本文章是基于当前AI业务项目梳理的一份SSE流式结构,简单介绍了一下,当前我们实现的AI流式消息的思路,其中可能有很多不合理的地方,欢迎大佬指正和建议🌹
一、整体架构
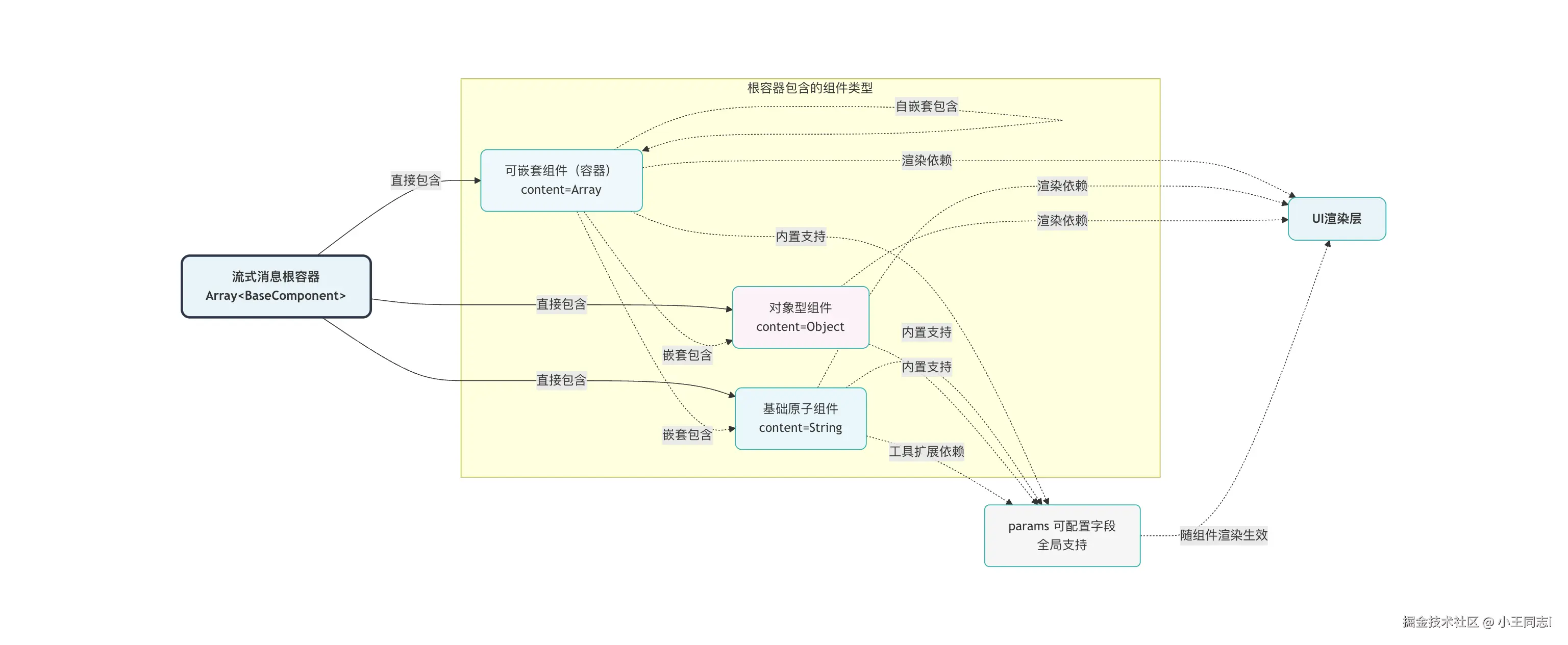
二、流式消息字段
首先提供一段完整的处理的消息格式
[
{
"msg_id": "xxx",
"content": [
{
"content": "调用联网搜索工具,查询北京近期天气。",
"is_finished": false,
"type": "text",
"type_end": true
},
{
"content": [
{
"content": "我来帮您查询北京最近的天气情况。",
"is_finished": false,
"type": "text",
"type_end": true
},
{
"content": "联网搜索",
"is_finished": false,
"params": {
"click": true,
"icon": "https://xxxx/xxxx.png",
"id": "web_search",
"status": "end",
"data_detail": {
"input": "北京天气 2026年2月13日",
"output": [
{
"content": [
{
"desc": "2026年02月13日北京天气预报",
"source": "搜狐",
"title": "2026年02月13日北京天气预报",
"url": "xxxx"
},
{
"desc": "2026年02月13日京山天气预报.",
"source": "百度",
"title": "2026年02月13日京山天气预报",
"url": "xxxx"
},
{
"desc": "北京市气象台13日6时发布天气预报,白天晴间多云。",
"source": "中华网新闻频道",
"title": "北京13日白天晴间多云",
"url": "xxxx"
}
],
"type": "web_search"
}
]
}
},
"type": "complex_tool",
"type_end": true
},
{
"content": "联网搜索",
"is_finished": false,
"params": {
"click": true,
"icon": "xxx",
"id": "web_search",
"status": "end",
"data_detail": {
"input": "北京未来一周天气预报 具体温度 降水",
"output": [
{
"content": [
{
"desc": "xxxx.",
"source": "网易",
"title": "xxxx",
"url": "xxxx"
},
{
"desc": "xxx.",
"source": "xxx",
"title": "2026年02月13日北京天气预报",
"url": "xxx"
},
{
"desc": "xxxx",
"source": "腾讯网",
"title": "今明两天,北京持续回暖!_腾讯新闻",
"url": "xxx"
},
{
"desc": "xxx",
"source": "腾讯网",
"title": "北京明天白天晴间多云,最高气温15°C_腾讯新闻",
"url": "xxx"
},
{
"desc": "xxxx",
"source": "网易新闻客户端",
"title": "今明两天,北京持续回暖!",
"url": "xxx"
}
],
"type": "web_search"
}
]
}
},
"type": "complex_tool",
"type_end": true
}
],
"is_finished": false,
"title": "使用联网搜索工具查询北京2026年2月13日及最近几天的天气信息,获取温度、天气状况、风力、降水概率等具体数据",
"type": "thought_chain",
"type_end": true,
"params": {}
},
{
"content": "xxxx",
"is_finished": false,
"type": "text",
"type_end": true
},
{
"content": "任务已完成",
"is_finished": false,
"type": "text",
"type_end": true
}
],
"is_finished": false,
"finish_reason": "",
"type": "think",
"type_end": true,
"params": {}
},
{
"msg_id": "xxxx",
"content": "根据最新的天气信息",
"is_finished": false,
"finish_reason": "",
"type": "text",
"type_end": true
}
]
整体,最外层是一个大数组,数组里面第一层是一个一个的json对象,一个json代表一个类型
[
{
"msg_id": "xxx",
"content": "根据最新的天气信息",
"is_finished": false,
"finish_reason": "",
"type": "text",
"params": {},
"type_end": true
},
....
]
字段解释如下:
- msg_id:消息id
- content:消息内容
- is_finished:整段流式消息是否结束
- finish_reason:流式消息结束原因
- type:消息类型
- params: 配置信息字段 (可不传,当组件支持的时候会支持对应的功能)
- type_end:当前类型消息是否结束
每个类型的消息基本都遵守这个字段组合,无论是文本还是复杂的嵌套关系,每一个类型都遵循。
三、流式消息类型规范
截止至今,我们总共支持的消息类型有:
- image 图片
- conf 配置字段
- think 思考
- step 步骤
- text 文本
- tool 工具调用
- complexTool 复杂工具
- thought_chain 思维链
八种消息类型,后续迭代可能继续新增。
根据我们处理的逻辑,这一系列类型可以分为内容为Array、Object、String三大类,主要类型是根据其内容的类型和最终处理的结果来定。主要划分如下
// 内容类型为对象的类型
const CONTENT_OBJECT_MAP = [
STREAM_TYPES.IMAGE,
STREAM_TYPES.CONFIG
]
// 内容类型为数组的类型
const CONTENT_ARRAY_MAP = [
STREAM_TYPES.THINK,
STREAM_TYPES.THOUGHTCHAIN
]
// 内容类型为字符串的类型
const CONTENT_INSTEAD_MAP = [
STREAM_TYPES.STEP,
STREAM_TYPES.TEXT,
STREAM_TYPES.TOOL,
STREAM_TYPES.COMPLEX_TOOL
]
// 类型定义
export enum STREAM_TYPES {
IMAGE = 'image',
CONFIG = 'conf',
THINK = 'think',
STEP = 'step',
TEXT = 'text',
TOOL = 'tool',
COMPLEX_TOOL = 'complex_tool',
THOUGHTCHAIN = 'thought_chain'
}
流式消息的处理过程有两个阶段,流式中和流式结束,下面我们按照三种不同的 content 结构来进行梳理
2.1、Array类型
内容为Array的类型是表示我们渲染的时候支持嵌套的组件,例如:在思考中,他有自己的内容区域,而在这个内容区域还支持渲染text类型,tool工具类型等。所以这种消息类型用Array数据结构
2.1.1、Think类型
think类型是主要用于我们的思考部分,分为两部分,外层展开收起容器,内嵌组合式消息内容。流式处理分为两个阶段,流式中,流式完成。
1、流式中
此时是接口SSE返回阶段,通过charles抓包,数据结构如下:
data: {"msg_id":"xxx","content":{"content":"调用","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":"联网","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":"搜索,","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":"","is_finished":false,"type":"text","type_end":true},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":"调用搜索工具","is_finished":false,"type":"tool","type_end":true},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":"","is_finished":false,"type":"text","type_end":true},"is_finished":false,"finish_reason":"","type":"think","type_end":true}
这一系列类型的content在流式过程中,返回的是json对象,此时的content里面包裹的其实是另外一个类型的消息,这个内容需要包含对应类型的消息的字段,所以流式过程中返回的是json,通过这种方式,我们可以在think类型中,嵌套多个其他类型的消息。
同时,当一个类型消息结束的时候,最后都会返回一个内容为空的,type_end为true的标识,表示当前类型消息结束
2、流式完成
流式完成就是将流式过程中返回的数据进行组合,组合成用于渲染的格式
[
{
"msg_id": "xxx",
"content": [
{
"content": "调用联网搜索",
"is_finished": false,
"type": "text",
"type_end": true
},
{
"content": "调用搜索工具",
"is_finished": false,
"type": "tool",
"type_end": true
}
],
"is_finished": false,
"finish_reason": "",
"type": "think",
"type_end": true
}
]
think类型支持一个params字段
cost_time:用于渲染耗时
具体用法
{
"msg_id": "xxx",
"content": [...],
"is_finished": false,
"finish_reason": "",
"type": "think",
"type_end": true,
"params": {
"cost_time": "38s"
}
}
2.1.2、thought_chain类型
thought_chain代表着一个思维链,是一个带状态的连续性的消息,可以用于渲染agent执行某个plan或者具体的环节,其结构与think类型一致,不过它支持更多的params字段配置,同样分为两个阶段。
1、流式中
data: {"msg_id":"xxx","content":{"content":{"content":"xxx","is_finished":false,"type":"text","type_end":false},"is_finished":false,"title":"使用联网搜索工具查询...","type":"thought_chain","type_end":false},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":{"content":"联网搜索","is_finished":false,"params":{"click":true,"data_detail":{"input":"xxx","output":[{"content":[{"desc":"xxx","source":"xxx","title":"2026年02月13日京山天气预报","url":"xxx"},{"desc":"xxx","source":"中华网新闻频道","title":"新闻频道_中华网","url":"xxx"}],"type":"web_search"}]},"icon":"xxx","id":"web_search"},"type":"complex_tool","type_end":true},"is_finished":false,"title":"使用联网搜索工具查询","type":"thought_chain","type_end":false},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
data: {"msg_id":"xxx","content":{"content":{"content":"联网搜索","is_finished":false,"params":{"icon":"xxx","id":"web_search","status":"end"},"type":"complex_tool","type_end":true},"is_finished":false,"title":"使用联网搜索工具查询","type":"thought_chain","type_end":true},"is_finished":false,"finish_reason":"","type":"think","type_end":false}
这里有一堆的字段,看起来很麻烦,实际上这里是在think中嵌套了thought_chain,thought_chain内部又嵌套了其他类型组件,简单一点来看,其实和think是一样的,无非是换了一个类型
data: {"msg_id":"xxx","content":{"content":"调用","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":false}
data: {"msg_id":"xxx","content":{"content":"联网","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":false}
data: {"msg_id":"xxx","content":{"content":"搜索,","is_finished":false,"type":"text","type_end":false},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":false}
data: {"msg_id":"xxx","content":{"content":"","is_finished":false,"type":"text","type_end":true},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":false}
data: {"msg_id":"xxx","content":{"content":"调用搜索工具","is_finished":false,"type":"tool","type_end":true},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":false}
data: {"msg_id":"xxx","content":{"content":"","is_finished":false,"type":"text","type_end":true},"is_finished":false,"finish_reason":"","type":"thought_chain","type_end":true}
2、流式完成
流式完成也和think一样,就是换了一个类型
[
{
"msg_id": "xxx",
"content": [
{
"content": "调用联网搜索",
"is_finished": false,
"type": "text",
"type_end": true
},
{
"content": "调用搜索工具",
"is_finished": false,
"type": "tool",
"type_end": true
}
],
"is_finished": false,
"finish_reason": "",
"type": "thought_chain",
"type_end": true
}
]
2.2、Object类型
目前就两种类型conf和image类型,本质上就是类型不同和字段不同的区别
image类型是存在两个字段
| 字段 |
类型 |
作用 |
| url |
string |
图片资源路径 |
| preview |
1|0 |
是否可预览 |
conf类型可以支持去配其他字段,比如在图文消息中会返回
| 字段 |
类型 |
作用 |
| no_share |
1|0 |
是否支持分享 |
2.2.1、image类型
1、流式中
// 图片类型
data: {"msg_id":"xxx","content":{"preview":1,"url":"xxx"},"is_finished":false,"finish_reason":"","type":"image","type_end":true}
data: {"msg_id":"xxx","content":"","is_finished":true,"finish_reason":"done","type":"text","type_end":false}
2、流式完成
[
{
"msg_id": "xxx",
"content": {
"preview": 1,
"url": "xxx"
},
"is_finished": false,
"finish_reason": "",
"type": "image",
"type_end": true
}
]
2.2.2、conf类型
当前场景为图文消息的时候,一般出现在画图技能,任务队列繁忙的时候
1、流式中
data: {"msg_id":"xxx","content":"xxx","is_finished":false,"finish_reason":"","type":"text","type_end":true}
data: {"msg_id":"xxx","content":{"preview":0,"url":"xxx"},"is_finished":false,"finish_reason":"","type":"image","type_end":true}
data: {"msg_id":"xxx","content":{"no_share":1},"is_finished":false,"finish_reason":"","type":"conf","type_end":true}
data: {"msg_id":"xxx","content":"","is_finished":true,"finish_reason":"done","type":"text","type_end":false}
2、流式完成
[
{
"msg_id": "xxx",
"content": {
"no_share": 1
},
"is_finished": false,
"finish_reason": "",
"type": "conf",
"type_end": true
},
{
"msg_id": "xxx",
"content": "xxx。",
"is_finished": false,
"finish_reason": "",
"type": "text",
"type_end": true
},
{
"msg_id": "xxx",
"content": {
"preview": 0,
"url": "xxx"
},
"is_finished": false,
"finish_reason": "",
"type": "image",
"type_end": true
}
]
2.3、String类型
这一分类指的是content为字符串string的一系列消息类,主要包括:
- step
- text
- tool
- complex_tool
四个类型,其中比较特殊的就是complex_tool,支持params进行配置
2.3.1、step类型
step类型主要用于步骤纯文案的渲染,
其采用的不是拼接而是替换,例如第一次内容返回的是“正在搜索中”,第二次返回“搜索完成”,渲染出来的ui会是先显示“正在搜索中”,然后显示“搜索完成”,不会进行组合拼接。并且一旦后续有其他类型消息进入,则不在显示
1、流式中
data: {"msg_id":"xxx","content":"正在搜索中","is_finished":false,"finish_reason":"","type":"step","type_end":false}
data: {"msg_id":"xxx","content":"搜索完成","is_finished":false,"finish_reason":"","type":"step","type_end":true}
2、流式完成
[
{
"msg_id":"xxx",
"content":"搜索完成",
"is_finished":false,
"finish_reason":"",
"type":"step",
"type_end":true
}
]
2.3.2、text类型
text类型就是我们最常见的文本,也是正文,主要采用markdown进行渲染,采用的是拼接逻辑
1、流式中
data: {"msg_id":"xxx","content":"这","is_finished":false,"finish_reason":"","type":"text","type_end":false}
data: {"msg_id":"xxx","content":"是","is_finished":false,"finish_reason":"","type":"text","type_end":false}
data: {"msg_id":"xxx","content":"文","is_finished":false,"finish_reason":"","type":"text","type_end":false}
data: {"msg_id":"xxx","content":"本","is_finished":false,"finish_reason":"","type":"text","type_end":false}
data: {"msg_id":"xxx","content":"","is_finished":false,"finish_reason":"","type":"text","type_end":true}
2、流式完成
[
{
"msg_id":"xxx",
"content":"这是文本",
"is_finished":false,
"finish_reason":"",
"type":"text",
"type_end":true
}
]
2.3.3、tool类型
最基础的工具类型,一次返回,没有过程,直接渲染
1、流式中
data: {"msg_id":"xxx","content":"正在调用xxx工具","is_finished":false,"finish_reason":"","type":"tool","type_end":true}
2、流式完成
[
{
"msg_id":"xxx",
"content":"正在调用xxx工具",
"is_finished":false,
"finish_reason":"",
"type":"tool",
"type_end":true
}
]
2.3.4、complex_tool类型
工具类型的进阶版,支持params字段配置额外的能力,目前支持:完成状态,点击侧边,耗时展示。
与工具类型的主要区分就是params字段
其params字段目前支持
| 字段 |
类型 |
作用 |
|
| id |
string |
工具id,必传,用于更新工具状态 |
|
| click |
boolean |
是否支持点击侧边 |
|
| data_detail |
object |
侧边详情数据 |
|
| icon |
string |
工具图标 |
|
| status |
“begin” |
“end” |
工具调用状态 |
| cost_time |
string |
工具耗时 |
|
如果需要点击,首次返回需要返回click字段
1、流式中
// 开始调用工具 支持点击首次返回click: true
data: {"content":"联网搜索","is_finished":false,"params":{"click":true,"icon":"xxx","id":"web_search","status":"begin"},"type":"complex_tool","type_end":true}
// 获取到结果
data: {"content":"联网搜索","is_finished":false,"params":{"click":true,"data_detail":{"input":"xxx","output":[{"content":[{"desc":"xxx","source":"xxx","title":"xxx","url":"xxx"}],"type":"web_search"}]},"icon":"xxxx","id":"web_search"},"type":"complex_tool","type_end":true}
// 调用完成
data: {"content":"联网搜索","is_finished":false,"params":{"icon":"xxxx","id":"web_search","status":"end"},"type":"complex_tool","type_end":true}
2、流式完成
[
{
"content": "联网搜索",
"is_finished": false,
"params": {
"click": true,
"icon": "xxx",
"id": "web_search",
"status": "end",
"data_detail": {
"input": "2222",
"output": [
{
"content": [
{
"desc": "xxx",
"source": "xxx",
"title": "xxx",
"url": "xxx"
},
{
"desc": "2222",
"source": "2222",
"title": "2222",
"url": "2222"
},
],
"type": "web_search"
}
]
}
},
"type": "complex_tool",
"type_end": true
}
]
然后data_detail也有一套规范,下面进行补充
2.3.5、data_detail规范
data_detail是params 中的一个可配置字段,主要作用是用于侧边栏的详情数据。
这个字段目前是直接返回,直接用的,所以没有流式状态和完成态,前后是保持一致
其有两个字段
| 字段 |
值 |
| input |
string |
| output |
Array |
1、input
是顶部输入的字段,展示的是用户的querry问题,目前只支持string。
2、output
output表示的智能体返回的输出部分,数组中接收的是一个个object,每一个object代表一个类型,对象的结构如下
| 字段 |
值 |
|
| type |
string |
|
| content |
Array |
Object |
type字段代表返回的类型,content则代表返回的详细内容
当前有三个类型做了处理:web_search、knowledge_recall、create_schedule
web_search,knowledge_recall :这两个类型会被渲染成卡片
create_schedule:对敏感信息进行了隐藏
| 类型 |
对应content |
| web_search |
Array(卡片) |
| knowledge_recall |
Array(卡片) |
| create_schedule |
object |
| 其他 |
object (直接展示) |
卡片消息类型字段一致为:
// web_search
{
"content": [
{
"desc": "描述",
"source": "源头",
"title": "标题",
"url": "源链接"
},
...
],
"type": "web_search"
}
// knowledge_recall
{
"content": [
{
"desc": "描述",
"source": "源头",
"title": "标题",
"url": "源链接"
},
{
"desc": "描述",
"source": "源头",
"title": "标题",
"url": "源链接"
}
],
"type": "knowledge_recall"
}
create\_schedule 创建日程 的output
{
"content": {
"end_time": "2026-02-25 15:00:00", // 结束时间
"participants": [ // 参与人
{
"id": 123, // id
"name": "xxx", // 名字
"pic": "xxx", // 头像
"workcode": "xxx" // 工号
},
{
"id": 123,
"name": "xxx",
"pic": "xxx",
"workcode": "xxx"
}
],
"start_time": "2026-02-25 14:00:00",// 开始时间
"title": "xxx" // 会议标题
},
"type": "create_schedule"
}
其他类型都是直接返回json,并且直接渲染json。
