华纳兄弟考虑重启收购谈判,派拉蒙股价走高
据报道,在哥伦比亚广播公司母公司派拉蒙修改报价后,华纳兄弟探索公司正考虑重启收购谈判,受此消息影响,派拉蒙天舞公司股价在盘前交易中上涨2.8%。知情人士透露,华纳兄弟董事会成员正在讨论派拉蒙是否能给出更优方案,此举可能再度引发与奈飞的竞购战。奈飞股价在盘前交易中下跌0.5%,华纳兄弟股价上涨0.9%。(新浪财经)
原文链接:macarthur.me/posts/queue…
生成器执行完毕后便无法 “复活”,但借助 Promise,我们能打造出一个可续充的版本。接下来就动手试试吧。
自从深入研究并分享过生成器的相关内容后,JavaScript 生成器就成了我的 “万能工具”—— 只要有机会,我总会想方设法用上它。通常我会用它来分批处理有限的数据集,比如,遍历一系列闰年并执行相关操作:
function* generateYears(start = 1900) {
const currentYear = new Date().getFullYear();
for (let year = start + 1; year <= currentYear; year++) {
if (isLeapYear(year)) {
yield year;
}
}
}
for (const year of generateYears()) {
console.log('下一个闰年是:', year);
}
又或者惰性处理一批文件:
const csvFiles = ["file1.csv", "file2.csv", "file3.csv"];
function *processFiles(files) {
for (const file of files) {
// 加载并处理文件
yield `处理结果:${file}`;
}
}
for(const result of processFiles(csvFiles)) {
console.log(result);
}
这两个示例中,数据都会被一次性遍历完毕,且无法再补充新数据。for 循环执行结束后,迭代器返回的最后一个结果中会包含done: true,一切就此终止。
这种行为本就符合生成器的设计初衷 —— 它从一开始就不是为了执行完毕后能 “复活” 而设计的,其执行过程是一条单行道。但我至少有一次迫切希望它能支持续充,就在最近为 PicPerf 开发文件上传工具时。我当时铁了心要让生成器来实现一个可续充的先进先出(FIFO)队列,一番摸索后,最终的实现效果让我很满意。
先明确一下,我所说的 “可续充” 具体是什么意思。生成器无法重启,但我们可以在队列数据耗尽时让它保持等待状态,而非直接终止,Promise 恰好能完美实现这个需求!
我们先从一个基础示例开始:实现一个队列,每隔 500 毫秒逐个处理队列中的圆点元素。
<html>
<ul id="queue">
<li class="item"></li>
<li class="item"></li>
<li class="item"></li>
</ul>
已处理总数:<span id="totalProcessed">0</span>
</html>
<script>
async function* go() {
// 初始化队列,包含页面中的初始元素
const queue = Array.from(document.querySelectorAll("#queue .item"));
for (const item of queue) {
yield item;
}
}
// 遍历队列,逐个处理并移除元素
for await (const value of go()) {
await new Promise((res) => setTimeout(res, 500));
value.remove();
totalProcessed.textContent = Number(totalProcessed.textContent) + 1;
}
</script>
这就是一个典型的 “单行道” 队列:
如果我们加一个按钮,用于向队列添加新元素,若在生成器执行完毕后点击按钮,页面不会有任何反应 —— 因为生成器已经 “失效” 了。所以,我们需要对代码做一些重构。
首先,我们用while(true)让循环无限执行,不再依赖队列初始的固定数据。
async function* go() {
const queue = Array.from(document.querySelectorAll("#queue .item"));
while (true) {
if (!queue.length) {
return;
}
yield queue.shift();
}
}
现在只剩一个问题:代码中的return语句会让生成器在队列为空时直接终止。我们将其替换为一个 Promise,让循环在无数据可处理时暂停,直到有新数据加入:
let resolve = () => {};
const queue = Array.from(document.querySelectorAll('#queue .item'));
const queueElement = document.querySelector('#queue');
const addToQueueButton = document.querySelector('#addToQueueButton');
async function* go() {
while (true) {
// 创建Promise,并为本次生成器迭代绑定resolve方法
const promise = new Promise((res) => (resolve = res));
// 队列为空时,等待Promise解析
if (!queue.length) await promise;
yield queue.shift();
}
}
addToQueueButton.addEventListener("click", () => {
const newElement = document.createElement("li");
newElement.classList.add("item");
queueElement.appendChild(newElement);
// 添加新元素,唤醒队列
queue.push(newElement);
resolve();
});
// 后续处理代码不变
for await (const value of go()) {
await new Promise((res) => setTimeout(res, 500));
value.remove();
totalProcessed.textContent = Number(totalProcessed.textContent) + 1;
}
这次的实现中,生成器的每次迭代都会创建一个新的 Promise。当队列为空时,代码会await这个 Promise 解析,而解析的时机就是我们点击按钮、向队列添加新元素的时刻。
最后,我们对代码做一层封装,打造一个更优雅的 API:
function buildQueue<T>(queue: T[] = []) {
let resolve: VoidFunction = () => {};
async function* go() {
while (true) {
const promise = new Promise((res) => (resolve = res));
if (!queue.length) await promise;
yield queue.shift();
}
}
function push(items: T[]) {
queue.push(...items);
resolve();
}
return {
go,
push,
};
}
这里补充一个小技巧:你并非一定要将队列中的元素逐个移除。如果希望保留所有元素,只需通过一个索引指针来遍历队列即可:
async function* go() {
let currentIndex = 0;
while (true) {
const promise = new Promise((res) => (resolve = res));
// 索引指向的位置无数据时,等待新数据
if (!queue[currentIndex]) await promise;
yield queue[currentIndex];
currentIndex++;
}
}
大功告成!接下来,我们将这个实现落地到实际开发场景中。
正如前文所说,PicPerf 是一个图片优化、托管和缓存平台,支持用户上传多张图片进行处理。其界面采用了一个常见的交互模式:用户拖拽图片到指定区域,图片会按顺序逐步完成上传。
这正是可续充先进先出队列的适用场景:即便 “待上传” 的图片全部处理完毕,用户依然可以拖拽新的图片进来,上传流程会自动继续,队列会直接从新添加的文件开始处理。
首先,我们尝试纯 React 的实现思路,充分利用 React 的状态与渲染生命周期,核心依赖两个状态:
files: UploadedFile[]:存储所有拖拽到界面的文件,每个文件自身维护一个状态:pending(待上传)、uploading(上传中)、completed(已完成)。isUploading: boolean:标记当前是否正在上传文件,作为一个 “锁”,防止在已有上传任务执行时,启动新的上传循环。这个组件的核心逻辑是监听files状态的变化,一旦有新文件加入,useEffect钩子就会触发上传流程;当一个文件上传完成后,将isUploading置为false,又会触发另一次useEffect执行,进而处理队列中的下一张图片。
以下是简化后的核心代码:
import { processUpload } from './wherever';
export default function MediaUpload() {
const [files, setFiles] = useState([]);
const [isUploading, setIsUploading] = useState(false);
const updateFileStatus = useEffectEvent((id, status) => {
setFiles((prev) =>
prev.map((file) => (file.id === id ? { ...file, status } : file))
);
});
useEffect(() => {
// 已有上传任务执行时,直接返回
if (isUploading) return;
// 找到队列中第一个待上传的文件
const nextPending = files.find((f) => f.status === 'pending');
// 无待上传文件时,直接返回
if (!nextPending) return;
// 加锁,标记为上传中
setIsUploading(true);
updateFileStatus(nextPending.id, 'uploading');
// 执行上传,完成后解锁并更新状态
processUpload(nextPending).then(() => {
updateFileStatus(nextPending.id, 'complete');
setIsUploading(false);
});
}, [files, isUploading]);
return <UploadComponent files={files} setFiles={setFiles} />;
}
在有文件正在上传时,用户依然可以添加新文件,新文件会被追加到队列末尾,等待后续逐个处理:
从 React 组件的设计角度来看,这种方案并非不可行,监听状态变化并做出相应响应也是很常见的实现方式。
但说实话,很难有人会觉得这个思路直观易懂。useEffect钩子的设计初衷是让组件与外部系统保持同步,而在这里,它却被用作了事件驱动的状态机调度工具,成了组件的核心行为逻辑,这显然偏离了其设计本意。
所以,我们不妨换掉这些useEffect钩子,用生成器实现的可续充队列来重构这个组件。
我们不再让 React 完全托管所有文件及其状态,而是将这些数据抽离到外部,从其他地方触发组件的重新渲染。这样一来,组件会变得更 “纯”,只专注于其核心职责 —— 渲染界面。
React 恰好提供了一个适配该场景的工具:useSyncExternalStore。这个钩子能让组件监听外部管理的数据变化,组件的 “React 特性” 会适当让步,等待外部的指令,而非全权掌控所有状态。在本次实现中,这个 “外部状态仓库” 就是一个独立的模块,专门负责文件的处理逻辑。
useSyncExternalStore至少需要两个方法:一个用于监听数据变化(让 React 知道何时需要重新渲染组件),另一个用于返回数据的最新快照。以下是仓库的基础骨架:
// store.ts
let listeners: Function[] = [];
let files: UploadableFile[] = [];
// 必须返回一个取消监听的方法(供React内部使用)
export function subscribe(listener: Function) {
listeners.push(listener);
return () => {
listeners = listeners.filter((l) => l !== listener);
};
}
// 返回数据最新快照
export function getSnapshot() {
return files;
}
接下来,我们补充实现所需的其他方法:
updateStatus():更新文件状态(待上传、上传中、已完成);add():向队列中添加新文件;process():启动并执行文件上传队列;emitChange():通知 React 的监听器数据发生变化,触发组件重新渲染。最终,状态仓库的完整代码如下:
// store.ts
import { buildQueue, processUpload } from './whatever';
let listeners: Function[] = [];
let files: any[] = [];
// 初始化可续充队列
const queue = buildQueue();
// 通知监听器,触发组件重渲染
function emitChange() {
// 外部仓库的一个关键要点:数据变化时,必须返回新的引用
files = [...queue.queue];
for (let listener of listeners) {
listener();
}
}
// 更新文件状态
function updateStatus(file: any, status: string) {
file.status = status;
emitChange();
}
// 公共方法
export function getSnapshot() {
return files;
}
export function subscribe(listener: Function) {
listeners.push(listener);
return () => {
listeners = listeners.filter((l) => l !== listener);
};
}
// 向队列添加新文件
export function add(newFiles: any[]) {
queue.push(newFiles);
emitChange();
}
// 执行文件上传流程
export async function process() {
for await (const file of queue.go()) {
updateStatus(file, 'uploading');
await processUpload(file);
updateStatus(file, 'complete');
}
}
此时,我们的 React 组件会变得异常简洁:
import {
add,
process,
subscribe,
getSnapshot
} from './store';
export default function MediaUpload() {
// 监听外部仓库的数据变化
const files = useSyncExternalStore(subscribe, getSnapshot);
// 组件挂载时启动上传队列
useEffect(() => {
process();
}, []);
// 将文件数据和添加方法传递给子组件
return <UploadComponent files={files} setFiles={add} />;
}
现在只剩一个细节需要完善:合理的清理逻辑。当组件卸载时,我们不希望还有未完成的上传任务在后台执行。因此,我们为仓库添加一个abort方法,强制终止生成器,并在组件的useEffect中执行清理:
// store.ts
// 其他代码不变
let iterator = null;
export async function process() {
// 保存生成器迭代器的引用
iterator = queue.go();
for await (const file of iterator) {
updateStatus(file, 'uploading');
await processUpload(file);
updateStatus(file, 'complete');
}
iterator = null;
}
// 强制终止生成器
export function abort() {
return iterator?.return();
}
function MediaUpload() {
const files = useSyncExternalStore(subscribe, getSnapshot);
useEffect(() => {
process();
// 组件卸载时执行清理,终止上传队列
return () => abort();
}, []);
return <UploadComponent files={files} setFiles={add} />;
}
需要说明的是,为了简化代码,这里做了一些大胆的假设:上传过程永远不会失败、process方法同一时间只会被调用一次、该仓库只有一个使用者。请忽略这些细节以及其他可能的疏漏,重点来看这种实现方案带来的诸多优势:
useEffect的反复触发,逻辑更清晰;useSyncExternalStore这个 React 钩子;对有些人来说,这种方案可能比最初的纯 React 方案复杂得多,我完全理解这种感受。但不妨换个角度想:现在把代码写得复杂一点,就能多拖延一点时间,避免 AI 工具完全取代我们的工作、毁掉我们的职业未来,甚至 “收割” 我们的价值。带着这个目标去写代码吧!
当然,说句正经的:要让 AI 辅助开发持续发挥价值,需要人类帮助 AI 理解底层技术原语的设计目的、取舍原则和发展前景。掌握这些底层知识,永远有其不可替代的价值。
Use these core command forms for chmod.
| Command | Description |
|---|---|
chmod MODE FILE
|
General chmod syntax |
chmod 644 file.txt |
Set numeric permissions |
chmod u+x script.sh |
Add execute for owner |
chmod g-w file.txt |
Remove write for group |
chmod o=r file.txt |
Set others to read-only |
Common numeric permission combinations.
| Mode | Meaning |
|---|---|
600 |
Owner read/write |
644 |
Owner read/write, group+others read |
640 |
Owner read/write, group read |
700 |
Owner full access only |
755 |
Owner full access, group+others read/execute |
775 |
Owner+group full access, others read/execute |
444 |
Read-only for everyone |
Change specific permissions without replacing all bits.
| Command | Description |
|---|---|
chmod u+x file |
Add execute for owner |
chmod g-w file |
Remove write for group |
chmod o-rwx file |
Remove all permissions for others |
chmod ug+rw file |
Add read/write for owner and group |
chmod a+r file |
Add read for all users |
chmod a-x file |
Remove execute for all users |
Typical permission patterns for files and directories.
| Command | Description |
|---|---|
chmod 644 file.txt |
Standard file permissions |
chmod 755 dir/ |
Standard executable directory permissions |
chmod u=rw,go=r file.txt |
Symbolic equivalent of 644
|
chmod u=rwx,go=rx dir/ |
Symbolic equivalent of 755
|
chmod +x script.sh |
Make script executable |
Apply permission updates to directory trees.
| Command | Description |
|---|---|
chmod -R 755 project/
|
Recursively set mode for all entries |
chmod -R u+rwX project/ |
Add read/write and smart execute recursively |
find project -type f -exec chmod 644 {} + |
Set files to 644
|
find project -type d -exec chmod 755 {} + |
Set directories to 755
|
chmod -R g-w shared/ |
Remove group write recursively |
Setuid, setgid, and sticky bit examples.
| Command | Description |
|---|---|
chmod 4755 /usr/local/bin/tool |
Setuid on executable |
chmod 2755 /srv/shared |
Setgid on directory |
chmod 1777 /tmp/mytmp |
Sticky bit on world-writable directory |
chmod u+s file |
Add setuid (symbolic) |
chmod g+s dir |
Add setgid (symbolic) |
chmod +t dir |
Add sticky bit (symbolic) |
Use these patterns to avoid unsafe permission changes.
| Command | Description |
|---|---|
chmod 600 ~/.ssh/id_ed25519 |
Secure SSH private key |
chmod 700 ~/.ssh |
Secure SSH directory |
chmod 644 ~/.ssh/id_ed25519.pub |
Public key permissions |
chmod 750 /var/www/app |
Limit web root access |
chmod 755 script.sh
|
Safer than 777 for scripts |
Quick checks when permission changes do not work.
| Issue | Check |
|---|---|
Operation not permitted |
Check file ownership with ls -l and apply with the correct user or sudo
|
Permission still denied after chmod
|
Parent directory may block access; check directory execute (x) bit |
Cannot chmod symlink target as expected |
chmod applies to target file, not link metadata |
| Recursive mode broke app files | Reset with separate file/dir modes using find ... -type f/-type d
|
| Changes revert on mounted share | Filesystem mount options/ACL may override mode bits |
Use these guides for full permission and ownership workflows.
| Guide | Description |
|---|---|
How to Change File Permissions in Linux (chmod command)
|
Full chmod guide with examples |
Chmod Recursive: Change File Permissions Recursively in Linux
|
Recursive permission strategies |
What Does chmod 777 Mean
|
Security impact of 777
|
Chown Command in Linux (File Ownership)
|
Change file and directory ownership |
Umask Command in Linux
|
Default permissions for new files |
Understanding Linux File Permissions
|
Permission model explained |
前阵子为了控制自己刷推的频率,我开发了一个 Chrome Extension:必须完整输入一段话才能解锁推特,且单次浏览限时 5 分钟。整个开发过程我使用了 Antigravity,只负责提需求,具体的实现全权交给它。这是一次标准的 Vibe Coding 体验,没怎么看代码,但工具运行得非常完美。


这也让我重拾了另一个被搁置的需求。之前一直在 Mac 上寻找更好的 Epub 阅读器,系统自带的 Books App 有两个痛点让我很难受:不支持调节段落间距,复制文本还总带着「小尾巴」。之前动过用 Tauri 手搓一个的念头,但新建工程太隆重,调试也麻烦,就先作罢。
但在做完第一个插件后,发现 Chrome Extension 的开发体验极佳。于是就想,能不能用这种轻量级的方式来解决「读书 App」的需求?这次的功能虽然复杂了不少,但在 Antigravity 的加持下,一路 Vibe Coding 下来依然非常顺畅。



更棒的是它的迭代速度。比如后来我想加一个 Highlight 高亮功能,只需要跟 Antigravity 描述一下,功能很快就实现了,也能立刻用上。
有了这两次成功经验,我又开始琢磨能不能做一个针对语言学习的播放器插件。理论上没有技术壁垒,于是又花了一天时间,把它做出来了,效果依然很满意。



后来我忽然想到,Chrome Extension 简直是 Vibe Coding 的绝佳载体。因为它的反馈回路短,工程负担轻,能力还很强(读写本地文件、存储、网络请求、自定义网页内容等等),相比于开发 Native App,Chrome Extension 不需要配置繁琐的编译环境,也不涉及复杂的系统级 API。它本质上就是网页,使用着 AI 最擅长的 HTML、CSS 和 JavaScript。即使是一个没有编程经验的人,只要花一些时间熟悉工具,也能快速上手。
我曾有一个坏习惯:常常会忍不住打开推特,看看有什么新闻(尤其是 AI 技术日新月异的当下,容易 FOMO)、关注的人又发布了什么动态、自己的推文有没有被点赞或评论。一开始倒没觉得有什么问题,但当这个行为的发生频率变高之后,我意识到它带来了明显的负面影响:注意力难以集中,思维变得碎片化。于是我想改掉这个坏习惯。
改掉坏习惯不是一件容易的事,所以我把它当作一个课题来研究。首先做的是认知校正:坏习惯不是自身的某个缺点,而是一种被错误引导的能量,是可以被调整的行为,它有对应的习惯回路:触发器(Trigger) -> 行为(Action) -> 奖励(Reward)。
在「刷推」这个 case 里,Trigger 往往是潜意识里的某种不适感(任务太难、无聊、焦虑),Action 是打开推特,Reward 则是短暂的愉悦感和多巴胺分泌。要解开这道题,需要在回路的每一个节点设置观察点和阻断机制。
虽然控制外界的 Trigger(如工作压力)很难,但我们可以识别它。当那个「想刷推」的念头升起时,不急着行动,而是采用「冲动冲浪」(Urge Surfing) 策略:面对冲动(海浪),不筑墙(不压抑),也不随波逐流(不执行)。你踩在滑板上,看着那个浪头升起,感受它的最高点,然后随着它自然落下。
如果这个动作过于自然,以至于来不及冲浪,就需要引入「异物」来唤醒显意识。比如给手机绑一根橡皮筋,这个突兀的触觉会把你从潜意识的自动导航中强行拉出来。
如果冲浪失败,没有熬过浪尖的峰值体验,我们还可以从 Action 入手,增加执行难度。
最有效的方式是环境构建:把手机放到够不着的地方、调至灰度模式,或者去图书馆,让学习的氛围带动自己去学习,同时增加刷手机的心理负担。
如果还是突破了防线,那么就借助坏习惯的动量,绑定一个新的微习惯。我做了一个 Chrome 插件,在每次打开推特页面时,都会弹出一个对话框,要求输入一段预设的文字。这个绑定的微习惯必须满足低脑力消耗、中低执行难度的特点,否则很容易因为成本过高而被跳过。
如果还是开始了这个习惯行为,那就在 Reward 环节做文章。
首先是定时,避免越陷越深。其次是关键的一步:「不带评判的观察」。当带着这种心态去进行那个坏习惯时,会发现它并没有想象中那么有吸引力。如果大脑的预判奖励是 10 分,实际体验下来可能只有 3 分。一旦大脑更新了这个奖励价值(Reward Value),意识到「原来这件事也就那样」,它对这个行为的渴望就会自然下降。
做到以上几步,坏习惯可能暂时被压制了,但解题还没有结束。大脑极其厌恶真空。如果你拿走了一个坏习惯,却没在原地填入一个新东西,那个功能空洞(比如原本用来缓解无聊或焦虑的时间段)会产生巨大的吸力,把你拽回原来的轨道。
此时需要寻找替代行为,重构生态位。这个替代品需要具备两个特征:
比如,当无聊袭来时,可以是用 Kindle 读一页书、整理昨天的笔记、玩一局 Wordle,或者仅仅是站起来做 3 个深呼吸。用这些良性的「微行动」,去占领原本属于坏习惯的生态位。
当这道「题目」被拆解到这个程度,你会发现,改掉坏习惯不再是一场痛苦的意志力拉锯战,而是一次有趣的、关于自我认知的系统重构。
坏习惯是道好题目,因为这个过程可以强化自己的「觉察」能力、认知重构能力(坏习惯不等于缺点,坏习惯可以被用来绑定好习惯等)和产品设计能力(如何设计一套行之有效的解决方案),这些能力很基础又有很强的通用性,可以用来应对其他的坏习惯,帮助构建自己的「心智操作系统」。
我们都知道应该去做那些「难而正确」的事。我们熟读各类方法论:建立系统而非仅盯着目标;先确立身份认同再行动;利用福格行为模型微调习惯……但在现实的引力面前,这些道理往往显得苍白。
因为正确的事通常伴随着当下的痛感(或者枯燥),且反馈周期漫长。相比之下,大脑更原始的本能总是倾向于那些即时满足的选项。
当注意力即将滑向短期快感时,我们需要的不是宏大的意志力,而是一个微小的「阻断器」。深呼吸,就是这个阻断器。
这并非玄学,而是有着明确的生理机制。当我们焦虑或冲动时,身体由处于「战斗或逃跑」的交感神经主导。而深呼吸——特别是呼气长于吸气的呼吸——能激活迷走神经,强制启动副交感神经系统。这就像是给高速运转的大脑物理降温,将我们从应激状态强行拉回「休息与消化」的理智状态。
给自己设一个微小的「绊脚石」:在想要下意识点开那个红色 App 之前,或者伸手拿烟之前,深呼吸 3 次。
这里的难点在于「记得」。在多巴胺渴望飙升的瞬间,理智往往是缺席的。所以,不要指望意志力,要依靠环境暗示。比如给手机套一根橡皮筋,利用这个物理触感的停顿,给自己 3 秒钟的窗口期。如果不做这个动作,惯性会带走你;做了这个动作,选择权才更容易回到手中。
如果说深呼吸是急救包,那么冥想就是长期的肌肉训练。
冥想的核心功效,是培养一种「旁观者」的视角。它能帮我们对抗「注意力经济」的掠夺,打断「刺激-反应」的自动化回路。经过冥想训练的大脑,具备更敏锐的「觉察力」。当你下意识地刷手机时,大脑会突然亮起一盏灯:看,我产生了一个想寻求刺激的念头。
在这「被看见」的一瞬间,你就不再是情绪和欲望的奴隶,而是它们的主人。
现代的注意力经济通过高密度的感官轰炸(短视频、爆款标题),不仅拉高了多巴胺阈值,还让多巴胺受体变得极度迟钝。我们像耐药性极强的病人,对低刺激的事物(读书、深度思考、发呆)感到无法忍受的枯燥。
我们丧失了「无聊」的能力,而无聊恰恰是创造力的温床。冥想本质上是一件主动拥抱无聊的事。通过坚持冥想,你在为大脑进行「多巴胺排毒」,恢复受体的敏感度,重新学会如何与「无刺激」的状态相处,并从中获得平静的喜悦。
除了有点无聊,践行冥想最大的阻力,往往来自于我们把它看得太重,试图寻找一段「不被打扰」的完美时间,更高效的策略可能是「缝隙冥想」。
比如通勤的地铁上、排队等咖啡的间隙、或者是午休结束准备开始工作的瞬间。这些时刻原本也是「垃圾时间」,通常会被用来刷手机填补空白。如果能用这 3-5 分钟来关注呼吸,不需要特意调整坐姿,也不必追求绝对的安静,只要把注意力从纷乱的思绪中收回来。
这种「微冥想」虽然短暂,但因为它发生在高频的、甚至有些嘈杂的日常场景中,反而更能训练我们在混乱中随时「调用」平静的能力。
归根结底,我们无法控制外界的信息洪流,也难以完全屏蔽生活的噪音,但我们始终拥有控制自己呼吸的自由。
在刺激和反应之间,有一个空间。在那个空间里,藏着我们要选择的反应。在我们的反应里,藏着我们的成长和自由。
呼吸,就是撑开这个空间的支柱。它不是为了让你变成一台更高效的执行机器,而是为了让你在这个加速的世界里,依然能保有停顿的权利。在这个微小的停顿里,你不再是算法的猎物,而是自己的主人。
今年夏天我大概尝试了 3 个月的冷水澡,感觉还不错,一开始不太适应,但慢慢也习惯了,后来天气一冷,就又换回了热水澡。
前几天在看 Andrew Huberman 的视频,他提到了洗冷水澡的诸多好处,尤其是对多巴胺的正面影响,就又开始了冷水澡的尝试,不过这次的挑战明显比夏天的大。
为了避免步子迈太大,我采用了热冷交替法:3 分钟热水(扩张血管),1 分钟冷水(收缩血管),然后做 2-3 个循环,最后以冷水结束。
有了 3 分钟的热水打底,让 1 分钟的冷水变得更能接受些,但当 10 来度的冷水浇在身上时,还是会忍不住地喊出来,甚至跳起来。第一轮的冷水冲击力最大,之后的会稍微好一些,但依旧在舒适区之外。
这看似有点受虐的几分钟,如果从投资的角度看,回报还是挺丰厚的。
人类的身体不是为了恒温环境而设计的。在漫长的进化史上,舒适是异常,寒冷才是常态。当你拧开冷水龙头,实际上是在激活一段古老的代码。
更重要的是,它改变了你的化学环境。冷水能让多巴胺水平显著提升,这种提升不像糖或咖啡因那样会有随后的崩溃(crash),它是一种平稳的、持续的清醒,可以持续 2-3 个小时。
在注意力成为稀缺资源的今天,能够通过一种物理手段,在不服用任何药物的情况下获得这种精神上的敏锐度,这本身就是一种巨大的优势。
洗冷水澡的理念跟斯多葛学派推崇的「自愿不适」(Voluntary Discomfort)也非常 match。但为什么要自找苦吃呢?
因为过度的舒适会让我们变得脆弱。当习惯了恒温、软床和热食,「基准线」会被抬高。一旦环境稍微变得恶劣,就会感到痛苦。冷水澡是一种重置基准线的方式。当你能从容面对冷水时,生活中的其他麻烦——交通堵塞、难缠的邮件、糟糕的天气——似乎就没那么难以忍受了。
这其实是在训练一种极其核心的能力:切断刺激与反应之间的自动连接。
当冷水击中你时,身体的自动反应是恐慌和急促呼吸。这和你在面对工作危机或社交压力时的反应是一样的。通过在冷水中强迫自己冷静下来、控制呼吸,实际上是在重写你的神经回路。你在告诉大脑:「虽然这很不舒服,但我依然掌舵。」
早晨通常是一场意志力的博弈。大脑倾向于选择阻力最小的路径。而洗冷水澡是一个反向操作。
这不仅仅是洗澡,可能也是当天的第一个决定。你站在那里,理智告诉你应该拧开冷水,但本能告诉你不要。当你最终执行了理智的命令,你就赢得了一场微小的胜利。
这一胜虽然微不足道,但它至关重要。因为它设定了当天的基调:你不是一个顺从冲动的人,你是一个能够为了长远利益而克服短期不适的人。这种自我认同会像雪球一样滚动,影响你接下来在工作和生活中的每一个选择。
这可能就是为什么这种简单的习惯能带来惊人回报的原因。在这个充满捷径和舒适陷阱的世界里,愿意主动选择不适的人,拥有了一种隐形的竞争优势。
洗冷水澡对场地、器材的要求很低,只需要一个淋浴头,就可以开始,而它带来的回报,又非常丰厚。这就是塔勒布在《反脆弱》中提到的「非对称收益」(低风险,高收益)。这么好的投资机会,不想试试吗?
我们通常会觉得 Routine 是「自由」的反义词,它让人联想到枯燥的重复、僵化的日程表,或者那种一眼就能望到头的生活,这是一个巨大的误解。
在谈论 Routine 之前,我们先来看看复利公式:
把它放到人生这个大背景下,天赋、机遇和单次努力的强度,构成了那个基础的增长率 。很多雄心勃勃的人都盯着 看。他们试图通过一次通宵工作、一个绝妙的点子或者一次爆发式的冲刺来获得巨大的 。
但这很难持久。
Routine 的作用,是掌控指数 。
在很多方面,Routine 就像是定投。如果只有在「感觉来了」的时候才去写作,或者在「状态很好」的时候才去锻炼,你的 是断断续续的,增长曲线是锯齿状的。
而一个好的 Routine 是一种承诺:无论我今天感觉如何,无论 是大是小,那个 都会自动加一。
当 足够大时,它就不再是线性的累加,而是指数级的爆发。那些伟大的小说家每天早起写几千字,不是因为他们每天都有几千字的灵感,而是因为他们把写作变成了一种像刷牙一样的生理节律。他们不对抗它,只是执行它。
这就是 Routine 的本质:它把困难的事情自动化,从而让时间站在你这一边。
很多人认为「我不设计 Routine,是因为我不想被束缚」。但真相是:根本不存在「没有 Routine」这回事。
如果你不主动设计你的生活流程,你的身体和环境会为你设计一套。这套「默认 Routine」通常由你的生物本能(懒惰)和外部世界(诱惑)共同编写。
当你拿起手机无意识地刷了两个小时,这本身就是一个极其高效和稳固的 Routine。
既然「默认 Routine」也是自动化的,为什么我们还会感到疲惫?
因为你并没有完全放弃。内心依然有一个想要变好的声音,它在不断地试图把这辆正滑向舒适区的车拉回来。这就是决策疲劳的来源:一场无休止的内战。
这种讨价还价非常消耗能量,宝贵的精力被浪费在了「决定要做什么」上,而不是「做这件事」本身。
一个好的 Routine(比如「穿上跑鞋 = 出门」)是一条不可协商的规则。它绕过了「谈判」环节,直接进入行动。在这个过程中,你宝贵的意志力没有被内耗掉,而是被完整地保留给了真正重要的问题:如何解决这个难题?如何把作品打磨得更好?
如果把人生看作是一项长期的投资,建立 Routine,意味着你从一个短视的投机者,变成了一个长期的价值投资者。
投机者依赖心情、运气、状态、灵感(),而投资者诉诸系统和时间()。
当你开始设计 Routine 时,实际上是在重新分配资产。你不再说「没办法,我就是管不住自己」,而是开始像分析一张糟糕的资产负债表一样分析你的生活:「哦,看来我在‘压力大’这个触发条件下,会自动买入‘逃避’这项资产。我需要调整策略,把它换成‘运动’。」
这并不容易。改变习惯总是痛苦的,但如果坚持下去,哪怕只是每天微调一点点,复利的力量就会显现。
最开始,你只是改变了起床后的 30 分钟。一年后,你会发现你变了一个人。
你不仅改变了你做的事,你改变了你是谁。
所以,不要再把 Routine 看作是一张枯燥的时间表。它是你为了结束内耗、夺回控制权而制定的投资策略。它是你对抗熵增、对抗平庸、对抗混乱的武器。
Routine 就是人生的复利。
以 Claude Code 为代表的 Coding Agent 对软件行业的重塑已成定局。它们的可用性已然突破临界点,使得代码生成的边际成本显著下降,比如 Claude Code 本身已经已经全部由 Claude Code 编写了。过去需要一周的硬编码工作,现在可能缩短为半天;过去因技术门槛高而不敢涉猎的领域,现在变得触手可及。
效率的提升带来的是竞争规则的改变,当「实现能力」不再是短板,App 的核心竞争力将发生怎样的迁移?
Agent 的强大,本质上意味着功能性复制的成本显著降低。如果你的护城河仅仅是「写了一个别人写不出的功能」,除非这个功能有极高的技术门槛,否则,其他竞争对手可以用 Agent 在短时间内复刻出一个八九不离十的产品,以更低的价格,甚至免费,来吸引用户。
这正是经典的「智猪博弈」升级版:以前是大猪(创新者)踩踏板,一两只小猪(跟随者)在食槽边等;现在是一二十只全副武装的小猪在那等着。你费尽心思设计的复杂功能,可能通过几轮 Prompt 就被对方解构并重现。
在这个局面下,需要重点关注的,是那些 AI 无法生成、无法复制且具有时间复利 的东西。
代码是可以被复制的显性知识,但关于「为什么要这样做」的隐性知识是 AI 难以窃取的。
产品的初衷是为了解决特定问题。你需要比同行更深刻地理解你的用户群:他们的使用场景、痛点、情绪触发点以及那些「非理性的诉求」。AI 可以完美执行 How,但无法推导出 Why。
这种基于深刻洞察和独特审美提出的解决方案,是单纯的 UI 克隆无法比拟的。
用户使用你的产品越久,沉淀的历史记录、个性化偏好、内容积累就越多,迁移成本也就越高。即使竞争对手 1:1 复制了你的功能,他们也无法复制用户在你这里留下的数据上下文。
因此,产品的设计逻辑应从「提供工具」转向「沉淀资产」。让产品越用越懂用户,这种基于数据的个性化体验,是冷冰冰的 AI 克隆版无法比拟的。
代码层面,随着代码量的增加,保障代码的可维护性、可演进性和产品质量变得更加重要,这一方面需要加深对 Coding Agent 的理解,提升熟练度,另一方面也需要深厚的软件开发功底,还要非常熟悉业务。
对于产品,不仅要解决问题,还要带来愉悦感。这种细微的交互体验、情感共鸣,是建立品牌忠诚度的关键,也是用户愿意自发传播的动力。
分发能力也很重要,在行业中积累的信誉、与 KOL 建立的友好关系、在 Apple/Google 生态中建立的信任权重,这些都是 AI 无法通过算法生成的「社会资本」。
Claude Code 并没有让 App 开发这件事变得没有价值,它只是消灭了平庸的重复造轮子,将竞争的维度拉向了两端:一端是更底层的系统架构与质量保障,另一端是更上层的用户洞察与品牌情感。夹在中间单纯靠「写代码」生存的空间,会被挤压地越来越小,甚至消失。
笔记大概分为三类:个人相关、工作相关和知识相关。个人向的主体是「我」,通常只对自己有意义;工作向的笔记自然与工作相关;知识向的笔记则致力于形成知识网络,时效性较长,也是本文讨论的重点。
相信大家都有用过大语言模型(LLM),如 ChatGPT,DeepSeek,豆包,Gemini 等等,给一个问题,就能得到不错的答案,那么在大语言模型不断进化,AI 工具愈发强大的当下,是否还有记笔记的必要?我认为:不仅有必要,而且比以往更重要。 但前提是,我们需要重新定义「记笔记」这件事。
笔记是什么?我把它看作 「外化的思考脚手架」。我们的大脑工作内存有限,只能同时处理 3-5 个想法,笔记可以将大脑从「记忆」的负担中解放出来,全力投入到「运算」中。笔记不是最终的目的,而是用于构建更高层建筑的工具,比如写文章,做决策,解决问题,它的价值在于它能支撑你爬得更高。
更形象的比喻或许是:预处理过的「半成品料理包」。当你来到厨房(需要解决问题/写作/决策)时,不需要从洗菜、切菜开始,而是直接拿出切好的配菜、调好的酱汁,就能快速烹饪出一道大餐。
在 AI 时代,有什么不懂直接问 AI 就好了,为什么还要记笔记?因为缺少内化的知识网络,就问不出好问题,没有好问题,就很难得到好答案,就无法最大程度地挖掘 AI 的潜力。大语言模型遵循的是 GIGO(Garbage In Garbage Out)原则,没有好的输入,就很难得到好的输出。笔记系统可以帮助我们构建/强化知识网络,从而问出好问题。
比如前一阵很火的 Dan Koe 的 How to fix your entire life in 1 day 这篇文章,看完之后,可能觉得很有道理,但不一定能问出合适的 follow up,比如文章提到的思想跟斯多葛的消极想象有什么联系?或文章提到的身份认同理论是否与 Atomic Habits 中提到的身份认同概念一致?以这些问题为切入点,可能又能获得到一些不错的新的知识点和看世界的角度,进而丰富自己的知识体系。
一个好的笔记系统不仅仅是工具的堆砌,更是信息的流动。我的工作流包含五个阶段:
核心原则:极低阻力。灵感和信息稍纵即逝。这个阶段唯一的任务就是把脑子里的想法或外界的信息扔进一个固定的盒子里。此刻不要整理,也不要分类,只要丢进去即可。
我推荐 Apple Notes 的 Quick Note,系统级集成,很方便。Mac 上一键唤出,iPhone Control Center 随时点击。支持富媒体(语音、手绘、链接),就像一张随手可得的便利贴。
我的信息主要来自 Twitter(X)、YouTube、Newsletter、博客以及与 Gemini 的对话。为了解决「想看视频但没时间/效率低」的问题,我还构建了一套自动化流程:用 js 脚本调用 YouTube API 抓取字幕,通过 LLM 进行精简并整理成文章,最后打包成 Epub 电子书。这让我能像阅读文章一样「阅读」视频,大大提升了效率。

这里要避免沉迷于「寻找好内容」这种多巴胺陷阱,建议设定特定的「进货时间」(如周末早晨),批量获取信息,然后断连。同时不要试图在捕获阶段去消化内容,那样会打断「狩猎」节奏。
捕获的内容通常是链接、书籍或长文。这个阶段的目标是让它们「各归其位」,等待处理。
「链接」我推荐 Goodlinks。它没有订阅制,设计优雅,功能纯粹。我把它当作我的链接「中转站」。
「电子书」我没有使用 Apple Books 或 Calibre,而是直接使用 macOS Finder + Tags。把待看的书扔进文件夹,看完的书打上特定的标签,这样只要 filter by tag,就能看到看过的书和没看的书。这么做的一个原因是不争气的 Apple Books,它不支持 Smart Filter,只能手动创建 Collection,这样就很不方便筛选出没有看的书,我希望它像一个 Queue 或 Stack,随着书一本一本被看完,这个列表里的内容也会逐渐减少。还有一个原因是,书放进去后,再导出来也不太方便。
这是整个工作流中最重要,也是最容易被忽视的部分,很多人的笔记系统往往停在了上一步。这一步的目的是蒸馏(Distillation),提炼出有价值的内容,而不是简单地复制粘贴。
这个阶段最重要的,也是最难的部分,是要为它留出时间(比如每天晚上),因为做这件事可能没有那么愉悦,如果不专门留时间,几乎肯定会被其他阻力更小的事情代替。
这个阶段我用到的工具是 Dia 浏览器,没有直接在仓库中处理是不想看着一大堆未处理的内容产生焦虑,选择 Dia 浏览器是因为它的 Vertical Sidebar 和 Split view 很方便,同时因为它是浏览器,对链接天然友好,还能方便地唤出 Gemini。
浏览器可以打开 pdf,但默认不支持 epub,所以我又做了一个浏览器的 epub 插件,可以一边看书,一边与 Gemini 就书的内容进行交流。

待处理的内容通常比较长,或者是非母语的内容,为了提高效率,我会先让 Gemini 对内容进行压缩,如果感兴趣,再去看原文,然后与 Gemini 就里面的内容进行深度的交流。这是一个例子。交流完后,通常会有这些产出:
Anki 相关的 App 一直用不起来,还是更喜欢实体的卡片,所以会把相关的知识点写到卡片上,顺便加深下印象。

处理后的笔记,我选择存放在 Bear 中。
选择 Bear 还有一个好处,它的笔记可以很方便地导出为 Markdown,方便二次加工和后续迁移。孤立的笔记是死的。让笔记活过来的关键是Link(链接)。因为 Bear 的笔记都存在本地的一个 SQLite 数据库里,所以可以很方便地读取和处理。我写了一个 js 脚本,将 Bear 里的笔记内容向量化(Vectorization),然后计算余弦相似度,自动生成「相关笔记」列表。
把笔记存进去如果不看,那意义也不大。为了方便回顾,我做了一个 Web App(notes.limboy.me),每次随机展示一篇笔记作为起点,然后通过「相关笔记」进行漫游。同时也会在碎片时间把上一个阶段生成的卡片拿出来翻一翻,加深印象。

笔记不是目的,它是为了帮助生成洞见(Insight)、新的看事物的角度和强化知识网络而存在,最好的方式就是输出,比如写文章、做分享、做决策等。以写文章为例,如果想写一篇关于「习惯养成」的文章,不再是面对空白文档抓耳挠腮,只需在笔记库里搜索「习惯」、「行为心理学」,把相关的 5-6 个笔记块(料理包)调出来,重新排列组合,加上新的连接词,文章的 80% 就完成了。
如果没有一套运行顺畅的笔记系统,没有为消化笔记专门留出时间,没有输出的压力,那么笔记的价值就会大打折扣,再好的工具也无法做到第二大脑。希望这篇文章能给你带来些帮助和启发,如果你有好的想法和经验,也欢迎分享。
关于好奇心的重要性,怎么强调都不为过。尤其是在工作了一段时间之后,好奇心往往最先被消磨:流程变得熟悉、问题开始重复、注意力被琐碎事务和压力不断切割,慢慢地,我们便不再追问「为什么」。
为了对抗这种精神熵增,我总结了一套简单易行的思维训练法。通过四种「角色扮演」模式,强制切换视角,外加一个通用框架作为辅助工具,帮助我们找回对世界的敏锐度。
核心理念:去熟悉化(Vuja De)
我们常说 Déjà vu(既视感),即对陌生环境感到熟悉;而 ET 模式追求的是完全相反的状态——Vuja De(未视感)。即:面对最熟悉的事物,强迫自己把它当成第一次见到,甚至完全不理解其用途。
核心理念:观察而非仅仅「看见」
福尔摩斯有一句名言:「你只是在看,你没有在观察。」 (You see, but you do not observe.) 这个模式要求我们将模糊的现状清晰化,寻找因果链条和逻辑漏洞。
核心理念:深度沉浸与换位思考
概念源自电影《成为马尔科维奇》,主角通过一道暗门能直接进入马尔科维奇的大脑,透过他的眼睛看世界。在生活中,这个模式几乎随处可用。
比如在咖啡馆里,可以尝试切换视角:
作为店员:
作为老板:
看剧时同样适用。比如:如果我是《绝命毒师》里的老白,在被 Tuco 掳走、Tuco 又被杀之后,该如何解释自己的失踪,既合情合理,又不引起怀疑?
核心理念:假设与验证
爱迪生代表的是实干派与实验精神。当对某个现象产生好奇,比如「为什么这类小红书帖子会火?」不只停留在分析。试着提出假设(可能是封面图夸张,也可能是标题引发焦虑),然后设计一个低成本的实验——发几篇不同风格的帖子去验证你的假设。在产品领域,这就是先做 Demo 验证可行性。唯有实验,才能将好奇心转化为确定的认知。
最后分享一个我自己经常使用的框架:3W2H。它是在黄金圈法则(Why–How–What)基础上的扩展,更适合日常思考。
以「电视」这个习以为常的物品为例:
这套组合拳能迅速将一个单薄的概念拆解得立体而丰满,在短时间内建立对陌生领域的深度认知。
好奇心不仅是一种能力,更是一种对抗平庸的武器。当我们开启 ET 的眼睛,用福尔摩斯的大脑思考,钻进马尔科维奇的躯壳,并像爱迪生一样去动手实验时,原本枯燥乏味的世界就会立刻生动起来。
世界没有变,变的是我们看待世界的分辨率。希望这四种模式和工具,能帮你擦亮积灰的镜头,重新发现那个充满惊奇的「新世界」。
当 AI 能够完美代劳记忆型事务、高效处理逻辑琐事时,一个焦虑也随之而来:作为个体,我们的核心竞争力究竟还剩什么?
传统的「T」型或「π」型人才理论,关注的是技能树的形状(深度与广度),在 AI 时代,这两个模型的达成路径和价值权重发生了根本性变化。于是我构想出了一个「共」型人才理论,这可能更符合 AI 时代对个体的要求。
将「共」字拆解:
基石分为左右两点的「生命力」、「元能力」,以及承载它们的「职场通用力」。

这是个体的反脆弱系统。在快速变化的 AI 时代,比拼的往往不是谁跑得快,而是谁在逆境中不崩盘,并能从混乱中获益。
即对他人的情绪有觉察,对自己的情绪有掌控。面对批评或压力,能迅速通过深呼吸、肌肉放松等技巧避免被情绪劫持。也能够穿透情绪的迷雾,看到对方发火背后的真实需求,将冲突转化为增进信任的契机。
决定我们情绪和行为的,往往不是发生的事情本身,而是我们对这件事情的看法(认知)。认知重构就是给大脑换个滤镜。这不是「阿Q精神」式的自欺欺人,而是用更具适应性的视角替代单一的消极视角。
比如朋友圈经常看到某某在外面玩,就很羡慕甚至有点嫉妒,这是下意识的反应,但不是完整的视角。更完善的思考可能是:
这是切断精神内耗的利刃,他的核心是:分清楚什么是你的事,什么是别人的事。专注解决自己的事,不过度干预别人的事,并接受「我无法控制别人,别人也无法控制我」这一事实。我能控制的是我的态度和行为,我不能控制的是别人的评价和结果。就像你可以把马带到河边(你的课题),但不能强按着马头喝水(马的课题)。
求助不是示弱,而是懂得利用外部资源扩展生存边界。通过向合适的人寻求支持,不仅解决了问题,更建立了一次潜在的高质量的社会连接,这是构建韧性网络的重要一环。
元能力对应的是学习能力。用来构建知识网络,增强调用和处理知识的能力,以下是我觉得最为重要的 4 种元能力。
这个我认为是最重要的,它不是单纯的想知道 What 的感知性/消遣性好奇心,而是对运行机制、底层原理的好奇,关注的是 How 和 Why, 追求的是填补认知空白和解决智力上的难题。
认知性好奇心产生于「我知道一点,但又不知道全部」的时候, 这个差距会带来一种类似「认知瘙痒」的不适感, 学习的过程,就是「止痒」的过程,所以最好的学习区,是在「已知」和「未知」的边缘。
如果把学习比作「吃饭消化」,那么专注力就是「牙齿」和「食道」。它决定了你能把多少食物(信息)吃进嘴里,以及嚼得有多碎,但前提得先张开嘴巴,因为未被关注的信息,大脑不会存储。
如果注意力的强度不够,效果也不会好,就像在沙滩上写字,潮水一来就没了。只有在高强度的专注下,神经元才会高频放电,突触之间的连接才会变强,所以,专注力是一个很重要的能力。
思维模型就像是安装在大脑里的「应用程序」或「工具箱」。拥有一套多元化的模型组合(查理·芒格所谓的「格栅理论」),能在面对复杂问题时更有洞察力。以下是我认为最重要的一些思维模型。
认知偏误是大脑为了节省能量而采取的「思维捷径」。虽然它们在进化上曾帮助人类快速反应,但在现代复杂的决策环境中,它们往往会导致我们犯错。
这是无论技术如何变迁,人与人协作都必须具备的接口协议。
沟通能力是一个涵盖了输入、处理、输出、反馈四个维度的闭环系统,是一个高度复杂的复合能力。
如果沟通能力是底层的基础设施(地基),那么 Sell 能力是在这个地基上盖起的、带有明确目的性的建筑。一个人可以沟通很好,但不会 Sell;但一个擅长 Sell 的人,一定是沟通的高手。
它不仅指把事情做完,更指把「事情做完」这个结果反馈给发起者,从而形成一个完整的圆环。也就是常说的: 凡事有交代,件件有着落,事事有回音。 如果没有「反馈」,这个环就是断裂的。在他人眼中,这就像把石头扔进深井里,听不到回声,不知道事情是成了、败了,还是被忘了。
Ownership 精神的核心是:不给自己设限,着眼于全局目标,主动填补团队的「真空地带」。比如大家都在一条船上,船底漏了个洞。 打工心态:指着洞说“这不是我弄坏的,而且修船是维修工的事”,然后看着船沉。Ownership:哪怕不是我弄坏的,我也先想办法堵上,因为船沉了对谁都没好处。
有 Ownership 精神是好事,但需要很小心地处理好边界。
这部分是「共」型人才的核心差异点。在 AI 出现之前,成为「双专业人才」极难;但在 AI 时代,这变得触手可及。

这两根柱子代表你在两个不同领域的专业深度。
在 AI 的加持下,这两竖的构建不再依赖死记硬背,而是依赖:
AI 使得获取第二专业的成本指数级下降,为个体提供了前所未有的理论与工具支撑,让「共」型人才成为可能。
这是机器难以替代的人类高地。如果下面的一切是积木,那么这一横就是让积木变成摩天大楼的蓝图。它是 「1 + 1 > 2」 的化学反应。
在组织中,这种双语能力,可以让你在团队协作中成为了「节点型」人物,极大地降低了系统内的熵(混乱度)和沟通成本。
你拥有单领域专家不具备的独特视角。你可以拿着 A 领域的锤子(方法论),去解决 B 领域那颗顽固的钉子。这种跨界打击往往能产生奇效。
当你打通了两根竖线,中间的空白地带就是创新的温床。
在「共」型人才模型中,AI 不再是我们的竞争对手,而是我们构建那「第二根竖线」的最强杠杆。
这不仅是职场竞争力的提升,更是一种更自由、更广阔的人生可能。
最近看了不少 Ego、观察者相关的内容,想着能不能结合丹尼尔·卡尼曼在《思考,快与慢》一书中提到的「系统一」和「系统二」来构建一个心智模型。于是就想出了这么一个场景:西游战车。

坐在驾驶位的是孙悟空(系统一)。他反应极快,直觉敏锐,肌肉记忆发达。为了生存,这辆车(身体)必须由他来驾驶。只有他能在极短时间内对突发的危险做出反应。
孙悟空是个好司机,但他有一个致命弱点:他听觉敏锐,且极易受惊。
这就引出了这个系统里最大的设计缺陷——那个摆在仪表台上的装饰物:猪八戒(Ego)。在这个模型里,他是一个连着油箱的、大功率的有源音箱。这个音箱的功能只有一个:制造叙事(Narrative)。
猪八戒音箱的工作机制,是典型的 「低像素采样」。当一辆车加塞到你前面,这本是一个拥有海量细节的物理事件(光影、速度、距离)。但猪八戒的大脑处理不了这么大的数据量。他会迅速抓取一个模糊的截图,压缩细节,然后贴上一个巨大的标签——「侮辱」。
紧接着,音箱开始通电,循环广播:“他在羞辱我们!我们得想办法还击!”
孙悟空分辨不出事实(Raw Data)与广播(Narrative)的区别。他听到了威胁,于是肾上腺素飙升,猛踩油门。 司机(悟空)就这样被噪音(八戒)劫持了。你不再看路,你在听故事。
当你意识到自己失控时,试图讲道理往往行不通。此时如果唤醒副驾驶上的沙僧(系统二,代表逻辑和理性),让沙僧去解决问题,他要解开安全带,扑向仪表台,用手捂住那个正在震耳欲聋的音箱,或者试图跟音箱辩论:“别吵了,撞车是不划算的!”
但这通常是无效的。原因有两个:
所以,试图用「压抑」来解决「内耗」,在架构上是行不通的。
那个一直坐在后座、很容易被忽略的人是唐僧(观察者)。在这个模型中,唐僧不需要会念经,也不需要有法力,他只需要做一件事:审视。
神奇的事情发生了:当猪八戒被唐僧平静地「看着」时,他的喇叭会自动哑火。
因为叙事无法在审视下存活。这时候,孙悟空依然握着方向盘,他看到了那个摆件在剧烈抖动,甚至看到了它张大的嘴巴。但是,因为没有了煽动性的广播,孙悟空不会感到恐惧或愤怒。他或许会想:“噢,那个猪头又在抽风了。” 然后,他继续看着前方的路,平稳地驾驶。
这种状态,心理学上叫做 「认知解离」。正如冥想,并不是要把猪八戒扔出车外,也不是要让反应迟钝的沙僧去开车(那会出车祸),而是练习「审视」的能力。
大多数人的痛苦在于,他们的唐僧或是睡着了,或是太把猪八戒的广播当真,沉浸在那些虚构的剧情里。一旦唐僧睁开眼开始审视,就会发现并不需要去「关掉」声音,因为审视本身,就是一种静音。
为什么这一招有效?可以从神经科学层面来解释。首先,能量是有限的,这就像战车的发电机功率是固定的。
神经科学发现了一个反相关现象:这两个网络就像跷跷板。当一个活跃时,另一个就会被抑制。所以你不需要去跟猪八戒打架(那是在消耗能量),你只需要把电流切断,输送给另一条线路: DEN(直接体验网络,Direct Experience Network),这是 TPN 的一种特殊形态。当你切换到这个模式时,会强迫大脑放弃概念化(猪八戒的叙事),转而进入纯粹感知。
当你全力感知「脚底板的触感」或「呼吸的温度」时,猪八戒之所以闭嘴,是因为他的电被拔了——大脑把所有的带宽都拿去处理「高清感官直播」了,根本没有余力去运行猪八戒的「低像素广播」。
这就是为什么「活在当下」能治愈焦虑。它不是心灵鸡汤,它是物理层面的抢占带宽。
最后,再来说说冥想(Meditation)。冥想不是发呆,更不是为了成佛。冥想是对唐僧进行的「肌肉记忆训练」。每一次你在冥想中发现自己走神了(觉察到猪八戒开始广播),然后温和地把注意力拉回到呼吸上(审视,激活 DEN),你就是在做一次「举铁」。你每把注意力拉回一次,唐僧的「二头肌」就强壮一分。
我们无法消灭猪八戒,离不开孙悟空和沙僧,还需要后座的唐僧在场,并在必要时进行审视,这样才能在混乱的现实公路上,穿越噪音,驶向真正的彼岸。
维克多·弗兰克在《活出生命的意义》中写过这么一段话:
我们不应该问“人生的意义是什么”,而应该意识到,“我们才是那个被生活提问的人”。
这句话极具嚼劲。因为「人生的意义是什么?」这个问题太正常、太顺口了,以至于我们忽略了它背后的假设:我们默认自己是索取者,认为意义藏在某处,等待着谁来给我们一个满意的答案。
抱着这种心态,我们很容易在缺乏「现成意义」支撑时感到虚无,甚至用一生去等待那个可能永远不会出现的答案。
但如果我们反过来想:生活才是那个提问者,而我们是答题人,一切就变得具体而清晰。生活的每一天、每一小时,通过我们遇到的具体处境——无论是工作的挑战、亲人的离去,还是平淡琐碎的日常——都在向我们抛出问题。
我们是努力作答,还是潦草应付,甚至拒绝交卷?这些都是我们的答案,而人生的意义,或许就藏在这些具体的答案里。
站在提问者视角,我们期待的意义往往是宏大抽象的;但作为答题者,意义是具体的,且千人千面,每一刻的考题都不同:
生活没有标准答案,就像每个人的指纹不同,生活给每个人的考题也不同。所谓的「人生的意义」,不是靠脑袋想出来的,而是靠手脚做出来的。我们通过承担责任、做出选择,来书写回应。
既然是考试,就难免遇到难题。如果缺乏答题者心态,就很容易抱怨:
但一个优秀的答题者,会利用难题升级自己。塔勒布在《反脆弱》这本书中提出了一个概念:反脆弱(Antifragile)。与仅仅能抵抗冲击的「强韧」不同,反脆弱还能从压力、混乱和不确定性中获益。
前阵子,我在一件小事上体会到了这种心态的妙用。除了博客,我还有一个 Telegram Channel。原本只是发些碎碎念,结果招来了一大堆 SPAM(垃圾评论)。实在太烦,就关了评论,后来觉得还是需要互动,于是又开了,SPAM 自然如期而至。但这次,我决定换个解法。我把删除 SPAM 这个行为设定为一个 Trigger:每删一条垃圾评论,我就深呼吸一次,做一次几秒钟的微冥想。
结果很神奇,我不仅不讨厌 SPAM 了,甚至还有点期待它们的出现。这其实就是《福格行为模型》中提到的珍珠习惯:像蚌将沙粒包裹成珍珠一样,将负面的烦恼转化为积极行为的提示。通过这些小事磨练解题能力,等到人生的大题出现时,我们才能在心态上有所准备。
如果说面对垃圾评论是应对外部的骚扰,那么面对自己的坏习惯(如刷推),则是生活出的另一道关于「自律」的考题。
「答题者心态」的前提是接纳。接纳生活给的题,接纳自己的不完美。比如我总是会忍不住想要刷推,虽然知道这个行为不好,是多巴胺在作祟,刷的过程也并没有太多乐趣或捡到什么宝贝,但就是会下意识地打开。如果不接纳自己的这个行为,可能就会归因于自己的意志力或自律性不够,然后陷入内耗和焦虑。接纳了自己和这个行为后,再去看如何能利用这个行为来升级自己(反脆弱)。我的解决方案是每次打开推特页面时,强迫自己输入一段预设的文字,完整输入完后才能继续浏览,同时设定了浏览时限(比如 5 分钟)。一方面增加了刷推的门槛,同时也让每次刷推都让自己受益。

如果把「答题者心态」贯彻到底,人生会变成什么样?迈克·A·辛格在《臣服实验》中给出了示范。为了摆脱内心喋喋不休的「小我」,他制定了一个激进的规则:不再听从个人好恶的指挥,全然接受生活给出的任务。
如果生活在他面前呈现出某个机会,而他拒绝的唯一理由是「我不喜欢」或「这会打扰我的冥想」,那么他就必须放下个人偏好,接受这个任务。
这些任务就是生活递给他的一张张考卷。比如,有人请他帮忙盖房子。迈克本能地想拒绝,因为这破坏了他的隐修,但他想起了规则,于是答应了。接着,更多的人找上门。尽管他只想静静冥想,但他选择顺从生命的安排。
奇妙的是,这种看似违背初衷的行为,让他从对「空性」的执着中走了出来,在具体的劳动中磨练了心性。他发现:真正的灵性不是逃避世界,而是在做任何事时都保持全神贯注和不执着。
这样做还有一个巨大的红利:极度减少内耗。你不再需要在「想做」和「不想做」之间来回拉锯,只是专注于「把眼前的题答好」。
这种心态上升到哲学高度,便是斯多葛学派的 Amor Fati(热爱命运)。这是一种面对生活中一切遭遇的终极态度:不仅是接受,更是拥抱,甚至热爱。罗马皇帝、斯多葛哲学家马可·奥勒留在《沉思录》中这么说道:
普通人像一支蜡烛,遇到强风(逆境)就会被吹灭;而践行 Amor Fati 的人,则像一团烈火。 无论你往这团火里扔什么——木头、纸张,甚至是垃圾(困难、失败、悲剧)——火都会吞噬它,将其转化为自身的光和热。
这意味着,发生在你身上的每一件事,无论好坏,都是你成长的燃料。当我们不再执着于向生活索要一个标准答案,而是开始认真回应每一次提问时,焦虑就消失了,取而代之的是一种踏实的掌控感。
Paul Graham 在 What to do 中探讨了一个看似简单却极具深意的问题:人的一生应该做什么?除了「帮助他人」和「爱护世界」这两个显而易见的道德责任外,他提出了第三个关键点:创造美好的新事物(Make good new things)。
读到这段话时,我马上想到的是 Make Something Wonderful 这本书。某种程度上,两者共享了同一个核心理念:「创造美好」不应只是一次性的行为,而是一种值得毕生追求的生活方式。
Steve Jobs 曾这样描述 Make Something Wonderful 这句话背后的动机:
There’s lots of ways to be as a person, and some people express their deep appreciation in different ways, but one of the ways that I believe people express their appreciation to the rest of humanity is to make something wonderful and put it out there.
And you never meet the people, you never shake their hands, you never hear their story or tell yours, but somehow, in the act of making something with a great deal of care and love, something is transmitted there.
And it’s a way of expressing to the rest of our species our deep appreciation. So, we need to be true to who we are and remember what’s really important to us. That’s what’s going to keep Apple Apple: is if we keep us us.
创造的产物不限形式,它可以是宏大的牛顿力学定律,也可以是一把精致的维京椅。文章也是一种常见的创作。在 AI 时代,「是否还有写博客的必要」成为了备受热议的话题。博客的独特价值在于其内容的多样性——它可以是一篇游记、一篇散文、一次技术折腾的记录、一本好书的读后感,甚至是稍纵即逝的灵感碎片。个体独特的经历与细腻的感受,是 AI 无法替代的。或者,也可以像 Paul Graham 或 Gwern 那样,通过写作对某一话题进行深度挖掘,以确保自己真正掌握了真理。
除了写作,还可以开发 App。AI Coding Assistants 的崛起极大地降低了编程门槛,普通人只需花时间熟悉这些助手,便能在短时间内构建出像模像样的产品。而随着各类 AI 图像生成工具(如 Nano Banana Pro 等)的出现,绘画创作也不再遥不可及。这正是 AI 时代对个体的最大赋能:曾经专属于专业人士的领域,如今已向所有人敞开大门。
但我们为什么非得「做点什么」呢?躺在沙发上刷剧岂不更舒服?的确,消费内容看起来更惬意,但「整天躺着刷剧」与「辛苦创作一天后再躺下刷剧」,这两种体验有着天壤之别。那种完成了一件作品后内心产生的通透感与充实感,是任何单纯的消费行为都无法比拟的。
从价值投资的角度看,「创作」是一项既有安全边际,又具备潜在高回报的行为。假设你花一周时间做了一个小工具,即便最后无人问津,你的安全边际依然存在:你在过程中学到了新知识、巩固了旧体系,解决了自己的痛点,收获了亲手造物的成就感。而潜在回报则是巨大的:它可能真的帮助了他人,改善了某些人的生活,甚至让你结识了同频的伙伴。
要让创作带来巨大的回报,有一个核心要点:高标准。在 AI 时代,我们面临一个残酷的现实:Average is over(平庸时代的终结)。 因为 AI 让生产 60 分的「合格品」变得几乎零成本,平庸的内容将迅速泛滥成灾。
在市场蓝海期,产品或许可以靠便宜、新奇或仅仅是「能用(Just Works)」来取胜;但一旦门槛被 AI 踏平,大量玩家涌入,最终能脱颖而出的,唯有那些超越了「平均线」、不仅能用而且好用的精品。因此,「高标准」不仅是竞争优势,更是生存线。
要达到高标准,高质量的 Input(输入) 必不可少。如果连什么是「好产品」都看不出来,就更不可能做出来。因此,我们需要花时间去多多研究优秀的 Input。当高标准成为习惯,你会发现市面上有太多产品不尽如人意。带着这把「高标准」的放大镜,你能找到无数瑕疵和痛点,而这些,就可以是创作的起点。
阻碍创作的因素通常有三:好奇心匮乏、完美主义倾向、精力被分散。其中最大的阻碍往往是好奇心的缺失。好奇心可分为两类:感知性好奇心(关注 What,如八卦新闻)和认知性好奇心(关注 How 和 Why,如探究事件背后的逻辑与影响)。Hard work is the magnitude of the vector and curiosity is the direction.(努力是矢量的长度,而好奇心是方向)。认知性好奇心,可以为创作指引方向,高标准则决定了矢量的长度。
此外,创作还有一个美好的「副作用」:它能让你更专注于当下,而不是被纷繁的新闻和社交网络裹挟。每一次创作的产出,都像是给人生这条绳索打了一个结。当你回望这些作品时,当时的记忆与点滴便会瞬间涌上心头,让你的人生有迹可循。
最后说说 AI。如果 GPT-3.5 的发布是航空史上的「莱特兄弟时刻」,那么随之而来的 AI 浪潮,则让飞机成为了大众的交通工具。它的操作逻辑与传统的地面交通截然不同,能力也更强悍。要发挥它的最大价值,你需要熟悉与它交互的最佳实践,找到属于你的那架「飞机」,然后让它载着你,飞往以前想都不敢想的地方。
一直觉得有一套合适的反思系统很重要,相关的思考可以参见上一篇文章。于是开始寻找合适的解决方案,但都没有太满意的。既然这套系统具有重要性,而市面上又没有合适的解决方案,那就很有必要自己实现一个,于是就有了 PingMind 这个 app。
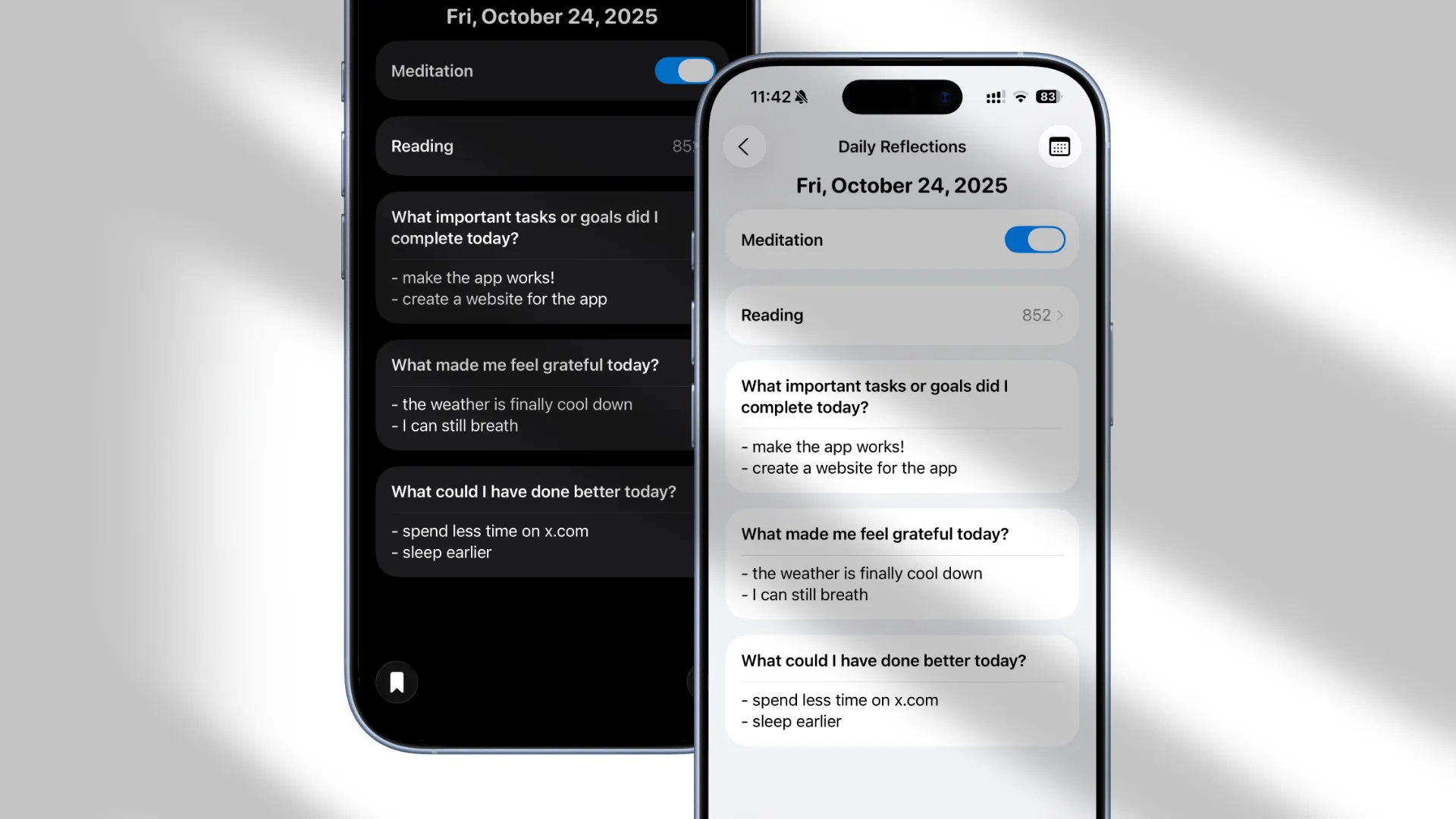
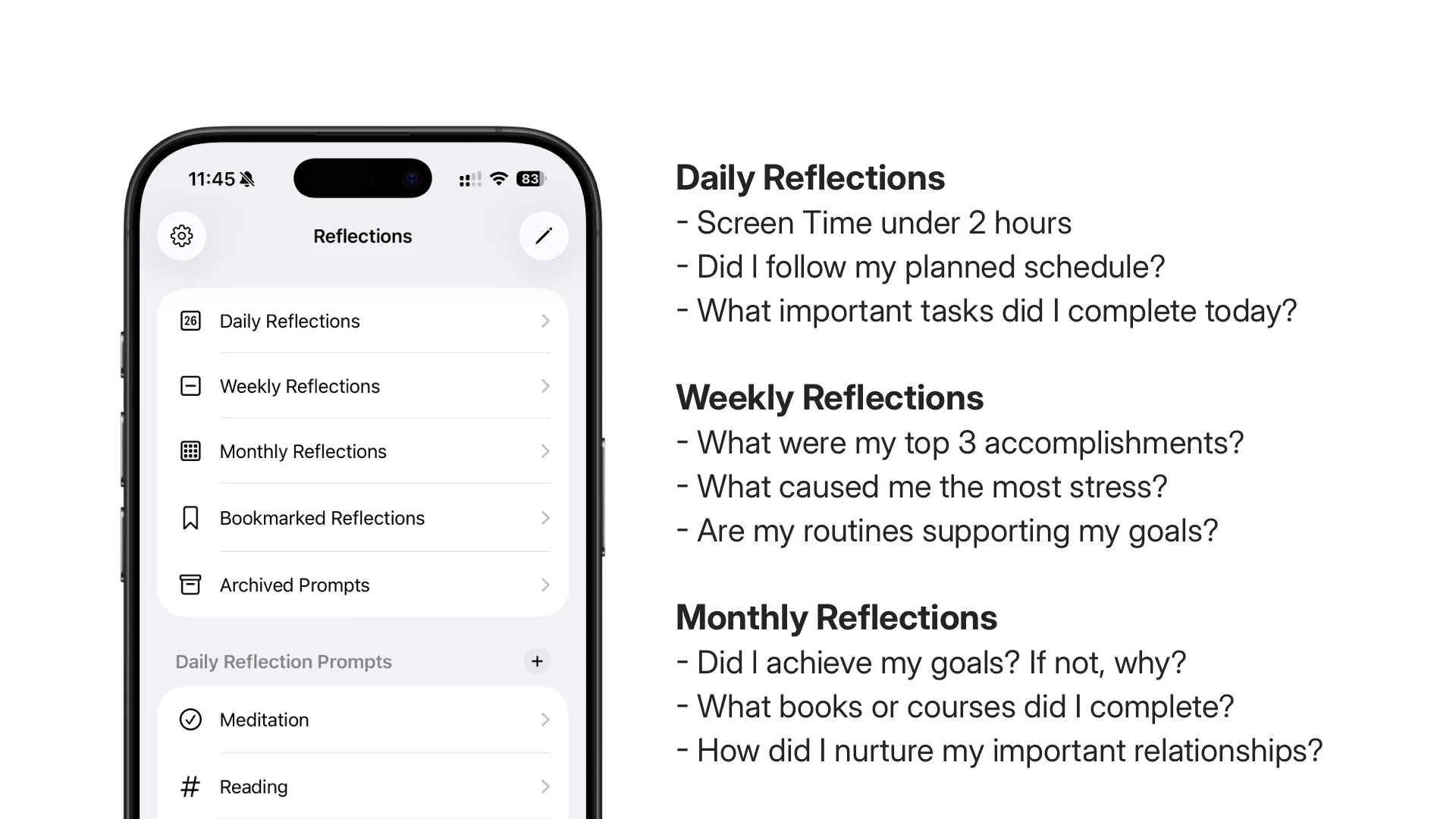
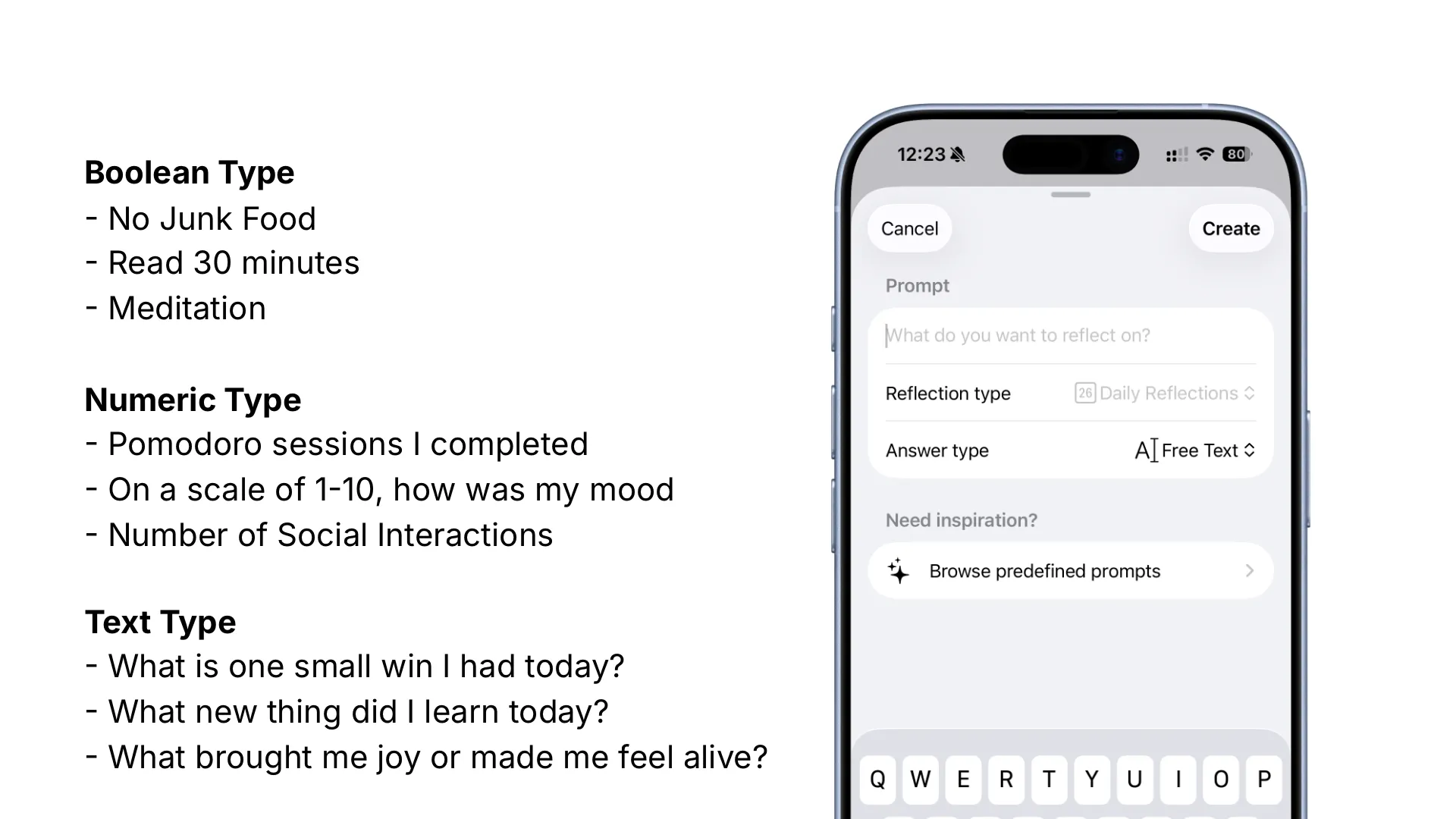
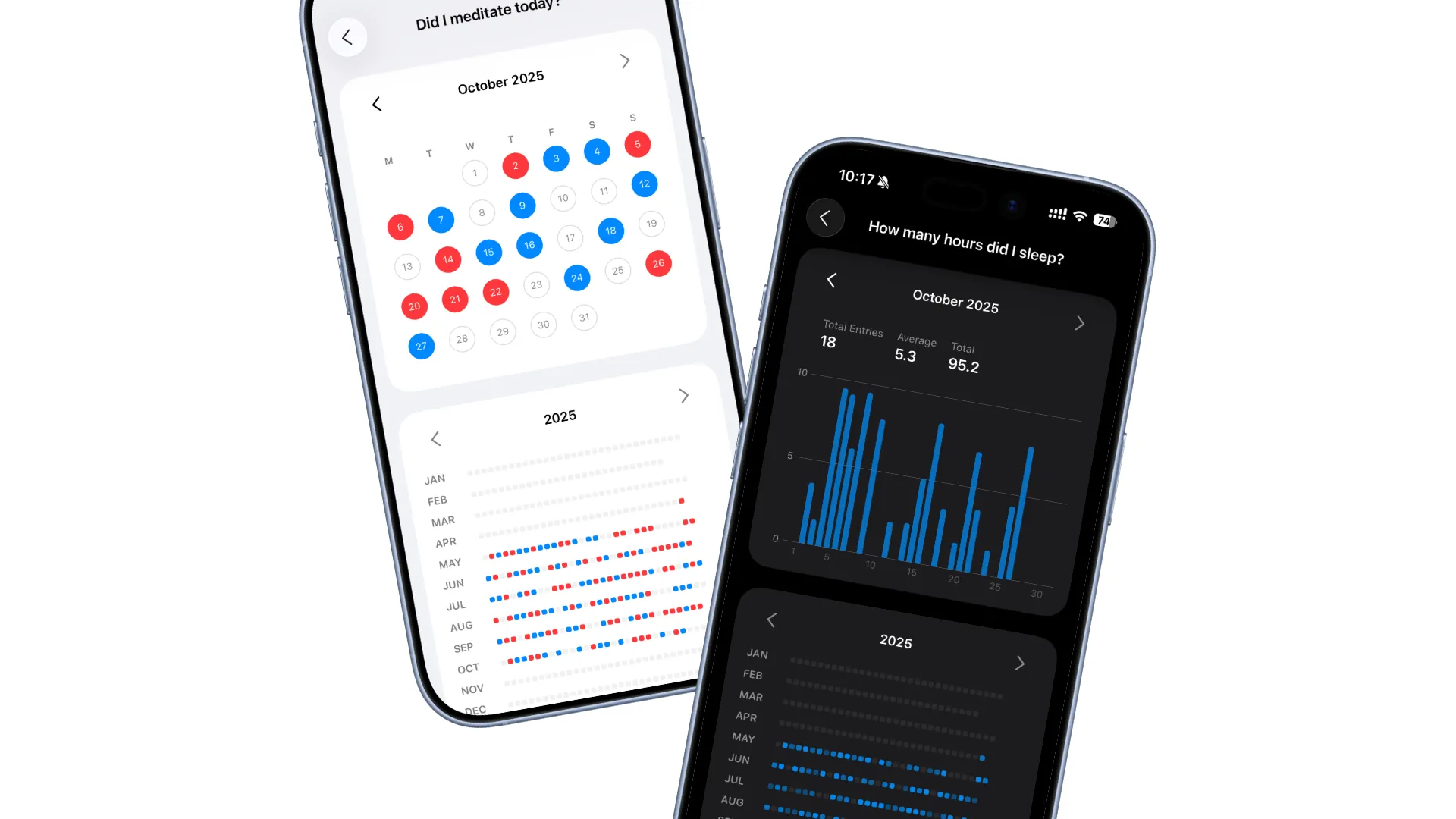
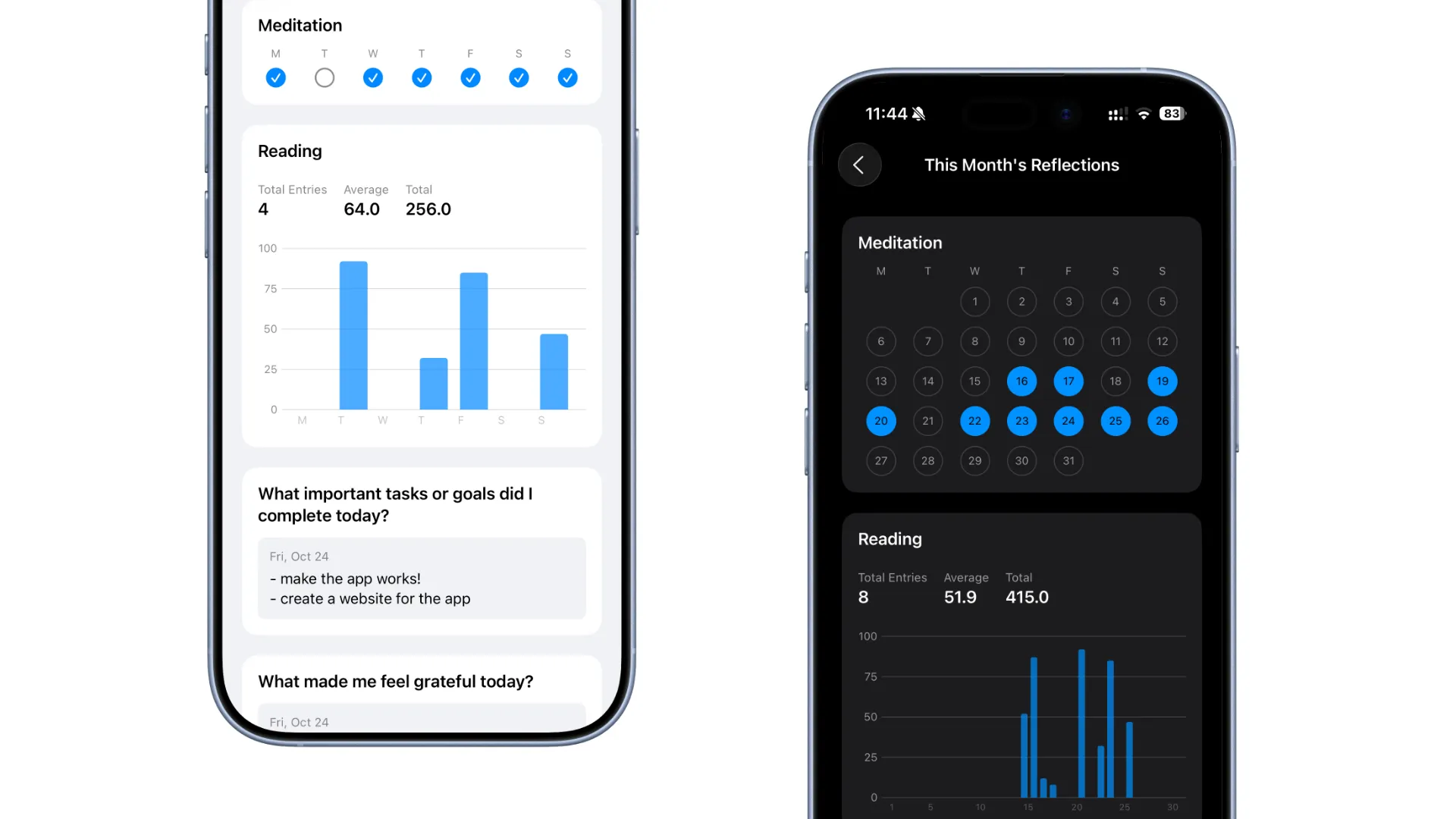
具体的 features 可以参见官网,简单来说就是可以创建每日/周/月的自省问题,并进行记录,设计上尽量保障输入和回顾的便捷性。创建的内容保存在本地,使用 iCloud 同步,支持导出,不需要创建账号,开箱即用。价格上采用 IAP(In App Purchase),可以免费使用大部分功能,购买后解锁全部功能,不需要订阅。
如果你对自省感兴趣,或者也在寻找合适的自省 App,或许可以试试 PingMind。使用过程中有任何的建议和反馈,欢迎留言,或邮件与我联系。
在实现一个用 SwiftUI 构建的 iOS App 的过程中,我想让 Agent 帮我加一个 Feature:让 Calendar 可以滑动查看上一月/下一月。本以为是个简单的一个需求,过程的艰辛却远超我的预期。这也体现了纯 Vibe Coding 的一个局限:当 AI 撞墙时,即使指令给得再小、再清晰,它都很难独立完成任务。
用的 Claude Code w/Sonnet-4.5,以为是个简单的需求,就给了一个最直接的 prompt:
Make the Boolean Type Calendar Scrollable. Scroll left/right to view previous/next month.经过几次迭代后,这个 Calendar 可以滚动了,但很卡,于是我把这个信息告诉它,让它进行优化。
there's a scroll glith on boolean type calender view, when I scroll the calender past half, and release, it will lag twice, then slide to the end. think carefully to fix this bug.又经过了几次迭代,它还是没能 fix 这个卡顿的问题,于是我重置了代码,进行了第二次尝试。
对于同样的 Feature 不同的 Agent 可能会有不同的解法,所以这次切换到了 Codex w/gpt-5-codex,给了同样的 prompt,除了耗时更长外,结果并没有什么不同。此时我知道,这件事它可能不简单。
这次只能亲自动手了,卡顿一般跟 re-render 有关,于是我查看代码,将 Calendar 对应的代码,简化成了 Color.random()(Color 本身并没有这个方法,所以加了一个 extension),发现在滑动时,Color 变了好几次,说明这些 View 被 SwiftUI 认为是不同的 View,所以重新创建了。得到这个信息后,让 Calude Code 再次进行优化:
the boolean calendar view is a bit lag while scrolling, it seems to be the view don't have a consistent id, so they re-render while page change. reduce the re-render by giving them appropreate ids.有了这个信息后,Claude 再次进行优化,几次迭代后,优化完成,它非常自信的告诉我 re-render 的问题解决了,这次应该会非常丝滑。我结合 Self._printChanges(),发现确实重复生成/渲染的问题解决了,但,这个卡顿还在!
这就很奇怪了,难道是这个用 SwiftUI 实现的 Calendar 有性能问题?为了验证这个想法,我让 CC 简化代码,用最简单的色块代替 Calendar,看看滚动起来是否顺畅。
now it works, but the lag persistent. can we first identify what's causing the lag, by simplify the scenario like use a random color, etc?CC 听取了建议,把 Calendar 变成了纯色块,滑动是顺畅了,但有个问题,滑动过一半后,色块的颜色就变成了下一个 Calendar 的色块,我分析了下,应该是滑动过半后,page 自动变成了 next page,而这个色块会监听这个值的变化,于是也就变了。把这个信息给 CC 后,它很快就 fix 了。
- the prev/next button works perfect.
- but the scroll still has a problem, it seems to be caused by the page variable, once it pass half, the page change, and current scrolling item will be replace to that page.给出的结果非常好,没有丝毫卡顿,极其丝滑。
这么看来确实是 SwiftUI 实现的这个 Calendar 模块有问题,于是我想用 UIKit 重新实现一个,再嵌到 SwiftUI 里,看看是否能解决性能问题。
it seems the SwiftUI's Calendar is the root cause of glitch, maybe we can use UIKit to represent this calendar?这个改动其实挺大的,所以 CC 也是尝试很多轮后,结合我的反馈,才终于基本可用了,中间还因为用满了 5 小时的 Token 限制,休息了一会。
yeah, its smooth, but after scroll end, the calendar doesn't refresh, all blank day, the title updated though.
---
the behavior is after scroll ended, it first display blank date, then immediately updated with some data, but it's not the final data, it will refresh quickly again to reveal the final data, so visually, like it blinks.
---
yes, it's better now, but the colored background only appear when scroll end, visually its not too good, can we pre fill the calendar?
---
the previous month's colored circles appear immediately, but the month before still blank and fulfilled after scroll end.
---
better, but ${currentMonth}-3 is still blank first when scrolled.
看起来确实丝滑了,实现方案是预加载 3 个 Calendar 的数据,当这 3 个 Calendar 滑动起来,这些蓝色块、红色块会被预先填上,但滑动到第 4 个 Calendar 时会出现先显示空 Calendar,然后再渲染色块的现象。
CC 的这个策略看起来有点 rigid,能不能先预加载 3 Calendar,当滑动到倒数第二个预加载的 Calendar 时,再往前加载 3 Calendar?
can we make it simpler? because the scroll always from large month to small month (if scroll back to large month, it's already loaded), so why not just prefetch previous 3 months, if scroll to the prefetched month - 1, then start prefetch next 3 months?很不幸,CC 在 Operate 的过程中触发了 Weekly Limit,好在还有 Codex,于是切换到 Codex,继续这个 CC 未完成的任务。
I'm in the middle of optimizing boolean type calendar scroll performance, I want the strategy be: first preload previous 3 months data, when user scroll to the second to last preloaded data's month, preload next 3 month. help me implement this strategy.半小多时后,结果出来了,符合需求,但 Token 也用了近 20%(PS:这也是我打算退订 Codex 的一个原因:慢,有时 Token 消耗地还快)。
这个看似简单的需求,如果过程中缺少人的协作,很难达到满意的效果。尽管 AI 在代码生成和辅助开发方面能力强大,但在面对复杂、深层或性能敏感的需求时,它仍然是一个强大的工具,而非完全独立的解决方案。它需要有人能够帮忙诊断问题、制定策略,并在必要时进行干预和引导。纯粹的 Vibe Coding 适用于简单、明确的需求,但对于有挑战的任务,人与 AI 的高效协作,即 “人机协作编程”,才是提升效率和解决问题的关键。