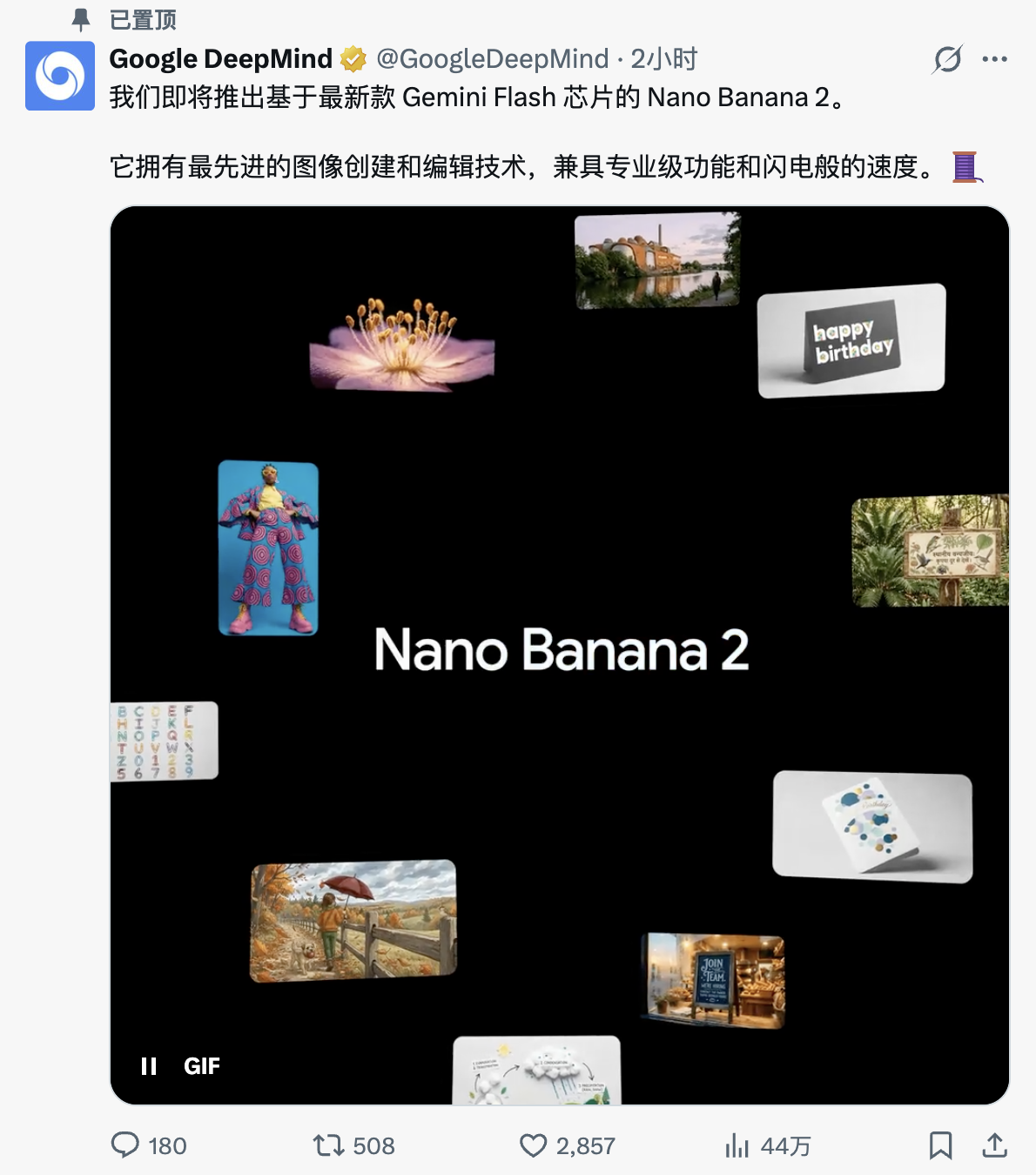
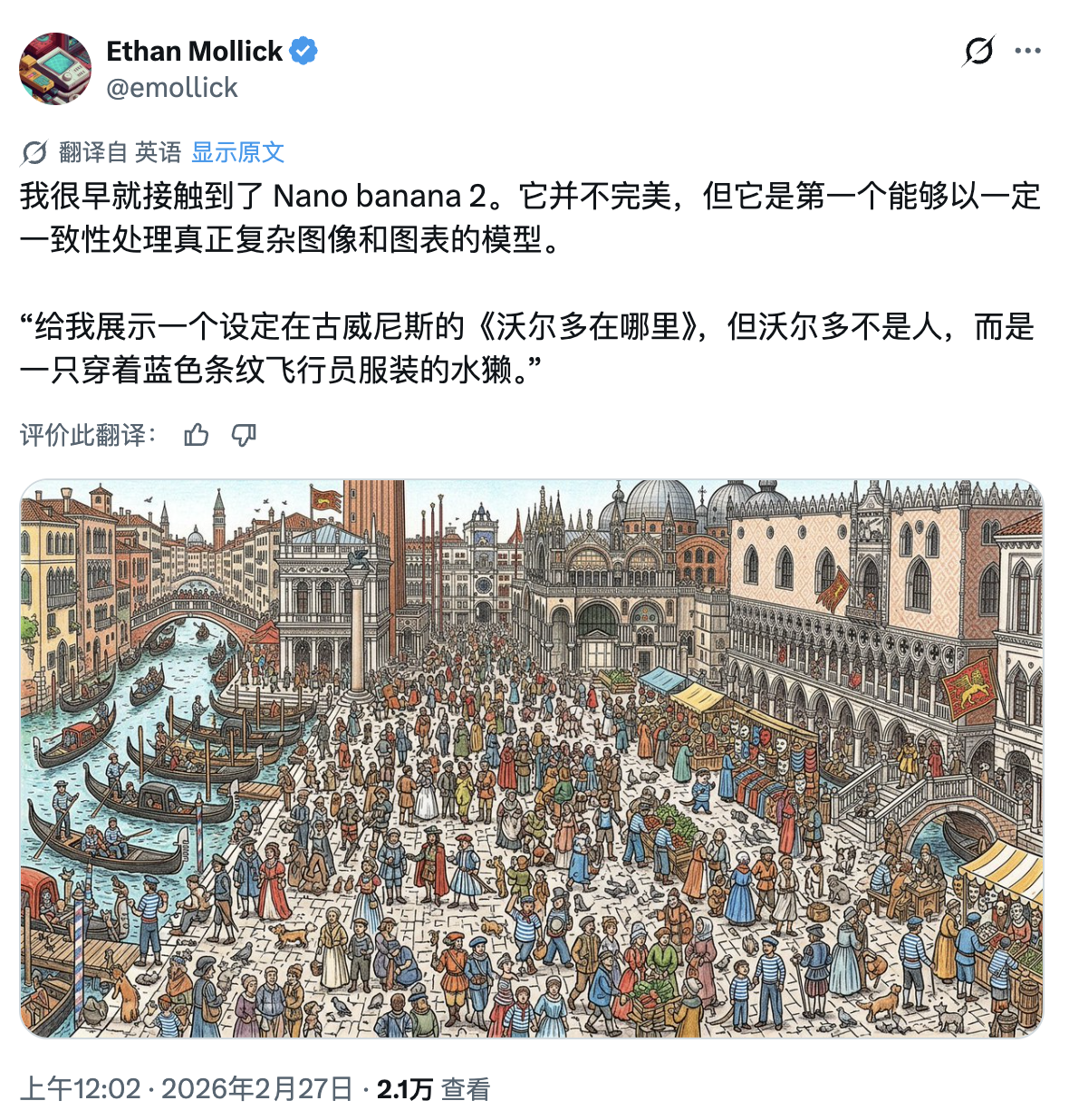
杨植麟、罗福莉、夏立雪、张鹏、黄超,五个AI圈顶流把龙虾、Token 、开源聊透了
龙虾,是最近 AI 圈出现频率最高的词汇。
它指的是 OpenClaw,一个近期在AI圈迅速蔓延的开源智能体框架。有人觉得它像贾维斯,有人觉得它像脚手架,有人觉得它像轻量级操作系统,所有人都在用,而且越用越停不下来。
围绕它的讨论也随之而来:龙虾能干什么,干不了什么,下一步往哪走,算力够不够,谁在受益,谁在焦虑。

现在,行业里最靠近前线的一批人坐下来,认真聊了聊这件事。就在刚刚,月之暗面创始人杨植麟在北京中关村论坛年会的开源主题圆桌中主持了一场五人谈话,智谱创始人张鹏、无问芯穹创始人夏立雪、小米 MiMo 大模型负责人罗福莉、香港大学助理教授黄超共同参与。
对话从 OpenClaw 的实际使用体验出发,延伸至模型定价逻辑、推理基础设施的结构性瓶颈、模型架构创新,以及对未来十二个月行业走向的集体判断。
从聊天到真正干活,OpenClaw 改变了什么
论坛开场,杨植麟抛出了一个共同话题:日常使用 OpenClaw 或类似产品,最有想象力的体验是什么?从技术角度看,如何理解今天智能体框架的演进方向?
张鹏说,他很早就开始自己动手折腾这类工具,当时还不叫 OpenClaw,最早叫 ClawBot。毕竟是程序员出身,折腾这些东西有自己的手感。在他看来,OpenClaw 最大的突破在于把顶尖模型的能力,尤其是编程和智能体方面的能力,交给了普通人。
「这件事不再是程序员或极客的专利。它在模型上方搭起了一个牢固又灵活的脚手架,让原来因为不会写代码而无法实现的想法,今天通过简单的对话就能完成。」他更愿意把 OpenClaw 这类工具称为脚手架,它提供的是一种可能性,而不是一个封闭的产品。
夏立雪的第一反应是不适应。他习惯了和大模型聊天的交流方式,一开始发现 OpenClaw 响应慢,觉得很卡。但后来他意识到,这类工具和聊天机器人有本质区别:它更像是一个能承接大型任务的人,而不是一个回答问题的工具。
「从按 token 计费的模型,到能帮你完成任务的智能体,AI 的想象力空间已经做了一次大的跃升。但与此同时,对整个系统能力的要求也大幅提升,这就是我一开始觉得它卡的原因。」
他随后披露了一个直观的数据:无问芯穹从今年一月底开始,基本上每两周 token 用量翻一番,到目前为止已经翻了十倍。「上次见到这个增速,还是 3G 时代手机流量刚普及的感觉。那时候大家每个月一百兆流量,现在的 token 用量就是那种感觉。」
他认为,现有的所有资源想要支撑这个快速增长的时代远远不够,需要更好的优化和整合。
罗福莉从产品框架设计角度给出了不同的观察。她把 OpenClaw 视为 agent 框架领域一次革命性和颠覆性的事件。她注意到,深度 coding 圈子里很多人的第一选择依然是 Claude Code,但她认为只有真正用过 OpenClaw 的人才能感受到这个框架在设计层面的独特之处,包括近期 Claude Code 的很多新更新,其实也在向 OpenClaw 的设计方向靠近。
她总结了 OpenClaw 核心价值的两个层次。
第一是开源。开源让整个社区能深度参与、持续改进,这是一个非常重要的前置条件。她认为,开源框架的一个关键价值在于把国内参数量不那么大、但水平仍然可观的模型的能力上限大幅拉高,
「在绝大部分场景下,任务完成度已经非常接近 Claude 最新模型的水平,同时它靠一套完整的 harness 系统和 skills 体系把下限也保证得很好。」
第二是点燃了大家对大模型之上那一层的想象力,也就是智能体层。她看到越来越多非研究员背景的人开始通过更强的 agent 框架参与 AGI 的变革,一定程度上替代自己工作中的重复任务,把时间释放出来做更有创造力的事情。
她还提到了一个具体的使用感受:相比 Claude Code 只能在桌面上延展创意,OpenClaw 可以随时随地参与进创意过程,想象力的扩展没有场景限制。
黄超从交互模式切入,分析了 OpenClaw 能引发广泛关注的原因。
他认为第一个关键因素是「活人感」。以往的 Cursor、Claude Code 这些 agent 工具,使用起来更像工具;OpenClaw 以 IM 软件嵌入的交互方式呈现,让人感觉更接近自己想象中的个人贾维斯。「这种活人感是很多人第一次真正觉得 AI 要来了的时刻。」
第二个因素是,OpenClaw 再次验证了 agent loop 这种看似简单但极为高效的框架范式。第三个值得思考的问题是,我们到底需要一个 all-in-one 的超级智能体,还是一套类似轻量级操作系统或脚手架的存在,去撬动整个生态里所有的工具和能力。
他倾向于后者,认为 OpenClaw 更像一个操作系统级别的小管家,通过这个入口,社区里越来越多的人开始设计面向这类系统的应用,以 skills 和 harness 的形式去赋能各行各业,这和整个开源生态天然结合得非常紧密。
干一个任务,消耗原来百倍的 token
杨植麟随后把问题引向了智谱最新发布的 GLM-5-Turbo 模型,以及伴随而来的提价策略,并问这背后反映了什么样的市场信号。
张鹏说,这次更新是在整个发展目标中提前放出来的一个阶段性成果。核心目标只有一个:从「对话」转向「干活」。OpenClaw 让大家意识到大模型真的能帮人完成任务,但这背后对模型能力的要求远超以往。
「它需要自己做长时间的任务规划,不断压缩上下文,随时 debug,还要处理多模态信息。这和传统面向对话的通用模型完全不同。」
GLM-5-Turbo 在这些方面做了专门的加强,尤其是在如何让模型持续自我 loop、不停执行任务这个问题上投入了大量工作。同时也做了效率优化,在面临复杂任务时能用更高效的推理路径完成,避免用户只看到账单上的数字在不停往下掉。
对于提价,在他看来,现在完成一个复杂任务,模型背后的推理链路很长,要写代码、要和底层基础设施打交道、要随时修正错误。消耗的 token 量可能是回答一个简单问题的十倍甚至百倍。模型变大了,推理成本相应提高,价格自然要回归正常的商业价值。
「长期靠低价竞争,对整个行业的发展都不利。我们需要一个良性的商业闭环,才能持续优化模型能力,持续给大家提供更好的服务。」
现有的云计算架构,并非为 AI 设计
随着 token 用量的爆发和行业从训练时代转向推理时代,推理基础设施的压力成为不可回避的话题。
夏立雪说,无问芯穹是一家诞生在 AI 时代的基础设施厂商,目前同时为 Kimi、智谱以及多所高校科研机构提供服务,也在和 memo 合作。他们一直在思考一个核心问题:AGI 时代需要的基础设施是什么样的,以及如何一步步去实现和推演它。
在他看来,当前脚下最紧迫的问题是如何打造一个更高效的 token 工厂。
无问芯穹的做法是从软硬件打通的角度出发,接入了国内几乎所有种类的计算芯片,将几十种芯片和几十个不同的算力集群统一连接起来。「资源不足时,最好的办法有两个:第一,把能用的资源都用起来;第二,让每一分算力都用在刀刃上,发挥出最大的转化效率。」他们也在探索最新的模型结构和硬件结构之间能否产生更深的化学反应。
但他认为,仅仅打造一个标准化的 token 工厂还不够。他提出了一个更根本的判断:当前大量云计算基础设施,在设计上服务的是人类工程师,而不是 AI。「我们做了一个基础设施,上面的接口是为人做的,再往上包一层才能接入智能体。这种方式用人的操作能力限制了智能体的发挥空间。」
他举了一个具体的例子:智能体能做到秒级甚至毫秒级地思考和发起任务,但现有的很多底层能力根本没有为这个速度做好准备,因为人类发起一个任务通常是分钟级别的。这个问题需要打造一套更智慧化的调控系统,他们把它称为 agency 能力的一部分。
从更长远的视角看,他认为真正 AGI 时代到来时,连基础设施本身也应该成为一个智能体,能够自我进化、自我迭代,形成自主的组织。「相当于基础设施有一个 CEO,这个 CEO 是一个 agent,它根据 AI 客户的需求自己提需求、迭代自己的基础设施。这样 AI 和基础设施之间才能产生真正的耦合,而不是一个接收需求、另一个执行的单向关系。」
他们目前也在探索让 agent 和 agent 之间更好地通信,以及 cache to cache 的复制能力。在他看来,基础设施和 AI 的发展应该产生非常丰富的化学反应,这才是真正意义上的软硬协同,也是无问芯穹一直想实现的使命。
算力限制,反而催生意外突破
罗福莉没有直接回答小米的独特优势,而是把问题拉到了整个中国大模型团队的层面,认为这个视角更有价值。
她说,大约两年前,她就看到中国基座大模型团队开始了一次非常重要的突破。这个突破来自于一个被逼出来的命题:在有限算力、尤其是 NVLink 互联带宽受限的情况下,如何突破低端算力的限制,在看似为了效率妥协的情况下做模型结构上的创新。
DeepSeek V2、V3 系列,以及后来的 MiniMax M1 等,都是这类探索的产物。
「这些创新引发了一次真正的变革:怎么在算力一定的情况下,把智能水平发挥到最高。DeepSeek 给所有国内大模型团队带来了一个勇气和信心。」她强调,虽然今天国产芯片的限制已经没有那么严峻,但这段时间被逼出来的对更高训练效率、更低推理成本的模型结构探索,形成了真正有价值的技术积累。
她提到了几个具体方向:混合稀疏架构(hybrid sparse)、Kimi 的 KSA 架构、小米面向下一代的新结构。这些都区别于当前这一代的 transformer 架构,是在思考如何为智能体时代做更好的模型结构创新。
她特别强调了长上下文能力的重要性,并把它和 OpenClaw 直接挂钩。
「OpenClaw 越用越好用、越用越聪明,前提是你的推理上下文足够长。但很多模型做不到一兆甚至十兆的 context,不是能力问题,是成本问题,推起来太贵、速度也太慢。只有在长上下文下成本够低、速度够快,才能把真正有生产力价值的复杂任务交给模型去完成。」
她进一步描述了这条路径的终点:在超长 context 的支撑下,模型可以在复杂的环境里完成对自我的进化,包括对框架本身的优化,也包括对模型参数本身的迭代。这个方向在预训练侧要做好长上下文架构,在后训练侧要构造更有效的学习算法,采集在一兆、十兆、百兆上下文里真实具有长期依赖性的文本和复杂环境轨迹数据。
她也分享了一个来自团队内部的数据:借助 Claude Code 加顶尖模型的组合,团队做大模型研究的同学,研究效率已经提升了近十倍。
规划、记忆与工具调用
黄超从技术角度系统梳理了当前智能体框架在三个核心模块上的主要痛点和未来方向。
规划层面,他认为面向复杂任务、超长上下文的规划能力仍然不足。比如五百步甚至更长的部署任务,很多模型做不好规划,本质上是缺乏垂直领域的隐性知识。他认为一个方向是把复杂任务的领域知识固化到模型里。skills 和 harness 这类工具,一定程度上也是在通过提供高质量的外部能力来缓解规划中出现的错误。
记忆层面,信息压缩和检索精度始终是难题。任务复杂度上升时,context 会暴增,目前各类智能体框架普遍采用的还是文件系统这种最简单的共享方式。他认为未来的 memory 机制需要走向分层设计,但通用化很难实现,因为 coding 场景、deep research 场景、多媒体场景的数据模态差异极大,如何对这些 memory 进行高效检索和索引,始终是一个 trade-off 问题。
他还指出了一个新的压力来源:未来可能不止一个智能体,每个人可能同时拥有一群智能体,Kimi 的 agent swarm 机制已经指向了这个方向。一群智能体带来的上下文暴增,会远超单个智能体,对 memory 机制和整个 agent 架构都是非常大的压力,目前还没有一套成熟的机制来应对这个问题。
工具调用层面,他认为高质量的 skill 依然稀缺,这和当年 MCP 时代高质量工具稀缺的问题如出一辙。低质量的 skill 会直接拉低任务完成率,恶意注入的安全风险也是一个不容忽视的问题。他认为这需要整个社区共同建设,甚至需要探索如何在执行过程中动态进化出新的 skill,而不是依赖人工预设。
未来十二个月:生态、自进化、可持续 Token 与算力
论坛最后,杨植麟请每位嘉宾用一个关键词描述未来十二个月最重要的趋势。
黄超感慨,十二个月在 AI 领域已经是很遥远的事情,不知道届时会发展成什么样子。他给出的关键词是「生态」。他认为现在大家使用智能体还带着新鲜感,但未来真正的挑战是让它沉淀成日常工具,从个人助手转变为真正的打工人和 coworker。这需要模型迭代、skills 平台建设、各类工具的共同推进,大家一起把整个生态向智能体原生的方向拉。
他还提出了一个有趣的判断:未来大量软件可能不再面向人类,而是面向智能体原生设计的。人类需要 GUI,但智能体不需要,整个生态正在从 GUI 和 MCP 的模式转向 CLI 模式。这意味着软件系统、数据乃至各种技术,都需要完成一次向 agent native 的转型。
罗福莉给出的词是「自进化」。她说这个概念听起来有点玄,但她最近对它有了更具体的体感和更务实的实操方案。关键在于:借助足够强大的模型,当你在智能体框架里叠加一个可验证的约束条件,再设定一个持续的 loop,让模型不停迭代优化这个目标,你会发现它能持续拿出更好的方案,而且能自主运行两三天。
她举了一个具体案例:在探索更好的模型结构这类有明确评估标准的科研任务上,模型已经能够自主运化和执行两三天。「自迭代是唯一能创造出这个世界上不存在的新东西的路径,它不是替代人的生产力,而是像顶尖科学家一样去探索未知。我一年前觉得这需要三到五年,但现在我认为一到两年内就可能真正实现。」
她预计,结合强大的自迭代 agent 框架,对科研的加速将达到指数级。
夏立雪选择了「可持续 Token」。他说,现在整个发展还在一个持续的过程中,需要让它有长久的生命力。他用了「AI made in China」来描述他的愿景:把中国在能源和算力上的优势,通过高效的 token 工厂持续转化为优质的 AI 能力,输出到全球。
「从 made in China 到 AI made in China,逻辑是一样的。中国能把低成本的制造能力变成好商品输出全球,同样可以把这种能力迁移到 token 的生产和输出上。」他希望在今年看到这件事真正成形,让中国成为世界的 token 工厂。
张鹏的关键词则是「算力」。
在他看来,「所有技术的前提,是大家用得起。你不能因为算力不够,提一个问题让它思考半天也不给答案,这肯定不行。」
他提到了一句在行业里流传的话:没卡没感情,谈卡伤感情。需求已经是十倍百倍地爆发,而很大一部分需求还没有被满足。他认为,算力问题是接下来十二个月最需要大家一起想办法的事情。龙虾打开了想象力的上限,但算力、架构和基础设施,还在进步的路上。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。



















 :https://lexfridman.com/jensen-huang-transcript
:https://lexfridman.com/jensen-huang-transcript














































 6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum
6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum