
如果要为 2025 年的车市选一个关键词,那么「重塑」或许最为贴切。
新能源渗透率已越过高速增长拐点,市场进入结构性调整阶段,不再是所有玩家都能分一杯羹的增量时代,而是优胜劣汰的存量竞争。无论车企宣传多么天花乱坠,最终都要靠销量兑现。
董车会统计了 2023 年、2024 年及 2025 年前 11 个月销量超过 18 万辆的车型,发现三年间榜单变动剧烈,有品牌快速崛起,也有曾经的头部选手掉出前列。这背后,是产品力、定价策略、渠道效率乃至组织反应速度的全面比拼。
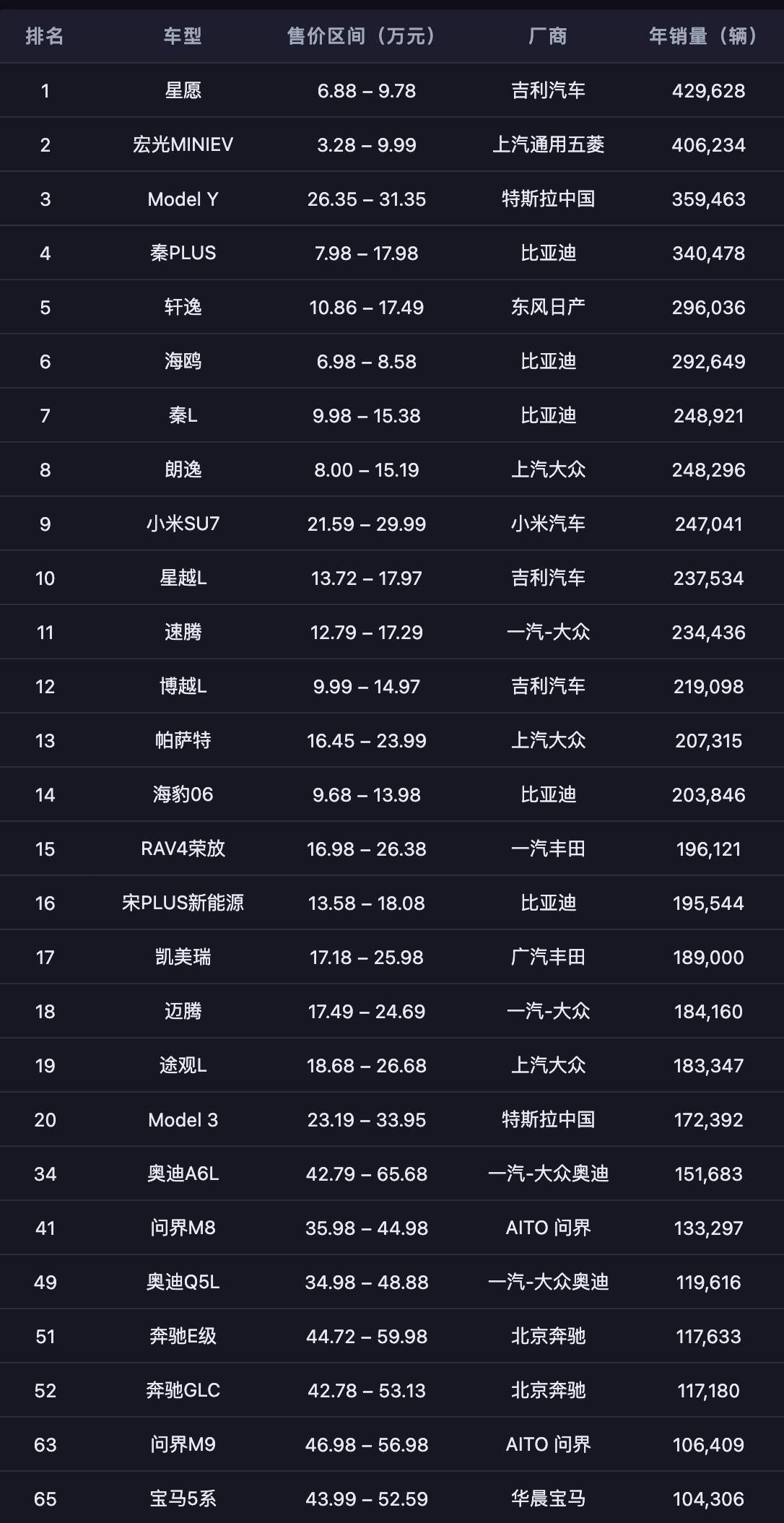
而这场重塑中最引人注目的信号,莫过于来到榜首位置的,不是特斯拉也不是比亚迪,而是一辆强势崛起的小车。
失去榜首的比亚迪
过去两年,国内新能源汽车销量榜首之争主要在特斯拉 Model Y 与比亚迪秦 PLUS 之间展开。Model Y 凭借其全球统一的产品力与品牌号召力,稳居第一梯队——2023 年售出 45.6 万辆,2024 年进一步提升至 48 万辆;而比亚迪则以「车海战术」全面出击,旗下秦、宋、元、海豚、海鸥等多款车型齐头并进,在 2024 年巅峰时期一举包揽销量 Top 10 中的五个席位,几乎占据半壁江山。

然而,进入 2025 年,格局骤变。吉利星愿以 44.6 万辆的成绩空降榜首,星越 L 与博越 L 也稳居榜单前列。作为老牌自主车企,吉利在经历转型阵痛后,凭借高性价比的小型与紧凑型产品成功反攻,一举打破了比亚迪此前近乎垄断的市场地位。
曾长期称霸该细分市场的海鸥与海豚,在 2023–2024 年合计贡献了可观销量,但到了 2025 年,二者双双失守。
海鸥销量跌至 34.1 万辆,排名滑落至第五;海豚更是一路下滑至第 32 位。与此同时,吉利星愿以更大空间、更精致的设计以及更具竞争力的配置,在同价位区间精准狙击了这两款比亚迪「走量利器」。

雪上加霜的是,曾经的旗舰轿车汉,也悄然消失在销量榜单之中。
2024 年尚能卖出 22.8 万辆的汉,2025 年销量几近腰斩,仅录得 13.7 万辆。面对小米 SU7(27.2 万辆)、特斯拉 Model 3(19.3 万辆)以及极氪、领克等新老对手的围剿,老款「汉」的产品力已显疲态;而改款后的新车型,无论在设计语言还是核心体验上,都未能赢得市场广泛认可,销量表现可谓惨淡。
海鸥
但也有好消息。
秦 L(第 8 名,27.8 万辆)和海豹 06(第 14 名,23 万辆)这两款更新的车型成功完成了迭代,稳固住了其在 10-15 万级轿车市场的基本盘。

旗下高端品牌腾势 D9 和方程豹钛 7 也表现出了不错的爆款潜力。
明年的比亚迪,如何在前后夹击的态势下稳住份额,相当值得期待。
吉利,成功渡劫
在一众合资品牌及传统自主品牌(如长城、长安、上汽)被比亚迪打得节节败退之际,吉利出手了。
此前两年,吉利在新能源销量榜上表现平平。然而到了 2025 年,局面彻底改写,吉利不仅一举夺得年度销冠,其星越 L 与博越 L 更强势稳居榜单前列,彰显出在紧凑型 SUV 领域的全面统治力。

吉利已成为目前唯一一家在燃油车与新能源两大赛道均跑赢行业大盘的传统车企。
尽管在新能源转型上起步较晚,且早期一度犹豫不决,但吉利的转身不可谓不坚决。早在 2015 年,吉利便提出「蓝色行动」战略,雄心勃勃地设下到 2020 年实现新能源车型销量占比达 90% 的目标。
然而到 2020 年之时,吉利实际的新能源车销量占比却只有 5.2%。
真正促使吉利下定决心的,是比亚迪与理想等新势力在混动与增程赛道上的爆发式成功。自此,吉利果断修订原战略,推出升级版「蓝色吉利行动计划」,全面押注节能技术(涵盖燃油、混动、增程)与智能纯电双线并进。
之后比亚迪的每个爆款吉利几乎都做了对标,银河 L6 对标秦 PLUS DM-i,银河 E8 对标汉 EV,银河 E5 对标元家族,星舰 7 则瞄准了宋 Pro DM-i,星愿则对标海豚和海豹两款小车。

产品矩阵上如此,技术竞争上同样如此。
2024 年 5 月,比亚迪发布第五代 DM-i 技术,以 46.06% 的量产发动机热效率刷新纪录;仅半年后,吉利便在银河星舰 7 上搭载全新 EM-i 雷神混动系统,以 46.5% 的热效率反超对手,重夺技术制高点。
今年 2 月,比亚迪宣布旗下 21 款车型全部搭载「天神之眼」辅助驾驶系统,仅在 1 个月之后,吉利就宣布银河系列的后续车型都将搭载「千里浩瀚」不同层级的辅助驾驶方案。

吉利的策略简单而高效,配置多一点、设计好一点、价格再低一点,期望用用极致的性价比与快速迭代能力,逐个击破比亚迪的主力车型。
星愿登顶销冠,或许只是吉利全面反攻的序章。
消失的埃安
对比三年的销量,有一个品牌的变化非常明显:广汽埃安。
2023 年,埃安尚处在高光时刻。AION Y 以 23.5 万辆的成绩位列第 12 名,AION S 也以 22 万辆紧随其后(第 15 名),两款车型共同撑起了品牌在主流市场的存在感。然而到了 2024 和 2025 年,这两款曾经的主力车型却彻底从销量榜上消失,再无踪影。

除了车型老化的问题外,背后更多折射出来的是 10-15 万级纯电市场的逻辑变了。2023 年,该细分市场仍由大量 B 端需求(尤其是网约车)托底;而进入 2024–2025 年后,随着比亚迪、吉利银河等兼具设计感、智能化与家庭属性的新车型密集入场,那些缺乏 C 端吸引力、仅具「工具属性」的纯电动车迅速被边缘化。
数据印证了这一趋势。据乘联会统计,2023 年全国用于出租及网约车的新车销量达 85 万辆,其中埃安贡献约 22 万辆,占其全年总销量的 45%,也占当年网约车新增总量的近四分之一。然而,随着网约车市场快速饱和,B 端订单锐减,埃安失去了最重要的销量支柱,市场表现随之急转直下。
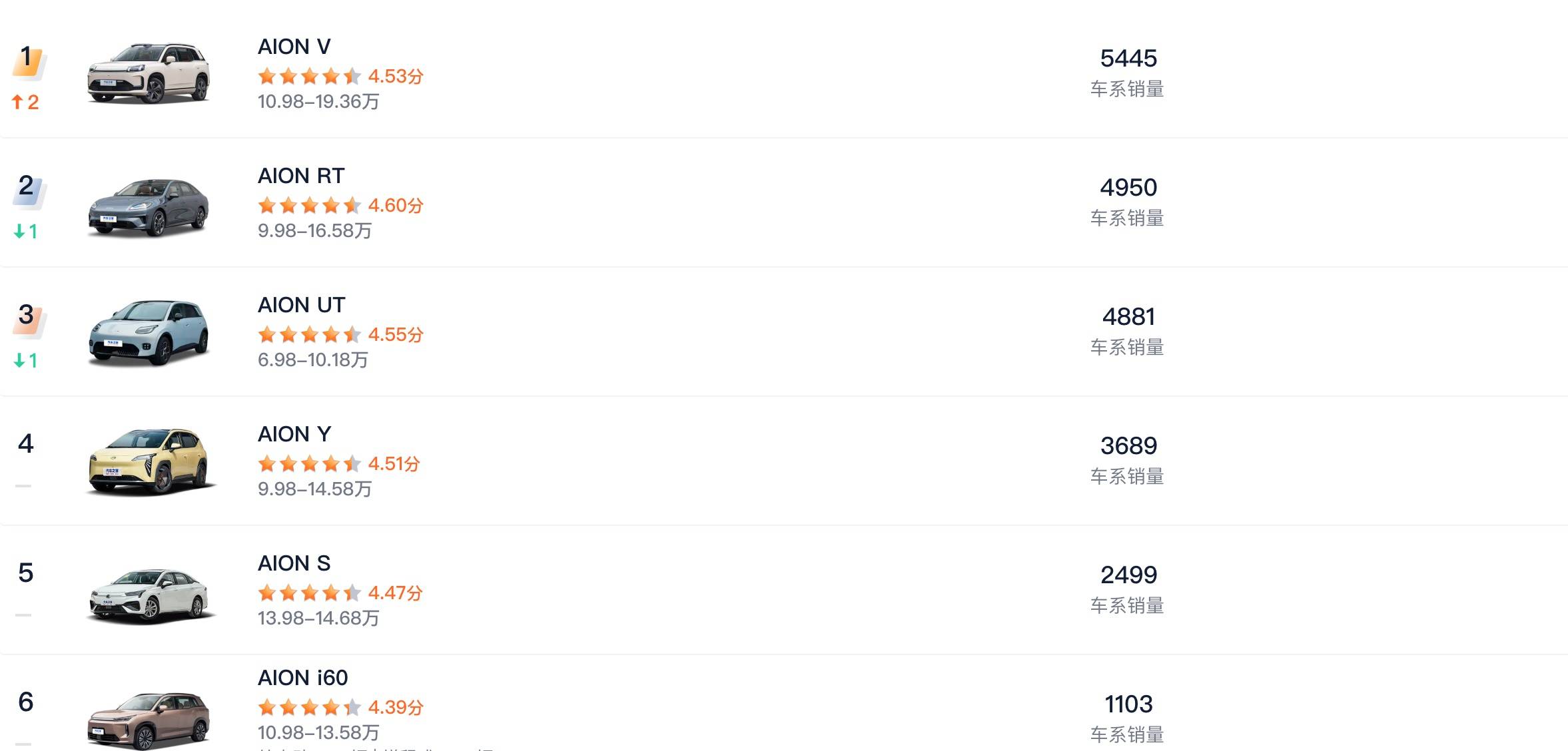
面对困局,埃安曾试图通过向上突破来寻找出路。他们推出了高端品牌「昊铂」,陆续布局了昊铂 GT、SSR、HT 等车型。
但高端品牌的建设本就依赖长期技术积累、用户信任与体系化运营,而彼时的埃安显然准备不足。结果,昊铂系列多数月份销量仅百辆上下,市场反响平平,不仅未能打开新局面,反而分散了本应用于主品牌的资源,导致埃安在 15 万元左右的核心价位段产品力停滞不前,尤其在智能化配置上明显落后于竞品。
所幸,埃安在今年终于意识到战略偏差。随着昊铂品牌正式独立运营,埃安得以重新聚焦主品牌,将研发、产品、渠道与营销资源全面回调。业内消息显示,公司内部已启动一轮深度调整,从组织架构到产品定义,从技术路线到用户运营,均在进行系统性「换血」。
最近几款新车的产品力都很能打,如 9 月份推出的埃安 RT 就以 9.98 万元起的亲民价格提供了十分越级的体验。市场反馈也比以往热烈了不少。
但究竟效果如何,只能明年再看了。

燃油车最后的堡垒
我们一直以来通常认为燃油车在溃败,表面上看,电动化浪潮席卷一切,但细看销量数据,会发现一个反直觉的现象,2023 年,两款车型全年销量分别约为 19 万辆和 18.9 万辆;而到了 2025 年前 11 个月,帕萨特已售出 23.8 万辆,迈腾也达到 20.2 万辆。是榜单上极少数还能维持 20 万+年销量的合资 B 级车。
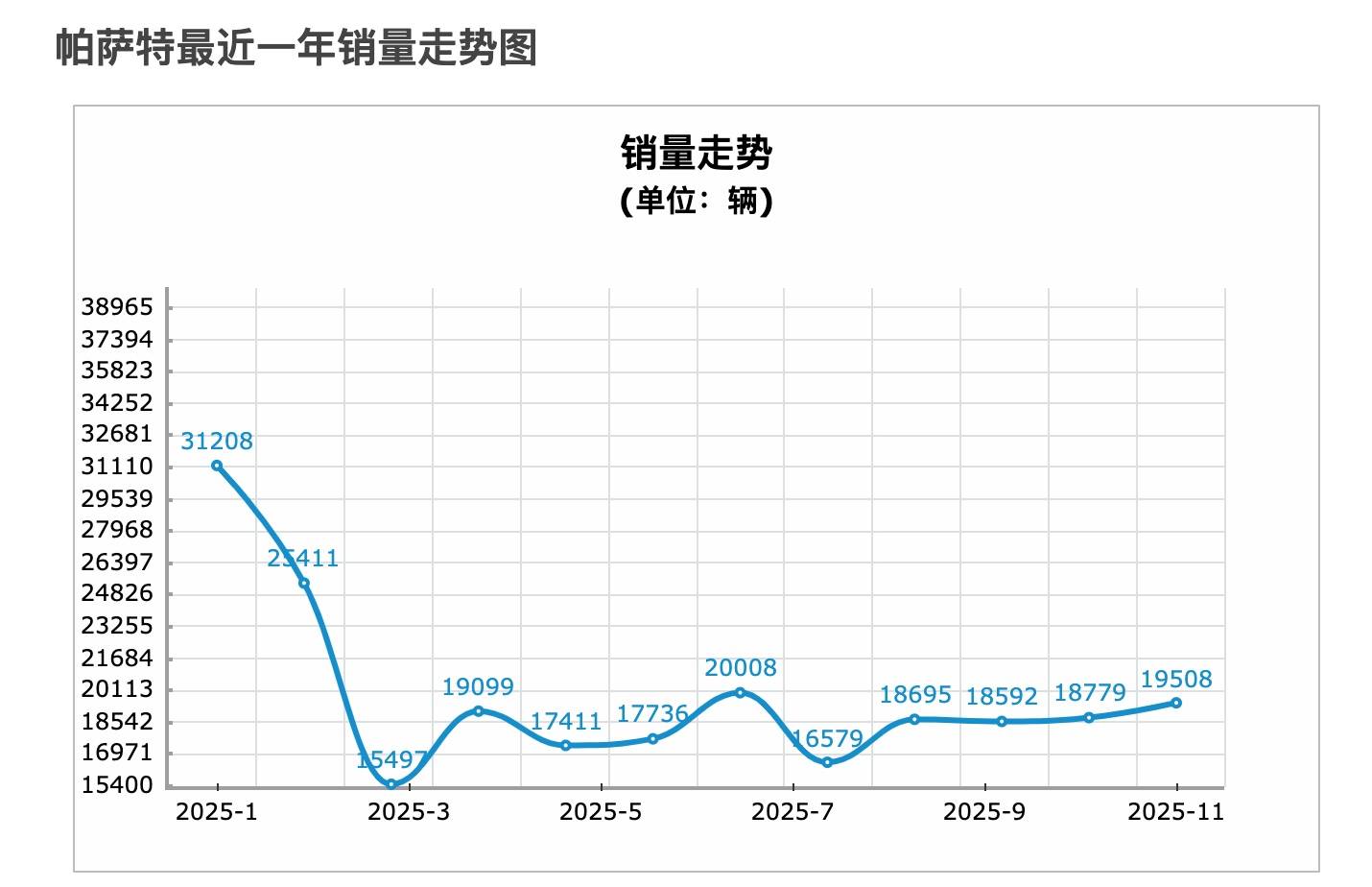
▲ 上汽大众帕萨特近一年销量走势 数据来源:车主之家
大众精准捕捉到了那些对新技术持谨慎态度、更看重可靠性与使用确定性的「保守派」用户。
面对价格战与电动化的双重压力,上汽大众和一汽-大众选择了一条务实路径——大幅降价、配置拉满、强化信任。
帕萨特部分车型终端售价已下探至 13 万元区间,IQ.Drive 智驾系统、自动泊车、全景影像等以往只属于高配车型的配置,也开始下放到中低配车型上。

整个合资阵营虽在新能源冲击下整体承压,却并未全面崩盘,而是退守到自己最擅长的细分市场。
日系的轩逸、RAV4 荣放和凯美瑞的销量确实较巅峰时期有所下滑,但依然稳居各自细分榜单前列。
这些车型的共同点在于,它们早已完成产品心智的沉淀,即便在智能化和加速性能上落后于新势力,它们在油耗、保值率、维修便利性和长期使用成本上的优势,依然对三四线城市用户家庭第二辆车等特定群体构成强大吸引力。尤其是在充电基础设施尚未完全覆盖的区域,燃油车仍是无可替代的实用工具。

市场的真相或许比「电替代油」的简单叙事复杂得多。未来几年,中国汽车市场大概率不会走向单一技术路线的垄断,而是进入一个油电长期共存、各取所需的多元阶段——电动化是方向,但燃油车仍有活路。
特斯拉 Model Y,铁杆盘稳固,但已到天花板
回顾特斯拉 Model Y 在中国市场近三年的销量,始终在 45 万至 48 万辆的区间内震荡。即便面对问界 M7、理想 L6 L7、小米 YU7 等强劲新势力车型的轮番冲击,甚至在价格战愈演愈烈的背景下,Model Y 的销量曲线依然异常平直——既未大幅下滑,也未显著上扬。
Model Y 在中国似乎已经形成一个高度稳定的「铁杆用户群」。这部分消费者对品牌高度认同,对产品性能、智能化体验或特斯拉生态有强烈偏好,其购买决策几乎不受外部竞争或短期促销影响。无论市场如何喧嚣,他们始终是 Model Y 最可靠的销量基石。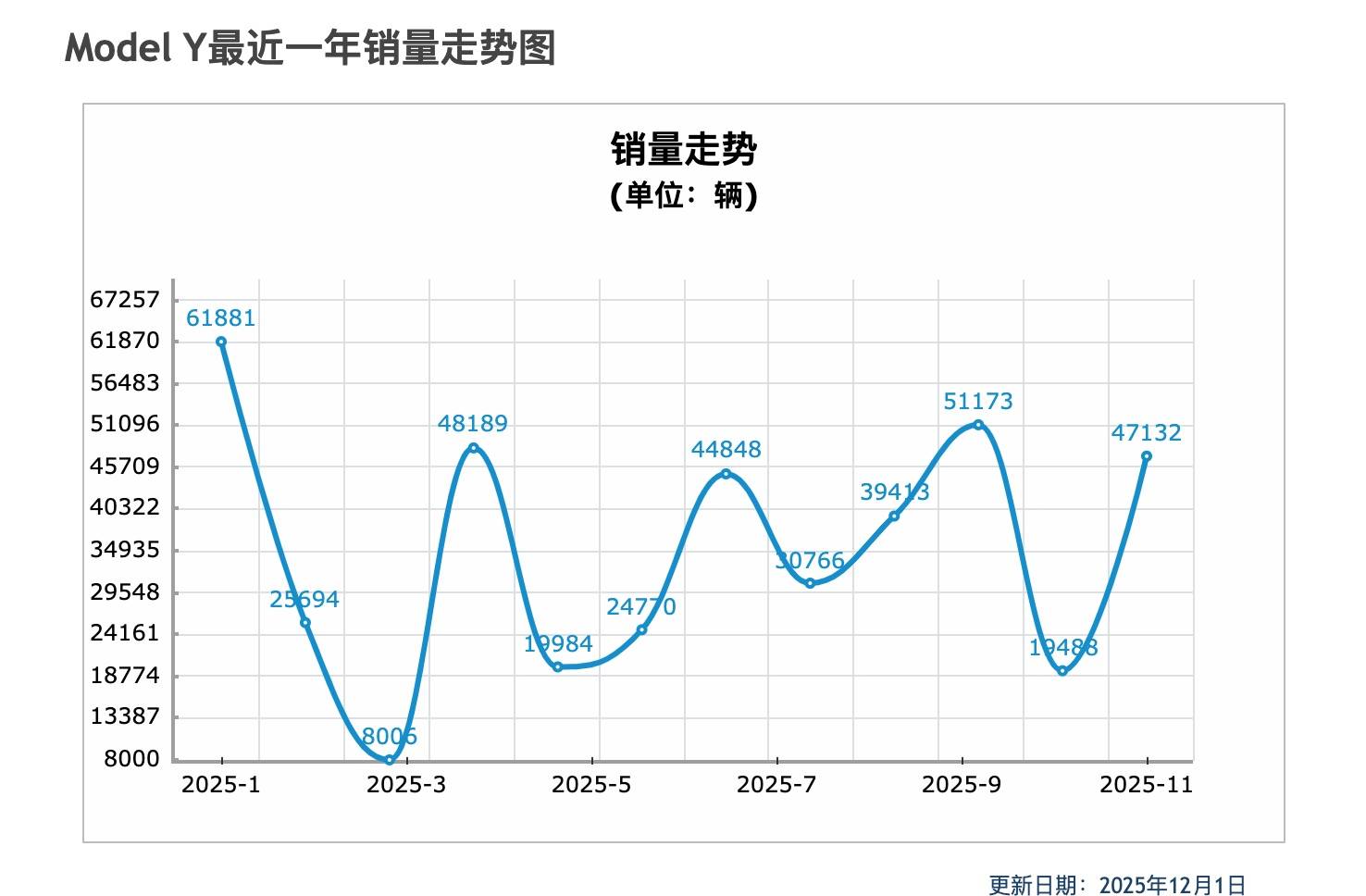
▲特斯拉 Model Y 近一年销量走势 数据来源:车主之家
然而,这种稳定性或许也说明 Model Y 的增长已经到达了天花板。
自 2021 年国产以来,Model Y 在核心设计、三电系统和智能座舱架构多年未有颠覆性更新。尽管特斯拉通过软件迭代和推出特供车型来维持竞争力,但增量空间极其有限。
正因如此即便 Model Y 本身并未「变弱」,它也在 2025 年让出了年度销冠的位置。取而代之的是星愿这类主打高性价比、精准切入大众市场的车型。
Model Y 的销量波动,或许也是中国新能源产品不断演进的缩影。特斯拉已经完成了「鲶鱼」的历史使命,若无下一代产品或重大技术突破,Model Y 很可能长期徘徊在 45–50 万辆/年的「稳态区间」,成为一座坚固但不再扩张的孤岛。

绕不开的小米 SU7
小米 SU7 和特斯拉 Model Y 是销量榜前十中唯二的平均售价在 20 万元以上高端车型。
曾经中国家庭用户的首选永远是 SUV,在 SU7 出现之前,纯电轿车被认为是一个上限不高的细分市场。
如蔚来 ET5、小鹏 P7 等车型都曾在细分市场都遇到了「月销 1 万」的的隐形墙,但小米 SU7 把年销量做到了 27 万辆,月均 2 万以上,证明了纯电轿车可以不仅是「代步工具」,更可以成为像 iPhone 一样的「科技时尚单品」。

另一个有象征意义的数据是,小米 SU7 今年的总销量超越了特斯拉 Model 3(19.3 万辆)。
Model 3 上市多年,虽然经历了改款,但在中国消费者眼中,它已经越来越像一个「标准化的纯电车」。它很强,但缺乏新鲜感和情绪价值。
而小米 SU7 在 Model 3 建立的「极简+操控」的基础上,做了两件 Model 3 做不到的事——「互联互通」和「配置堆料」。
中国消费者虽然认可特斯拉的品牌,但如果能用同样甚至更低的价格,买到更大的空间、更好的内饰、更本土化的智能生态,他们会毫不犹豫地倒戈。

小米 SU7 实际上是吃掉了 Model 3 增长停滞后的溢出份额,并抢夺了那些原本还在犹豫是否购买特斯拉的摇摆用户。
过去年轻人的第一台「体面车」通常是 34C,而现在,在马力变得廉价之后,开一辆「科技属性」更强的小米,比开一辆丐版「宝马 3 系似乎更能代表」现代生活方式。
问界,突破 BBA 的护城河
如果把榜单往后再翻几页,我们还能看到另一个有意思的现象。
在 40 万元以上,且年销能超过 10 万辆的高端豪华车市场,能和 BBA 掰手腕的国产品牌,依旧只有问界。
如果单看 SUV 车型,问界 M8 以 13.3 万辆的成绩超越了奥迪 Q5L 的 11.9 万辆,是过去一年卖得最好的豪华 SUV。

要理解问界的上位,首先要理解 BBA 等传统豪车护城河的消解。
在燃油车时代,BBA 的溢价逻辑是可感知的物理豪华感,V6/V8 发动机的轰鸣、毫秒级换挡的变速箱,底盘调教的厚重感,这些都是极高门槛的技术壁垒。
消费者为此买单,买的是这一套复杂的机械艺术品,以及随之而来的社会地位。那时候的「豪华」,是静态的展示,无论你开不开它,那个立在车头的 Logo 和车内的真皮实木都在彰显价值。

然而,电动化时代带来了一场残酷的「机械平权」。电机轻易地让 20 几万的车型拥有了过去百万级豪车的加速体验;空气悬架和 CDC 减震器的供应链下放,让底盘质感的差异被无限缩小。
当原本的稀缺资源变得廉价,传统豪车就出现了「价值真空」。 这正是问界切入的时刻,它没有在旧赛道上过多纠缠,而是通过智能化,建立了一套新的价值坐标系。
在旧时代,车是冷冰冰的工具,人必须去适应车,而在问界构建的体系里,车更像是一个有感知能力的智能终端。

鸿蒙座舱让车机像手机一样省心顺手,不需要你去适应机器,而乾崑智驾把安全从「耐撞」升维成了「避险」,能在关键时刻帮你踩停、替你挡灾,这种实实在在的「保命」能力,才是科技时代最高级的溢价。
系统能力之争
如果把这些品牌和车型放在一张更大的时间轴上看,会发现一个越来越清晰的事实:中国汽车市场已经从「技术路线之争」,进入了「系统能力之争」。
过去几年,电动化是唯一的主线,谁能更快「上电」,谁就能拿到红利。但当新能源渗透率越过拐点,技术不再是稀缺品,真正拉开差距的,开始变成三件事:对用户的理解深度、产品迭代的速度,以及组织执行的确定性。
比亚迪今年的转变是最好的例子。
比亚迪的下滑很大程度上在于它太早成功,也太早暴露了边界。当所有对手都学会用更低的价格、更精细的定位、更快的反应去拆解它的优势时,比亚迪需要重新回答一个问题:除了性价比,它还能用什么继续扩大用户池?
他们花了一整年找到的答案是「用户价值」。
他们为多款车型都增加了配置更高,价格更低的车型。升级点都集中在用户最关注的续航和舒适性的部分,像联动底盘、动力、座舱三大系统的定眩智能防晕车功能、与生态伙伴共同定制的宠物座椅和安全座椅配件都能让用户感知更强,用车舒适度更高。
简单点说就是尝试将技术转化为用户实实在在的体验。

市场营销学中有个经典的 4P 理论。
产品(Product)、价格(Price)、营销(Promotion)、渠道(Place)是四个决定销量的关键要素。
今天的中国车市,奖励的就是两点以上的长期稳定输出。
能把产品和价格同时做到极致的,才能吃下最大规模;能把产品和营销高度耦合的,才能制造现象级爆款;而三点、四点同时成立的玩家,才有资格谈「长期统治」。
未来几年,中国汽车市场不会有单一赢家,但一定会不断淘汰那些,只靠运气和红利活着的玩家。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博







