前端直连大模型:用原生 JavaScript 调用 DeepSeek API
在 AI 应用快速普及的今天,大语言模型(LLM)不再只是后端服务的专属能力。通过标准的 HTTP 接口,前端应用也能直接与模型对话——无需中间服务器,只需一个 API Key 和几行代码。本文将带你
无需后端支持,纯前端技术栈也能集成人工智能大模型
作为一名前端开发者,我最近探索了一个有趣的技术方案:如何在前端项目中直接调用大型语言模型。在这个过程中,我发现了不少值得分享的经验和技巧,今天就带大家一步步实现前端调用DeepSeek大模型的全过程。
传统上,调用AI大模型通常需要后端服务的支持,前端通过API与自己的服务器交互,再由服务器调用AI服务。这样做主要是出于安全考虑,特别是为了保护API密钥。但有时候,我们只是想快速原型验证,或者构建简单的个人项目,这时候如果能直接从前端调用大模型,会大大简化开发流程。
我决定尝试使用纯前端技术栈调用DeepSeek大模型,并记录下整个过程。
为了简化开发流程,我使用了 Trae(一种 AI 辅助开发工具)帮我快速初始化了一个基于 Vite 的前端项目。V
我选择了Vite作为项目构建工具,它不仅速度快,而且内置了丰富的功能,特别是对环境变量的支持,这对保护API密钥至关重要。
npm create vite@latest frontend-llm-demo
cd frontend-llm-demo
npm install
保持简洁的项目结构:
frontend-llm-demo/
├── index.html
├── styles/
│ └── style.css
├── scripts/
│ └── app.js
└── .env.local
其中,index.html 是主页面,app.js 负责发起 API 请求,而 .env.local 将用于存放敏感的 API Key。
在app.js中,我实现了完整的API调用逻辑:
// DeepSeek API端点
const endpoint = 'https://api.deepseek.com/chat/completions'
// 设置请求头
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${import.meta.env.VITE_DEEPSEEK_API_KEY}`
}
// 构建请求体
const payload = {
model: 'deepseek-chat',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.'
},
{
role: 'user',
content: '你好 DeepSeek'
}
]
}
// 发送请求并处理响应
const response = await fetch(endpoint, {
method: 'POST',
headers: headers,
body: JSON.stringify(payload)
})
const data = await response.json()
console.log(data)
// 将模型回复动态挂载到页面
document.getElementById('reply').textContent = data.choices[0].message.content
我使用了POST而非GET方法,原因有二:
messages 结构,必须使用 POST请求头包含了两个关键信息:
Content-Type: application/json - 告诉服务器我们发送的是JSON格式数据Authorization: Bearer ... - 用于身份验证的API密钥请求体是一个JSON对象,包含:
model - 指定要使用的模型版本messages - 对话消息数组,包含角色和内容使用JSON.stringify()将JavaScript对象转换为JSON字符串,因为HTTP协议只能传输文本或二进制数据,不能直接传输对象。
直接将API密钥硬编码在前端代码中是极其危险的,任何用户都可以查看源代码获取密钥。为了解决这个问题,我使用了环境变量。
Vite使用特殊的import.meta.env对象来访问环境变量。以VITE_开头的变量会被嵌入到客户端代码中。
.env文件:VITE_DEEPSEEK_API_KEY=your_api_key_here
const apiKey = import.meta.env.VITE_DEEPSEEK_API_KEY
注意:即使使用环境变量,前端代码中的API密钥仍然可能被有心人获取。对于生产环境,最佳实践仍然是使用后端服务作为代理。
fetch(endpoint, options)
.then(response => response.json())
.then(data => {
// 处理数据
})
.catch(error => {
// 错误处理
})
我选择了async/await语法,因为它更简洁、更易读:
try {
const response = await fetch(endpoint, options)
const data = await response.json()
// 处理数据
} catch (error) {
// 错误处理
}
获取到API响应后,需要将结果显示在页面上:
document.getElementById('reply').textContent = data.choices[0].message.content
这里使用了直接操作DOM的方式,在现代前端框架流行的今天,这种原生方法依然简单有效。
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="color-scheme" content="light dark">
<title>前端调用大模型示例</title>
<link rel="stylesheet" href="styles/style.css">
</head>
<body>
<h1>Hello DeepSeek</h1>
<div id="reply"></div>
<script type="module" src="./scripts/app.js"></script>
</body>
</html>
通过这个项目,我获得了以下几点经验:
事实证明,前端直接调用大模型API是完全可行的,这为快速原型开发和个人项目提供了便利。但需要注意安全性问题,不建议在生产环境中直接暴露API密钥。
调用外部API时,请求的每个部分都很重要:
ES6+的特性让代码更加简洁:
Vite等现代构建工具不仅提供开发服务器和打包功能,还解决了环境变量、模块化等工程化问题。
即使是在个人项目中,也应该养成良好的安全习惯,使用环境变量管理敏感信息。
前端技术日新月异,如今我们甚至可以直接在前端调用强大的人工智能模型。这个项目虽然简单,但展示了前端开发的强大能力和无限可能性。作为前端开发者,我们不应该将自己局限在传统的界面开发中,而应该积极探索前端技术的边界。
希望这篇文章能为想要在前端项目中集成AI能力的开发者提供一些参考和启发。前端的世界很精彩,让我们一起探索更多可能性!
注意:本文示例仅适用于开发和测试环境,生产环境中请务必通过后端服务调用第三方API,确保API密钥的安全性。
就在刚刚,DeepSeek 开源了一个 3B 模型 DeepSeek-OCR。虽然 3B 体量不大,但模型思路创新的力度着实不小。
众所周知,当前所有 LLM 处理长文本时都面临一个绕不开的困境:计算复杂度是平方级增长的。序列越长,算力烧得越狠。
于是,DeepSeek 团队想到了一个好办法。既然一张图能包含大量文字信息,而且用的 Token 还少,那不如直接把文本转成图像?这就是所谓的「光学压缩」——用视觉模态来给文本信息「瘦身」。
而 OCR 正好天然适合验证这个思路,因为它本身就是在做「视觉→文本」的转换,而且效果还能量化评估。
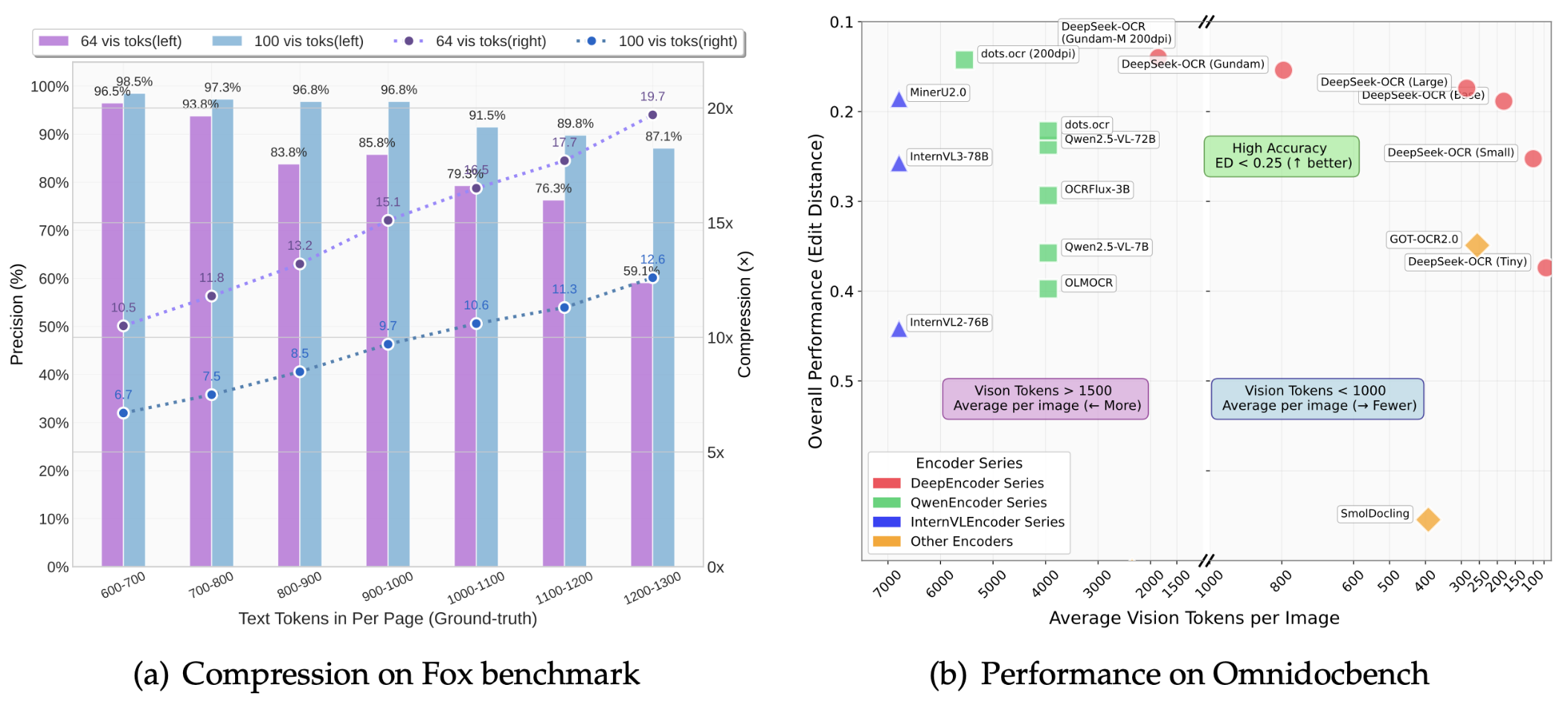
论文显示,DeepSeek-OCR 的压缩率能达到 10 倍,OCR 准确率还能保持在 97% 以上。
啥意思呢?就是说,原本需要 1000 个文本 Token 才能表达的内容,现在只用 100 个视觉 Token 就搞定了。即使压缩率拉到 20 倍,准确率也还有 60% 左右,整体效果相当能打。
OmniDocBench 基准测试结果显示:
在实际生产中,一块 A100-40G 显卡就能每天生成超过 20 万页的 LLM/VLM 训练数据。20 个节点(160 块 A100)直接飙到每天 3300 万页。
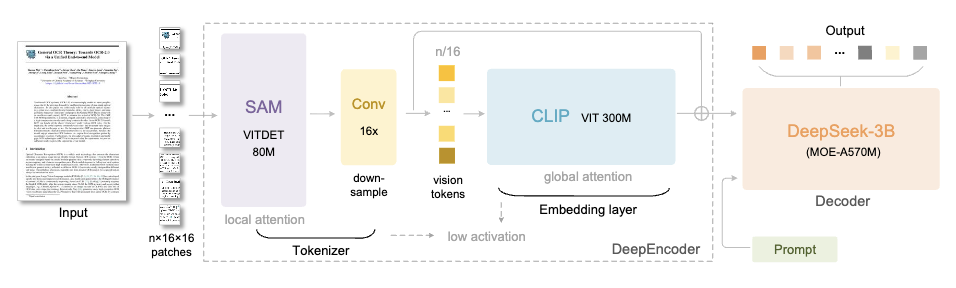
DeepSeek-OCR 由两个核心组件组成:
让我们来重点说说 DeepEncoder 这个引擎。
它的架构很巧妙,通过把 SAM-base(8000 万参数)和 CLIP-large(3 亿参数)串联起来,前者负责「窗口注意力」提取视觉特征,后者负责「全局注意力」理解整体信息。
中间还加了个 16×卷积压缩器,在进入全局注意力层之前把 Token 数量大幅砍掉。
举例而言,一张 1024×1024 的图像,会被切成 4096 个 patch token。但经过压缩器处理后,进入全局注意力层的 Token 数量会大幅减少。
这样的好处是,既保证了处理高分辨率输入的能力,又控制住了激活内存的开销。
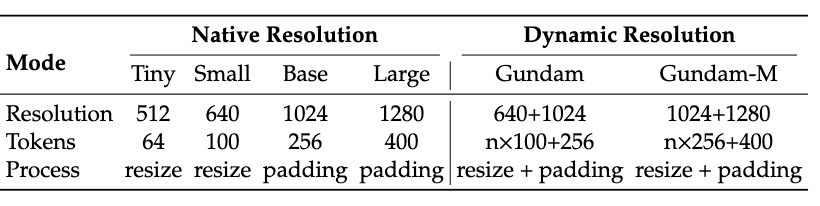
而且 DeepEncoder 还支持多分辨率输入,从 512×512 的 Tiny 模式(64 个 Token)到 1280×1280 的 Large 模式(400 个 Token),一个模型全搞定。
目前开源版本支持的模式包括原生分辨率的 Tiny、Small、Base、Large 四档,还有动态分辨率的 Gundam 模式,灵活性拉满。
解码器用的是 DeepSeek-3B-MoE 架构。
别看只有 3B 参数,但采用了 MoE(混合专家)设计——64 个专家中激活 6 个,再加 2 个共享专家,实际激活参数约 5.7 亿。这也让模型既有 30 亿参数模型的表达能力,又保持了 5 亿参数模型的推理效率。
解码器的任务就是从压缩后的视觉 Token 中重建出原始文本,这个过程可以通过 OCR 风格的训练被紧凑型语言模型有效学习。
数据方面,DeepSeek 团队也是下了血本。
从互联网收集了 3000 万页多语言 PDF 数据,涵盖约 100 种语言,其中中英文占 2500 万页。
数据分两类:粗标注直接用 fitz 从 PDF 提取,主要训练少数语言的识别能力;精标注用 PP-DocLayout、MinerU、GOT-OCR2.0 等模型生成,包含检测与识别交织的高质量数据。
对于少数语言,团队还搞了个「模型飞轮」机制——先用有跨语言泛化能力的版面分析模型做检测,再用 fitz 生成的数据训练 GOT-OCR2.0,然后用训练好的模型反过来标注更多数据,循环往复最终生成了 60 万条样本。
此外还有 300 万条 Word 文档数据,主要提升公式识别和 HTML 表格解析能力。
场景 OCR 方面,从 LAION 和 Wukong 数据集收集图像,用 PaddleOCR 标注,中英文各 1000 万条样本。

DeepSeek-OCR 不仅能识别文字,还具备「深度解析」能力,只需一个统一的提示词,就能对各种复杂图像进行结构化提取:
这在 STEM 领域的应用潜力巨大,尤其是化学、物理、数学等需要处理大量符号和图形的场景。
这里就不得不提 DeepSeek 团队提出的一个脑洞大开的想法——用光学压缩模拟人类的遗忘机制。
人类的记忆会随时间衰退,越久远的事情记得越模糊。DeepSeek 团队想,那能不能让 AI 也这样?于是,他们的方案是:
这就很像人类记忆的衰退曲线,近期信息保持高保真度,久远记忆自然淡化。
虽然这还是个早期研究方向,但如果真能实现,对于处理超长上下文将是个巨大突破——近期上下文保持高分辨率,历史上下文占用更少计算资源,理论上可以支撑「无限上下文」。
简言之,DeepSeek-OCR 表面上是个 OCR 模型,但实际上是在探索一个更宏大的命题:能否用视觉模态作为 LLM 文本信息处理的高效压缩媒介?
初步答案是肯定的,7-20 倍的 Token 压缩能力已经展现出来了。
当然,团队也承认这只是个开始。单纯的 OCR 还不足以完全验证「上下文光学压缩」,后续还计划开展数字–光学文本交替预训练、「大海捞针」式测试,以及其他系统性评估。
不过不管怎么说,这在 VLM 和 LLM 的进化路上,又多了一条新赛道。
去年这个时候,大家还在卷想着怎么让模型「记得更多」。
今年 DeepSeek 直接反其道行之:不如让模型学会「忘掉一些」?确然,AI 的进化,有时候不是做加法,而是做减法。小而美,也能玩出大花样,DeepSeek-OCR 这个 3B 小模型就是最好的证明。
GitHub 主页:
http://github.com/deepseek-ai/DeepSeek-OCR
论文:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
模型下载:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。