我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于 Tiptap 的富文本编辑器、NestJs 后端服务、AI 集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了 Tiptap 的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
如果你对 AI全栈 感兴趣,也欢迎添加我微信,我拉你进交流群
2026 年的前端圈卷出了新高度,AI Agent 已是各类 Web 应用的标配。官网智能客服、内部任务助手、产品内的搜索与推荐,都绕不开一件事:用哪个框架把大模型和工具串起来。不少团队会在 LangChain.js 和 Mastra 之间反复纠结,架构评审时也常为此争论。
两者没有绝对优劣,差别主要在"设计哲学"和"业务场景"的匹配度。Mastra 像为前端量身定制的厨师刀,刀刃顺手、切菜切肉都轻松;LangChain.js(尤其是 LangGraph.js)则像重型瑞士军刀,刀锯镊子开瓶器齐全,能应付各种复杂场景,代价是重量和复杂度都更高。下文从 2026 年技术生态出发做一次对比,并配上代码与图示,方便你理清思路、少走弯路。
为什么前端选型会卡在这两个框架上
前端接大模型、做 Agent,本质是三件事:把用户输入送给 LLM、根据输出决定下一步(是否调工具、是否多轮对话)、再把结果还给用户。不同框架在这三条链路上的抽象程度和侧重点差异很大。一类把"循环调工具、拼消息"全包在内部,对外只暴露"发消息、拿回复",你几乎不用关心内部调了几轮工具;另一类把节点、边、状态都暴露给你,自己搭图,灵活性高,但概念和代码量都上去,得先建立"图"的思维才能写得顺手。
LangChain 从 Python 生态长出来,后有 langchain-js,再后来复杂编排催生了 LangGraph,面向任意语言和部署环境的通用编排,概念多、集成广,前端只是消费端之一。文档里会反复出现 Runnables、LCEL、RunnableSequence、RunnablePassthrough 以及各种 @langchain/xxx 包,学习路径会先经过"什么是 Runnable、reducer、checkpointer"这一串概念。Mastra 则从 TypeScript 和现代前端框架出发,默认你在用 Next.js、Nuxt 等全栈框架,API 和类型系统都围着前端习惯转,包名和概念更收敛,文档集中在"在 React、Server Actions 里怎么用",很少逼你先学一整套编排术语。
选型归根结底就两点:团队和产品更接近"通用 AI 编排"还是"前端优先的轻量 Agent"。前者偏向后端或全栈做复杂系统,愿意为灵活性和生态付学习成本;后者偏向前端或小团队在现有 Web 应用里快速接一层智能,希望少概念、少依赖、快上线。
如下图所示。
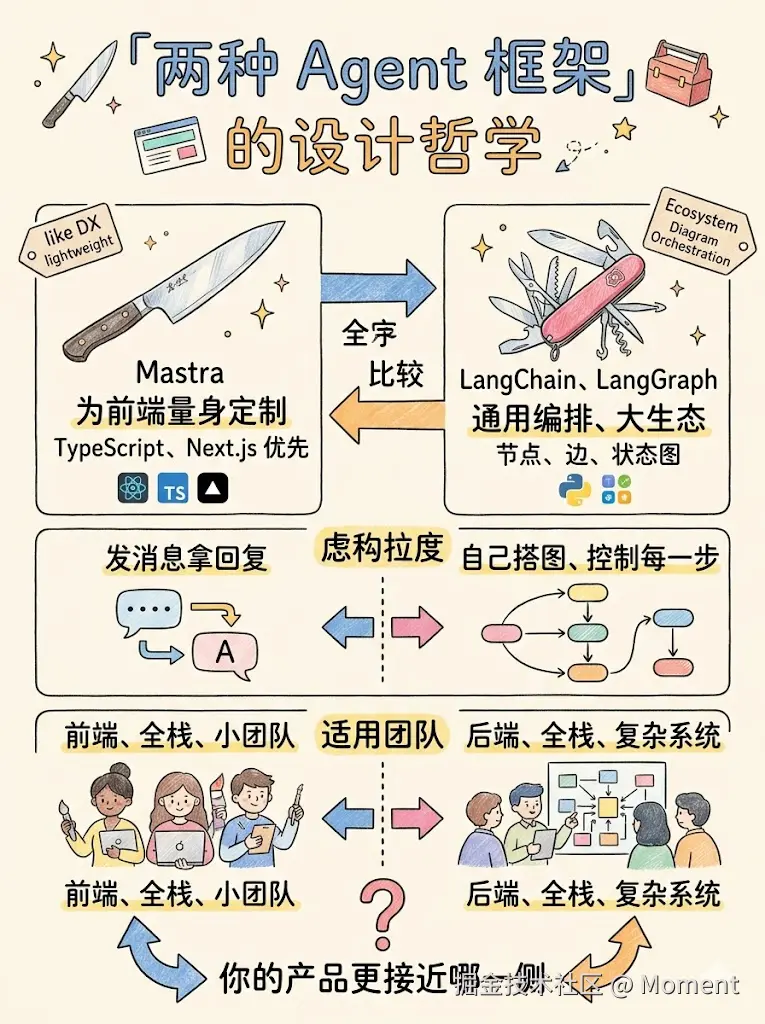
两种哲学一目了然:一侧是前端优先的轻量体验,一侧是通用编排与生态。
Mastra 的定位与优势
Mastra 从诞生起就面向 TypeScript 和现代前端框架(Next.js、Nuxt 等),针对前端痛点,主打开发者体验(DX)。
TypeScript 原生与类型安全
端到端类型推导做得很好:Agent 的输入、输出和工具调用参数在 IDE 里都有完整类型提示和自动补全,不必手写类型转换或 as 断言。工具用 zod 或 TypeScript 类型定义入参,框架自动生成模型可用的 schema 并做运行时校验。例如在 createTool 里写 inputSchema: z.object({ location: z.string() }),调用时入参即被推断为 { location: string },返回值与 outputSchema 对齐,和现有基于 zod 的表单校验、API 契约也容易打通。
轻量且贴合全栈框架
部署在 Vercel、Cloudflare Workers 等 Serverless 或 Edge 上时,Mastra 的冷启动和边缘兼容性通常更好。没有 LangChain 那套 Runnables、LCEL 等抽象层,依赖树干净,打包体积可控,不必为"跑通一个带工具的 Agent"拉满 @langchain/core、@langchain/openai、@langchain/langgraph 等一长串包。在 Next.js 的 Server Action、Route Handler 里直接调 Mastra Agent,心智负担小,和现有数据流(表单、状态、API)易对齐,也方便和 React Server Components、流式 SSR 配合。
心智负担低
API 贴近前端数据流直觉:发一段消息、拿一段回复、必要时调几个工具。Mastra 把 LLM 调度、工具解析和流式输出包起来,用简单异步函数或 React 友好接口暴露,不必理解"图、节点、条件边、reducer",会写 createTool 和 new Agent、会调 generate 或流式方法就能跑通,适合作为团队第一个 Agent 项目的起点。
适合的场景小结
Mastra 特别适合这几类情况:
- Agent 主要是 Web 应用的辅助功能(智能搜索、客服助手、简单数据总结或表单建议),且深度绑定 Next.js、React 生态。
- 团队以前端或全栈为主,不想引入过重后台架构,希望快速迭代上线,同时要类型安全和良好调试体验。
- 对依赖体积、冷启动和 Edge 兼容性敏感,不想为用不到的能力背上整座 LangChain 生态。
LangChain.js 与 LangGraph 的定位与优势
到 2026 年,单纯用 LangChain 搞复杂 Agent 已不够用,实际在评估的往往是 LangGraph.js,它是处理复杂、有状态、多 Agent 协作时的常用方案。
生态系统覆盖广
冷门向量库、大模型厂商、各种外部 API,LangChain 生态里大多已有现成集成。Pinecone、Weaviate、Qdrant、Chroma、自建 REST、OpenAI、Anthropic、Cohere、国产大模型,以及 Tavily、SerpAPI 等,多数有官方或社区的 @langchain/xxx 包。公司内有老旧系统、私有模型或特定协议时,也容易在现有集成上做薄封装,复用 LangChain 的 Runnable、消息格式和工具约定,快速对接大量外部依赖时能省下不少适配和调试时间。
状态机与图逻辑(LangGraph)
需要"循环思考、多路分支、人类介入(Human-in-the-loop)"的复杂工作流时,LangGraph 的图架构能精确控制节点流转。节点是处理单元(一次 LLM 调用、工具执行或人工审核),边是状态转移(固定边或条件边)。状态可持久化到 checkpointer,刷新或断线重连后从断点继续,适合多轮任务和多人协作,也是 Mastra 目前不直接提供的部分。
过度抽象的代价
学习曲线陡:Runnables、Chains、Tools、Nodes、Edges、Annotation、reducer、checkpointer 等概念交织,新手易迷路。实现"用户问一句、模型调一次工具再回答"这种简单功能,也要先理解状态结构、写 agent 与 tools 节点、配条件边和普通边再 compile,代码量明显多于"Agent 配置 + 一次 generate"。报错常来自链式调用的某一层,堆栈里是 LangChain 内部的 Runnable 名,前端背景的开发者需要时间习惯"从图的角度想问题"。LangGraph 的 TypeScript 类型虽完整,但状态是运行时用 Annotation 和 reducer 拼出来的,和 Mastra 那种"工具入参即 zod schema、一眼能看出类型"的体验比,心智负担更大。
适合的场景小结
LangChain、LangGraph 更适合这几类情况:
- 核心业务就是复杂 AI 系统:多 Agent 协作、长时运行异步任务、或需精准控制"思考中断与恢复"。
- 集成需求多且杂,要接内部老旧系统或非常小众的向量库、模型接口。
- 要对底层 Prompt、重试、记忆(Memory)做深度定制,甚至改框架默认行为。
核心能力对比
用一张表概括两个方向在关键维度上的差异,细节在前后文展开。
| 维度 |
Mastra |
LangChain.js / LangGraph |
| 设计核心 |
极致 DX、原生 TS、轻量化 |
复杂编排、状态管理、大生态 |
| 学习曲线 |
平缓,熟悉 TS 即可快速上手 |
陡峭,需理解大量框架专属概念 |
| 调试体验 |
堆栈清晰,贴合前端习惯 |
多层抽象,报错有时难以定位 |
| 多 Agent |
支持,更适合简单链式交互 |
极强,循环与状态打断控制完善 |
| 生态与集成 |
精选集成,覆盖主流工具 |
海量集成,几乎覆盖常见基础设施 |
| 依赖与体积 |
包少、体积小,Edge 友好 |
多包组合,体积与冷启动略大 |
Mastra 通常只需 @mastra/core 加模型适配(如 OpenAI),LangChain 则常需 @langchain/core、@langchain/openai(或其它模型包)、@langchain/langgraph,再接向量库或 RAG 还会多几个包,在 Serverless 冷启动和 Edge 里更敏感一些。
如下图所示。
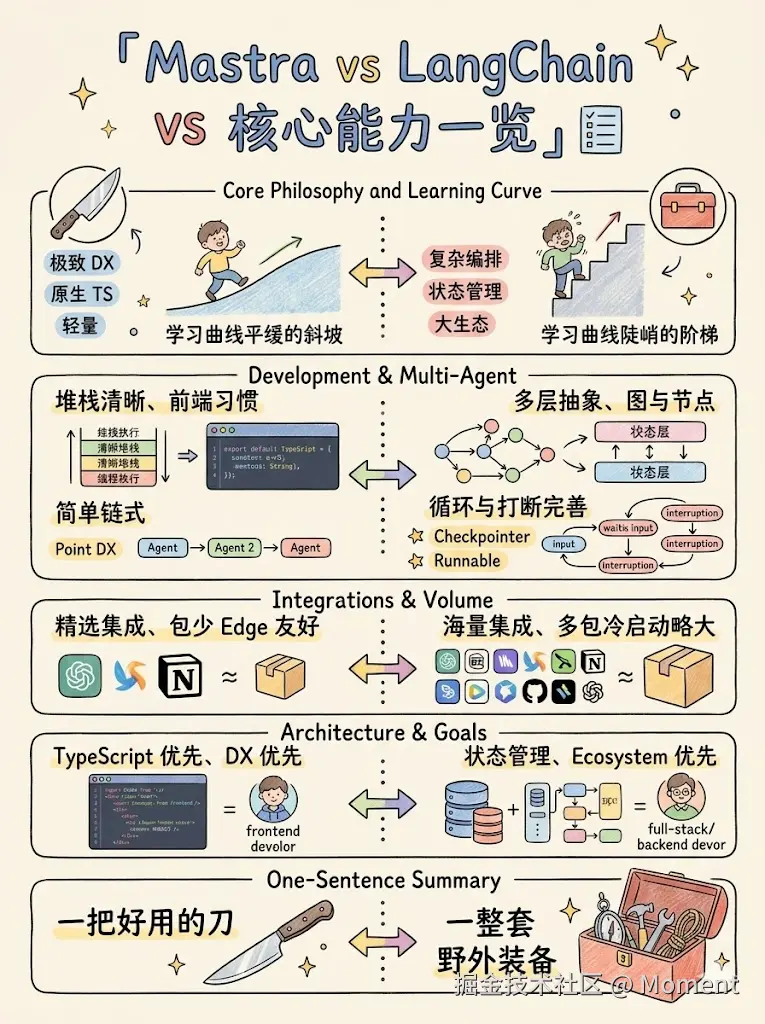
从设计重心到依赖体积,一张图能看清两边差异。下面用两段代码对比同一需求的实现方式,再给出选型决策说明。
用代码感受两种 API 风格
同一需求"做一个能查天气的对话 Agent",在 Mastra 和 LangGraph 里写出来的代码量和抽象层次差很多,看一遍再想选型会直观不少。
Mastra:工具 + Agent 几行搞定
在 Mastra 里用 createTool 定义工具的入参(zod)、描述和执行函数,创建 Agent 时把工具挂上去即可。调用时直接 agent.generate() 或流式接口,不用关心"模型要不要调工具、调完要不要再推理",框架内部处理。
下面示例定义了一个查天气工具和一个使用该工具的 Agent。工具入参用 z.object 声明,execute 的返回值与 outputSchema 一致,整条链路在 IDE 里都有类型推导。示例使用 OpenAI 当前主力模型 gpt-5.4,实际项目里可通过环境变量配置 API Key。
import { createTool } from "@mastra/core/tools";
import { Agent } from "@mastra/core/agent";
import { z } from "zod";
const getWeather = createTool({
id: "get_weather",
description: "根据城市名称查询当前天气,适合回答天气相关提问",
inputSchema: z.object({
location: z.string().describe("城市名称,如北京、上海"),
}),
outputSchema: z.object({ summary: z.string(), temp: z.number().optional() }),
execute: async ({ location }) => {
// 实际项目里这里调和风、OpenWeather 等 API
return { summary: `${location} 晴`, temp: 22 };
},
});
const weatherAgent = new Agent({
id: "weather-agent",
name: "天气助手",
instructions: "你是天气助手,用 get_weather 查天气并简洁回复用户。",
model: "openai/gpt-5.4",
tools: { getWeather },
});
// 在 Next.js Route Handler 或 Server Action 里直接调用
const result = await weatherAgent.generate("北京今天天气怎么样?");
console.log(result.text);
在 Next.js 的 Route Handler 里暴露成 API 时,导入 weatherAgent,对请求体里的消息调 generate 或流式方法即可,不必再写状态机或图。
LangGraph:显式建图与状态
在 LangGraph 里,要先定义状态结构(例如消息列表)、再定义"agent"节点(调用模型、可能产生 tool_calls)和"tools"节点(执行工具并返回 ToolMessage),最后用边把节点串起来,并加上"是否继续调工具"的条件边。模型用 LangChain 的 ChatOpenAI 接 OpenAI 最新模型,工具用 bindTools 绑定,循环由图的拓扑自然形成。
下面这段示例用 StateGraph 定义了一个单 Agent、带一个天气工具的最小图。状态里只有 messages,agent 节点读最后一条用户消息并调用模型,若返回 tool_calls 则路由到 tools 节点,执行完再回到 agent,直到模型不再调工具为止。可与上面 Mastra 示例对照,体会"图"和"状态"的显式写法。
import { StateGraph, Annotation, END } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
import { tool } from "@langchain/core/tools";
import { z } from "zod";
import { HumanMessage, AIMessage, BaseMessage } from "@langchain/core/messages";
import { ToolNode } from "@langchain/langgraph/prebuilt";
const model = new ChatOpenAI({
model: "gpt-5.4",
apiKey: process.env.OPENAI_API_KEY,
});
const getWeather = tool(
async (input: { location: string }) => `${input.location} 晴,22℃`,
{
name: "get_weather",
description: "根据城市名称查询当前天气",
schema: z.object({ location: z.string() }),
},
);
const modelWithTools = model.bindTools([getWeather]);
const toolNode = new ToolNode([getWeather]);
const AgentState = Annotation.Root({
messages: Annotation<BaseMessage[]>({
reducer: (left, right) => left.concat(right),
default: () => [],
}),
});
async function agentNode(state: typeof AgentState.State) {
const response = await modelWithTools.invoke(state.messages);
return { messages: [response as AIMessage] };
}
function shouldContinue(state: typeof AgentState.State): "tools" | "end" {
const last = state.messages[state.messages.length - 1] as AIMessage;
return last.tool_calls?.length ? "tools" : "end";
}
const graph = new StateGraph(AgentState)
.addNode("agent", agentNode)
.addNode("tools", toolNode)
.addEdge("tools", "agent")
.addConditionalEdges("agent", shouldContinue, { tools: "tools", end: END })
.compile();
const result = await graph.invoke({
messages: [new HumanMessage("北京今天天气怎么样?")],
});
console.log(result.messages[result.messages.length - 1]);
同样实现"用户问天气、模型调工具、再回复":Mastra 是"Agent + tools 配置 + 一次 generate",LangGraph 是"状态注解 + 两节点 + 条件边 + compile"。前者适合快速落地和前端集成,后者适合加人工审核、多 Agent 分支、断点续跑等复杂控制。示例中 LangGraph 使用 gpt-5.4,API Key 建议从环境变量 OPENAI_API_KEY 读取。
选型决策思路
可以按"产品形态、团队基因、集成与定制需求"三条线问自己,再对照上文对比。决策主线就一条:先看 Agent 是"应用的核心"还是"应用里的辅助能力"。核心场景(多 Agent、长任务、状态中断与恢复、大量冷门集成或深度定制)更倾向 LangGraph;辅助能力(Next/React 为主、快速迭代、极重 TypeScript 与 DX)更倾向 Mastra。不必二选一,也可以简单对话用 Mastra、复杂管线用 LangGraph,按模块边界拆。
如下图所示。

从"核心还是辅助"出发,到倾向 LangGraph 或 Mastra(或两者组合)的决策路径。
更偏向选 Mastra 的情况
- 产品形态上,Agent 主要作为 Web 应用的辅助功能(智能搜索、客服助手、简单数据总结等),且深度绑定 Next.js、React 生态。
- 团队以前端、全栈为主,不想引入过重的后台架构,希望快速迭代、快速上线。
- 你非常看重 TypeScript 的类型安全和开发体验,对臃肿依赖和难以排查的报错比较排斥。
更偏向选 LangChain / LangGraph 的情况
- 产品形态上,核心业务就是一个复杂的 AI 系统,例如多 Agent 协作、长时间运行的异步任务、或需要精准控制思考中断与恢复。
- 集成需求多且杂,需要连接内部各种老旧系统,或使用非常小众的向量数据库、模型接口。
- 需要对底层 Prompt、重试、Memory 等做深度定制,甚至改动框架默认行为。
结合业务场景做更细的取舍
光看框架特性不够,最终要落到"这个 Agent 具体负责什么"上。下面四类典型场景方便对号入座,每类对应不同复杂度和集成需求,选错框架要么大材小用,要么后期自己造轮子。
如下图所示。
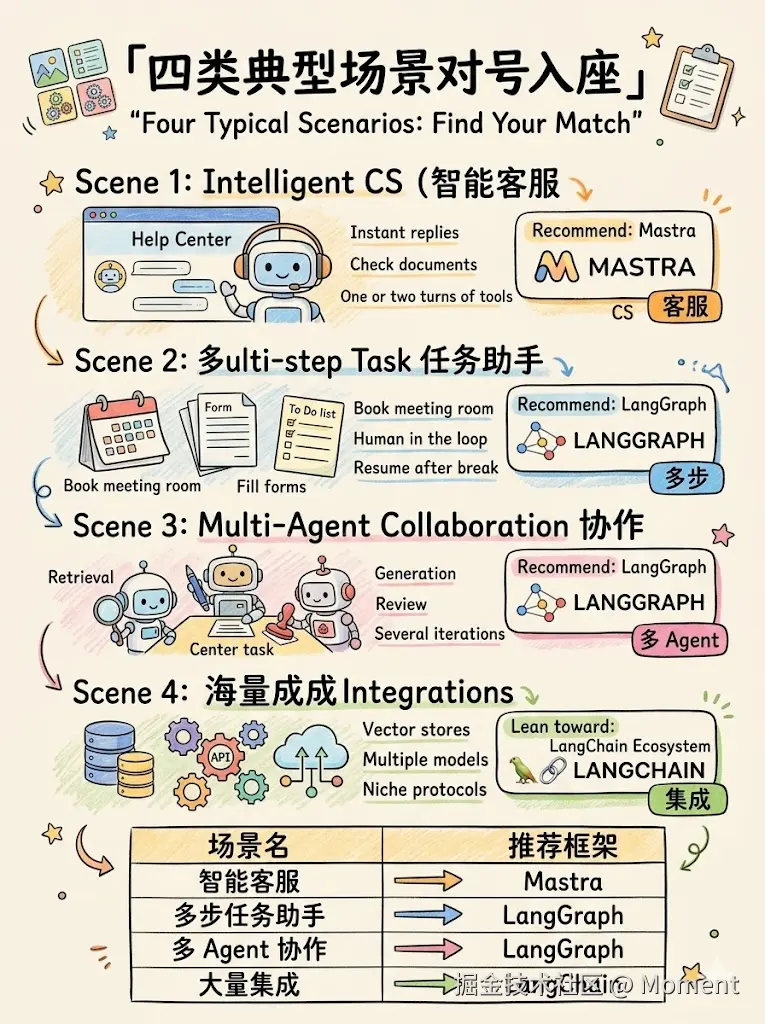
四类场景与推荐方向的对应关系。
场景一:官网或产品里的智能客服、搜索建议
用户在一页里问几句,要即时、简洁的回复,必要时查文档或知识库。流程短、状态简单,不需要多 Agent 博弈或断点续跑,前端发一条消息、收一条(或流式)回复,至多一两轮工具调用。这类需求 Mastra 的轻量 API 和 TypeScript 体验很顺手,一个 Agent 配几个工具、在 Route Handler 里调 generate 就能上线;用 LangGraph 容易杀鸡用牛刀,要先建图、理解条件边和状态,对只想做一个会查文档的客服的团队来说性价比不高。
场景二:内部工具里的"多步任务助手"
例如用自然语言帮用户订会议室、填工单、查数据并生成报告。步骤多,有时要人工确认或回退(如"是否确认提交工单"),状态要在多轮请求间保持,甚至支持"离开页面再回来从断点继续"。这类需求用 LangGraph 的状态图和 checkpointer 更自然:节点对应步骤或人工介入,边上挂条件判断,状态持久化后刷新或重连都能恢复。用 Mastra 也能做,但分支和人工介入一多,就得自己维护"当前步骤、待确认项、历史结果",等于在业务层再造状态机,不如直接用图建模,让框架负责持久化。
场景三:多 Agent 协作(检索、生成、审核等分工)
多角色各司其职,之间有固定或动态调用关系,甚至要循环几轮才产出结果。这类编排是 LangGraph 的强项;Mastra 更适合"一个主 Agent 调若干工具"的链式交互,多 Agent 的路由和状态共享要自己写胶水代码。
场景四:向量库、模型、外部 API 集成种类多
公司内有自建向量库、多种大模型和第三方 API,希望用同一套抽象管住"检索、调用、解析"。LangChain 的集成生态在这里优势明显:Pinecone、Weaviate、Qdrant、自建 REST、各类 LLM 与 RAG 预制链和图,大多有现成包。Mastra 偏向精选常用组合,技术栈若较"非主流"(内网模型、私有协议、冷门向量库),可能要自己写适配层,把外部能力包成 Mastra 能识别的工具或模型接口。要权衡多写的适配代码是否被 Mastra 的 DX 和轻量部署抵消;若集成种类还会持续增加,直接上 LangChain 生态往往更省事。
常见误区与落地注意点
选型时容易踩的坑和落地前值得想清楚的几点,简单归纳如下。
不必纠结的两点。第一,没有"用了 Mastra 就不能用 LangChain"这回事,两者可共存,例如边缘或 BFF 用 Mastra 做轻量对话,后台用 LangGraph 做复杂管线,用 HTTP 或消息队列打通。第二,没有"LangGraph 一定比 Mastra 重"的绝对结论,重的是你要维护的图与状态逻辑;若你只需要一张简单 agent-tools 图,编译后运行时开销可接受,主要是上手成本高。
需要提前想清楚的两点。一是"先简单后复杂"时,若判断半年内会演进到多 Agent 或人机协同,可早点把复杂子流程用 LangGraph 建模,哪怕先只实现单 Agent,图结构也为后续加节点留好位置,避免以后在 Mastra 里手写状态机再迁一轮。二是"先复杂后简化"时,若团队普遍抱怨 LangChain 报错难查、概念太多,可把"单轮或短对话"抽成独立服务,用 Mastra 重写,接口不变、前端无感,逐步降维护成本。
最后,无论选哪边,都建议一开始就把"输入输出契约"(请求体格式、流式 SSE、错误码)定好,并用 TypeScript 类型或 OpenAPI 描述出来,以后换实现、做 A/B 或拆服务时,前端和网关都不必大动。
混合使用与迁移成本
不少团队会折中:简单、面向用户的 Agent 用 Mastra,部署在前端或边缘;复杂、长链路、多 Agent 的管线放后端,用 LangGraph 或 LangChain 实现,通过 API 暴露。这样既保住前端侧的开发体验和性能,又在需要复杂编排时用上 LangChain 生态。
若一开始选了 Mastra,后面业务演进到必须上状态图、多 Agent,可以只把"复杂子流程"迁到 LangGraph,用 HTTP 或消息队列和现有 Mastra Agent 对接,不必全盘重写。例如前端仍用 Mastra 做即时问答,把多步审批、长任务编排单独做成 LangGraph 服务,Mastra 在需要时调该服务 API。反过来,若一开始用 LangChain 搭了简单客服,发现维护成本高、报错难排查,可以把单轮或短对话抽成独立服务,用 Mastra 重写,逐步迁移。关键是想清楚边界(按功能、按请求路径、按团队 ownership 都行),按边界拆模块,而不是非此即彼。迁移时优先保证输入输出契约稳定(统一 JSON 请求体、流式 SSE 格式),前端或网关就不必大改。
总结与下一步
Mastra 和 LangChain(LangGraph)代表两种设计哲学:前者为前端和 TypeScript 优化,追求轻量和 DX;后者面向通用 AI 编排和复杂状态,追求生态和表达能力。没有谁一定更好,只看和你的业务场景、团队结构、集成与定制需求是否匹配。
一句话记住选型心法:Agent 是"应用里的辅助能力"、团队偏前端、要快上线,优先看 Mastra;Agent 是"业务核心"、有多 Agent、长任务、人机协同或大量冷门集成,优先看 LangGraph。两者也可组合,按模块边界拆,契约定好即可。
建议先明确两件事:当前要做的 Agent 主要负责什么(辅助功能还是核心 AI 系统),以及半年到一年内会不会出现多 Agent、长任务、复杂集成或深度定制。有了这两个问题的答案,再对照文中的对比表、决策说明和四类场景,选型会清晰很多。若你愿意说一下目前在规划的 Agent 具体负责什么业务、会接哪些系统,可以在此基础上再做一轮更细的技术栈评估和落地方案设计。文中的代码示例使用当前主流的 gpt-5.4,可直接复制后按需改模型名和 API Key 配置。