1. 前言
最近在负责 Agent 项目前端部分的落地,深感 Agent + ToB 不仅仅是功能的叠加,更是一个需要前端开发、交互设计与业务逻辑深度融合的全新领域。因此,我想通过这篇文章梳理一下架构设计层面的思考。
在过去二十年里,ToB软件已经形成了一套成熟且稳固的交互范式(GUI图形用户界面)。为了承载复杂的业务逻辑,业界构建了深度的树状导航、高密度的业务逻辑和繁复的表单系统。这种设计通过将业务流程抽象为标准化的功能模块,有效地解决了信息化的问题。
此时,用户与系统的关系是典型的 “人适应系统” :用户必须接受培训,记忆固定的操作路径,通过“点击 + 键盘”的机械指令来驱动软件。
近年,AI Agent 技术开始被引入 ToB 领域。但目前的普遍做法,仅仅是在现有界面上叠加一个聊天机器人(Chatbot)。但是,AI Agent 的出现不是为了在界面上加一个聊天框,而是为了打破“人去寻找功能”的旧模式。
未来,Agent 必然不再是一个边缘的辅助工具,而是系统的核心驱动力,可以深入介入用户的作业流,ToB 前端软件的人机交互应当如何重构?
本文分以下几个方面来深入探讨这个问题:
- 静态界面变迁:静态渲染 => 混合渲染(生成式 UI + 静态渲染)
- 人机交互变迁:功能导航 => 意图引导
- 前端开发变迁:页面构建 => 原子组件 + 能力架构
最后,我还会加入一些杂七杂八但是重要的思考
以下内容纯属个人预测,如有指教请在评论区指正!
2. 定义:Agent是个啥?有啥用?
2.1 先定义:我说的Agent是什么?
我说的AI Agent不是我们熟知的聊天机器人或任务助手。
聊天机器人或者任务助手其本质是反应式的。它们在预设的规则或模型内,针对用户的明确指令执行单一、具体的任务 ,比如基于知识库的业务问答
而AI Agent则代表了一种主动式的、具备自主性的新形态(常用Cursor的朋友应该能够明白我在说啥)。
一个真正的AI Agent具备以下核心特征:
- 感知: 能够感知并处理其数字环境中的信息,包括视觉、文本和各类数据输入 。
- 规划: 能够将一个复杂、高阶的目标分解为一系列可执行的、具体的子任务 。这是其区别于普通LLM的关键能力。
- 工具使用: 能够调用外部工具(如API、代码执行环境、数据库查询)来获取信息或执行动作,从而与外部世界进行交互。
- 记忆: 能够记忆过去的交互、行动和结果,并利用这些记忆来指导未来的决策,实现上下文的连续性和学习改进 。
2.2 ToB软件对于AI Agent的核心诉求: 在复杂工作流程中提升用户生产力
ToB Web 应用对 AI 智能体的需求,可以总结为在复杂工作流程中提升用户生产力
引入AI Agent的最终目标,并非仅仅加速单个任务,而是从根本上重构涉及业务整体工作流 。这一理念的转变,要求前端交互设计需要进行变革。前端不再仅仅是用户与单一功能的交互界面,而是用户与一个持续进行的、复杂的业务流程进行协作的平台。
3. 静态界面变迁: 从静态渲染 => 混合渲染(生成式 UI + 静态渲染)
Agent所代表的生成式 UI 并非要消灭现有的菜单和页面,而是作为一种高维度的补充。它让软件能够像乐高积木一样,根据用户的即时需求,实时重组最适合的交互形态。
3.1 静态页面的“确定性”与意图的“无限性”
1、静态渲染的局限性:被“确定性”锁死的路由
现有的 ToB 架构建立在 “确定性路由” 之上。前端工程师预先定义好 /dashboard、/report 等路由,并在每个路由下硬编码固定的组件布局。这种模式的前提是:用户的需求是可枚举的,操作路径是线性的。
这种模式有两个缺陷:
-
路径冗余:用户想要完成一个跨模块的任务(例如:“把 A 项目的数据经过 B模块的处理后导出”),往往需要在三四个页面间跳转、复制、粘贴。
-
僵尸组件:为了覆盖长尾需求,ToB 软件的页面里塞满了平时根本用不到的高级筛选器和按钮,导致界面臃肿。
然而,Agent 的核心价值在于处理发散性意图。当用户提出“请分析上季度华东区销售异常的原因,并给出整改建议”时,这一需求涉及数据查询、图表分析、文本推理等多个维度。传统的静态页面无法预知并覆盖此类组合式需求。若强行通过跳转多个页面来解决,会让用户很不爽。
2、生成式 UI 的核心逻辑: 图形界面(GUI)和语言界面(LUI)的融合
生成式 UI 指的是:系统根据对用户意图的理解和当前上下文,在运行时动态决策并渲染出的用户界面。
在 Ant Design X 的范式中,这被称为“富交互组件的流式渲染”。其工作流包含三个阶段:
-
意图识别 :Agent 识别用户需求,判断单纯的文本回复不足以解决问题,需要调用特定的 UI 组件。
-
结构化描述 :Agent 输出一段包含组件类型和Props的 JSON 描述
-
动态渲染 :前端接收 Schema,映射到本地的“原子组件库”,在对话流中即时渲染出可交互的卡片。
未来ToB软件的界面,可能不再是密密麻麻的菜单和按钮。而是一个全局的、智能的 语言用户界面(LUI) 将成为最高优的交互入口。用户可以通过自然语言直接下达指令,而GUI则会变成为:
-
歧义消除与能力展示区: 当Agent对指令理解不清时,会通过GUI提供选项让用户选择。同时,GUI也直观地展示了当前软件“能做什么”,为用户提供输入指令的灵感。
-
过程的监控区: Agent的执行计划、步骤和状态,会以可视化的方式在GUI中呈现。 比如
任务规划List(以流程图或任务列表的形式,展示Agent为了完成用户目标而制定的详细计划)、实时日志流(实时显示Agent正在执行哪一步、调用了哪个工具、工具返回了什么结果)。
-
结果的呈现区: Agent执行任务后的结果(如生成的报表、更新后的数据列表)依然通过确定的GUI来展示。
这标志着前端开发重心的转移:从构建静态页面转向定义组件能力 。
3.2 具体有哪些新的UI形态?
为了让 Agent 的抽象工作过程变得透明、可控和可信,一系列新的UI模式应运而生。这些模式可以根据其核心功能分为三大类 。
3.2.1 为了提高透明度和可观测性的新形态
这类模式的核心目标是打开Agent的“黑盒”,让用户能够理解其“思考”过程。
1、双栏视图
这是展示Agent思考过程的关键模式。界面被分为两栏,一栏实时展示Agent的内部推理过程;另一栏则展示其采取的具体行动。
例子: Cursor的主界面一般被分成两块,一边是代码编辑区(具体行动);另外一边是思考和推理过程。
2、多智能体流程图
在由多个Agent协作的系统中,使用流程图或活动图来展示任务的分配和流转,清晰地标明哪个Agent在何时执行了何种操作。用户可以通过可展开的卡片深入了解每个Agent的具体贡献 。
例子: 秘塔AI搜索研究版\ 
3、来源引用与追溯
对于使用检索增强生成(RAG)技术的Agent,UI必须将生成的内容链接回其引用的原始文档或数据源。这极大地增强了信息的可信度,并允许用户进行事实核查 。
例子: Gemini的深度研究,使用了大量展示数据源的交互。
3.2.2 为了更好地和Agent交互与协作的新形态
这类新UI和交互目的是将Agent的能力无缝地融入用户的工作流中。
1、协作画布
AI能力被直接嵌入用户的主要工作区,如设计工具或文档编辑器。用户通过行内建议、斜杠命令(/)或专用的AI功能块与Agent交互,整个过程无需离开当前的工作上下文,保持了心流体验 。
例子: copliot中的自动代码补全
2、提示工程化表单
将复杂的自然语言提示(Prompt)工程抽象成结构化的表单,用户只需填写几个关键字段,系统就会在后台将这些输入转换成一个优化过的、高质量的提示,然后提交给Agent。这有效降低了用户使用AI的门槛 。
例子: 抖音“创作灵感”工具的主动引导。抖音的“AI脚本生成”功能早期面临用户输入模糊的问题(如用户仅输入“拍一条美食视频”)。通过“提示工程化表单”方案优化后,交互流程变为:
- 用户输入“拍一条美食视频”,意图分类模型判断明确度0.4(模糊)。
- 系统生成候选引导项:
- “选项1:家常菜教程(步骤清晰,适合新手)”
- “选项2:探店测评(突出口感描述,适合推荐)”
- “选项3:创意摆盘(视觉化强,适合短视频)”
- 用户点击“选项1”,系统自动补全提示词:“帮我生成一条家常菜教程的视频脚本,目标人群是厨房新手,需要包含食材准备、步骤拆解和小贴士。”
3、生成式UI
AI不仅填充数据,还能动态生成或修改UI组件本身。
例子: 用户可以要求一些办公软件中的Agent“在表格中增加一列,显示每个订单的利润率”,Agent会直接修改表格组件的结构;或者要求“生成一个展示用户增长趋势的图表”,Agent会在仪表盘上创建一个新的图表组件
3.2.3 增加用户对Agent的掌控的UI
1、人在回路
Agent的工作流在执行关键或高风险操作(如撤销git 暂存区内容时)之前会被明确地暂停。UI会清晰地展示Agent将要执行的动作及其可能带来的后果,并要求用户进行明确的批准后才能继续 。
例子:Cursor 和 Copilot 在agent模式下,是可以自动执行终端命令并读取执行结果的的。默认情况下,绝大多数终端命令(尤其是删除、安装依赖等)都需要用户点击 "Run Command"
2、可编辑计划与“check point”回溯
在Agent开始执行任务之前,UI会展示其完整的行动计划。用户可以审阅、编辑、重新排序甚至取消计划中的某些步骤。
通过“check point”,用户可以“回溯”到Agent执行过程中的任一历史状态,并从该点开始探索一条不同的执行路径 。
例子:Gemini的研究模式 或者是 Cursor 的 plan模式\ 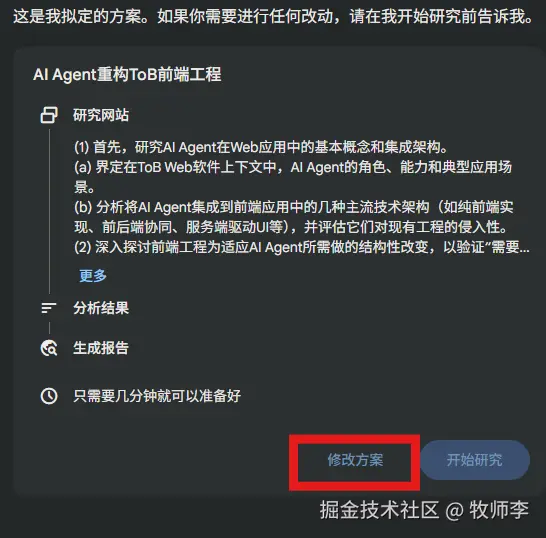
-
中断与恢复控制: UI必须始终提供一个明确的“停止”按钮,允许用户随时中断正在运行的Agent。中断后,UI应提供恢复、重试或放弃任务的选项 。
4. 人机交互变迁:“操作员” => “指挥官”
在过去几十年里, GUI(图形用户界面)将用户规训成了软件的 “操作员”。而在 Agent 时代,交互设计的终极目标是将人还原为 “决策者”。
4.1 Agent时代的B端交互需要解放用户
4.1.1 交互逻辑:从“过程导向”到“结果导向”
在传统的 GUI(图形用户界面)中,交互是指令式的。
用户必须清楚地知道每一个步骤:点击菜单 A → 选择子项 B → 输入参数 C → 点击确认。
这是一种“手把手教机器做事”的模式,对于一个有明确目的复杂工作流来说很繁琐
在 Agent 介入后,交互变成了意图式的。用户不再关注步骤,只关注结果:“帮我把这周异常的监控数据发给XXX”。系统内部自动完成了“检索数据 → 过滤异常 → 格式化报表 → 查找联系人 → 发送邮件”这一系列复杂工作流。
用户不再需要记忆软件的操作路径,只需要清晰地定义目标。
4.1.2 反馈机制:从“单向执行”到“双向对齐”
在 GUI中,反馈通常是二元的:成功 or 失败。机器默认用户是永远正确的,只管执行。
但在意图式交互中,由于自然语言天然存在模糊性(例如用户说“清理一下”,是指删除媒体文件还是清理一下数据库?),交互的重心从“执行”转移到了“对齐”。
包括但不限于以下反馈机制:
-
授权: 用户可以设定Agent的权限范围,决定哪些操作它可以自动执行,哪些需要审批。 比如 Copliot 可以设置哪些命令行命令是不可以自动执行的。
-
“急停”与接管: 在Agent执行任务的任何时刻,用户都应该可以暂停任务,审查状态,甚至手动接管后续步骤。
-
纠错与反馈: 当Agent执行出错或不符合预期时,用户可以方便地提供反馈,帮助Agent学习和改进。
这种交互更像人类之间的协作:听懂 → 确认 → 行动,而不是冰冷的 点击 → 运行。
4.2 具体有哪些新的交互模式?
交互的内核正从“指令驱动”向“意图驱动”迁移。面对 AI 输出的不确定性与生成特性,旧的“点击-响应”模式已捉襟见肘。为了解决这些新问题,衍生出了三大类全新的交互模式。
4.2.1 “协商式”交互:精准对齐意图
这类模式的核心是为了解决自然语言天然的“模糊性”。Agent 不再闷头执行指令,而是像一个经验丰富的助手,通过多轮沟通来“对齐”需求,确保做正确的事。
1、主动追问与澄清
当用户的指令太宽泛或缺少关键参数时,Agent 不应该“瞎猜”(那会带来不可控的风险),而应该采取兜底策略,主动抛出选项或反问,引导用户补全信息。
例子: Cursor的 Plan 模式
用户的编码意图不够清晰,方案有模糊的监视空间,plan模式就会主动向用户进行询问
2、上下文锚定
这是“LUI+ GUI”协同工作的典型场景。用户无需费力用语言去描述一个复杂的对象,只需通过“圈选”或“指代”来锁定上下文,再辅以语言指令。
例子: Photoshop 的 Generative Fill(创成式填充)
用户用套索工具圈选画面中的一只狗(GUI 操作),然后在输入框里敲下“换成一只猫”(LUI 操作),用户不用费劲描述“请把画面左下角坐标 (x,y) 处的那只黑色小狗...”,极大降低了表达成本。
4.2.2 “共创式”交互:人机实时协作
这类模式旨在打破传统交互“你输完指令、我慢慢跑进度条”的回合制感,让用户和 Agent 能够实时配合,实现人机“同频”。
1、流式输出与即时干预
大模型推理需要时间,界面除了用“打字机效果”缓解等待焦虑外,更关键的是要允许用户随时插嘴或叫停。
例子: Cursor的“Stop Generating”与实时纠偏
代码写的有问题,此时你不需要等它全写完再提意见,而是直接点停止,并且重新提交prompt,cursor会自动撤销原来有问题的代码生成。 这种机制把“事后验收”变成了“事中纠偏”,极大地压缩了试错成本。
2、预测性推荐
Agent 基于当前上下文和用户画像,预判你的下一步意图,并直接把“下一步动作”封装成按钮递到你手边。
例子: Cursor、Gemini、元宝啥的都有这个功能
4.2.3 “方便修正结果”的交互
AI 的产出往往是概率性的“半成品”。交互设计必须提供极低成本的修改能力,让用户通过简单的操作将结果调整至完美。
1、基于 GUI 的修正
用户不需要为了修改一点小细节而重新组织Prompt,而是直接在生成的 GUI 组件上动手改。Agent 能感知到这些修改,并自动同步到底层逻辑。
例子: Claude 的 Artifacts 预览修改
Agent 生成了一个网页按钮,颜色你不喜欢。你不需要打字说“把按钮改成深蓝色”,而是直接用右侧预览窗口里的取色器吸取一个蓝色。 此时,Agent 会自动重写左侧的代码以匹配你的视觉修改。这种“所见即所得”的修改方式,远比语言描述高效。
2、给用户选择题!
针对创意类或没有标准答案的任务,Agent 不做“填空题”而是做“选择题”。它一次性提供多个草稿,用户负责做决策。
例子: Midjourney 的 U/V 模式。
输入提示词后,系统先出 4 张缩略图。用户点击“V2”(基于第 2 张图生成变体),系统会保留第 2 张图的构图,仅在细节上微调。 这是一种典型的通过选择表达审美。在难以用语言描述清楚“具体哪里感觉不对”的时候,让用户做选择题是最高效的。
5. 前端开发的变迁:页面构建 => 原子组件 + 能力架构
前端开发的核心变迁可以用以下两个公式描述
传统模式: UI=f(State)。状态变了,界面变。但 f (渲染逻辑) 是写死的。
Agent 模式: UI=f(Intent,Context,Components)。意图决定展示什么组件,上下文决定填充什么数据。
5.1 组件设计的变革:从“Props 定义”到“语义自述”
在传统的 Vue 或 React 开发中,我们定义一个组件(比如一个日期选择器),最关注的是它的 Props:需要传什么值,触发什么事件。这是写给 人类程序员 看的。
但在 Agent 体系下,组件的第一受众变成了 AI 模型。AI 不看源码,它需要知道这个组件“是干什么的?”、“数据结构是啥?”、“什么时候该用它?”。
因此,前端组件的开发标准增加了两个新维度:
-
语义描述: 你需要用自然语言告诉 Agent:“这是一个日期范围选择器,适用于需要筛选特定时间段数据的场景。”这种描述不再是注释,而是会作为系统提示词(System Prompt)的一部分实时喂给 AI。
-
Schema 标准化: 组件的输入必须严格遵循 JSON Schema 标准。因为 LLM(大模型)输出的是结构化数据,前端必须确保组件能无缝“消化” AI 生成的配置参数,具备极强的鲁棒性,避免因参数错误导致页面崩溃。
-
唯一可寻址性:每个组件实例都应拥有一个稳定且唯一的标识符,Agent可以通过这个ID精确地引用它。
-
API驱动的状态:组件的状态不仅应能通过用户的直接交互(如点击、输入)来改变,还必须能通过编程接口被读取和修改。例如,Agent需要能够通过调用API来对表格组件应用一个筛选条件。
这一转变意味着,前端组件开发不再仅仅是关于UI还原和交互处理,更是一项API设计工作。组件需要定义清晰的API供Agent调用,还需要能够文档化和测试其对Agent暴露的API。
5.2 前端数据通信的变革:从“请求-响应”到“流式驱动”
传统的 CRUD 应用中,数据流是离散的:发起请求 → 等待 → 拿到全量 JSON → 渲染。
但在 Agent 交互中,这种模式会让用户体验崩溃。因为 AI 的推理和生成是缓慢的。如果等 10 秒钟才一次性刷出结果,用户早就关掉了页面。
前端的数据通信架构正在向 流式驱动 转型:
-
增量渲染能力: 前端不能傻等完整的 JSON。当 Agent 刚刚吐出
{"type": "chart", "tit... 时,前端就应该渲染出一个带有标题骨架的图表占位符。随着数据流 ...le": "Q3 Revenue"} 的到达,标题被实时填入。
-
状态的颗粒度更细: 我们需要处理一种全新的状态—— “思考中” 。这不同于传统的
loading。Loading 是单纯的转圈,而 Thinking 需要展示 Agent 正在调用的工具、正在阅读的文档,甚至允许用户在这个过程中打断。
这对前端的状态管理库提出了很高的要求:它必须能像处理水流一样处理数据,而不是像处理砖块一样。
5.3 路由系统的变革:从“URL 映射”到“意图路由”
传统前端应用中/user/detail/xxx等 严格对应着一个组件树。
但在混合渲染的架构中,URL 的统治力开始下降。当用户说“看看张三的绩效”时,系统可能不需要跳转 URL,而是直接在当前的对话流中“挂载”一个绩效卡片组件。
前端的路由逻辑发生裂变:
-
宏观路由(保留): 依然使用 URL 管理大的模块(如“工作台”、“设置页”),保证浏览器的刷新和回退机制正常工作。
-
微观路由(新增): 在页面内部,引入一个 “意图导航”。它根据 AI 识别出的意图,动态决定在当前视图中加载哪个组件。
这意味着前端架构必须支持动态组件注册和沙箱隔离,防止 AI 随意生成的组件把主应用搞挂。
5.4 容错设计的变革:从“防止代码逻辑错误”到“给Agent的幻觉进行容错”
传统前端的主要捕获代码逻辑错误(比如 undefined is not a function)。
现在的挑战在于:代码没报错,但 AI一本正经地胡说八道。 比如,AI 返回了一个不存在的枚举值,或者生成了一段格式错误的 JSON。
前端开发必须构建一层容错机制:
-
校验: 在渲染 AI 生成的内容前,必须进行严格的 Schema 校验。
-
降级: 如果 AI 想要渲染一个复杂的图表但参数错了,前端应该能自动降级显示为纯文本,或者是提示用户“数据解析失败,请重试”,而不是直接白屏。
-
可控: 在 UI 上提供“重新生成”或“手动编辑”的入口,把最终的纠错权交还给用户。
5.5 总结
前端并没有死,它只是向上进化了。
我们不再专注于于像素级的对齐、编写确定的组件(这些 AI 已经能写得很好了),而是开始关注组件的语义、数据流的实时性、以及系统的鲁棒性。
我们将从构建界面的工程师,转变为构建 AI 运行时环境的工程师。这才是 Agent 时代前端开发的真正价值所在。
6. 一些系统性的思考问题
6.1 Agent进步那么快,会话式交互(自然语言LUI)会完全取代GUI吗?
不会!
所有交互创新都是为了这一个目的:“让输入更简单,让结果更易懂”。
Agent时代的到来似乎冲昏了一些产品或者交互的头脑?认为 LUI(语言交互)会取代 GUI。
我现在可以举一个反例:在游戏过程中,你想让飞机升高10米,实际上用上下左右的按键会比在聊天界面输入“这台飞机马上升高10米”更高效得多。
1、GUI 的本质:直接操作
2、LUI (自然语言) 的本质:代理委托
3、案例分析
案例:在游戏过程中,你想让飞机升高10米,实际上用上下左右的按键会比在聊天界面输入“这台飞机马上升高10米”更高效得多。
刚才“飞机升高”案例,为什么 GUI 完胜? 因为 “空间运动”是低维度的、物理直觉的任务。 人脑对空间的理解是直接的,不需要经过“语言中枢”的转译。
-
GUI 路径: 眼睛看到位置 -> 大脑空间计算 -> 手指移动。(快,生物本能)
-
LUI 路径: 眼睛看到位置 -> 大脑空间计算 -> 转化为语义("升高") -> 量化数值("10米") -> 组织语言 -> 输入 -> AI 解析 -> 执行。(慢,且容易累)
4、方法论
到底是GUI好还是LUI好?以下给出两个维度进行评估:
| 维度 |
GUI (图形交互) |
LUI (自然语言/AI) |
| 操作粒度 |
原子级操作。适合微调、实时控制。(如:向左偏一点点) |
意图级操作。适合批处理、复杂指令。(如:按顺时针巡检A区) |
| 学习曲线 |
初学者难,专家快。需要学习界面布局,但熟练后可形成“肌肉记忆”。 |
初学者快,专家慢。无需学习(会说话就行),但无法形成肌肉记忆,每次都要组织语言。 |
| 信息带宽 |
输入低,输出高。鼠标只有一个坐标,但屏幕能显示千万像素。 |
输入高,输出低。一句话包含丰富信息,但文本输出往往难以一目了然。 |
| 容错率 |
低风险。通常有限制,难以产生严重越界操作。 |
高风险。可能因为歧义(幻觉)导致灾难性后果(如 AI 误解了“降落”和“坠落”)。 |
回到刚才的那个原则:“让输入更简单,让结果更易懂”。
- 对于在游戏中移动飞机:推摇杆是输入最简单(符合直觉),看飞机动了是结果最易懂(视觉反馈)。
- 对于数据查询:说句话是输入最简单(省去筛选),看生成的图表是结果最易懂。
真正高效的交互应该应该采用 GUI + LUI 的方式:
6.2 交互元素的“考古分析”

要讲计算机上的人机交互变革,肯定离不开施乐+苹果当年发扬光大的GUI。GUI和NUI在现在似乎稀松平常,但是当年实际上隐含着很多深层的思考和价值,这极大地改变了我们现在的世界。
很有必要考考古,才能指导未来的设计!
6.2.1 PC GUI
所以要讲Agent的交互元素的思考,肯定要先讲清楚GUI时代的内容
1、Icon 图标
-
思考: 在命令行(CLI)时代,用户必须记住命令(如
delete 或 rm)。图标的出现利用了人类从物理世界继承来的视觉经验——比如用一个“垃圾桶”代表删除,用一个“放大镜”代表搜索。这本质上是一种语义的视觉压缩。
-
价值: 它是认知负荷的极度减负。它建立了一座通用的桥梁,跨越了语言障碍(不识字的人也能看懂图标),让计算机的操作从“背诵语法”变成了“看图说话”,极大地降低了数字世界的准入门槛。
2、 Menu 菜单
-
思考: 软件的功能往往成百上千,如果全部铺在屏幕上,用户会崩溃。菜单本质上是一种信息的分类 。它通过层级结构(文件、编辑、视图)将混乱的功能有序折叠。它解决的是 “有限屏幕”与“无限软件功能”之间的矛盾。
-
价值: 它提供了可发现性和 安全感。用户不需要预先知道软件能做什么,只要打开菜单逛一逛就能知道。它为用户建立了一张“功能地图”,让用户在面对庞大系统时,能通过逻辑推演找到目标,而不是盲目乱撞。
3、Pointing 指点设备(鼠标/光标)
-
思考: 在键盘交互时代,操作是线性的、离散的。而鼠标引入了二维空间坐标的概念。它将人类的手部动作(物理位移)映射到屏幕上的光标运动(虚拟位移)。这引入了费茨定律 :操作效率取决于目标的大小和距离。它是“手眼协调”在数字世界的第一次完美投射。
-
价值: 用户可以跳过屏幕上的任何内容,直接随机访问任何他想操作的那个像素点,而不必像填写表格一样按 Tab 键逐个切换。
4、Windows 窗口
-
思考: 在单任务时代(DOS),屏幕就是全部。窗口的发明,创造了 **“屏幕中的屏幕” ** 。它模拟了物理世界中的“办公桌桌面”:你可以同时摊开好几份文件,有的在上面,有的被压在下面。它在心理学上契合了人类的 工作记忆 模型——我们需要同时关注多个相关联的信息源。
-
价值: 它实现了多任务并行与信息隔离。用户可以在一个窗口看文档,在另一个窗口写代码,无需频繁切换上下文导致思路中断。它通过空间复用,让有限的显示器承载了逻辑上无限的信息流。
5、Toast 轻提示:
-
思考: 弹窗 model 会强行打断用户,强迫用户点击“确定”。
-
价值: 它是非阻断式的反馈。它承认“用户的注意力很宝贵”,只在视觉边缘告知结果(如“保存成功”),让交互的主流程不被打断。
6.2.2 移动互联网NUI(触控与感知)
在移动端,屏幕变小了,鼠标消失了,交互从“指向”变成了“直接操纵”。
1、手势(滑动/捏合):
-
思考: PC GUI里的滚动条是一个独立的控件,用户需要把鼠标移过去拖动它。而手势让用户直接作用于内容本身。
-
价值: 它是“动作”与“结果”的零距离融合。用户想翻页,直接拨动页面,而不是拨动控制器(滚动条)。这极大降低了操作的抽象程度。
2、下拉刷新
-
思考: 这是一个极其经典的发明。它利用了自然的物理隐喻(像拉动弹簧一样)。
-
价值: 它创造了一个**“无界面”的按钮**。用户不需要寻找“刷新”图标,而是通过一种符合直觉的动律(Ritual)来触发更新,同时通过回弹动画告知用户“系统正在处理”。
3、侧滑操作(列表项左滑/右滑)
插一句,玩过“探探”的朋友们有没有想过左滑右滑不感兴趣的匹配对象的交互逻辑?以下解析应该可以帮助你们
-
思考: 在 PC GUI 时代,处理列表数据(如邮件)通常需要三步:1. 选中某一行;2. 移动鼠标去找工具栏上的“删除”图标;3. 点击确认。而侧滑操作利用了 “扔掉” 的物理隐喻。
-
价值: 它是高频决策的极速通道。它将“选择对象”与“执行动作”合二为一。用户不需要把视线从内容(邮件标题)移开去寻找按钮,手指一滑即处理。这种交互极大地提升了信息筛选和清理的效率(如 探探 的左滑右滑,Mail 的滑动归档)。
4、Haptic Touch 长按呼出
-
思考: 移动设备没有鼠标右键,屏幕只有二维平面(X轴和Y轴)。长按操作引入了时间维度(或压力维度,如 3D Touch),模拟了Z轴的深度。它类似于在物理世界中“注视”或“用力按压”一个物体以探究其内部结构。
-
价值: 它是渐进式的信息披露。它允许界面保持简洁(不展示复杂的菜单按钮),但又隐藏了深度的操作选项(如快捷方式、预览)。它解决了移动端“屏幕太小”与“功能太多”的矛盾,让用户在不离开当前页面的情况下获取上下文信息。
5、无限滚动(瀑布流)
-
思考: WIMP 时代的网页浏览基于“分页器”,看完了要点“下一页”,这强迫用户进行一次“是否继续”的理性决策,打断了体验。而无限滚动创造了 “流(Stream)” 的隐喻,内容像水流一样源源不断。
-
价值: 它创造了沉浸式的无意识消费。消除了“翻页”带来的认知中断,极大地延长了用户停留时间。对于内容型产品,这是将用户留存率最大化的“交互黑洞”。
6、底部的导航栏
-
思考: PC GUI的导航栏通常在顶部或左侧(为了配合 F 型阅读顺序)。但移动设备的交互核心限制是 “拇指热区”。底部导航栏是对人体工程学的妥协与尊重。
-
价值: 在高频切换的核心功能区,用户不需要调整握持姿势,拇指仅需微动即可完成路由跳转。这是硬件形态(单手握持)反向定义软件交互的典型案例。



