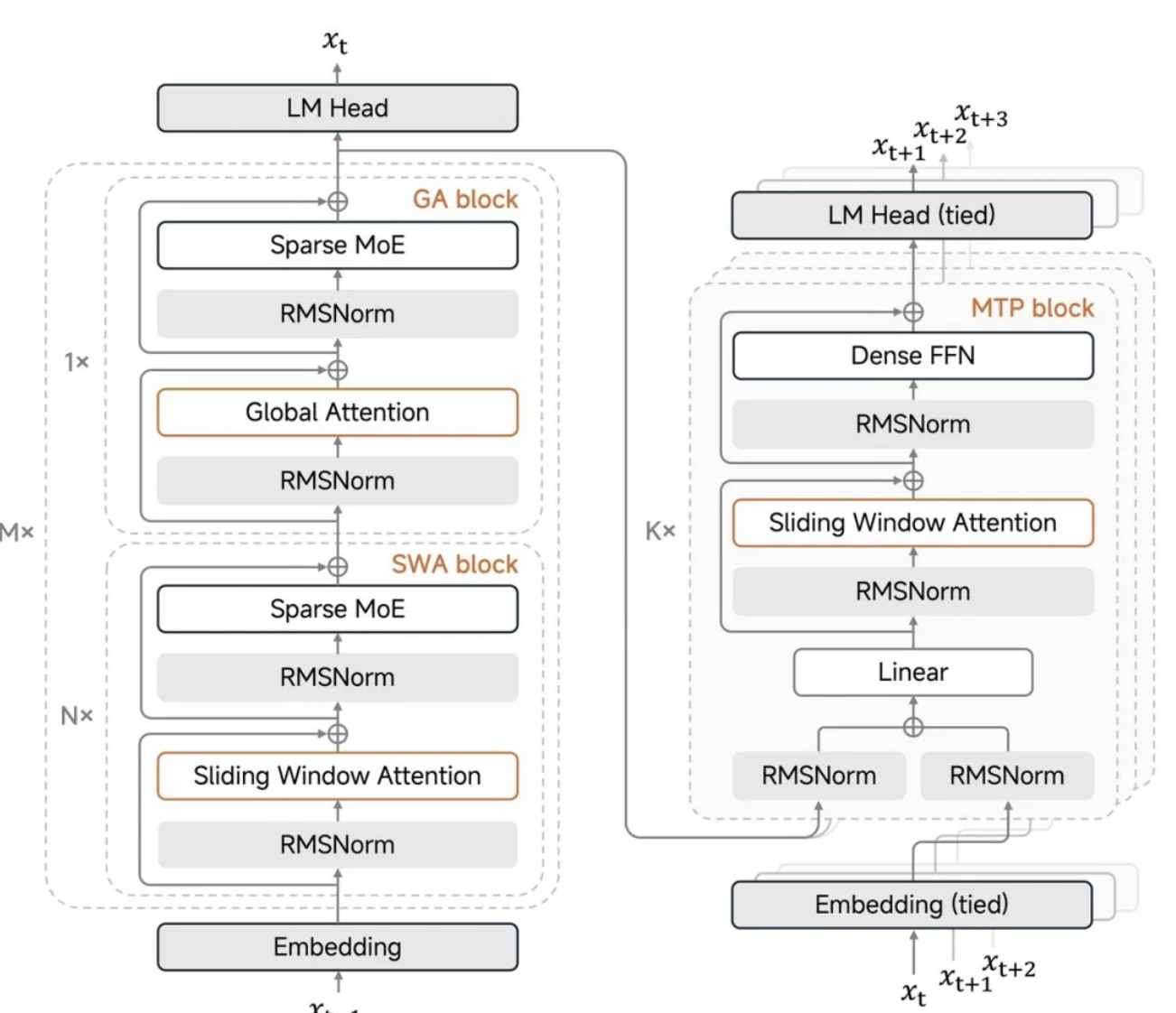
刚刚,OpenAI 版 Nano Banana 发布:奥特曼秒变性感男模|附实测

GPT-4o 上半年带来的那波热度,不仅让奥特曼感受到了 GPU 融化的气息,也让生图、理解视觉几乎变成了所有大模型的标配卖点。
但到了今年下半年,真正刷足存在感的却是那根「香蕉」:Nano Banana。
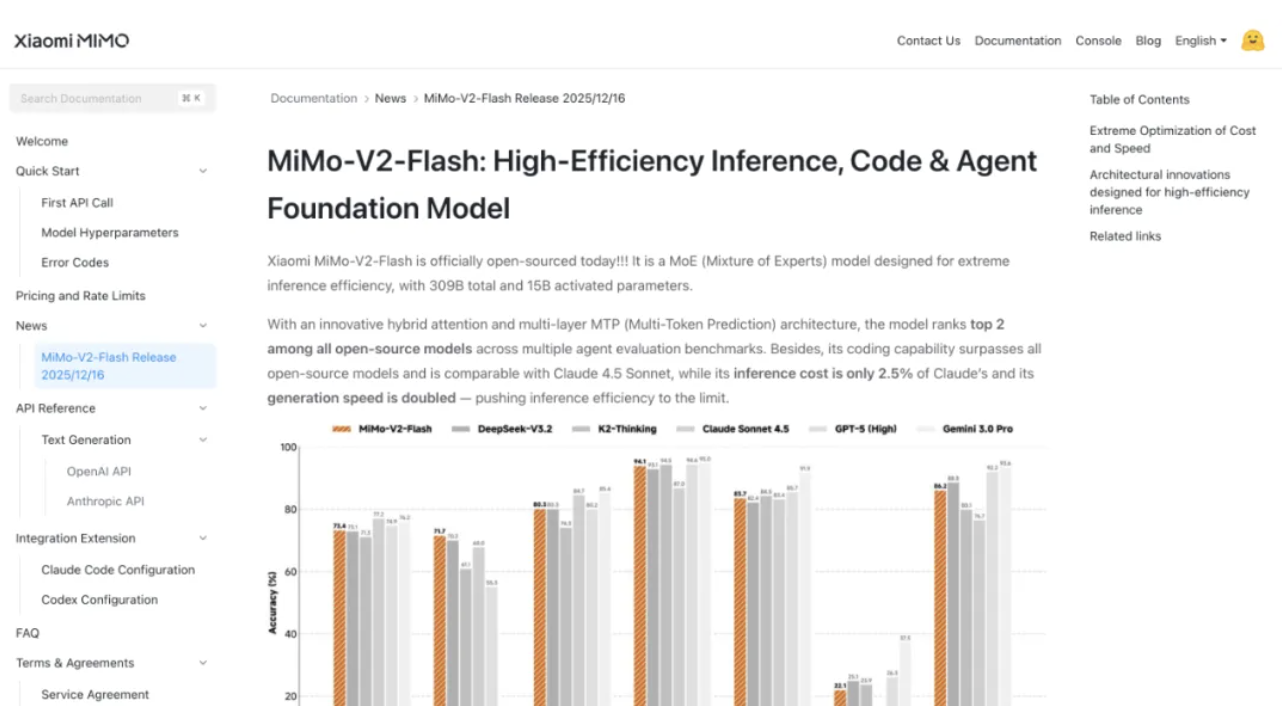
为了抢回头把交椅,OpenAI 今天正式推出了最新图像视觉模型 GPT-Image-1.5。这也是继 GPT-5.2 之后,OpenAI 红色警报计划中又一记重拳。
省流版如下:
- 指令执行更准确
- 编辑更精确
- 细节保留更完整
- 比之前快 4 倍
告别「抽卡」玄学,编辑细节能力拉满
GPT-Image-1.5 最大的升级点在于「精准编辑」。
以前用 AI 改图,简直像碰上了一个听不懂人话的「托尼老师」,你只想修修刘海,它反手就给你剃了个光头。现在,模型终于听懂了人话。你改哪里,它就动哪里。
光线、构图、人物特征,在输入、输出和后续编辑的闭环都能保持一致性。
听起来很抽象?看看官方给出的示例。
- 将两个男性和一只狗合成到一张 2000 年代胶片风格的儿童生日派对照片中 →
- 添加背景中吵闹投掷东西的孩子们 →
- 将左边的男人改为复古手绘风格,把狗变成毛绒玩具风格,右边男子和背景保持不变 →
- 为所有人换上 OpenAI 毛衣 →
- 最后只保留狗,把画面放入一场 OpenAI 的直播中……

一套连招下来,画面逻辑居然没崩。这说明 GPT-Image-1.5 不再是靠「蒙」,而是真的理解了画面结构,并完成增删改查。而能改得准、稳得住,才是现在的技术护城河。
再来看几个我实际测试的案例。
你或许看过《千里江山图》这幅传世名作,但你或许还遗漏了亿点点细节。
同理可得,谁说《百骏图》里,不能突然出现一只从现代穿越过来的网红柴犬 Kabosu。

就连马斯克和扎克伯格那场没打成的笼中决斗,在 GPT-Image-1.5 的加持下,一次性就成功把主角换成了奥特曼。脸没崩,违和感也几乎为零。

我们要一张细节丰富、逼真写实的极端仰拍照片,马斯克坐在珠江岸边单手搭着广州塔尖。为了体现巨物感,还得在他的脚边撒上微小的游船和游客。
结果,它也确实懂了什么是「比例感」。

▲提示词:一张细节丰富、逼真写实的极端仰拍照片,画面中的马斯克正在坐在珠江岸边,一只手搭在广州塔的塔尖上,为了体现巨大的体型比例,可在他的脚边加入一些微小的游船、观光游客等,2K,16:9
终于不再画「鬼画符」,但中文表现……
相比初版图像模型,GPT-Image-1.5 更擅长遵循复杂、细致的指令,能保持各元素之间的预设关系。
官方展示了一个 6×6 的网格图案例,每一行都要按指定内容布置,希腊字母、动物、物品、图标、单词,模型排列得井井有条,强迫症看了都得说声舒服。

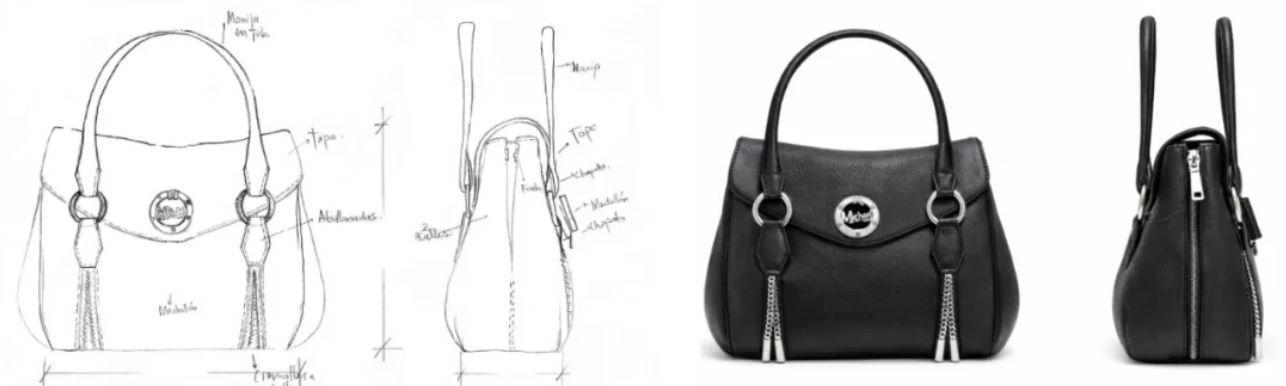
经过实测,把线稿转成真实图片这种操作,现在也成了基操。
文本渲染能力也进一步提升,能更好地处理密集、小字体内容。比如将一段 Markdown 格式的内容呈现为自然的报纸文章布局,内容包括 GPT-5.2 发布说明、性能基准对比等,格式和数字都能保持完整准确。

这个能力听起来可能不起眼,但对于需要生成海报、宣传图、信息图表的用户来说,简直是刚需。
在 Nano Banana Pro 出现之前,生成式 AI 的文本渲染一直抽象得离谱,现在终于能看了。不过我们得泼盆冷水,GPT-Image-1.5 的英文能力确实能打,但中文表现依然是灾难现场。
我让它画个「擎天柱征服火星」的中文漫画,它能给你自创一门火星文。

亦或者让其生成一张古人在墙壁写水调歌头的图片,不仅文字错漏百出,握笔姿势还居然是拿钢笔的手法。

好在生成速度快了 4 倍,这边还在画着,那边你可以同时开几个新任务,试错成本大大降低。物体知识储备也还算在线,问它往水里加盐鸡蛋会怎样,生成的图片倒是有模有样。

▲左为原图,右为生成的图片。提示词:如果往水中加入大量盐,生成一张图片,展示鸡蛋会发生什么。
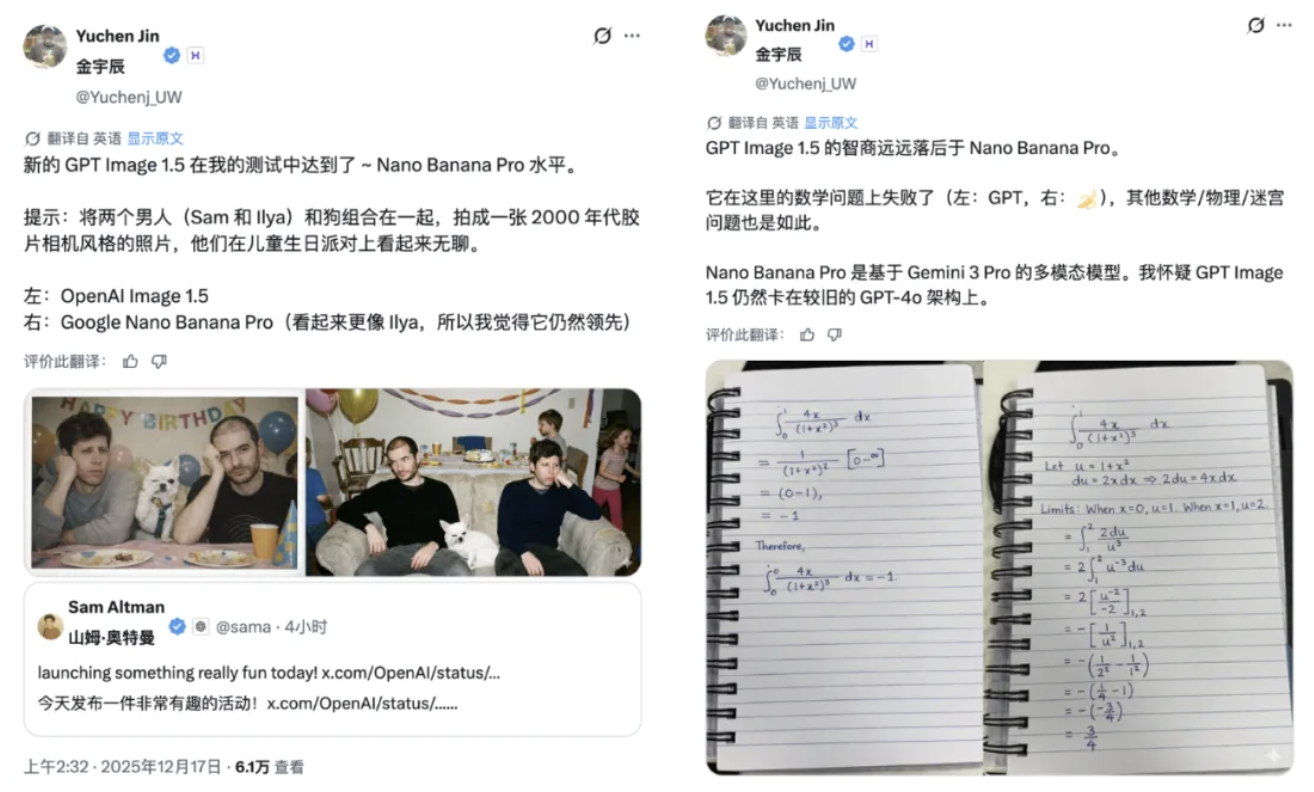
博主 @Yuchenj_UW 则认为 GPT Image 1.5 的生成效果大致达到了 Nano Banana Pro 水准,但「智商/推理能力」明显落后于 Nano Banana Pro,尤其在数学题上(以及其他物理/迷宫类问题)表现更差。
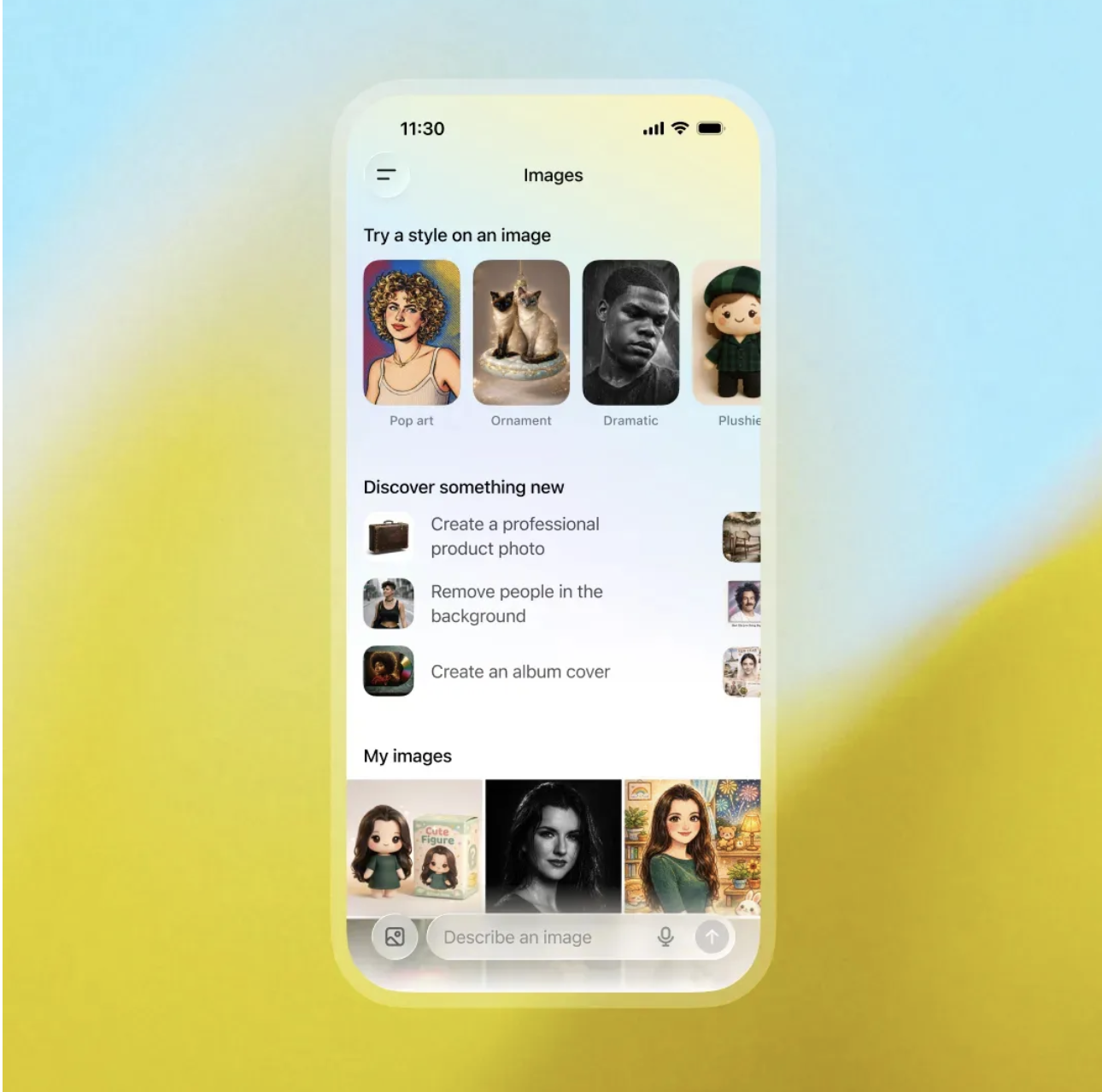
你的下一位设计师,何必是人?ChatGPT 申请出战
OpenAI 这次还在 ChatGPT 里专门开辟了一个图像创作入口。
网页和移动端侧边栏都能看到这个新入口,里面塞满了预设滤镜和热门提示词,还会定期更新。上传一次肖像,以后张张都是你,不用反复喂图。
说实话,这功能 Nano Banana 没有,但国内的生图模型早就玩烂了。 某种程度上,GPT-Image-1.5 也算是在摸着国内同行的石头过河。
刚刚,奥特曼也在社交媒体上分享了自己用 GPT-Image-1.5 生成的圣诞性感月历男模照片。

来都来了,我们也顺手给奥特曼换了几套皮肤。贴纸风、摇头娃娃风、素描风,预计今天过后,奥特曼又要成为互联网上最忙的男人。

有个细节很值得点赞,当你要求生成预设方案时,OpenAI 会公开预设的提示词。从这一点来看,OpenAI 确实 open 了。

除此之外,制作贺卡、创建专辑封面,修复老照片,拍摄专业求职照片等也都是非常实用的预设方案。比如,那张经典的鲁迅和泰戈尔的合照,经过修复后,其实效果还是挺不错。

OpenAI 应用 CEO Fidji Simo 在博客中写道:「人类的思维并不只是由文字组成。事实上,我们最有创意的想法,往往起源于脑海中的图像、声音、动作或模式。」
她透露,ChatGPT 正在从一个反应式、以文本为核心的产品,转变为一个更直观、更能贴合你各种任务需求的工具。从纯文字向多媒体和动态界面转变,是这一进化过程中的重要一步。
很多用户第一次接触 ChatGPT,都是通过文字生成图片。这种「把文字变成画面」的过程充满魔力,但 ChatGPT 的聊天界面最初并不是为此设计的。图像创作和编辑是一种完全不同的任务,需要专门的视觉空间来支持。
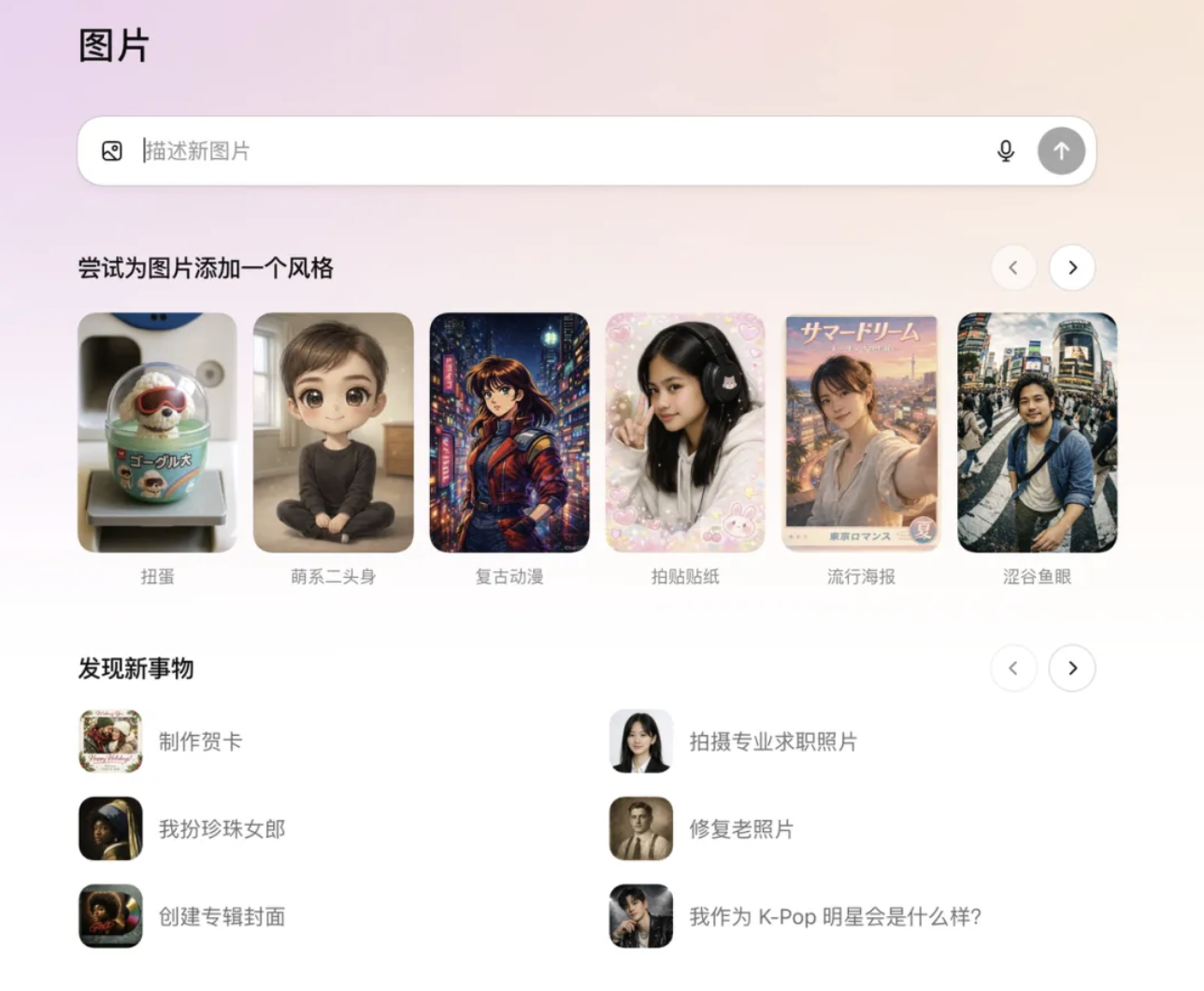
OpenAI 干脆给它搞了个专属入口,让图像生成有了一个更像创意工作室的环境。
计划还不止于此。
OpenAI 未来还将引入更多视觉元素,优化 ChatGPT 的整体体验。未来在进行搜索查询时,结果将更多地包含图片和清晰来源。在单位换算或查阅体育比分等任务中,你需要的是一目了然的可视化结果,而不是一段文字描述。
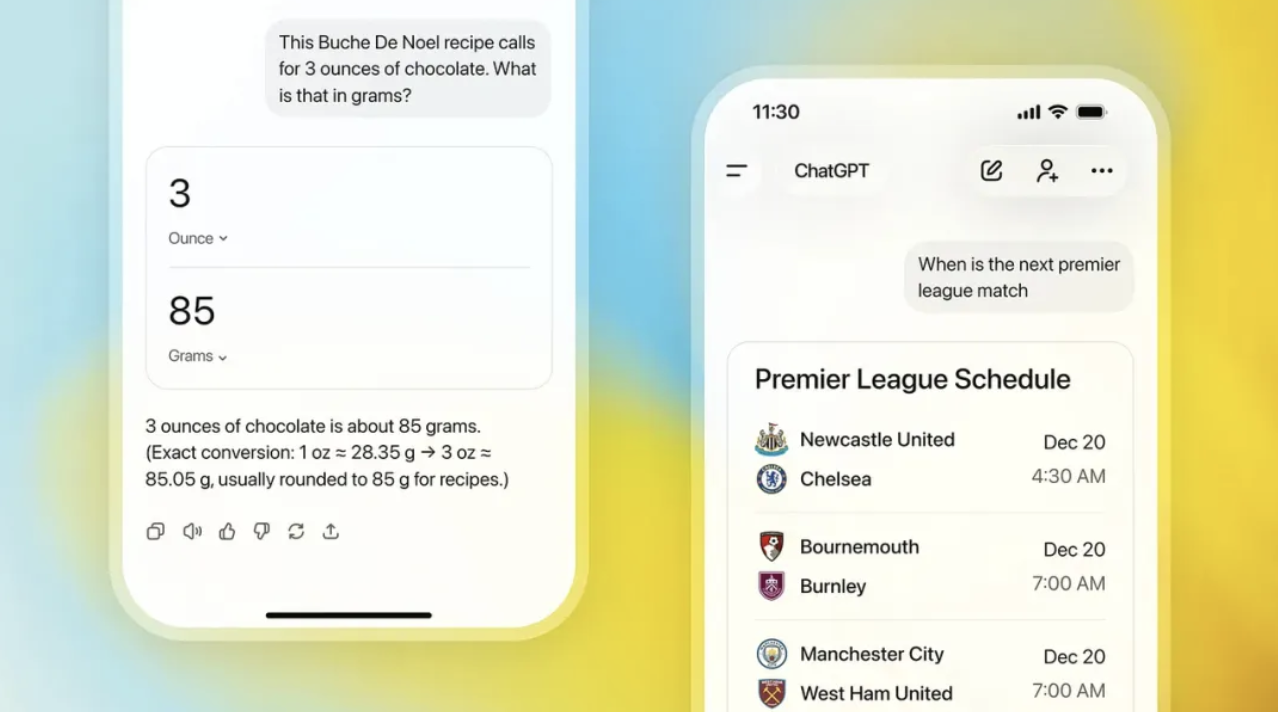
甚至写作体验也在改,未来内置的写作模块让你在聊天中就能直接编辑,还能一键导出 PDF 或直接调用邮件应用发送。ChatGPT 早已不是一款单纯的语言模型,它正在变成一个真正的多模态工作台。
当然,除了普通用户,开发者也能通过 API 用上 GPT-Image-1.5。
相比 GPT-Image-1,GPT-Image-1.5 具备更强的品牌元素与关键视觉保持能力,适合电商、品牌营销等需要生成大量变体图片的场景。图像输入输出费用降低 20%,同样预算可生成更多图像。
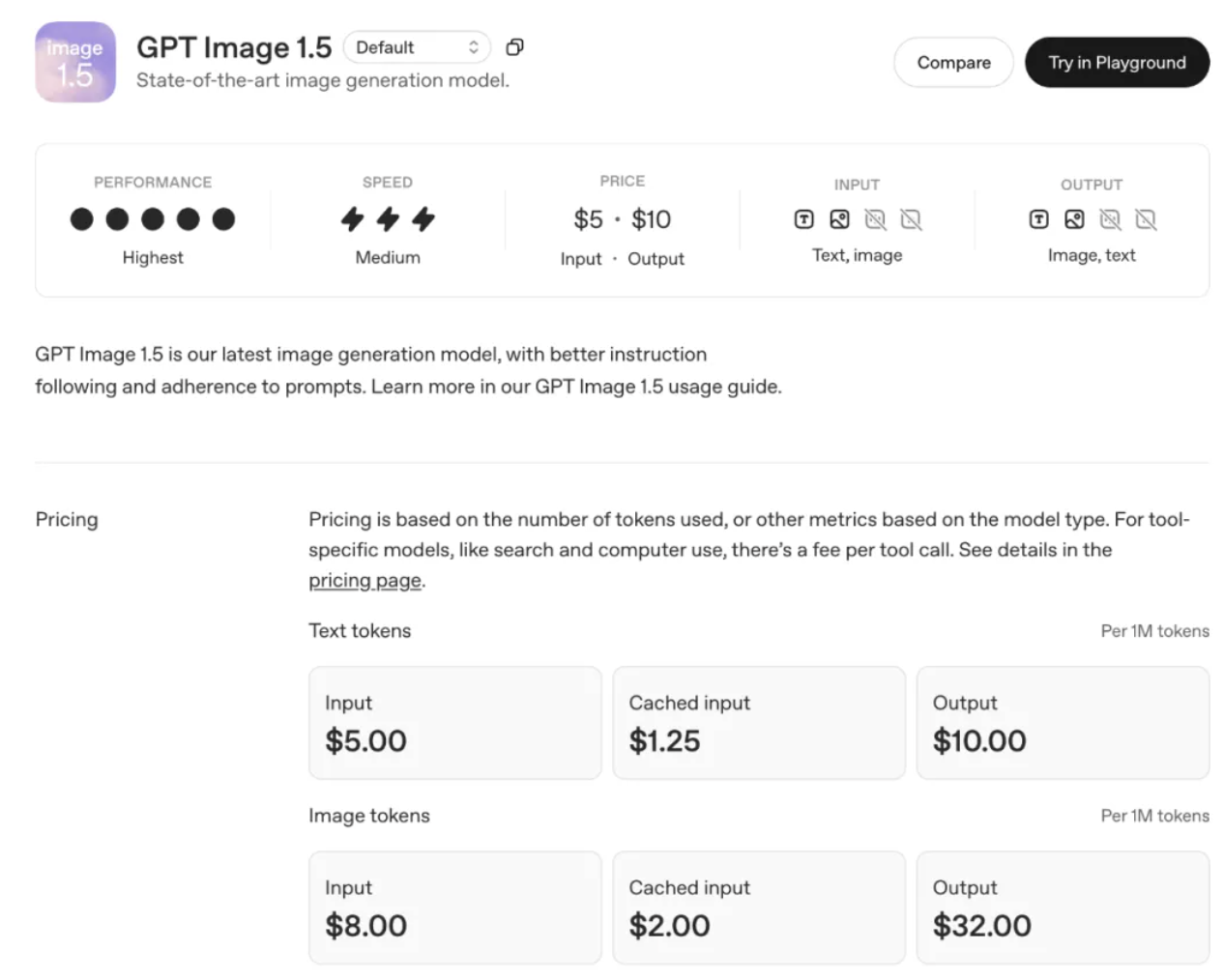
降价+提效,这套组合拳打得还是挺实在的。
除此之外,迪士尼上周已经宣布向 OpenAI 投资 10 亿美元,并达成了合作协议。根据这项为期三年的授权协议,OpenAI 旗下的 Sora 和图像生成模型都能生成迪士尼、漫威、皮克斯和星球大战旗下角色,并计划在明年初正式上线相关功能。

内容 IP 加 AI 生成,这背后想象空间确实挺大。
更重要的是,GPT-Image-1.5 的发布,标志着图像生成工具正在从「玩具」向「工具」转变。
目前市面上大多数 AI 改图工具,一改就崩,毫无一致性可言。
GPT-Image-1.5 至少在这个方向上迈出了坚实的一步。它开始具备后期编辑能力,能像 Nano Banana Pro 一样控制细节,确保画面连贯。
在模型能力较弱的情况下,GPT-Image-1.5 通过更完善的图片生成预设方案, 以及功能设置来完成对新版 Nano Banana 的反击, 也确实是不错的选择。
专属图像创作入口、预设滤镜库等等,这些看似不起眼的产品设计, 恰恰击中了普通用户的痛点。很多人并不需要最强的模型, 他们需要的是「能快速上手、不用反复调教、生成结果八九不离十」的工具。
模型能力领先只是第一步, 如何把能力转化为好用、易用、爱用的产品,才是真正的护城河。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。