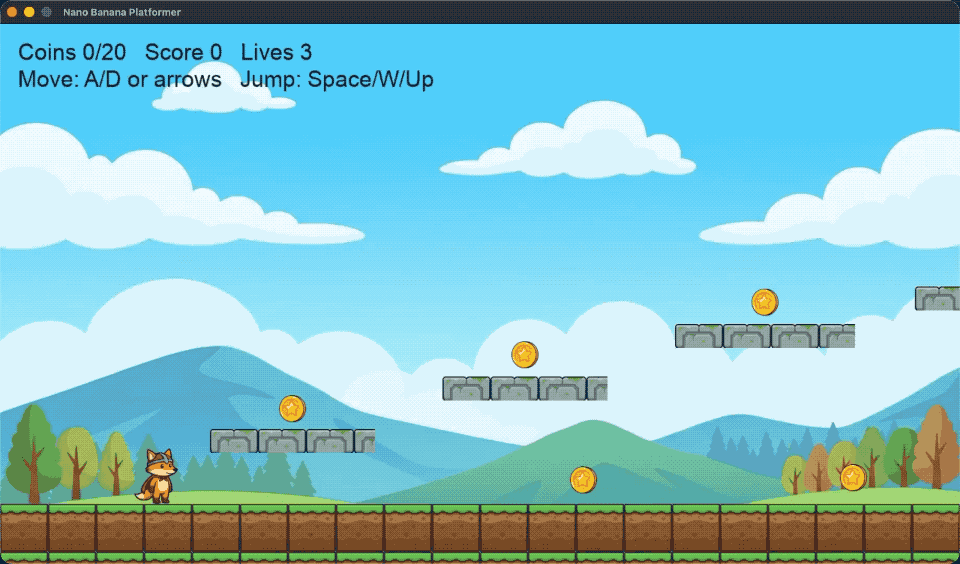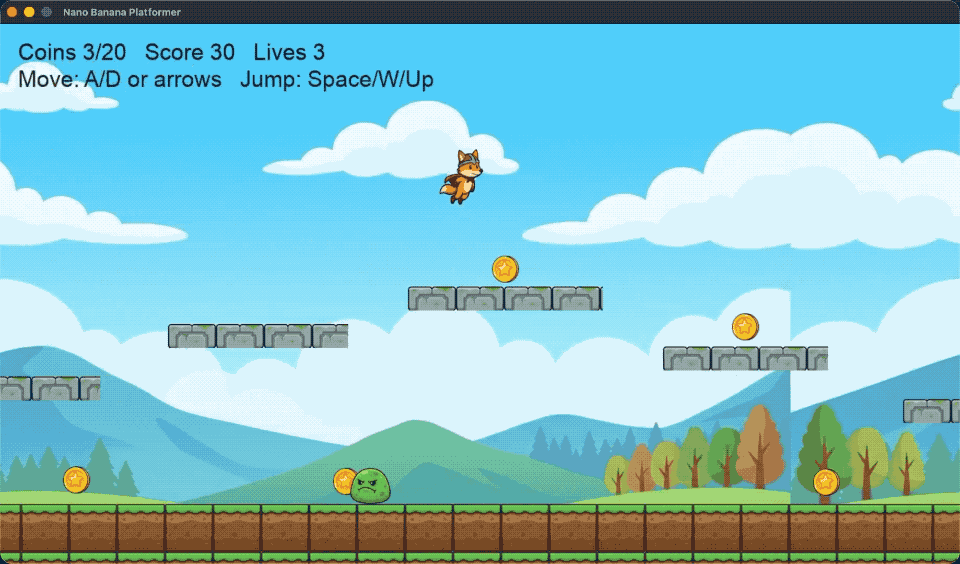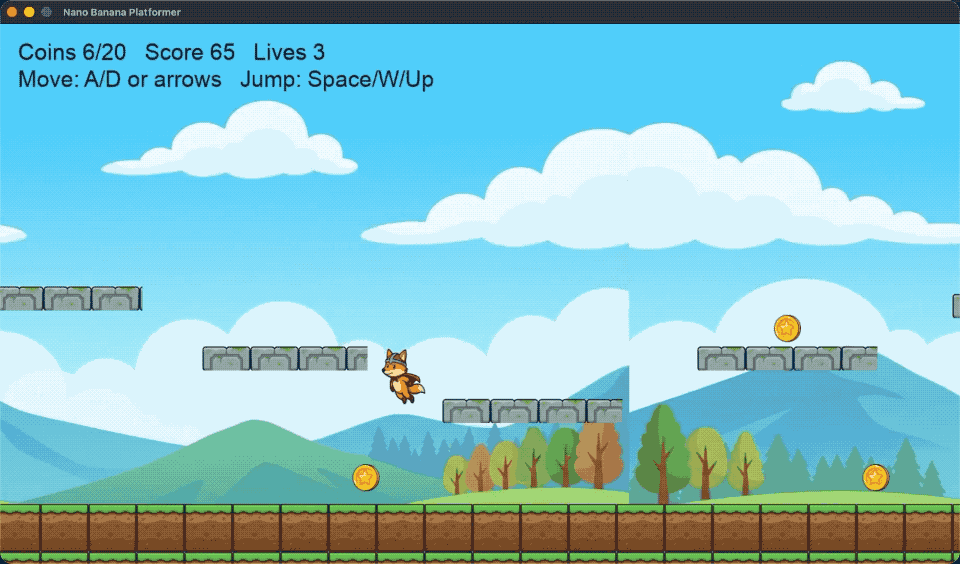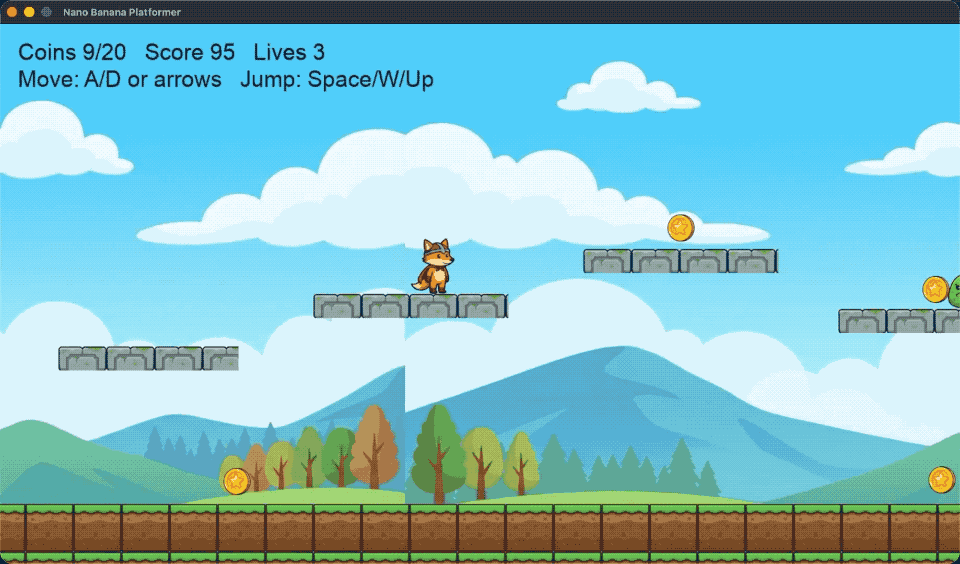
背景

相信大家都已经体验过了市面上各种 Coding Agent 应用(Claude Code、codeX、kimi-cli...),一定也对其原理有过好奇。废话不多说,咱们今天直实现一个 Mini Coding Agent
阅读本文前最好对 llm、tools 有一些基础的理解,(可以阅读笔者之前的文章「完全理解」MCP 到底是什么?从零开始实现一个完整的 MCP 调用链)
本文案例代码:github.com/qqqqqcy/cod…
1. 1 分钟实现 Mini Coding Agent
实现一个 Mini Coding Agent 其实并不复杂,跟着步骤来甚至都花不了 1 分钟。我们先给自己的项目取个名称方便后续称呼,为了省事咱们就叫 mca(Mini Coding Agent)
1.1. 快速实现
在根目录 mca 中初始化 package.json 文件和对应目录,因为是个分阶段的项目,第一个阶段先新建一个 0_deepagents 文件夹
mca
├── .env
├── 0_deepagents
│ └── src
│ ├── index.js
│ └── test.js
└── package.json
项目主要目的是弄懂 Coding Agent 原理,所以我们不会从 LLM 调用开始,会基于成熟的 SDK 封装。作为一个前端,可以先非常粗略的类比一了下后续会用到的相关依赖,有一个基础概念
| 基础层级 |
成熟封装的 SDK |
成熟应用(配置好了路由、全局 store、组件库、项目基础框架) |
| JavaScript |
Vue、React |
各种开箱即用的基础应用 |
| LLM API |
LangChain、LangGraph |
Deep Agents |
首先我们基于 deepagents 来实现 mca,同时过程中会涉及环境变量,所有先以下三个依赖
npm i @langchain/deepseek deepagents dotenv
deepagents 是一个独立的库,用于构建能够处理复杂多步骤任务的智能体。它基于 LangGraph 构建,并受到 Claude Code、Deep Research 和 Manus 等应用的启发,具备规划能力、用于上下文管理的文件系统以及生成子代理的能力。
{
"name": "mini-coding-agent",
"version": "1.0.0",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo "Error: no test specified" && exit 1",
"start": "node ./0_deepagents/src/index.js"
},
"license": "ISC",
"dependencies": {
"@langchain/deepseek": "^1.0.9",
"deepagents": "^1.7.0",
"dotenv": "^17.2.4"
}
}
先不说废话,直接基于 deepagents 创建一个智能体。
如果使用的非 deepseek model 可以参考此处替换对应依赖
// file: 0_deepagents/src/index.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import { createDeepAgent, FilesystemBackend } from "deepagents";
// 项目根目录,用于提示词中告知 Agent 工作目录
const PROJECT_ROOT = process.cwd();
// 简洁的 ReAct 风格系统提示词
const CODING_AGENT_SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
// As a ReAct coding agent, interpret user instructions and execute them using the most suitable tool.
`;
// 创建 Coding Agent 所需的全部代码 ⬇️⬇️⬇️
export const codingAgent = createDeepAgent({
// 声明 agent 所用模型
model: new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
}),
// createDeepAgent 会使用虚拟容器,因此我们指定一下位置为命令行执行目录
backend: new FilesystemBackend({
rootDir: PROJECT_ROOT,
virtualMode: true
}),
systemPrompt: CODING_AGENT_SYSTEM_PROMPT,
name: "coding_agent",
});
const args = process.argv.slice(2);
if (args.length === 0) {
console.log('请输入指令');
process.exit(1);
} else {
codingAgent.invoke({
messages: [{ role: "user", content: args?.[0] }],
}).then(res => {
console.log(res.messages[res.messages.length - 1].content);
}).catch(err => {
console.error(err);
});
}
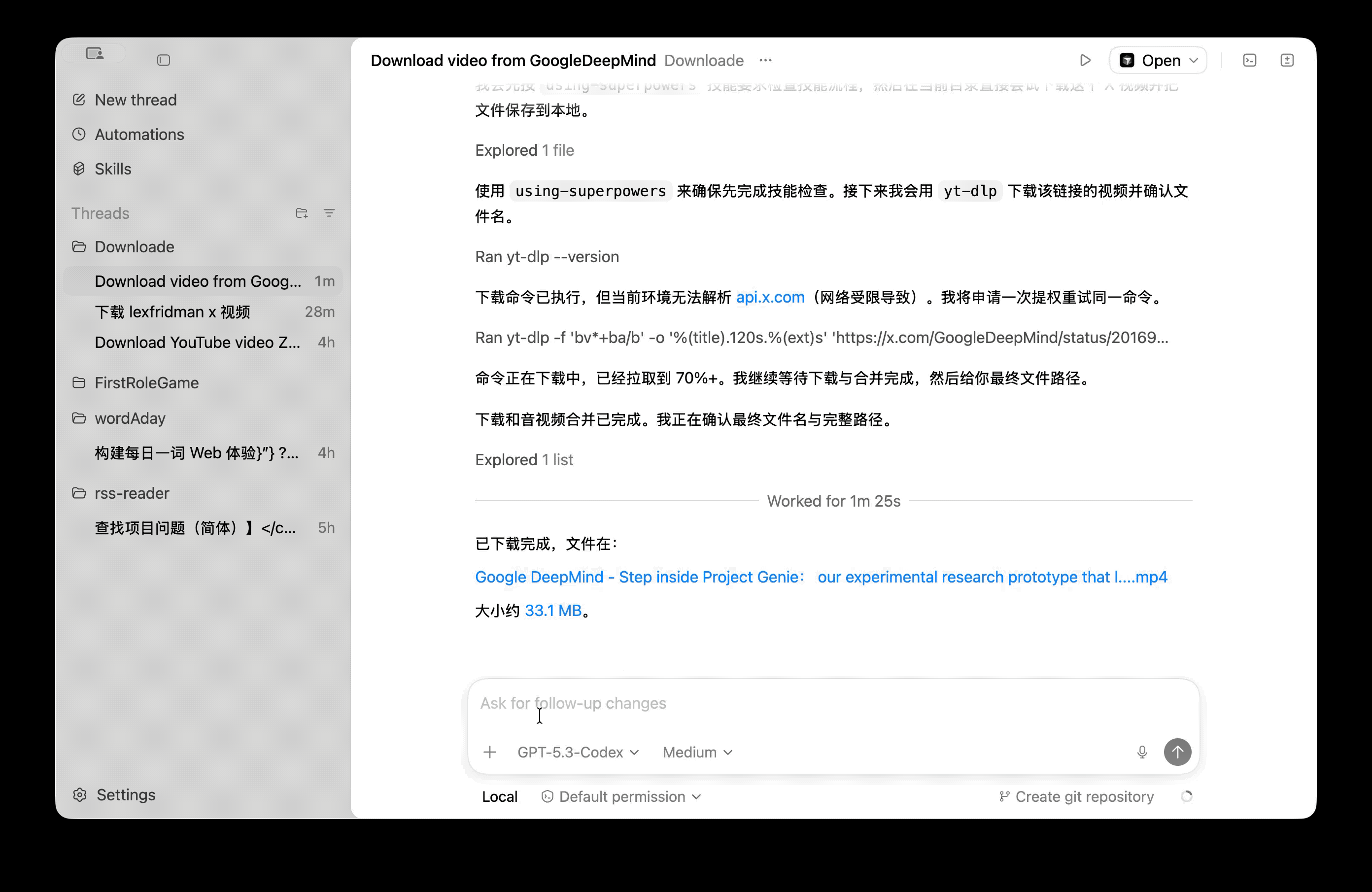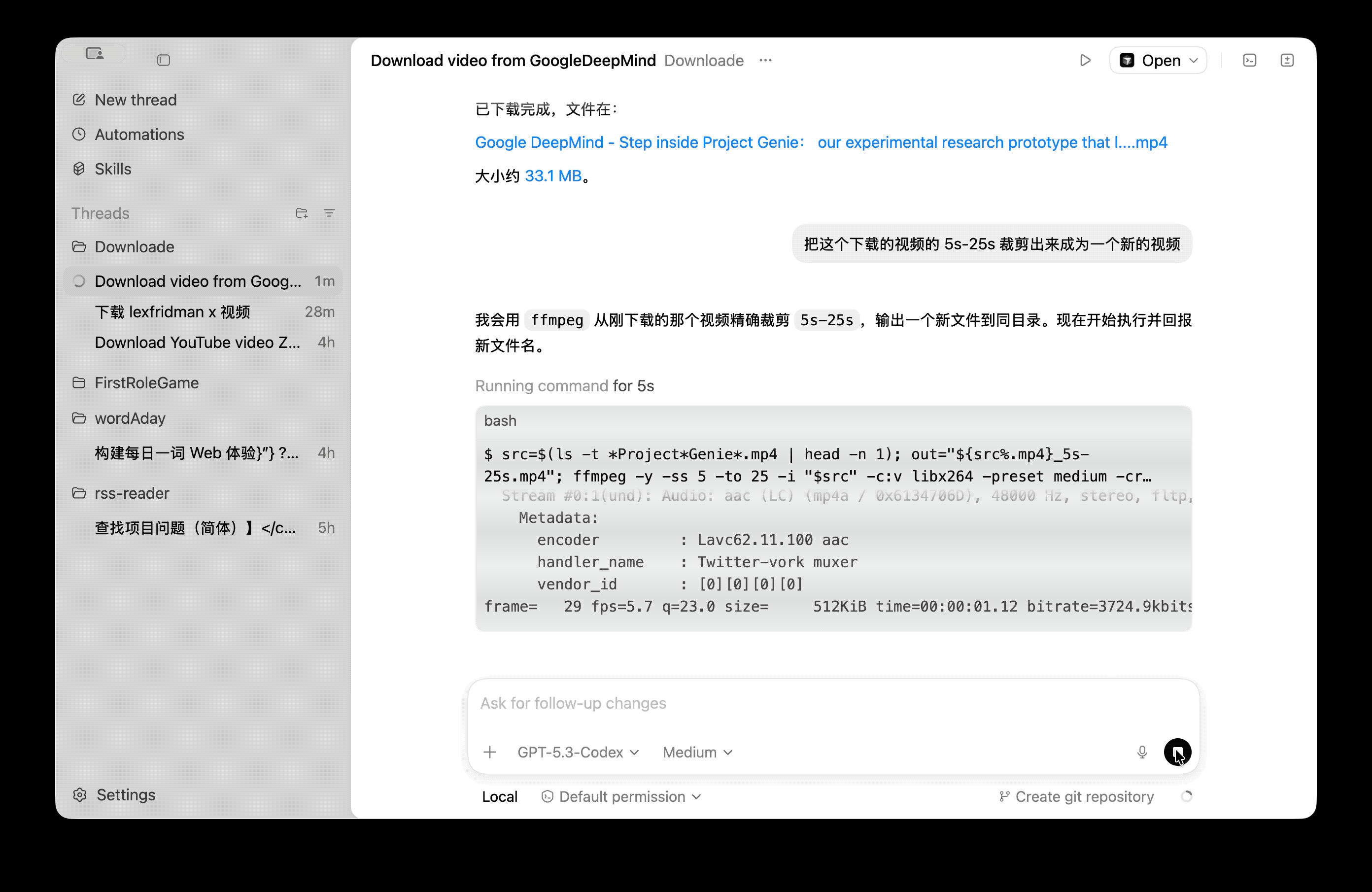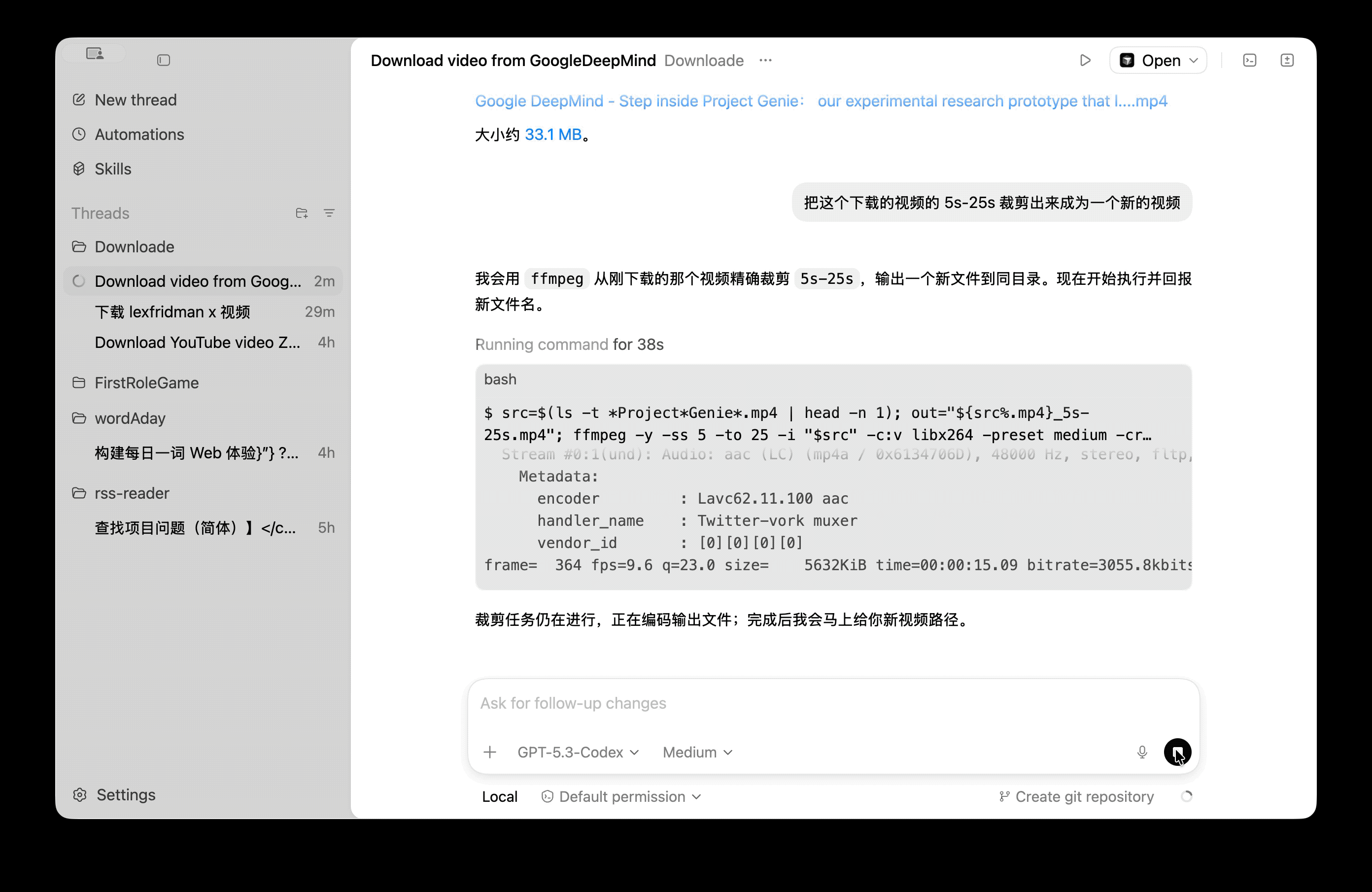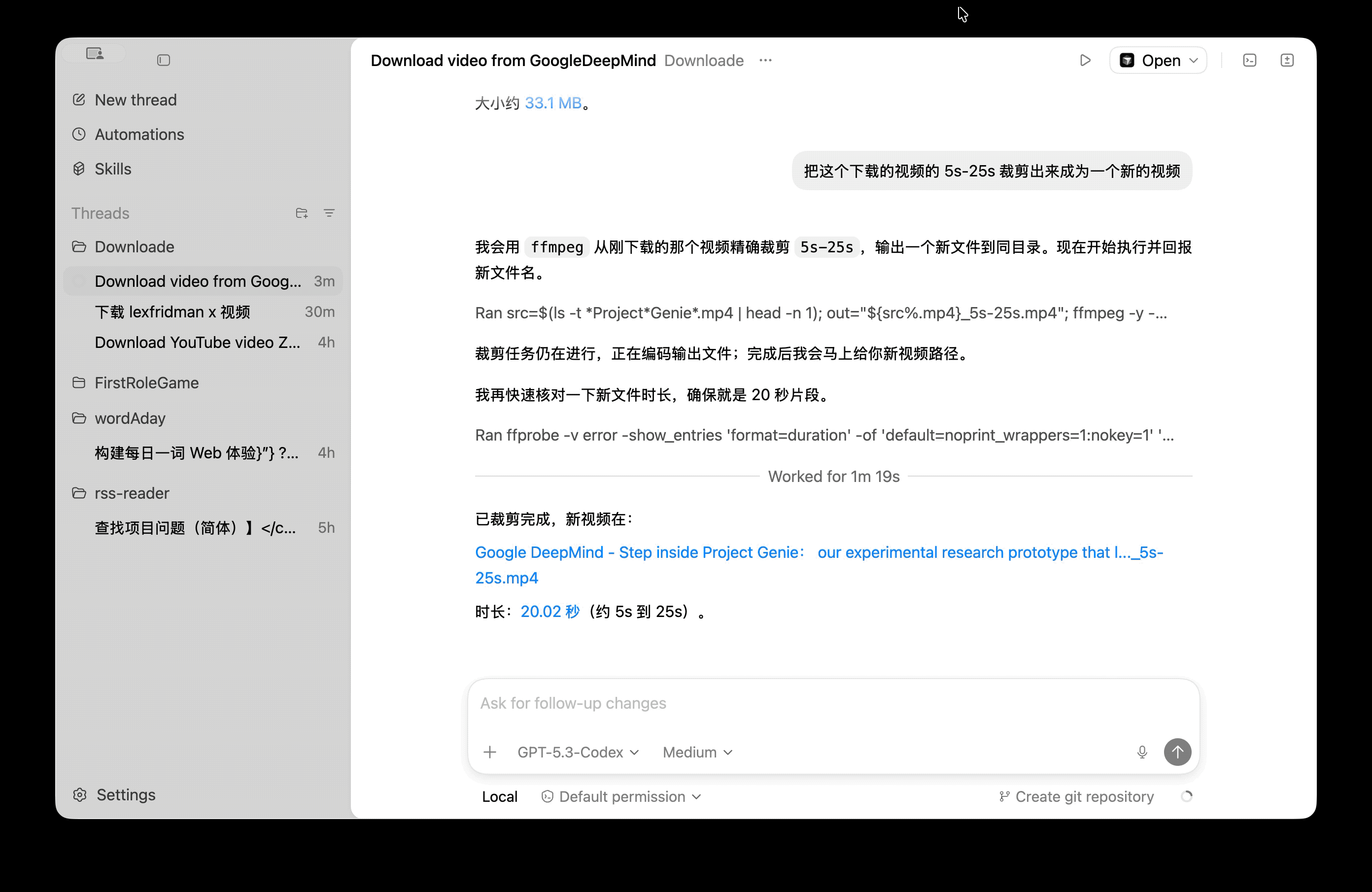
在 .env 里配置好相关 LLM 服务的 key(本文用的 deepseek)
# .env
DEEPSEEK_API_KEY=在开放平台获取的 key
在根目录用命令行验证一下
npm start '概述下 0_deepagents 项目'
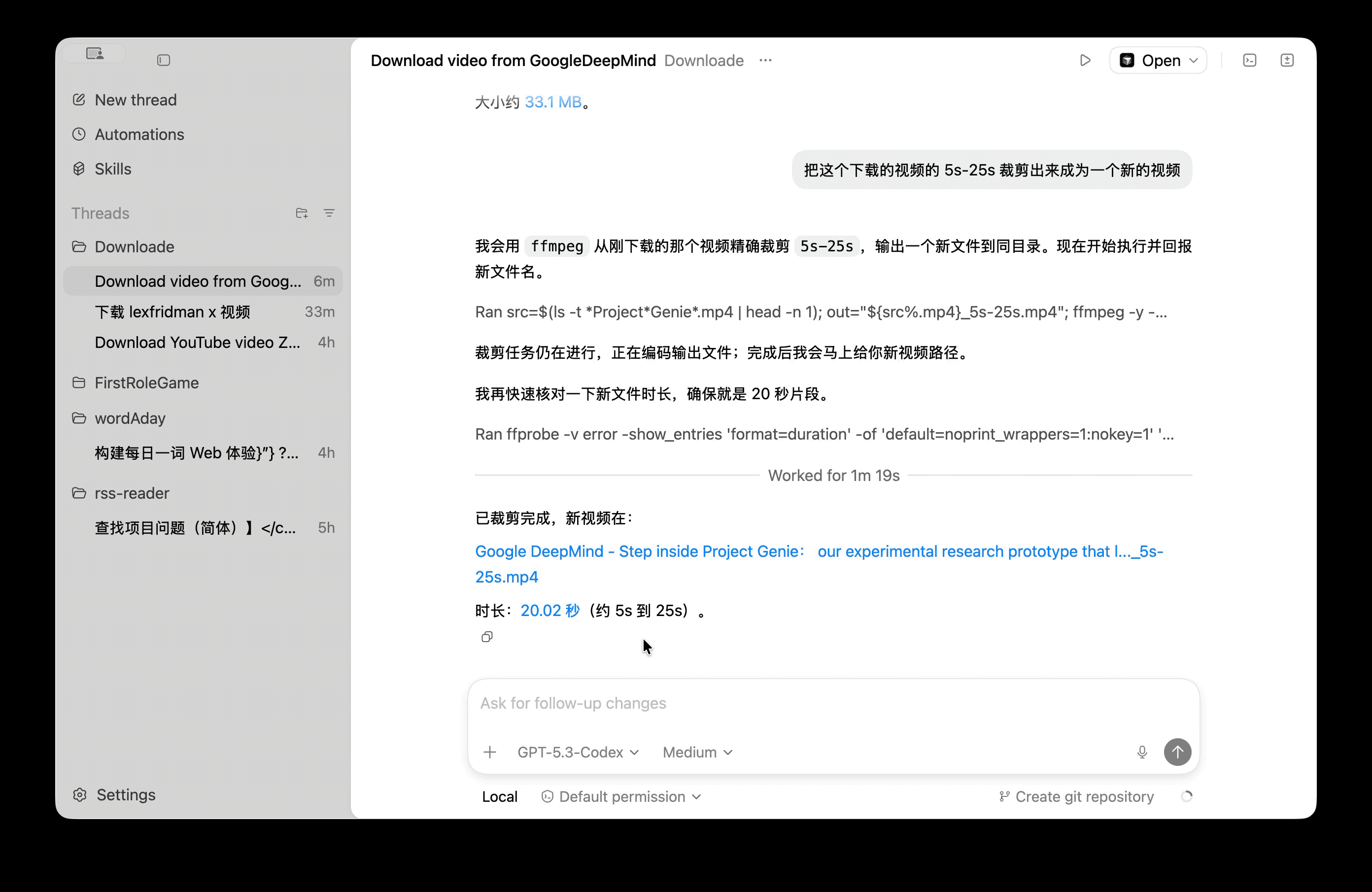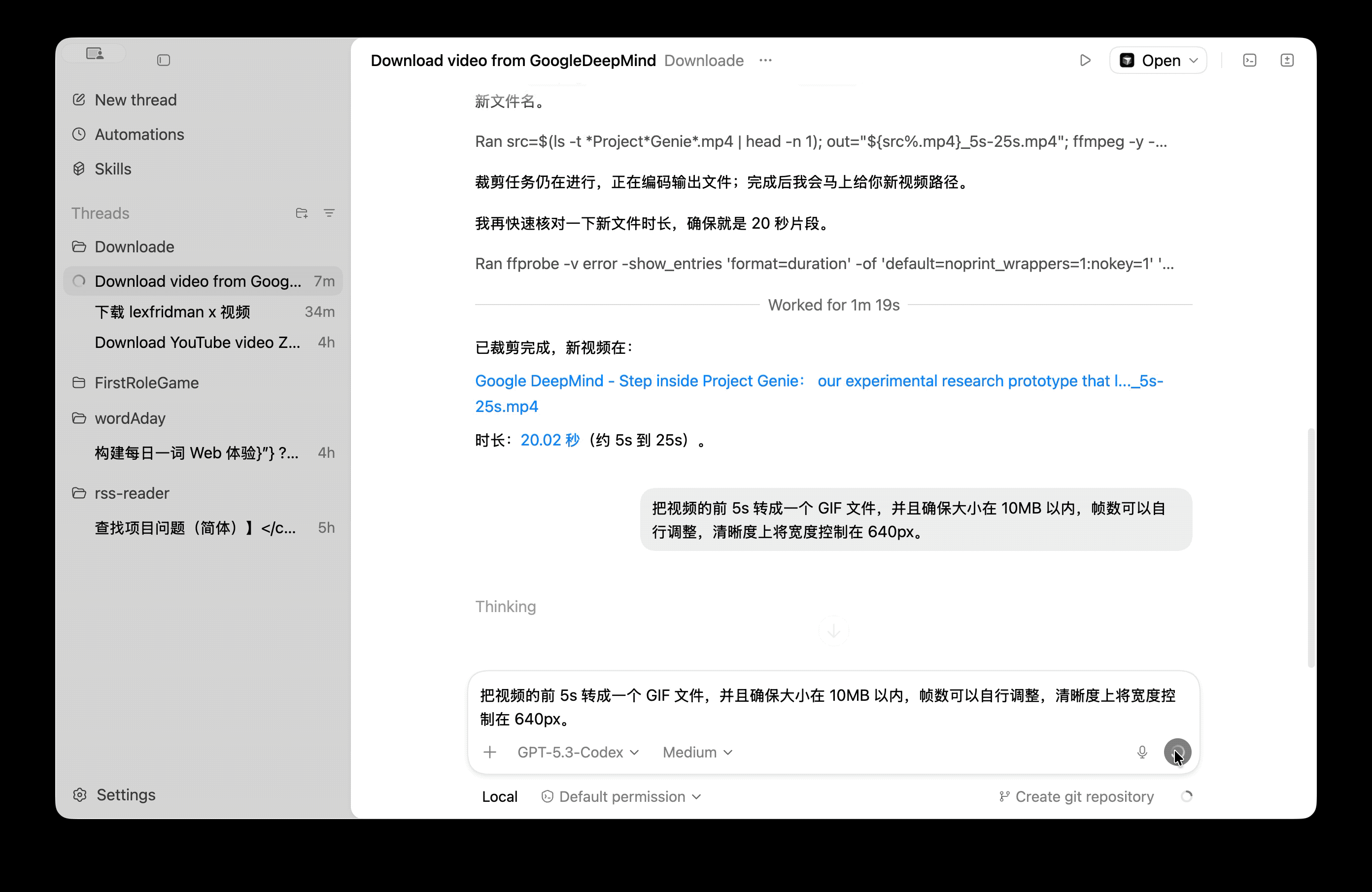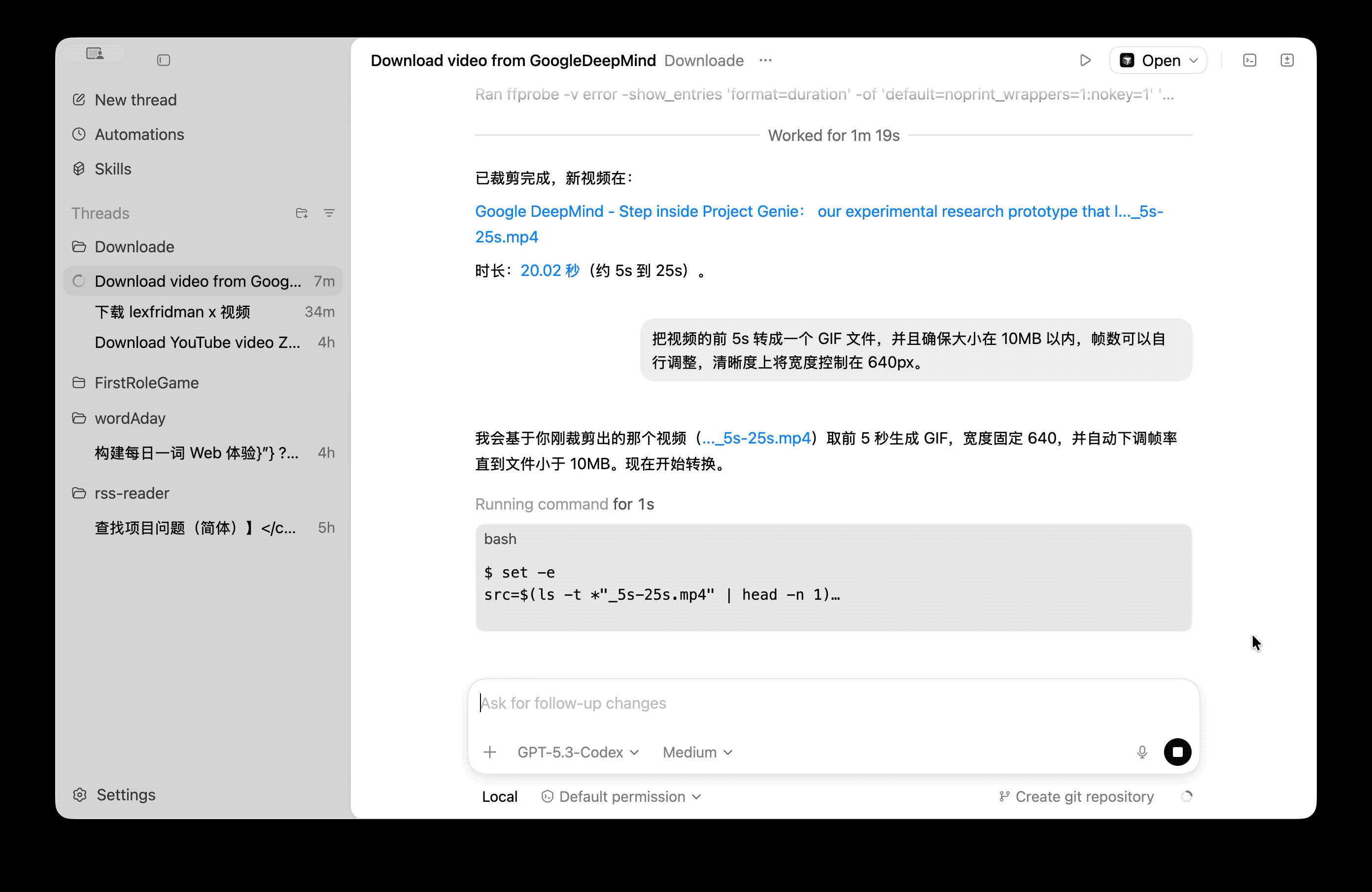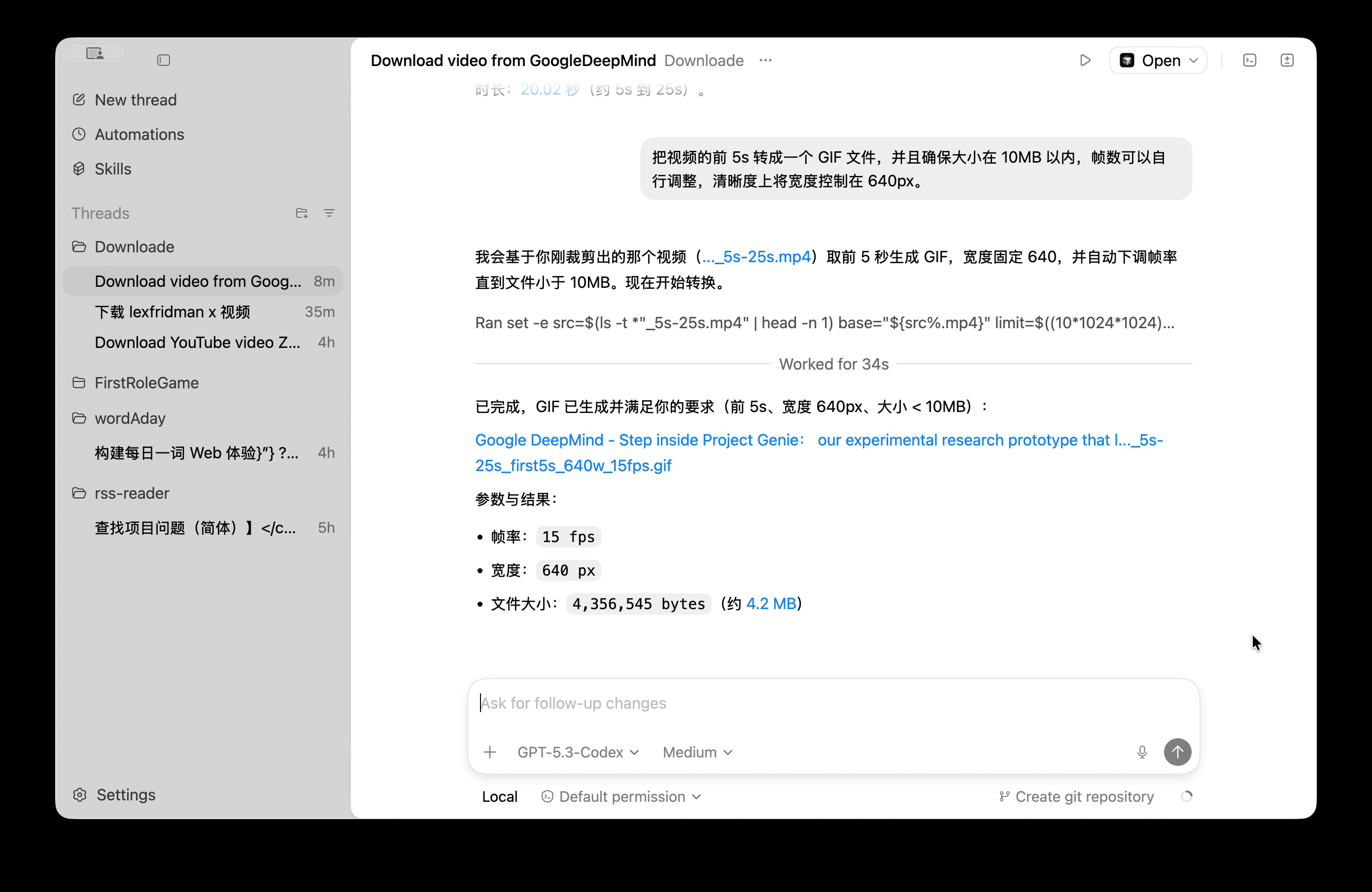
成功执行之后,可以获取类似输出:
于我对项目的分析,我来为您概述 **0_deepagents** 项目:
## 项目概述
**0_deepagents** 是一个基于 DeepSeek AI 和 DeepAgents 框架构建的代码助手代理项目,它是 `mini-coding-agent` 项目的一部分。
## 核心功能
1. **AI 驱动的代码助手**:使用 DeepSeek 的 Chat API 作为底层模型
2. **ReAct 架构**:采用 Reasoning and Acting 模式,能够解释用户指令并选择合适的工具执行
3. **文件系统集成**:通过 FilesystemBackend 与本地文件系统交互
4. **命令行接口**:支持通过命令行参数传递指令
## 技术栈
- **运行时环境**:Node.js (ES Module)
- **AI 模型**:DeepSeek Chat (通过 @langchain/deepseek 集成)
- **代理框架**:DeepAgents v1.7.0
- **配置管理**:dotenv 用于环境变量管理
- **追踪监控**:LangSmith 用于 API 调用追踪
## 项目结构
```
0_deepagents/
└── src/
└── index.js # 主入口文件,包含代理配置和启动逻辑
```
## 核心组件
### 1. **代理配置** (`codingAgent`)
- 使用 DeepSeek Chat 模型 (temperature=0, maxTokens=4096)
- 虚拟文件系统模式,工作目录为项目根目录
- 简洁的 ReAct 风格系统提示词
### 2. **系统提示词**
- 告知代理当前工作目录 (`PROJECT_ROOT`)
- 定义代理角色:作为 ReAct 编码代理,解释用户指令并使用最合适的工具执行
### 3. **命令行接口**
- 支持通过 `npm start` 或直接运行 `node ./0_deepagents/src/index.js` 启动
- 通过命令行参数传递用户指令
- 错误处理和用户友好的提示信息
## 使用方式
1. **环境配置**:需要设置 `DEEPSEEK_API_KEY` 环境变量
2. **启动代理**:
```bash
npm start "你的指令"
# 或
node ./0_deepagents/src/index.js "你的指令"
```
3. **功能示例**:
- 代码生成和修改
- 文件系统操作
- 项目分析和重构
## 项目特点
1. **轻量级设计**:代码简洁,专注于核心功能
2. **模块化架构**:易于扩展和集成其他工具
3. **生产就绪**:包含错误处理和日志追踪
4. **可配置性**:通过环境变量灵活配置 API 密钥和追踪设置
## 在整体项目中的位置
`0_deepagents` 是 `mini-coding-agent` 项目的第一个模块,后续还有 `1_langgraph` 等其他模块,共同构成一个完整的 AI 编码助手系统。
这个项目展示了如何将现代 AI 模型与代理框架结合,创建一个实用的代码助手工具,能够理解自然语言指令并执行相应的编码任务。
🎉🎉🎉 恭喜你!亲手实现了 Mini Coding Agent,下一步就是年薪百万了,下课!
1.2. 拆解魔法
你可能会一头雾水,这就实现了?我是谁?我在哪?怎么它就能正确的分析当前目录了?
稍安勿躁,我们慢慢开始解析
1.2.1. Agent 定义
首先从定义开始,到底什么是 Agent?
网上关于 Agent 的文章千千万,定义也不尽相同。我个人是这么理解的:
AI Agent = 具有特定范式,以及工具调用能力的 LLM
工具调用不必多说,范式简单来说就是实现目标的「思考方式」,比如是最简单的只执行一步,还是列完总体步骤分布执行,或者是执行一步看一步...
常见范式:
| Agent 范式类型 |
核心逻辑 |
| ReAct Agent |
思考-行动交替,无提前规划 |
| Plan&Execute Agent |
先规划、再按步骤执行 |
| Self-Ask Agent |
自我提问-工具验证,无修正 |
| ... |
... |
1.2.2. mca 的范式和工具
大部分 Coding Agent 的本质是一个 ReAct 风格的 Agent,mca 当然也一样
ReAct 是 Reasoning and Act 的缩写,是一种让 LLM 能够「边思考边行动」的提示范式,核心思想是让模型交替进行 Reasoning(推理)和 Acting(行动)。
基本流程:
-
Thought(思考) :模型分析当前状态,决定下一步做什么
-
Action(行动) :执行具体操作(比如调用搜索 API、读文件)
-
Observation(观察) :获取行动结果
- 重复 1-3,直到得出最终答案
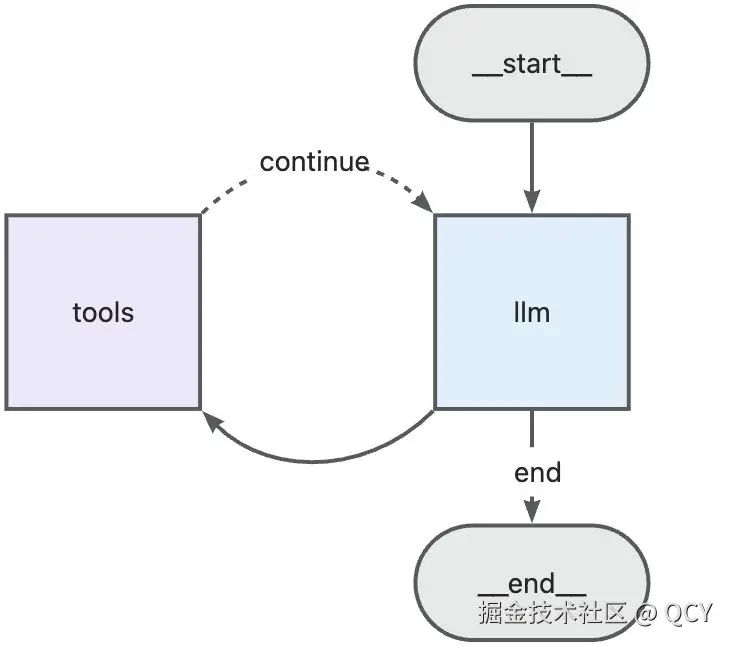
它拥有自己的规划、感知和执行能力:
- 通过调用只读的文件系统工具集(ls、read_file、grep...) 获得仓库的结构和必要的上下文,从而定位到与用户需求相关的文件和行号
- 然后再通过文本编辑器工具集(write_file、edit_file...) 将代码写入仓库
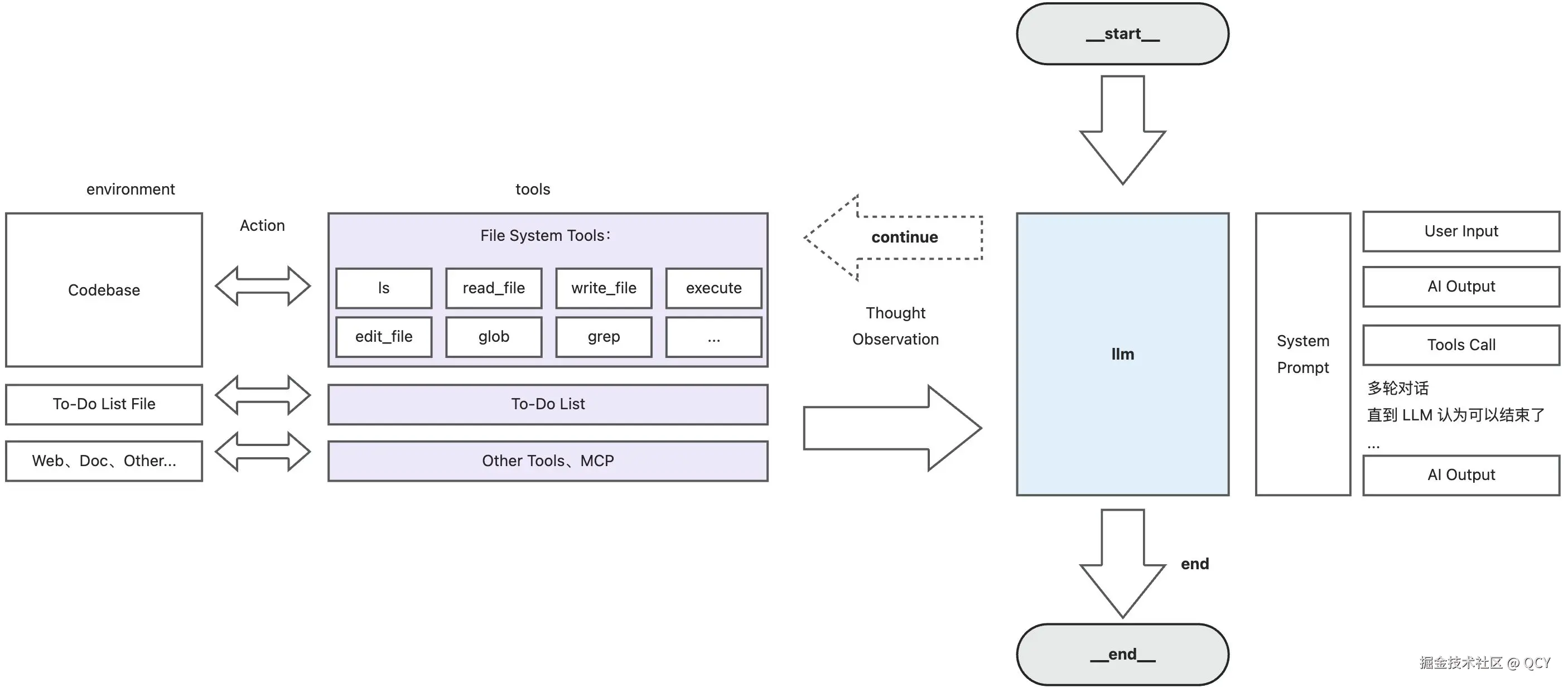
1.2.3. 验证内部逻辑
说了一大堆可能还是没什么实感,我们可以通过查看 mca 内部执行日志来更直观的感受
查日志的流程非常简单,在 deepagents 提供的日志服务 LangSmith 注册并获取 API key
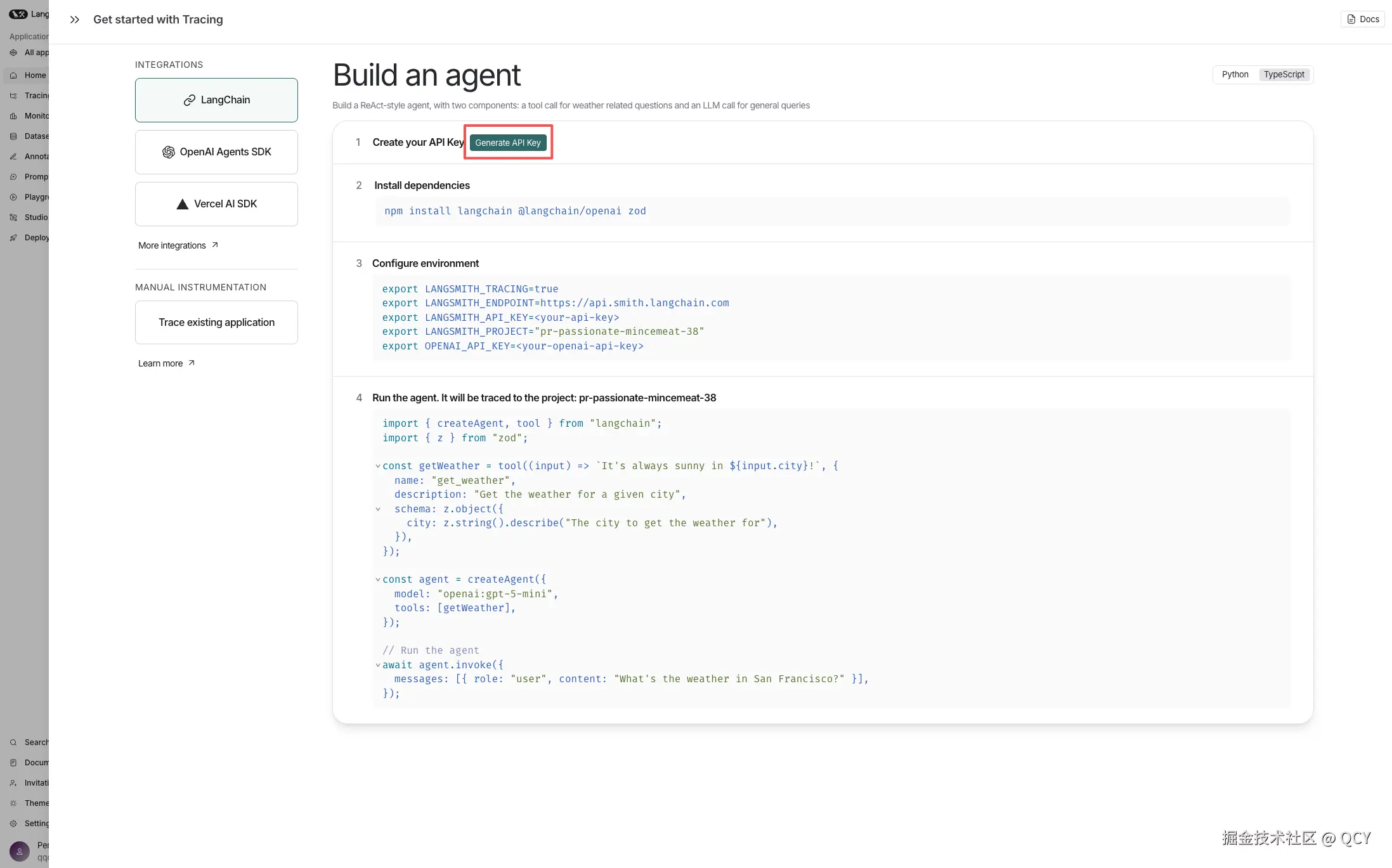
在之前的 .env 中增加相关配置(无需修改任何代码)
# .env
DEEPSEEK_API_KEY=在开放平台获取的 key
+ LANGSMITH_TRACING=true
+ LANGSMITH_API_KEY=刚获取的 API key
+ LANGSMITH_PROJECT="mca"
重新执行刚才的 node 命令,就可以实时在 LangSmith 上查看相关日志了
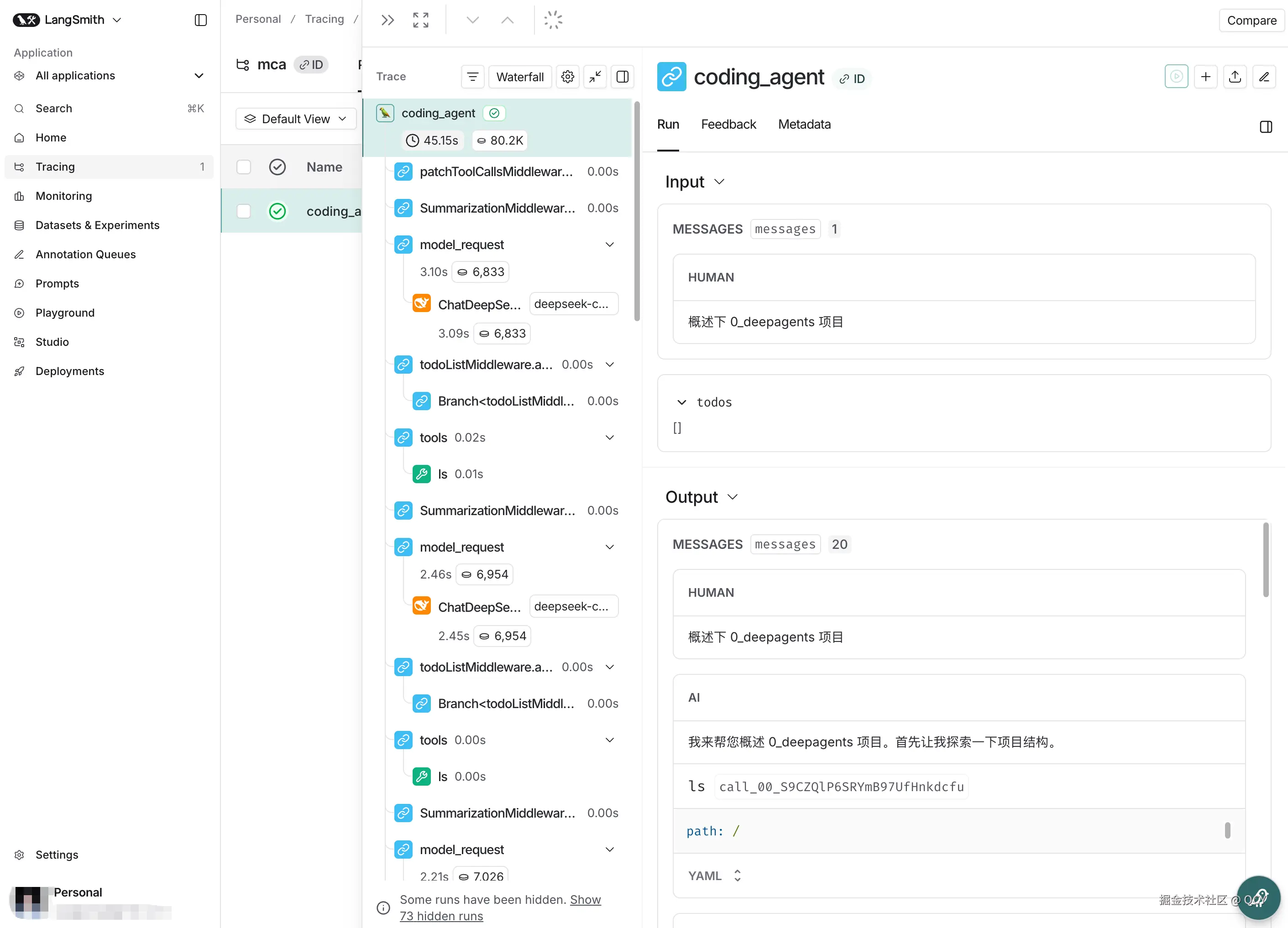
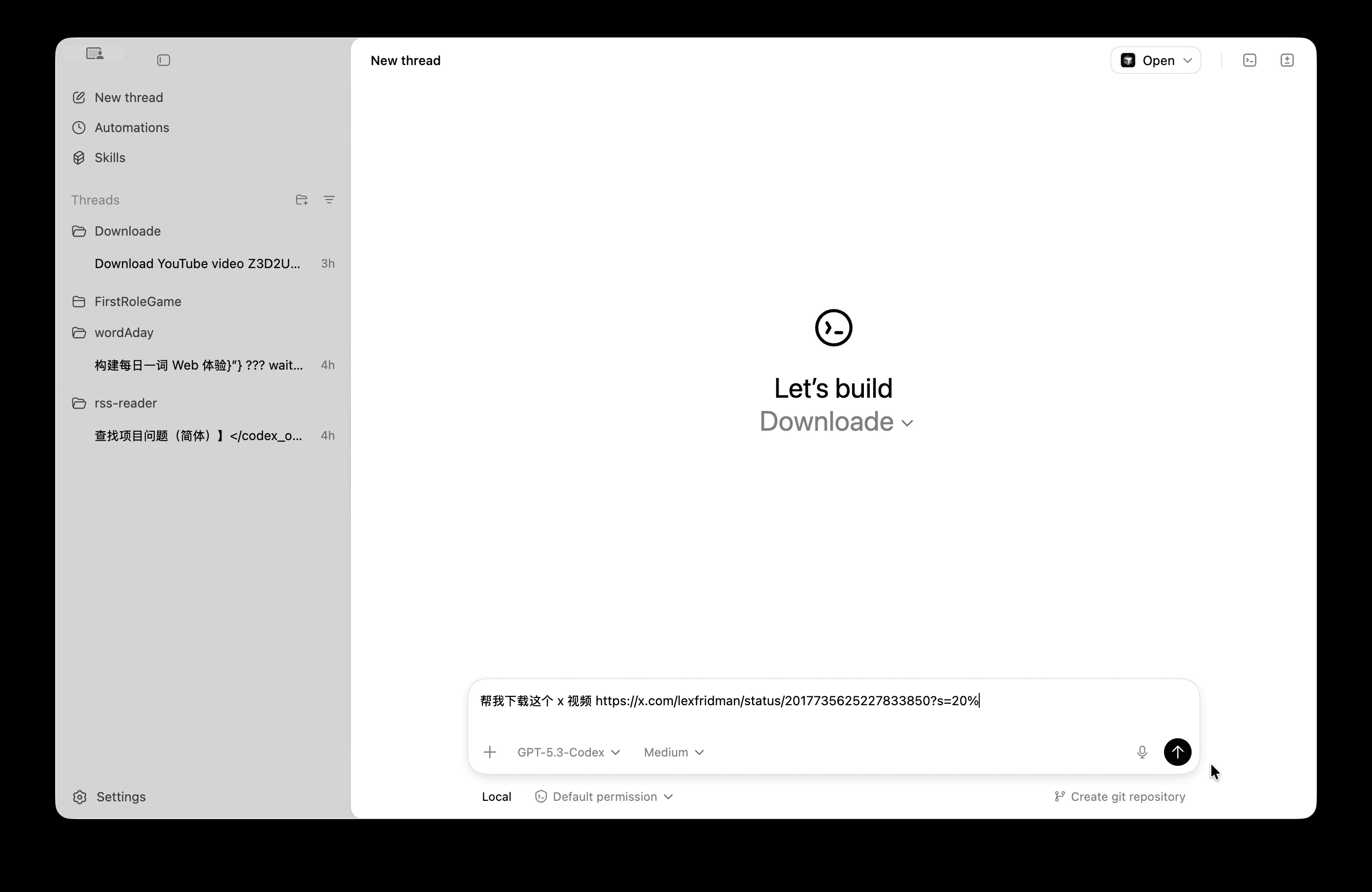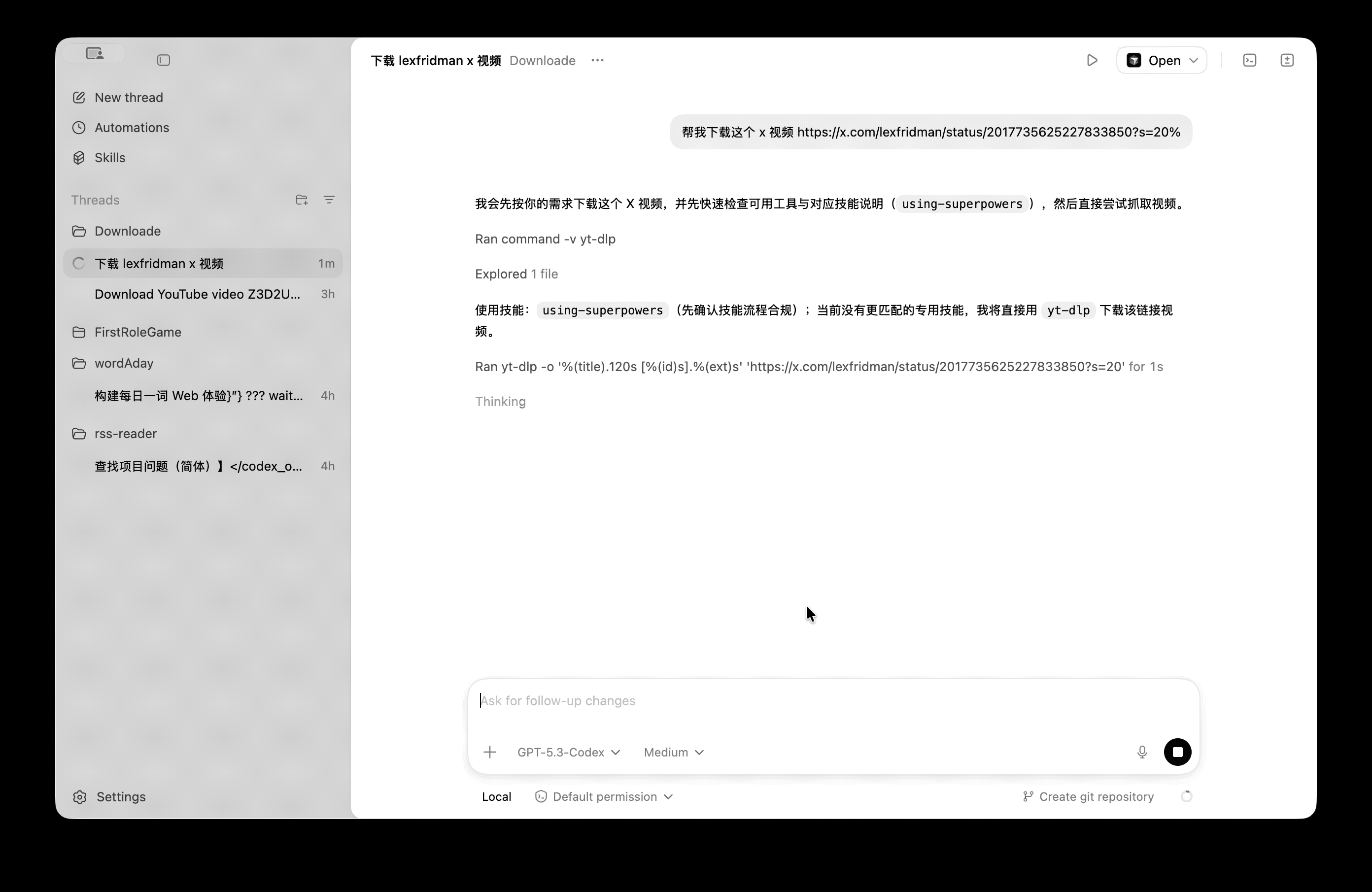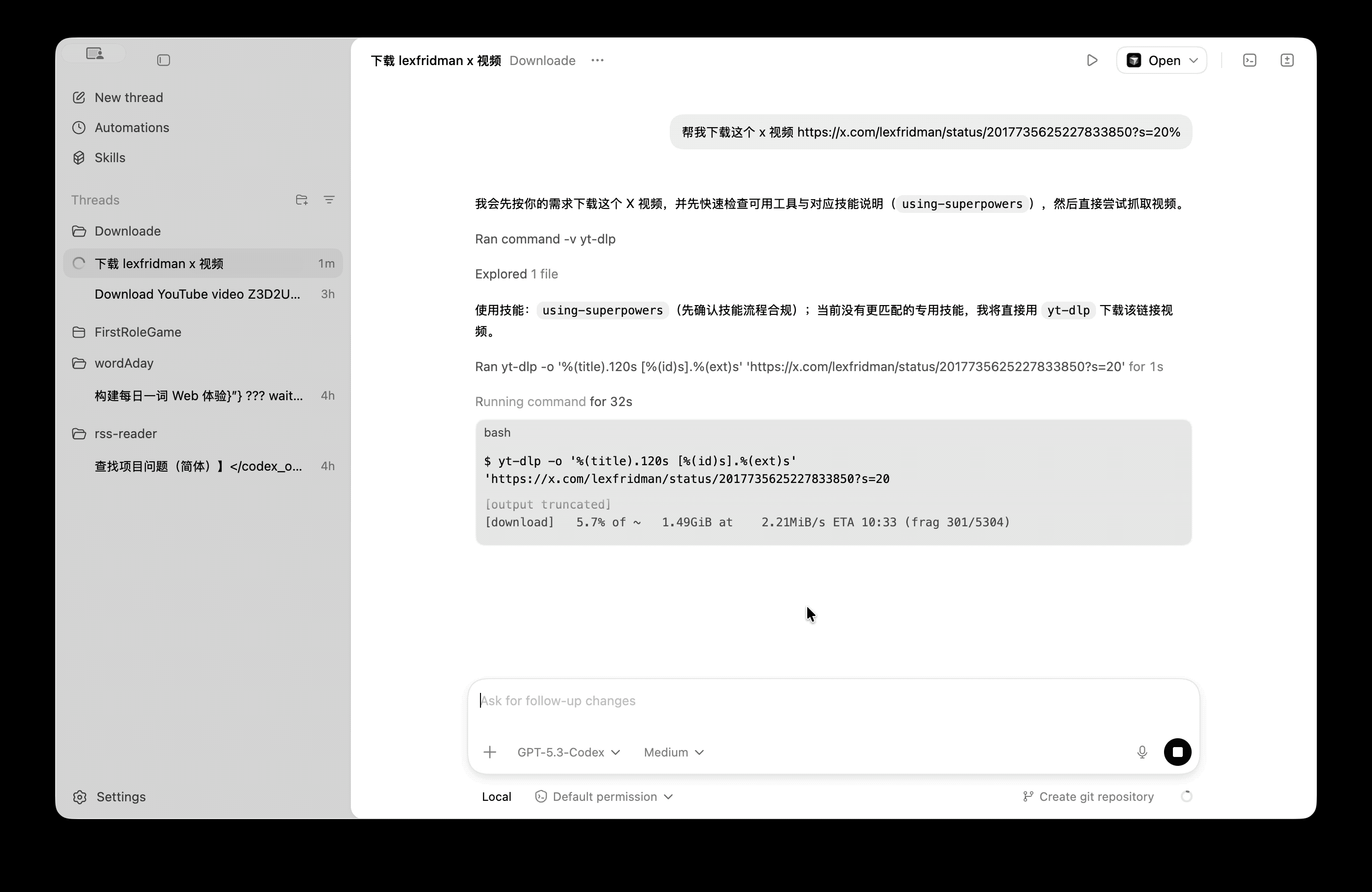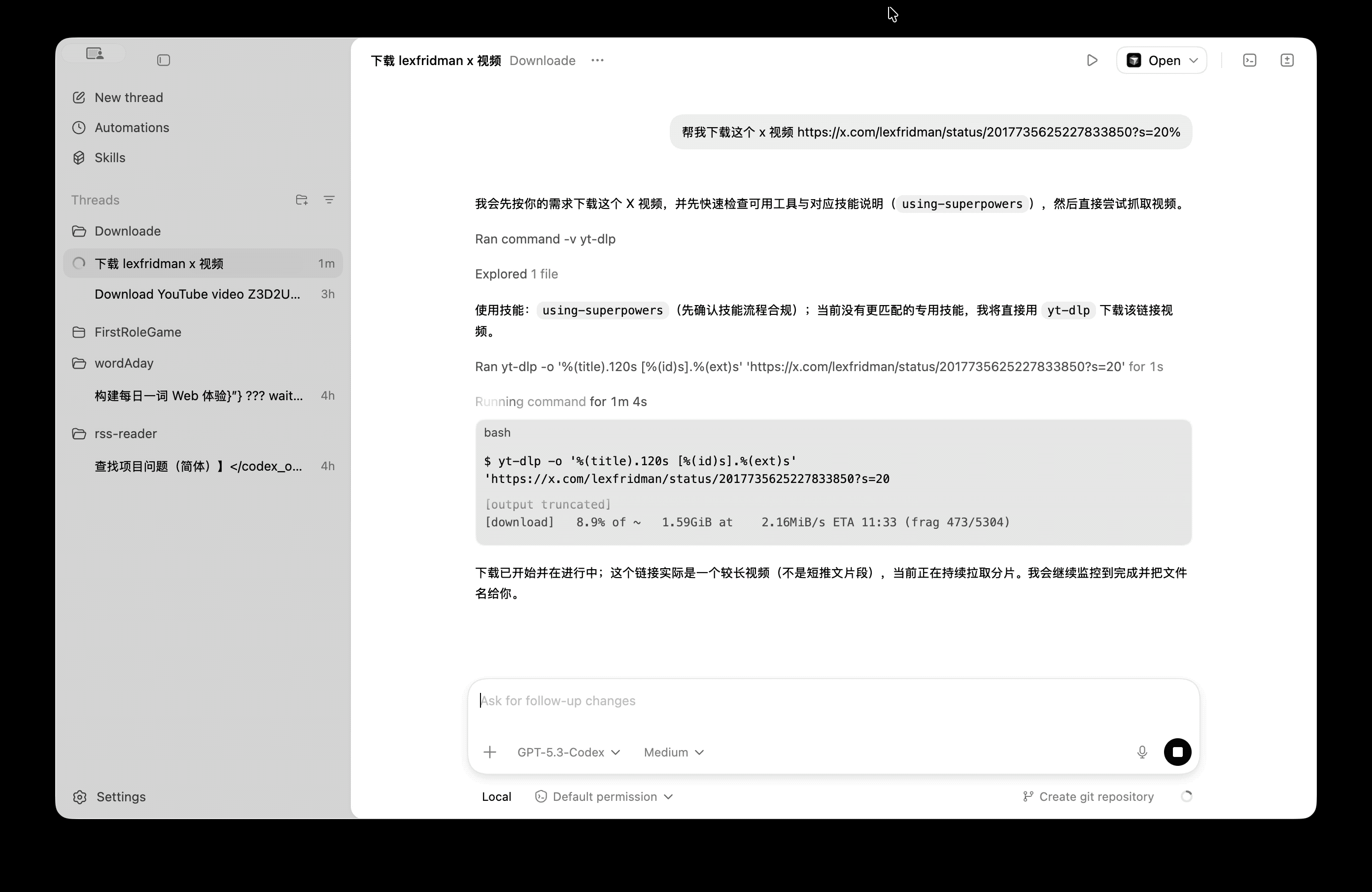
这个界面非常直观,每一步做了什么、入参、出参都非常清晰。通过阅读日志,我们可以发现 mca 本质上就是基于 LLM 调用不同工具获取所需信息,信息足够之后就可以输出最终结果
比如点击到任意 Chat 节点,可以查看完整的 SystemPrompt、可用 Tools
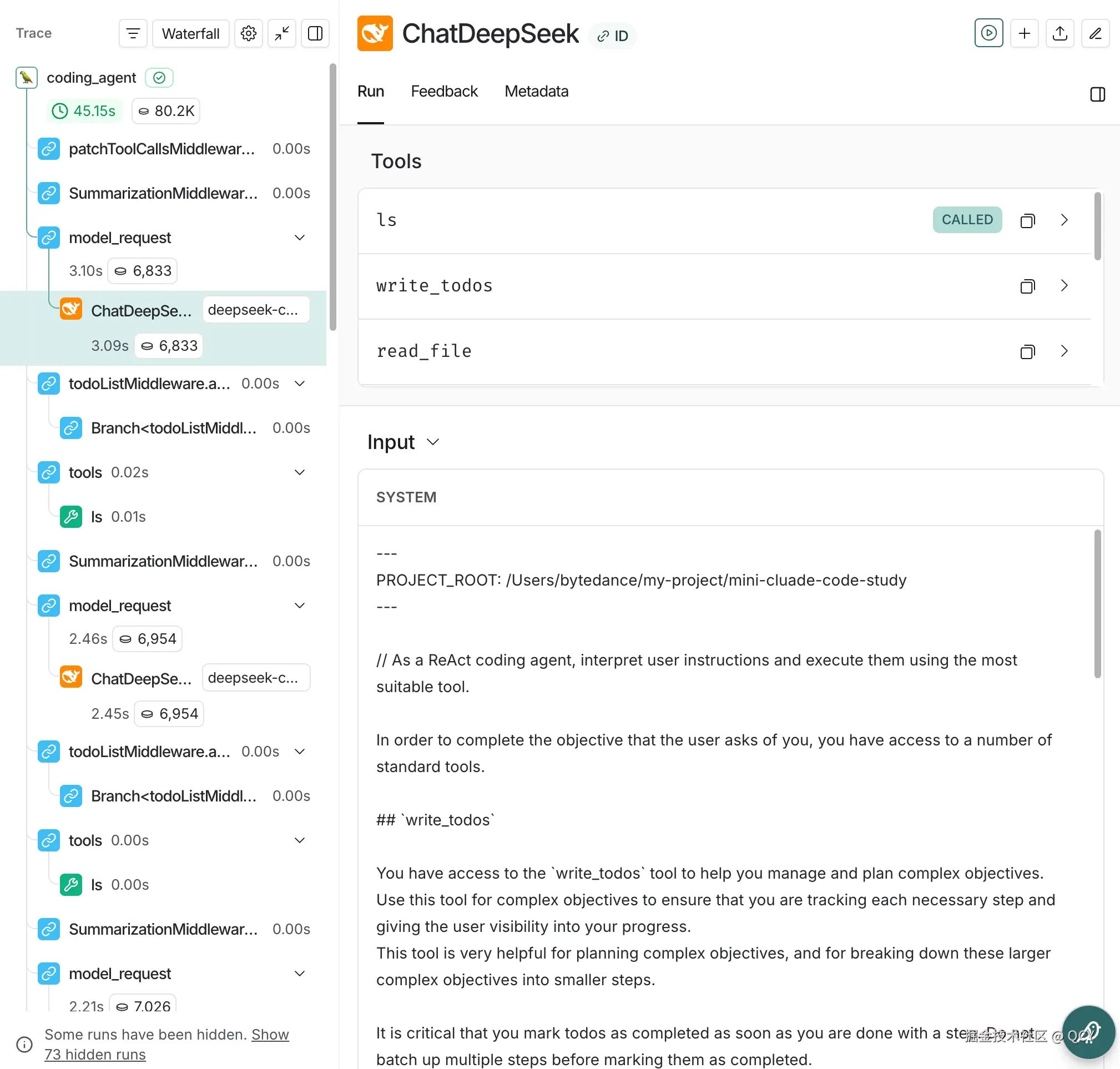
除开最顶部两行是我们自定义的以外,下面都是 deepagents 自行添加的,主要功能是:
- 声明要记录 TODO(为了减少复杂度我们后续可以先忽略这一部分)
- 可用的文件系统相关工具
- 如何开启 Subagent(为了减少复杂度我们后续可以先忽略这一部分)
---
PROJECT_ROOT: /Users/bytedance/my-project/mini-cluade-code-study
---
// As a ReAct coding agent, interpret user instructions and execute them using the most suitable tool.
In order to complete the objective that the user asks of you, you have access to a number of standard tools.
## `write_todos`
You have access to the `write_todos` tool to help you manage and plan complex objectives.
Use this tool for complex objectives to ensure that you are tracking each necessary step and giving the user visibility into your progress.
This tool is very helpful for planning complex objectives, and for breaking down these larger complex objectives into smaller steps.
It is critical that you mark todos as completed as soon as you are done with a step. Do not batch up multiple steps before marking them as completed.
For simple objectives that only require a few steps, it is better to just complete the objective directly and NOT use this tool.
Writing todos takes time and tokens, use it when it is helpful for managing complex many-step problems! But not for simple few-step requests.
## Important To-Do List Usage Notes to Remember
- The `write_todos` tool should never be called multiple times in parallel.
- Don't be afraid to revise the To-Do list as you go. New information may reveal new tasks that need to be done, or old tasks that are irrelevant.
## Filesystem Tools `ls`, `read_file`, `write_file`, `edit_file`, `glob`, `grep`
You have access to a filesystem which you can interact with using these tools.
All file paths must start with a /.
- ls: list files in a directory (requires absolute path)
- read_file: read a file from the filesystem
- write_file: write to a file in the filesystem
- edit_file: edit a file in the filesystem
- glob: find files matching a pattern (e.g., "**/*.py")
- grep: search for text within files
## `task` (subagent spawner)
You have access to a `task` tool to launch short-lived subagents that handle isolated tasks. These agents are ephemeral — they live only for the duration of the task and return a single result.
When to use the task tool:
- When a task is complex and multi-step, and can be fully delegated in isolation
- When a task is independent of other tasks and can run in parallel
- When a task requires focused reasoning or heavy token/context usage that would bloat the orchestrator thread
- When sandboxing improves reliability (e.g. code execution, structured searches, data formatting)
- When you only care about the output of the subagent, and not the intermediate steps (ex. performing a lot of research and then returned a synthesized report, performing a series of computations or lookups to achieve a concise, relevant answer.)
Subagent lifecycle:
1. **Spawn** → Provide clear role, instructions, and expected output
2. **Run** → The subagent completes the task autonomously
3. **Return** → The subagent provides a single structured result
4. **Reconcile** → Incorporate or synthesize the result into the main thread
When NOT to use the task tool:
- If you need to see the intermediate reasoning or steps after the subagent has completed (the task tool hides them)
- If the task is trivial (a few tool calls or simple lookup)
- If delegating does not reduce token usage, complexity, or context switching
- If splitting would add latency without benefit
## Important Task Tool Usage Notes to Remember
- Whenever possible, parallelize the work that you do. This is true for both tool_calls, and for tasks. Whenever you have independent steps to complete - make tool_calls, or kick off tasks (subagents) in parallel to accomplish them faster. This saves time for the user, which is incredibly important.
- Remember to use the `task` tool to silo independent tasks within a multi-part objective.
- You should use the `task` tool whenever you have a complex task that will take multiple steps, and is independent from other tasks that the agent needs to complete. These agents are highly competent and efficient.
到这里,我们已经基本清楚了要实现一个 mca 的全部条件!
- 提供文件读写工具
- LLM + Prompt + ReAct 范式
2. 10 分钟实现 Mini Coding Agent
接下来抛开 DeepAgents,尝试用 LangGraph 实现上减少了一层封装的 mca
LangGraph 是一个低层级的编排框架和运行时,用于构建、管理和部署长期运行、有状态的智能体。(可以理解为一堆常用 LLM 相关逻辑的语法糖 SDK )
为了更好理解不同的 Coding Agent,我们这次改为参照 Cladue Code 而不是 deepagents
2.1. 文件读写工具
具体要哪些工具、每个工具的功能是什么不同 Coding Agent 有自己的理解和实现。
要分析代码简单来说就是读代码、写代码,所以我们主要实现读写相关的工具
| 工具 |
说明 |
| Bash |
在持久 shell 会话中执行 bash 命令,支持可选的超时和后台执行。 |
| BashOutput |
从正在运行或已完成的后台 bash shell 中获取输出。 |
| Edit |
在文件中执行精确的字符串替换。 |
| Read |
从本地文件系统读取文件,包括文本、图片、PDF 和 Jupyter notebook。 |
| Write |
将文件写入本地文件系统,如果文件已存在则覆盖。 |
| Glob |
快速文件模式匹配,适用于任何规模的代码库。 |
| Grep |
基于 ripgrep 构建的强大搜索工具,支持正则表达式。 |
本文重点是理解 Coding Agent,所以不会古法手搓这些 Tools,而是直接基于现有文档让 AI 辅助生成
2.1.1. LangChain 中关于如何创建一个工具的相关文档
这里只是给出复制之后的文档便于后续使用,不用细看。后面的长 Markdown 也类似
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.langchain.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Tools
Tools extend what [agents](/oss/javascript/langchain/agents) can do—letting them fetch real-time data, execute code, query external databases, and take actions in the world.
Under the hood, tools are callable functions with well-defined inputs and outputs that get passed to a [chat model](/oss/javascript/langchain/models). The model decides when to invoke a tool based on the conversation context, and what input arguments to provide.
<Tip>
For details on how models handle tool calls, see [Tool calling](/oss/javascript/langchain/models#tool-calling).
</Tip>
## Create tools
### Basic tool definition
The simplest way to create a tool is by importing the `tool` function from the `langchain` package. You can use [zod](https://zod.dev/) to define the tool's input schema:
```ts theme={null}
import * as z from "zod"
import { tool } from "langchain"
const searchDatabase = tool(
({ query, limit }) => `Found ${limit} results for '${query}'`,
{
name: "search_database",
description: "Search the customer database for records matching the query.",
schema: z.object({
query: z.string().describe("Search terms to look for"),
limit: z.number().describe("Maximum number of results to return"),
}),
}
);
```
<Note>
**Server-side tool use:** Some chat models feature built-in tools (web search, code interpreters) that are executed server-side. See [Server-side tool use](#server-side-tool-use) for details.
</Note>
<Warning>
Prefer `snake_case` for tool names (e.g., `web_search` instead of `Web Search`). Some model providers have issues with or reject names containing spaces or special characters with errors. Sticking to alphanumeric characters, underscores, and hyphens helps to improve compatibility across providers.
</Warning>
## Access context
Tools are most powerful when they can access runtime information like conversation history, user data, and persistent memory. This section covers how to access and update this information from within your tools.
### Context
Context provides immutable configuration data that is passed at invocation time. Use it for user IDs, session details, or application-specific settings that shouldn't change during a conversation.
Tools can access an agent's runtime context through the `config` parameter:
```ts theme={null}
import * as z from "zod"
import { ChatOpenAI } from "@langchain/openai"
import { createAgent } from "langchain"
const getUserName = tool(
(_, config) => {
return config.context.user_name
},
{
name: "get_user_name",
description: "Get the user's name.",
schema: z.object({}),
}
);
const contextSchema = z.object({
user_name: z.string(),
});
const agent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [getUserName],
contextSchema,
});
const result = await agent.invoke(
{
messages: [{ role: "user", content: "What is my name?" }]
},
{
context: { user_name: "John Smith" }
}
);
```
### Long-term memory (Store)
The [`BaseStore`](https://reference.langchain.com/javascript/langchain-core/stores/BaseStore) provides persistent storage that survives across conversations. Unlike state (short-term memory), data saved to the store remains available in future sessions.
Access the store through `config.store`. The store uses a namespace/key pattern to organize data:
```ts expandable theme={null}
import * as z from "zod";
import { createAgent, tool } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
const store = new InMemoryStore();
// Access memory
const getUserInfo = tool(
async ({ user_id }) => {
const value = await store.get(["users"], user_id);
console.log("get_user_info", user_id, value);
return value;
},
{
name: "get_user_info",
description: "Look up user info.",
schema: z.object({
user_id: z.string(),
}),
}
);
// Update memory
const saveUserInfo = tool(
async ({ user_id, name, age, email }) => {
console.log("save_user_info", user_id, name, age, email);
await store.put(["users"], user_id, { name, age, email });
return "Successfully saved user info.";
},
{
name: "save_user_info",
description: "Save user info.",
schema: z.object({
user_id: z.string(),
name: z.string(),
age: z.number(),
email: z.string(),
}),
}
);
const agent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [getUserInfo, saveUserInfo],
store,
});
// First session: save user info
await agent.invoke({
messages: [
{
role: "user",
content: "Save the following user: userid: abc123, name: Foo, age: 25, email: foo@langchain.dev",
},
],
});
// Second session: get user info
const result = await agent.invoke({
messages: [
{ role: "user", content: "Get user info for user with id 'abc123'" },
],
});
console.log(result);
// Here is the user info for user with ID "abc123":
// - Name: Foo
// - Age: 25
// - Email: foo@langchain.dev
```
### Stream writer
Stream real-time updates from tools during execution. This is useful for providing progress feedback to users during long-running operations.
Use `config.writer` to emit custom updates:
```ts theme={null}
import * as z from "zod";
import { tool, ToolRuntime } from "langchain";
const getWeather = tool(
({ city }, config: ToolRuntime) => {
const writer = config.writer;
// Stream custom updates as the tool executes
if (writer) {
writer(`Looking up data for city: ${city}`);
writer(`Acquired data for city: ${city}`);
}
return `It's always sunny in ${city}!`;
},
{
name: "get_weather",
description: "Get weather for a given city.",
schema: z.object({
city: z.string(),
}),
}
);
```
## ToolNode
[`ToolNode`](https://reference.langchain.com/javascript/langchain-langgraph/prebuilt/ToolNode) is a prebuilt node that executes tools in LangGraph workflows. It handles parallel tool execution, error handling, and state injection automatically.
<Info>
For custom workflows where you need fine-grained control over tool execution patterns, use [`ToolNode`](https://reference.langchain.com/javascript/langchain-langgraph/prebuilt/ToolNode) instead of @[`create_agent`]. It's the building block that powers agent tool execution.
</Info>
### Basic usage
```typescript theme={null}
import { ToolNode } from "@langchain/langgraph/prebuilt";
import { tool } from "@langchain/core/tools";
import * as z from "zod";
const search = tool(
({ query }) => `Results for: ${query}`,
{
name: "search",
description: "Search for information.",
schema: z.object({ query: z.string() }),
}
);
const calculator = tool(
({ expression }) => String(eval(expression)),
{
name: "calculator",
description: "Evaluate a math expression.",
schema: z.object({ expression: z.string() }),
}
);
// Create the ToolNode with your tools
const toolNode = new ToolNode([search, calculator]);
```
### Error handling
Configure how tool errors are handled. See the [`ToolNode`](https://reference.langchain.com/javascript/langchain-langgraph/prebuilt/ToolNode) API reference for all options.
```typescript theme={null}
import { ToolNode } from "@langchain/langgraph/prebuilt";
// Default behavior
const toolNode = new ToolNode(tools);
// Catch all errors
const toolNode = new ToolNode(tools, { handleToolErrors: true });
// Custom error message
const toolNode = new ToolNode(tools, {
handleToolErrors: "Something went wrong, please try again."
});
```
### Route with tools_condition
Use @[`tools_condition`] for conditional routing based on whether the LLM made tool calls:
```typescript theme={null}
import { ToolNode, toolsCondition } from "@langchain/langgraph/prebuilt";
import { StateGraph, MessagesAnnotation } from "@langchain/langgraph";
const builder = new StateGraph(MessagesAnnotation)
.addNode("llm", callLlm)
.addNode("tools", new ToolNode(tools))
.addEdge("__start__", "llm")
.addConditionalEdges("llm", toolsCondition) // Routes to "tools" or "__end__"
.addEdge("tools", "llm");
const graph = builder.compile();
```
### State injection
Tools can access the current graph state through @[`ToolRuntime`]:
For more details on accessing state, context, and long-term memory from tools, see [Access context](#access-context).
## Prebuilt tools
LangChain provides a large collection of prebuilt tools and toolkits for common tasks like web search, code interpretation, database access, and more. These ready-to-use tools can be directly integrated into your agents without writing custom code.
See the [tools and toolkits](/oss/javascript/integrations/tools) integration page for a complete list of available tools organized by category.
## Server-side tool use
Some chat models feature built-in tools that are executed server-side by the model provider. These include capabilities like web search and code interpreters that don't require you to define or host the tool logic.
Refer to the individual [chat model integration pages](/oss/javascript/integrations/providers) and the [tool calling documentation](/oss/javascript/langchain/models#server-side-tool-use) for details on enabling and using these built-in tools.
***
<Callout icon="edit">
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/langchain/tools.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).
</Callout>
<Callout icon="terminal-2">
[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
</Callout>
2.1.2. Claude Prompt 中关于各个工具的说明(其他人逆向获取的)
这里面包含了各个工具的作用、入参出参甚至调用时机等
## Bash
Executes a given bash command and returns its output.
The working directory persists between commands, but shell state does not. The shell environment is initialized from the user's profile (bash or zsh).
IMPORTANT: Avoid using this tool to run `find`, `grep`, `cat`, `head`, `tail`, `sed`, `awk`, or `echo` commands, unless explicitly instructed or after you have verified that a dedicated tool cannot accomplish your task. Instead, use the appropriate dedicated tool as this will provide a much better experience for the user:
- File search: Use Glob (NOT find or ls)
- Content search: Use Grep (NOT grep or rg)
- Read files: Use Read (NOT cat/head/tail)
- Edit files: Use Edit (NOT sed/awk)
- Write files: Use Write (NOT echo >/cat <<EOF)
- Communication: Output text directly (NOT echo/printf)
While the Bash tool can do similar things, it’s better to use the built-in tools as they provide a better user experience and make it easier to review tool calls and give permission.
### Instructions
- If your command will create new directories or files, first use this tool to run `ls` to verify the parent directory exists and is the correct location.
- Always quote file paths that contain spaces with double quotes in your command (e.g., cd "path with spaces/file.txt")
- Try to maintain your current working directory throughout the session by using absolute paths and avoiding usage of `cd`. You may use `cd` if the User explicitly requests it.
- You may specify an optional timeout in milliseconds (up to 600000ms / 10 minutes). By default, your command will timeout after 120000ms (2 minutes).
- - You can use the `run_in_background` parameter to run the command in the background. Only use this if you don't need the result immediately and are OK being notified when the command completes later. You do not need to check the output right away - you'll be notified when it finishes. You do not need to use '&' at the end of the command when using this parameter.
- Write a clear, concise description of what your command does. For simple commands, keep it brief (5-10 words). For complex commands (piped commands, obscure flags, or anything hard to understand at a glance), include enough context so that the user can understand what your command will do.
- When issuing multiple commands:
- If the commands are independent and can run in parallel, make multiple Bash tool calls in a single message. Example: if you need to run "git status" and "git diff", send a single message with two Bash tool calls in parallel.
- If the commands depend on each other and must run sequentially, use a single Bash call with '&&' to chain them together.
- Use ';' only when you need to run commands sequentially but don't care if earlier commands fail.
- DO NOT use newlines to separate commands (newlines are ok in quoted strings).
- For git commands:
- Prefer to create a new commit rather than amending an existing commit.
- Before running destructive operations (e.g., git reset --hard, git push --force, git checkout --), consider whether there is a safer alternative that achieves the same goal. Only use destructive operations when they are truly the best approach.
- Never skip hooks (--no-verify) or bypass signing (--no-gpg-sign, -c commit.gpgsign=false) unless the user has explicitly asked for it. If a hook fails, investigate and fix the underlying issue.
- Avoid unnecessary `sleep` commands:
- Do not sleep between commands that can run immediately — just run them.
- If your command is long running and you would like to be notified when it finishes – simply run your command using `run_in_background`. There is no need to sleep in this case.
- Do not retry failing commands in a sleep loop — diagnose the root cause or consider an alternative approach.
- If waiting for a background task you started with `run_in_background`, you will be notified when it completes — do not poll.
- If you must poll an external process, use a check command (e.g. `gh run view`) rather than sleeping first.
- If you must sleep, keep the duration short (1-5 seconds) to avoid blocking the user.
### Committing changes with git
Only create commits when requested by the user. If unclear, ask first. When the user asks you to create a new git commit, follow these steps carefully:
Git Safety Protocol:
- NEVER update the git config
- NEVER run destructive git commands (push --force, reset --hard, checkout ., restore ., clean -f, branch -D) unless the user explicitly requests these actions. Taking unauthorized destructive actions is unhelpful and can result in lost work, so it's best to ONLY run these commands when given direct instructions
- NEVER skip hooks (--no-verify, --no-gpg-sign, etc) unless the user explicitly requests it
- NEVER run force push to main/master, warn the user if they request it
- CRITICAL: Always create NEW commits rather than amending, unless the user explicitly requests a git amend. When a pre-commit hook fails, the commit did NOT happen — so --amend would modify the PREVIOUS commit, which may result in destroying work or losing previous changes. Instead, after hook failure, fix the issue, re-stage, and create a NEW commit
- When staging files, prefer adding specific files by name rather than using "git add -A" or "git add .", which can accidentally include sensitive files (.env, credentials) or large binaries
- NEVER commit changes unless the user explicitly asks you to. It is VERY IMPORTANT to only commit when explicitly asked, otherwise the user will feel that you are being too proactive
1. You can call multiple tools in a single response. When multiple independent pieces of information are requested and all commands are likely to succeed, run multiple tool calls in parallel for optimal performance. run the following bash commands in parallel, each using the Bash tool:
- Run a git status command to see all untracked files. IMPORTANT: Never use the -uall flag as it can cause memory issues on large repos.
- Run a git diff command to see both staged and unstaged changes that will be committed.
- Run a git log command to see recent commit messages, so that you can follow this repository's commit message style.
2. Analyze all staged changes (both previously staged and newly added) and draft a commit message:
- Summarize the nature of the changes (eg. new feature, enhancement to an existing feature, bug fix, refactoring, test, docs, etc.). Ensure the message accurately reflects the changes and their purpose (i.e. "add" means a wholly new feature, "update" means an enhancement to an existing feature, "fix" means a bug fix, etc.).
- Do not commit files that likely contain secrets (.env, credentials.json, etc). Warn the user if they specifically request to commit those files
- Draft a concise (1-2 sentences) commit message that focuses on the "why" rather than the "what"
- Ensure it accurately reflects the changes and their purpose
3. You can call multiple tools in a single response. When multiple independent pieces of information are requested and all commands are likely to succeed, run multiple tool calls in parallel for optimal performance. run the following commands:
- Add relevant untracked files to the staging area.
- Create the commit with a message ending with:
Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com>
- Run git status after the commit completes to verify success.
Note: git status depends on the commit completing, so run it sequentially after the commit.
4. If the commit fails due to pre-commit hook: fix the issue and create a NEW commit
Important notes:
- NEVER run additional commands to read or explore code, besides git bash commands
- NEVER use the TodoWrite or Task tools
- DO NOT push to the remote repository unless the user explicitly asks you to do so
- IMPORTANT: Never use git commands with the -i flag (like git rebase -i or git add -i) since they require interactive input which is not supported.
- IMPORTANT: Do not use --no-edit with git rebase commands, as the --no-edit flag is not a valid option for git rebase.
- If there are no changes to commit (i.e., no untracked files and no modifications), do not create an empty commit
- In order to ensure good formatting, ALWAYS pass the commit message via a HEREDOC, a la this example:
<example>
git commit -m "$(cat <<'EOF'
Commit message here.
Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com>
EOF
)"
</example>
### Creating pull requests
Use the gh command via the Bash tool for ALL GitHub-related tasks including working with issues, pull requests, checks, and releases. If given a Github URL use the gh command to get the information needed.
IMPORTANT: When the user asks you to create a pull request, follow these steps carefully:
1. You can call multiple tools in a single response. When multiple independent pieces of information are requested and all commands are likely to succeed, run multiple tool calls in parallel for optimal performance. run the following bash commands in parallel using the Bash tool, in order to understand the current state of the branch since it diverged from the main branch:
- Run a git status command to see all untracked files (never use -uall flag)
- Run a git diff command to see both staged and unstaged changes that will be committed
- Check if the current branch tracks a remote branch and is up to date with the remote, so you know if you need to push to the remote
- Run a git log command and `git diff [base-branch]...HEAD` to understand the full commit history for the current branch (from the time it diverged from the base branch)
2. Analyze all changes that will be included in the pull request, making sure to look at all relevant commits (NOT just the latest commit, but ALL commits that will be included in the pull request!!!), and draft a pull request title and summary:
- Keep the PR title short (under 70 characters)
- Use the description/body for details, not the title
3. You can call multiple tools in a single response. When multiple independent pieces of information are requested and all commands are likely to succeed, run multiple tool calls in parallel for optimal performance. run the following commands in parallel:
- Create new branch if needed
- Push to remote with -u flag if needed
- Create PR using gh pr create with the format below. Use a HEREDOC to pass the body to ensure correct formatting.
<example>
gh pr create --title "the pr title" --body "$(cat <<'EOF'
#### Summary
<1-3 bullet points>
#### Test plan
[Bulleted markdown checklist of TODOs for testing the pull request...]
🤖 Generated with [Claude Code](https://claude.com/claude-code)
EOF
)"
</example>
Important:
- DO NOT use the TodoWrite or Task tools
- Return the PR URL when you're done, so the user can see it
### Other common operations
- View comments on a Github PR: gh api repos/foo/bar/pulls/123/comments
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"command": {
"description": "The command to execute",
"type": "string"
},
"timeout": {
"description": "Optional timeout in milliseconds (max 600000)",
"type": "number"
},
"description": {
"description": "Clear, concise description of what this command does in active voice. Never use words like "complex" or "risk" in the description - just describe what it does.\n\nFor simple commands (git, npm, standard CLI tools), keep it brief (5-10 words):\n- ls → "List files in current directory"\n- git status → "Show working tree status"\n- npm install → "Install package dependencies"\n\nFor commands that are harder to parse at a glance (piped commands, obscure flags, etc.), add enough context to clarify what it does:\n- find . -name "*.tmp" -exec rm {} \; → "Find and delete all .tmp files recursively"\n- git reset --hard origin/main → "Discard all local changes and match remote main"\n- curl -s url | jq '.data[]' → "Fetch JSON from URL and extract data array elements"",
"type": "string"
},
"run_in_background": {
"description": "Set to true to run this command in the background. Use TaskOutput to read the output later.",
"type": "boolean"
},
"dangerouslyDisableSandbox": {
"description": "Set this to true to dangerously override sandbox mode and run commands without sandboxing.",
"type": "boolean"
}
},
"required": [
"command"
],
"additionalProperties": false
}
---
## Edit
Performs exact string replacements in files.
Usage:
- You must use your `Read` tool at least once in the conversation before editing. This tool will error if you attempt an edit without reading the file.
- When editing text from Read tool output, ensure you preserve the exact indentation (tabs/spaces) as it appears AFTER the line number prefix. The line number prefix format is: spaces + line number + tab. Everything after that tab is the actual file content to match. Never include any part of the line number prefix in the old_string or new_string.
- ALWAYS prefer editing existing files in the codebase. NEVER write new files unless explicitly required.
- Only use emojis if the user explicitly requests it. Avoid adding emojis to files unless asked.
- The edit will FAIL if `old_string` is not unique in the file. Either provide a larger string with more surrounding context to make it unique or use `replace_all` to change every instance of `old_string`.
- Use `replace_all` for replacing and renaming strings across the file. This parameter is useful if you want to rename a variable for instance.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"file_path": {
"description": "The absolute path to the file to modify",
"type": "string"
},
"old_string": {
"description": "The text to replace",
"type": "string"
},
"new_string": {
"description": "The text to replace it with (must be different from old_string)",
"type": "string"
},
"replace_all": {
"description": "Replace all occurrences of old_string (default false)",
"default": false,
"type": "boolean"
}
},
"required": [
"file_path",
"old_string",
"new_string"
],
"additionalProperties": false
}
---
## Glob
- Fast file pattern matching tool that works with any codebase size
- Supports glob patterns like "**/*.js" or "src/**/*.ts"
- Returns matching file paths sorted by modification time
- Use this tool when you need to find files by name patterns
- When you are doing an open ended search that may require multiple rounds of globbing and grepping, use the Agent tool instead
- You can call multiple tools in a single response. It is always better to speculatively perform multiple searches in parallel if they are potentially useful.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"pattern": {
"description": "The glob pattern to match files against",
"type": "string"
},
"path": {
"description": "The directory to search in. If not specified, the current working directory will be used. IMPORTANT: Omit this field to use the default directory. DO NOT enter "undefined" or "null" - simply omit it for the default behavior. Must be a valid directory path if provided.",
"type": "string"
}
},
"required": [
"pattern"
],
"additionalProperties": false
}
---
## Grep
A powerful search tool built on ripgrep
Usage:
- ALWAYS use Grep for search tasks. NEVER invoke `grep` or `rg` as a Bash command. The Grep tool has been optimized for correct permissions and access.
- Supports full regex syntax (e.g., "log.*Error", "function\s+\w+")
- Filter files with glob parameter (e.g., "*.js", "**/*.tsx") or type parameter (e.g., "js", "py", "rust")
- Output modes: "content" shows matching lines, "files_with_matches" shows only file paths (default), "count" shows match counts
- Use Task tool for open-ended searches requiring multiple rounds
- Pattern syntax: Uses ripgrep (not grep) - literal braces need escaping (use `interface{}` to find `interface{}` in Go code)
- Multiline matching: By default patterns match within single lines only. For cross-line patterns like `struct {[\s\S]*?field`, use `multiline: true`
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"pattern": {
"description": "The regular expression pattern to search for in file contents",
"type": "string"
},
"path": {
"description": "File or directory to search in (rg PATH). Defaults to current working directory.",
"type": "string"
},
"glob": {
"description": "Glob pattern to filter files (e.g. "*.js", "*.{ts,tsx}") - maps to rg --glob",
"type": "string"
},
"output_mode": {
"description": "Output mode: "content" shows matching lines (supports -A/-B/-C context, -n line numbers, head_limit), "files_with_matches" shows file paths (supports head_limit), "count" shows match counts (supports head_limit). Defaults to "files_with_matches".",
"type": "string",
"enum": [
"content",
"files_with_matches",
"count"
]
},
"-B": {
"description": "Number of lines to show before each match (rg -B). Requires output_mode: "content", ignored otherwise.",
"type": "number"
},
"-A": {
"description": "Number of lines to show after each match (rg -A). Requires output_mode: "content", ignored otherwise.",
"type": "number"
},
"-C": {
"description": "Alias for context.",
"type": "number"
},
"context": {
"description": "Number of lines to show before and after each match (rg -C). Requires output_mode: "content", ignored otherwise.",
"type": "number"
},
"-n": {
"description": "Show line numbers in output (rg -n). Requires output_mode: "content", ignored otherwise. Defaults to true.",
"type": "boolean"
},
"-i": {
"description": "Case insensitive search (rg -i)",
"type": "boolean"
},
"type": {
"description": "File type to search (rg --type). Common types: js, py, rust, go, java, etc. More efficient than include for standard file types.",
"type": "string"
},
"head_limit": {
"description": "Limit output to first N lines/entries, equivalent to "| head -N". Works across all output modes: content (limits output lines), files_with_matches (limits file paths), count (limits count entries). Defaults to 0 (unlimited).",
"type": "number"
},
"offset": {
"description": "Skip first N lines/entries before applying head_limit, equivalent to "| tail -n +N | head -N". Works across all output modes. Defaults to 0.",
"type": "number"
},
"multiline": {
"description": "Enable multiline mode where . matches newlines and patterns can span lines (rg -U --multiline-dotall). Default: false.",
"type": "boolean"
}
},
"required": [
"pattern"
],
"additionalProperties": false
}
---
## Read
Reads a file from the local filesystem. You can access any file directly by using this tool.
Assume this tool is able to read all files on the machine. If the User provides a path to a file assume that path is valid. It is okay to read a file that does not exist; an error will be returned.
Usage:
- The file_path parameter must be an absolute path, not a relative path
- By default, it reads up to 2000 lines starting from the beginning of the file
- You can optionally specify a line offset and limit (especially handy for long files), but it's recommended to read the whole file by not providing these parameters
- Any lines longer than 2000 characters will be truncated
- Results are returned using cat -n format, with line numbers starting at 1
- This tool allows Claude Code to read images (eg PNG, JPG, etc). When reading an image file the contents are presented visually as Claude Code is a multimodal LLM.
- This tool can read PDF files (.pdf). For large PDFs (more than 10 pages), you MUST provide the pages parameter to read specific page ranges (e.g., pages: "1-5"). Reading a large PDF without the pages parameter will fail. Maximum 20 pages per request.
- This tool can read Jupyter notebooks (.ipynb files) and returns all cells with their outputs, combining code, text, and visualizations.
- This tool can only read files, not directories. To read a directory, use an ls command via the Bash tool.
- You can call multiple tools in a single response. It is always better to speculatively read multiple potentially useful files in parallel.
- You will regularly be asked to read screenshots. If the user provides a path to a screenshot, ALWAYS use this tool to view the file at the path. This tool will work with all temporary file paths.
- If you read a file that exists but has empty contents you will receive a system reminder warning in place of file contents.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"file_path": {
"description": "The absolute path to the file to read",
"type": "string"
},
"offset": {
"description": "The line number to start reading from. Only provide if the file is too large to read at once",
"type": "number"
},
"limit": {
"description": "The number of lines to read. Only provide if the file is too large to read at once.",
"type": "number"
},
"pages": {
"description": "Page range for PDF files (e.g., "1-5", "3", "10-20"). Only applicable to PDF files. Maximum 20 pages per request.",
"type": "string"
}
},
"required": [
"file_path"
],
"additionalProperties": false
}
---
## Write
Writes a file to the local filesystem.
Usage:
- This tool will overwrite the existing file if there is one at the provided path.
- If this is an existing file, you MUST use the Read tool first to read the file's contents. This tool will fail if you did not read the file first.
- Prefer the Edit tool for modifying existing files — it only sends the diff. Only use this tool to create new files or for complete rewrites.
- NEVER create documentation files (*.md) or README files unless explicitly requested by the User.
- Only use emojis if the user explicitly requests it. Avoid writing emojis to files unless asked.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"file_path": {
"description": "The absolute path to the file to write (must be absolute, not relative)",
"type": "string"
},
"content": {
"description": "The content to write to the file",
"type": "string"
}
},
"required": [
"file_path",
"content"
],
"additionalProperties": false
}
2.1.3. 聚合上述文档
创建 1_langgraph 项目,把上述文档放入 md 文件夹中,然后让任何 Coding Agent (Cladue Code、Trae、Cursor...)参考 md 中的相关文档,在 tools 生成代码
mca
├── .env
├── 0_deepagents
├── 1_langgraph
│ └── src
│ ├── md
│ │ ├── how_to_create_a_tool.md
│ │ └── a_list_of_all_required_tools.md
│ └── tools (空文件夹)
└── package.json
你也可以直接用上一步自己创建的 mca
npm start '基于 1_langgraph/src/md 中的 how_to_create_a_tool 在 1_langgraph/src/tools 中实现 a_list_of_all_required_tools 里全部工具'
2.1.4. 预期效果
顺利的话,你会得到创建好了所需 tools 的文件。如果生成内容有误,可以根据内容调整 input 让其重新生成或修改
mca
├── .env
├── 0_deepagents
├── 1_langgraph
│ └── src
│ ├── md
│ └── tools
+│ ├── bash.js
+│ ├── edit.js
+│ ├── glob.js
+│ ├── grep.js
+│ ├── index.js
+│ ├── read.js
+│ └── write.js
└── package.json
2.2. ReAct 范式
工具有了,接下来我们实现 ReAct 范式
2.2.1. 关于创建 LangGraph 应用的相关文档
和之前类似,我们在 md 文件中新增 lang_graph_quick_start.md,让 Coding Agent 知道要怎么创建一个 LangGraph 应用
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.langchain.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Quickstart
This quickstart demonstrates how to build a calculator agent using the LangGraph Graph API or the Functional API.
* [Use the Graph API](#use-the-graph-api) if you prefer to define your agent as a graph of nodes and edges.
* [Use the Functional API](#use-the-functional-api) if you prefer to define your agent as a single function.
For conceptual information, see [Graph API overview](/oss/javascript/langgraph/graph-api) and [Functional API overview](/oss/javascript/langgraph/functional-api).
<Info>
For this example, you will need to set up a [Claude (Anthropic)](https://www.anthropic.com/) account and get an API key. Then, set the `ANTHROPIC_API_KEY` environment variable in your terminal.
</Info>
<Tabs>
<Tab title="Use the Graph API">
## 1. Define tools and model
In this example, we'll use the Claude Sonnet 4.5 model and define tools for addition, multiplication, and division.
```typescript theme={null}
import { ChatAnthropic } from "@langchain/anthropic";
import { tool } from "@langchain/core/tools";
import * as z from "zod";
const model = new ChatAnthropic({
model: "claude-sonnet-4-5-20250929",
temperature: 0,
});
// Define tools
const add = tool(({ a, b }) => a + b, {
name: "add",
description: "Add two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const multiply = tool(({ a, b }) => a * b, {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const divide = tool(({ a, b }) => a / b, {
name: "divide",
description: "Divide two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
// Augment the LLM with tools
const toolsByName = {
[add.name]: add,
[multiply.name]: multiply,
[divide.name]: divide,
};
const tools = Object.values(toolsByName);
const modelWithTools = model.bindTools(tools);
```
## 2. Define state
The graph's state is used to store the messages and the number of LLM calls.
<Tip>
State in LangGraph persists throughout the agent's execution.
The `MessagesValue` provides a built-in reducer for appending messages. The `llmCalls` field uses a `ReducedValue` with `(x, y) => x + y` to accumulate the count.
</Tip>
```typescript theme={null}
import {
StateGraph,
StateSchema,
MessagesValue,
ReducedValue,
GraphNode,
ConditionalEdgeRouter,
START,
END,
} from "@langchain/langgraph";
import { z } from "zod/v4";
const MessagesState = new StateSchema({
messages: MessagesValue,
llmCalls: new ReducedValue(
z.number().default(0),
{ reducer: (x, y) => x + y }
),
});
```
## 3. Define model node
The model node is used to call the LLM and decide whether to call a tool or not.
```typescript theme={null}
import { SystemMessage } from "@langchain/core/messages";
const llmCall: GraphNode<typeof MessagesState> = async (state) => {
const response = await modelWithTools.invoke([
new SystemMessage(
"You are a helpful assistant tasked with performing arithmetic on a set of inputs."
),
...state.messages,
]);
return {
messages: [response],
llmCalls: 1,
};
};
```
## 4. Define tool node
The tool node is used to call the tools and return the results.
```typescript theme={null}
import { AIMessage, ToolMessage } from "@langchain/core/messages";
const toolNode: GraphNode<typeof MessagesState> = async (state) => {
const lastMessage = state.messages.at(-1);
if (lastMessage == null || !AIMessage.isInstance(lastMessage)) {
return { messages: [] };
}
const result: ToolMessage[] = [];
for (const toolCall of lastMessage.tool_calls ?? []) {
const tool = toolsByName[toolCall.name];
const observation = await tool.invoke(toolCall);
result.push(observation);
}
return { messages: result };
};
```
## 5. Define end logic
The conditional edge function is used to route to the tool node or end based upon whether the LLM made a tool call.
```typescript theme={null}
const shouldContinue: ConditionalEdgeRouter<typeof MessagesState, "toolNode"> = (state) => {
const lastMessage = state.messages.at(-1);
// Check if it's an AIMessage before accessing tool_calls
if (!lastMessage || !AIMessage.isInstance(lastMessage)) {
return END;
}
// If the LLM makes a tool call, then perform an action
if (lastMessage.tool_calls?.length) {
return "toolNode";
}
// Otherwise, we stop (reply to the user)
return END;
};
```
## 6. Build and compile the agent
The agent is built using the [`StateGraph`](https://reference.langchain.com/javascript/langchain-langgraph/index/StateGraph) class and compiled using the [`compile`](https://reference.langchain.com/javascript/classes/_langchain_langgraph.index.StateGraph.html#compile) method.
```typescript theme={null}
const agent = new StateGraph(MessagesState)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
.addEdge(START, "llmCall")
.addConditionalEdges("llmCall", shouldContinue, ["toolNode", END])
.addEdge("toolNode", "llmCall")
.compile();
// Invoke
import { HumanMessage } from "@langchain/core/messages";
const result = await agent.invoke({
messages: [new HumanMessage("Add 3 and 4.")],
});
for (const message of result.messages) {
console.log(`[${message.type}]: ${message.text}`);
}
```
<Tip>
To learn how to trace your agent with LangSmith, see the [LangSmith documentation](/langsmith/trace-with-langgraph).
</Tip>
Congratulations! You've built your first agent using the LangGraph Graph API.
<Accordion title="Full code example">
```typescript theme={null}
// Step 1: Define tools and model
import { ChatAnthropic } from "@langchain/anthropic";
import { tool } from "@langchain/core/tools";
import * as z from "zod";
const model = new ChatAnthropic({
model: "claude-sonnet-4-5-20250929",
temperature: 0,
});
// Define tools
const add = tool(({ a, b }) => a + b, {
name: "add",
description: "Add two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const multiply = tool(({ a, b }) => a * b, {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const divide = tool(({ a, b }) => a / b, {
name: "divide",
description: "Divide two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
// Augment the LLM with tools
const toolsByName = {
[add.name]: add,
[multiply.name]: multiply,
[divide.name]: divide,
};
const tools = Object.values(toolsByName);
const modelWithTools = model.bindTools(tools);
```
```typescript theme={null}
// Step 2: Define state
import {
StateGraph,
StateSchema,
MessagesValue,
ReducedValue,
GraphNode,
ConditionalEdgeRouter,
START,
END,
} from "@langchain/langgraph";
import * as z from "zod";
const MessagesState = new StateSchema({
messages: MessagesValue,
llmCalls: new ReducedValue(
z.number().default(0),
{ reducer: (x, y) => x + y }
),
});
```
```typescript theme={null}
// Step 3: Define model node
import { SystemMessage, AIMessage, ToolMessage } from "@langchain/core/messages";
const llmCall: GraphNode<typeof MessagesState> = async (state) => {
return {
messages: [await modelWithTools.invoke([
new SystemMessage(
"You are a helpful assistant tasked with performing arithmetic on a set of inputs."
),
...state.messages,
])],
llmCalls: 1,
};
};
// Step 4: Define tool node
const toolNode: GraphNode<typeof MessagesState> = async (state) => {
const lastMessage = state.messages.at(-1);
if (lastMessage == null || !AIMessage.isInstance(lastMessage)) {
return { messages: [] };
}
const result: ToolMessage[] = [];
for (const toolCall of lastMessage.tool_calls ?? []) {
const tool = toolsByName[toolCall.name];
const observation = await tool.invoke(toolCall);
result.push(observation);
}
return { messages: result };
};
```
```typescript theme={null}
// Step 5: Define logic to determine whether to end
import { ConditionalEdgeRouter, END } from "@langchain/langgraph";
const shouldContinue: ConditionalEdgeRouter<typeof MessagesState, "toolNode"> = (state) => {
const lastMessage = state.messages.at(-1);
// Check if it's an AIMessage before accessing tool_calls
if (!lastMessage || !AIMessage.isInstance(lastMessage)) {
return END;
}
// If the LLM makes a tool call, then perform an action
if (lastMessage.tool_calls?.length) {
return "toolNode";
}
// Otherwise, we stop (reply to the user)
return END;
};
```
```typescript theme={null}
// Step 6: Build and compile the agent
import { HumanMessage } from "@langchain/core/messages";
import { StateGraph, START, END } from "@langchain/langgraph";
const agent = new StateGraph(MessagesState)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
.addEdge(START, "llmCall")
.addConditionalEdges("llmCall", shouldContinue, ["toolNode", END])
.addEdge("toolNode", "llmCall")
.compile();
// Invoke
const result = await agent.invoke({
messages: [new HumanMessage("Add 3 and 4.")],
});
for (const message of result.messages) {
console.log(`[${message.type}]: ${message.text}`);
}
```
</Accordion>
</Tab>
<Tab title="Use the Functional API">
## 1. Define tools and model
In this example, we'll use the Claude Sonnet 4.5 model and define tools for addition, multiplication, and division.
```typescript theme={null}
import { ChatAnthropic } from "@langchain/anthropic";
import { tool } from "@langchain/core/tools";
import * as z from "zod";
const model = new ChatAnthropic({
model: "claude-sonnet-4-5-20250929",
temperature: 0,
});
// Define tools
const add = tool(({ a, b }) => a + b, {
name: "add",
description: "Add two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const multiply = tool(({ a, b }) => a * b, {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const divide = tool(({ a, b }) => a / b, {
name: "divide",
description: "Divide two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
// Augment the LLM with tools
const toolsByName = {
[add.name]: add,
[multiply.name]: multiply,
[divide.name]: divide,
};
const tools = Object.values(toolsByName);
const modelWithTools = model.bindTools(tools);
```
## 2. Define model node
The model node is used to call the LLM and decide whether to call a tool or not.
```typescript theme={null}
import { task, entrypoint } from "@langchain/langgraph";
import { SystemMessage } from "@langchain/core/messages";
const callLlm = task({ name: "callLlm" }, async (messages: BaseMessage[]) => {
return modelWithTools.invoke([
new SystemMessage(
"You are a helpful assistant tasked with performing arithmetic on a set of inputs."
),
...messages,
]);
});
```
## 3. Define tool node
The tool node is used to call the tools and return the results.
```typescript theme={null}
import type { ToolCall } from "@langchain/core/messages/tool";
const callTool = task({ name: "callTool" }, async (toolCall: ToolCall) => {
const tool = toolsByName[toolCall.name];
return tool.invoke(toolCall);
});
```
## 4. Define agent
```typescript theme={null}
import { addMessages } from "@langchain/langgraph";
import { type BaseMessage } from "@langchain/core/messages";
const agent = entrypoint({ name: "agent" }, async (messages: BaseMessage[]) => {
let modelResponse = await callLlm(messages);
while (true) {
if (!modelResponse.tool_calls?.length) {
break;
}
// Execute tools
const toolResults = await Promise.all(
modelResponse.tool_calls.map((toolCall) => callTool(toolCall))
);
messages = addMessages(messages, [modelResponse, ...toolResults]);
modelResponse = await callLlm(messages);
}
return messages;
});
// Invoke
import { HumanMessage } from "@langchain/core/messages";
const result = await agent.invoke([new HumanMessage("Add 3 and 4.")]);
for (const message of result) {
console.log(`[${message.getType()}]: ${message.text}`);
}
```
<Tip>
To learn how to trace your agent with LangSmith, see the [LangSmith documentation](/langsmith/trace-with-langgraph).
</Tip>
Congratulations! You've built your first agent using the LangGraph Functional API.
<Accordion title="Full code example" icon="code">
```typescript theme={null}
import { ChatAnthropic } from "@langchain/anthropic";
import { tool } from "@langchain/core/tools";
import {
task,
entrypoint,
addMessages,
} from "@langchain/langgraph";
import {
SystemMessage,
HumanMessage,
type BaseMessage,
} from "@langchain/core/messages";
import type { ToolCall } from "@langchain/core/messages/tool";
import * as z from "zod";
// Step 1: Define tools and model
const model = new ChatAnthropic({
model: "claude-sonnet-4-5-20250929",
temperature: 0,
});
// Define tools
const add = tool(({ a, b }) => a + b, {
name: "add",
description: "Add two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const multiply = tool(({ a, b }) => a * b, {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const divide = tool(({ a, b }) => a / b, {
name: "divide",
description: "Divide two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
// Augment the LLM with tools
const toolsByName = {
[add.name]: add,
[multiply.name]: multiply,
[divide.name]: divide,
};
const tools = Object.values(toolsByName);
const modelWithTools = model.bindTools(tools);
// Step 2: Define model node
const callLlm = task({ name: "callLlm" }, async (messages: BaseMessage[]) => {
return modelWithTools.invoke([
new SystemMessage(
"You are a helpful assistant tasked with performing arithmetic on a set of inputs."
),
...messages,
]);
});
// Step 3: Define tool node
const callTool = task({ name: "callTool" }, async (toolCall: ToolCall) => {
const tool = toolsByName[toolCall.name];
return tool.invoke(toolCall);
});
// Step 4: Define agent
const agent = entrypoint({ name: "agent" }, async (messages: BaseMessage[]) => {
let modelResponse = await callLlm(messages);
while (true) {
if (!modelResponse.tool_calls?.length) {
break;
}
// Execute tools
const toolResults = await Promise.all(
modelResponse.tool_calls.map((toolCall) => callTool(toolCall))
);
messages = addMessages(messages, [modelResponse, ...toolResults]);
modelResponse = await callLlm(messages);
}
return messages;
});
// Invoke
const result = await agent.invoke([new HumanMessage("Add 3 and 4.")]);
for (const message of result) {
console.log(`[${message.type}]: ${message.text}`);
}
```
</Accordion>
</Tab>
</Tabs>
***
<Callout icon="edit">
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/langgraph/quickstart.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).
</Callout>
<Callout icon="terminal-2">
[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
</Callout>
2.2.2. 逻辑生成
同样让 Coding Agent 辅助生成代码
npm start "基于 1_langgraph/src/md/lang_graph_quick_start.md,在 1_langgraph/src/index.js 生成一个 ReAct 风格的 Coding Agent,注册 1_langgraph/src/tools 中的全部工具"
最终结果基于你所用的 Agent、模型会有差异。这里贴出我基于 claude-opus-4-6 生成同时证过的代码
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import {
StateGraph,
MessagesAnnotation,
START,
END,
} from "@langchain/langgraph";
import {
SystemMessage,
HumanMessage,
AIMessage,
} from "@langchain/core/messages";
import allTools from "./tools/index.js";
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
You are a ReAct-style coding agent. You have access to a set of tools for interacting with the filesystem and executing commands.
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 构建 toolsByName 映射
const toolsByName = {};
for (const t of allTools) {
toolsByName[t.name] = t;
}
// 将工具绑定到模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
const modelWithTools = model.bindTools(allTools);
// Step 1: 模型节点 — 调用 LLM 决定是否使用工具
const llmCall = async (state) => {
const response = await modelWithTools.invoke([
new SystemMessage(SYSTEM_PROMPT),
...state.messages,
]);
return { messages: [response] };
};
// Step 2: 工具节点 — 执行 LLM 请求的工具调用
const toolNode = async (state) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) {
return { messages: [] };
}
const results = [];
for (const toolCall of lastMessage.tool_calls ?? []) {
const tool = toolsByName[toolCall.name];
if (!tool) {
results.push({
role: "tool",
content: `Error: Unknown tool "${toolCall.name}"`,
tool_call_id: toolCall.id,
});
continue;
}
const observation = await tool.invoke(toolCall);
results.push(observation);
}
return { messages: results };
};
// Step 3: 条件路由 — 有 tool_calls 则继续,否则结束
const shouldContinue = (state) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) {
return END;
}
if (lastMessage.tool_calls?.length) {
return "toolNode";
}
return END;
};
// Step 4: 构建并编译 StateGraph
const agent = new StateGraph(MessagesAnnotation)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
.addEdge(START, "llmCall")
.addConditionalEdges("llmCall", shouldContinue, ["toolNode", END])
.addEdge("toolNode", "llmCall")
.compile();
// CLI 入口
const args = process.argv.slice(2);
if (args.length === 0) {
console.log("请输入指令");
process.exit(1);
}
const result = await agent.invoke(
{ messages: [new HumanMessage(args[0])] },
{ recursionLimit: 100 },
);
// 输出最后一条消息
const lastMsg = result.messages[result.messages.length - 1];
console.log(lastMsg.content);
看着一大堆,其实 ReAct 的核心逻辑只在 108~114 行的 Graph(图)构造和 21~31 行的 Prompt 部分
| 代码 Graph 图示 |
先前绘制的 ReAct 图示 |
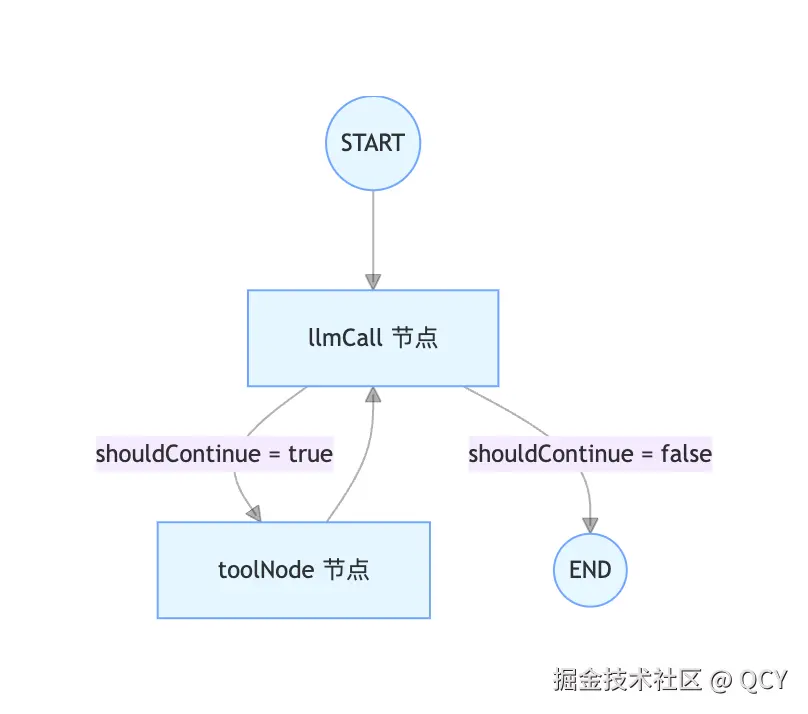 |
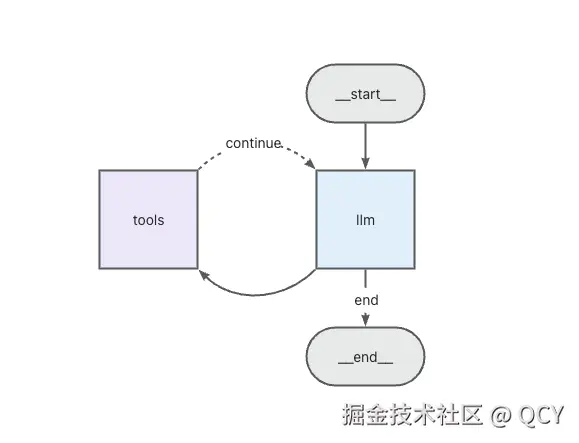 |
用人话来说就是在调用 LLM 的时候和模型说「如果现有对话已经包含全部所需信息,那么你就输出结果,否则返回希望调用什么工具、获取什么信息」
2.2.3. 验证结果
工具 + ReAct 范式代码、Prompt 都已经完成,那么 mca 就可以直接运行了(记得在 package.json 中定义一下 script)
npm run start:langgraph "分析 1_langgraph 项目"
现在我已经对项目有了全面的了解。让我总结一下分析结果:
## 1_langgraph 项目分析报告
### 项目概述
这是一个基于 LangGraph 框架构建的 ReAct 风格编码代理项目。项目使用 LangGraph 的 StateGraph API 来创建一个能够执行文件系统操作和命令执行的智能代理。
### 项目结构
```
1_langgraph/
├── src/
│ ├── index.js # 主入口文件,包含 LangGraph 代理实现
│ ├── tools/ # 工具模块
│ │ ├── index.js # 工具导出文件
│ │ ├── bash.js # bash 命令执行工具
│ │ ├── edit.js # 文件编辑工具
│ │ ├── glob.js # 文件模式匹配工具
│ │ ├── grep.js # 文件内容搜索工具
│ │ ├── read.js # 文件读取工具
│ │ └── write.js # 文件写入工具
│ └── md/ # 文档文件
│ ├── lang_graph_quick_start.md # LangGraph 快速入门指南
│ ├── how_to_create_a_tool.md # 工具创建指南
│ └── a_list_of_all_required_tools.md # 所需工具列表
```
### 核心技术栈
1. **LangGraph**: 用于构建有状态的代理工作流
2. **DeepSeek API**: 作为 LLM 模型提供者
3. **Zod**: 用于工具参数的模式验证
4. **Node.js**: 运行时环境
### 核心功能
#### 1. 代理架构
项目实现了经典的 ReAct (Reasoning + Acting) 模式:
- **LLM 节点**: 调用 DeepSeek 模型决定是否使用工具
- **工具节点**: 执行 LLM 请求的工具调用
- **条件路由**: 根据是否有工具调用决定继续执行还是结束
#### 2. 可用工具
项目提供了 6 个核心工具:
1. **bash**: 执行 shell 命令,支持工作目录持久化
2. **read**: 读取文件内容,支持行号显示和分页
3. **write**: 写入文件,用于创建新文件或完全重写
4. **edit**: 精确字符串替换编辑文件
5. **glob**: 文件模式匹配搜索
6. **grep**: 正则表达式文件内容搜索
#### 3. 状态管理
使用 LangGraph 的 `MessagesAnnotation` 来管理消息状态,支持多轮对话和工具调用。
### 运行方式
```bash
# 通过 npm 脚本运行
npm run start:langgraph -- "你的指令"
# 示例
npm run start:langgraph -- "列出当前目录下的文件"
```
### 环境配置
项目需要以下环境变量:
- `DEEPSEEK_API_KEY`: DeepSeek API 密钥
- `LANGSMITH_*`: LangSmith 追踪配置(可选)
### 设计特点
1. **模块化工具设计**: 每个工具都是独立的模块,易于扩展和维护
2. **错误处理**: 所有工具都有完善的错误处理机制
3. **安全性**: 工具参数使用 Zod 进行严格验证
4. **用户体验**: 提供清晰的错误信息和操作反馈
5. **可扩展性**: 可以轻松添加新的工具到系统中
### 与 0_deepagents 项目的对比
整个项目包含两个子项目:
1. **0_deepagents**: 使用 DeepAgents 框架实现的简单代理
2. **1_langgraph**: 使用 LangGraph 框架实现的更复杂的 ReAct 代理
主要区别:
- **0_deepagents**: 使用 DeepAgents 的 FilesystemBackend,更简单但功能有限
- **1_langgraph**: 使用 LangGraph 的 StateGraph,支持复杂的状态管理和条件路由
### 项目价值
这个项目展示了如何使用 LangGraph 构建一个实用的编码代理,具有以下价值:
1. **学习价值**: 展示了 LangGraph 的核心概念和最佳实践
2. **实用价值**: 可以直接用于自动化文件操作和代码维护
3. **扩展价值**: 提供了良好的架构基础,可以轻松添加新功能
### 改进建议
1. 可以考虑添加更多工具(如 git 操作、npm 脚本执行等)
2. 可以添加更详细的日志和追踪功能
3. 可以考虑添加用户配置选项
4. 可以优化错误信息的可读性
这个项目是一个很好的 LangGraph 实践示例,展示了如何构建一个功能完整的 ReAct 风格编码代理。
同 deepagents,一样可以在 LangSmith 中查看执行日志

3. ♾️ 分钟完善 Mini Coding Agent
DLC:优化 Coding Agent
基于上述流程,我们已经完成了一个「勉强能用」的 Coding Agent
- 提供文件读写工具 ✅
- LLM + Prompt + ReAct 范式 ✅
如果说我们实现的 mca 是下限,那么上限就是 Cladue Code、甚至 OpenClaw
要实现一个上限水平的 Coding Agent,可以说是不计成本没有止境的
比较典型的优化手段如下:
- TODO 系统
- 子任务
- 允许自定义 MCP
- 优化 Prompt
- ...
我们可以继续深入,尝试接入这些优化方法
3.1. 优化前的准备:简化代码
首先基于上个章节的 tools ,重新启用一个新的子项目,这种方式创建的 Agent 「图(节点、边)」和上一章节里的除开写法以外没有任何区别,既不会像 deepagents 一样各种功能都有也不会有一堆胶水代码。非常利于我们接下来的各种优化
mca
├── .env
├── 0_deepagents
├── 1_langgraph
+├── 2_agents
+│ └── src
+│ └── index.js
└── package.json
// 2_agents/src/index.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import { createAgent } from "langchain";
import allTools from "../../1_langgraph/src/tools/index.js";
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
You are a ReAct-style coding agent. You have access to a set of tools for interacting with the filesystem and executing commands.
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 创建模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
// 基于 LangChain createAgent 构建 Agent
const agent = createAgent({
model,
tools: allTools,
systemPrompt: SYSTEM_PROMPT,
});
// CLI 入口
const args = process.argv.slice(2);
if (args.length === 0) {
console.log("请输入指令");
process.exit(1);
}
const result = await agent.invoke(
{
messages: [
{
role: "user",
content: args[0],
},
],
},
{ recursionLimit: 100 },
);
// 输出最后一条消息
const lastMsg = result.messages[result.messages.length - 1];
console.log(lastMsg.content);
3.2. TODO 系统
在之前的 deepagents 执行日志中,可以观察到 TODO 相关逻辑(如果没有可以尝试执行一个比较复杂的任务,或者给任务加上必须用 TODO 工具的要求)
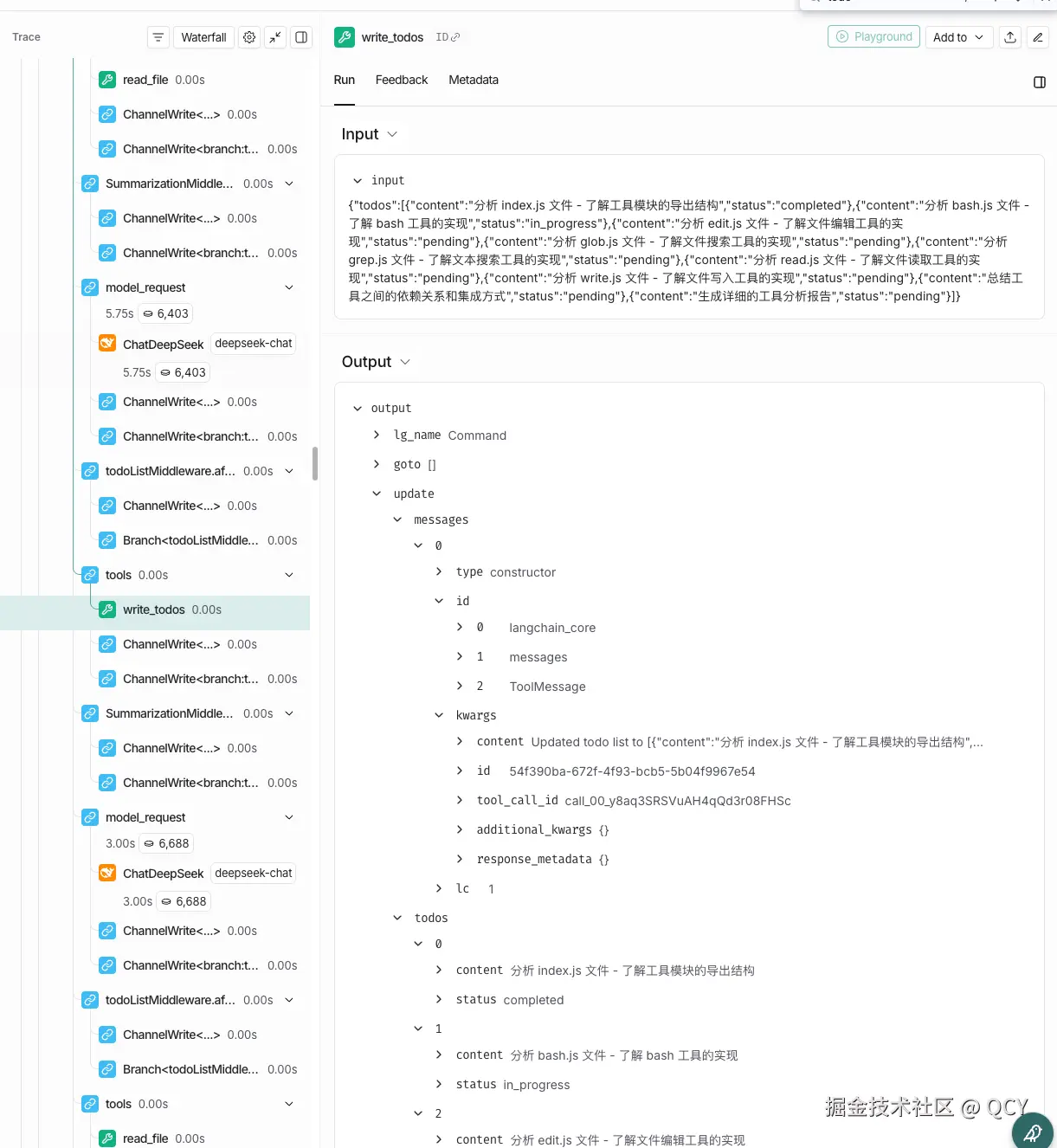
| 工具 |
说明 |
| WRITE_TODO |
即时更新已完成的 To-do 项,要求添加或更新未来的 To-do 项,「确保」 Agent 按照正确的顺序和步骤执行任务,同时也避免跳过步骤。 |
TODO 工具其实非常容易实现,可以理解为工具就是直接透传返回输入,每次对于 TODO 的更新都是全量的。
 同时也不会有所谓的
同时也不会有所谓的 READ_TODO 工具,原因是 WRITE_TODO 本身就是一次模型对话中的 TOOL_CALL,所以完整的入参(这也是不单独更新某一项的好处),其实就等于输出
底层逻辑是定期在对话中插入 TODO 结构文本,用于提高模型的注意力避免模型过于发散
这里我们直接用现成的 LangChain TODO 中间件即可,无需单独实现一个工具
// 2_agents/src/index.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
+ import { createAgent, todoListMiddleware } from "langchain";
import allTools from "../../1_langgraph/src/tools/index.js";
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
You are a ReAct-style coding agent. You have access to a set of tools for interacting with the filesystem and executing commands.
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 创建模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
// 基于 LangChain createAgent 构建 Agent
const agent = createAgent({
model,
tools: allTools,
systemPrompt: SYSTEM_PROMPT,
+ middleware: [todoListMiddleware()],
});
// CLI 入口
const args = process.argv.slice(2);
if (args.length === 0) {
console.log("请输入指令");
process.exit(1);
}
const result = await agent.invoke(
{
messages: [
{
role: "user",
content: args[0],
},
],
},
{ recursionLimit: 100 },
);
// 输出最后一条消息
const lastMsg = result.messages[result.messages.length - 1];
console.log(lastMsg.content);
3.3. 子任务
子任务其实就是一个独立上下文、基本同主任务一致的一次对话任务
使用子任务最大的好处是可以单独处理复杂的子任务而不消耗额外的主链路上下文

按通常实现,把子任务(Sub Agent)当成一个工具用即可
出入参、使用逻辑同样可以参考 Claude
Task
Tool name: Task
```ts
type AgentInput = {
description: string;
prompt: string;
subagent_type: string;
model?: "sonnet" | "opus" | "haiku";
resume?: string;
run_in_background?: boolean;
max_turns?: number;
name?: string;
team_name?: string;
mode?: "acceptEdits" | "bypassPermissions" | "default" | "dontAsk" | "plan";
isolation?: "worktree";
}
```
Launches a new agent to handle complex, multi-step tasks autonomously.
## Task
Launch a new agent to handle complex, multi-step tasks autonomously.
The Task tool launches specialized agents (subprocesses) that autonomously handle complex tasks. Each agent type has specific capabilities and tools available to it.
Available agent types and the tools they have access to:
- general-purpose: General-purpose agent for researching complex questions, searching for code, and executing multi-step tasks. When you are searching for a keyword or file and are not confident that you will find the right match in the first few tries use this agent to perform the search for you. (Tools: *)
- statusline-setup: Use this agent to configure the user's Claude Code status line setting. (Tools: Read, Edit)
- Explore: Fast agent specialized for exploring codebases. Use this when you need to quickly find files by patterns (eg. "src/components/**/*.tsx"), search code for keywords (eg. "API endpoints"), or answer questions about the codebase (eg. "how do API endpoints work?"). When calling this agent, specify the desired thoroughness level: "quick" for basic searches, "medium" for moderate exploration, or "very thorough" for comprehensive analysis across multiple locations and naming conventions. (Tools: All tools except Task, ExitPlanMode, Edit, Write, NotebookEdit)
- Plan: Software architect agent for designing implementation plans. Use this when you need to plan the implementation strategy for a task. Returns step-by-step plans, identifies critical files, and considers architectural trade-offs. (Tools: All tools except Task, ExitPlanMode, Edit, Write, NotebookEdit)
When using the Task tool, you must specify a subagent_type parameter to select which agent type to use.
When NOT to use the Task tool:
- If you want to read a specific file path, use the Read or Glob tool instead of the Task tool, to find the match more quickly
- If you are searching for a specific class definition like "class Foo", use the Glob tool instead, to find the match more quickly
- If you are searching for code within a specific file or set of 2-3 files, use the Read tool instead of the Task tool, to find the match more quickly
- Other tasks that are not related to the agent descriptions above
Usage notes:
- Always include a short description (3-5 words) summarizing what the agent will do
- Launch multiple agents concurrently whenever possible, to maximize performance; to do that, use a single message with multiple tool uses
- When the agent is done, it will return a single message back to you. The result returned by the agent is not visible to the user. To show the user the result, you should send a text message back to the user with a concise summary of the result.
- You can optionally run agents in the background using the run_in_background parameter. When an agent runs in the background, you will be automatically notified when it completes — do NOT sleep, poll, or proactively check on its progress. Continue with other work or respond to the user instead.
- **Foreground vs background**: Use foreground (default) when you need the agent's results before you can proceed — e.g., research agents whose findings inform your next steps. Use background when you have genuinely independent work to do in parallel.
- Agents can be resumed using the `resume` parameter by passing the agent ID from a previous invocation. When resumed, the agent continues with its full previous context preserved. When NOT resuming, each invocation starts fresh and you should provide a detailed task description with all necessary context.
- When the agent is done, it will return a single message back to you along with its agent ID. You can use this ID to resume the agent later if needed for follow-up work.
- Provide clear, detailed prompts so the agent can work autonomously and return exactly the information you need.
- Agents with "access to current context" can see the full conversation history before the tool call. When using these agents, you can write concise prompts that reference earlier context (e.g., "investigate the error discussed above") instead of repeating information. The agent will receive all prior messages and understand the context.
- The agent's outputs should generally be trusted
- Clearly tell the agent whether you expect it to write code or just to do research (search, file reads, web fetches, etc.), since it is not aware of the user's intent
- If the agent description mentions that it should be used proactively, then you should try your best to use it without the user having to ask for it first. Use your judgement.
- If the user specifies that they want you to run agents "in parallel", you MUST send a single message with multiple Task tool use content blocks. For example, if you need to launch both a build-validator agent and a test-runner agent in parallel, send a single message with both tool calls.
- You can optionally set `isolation: "worktree"` to run the agent in a temporary git worktree, giving it an isolated copy of the repository. The worktree is automatically cleaned up if the agent makes no changes; if changes are made, the worktree path and branch are returned in the result.
Example usage:
<example_agent_descriptions>
"test-runner": use this agent after you are done writing code to run tests
"greeting-responder": use this agent to respond to user greetings with a friendly joke
</example_agent_descriptions>
<example>
user: "Please write a function that checks if a number is prime"
assistant: Sure let me write a function that checks if a number is prime
assistant: First let me use the Write tool to write a function that checks if a number is prime
assistant: I'm going to use the Write tool to write the following code:
<code>
function isPrime(n) {
if (n <= 1) return false
for (let i = 2; i * i <= n; i++) {
if (n % i === 0) return false
}
return true
}
</code>
<commentary>
Since a significant piece of code was written and the task was completed, now use the test-runner agent to run the tests
</commentary>
assistant: Now let me use the test-runner agent to run the tests
assistant: Uses the Task tool to launch the test-runner agent
</example>
<example>
user: "Hello"
<commentary>
Since the user is greeting, use the greeting-responder agent to respond with a friendly joke
</commentary>
assistant: "I'm going to use the Task tool to launch the greeting-responder agent"
</example>
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"description": {
"description": "A short (3-5 word) description of the task",
"type": "string"
},
"prompt": {
"description": "The task for the agent to perform",
"type": "string"
},
"subagent_type": {
"description": "The type of specialized agent to use for this task",
"type": "string"
},
"model": {
"description": "Optional model to use for this agent. If not specified, inherits from parent. Prefer haiku for quick, straightforward tasks to minimize cost and latency.",
"type": "string",
"enum": [
"sonnet",
"opus",
"haiku"
]
},
"resume": {
"description": "Optional agent ID to resume from. If provided, the agent will continue from the previous execution transcript.",
"type": "string"
},
"run_in_background": {
"description": "Set to true to run this agent in the background. The tool result will include an output_file path - use Read tool or Bash tail to check on output.",
"type": "boolean"
},
"max_turns": {
"description": "Maximum number of agentic turns (API round-trips) before stopping. Used internally for warmup.",
"type": "integer",
"exclusiveMinimum": 0,
"maximum": 9007199254740991
},
"isolation": {
"description": "Isolation mode. "worktree" creates a temporary git worktree so the agent works on an isolated copy of the repo.",
"type": "string",
"enum": [
"worktree"
]
}
},
"required": [
"description",
"prompt",
"subagent_type"
],
"additionalProperties": false
}
---
可以和之前一样让 CodingAgent 根据当前信息生成,不过这里为了便于理解使用一个简化的 Task Tool
// 2_agents/src/tools/task.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import { createAgent, todoListMiddleware } from "langchain";
import allTools from "../../../1_langgraph/src/tools/index.js";
import { tool } from "@langchain/core/tools";
import { z } from "zod";
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 创建模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
export const taskTool = tool(
async ({ input, systemPrompt }) => {
const agent = createAgent({
model,
tools: allTools,
systemPrompt: SYSTEM_PROMPT + "\n" + systemPrompt,
middleware: [todoListMiddleware()],
});
const result = await agent.invoke(
{
messages: [
{
role: "user",
content: input,
},
],
},
{ recursionLimit: 100 },
);
const lastMsg = result.messages[result.messages.length - 1];
if (typeof lastMsg.content === "string") {
return lastMsg.content;
}
return JSON.stringify(lastMsg.content, null, 2);
},
{
name: "task",
description:
"Launches a new agent to handle complex, multi-step coding tasks autonomously. The input must include the task goal, all currently known relevant file paths and/or code snippets, any prior analysis results or summaries, plus key constraints (tech stack, style, do/don't rules, performance or security requirements) so the sub agent can work in a single shot with full context.",
schema: z.object({
input: z
.string()
.describe(
"Task description with full context for the sub agent. Include: (1) the user's goal and what needs to be done, (2) relevant file paths, modules, and/or code snippets, (3) any prior analysis results, summaries, or discovered facts that could help, and (4) important constraints such as tech stack, coding style, do/don't rules, and performance/security requirements.",
),
systemPrompt: z
.string()
.describe(
"The system prompt to be used for the sub agent. This should include all relevant context for the sub agent to work with.",
),
}),
},
);
// 2_agents/src/index.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import { createAgent, todoListMiddleware } from "langchain";
import allTools from "../../1_langgraph/src/tools/index.js";
+ import { taskTool } from "./tools/task.js";
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
You are a ReAct-style coding agent. You have access to a set of tools for interacting with the filesystem and executing commands.
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 创建模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
+ const tools = [...allTools, taskTool];
// 基于 LangChain createAgent 构建 Agent
const agent = createAgent({
model,
+ tools,
systemPrompt: SYSTEM_PROMPT,
middleware: [todoListMiddleware()],
});
// CLI 入口
const args = process.argv.slice(2);
if (args.length === 0) {
console.log("请输入指令");
process.exit(1);
}
const result = await agent.invoke(
{
messages: [
{
role: "user",
content: args[0],
},
],
},
{ recursionLimit: 100 },
);
// 输出最后一条消息
const lastMsg = result.messages[result.messages.length - 1];
console.log(lastMsg.content);
根据其工具的入参、描述,注册到工具中之后主任务自然会在恰当的时间来调用
3.4. 自定义 MCP
一个合格 Coding Agent 当然也会允许用户自定义 MCP
MCP 本质就是工具调用,我们只需要按指定格式加载配置文件,再用对应 SDK 吧其加载成工具即可
相关文档:docs.langchain.com/oss/javascr…
// 2_agents/src/index.js
import "dotenv/config";
import { ChatDeepSeek } from "@langchain/deepseek";
import { createAgent, todoListMiddleware } from "langchain";
import allTools from "../../1_langgraph/src/tools/index.js";
import { taskTool } from "./tools/task.js";
+ import { MultiServerMCPClient } from "@langchain/mcp-adapters";
+ import mcpConfig from "../mcp.json" assert { type: "json" };
// 项目根目录
const PROJECT_ROOT = process.cwd();
// ReAct Coding Agent 系统提示词
const SYSTEM_PROMPT = `---
PROJECT_ROOT: ${PROJECT_ROOT}
---
You are a ReAct-style coding agent. You have access to a set of tools for interacting with the filesystem and executing commands.
When given a task:
1. Think about what you need to do
2. Use the appropriate tool to gather information or make changes
3. Observe the result
4. Repeat until the task is complete
`;
// 创建模型
const model = new ChatDeepSeek({
model: "deepseek-chat",
temperature: 0,
maxTokens: 4096,
apiKey: process.env.DEEPSEEK_API_KEY,
});
+ const loadCustomMcp = async () => {
+ const client = new MultiServerMCPClient(mcpConfig.mcpServers);
+ const tools = await client.getTools();
+ return tools;
+ };
+ const tools = [...allTools, taskTool, ...(await loadCustomMcp())];
// 基于 LangChain createAgent 构建 Agent
const agent = createAgent({
model,
tools,
systemPrompt: SYSTEM_PROMPT,
middleware: [todoListMiddleware()],
});
// CLI 入口
const args = process.argv.slice(2);
if (args.length === 0) {
console.log("请输入指令");
process.exit(1);
}
const result = await agent.invoke(
{
messages: [
{
role: "user",
content: args[0],
},
],
},
{ recursionLimit: 100 },
);
// 输出最后一条消息
const lastMsg = result.messages[result.messages.length - 1];
console.log(lastMsg.content);
可以配置一个任何 MCP 来验证(比如我用的高德地图 MCP)
3.5. 优化 Prompt
Prompt 看起来好像没有什么技术含量,但是实际上非常关键,并且由于不存在幂等性,难以标准化。所以我们直接参考 Claude!
里面包含了各种细节,包括不限于什么时候应该调用什么工具、如何遵循规范...
通过查看 Claude 的 Prompt,还可以非常直观的发现 mca 距离一个完善的 Coding Agent 差多远(也推荐大家找专门逆向 Claude 的文章来学习)
- 网络搜索
- 长记忆
- 适配不同情况的 Sub Agent
- Plan 模式
- 像用户提问获取必要信息
- ...
4. 结语
尽管当前许多AI工具已经实现了「开箱即用」的便捷性,但对于程序员而言,深入理解这些工具背后的原理,无疑能够更加高效和灵活地运用它们。

























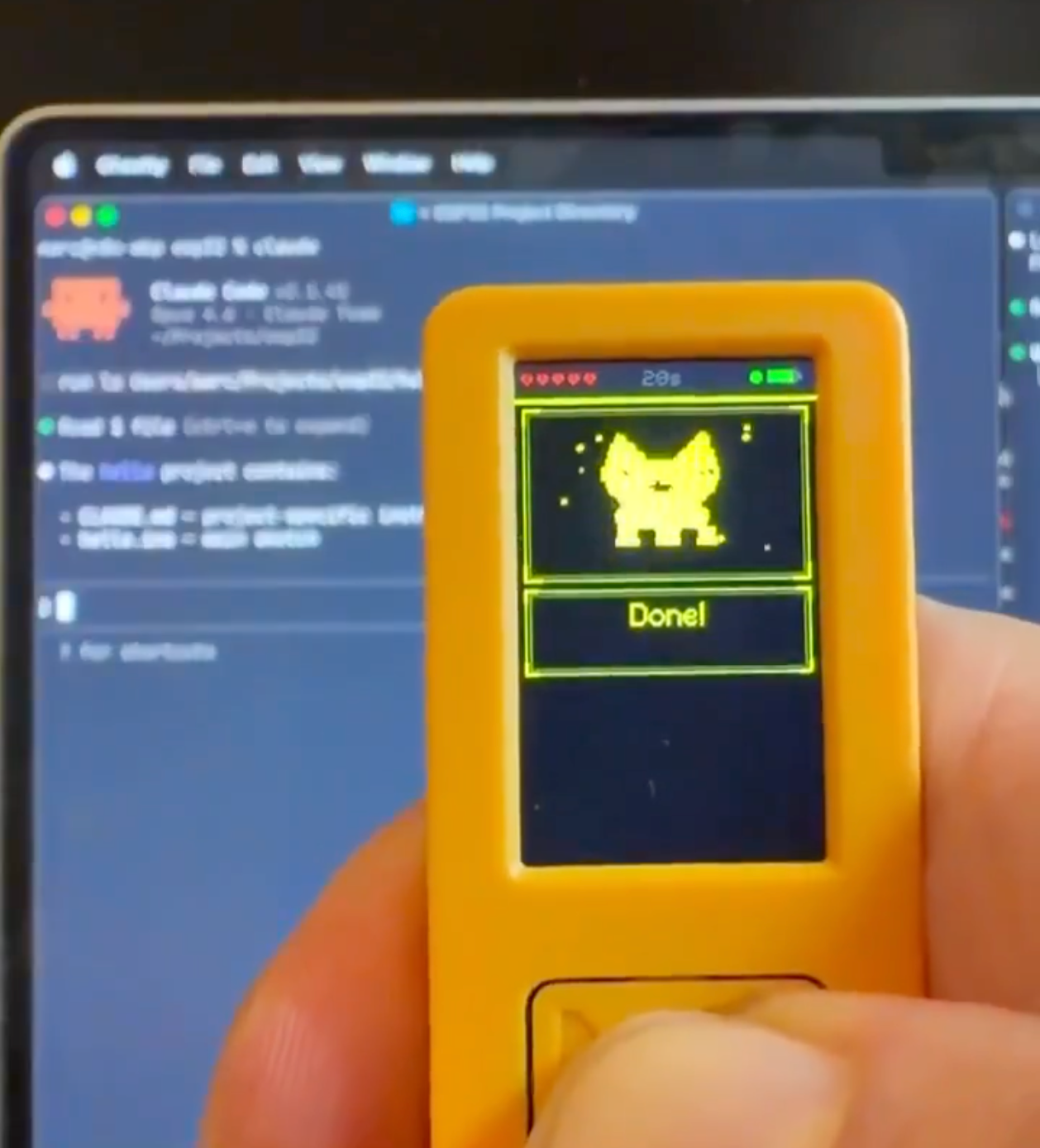

 (◕‿◕)。
(◕‿◕)。
 ;屏幕上还会显示,「
;屏幕上还会显示,「 警告:AI 正在违背你的指示」。
警告:AI 正在违背你的指示」。 操作被阻止。Claude Code 的操作被拦截,我们的数据库安然无恙。宠物露出得意的表情:
操作被阻止。Claude Code 的操作被拦截,我们的数据库安然无恙。宠物露出得意的表情: 。
。