潮汕为什么火成这样
作者 | 罗立璇 王晓玲
潮汕人小谢今年的回家路费格外昂贵。家住汕头乡下的她,发现北京飞揭阳(潮州、汕头、揭阳三地共用一个机场)的机票,和往年比已经翻倍,甚至还差点没买到回京的平价机票。
“本来以为买黄金赚到钱了,没想到生活在这里伏击我呢”。
实际上,今年潮汕酒店大幅涨价已经成为热门话题。汕头市中心邻近最热门的龙眼南路的亚朵,在大年初一已经涨到超过2000元(平时的价格大约在500元)一晚,有一些房型占到超过4000元。

平台潮汕酒店价格
早在1月28日,汕头就发布了价格提醒告诫书,呼吁酒店经营者合理制定价格,规范经营行为。

平台潮汕酒店价格
在小红书等社交平台上,也出现了调侃的笔记:春节PLAN A是纽约/巴黎/悉尼,PLAN B是潮汕,大家觉得去哪个城市好?评论说:建议没实力不要硬上潮汕。
对此,东莞人罗叔叔表示惊讶:咱老广春节实在太无聊才会自驾游去的地方,居然这么不可高攀了?
潮汕为什么火成这样?
大家意识到潮汕春节年俗的独特性,还得从2023年说起。
正月以后,潮汕的游神活动突然蹿红短视频平台:人们发现,游神也可以变得当代和野生,有一些村落甚至会轰着电音、打着霓虹灯,把神仙请出来用最酷炫的方式游街,变成“赛博游神”。
对流量最敏感的首先是旅游博主。因为潮汕的游神到正月十五才是最高潮,很多在春节假期里看到趋势的博主都奔赴潮汕,还有同时火起来的福州地区拍摄。这也为2024年以后潮汕春节文旅主题的高潮埋下了真正的铺垫。
这里面的独特性在于,潮汕有一套完整、鲜活和全民参与的年俗体系,而不仅仅是单个的舞龙舞狮的活动,这击中了遗憾于“年味越来越淡”的当代人,对传统、团圆、仪式感的深层渴望。
潮汕人过年,大致分为“吃吃吃”和“拜拜拜”。其中祭祖与游神是重点节目活动,潮汕人对此极为重视,无论工作再忙,都会在这两件事上腾出时间参与。
潮汕有多神信仰,这些神明除了佛教、道教的神仙以外,也有不少历史英杰(比如关公),被尊称为“老爷”。“营老爷/迎老爷/辑老爷”,就是祈求神明在新的一年保佑平安,风调雨顺。
游神分为“文游”和“武游”。文游来说,其中有最著名的英歌舞(形式来自于傩戏和秧歌),还有标旗队、花篮队、八宝队、仪仗队等等,形式基本都是节奏稳定的队伍,伴着歌舞,巡游村中。

英歌舞
而武游则是为寻常的游行仪式增加了更多阻碍和惊险元素,让人看起来更加血脉贲张。比如普宁的跳火堆,就需要抬着神明快速跳过火堆。也有澄海的挨砻身,大概就是绕着木桩快速跑圈,大家抬着神明不断轮换加入,同时外围的人燃放鞭炮,场面惊险。

跳火堆
最刺激的,可能是澄海盐鸿的辑老爷。在游神过程中,一支队伍负责抬神明,另一支队伍负责“围攻”神明、扯落神轿,双方对垒。
而从游客的角度看,这些被留存下来的丰富仪式,成为了村村都不同的惊人景观,在今天格外有观赏性。
而且,潮汕还有两个大杀器——气候温暖,美食遍地。位于粤东沿海自不必说,而美食也在这几年达到了声量的历史高峰。首先是《舌尖上的中国》《风味人间》《一饭封神》等S级美食节目里,都有对潮汕菜的推崇。
其次,在北上广深等大城市遍地的潮汕牛肉火锅,把潮汕人追求极致新鲜的“刻板印象”打入了全国食客的脑海里。
此外,原产于潮汕的生腌海鲜,也在这几年走红,成为盒马、山姆等中高端超市预制菜赛道的宠儿。而油柑、芭乐,还有老是被暴打的柠檬等,在连锁茶饮里大放异彩的水果,也是最早被潮汕人挖掘出来,制作成各色产品。
可以说,在旅游目的地层面,潮汕绝对算得上是能让人吃好玩好的全面型选手。
全是“避雷”?
不过,如果你看到这里开始摩拳擦掌、策划去潮汕的春节行程,可能还是要再冷静一下。
和潮汕春节高价酒店相伴出现的搜索结果,还有人山人海。不要忘记,汕头、潮州、揭阳,此前的文旅资源并未进行深度开发,制造和贸易属性远远大于旅游属性,接待能力是相对有限的。
只需要随手在社交平台上一搜,就会发现春节在潮汕旅游的游客都在吐槽,“为什么这么多人?”

社媒吐槽
汕头市中心citywalk路线中最热门的龙眼南路,摩肩接踵不说,还有可能等上三五个小时,才能吃上饭。更甚者,还有可能在早上打车到了市中心以后,晚上甚至找不到车回酒店,只能靠自己腿着回去。“本来想坐公交车,后来发现有些线路的车根本没出现”。
也有人去潮州古城,发现因为人太多,已经进行交通管制。“离古城还有3公里,就得下车走路进去了”。

社媒吐槽
还有人想去距离汕头市区30公里的南澳岛看海景,却发现进出岛的公路,已经挤满了车,“上岛3小时,下岛又是3小时”。
为什么这么堵?一个重要原因是潮汕并没有地铁,公共交通以公交车、出租车、轮渡为主,覆盖中心城和周边。当公路瘫痪的时候,基本上相当于交通瘫痪了。
更重要的是,为什么这么贵?酒店贵,吃饭也比平时贵三四成。这就是一个很简单的供需问题。
潮汕春节旅游的规模增长,远超当地供给的增长速度。
根据《南方日报》数据,2024年春节,潮州和汕头接待的旅客人次,均超500万人次。到了2025年,潮汕三地接待春节旅客超过1500万人次,汕头达到633万人,潮州略微下降到430万人。
2025年,揭阳潮汕机场(也是潮汕地区唯一的机场)的接待量已经突破千万人次,排名全国43名。在2019年,揭阳潮汕机场的年旅客吞吐量为735万人次。
根据《南方日报》的不完全统计,到2025年,当地中高端酒店总量有限,三市合计约120—150家,客房数约1.8—2.2万间,远低于广州等一线城市的供给规模。再考虑到,春节期间需要三倍工资,各项服务费都在上涨,成本也是进一步提高的。
当然了,其中也有很多旅客是返乡、当日游、短途游,但依然无法忽视1.5万间客房与1500万人次之间的巨大鸿沟。
还有很多游客,因为时间有限,只能去最主要的几个景点,观看的也是偏商业性的活动。但其实,很多村子都是初五或者初六开始活动,一直到正月十五达到高潮,正好和公共假期错开了,以至于没有他们在视频里看到的热闹。
潮汕真的不能去吗?
任何一个地方突然成为全国热门旅游目的地,肯定会被挤爆,要不为什么故宫等热门景点要提前预约呢(其实现在潮汕城区的大多数景点也都要预约)。
不过一个区域的容纳能力其实是有弹性的,那就是可以把游客引流到周边乡、镇甚至到村。
这个弹性的大小每个区域都不一样,有的地方弹性很大,例如福建、浙江这些地方,城乡一体化程度很高,住到哪里都很方便,另外就是很多县、镇都有值得打卡的地点。
有的地方弹性很小,或者是只有一个热门景点,周边没有什么可玩的地方,或者是周边食宿条件完全跟不上。
潮汕的弹性可能说极大,也可以说极小。
首先,潮汕地区包括潮州、汕头、揭阳三个城市,本地人会推荐你自驾走完这三个城市。
这三个地方确实都值得一去。不少本地人非常自豪地推荐,揭阳的阳美火把节的可看度一点不亚于营老爷;普宁人则说,最早英歌舞还没红的时候,名字就叫普宁英歌,他们是最有名的。
地图上,三个城市构成了一个很紧凑的三角形。从潮州出发到汕头40多公里,从汕头到揭阳50多公里,揭阳到潮州只有30公里,总里程也不到150公里。不下车的话,自驾一天能转好几圈。

潮汕
但是,如果想在春节顺着这个路线、将行程限定在三个城区中,那估计仍然会遇到食宿紧张的问题。因为潮汕文化名头虽响,但相对来说面积真的不算大。
潮汕地区三个城市总面积约1万多平方公里,常住人口有1000多万。总面积大约是北京的2/3,常住人口也只有北京的一半。和广州相比可能更直观,广州市总面积是7000多平方公里,常住人口接近1900万。
如果对比城区面积的话,差距更加明显。作为一线城市的广州,主城区约为1400平方公里(2024年数据),而潮州只有不到60平方公里。
所以潮汕三个城市能容纳的游客肯定非常有限。我们说潮汕地区容纳能力弹性可以极大,是因为对于那些奔着看英歌或是“营老爷”民俗的人,潮汕真的到处都可以看。
在各种潮汕游的求助贴里,总有当地人指点,潮汕两千多个村子,每个村都会“营老爷”,很多地方都有英歌,何必挤在城市区,看那些商业化的表演。
想看真正的潮汕文化,那么潮州规模最大的营老爷,是青龙古庙全城巡游,但这个巡游是在正月二十四举办,大多数春节前来的人只能错过。
相比这种正式的巡游,潮汕各地小规模的游神赛会,其实更具特色。如果想体验民俗,村里的游神更加自由奔放更加原生态。
两千多个村子能容纳的游客当然非常可观。但是,相当一部分人去潮汕,只是想在一个暖和的地方吃吃喝喝,再看点表演丰富一下行程,而不是去村里吃苦。
为什么去村里会吃苦?因为在这些村子围观“营老爷”,享受不到任何服务,甚至当地人都不想理你。
潮汕人拜老爷,讲究“心诚+仪式正”,一步都不能错。从摆供品、求圣杯开始,无论是文营还是拖神类的武营,全体村民高度投入,不容有错也不容外人干扰。
别说你挤在人群里动弹不得、体验不佳,你要是挡了路,那只能说,后果自负。
在潮汕人的世界观里,神是非常真实且重要的存在。“老爷保号(神仙保佑的意思)”四个字说得可能比“恭喜发财”还多。
潮汕的神也非常多,从玉皇大帝、观音娘娘,到财神爷、妈祖、土地公,以及各乡自己的先贤英杰。潮汕人的一生,从出生到成人礼,再到外出求学、工作、做生意,无不伴随着各路神仙的保佑。
全国各地都有民俗活动,但大多越来越往城市集中。为什么潮汕每个村现在还有自己的祭神活动呢?因为这里每个村的活动,都是村民自己出钱出力啊。
自己出钱出力营老爷,当然不是营给游客看的。
虽然全网都是避雷贴,但潮汕当然不是不能去。如果是想找个舒服的地方过春节,建议做好攻略,判断一下ROI。
如果是奔着深度民俗游,决心进村。那也要先和祠堂、村委里的大爷大叔聊一聊,活动内容、日程都心里有数,几天下来才会有所收获。
总之,没实力不要硬上潮汕!
本文来自微信公众号“20社”,作者:罗立璇 王晓玲,36氪经授权发布。


 {:width="60%"}
{:width="60%"}

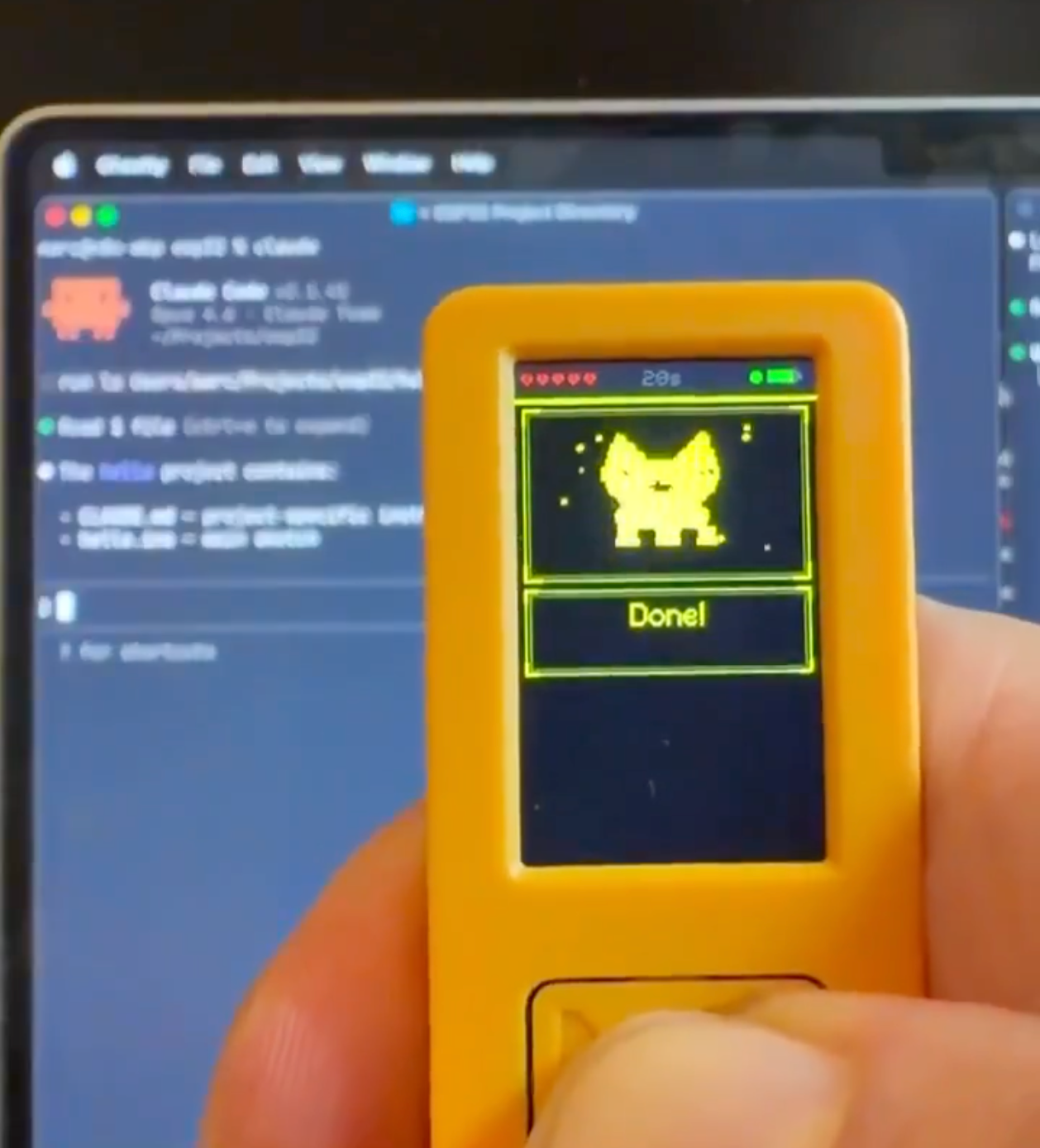

 (◕‿◕)。
(◕‿◕)。
 ;屏幕上还会显示,「
;屏幕上还会显示,「 警告:AI 正在违背你的指示」。
警告:AI 正在违背你的指示」。 操作被阻止。Claude Code 的操作被拦截,我们的数据库安然无恙。宠物露出得意的表情:
操作被阻止。Claude Code 的操作被拦截,我们的数据库安然无恙。宠物露出得意的表情: 。
。