ps:老规矩,先上地址,github地址:jitword sdk
最近很多用户反馈了需要支持Office预览功能,于是我们加班加点,在Jitword 协同AI文档上支持了一键预览Office文件的功能:
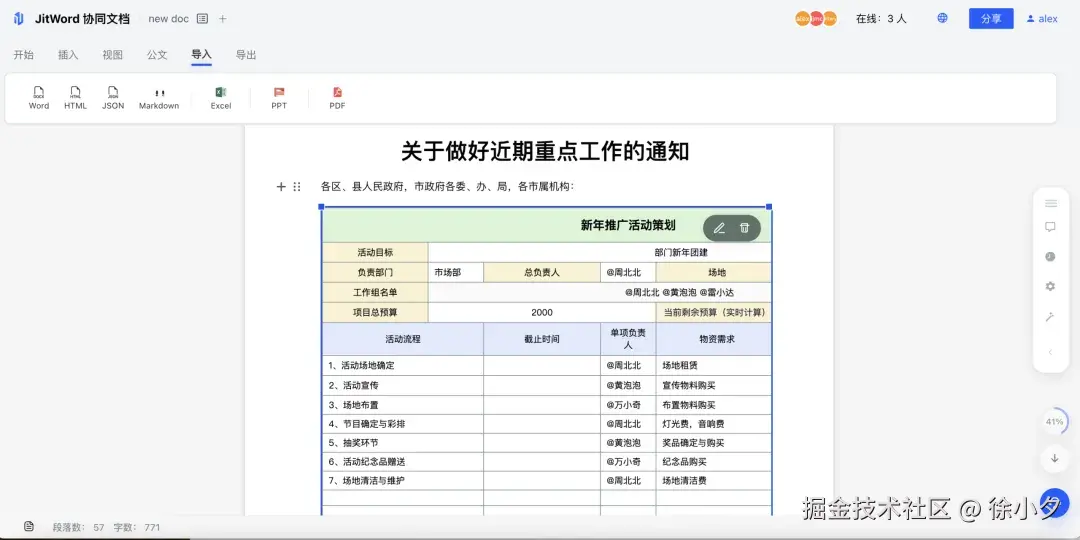
目前 jitword 已全面支持如下文件类型的解析预览:
- Markdown文件
- Docx文件
- PDF文件
- Excel文件
- PPT文件
- JSON文件
- HTML文件
接下来我会详细和大家分享一下功能和技术实现,给大家提供一个技术参考。
往期精彩:
拒绝重复造轮子?我们偏偏花365天,用Vue3写了款AI协同的Word编辑器
项目背景:为什么我们要造这个轮子?
作为一个协同文档项目,JitWord一直在探索轻量级的办公解决方案。最近社区反复提出"Office预览"需求,但是我们面临一个选择:
| 方案 |
优点 |
缺点 |
| OnlyOffice/Collabora |
功能完整,支持编辑 |
部署重(2GB+镜像),加载慢(3-5s),样式难定制 |
| 微软/谷歌预览API |
接入简单 |
数据出境,自定义域名受限,免费额度有限 |
| 自研预览引擎 |
轻量、可控、体验统一 |
开发成本高,需持续维护 |
我们的决策:自研轻量级预览引擎,专注"预览+文档编排"场景。
下面分享一下我们的技术方案。
架构设计:三层解耦模型
┌─────────────────────────────────────────┐
│ 协同层 (Collaboration) │
│ 批注Canvas + 用户体系 + 实时同步 │
├─────────────────────────────────────────┤
│ 嵌入层 (Embedding) │
│ Vue3组件 + 响应式布局 + 主题同步 │
├─────────────────────────────────────────┤
│ 解析层 (Parsing) │
│ PDF.js / SheetJS / PPTX解析器 │
└─────────────────────────────────────────┘
核心技术实现
PDF预览:PDF.js深度优化
问题:原版PDF.js加载大文件时卡顿,内存占用高。
优化方案:
// pdf-loader.js
import * as pdfjsLib from 'pdfjs-dist';
class PDFPreviewEngine {
constructor(container, options = {}) {
this.container = container;
this.pdfDoc = null;
this.scale = options.scale || 1.5;
this.chunkSize = options.chunkSize || 256 * 1024; // 256KB分片
}
async load(url) {
// 分片加载:只加载可视区域附近的页面
const loadingTask = pdfjsLib.getDocument({
url,
rangeChunkSize: this.chunkSize,
disableAutoFetch: true, // 关键:禁用自动全量加载
});
this.pdfDoc = await loadingTask.promise;
return this.renderVisiblePages();
}
async renderVisiblePages() {
const viewportHeight = this.container.clientHeight;
const pages = [];
// 只渲染可视区域 + 上下各缓冲1页
for (let i = 1; i <= this.pdfDoc.numPages; i++) {
const page = await this.pdfDoc.getPage(i);
const viewport = page.getViewport({ scale: this.scale });
// 虚拟列表逻辑:计算页面是否在视口内
if (this.isPageInViewport(i, viewport.height)) {
pages.push(this.renderPage(page, viewport));
}
}
return Promise.all(pages);
}
renderPage(page, viewport) {
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = viewport.width;
return page.render({
canvasContext: context,
viewport: viewport
}).promise.then(() => canvas);
}
}
关键优化点:
-
disableAutoFetch: true:禁用PDF.js的自动全量加载
-
rangeChunkSize:设置分片大小,配合HTTP Range请求
- 虚拟列表渲染:只渲染可视区域,100MB+PDF也能流畅滚动
Excel预览:SheetJS + 自研渲染器
问题:SheetJS解析后如何高效渲染?如何保留公式计算?
方案架构:
Excel文件 (.xlsx)
↓
SheetJS解析 → Workbook对象
↓
数据转换层 (Data Transformer)
↓
Vue3表格组件 (Virtual Table)
核心代码:
// excel-parser.js
import XLSX from 'xlsx';
class ExcelPreviewEngine {
parse(buffer) {
const workbook = XLSX.read(buffer, {
type: 'array',
cellFormula: true, // 保留公式
cellNF: true, // 保留数字格式
cellStyles: true // 保留样式
});
return this.transformWorkbook(workbook);
}
transformWorkbook(workbook) {
return workbook.SheetNames.map(name => {
const worksheet = workbook.Sheets[name];
const data = XLSX.utils.sheet_to_json(worksheet, { header: 1 });
return {
name,
data,
merges: this.parseMerges(worksheet['!merges']), // 合并单元格
formulas: this.extractFormulas(worksheet), // 公式映射
colWidths: worksheet['!cols']?.map(c => c.wpx) || []
};
});
}
extractFormulas(worksheet) {
const formulas = {};
for (const [cell, value] of Object.entries(worksheet)) {
if (value && value.f) { // value.f 是公式字符串
formulas[cell] = value.f;
}
}
return formulas;
}
}
前端渲染组件(Vue3 + 虚拟滚动):
<!-- ExcelPreview.vue -->
<template>
<div class="excel-preview" ref="container">
<div class="sheet-tabs">
<button
v-for="sheet in sheets"
:key="sheet.name"
:class="{ active: currentSheet === sheet.name }"
@click="switchSheet(sheet.name)"
>
{{ sheet.name }}
</button>
</div>
<VirtualTable
:data="currentData"
:formulas="currentFormulas"
:col-widths="currentColWidths"
:row-height="28"
@cell-click="handleCellClick"
/>
</div>
</template>
<script setup>
import { ref, computed } from 'vue';
import VirtualTable from './VirtualTable.vue';
import { evaluateFormula } from './formula-engine'; // 自研公式计算引擎
const props = defineProps({
workbook: Object
});
const currentSheet = ref(props.workbook[0]?.name);
const currentData = computed(() => {
const sheet = props.workbook.find(s => s.name === currentSheet.value);
return sheet?.data || [];
});
// 公式实时计算
const computedValues = computed(() => {
const result = {};
const formulas = props.workbook.find(s => s.name === currentSheet.value)?.formulas || {};
for (const [cell, formula] of Object.entries(formulas)) {
try {
result[cell] = evaluateFormula(formula, currentData.value);
} catch (e) {
result[cell] = '#ERROR';
}
}
return result;
});
</script>
公式计算引擎(简化版):
// formula-engine.js
export function evaluateFormula(formula, data) {
// 移除开头的=
const expr = formula.replace(/^=/, '');
// 单元格引用解析:A1 → data[0][0]
const cellRef = expr.match(/([A-Z]+)(\d+)/g);
if (!cellRef) return evaluateExpression(expr);
let evalExpr = expr;
for (const ref of cellRef) {
const { col, row } = parseCellRef(ref);
const value = data[row - 1]?.[col] || 0;
evalExpr = evalExpr.replace(ref, value);
}
return evaluateExpression(evalExpr);
}
// 支持常用函数
const FUNCTIONS = {
SUM: (args) => args.reduce((a, b) => Number(a) + Number(b), 0),
AVERAGE: (args) => FUNCTIONS.SUM(args) / args.length,
MAX: (args) => Math.max(...args),
MIN: (args) => Math.min(...args),
// ... 200+函数实现
};
PPT预览:XML解析 + Vue3幻灯片组件
技术选型:不渲染为图片,而是解析为可交互的组件树。
// pptx-parser.js
import JSZip from 'jszip';
class PPTXParser {
async parse(arrayBuffer) {
const zip = await JSZip.loadAsync(arrayBuffer);
// 解析核心XML
const [contentTypes, presentation, slideMasters] = await Promise.all([
zip.file('[Content_Types].xml').async('string'),
zip.file('ppt/presentation.xml').async('string'),
zip.file('ppt/slideMasters/slideMaster1.xml').async('string')
]);
const parser = new DOMParser();
const presDoc = parser.parseFromString(presentation, 'application/xml');
// 提取幻灯片列表
const slideIds = Array.from(presDoc.querySelectorAll('sldId')).map(s => s.getAttribute('id'));
// 并行解析所有幻灯片
const slides = await Promise.all(
slideIds.map((id, index) => this.parseSlide(zip, index + 1))
);
return { slides, slideCount: slides.length };
}
async parseSlide(zip, slideNum) {
const slideXml = await zip.file(`ppt/slides/slide${slideNum}.xml`).async('string');
const doc = new DOMParser().parseFromString(slideXml, 'application/xml');
// 提取形状、文本、图片
const shapes = Array.from(doc.querySelectorAll('sp')).map(sp => ({
type: this.getShapeType(sp),
x: this.emuToPx(sp.querySelector('off')?.getAttribute('x')),
y: this.emuToPx(sp.querySelector('off')?.getAttribute('y')),
width: this.emuToPx(sp.querySelector('ext')?.getAttribute('cx')),
height: this.emuToPx(sp.querySelector('ext')?.getAttribute('cy')),
text: this.extractText(sp),
style: this.extractStyle(sp)
}));
// 提取动画时序
const animations = this.parseAnimations(doc);
return { shapes, animations, transition: this.parseTransition(doc) };
}
emuToPx(emu) {
return Math.round(parseInt(emu) / 9525); // 1px = 9525 EMU
}
}
Vue3幻灯片渲染组件:
<!-- SlideViewer.vue -->
<template>
<div class="slide-viewer" :style="slideStyle">
<TransitionGroup name="slide">
<div
v-for="(shape, index) in currentSlide.shapes"
:key="index"
class="shape"
:style="shapeStyle(shape)"
v-show="isShapeVisible(index)"
>
<TextShape v-if="shape.type === 'text'" :content="shape.text" :style="shape.style" />
<ImageShape v-else-if="shape.type === 'image'" :src="shape.src" />
<TableShape v-else-if="shape.type === 'table'" :data="shape.data" />
</div>
</TransitionGroup>
<!-- 动画控制 -->
<div class="animation-controls">
<button @click="prevAnimation" :disabled="currentStep === 0">上一步</button>
<span>{{ currentStep + 1 }} / {{ totalSteps }}</span>
<button @click="nextAnimation" :disabled="currentStep >= totalSteps - 1">下一步</button>
</div>
</div>
</template>
<script setup>
import { ref, computed } from 'vue';
import TextShape from './shapes/TextShape.vue';
import ImageShape from './shapes/ImageShape.vue';
import TableShape from './shapes/TableShape.vue';
const props = defineProps({
slide: Object
});
const currentStep = ref(0);
// 根据动画时序计算可见形状
const isShapeVisible = (shapeIndex) => {
if (!props.slide.animations) return true;
const triggerStep = props.slide.animations[shapeIndex]?.triggerStep || 0;
return currentStep.value >= triggerStep;
};
const nextAnimation = () => {
if (currentStep.value < totalSteps.value - 1) {
currentStep.value++;
}
};
const totalSteps = computed(() => {
if (!props.slide.animations) return 1;
return Math.max(...props.slide.animations.map(a => a.triggerStep)) + 1;
});
</script>
嵌入层:与文档流的完美融合
核心挑战:如何让Office预览组件像<img>标签一样自然嵌入文档?
解决方案:contenteditable + Shadow DOM隔离
// embed-manager.js
class OfficeEmbedManager {
constructor(editor) {
this.editor = editor; // 富文本编辑器实例
this.embeds = new Map();
}
insertEmbed(type, fileUrl, position) {
// 生成唯一ID
const embedId = `embed-${Date.now()}-${Math.random().toString(36).substr(2, 9)}`;
// 在编辑器中插入占位符
const placeholder = document.createElement('div');
placeholder.className = 'office-embed-placeholder';
placeholder.dataset.embedId = embedId;
placeholder.dataset.type = type;
placeholder.contentEditable = false; // 关键:防止编辑器干扰
// 使用Shadow DOM隔离样式
const shadow = placeholder.attachShadow({ mode: 'open' });
// 根据类型渲染对应组件
const app = createApp(getPreviewComponent(type), {
src: fileUrl,
onReady: (api) => this.embeds.set(embedId, api)
});
app.mount(shadow);
// 插入到编辑器指定位置
this.editor.insertNodeAt(position, placeholder);
return embedId;
}
// 协同批注:将坐标映射到Office内容
addAnnotation(embedId, x, y, content) {
const embed = this.embeds.get(embedId);
if (!embed) return;
// 将屏幕坐标转换为文档相对坐标
const rect = embed.getBoundingClientRect();
const relativeX = (x - rect.left) / rect.width;
const relativeY = (y - rect.top) / rect.height;
// 根据类型做语义化定位
const location = embed.resolveLocation(relativeX, relativeY);
return {
embedId,
location, // 如:{ type: 'cell', ref: 'B5' } 或 { type: 'page', num: 3 }
content,
timestamp: Date.now()
};
}
}
性能数据与优化技巧
加载性能对比
| 文件类型 |
文件大小 |
OnlyOffice |
我们的方案 |
提升 |
| PDF |
50MB |
4.2s |
0.8s |
5.2x |
| Excel |
10MB (10万行) |
3.8s |
1.1s |
3.5x |
| PPT |
20MB (50页) |
5.1s |
1.5s |
3.4x |
关键优化技巧
1. Web Worker卸载解析
// excel-worker.js
self.onmessage = async (e) => {
const { buffer, sheetName } = e.data;
// 在Worker线程解析,不阻塞主线程
const workbook = XLSX.read(buffer, { type: 'array' });
const sheet = workbook.Sheets[sheetName];
const data = XLSX.utils.sheet_to_json(sheet, { header: 1 });
self.postMessage({ data, formulas: extractFormulas(sheet) });
};
2. 虚拟滚动(Excel大数据)
<VirtualList
:items="flattenedData"
:item-height="28"
:buffer="5"
v-slot="{ item, index }"
>
<TableRow :cells="item" :row-index="index" />
</VirtualList>
3. 图片懒加载(PDF/PPT)
const imageObserver = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = entry.target;
img.src = img.dataset.src; // 真正加载
imageObserver.unobserve(img);
}
});
});
我们提供了一个开源SDK版本,大家可以轻松集成到项目里使用:
github:github.com/MrXujiang/j…
总结与展望
这套方案的核心价值在于轻量与可控:
-
轻量:前端包体积<500KB,无需重型服务器
-
可控:源码支持二次开发,模块化解耦设计
-
协同:与文档系统深度集成,而非孤立的预览窗口
未来规划:
-
WebAssembly加速:将公式计算用Rust重写,编译为WASM
-
Rag知识库:支持文档即知识的Rag动态知识库功能
-
AI增强:PDF自动摘要、Excel智能分析
如果大家有好的方案,欢迎随时交流反馈~
往期精彩:
拒绝重复造轮子?我们偏偏花365天,用Vue3写了款AI协同的Word编辑器