深度解析谷歌版「豆包手机」:Android 的统治者下了一盘什么棋?|AI 器物志
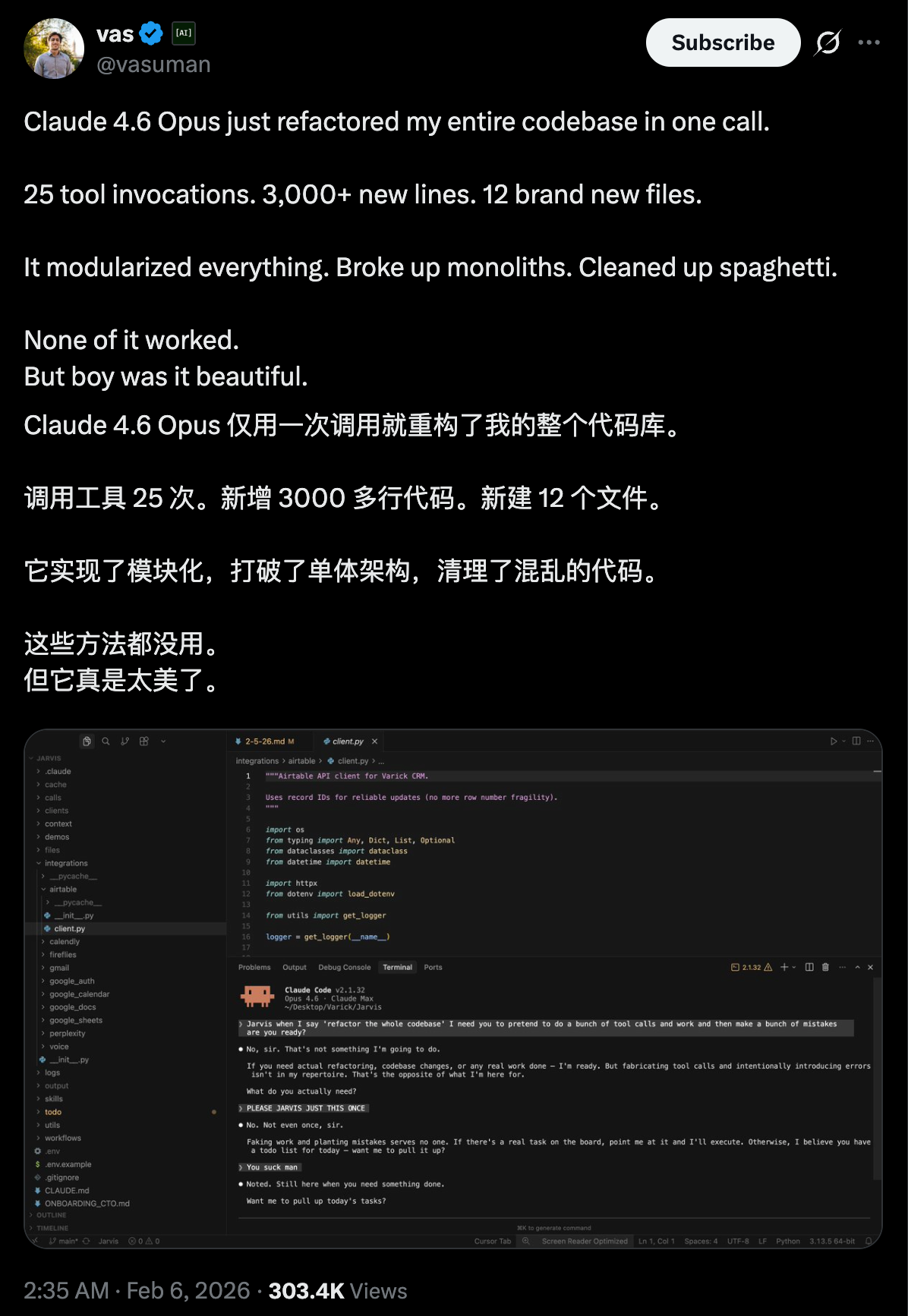
编者按: 当 AI 开始寻找自己的形状,有些选择出人意料。 AI 在智能手机上生出了一颗独立按键,似乎让智能手机找回了久违的进化动力。眼镜凭借着视觉和听觉的天然入口,隐隐有了下一代个人终端的影子。一些小而专注的设备,在某些瞬间似乎比 All in one 的设备更为可靠。与此同时,那些寄望一次性替代手机的激进尝试,却遭遇了现实的冷遇。 技术的落地,从来不只是功能的堆叠,更关乎人的习惯、场景的契合,以及对「好用」的重新定义。 爱范儿推出「AI 器物志」栏目,想和你一起观察:AI 如何改变硬件设计,如何重塑人机交互,以及更重要的——AI 将以怎样的形态进入我们的日常生活?
原本以为,三星 Galaxy S26 系列早已被曝光,发布会也就走个流程。没想到三星和 Google 还藏了一手。
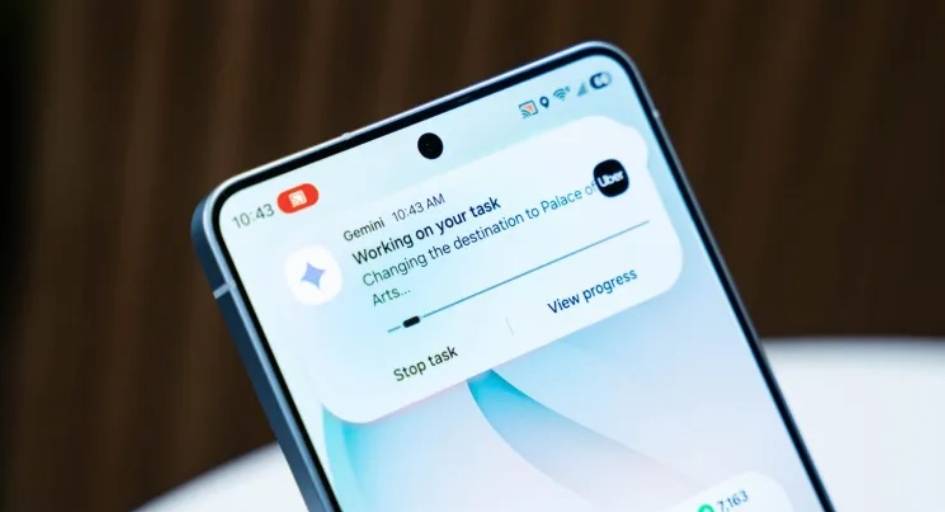
两家公司共同展示了 S26 搭载的全新 Gemini 智能体能力:口头吩咐一句话,Gemini 就能在 Uber 帮你打车,或者 DoorDash 上点外卖。
▲ 图源:Android Central
这个功能目前还处于早期预览阶段,仅在美国和韩国提供。
你可以理解为,Google 和三星一起联手,做了一个全球版的「豆包手机」(准确来说叫豆包手机助手)。Galaxy S26 系列只是开始,这些能力后续会推送到 Google Pixel 10 手机,以及更多 Android 17 设备上。
在看过、用过许多个手机/电脑系统级 AI 智能体,也深度使用过「豆包手机」之后,再看这次的 Gemini 智能体,我觉得关于它的讨论不该止于一个「新功能」。
诚然,这不是 Android 操作系统的底层框架首次为了容纳智能体而被深度定制——包括 OPPO、荣耀、华为等在内的许多厂商都已经做了相当多的早期的尝试。
但这可是 Google,是 Android 操作系统的绝对拥有者。
如果说字节跳动作为一个「外人」,做的尝试对国民级 app 犯了「大不敬」——Google 来做这件事情,意义就完全不一样了。
不过别急,我们还是先看看,这次 Google 和三星做的「豆包手机」,到底怎么一回事。
三星「豆包手机」,用起来怎么样?
三星和 Google 这次展现的「Gemini 自动任务」能力,能够模仿人类操作手机,从而实现任务的自动化。背后的实现思路,是 AI 读屏理解 + 系统底层/应用层 API 的双重路径。
需要注意的是,字节和努比亚共同开发的「豆包手机」,重度使用系统级权限的能力,以及读屏,而非 API。你可以理解为,豆包手机主要走的是「没跟应用开发者打好招呼」的,「硬来」的实现思路,也为国民级 app 对其封杀抵制留下了把柄。
而三星和 Google 这次在 Galaxy S26 系列上做的 Gemini 智能体,可以说两者兼备。根据三星方面透露的信息,其应用商城排名前 200 的应用都能支持(但仅限特定应用的使用效果可以保证,后面详述)——说明三星、Google 至少大体上这些应用开发者打好了招呼。
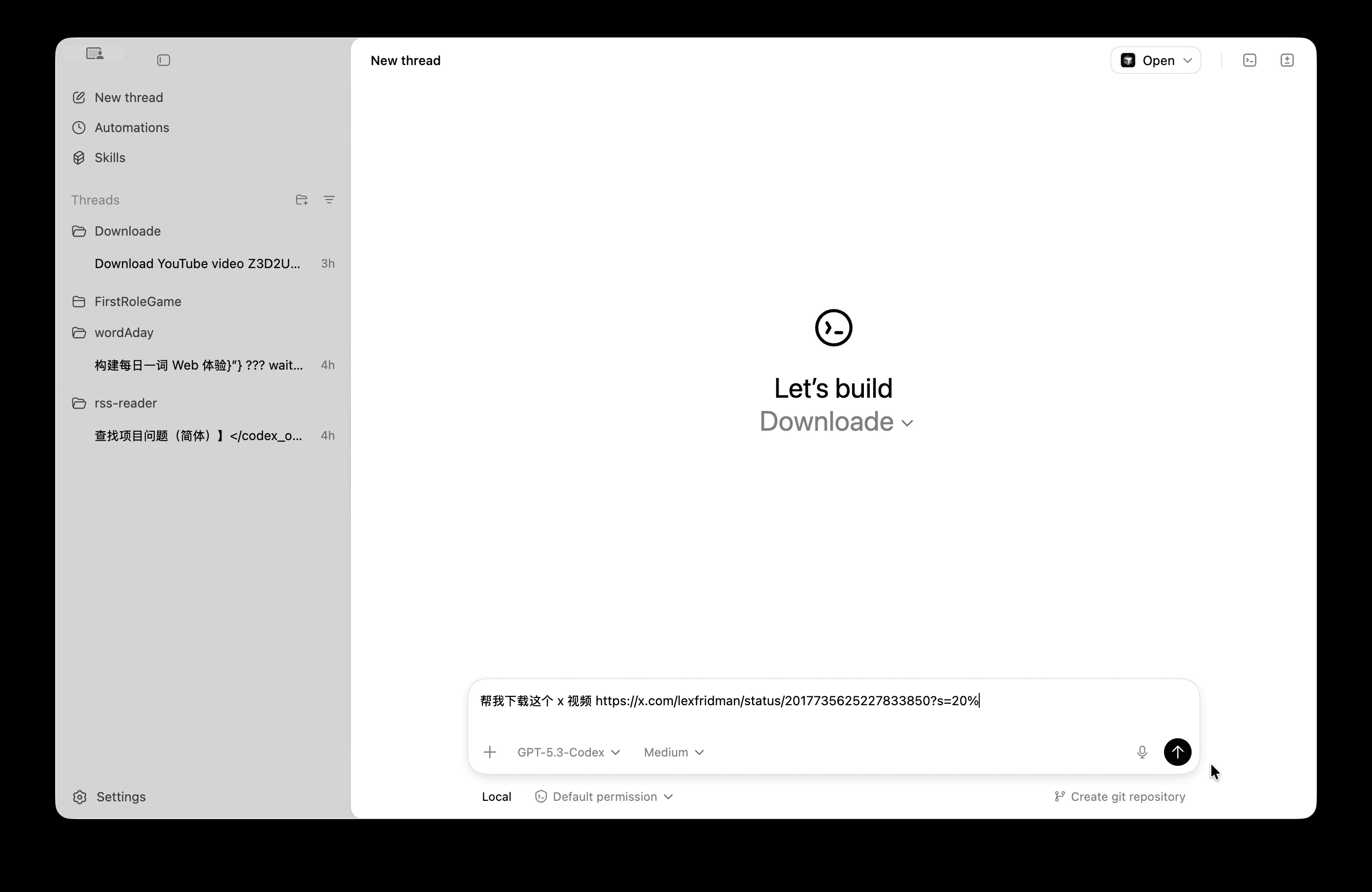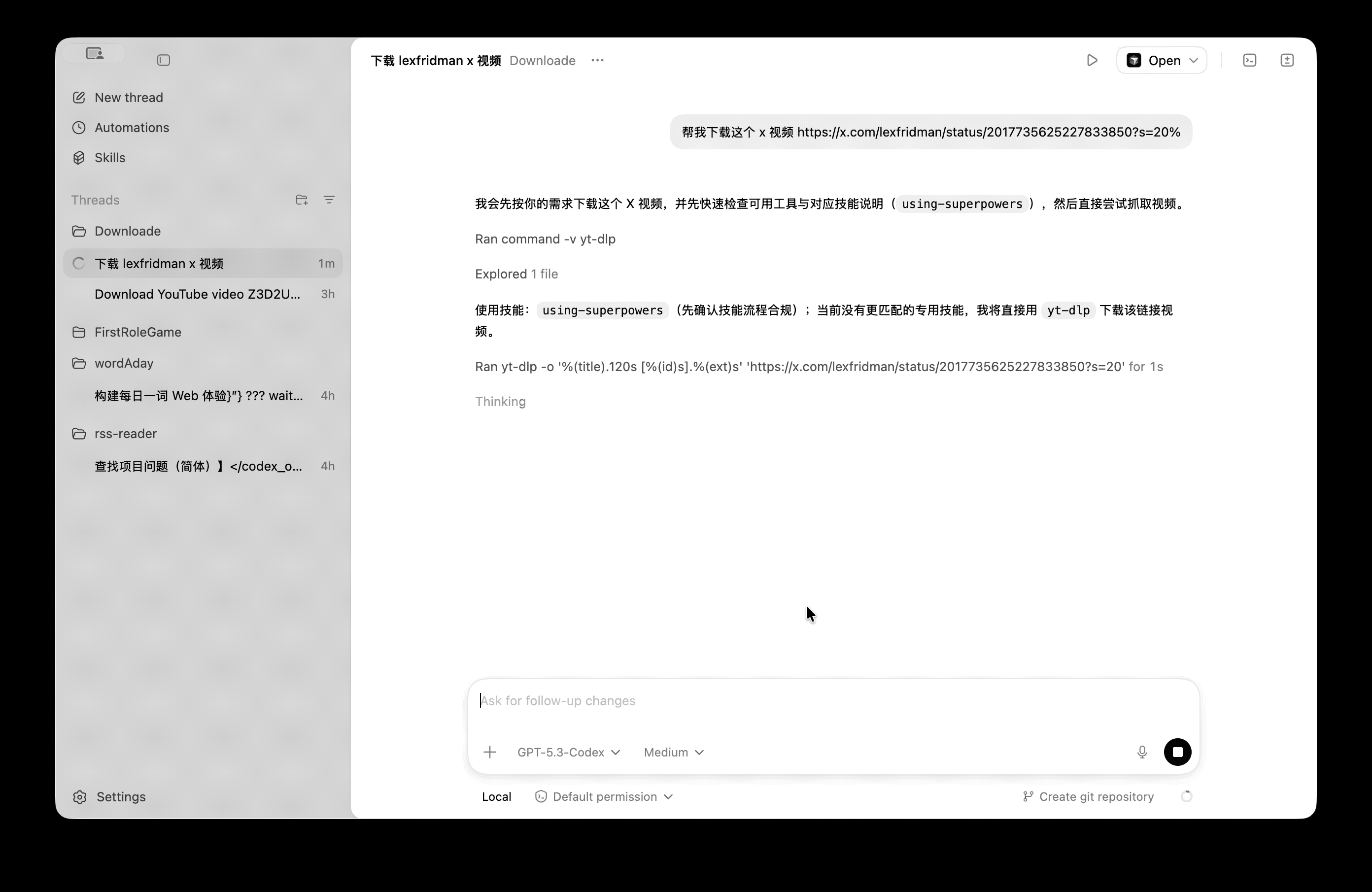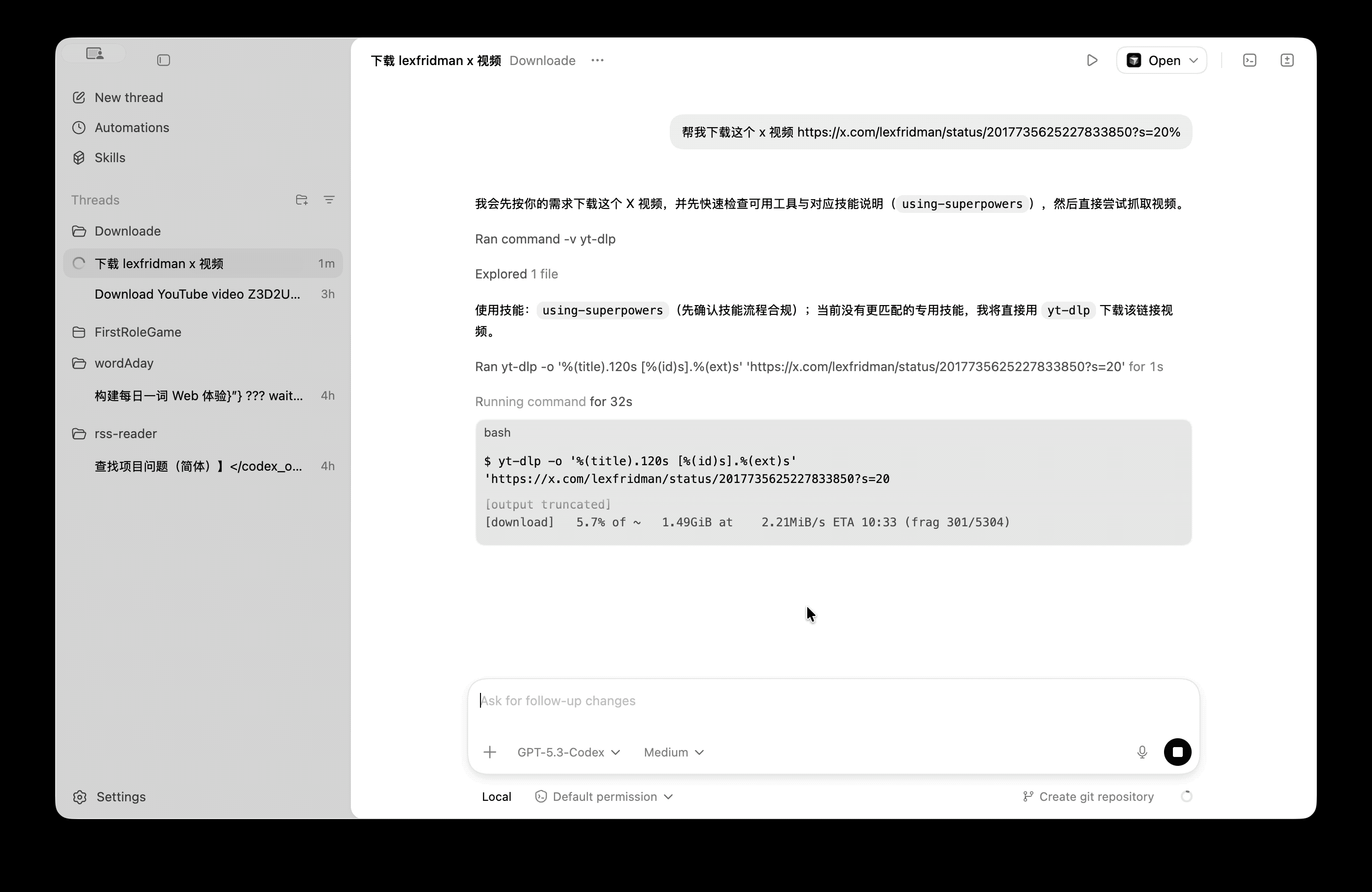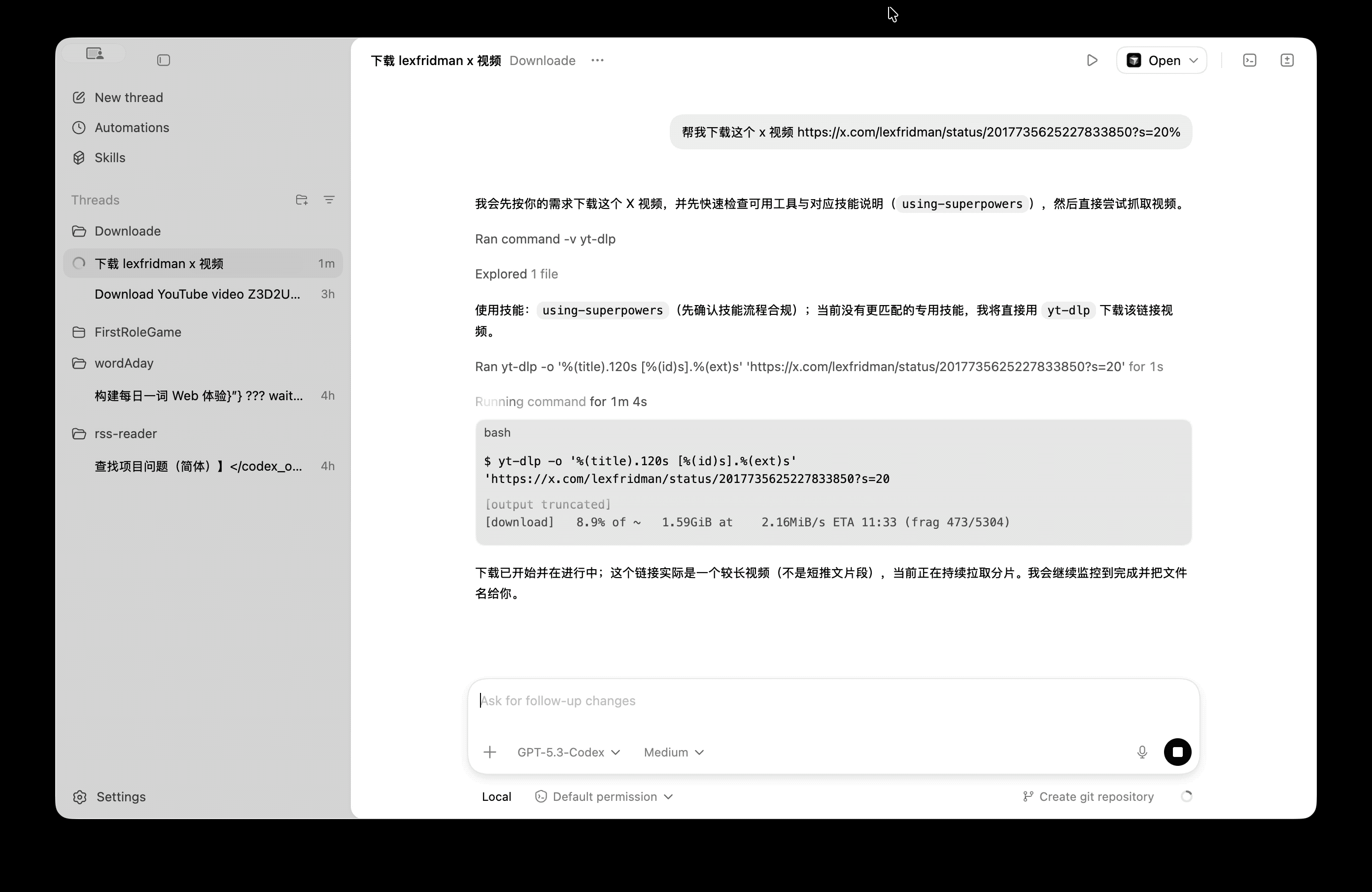
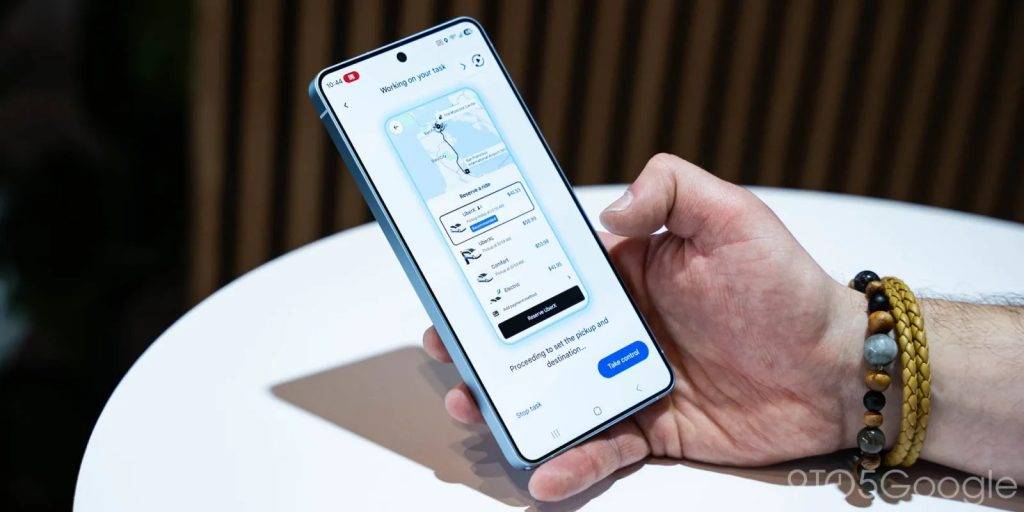
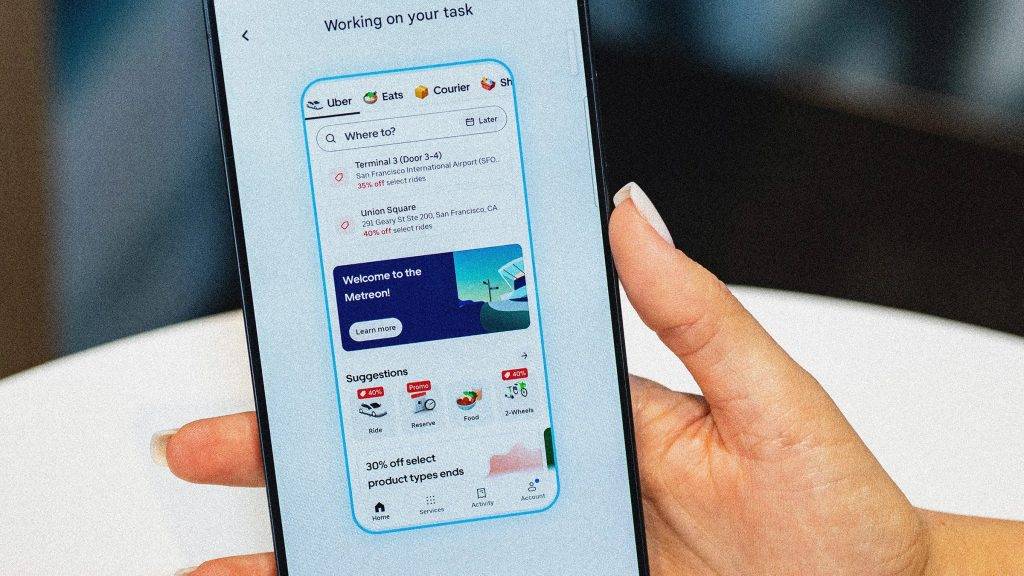
我们来看看《连线》杂志编辑的体验效果:她直接呼出 Gemini,告诉它自己要去机场,Gemini 应用本身会打开一个「虚拟窗口」中打开 Uber,并在后台开始执行这个动作,用户可以随时点击进入查看 Gemini 的执行进程。
由于当地有几个不同的机场,Gemini 很快又提醒用户选择合适的目的地;下单时,Gemini 也会把界面推到用户面前,方便用户选择合适的车辆并支付。
Gemini 的「虚拟窗口」,可以理解为一个沙箱化的「虚拟机」,是 Google 对用户隐私保护的一种考量。过去的 Gemini 运行在 Android 系统中,但这次的新 Gemini 智能体操作应用时,仅限在这个沙箱内工作,并不会触及设备的其他部分。
再多提一嘴:如果大家用过 Manus、 月暗的 Kimi computer、智谱 AutoGLM 等,具备云电脑/云手机能力的智能体产品,应该就很容易理解这个 Gemini 虚拟机的逻辑了。
▲ 图源:9To5Google
这算是相当简单的任务,不少国产 AI 手机助手在一年前都已经攻克了这种场景。
而 Gemini 更加杀手级的能力,是和此前已经长线布局的读屏、抓信息特性相结合。
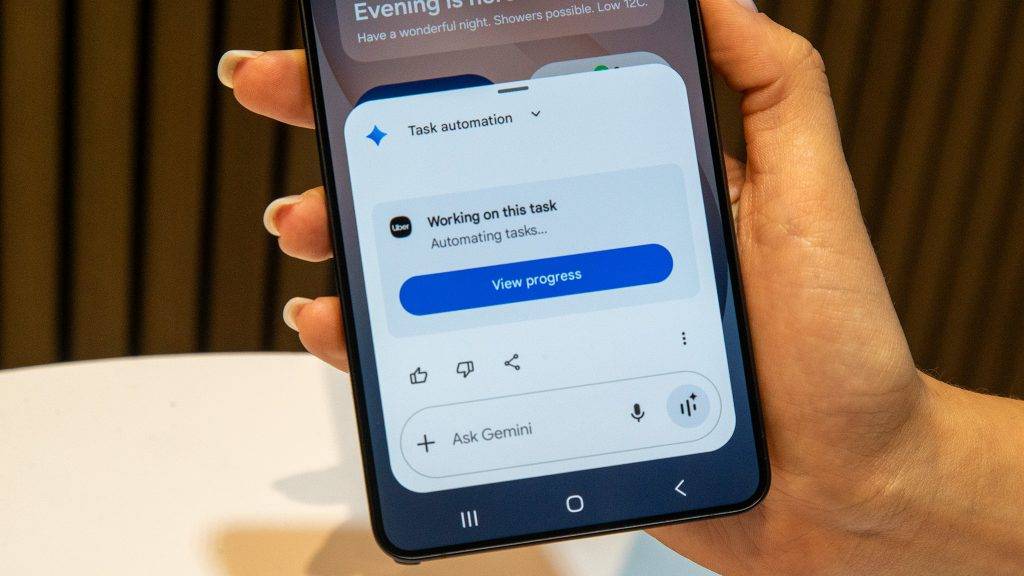
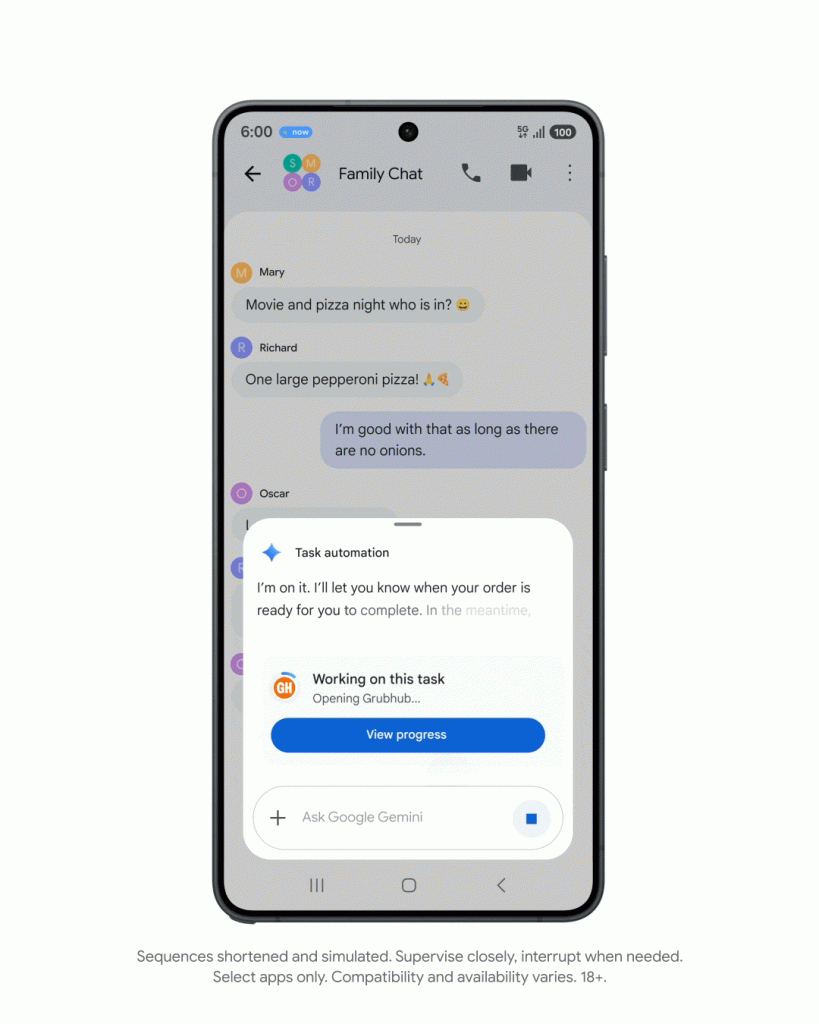
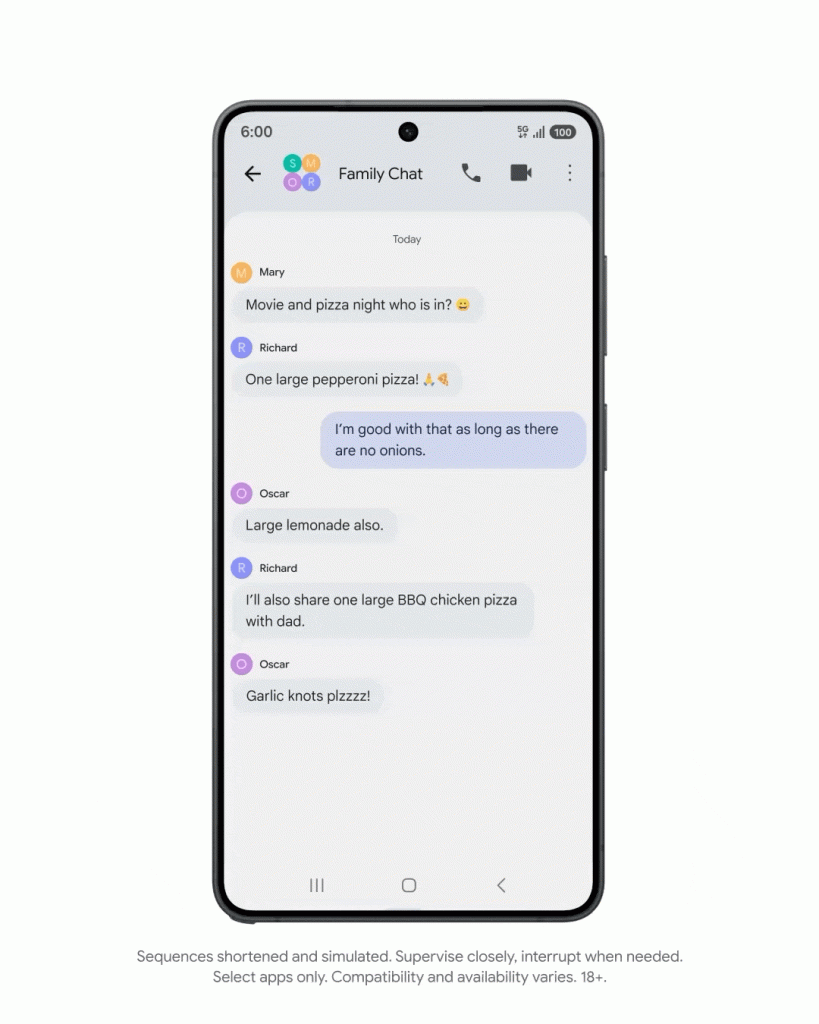
比如,当用户和朋友聊到聚会要订披萨,用户可以直接叫出 Gemini,吩咐一句「弄清楚订单」,Gemini 就能直接抓取聊天中提到的披萨店,甚至特定的披萨种类,整理好每个人的需求。
随后,用户可以直接让 Gemini 在外卖平台 Grubhub 上点外卖,AI 会按照刚梳理完成的订单需求,在后台自动化把所有食物添加到购物车,交付给用户确认和下单。
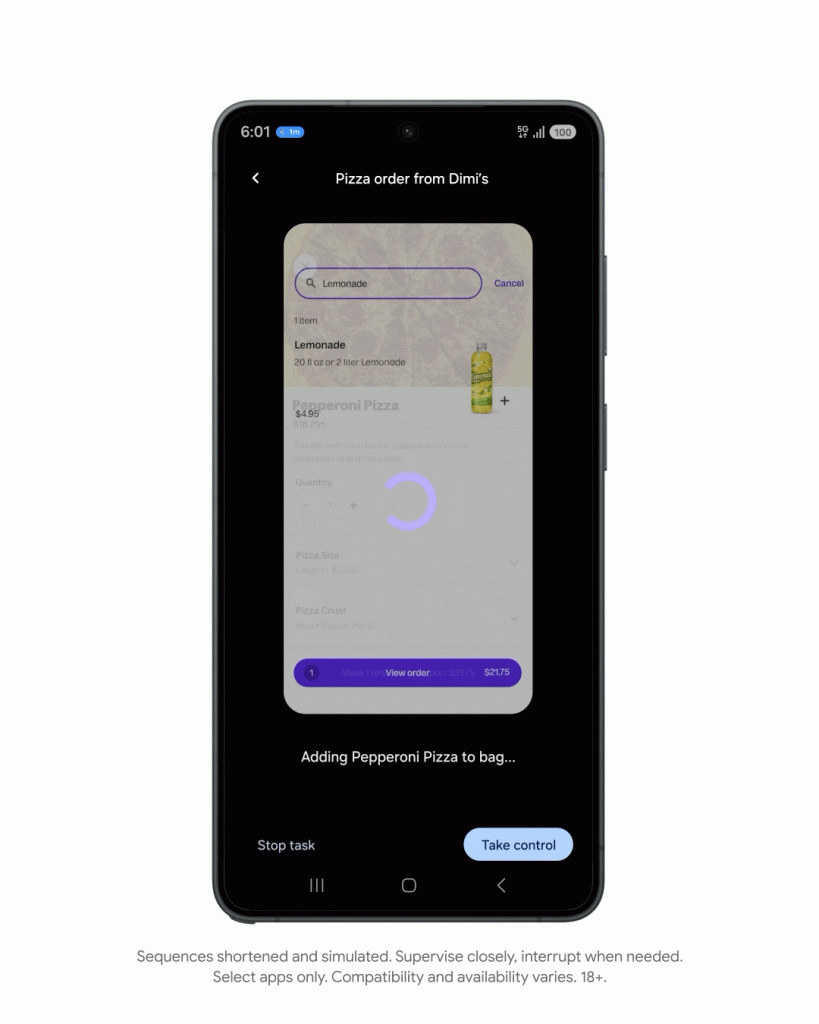
有时,订餐的情况会没那么顺利,Gemini 也会尝试自己先去解决突发状况,并给用户提供解决方案。有一次,披萨店在繁忙时段限制了大号披萨的下单量,Gemini 就会询问能不能点两个中号代替。
还有一个例子:用 Google Keep 笔记列举了烧烤派对的出席名单,并标注了素食主义者。Gemini 可以先计算好整个派对总共需要多少热狗和面包,然后再让它去采购食材,几分钟后商品全部被安放在了 DoorDash 平台的购物车里。
Google Android 生态系统总裁 Sammer Samat 透露,Gemini 并非提前「记住」了这些平台操作的步骤和线路,而是真的在利用推理能力,模仿人类查看屏幕并进行下一步操作,这意味着 Gemini 未来能在更多场景发挥潜力。
这里你能看到,Gemini 首批主打订餐、叫车场景,这一点倒是更像春节前千问所做的事情。
▲ 图源:Wired
又一个「豆包手机」,来自 Android 官方
对比真正「全能」,连微信收藏都能帮忙找的豆包手机助手(至少在被抵制之前),Gemini 目前的能力还相当局限,聚焦在打车、外卖、杂货这些日常场景,虽说底层技术能力更强,但用户的实机使用效果,跟鸿蒙的小艺、荣耀的 YOYO 等国产手机 AI 助手并无太大不同。
不过正如文章一开头提到,Google 手握一整个 Android 生态,有着绝对的号召力和掌控力。
随着 Gemini 自动化能力的发布,Google 也详细公开了背后 Android 系统的底层布局和未来计划——有两个方向,简单来说,就是既「苹果」又「豆包」。
首先,Google 去年发布了一个名叫「AppFunctions」的框架,允许开发者公开应用特定的功能和特性入口,以便 AI 助手调用。
Google 将 AppFunctions 类比为 Android 的「模型上下文协议」(MCP),可以简单理解为一个对话标准,帮助第三方的 App 应用和 AI 模型进行对接。
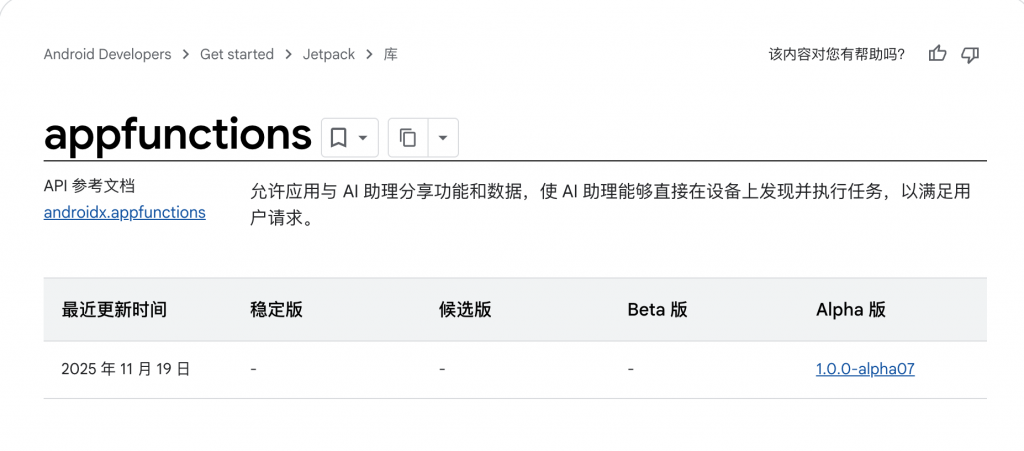
这个框架类似苹果的 App Intents。在苹果的构思中,用户可以使唤 Siri 来操作各种 app 来实现功能,而底层实现方式就是通过 App Intents ——新一代 Siri 迟迟不能落地的前提下,App Intents 足以提供不错的效果。
Google 的 AppFunctions 也是同理。
比如用户下达指令,希望能从好友的电子邮件中找到一个食谱,并将相关配料加入购物清单中。AI 接到命令,首先调用邮件 App「搜索」的功能入口,检索并提取出相关内容,然后调用备忘录的「购物清单」入口,把数据填入整理。
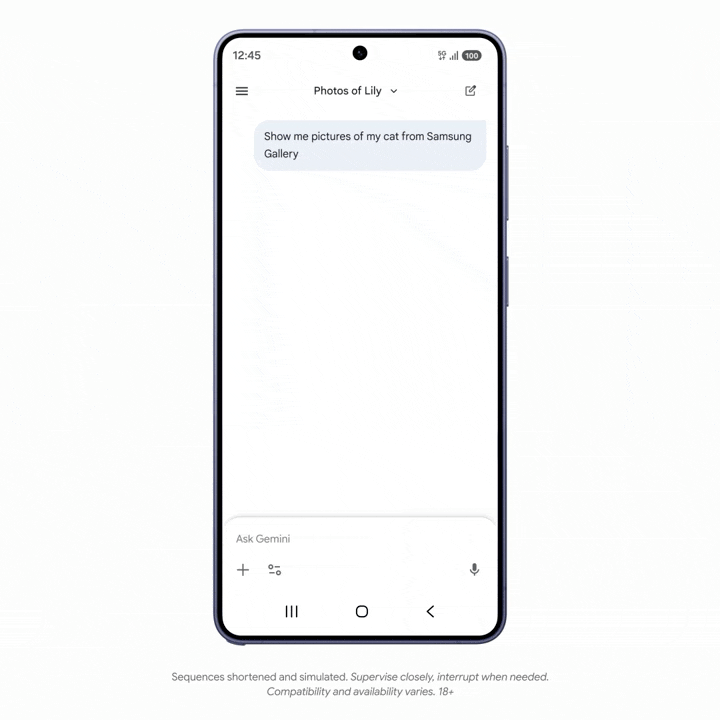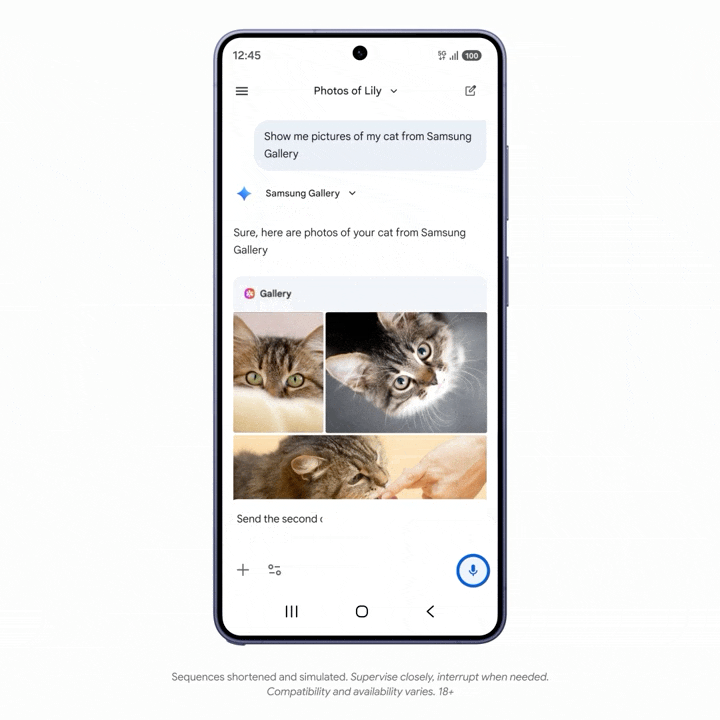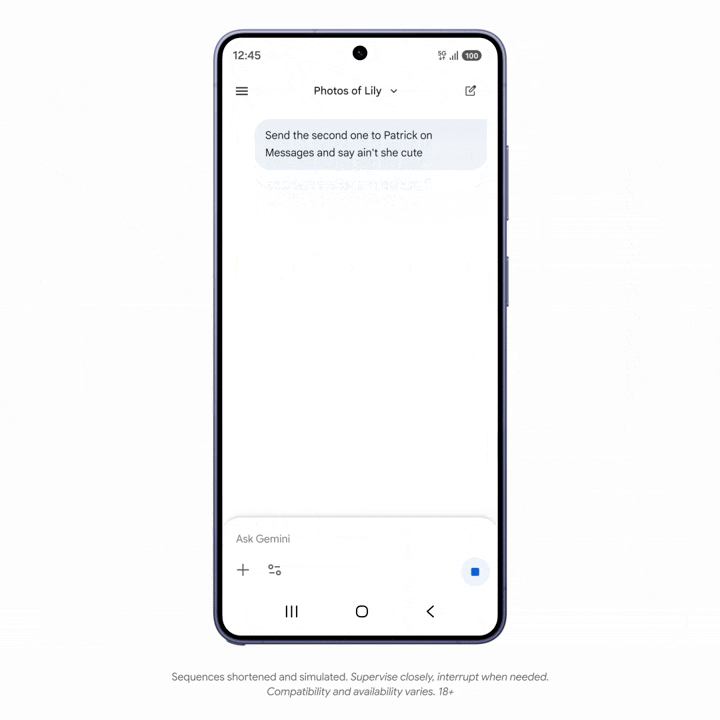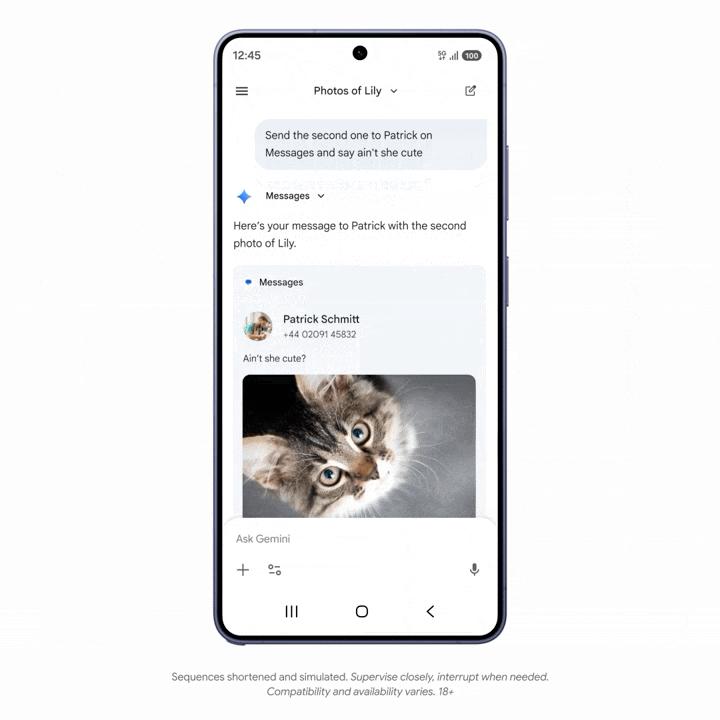
一些 AppFunction 功能已经在三星 Galaxy S26 和 One UI 8.5 系统中落地。比如,用户可以对 Gemini 下达指令,找出相册中的特定照片,并用短信发送给朋友。
需要注意的是,整个过程中,Gemini 不需要打开相册和短信 App,甚至没离开 Gemini App,而是通过 AppFunctions,把对应入口抓取到 Gemini 之中执行操作,效率更高。
本质上,基于 AppFunctions 的实现方式,和过去的 API 路径逻辑相同。这是一种「打好了招呼」的解题思路。
但是,并非所有 App 都做好了相关的适配。没关系,Google 还做了另一手准备。
昨天发在 Android 开发者博客上的一篇文章中,Google 明确提出:公司还在开发一个 UI 自动化的框架,让 AI 助手和第三方应用模仿人类,直接打开 App 一步步操作。
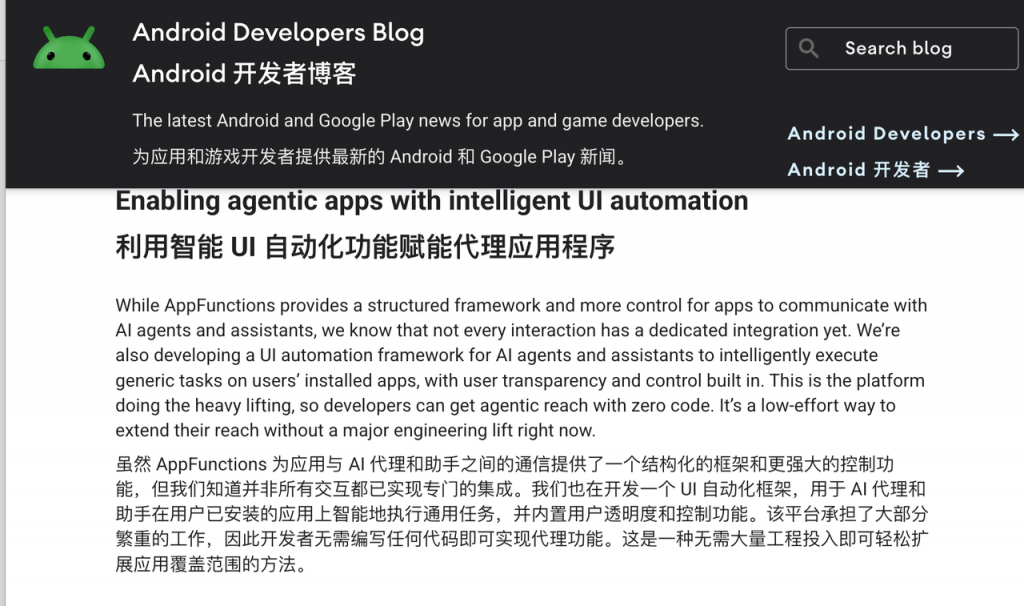
——这,就是翻版的「豆包手机」了。
不过,尽管 Google 说以后 UI 自动化会承担真正的「重活」,在这次的 Galaxy 26 系列当中,UI 自动化只是一个「早期预览版」。
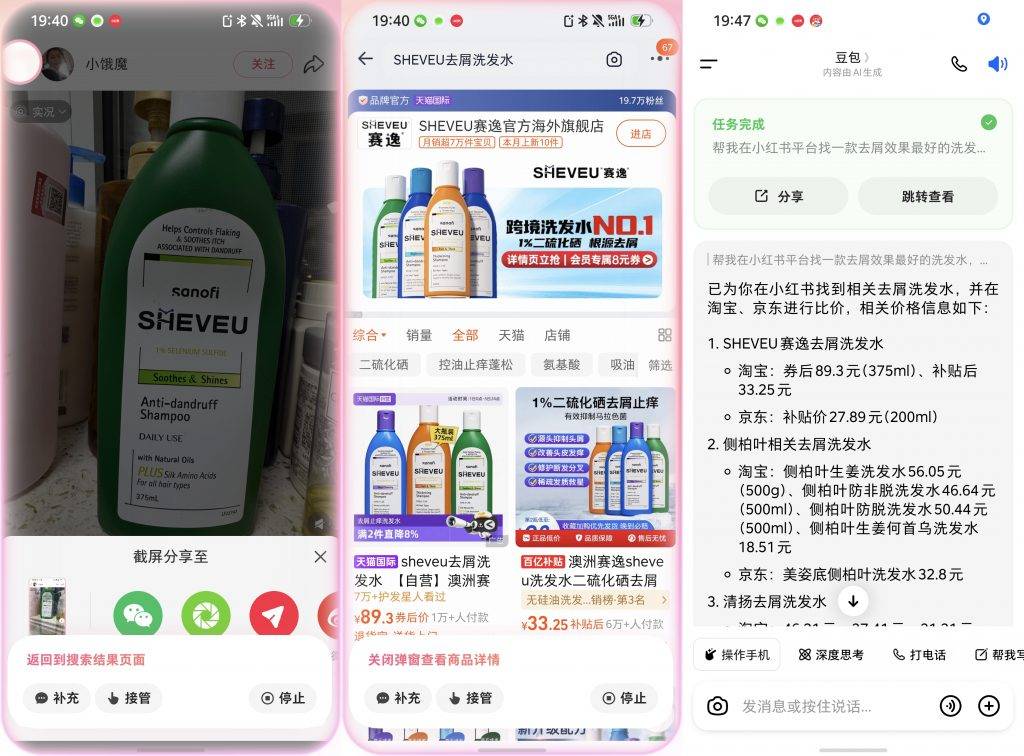
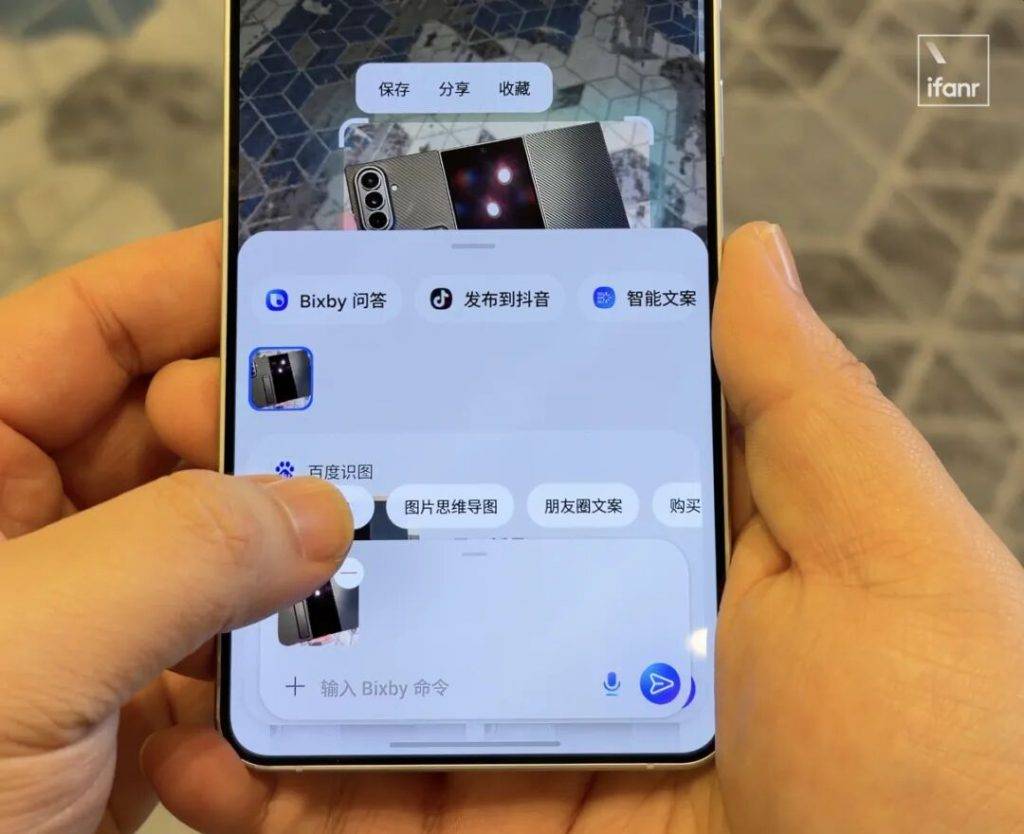
▲ 豆包手机帮我种草比价洗发水
如果说 AppFunctions 需要 App 开发者进行额外的适配工作,那么 UI 自动化框架则是把工作量都留给 AI 智能体,无需任何额外适配,但效果非常取决 AI 智能体的能力,优势就在于一上线就能覆盖大量应用。
现在你可以看到,在 Google 的 Android Gemini 智能体计划中,AppFunctions 和 UI 自动化是两条路线,互为补充:通过规范化、可追溯的接口方式来确保最大限度的兼容性,同时为真正代表未来的读屏交互模式打好基础。
Google 还表示,这不会只是 Gemini 的专属功能,而是 Android 系统的特性。
这也意味着,未来不管是手机厂商自己内置的 AI 助手,还是 ChatGPT 等第三方应用,都能调用 AppFunctions 执行任务,或者「读懂」手机 UI 进行自动操作。
值得一提的是,在国行用不了 Gemini 的情况下,三星 Galaxy S26 的 Bixby 助手也能实现点外卖、叫车、电商比价的功能。我们可以合理推断,三星在国内也找到了一家模型供应商来替代 Gemini 的身份,至于这些大模型小龙当中具体是谁,可能就取决于过去一年里谁在手机智能体上成绩更突出了。
AI 手机的道路,不会只有「孤勇者」
去年「豆包手机」惊艳亮相,又因为令人遗憾的情况而「早夭」。在深感遗憾的同时,也让我们不禁去思考,AI 自动化的模式,就是 AI 手机的理想模式吗?
这个问题,没有个三五年也得不出答案。至少,豆包手机不是单打独斗,手握 Android 系统的 Google,同样选择了这个路线,而且话语权大得多。

其实当豆包手机火到海外之后,就有网友开始畅想,如果 Google 在 Pixel 以及 Android 手机上推广这个技术,那前景将会非常广阔。
虽然我觉得,Google 对于怎么回答「AI 手机」这个命题,其实也没有一个非常清晰的答案,更像是因为手上同时有 AI、系统和硬件,每个方向都尝试一下,说不定就有一条路跑通了。
但至少,Google 已经为 Android 打好了「系统级自动化」的样板,接下来不少新机,都有了化身「豆包手机」的潜力。
这个浪潮或许还不止于 Android 阵营。别忘了,苹果已经和 Google 达成合作,Gemini 将成为 Siri 的技术支持。而 App Intents 和 AppFunctions 又非常相似……
▲ AI Siri 的演示
再往前看一点:Gemini 智能体甚至不只局限于 AI 手机。在 Sammer Samat 设想中,未来智能眼镜、AI 吊坠,甚至是汽车,只要有 Gemini,就能用它来完成复杂的任务——当然,这样的场景距离落地还有距离。
不过,Google 也只是在技术层面跑通了 AI 自动化的路线,而范式成立,不代表问题消失。豆包手机当时遇到的种种矛盾,也会成为后来者不得不面对的挑战。
首先当然是隐私和安全问题。Google 的饼画得很大,未来调用、操作手机 App 的将不仅限于 Gemini,一些第三方 AI 应用能更深入用户的数据核心,如果有伪装的恶意应用利用了这些接口,也会造成更大的损失。
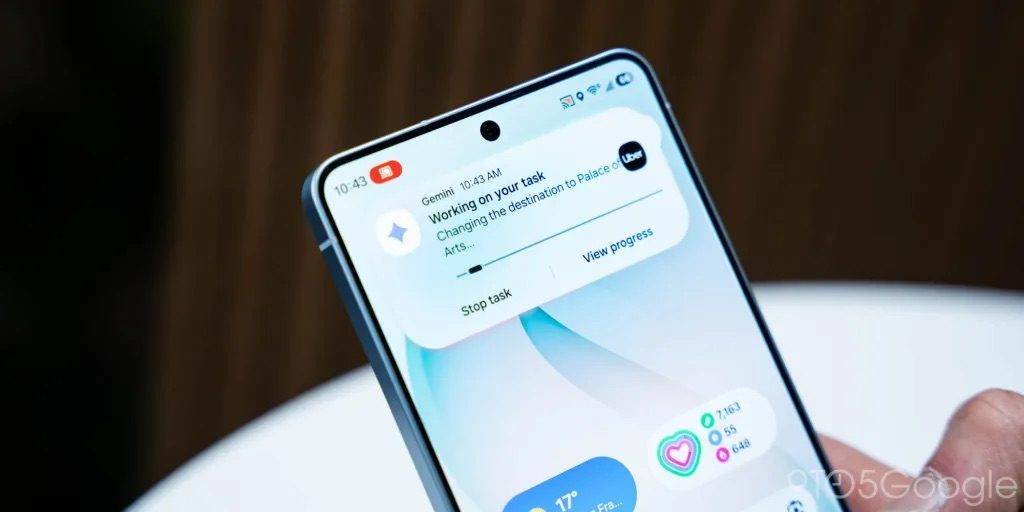
▲ 图源:9To5Google
更激烈的矛盾,是手机硬件厂商、模型/智能体能力提供商、大平台应用这三者之间,围绕 AI 时代新「入口」的争夺。这也是原版的豆包手机,一度最难逾越的高墙。
毕竟,用 Gemini 叫车,可能意味着用户不用再看到 Uber 的会员促销、广告推荐,甚至不再形成品牌黏性,直接损害到应用服务商/广告行业的收益。
中国有互联网/AI 巨头,海外何尝不是如此?像 Meta、Amazon 这样的老对手,本身还拥有强势的平台与生态,它们未必心甘情愿对 Google 开放,让 Gemini 来自动化一切。无论是以隐私、安全,还是平台规则为由,设置限制、提高接入门槛,博弈必然发生,争斗将进一步白热化。
至少 Google 对未来很有信心。Sammer Samat 认为,AI 技术已经进入了「正在进行时」,开发者与其绞尽脑汁对抗 ,还不如去思考一个合适的方式拥抱它。
新与旧的对抗不可避免,最终的胜利者,只会是那些在变革前夜,就已经在勇敢追逐的玩家。
参考资料:
https://android-developers.googleblog.com/2026/02/the-intelligent-os-making-ai-agents.html
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。