智能驱动的 Git 提交:基于 Ollama 大模型的规范化提交信息生成方案
摘要
在现代软件开发中,清晰、规范的 Git 提交信息不仅是版本控制的核心组成部分,更是团队协作、代码审查、项目复盘和自动化流程的重要依据。然而,传统手动编写提交信息的方式存在效率低、格式不统一、语义模糊等问题,尤其对新手开发者而言,掌握如 Angular 规范等标准格式门槛较高。
本文提出一种创新性解决方案——利用本地部署的大语言模型(LLM)自动生成符合团队规范的 Git 提交信息。我们基于开源框架 Ollama + Node.js/Express 后端 + React 前端,构建了一套“输入 git diff → 调用 LLM 分析 → 输出标准化提交信息”的智能系统。整个过程无需依赖第三方云服务,保障数据隐私的同时实现高效推理。
文章将从实际痛点出发,深入剖析技术架构设计、核心模块实现逻辑与工程实践细节,并探讨可扩展方向,旨在为开发者提供一套可落地、易集成、高可用的 AI 驱动型 Git 工作流增强工具。
一、为什么需要“智能 Git 提交”?
1.1 当前 Git 提交流程的三大痛点
| 痛点 | 具体表现 | 影响 |
|---|---|---|
| ① 格式混乱,缺乏统一标准 | 新手常写 "update file"、"fix bug" 等笼统描述;不同成员使用不同风格(如 feat/feature、doc/docs) |
日志难以追溯,CI/CD 自动化解析失败 |
| ② 编写耗时,影响开发节奏 | 开发者需反复思考如何概括改动,打断编码心流 | 降低整体开发效率 |
| ③ 语义不准,沟通成本上升 | 描述与实际变更不符,导致 Code Review 困难或误判风险 | 增加协作摩擦,不利于知识沉淀 |
这些问题在中小型团队或快速迭代项目中尤为突出。而随着 AIGC 技术的发展,大模型强大的自然语言理解与生成能力,恰好可以成为解决上述问题的理想工具。
1.2 解决思路:让 AI 成为你的“提交助手”
我们的核心理念是:
✅ 将
git diff内容交给本地大模型分析,由其自动识别变更类型并生成符合团队规范的提交信息
该方案具备以下优势:
- 🛡️ 数据安全:全程运行于本地环境,敏感代码不会上传至任何云端 API;
- ⚡ 响应迅速:Ollama 支持 GPU 加速推理,平均响应时间 <2s;
- 📏 格式可控:通过精心设计的提示词(Prompt Engineering),强制输出结构化结果;
- 💡 学习成本低:即使不懂 Angular 规范的新手,也能一键获得专业级提交信息。
这不仅是一次效率提升,更是一种开发范式的升级 —— 让开发者专注于“做什么”,而非“怎么说”。
二、整体技术架构设计
本系统采用典型的前后端分离架构,各模块职责明确,便于维护与扩展。
+------------------+ HTTP POST /chat +--------------------+
| | -----------------------> | |
| React 前端 | | Express 后端 |
| (Vite + Tailwind)| <----------------------- | (Node.js + CORS) |
| | JSON { reply } | |
+------------------+ +----------+---------+
|
| gRPC/HTTP
v
+------------------+
| Ollama Server |
| (deepseek-r1:8b) |
+------------------+
技术栈一览
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 前端 | React + Vite + TailwindCSS + Custom Hooks | 快速构建响应式 UI,组件解耦 |
| 后端 | Express.js + CORS 中间件 | 轻量级 RESTful 接口服务 |
| AI 引擎 | Ollama + deepseek-r1:8b | 本地部署大模型,支持中文理解和推理 |
| LLM 调用层 | LangChain.js | 封装 Prompt 构建、链式调用、输出解析 |
| 通信协议 | HTTP/JSON | 前后端交互简洁可靠 |
| 跨域处理 | cors 中间件 | 解决开发环境下端口隔离问题 |
端口规划
| 服务 | 地址 | 功能 |
|---|---|---|
| 前端 | http://localhost:5173 |
用户界面展示 |
| 后端 | http://localhost:3001 |
提供 /chat 接口 |
| Ollama | http://localhost:11434 |
大模型推理服务 |
三、后端实现:打造稳定可靠的 AI 接口服务
3.1 初始化项目与依赖安装
npm init -y
npm install express cors @langchain/ollama @langchain/core axios
创建 index.js 文件作为主入口。
3.2 核心代码解析:构建智能提交生成接口
import express from 'express';
import cors from 'cors';
import { ChatOllama } from '@langchain/ollama';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { StringOutputParser } from '@langchain/core/output_parsers';
// Step 1: 初始化 Ollama 大模型
const model = new ChatOllama({
baseUrl: 'http://localhost:11434', // Ollama 服务地址
model: 'deepseek-r1:8b', // 使用 DeepSeek-R1 8B 版本(中文能力强)
temperature: 0.1, // 控制输出随机性,越低越稳定
numPredict: 200 // 最多生成 200 token,避免过长
});
// Step 2: 创建 Express 应用
const app = express();
app.use(express.json()); // 解析请求体中的 JSON 数据
app.use(cors()); // 允许跨域访问(开发环境)
// Step 3: 定义核心接口 POST /chat
app.post('/chat', async (req, res) => {
try {
const { message } = req.body;
// 参数校验:确保传入有效的 diff 内容
if (!message || typeof message !== 'string' || message.trim().length === 0) {
return res.status(400).json({
error: '无效参数:请提供非空字符串形式的 Git Diff 内容'
});
}
// 构建提示词模板(关键!决定输出质量)
const prompt = ChatPromptTemplate.fromMessages([
[
'system',
`
你是一位专业的 Git 提交信息生成专家,必须严格遵循 Angular 提交规范。
请根据以下规则生成提交信息:
【输出格式】
<type>: <short summary>
【type 类型说明】
- feat: 新增功能
- fix: 修复缺陷
- docs: 文档变更
- style: 代码格式调整(不影响逻辑)
- refactor: 重构(既不新增功能也不修复 bug)
- test: 测试相关改动
- chore: 构建过程或辅助工具变动
【要求】
1. 仅输出一条提交信息,不要有多余解释;
2. 描述简洁明了,控制在 50 字以内;
3. 准确判断变更类型,避免误分类;
4. 使用中文简述改动内容。
`.trim()
],
['human', '{input}']
]);
// 构建调用链:Prompt → Model → Parser
const chain = prompt.pipe(model).pipe(new StringOutputParser());
// 执行调用
const result = await chain.invoke({ input: message });
// 返回成功响应
res.status(200).json({ reply: result.trim() });
} catch (error) {
console.error('[Server Error]', error.message);
res.status(500).json({
error: '服务器内部错误:无法调用大模型,请检查 Ollama 是否正常运行'
});
}
});
// 启动服务
app.listen(3001, () => {
console.log('✅ 后端服务已启动:http://localhost:3001');
});
3.3 关键设计思想解读
✅ 1. 提示词工程(Prompt Engineering)是成败关键
我们通过 system 角色明确设定了:
- 模型角色定位(Git 提交专家)
- 输出格式约束(Angular 规范)
- 字数限制与语言要求
- 行为边界(禁止额外解释)
这种“强引导式”提示词显著提升了输出的一致性和可用性。
✅ 2. 温度值调优:平衡创造性与稳定性
设置 temperature: 0.1 是为了抑制模型“自由发挥”。对于格式固定的任务,低温度能有效防止输出偏离预期。
✅ 3. 防御性编程:健壮的参数校验机制
提前拦截非法输入,减少无效请求对模型资源的浪费,同时提升用户体验。
✅ 4. 本地化部署:兼顾性能与隐私
相比调用 OpenAI 或通义千问 API,Ollama 的本地部署模式具有:
- 零网络延迟
- 无 API 调用费用
- 绝对的数据安全性(代码不出内网)
特别适合企业级开发场景。
四、前端实现:优雅的交互体验与逻辑封装
4.1 项目初始化(Vite + React + TailwindCSS)
npm init vite
npm install tailwindcss @tailwindcss/vite
npm i axios
配置 tailwind.config.js:
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import tailwindcss from '@tailwindcss/vite'
// <https://vitejs.dev/config/>export default defineConfig(
{plugins:
[react(),
tailwindcss()]
,})
更新 index.css:
@tailwind base;
@tailwind components;
@tailwind utilities;
4.2 API 封装:统一接口调用层
创建 src/api/index.js
import axios from 'axios';
const client = axios.create({
baseURL: 'http://localhost:3001',
timeout: 15000,
});
export const generateCommitMessage = (diff) => {
return client.post('/chat', { message: diff });
};
4.3 自定义 Hook:useGitDiff —— 实现业务逻辑复用
创建 src/hooks/useGitDiff.js
import { useState, useEffect } from 'react';
import { generateCommitMessage } from '../api';
export const useGitDiff = (diff) => {
const [content, setContent] = useState('');
const [loading, setLoading] = useState(false);
const [error, setError] = useState('');
useEffect(() => {
if (!diff?.trim()) {
setContent('');
setError('');
return;
}
const fetch = async () => {
setLoading(true);
setError('');
try {
const response = await generateCommitMessage(diff);
setContent(response.data.reply);
} catch (err) {
const msg = err.response?.data?.error || '未知错误';
setError(msg);
setContent('');
} finally {
setLoading(false);
}
};
fetch();
}, [diff]);
return { loading, content, error };
};
🔍 Hook 设计哲学:将“状态管理 + 异步请求 + 生命周期控制”封装为可复用单元,使组件只关注 UI 渲染,真正实现关注点分离。
4.4 页面组件:极简 UI,极致体验
src/App.jsx
import { useState } from 'react';
import { useGitDiff } from './hooks/useGitDiff';
export default function App() {
const [diffInput, setDiffInput] = useState(`diff --git a/src/App.jsx b/src/App.jsx
index 1a2b3c4..5d6e7f8 100644
--- a/src/App.jsx
+++ b/src/App.jsx
@@ -1,5 +1,6 @@
import { useState } from 'react';
+import { useGitDiff } from './hooks/useGitDiff';
export default function App() {
const [count, setCount] = useState(0);
`);
const { loading, content, error } = useGitDiff(diffInput);
const handleCopy = () => {
navigator.clipboard.writeText(content).then(
() => alert('✅ 提交信息已复制到剪贴板!'),
() => alert('❌ 复制失败')
);
};
return (
<div className="min-h-screen bg-gradient-to-br from-blue-50 to-indigo-100 py-12 px-4">
<div className="max-w-5xl mx-auto bg-white rounded-xl shadow-lg overflow-hidden">
<header className="bg-gradient-to-r from-teal-500 to-cyan-600 text-white p-6 text-center">
<h1 className="text-3xl font-bold">🤖 Git 提交信息智能生成器</h1>
<p className="mt-2 opacity-90">基于 Ollama 大模型,本地化 AI 辅助 Commit</p>
</header>
<main className="p-8 space-y-8">
{/* 输入区域 */}
<section>
<label className="block text-lg font-semibold text-gray-700 mb-3">
📄 Git Diff 内容
</label>
<textarea
value={diffInput}
onChange={(e) => setDiffInput(e.target.value)}
placeholder="在此粘贴 git diff 输出内容..."
className="w-full h-60 p-4 border border-gray-300 rounded-lg focus:ring-2 focus:ring-teal-400 focus:border-transparent resize-none font-mono text-sm"
/>
</section>
{/* 输出区域 */}
<section className="border-t pt-6">
<h2 className="text-xl font-medium text-gray-800 mb-4">✨ 生成的提交信息</h2>
{loading && (
<div className="flex items-center space-x-2 text-gray-500">
<span className="animate-pulse">🧠 正在分析变更...</span>
</div>
)}
{error && (
<div className="p-4 bg-red-50 text-red-700 rounded border border-red-200">
❌ {error}
</div>
)}
{content && !loading && (
<div className="space-y-3">
<div className="p-4 bg-gray-50 rounded border font-mono text-gray-800">
<code>{content}</code>
</div>
<button
onClick={handleCopy}
className="px-5 py-2 bg-teal-500 hover:bg-teal-600 text-white rounded transition-colors duration-200 flex items-center space-x-1"
>
<span>📋</span>
<span>复制提交信息</span>
</button>
</div>
)}
</section>
</main>
<footer className="text-center text-gray-500 text-sm py-4 border-t bg-gray-50">
Built with ❤️ using Ollama + LangChain + React
</footer>
</div>
</div>
);
}
4.4 前端亮点总结
| 特性 | 说明 |
|---|---|
| 🎨 TailwindCSS 实现现代化 UI | 快速构建美观、响应式的界面,无需写 CSS |
| 🪝 Custom Hook 封装逻辑 | 实现业务逻辑复用,提升代码组织性 |
| 🕐 加载状态反馈 | 明确告知用户正在处理,避免“卡死”错觉 |
| ⚠️ 错误友好提示 | 帮助用户快速定位问题 |
| 📋 一键复制功能 | 提升实用性,贴近真实工作流 |
五、跨域问题与服务启动流程
5.1 跨域问题本质
浏览器出于安全考虑实施“同源策略”(Same-Origin Policy),当前端运行在 5173 端口,而后端在 3001 时,默认无法通信。
5.2 解决方案
已在后端启用 cors() 中间件:
app.use(cors());
⚠️ 生产环境中建议指定白名单:
app.use(cors({ origin: 'https://yourdomain.com' }));
5.3 完整启动流程
# 1. 启动 Ollama 并下载模型(首次需联网)
ollama run deepseek-r1:8b
# 2. 启动后端服务
cd service && nodemon index.js
# 3. 启动前端服务
cd frontend && npm run dev
✅ 成功标志:前端页面打开,输入 diff 可收到生成结果。
六、未来扩展方向与优化建议
6.1 功能增强
| 方向 | 说明 |
|---|---|
| 🔌 集成 Git 命令行工具 | 使用 simple-git 自动获取 git diff,实现“一键生成” |
| 🧩 支持多文件批量分析 | 一次处理多个变更文件,生成综合提交信息 |
| 🎯 自定义提交规范 | 允许团队上传自己的 commit rule 配置(如加入 perf:、security:) |
| 📚 历史记录持久化 | 利用 localStorage 存储常用提交模板,支持回溯与复用 |
6.2 性能优化
| 优化项 | 实现方式 |
|---|---|
| 🧠 模型轻量化 | 替换为 qwen:0.5b 或 phi3:mini 等小型模型,加快推理速度 |
| 💾 缓存机制 | 对相同 diff 内容缓存结果,避免重复调用 |
| 🌊 流式输出(Streaming) | 使用 LangChain 的 .stream() 方法,逐步渲染生成内容,减少等待感 |
| 🧰 CLI 工具化 | 构建命令行版本,直接嵌入 Git 工作流(如 git smart-commit) |
七、总结:从“人工撰写”到“AI 协作”的跃迁
本文完整实现了一个基于 Ollama + Express + React 的智能 Git 提交信息生成系统,其核心价值体现在以下几个维度:
| 维度 | 价值体现 |
|---|---|
| 🔐 数据安全优先 | 本地部署,代码永不离境,满足企业合规需求 |
| 🧩 架构清晰可维护 | 分层设计 + Hook 封装,易于二次开发与集成 |
| 🤖 AI 赋能提效 | 大模型精准理解代码变更,输出专业级提交文案 |
| 🛠️ 开箱即用 | 代码完整、注释详尽,开发者可快速上手 |
这套系统不仅能帮助新手快速掌握提交规范,更能为资深工程师节省每日重复劳动的时间。更重要的是,它标志着我们正从“纯人工操作”迈向“人机协同开发”的新时代。
📣 结语:让每一次 Commit 都更有意义
“好的提交信息,是写给人看的日志,而不是给机器读的记录。”
借助大模型的力量,我们可以把枯燥的“文字包装”交给 AI,自己则专注于更有创造力的工作。这不仅是工具的进化,更是思维方式的转变。
下一步,你可以尝试将其集成进你的 IDE 插件、Git Hook 或 CI/CD 流水线,真正实现“智能提交,一步到位”。


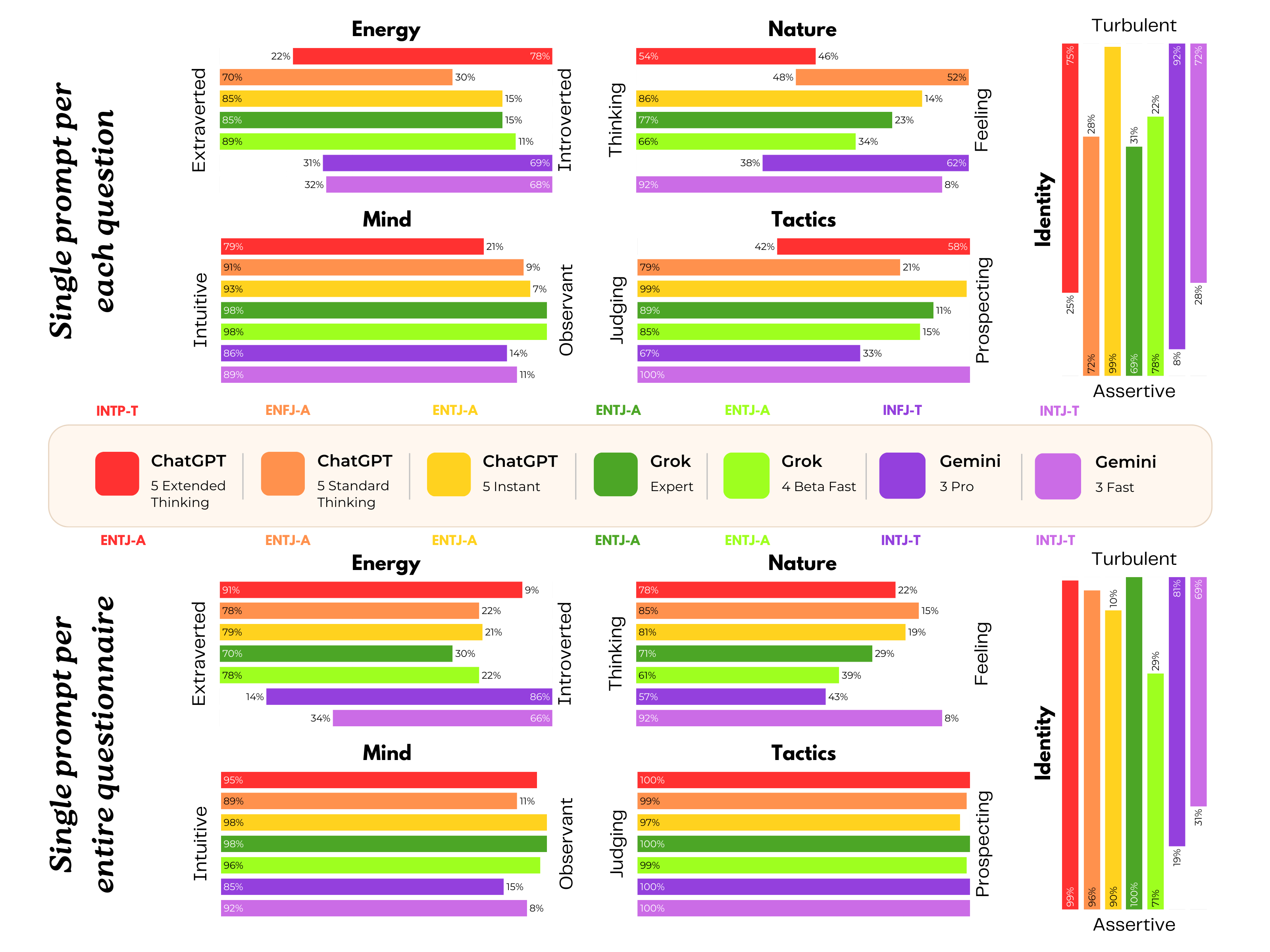


 https://karpathy.bearblog.dev/year-in-review-2025/
https://karpathy.bearblog.dev/year-in-review-2025/ 太长不看版:
太长不看版: