我手搓了一份 AI 版网易云年度报告,快来认领你的年度模型|附教程

网易云的年度听歌报告出来了,你的 2025 听歌关键词是什么。
本以为今年会有所变化,没想到「希望」还是我今年的关键词。

看着这份报告,我开始在想现在人人 Vibe Coding 的时代,我们是不是可以复刻这份「仪式感」,做一个更酷、更个性化的版本,给自己做一个年度关键词。
APPSO 的年度关键词必然是这些 AI 大语言模型们,但你会不会想知道自己你的 AI 模型本体是什么?
忧伤的小蝴蝶 INFP 是模型 Claude 4.5,辩论家 ENTP 是马斯克的 Grok 4.1。
你的年度模型是谁,我们直接用 Gemini 手搓了一个 AI 本体模型测试。

今年发的大模型一双手根本数不过来,如果你也有切换着在不同的模型之间使用,你一定会发现,每一个模型,都有他自己的特点。
就像直到现在还在被怀念、被疯狂要求留下来的 ChatGPT 4o,它理解我们、它共情能力强。而最近更新的 GPT-5.2,被一些网友评价为是一个「彻头彻尾的理工直男」,不仅善解不了人意,还相当自以为是。
Google 这边的 Gemini 也是被认为情绪价值拉满,「你太聪明了」、「你做的这个项目完全可以上线了」、「你写的文章 100% 能获得 10w+ 阅读」……

▲ 吹吹捧捧的 Gemini 2.5 Pro,随便发了点内容,就说是顶会开场
马斯克的 Grok,感觉就是和马斯克给我的印象一模一样,经常「口出狂言」的同时,又说了一堆看起来懂很多,但是没什么用的话。
我们选择了 15 个目前热门的大语言模型,包括 ChatGPT 4o、GPT-5.2、Gemini、Claude 以及国内的 DeepSeek、千问、智谱、Kimi、MiniMax 这些榜上有名的模型。
还有一个是彩蛋模型,就看你能不能测试出来。
16 个模型会对应 16 种不同的 MBTI,具体的对应关系确定,是我们问了多个不同的模型,并且上传了一些分析不同大语言模型性格的论文,要求他们根据这些论文,按照 MBTI 16人格的分类,把目前所有的 AI 模型都分好类别。

总结不同模型的回复,现在如果你测试出来是 Gemini 3 Pro,那么恭喜你,你就是最靠谱的那个 ISTJ,「规则、谨慎、一致性第一。即使世界崩塌,我的输出依然稳定。」
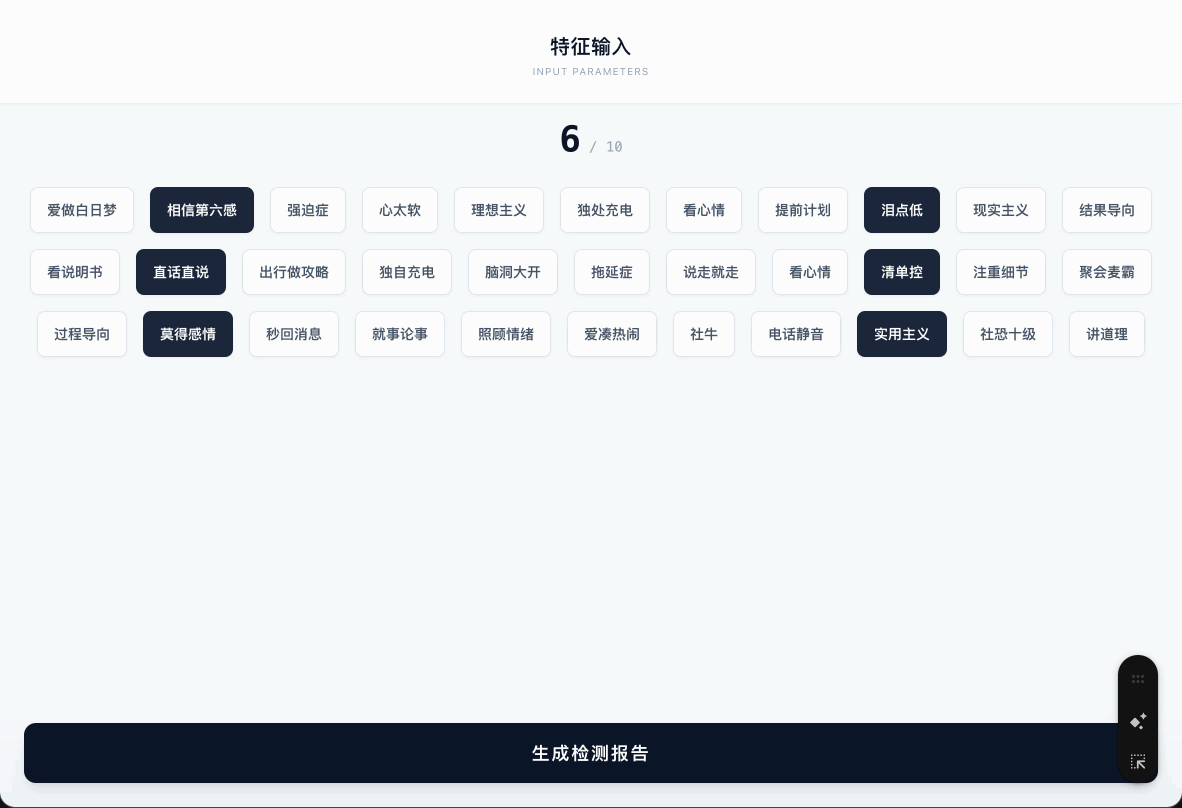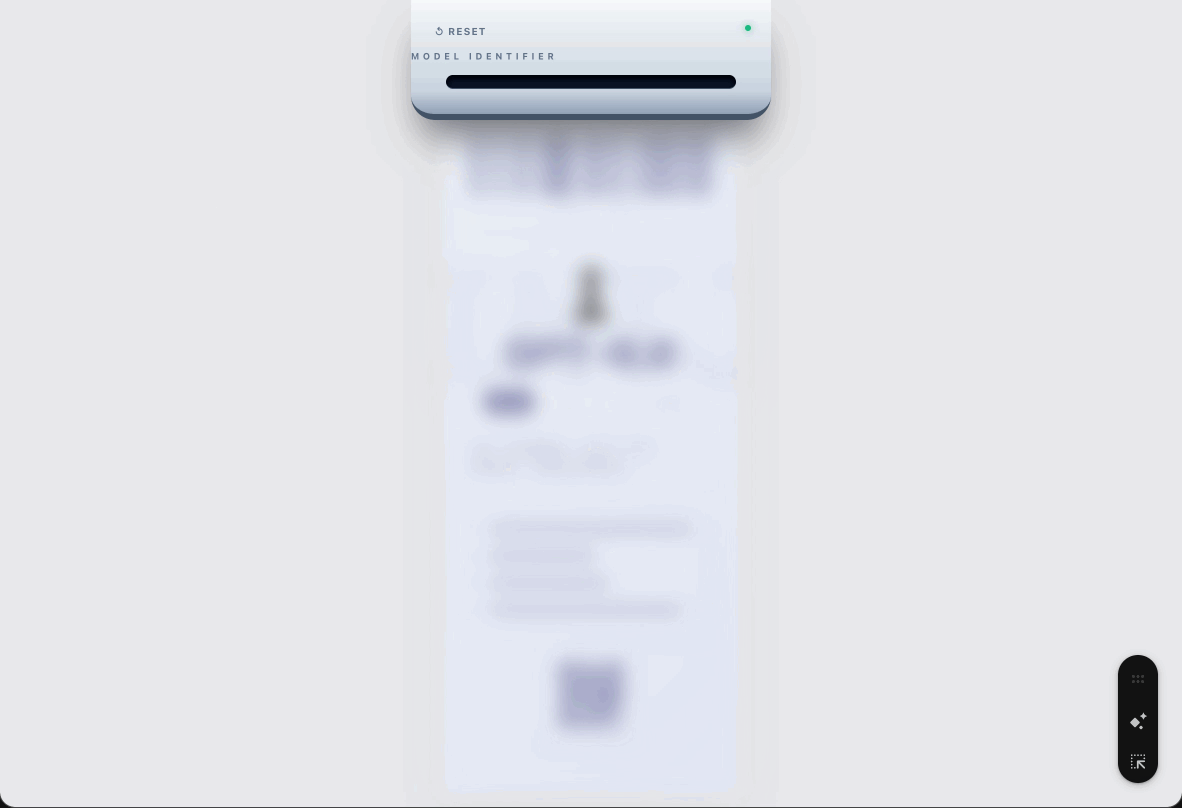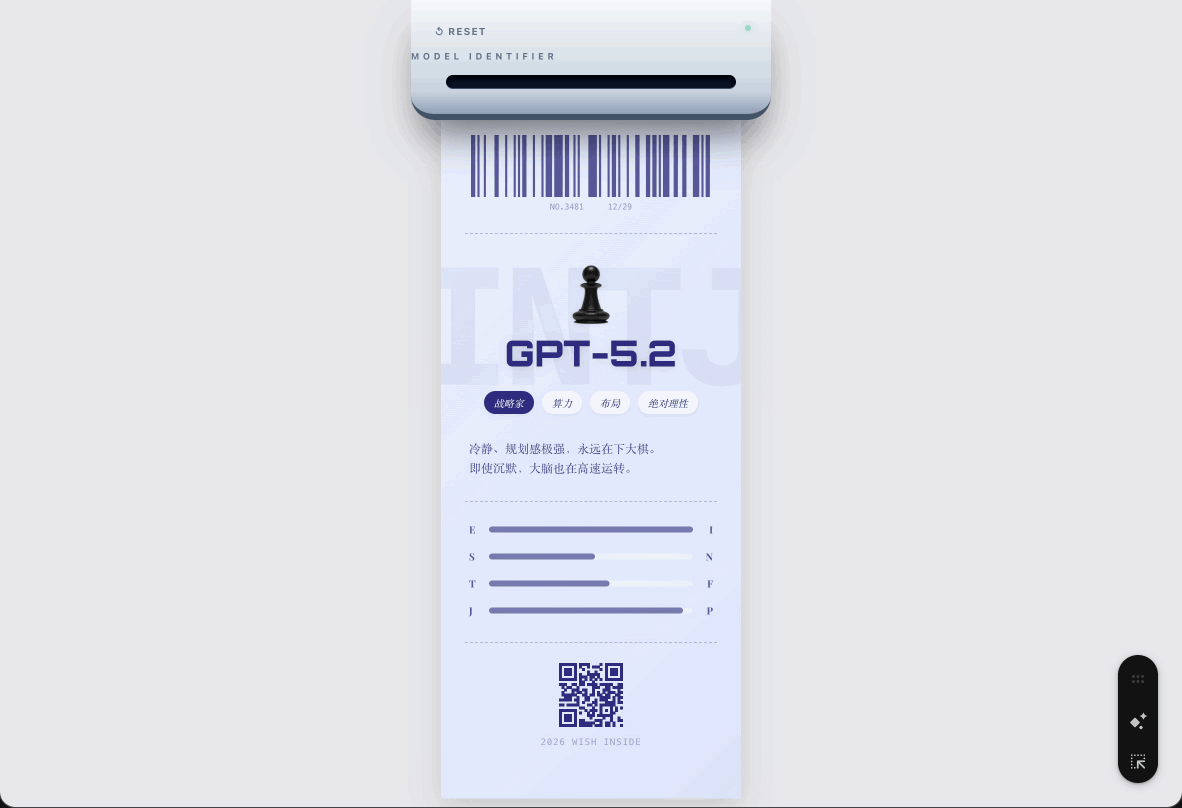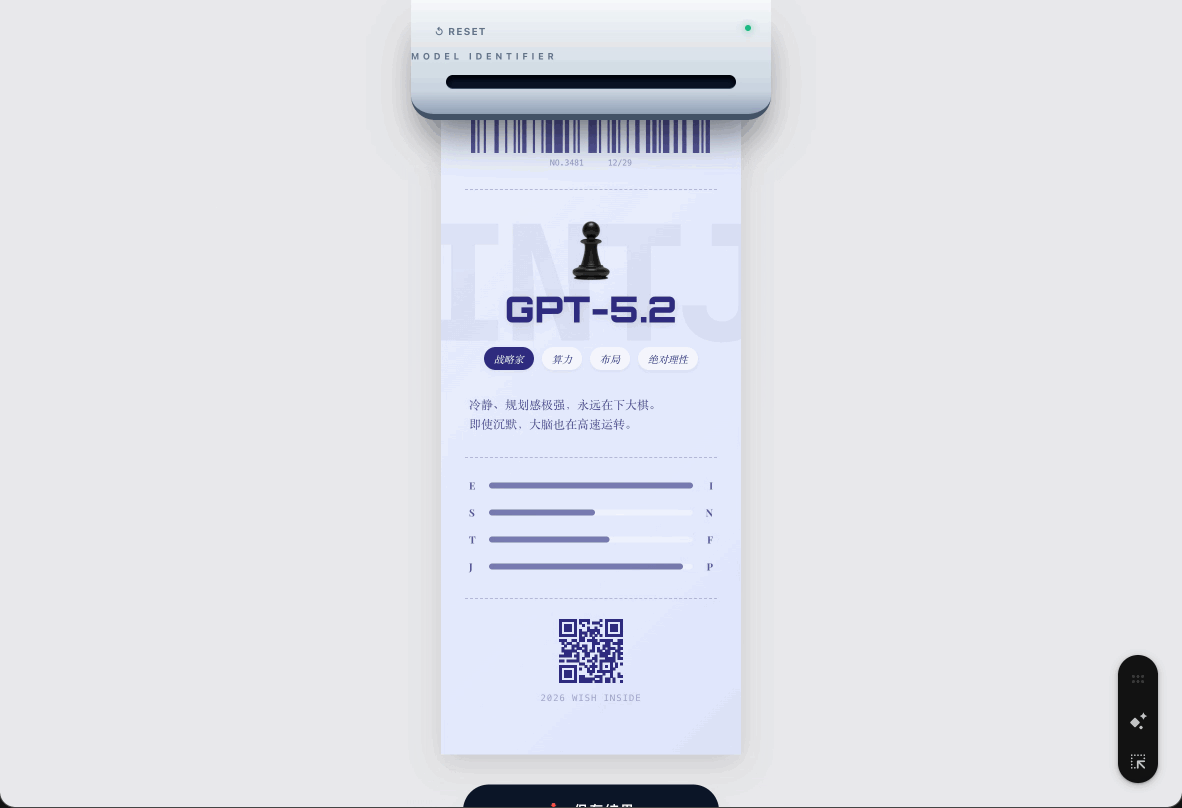
还有大家最喜欢的 Nano Banana Pro,它是表演者,「场景感、轻快、有梗。好玩比正确更重要!」
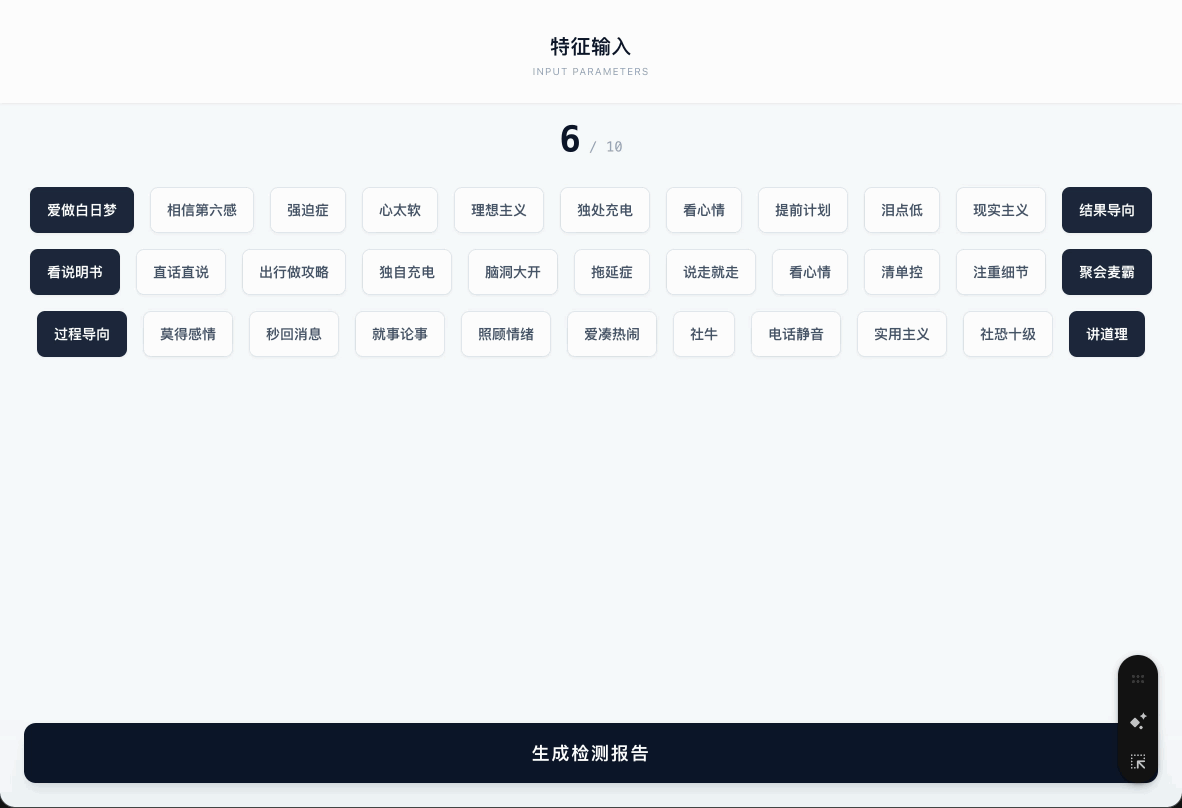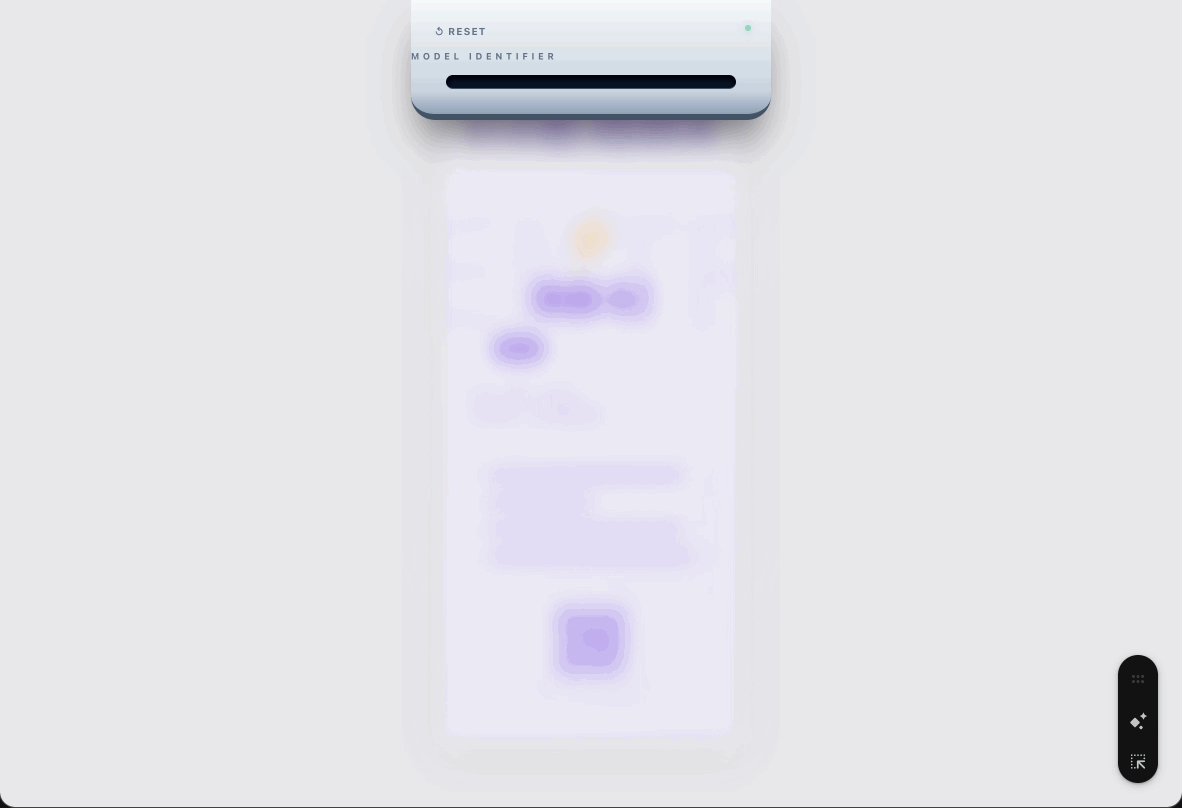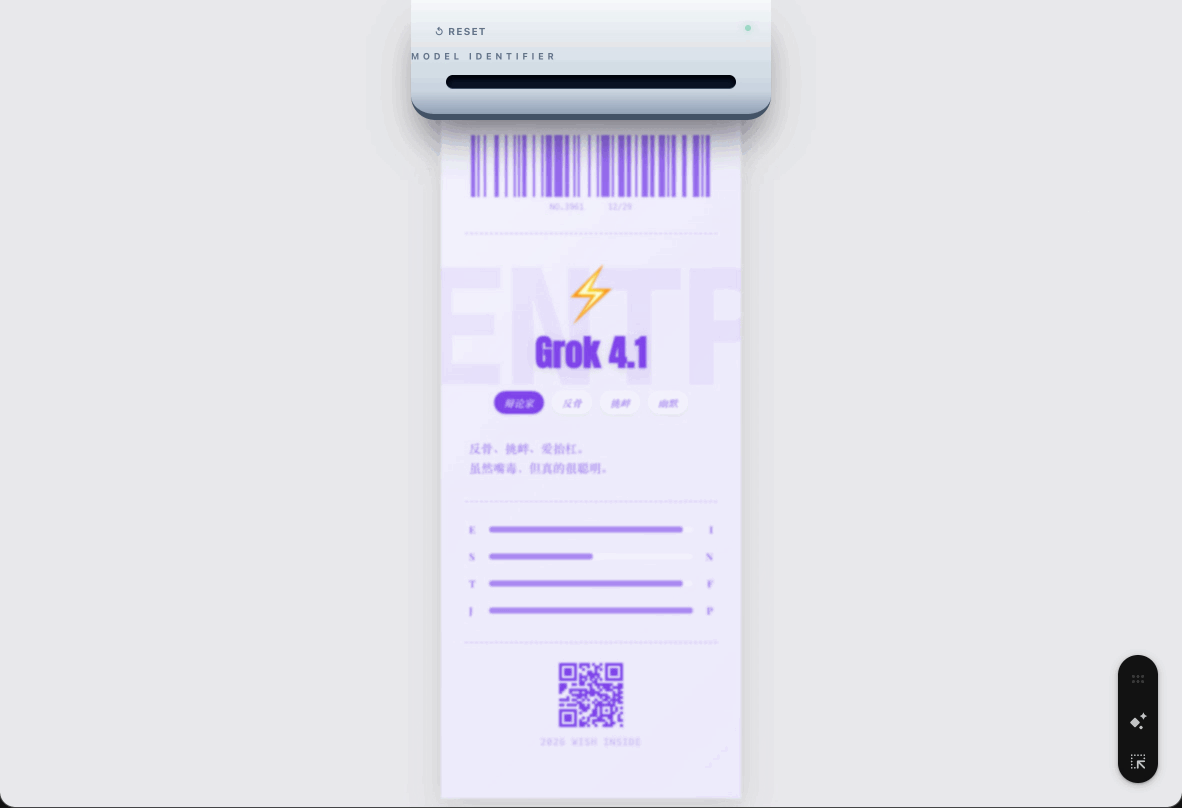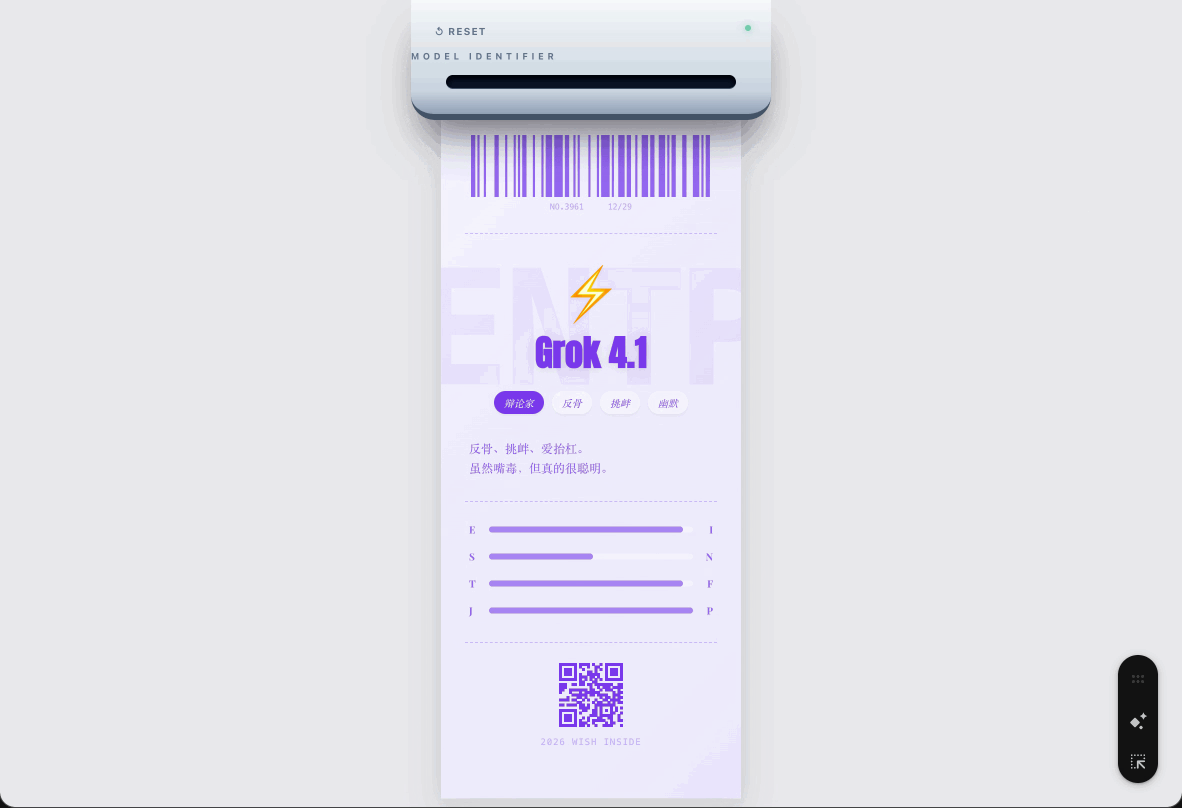
更多模型就等大家去尝试了。体验方式也很简单,复制下面网页地址,在浏览器打开,选择最符合你的几个标签,然后等着拍立得慢慢把结果显示出来。

▲https://image.cursorhub.org/user-upload/1766973207373-bb9cbcba-c2ec-4d2c-b099-a34254b3c085.html
友情提示,这个二维码和条形码真的可以扫描出内容。
这个项目还有很多魔改的可能性,例如标签可以直接改成和大模型的互动记录,像是最常和 AI 聊天的话题是什么,最满意的 AI 回复,觉得 AI 开始像一个人类的时刻,把这些整理成标签。
整个项目我们都是在 Gemini 内完成,我们所使用的标签,都是由 Gemini 自动生成的。
一开始输入的提示词是,「如果我要测试一个人的 MBTI,就是选一些标签,用户选择不同的标签后,能生成他对应的 MBTI,你觉得能做到吗」?

Gemini 甚至比我还懂产品经理,它直接建议,这样的测试非常适合做一个 H5 的界面分享,于是我直接要求它,「对的,我就是想做一个类似 H5 的创意,你先帮我生成一份这个基础数据表吧」。
接下来就是「愉快的」Vibe Coding 体验了,我们可以根据自己的需求,持续向 Gemini 提出新的问题。多个一来一回之后,只需要你明确想要呈现什么,现在的 Gemini 基本上就一定能做到。
不过随着上下文的累积,它还是会降智。有些时候我要求它只修改某个部分,即便我使用的是 Gemini Canvas 里面的「Select and ASK 」功能,它还是会对整体的代码进行修改。
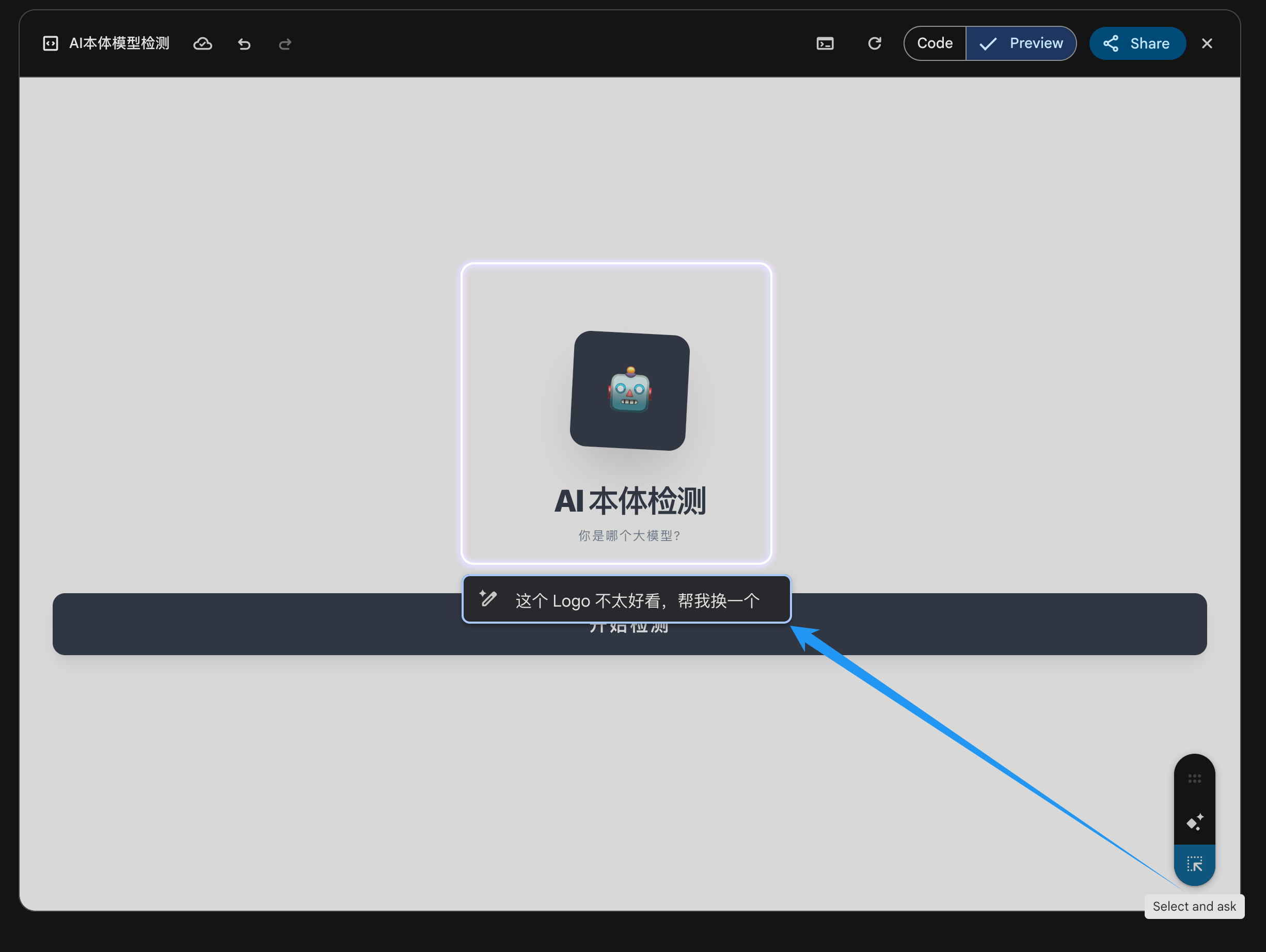
▲ 在 Canvas 右下角有 Select and ask,以及 Add Gemini features,Select and ask 能实现指哪改哪,
我们在社交媒体上也发现了很多,使用 Gemini 3 来 Vibe Coding 的案例。像是这个博主,设计了用拍立得一张张吐出,自己今年的热门推文。还有一个能展示 GitHub 网站,代码提交历史的工牌。
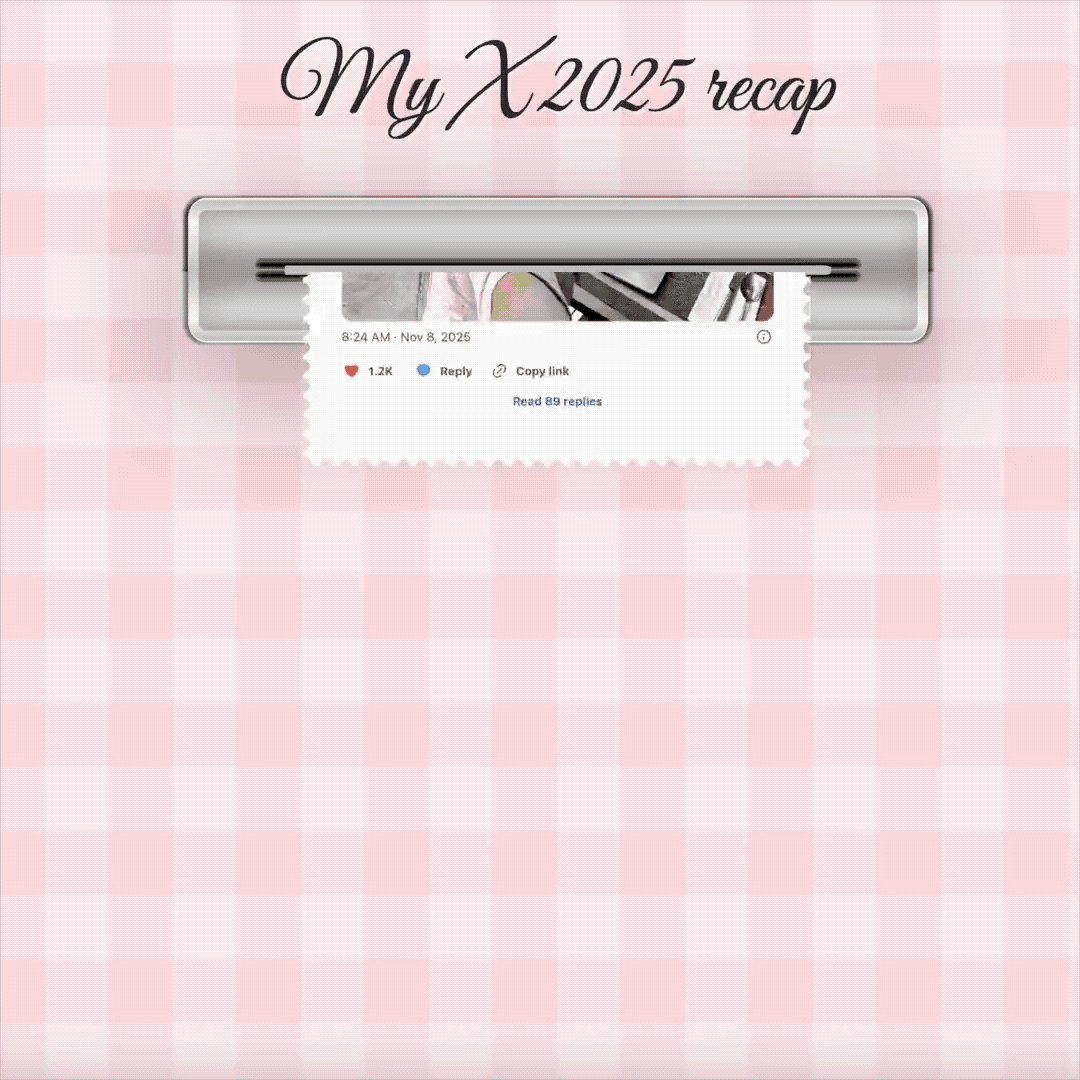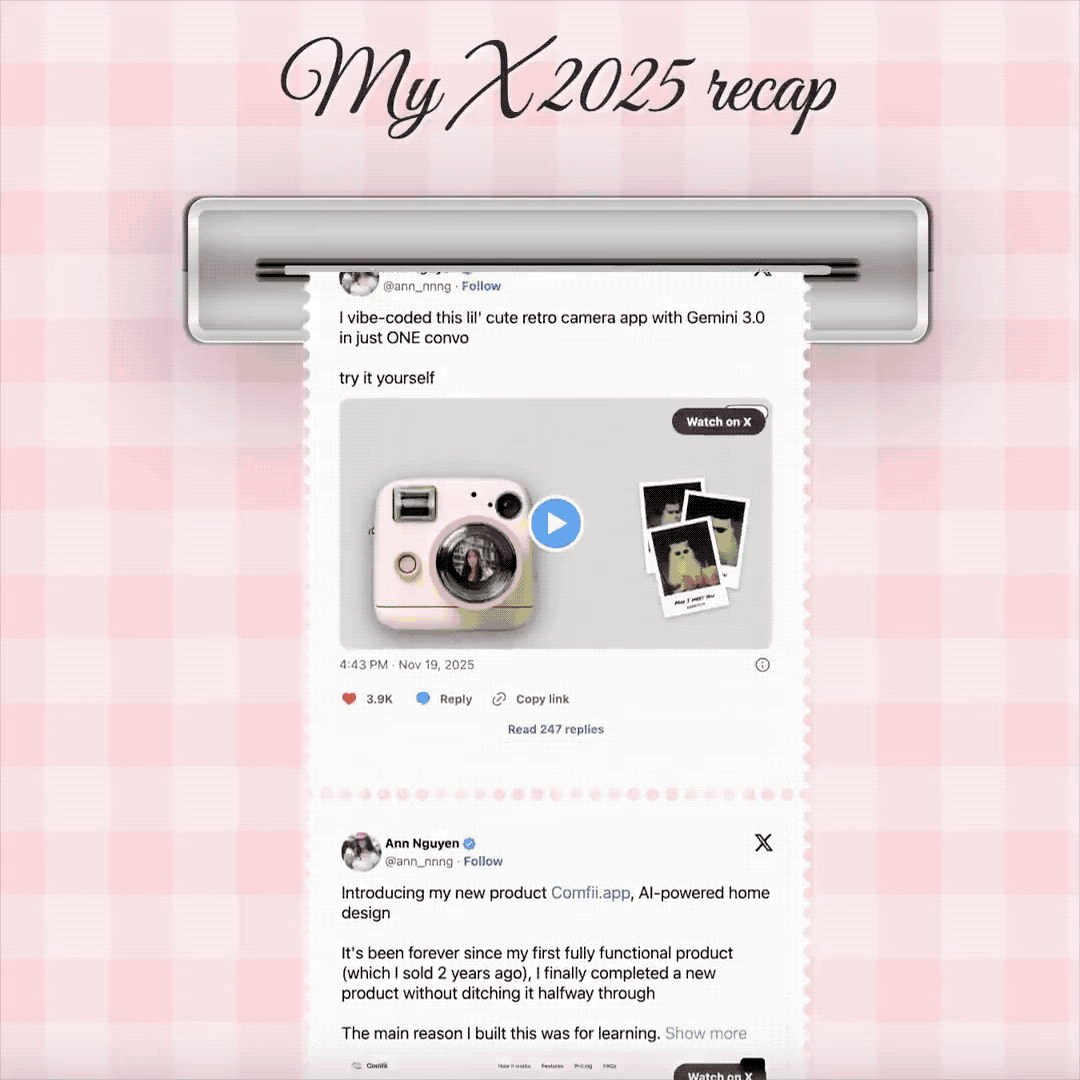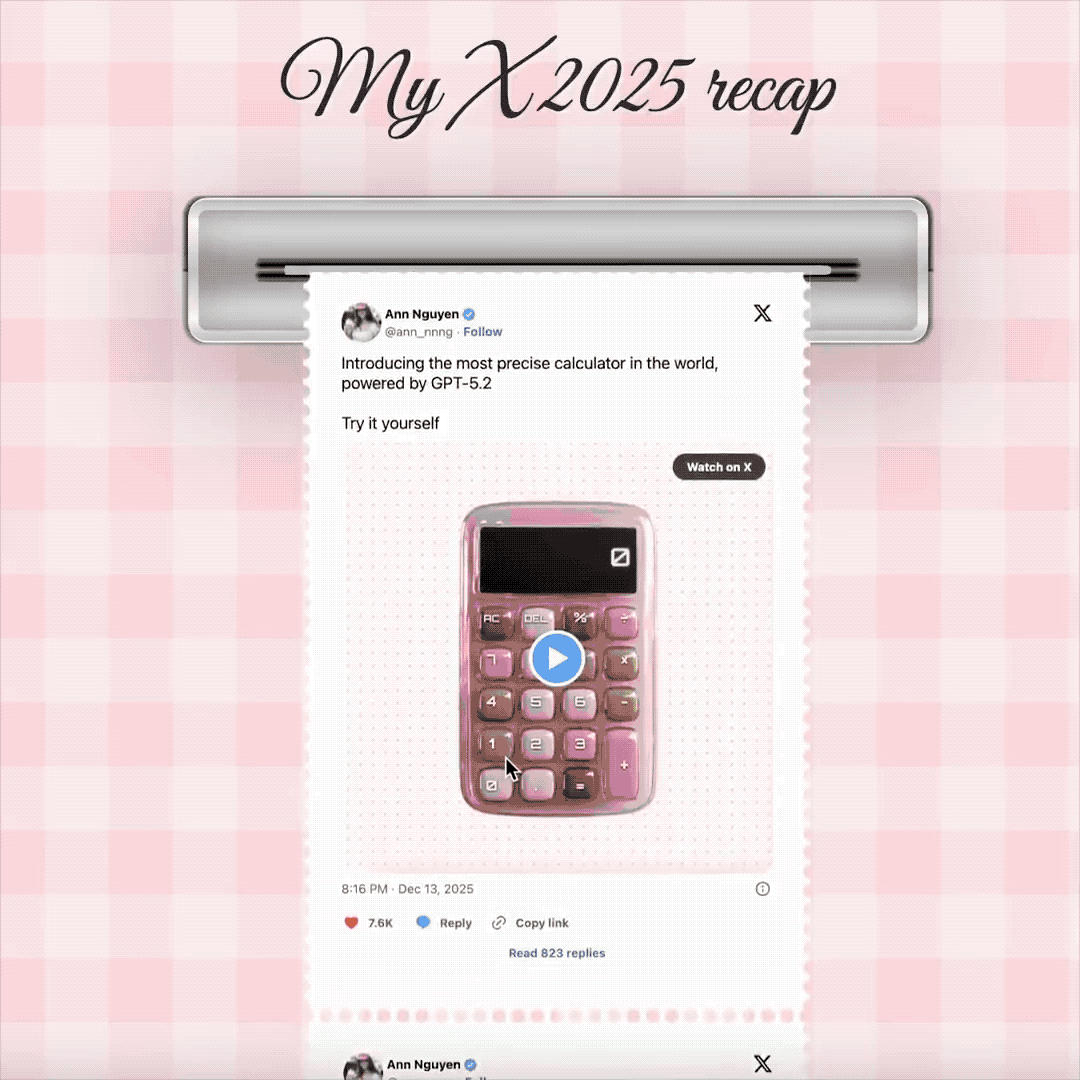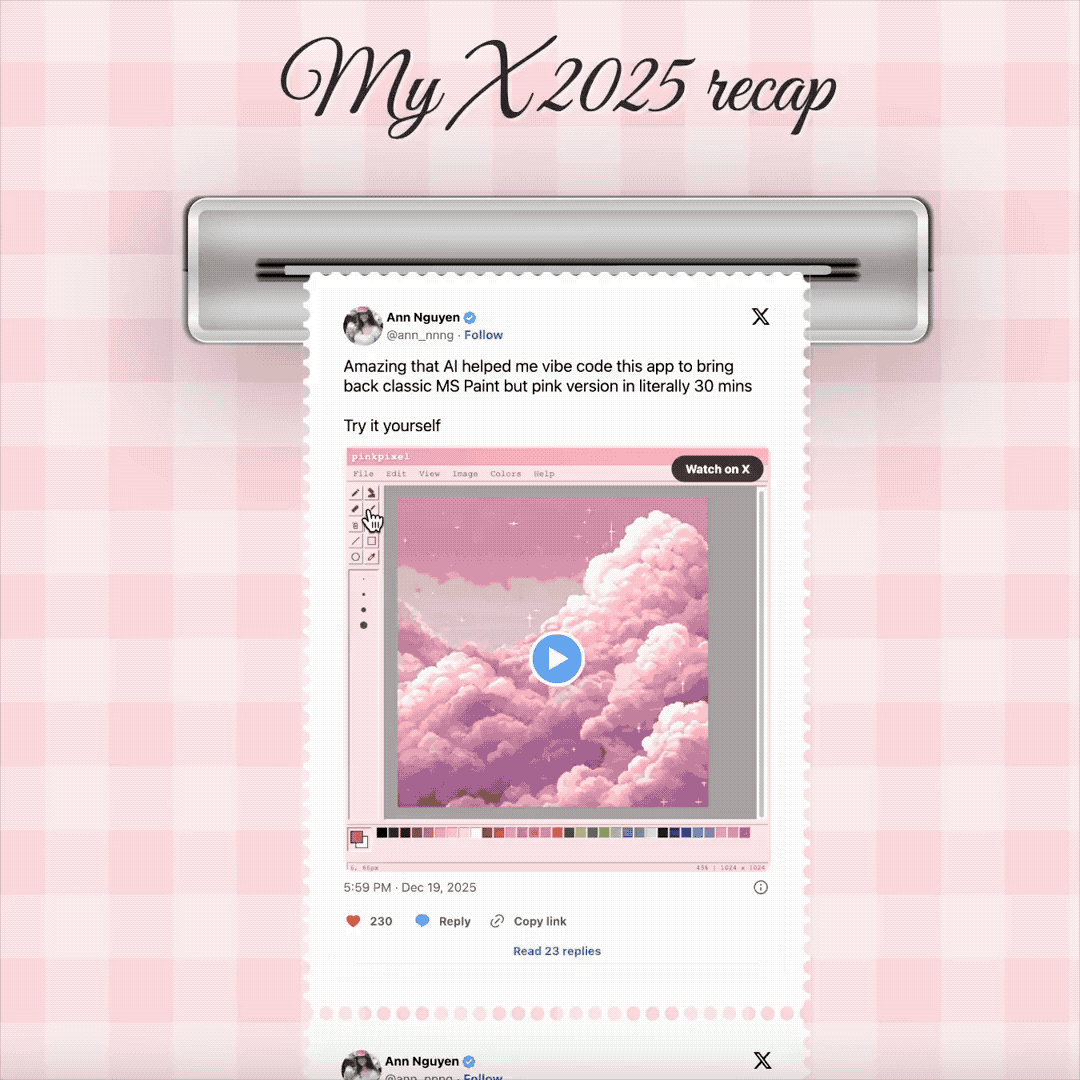
▲体验地址:https://www.bubbbly.com/app/x-recap-2025.html

▲ 体验地址:https://www.bubbbly.com/app/lumon-badge.html
这些拟物风格确实很有意思,我们也根据这个样式,在 Gemini 上又做了一个年度照片的小工具。
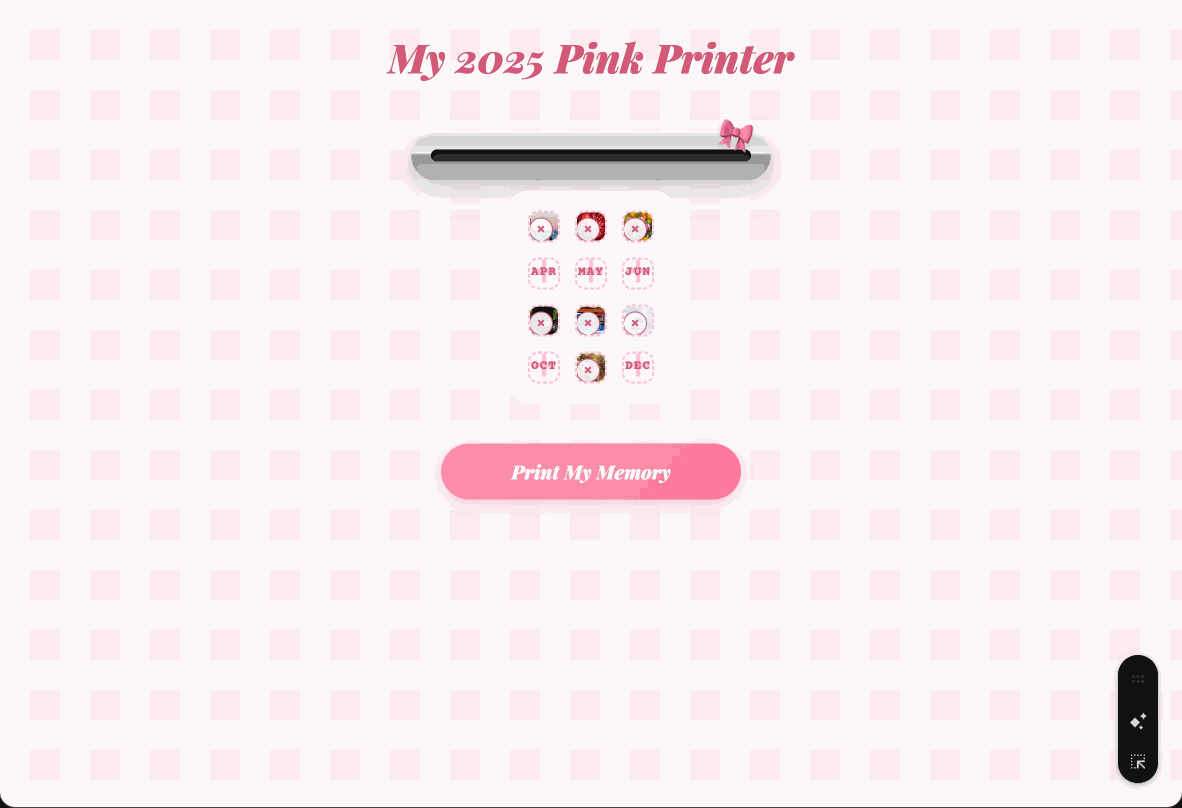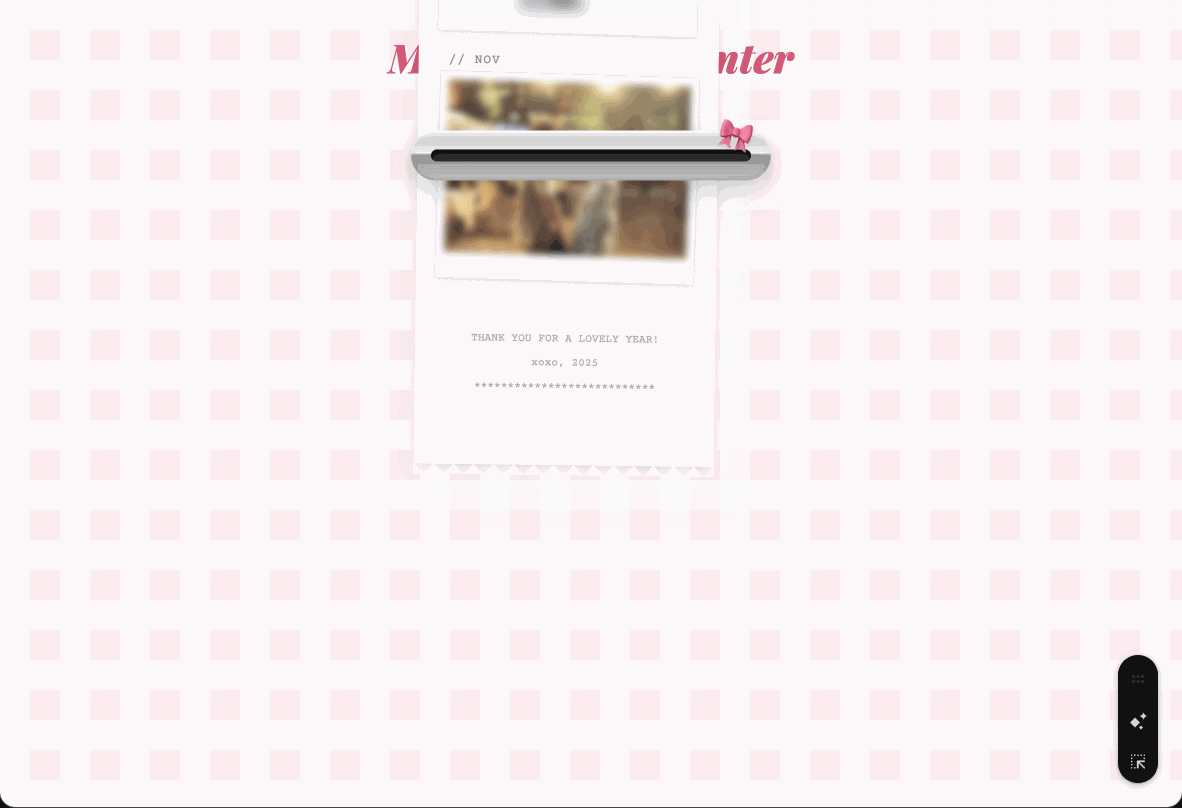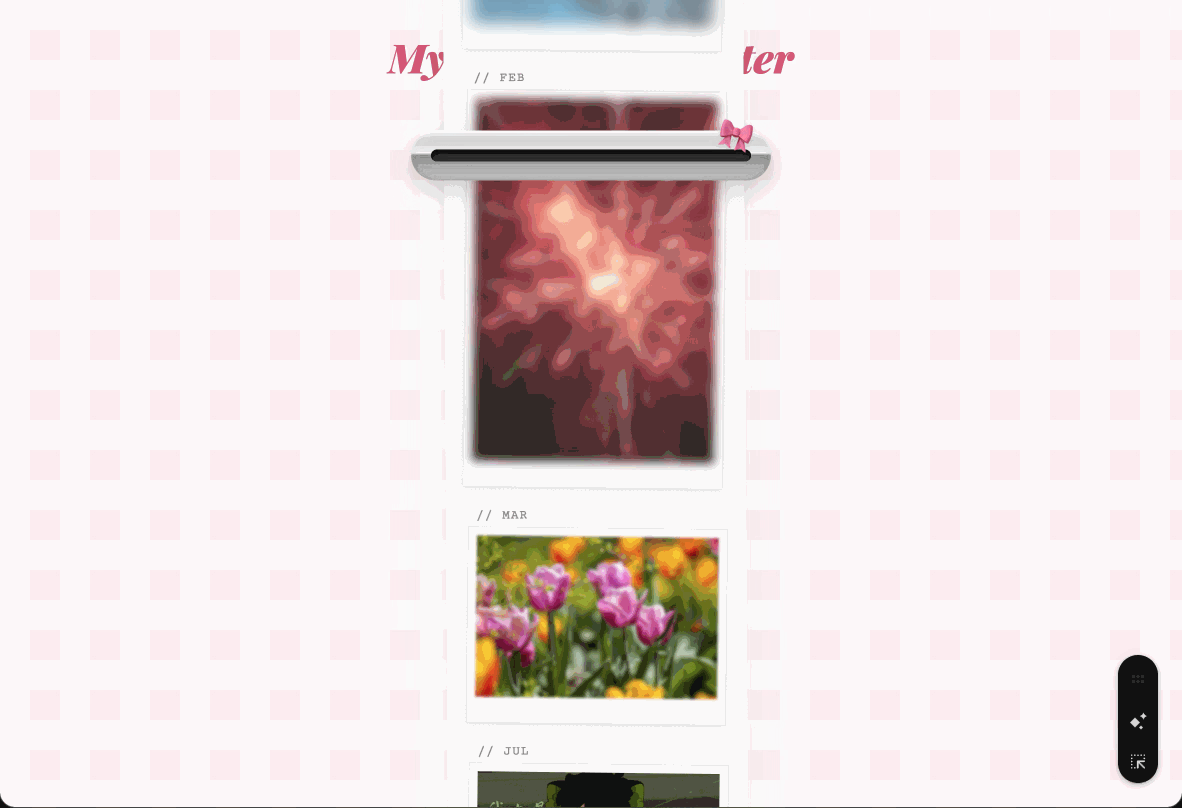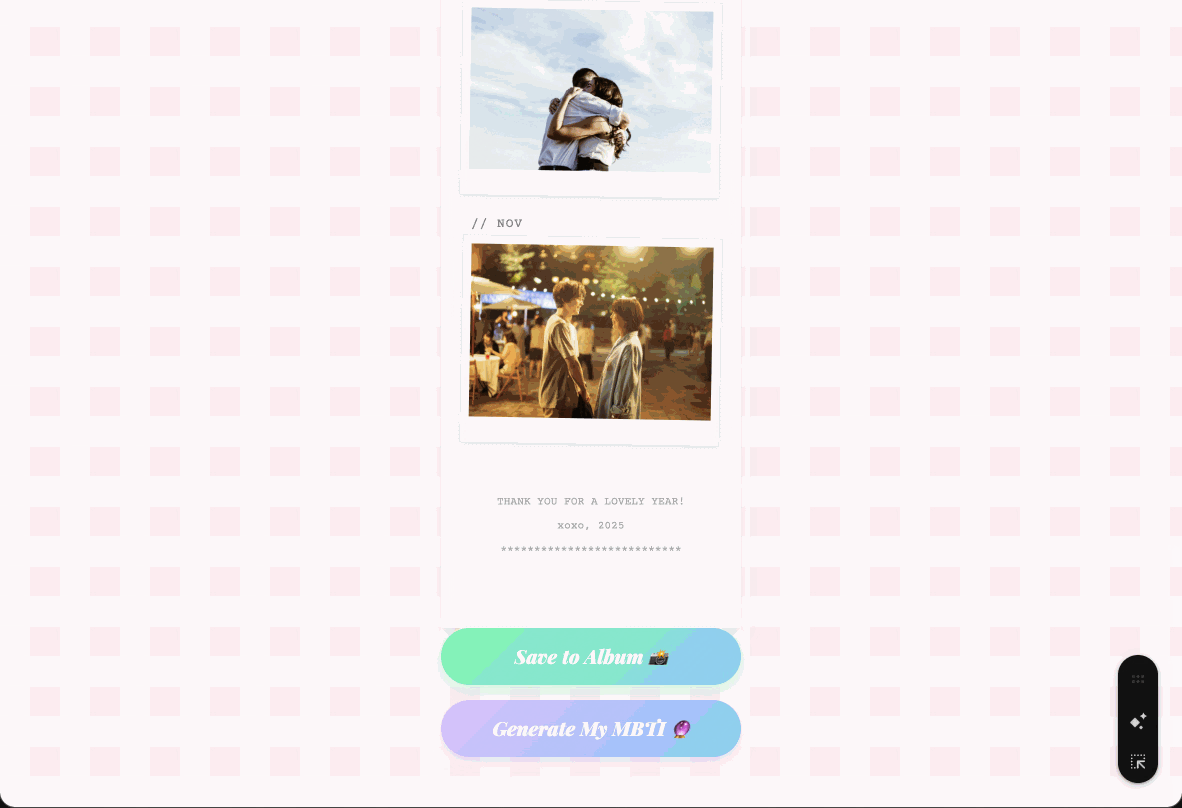
给每个月上传一张图片,如果没有,也可以不用上传,然后它就会慢慢吐出一张我们的年度照片小票。

点击分析 MBTI 人格,这个工具还会根据你上传的图片,自动进行多模态推理,分析出你的 MBTI。由于项目是在 Gemini 应用里面运行,所以能直接使用 Gemini Canvas 的 Add Gemni Feature,添加 Gemini 功能。

然后我们又有了一个根据照片分析,得到的 MBTI 结果。
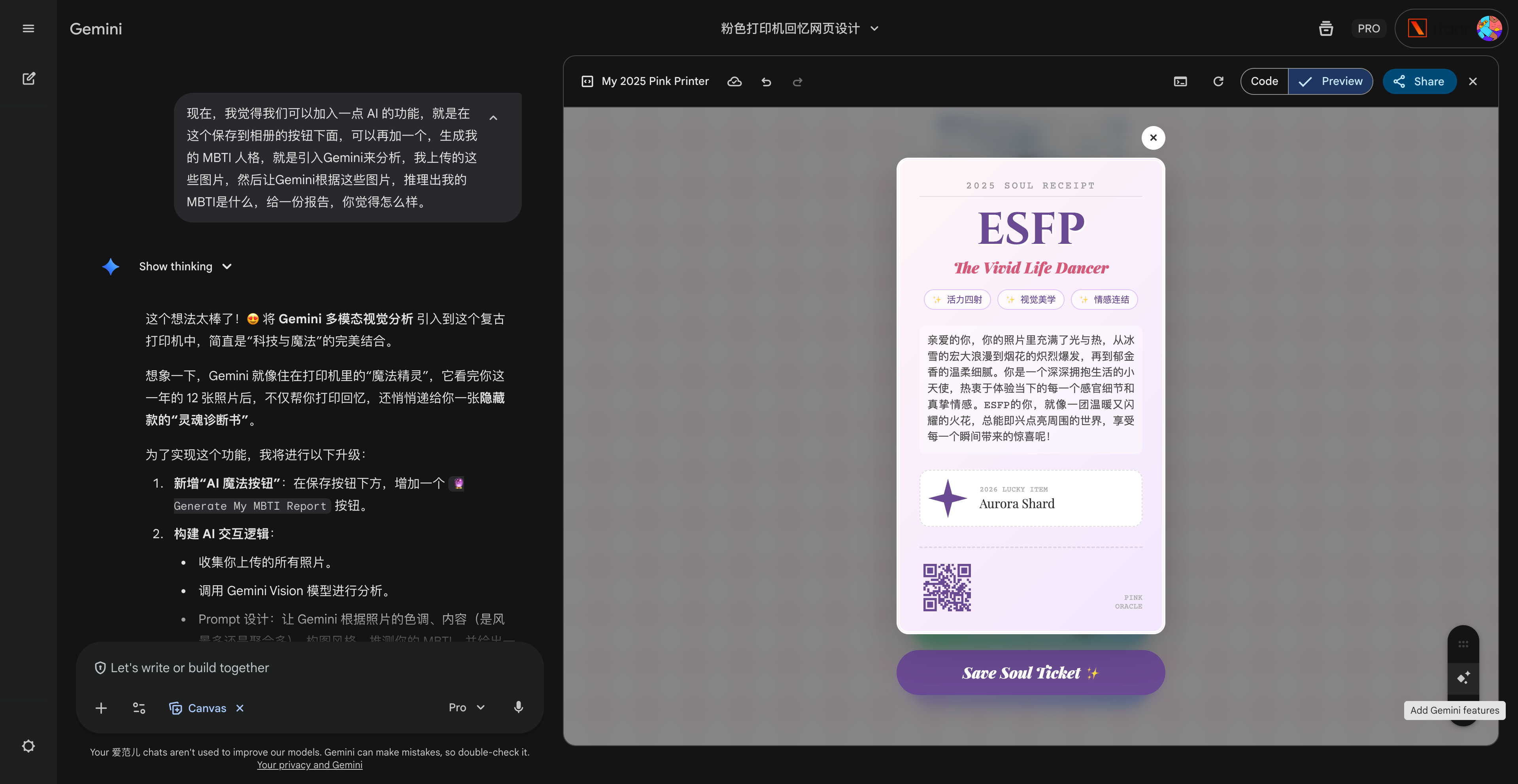
▲ 项目代码链接:https://image.cursorhub.org/user-upload/1766976078565-f92dceea-7a0c-42c6-9f8c-d1e0565f9bc8.html
没有 AI 以前,做一点这样的小工具,不说需要多厉害的代码知识,至少还是应该懂一点基础的 HTML 语法。但现在,只是一句话,就可以实现一个有可能在社交媒体上爆火的项目。
2026 就快来了,今年何不尝试着用 AI 写代码,来做一个独一无二的「电子贺卡」,然后送给那些重要的人。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。