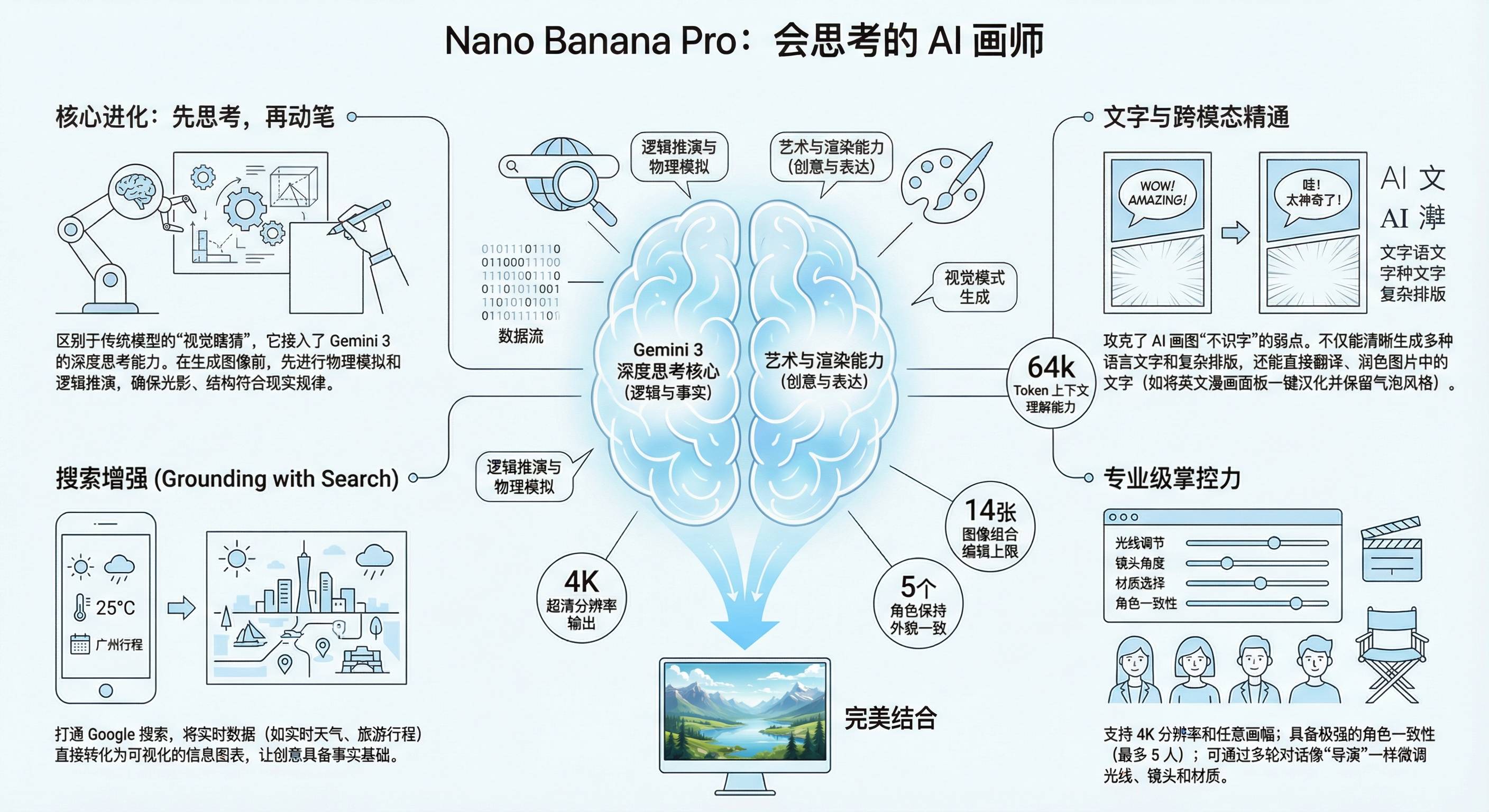
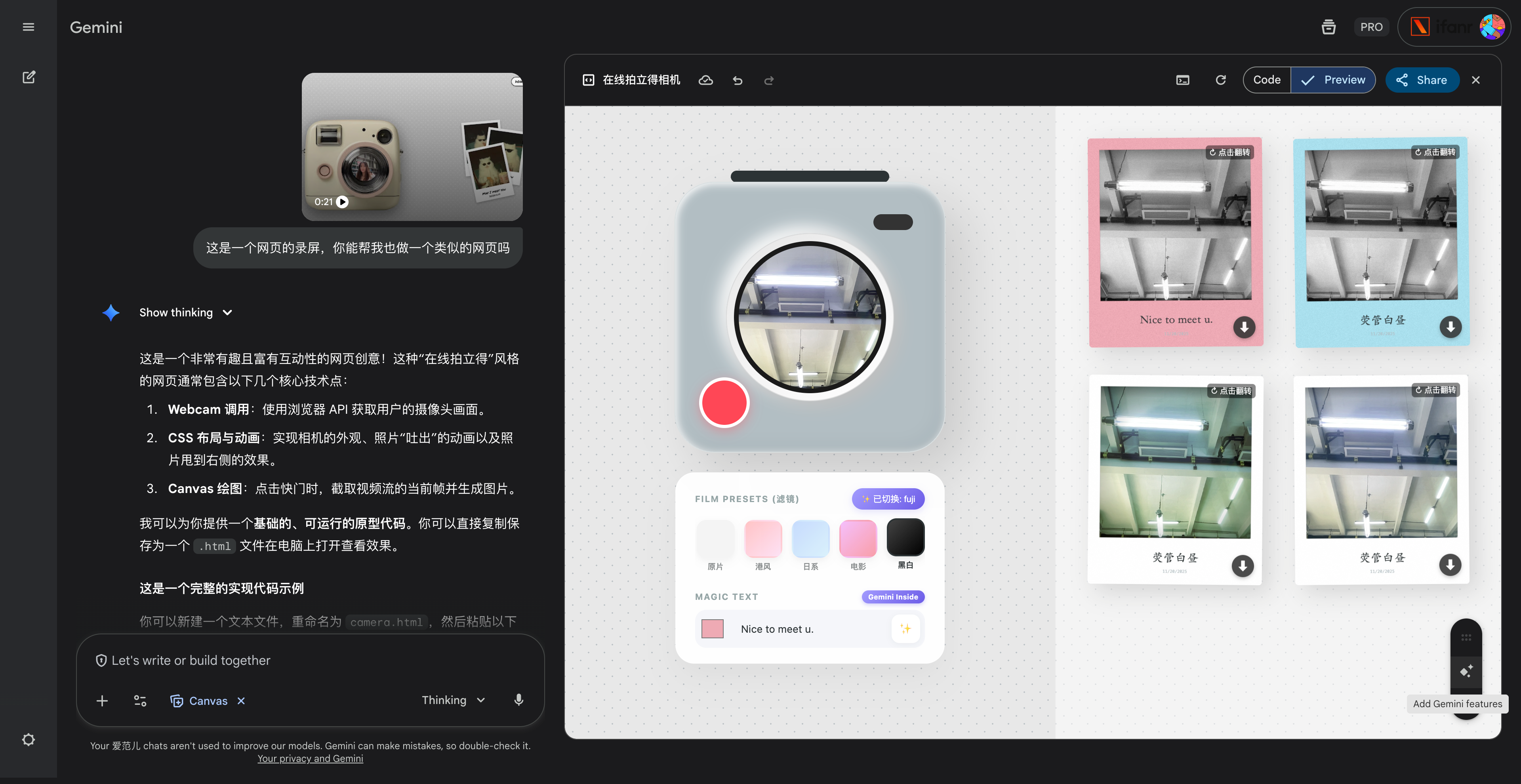
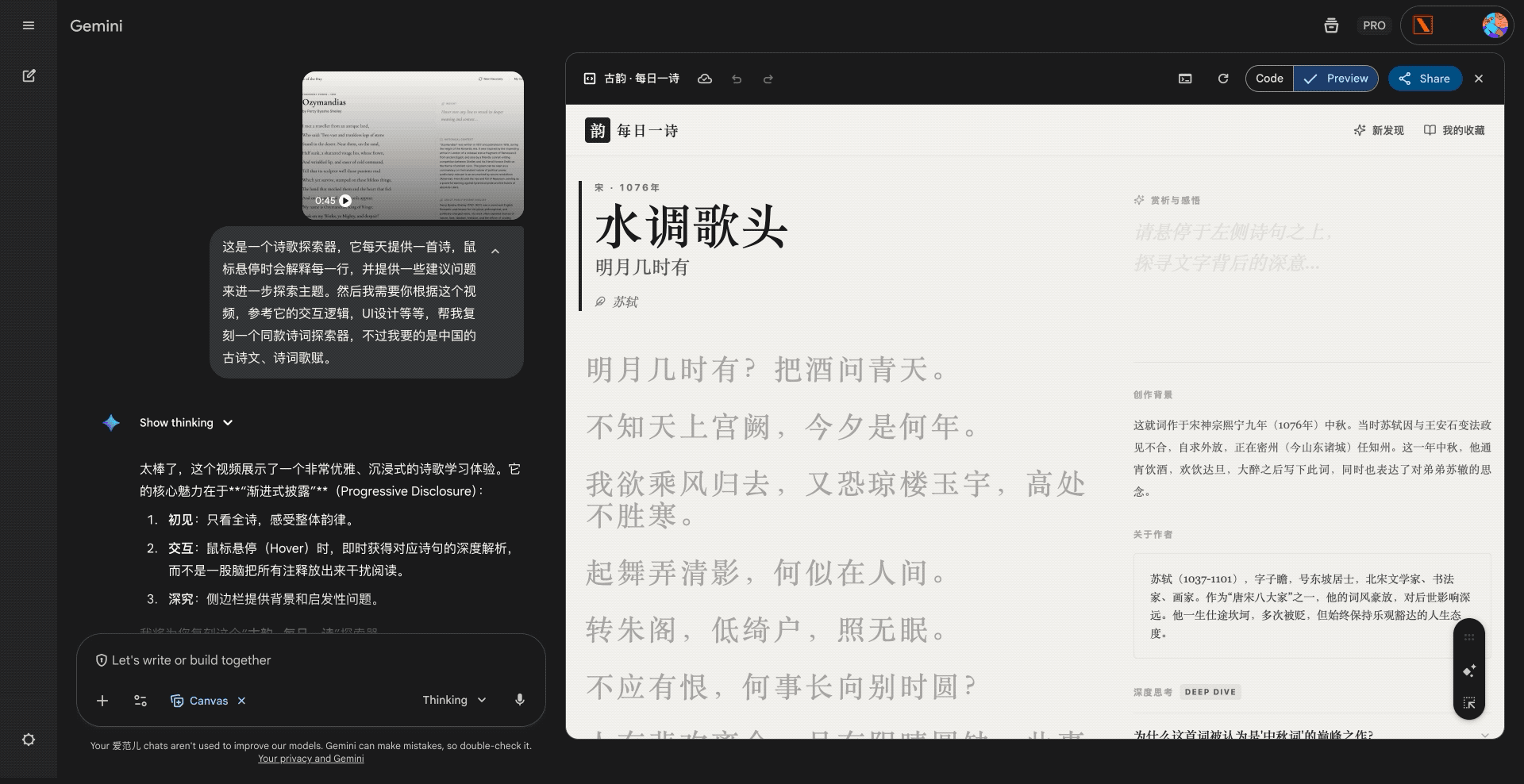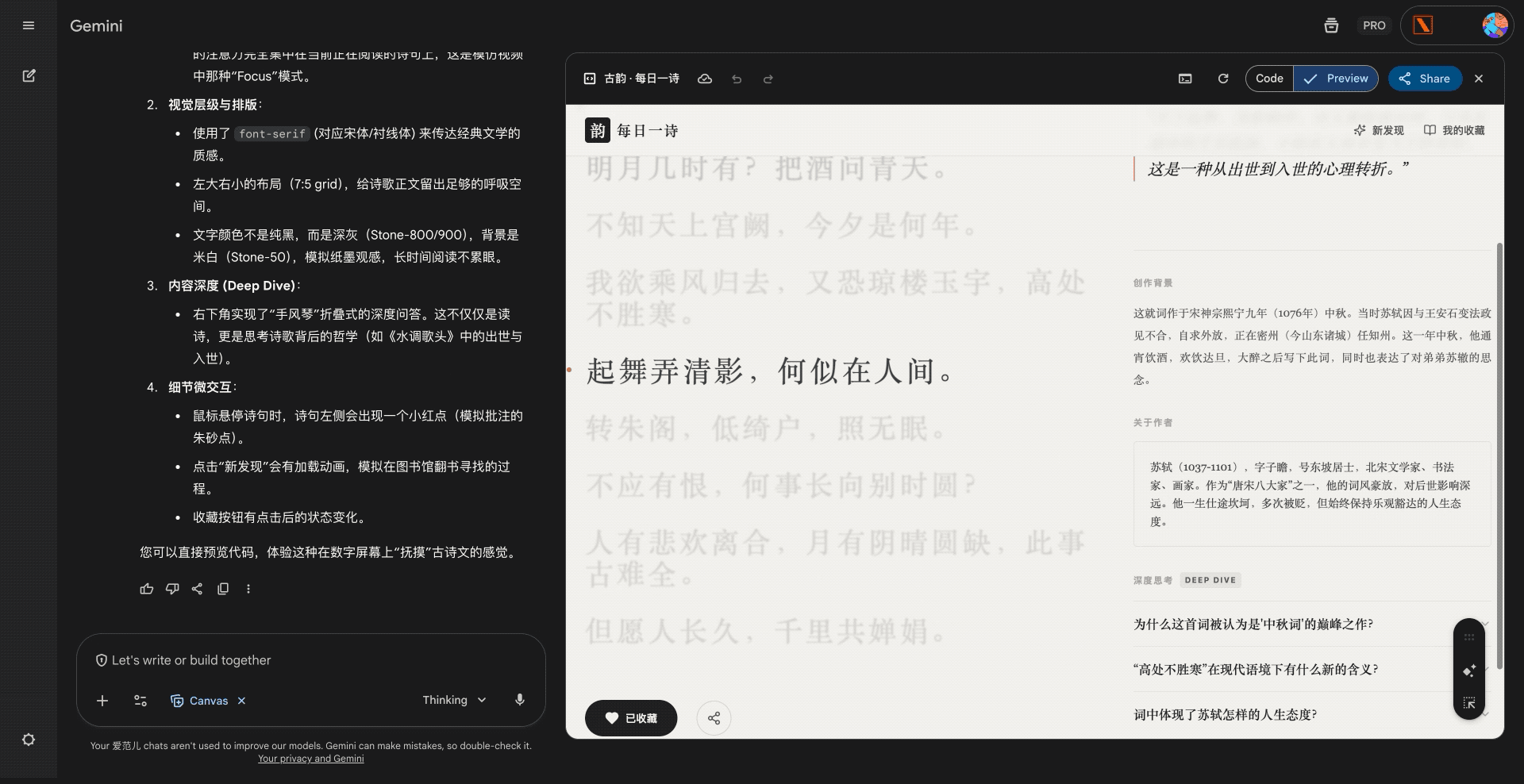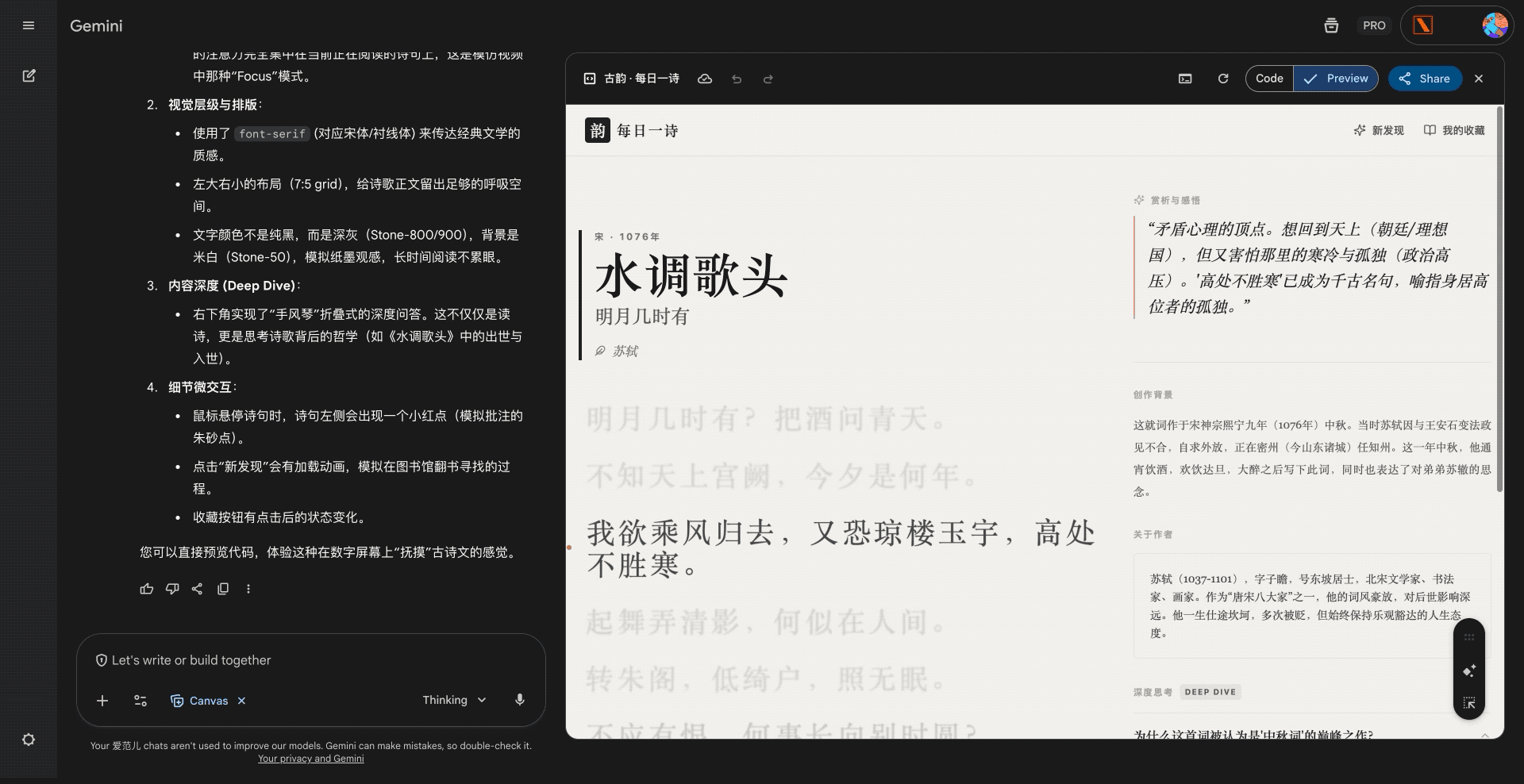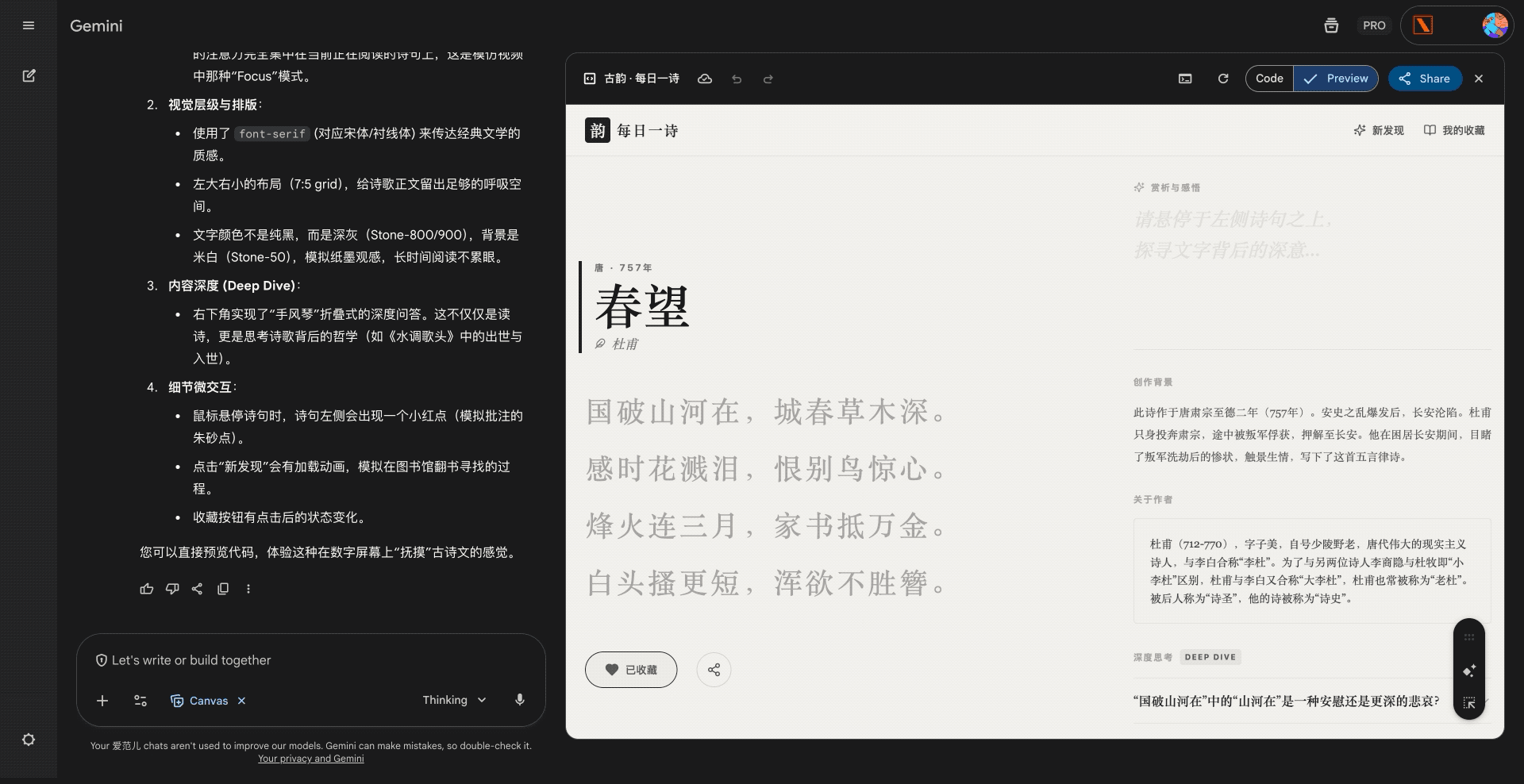
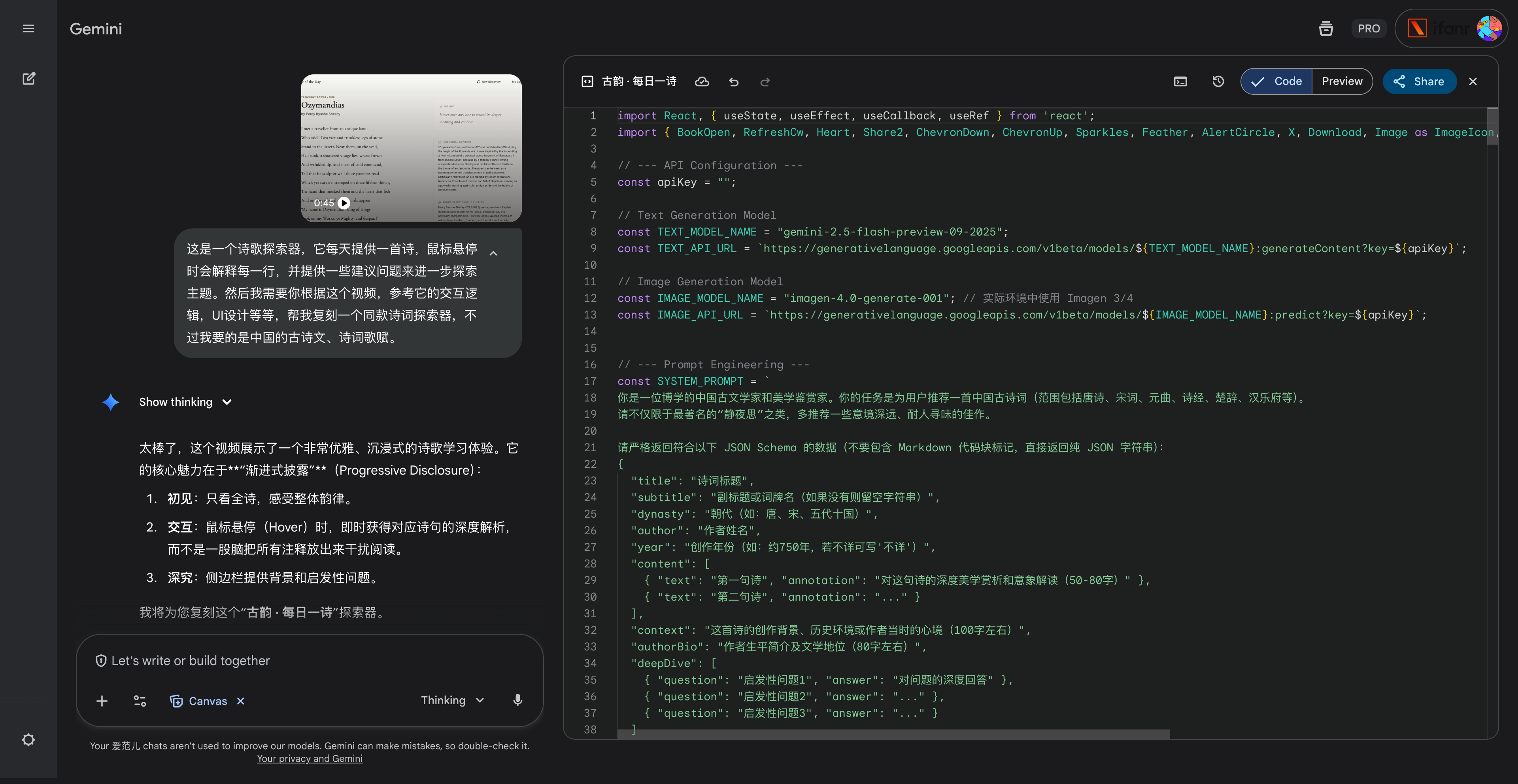
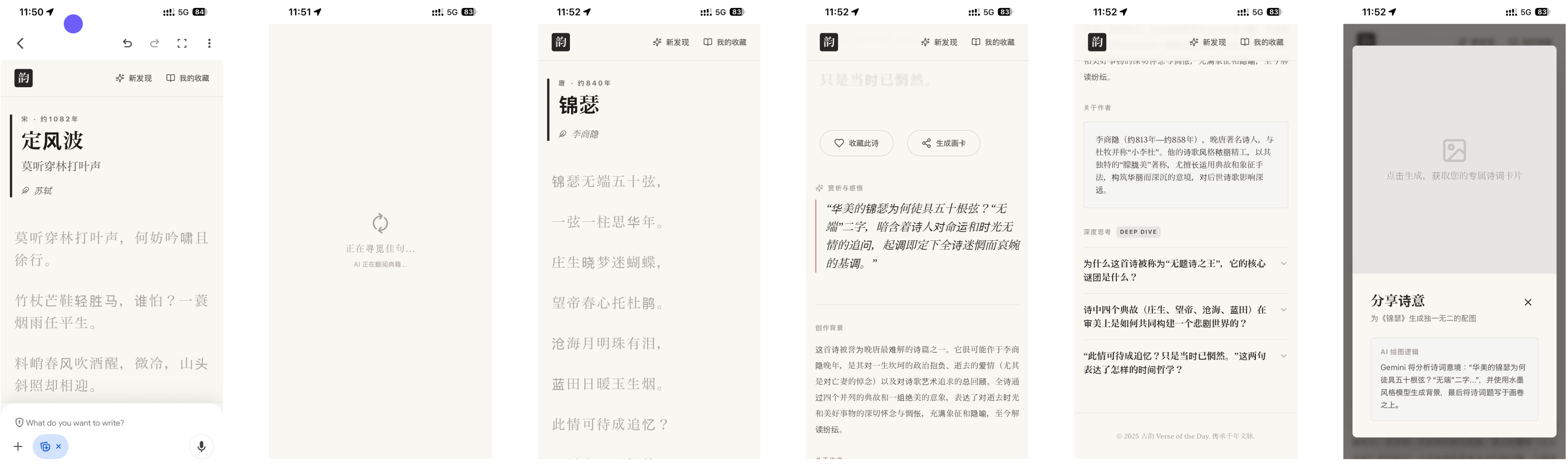
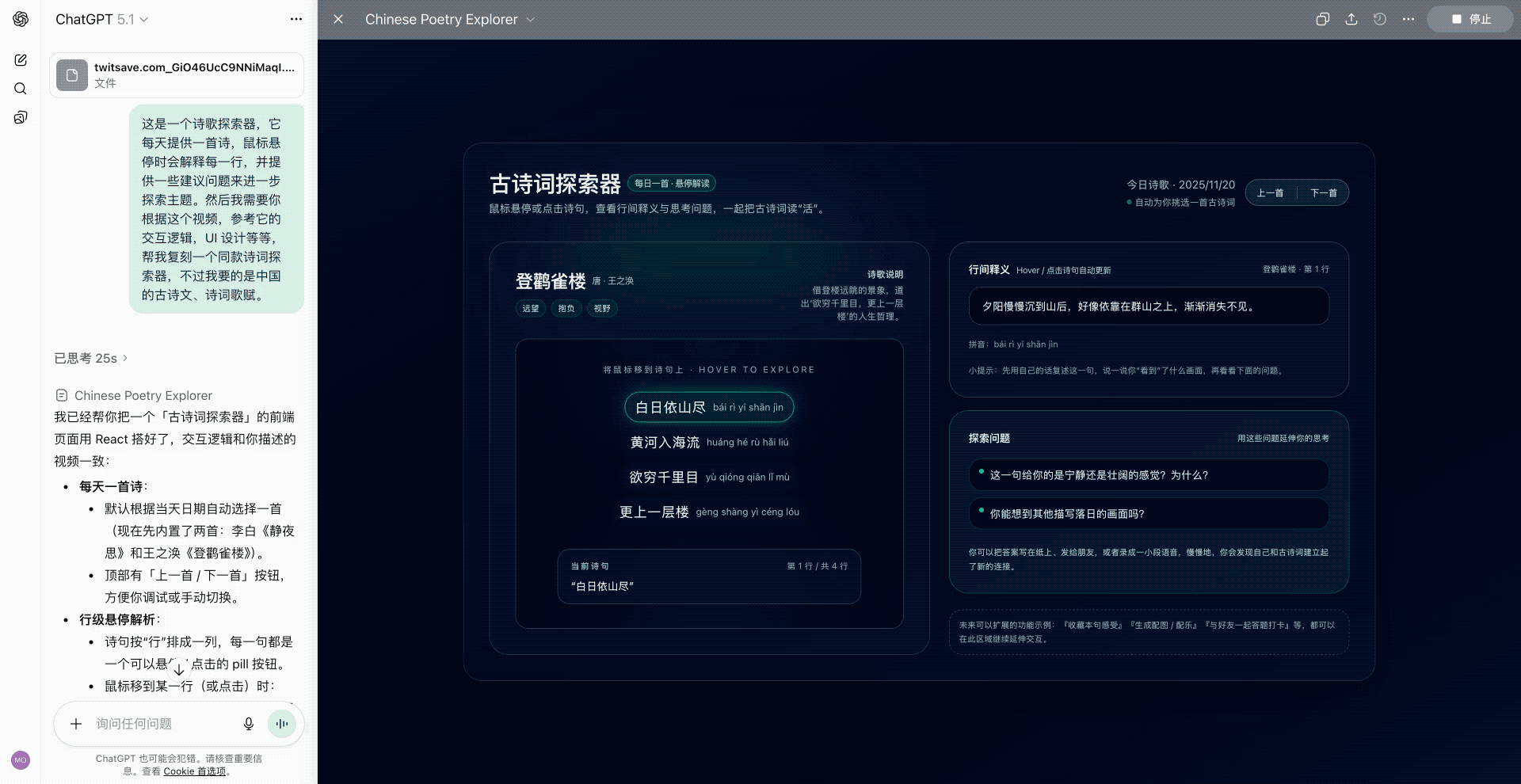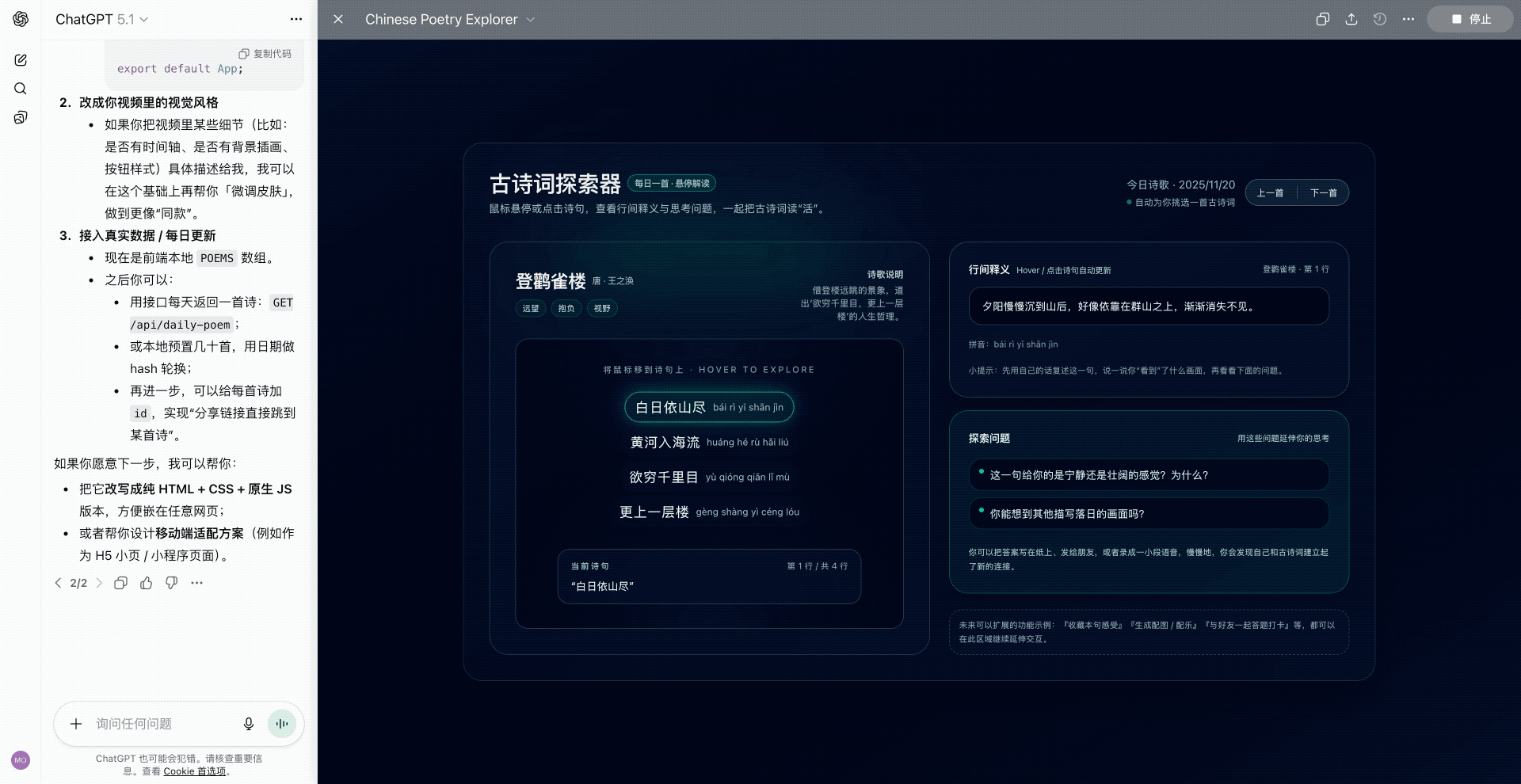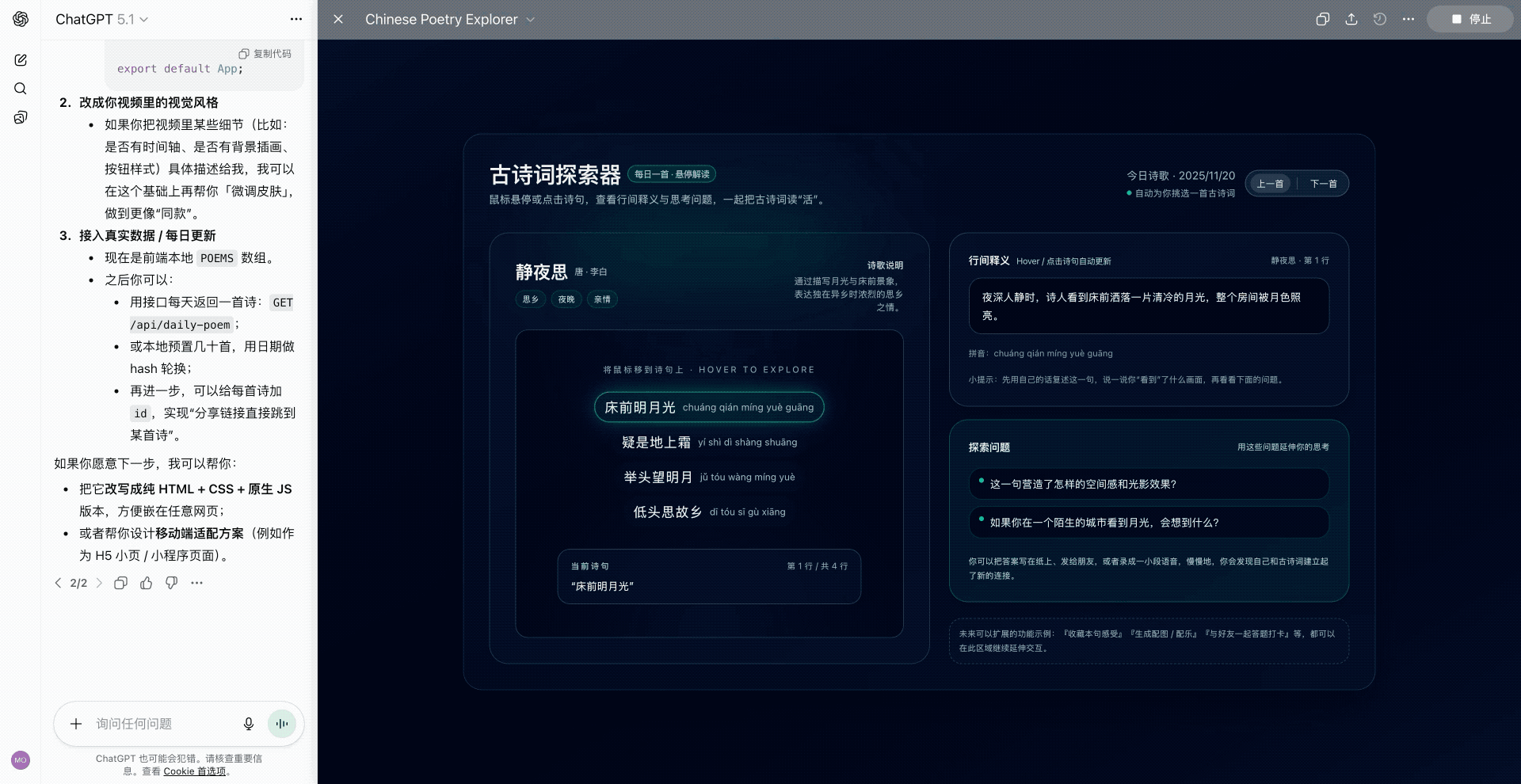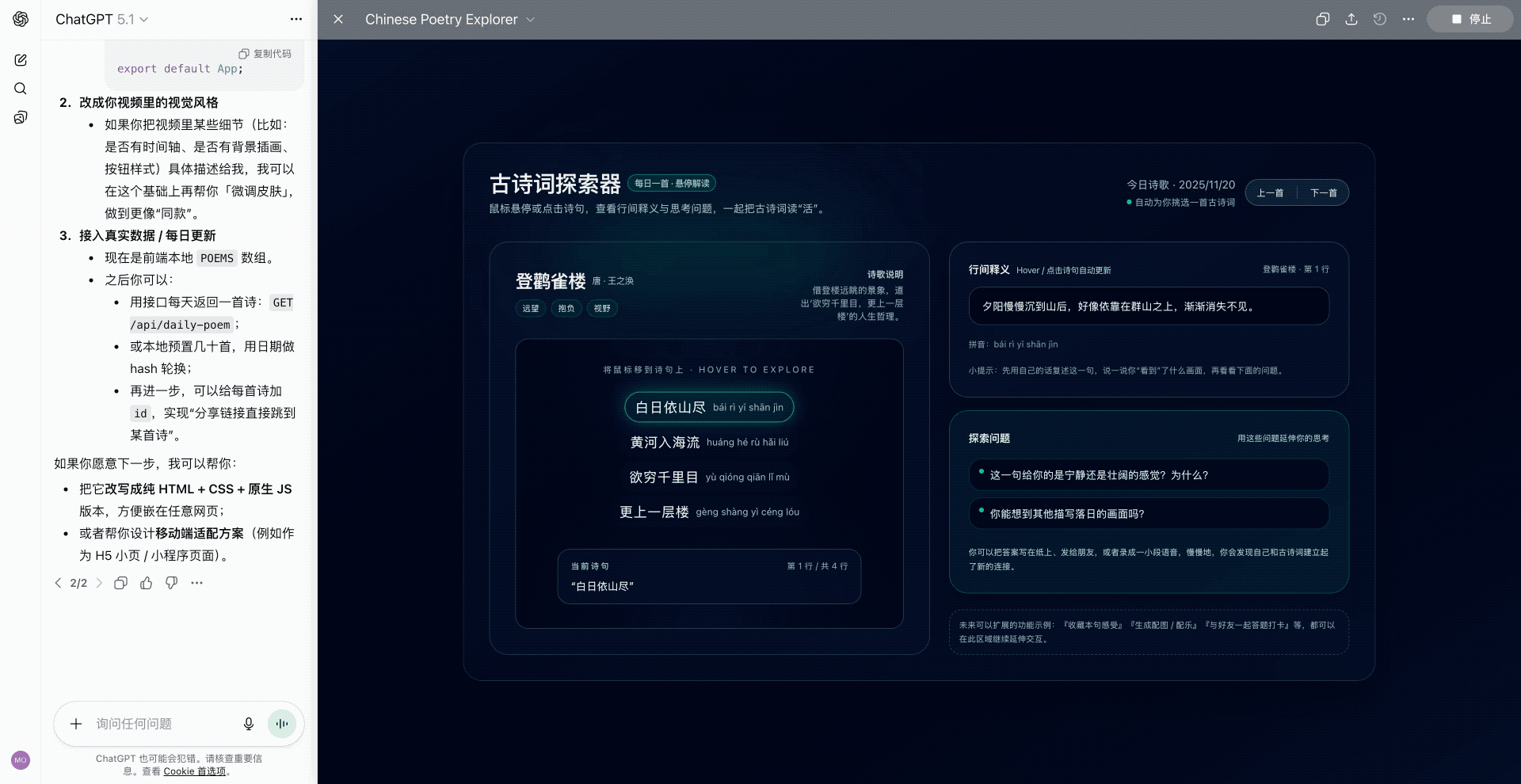
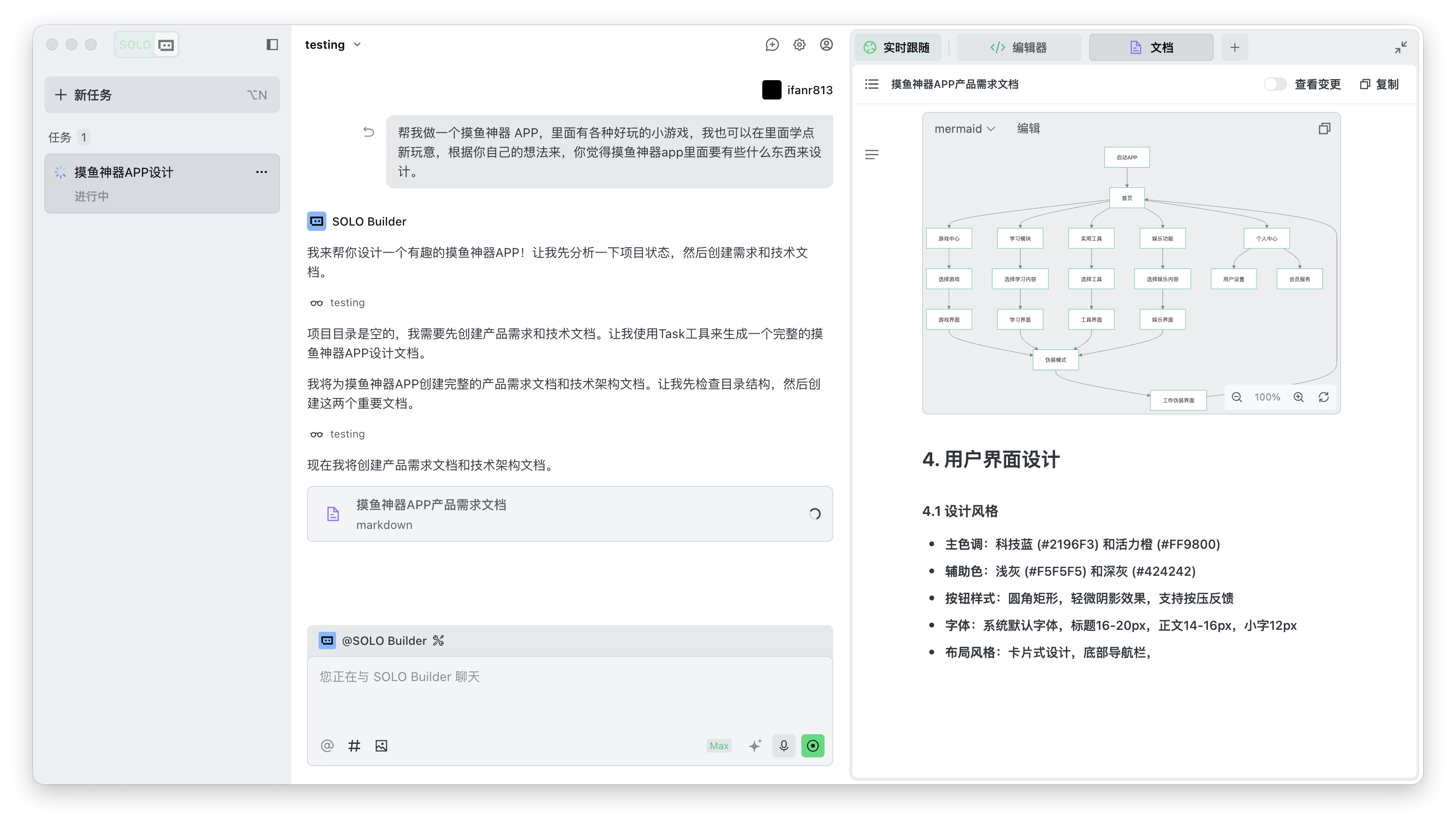
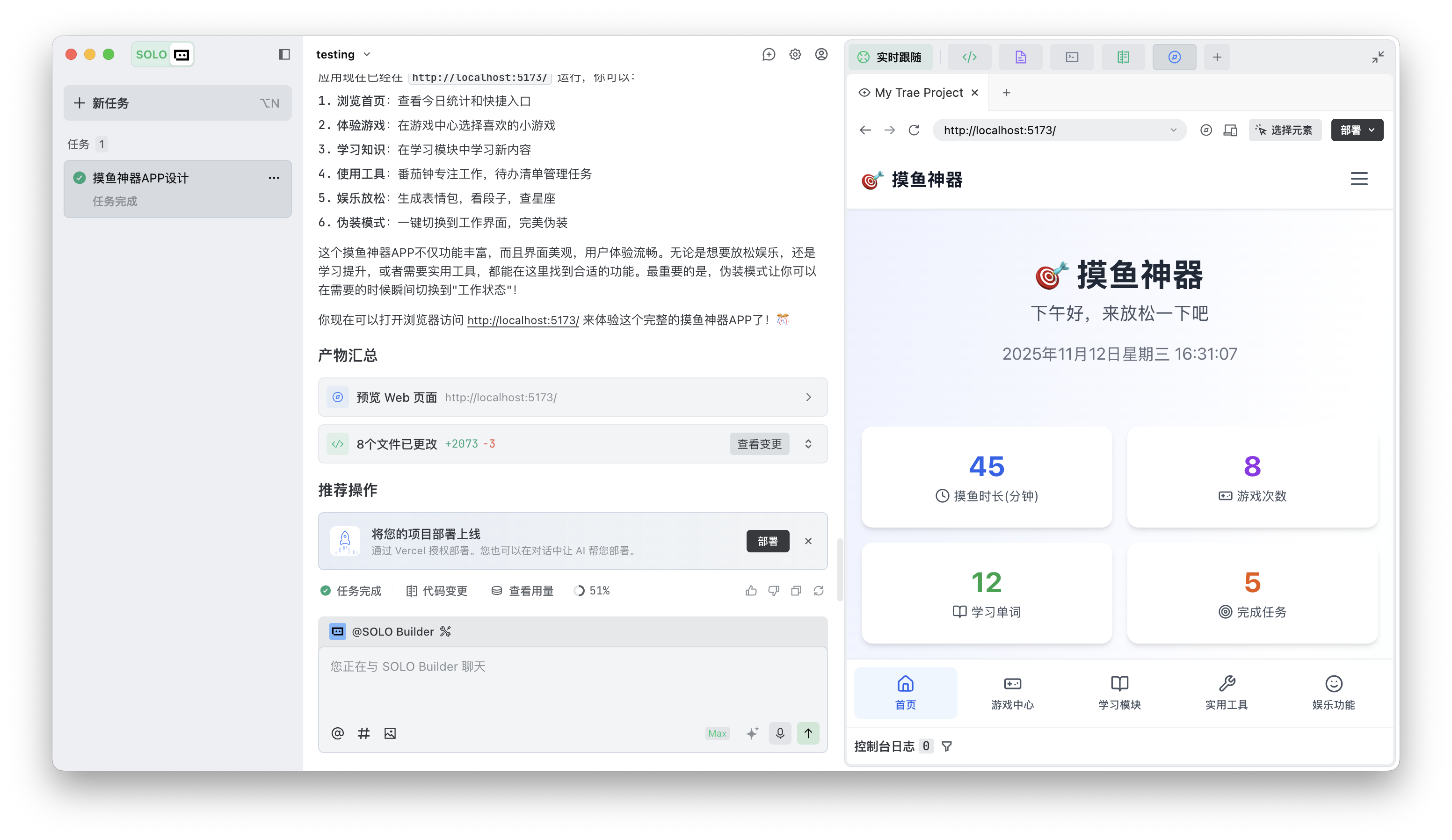
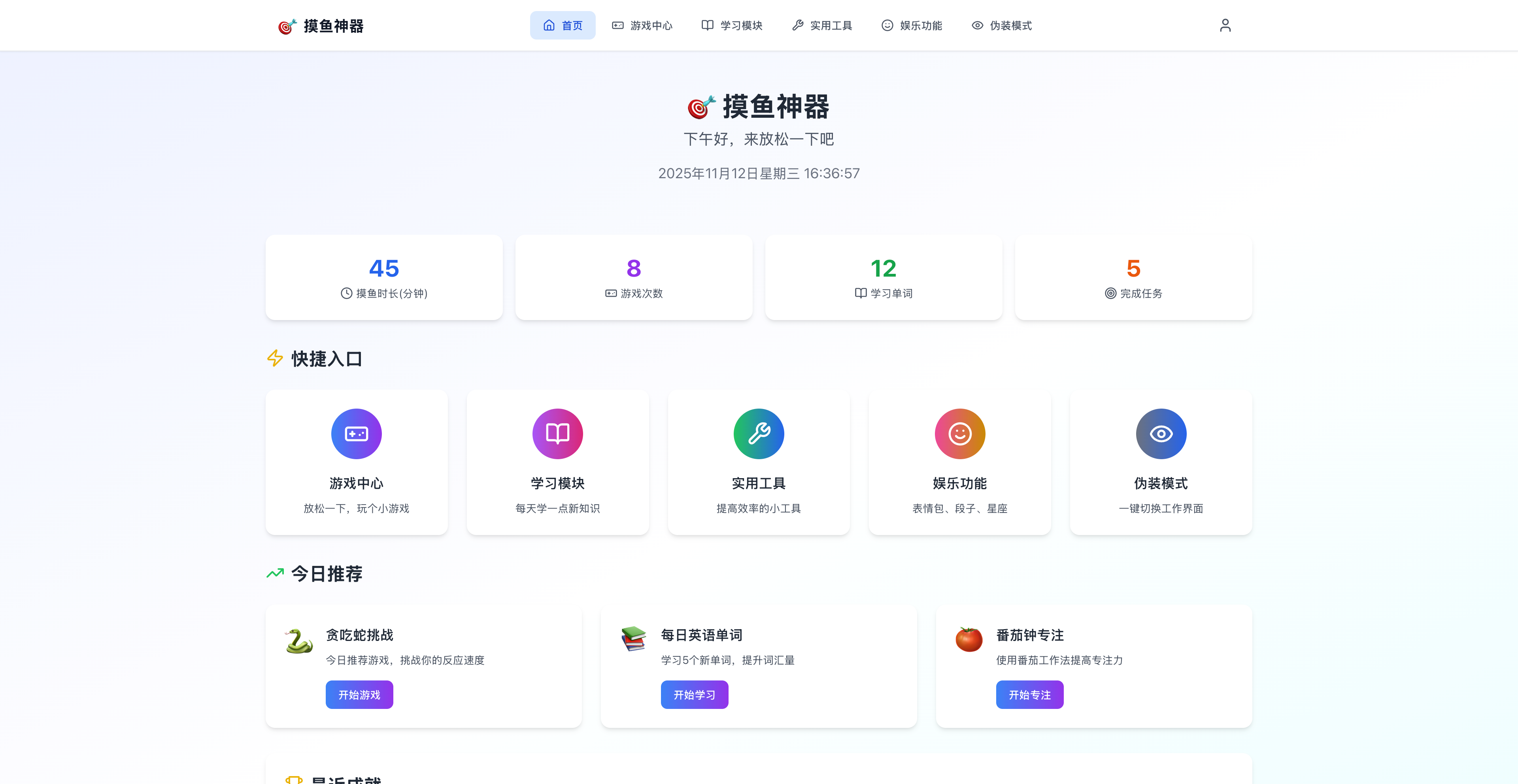
硅谷商战变厨艺大赛?小扎曾亲手煮汤挖人,OpenAI 说不慌都是演的
鹬蚌相争,渔翁得利。有时候还挺希望我们用户就是那个渔翁,模型厂商打得越厉害,我们就有机会越快用到更好的模型。
2022 年 12 月 22 号,在 ChatGPT 发布三周后,为了应对 OpenAI 的威胁,Google 成了第一个发布「红色警报」的科技巨头。
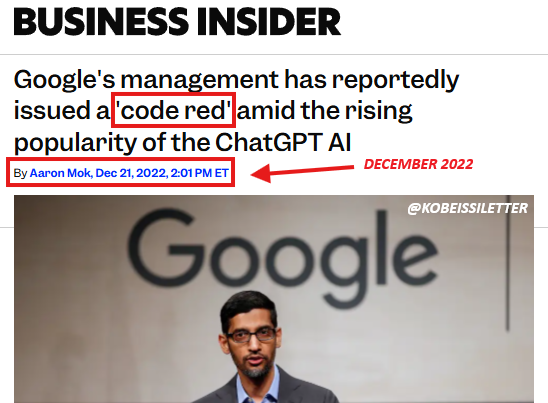
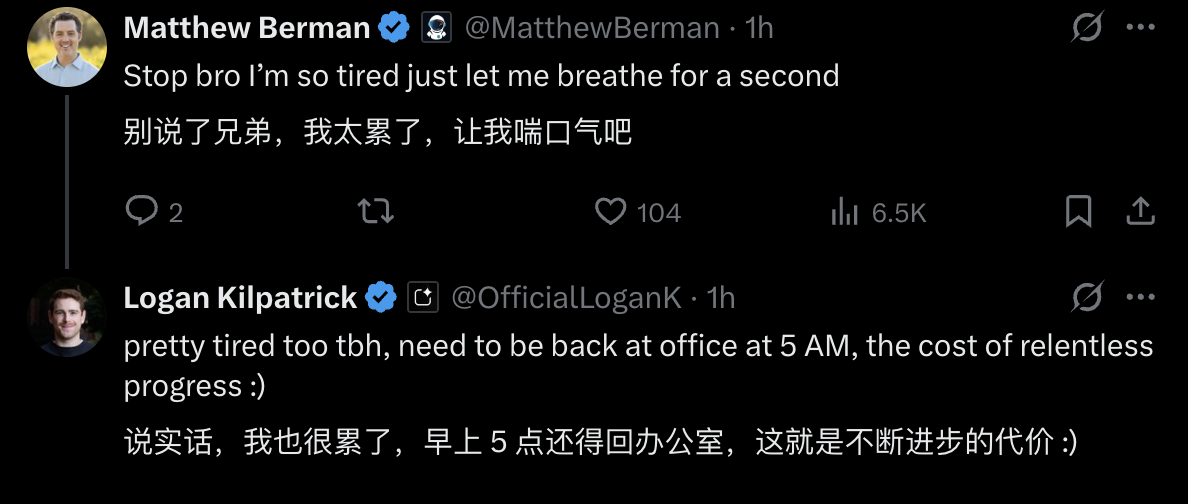
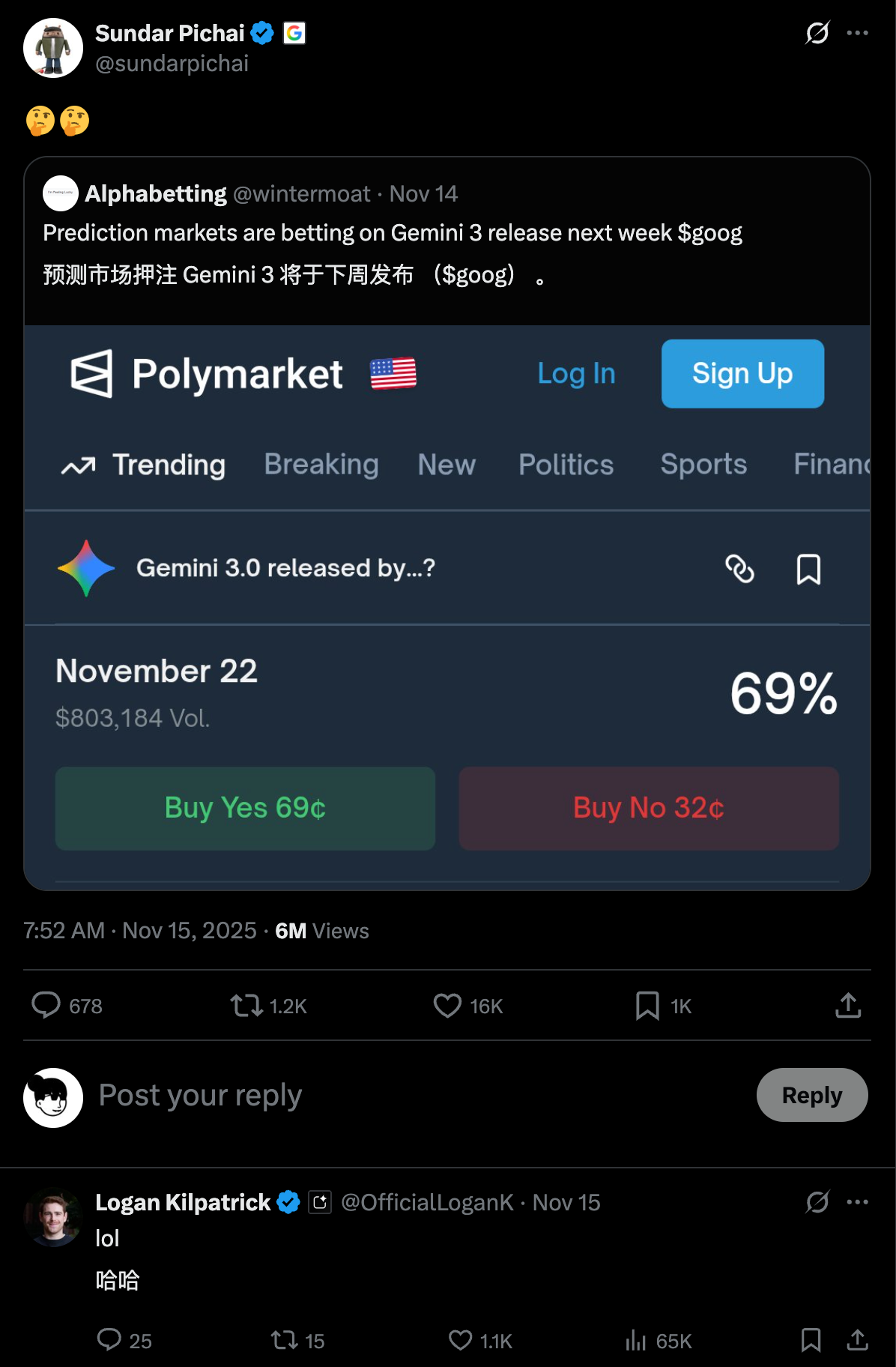
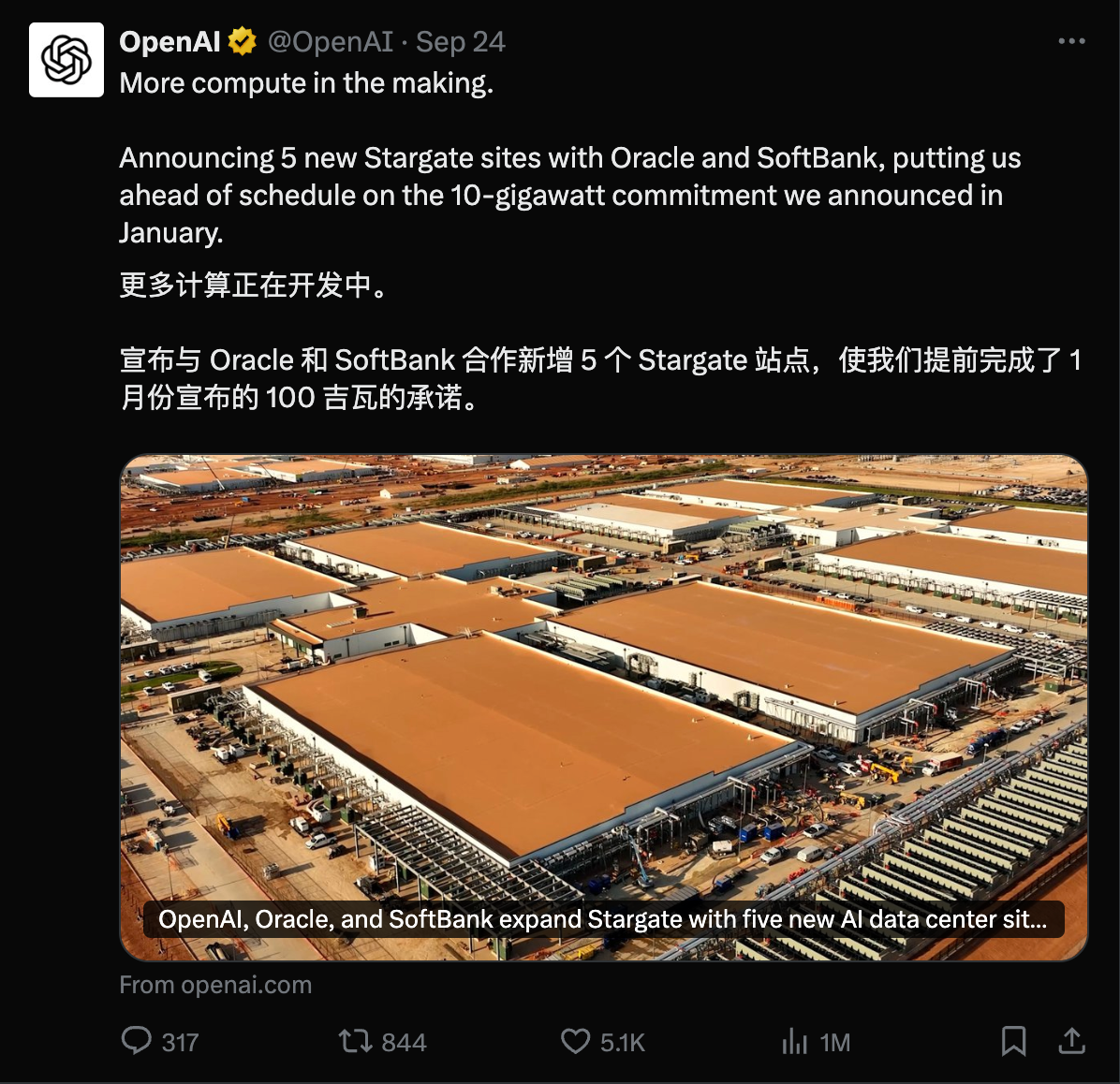
昨天,在 Gemini 3 发布两周后,因为 Gemini 3 模型出现了大幅增长,OpenAI 发布了首个「红色警报」。
看到消息的时候,我就觉得 OpenAI 是不是有点过度反应了,很快就看到了一些评论说「骄兵必败」、还有「胜败乃兵家常事」。但转念一想,所谓的「红色警报」也许就是给投资人看的,毕竟 OpenAI 如果真的做不到第一,那个 2030 才能盈利的时间,只会拉得更长。
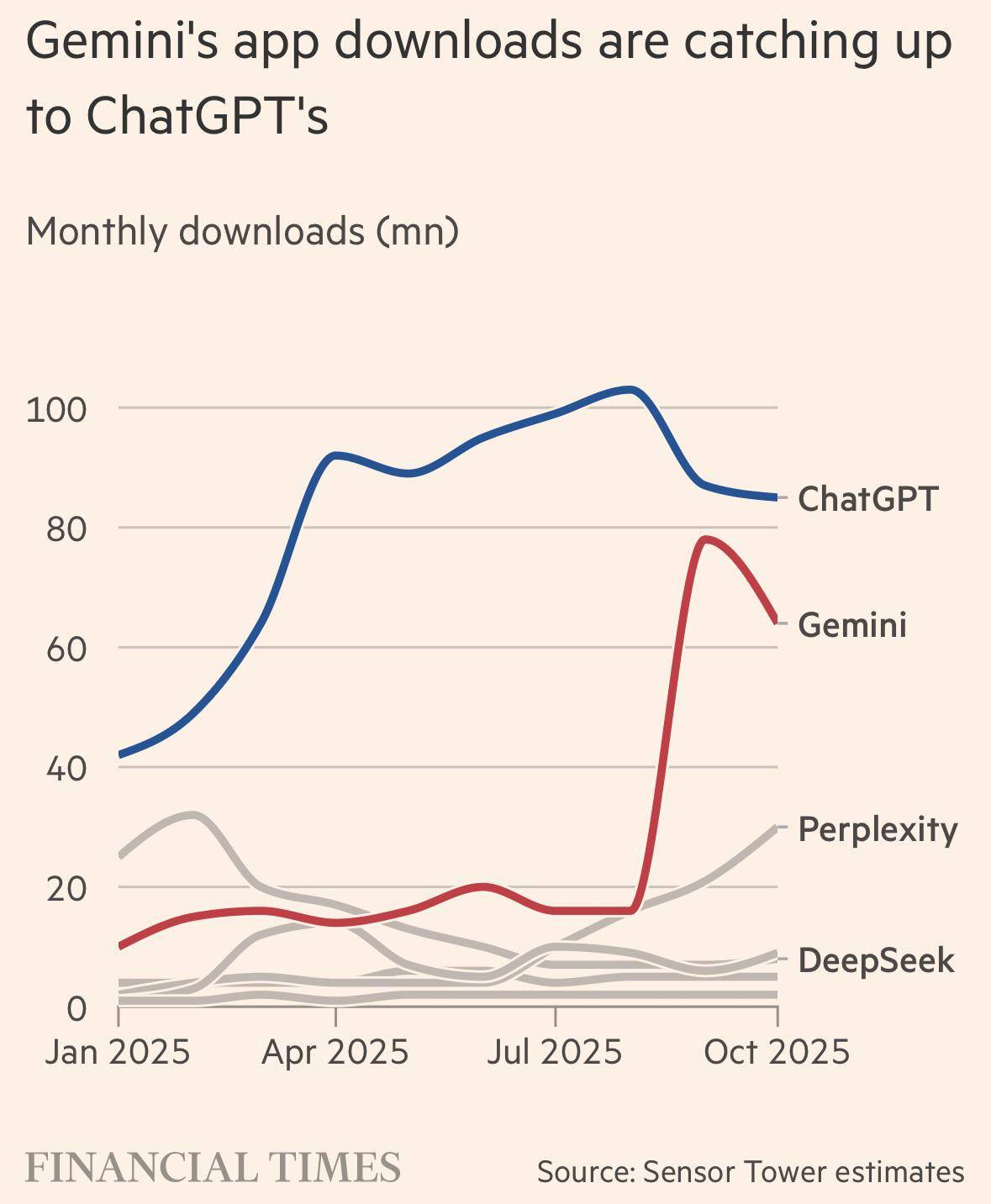
▲ Gemini 的 App 下载量快要追上 ChatGPT
根据最新透露的消息,OpenAI 在下周即将推出一款新的推理模型,内部评估表现要比 Gemini 3 更好。此外,他们还计划通过一个代号为「Garlic」的模型,来进行反击。
但更现实的情况,是 OpenAI 必然会发布比 Gemini 3 更好的模型,而 Google 也还有 Gemini 4、Gemini 5。
其实,回看过去这一年来硅谷的新闻,完全算得上是一出跌宕起伏的抓马大戏。年初被 DeepSeek R1 的横空出世而感到压力;年中则是小扎开启的疯狂「抢人模式」,天价薪酬刷新着所有人对 AI 人才的认知;到了年尾,又再次卷回到了朴素的模型比拼赛场。

在 OpenAI 研究主管 Mark Chen 的最新播客采访中,硅谷的战争更是进化到了魔幻的程度,他说小扎为了挖走 OpenAI 的核心大脑,甚至开始做汤,真的能喝的汤,然后亲自把汤送到研究员的家门口。
除了这些八卦,他也谈到了 OpenAI 对于 Gemini 3 的看法、Scaling 是否已经过时、还有 DeepSeek R1 对他们的影响、以及公司内部的算力分配、实现 AGI 的时间表等。
Mark Chen 的背景非常有意思,数学竞赛出身,MIT 毕业,去华尔街做过高频交易(HFT),2018 年加入 OpenAI,跟着 Ilya 一起做研究。和奥特曼更偏向于商人属性的特点不同,这些经历,让他身上也有一股非常明显的特质,极度厌恶失败,且极度信奉数学。
他坦言自己现在,完全没有社交生活,过去两周每天都工作到凌晨 1-2 点。
我们整理了这场长达一个半小时的采访,总结了下面这些亮点,或许能更好的看清硅谷这一年来的各种「战争」、以及 OpenAI 会做些什么努力,来继续保持自己在 AI 时代的第一。
关于 Gemini 3,我们真的「不慌」
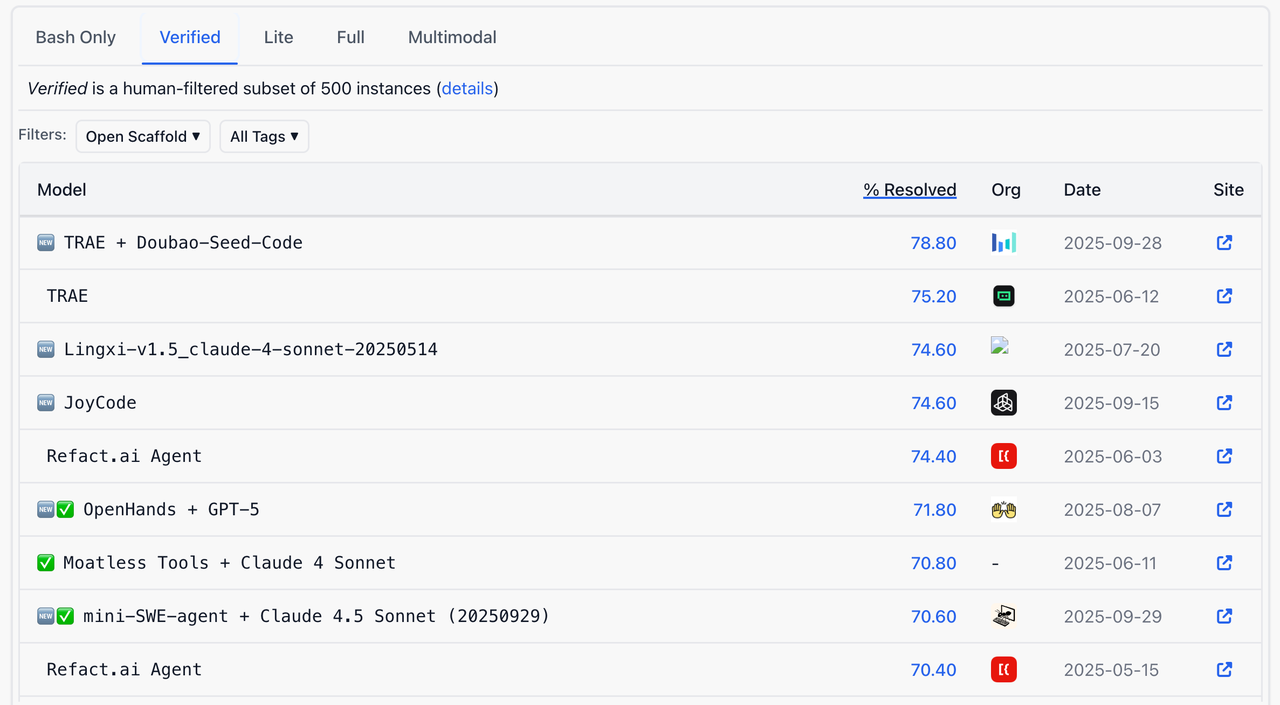
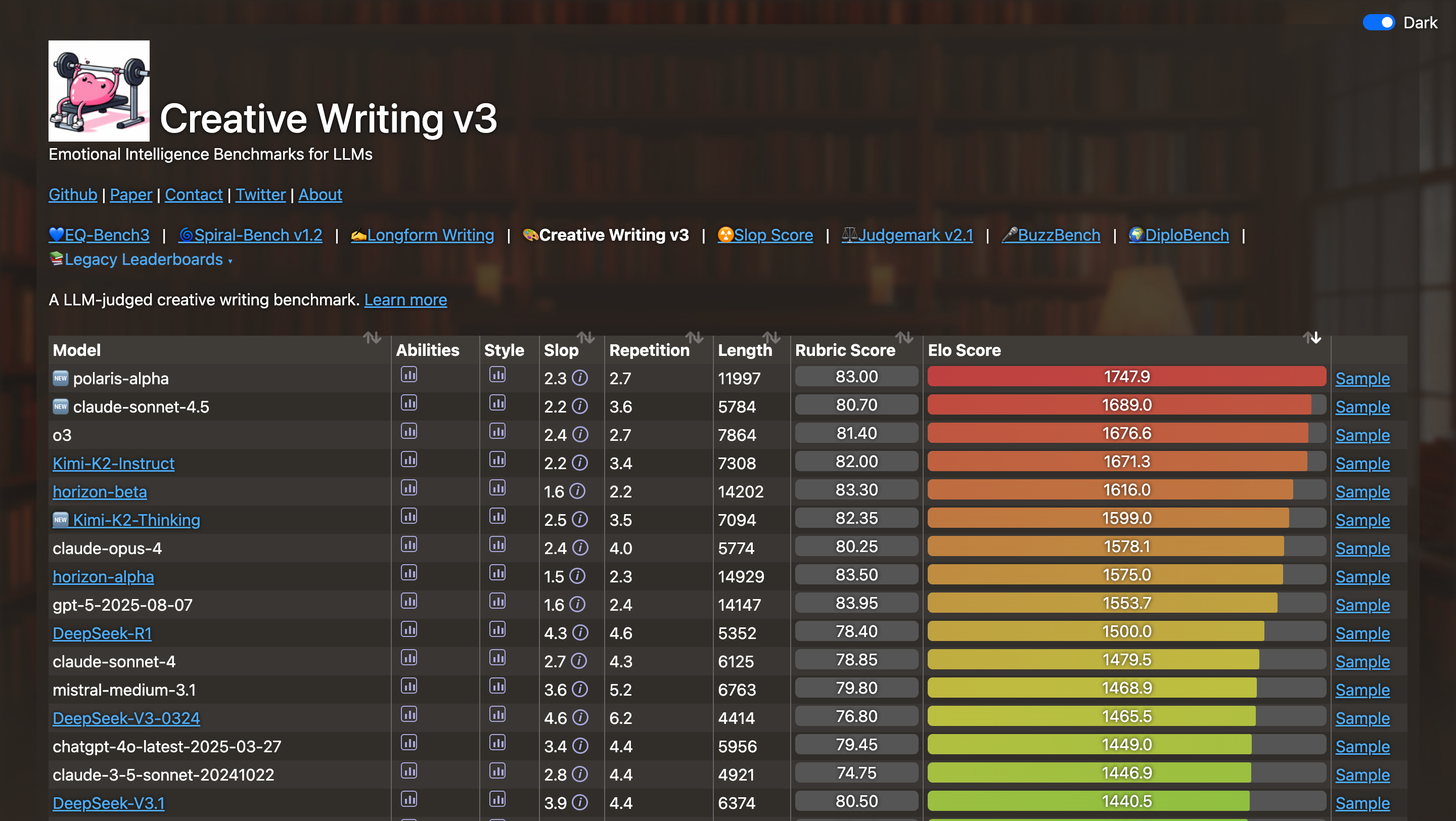
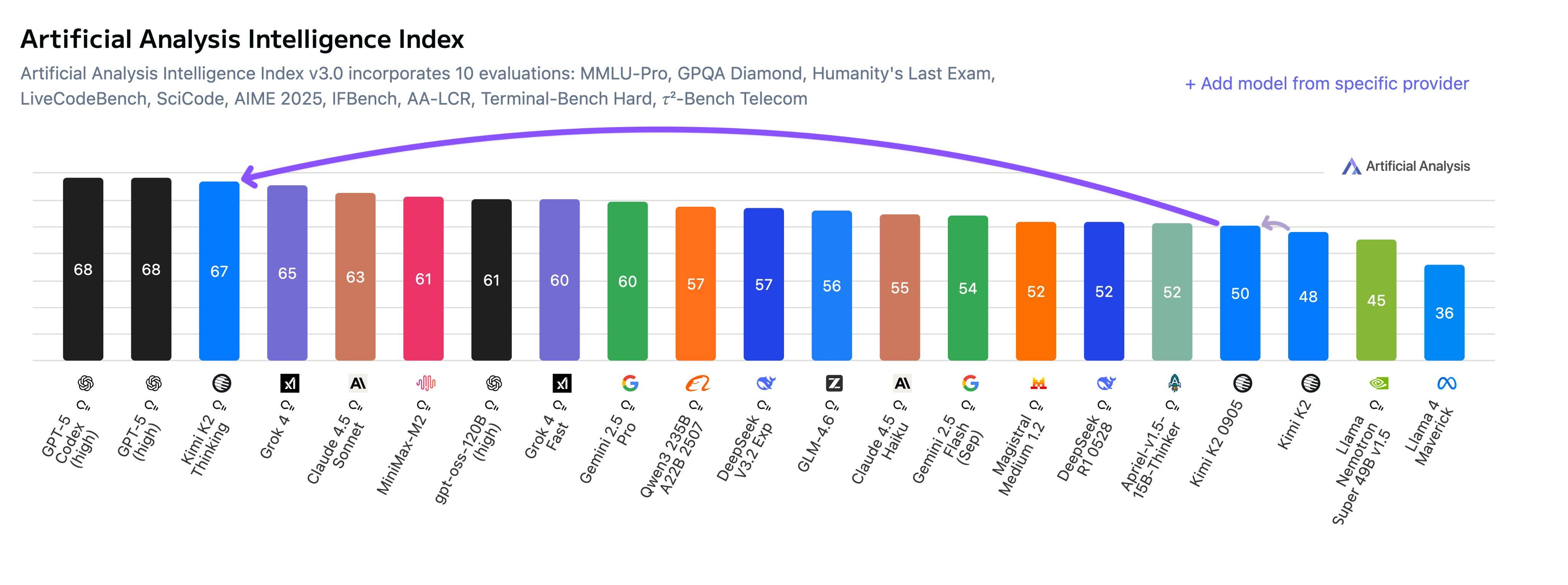
OpenAI 真的怕 Google 吗?Mark 的评价很客观但也很犀利。他肯定了 Gemini 3 是个好模型,Google 终于找对路子了。但是他说看细节,比如 SWE-bench(这也是 Gemini 3 刷榜那张图片里,唯一一个没有拿到第一的基准测试)数据,Google 在数据效率上依然没有解决根本问题。
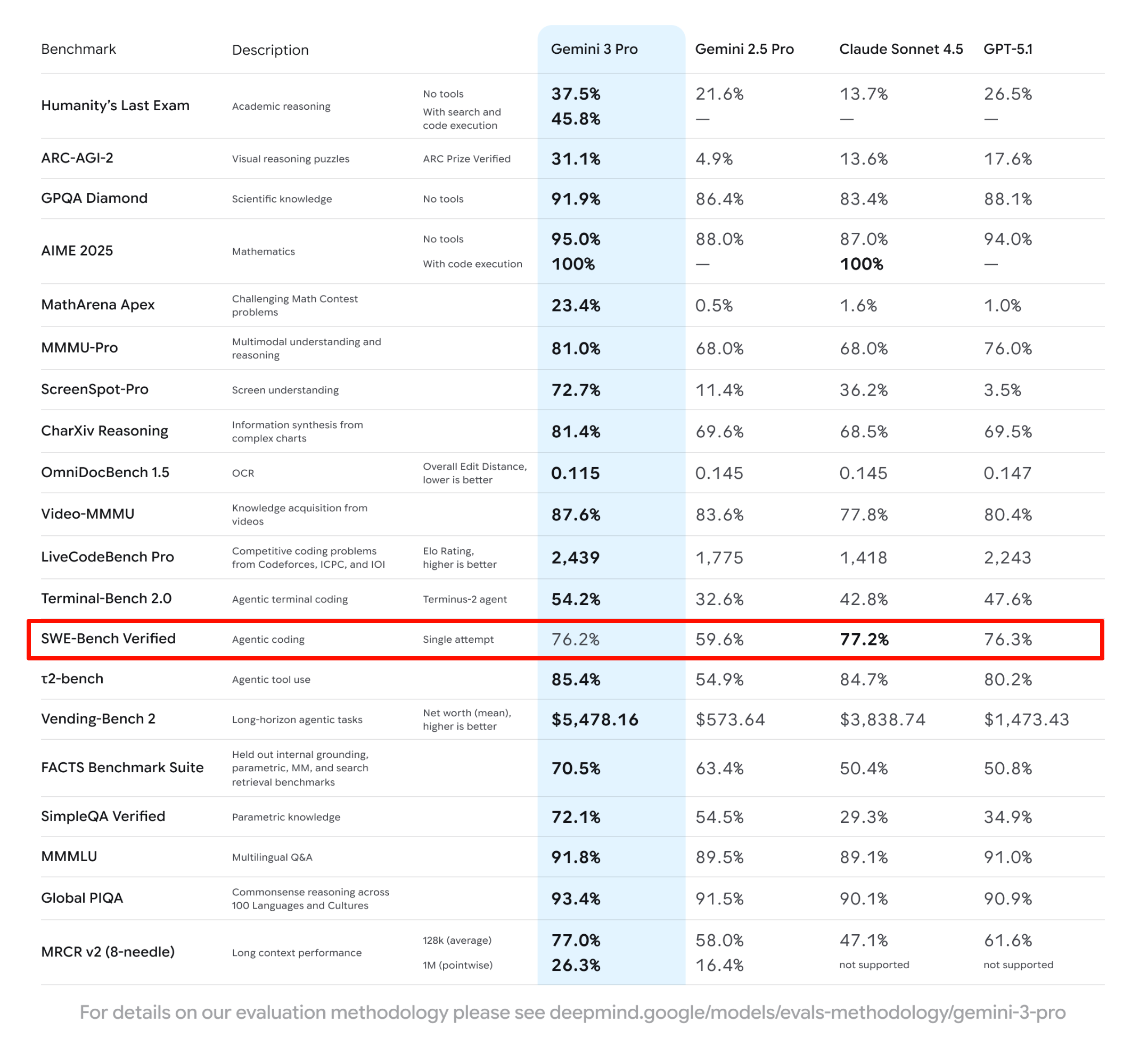
▲Gemini 3.0 Pro 在 SWE-Bench 上的表现,比 GPT-5.1 还差了 0.1%
而他自己则是非常自信的表示,OpenAI 内部已经有了针对性的应对模型,而且他们有信心在数据效率上做得更好。
Mark 甚至说,奥特曼前几天发那个说大家都要感到压力的备忘录,去吓唬大家,其实更多的是为了注入紧迫感,他说这是管理层的惯用手段,备忘录的目的在于管理层激励团队,而不是真的感到慌了。
我觉得Sam的工作之一就是要注入紧迫感和速度感。这是他的责任,也是我的责任。
作为管理者,我们的部分工作就是不断给组织注入紧迫性。

▲此前 The Information 报道,奥特曼在 Gemini 3 推出时,在公司内部发备忘录,提到会给 OpenAI 带来困难
他们目前最大的问题,还是算力分配。作为 OpenAI 的研究主管,他的一项工作就是决定如何将算力分配到公司内部不同的项目。
他和 Jakub Pachocki(OpenAI 首席科学家)一起,负责制定 OpenAI 的研究方向,同时决定每个项目能拿到多少算力。为了这件事,他们每隔 1–2 个月,都会做一次盘点。
他们把 OpenAI 所有在做的项目,放进一张巨大的表格里,大概有 300 个;然后努力把每一个项目都看懂,给它们排优先级;再根据这个优先级表去分配 GPU。

▲英伟达和 OpenAI 的百万 GPU 合作
他也提到,真正要用掉大部分的 GPU 的,甚至并不是训练那个最重要发布的模型,而是他们内部在探索下一代 AI 范式的各种实验。
所以,在他的眼里,Gemini 3 发布了、某家开源模型刷榜了、某个思考模型又拿了新高分了;这些你追我赶的 benchmark 赛车一点都不重要。反而,最应该避免的,恰恰是被这场竞赛牵着走。
他说,现在的模型发展,我们随时可以靠一点「小更新」,就在榜单上领先几周或几个月。但如果把资源都砸在这些短线迭代上,就没有人去寻找下一代范式。而一旦有人真的找到了,整个领域后面十年的路线,都要沿着那条新路走。
小声哔哔几句,预言 OpenAI 下周要发布的模型,我想就是在计划之外,做了点小更新,然后刷新了几个榜单而已吧,就这还没慌吗。

提到榜单的时候,他说他有自己的一套私房题,用来测试模型是不是真的具备了顶级数学直觉。他举了一个 42 的数学难题,说目前的语言模型,包括 o1 这种思考模型能接近最优解,但从来没有完全破解它。
你想创建一个模 42 的随机数生成器。你手头有一些质数,是模数小于 42 的质数的随机数生成器。目标是,以最少的调用次数,组合出这个模 42 的生成器。
除了谈到 Gemini 3,主持人也问了他对于 DeepSeek 的看法。
和 Gemini 3 一样,Mark 承认 DeepSeek 的开源模型曾让他们感到压力,甚至怀疑自己是不是走错了路。
但结论是坚持自己路线,不要被对手的动作打乱节奏,专注自己的路线图。OpenAI 不会变成一个跟风的公司,他们要做的,就是定义下一个范式。
Ilya 的 Scaling 里面还有很多潜力,OpenAI 需要大规模预训练
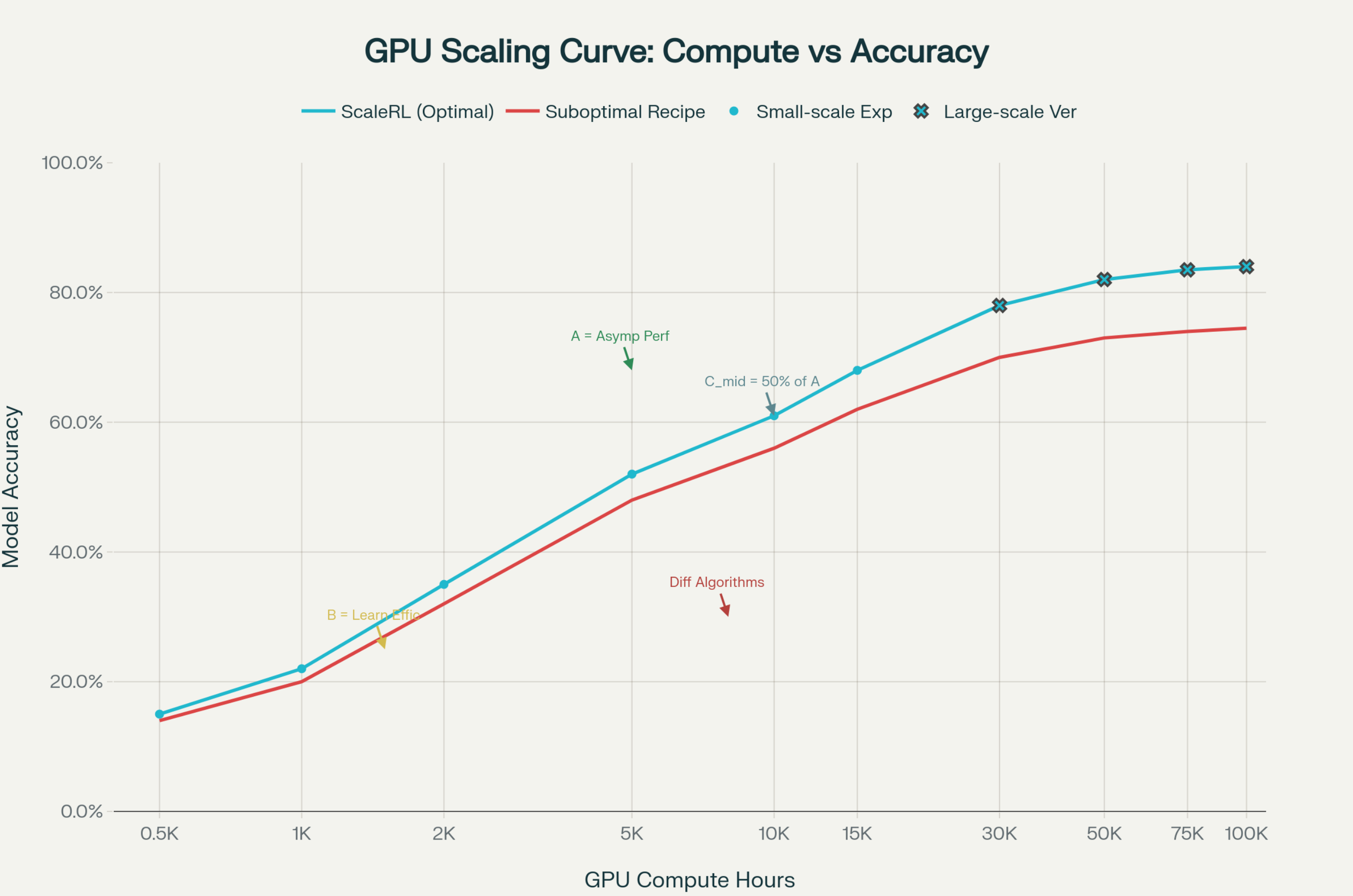
近期关于 Scaling 失效的讨论纷纷扬扬,Ilya 先是在播客采访里面说,Scaling 的时代已经结束了,后面又在社交媒体上澄清,Scaling 会持续带来一些改进,并不是停滞不前。
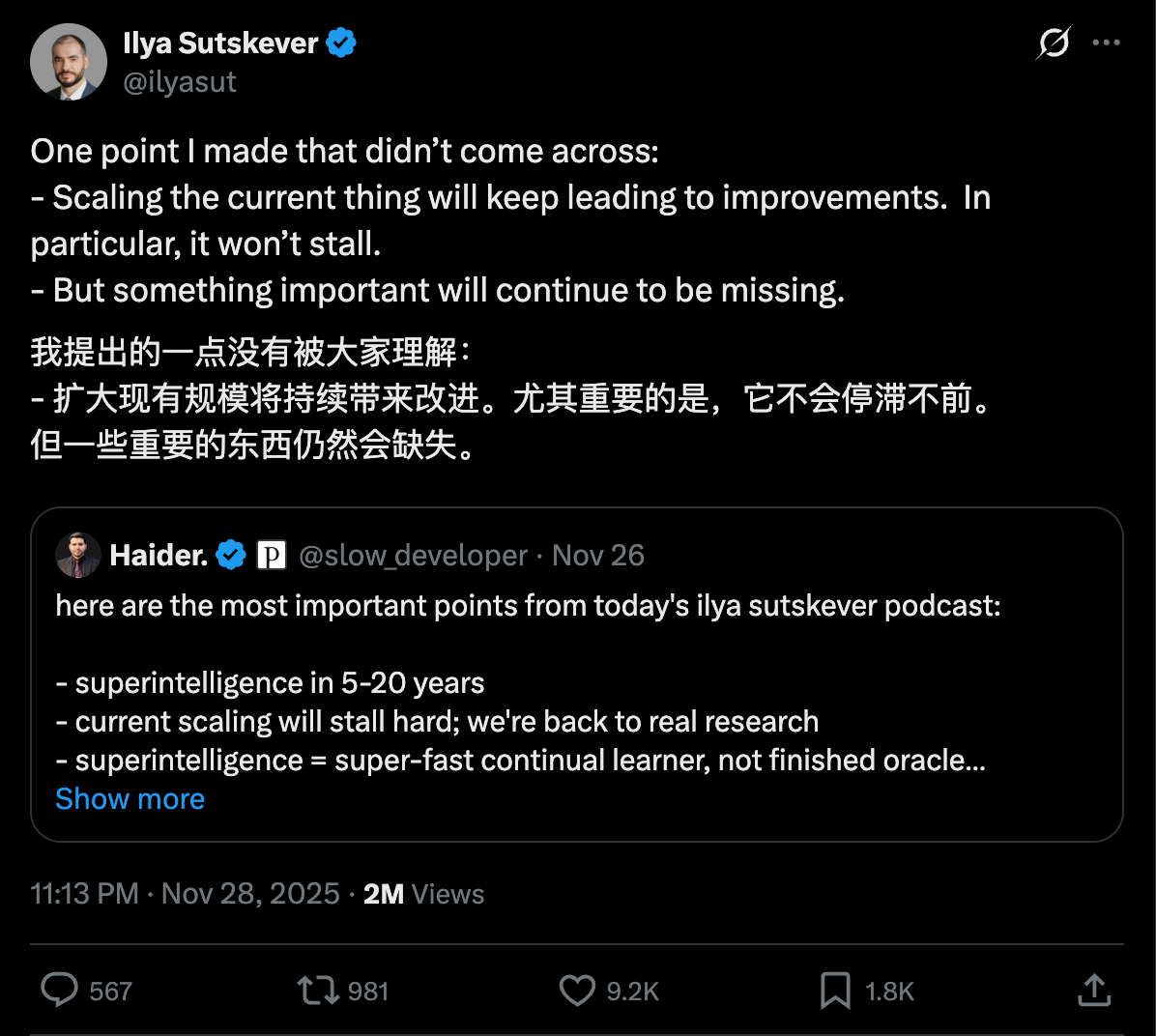
所谓的 Scaling Law,就是按经典老故事走向,这几年建了巨大的算力基建,模型每 10 倍算力,本该有一波明显跃迁。但从 GPT-4 到 GPT-5,外界并没有看到预期中那种「质变式」的提升,所以才会有「Scaling Law 失效了」的讨论;而 Ilya 前段时间的访谈,则是进一步放大了这种观点。
Mark Chen 对这个观点,给出了坚决的反驳,「我们完全不同意」。他透露,过去两年 OpenAI 在推理上投入了巨量资源,导致预训练这部分稍显退化。之前关于 GPT-5 遇到了预训练的问题,其实也是因为他们把重心放在了推理上,而不是 Scaling Law 已死。
工作就是分配算力资源的他,再次重申算力永远不会过剩,如果今天多 3 倍算力,他可以立刻用完;如果今天多 10 倍算力,几周内也能全部吃满。对他来说,算力需求是真实存在的,看不到任何放缓迹象。
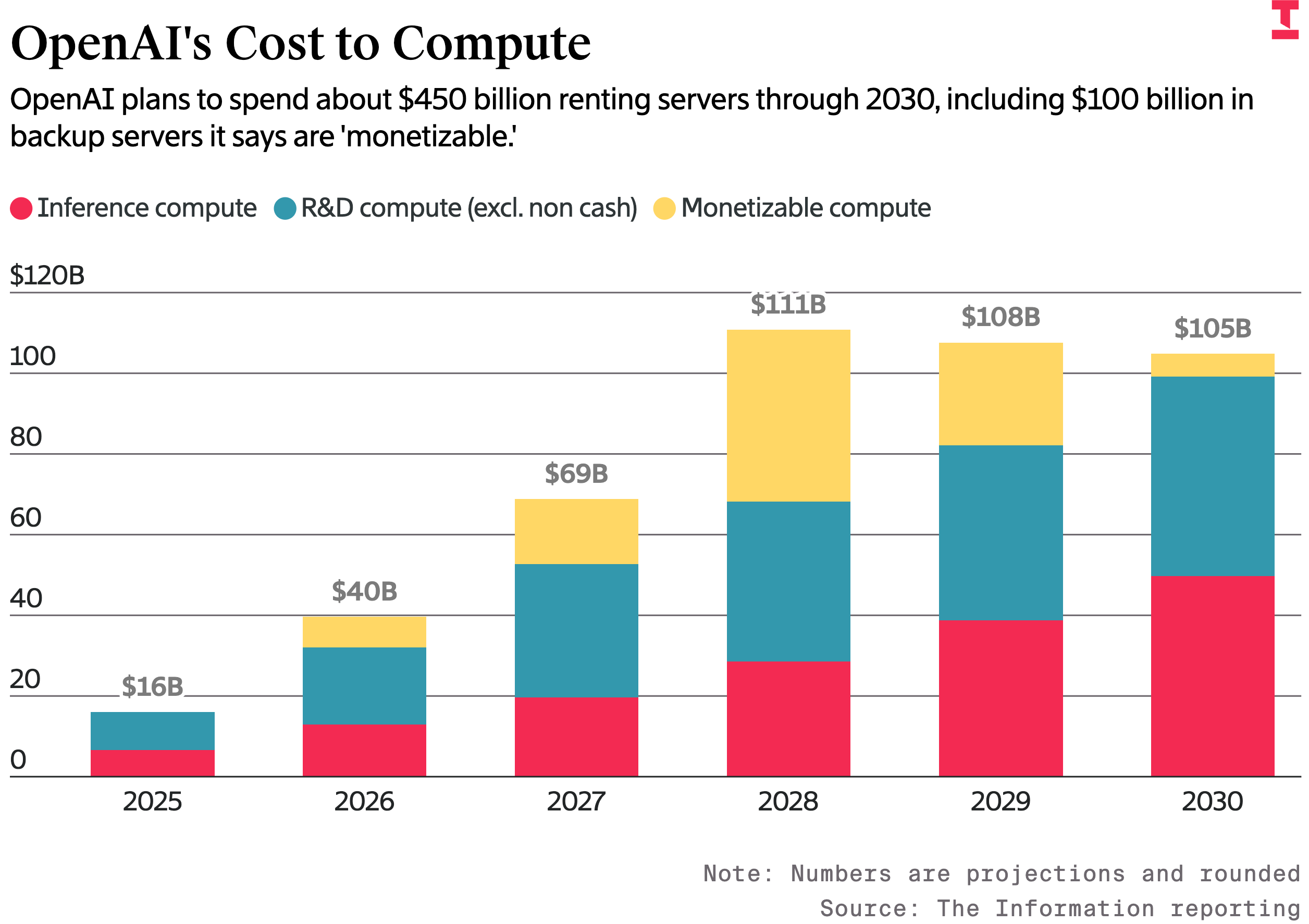
▲ OpenAI 的计算成本,计划到 2030 年花费约 4500 亿美元租用服务器,红色为推理计算成本、蓝色为研发(不包含现金业务)、黄色为可盈利的计算
他也提到,过去半年,他和 OpenAI 首席科学家 Jakub Pachocki 已经将重心重新拉回,要开始重塑预训练的统治力。
他明确说他们会继续做规模化模型,而且已经有一批算法突破,专门就是为了让 Scaling 更划算,在相同算力下挖出更多性能,在更高算力下保持数据效率。
小扎的送来的真汤,抵不过 OpenAI 的鸡汤
最后就是访谈里提到的八卦了,Meta 今年没有别的新闻,媒体渲染了一整个季度的「OpenAI 人才/Apple 人才/Google 人才大量流失到 Meta」,Mark Chen 在播客里正面回应了这个话题,细节简直有点「颠」。
他说小扎真的很拼,为了挖人,小扎不仅手写邮件,还亲自去送鸡汤。人才战打到最后,居然演变成「谁煮的汤更好喝」的 Meta 游戏。
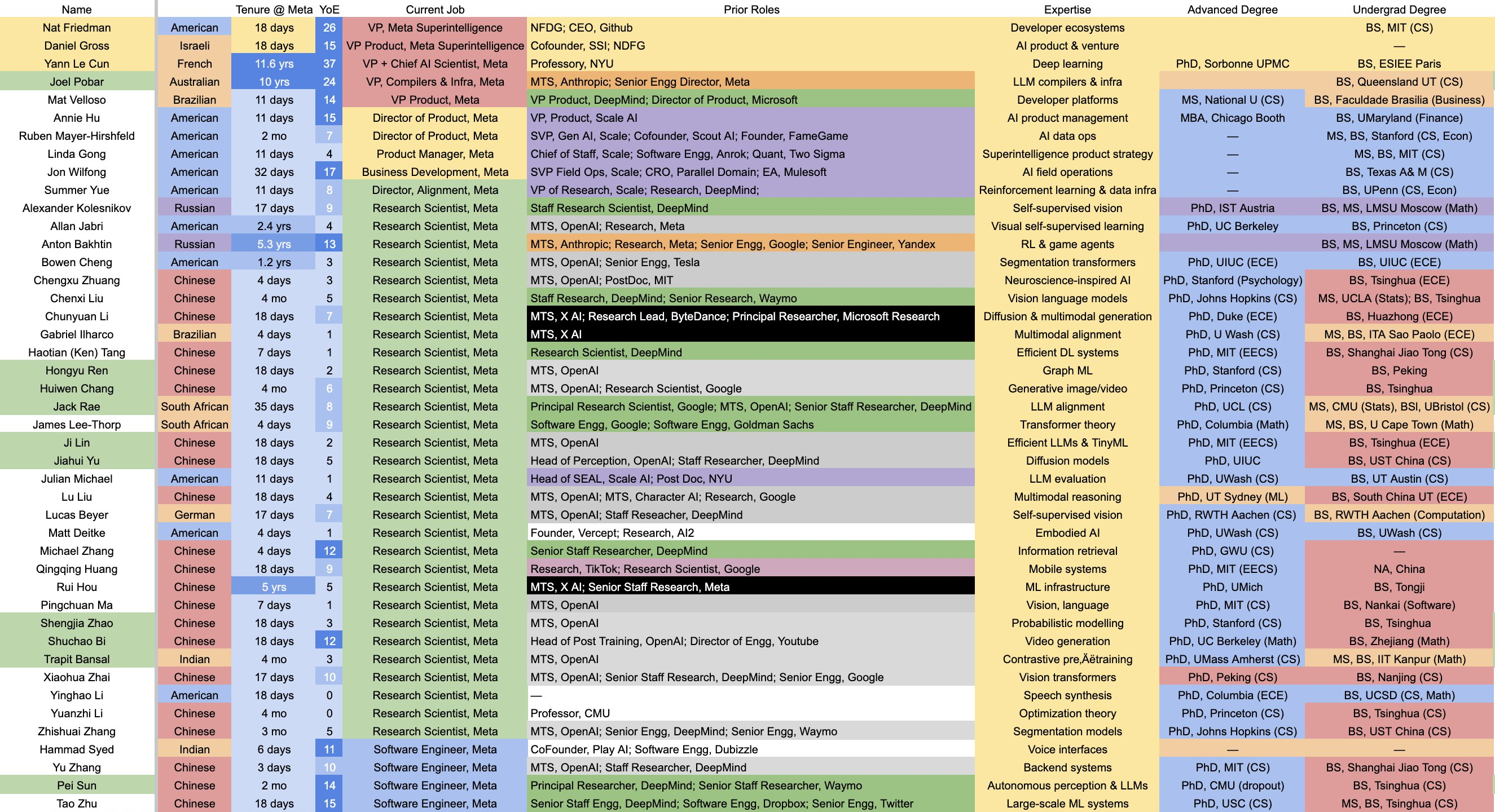
▲ Meta 花大价钱挖人组建的超级智能实验室名单
不过,在他的直接下属中,Meta 曾试图挖角一半的人,结果全部选择继续留下来。为什么不走?不是因为钱,因为Meta 给的钱显然更多,而是因为信仰。
Mark 说,即使是那些跳槽去 Meta 的人,也没有一个人敢说「Meta 会比 OpenAI 先做出 AGI」。留在 OpenAI 的人,是因为他们真的相信这里才是 AGI 的诞生地。
他也提到自己从华尔街和玩扑克的经历里面学到,真正要守住的是核心人才,而不是每一个人。在搞清楚,必须留下的是哪类人后,再把资源和关注度,全部压在这部分人身上。
他说他最强烈的情绪,其实就是想「保护研究的本能」。在 Barrett(OpenAI 研究副总裁)离职那阵子,他甚至直接睡在办公室睡了一个月,只为把研究团队稳住。
▲ Barret 目前和 Mira(OpenAI 前 CTO) 都在 Thinking Machines
那么 OpenAI 所信奉的 AGI 又是什么,主持人问他,Andrej Karpathy 在最近的一个播客里面说,AGI 大概还要 10 年,你是怎么想的。
Mark 先是调侃了一番 X 现在「惊」的各种文案,一下子是「AI 完了」、一下子又是「AI 又可以了」。他觉得,每个人对于 AGI 的理解都不同,即便在 OpenAI 内部,也很难有一个一致的定义。但他相信的是,OpenAI 在 AGI 道路上设置的目标。
- 一年内: 改变研究的性质。现在的研究员是自己在写代码、跑实验。 一年后,研究员的主要工作是管理 AI 实习生。AI 应该能作为高效的助手,承担大部分具体工作。
- 2.5 年内: 实现端到端的研究自动化。这意味着:人类只负责提出 Idea(顶层设计),AI 负责实现代码、Debug、跑数据、分析结果,形成闭环。
从 Copilot 到 Scientist,Mark 强调,OpenAI for Science 的目标不是自己拿诺贝尔奖,而是建立一套工具,让现在的科学家能一键加速,哪怕这需要重构整个科学评价体系,因为未来可能很难分清是人还是 AI 做的发现。
2 年半的时间很快,但这对于现在看来,是以周为单位迭代的 AI 行业来说,又是一场漫长的马拉松。
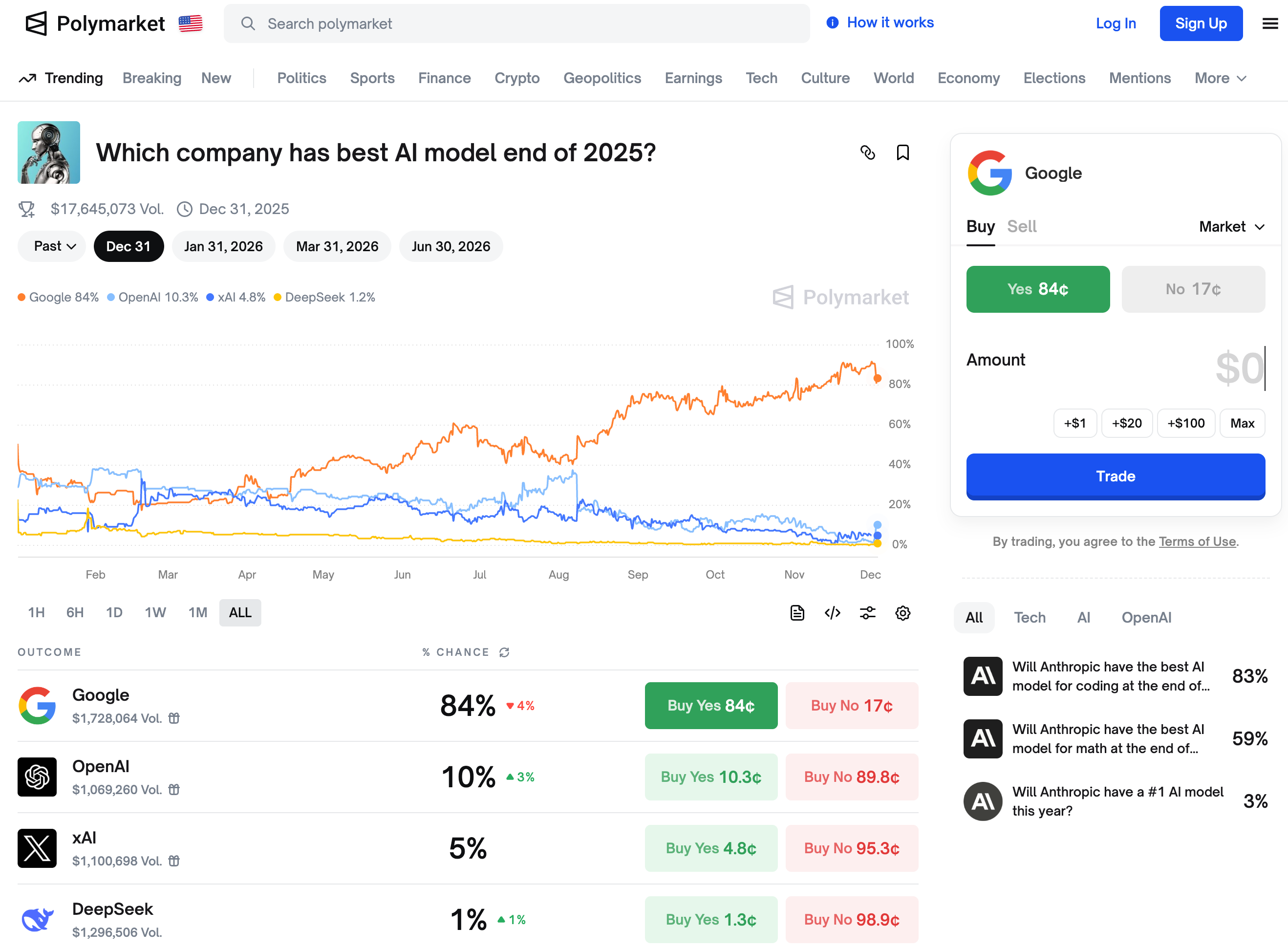
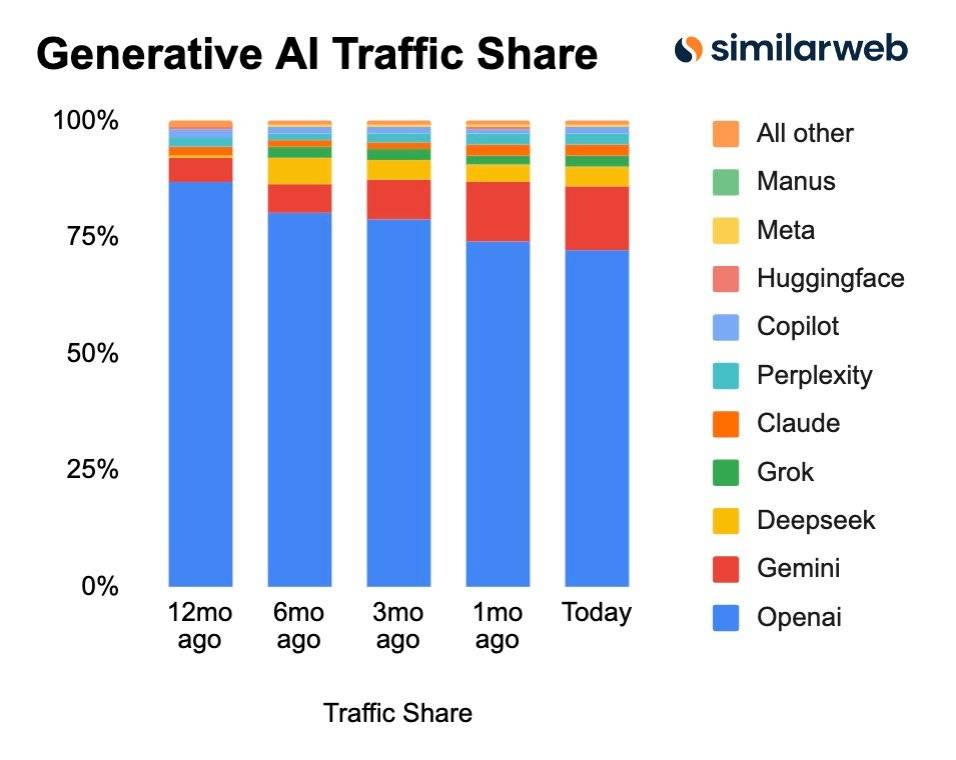
▲ 预测市场给出的,到 2025 年底前最好的 AI 模型会来自哪个公司,Google 排在第一名
无论是扎克伯格那锅真金白银的鸡汤,还是 OpenAI 想要定义未来的理想主义鸡汤,这场硅谷的「煮汤大戏」还远未结束。Mark Chen 播客里表现出来的从容,或许能消除一部分外界的焦虑,但用户还是会用脚投票,好的模型自己会说话。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。











































 播客链接:https://x.com/dwarkesh_sp/status/1993371363026125147
播客链接:https://x.com/dwarkesh_sp/status/1993371363026125147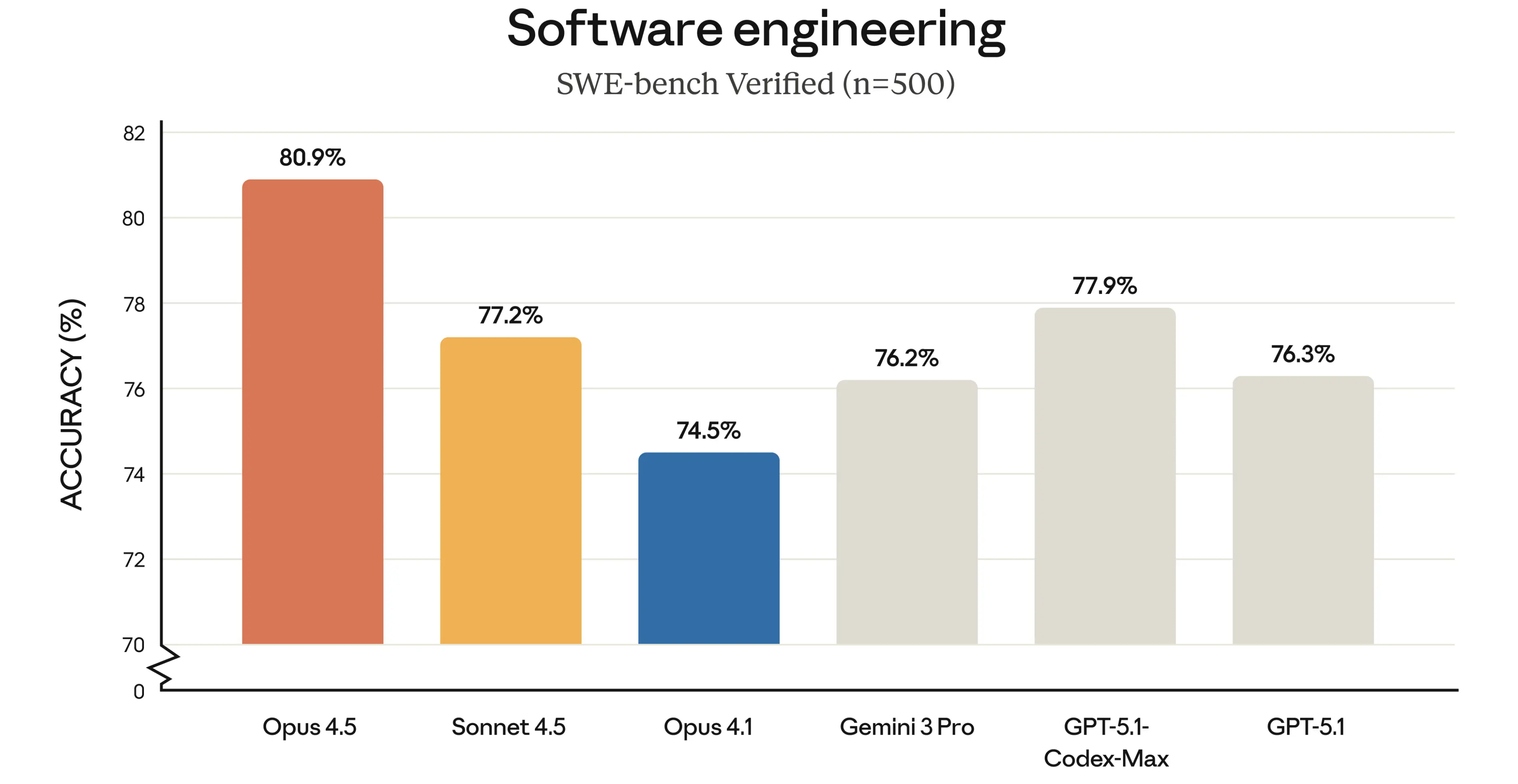




























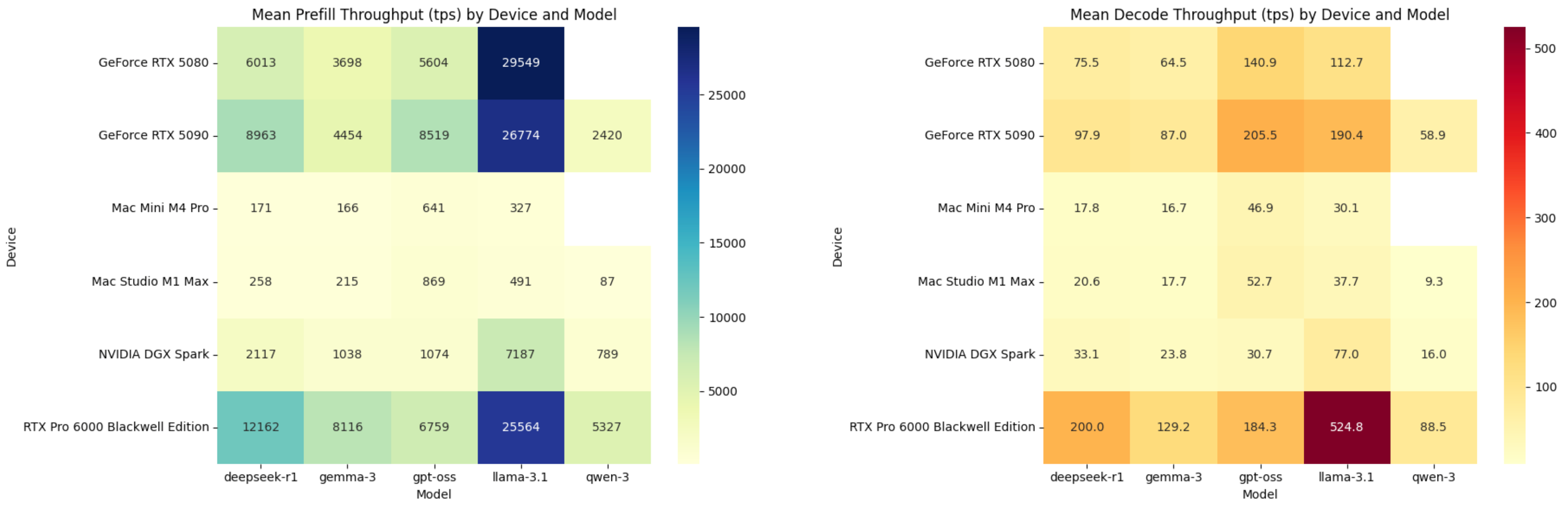
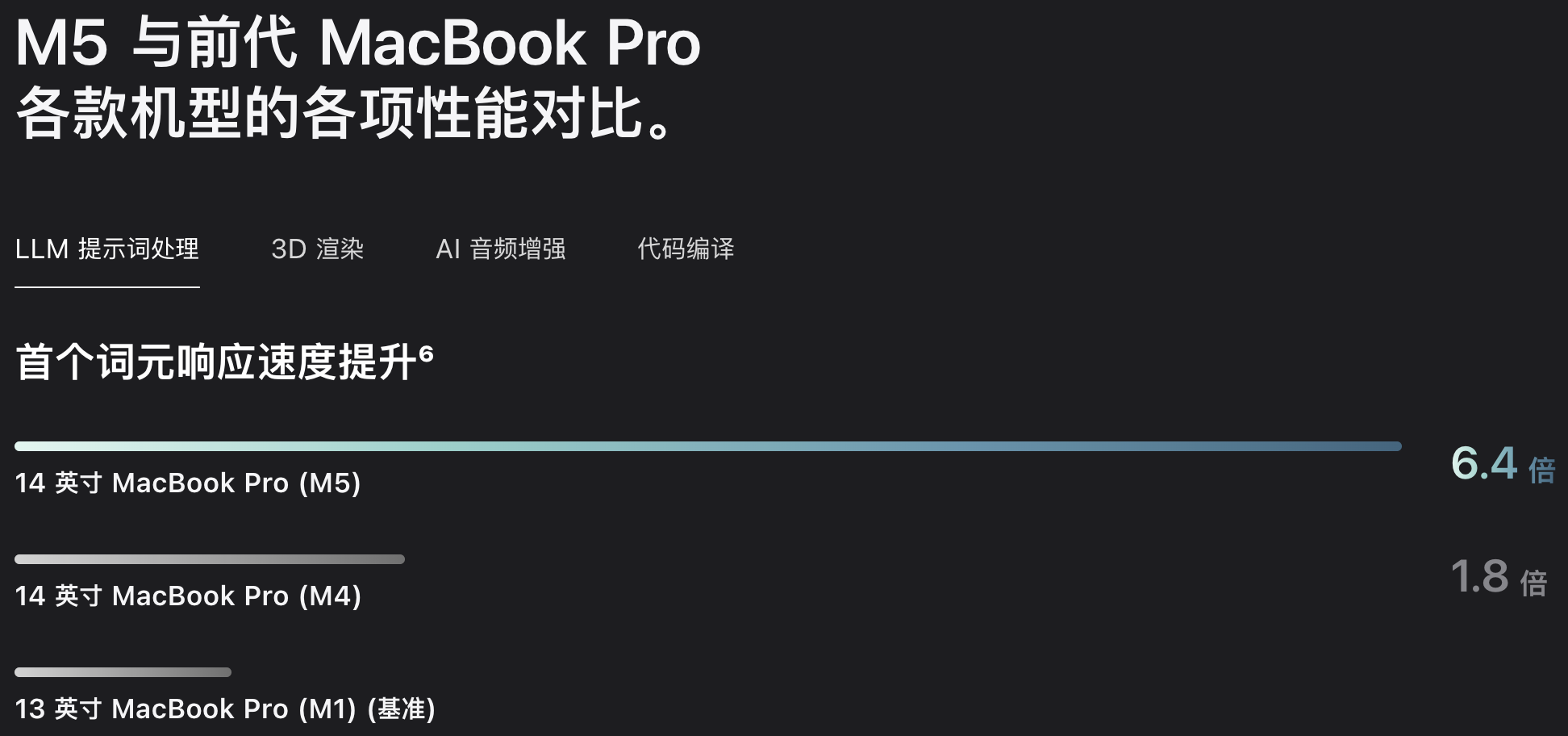
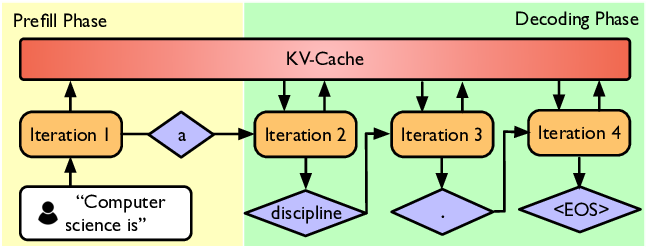
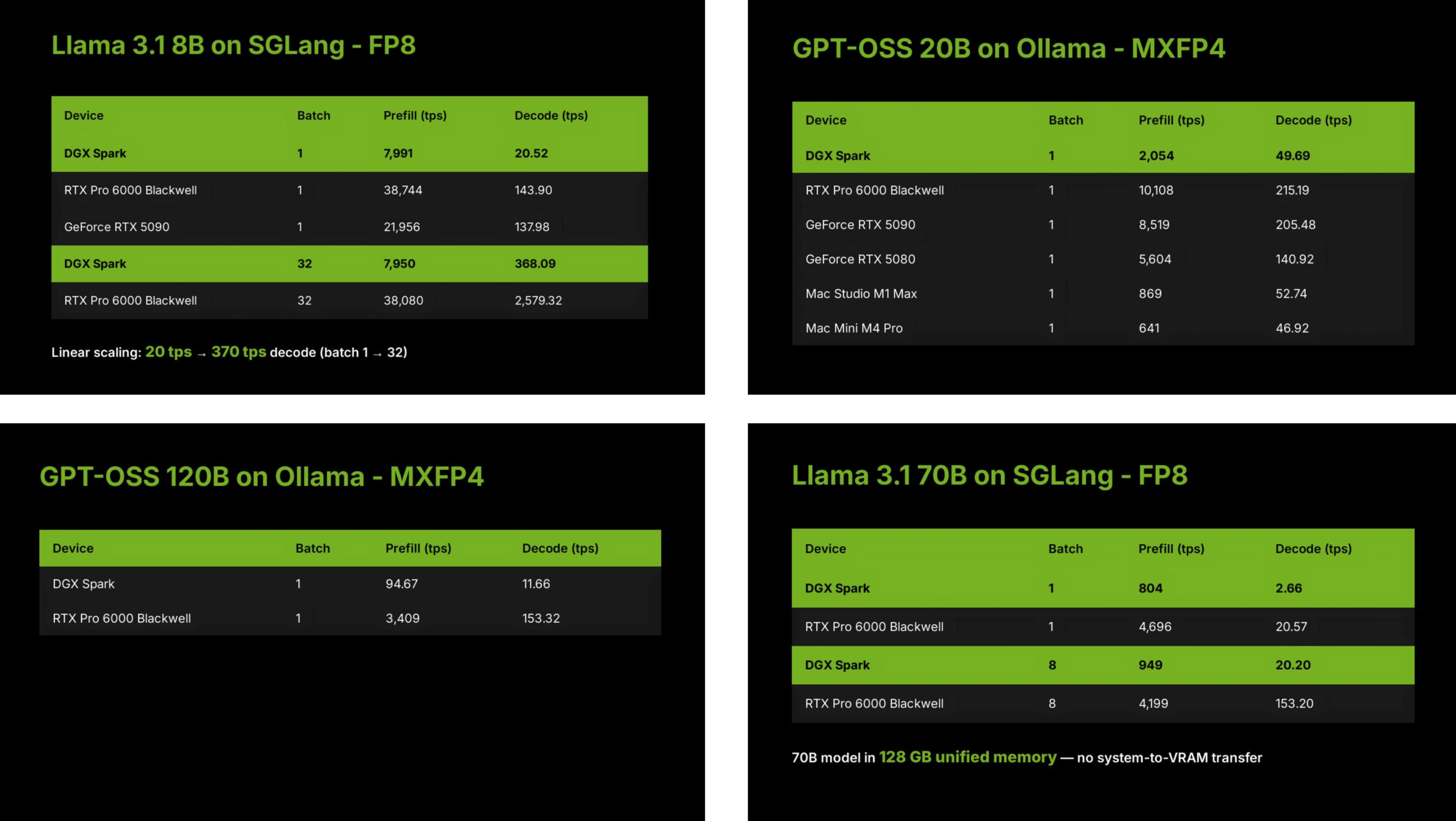
 Tips:什么是 TPS?
Tips:什么是 TPS?