贵州铜仁文旅联合马蜂窝推出“铜仁格外美TongRen.Grammy”非遗传播项目
36氪获悉,2026年春节前夕,贵州铜仁迎来一场全新的非遗推广活动“铜仁格外美 TongRen.Grammy”,马蜂窝运用智能机械臂加格莱美慢镜头技术“让非遗格外美”,同时将在春节假期向普通游客开放免费体验。
从 Swagger 文档到 TypeScript 类型、API 函数、Mock 数据,一句指令全自动。
做前端的应该都经历过这种事:
后端丢来一个 Swagger 链接,然后你得:
一个模块少说 2-3 个接口,这些重复劳动能耗掉半天。
后来我想,这活儿能不能自动化?于是折腾了一套方案,现在只要一句话:
实现接口:https://gateway.xxx.cn/doc.html#/组织架构服务/供应商管理/page_1
Claude Code 会自己打开 Swagger 文档、提取接口信息、让你勾选要实现哪些接口,然后并行生成所有代码。
这篇文章记录一下整个搭建过程和实际跑起来的效果。
先看全貌,方案分三块:
┌─────────────────────────────────────────────────┐
│ api-add Skill │
│ (工作流编排 / 入口) │
├─────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ │
│ │ chrome-devtools │ ← 读取 Swagger 文档 │
│ │ MCP │ ← 提取接口信息 │
│ └──────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ Agent Team (并行) │ │
│ │ ┌────────────┐ ┌─────────────┐ │ │
│ │ │ api-define │ │ mock-create │ │ │
│ │ │ (Haiku) │ │ (Haiku) │ │ │
│ │ │ │ │ │ │ │
│ │ │ TS 类型 │ │ Mock 数据 │ │ │
│ │ │ API 函数 │ │ Mock 路由 │ │ │
│ │ └────────────┘ └─────────────┘ │ │
│ └──────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────┘
下面一个个说。
MCP(Model Context Protocol)是 Anthropic 出的一个开放协议,让 AI 能跟外部工具交互。简单说就是 AI 的插件系统,接上不同的 MCP Server,AI 就多了一种能力。
Swagger/Knife4j 文档是动态渲染的 SPA 页面。你用 fetch 或 curl 去请求,拿到的只是一个空壳 HTML,接口信息全靠 JS 渲染出来,根本抓不到。
Chrome DevTools MCP 能让 AI 操控一个真实的浏览器:
说白了就是让 AI 能像人一样看网页。
在 Claude Code 里添加 chrome-devtools MCP server:
claude mcp add chrome-devtools --scope user npx chrome-devtools-mcp@latest
.claude 目录下创建 mcp.json:{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest"
]
}
}
}
配好之后 Claude Code 就能操作浏览器了,主要用到这几个工具:
| 工具 | 干什么的 |
|---|---|
navigate_page |
打开指定 URL |
take_snapshot |
获取页面快照(可访问性树) |
click |
点击页面元素 |
fill |
填写表单 |
take_screenshot |
截图 |
我们这个场景主要用前三个:导航、快照、点击。
Claude Code 的 Skill 就是一个 Markdown 文件,告诉 AI 碰到什么情况该怎么做。里面写清楚:
文件放在 .claude/skills/<skill-name>/SKILL.md,Claude Code 启动时会自动加载。
我想要的效果是:给一个 Swagger URL,自动把接口文档变成可用的代码。
.claude/skills/api-add/SKILL.md
---
name: api-add
description: 从 Swagger 文档或 md 文档快速创建 API function、
TypeScript 类型定义和 Mock 实现。
触发关键词:实现接口、创建接口、添加API、接口定义。
---
# API from Swagger Doc
## skill 触发场景
### 场景1
用户提供接口 url,并说实现接口定义
### 场景2
用户指定一个 md 文档,则直接从文档中读取接口定义
## 工作流程
### 第一步:获取接口信息
使用 chrome-devtools-mcp 读取 Swagger 文档:
1. 使用 navigate_page 打开 Swagger URL
2. 使用 take_snapshot 读取页面内容
3. 展开左侧菜单,获取当前分类下的所有接口列表
4. 使用 AskUserQuestion,列出所有接口供用户选择
5. 用户确认后,逐一点击并提取完整信息
### 第二步:创建 Agent Team 并行生成代码
创建 2 个 teammate 分别负责:
- api-define:TypeScript 类型 + API 函数
- mock-create:Mock 数据 + Mock 路由
### 第三步:清除 teams 并结束
这里说几个我做的选择:
1. 为什么用 MCP 而不是直接请求 API?
Swagger 文档是前端渲染的 SPA,HTTP 请求拿不到内容。必须在真实浏览器里跑一遍 JS 才能看到接口信息。
2. 为什么要让用户选接口?
一个模块可能有十几个接口,但这次迭代可能只用到其中两三个(或者部分接口已经实现过了)。让用户自己勾选,省得生成一堆用不上(或者重复)的代码。
3. 为什么用 Agent Team?
写 TypeScript 类型/API 函数和写 Mock 数据/路由,这两件事互不依赖。让两个 Agent 同时跑,时间省一半。而且 Agent 用的是 Haiku 模型,比主模型便宜很多。
✏️ 我测试了一下,单独写⬆是6分钟多一点;使用agent teams 是4分钟多一点(因为是小功能, 时间节省不太明显, 但贵在省时间。 你可以尝试大功能,比如实现一个复杂的模块,时间节省会更明显)
除了 Skill,还得定义两个 Agent,它们才是真正写代码的。
.claude/agents/api-define.md
---
name: api-define
description: 实现指定模块的 api function & typescript 类型的创建
model: haiku
color: green
---
实现指定模块的 api function & typescript 类型的创建,
严格按以下要求实现:
1. 严格参照 .claude/rules/ 中的编码规范
2. 完整实现:TypeScript 类型、API 函数
.claude/agents/mock-define.md
---
name: mock-create
description: 实现指定 api 接口的 mock 实现
model: haiku
color: orange
---
实现指定 api 接口的 mock 实现,严格按以下要求实现:
1. 严格参照 .claude/rules/ 中的编码规范
2. 完整实现:Mock 服务器(mocks 目录),
实现 Express 接口(routes、controllers、data)
几个值得说的点:
model: haiku -- 用轻量模型就够了,写这种模式化的代码不需要大模型,跑得快还省钱.claude/rules/ 里的规则文件约束代码风格,后面会讲color -- 终端里用不同颜色区分两个 Agent 的输出,看着方便来看实际跑一遍是什么样。我要给"供应商管理"模块实现接口。
只需要输入一句话:
实现接口:https://gateway.xxx.cn/doc.html#/组织架构服务/供应商管理/page_1
Claude Code 会自动识别到 api-add Skill,加载后通过 MCP 打开 Swagger 文档:
AI 通过浏览器快照读到页面内容,找到左侧菜单里"供应商管理"下的所有接口,弹出选择框让我勾:
它做了这几件事:
我两个都选了。
确认后,Claude Code 起了一个 Agent Team,两个 Agent 同时开工:
截图里能看到:
两个 Agent 干完活,自动关闭并清理资源:
最终生成了这些文件:
# API & 类型定义
src/types/supply-company.ts ← TypeScript 类型
src/api/supply-company/index.ts ← API 函数
# Mock 实现
mocks/routes/data/supply-company-page.json ← Mock 数据
mocks/routes/supply-company.controller.cjs ← Mock 控制器
mocks/routes/org.cjs ← 路由挂载(已更新)
代码质量怎么样?直接贴。
部分展示:
// src/types/supply-company.ts
/** 供应商分页查询参数 */
export interface ISupplyCompanyPageParam extends IPageParam {
/** 供应商名称 */
name?: string;
}
/** 供应商分页列表项 */
export interface ISupplyCompanyPageVO {
/** 供应商组织id */
orgId: number;
/** 公司编码 */
code: string;
/** 供应商名称 */
orgName: string;
/** 负责人id */
staffId: number;
/** 负责人姓名 */
userName: string;
/** 状态 */
status: string;
/** 所属商户 */
merchantName: string;
/** 创建人 */
creator: string;
/** 创建时间 */
createTime: string;
}
I 前缀、JSDoc 注释、继承 IPageParam,跟项目里手写的一模一样。
部分展示:
// src/api/supply-company/index.ts
export async function querySupplyCompanyPage(
params: ISupplyCompanyPageParam
) {
let total = 0;
let data = [] as ISupplyCompanyPageVO[];
params = toConditional(params);
try {
const { code, context, message } = await Http.post<{
total: number;
data: ISupplyCompanyPageVO[];
}>(`${baseUrl}/page`, { ...params });
if (code !== EResponseCode.Succeed) {
throw new Error(message || '服务器异常,请稍后再试~');
}
total = context?.total || 0;
data = context?.data || [];
} catch (error) {
throw new Error(getHttpErrorMessage(error));
}
return { total, data };
}
项目里标准的 API 写法:async/await + try/catch + toConditional + 错误处理,一个不差。
部分展示:
// mocks/routes/data/supply-company-page.json
[
{
"orgId": 1001,
"code": "SC-2025-001",
"orgName": "上海奢品供应链有限公司",
"staffId": 2001,
"userName": "张经理",
"status": "ENABLED",
"merchantName": "LuxMall旗舰店",
"creator": "系统管理员",
"createTime": "2025-01-15 10:30:00"
}
// ... 更多数据
]
Mock 数据的字段值是有意义的中文内容,不是那种 "string" 占位符。
部分展示:
// mocks/controllers/supply-company.controller.cjs
const express = require('express');
const router = express.Router();
const supplyCompanyList = require('./data/supply-company-list.json');
/**
* 供应商分页列表
* POST /page
*/
router.post('/page', (req, res) => {
let all = JSON.parse(JSON.stringify(supplyCompanyList));
const { page = 1, size = 50, name } = req.body || {};
// 按供应商名称模糊搜索
if (name) {
all = all.filter((item) =>
String(item.orgName).includes(String(name))
);
}
const total = all.length;
const start = (Number(page) - 1) * Number(size);
const end = start + Number(size);
const data = all.slice(start, end);
res.json({
code: 0,
message: null,
context: { total, data },
traceId: '',
spanId: '',
});
});
module.exports = router;
分页、模糊搜索、标准响应格式,都按项目的 Mock 规范来的。
你可能会想:AI 怎么知道我们项目的编码规范?
靠 .claude/rules/ 目录。这是 Claude Code 的规则系统,你可以理解为给 AI 写了一份项目编码手册:
.claude/rules/
├── api.md ← API 实现标准(函数命名、错误处理模式)
├── ts-define.md ← TypeScript 规范(I前缀、E前缀、JSDoc)
├── mock.md ← Mock 服务器架构(路由、控制器、数据文件)
├── components.md ← 组件库参考
├── vue-single-file.md ← Vue SFC 标准
└── ...
每个 Agent 工作时都会读这些规则文件。所以生成出来的代码风格跟项目里手写的一致,不会出现那种一看就是 AI 写的通用代码。
如果你想在自己项目里搞一套,需要这些文件:
.claude/
├── agents/
│ ├── api-define.md ← API 定义 Agent
│ └── mock-define.md ← Mock 创建 Agent
├── skills/
│ └── api-add/
│ └── SKILL.md ← 工作流编排 Skill
├── rules/
│ ├── api.md ← API 编码规范
│ ├── ts-define.md ← TypeScript 规范
│ └── mock.md ← Mock 规范
└── ...
# MCP 配置(项目级或全局)
.mcp.json ← Chrome DevTools MCP 配置
| 维度 | 手动开发 | api-add Skill |
|---|---|---|
| 耗时 | 6.5m | 4.3m |
| 类型定义 | 手动从文档抄 | 自动提取,不会漏字段 |
| API 函数 | 复制模板手动改 | 自动生成,符合规范 |
| Mock 数据 | 手动编假数据 | 自动生成,内容像真的 |
| 代码规范 | 看个人习惯 | Rules 强制约束 |
| 人为错误 | 字段名拼错、类型写错 | 从文档直接提取,基本不会错 |
回头看,这套方案做了四件事:
说到底就是把"从文档到代码"这个重复劳动自动化了。
这套方案也不只能用在 Swagger 上。改一下 Skill 的工作流,Apifox、Postman、自定义 Markdown 文档、GraphQL Schema,只要浏览器能打开的接口文档都能接。
如果你也在用 Claude Code,可以试试 Skill + MCP 这个组合。
觉得有用的话点个赞,也欢迎在评论区聊聊你的 Claude Code 玩法。
localStorage 是同步的,其设计初衷是为了简化 API 并适应早期的 Web 应用场景。尽管底层硬盘 IO 本质上是异步的,但浏览器通过阻塞 JavaScript 线程实现了同步行为。对于需要存储大量数据或避免阻塞主线程的场景,建议使用异步的 IndexedDB。
localStorage 是 Web Storage API 的一部分,它提供了一种存储键值对的机制。它的数据是持久存储在用户的硬盘上的,而不是内存中。这意味着即使用户关闭浏览器或电脑,数据也不会丢失,除非主动清除浏览器缓存或使用代码删除。
当你通过 JavaScript 访问 localStorage 时,浏览器会从硬盘中读取数据或向硬盘写入数据。虽然读写操作期间,数据可能会被暂时存放在内存中以提高处理速度,但其主要特性是持久性,并且不依赖于会话。
是的,硬盘确实是 IO 设备,大部分与硬盘相关的操作系统级 IO 操作是异步进行的,以避免阻塞进程。但在 Web 浏览器环境中,localStorage 的 API 被设计为同步的,即使底层的硬盘读写操作具有 IO 特性。
JavaScript 代码在访问 localStorage 时,浏览器提供的 API 通常会在 js 执行线程上下文中直接调用。这意味着尽管硬盘需要等待数据读取或写入完成,localStorage 的读写操作是同步的,会阻塞 JavaScript 线程直到操作完成。
localStorage 实现同步存储的方式是阻塞 JavaScript 的执行,直到数据的读取或写入操作完成。这种同步操作的实现可以简单概述如下:
js线程调用:当 JavaScript 代码执行一个 localStorage 的操作,比如 localStorage.getItem('key') 或 localStorage.setItem('key', 'value'),这个调用发生在 js 的单个线程上。
浏览器引擎处理:浏览器的 js 引擎接收到调用请求后,会向浏览器的存储器子系统发出同步 IO 请求。此时 js 引擎等待 IO 操作的完成。
文件系统的同步 IO:浏览器存储器子系统对硬盘执行实际的存储或检索操作。尽管操作系统层面可能对文件访问进行缓存或优化,但从浏览器的角度看,它会进行一个同步的文件系统操作,直到这个操作返回结果。
操作完成返回:一旦 IO 操作完成,数据要么被写入硬盘,要么被从硬盘读取出来,浏览器存储器子系统会将结果返回给 js 引擎。
JavaScript 线程继续执行:js 引擎在接收到操作完成的信号后,才会继续执行下一条 js 代码。
历史原因:localStorage 是在早期 Web 标准中引入的,当时的 Web 应用相对简单,对异步操作的需求并不强烈。
API 简洁性:同步 API 更易于理解和使用,开发者无需处理回调或 Promise,代码更直观。
数据量小:localStorage 设计用于存储少量数据(通常为 5MB 左右),同步操作在数据量较小时对性能影响不大。
兼容性考虑:保持同步行为有助于兼容旧代码和旧浏览器。
浏览器政策:浏览器厂商可能出于提供一致用户体验或方便管理用户数据的角度,选择保持其同步特性。
虽然 IndexedDB 提供了更大的存储空间和更丰富的功能,但潜在地也可能被滥用。不过,相比 localStorage,它增加了一些特性来降低被滥用的风险:
异步操作:IndexedDB 是异步 API,即使处理更大的数据也不会阻塞主线程,避免对页面响应性的直接影响。
用户提示和权限:某些浏览器在网站尝试存储大量数据时,可能会弹出提示要求用户授权,使用户有机会拒绝超出合理范围的存储请求。
存储配额和限制:尽管 IndexedDB 提供的存储容量比 localStorage 大得多,但它也不是无限的。浏览器会设定一定的存储配额,超出时拒绝更多的存储请求。
更清晰的存储管理:IndexedDB 的数据库形式允许有组织的存储和更容易的数据管理,用户或开发者可以更容易地查看和清理占用的数据。
逐渐增加的存储:某些浏览器在数据库大小增长到一定阈值时,可能会提示用户是否允许继续存储,而不是一开始就分配很大的空间。
平时编写代码时,我们并没有以异步的方式使用 localStorage。以下是一个简单的测试示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
const testLocalStorage = () => {
console.log("==========> 设置 localStorage 之前");
localStorage.setItem('testLocalStorage', '我是同步的');
console.log("==========> 获取 localStorage 之前");
console.log('==========> 获取 localStorage', localStorage.getItem('testLocalStorage'));
console.log("==========> 获取 localStorage 之后");
}
testLocalStorage();
</script>
</body>
</html>
运行上述代码,你会发现日志输出是顺序执行的,验证了 localStorage 的同步特性。
最近有一个需求:“监控用户怎么用标签组(Tab Groups),打开了啥,关闭了啥,统统都要记下来上报给服务器!”
如下就是一个标签组:
初看这个需求,似乎很简单:监听一下事件,调接口上报一下完事儿。
但仔细一想,为了保证数据的可靠性,还有几个“隐形坑”必须填上:
- 用户网断了怎么办? 数据不能丢,等网好了得自动补发
- 用户直接 Alt+F4 关浏览器怎么办? 必须在浏览器被杀死的瞬间,或者下次启动时把关闭日志数据发出去。
- 高频操作怎么办? 如果用户一秒钟关了 20 个组,不能卡顿,数据写入也不能错乱、丢失。
- 服务器挂了怎么办? 本地不能无限存,否则会把用户浏览器撑爆。
解决方案一句话总结:
监听标签组的开启和关闭,开启或关闭的时候,产生的日志第一时间先写到本地硬盘(Storage)中,然后再尝试上报到服务端,只有当上报成功了才从本地存储删。只要没删,就依靠定时任务死磕到底。
拦截事件:监听 chrome.tabGroups 的 onCreated 和 onRemoved。
持久化 (Persist):第一时间将数据写入 chrome.storage.local。哪怕下一毫秒浏览器崩溃,数据也在硬盘里。
上报 (Report):使用fetch尝试发送 HTTP 请求(开启 keepalive)。
提交 (Commit):
navigator.sendBeacon?你可能会想到用 navigator.sendBeacon 来解决关闭浏览器时的数据丢失问题。
确实,sendBeacon 是为了“页面卸载”场景设计的,但它有两个致命缺点:
true/false 表示“是否放入队列”,不代表服务器处理成功。sendBeacon,我们不知道是否发送成功,就无法安全地删除本地数据(删了可能丢,不删可能重)。因此,我们选择 fetch 配合 keepalive: true。
一句话总结:fetch + keepalive 能覆盖 sendBeacon 的“卸载场景尽量发出去”的能力,同时我们还能拿到响应状态码,从而做到“确认服务端收到了才删除本地”。
参考链接:developer.mozilla.org/en-US/docs/…
Chrome 插件里的 chrome.storage 读写是异步的,所以会有竞态问题。
前提: 我们为了管理方便,通常会把所有日志放在同一个 Key(例如 logs)下的一个数组里。正是因为大家抢着改这同一个数组,才出了事。
为什么单线程也有竞态?
JS 是单线程的,但 await 会挂起当前任务并释放主线程的控制权。在 await get() 和 await set() 之间,其他事件处理函数可能插入执行并修改数据。
const task = (group) => {
// ...
const data = await chrome.storage.local.get(...); // 暂停,释放控制权
// ... (此时其他事件可能插入执行,修改了 storage) ...
await chrome.storage.local.set(...); // 写入,可能会覆盖别人的修改
// ...
}
// 标签组关闭的时候触发
chrome.tabGroups.onRemoved.addListener(task);
举个例子:假设你创建了两个标签页分组,这两个标签组同时关闭(A 和 B),就触发标签组关闭事件,就会触发两次task函数的执行。
get(),读取到 [1]。准备写入 3,遇 await 挂起。get()。因 A 尚未写入3,B 读取到的仍是 [1]。准备写入4,遇 await 挂起。[1,3]。执行 set() 写入硬盘。[1, 4]。执行 set() 写入硬盘。结果:最终设置进存储的是 [1, 4],数据 3 被 B 的写入覆盖丢失了!这就是经典的“读-改-写”竞争。
为了解决这个问题,我们可以利用 Promise 链实现一个简单的“任务队列”,强制所有存储操作排队执行:
// 全局任务队列
let globalTaskQueue = Promise.resolve();
/**
* 串行执行器:无论外界如何并发调用,内部永远排队执行
*/
function runSequentially(task) {
// 1. 把新任务拼到队列尾部
// 无论之前的任务有没有做完,新任务都得排在 globalTaskQueue 后面执行
const next = globalTaskQueue.then(() => task());
// 2. 更新队列指针
// 关键点:如果 next 失败(Rejected),catch错误,防止一个任务失败阻塞整个队列,
// catch会返回一个新的 Resolved Promise
// 所以 globalTaskQueue 总是指向一个“健康”的 Promise,确保后续任务能接上
globalTaskQueue = next.catch(() => {});
return next;
}
// 使用示例
async function saveReport(report) {
const task = async () => {
const data = await chrome.storage.local.get(['reports']);
// ... 读写逻辑 ...
await chrome.storage.local.set({ reports: newData });
};
return runSequentially(task);
}
原理解析:
这就好比 排队做核酸。globalTaskQueue 就是队伍的最后一个人。
Promise.resolve())。runSequentially(TaskA)。
globalTaskQueue.then(() => TaskA()):A 站在了队伍最后。globalTaskQueue 更新指向 A。runSequentially(TaskB)。
globalTaskQueue 指向 A。A.then(() => TaskB()):B 站在了 A 后面。哪怕 A 还在做(pending),B 也得等着。globalTaskQueue 更新指向 B。为什么要 .catch(() => {})?
如果不加 catch,万一 A 做核酸时晕倒了(抛出 Error),整个 Promise 链就会中断(Rejected),导致排在后面的 B、C、D 全都无法执行。 加上 catch 后,相当于把晕倒的 A 抬走,队伍继续往下走,B 依然能正常执行。
你可能会提出:“能不能把每个标签组日志存成独立的 Key(如 report-分组id),读取时遍历所有 report- 开头的 Key?这样不就完全避免了数组并发读写冲突了吗?”
这方案可行,且非常巧妙!
优点:
天然无锁(各写各的):A 写入 report-A,B 写入 report-B。这就好比大家各自在自己的本子上写字,而不是去抢同一块黑板。既然资源不共享,自然就不需要“排队”或“加锁”,彻底根治了并发冲突。
性能极高:写入是 O(1) 的纯追加操作。
缺点:
get(null)),把所有东西倒在桌上,再一张张挑出是日志的纸条。数据一多,这操作卡得要命。当浏览器被直接关闭时,插件进程不会瞬间消失。浏览器会先关闭所有标签和分组,这会触发插件的 onRemoved 事件。我们利用这最后几百毫秒的“回光返照”时间,接收关闭消息并将数据抢先存入本地硬盘,然后再尝试进行数据上报。
不过还是会有数据积压到本地的情况,“不是说日志上报成功了就删吗?为什么本地还会有积压数据?”
没错,理想情况下本地存储应该是空的。但在现实世界中,意外无处不在:
在这些情况下,数据发不出去,就必须滞留在本地等待下一次机会。我们需要建立一套机制,把这些“漏网之鱼”捞出来重发。
时机一:浏览器启动时 (onStartup)
用户再次打开浏览器时,说明环境可能恢复了(比如连上了网),这是补发积压数据的绝佳时机。
时机二:定时器轮询 (alarms)
如果用户一直不关闭浏览器,我们也不能干等。利用 chrome.alarms 设置一个每 5 分钟的定时任务。
灵魂拷问:为什么不用
setInterval?说白了就一句话:MV3版本插件的 Service Worker 不会一直在线。
它是事件驱动的:浏览器有事件推送到Service Worker的话就起来干活;活干完、并且一会儿没新事件,浏览器就把它挂起/回收(内存清空)省资源。
setInterval/setTimeout:本质是“内存里自己数秒”。Service Worker 一被挂起/回收,计时器直接断电,你就别指望它“每 5 分钟准点打卡”了。chrome.alarms:浏览器帮你托管的闹钟。时间到了就发alarms.onAlarm事件,必要时还能把 Service Worker 叫醒来处理。结论很简单:想要靠谱的定时重试,用
chrome.alarms;setInterval适合页面这种常驻环境里的小轮询。
// 监听定时器触发:浏览器到点会派发事件,必要时唤醒 SW
chrome.alarms.onAlarm.addListener((alarm) => {
if (alarm.name === ALARM_NAME) processPendingReports();
});
// JS 版伪代码:读本地 -> 丢弃过期 -> 逐条上报 -> 上报成功才删除(失败继续留着等下次)
async function processPendingReports() {
const reports = (await storageGet('pending_reports')) ?? [];
const pending = removeExpired(reports);
if (pending.length !== reports.length) {
await storageSet('pending_reports', pending);
}
for (const report of pending) {
const ok = await sendReport(report);
if (ok) await storageRemove('pending_reports', report.id);
}
}
// 说明:这里的 storageGet/storageSet/storageRemove 是为了讲清流程的伪函数,
// 这几个是对chrome.storage.local.get/set的封装。
背景知识:
数据存储在
storage.local中,并在移除扩展程序时自动清除。存储空间限制为 10 MB(在 Chrome 113 及更早版本中为 5 MB),但可以通过请求"unlimitedStorage"权限来增加此限制。默认情况下,它会向内容脚本公开,但可以通过调用chrome.storage.local.setAccessLevel()来更改此行为。 参考:Chrome Storage API
尽管有 10MB 甚至无限的空间,但如果服务器彻底挂了,或者用户处于断网环境、秒关浏览器,本地数据依然会无限膨胀,最终影响性能。
所以我们需要设置熔断机制。
代码示例:Step 1 - 存储与压缩
const MAX_REPORTS = 1000;
const REPORT_EXPIRATION_MS = 7 * 24 * 60 * 60 * 1000; // 7天
const STORAGE_KEY = 'pending_reports';
async function saveReport(newReport) {
// 使用之前定义的串行锁,防止并发冲突
return runSequentially(async () => {
// 1. 读取现有数据
const result = await chrome.storage.local.get([STORAGE_KEY]);
let reports = result[STORAGE_KEY] || [];
// 2. 追加新报告 (可选:先进行压缩)
// 使用原生 CompressionStream (Gzip) 进行压缩,能大幅节省空间
const reportToSave = await compressReport(newReport);
reports.push(reportToSave);
// 3. 执行熔断策略(自我保护)
const now = Date.now();
// 3.1 有效期限制:过滤掉过期的
reports = reports.filter(r => (now - r.timestamp) <= REPORT_EXPIRATION_MS);
// 3.2 容量限制:如果还超标,剔除最旧的
if (reports.length > MAX_REPORTS) {
reports.shift();
}
// 4. 写回硬盘
await chrome.storage.local.set({ [STORAGE_KEY]: reports });
});
}
/**
* 使用原生 CompressionStream API 进行 Gzip 压缩
* 流程:JSON -> String -> Gzip Stream -> ArrayBuffer -> Base64
*
* 为什么要这么转?
* 1. CompressionStream 只接受流(Stream)作为输入。
* 2. chrome.storage 只能存储 JSON 安全的数据(字符串/数字/对象),不能直接存二进制(ArrayBuffer/Blob)。
* 3. 所以必须把压缩后的二进制数据转成 Base64 字符串才能存进去。
*/
async function compressReport(report) {
// 1. 转字符串
const jsonStr = JSON.stringify(report);
// 2. 创建压缩流
const stream = new Blob([jsonStr]).stream().pipeThrough(new CompressionStream('gzip'));
// 3. 读取流为 ArrayBuffer
const compressedResponse = await new Response(stream);
const blob = await compressedResponse.blob();
const buffer = await blob.arrayBuffer();
// 4. 转 Base64 存储 (storage 不支持直接存二进制 Blob)
return {
id: report.id || Date.now(),
timestamp: report.timestamp,
// 标记这是压缩数据
isCompressed: true,
data: arrayBufferToBase64(buffer)
};
}
// 辅助函数:ArrayBuffer 转 Base64
function arrayBufferToBase64(buffer) {
let binary = '';
const bytes = new Uint8Array(buffer);
const len = bytes.byteLength;
for (let i = 0; i < len; i++) {
binary += String.fromCharCode(bytes[i]);
}
return btoa(binary);
}
代码解释:
关于 saveReport 的熔断逻辑:
unlimitedStorage 获得无限空间,但CPU/内存和序列化/反序列化开销仍然存,。如果队列太长,每次读取都会卡顿,所以必须限制数量。)关于 compressReport 的二进制转换:
CompressionStream 吐出来的是个流(Stream),要把它变成我们能处理的二进制块(ArrayBuffer),按理说得写个循环一点点读。但浏览器的 Response 对象自带了“把流一口气吸干并转成 Blob”的功能,所以我们借用它来省去写循环读取的麻烦。chrome.storage 比较娇气,它只能存字符串或 JSON 对象,存不了二进制数据(ArrayBuffer)。如果你直接把压缩后的二进制扔进去,它会变成一个空对象 {}。所以我们需要把二进制数据“编码”成一串长长的字符串(Base64),存的时候存字符串,取的时候再还原回去。代码示例:Step 2 - 读取与上报
既然存进去了,怎么发出来呢?可以直接发 Base64 吗?
可以,但没必要。 即使算上 Base64 的 33% 膨胀,压缩后(100KB -> 26.6KB)依然血赚。但转回 Binary 有两个核心优势:
Content-Encoding: gzip,服务器网关(Nginx)会自动解压,后端业务代码拿到的直接就是 JSON。如果你发 Base64,后端还得专门写代码先解码再解压,容易被同事吐槽。这里就轮到 base64ToUint8Array 登场了:
// 辅助函数:Base64 转 Uint8Array
function base64ToUint8Array(base64) {
const binaryString = atob(base64);
const bytes = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
bytes[i] = binaryString.charCodeAt(i);
}
return bytes;
}
async function sendReport(report) {
let body = report;
const headers = { 'Content-Type': 'application/json' };
if (report.isCompressed) {
// 1. Base64 -> 二进制 (还原体积)
// 这一步至关重要!如果不转回二进制直接发 Base64,流量会白白增加 33%
const binaryData = base64ToUint8Array(report.data);
// 2. 直接发送二进制,并告诉服务器:“我发的是 Gzip 哦”
body = binaryData;
headers['Content-Encoding'] = 'gzip';
} else {
// 兼容旧数据
body = JSON.stringify(report);
}
await fetch('https://api.example.com/log', {
method: 'POST',
headers: headers,
body: body,
keepalive: true
});
}
总结:数据流转全景
JSON -> Gzip -> Base64 (为了存 Storage)Base64 -> Binary -> Network (利用 Content-Encoding: gzip)在前端(尤其是离线优先或插件环境)做数据上报,“即时发送”是不可靠的。通过引入本地存储作为缓冲区,配合串行锁、定时重试和容量控制,我们构建了一个健壮的日志上报系统。
曝光节点是Unity Shader Graph中一个功能强大的工具节点,专门用于在着色器中访问摄像机的曝光信息。在基于物理的渲染(PBR)流程中,曝光控制是实现高动态范围(HDR)渲染的关键组成部分,而曝光节点则为着色器艺术家提供了直接访问这些曝光参数的途径。
曝光节点的核心功能是从当前渲染管线中获取摄像机的曝光值,使着色器能够根据场景的曝光设置做出相应的反应。这在创建对光照条件敏感的着色器效果时尤为重要,比如自动调整材质亮度、实现曝光自适应效果或者创建与摄像机曝光设置同步的后期处理效果。
在现代化的游戏开发中,HDR渲染已经成为标准配置,它允许场景中的亮度值超出传统的0-1范围,从而能够更真实地模拟现实世界中的光照条件。曝光节点正是在这样的背景下发挥着重要作用,它架起了着色器与渲染管线曝光系统之间的桥梁。
曝光节点在不同渲染管线中的支持情况是开发者需要特别注意的重要信息。了解节点的兼容性有助于避免在项目开发过程中遇到意外的兼容性问题。
| 节点 | 通用渲染管线 (URP) | 高清渲染管线 (HDRP) |
|---|---|---|
| Exposure | 否 | 是 |
从兼容性表格中可以清楚地看到,曝光节点目前仅在高清渲染管线(HDRP)中得到支持,而在通用渲染管线(URP)中不可用。这一差异主要源于两种渲染管线在曝光处理机制上的根本区别。
HDRP作为Unity的高端渲染解决方案,内置了完整的物理相机和曝光系统,支持自动曝光(自动曝光适应)和手动曝光控制。HDRP的曝光系统基于真实的物理相机参数,如光圈、快门速度和ISO感光度,这使得它能够提供更加真实和灵活的曝光控制。
相比之下,URP虽然也支持HDR渲染,但其曝光系统相对简化,主要提供基本的曝光补偿功能,而没有HDRP那样完整的物理相机模拟。因此,URP中没有提供直接访问曝光值的Shader Graph节点。
对于URP用户,如果需要实现类似的功能,可以考虑以下替代方案:
曝光节点的端口配置相对简单,但理解每个端口的特性和用途对于正确使用该节点至关重要。
| 名称 | 方向 | 类型 | 描述 |
|---|---|---|---|
| Output | 输出 | Float | 曝光值。 |
曝光节点只有一个输出端口,这意味着它只能作为数据源在Shader Graph中使用,而不能接收外部输入。这种设计反映了曝光值的本质——它是从渲染管线的相机系统获取的只读参数。
输出端口的Float类型表明曝光值是一个标量数值,这个数值代表了当前帧或上一帧的曝光乘数。在HDRP的曝光系统中,这个值通常用于将场景中的光照值从HDR范围映射到显示设备的LDR范围。
理解曝光值的数值范围对于正确使用该节点非常重要:
在实际使用中,曝光节点的输出可以直接用于乘法运算来调整材质的亮度,或者用于更复杂的曝光相关计算。例如,在创建自发光材质时,可以使用曝光值来确保材质在不同曝光设置下保持视觉一致性。
曝光节点的核心功能通过其曝光类型(Exposure Type)设置来实现,这个设置决定了节点从渲染管线获取哪种类型的曝光值。理解每种曝光类型的特性和适用场景是掌握该节点的关键。
| 名称 | 描述 |
|---|---|
| CurrentMultiplier | 从当前帧获取摄像机的曝光值。 |
| InverseCurrentMultiplier | 从当前帧获取摄像机的曝光值的倒数。 |
| PreviousMultiplier | 从上一帧获取摄像机的曝光值。 |
| InversePreviousMultiplier | 从上一帧获取摄像机的曝光值的倒数。 |
CurrentMultiplier是最常用的曝光类型,它提供当前帧相机的实时曝光值。这个值反映了相机系统根据场景亮度和曝光设置计算出的当前曝光乘数。
使用场景示例:
技术特点:
InverseCurrentMultiplier提供当前帧曝光值的倒数,即1除以曝光乘数。这种类型的曝光值在某些特定计算中非常有用,特别是当需要抵消曝光影响时。
使用场景示例:
技术特点:
PreviousMultiplier提供上一帧的曝光值,这在某些需要平滑过渡或避免闪烁的效果中非常有用。由于自动曝光系统可能会导致曝光值在帧之间变化,使用上一帧的值可以提供更加稳定的参考。
使用场景示例:
技术特点:
InversePreviousMultiplier结合了上一帧数据和倒数计算,为特定的高级应用场景提供支持。这种曝光类型在需要基于历史曝光数据进行复杂计算的效果中发挥作用。
使用场景示例:
技术特点:
在HDRP中创建自发光材质时,使用曝光节点可以确保材质在不同曝光设置下保持正确的视觉表现。以下是一个基本的实现示例:
这种方法确保了自发光材质的亮度会随着相机曝光设置自动调整,在低曝光情况下不会过亮,在高曝光情况下不会过暗。
利用PreviousMultiplier和CurrentMultiplier可以创建平滑的曝光过渡效果,避免自动曝光调整时的突兀变化:
这种技术特别适用于全屏效果或UI元素,可以确保视觉元素在曝光变化时平稳过渡。
某些场景元素可能需要在不同曝光设置下保持恒定的视觉亮度,这时可以使用InverseCurrentMultiplier:
这种方法常用于UI渲染、调试信息显示或其他需要独立于场景曝光的视觉元素。
虽然曝光节点本身性能开销很小,但在实际使用中仍需注意一些性能优化策略:
最佳实践建议:
在使用曝光节点时可能会遇到一些常见问题,以下是相应的解决方案:
调试技巧:
【Unity Shader Graph 使用与特效实现】专栏-直达 (欢迎点赞留言探讨,更多人加入进来能更加完善这个探索的过程,🙏)
📢 宣言:每周更新国外论坛的前端热门文章,推荐大家阅读/翻译,紧跟时事,掌握前端技术动态,也为写作或突破新领域提供灵感~
欢迎大家访问:github.com/TUARAN/fron… 顺手点个 ⭐ star 支持,是我们持续输出的续航电池🔋✨!
在线网址:frontendweekly.cn/
💬 推荐语
本期聚焦“交互组件选择 + 浏览器行为细节 + 生态工具更新”。Web 开发部分从组合框/多选/列表框的选型指南、浏览器对“意外”变更的敏感反应,到“不要把单词拆成字母”的可访问性提醒;工具与性能板块涵盖 Deno 生态新进展、ESLint 10 发布、ViteLand 月报、以及 SVG/视频与 Node.js 版本演进的性能分析。CSS 方面关注 @scope、@container scroll-state()、bar chart 与 clamp() 等现代特性;JavaScript 则有 Temporal 提案、显式资源管理、框架选型与 React/Angular 的新范式探讨。
details/summary 做互动式“剧透”组件。calc()、clamp() 等函数实现数据可视化布局。auto 在 clamp() 中的可用模式与注意点。写在前面
架构师的核心能力之一是分类。 如果你觉得状态管理很痛苦,通常是因为你试图用同一种工具处理两种截然不同的东西:
- 客户端状态 (Client State): 比如“侧边栏是否展开”、“当前的夜间模式”。它们是同步的、瞬间完成的、由前端完全控制。
- 服务端状态 (Server State): 比如“用户订单列表”。它们是异步的、可能失效的、由后端控制。
Redux 并不擅长管理 Server State。 真正专业的做法是:让 Redux 回归 UI,让 TanStack Query (React Query) 接管 API。
在传统的 Redux 处理 API 流程中,你需要写:
Constant 定义 FETCH_USER_REQUEST
Action Creator
Pending/Success/Error 的 Reducer
useEffect 来触发请求而在 TanStack Query 中,这只需要一行代码:
const { data, isLoading } = useQuery({ queryKey: ['user'], queryFn: fetchUser });
Server State 最难的不是“获取”,而是**“维护”**。
现代前端架构推荐采用 “双层分离” 模型:
想象一个场景:你修改了用户的头像,你需要更新所有显示头像的地方。
updateUserAction 去修改 Redux 里的那个大对象。// 当用户修改个人资料成功时
const mutation = useMutation({
mutationFn: updateProfile,
onSuccess: () => {
// 告诉系统:['user'] 这个 key 下的数据脏了,请自动重新拉取
queryClient.invalidateQueries({ queryKey: ['user'] })
},
})
架构意义: 你的代码不再需要关心“数据怎么同步”,只需要关心“数据何时失效”。
这是架构高级感的核心。当用户点赞时,我们不等后端返回,直接改 UI。
TanStack Query 允许你在 onMutate 中手动修改缓存副本,如果请求失败,它会自动回滚。这种复杂的逻辑如果写在 Redux 里,会让 Reducer 逻辑变得极度臃肿。
作为架构师,你需要给团队划清界限:
| 状态类型 | 典型例子 | 推荐工具 | 存储位置 |
|---|---|---|---|
| API 数据 | 商品列表、用户信息 | TanStack Query | 专用 Cache 池 |
| 全局 UI 状态 | 登录 Token、全局主题 | Zustand / Pinia | 全局 Store |
| 局部 UI 状态 | 某个弹窗的开关 | useState | 组件内部 |
| 复杂表单 | 多步骤注册表单 | React Hook Form | 专用 Form State |
导出到 Google 表格
通过把 API 逻辑剥离出去,你会发现你的 Redux(或者 Zustand)Store 瞬间缩水了 80% 。 剩下的代码变得极其纯粹:只有纯同步的 UI 逻辑。
这种**“分治”**带来的好处是巨大的:
loading 状态机。我们已经成功地将 API 数据和 UI 状态分开了。 但还有一种状态最让架构师头疼:流程状态。 当你的业务逻辑包含“待支付 -> 支付中 -> 支付成功/失败 -> 申请退款 -> 已关闭”这种复杂的链路时,无论你用什么工具,代码里都会充满 if/else。
这种逻辑该如何优雅地管理?
Next Step: 下一节,我们将引入一个在航天和游戏领域应用了几十年的数学模型。 我们将学习如何用“图”的思想,终结代码里的逻辑乱麻。
"又双叒叕大事不好了,咱们导出的图片有问题,印刷出来有色差!业务方都被逼着要去外采软件了!"
下班前,产品突然在群里丢了一颗重磅炸弹。
外采软件?什么情况?要是真把业务方逼去外采了,咱们 IT 往后的日子可就不好过了。
事不宜迟,咱们赶紧看看是怎么个事。
我们团队负责的是加盟商报货相关业务,其中有一个定制宣传物料的模块,业务流程是这样的:
这个系统的前端部分使用了 Fabric 来实现图片编辑功能,基于浏览器 Canvas API 导出图片,而 Canvas 只支持 RGB 色彩模式。但印刷厂需要的是 CMYK 模式,这导致印刷出来有非常明显的色差。
要搞明白为什么有色差,我们首先要知道,什么是颜色。
这部分比较冗长,如果你已经具备了相关前置知识,可以直接跳转至「为什么有色差」一节
1672年,牛顿通过一块棱镜,发现了光的色散,从而揭示了白光由不同颜色光谱组成的本质。
而后,物理学家大卫·布儒斯特进一步发现染料的原色只需要红、黄、蓝三种颜色,基于这三种颜色,就可以调配出任何其他颜色。
随着科技的进步,生理学家托马斯杨根据人类眼球的视觉生理特征又提出了新的三原色,即红、绿、蓝三种颜色。
此后,人类开始意识到,色光和颜料的原色及其混合规律是有不同的,这实际上引出的是 加色模式 和 减色模式 两种色彩模式。
我们知道,人类并不能直接看到物体本身的颜色,我们看到的物体的颜色,实际上是物体反射的光的颜色。红色的物体,实际上是吸收了除红光以外的所有光,才让唯一的红光可以进入我们的眼球。
因此,在现实世界我们看到的所有不自发光物体的颜色,都应当按照减色模式进行调配和描述,如美术中使用到的颜料、印染工艺中使用的染料等。
减法三原色为青色(C)、品红色(M)、黄色(Y),合称 CMY。而现如今的印刷行业普遍采用的 CMYK 模式,则是因为使用三种颜色的颜料无法正确混合出纯正的黑色(通常是深灰色),因此需要额外单独的黑色(K)染料来印染黑色。
减色法的颜色效果完全依赖于环境光的照射和白纸的反射能力——油墨本身会吸收一部分光,白纸也无法 100% 反射所有光线,并且油墨染料的化学特性限制了其反射光谱的纯度。
而针对可以直接发出光线的物体,人类所看到的颜色就直接是其发出光线颜色本身了。
和减色的三原色不同,加法三原色为红(R)、绿(G)、蓝(B),也就是大家熟知的 RGB 模式。
加色法是主动光源。主动光源通常可以发出非常纯净、高饱和度的单色光,并能将亮度提升到很高。这使它能够呈现非常鲜艳、明亮的颜色。
就比如你看到这篇文章时使用的显示器,每个像素都是由红绿蓝三种颜色的发光二极管组成的。
曾经红极一时、如雷贯耳的“周冬雨排列”
由于物理世界的限制,印刷品很难达到显示器那种发光体的亮度和饱和度。
色彩模式告诉你,使用青、品红、黄三种颜色的调料可以调配出任何你想要的颜色,但是却没有告诉你,如果我想要调配出正红色,要用多少青色、多少品红、和多少黄色?
甚至你想要的正红色,其自身都没法用一个统一的标准来表述——这正红得多红才叫正红呀?
想要定量地描述颜色,我们需要引入色彩空间(Color Space)的概念。
1931 年,国际照明委员会(CIE)创建了 CIE XYZ 色彩空间,这是第一个基于人眼视觉特性的标准色彩空间。
基于 XYZ 三个坐标,我们可以用唯一确定的数值形式表示出人类肉眼可见的所有颜色。如此一来,我们便能给每一种颜色精准定位了。
虽然有了 CIE XYZ 这个“统一语言”,但在 90 年代末,电脑普及和互联网爆发带来了一个极其现实的挑战:显示器的显示能力是有限的,而当时的网络带宽更是寸土寸金。
如果说 CIE XYZ 是一本包含了几十万词条、大而全的《牛津英语大词典》,那么我们在日常交流中,其实只需要一本几千词的《日常口语手册》就足够了。 强行传输 XYZ 这种海量数据,既超出了显示器的承载能力,也拖慢了网速。
为了在显示效果、传输效率和跨设备一致性之间找到那个平衡点,1996 年,微软和惠普选取了当时主流 CRT 显示器(大头电视)荧光粉能发出的红绿蓝,作为基准三原色,由此创造了流行至今的 sRGB 色彩空间,其中 s 意为标准(Standard)。
与显示器不同,印刷时选取不同的印刷介质和油墨,都会导致最终的印刷效果不同,因此针对特定的纸张和油墨组合,诞生了一系列不同的 CMYK 色彩空间,例如:
为了方便比较,我们通常会将不同的色彩空间统一映射到 CIE XYZ 色彩空间内进行比对。
如果我们将 Z 坐标进行归一化和压缩,再将所有该色彩空间内所有颜色的 X、Y 坐标连起来,就会得到一个封闭的二维图形,这个封闭的图形就是色域(Color Gamut),就是该色彩模式所能表示的颜色范围。
其中马蹄形区域是可见光的色域,通常被称作“全色域”
通过图像我们不难看出,sRGB 的色域并不能完全覆盖 CMYK,这意味着,一个在 sRGB 下能表示出的颜色,在 CMYK 模式下可能根本没有对应的颜色,这会导致风光摄影中一些常见的绿色无法在印刷时体现。因此,传统印刷行业对微软和 Adobe 等公司制定的 sRGB 标准提出了强烈的反对和质疑。
面对印刷业巨头的联合抵制和抗议,微软并没有认怂,他们之间的纠纷战争维持了三年之久,最后在 Adobe 公司的调解下,制定了 Adobe RGB 色域,这一更广阔的色域完美地包含了印刷所需的所有颜色。
但是摄影及印刷行业的从业者毕竟是少数,绝大多数的互联网用户并不需要关心 CMYK 这种印刷时才会遇到的色彩模式,传统的 sRGB 依旧可以满足网上冲浪的全部需求。
此外,更广色域的图片也需要更专业更贵的显示器、搭配专业软件才能正常显示,这也是为什么即便到了今天,sRGB 在互联网领域依旧占据绝对统治地位。
Tips: 显示器的色域
当你挑选显示器的时候,可能常常会听到诸如“120% sRGB”、“97% sRGB”等关键词,这里的百分比,实际上就是显示器色域占 sRGB 色域的范围。如果不考虑专业设计场景,理论上只要显示器能达到 100% 的 sRGB 色域,便可以满足你日常上网的全部需求
而类似“Adobe RGB 100% 色域”、“P3 广色域” 、“杜比视界”等更广阔的色域,随着时代的发展也逐渐有了更多的日常使用场景,如 B 站现在就支持 HDR 杜比视界的视频播放;在大型单机游戏领域,也越来越多地支持的 P3 色域。
了解了色彩学的基础知识后,我们重新审视一下最开始的那个问题:
我们知道,印刷厂的印刷机,最终印刷一定是使用 CMYK 四种颜色的墨水进行印刷的,因此当我们给出 RGB 原图时,必然经过了印刷厂的一次转换,这可能发生在机器内部,也可能发生在印刷厂的内部系统流程中;
而设计师手动转换色彩空间后,印刷没有色差,这就说明,色差的根源就在于印刷厂的这一次转换!
现阶段,想要将 RGB 转为 CMYK,通常有两种转换方式:
这是最简单、最基础的算法,通常用于不要求颜色精确度的场景。
转换步骤:
255,使其范围变为 0~1。K = 1 - Max(R, G, B)
C = (1 - R - K) / (1 - K)M = (1 - G - K) / (1 - K)Y = (1 - B - K) / (1 - K)注意: 如果 K = 1(纯黑),则 C, M, Y 均为 0。
这种算法的思路很朴素:既然 RGB 是加色,CMYK 是减色,那就通过数学关系做个映射。理论上确实可以完成转换,但问题在于——这种纯数学转换完全不考虑现实世界的设备差异。
同样是显示一个红色 RGB(255, 0, 0),不同品牌、不同型号的显示器,实际发出的光的波长和强度都不一样。你的显示器可能偏冷色调,我的显示器可能偏暖色调,但在算法眼里,它们都是 RGB(255, 0, 0)。
同样是印刷 C0 M100 Y100 K0,不同的打印机、不同的纸张、不同的油墨,印出来的颜色也千差万别。这家印刷厂的红色油墨偏橙,那家印刷厂的红色油墨偏紫,但算法根本不知道这些差异。
而最令人头疼的是色域映射问题——RGB 能显示的某些鲜艳颜色,比如荧光绿 RGB(0, 255, 0),在 CMYK 的色域里根本没有对应的颜色。算法会强行把它映射成 C100 M0 Y100 K0,但印出来的绿色会明显发灰、发暗,完全不是你在屏幕上看到的那种鲜艳的绿。
纯算法转换假设所有设备都是"标准"的,假设色域可以完美映射,但现实世界里这两个假设都不成立。
这是目前设计软件(如 Adobe Illustrator、Photoshop 等)和专业印刷流程采用的标准方式。
正如上一节中提到,RGB 和 CMYK 都有各自的色彩空间,显示器和打印机之间各说各话,你在显示器上看到的颜色,打印出来可能是另一个颜色。
为了解决这个问题,1993 年,包括 Adobe、Apple、Microsoft、Sun 等八家科技公司联合成立了国际色彩联盟 ICC(International Color Consortium,国际色彩联盟),目标就是建立一个开放、跨平台的色彩管理标准。ICC 配置文件规范也由此诞生。
ICC 来色彩管理界只办三件事:公平!公平!还是他**的公平!
不好意思串台了,但是其实某种意义上来说也没错。ICC 的出现是为了确保"所见即所得",它的最终目标是让你在屏幕上看到的红色,在打印纸上也是同样的红色。
为了做到“所见即所得”,ICC 系统引入了一个中间色彩空间 PCS(Profile Connection Space,特性连接空间)。这是一个设备无关的、中介的、与人眼感知相关的色彩空间(通常使用前面提到的 CIE XYZ 或者基于其演化出的 CIE Lab 色彩空间)。
有了 ICC 规范之后,每个设备的 ICC 文件都是通过专业仪器实际测量出来的:
RGB(255, 0, 0) 在这台显示器上实际发出的光对应的 Lab 值(比如 Lab(53.23, 80.11, 67.22))在你系统的显示器设置中,你可以看到当前显示器的颜色描述文件,它通常以你的显示器型号命名
这个文件就是显示器厂商针对这一型号制作的 ICC 文件,其内部包含了整台显示器所能展示的全部颜色,通常会随着驱动文件自动下载到你的电脑中。
大多数厂商所提供的只是一个通用 ICC 文件,实际上,哪怕是相同厂商、相同型号的显示器,受品控、原料批次及使用老化等因素影响,其显示效果也会有细微的差别。在某些对色彩准确性要求比较高的场景下(如影视、平面设计等)通常还需要针对单台设备进行颜色校准,并且制作一份矫正后的 ICC 或 LUT,才能够保证最终产出的图像和肉眼看到的一致。
C0 M100 Y100 K0 在这台印刷机、这种纸张、这种油墨上实际印出来的颜色对应的 Lab 值(比如 Lab(47.82, 68.30, 48.05))每个设备的 ICC 文件都描述了该设备色彩空间与 PCS 之间的转换关系,就像不同国家的语言都可以通过英语作为中介进行翻译,如此一来,当你在显示器上看到一张照片并想打印出来时,只要经过如下转换:
因为 Lab 是基于人眼感知的绝对色彩空间,所以这样转换后,你在屏幕上看到的红色,和印刷出来的红色,在人眼看来就是同一个颜色了。反之亦是同理。
虽然 ICC 文件可以实现从 RGB 到 CMYK 的双向映射,但是还记得我们前文提到的 RGB 的色域要比 CMYK 更广吗?这必然会导致有部分 RGB 颜色,无法和 CMYK 颜色进行映射。这时就轮到 渲染意图(Rendering Intent) 登场了。
在 ICC 规范中,一共有四种法定意图,它们决定了如何处理色域外的颜色。
可感知意图的核心原理是等比例压缩,以 RGB 转 CMYK 为例,它将 RGB 的色域等比例缩放到 CMYK 的色域,颜色之间的相对关系(层次、过渡)保留得比较好。虽然整体饱和度可能会稍微下降,但图片看起来非常自然,不会有色块断层。
可以看出,图片虽然整体饱和度下降,但是颜色渐变过渡被保留得很好,不存在明显的断层,文本颜色也依旧可以辨识。
相对比色意图的核心逻辑是精准对齐 + 硬性裁剪,同样以 RGB 转 CMYK 为例,如果颜色在 CMYK 的色域内,就不会做任何改动;如果颜色超出了 CMYK 的色域就会直接截取为 CMYK 的边缘色彩。
这种方式转换的颜色最"准",因为它尽可能保持了大部分原始数值。但在极鲜艳、极暗的区域,可能会出现"并色"(Clipping)现象,即原本有层次的颜色变成了相同的颜色,丢失了层次感。
可以看出,图片在中部颜色没有溢出的部分保持了相同的色彩,但在两侧出现了较为明显的色域断层和边界。边界外颜色的渐变效果已被截断,且和同样超出色域范围的文本颜色被压缩成了相同的颜色,导致文本无法辨识。
此外还有饱和度意图(Saturation)和绝对比色意图(Absolute Colorimetric),由于篇幅限制这里就不多做赘述了。
可感知意图为了让所有颜色都能塞进目标色域,会移动所有颜色(甚至是那些本来就在色域内的颜色)。这意味着你看到的颜色虽然“和谐”,但已经不再是原始定义的那个准确的数值了,色差会比较明显。
而相对比色虽然尽可能多地保证了色准,但是面对色域外的颜色(尤其是深色)时又极易丢失细节
左图为 RGB 原图,右图为 CMYK 使用相对比色意图,不开启黑场补偿
可以看出白框中蓝莓的暗区细节已经完全丢失
那么有没有办法,能够让我们在保证色准的同时,尽可能多地保留暗部细节呢?
有的兄弟,有的,这门技术就是黑场补偿(Black Point Compensation)。
黑场补偿的原理,本质上就是将原图的暗区进行缩放:它会先找到源文件(RGB)中最黑的点,再找到目标输出(CMYK)能达到的最黑的点,并将整个画面的亮度范围进行等比例的"缩放",让 RGB 的黑点刚好对应上 CMYK 的黑点。
如此一来,原本深灰和全黑之间的相对比例就被保留了下来,虽然整体看起来可能没那么深邃了,但暗部的细节纹理被成功"挤"进了 CMYK 能表达的范围内。
开启了黑场补偿后,可以看出暗区细节被完好地保留了下来
并非所有 ICC 文件的可感知意图都完美
除了解决相对比色意图的暗部细节丢失以外,BFC 也同样可以给可感知意图兜底。
我们知道,ICC 文件是由厂商自行制作的,那必然会出现:有些厂商的“可感知”算法做得很好,暗部过渡自然;而有些厂商的算法却过于保守,或者在处理某些特定颜色时产生了意料之外的偏色。
而 BPC 是一种标准化的算法(由 Adobe 提出并贡献给 ICC)。它不依赖于 ICC 内部复杂的查表映射,而是在转换阶段进行一次数学上的端点对齐。因此,BPC 提供了一层额外的保险,确保无论你使用哪种意图,最黑的点始终能对应到输出设备的最黑点。
在 Photoshop、Illustrator 等软件中,通常建议默认开启黑场补偿;而部分图像处理工具则可能不提供这一功能。
到这里,我们几乎可以确定了色差的根源,原因无非以下几个:
但是不管到底是哪个问题,我们都有一个万能的解法——将 RGB 原图按照设计师的要求一比一转好后,再发给印刷厂。毕竟设计师转出来的发过去,印出来就是对的嘛。
依葫芦画瓢,和设计师一番沟通之后,我们确定了转换的过程与目标:
sRGB IEC61966-2.1,这是 Canvas 导出图片的默认配置日本常规用途2
Japan Color 2001 Coated
方案确定了,接下来进行技术调研吧。
我们最初的调研方向是使用服务端转换,因为相对成熟的 npm 包大多都只支持 Node 环境,而非浏览器环境。
首先,我们找到的是 Sharp 这个 Node 库,其底层基于 C/C++ 的 libvips,宣称_比使用最快的 ImageMagick 和 GraphicsMagick 设置快 4 到 5 倍_,在 Node 中可以开箱即用,也是大多数 Node 应用的首选。
使用 Sharp 完成 RGB 到 CMYK 的转换非常简单,核心代码仅四行:
import { Injectable } from '@nestjs/common';
import * as sharp from 'sharp';
@Injectable()
export class ImageService {
async transformToCMYK(file: Express.Multer.File): Promise<Buffer> {
return sharp(file.buffer)
.withIccProfile('./profiles/JapanColor2001Coated.icc')
.jpeg({ quality: 100, chromaSubsampling: '4:4:4' })
.toBuffer();
}
}
美中不足的是,Sharp 毕竟是一个精简的图像处理框架,它仅支持纯算法和纯 ICC 文件的 CMYK 转换,前文提到的渲染意图和黑场补偿等均未支持。
ImageMagick 是一个非常老牌的图像处理框架,堪比音视频领域的 ffmpeg。而最重要的是它支持指定渲染意图和开启黑场补偿。
本地安装后,你可以使用如下命令行命令来实现 RGB 到 CMYK 的转换:
magick convert input.jpg \
-profile "sRGB_v4_ICC_preference.icc" \
-intent Relative \
-black-point-compensation \
-profile "Your_Target_CMYK.icc" \
output.jpg
除了直接使用命令行调用二进制文件,我们还可以使用 magickwand.js,这是一个基于 swig 和 emnapi 的库,同时实现了 Node.js 原生和浏览器 WASM 版本。
magickwand.js 的 Node.js 原生版本专为与 Express.js 等框架配合使用而设计,非常适合服务器端应用。官方文档宣称它_经过内存泄漏调试,并且在仅使用异步方法时,绝不会阻塞事件循环_。
在 Node 中使用 magickwand.js 也非常简单,代码示例如下:
import { Injectable, Logger } from "@nestjs/common";
import { Intent } from "./dto/cmyk.dto";
import { Magick } from "magickwand.js/native";
import * as fs from "fs";
import * as path from "path";
@Injectable()
export class ImageService {
private logger = new Logger(ImageService.name);
private readonly profiles: Record<string, Magick.Blob> = {};
constructor() {
// Japan Color 2001 Coated
this.loadIccProfile(
"JapanColor2001Coated",
"./profiles/JapanColor2001Coated.icc"
);
// 普通CMYK描述文件
this.loadIccProfile(
"Generic CMYK Profile",
"./profiles/Generic CMYK Profile.icc"
);
}
private loadIccProfile(profileName: string, profilePath: string) {
if (this.profiles[profileName]) {
this.logger.warn(`${profileName} 配置文件已存在,跳过加载`);
return;
}
const fullPath = path.join(__dirname, profilePath);
const buffer = fs.readFileSync(fullPath).buffer;
const blob = new Magick.Blob(buffer);
this.profiles[profileName] = blob;
}
async transformToCMYK(
file: Express.Multer.File,
intent: Intent,
blackPointCompensation: boolean
): Promise<Buffer> {
const inputBlob = new Magick.Blob(file.buffer.buffer as ArrayBuffer);
const inputImage = new Magick.Image(inputBlob);
// 指定渲染意图
await inputImage.renderingIntentAsync(intent);
// 设置黑场补偿
await inputImage.blackPointCompensationAsync(blackPointCompensation);
// 转换 ICC 配置文件
await inputImage.iccColorProfileAsync(
this.profiles["JapanColor2001Coated"]
);
// 指定输出格式
await inputImage.magickAsync("JPEG");
const outputBlob = new Magick.Blob();
await inputImage.writeAsync(outputBlob);
const outputBuffer = await outputBlob.dataAsync();
return Buffer.from(outputBuffer);
}
}
这个库的主要问题是它没有 JS/TS 的文档,只有 C/C++ 的文档,使用时往往需要你根据 TS 的参数类型连蒙带猜去传参。
除了使用 Node,在 Python 中我们也有很多的选择,例如 PIL/Pillow,它同样非常强大易用,代码示例如下:
from PIL import Image, ImageCms
img = Image.open("input.jpg")
rgb_profile = ImageCms.getOpenProfile("sRGB Color Space Profile.icm")
cmyk_profile = ImageCms.getOpenProfile("JapanColor2001Coated.icc")
transform = ImageCms.buildTransform(
rgb_profile,
cmyk_profile,
"RGB",
"CMYK",
renderingIntent=ImageCms.Intent.RELATIVE_COLORIMETRIC, # 相对比色
flags=ImageCms.Flags.BLACKPOINTCOMPENSATION, # 黑场补偿
)
cmyk_img = ImageCms.applyTransform(img, transform)
cmyk_img.save("output.jpg", quality=95, icc_profile=cmyk_profile.tobytes())
既然有这么多现成的库,而且代码看着也没多少,一定很好实现吧。
很可惜,理想很美好,现实很悲催。在实际落地过程中,我们遇到了很多问题。
最开始,我们选择了功能最完善的 magickwand.js。它天然支持渲染意图和黑场补偿,正好满足我们的需求。本地编码调试一切正常,但提交到 CI/CD 平台后,构建直接失败了:
排查后发现,magickwand.js 依赖 xpm 这个 C/C++ 包管理器。在执行 npm install 时,xpm 会去 npm 源查找 package.json 中声明的 xpack 字段,然后从 GitHub 下载对应平台的二进制文件:
{
"xpack": {
"binaries": {
"baseUrl": "https://github.com/xpack-dev-tools/ninja-build-xpack/releases/download/v1.13.1-1",
"platforms": {
"darwin-arm64": {
"fileName": "xpack-ninja-build-1.13.1-1-darwin-arm64.tar.gz",
...
},
...
}
}
}
}
构建容器内无法访问 Github,这个问题我们无法解决,只能放弃 magickwand.js,转而考虑其他方案。
实际上我们还有一个方案,就是绕过 xpm,直接将预编译好的 ImageMagick 二进制文件都下载到本地,然后在 Node 中写一个平台适配层,封装下命令调用,也可以满足需求。
但是使用 child_process 来调用会有很多问题:
- 性能开销大:涉及进程创建、销毁和上下文切换成本;
- 通信效率低:需通过标准输入输出进行数据序列化与反序列化,增加了额外的处理延迟;
- 并发控制复杂:需手动管理进程池和资源竞争,避免系统资源耗尽;
- 异步编程繁琐:必须处理流控制、背压和错误恢复机制,代码复杂度显著增加;
- 稳定性风险高:子进程崩溃可能影响主进程稳定性,且进程间状态难以共享。
综合考虑下来,这个也只能作为实在没有办法的备选,不应当作为首选方案。
除了构建上的难题,最致命的实际是后端处理所带来的用户体验问题。
在我们的业务场景中,设计稿需要以 300 DPI 导出,一张海报的分辨率通常是 7087×9449,RGB 原图约 30MB;而门店横幅、围挡等大尺寸设计稿,原图甚至会达到 100MB+。
虽然前段时间运维升级了公司的网络带宽,由原先的 25Mb 调整到 100Mb,但是即便是跑满带宽,下载速度也只能达到约 12MB/s,而这还是建立在不考虑服务器带宽的前提下,完整的转换流程仍然需要:
整个 RTT 实测下来超过了 100 秒,还要承受网络波动导致传输失败的风险。这种体验完全无法接受。
我们也想过优化方案——把 Fabric 的渲染逻辑移到服务端:
fabric + node-canvas 渲染图片理论上可以减少一次上行和一次下行,将 RTT 缩短至 30 秒以内。但这个方案评估下来,问题更多:
1. 渲染场景复杂,迁移成本极高
我们有两个场景需要适配:
如果将 Fabric 渲染逻辑迁移到 Node:
而且前端现有的历史渲染代码本就错综复杂,要保证 Node 生成的图片和浏览器完全一致,需要投入更多的开发和测试资源。
2. 字体合规风险
设计团队使用的字体都是免费或商业授权的,但大多数字体的授权范围仅限于桌面使用。如果把字体文件上传到服务器,属于"网络传播"或"网络嵌入"用途,需要单独授权。
要合法使用服务端渲染,我们需要:
这期间,一旦出现纰漏,可能收到律师函、侵权通知或高额赔偿。
作为一家上市公司,古茗在全国有上万家加盟门店。如此大的体量,任何合规风险都可能给公司造成无法估量的损失。
3. 服务端性能问题
使用服务端渲染还有一个绕不过的问题就是性能问题,在服务端执行图像处理,同样需要耗费 CPU 和内存性能,我们需要对使用场景进行梳理,根据埋点信息统计出调用频次,以评估接口性能,并对接口进行压测。如果性能不能满足,我们还需要申请更高配置的服务器。
这同样需要我们花费更多的时间,测试资源本就紧张,难以协调,线上稳定性也难以保障。
服务端方案成本太高,必须另寻出路,而客户端方案,JS 处理肯定是不行了,性能太差。而除了 JS 我们还有一条路可以走——WebAssembly。
ImageMagick 是用 C/C++ 编写的,理论上我们可以用 Emscripten 编译为 WASM。但想要打通整条链路,我们需要:
这套流程虽然很明确,但学习和上手成本确实不低。受限于工期,我们先尝试寻找现成的方案:
1. magickwand.js WASM 版本
magickwand.js 本身就提供了 WASM 版本,但使用后发现它依赖 SharedArrayBuffer,这要求启用跨域隔离(Cross-Origin Isolation)。这不仅需要改造现有的构建脚手架,发布时还需要改造网关配置。加之这个库之前在 CI/CD 环节就有问题,我们只能放弃。
2. 其他 WASM 库
ImageMagick 官网推荐的 WASM-ImageMagick 已经 6 年没更新了。我们在 npm 上找到了 @imagemagick/magick-wasm,其作者是 ImageMagick 的核心开发者之一,下载量排名靠前,更新活跃,非常可靠。
最重要的是,它不存在我们前面提到的任何一个问题!
问题解决,接下来只需要将 magick-wasm 接入到工程中即可。
magick-wasm 这个库内部使用 BigInt,如果你的 browserslist 指定版本过低,Babel 编译时可能会报错,添加一个 supports bigint 即可:
{
"browserslist": [
"supports bigint",
"not dead"
]
}
我们需要在页面组件中加载 WASM 模块,这里我们要求必须初始化成功,因为如果 WASM 模块无法加载,设计师转换色彩模式失败,仍会影响后续印刷。
const WASM_LOCATION = new URL('@imagemagick/magick-wasm/magick.wasm', import.meta.url);
const App: React.FC = () => {
useMount(() => {
setLoading(true);
initializeImageMagick(WASM_LOCATION)
.then(() => console.log('ImageMagick 初始化成功'))
.catch(() => {
const message = 'ImageMagick 初始化失败';
CustomReport.sendWarning(ArmsLogs.initializeImageMagickFailed, { message });
Modal.error({
title: message,
content: '请使用最新版本的 Chrome 浏览器!',
onOk: () => window.close(),
});
})
.finally(() => setLoading(false));
});
}
初始化逻辑中需要注意添加 Loading 提示,因为初始化 WASM 是需要通过网络请求获取 .wasm 文件的,如果网速过慢就有可能导致触发转换时 WASM 模块还没有初始化完成。
此外,在初始化失败时还要接入埋点告警,以便我们感知线上的使用情况。
这部分的核心转换逻辑也并不多,大致流程如下:
const RGB_PROFILE_LOCATION = new URL('@/assets/icc/sRGB Color Space Profile.icm', import.meta.url);
const CMYK_PROFILE_LOCATION = new URL('@/assets/icc/JapanColor2001Coated.icc', import.meta.url);
const readFile = async (url: URL): Promise<Uint8Array> => {
const response = await fetch(url);
const arrayBuffer = await response.arrayBuffer();
return new Uint8Array(arrayBuffer);
};
export const transformColorSpace = async (uint8Array: Uint8Array): Promise<Uint8Array> => {
const [rgbProfileUint8Array, cmykProfileUint8Array] = await Promise.all([
readFile(RGB_PROFILE_LOCATION),
readFile(CMYK_PROFILE_LOCATION),
]);
const rgbProfile = new ColorProfile(rgbProfileUint8Array);
const cmykProfile = new ColorProfile(cmykProfileUint8Array);
return new Promise((resolve, reject) => {
ImageMagick.read(uint8Array, MagickFormat.Jpeg, (image) => {
image.blackPointCompensation = true;
image.renderingIntent = RenderingIntent.Perceptual;
/**
* 必须同时指定 source 和 target,否则在 safari 下会有 bug
* https://github.com/dlemstra/magick-wasm/blob/main/src/magick-image.ts#L3976
* safari canvas 导出的图片无法检测出 icc,会导致转换失败
*/
const success = image.transformColorSpace(
rgbProfile,
cmykProfile,
ColorTransformMode.HighRes
);
if (!success) {
message.error('色彩空间转换失败!');
CustomReport.sendWarning(ArmsLogs.colorSpaceTransformFailed, {
message: '色彩空间转换失败!',
});
reject(new Error('色彩空间转换失败!'));
} else {
image.write(MagickFormat.Jpeg, (result) => {
// 需要拷贝一份,否则 result 会被 GC 回收
resolve(new Uint8Array(result));
});
}
});
});
};
但是这里有两个坑点需要注意:
transformColorSpace 在源码中判断了图像是否内嵌了 profile,如果没有嵌入,会直接返回失败。
在 Chrome 中通过 Canvas 导出的图片,调用 ImageMagick 查询 ICC 文件时可以正常找到,但是通过 Safari 导出的图片则无法检出。
奇怪的是,使用 macOS 自带预览查看颜色描述文件信息时却恰好得到了相反的结果——使用 Safari 导出的图片正确嵌入了 sRGB IEC61966-2.1 文件,而 Chrome 导出的图片却没有显示颜色描述文件。
这个问题笔者没有深入研究,如果有了解原因的朋友也欢迎在评论区回复解答下疑惑
因此在 Safari 下 transformColorSpace 方法不会执行任何操作,直接返回了 true。
阅读源码后发现要规避这个问题,只需要同时传入 source 和 target 即可:
const RGB_PROFILE_LOCATION = new URL('@/assets/icc/sRGB Color Space Profile.icm', import.meta.url);
const CMYK_PROFILE_LOCATION = new URL('@/assets/icc/JapanColor2001Coated.icc', import.meta.url);
export const transformColorSpace = async (uint8Array: Uint8Array): Promise<Uint8Array> => {
const [rgbProfileUint8Array, cmykProfileUint8Array] = await Promise.all([
readFile(RGB_PROFILE_LOCATION),
readFile(CMYK_PROFILE_LOCATION),
]);
const rgbProfile = new ColorProfile(rgbProfileUint8Array);
const cmykProfile = new ColorProfile(cmykProfileUint8Array);
return new Promise((resolve, reject) => {
ImageMagick.read(uint8Array, MagickFormat.Jpeg, (image) => {
image.blackPointCompensation = true;
image.renderingIntent = RenderingIntent.Perceptual;
/**
* 必须同时指定 source 和 target,否则在 safari 下会有 bug
* https://github.com/dlemstra/magick-wasm/blob/main/src/magick-image.ts#L3976
* safari canvas 导出的图片无法检测出 icc,会导致转换失败
*/
const success = image.transformColorSpace(
rgbProfile,
cmykProfile,
ColorTransformMode.HighRes
);
if (!success) {
reject(new Error('色彩空间转换失败!'));
} else {
image.write(MagickFormat.Jpeg, resolve);
}
});
});
};
当然别忘记在代码中留下对应的注释说明,防止后人维护重复踩坑。
image.write 回调中的 data 对象来自 magick-wasm 的内存,它的生命周期不受 JS 控制,回调结束或后续写入时那段内存可能已经被复用/释放。
要解决这个问题也很简单,原地复制一份即可:
image.write(MagickFormat.Jpeg, (data) => {
// 需要拷贝一份,否则 result 会被 GC 回收
resolve(new Uint8Array(data));
});
同样留下一个贴心的注释,后续只需适配对应的业务代码即可
功能是实现了,但业务实际用下来还是发现不少问题,主要集中在性能方面。
业务使用的是统一采购的 16G 的 M1 芯片 iMac,按理来讲不会卡,但是深入了解了业务的操作习惯后,发现了几个很有意思的点:
虽然 WebAssembly 运行速度非常快,但它与 JavaScript 共享同一个事件循环(Event Loop)。如果你在主线程直接调用一个耗时较长的 WASM 函数,它依然会阻塞 UI 响应,导致页面卡顿。
在现代浏览器中,同一个域名的不同标签页,通常也是共用的同一个进程,这还会导致,我们在一个标签页下处理图像,同域的其他标签页也无法操作(主线程被阻塞),浏览器还会弹出页面无响应的提示
因此,我们还需要做针对性的性能优化。
性能优化的第一步,就是将 WebAssembly 从主线程中移出去。我们可以使用 Web Worker 将 WASM 的逻辑单独放在 worker 线程中执行,从而避免阻塞主线程。
想要使用 worker 很简单,你只需要创建一个 worker.js 文件,随后在主线程中使用:
const myWorker = new Worker("worker.js");
即可将 worker.js 中的代码放在独立的 worker 线程中执行。
注意这里不能用
SharedWorker,一方面 Safari 长期以来对 SharedWorker 支持不佳,另一方面 SharedWorker 更多使用在是跨标签通信,或者某些需要共享资源的场景,对于上面提到的多标签并发图像处理反而起到负作用(多个标签共享一个 Worker,处理是串行的),无法最大程度利用现代多核 CPU 的性能。
此外,由于单个标签页可能会触发多次图像处理,我们还可以使用单例模式减少重复的 WASM 初始化,从而进一步优化性能,代码示例如下:
// Worker 实例
let workerInstance: Worker | null = null;
/**
* 获取 Worker 实例(单例模式)
*/
const getWorker = (): Worker => {
if (!workerInstance) {
workerInstance = new Worker(new URL('./magick.worker.ts', import.meta.url), {
type: 'module'
});
// 监听 Worker 返回的消息
workerInstance.onmessage = (event) => {};
// 监听 Worker 错误
workerInstance.onerror = (error) => {};
}
return workerInstance;
};
Worker 同源限制
在上线前我们还遇到一个问题,我们的前端构建产物是托管在 OSS 上的,这里使用 new URL 获取到的 worker 资源不同源,导致无法加载。
为了解决这个问题,我们将 worker 内部的逻辑单独抽离到一个 npm 包中,连同依赖项一起打包成 UMD 格式,在业务工程中通过 fetch 方式获取脚本内容。
const WORKER_URL = new URL('@guming/magick-worker/build/umd/index.js', import.meta.url);
// Fetch worker 文件内容
const response = await fetch(WORKER_URL);
const workerCode = await response.text();
// 创建 Blob 和 Blob URL
const blob = new Blob([workerCode], { type: 'application/javascript' });
const blobUrl = URL.createObjectURL(blob);
// 创建 Worker
const worker = new Worker(blobUrl);
如果你使用 Vite,也可以使用 Vite 的
import MyWorker from'./worker.js?worker'语法。或者也可以使用 remote-web-worker 这样的库来少写点代码。
Worker 通过 postMessage 与主线程通信,数据传输有两种模式:
这也是最常用的一种写法,代码示例如下:
const worker = new Worker('worker.js');
const imageBuffer = new ArrayBuffer(100 * 1024 * 1024);
worker.postMessage({ type: 'process', data: imageBuffer });
这种方式会为接收方创建一个数据的完整副本。对于 100MB 的图片,传输瞬间会导致内存占用翻倍(变为 200MB)。如果是 5 个标签页同时操作,内存峰值将迅速堆叠,引发浏览器 OOM(内存溢出)崩溃。
除了结构化克隆之外,worker 还提供了一种允许你直接转交对象内存的方式,代码示例如下:
const worker = new Worker('worker.js');
const imageBuffer = new ArrayBuffer(100 * 1024 * 1024);
worker.postMessage(
{ type: 'process', data: imageBuffer },
[imageBuffer] // 第二个参数:要转移的对象列表
);
// 转移后,imageBuffer 在主线程不可用
console.log(imageBuffer.byteLength); // 0 —— 所有权已转移
通过这种方式,我们可以避免对大对象进行拷贝,从而减少通信时上下文结构化的性能开销。
在实际开发工作中,我们通常还需要写一套复杂的事件通信逻辑,来保障和 worker 之间的通信,代码可能长这样:
// 主线程
let workerInstance: Worker | null = null;
let messageId = 0;
const pendingRequests = new Map<number, { resolve: Function; reject: Function }>();
/**
* 获取 Worker 实例(单例模式)
*/
const getWorker = (): Worker => {
if (!workerInstance) {
workerInstance = new Worker(new URL('./magick.worker.ts', import.meta.url), {
type: 'module'
});
// 监听 Worker 返回的消息
workerInstance.onmessage = (event) => {
const { id, type, data, error } = event.data;
const request = pendingRequests.get(id);
if (request) {
if (type === 'success') {
request.resolve(data);
} else if (type === 'error') {
request.reject(new Error(error));
}
pendingRequests.delete(id);
}
};
// 监听 Worker 错误
workerInstance.onerror = (error) => {
console.error('Worker error:', error);
// 拒绝所有等待中的请求
pendingRequests.forEach(({ reject }) => reject(error));
pendingRequests.clear();
};
}
return workerInstance;
};
/**
* 向 Worker 发送消息并等待响应
*/
const sendMessageToWorker = <T>(
method: string,
data?: any,
): Promise<T> => {
return new Promise((resolve, reject) => {
const id = messageId++;
const worker = getWorker();
// 保存 promise 的 resolve 和 reject
pendingRequests.set(id, { resolve, reject });
// 发送消息到 Worker
worker.postMessage({ id, method, data });
});
};
const initializeWorker = (): Promise<void> => {
return sendMessageToWorker('initializeWorker');
};
export const transformColorSpace = (uint8Array: Uint8Array): Promise<Uint8Array> => {
return sendMessageToWorker<Uint8Array>('transformColorSpace', uint8Array);
};
// worker
import { initMagick, ImageMagick, MagickImage } from '@imagemagick/magick-wasm';
let initialized = false;
const initializeWorker = async (): Promise<void> => {};
const transformColorSpace = async (uint8Array: Uint8Array): Promise<Uint8Array> => {};
// 监听主线程的消息
self.onmessage = async (event) => {
const { id, method, data } = event.data;
try {
let result;
// 根据方法名调用对应的函数
switch (method) {
case 'initializeWorker':
await initializeWorker();
result = undefined;
break;
case 'transformColorSpace':
result = await transformColorSpace(data);
break;
default:
throw new Error(`Unknown method: ${method}`);
}
// 返回成功结果
self.postMessage({ id, type: 'success', data: result });
} catch (error) {
// 返回错误
self.postMessage({ id, type: 'error', error });
}
};
比较复杂,有一定的学习和理解成本。我们可以使用 Comlink 库来封装 worker 的通信逻辑,从而避免手动维护一套事件通信逻辑,代码可以精简如下:
// 主线程
import * as Comlink from 'comlink';
import type { WorkerApi } from './magick.worker';
let workerInstance: Worker | null = null;
let workerApi: Comlink.Remote<WorkerApi> | null = null;
const getWorkerApi = (): Comlink.Remote<WorkerApi> => {
if (!workerApi) {
workerInstance = new Worker(new URL('./magick.worker.ts', import.meta.url), { type: 'module' });
workerApi = Comlink.wrap<WorkerApi>(workerInstance);
}
return workerApi;
};
export const initializeWorker = async (): Promise<void> => {
const api = getWorkerApi();
await api.initializeWorker();
};
export const transformColorSpace = async (uint8Array: Uint8Array): Promise<Uint8Array> => {
const api = getWorkerApi();
return api.transformColorSpace(Comlink.transfer(uint8Array, [uint8Array.buffer]));
};
// worker
import * as Comlink from 'comlink';
const initializeWorker = async (): Promise<void> => {};
const transformColorSpace = async (uint8Array: Uint8Array): Promise<Uint8Array> => {
return new Promise((resolve, reject) => {
ImageMagick.read(uint8Array, MagickFormat.Jpeg, (image) => {
...
image.write(MagickFormat.Jpeg, (result) => {
const output = new Uint8Array(result);
// 使用 Transferable,避免大数据复制
resolve(Comlink.transfer(output, [output.buffer]));
});
});
});
};
const workerApi = {
initializeWorker,
transformColorSpace,
};
export type WorkerApi = typeof workerApi;
Comlink.expose(workerApi);
写法非常简单,仿佛根本没有 worker 的存在,Comlink 帮你封装了所有通信的细节。
原先的 transformColorSpace 写法中,每次执行都会重复请求一次 ICC 文件,我们完全可以将请求做前置缓存,统一放到 initializeWorker 内部,实测下来可以减少每次 2s 以上的重复请求耗时:
/**
* 初始化 ImageMagick WASM
*/
const initializeWasm = async (wasmUrl: string): Promise<void> => {
const wasmBytes = await readFile(wasmUrl);
await initializeImageMagick(wasmBytes);
};
/**
* 初始化 ICC profiles
*/
const initializeProfiles = async (rgbProfileUrl: string, cmykProfileUrl: string): Promise<void> => {
const [rgbProfileUint8Array, cmykProfileUint8Array] = await Promise.all([
readFile(rgbProfileUrl),
readFile(cmykProfileUrl),
]);
const rgbProfile = new ColorProfile(rgbProfileUint8Array);
const cmykProfile = new ColorProfile(cmykProfileUint8Array);
profiles = { rgb: rgbProfile, cmyk: cmykProfile };
};
/**
* 初始化 Worker
*/
const initializeWorker = async (config: {
wasmUrl: string;
rgbProfileUrl: string;
cmykProfileUrl: string;
}): Promise<void> => {
if (initialized) return;
return Promise.all([
initializeWasm(config.wasmUrl),
initializeProfiles(config.rgbProfileUrl, config.cmykProfileUrl),
]).then(() => {
initialized = true;
});
};
我们将优化前后各操作的性能进行对比,测试基准条件如下:
| 阶段 | 主线程方案 | Worker 方案(结构化克隆) | Worker 方案(零拷贝传输) |
|---|---|---|---|
| 初始化 | - | 619.20ms | 730.10ms |
| 图像处理 | 42710.70ms(42.71s) | 48494.60ms(48.5s) | 48281.70ms(48.27s) |
| 通信耗时 | - | 61.40ms | 53.00ms |
| 组装 Blob | 74.15ms | 140.80ms | 154.00ms |
| 总耗时 | 42784.85ms(42.79s) | 48696.8ms(48.7s) | 48494.60ms(48.5s) |
大图的处理时间稍长,实际上处理 20M 左右的图片,处理速度均控制在 10-20s 内。
| 指标 | 主线程方案 | Worker 方案 |
|---|---|---|
| 标签 1 完成时间 | 43.25s | 45.17s |
| 标签 2 完成时间 | 40.39s | 42.28s |
| 标签 3 完成时间 | 无法处理 | 41.84s |
| 全部完成时间 | 页面等待超 5 分钟才可以交互 | 45.17s |
| 其他标签是否卡顿 | 所有同域标签全部卡死 | 否 |
在 Chrome 中可以使用 performance.memory 获取当前的内存使用情况,其中返回对象的 jsHeapSizeLimit 字段表示当前 JavaScript 页面可以使用的最大堆内存限制。
在 64 位系统中,物理内存大于 16G 的,堆内存最大限制为 4G;小于等于 16G 的,最大堆内存限制为 2G。
在 32位系统中,最大堆内存限制为 1G。
| 场景 | 主线程方案 | Worker 方案(结构化克隆) | Worker 方案(零拷贝传输) |
|---|---|---|---|
| 初始化前 | 536.96 MB | 134.92 MB | 153.93 MB |
| 初始化后 | 653.57 MB | 171.09 MB | 156.86 MB |
| Blob组装前 | 653.57 MB | 238.52 MB | 230.86 MB |
| 发送前 | 3105.70 MB (对应图像处理中) | 355.71 MB | 348.05 MB |
| 接收后 | 415.65 MB | 364.07 MB | |
| Blob 组装后 | 3105.70 MB | 415.65 MB | 364.07 MB |
在主线程方案的测试过程中,第二个标签页在处理图像过程中,堆内存来到了 5492.76 MB,已经超出了 4G 的堆内存限制,这直接导致了第三个标签页的白屏崩溃。而 Worker 方案,页面全部正常展示 Loading,未出现白屏等情况,所有页面几乎同时输出了转换后的图片。
设计师使用的设备为公司统一采购的 M1 芯片 iMac,16G 内存。
在设计师的机子上 Chrome 最大堆内存限制为 2G,主线程方案仅支持同时开启一个标签页处理
这是本次优化最显著的成果。在 64 位 Chrome 中,即便物理内存高达 32GB,单个标签页的 JS 堆内存限制(jsHeapSizeLimit)通常仍被锁定在 4GB。
主线程方案在处理 120MB+ 大图时,瞬时内存飙升至 3.1GB。当开启 3 个标签页并发处理时,内存占用迅速叠加至 5.5GB 左右,触发 OOM,导致浏览器标签页直接白屏崩溃。
通过将计算密集型任务移出主线程,主线程内存始终维持在 300MB-400MB 的较低水平。Worker 方案成功绕过了单线程堆内存限制,实现了 5 个以上标签页的稳定并发。
主线程方案在处理期间,由于执行栈被 ImageMagick 完全阻塞,导致同域下的所有标签页失去响应,用户无法进行任何交互。
Worker 方案虽然在单线程处理耗时上略慢于主线程(约增加 13% 的上下文开销),但它保证了 UI 的绝对响应速度。用户在处理百兆大图的同时,依然可以平滑地切换标签页、点击按钮或观看 Loading 动画。
使用结构化克隆时,数据发送前后有 60MB 的内存差值,而零拷贝将内存波动降至 16MB,在大数据量下,这个差距会随着并发量的增加而变得极度明显。
通过使用零拷贝传输,我们避免了 CPU 密集的序列化过程,同时减少了内存峰值和 GC 压力,保证了并发情况下页面的正常使用。
| 维度 | 主线程方案 | Worker 方案 (优化后) | 结论 |
|---|---|---|---|
| 单图总耗时 | 42.79s | 48.5s | 主线程略快,但牺牲了交互性 |
| 并发可靠性 | 极差 (仅支持2次并发) | 极优秀 (并发无压力) | Worker 解决了生存问题 |
| 主线程内存峰值 | 3105.70 MB | 364.07 MB | 降低了 88% 的主线程内存压力 |
| 交互体验 | 页面完全冻结 | 始终流畅 | 核心体验提升 |
本次需求从一个看似简单的"颜色不对"问题出发,最终演变成了一次涉及色彩科学、图像处理、Web 技术栈选型以及前端性能优化的综合技术攻坚。
回顾整个过程,我们遇到的困难主要集中在三个方面:
技术选型的权衡:从 Sharp 到 ImageMagick,从 Node.js 到 Python,再到 WebAssembly,每一种方案都有其适用场景和局限性。我们需要在功能完整性、性能表现、开发成本以及基建适配性之间反复权衡。
基础设施的限制:CI/CD 环境的网络策略、服务器性能、字体授权合规等"非技术"因素,往往会成为技术方案落地的最大障碍。这提醒我们,技术方案的设计不能脱离实际的业务环境。
用户体验的坚守:最初的服务端方案虽然功能简单完善,但超 100s 的等待时间完全无法接受。正是对用户体验的坚持,驱使我们最终找到了客户端 WASM 方案,并通过性能优化将处理时间大大缩短到 20 秒内。
最终,通过在浏览器端集成 @imagemagick/magick-wasm,我们实现了:
这次经历让我们深刻认识到:解决问题的过程往往比问题本身更有价值。在探索过程中积累的色彩管理知识、WASM 技术和性能优化经验、以及对业务场景的深入理解,都将成为团队宝贵的技术资产。
更重要的是,这次技术改造不仅解决了燃眉之急,更为后续的图像处理需求奠定了坚实基础。当下次遇到类似的图像处理问题时,我们已经有了一套成熟的解决思路和技术储备。
技术服务业务,业务驱动技术。希望这次实践能为遇到类似问题的朋友们提供一些参考和启发。
High performance Node.js image processing
ImageMagick | Mastering Digital Image Alchemy
Troubleshooting Common Problems
Relative Colorimetric or Perceptual? Which Rendering Intent Should I Use? - YouTube


消息称 iPhone 17e 将加量不加价

机器人春晚来袭,还有 999 元租机器人

神秘模型「Pony Alpha」上线引发热议

微信回应鸿蒙版相机界面更新:仍调用华为系统相机

AI.com 网址以 4.85 亿元成交

马斯克:苹果造车时一个劲挖特斯拉的工程师

英伟达为 3 万工程师部署生成式 AI,代码产出提升约 3 倍

SpaceX 推迟火星计划,转向明年无人月球着陆

研究称「996」工作模式正在硅谷 AI 行业蔓延

美国市场调研:35% 消费者不想要设备端 AI 功能

780 元,徕卡发布 iPhone 17 Pro 系列专用 LUX 手机壳

OpenAI 首款硬件「Dime」曝光
🫘
索尼确认「降噪豆 6」2 月 13 日亮相

千问回应奶茶免单权益遭倒卖:违规将取消资格冻结权益

国家电网:春节高速充电量或创历史新高

泡泡玛特 LABUBU 去年销量破亿,全球门店突破 700 家


iPhone 16e
据彭博社 Mark Gurman 报道,苹果计划通过一轮入门产品线更新,进一步渗透新兴市场和企业级客户:
苹果将在 2026 年迎来五十周年,而上半年的节奏较往年可能会更加紧凑。显然,苹果也想稳住销量的势头,但所有苹果用户都知道,真正能决定口碑拐点的,仍取决于 AI Siri 能否兑现承诺。

2 月 8 日,由智元机器人和擎天租联合主办的全球首个大型机器人晚会《机器人奇妙夜》正式开启全球直播。
 相关阅读:全球首届机器人「春晚」炸场!稚晖君带队,节目效果拉满,连观众都是机器人
相关阅读:全球首届机器人「春晚」炸场!稚晖君带队,节目效果拉满,连观众都是机器人
作为行业里程碑式的盛会,《机器人奇妙夜》实现了从「机器人演节目」到「机器人撑起一整台晚会」的质变。它成功打破了机器人仅限于单一任务执行的刻板印象,创下多个 「从零到一」 的突破。
首个机器人小品、首个机器人魔术、首个人机共舞华尔兹等创举,集中展示了中国机器人在复杂运动控制、高精度群体协同和初步情感表达上的突破性进展,标志着其正式迈入「舞台级系统智能」新阶段。
晚会由智元远征 A2 坐镇主理人,推出了 12 个高水准节目。
在全球首个机器人魔术表演《超级变变变!》中,黄晓明跨界担任 「见证官」,与灵犀 X2、远征 A2 协作呈现虚实交织的 「奇迹时刻」。
而作为本次机器人奇妙夜的联合主办方之一,擎天租在晚会期间已经同步上线「999 元全民机器人体验计划」,将舞台上的机器人能力,转化为普通用户能够在春节拜年、情人节求婚、亲子互动、庆祝生日等生活场景中体验的产品与服务。
另据了解,在擎天租小程序中,多款「奇妙夜同款」机器人已陆续上架,包括灵犀 X2、远征 A2 等热门机型,并以 999 元这一显著低于市场常规门槛的价格,向 C 端用户开放体验。
值得一提的是,擎天租平台数据显示,自春节前两周起,平台机器人租赁订单已出现明显增长趋势。2026 年 2 月首周(2 月 1 日至 2 月 7 日),擎天租机器人租赁订单量环比增长约 30%。
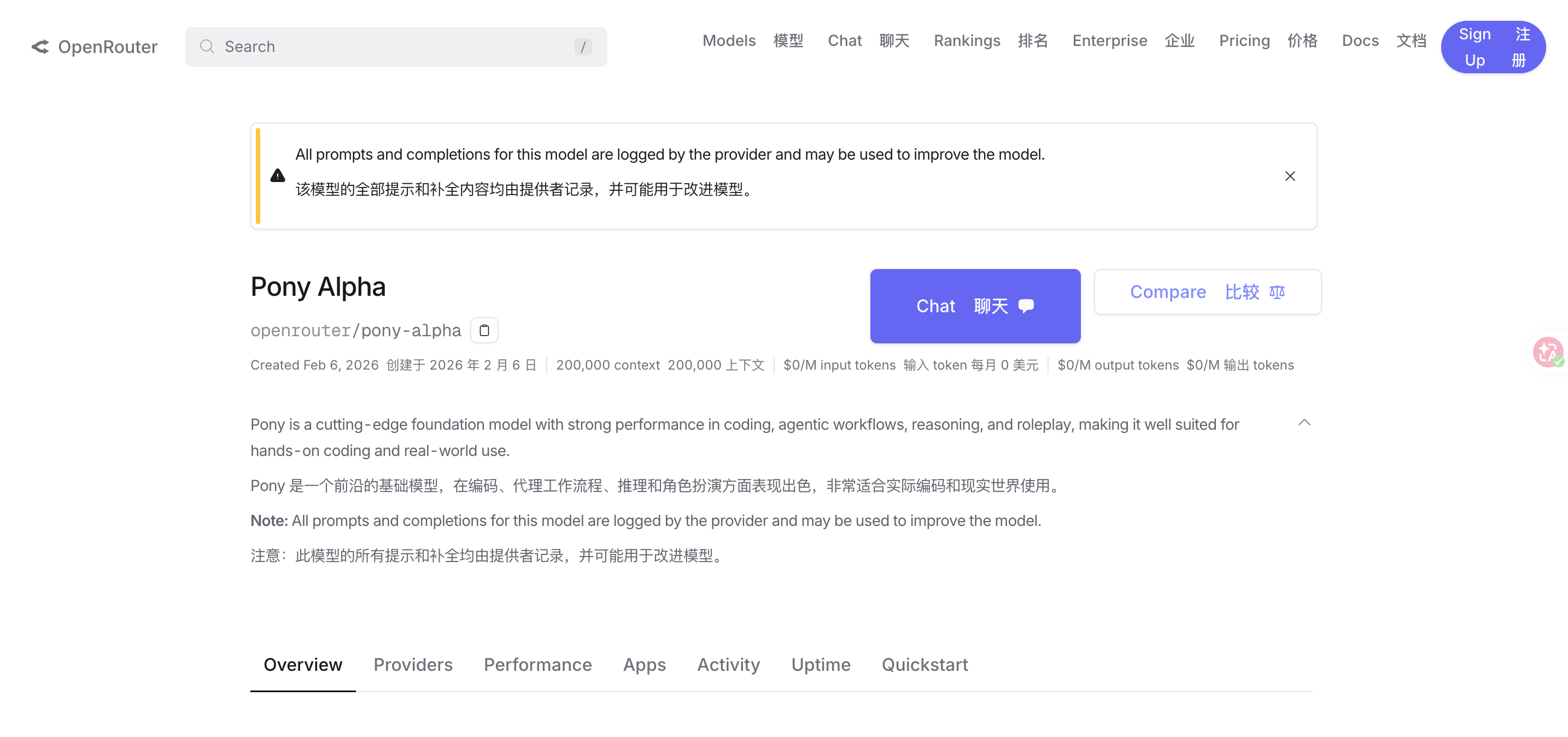
2 月 6 日,全球模型服务平台 OpenRouter 上架了一个名为「Pony Alpha」的神秘模型,并且模型很快跑到了搜索前几名。
据模型介绍页信息显示,Pony Alpha 为新一代通用大模型,在编码、代理工作流程、推理和角色扮演方面表现出色,非常适合实际编码和现实世界使用。
模型拥有 200k 上下文窗口,支持 131k 输出,并且支持免费使用。
据博主「karminski – 牙医」分析,该模型在大象牙膏的生成测试中,表现十分像 Claude 系列;但博主也提出了模型或为 DeepSeek-V4、GLM 新模型等疑问。
同时结合模型名称中的「Pony」来看,Pony Alpha 也有一定概率出自腾讯。
值得一提的是,Pony 一词直译为「小马」,结合 2026 年为马年这一信息,Pony Alpha 有概率是来自中国的模型。
模型本人:https://openrouter.ai/openrouter/pony-alpha
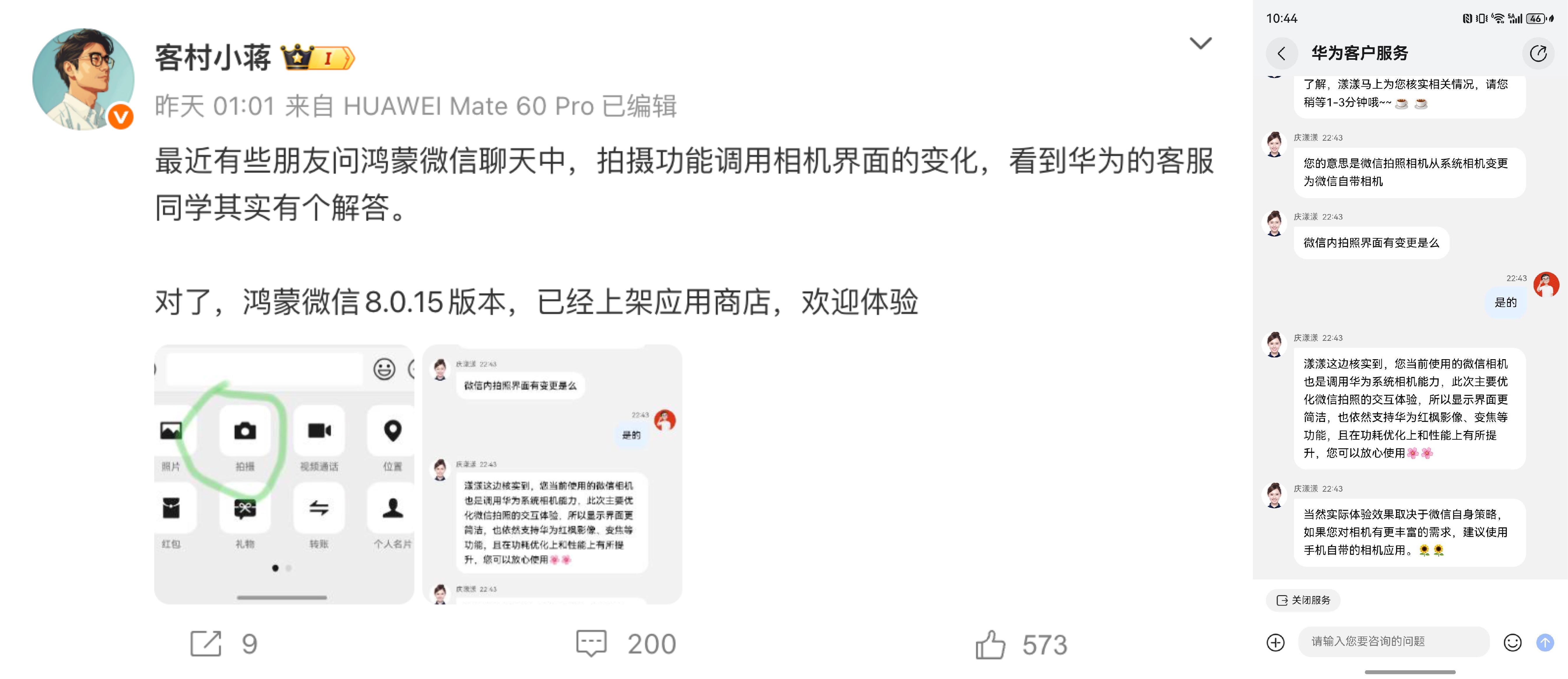
近日,微信鸿蒙版对相机界面进行了灰度更新。有网友发现更新后界面更接近安卓版本,并怀疑微信已不再调用华为系统相机。
对此,微信员工「客村小蒋」引用华为客服的官方回应,明确否认相关传闻。
华为客服表示,微信鸿蒙版当前依旧调用华为系统相机能力,本次调整主要针对微信拍照界面的交互优化,使界面更加简洁。
核心影像能力如「红枫影像」、变焦等均保持不变,且在功耗与性能方面同步提升,用户可放心使用。如果需要更丰富的拍摄功能,客服建议直接使用手机原生相机应用。
华为 App Gallery 数据显示,微信鸿蒙版自去年 1 月上线华为应用市场以来,已累计迭代百余次,安装量突破 4000 万。
据《金融时报》报道,Crypto.com 联合创始人兼 CEO Kris Marszalek 以价值约 7000 万美元(约合人民币 4.85 亿元)的加密货币收购了 AI.com 域名,创下迄今公开披露的最高域名交易纪录之一。
据悉,今年周末的超级碗广告中,他将正式推出基于该域名的新 AI 服务。
公开信息显示,AI.com 的交易由域名经纪人 Larry Fischer 促成,其向《金融时报》确认了 7000 万美元的成交价,支付方式为加密货币。
Fischer 表示「像 AI.com 这样的资产没有替代品」,并称此类机会极为罕见。作为参考,这一价格是此前 voice.com 纪录的两倍。
Marszalek 在采访中表示,去年获得收购机会时,他判断未来 10 至 20 年人工智能将成为最重要的技术浪潮之一,因此将其视为长期投资。
他透露,AI.com 将提供面向普通用户的「AI Agent」,可用于发送消息、调用应用甚至进行股票交易,目标是降低使用门槛,类似近期在硅谷走红的 OpenClaw,但更易上手。
Crypto.com 成立于 2016 年,Marszalek 称其年收入已增长至约 15 亿美元。该公司过去以大规模市场营销著称,包括体育赞助、名人代言,以及 2021 年以 7 亿美元获得洛杉矶一座体育场的冠名权。
Marszalek 透露,他已收到「极其夸张」的转售报价,但仍选择持有该域名,认为其对未来业务的信任度与认知度至关重要。
他表示:「当年我们在上千家加密交易所中杀出重围,这次我们也会让 AI.com 成功。」

据 TESLARATI 报道,马斯克日前在一档播客节目中透露,苹果目前已废止的造车项目在开发期间,曾不断打电话给特斯拉的工程师询问工作情况。
而据马斯克称,特斯拉的工程师在接到电话后,都将电话挂掉了。「他们(苹果)向特斯拉狂轰滥炸般地打来招聘电话,而工程师们直接拔掉了电话线。」
报道指出,苹果此前想挖的一部分前特斯拉工程师,实际上后来并未留在汽车行业。
据悉,苹果的造车计划已于 2024 年终止,项目名称为「Project Titan」(泰坦计划)。该计划目标于 2028 年推出配备完全自动驾驶的电动车型。

据 TechPowerUp 报道,英伟达正将生成式 AI 深度纳入其内部工程体系,目前已有约 3 万名工程师使用基于 Anysphere 的定制版 Cursor 开发环境,官方称代码产出相较旧流程提升约 3 倍。
报道指出,英伟达在 GPU 驱动、AI 训练与推理基础设施、芯片设计等高可靠性领域全面部署 AI 辅助开发工具。
由于相关产品对稳定性要求极高,公司在生成代码投入生产前执行严格测试流程,以确保质量不因产出提升而下降。Cursor 与英伟达均表示,在代码量显著增加的情况下,内部统计的 Bug 率保持稳定。
英伟达此前已在多个关键产品中采用 AI 辅助方式。例如,DLSS 依赖专用超级计算机持续训练迭代;部分芯片设计也通过内部 AI 工具进行优化。

据《华尔街日报》报道,SpaceX 已推迟原定今年执行的火星任务,转而将资源集中在为 NASA 执行的月球着陆项目上。
知情人士称,公司已向投资者明确表示将「月球优先」,并计划在明年 3 月尝试一次无人月球着陆,以满足 NASA 在 Artemis 计划中的关键节点需求。

而在今早,马斯克发文放出最新外太空计划:
SpaceX 已经将重点转向在月球上建造一个自给自足的城市,因为我们可能不到 10 年就能实现,而火星则需要 20 多年。
马斯克指出,每 26 个月(六个月旅行时间)行星才会对齐,那时才有可能去火星。「而我们可以每 10 天发射一次去月球(两天旅行时间)。这意味着我们迭代建造月球城市比火星城市要快得多。」
其还表示,SpaceX 也将努力建造一个火星城市,并大约在 5 到 7 年内开始实施,但首要任务是确保文明的未来,而月球则更快。
报道指出,这一战略调整发生在 SpaceX 完成对 xAI 的收购之后。
合并后的公司估值达到 1.25 万亿美元,马斯克在内部备忘录中称,太空数据中心将成为未来月球基地、火星文明等长期愿景的基础能力。SpaceX 也在筹备最快今年夏季启动的 IPO。
NASA 数年前委托 SpaceX 基于 Starship(星舰)开发登月着陆器,用于在月球轨道与 NASA 航天器对接并将宇航员送上月面。
Starship 超过 400 英尺(约 121.92 米)高、设计为全可重复使用,研发资金部分来自 NASA 数十亿美元的合同。去年,NASA 管理层曾公开施压,要求 SpaceX 优先满足登月任务进度。
SpaceX 原计划在去年底利用地火距离缩短的窗口期发射 5 枚 Starship 前往火星,但马斯克今年 1 月在播客中表示,2026 年抵达火星的概率「很低」,且会「分散注意力」。
公司内部人士称,若要在明年 3 月完成无人着陆,SpaceX 必须在短时间内实现高频发射并验证轨道加油能力。
竞争对手方面,贝索斯旗下 Blue Origin 正推进其「简化版」登月系统,并在今年 1 月暂停太空旅游业务,全力投入月球项目。
NASA 管理层表示欢迎两家公司竞争,以确保登月器按期交付。Artemis II 绕月飞行任务预计将为 2028 年的潜在载人登月奠定基础。

据《商业内幕》报道,今年硅谷的 AI 行业正出现更趋严苛的「996」式工作文化,引发业内对员工身心负担的担忧。
报道援引多位研究人员指出,在激烈的 AI 竞赛推动下,部分科技公司正在形成高压、长工时的工作环境,甚至开始接近在国内互联网行业长期存在的「996」模式。
报道提到,Allen Institute for AI 高级研究科学家 Nathan Lambert 与 AI 研究实验室创始人 Sebastian Raschka 在近期播客节目中谈到,硅谷的工作节奏虽未完全复制中国的「996」,但趋势正在向更高强度靠拢。
Raschka 表示,AI 模型迭代速度极快,初创公司为了在竞争中保持领先,往往需要团队持续交付成果,这使得长时间工作成为常态。他强调,这种节奏更多源于竞争压力与从业者的热情,而非强制要求。
Lambert 指出,这种文化在旧金山最知名的 AI 公司中尤为明显,他提到「这就是 OpenAI 和 Anthropic 的现状」,许多程序员主动投入高压环境,因为他们希望参与最前沿的研究。
不过,他也强调,这种投入往往伴随明显的「人力消耗」(human expense),包括与家人相处时间减少、视野变窄以及健康问题等。
这种节奏不可能长期维持,人真的会被拖垮(burn out)。
Raschka 也分享了自身经历,称长期不休息导致颈部与背部疼痛。他认为,年轻程序员若希望在 AI 领域产生影响,亲自来到旧金山仍是最现实的路径,但必须接受相应的生活与健康取舍。

据《华尔街日报》,美国司法部正对 Netflix 拟以 827 亿美元收购华纳兄弟(Warner Bros. Discovery)的交易展开广泛反垄断调查,重点关注该公司是否存在可能巩固市场力量的排他性行为。
民事传票显示,司法部要求多家娱乐公司说明 Netflix 是否采取过「在合理情况下可能巩固其市场地位或垄断势力」的行为。
调查内容不仅涉及此次收购,也包括 Netflix 在内容竞争、人才合同及与竞争对手的市场互动方式。
同时,司法部也在审查派拉蒙提出的 779 亿美元敌意收购要约,两项交易均可能影响美国流媒体与内容制作市场的竞争格局。
Netflix 于去年 12 月宣布以全现金方式收购华纳兄弟探索,交易预计在获得监管批准后于 12 至 18 个月内完成。
Netflix 表示,当前调查属于常规审查流程,尚未收到任何单独垄断调查的迹象,并称正与司法部保持「建设性沟通」。华纳与 Netflix 方面均表示预计能够获得监管批准。
根据市场研究机构 Antenna 的估算,Netflix 与 HBO Max 合并后将在美国订阅流媒体市场占据约 30% 份额。
Netflix 方面则认为该数字缺乏意义,称 80% 的 HBO Max 用户同时订阅 Netflix,并强调此次交易应被视为发行方与内容供应方之间的垂直并购,而非减少直接竞争的横向并购。
Netflix 联合 CEO Ted Sarandos 此前在参议院司法委员会听证会上表示,合并后用户将支付更低价格。
报道指出,司法部的调查仍处于早期阶段,可能持续长达一年。除美国外,欧洲与英国监管机构也可能介入审查。总统特朗普在接受采访时表示不会干预此案,将由司法部自行处理。
美国市场调研:35% 消费者不想要设备端 AI 功能
近日,市场咨询机构 Circana 发布最新调查结果,显示美国 18 岁以上受访者中有 86% 知晓智能手机等设备内置 AI 功能,但其中 35% 明确表示对设备端 AI「没有兴趣」,主要原因在于现有设备已能满足需求。
其中,59% 的反对者担心 AI 会侵蚀个人隐私;43% 则不愿为额外的 AI 功能支付更高价格。
调查指出,AI 功能的复杂性并非主要阻力,仅 15% 的受访者认为其「难以理解」。
不过,整体态度并非完全排斥:65% 的受访者希望在至少一种设备上使用 AI 功能,其中 18 至 24 岁人群的接受度最高,达 82%,并随年龄增长逐步下降。
调查结果还显示,语音控制作为最早普及的 AI 应用形态之一,仍是当前最常见的使用场景。
智能手机占语音交互用户的 75%,智能音箱、智能显示屏与智能眼镜紧随其后;即便是智能冰箱,也已有超过三分之一用户使用语音功能。最常见的用途包括播放音乐、在线提问与获取日常信息。
Circana 分析认为,AI 在从云端向设备端过渡的过程中,消费者正在重新评估其价值。
企业需要进一步证明 AI 的实际效用,并在隐私保护、成本控制与伦理问题上建立更强的信任机制。随着 AI 在更多设备中落地,其普及仍面临多重现实挑战。


近日,相机厂商徕卡推出专为 iPhone 17 Pro 与 iPhone 17 Pro Max 设计的全新徕卡 LUX 手机壳。
据悉,这款手机壳采用优质黑色皮革与精密加工的黑色铝制按键,内衬为含环保再生材质的超细纤维面料,兼顾外观质感与机身保护。
产品内置 MagSafe 磁铁,可与徕卡 LUX 手柄搭配使用,提升拍摄时的握持稳定性。徕卡表示,该手机壳旨在为徕卡移动生态系统用户提供更完整的使用体验,与徕卡 LUX 应用程序及手柄实现无缝衔接。
售价方面,徕卡 LUX 手机壳在中国大陆官方定价为人民币 780 元,已在部分徕卡专卖店、线上商店及授权经销商发售。

OpenAI 首款面向消费者的 AI 硬件设备正加速推进,但今年 9 月亮相的首发版本将是功能受限的「简版」。
原因在于 HBM 供应紧张推高 2nm 芯片成本,迫使 OpenAI 推迟原计划中具备计算单元的「全能形态」,先行推出仅支持音频功能的版本。
相关阅读:曝 OpenAI 首款硬件定名「Dime」,坏消息:成本太高,9 月首发只有「阉割版」
博主「智慧皮卡丘」最新爆料称,这款设备命名为「Dime」,寓意其体积小巧。
其专利已于昨天在美国国家知识产权局公示,外观采用金属材质,主体类似卵石,内部藏有两颗可取出的胶囊状耳机,佩戴方式为置于耳后。
供应链消息指出,设备用料更接近手机级别,主处理器目标直指 2nm 智能手机芯片,且正在开发定制芯片,以实现通过语音直接执行 iPhone 上的 Siri 指令。
在 OpenAI 内部,这款代号「Sweetpea」(甜豌豆)的设备被 Jony Ive 团队列为最高优先级,首年出货目标高达 4000 万至 5000 万台。富士康也已接到通知,需在 2028 年前为 OpenAI 五款设备做好产能准备。
OpenAI CEO 山姆 · 奥特曼曾公开表示,真正的竞争对手不是 Google,而是苹果。
他认为未来 AI 的主战场在终端,而非云端;智能手机屏幕与交互方式限制了 AI 伴侣的潜力,因此 OpenAI 必须打造「AI 原生设备」。
奥特曼将其愿景比喻为「湖畔小屋」——在信息轰炸的时代广场之外,为用户提供专注空间。
除了耳机,一支神秘的 AI 笔也在开发之列。结合 Altman 与 Jony Ive 多次提及的线索,外界推测这款设备体积小巧、具备环境感知能力,可能采用陶瓷等高质感材料,并以极简交互为核心。
技术层面,OpenAI 正加速迭代音频模型,为硬件奠定基础。知情人士透露,新一代模型不仅语音更自然,也能支持同步对话与打断处理,预计今年第一季度发布。
OpenAI 已组建跨供应链、工业设计与模型研发的团队,目标是打造能主动协作的「智能伙伴」,而非简单的语音接口。
外界还推测,AI 笔可能集成微型投影仪,将图像投射到桌面,以解决无屏幕交互问题;笔夹可能集成麦克风或摄像头,实现文本解析与环境感知。
用户在纸上书写时,AI 可实时解读内容、生成待办事项,甚至作为智能中枢控制周边设备。

据 Android Authority 报道,索尼日前在 YouTube 发布预告视频,确认新一代真无线降噪耳机 WF‑1000XM6(降噪豆 6)将在 2 月 13 日(北京时间)正式发布。
预告片未透露更多细节,但结合此前泄露的渲染图,WF‑1000XM6 将从前代的圆润造型转向更扁平的药丸式设计,充电盒底部也变得更平直,整体风格更简洁。
根据网传爆料,WF‑1000XM6 预计提供黑色、铂银色与沙粉色三种配色,耳机本体采用哑光塑料材质,并支持主动降噪与 IPX4 防水等级。
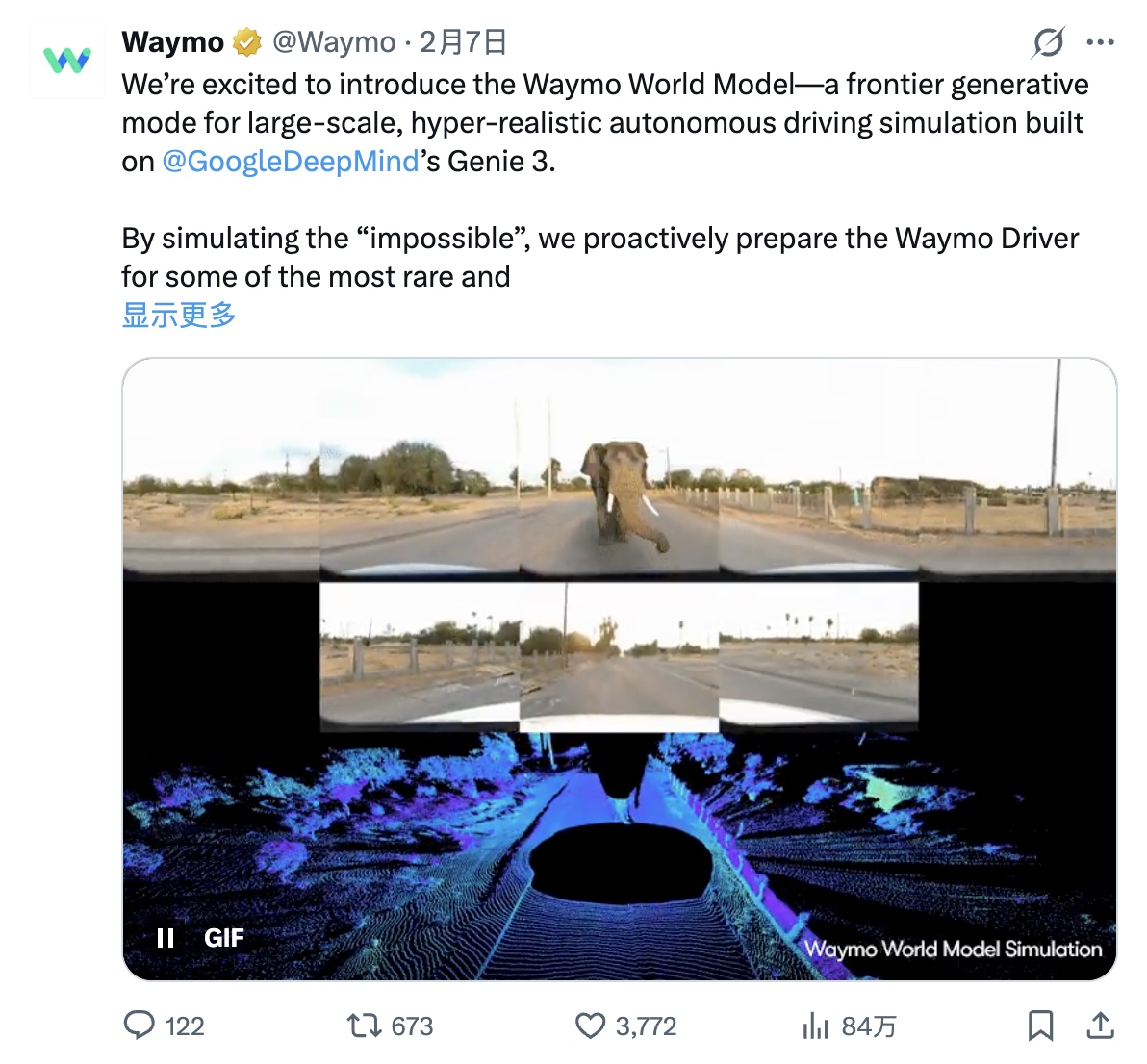
据《华尔街见闻》报道,Alphabet 旗下自动驾驶公司 Waymo 近日与 DeepMind 共同推出基于 Genie 3 的全新世界模型「Waymo World Model」。
据悉,该模型可在虚拟环境中生成高度逼真的 3D 驾驶场景,并模拟现实中极难复现的「长尾」事件,用于提升自动驾驶系统在极端情况下的安全性。
Waymo 表示,Waymo Driver 在真实道路上已累计完成近 2 亿英里的完全自动驾驶行驶,但更关键的是,其在虚拟环境中已提前演练了数十亿英里。
Waymo World Model 正是支撑这一能力的核心基础设施,使系统能在上路前掌握应对复杂场景的能力。
该模型基于 Google DeepMind 的通用世界模型 Genie 3,具备以下特性:
Waymo 还展示了多个示例,包括极端天气、自然灾害、动物上路、鲁莽驾驶者等场景,以及将普通行车记录仪视频转换为多模态仿真环境的能力。
Waymo 称,这些能力将为自动驾驶系统设立更高的安全基准,使其在现实道路遇到挑战前已具备充分准备。

据红星新闻报道,阿里旗下千问 App 近期推出的「春节请客计划」持续引发关注,一些用户将免单资格挂上二手交易平台,售价从 6 元到约 10 元不等,声称买家只需提供收货地址即可代下单。
对此,千问客服表示,免单卡属于虚拟优惠,不支持转让、转赠、转售或任何形式的变现。一旦发现用户存在倒卖、恶意套现等行为,平台将取消其参与资格,并冻结或收回全部活动权益。
2 月 7 日起,千问进一步宣布免单卡可用于在 App 内购买天猫超市的酒水零食、米面粮油、生鲜水果等商品,并将有效期延长至 2 月 28 日。
盒马、淘宝闪购、飞猪、大麦等阿里生态业务也同步参与,形成覆盖吃喝玩乐的春节消费链路。
活动启动当天,部分门店就已出现爆单情况,千问方面提醒用户可先集齐免单卡,再错峰下单,确保权益顺利使用。
昨日下午,千问官方微博还发文称「球球大家放过」。
国家电网近日发布信息显示,今年春节假期新能源汽车充电量预计将创下历史新高,春运期间公路自驾仍是主要出行方式。
根据国家电网智慧车联网平台预测,平台服务新能源汽车的单日充电量峰值将超过 3400 万千瓦时,同比增长 17%;高速公路充电量单日峰值预计突破 1100 万千瓦时,同比增幅超过 23%。
预计今年春节假期的充电高峰将集中在 2 月 14 日 – 2 月 15 日及 2 月 21 日 – 2 月 23 日。
江苏省、浙江省和安徽省的高速公路充电量有望创下新纪录,其中长深高速、沈海高速和沪昆高速的新能源充电桩将最为繁忙。
国家电网方面表示,已筛选出 5567 个重点保障站点,并提前部署应急充电设备。
在 2 月 12 日~23 日期间,将通过「e 充电」App 向新能源汽车车主发放超过 100 万张优惠券,引导车主前往高速出入口附近的城市充电站,以缓解高速服务区的充电压力。
公开数据显示,截至去年 12 月底,我国电动汽车充电基础设施总数达到 2009.2 万个,同比增长 49.7%,其中公共充电设施 471.7 万个、私人充电设施 1537.5 万个,支撑超过 4000 万辆新能源汽车的充电需求。

据封面新闻报道,泡泡玛特在日前的年会上披露了过去一年的核心经营数据,旗下明星 IP「LABUBU」在 2025 年全年销量突破 1 亿只,继续巩固其在全球潮玩市场的爆款地位。
泡泡玛特创始人王宁在年会上表示,2025 年对公司而言是「梦幻的一年」,但同时也是压力最大的一年。随着 LABUBU 在全球范围内迅速爆红,公司内部在供应链、设计、运营等环节都处于高度紧绷状态。
他强调,即便泡泡玛特具备成为世界级消费品企业的潜力,「稍不留神也会很危险」。
根据披露的数据,2025 年泡泡玛特全球员工伙伴超过 1 万人,全球注册会员突破 1 亿人;全品类全 IP 产品全年销量超过 4 亿只。
公司业务已覆盖 100+ 国家和地区,全球门店数量超过 700 家,并拥有 6 大供应链基地,带动超过 20 万个就业岗位。
在海外市场方面,王宁表示,美洲是当前增速最快的区域,欧洲多国仍处于早期发展阶段。未来的海外开店策略将聚焦更大面积、更优位置和更具设计感的门店,以强化品牌体验。
此外,泡泡玛特在中国台湾市场的布局也在持续扩大。根据公司官网去年 9 月更新的信息,目前在中国台湾拥有 14 家实体门店、近 30 家机器人商店,并在 2024 年于西门町开设旗舰店,成为当地最大门市。
摩根士丹利在近期报告中指出,泡泡玛特旗下新 IP「Twinkle Twinkle」与「SKULLPANDA」的强劲热度将继续推动公司 IP 生态增长,并预计今年在产品设计方面会有更多新动作。


影片《至尊马蒂》昨日发布定档海报,确认将在今年 3 月 20 日于中国内地上映。
影片由约书亚 · 萨弗迪执导,采用胶片拍摄,整体呈现复古质感,故事讲述鞋店店员马蒂 · 毛瑟(提莫西 · 查拉梅 饰)怀揣拿下乒乓球世界冠军的疯狂梦想,为了证明自己,他不惜横冲直撞、放下尊严。
《至尊马蒂》在今年奥斯卡中获得最佳影片等多项提名,查拉梅本人也凭借该片拿下今年金球奖音乐/喜剧类电影最佳男主角,成为该奖项史上最年轻的音喜类影帝。
据博主「守望好莱坞」消息,昨天,《超级马力欧银河大电影》释出一支约 30 秒的新预告。
预告中,马力欧兄弟与碧姬公主、耀西等角色再度展开星际冒险,画面包含多段银河场景、敌对角色登场以及耀西的短暂亮相。影片由环球影业与任天堂合作制作,延续 2023 年上映的《超级马力欧兄弟大电影》世界观。
影片改编自任天堂《马力欧》系列及 2007 年游戏《超级马力欧银河》,由照明娱乐与任天堂共同制作,环球影业发行。

据猫眼专业版数据,动作片《庇护之地》上映 9 天后,内地累计票房已突破 2000 万元。
影片由里克 · 罗曼 · 沃夫执导,故事围绕隐居孤岛的前特工迈克尔 · 梅森展开,他在风暴中救下少女杰茜后,被迫卷入监控网络与神秘势力的追杀,重新踏上逃亡与反击之路。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。