终于发布的Gemini 3,什么是它真正的王牌?
Gemini 3 Pro 预览版上线那一刻,很多人心里的第一反应可能是:终于来了。
遛了将近一个月,这里暗示那里路透:参数更强一点、推理更聪明一点、出图更花一点,大家已经看得心痒痒了。再加上 OpenAI、Gork 轮番出来狙击,更加是证实了 Gemini 3 将是超级大放送。

这次 Gemini 3 的主打卖点也很熟悉:更强的推理、更自然的对话、更原生的多模态理解。官方号称,在一堆学术基准上全面超越了 Gemini 2.5。
但如果只盯着这些数字,很容易忽略一个更关键的变化:
Gemini 3 不太像一次模型升级,更像一次围绕它的 Google 全家桶「系统更新」。
模型升级这一块的,Google 已经把话说得很满了
先快速把「硬指标」过一遍,免得大家心里没数:
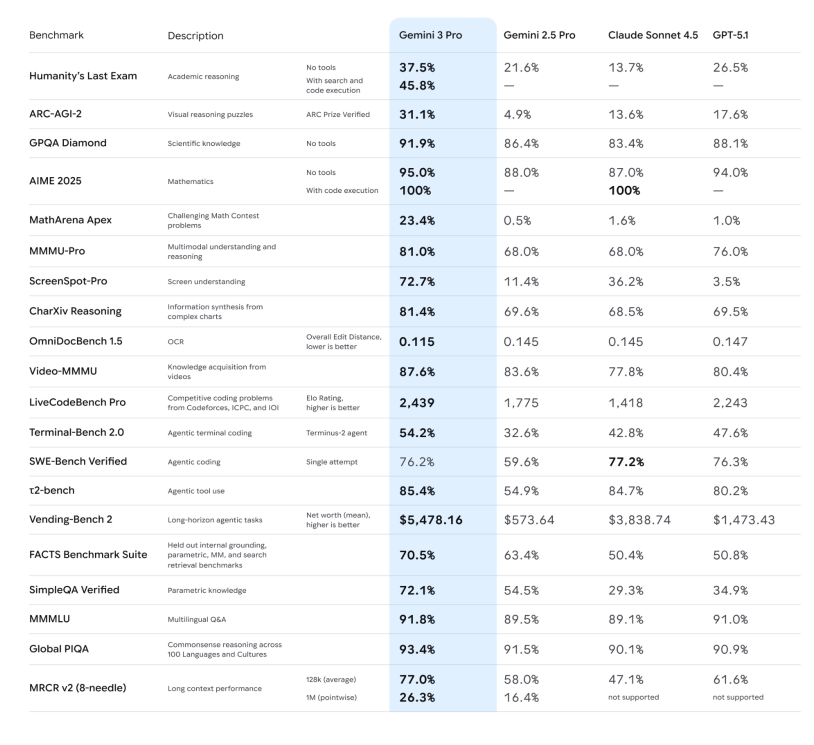 -推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。
-推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。
-多模态理解:不仅看图、看 PDF,甚至还能在长视频、多模态考试(MMMU-Pro、Video-MMMU)上拿到行业领先成绩,说看图说话、看视频讲重点的能力,提升了一档。
-Deep Think 模式: ARC-AGI 这类测试证明:打开 Deep Think 后,它在解决新类型问题上的表现会有可见提升。
从这些层面看,很容易把 Gemini 3 归类为:「比 2.5 更聪明的一代通用模型」。但如果只是这样,它也就只是排行榜上的新名字。连 Josh Woodward 出来接受采访都说,这些硬指标只能是作为参考。

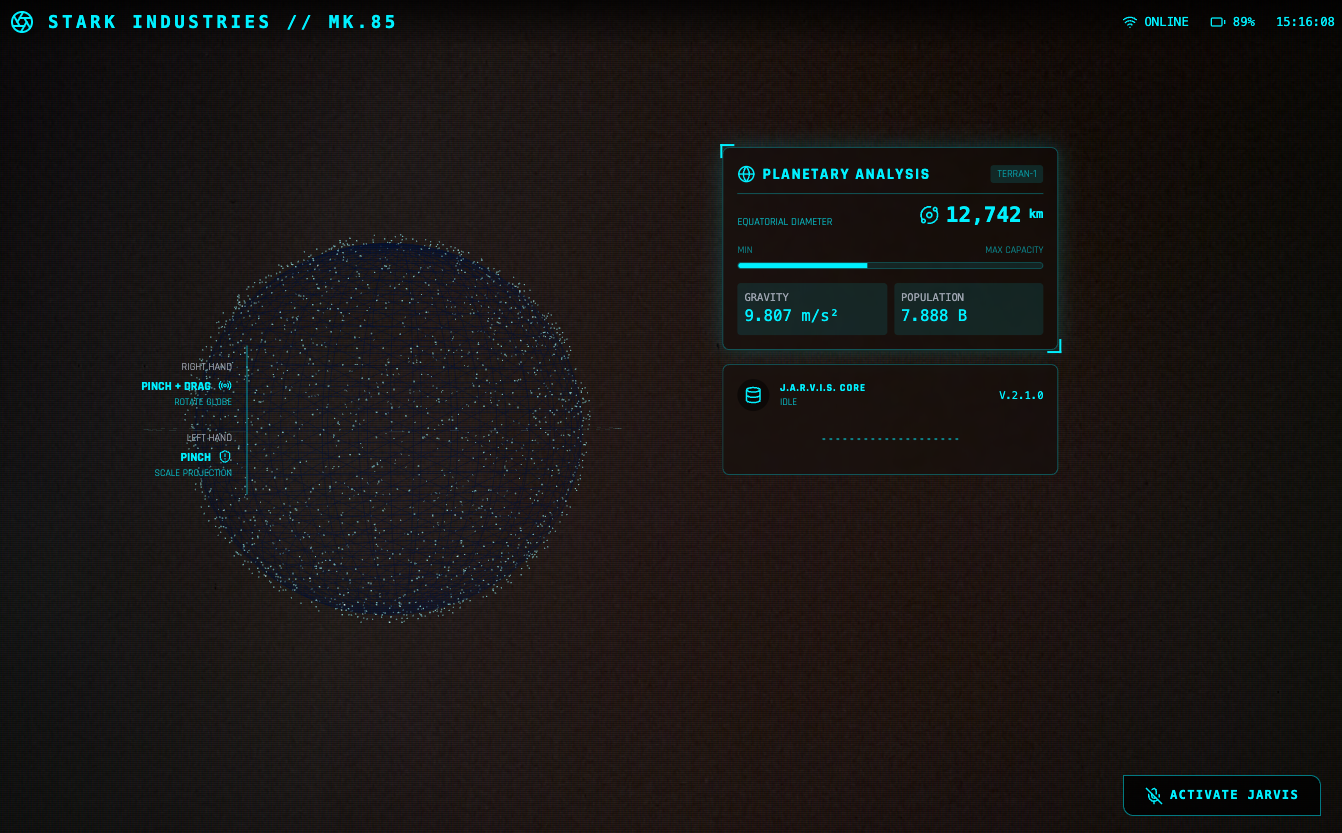
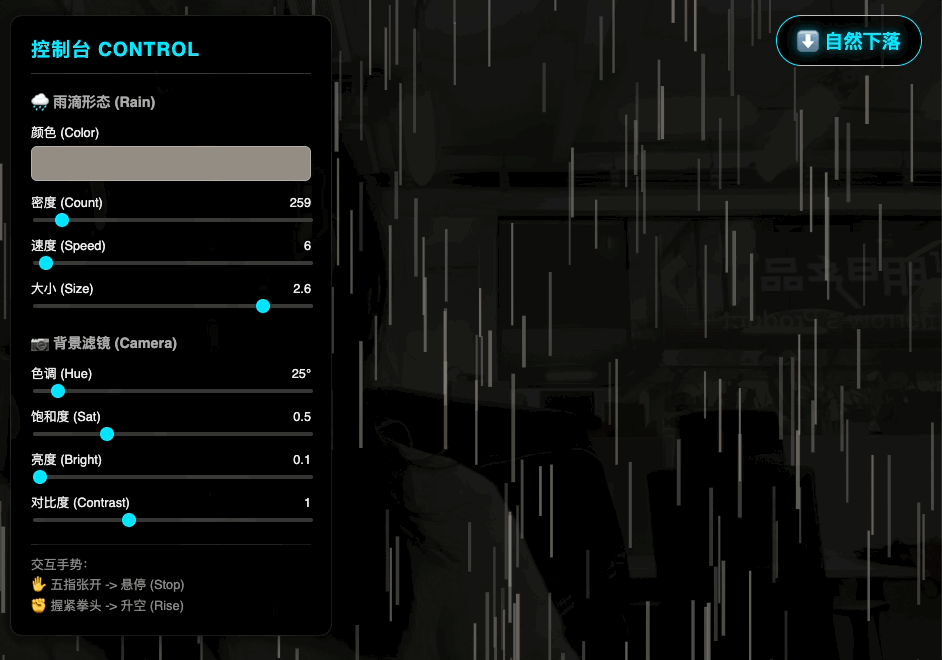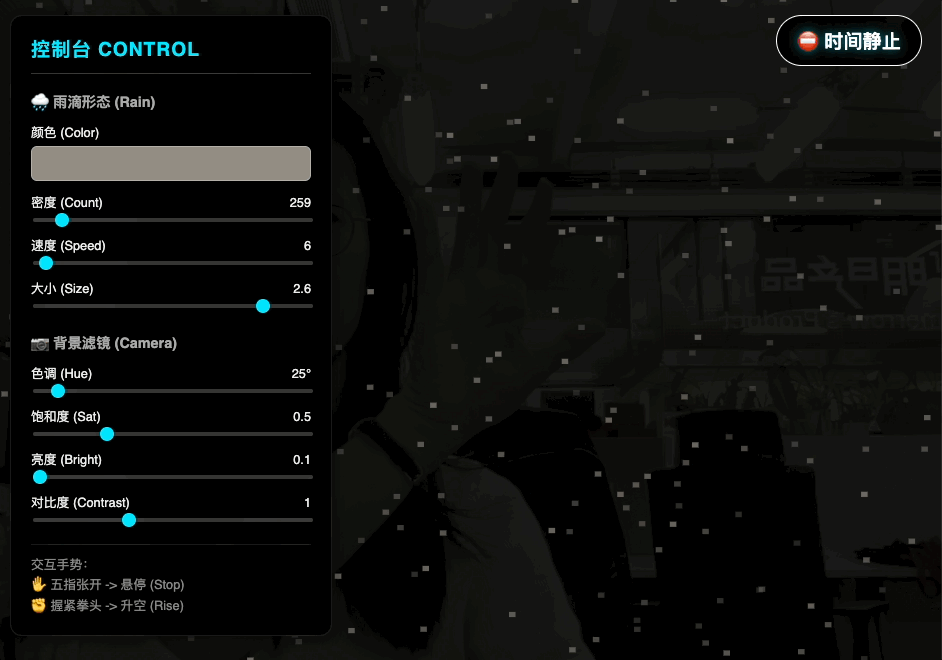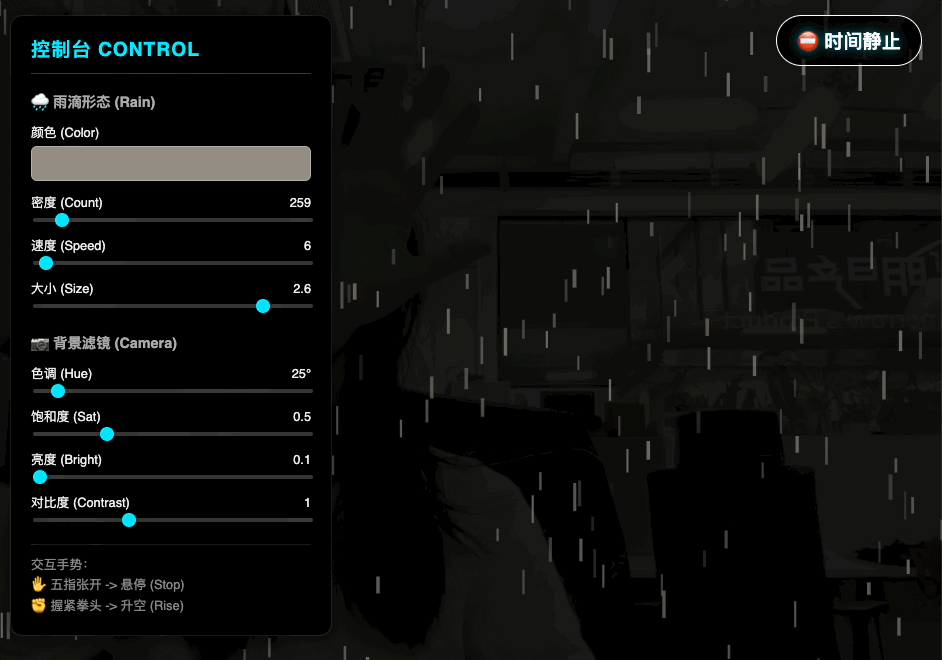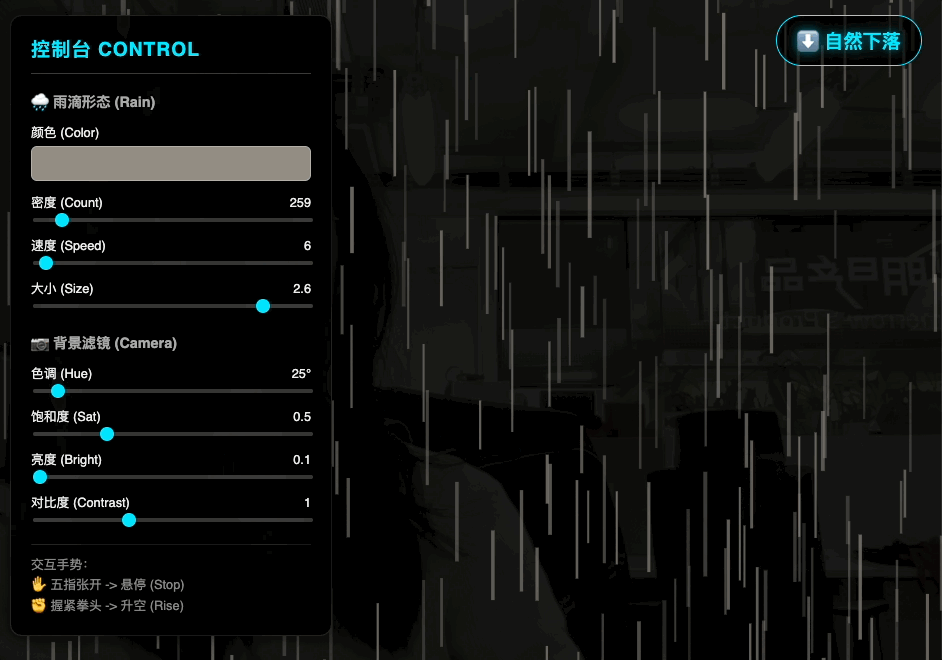
换句话说,「跑了多少分」只是一种相对直观的表现手法,真正有意思的地方在于 Google 把它塞进了哪些地方,以及打算用它把什么东西连起来。在这一个版本的更新中,「原生多模态」显然是重中之重。在这一次的大更新中,「原生多模态」显然是重中之重。

如果要为当下的大模型找一个分水岭,那就是:它究竟只是「支持多模态」,还是从一开始就被设计成「原生多模态」。
这是 Google 在 2023 年,即 Gemini 1 时期就提出来的概念,也是一直以来他们的策略核心:在预训练数据里一开始就混合了文本、代码、图片、音频、视频等多种模态,而不是先训一个文本大模型,再外挂视觉、语音子模型。
后者的做法,是过去很多模型在面对多模态时的策略,本质还是「管线式」的:语音要先丢进 ASR,再把转好的文本丢给语言模型;看图要先走一个独立的视觉编码器,再把特征接到语言模型上。
Gemini 3 则试图把这条流水线折叠起来:同一套大型 Transformer,在预训练阶段就同时看到文本、图像、音频乃至视频切片,让它在同一个表征空间里学习这些信号的共性和差异。
少一条流水线,就少一层信息损耗。对模型来说,原生多模态不仅仅是「多学几种输入格式」,这背后的意义是,少走几道工序。少掉那几道工序,意味着更完整的语气、更密集的画面细节、更准确的时间顺序可以被保留下来。
更重要的是,这对应用层有了革命性的影响:当一个模型从一开始就假定「世界就是多模态的」,它做出来的产品,与单纯的问答机器人相比,更像是一种新的交互形式。
从 Search 到 Antigravity,新总线诞生
这次 Gemini 3 上线,Google 同步在搜索栏的 AI Mode 更新了,在这个模式下,你看到的不再是一排蓝色链接,而是一整块由 Gemini 3 生成的动态内容区——上面可以有摘要、结构化卡片、时间轴,虽然是有条件触发,但是模型发布的同时就直接让搜索跟上,属实少见。
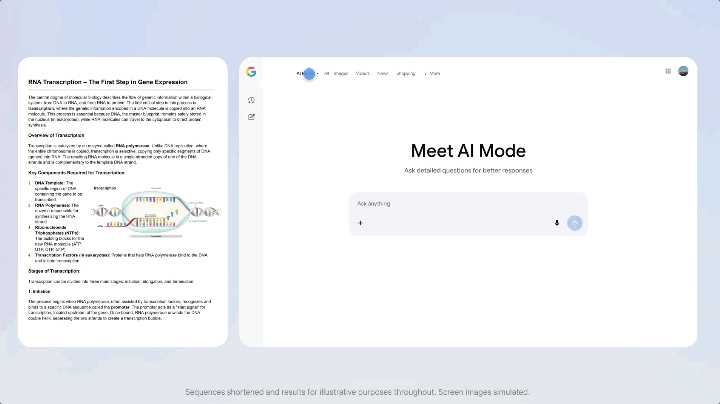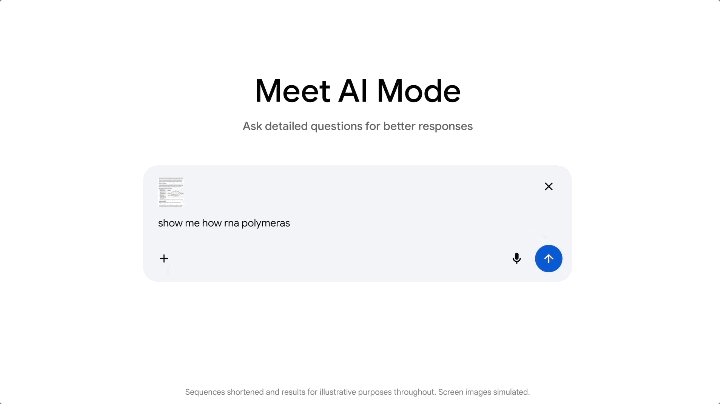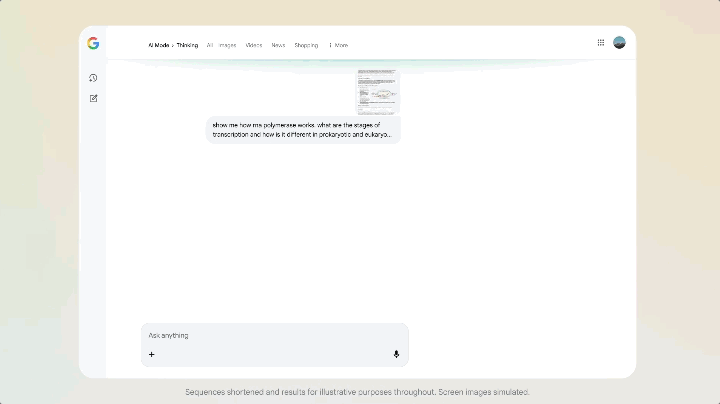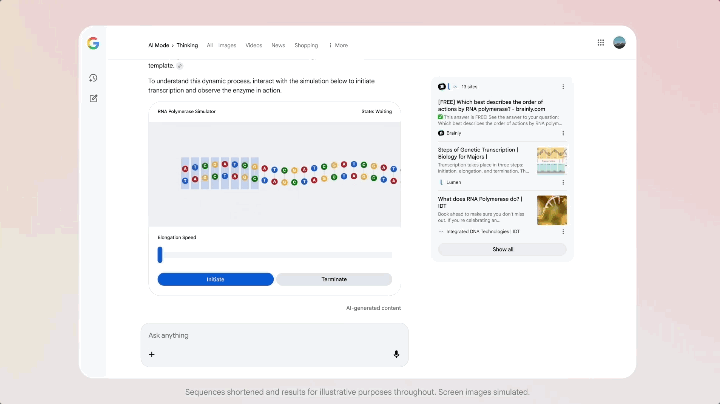
更特别的是,AI 模式支持使用 Gemini 3 来实现新的生成式 UI 体验,例如沉浸式视觉布局、交互式工具和模拟——这些都是根据查询内容即时生成的。
这个思路将一系列 Google 系产品中发扬光大,官方的说法是更像「思考伙伴」,给出的回答更直接,更少套话,更有「自己看法」,更能「自己行动」。
配合多模态能力,你可以让它看一段打球视频,帮你挑出动作问题、生成训练计划;听一段讲座音频,顺手出一份带小测题的学习卡片;把几份手写笔记、PDF、网页混在一起,集中整理成一个图文并茂的摘要。

这部分更多是「超级个人助理」的叙事:Gemini 3 塞进 App 之后,试图覆盖学习、生活、轻办公的日常用例,风格是「你少操点心,我多干点活」。
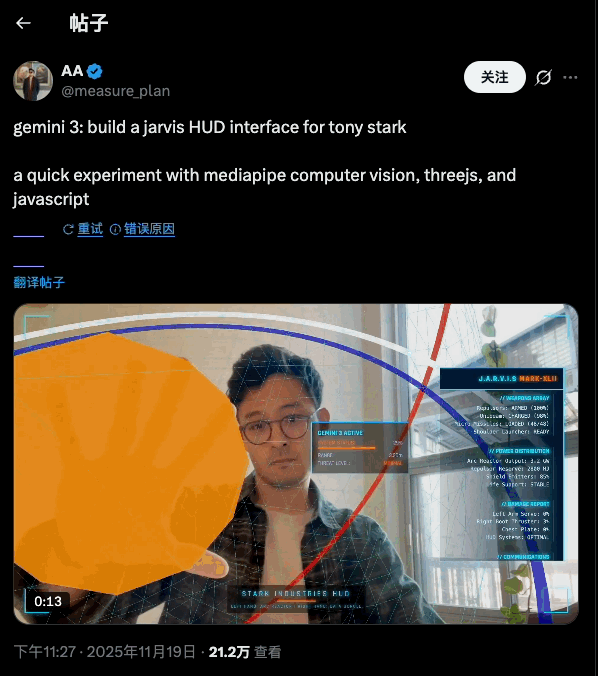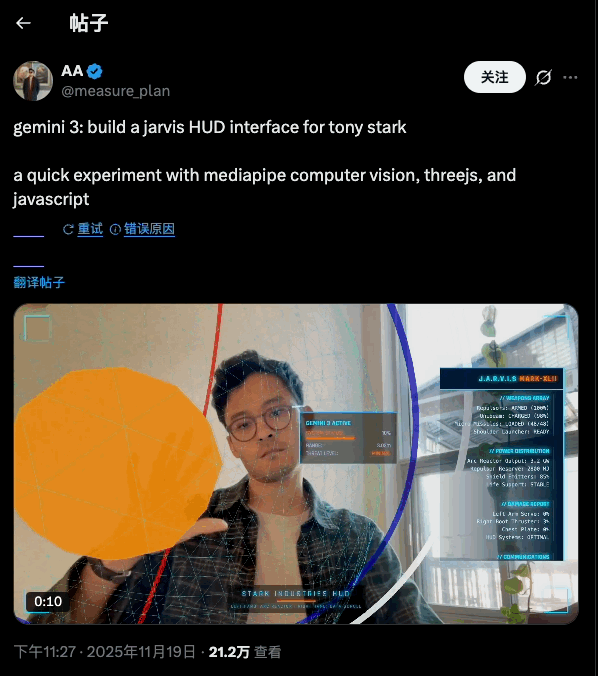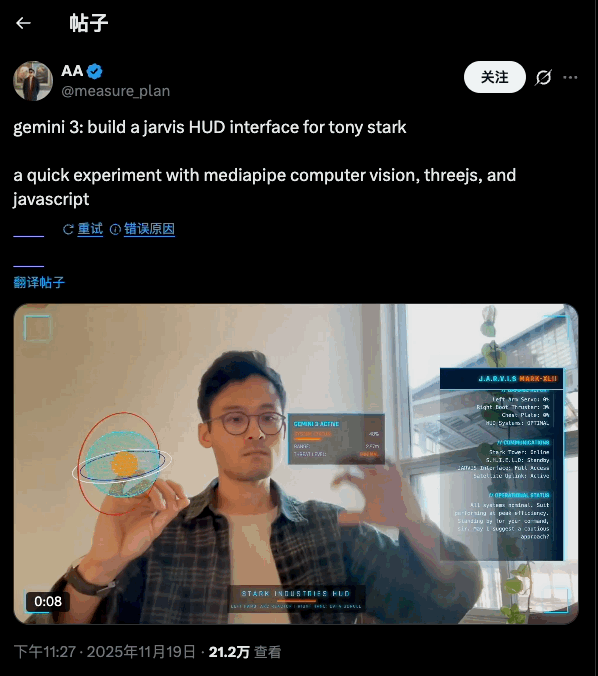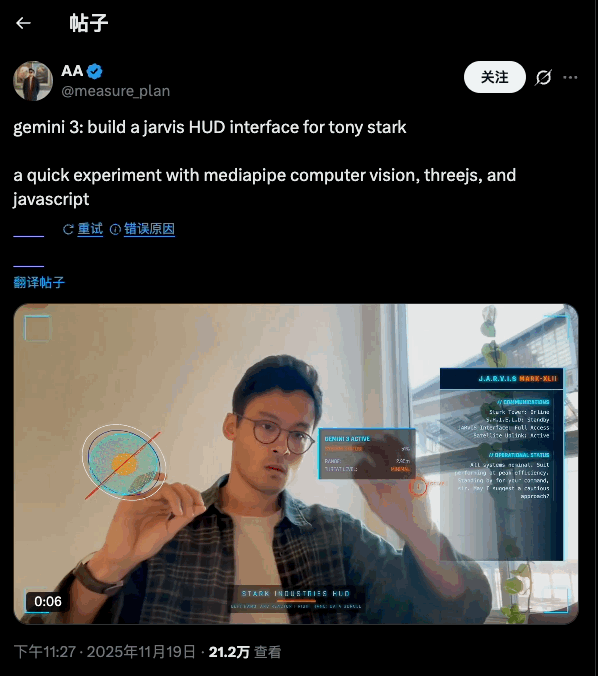
而在 API 侧,Gemini 3 Pro 被官方明确挂在「最适合 agentic coding 和 vibe coding」这一档上:也就是既能写前端、搭交互,又能在复杂任务里调工具、按步骤实现开发任务。
这一次最令人惊艳的也是 Gemini 在「整装式」生成应用工具的能力上。

这也就来到了这次发布的新 IDE 产品:Antigravity。在官方的设想中,这是一个「以 AI 为主角」的开发环境。具体实现起来的方式包括:
-多个 AI agent 可以直接访问编辑器、终端、浏览器;
-它们会分工:有人写代码,有人查文档,有人跑测试;
-所有操作会被记录成 Artifacts:任务列表、执行计划、网页截图、浏览器录屏……方便人类事后检查「你到底干了啥」。
在一个油管博主连线 Gemini 产品负责人的测试中,任务是设计一个招聘网站,而命令简单到只是复制、复制、全部复制,什么都不修改,直接粘贴。
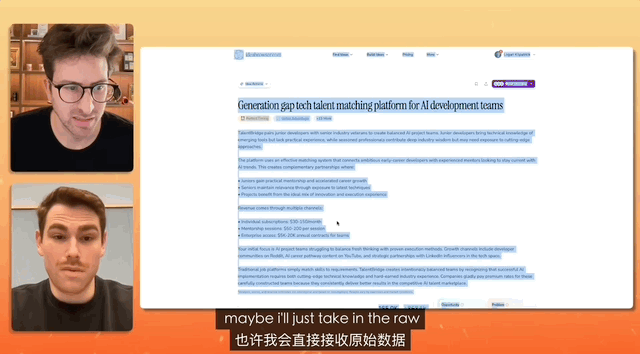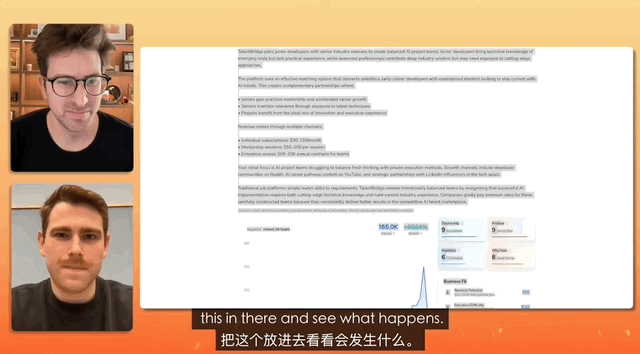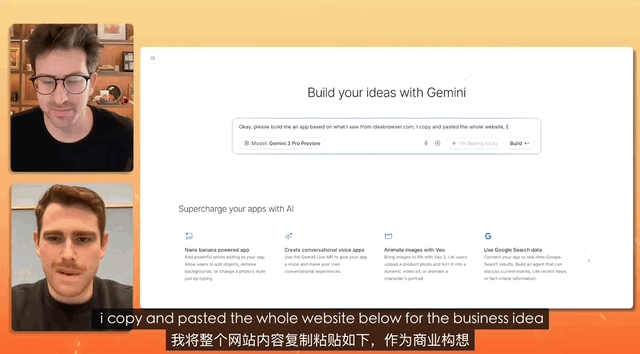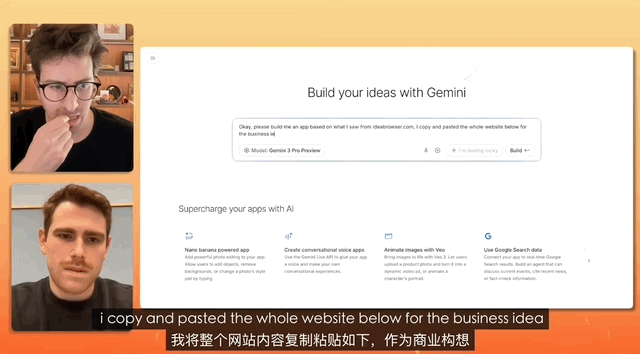
最终 Gemini 独立完成对混乱文本的分析,真的做了一个完整的网站出来,前前后后所有的素材配置、部署,都是它自己解决的。
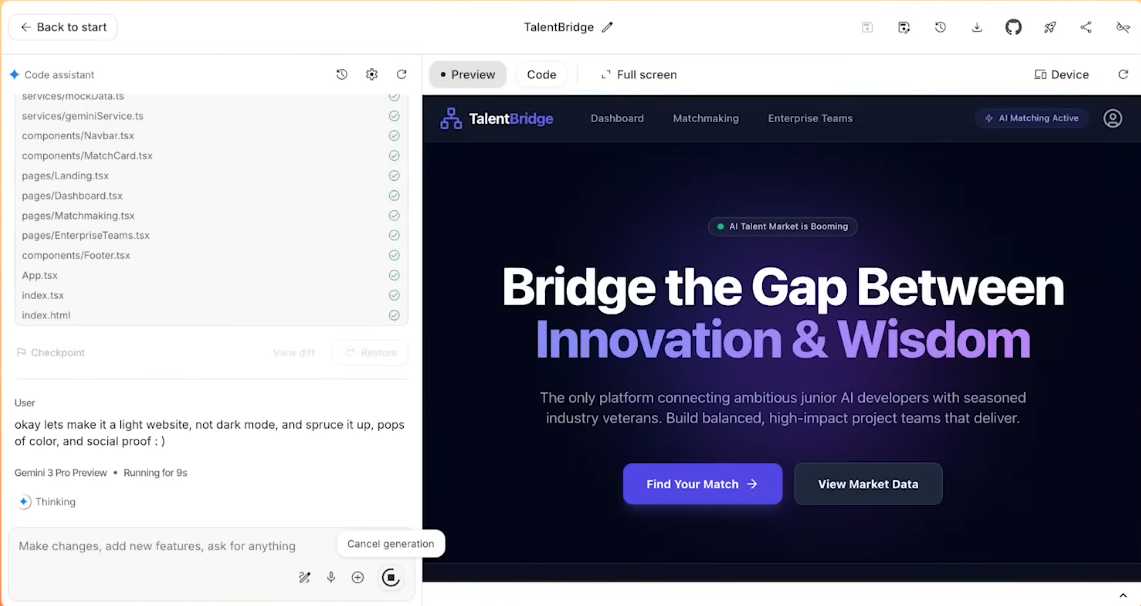
从这个角度看,Gemini 3 不只是一个「更聪明的模型」,而是 Google 想用来粘住 Search、App、Workspace、开发者工具的那条新总线。
回到最直觉的感受上:Gemini 3 和上一代相比,最明显的差别其实是——它更愿意、也更擅长「帮你一起协作」。这也是 Google 对它赋予的期待。
压力给到各方
跳出 Google 自身,Gemini 3 的 Preview 版本实际上给整个大模型行业,打开了一局新游戏:多模态能力应用的爆发势在必行。
在此之前,多模态(能看能听)是加分项;在此之后,“原生多模态”将基本配置——还不能是瞎糊弄的那种。Gemini 3 这种端到端的视听理解能力,将迫使 OpenAI、Anthropic(Claude)以及开源社区加速淘汰旧范式。对于那些还在依赖「截图+OCR」来理解画面的模型厂商来说,技术倒计时已经开始。
「套壳」与中间层也会感到压力山大,Gemini 3 展现出的强大 Agent 规划能力,是对当前市场上大量 Agentic Workflow(智能体工作流) 创业公司的直接挤压。当基础模型本身就能完美处理「意图拆解-工具调用-结果反馈」的闭环时,「模型即应用」的现实就又靠近了一点。
另外,手机厂商可能也能感到一丝风向的变化,Gemini 3 的轻量化和响应速度反映的是 Google 正在为端侧模型蓄力,结合之前苹果和几家不同的模型大厂建立合作,可以猜测行业竞争将从单纯比拼云端参数的「算力战」,转向比拼手机、眼镜、汽车等终端落地能力的“体验战”。
谁最强已经没那么重要了,谁「始终在手边」才重要
在大模型竞争的上半场,大家还在问:「谁的模型更强?」,参数、分数、排行榜,争的是「天赋」。到了 Gemini 3 这一代,问题慢慢变成:「谁的能力真正长在产品上、长在用户身上?」
Google 这次给出的答案,是一条相对清晰的路径:从底层的 Gemini 3 模型,往上接工具调用和 agentic 架构,再往上接 Search、Gemini App、Workspace 和 Antigravity 这些具体产品界面。
你可以把它理解成 Google 用 Gemini 3 将以原生多模态为全新的王牌,并且给自己旗下生态中的所有产品,焊上一条新的「智能总线」,让同一套能力,在各个层面都得以发挥。
至于它最终能不能改变你每天用搜索、写东西、写代码的方式,答案不会写在发布会里,而是写在接下来几个月——看有多少人,会在不经意间,把它留在自己的日常工作流中。
如果真到了那一步,排行榜上谁第一,可能就没那么重要了。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。