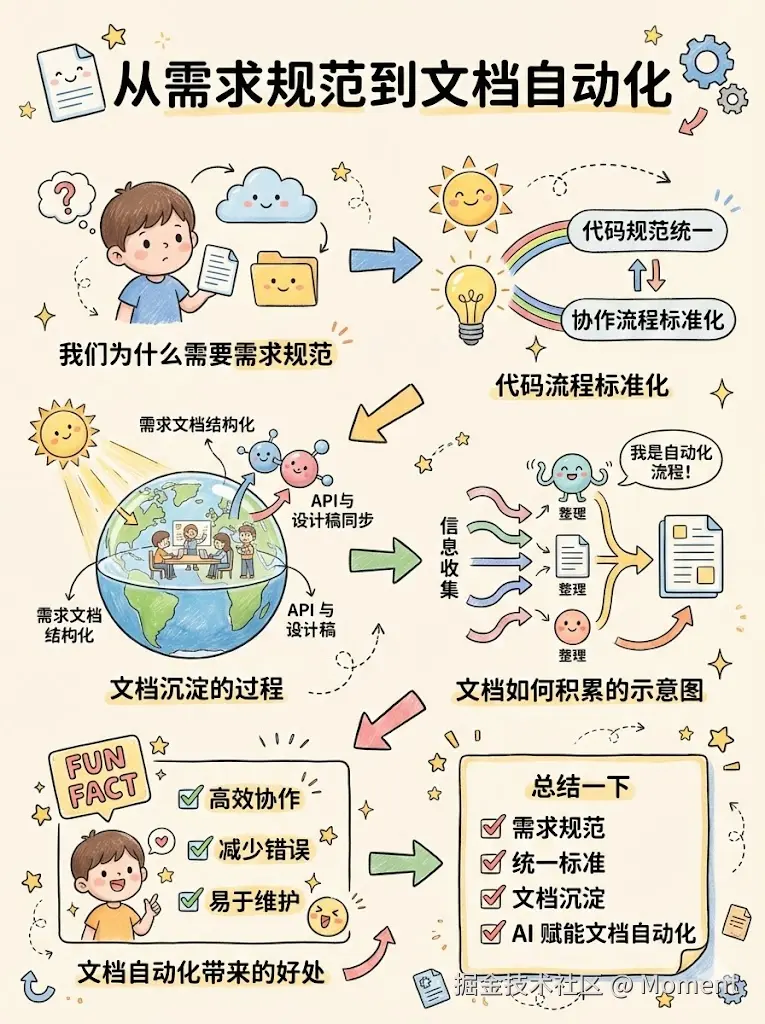
需求规范阶段是整条链路的起点。先把这一步打牢,后面的开发联调、测试优化才不会一路踩坑。这里要做的事,本质上是把团队里各自为战的习惯和经验,沉淀成一套大家都认可的统一标准,既预防潜在风险,又减少日常协作里的摩擦。为了方便梳理,可以把这一阶段拆成三块,对应代码与接口、文档与知识库,以及用 AI 做文档自动化。
下图是这一阶段的手绘示意,可以当作后文三小节的导航来对照着看。
需求与接口规范
落到开发这侧,最直观的感受就是,大家写出来的代码和提交流程要像是一个团队,而不是各写各的。第一步是把代码规范和协作流程统一,用一套约定来消除协作摩擦。代码这一块,可以用 ESLint、Prettier 配合 Husky 去强制约束代码风格,缩进、命名这些细节交给工具,提交前自动跑一遍,不通过就推不上去,讨论就能更多回到设计和实现本身。
协作流程方面,建议一开始就说清楚 Git 分支策略(例如简化版 Git Flow)和 Commit 信息格式,例如用 Commitizen 这样的工具来规范提交说明。久而久之,提交历史会变成一本可以查账的项目日记,谁在什么时间、因为什么调整了哪些代码,一目了然。
这里有两类问题,最好在一开始就通过规范挡住。一类是随手写 fix bug、update 这类没有信息量的提交信息,事后谁也看不出当时改动的动机。另一类是没经过 Code Review 就把改动直接合进主分支,质量风险一路带到线上。有些团队会要求,所有人都基于 master 拉分支开发,在 test、uat、release 这些共享环境分支以及 master 上都禁止直接 push,只能通过合并请求进入,这样一旦出问题,也能顺着合并记录快速定位到具体改动。
文档沉淀与知识库
文档沉淀这块,目标是打破信息孤岛,让新人靠看文档也能尽量还原当时的需求背景和取舍过程。需求如果只散落在聊天记录里,过一阵子连原作者自己都很难说清楚当时为什么要这么定。比较实用的做法,是用语雀、飞书文档把业务需求拆成技术方案,把功能边界和验收标准写清楚,再准备一套固定的需求文档模板,背景、原型、接口定义这些模块都预留好位置,后面类似需求直接套用,既省事又不容易漏。
接口和设计的配合,同样可以通过工具来固化。可以用 Apifox 维护接口文档,后端接口还没完全就绪时,前端先基于 Mock 数据开发,不必干等。与此同时,联动 Figma、即时设计这类工具里的设计稿标注,让 API 与设计稿保持同步,很多本来要靠口头解释的细节,直接在文档和设计稿里就能对齐。
AI 赋能文档自动化
如果完全手写,一份中等复杂度的技术文档,往往要花上两到四个小时,写着写着还容易走神。现在可以把这种重复性工作交给 AI。例如用 Writely(飞书 AI),输入 PRD 里的关键词(例如"用户管理系统"),让它先生成一份大致合理的技术文档目录和示例代码片段,你再根据实际业务补充细节、删掉不适用的部分。
实际体验下来,传统纯手写从零到一可能要两到四个小时,而让 AI 先搭好骨架、再人工完善,大多数情况下半小时左右就能收工。这样的方式尤其适合需求说明、接口说明、技术方案骨架这类重复度很高的文档,一方面整体结构更统一,另一方面也把时间留给那些必须由人来判断的业务决策和权衡。
开发联调阶段
开发联调阶段是前端工程化真正动手写代码、跑起来的那一段,目标很清晰,就是高效协作、减少阻塞、保障代码质量,让前后端和设计之间尽量无缝衔接。下面按基础框架、物料复用、工程化流水线、前后端协作四块来说,最后补几条联调时容易踩的坑。
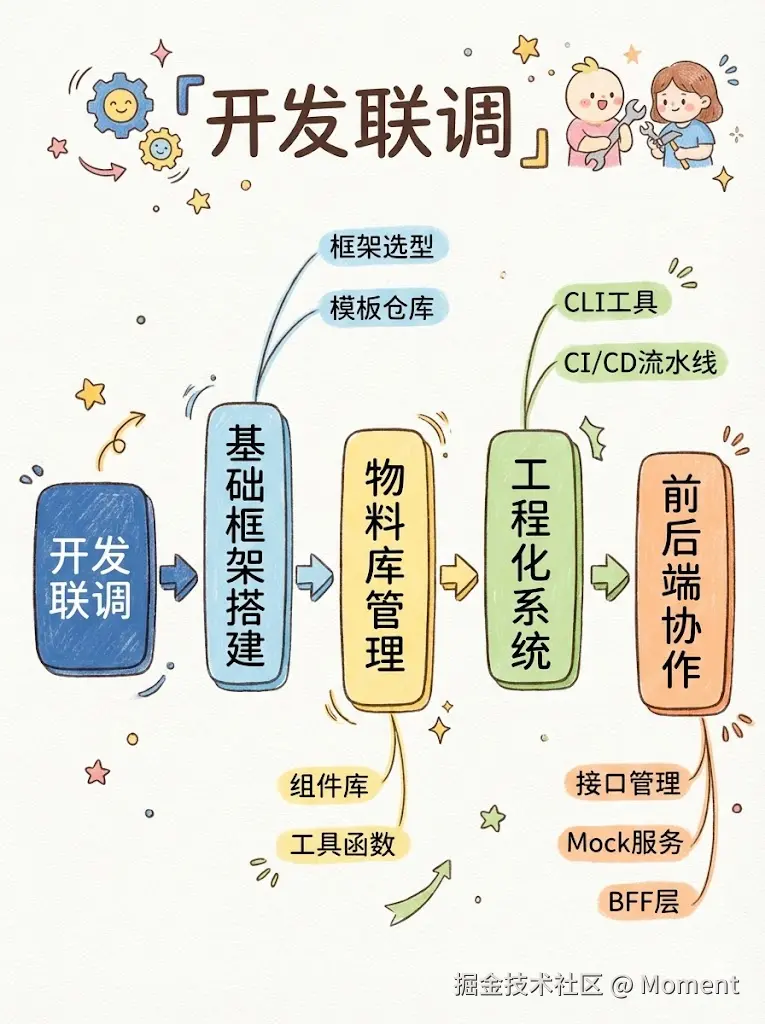
基础框架搭建
框架选型决定了团队未来几年的技术底座,选好了能少踩很多坑。轻量一点、迭代快的项目,可以用 Vue 3 或 React 配 Vite,开发体验好、上手也快,Vite 后续会集成 Rust 实现的 Rolldown,生产构建会更快。业务比较复杂、偏中后台或需要 SSR 的,可以看 Next.js、Rsbuild 等,Next.js 开发环境已支持 Turbopack,大仓冷启和 HMR 更猛。超大体量或需要兼容现有 Webpack 生态的,可以看 Rust 系的 Rspack。运行时除了 Node.js,也可按需选 Bun 做脚本和工具链。要是还有小程序、H5 等多端需求,可以看 Taro、Uni-App 这类跨端方案,一套代码多端跑。
选完框架,最好再准备一套模板仓库,新项目直接基于模板拉,而不是每次从零配。例如预置好 ESLint、Prettier 的脚手架,或者用 Next.js、Rsbuild 等自带的脚手架快速生成项目,再按需加权限、数据流等。如果团队里会有多个应用、共享组件库或公共包需要一起维护,可以提前考虑是否采用 Monorepo 架构(例如用 pnpm workspace、Turborepo、Nx 等),把多包放在一个仓库里统一依赖和构建,能减少后期拆仓、版本对齐的折腾。这一步也可以交给 AI 省时间,例如在 Cursor 里输入"创建 NextJs + TypeScript 项目",让它生成基础配置。
物料库管理
组件、工具函数、页面模板如果能复用,重复开发会少很多。有条件的团队会做企业自研组件库,常见两条路。一条是在 Ant Design、Element Plus 这类开源组件库上做二次封装,贴合自家业务和设计规范,再用 Bit 这类工具管理组件版本和依赖,甚至支持私有化部署。
另一条是,如果团队已经在用 Tailwind CSS,并且用过 shadcn/ui 这类"拷贝即用"的组件方案,可以在现有基础上做二开,例如统一品牌色、间距和圆角等设计 token,把常用变体收拢成团队约定,再补一份内部文档(哪些组件可直接用、哪些改过、使用示例和注意事项),这样既保留 Tailwind 的灵活度,又有一致的设计和可维护的物料沉淀。Tailwind CSS v4 已发布,构建更快、配置更简单,新项目可以直接上 v4。工具函数这块,用 lodash、dayjs 等成熟库即可,不必自己造。
AI 在这块也能帮上忙。例如即时 AI 可以把 Figma 设计稿转成 Vue、React 组件代码,减少从设计到代码的重复劳动。CodeGeeX 可以根据组件的 Props 描述自动生成单元测试用例。当然,小团队或小公司不一定要自建组件库和物料体系,先把业务跑稳、再按需沉淀组件和模板,会更现实。
工程化系统
工程化系统说白了就是通过工具链把创建项目、检查、构建、部署串成一条流水线,减少人工操作。创建项目阶段,现在普遍用 Vite 创建 Vue、React 项目(create-vite 或各框架官方模板),或用 Next.js 自带的脚手架起手,预置好规范与配置即可。到了持续集成和部署,可以用 GitHub Actions、GitLab CI 在提交后自动跑代码检查、构建和部署,或者用 Jenkins 做更复杂的多环境流水线。如果希望需求、开发、部署都在一个平台里完成,可以选阿里云效这类一站式 DevOps 平台,功能全、上手相对简单,也支持私有化部署,不少团队的实际项目就是用云效搭的流水线。
前后端协作
前后端联调最容易出问题的地方,往往是接口约定不一致、文档滞后、环境对不齐。接口文档建议用 Apifox、Apidog 这类工具维护,支持 OpenAPI 规范、自动 Mock 和接口测试。很多平台还能根据接口文档自动生成前端的请求代码和 TypeScript 类型,文档一改、类型跟着变,减少手写接口定义。后端接口还没好时,前端可以先用 Mock.js、Faker.js 生成贴近真实的测试数据,或者用 MSW(Mock Service Worker)在浏览器层做请求拦截,配合 TypeScript 做类型安全的 Mock,适合单测和本地联调。全栈都是 TypeScript 的项目,还可以考虑 tRPC 或更轻量的 Hono RPC,前后端共享类型定义,服务端改接口、客户端立刻有类型提示,无需单独维护一份接口文档和类型。Hono RPC 用 hc 客户端加 Zod 校验即可实现类型安全,适合前后端同仓或协作紧密的团队。
当接口多了、前端需要聚合多个接口或按需拉字段时,可以加一层 BFF(Backend For Frontend),用 Node.js 中间层(例如 NestJS、Midway.js、Express)聚合多接口,或者用 GraphQL(如 Apollo Server)让前端按需定制响应字段。BFF 可以由后端团队维护,也可以由前端团队自建,实现真正的接口层解耦。
接口文档若能通过统一协议进到开发环境里,前后端对接会轻松很多。可以把后端的 OpenAPI 规范用 MCP(Model Context Protocol)暴露出来,例如用 OpenAPI MCP Server 把接口定义转成 MCP 的 tools、resources,在 Cursor、VS Code 等 IDE 里配置好 MCP 后,就能在写代码时直接读到最新接口文档、让 AI 按文档生成请求代码或类型,避免文档和实现脱节。
阿里云、腾讯云等也有 OpenAPI MCP Server,适合把云产品 API 接到 IDE。自建后端可以用 @reapi/mcp-openapi、FastMCP 的 from_openapi() 等从 OpenAPI 规范生成 MCP 服务,前后端共用同一份文档,联调时接口变更能更快同步到前端。
AI 也能参与进来,例如 Apifox 的 AI 可以根据接口文档自动生成 Mock 规则和测试用例,CodeGeeX 可以根据现有 RESTful 接口生成一层 GraphQL 包装代码,减少手写胶水代码。
联调时还有几点值得注意。一是接口变更要及时同步,用 Apifox 这类工具把最新接口定义推给前端,或通过 OpenAPI 自动生成类型,避免文档和实现各说各的。二是开发、测试、生产环境要隔离,用 .env.development、.env.production 等把配置拆开,别在本地写死生产地址。三是依赖版本要锁死,用 pnpm 等包管理器严格锁定依赖,能少很多"在我机器上是好的"这类问题。
测试优化阶段
测试优化阶段的目标很明确,就是提前暴露风险、保障线上稳定、提升用户体验,用分层测试把核心场景兜住,减少漏测和线上事故。从人工点点点到自动化、再配合 AI 生成用例,测试效率会明显上去。
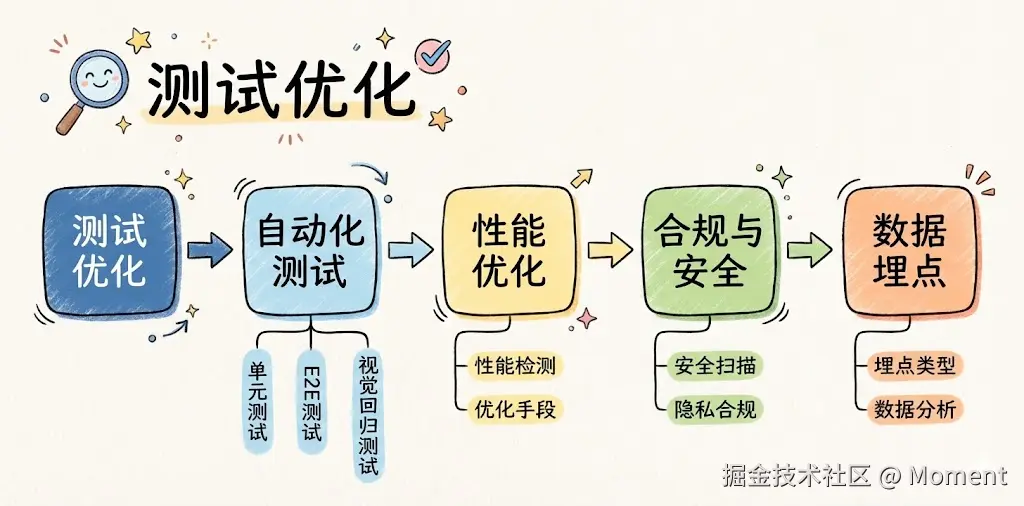
自动化测试
建议按单元测试、E2E、视觉回归三层建体系,而不是一上来就全押 E2E。单元测试负责验证组件逻辑和工具函数,用 Jest 或 Vitest 配 React Testing Library 即可,Vitest 与 Vite 同源、冷启和 HMR 更快,适合在每次提交时跑。组件层若要在真实浏览器里跑,可用 Vitest 的 Browser Mode 配 Playwright 驱动。例如下面这段,用 render 渲染按钮组件、screen.getByRole 找到按钮并模拟点击,再断言传入的 onClick 被调用了一次,用来保证点击回调不会丢。
test("Button 点击触发事件", async () => {
const handleClick = vi.fn<[], void>();
render(<MyButton onClick={handleClick} />);
await userEvent.click(screen.getByRole("button"));
expect(handleClick).toHaveBeenCalledTimes(1);
});
E2E 测试覆盖真实用户路径,在浏览器里跑完整流程。Playwright 支持 Chromium、WebKit、Firefox 多端,自带录制回放,适合做跨浏览器回归。Cypress 的可视化调试和时间旅行对复杂交互(例如购物车、多步表单)很友好,按团队习惯二选一或搭配用即可。
视觉回归测试解决的是"功能没坏、但界面悄悄变了"的问题。改了一处样式或依赖升级导致组件渲染异常,单测和 E2E 不一定能发现,视觉回归通过对比页面或组件的截图,先拍一份基准快照,后续每次跑用例时再拍一张,和基准做像素或区域对比,有差异就报出来,由人确认是预期改动还是误伤。可以用 BackstopJS 在本地或 CI 里跑,配置好要截的 URL 或组件,生成基准后纳入版本管理,以后每次 PR 自动跑一遍对比。组件库或设计系统也可以用 Chromatic、Percy 这类托管服务,和 Storybook 结合,每个 Story 自动做视觉回归。适合对 UI 稳定性要求高的首页、关键流程页和公共组件,基准图多了之后要注意维护,避免无关改动带来大量噪点。
AI 也能参与测试用例的生成和验证。一类是依据行为数据生成脚本,例如 Testin AI 分析用户行为日志,把高频操作转成 E2E 用例,先覆盖核心路径再补边缘场景。另一类是让 AI 直接连上真实浏览器做调试和验证,例如 Chrome 官方的 Chrome DevTools MCP,在 Cursor、Claude 等里配置好 MCP 后,AI 可以调 DevTools 能力做性能追踪、网络与 Console 排查、DOM 与样式检查、表单与用户行为模拟,并在浏览器里实时验证改动的效果,相当于"边写代码边在真机里跑一遍"。和 Playwright MCP 搭配时,Playwright 负责 UI 自动化与用例执行,DevTools MCP 补足性能与运行时观测,适合做智能回归和 Core Web Vitals 等自动化检查。
性能优化
测试通过之后,还要保证页面秒开、交互不卡。可以给自己定一个简单目标,例如首屏可交互 FCP 控制在 1.5 秒内、首次输入延迟 FID 在 100ms 以内。性能检测方面,用 Lighthouse CI 把跑分集成进 CI 流水线,分数低于阈值(例如 90)就拦掉合并,避免性能劣化代码进主干。真实用户数据用 Google Analytics 4 或阿里云 ARMS 采集 Web Vitals,看线上实际表现而不是只看本机。
优化手段按资源、代码、分发来拆。资源上,构建阶段自动压缩图片,例如用 vite-plugin-imagemin 在打包时处理;代码上,用 React.lazy 配 Suspense 做路由级懒加载,首屏只拉当前路由需要的 chunk。分发上,静态资源扔到阿里云 OSS 再挂 CDN,利用全球节点做加速。AI 也能参与,例如阿里云 ARMS 的智能诊断会根据性能数据推荐优化项(如未压缩图片列表),部分构建工具已支持基于预测的 Tree Shaking 策略,进一步剔除无效代码。
合规与安全
合规与安全要从代码和数据两头抓,避免法律风险和用户隐私问题。代码侧,用 SonarQube 做静态扫描,揪出 XSS、SQL 注入等常见漏洞。依赖侧,用阿里云安全中心等扫描已知漏洞(例如 Log4j、老旧版本的 lodash),有风险就升级或替换。隐私合规方面,用腾讯云合规助手这类工具检查隐私政策是否满足 GDPR、个保法等要求。日志里对手机号、身份证号等做脱敏,例如通过 log4js 等插件的过滤规则自动打码,避免敏感数据落盘。
AI 可以辅助安全扫描,例如用大模型扫描代码里的敏感信息(如硬编码的 API 密钥)。部分 AI 代码助手能自动把不安全写法替换成更安全的实现(如将 eval 改为 Function),适合在 Code Review 前跑一遍。
数据埋点
埋点做得好,产品迭代才有数据支撑,否则容易变成"盲人摸象"。埋点大致分无埋点和自定义埋点。若注重隐私或希望数据自托管,可以用 Umami 这类开源方案,无 Cookie、符合 GDPR,脚本轻量(约 2KB),支持页面浏览与自定义事件,可 Docker 自建或使用官方云,适合中小站点和不想依赖第三方统计的场景。
无埋点还可用 GrowingIO 等方案自动采集页面点击、曝光等事件,接入简单、覆盖面大。自定义埋点用神策数据等 SDK 在关键行为(如按钮点击、表单提交)上手动上报,灵活、可针对业务做分析。数据进来之后,用 Metabase 这类开源 BI 做 SQL 自助分析,或用阿里 DataV 做大屏展示核心指标(如 DAU、转化率)。AI 也能参与,例如 GrowingIO 的智能推荐会根据用户路径建议高价值埋点事件,神策的聚类分析能自动识别用户分群(如高流失风险用户),方便做精细化运营。
测试与优化阶段还有几点容易踩坑。一是别盲目追求 100% 测试覆盖率,优先把核心链路(登录、支付等)兜住,再按需补边缘场景。二是性能优化别撒胡椒面,内部管理后台等低频页面不必死磕,把资源留给用户高频访问的页面。三是埋点必须拿到用户授权,禁止收集设备 ID、IMEI 等敏感信息,否则会踩数据隐私的雷。
构建部署阶段
构建与部署阶段是前端工程化的交付出口,目标是高效交付、稳定发布、灵活回滚,让代码从开发环境到生产环境顺畅流转。下面按构建优化、部署方案、灰度与回滚三块说。
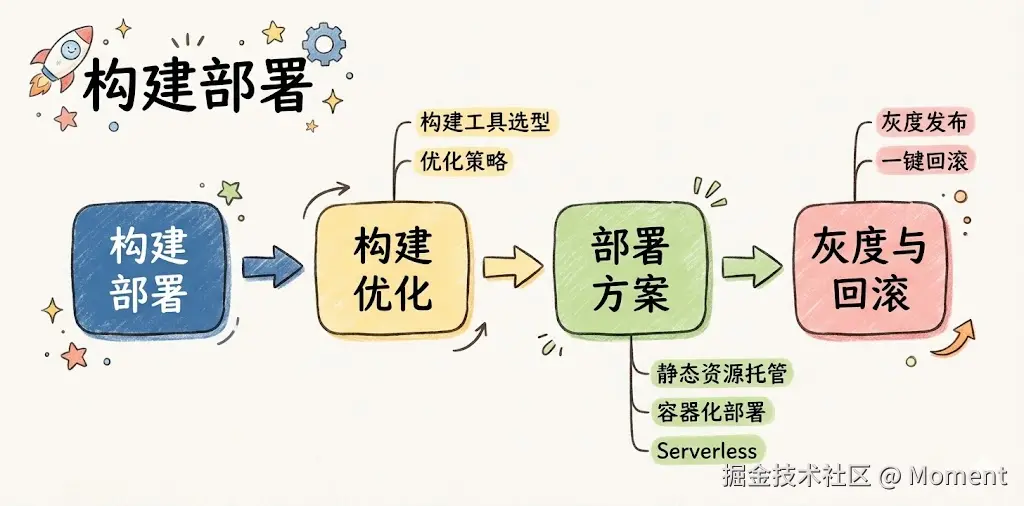
构建优化
构建工具在技术选型阶段通常已经定好了(例如 Vite、Webpack 5、Rspack、Next.js),这里侧重在既定工具上的优化策略。Vite 新版本已接入 Rust 实现的 Rolldown 做生产打包,构建耗时明显下降。选 Next.js 的可以用 Turbopack 做开发和生产构建,冷启和增量构建更快。Rspack 等 Rust 系方案在大仓下同样有优势。
优化时先把 Tree Shaking 开满,在库和业务里合理配置 sideEffects: false,让打包器删掉未引用代码。代码拆分用动态 import、React.lazy 把非首屏做成按需加载,再用 manualChunks 把大依赖(如 monaco-editor、图表库)单独拆包,避免首屏 chunk 过大。产物体积可用 rollup-plugin-visualizer 或 vite-plugin-perfsee 做分析,一眼看出谁在占空间。线上传输用 vite-plugin-compression 做 Gzip 或 Brotli,Nginx 侧开 gzip_static 即可。
部分构建工具已支持基于 AI 的智能缓存和构建日志分析,自动推荐合并重复 Chunk、优化依赖顺序等,可在 CI 里跑一遍看报告。
部署方案
部署从手动发包走向一键发布、多环境隔离,才能做到分钟级回滚。静态资源托管最常见,用阿里云 OSS 挂 CDN 按量付费、支持缓存刷新,或选托管平台:Vercel 和 Git 深度集成、推分支即发布,适合 Next.js。Cloudflare Pages 边缘节点多、免费带宽大,已支持 Docker 和 @opennextjs/cloudflare 跑 Next,还有 Workers AI 做边缘推理。Netlify 在组合式架构和 CMS 集成上比较顺手。需要极快 git 部署、少建站过程的可以看 Deno Deploy,代码直传边缘、无需拉机子做长构建,适合接口或中间层。
需要跑 Node 或做 SSR 的,用 Docker 多阶段构建把镜像压到几十 MB,再配合 Kubernetes(如阿里云 ACK)做集群。不想管机器的用 Serverless,阿里云函数计算、Vercel Edge Functions 等按需执行、边缘就近跑。
AI 也能参与,例如 GitLab Code Suggestions 可根据项目生成 Dockerfile 或 CI 脚本,观测云等能根据资源负载推荐扩缩容策略。
灰度与回滚
发布要可控,灰度把风险压到最小,回滚要能快速切回去。灰度本质是流量逐步切到新版本,常见做法有 Nginx 按 IP 或 Cookie 分流,先给 5%~10% 用户上新版,观察一段时间再放量。阿里云 EDAS 支持全链路灰度,应用和数据库都能隔离。云原生 API 网关也支持蓝绿、金丝雀发布,按比例或规则切流量。除了流量灰度,还可以用特性开关(Feature Flags),在代码里用开关控制功能是否露出,用 ConfigCat、LaunchDarkly 等或自研,发版和上线解耦,随时可关。
灰度期间要有可观测,接 Prometheus、Grafana 或现有监控,盯错误率、响应时间,一旦超阈值(例如错误率 >0.5%)自动回滚或告警。回滚要提前准备好,在 GitLab CI 或 GitHub Actions 里做基于版本 Tag 的回滚脚本,出问题一键切回上一版。静态资源用 OSS 版本控制保留历史,回滚时改 CDN 回源即可。
AI 也能参与,例如阿里云 AHAS 可根据历史流量推荐灰度比例,Sentry 等可在错误率突增时自动触发回滚或通知,减少人工判断时间。
运维监控阶段
运维与监控是前端工程化的最后一道防线,目标是实时感知风险、快速定位原因、持续优化体验,让线上系统稳定、用户行为可观测。下面按性能监控、异常监控、用户行为分析、可视化与告警四块说,最后补一版低成本与大型企业的工具链参考,以及几条容易踩的坑。
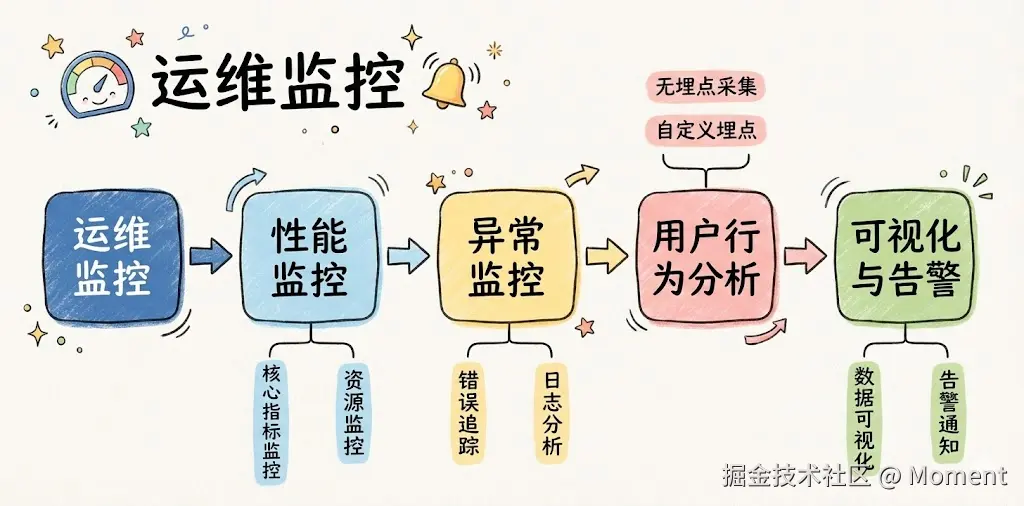
性能监控
性能监控要保障 Web Vitals 等核心体验指标达标,并持续发现瓶颈。核心指标用 Google Analytics 4 或阿里云 ARMS 等采集真实用户数据(RUM),关注 LCP(最大内容绘制)、INP(交互到下一帧,已逐步替代 FID)、CLS(累计布局偏移)等,可配合 web-vitals 库在端上采集后上报。除了平台自动采集,关键链路可以加自定义性能埋点,例如在页面加载完成后取 performance.timing 算出加载耗时并上报,方便按页面或版本对比。下面示例在 load 事件后计算从导航开始到加载结束的耗时,并通过自有 SDK 上报,用于做首屏性能趋势分析。
const timing: PerformanceTiming = performance.timing;
const loadTime: number = timing.loadEventEnd - timing.navigationStart;
SDK.report({ type: "page_load", duration: loadTime });
资源侧可以看 CDN 日志分析请求成功率、缓存命中率(如阿里云 CDN)。接口耗时用 SkyWalking、Zipkin 或 OpenTelemetry 做链路追踪,约定 P99 等目标(例如 500ms 以内)。Sentry 等已支持与 OpenTelemetry 对接,前端错误和接口链路可以串成一条 trace,排查时从页面一路跟到后端。AI 也能参与,例如阿里云 ARMS 智能诊断会关联 JS 错误与接口超时,给出根因建议。New Relic 等可根据历史数据预测流量峰值,辅助提前扩容。
异常监控
异常监控要争取分钟级发现线上问题,把 MTTR(平均修复时间)压下去。错误追踪用 Sentry 捕获前端 JS 错误、自动聚合相似问题,并支持 SourceMap 解析还原源码位置。国内团队也可以用支持微信、钉钉实时告警的国产方案,和现有协作习惯对齐。日志分析用阿里云 SLS 做 Nginx 访问日志的实时分析,快速发现 5xx 突增等异常。自建可选 Loki 配 Grafana,资源占用比传统 ELK 小,用 LogQL 查"近 1 小时 404 TOP10"这类问题很顺手。
AI 可以辅助降噪和归因,例如 Sentry 的智能聚类能把大量错误归成少量根因(如未捕获的 TypeError)。基于 Elasticsearch Machine Learning 或类似能力可以做日志模式异常检测,例如发现突然出现大量非常规 UA 或异常请求路径,提前发现爬虫或攻击。
用户行为分析
用户行为数据用来驱动产品优化和转化率提升。无埋点用 GrowingIO 等自动采集页面点击、跳转、停留时长,并生成热力图。自定义分析用神策等做事件与漏斗(如注册流程各步转化)。关键业务节点需要自定义埋点时,在按钮或流程节点上打点上报事件和业务参数,例如下单按钮点击时上报商品 ID 和价格,便于后续做转化和营收分析。下面示例在购买按钮点击时上报事件名和业务字段,接入方替换成实际 SDK 即可。
document.getElementById("buy-button")?.addEventListener("click", () => {
SDK.track("purchase_click", { product_id: "123", price: 299 });
});
AI 能参与分析结论的产出,例如神策的智能路径分析用户流失点并给出优化建议,GrowingIO 可根据行为聚类生成推荐或运营策略参数。
可视化与告警
监控数据要通过大屏和告警变成可执行的决策。可视化用 Grafana 做自定义监控面板,或用阿里云 DataV 搭实时运维大屏。告警用 Prometheus 配 Alertmanager 配置阈值(如 CPU 使用率 >80% 持续 5 分钟),告警事件通过钉钉、飞书机器人推到协作群,并支持 @ 负责人。AI 可以用于智能阈值和降噪,例如根据历史数据动态计算合理阈值(如凌晨自动放宽延迟阈值),或把重复告警合并成一条,减少告警风暴。
工具链参考
中小团队、预算有限时,可以组合:监控用 Prometheus 自建 + Grafana,告警接微信或钉钉。日志用 Loki 替代 ELK,资源消耗更低。再搭配阿里云 ARMS 免费版做基础性能分析、或开源组件的异常检测能力,整体月成本可控。对高可用要求高、数据量大的团队,可以用阿里云 ARMS 做全链路、SLS 做 PB 级日志,配合 DataV 大屏和自研或第三方 AI 分析平台。
运维监控还有几点要注意。一是避免过度监控,只采核心业务相关指标,否则存储和告警成本都会上去。二是告警要设静默期,同一类告警在 30 分钟内不重复推送,减少告警疲劳。三是日志必须脱敏,避免原始敏感数据泄露。