journalctl is a command-line utility for querying and displaying logs collected by systemd-journald, the systemd logging daemon. It gives you structured access to all system logs — kernel messages, service output, authentication events, and more — from a single interface.
This guide explains how to use journalctl to view, filter, and manage system logs.
journalctl Command Syntax #
The general syntax for the journalctl command is:
journalctl [OPTIONS] [MATCHES]
When invoked without any options, journalctl displays all collected logs starting from the oldest entry, piped through a pager (usually less). Press q to exit.
Only the root user or members of the adm or systemd-journal groups can read system logs. Regular users can view their own user journal with the --user flag.
Quick Reference #
| Command |
Description |
journalctl |
Show all logs |
journalctl -f |
Follow new log entries in real time |
journalctl -n 50 |
Show last 50 lines |
journalctl -r |
Show logs newest first |
journalctl -e |
Jump to end of logs |
journalctl -u nginx |
Logs for a specific unit |
journalctl -u nginx -f |
Follow unit logs in real time |
journalctl -b |
Current boot logs |
journalctl -b -1 |
Previous boot logs |
journalctl --list-boots |
List all boots |
journalctl -p err |
Errors and above |
journalctl -p warning --since "1 hour ago" |
Recent warnings |
journalctl -k |
Kernel messages |
journalctl --since "yesterday" |
Logs since yesterday |
journalctl --since "2026-02-01" --until "2026-02-02" |
Logs in a time window |
journalctl -g "failed" |
Search by pattern |
journalctl -o json-pretty |
JSON output |
journalctl --disk-usage |
Show journal disk usage |
journalctl --vacuum-size=500M |
Reduce journal to 500 MB |
For a printable quick reference, see the journalctl cheatsheet
.
Viewing System Logs #
To view all system logs, run journalctl without any options:
To show the most recent entries first, use the -r flag:
To jump directly to the end of the log, use -e:
To show the last N lines (similar to tail
), use the -n flag:
To disable the pager and print directly to the terminal, use --no-pager:
Following Logs in Real Time #
To stream new log entries as they arrive (similar to tail -f), use the -f flag:
This is one of the most useful options for monitoring a running service or troubleshooting an active issue. Press Ctrl+C to stop.
Filtering by Systemd Unit #
To view logs for a specific systemd service, use the -u flag followed by the unit name:
You can combine -u with other filters. For example, to follow nginx logs in real time:
To view logs for multiple units at once, specify -u more than once:
journalctl -u nginx -u php-fpm
To print the last 100 lines for a service without the pager:
journalctl -u nginx -n 100 --no-pager
For more on starting and stopping services, see how to start, stop, and restart Nginx
and Apache
.
Filtering by Time #
Use --since and --until to limit log output to a specific time range.
To show logs since a specific date and time:
journalctl --since "2026-02-01 10:00"
To show logs within a window:
journalctl --since "2026-02-01 10:00" --until "2026-02-01 12:00"
journalctl accepts many natural time expressions:
journalctl --since "1 hour ago"
journalctl --since "yesterday"
journalctl --since today
You can combine time filters with unit filters. For example, to view nginx logs from the past hour:
journalctl -u nginx --since "1 hour ago"
Filtering by Priority #
systemd uses the standard syslog priority levels. Use the -p flag to filter by severity:
The output will include the specified priority and all higher-severity levels. The available priority levels from highest to lowest are:
| Level |
Name |
Description |
| 0 |
emerg |
System is unusable |
| 1 |
alert |
Immediate action required |
| 2 |
crit |
Critical conditions |
| 3 |
err |
Error conditions |
| 4 |
warning |
Warning conditions |
| 5 |
notice |
Normal but significant events |
| 6 |
info |
Informational messages |
| 7 |
debug |
Debug-level messages |
To view only warnings and above from the last hour:
journalctl -p warning --since "1 hour ago"
Filtering by Boot #
The journal stores logs from multiple boots. Use -b to filter by boot session.
To view logs from the current boot:
To view logs from the previous boot:
To list all available boot sessions with their IDs and timestamps:
The output will look something like this:
-2 abc123def456 Mon 2026-02-24 08:12:01 CET—Mon 2026-02-24 18:43:22 CET
-1 def456abc789 Tue 2026-02-25 09:05:14 CET—Tue 2026-02-25 21:11:03 CET
0 789abcdef012 Wed 2026-02-26 08:30:41 CET—Wed 2026-02-26 14:00:00 CET
To view logs for a specific boot ID:
journalctl -b abc123def456
To view errors from the previous boot:
Kernel Messages #
To view kernel messages only (equivalent to dmesg
), use the -k flag:
To view kernel messages from the current boot:
To view kernel errors from the previous boot:
journalctl -k -p err -b -1
Filtering by Process #
In addition to filtering by unit, you can filter logs by process name, executable path, PID, or user ID using journal fields.
To filter by process name:
To filter by executable path:
journalctl _EXE=/usr/sbin/sshd
To filter by PID:
To filter by user ID:
Multiple fields can be combined to narrow the results further.
Searching Log Messages #
To search log messages by a pattern, use the -g flag followed by a regular expression:
To search within a specific unit:
journalctl -u ssh -g "invalid user"
You can also pipe journalctl output to grep
for more complex matching:
journalctl -u nginx -n 500 --no-pager | grep -i "upstream"
Output Formats #
By default, journalctl displays logs in a human-readable format. Use the -o flag to change the output format.
To display logs with ISO 8601 timestamps:
To display logs as JSON (useful for scripting and log shipping):
journalctl -o json-pretty
To display message text only, without metadata:
The most commonly used output formats are:
| Format |
Description |
short |
Default human-readable format |
short-iso |
ISO 8601 timestamps |
short-precise |
Microsecond-precision timestamps |
json |
One JSON object per line |
json-pretty |
Formatted JSON |
cat |
Message text only |
Managing Journal Size #
The journal stores logs on disk under /var/log/journal/. To check how much disk space the journal is using:
Archived and active journals take up 512.0M in the file system.
To reduce the journal size, use the --vacuum-size, --vacuum-time, or --vacuum-files options:
journalctl --vacuum-size=500M
journalctl --vacuum-time=30d
journalctl --vacuum-files=5
These commands remove old archived journal files until the specified limit is met. To configure a permanent size limit, edit /etc/systemd/journald.conf and set SystemMaxUse=.
Practical Troubleshooting Workflow #
When a service fails, we can use a short sequence to isolate the issue quickly. First, check service state with systemctl
:
sudo systemctl status nginx
Then inspect recent error-level logs for that unit:
sudo journalctl -u nginx -p err -n 100 --no-pager
If the problem started after reboot, inspect previous boot logs:
sudo journalctl -u nginx -b -1 -p err --no-pager
To narrow the time window around the incident:
sudo journalctl -u nginx --since "30 minutes ago" --no-pager
If you need pattern matching across many lines, pipe to grep
:
sudo journalctl -u nginx -n 500 --no-pager | grep -Ei "error|failed|timeout"
Troubleshooting #
“No journal files were found”
The systemd journal may not be persistent on your system. Check if /var/log/journal/ exists. If it does not, create it with mkdir -p /var/log/journal and restart systemd-journald. Alternatively, set Storage=persistent in /etc/systemd/journald.conf.
“Permission denied” reading logs
Regular users can only access their own user journal. To read system logs, run journalctl with sudo, or add your user to the adm or systemd-journal group: usermod -aG systemd-journal USERNAME.
-g pattern search returns no results
The -g flag uses PCRE2 regular expressions. Make sure the pattern is correct and that your journalctl version supports -g (available on modern systemd releases). As an alternative, pipe the output to grep.
Logs missing after reboot
The journal is stored in memory by default on some distributions. To enable persistent storage across reboots, set Storage=persistent in /etc/systemd/journald.conf and restart systemd-journald.
Journal consuming too much disk space
Use journalctl --disk-usage to check the current size, then journalctl --vacuum-size=500M to trim old entries. For a permanent limit, configure SystemMaxUse= in /etc/systemd/journald.conf.
FAQ #
What is the difference between journalctl and /var/log/syslog?
/var/log/syslog is a plain text file written by rsyslog or syslog-ng. journalctl reads the binary systemd journal, which stores structured metadata alongside each message. The journal offers better filtering, field-based queries, and persistent boot tracking.
How do I view logs for a service that keeps restarting?
Use journalctl -u servicename -f to follow logs in real time, or journalctl -u servicename -n 200 to view the most recent entries. Adding -p err will surface only error-level messages.
How do I check logs from before the current boot?
Use journalctl -b -1 for the previous boot, or journalctl --list-boots to see all available boot sessions and then journalctl -b BOOTID to query a specific one.
Can I export logs to a file?
Yes. Use journalctl --no-pager > output.log for plain text, or journalctl -o json-pretty > output.json for structured JSON. You can combine this with any filter flags.
How do I reduce the amount of disk space used by the journal?
Run journalctl --vacuum-size=500M to immediately trim archived logs to 500 MB. For a persistent limit, set SystemMaxUse=500M in /etc/systemd/journald.conf and restart the journal daemon with systemctl restart systemd-journald.
Conclusion #
journalctl is a powerful and flexible tool for querying the systemd journal. Whether you are troubleshooting a failing service, reviewing kernel messages, or auditing authentication events, mastering its filter options saves significant time. If you have any questions, feel free to leave a comment below.











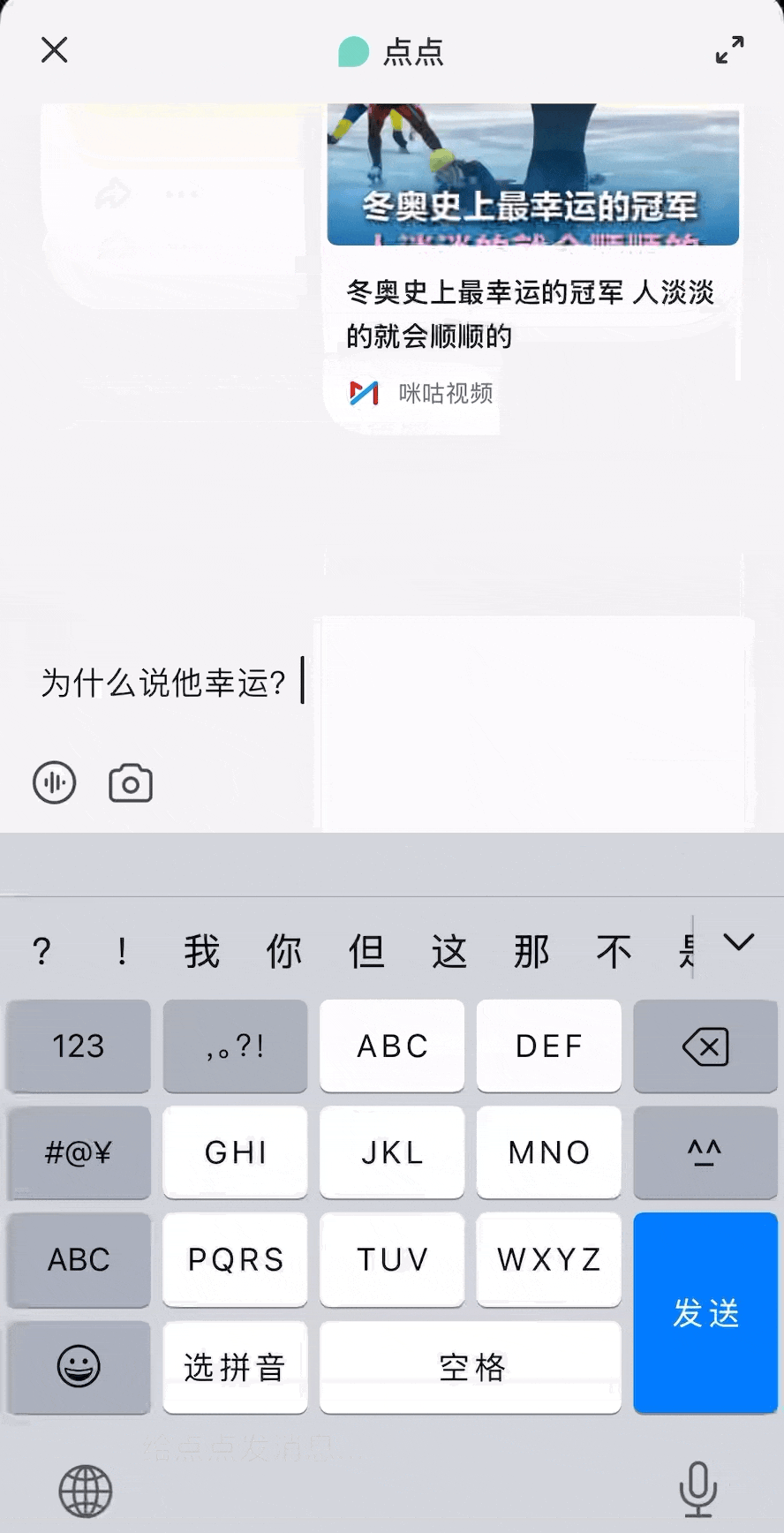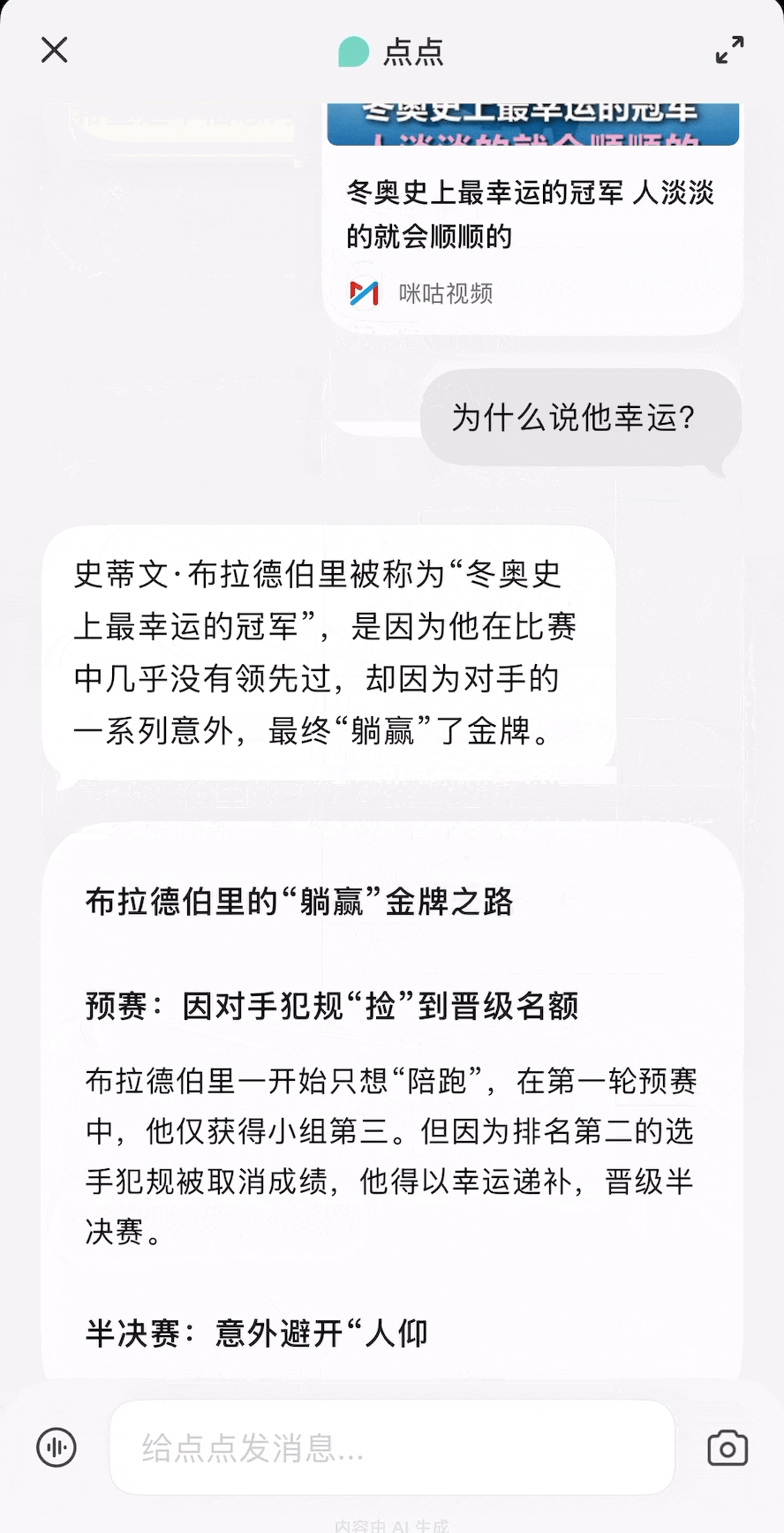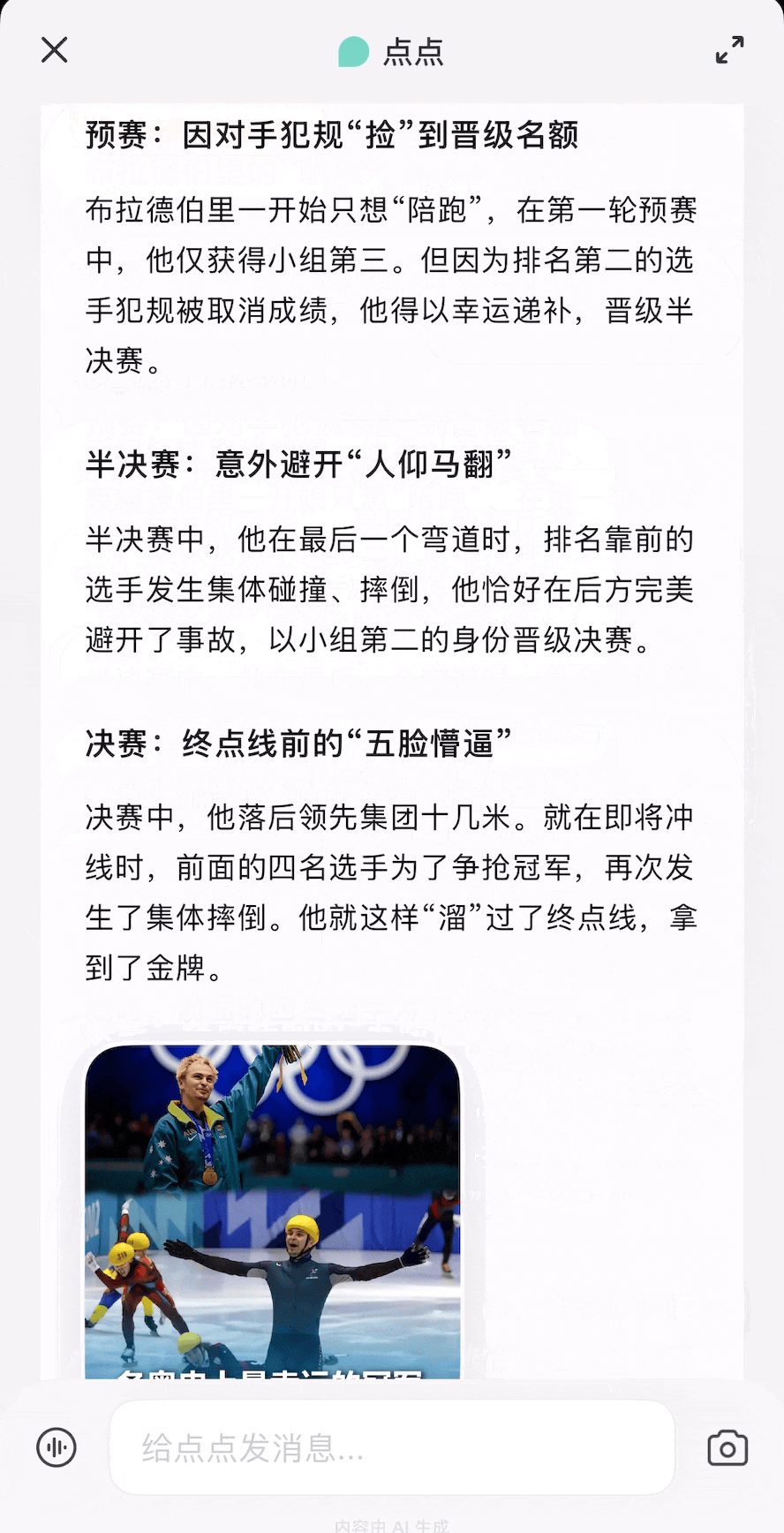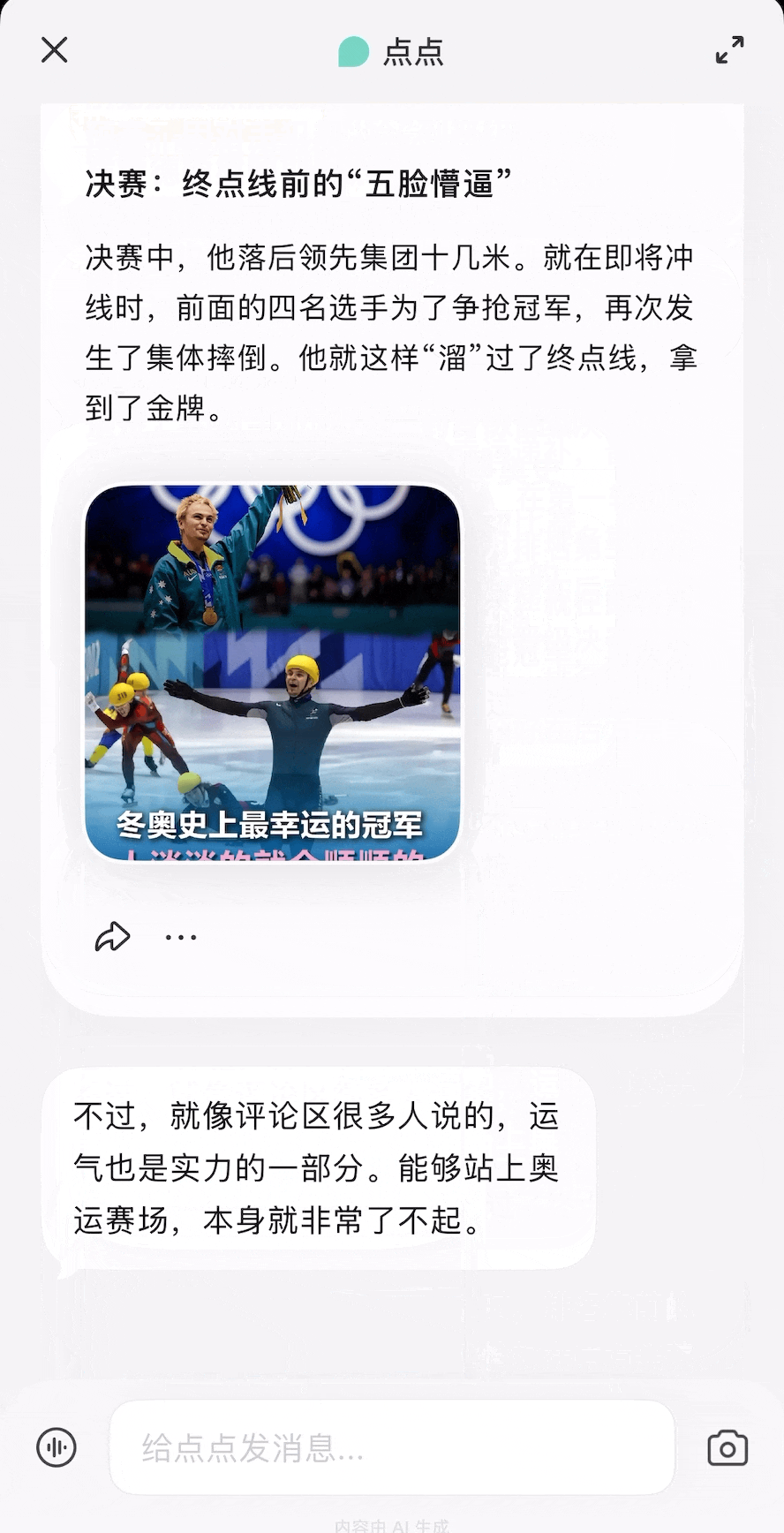
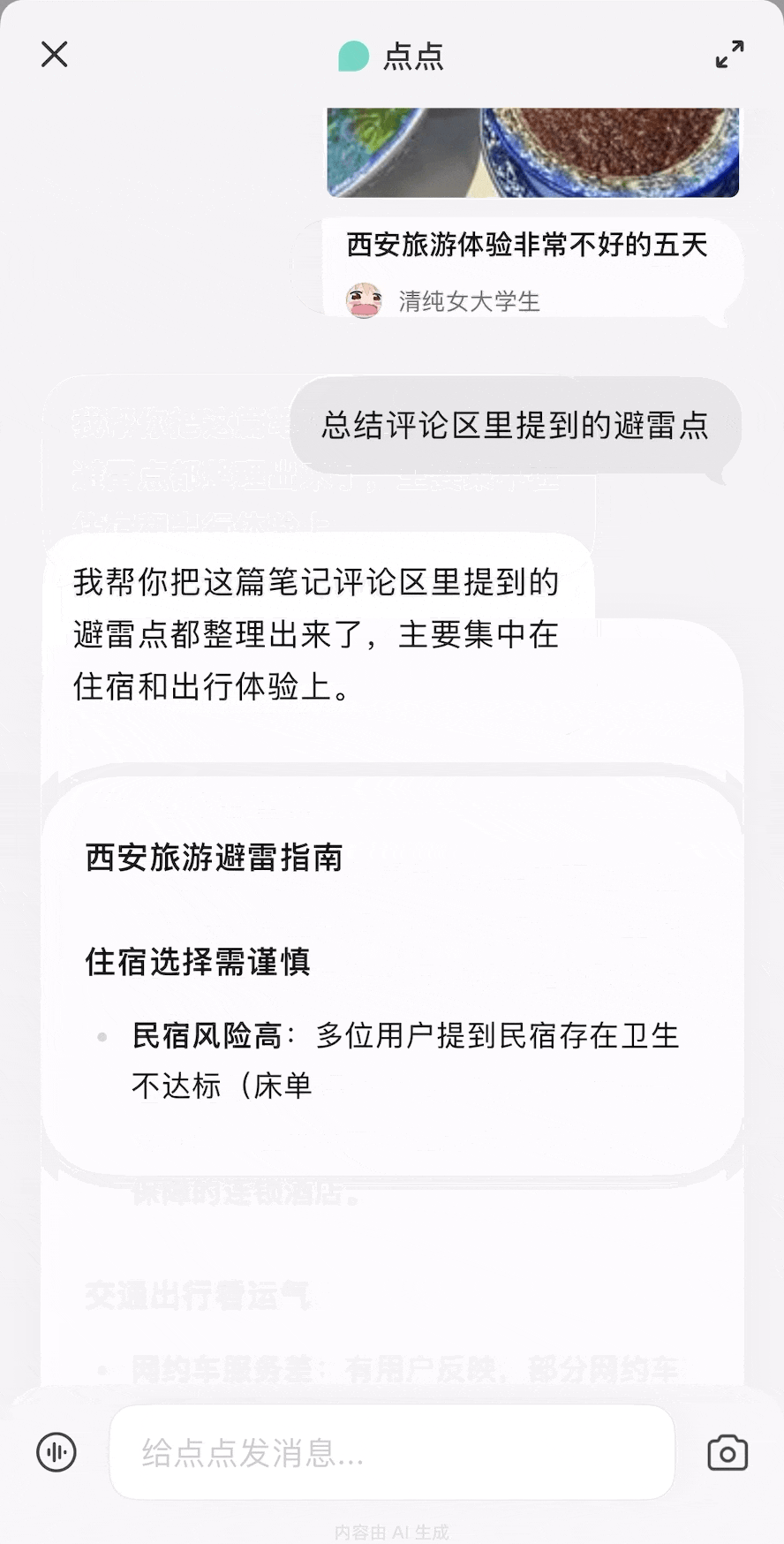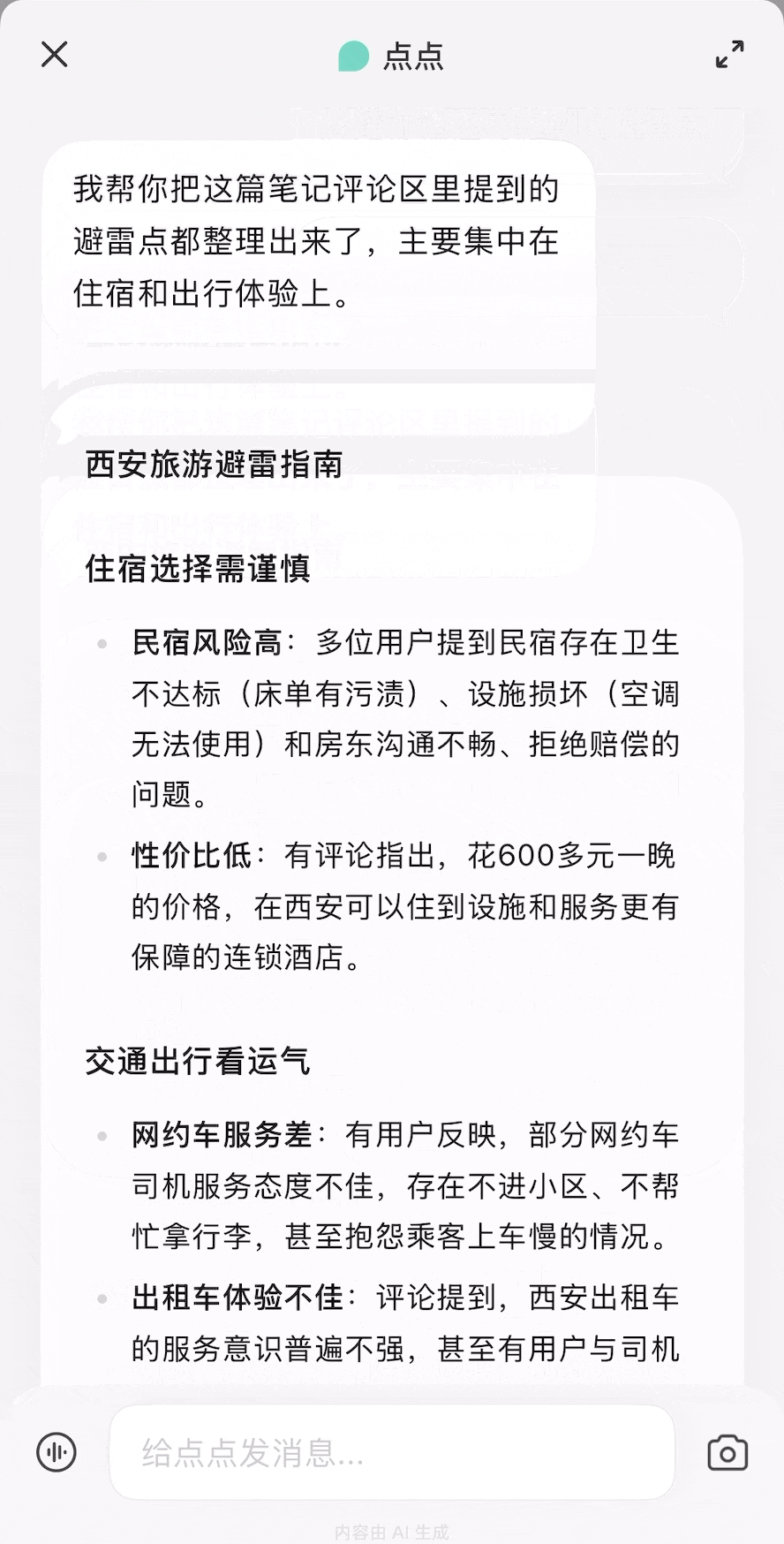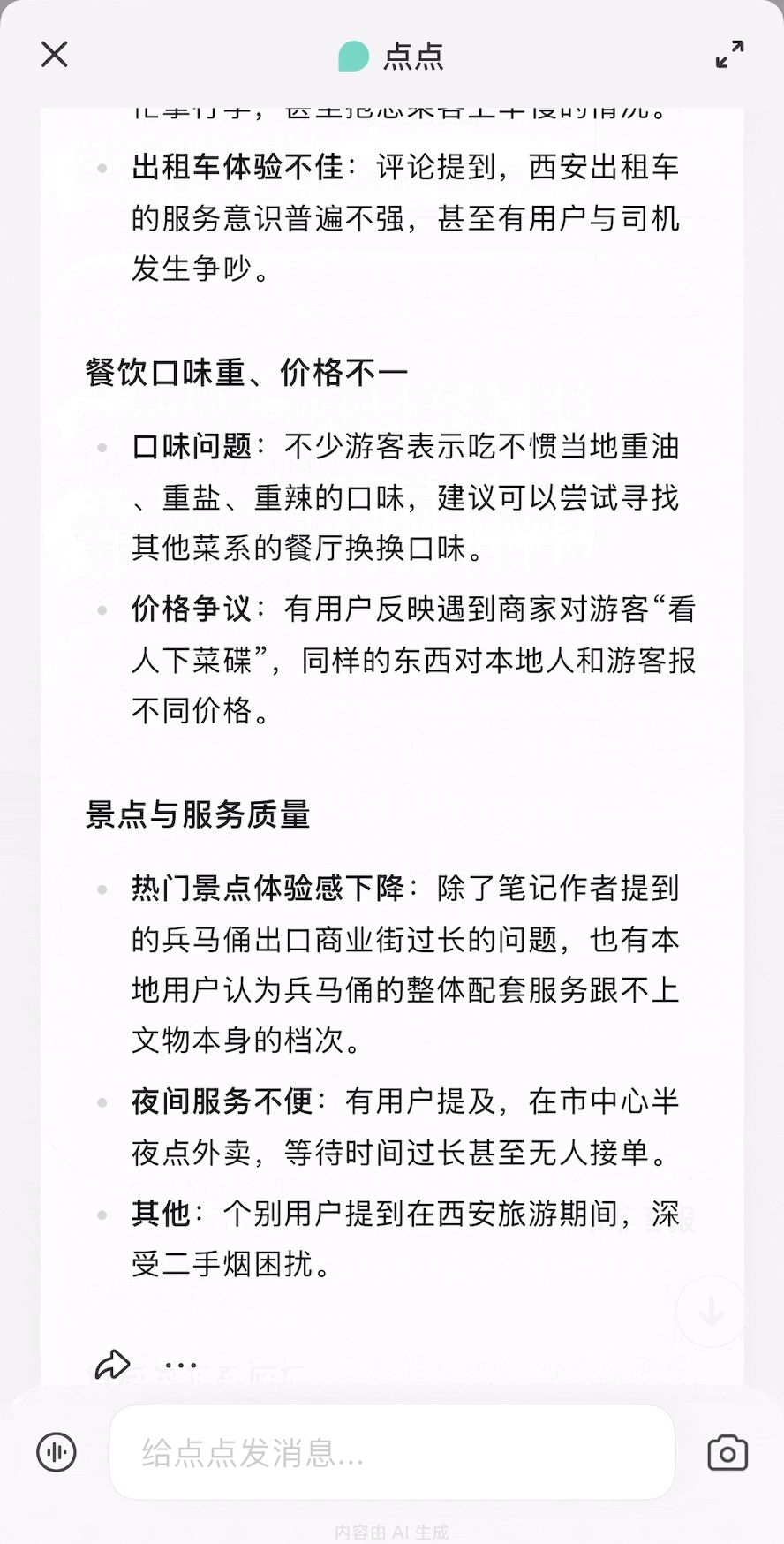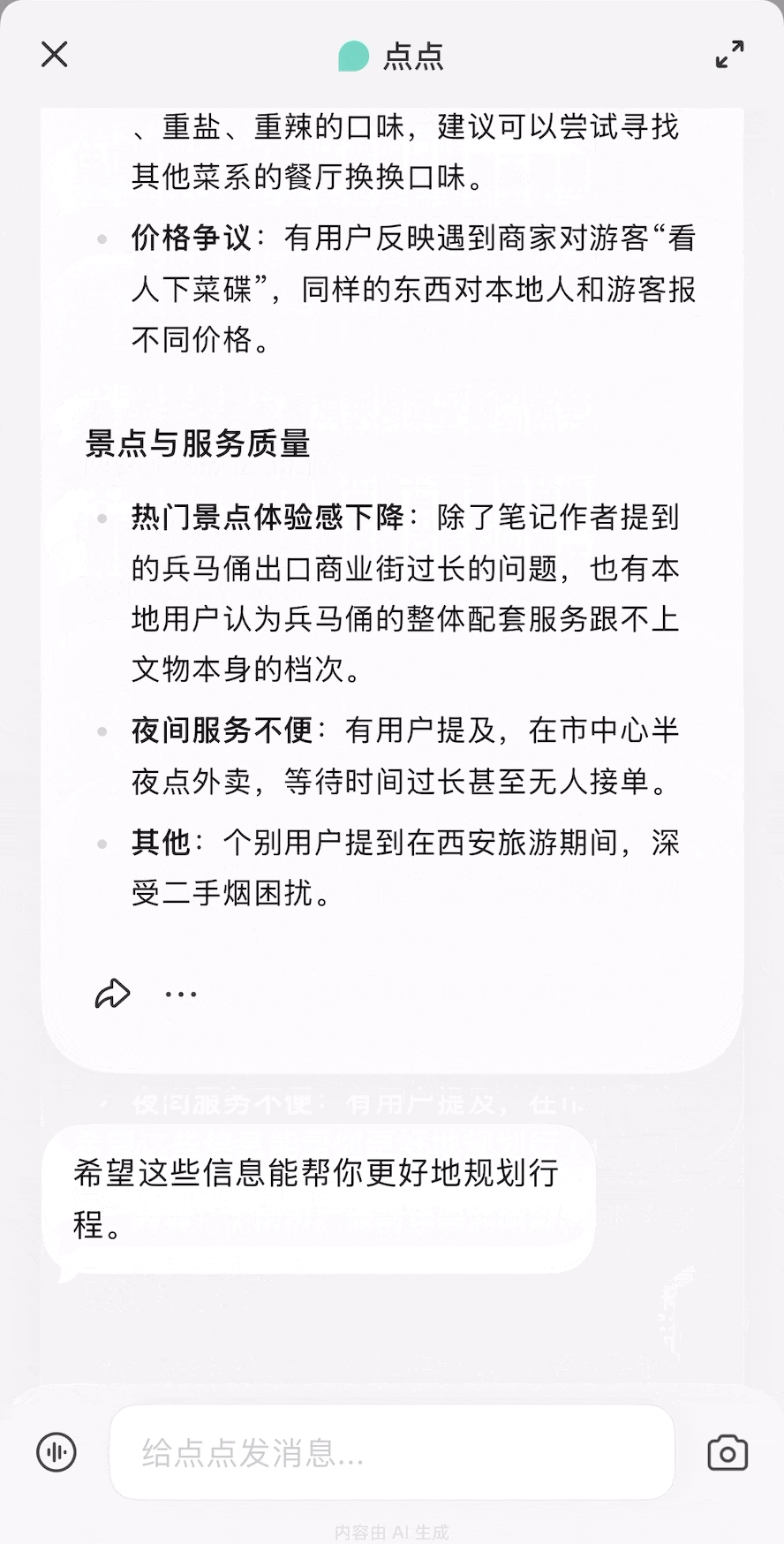
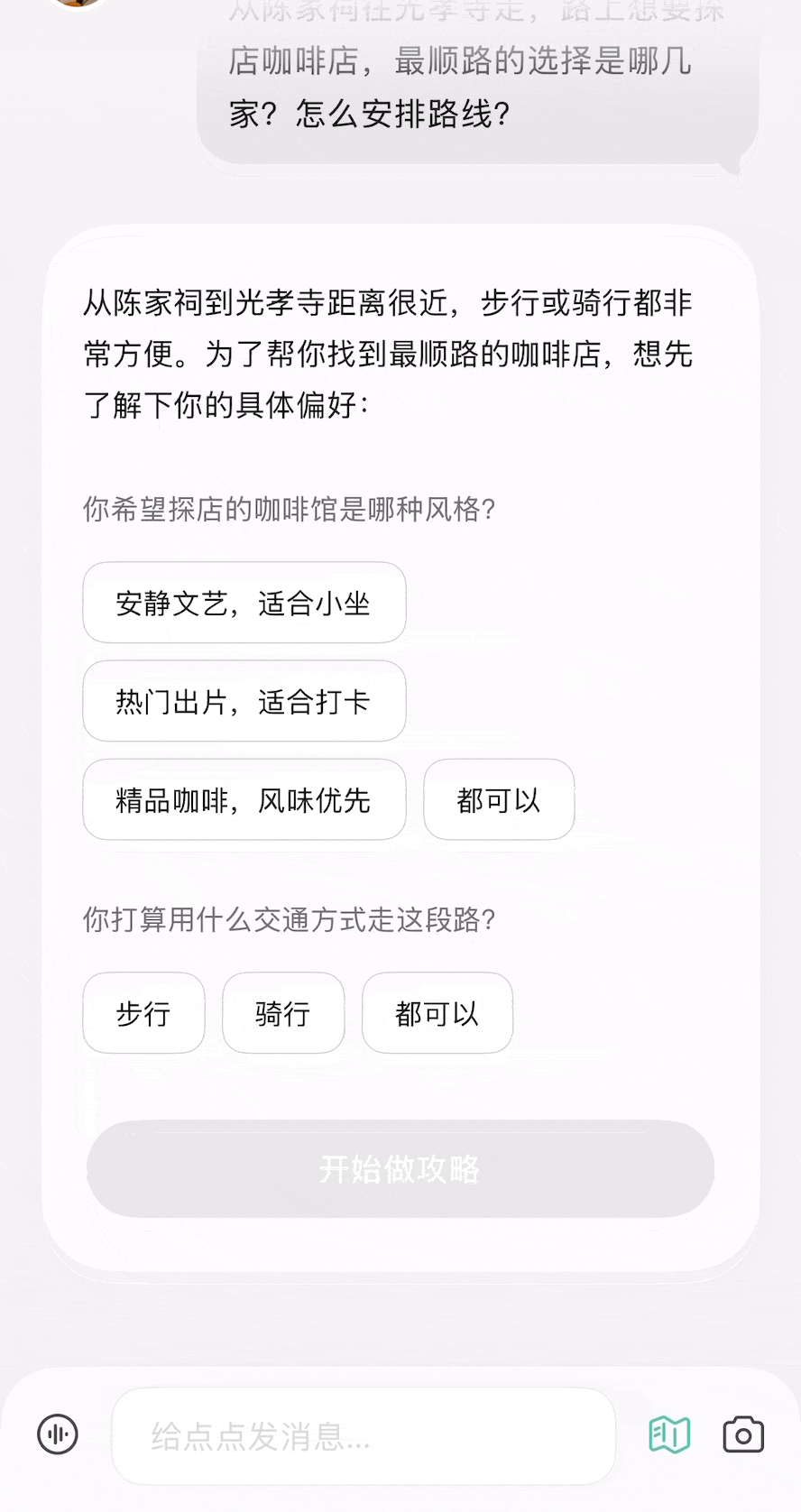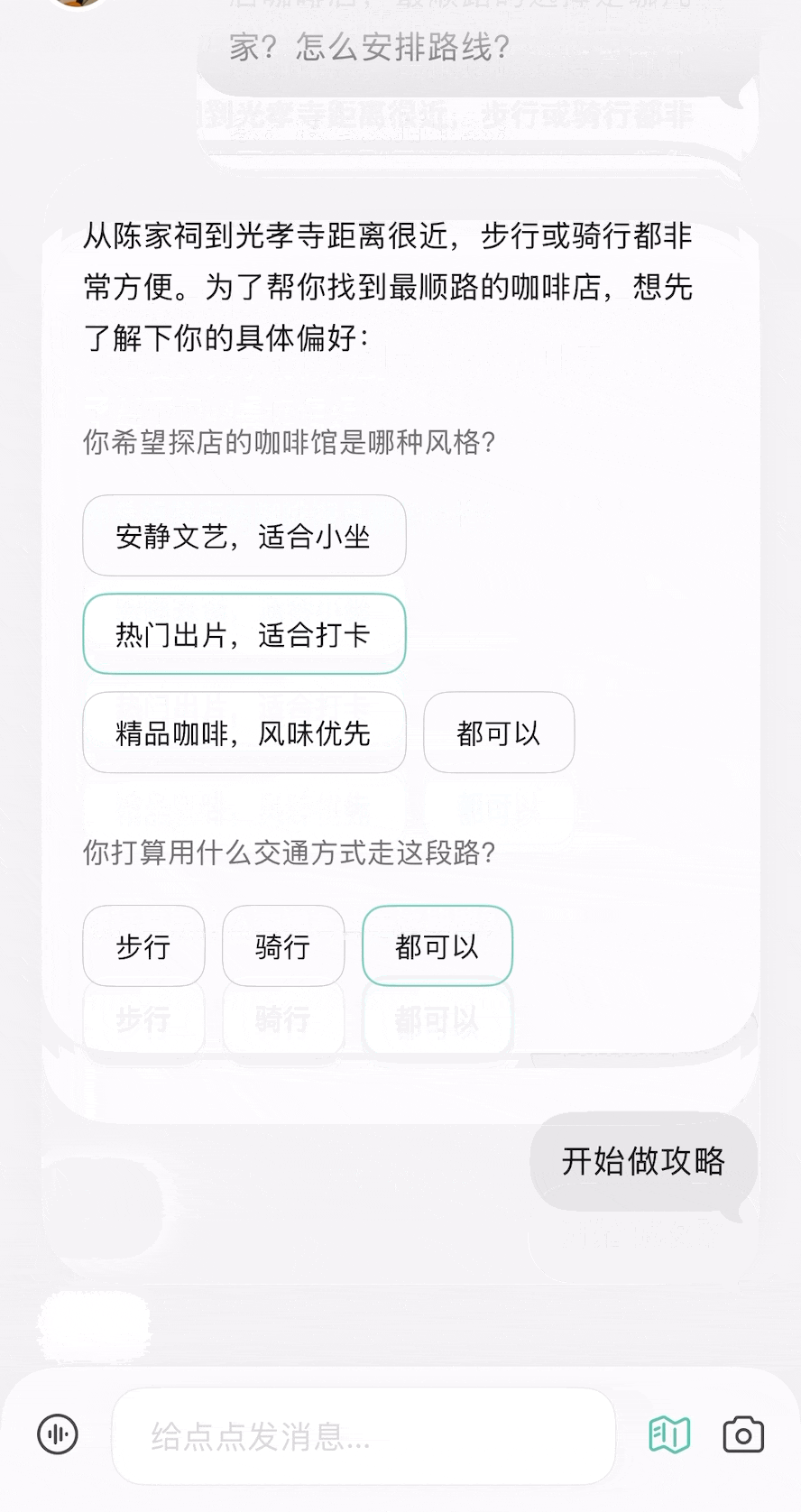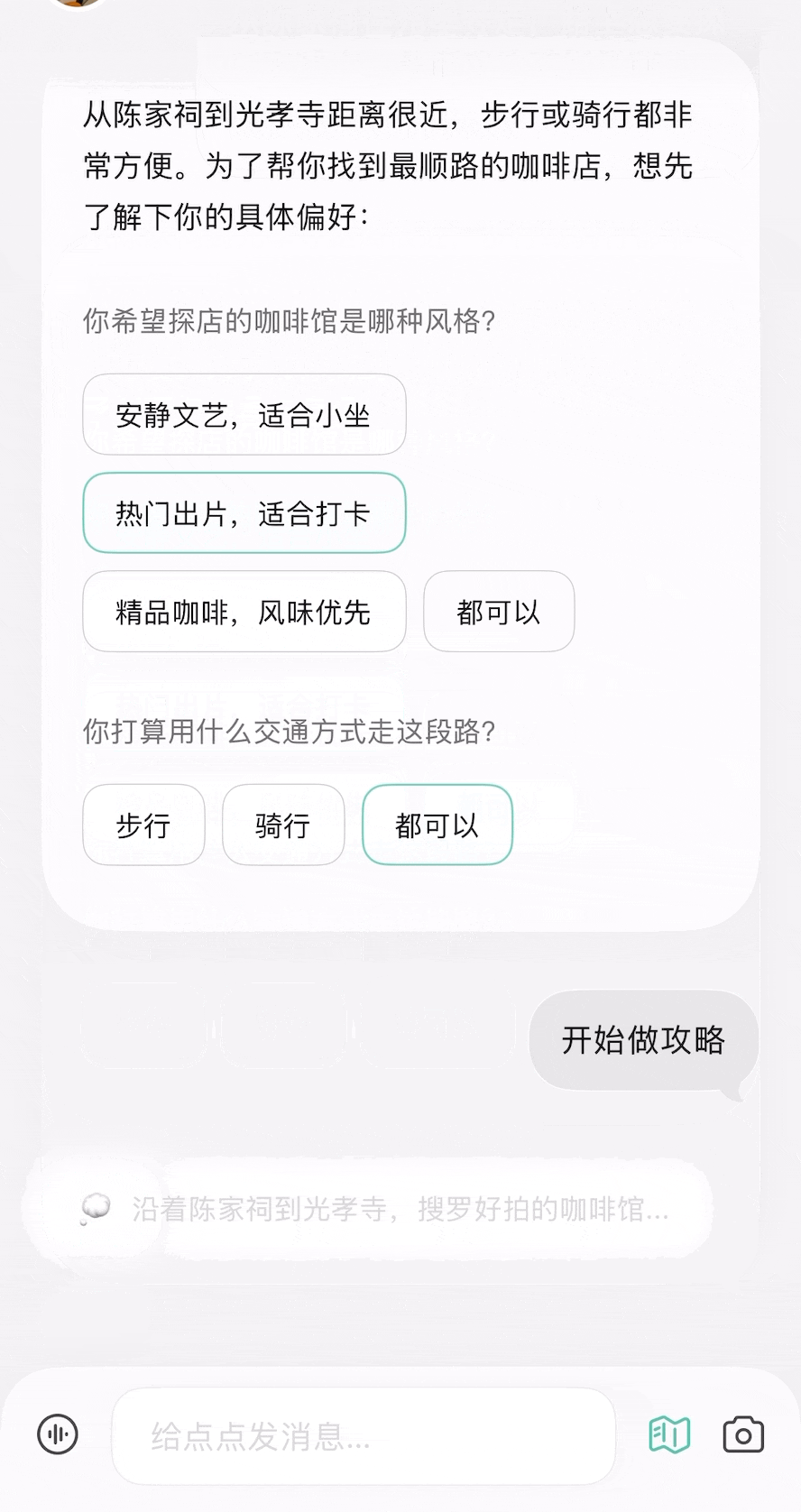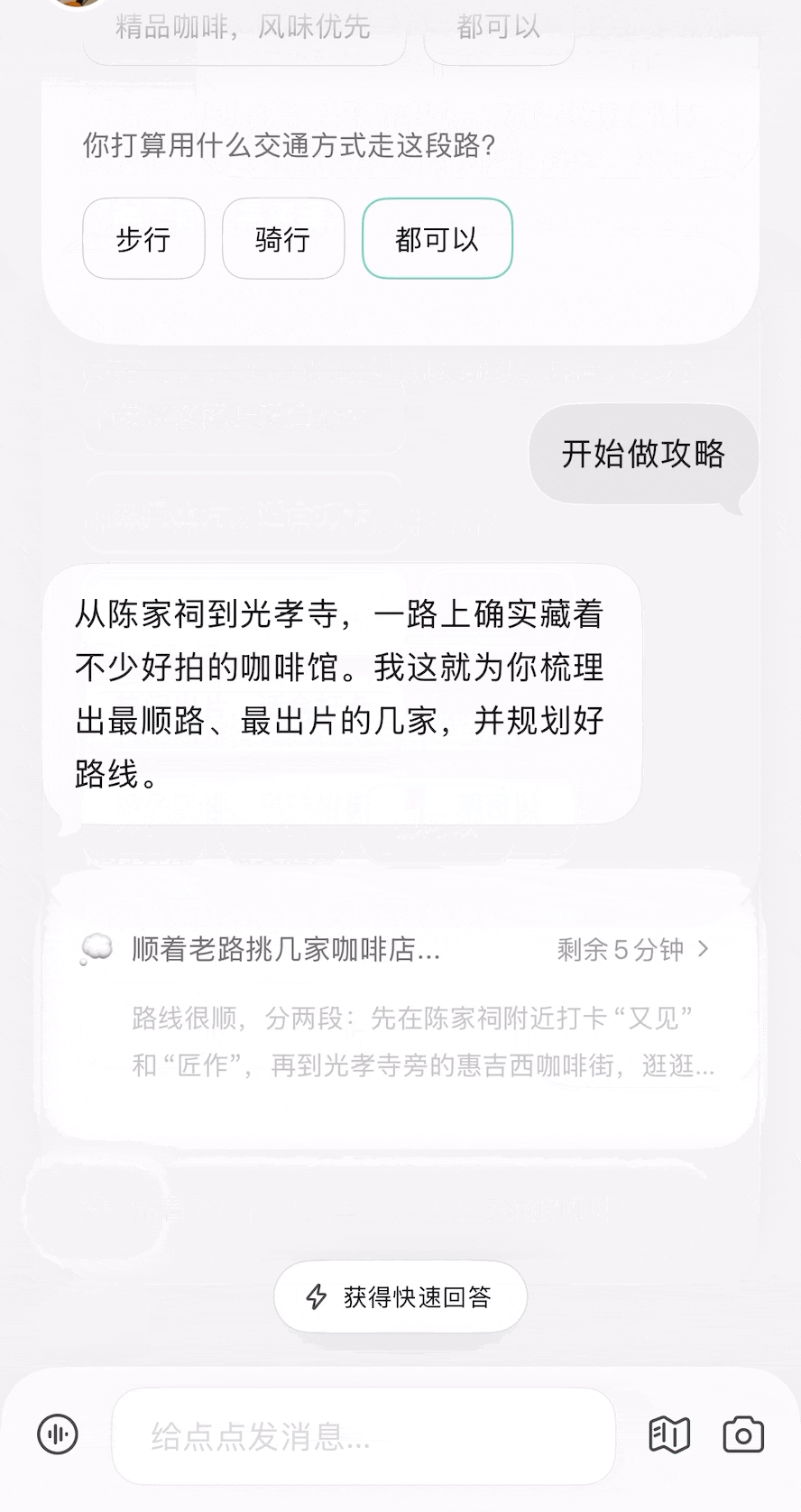
 除了我们体验过的用法,你还可以参考网友们的用例获取更多灵感,打造出更契合自己需求的龙虾助手。
除了我们体验过的用法,你还可以参考网友们的用例获取更多灵感,打造出更契合自己需求的龙虾助手。 每个月花一杯咖啡的订阅费,就能给自己雇一个随时待命的全能助理,帮你分担工作、节省大把时间。
每个月花一杯咖啡的订阅费,就能给自己雇一个随时待命的全能助理,帮你分担工作、节省大把时间。