一、概述
Fastjson 是阿里巴巴开源的高性能 JSON 序列化处理库,其主要以处理小数据时速度最快而著称,功能全面。Fastjson1.X版本目前已停止维护,被Fastjson2.X代替,但1.X版本国内被广泛使用,通过学习其技术架构,剖析架构上优缺点,对技术人员提升软件设计工程实践能力很有价值。
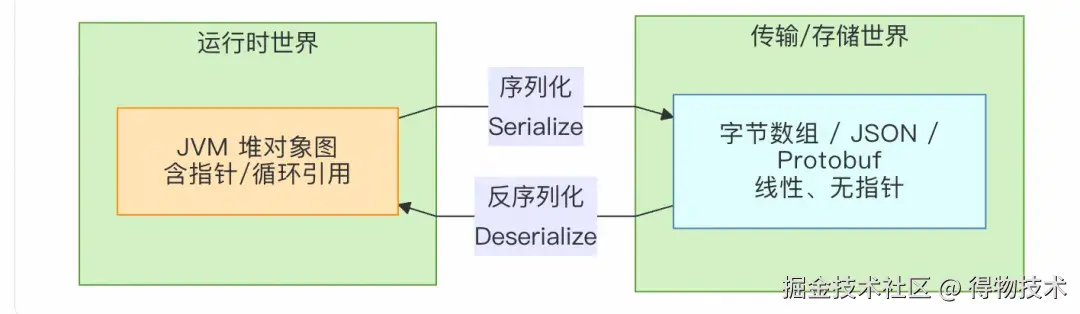
首先我们对“序列化 / 反序列化”概念上建立直观认识,把Java对象转化为JSON格式的字符串的过程叫做序列化操作,反之则叫反序列化。如果把“序列化 / 反序列化”放到整个计算机系统的坐标系里,可以把它看成一次数据的“跨边界搬家”。
对象在“内存世界”里活得很好,但只要一离开进程地址空间(网络、磁盘、数据库、浏览器、异构语言),就必须先打成包裹(序列化),到对岸再拆包裹(反序列化)。
二、核心模块架构
从高层次视图看Fastjson框架的结构,主要可以分为用户接口层、配置管理层、序列化引擎、反序列化引擎和安全防护层。其中用户接口提供了门面类用户编码直接与门面类交互,降低使用复杂度;配置管理层允许用户对框架行为进行配置;序列化引擎是序列化操作的核心实现;反序列引擎是反序列化操作的核心实现;安全模块解决框架安全问题,允许用户针对安全问题设置黑白名单等安全检查功能。下图为Fastjson模块关系图:
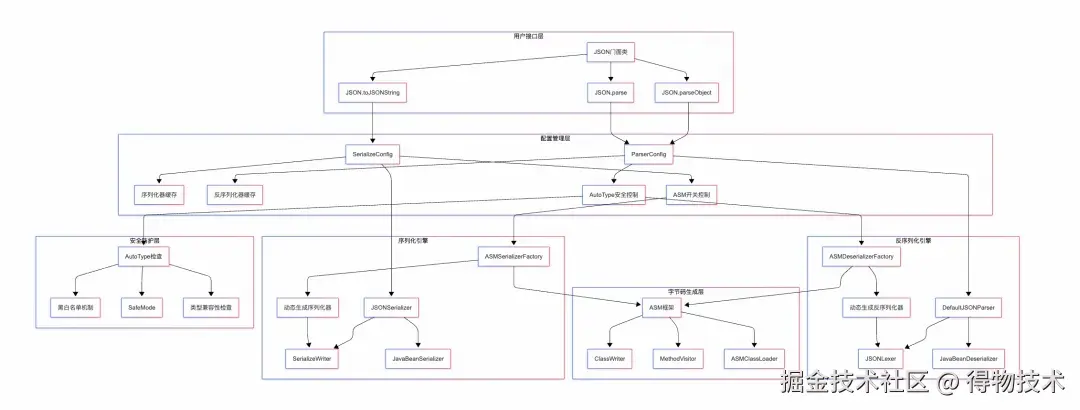
模块关系图
三、项目结构
com.alibaba.fastjson/
├── JSON.java # 核心入口类
├── annotation/ # 注解定义
├── asm/ # ASM字节码精简库
├── parser/ # 解析器模块
│ ├── DefaultJSONParser.java # 默认JSON解析器
│ ├── JSONLexer.java # 词法分析器接口
│ ├── JSONScanner.java # 词法分析器实现
│ └── deserializer/ # 反序列化器
├── serializer/ # 序列化器模块
│ ├── JSONSerializer.java # JSON序列化器
│ ├── SerializeConfig.java # 序列化配置
│ └── ObjectSerializer.java # 对象序列化器接口
├── spi/ # SPI扩展机制
├── support/ # 框架支持
└── util/ # 工具类
3.1 项目结构说明
主要可以划分为以下几个核心模块(包):
com.alibaba.fastjson (核心 API 与数据结构)
- 关键类 :
-
- JSON.java: 整个库的门面(Facade),提供了最常用、最便捷的静态方法,如 toJSONString() (序列化), parseObject() (反序列化为对象), parseArray() (反序列化为数组)。通常它是用户最先接触到的类。
- JSONObject.java: 继承自java.util.HashMap,用于表示 JSON 对象结构( {key: value} )。
- JSONArray.java: 继承自java.util.ArrayList,用于表示 JSON 数组结构 ( [value1, value2] )。
com.alibaba.fastjson.serializer (序列化模块)
此模块负责将 Java 对象转换为 JSON 格式的字符串
- 关键类 :
-
- JSONSerializer.java: 序列化的核心调度器。它维护了序列化的上下文信息,如对象引用、循环依赖检测、特性( SerializerFeature )开关等,并驱动整个序列化过程。
- SerializeWriter.java: 一个高度优化的 Writer 实现,专门用于生成 JSON 字符串。它内部使用 char[] 数组来拼接字符串,避免了 String 的不可变性带来的性能损耗,是 Fastjson 高性能写入的关键。
- JavaBeanSerializer.java: 默认的 JavaBean 序列化器。在未启用 ASM 优化时,它通过反射获取对象的属性( getter 方法)并将其序列化。
- ASMSerializerFactory.java: 性能优化的核心 。它使用 ASM 字节码技术在运行时动态生成序列化器类,这些类直接调用 getter 方法并操作SerializeWriter,避免了反射的性能开销。
- ObjectSerializer.java: 序列化器接口。用户可以通过实现此接口来为特定类型提供自定义的序列化逻辑。
- SerializeConfig.java: 序列化配置类。它维护了 Java 类型到 ObjectSerializer 的缓存。 SerializeConfig.getGlobalInstance() 提供了全局唯一的配置实例。
- SerializerFeature.java: 序列化特性枚举。定义了各种序列化行为的开关,例如 WriteMapNullValue (输出 null 值的字段)、 DisableCircularReferenceDetect (禁用循环引用检测) 等。
com.alibaba.fastjson.parser (反序列化模块)
此模块负责将 JSON 格式的字符串解析为 Java 对象。
- 关键类 :
-
- DefaultJSONParser.java: 反序列化的核心调度器。它负责解析 JSON 字符串的整个过程,管理 JSONLexer进行词法分析,并根据 Token (如 { , } , [ , ] , string , number 等)构建 Java 对象。
- JSONLexer.java / JSONLexerBase.java: JSON 词法分析器。它负责扫描输入的 JSON 字符串,将其切割成一个个有意义的 Token ,供 DefaultJSONParser 使用。
- JavaBeanDeserializer.java: 默认的 JavaBean 反序列化器。在未启用 ASM 优化时,它通过反射创建对象实例并设置其属性值。
- ASMDeserializerFactory.java: 与序列化类似,它动态生成反序列化器字节码,直接调用 setter 方法或直接对字段赋值,避免了反射。
- ObjectDeserializer.java: 反序列化器接口。用户可以实现此接口来自定义特定类型的反序列化逻辑。
- ParserConfig.java: 反序列化配置类。维护了 Java 类型到 ObjectDeserializer 缓存,并负责管理 ASM 生成的类的加载。
- Feature.java: 反序列化特性枚举,用于控制解析行为。
com.alibaba.fastjson.annotation (注解模块)
提供了一系列注解,允许用户通过声明式的方式精细地控制序列化和反序列化的行为。
- 关键注解 :
-
- @JSONField: 最核心的注解,可用于字段或方法上,用于自定义字段名、格式化、序列化/反序列化顺序、是否包含等。
- @JSONType: 可用于类上,用于配置该类的序列化器、反序列化器、特性开关等。
3.2 项目结构小结
Fastjson 框架在架构设计体现了“关注点分离”的原则,将序列化、反序列化、API、工具类等清晰地划分到不同的模块中。整个框架具有高度的可扩展性,用户可以通过 ObjectSerializer / ObjectDeserializer接口和丰富的注解来满足各种复杂的定制化需求。
四、核心源码分析
为了更直观说明框架实现原理,本文对部分展示的源代码进行了删减,有些使用了伪代码,如需了解更多实现细节请读者阅读项目源码(github.com/alibaba/fas…)
整体上Fastjson通过统一的门面API(JSON.toJSONString/parseObject)调用核心控制器(JSONSerializer/DefaultJSONParser),利用ASM字节码生成或反射机制,配合SerializeWriter/JSONLexer进行高效的Java对象与JSON字符串间双向转换,同时提供配置缓存、循环引用检测和AutoType安全防护等优化机制。下图为框架处理数据流:
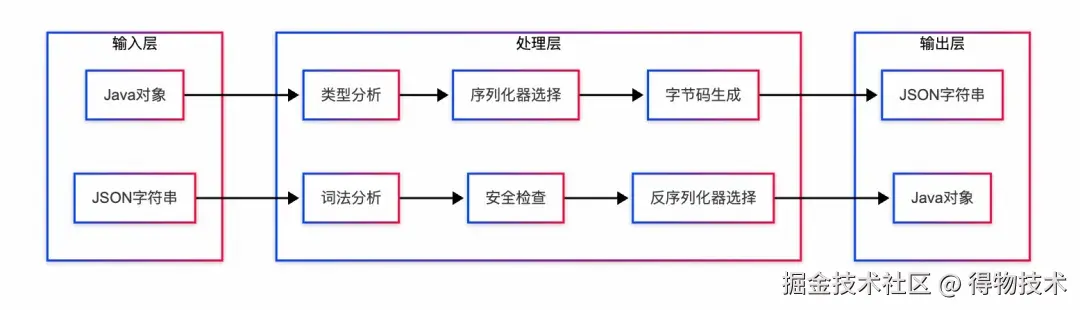
数据流
4.1 序列化原理介绍
序列化步骤主要包括:序列化器查找→JavaBean字段解析→字段值转换和JSON字符串构建等过程。下图为序列化处理时序图:
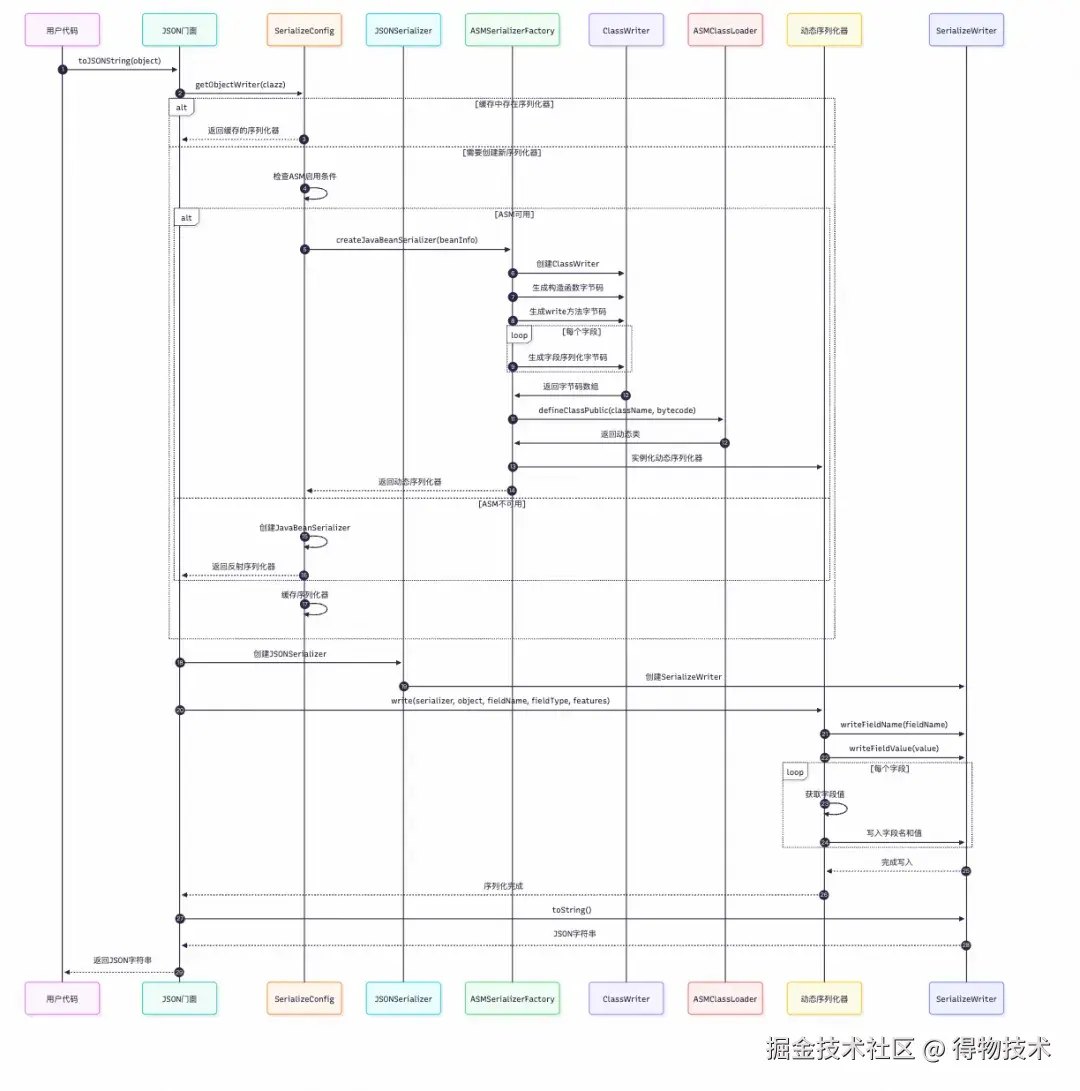
序列化时序图
序列化入口与初始化
使用JSON.toJSONString()入口,将person对象转换为JSON字符串。
Person person = new Person();
String json = JSON.toJSONString(person);
用户调用toJSONString方法进行对象序列化操作,JSON.java包含了多个toJSONString重载方法,共同完成核心类初始化:SerializeConfig,SerializeWriter,JSONSerializer。
//用户不指定SerializeConfig,默认私有全局配置
public static String toJSONString(Object object, SerializeFilter[] filters,
SerializerFeature... features) {
return toJSONString(object, SerializeConfig.globalInstance, filters, null, DEFAULT_GENERATE_FEATURE, features);
}
public static String toJSONString(Object object,
SerializeConfig config,
SerializeFilter[] filters,
String dateFormat,
int defaultFeatures,
SerializerFeature... features) {
SerializeWriter out = new SerializeWriter((Writer) null, defaultFeatures, features);
try {
JSONSerializer serializer = new JSONSerializer(out);
//省略其他代码...
serializer.write(object); // 核心序列化调用
return out.toString();
} finally {
out.close();
}
}
序列化控制流程
JSONSerializer.write()核心逻辑
write方法的逻辑比较简单,首先处理null值,然后根据类型查找序列器(ObjectSerializer),最后将序列化逻辑委派给序列化器处理。
public final void write(Object object) {
//如何序列化对象为null,直接写入"null"字符串
if (object == null) {
out.writeNull();
return;
}
Class<?> clazz = object.getClass();
ObjectSerializer writer = getObjectWriter(clazz); // 类型识别与序列化器选择
try {
writer.write(this, object, null, null, 0); // 委托给具体序列化器
} catch (IOException e) {
throw new JSONException(e.getMessage(), e);
}
}
类型识别与序列化器策略
框架采用策略化模式将不同类型序列化逻辑封装成不同的序列化器:
- 基础类型 : 使用专门的Codec(如StringCodec、IntegerCodec)
- 集合类型 : 使用ListSerializer、MapSerializer等
- JavaBean : 使用JavaBeanSerializer或ASM动态生成的序列化器
- 枚举类型 : 使用EnumSerializer
SerializeConfig.getObjectWriter方法负责序列化器查找工作:
public ObjectSerializer getObjectWriter(Class<?> clazz, boolean create) {
// 第一步:缓存查找
ObjectSerializer writer = get(clazz);
if (writer != null) {
return writer;
}
// 第二步:SPI扩展加载(当前线程类加载器)
try {
final ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
for (Object o : ServiceLoader.load(AutowiredObjectSerializer.class, classLoader)) {
if (!(o instanceof AutowiredObjectSerializer)) {
continue;
}
AutowiredObjectSerializer autowired = (AutowiredObjectSerializer) o;
for (Type forType : autowired.getAutowiredFor()) {
put(forType, autowired);
}
}
} catch (ClassCastException ex) {
// skip
}
writer = get(clazz);
if (writer == null) {
// 第三步:SPI扩展加载(JSON类加载器)
final ClassLoader classLoader = JSON.class.getClassLoader();
if (classLoader != Thread.currentThread().getContextClassLoader()) {
// 重复SPI加载逻辑...
}
}
// 第四步:模块扩展
for (Module module : modules) {
writer = module.createSerializer(this, clazz);
if (writer != null) {
put(clazz, writer);
return writer;
}
}
// 第五步:内置类型匹配
if (writer == null) {
String className = clazz.getName();
Class<?> superClass;
if (Map.class.isAssignableFrom(clazz)) {
put(clazz, writer = MapSerializer.instance);
} else if (List.class.isAssignableFrom(clazz)) {
put(clazz, writer = ListSerializer.instance);
} else if (Collection.class.isAssignableFrom(clazz)) {
put(clazz, writer = CollectionCodec.instance);
} else if (Date.class.isAssignableFrom(clazz)) {
put(clazz, writer = DateCodec.instance);
} else if (clazz.isEnum()) {
// 枚举处理逻辑
} else if (clazz.isArray()) {
// 数组处理逻辑
} else {
// 第六步:JavaBean序列化器创建
if (create) {
writer = createJavaBeanSerializer(clazz);
put(clazz, writer);
}
}
}
return writer;
}
JavaBean序列化处理
JavaBeanSerializer的write方法实现了Java对象序列化处理核心逻辑:
方法签名分析:
protected void write(JSONSerializer serializer, //JSON序列化器,提供序列化上下文和输出流
Object object, //待序列化的Java对象
Object fieldName, //字段名称,用于上下文追踪
Type fieldType, //字段类型信息
int features, //序列化特性标志位
boolean unwrapped //是否展开包装,用于嵌套对象处理
) throws IOException
序列化流程概览:
// 1. 空值检查和循环引用处理
if (object == null) {
out.writeNull();
return;
}
if (writeReference(serializer, object, features)) {
return;
}
// 2. 字段序列化器选择
final FieldSerializer[] getters;
if (out.sortField) {
getters = this.sortedGetters;
} else {
getters = this.getters;
}
// 3. 上下文设置和格式判断
SerialContext parent = serializer.context;
if (!this.beanInfo.beanType.isEnum()) {
serializer.setContext(parent, object, fieldName, this.beanInfo.features, features);
}
// 4.遍历属性序列化器,完成属性序列化
for (int i = 0; i < getters.length; ++i) {
FieldSerializer fieldSerializer = getters[i];
// 获取属性值
Object propertyValue = this.processValue(serializer, fieldSerializer.fieldContext, object, fieldInfoName,
propertyValue, features);
// 写入属性值
fieldSerializer.writeValue(serializer, propertyValue);
}
循环引用检测:
JavaBeanSerializerwriteReference 方法执行循环引用检测,Fastjson使用$ref占位符处理循环引用问题,防止对象循环引用造成解析查询栈溢出。
public boolean writeReference(JSONSerializer serializer, Object object, int fieldFeatures) {
SerialContext context = serializer.context;
int mask = SerializerFeature.DisableCircularReferenceDetect.mask;
// 检查是否禁用循环引用检测
if (context == null || (context.features & mask) != 0 || (fieldFeatures & mask) != 0) {
return false;
}
// 检查对象是否已存在于引用表中
if (serializer.references != null && serializer.references.containsKey(object)) {
serializer.writeReference(object); // 写入引用标记
return true;
}
return false;
}
上下文管理与引用追踪:
序列化采用DFS(深度优先)算法遍历对象树,使用 IdentityHashMap<Object, SerialContext> references 来追踪对象引用:
- setContext: 建立序列化上下文,记录对象层次关系
- containsReference: 检查对象是否已被序列化
- popContext: 序列化完成后清理上下文
protected IdentityHashMap<Object, SerialContext> references = null;
protected SerialContext context;
//使用链表建立序列化上下文引用链,记录对象层次关系
public void setContext(SerialContext parent, Object object, Object fieldName, int features, int fieldFeatures) {
if (out.disableCircularReferenceDetect) {
return;
}
//构建当前上下文到parent上下文引用链
this.context = new SerialContext(parent, object, fieldName, features, fieldFeatures);
if (references == null) {
references = new IdentityHashMap<Object, SerialContext>();
}
this.references.put(object, context);
}
//检查对象是否已被序列化,防止重复序列化
public boolean containsReference(Object value) {
if (references == null) {
return false;
}
SerialContext refContext = references.get(value);
if (refContext == null) {
return false;
}
if (value == Collections.emptyMap()) {
return false;
}
Object fieldName = refContext.fieldName;
return fieldName == null || fieldName instanceof Integer || fieldName instanceof String;
}
//清理上下文,将当前序列化上下文指向父亲节点
public void popContext() {
if (context != null) {
this.context = this.context.parent;
}
}
字段值转换与序列化
FieldSerializer.writeValue()核心逻辑
FieldSerializer 的writeValue方法实现了字段值的序列化操作:
public void writeValue(JSONSerializer serializer, Object propertyValue) throws Exception {
// 运行时类型识别
Class<?> runtimeFieldClass = propertyValue != null ?
propertyValue.getClass() : this.fieldInfo.fieldClass;
// 查找属性类型对应的序列化器
ObjectSerializer fieldSerializer = serializer.getObjectWriter(runtimeFieldClass);
// 处理特殊格式和注解
if (format != null && !(fieldSerializer instanceof DoubleSerializer)) {
serializer.writeWithFormat(propertyValue, format);
return;
}
// 委托给具体序列化器处理
fieldSerializer.write(serializer, propertyValue, fieldInfo.name,
fieldInfo.fieldType, fieldFeatures);
}
不同类型的序列化策略
基础类型序列化 :
- 直接调用SerializeWriter的对应方法(writeInt、writeString等)
复杂对象序列化 :
- 递归调用JSONSerializer.write()方法
- 维护序列化上下文和引用关系
- 应用过滤器和特性配置
ASM定制化序列化器加速,下文会进行详细讲解。
- 为序列化的类动态生成定制化的序列化器,避免反射调用开销
JSON字符串构建
SerializeWriter.java采用线程本地缓冲机制,提供高效的字符串构建:
//用于存储存JSON字符串
private final static ThreadLocal<char[]> bufLocal = new ThreadLocal<char[]>();
//将字符串转换为UTF-8字节数组
private final static ThreadLocal<byte[]> bytesBufLocal = new ThreadLocal<byte[]>();
- 字符缓冲区 : 线程本地char[]数组减少内存分配,避免频繁创建临时数组对象。
- 动态扩容 : 根据内容长度自动调整缓冲区大小。
bufLocal初始化创建2048字符的缓冲区,回收阶段当缓冲区大小不超过 BUFFER_THRESHOLD (128KB)时,将其放回ThreadLocal缓存,超过阈值的大缓冲区不缓存,避免内存占用过大。
bytesBufLocal专门用于UTF-8编码转换过程,初始缓冲区大小:8KB(1024 * 8),根据字符数量估算所需字节数(字符数 × 3),只有不超过 BUFFER_THRESHOLD 的缓冲区才会被缓存。
4.2 序列化小结
Fastjson通过JSON.toJSONString()门面API调用JSONSerializer控制器,利用ASM字节码生成的高性能序列化器或反射机制遍历Java对象字段,配合SerializeWriter将字段名和值逐步写入缓冲区构建JSON字符串。
4.3 反序列化流程
虽然“序列化”与“反序列化”在概念上是对偶的(Serialize ↔ Deserialize),但在实现层面并不严格对偶,反序列化实现明显比序列化复杂。核心步骤包括:反序列化器查找→ 反序列流程控制→词法分析器(Tokenizer) → 安全检查→反射/ASM 字段填充等,下图为处理时序图:
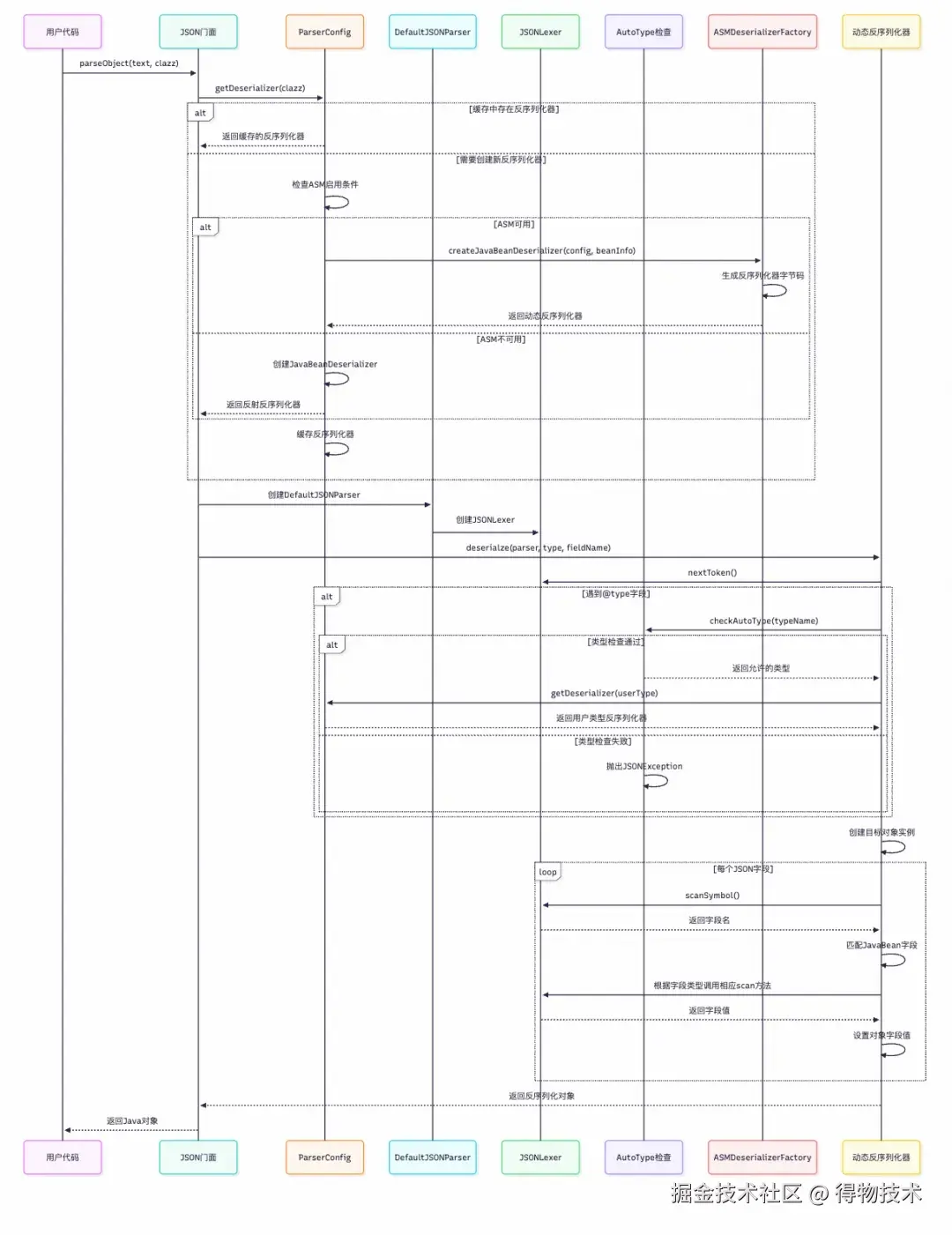
反序列化入口与反序列化器选择
反序列化从 JSON.java的parseObject方法开始:
// JSON.java - 反序列化入口
public static <T> T parseObject(String text, Class<T> clazz, int features) {
if (text == null) {
return null;
}
DefaultJSONParser parser = new DefaultJSONParser(text, ParserConfig.getGlobalInstance(), features);
T value = (T) parser.parseObject(clazz);
parser.handleResovleTask(value);
parser.close();
return value;
}
查找反序列化器
在 DefaultJSONParser.java 中选择合适的反序列化器:
// DefaultJSONParser.java - 反序列化器选择
public <T> T parseObject(Type type, Object fieldName) {
int token = lexer.token();
if (token == JSONToken.NULL) {
lexer.nextToken();
return (T) TypeUtils.optionalEmpty(type);
}
//从缓存中查找反序列化器
ObjectDeserializer deserializer = config.getDeserializer(type);
try {
if (deserializer.getClass() == JavaBeanDeserializer.class) {
return (T) ((JavaBeanDeserializer) deserializer).deserialze(this, type, fieldName, 0);
} else {
return (T) deserializer.deserialze(this, type, fieldName);
}
} catch (JSONException e) {
throw e;
} catch (Throwable e) {
throw new JSONException(e.getMessage(), e);
}
}
ParserConfig.java 负责获取对应类型的反序列化器:
// ParserConfig.java - 反序列化器获取
public ObjectDeserializer getDeserializer(Type type) {
ObjectDeserializer deserializer = this.deserializers.get(type);
if (deserializer != null) {
return deserializer;
}
//通过Class查找
if (type instanceof Class<?>) {
return getDeserializer((Class<?>) type, type);
}
//通过泛型参数查找
if (type instanceof ParameterizedType) {
Type rawType = ((ParameterizedType) type).getRawType();
if (rawType instanceof Class<?>) {
return getDeserializer((Class<?>) rawType, type);
} else {
return getDeserializer(rawType);
}
}
return JavaObjectDeserializer.instance;
}
反序列化控制流程
JavaBeanDeserializer.java 的deserialze实现了反序列化主要处理流程。
// JavaBeanDeserializer.java - 类型识别与字段匹配
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName, int features, int[] setFlags) {
// 1.特殊类型快速处理
if (type == JSON.class || type == JSONObject.class) {
return (T) parser.parse();
}
//2.初始化核心组件
final JSONLexer lexer = parser.lexer;
//3.反序列化上下文管理
ParseContext context = parser.getContext();
if (object != null && context != null) {
context = context.parent;
}
ParseContext childContext = null;
//保存解析后字段值
Map<String, Object> fieldValues = null;
// JSON关键字分支预处理
if (token == JSONToken.RBRACE) {
lexer.nextToken(JSONToken.COMMA);
if (object == null) {
object = createInstance(parser, type);
}
return (T) object;
}
//处理其他JSON关键字
...
//4.字段解析主循环
for (int fieldIndex = 0, notMatchCount = 0;; fieldIndex++) {
boolean customDeserializer = false;
//这是一个性能优化的设计,通过预排序和索引访问来提高字段匹配的效率,
//通常情况下JSON串按字段定义顺序排列,因此能快速命中
if (fieldIndex < sortedFieldDeserializers.length && notMatchCount < 16) {
fieldDeserializer = sortedFieldDeserializers[fieldIndex];
fieldInfo = fieldDeserializer.fieldInfo;
fieldClass = fieldInfo.fieldClass;
fieldAnnotation = fieldInfo.getAnnotation();
if (fieldAnnotation != null && fieldDeserializer instanceof DefaultFieldDeserializer) {
customDeserializer = ((DefaultFieldDeserializer) fieldDeserializer).customDeserilizer;
}
}
Object fieldValue = null;
if (fieldDeserializer != null) {
char[] name_chars = fieldInfo.name_chars;
//指定了自定义发序列化器,后续使用自定义序列化器处理
if (customDeserializer && lexer.matchField(name_chars)) {
matchField = true;
// 基本类型快速路径匹配
} else if (fieldClass == int.class || fieldClass == Integer.class) {
//词法分析,解析int值
int intVal = lexer.scanFieldInt(name_chars);
if (intVal == 0 && lexer.matchStat == JSONLexer.VALUE_NULL) {
fieldValue = null;
} else {
fieldValue = intVal;
}
if (lexer.matchStat > 0) {
matchField = true;
valueParsed = true;
} else if (lexer.matchStat == JSONLexer.NOT_MATCH_NAME) {
//增加计算,记录未命中次数以调整匹配策略
notMatchCount++;
continue;
}
} else if(...){
//省略其他基础类型处理
}
}
// 快速匹配失败,动态扫描字段名,通过符号表优化:返回的字符串可能是符号表中的缓存实例
if (!matchField) {
key = lexer.scanSymbol(parser.symbolTable);
// $ref 引用处理
if ("$ref" == key && context != null) {
handleReferenceResolution(lexer, parser, context)
}
// @type 类型处理
if ((typeKey != null && typeKey.equals(key))
|| JSON.DEFAULT_TYPE_KEY == key) {
//AutoType安全检查
config.checkAutoType(typeName, expectClass, lexer.getFeatures());
handleTypeNameResolution(lexer, parser, config, beanInfo, type, fieldName);
}
}
}
// 5.如果对象为空,则创建对象实例
if (object == null && fieldInfo == null) {
object = createInstance(parser, type);
if (object == null) {
return null;
}
}
//6. 字段值设置
for (Map.Entry<String, Object> entry : fieldValues.entrySet()) {
FieldDeserializer fieldDeserializer = getFieldDeserializer(entry.getKey());
if (fieldDeserializer != null) {
fieldDeserializer.setValue(object, entry.getValue());
}
}
return (T) object;
}
字符串解析阶段(词法分析)
JSONLexerBase内部维护词法解析状态机,实现词法分析核心逻辑,下面展示了Integer值类型处理源码:
public int scanFieldInt(char[] fieldName) {
matchStat = UNKNOWN;
// 1. 字段名匹配阶段
if (!charArrayCompare(fieldName)) {
matchStat = NOT_MATCH_NAME;
return 0;
}
int offset = fieldName.length;
char chLocal = charAt(bp + (offset++));
// 2. 负号处理
final boolean negative = chLocal == '-';
if (negative) {
chLocal = charAt(bp + (offset++));
}
// 3. 数字解析核心算法
int value;
if (chLocal >= '0' && chLocal <= '9') {
value = chLocal - '0';
for (;;) {
chLocal = charAt(bp + (offset++));
if (chLocal >= '0' && chLocal <= '9') {
value = value * 10 + (chLocal - '0');// 十进制累加
} else if (chLocal == '.') {
matchStat = NOT_MATCH; // 拒绝浮点数
return 0;
} else {
break;
}
}
// 4. 溢出检测
if (value < 0 //
|| offset > 11 + 3 + fieldName.length) {
if (value != Integer.MIN_VALUE //
|| offset != 17 //
|| !negative) {
matchStat = NOT_MATCH;
return 0;
}
}
} else {
matchStat = NOT_MATCH;
return 0;
}
// 5. JSON 结束符处理
if (chLocal == ',') {
bp += offset;
this.ch = this.charAt(bp);
matchStat = VALUE;
token = JSONToken.COMMA;
return negative ? -value : value;
}
if (chLocal == '}') {
// ... 处理对象结束和嵌套结构
chLocal = charAt(bp + (offset++));
if (chLocal == ',') {
token = JSONToken.COMMA;
bp += offset;
this.ch = this.charAt(bp);
} else if (chLocal == ']') {
token = JSONToken.RBRACKET;
bp += offset;
this.ch = this.charAt(bp);
} else if (chLocal == '}') {
token = JSONToken.RBRACE;
bp += offset;
this.ch = this.charAt(bp);
} else if (chLocal == EOI) {
token = JSONToken.EOF;
bp += (offset - 1);
ch = EOI;
} else {
matchStat = NOT_MATCH;
return 0;
}
matchStat = END;
} else {
matchStat = NOT_MATCH;
return 0;
}
return negative ? -value : value;
}
类型安全检查(AutoType检查)
ParserConfig.java 中的checkAutoType方法对反序列化类型做黑白名单检查。
// ParserConfig.java - AutoType安全检查
public Class<?> checkAutoType(String typeName, Class<?> expectClass, int features) {
if (typeName == null) {
return null;
}
if (typeName.length() >= 192 || typeName.length() < 3) {
throw new JSONException("autoType is not support. " + typeName);
}
String className = typeName.replace('$', '.');
Class<?> clazz = null;
final long BASIC = 0xcbf29ce484222325L;
final long PRIME = 0x100000001b3L;
final long h1 = (BASIC ^ className.charAt(0)) * PRIME;
// hash code编码匹配性能优化
if (h1 == 0xaf64164c86024f1aL) {
throw new JSONException("autoType is not support. " + typeName);
}
if ((h1 ^ className.charAt(className.length() - 1)) * PRIME == 0x9198507b5af98f0L) {
throw new JSONException("autoType is not support. " + typeName);
}
final long h3 = (((((BASIC ^ className.charAt(0))
* PRIME)
^ className.charAt(1))
* PRIME)
^ className.charAt(2))
* PRIME;
if (autoTypeSupport || expectClass != null) {
long hash = h3;
for (int i = 3; i < className.length(); ++i) {
hash ^= className.charAt(i);
hash *= PRIME;
if (Arrays.binarySearch(denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null) {
throw new JSONException("autoType is not support. " + typeName);
}
if (Arrays.binarySearch(acceptHashCodes, hash) >= 0) {
clazz = TypeUtils.loadClass(typeName, defaultClassLoader, false);
if (clazz != null) {
return clazz;
}
}
}
}
// ... 更多安全检查逻辑
return clazz;
}
对象实例化过程
JavaBeanDeserializer.java中的createInstance方法创建对象实例:
// JavaBeanDeserializer.java - 对象实例化
protected Object createInstance(DefaultJSONParser parser, Type type) {
if (type instanceof Class) {
if (clazz.isInterface()) {
// 接口类型使用Java反射创建实例
Class<?> clazz = (Class<?>) type;
ClassLoader loader = Thread.currentThread().getContextClassLoader();
final JSONObject obj = new JSONObject();
Object proxy = Proxy.newProxyInstance(loader, new Class<?>[] { clazz }, obj);
return proxy;
}
}
if (beanInfo.defaultConstructor == null && beanInfo.factoryMethod == null) {
return null;
}
Object object;
try {
//通过构造器创建实例
Constructor<?> constructor = beanInfo.defaultConstructor;
if (beanInfo.defaultConstructorParameterSize == 0) {
object = constructor.newInstance();
} else {
ParseContext context = parser.getContext();
if (context == null || context.object == null) {
throw new JSONException("can't create non-static inner class instance.");
}
final Class<?> enclosingClass = constructor.getDeclaringClass().getEnclosingClass();
object = constructor.newInstance(context.object);
}
} catch (JSONException e) {
throw e;
} catch (Exception e) {
throw new JSONException("create instance error, class " + clazz.getName(), e);
}
return object;
}
FieldDeserializer.java中的setValue方法通过反射实现字段设置:
// FieldDeserializer.java - 属性赋值的核心实现
public void setValue(Object object, Object value) {
if (value == null && fieldInfo.fieldClass.isPrimitive()) {
return;
} else if (fieldInfo.fieldClass == String.class
&& fieldInfo.format != null
&& fieldInfo.format.equals("trim")) {
value = ((String) value).trim();
}
try {
Method method = fieldInfo.method;
if (method != null) {
if (fieldInfo.getOnly) {
// 处理只读属性的特殊情况
if (fieldInfo.fieldClass == AtomicInteger.class) {
AtomicInteger atomic = (AtomicInteger) method.invoke(object);
if (atomic != null) {
atomic.set(((AtomicInteger) value).get());
}
} else if (Map.class.isAssignableFrom(method.getReturnType())) {
Map map = (Map) method.invoke(object);
if (map != null) {
map.putAll((Map) value);
}
} else {
Collection collection = (Collection) method.invoke(object);
if (collection != null && value != null) {
collection.clear();
collection.addAll((Collection) value);
}
}
} else {
// 通过setter方法赋值
method.invoke(object, value);
}
} else {
// 通过字段直接赋值
final Field field = fieldInfo.field;
if (field != null) {
field.set(object, value);
}
}
} catch (Exception e) {
throw new JSONException("set property error, " + clazz.getName() + "#" + fieldInfo.name, e);
}
}
4.4 反序列化小结
Fastjson通过JSON.parseObject()门面API调用DefaultJSONParser控制器,利用JSONLexer进行词法分析解析JSON字符串,经过AutoType安全检查后使用ASM字节码生成动态反序列化器或反射机制创建Java对象实例并逐字段赋值。
五、特性讲解
5.1 ASM性能优化
ASM 是 fastjson 类似于 JIT,在运行时把「反射调用」翻译成「直接字段访问 + 方法调用」的字节码,从而把序列化/反序列化性能提升 20% 以上,当然随着JVM对反射性能的优化性能差正在逐渐被缩小。下图是作者使用工具类读取的动态序列化/反序列化器源码片段。

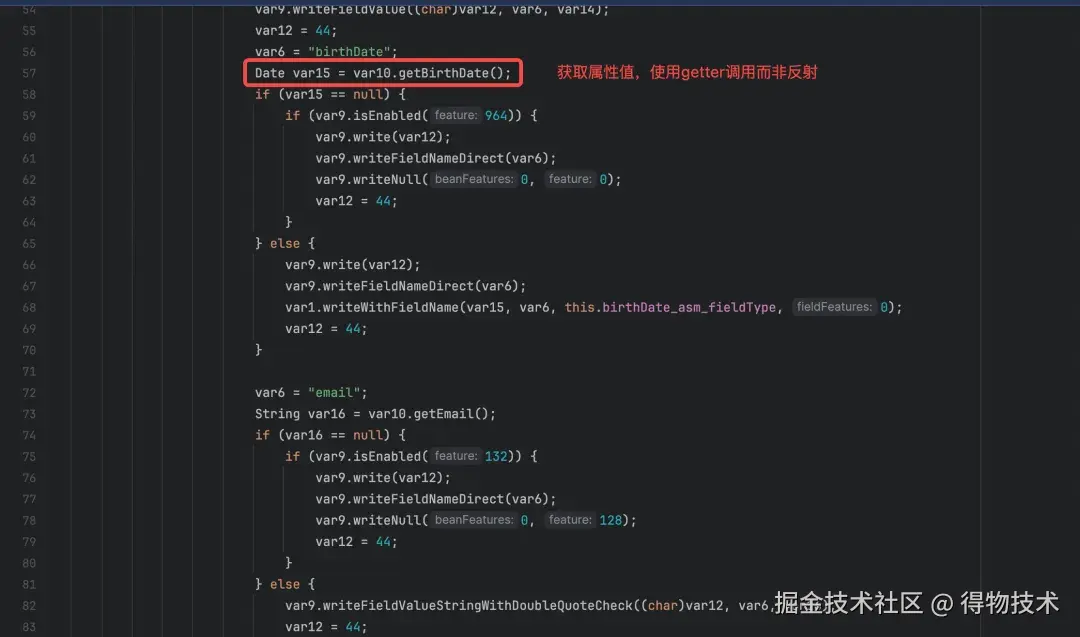

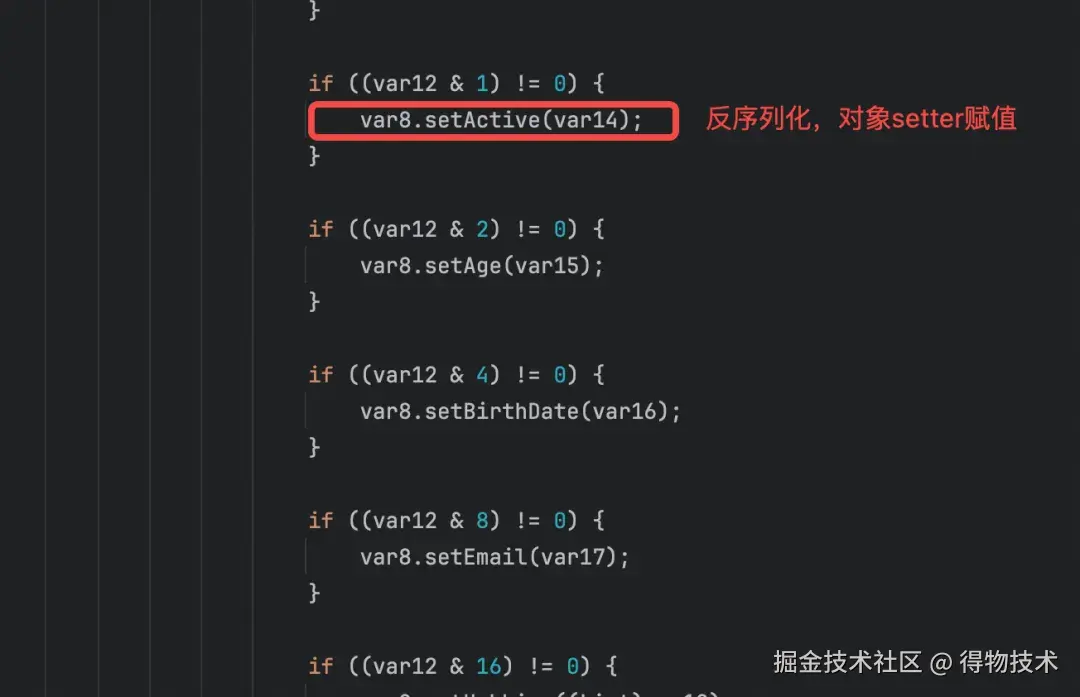
5.2 AutoType机制
AutoType是 fastjson 的“动态多态还原”方案:
序列化时把具体子类名字写进 "@type",反序列化时先加载类 → 再调 setter → 完成还原。
速度上“指针引用”即可定位序列化器,功能上靠 @type 字段把被擦除的泛型/接口/父类重新映射回具体实现。
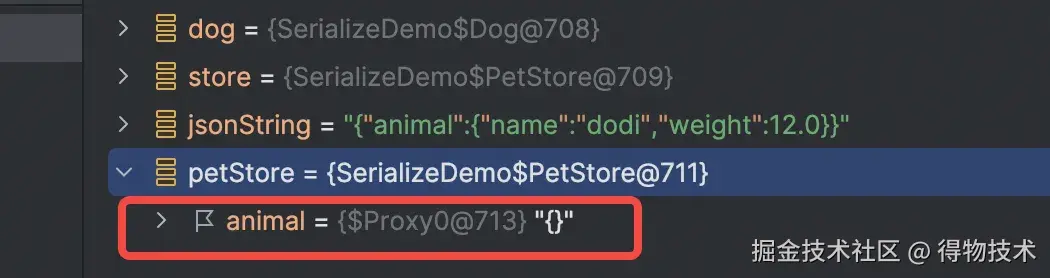
在未开启AutoType机制情况下,在将store对象序列化成JSON串后,再反序列化为对象时由于字段的类型为接口无法转换成具体的Dog类型示例;开启AutoType机制后,序列化时将类型一并写入到JSON串内,后续进行反序列化时可以根据这个类型还原成具体的类型实例。
interface Animal {}
class Dog implements Animal {
private String name;
private double weight;
//省略getter,setter
}
class PetStore {
private Animal animal;
}
public static void main(String[] args) {
Animal dog = new Dog("dodi", 12);
PetStore store = new PetStore(dog);
String jsonString = JSON.toJSONString(store);
PetStore petStore = JSON.parseObject(jsonString, PetStore.class);
Dog parsedDog = (Dog) petStore.getAnimal();
}

public static void main(String[] args) {
Animal dog = new Dog("dodi", 12);
PetStore store = new PetStore(dog);
String jsonString = JSON.toJSONString(store, SerializerFeature.WriteClassName);
PetStore petStore = JSON.parseObject(jsonString, PetStore.class);
Dog parsedDog = (Dog) petStore.getAnimal();
}
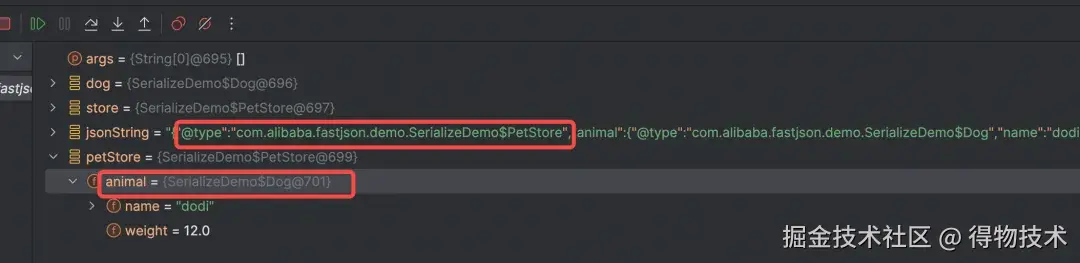
AutoType 让 fastjson 在反序列化时根据 @type 字段动态加载任意类,这一“便利”却成为攻击者远程代码执行的快捷通道:通过把JdbcRowSetImpl等 JNDI 敏感类写进 JSON,服务端在调用 setter 的瞬间就会向外部 LDAP/RMI 服务器拉取恶意字节码,完成 RCE;而官方长期依赖“黑名单”堵漏,导致 1.2.25→1.2.80 出现 L 描述符、Throwable 二次反序列化、内部类等连续绕过,形成“补丁-绕过-再补丁”的猫鼠游戏, 虽然在1.2.68 引入 safeMode 但为了兼容性需要使用者手动开启 ,而且实现也不够健壮,开启safeMode仍有利用代码漏洞绕过检查风险,后续版本对safeMode加固并对已知安全漏洞清零,直到最新1.2.83版本安全问题也不能说彻底解决。
5.3 流式解析
Fastjson 提供一套 Streaming API,核心类JSONReader /JSONWriter,行业内惯称「流式解析」或「增量解析」,主要用于处理JSON大文件解析。技术上流式解析采用“拉模式(pull parsing)”,底层维护 8 KB 滑动缓冲,词法分析器(Tokenizer)把字节流切成 token 流,语法状态机根据 token 类型驱动反序列化器(ObjectReader)即时产出 Java 对象,对象一旦交付给用户代码处理后,内部引用立即释放。这种方式内存中不会保存所有对象,对象处理完即被丢弃,因此可以处理数据量远大于内存的数据,而不会出现OOM。下面是使用流式解析的示例代码:
// 依赖:com.alibaba:fastjson:1.2.83
try (JSONReader reader = new JSONReader(
new InputStreamReader(
new FileInputStream("huge-array.json"), StandardCharsets.UTF_8))) {
reader.startArray(); // 告诉解析器:根节点是 []
while (reader.hasNext()) { // 拉取下一条
Order order = reader.readObject(Order.class); // 瞬时对象
processOrder(order);//业务处理
orderRepository.save(order); // 立即落盘,内存即可回收
}
reader.endArray();
}
六、总结
Fastjson核心特性在于高速序列化/反序列化,利用ASM在运行时生成字节码动态创建解析器,减少反射;AutoType字段支持多态,却带来反序列化RCE风险,建议关闭AutoType,开启safeMode。选型建议:在选择JSON序列化框架时对于非极端性能要求推荐Jackson,或者使用Fastjson2,其改用LambdaMetafactory替换ASM,性能再提升30%,默认关闭AutoType安全性有保证。
参考资料:
往期回顾
1. 用好 TTL Agent 不踩雷:避开内存泄露与CPU 100%两大核心坑|得物技术
2. 线程池ThreadPoolExecutor源码深度解析|得物技术
3. 基于浏览器扩展 API Mock 工具开发探索|得物技术
4. 破解gh-ost变更导致MySQL表膨胀之谜|得物技术
5. MySQL单表为何别超2000万行?揭秘B+树与16KB页的生死博弈|得物技术
文 /剑九
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。