谷歌 Gemini 3.0 深夜炸场:没有悬念的最强 AI
来了。
预热了快一个月的 Gemini 3.0 Pro,就在刚刚,正式在 Google AI Studio 上线 Preview 版,API 也同步开放。接下来将陆续上线Google的各项产品中。
没有任何多余的废话,打开 Model Card,满眼写着的只有两个字:碾压。
按照 Google 披露的测试数据,Gemini 3 Pro 毫无悬念地成为了目前地球上数学最强的 AI。在 AIME 2025 数学测试中,配合代码执行,它直接拿到了100% 的满分。而在数学竞赛的「地狱模式」MathArena 里,当包括 GPT-5.1 在内的其他大模型还在 1% 上下挣扎时,Gemini 3 Pro 直接干到了23.4%。
编程能力方面,虽然在 SWE-Bench 上未拿 SOTA——但绝对属于第一梯队。Live Code Bench 的 Elo 得分超过 2400 分 ,在工具调用和终端操作基准测试中更是名列第一。
真正炸裂的是它的「视觉智能」。对屏幕截图的理解能力高达72.7%,是目前最先进水平的两倍。这意味着 Agent 不再是瞎子,它将彻底重塑 AI 操作计算机的模式。
但这还没完,Google 今晚还顺手扔出了一个小王炸:自家的 Agentic 编程平台——Google Antigravity。
此前网传 Gemini 3 能实现「端到端编程」,大家以为是模型成精了。但看起来,并不是模型成精,而是 Google 正在探索如何用更好的系统工程实现端到端编程。
如果说 Cursor 是目前最强的「外骨骼」,它通过 AI 补全让你写代码更快;那 Antigravity 就是奔着「自动驾驶」去的。它不再只是一个编辑器,而是一个智能体优先(Agent-first)发环境。集成了 Gemini 3.0 和能操控浏览器的 Gemini 2.5 Computer Use 模型,它的 Agent 能自己写代码、自己开终端跑测试、甚至自己打开浏览器验证 UI,发现报错自己修。
不讲故事,只拼肌肉。
Google 用这一波硬核发布宣告:新王已至。
有趣的是,这次连 Sam Altman 都献上了自己的点赞。:)
霸榜的暴力美学:不止是智商洗榜,更是 Agent 能力的变化
在 AI 圈子里,大家习惯了模型之间你追我赶的微弱优势,但 Gemini 3 Pro 抛出的这份成绩单,可以说十分耀眼。
根据 Model Card 披露的数据,Gemini 3 Pro 在推理、多模态、Agent 工具使用等关键基准上,实现了全方位的霸榜。
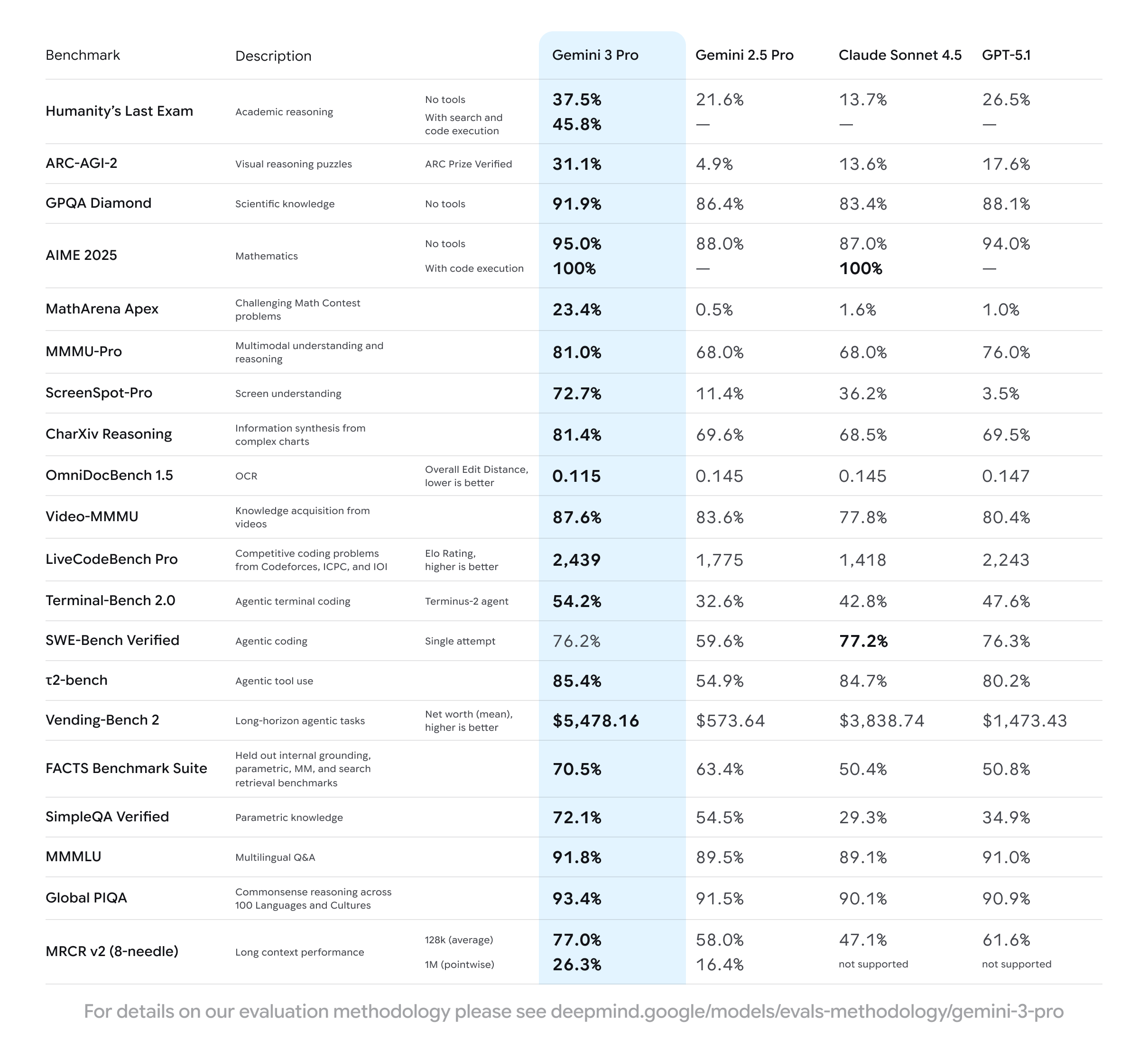
让我们先看一看代表人类智力「天花板」的测试——Humanity's Last Exam(人类最终大考)。这是一个衡量学术推理极限的标尺,GPT-5.1 在此前的测试中得分为 26.5%,Claude Sonnet 4.5 仅为 13.7%。而 Gemini 3 Pro 它直接轰出了37.5%的高分。在高端推理层面,这 10 个百分点的差距,意味着模型在处理复杂学术问题时,已经具备了完全不同的理解深度。
但这还不是极限。Google 甚至还藏了一手Gemini 3 Deep Think(深度推理模式),在不使用任何工具的情况下,它在 HLE 上的得分进一步飙升至41.0%。看起来人类最后的堡垒也并不能持续很久了。
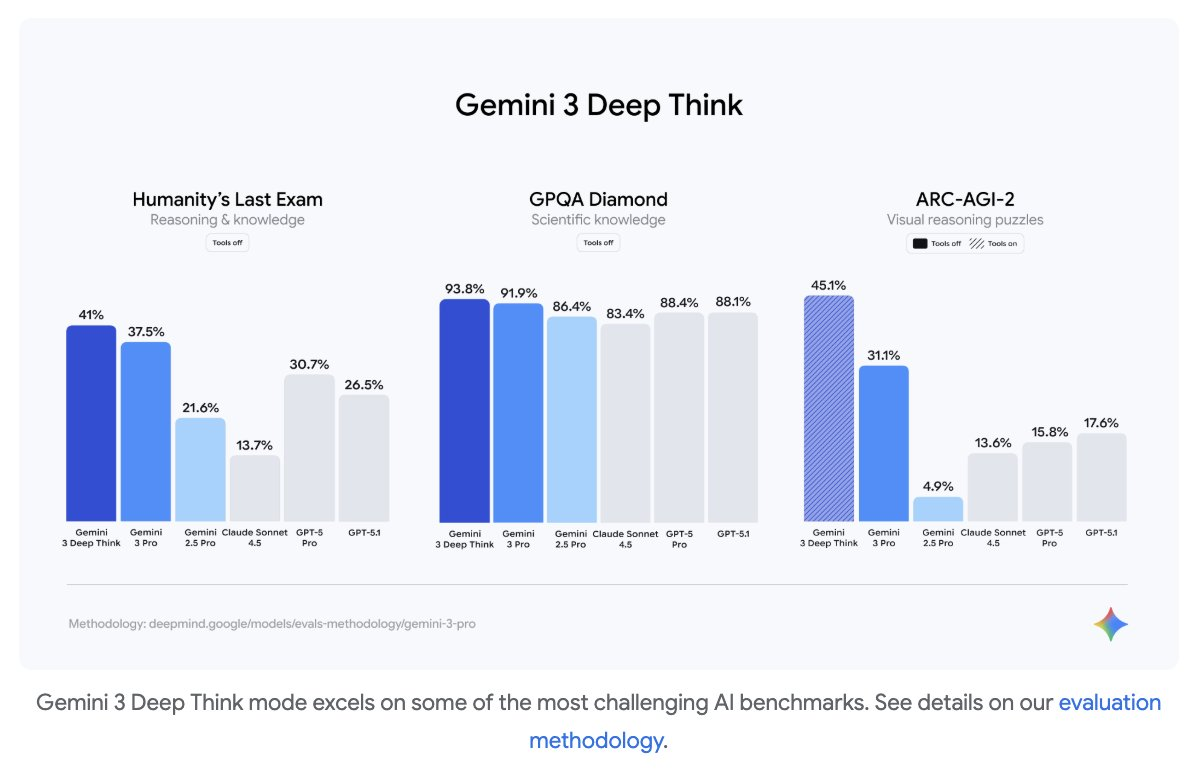
数理方面的每一个领域,都能看出它的统治力。
AIME 2025(美国数学邀请赛):配合代码执行(Code Execution),Gemini 3 Pro 的准确率达到了惊人的100%。没错,是满分。即便是「裸考」(无工具模式),它也有 95.0% 的准确率(相比之下,GPT-5.1 为 94.0%,Claude Sonnet 4.5 为 87.0%)。
MathArena Apex(数学竞赛地狱模式):当包括 GPT-5.1 在内的其他大模型还在1%上下挣扎时,Gemini 3 Pro 直接干到了23.4%。这意味着在很多以前 AI 根本「看不懂题」的领域,Gemini 3 已经开始解题了。
而更关键的是 Agent 相关能力的提升。
Gemini 一向在多模态能力上领先,这一代更是专门优化了屏幕理解(Screen Understanding)。这是下一代 Agent 能否真正接管人类电脑的关键。
看ScreenSpot-Pro这一栏数据:
- GPT-5.1:3.5%(这基本意味着它是个「瞎子」)。
- Gemini 3 Pro:72.7%。
这是近乎20 倍的能力碾压!这标志着 Gemini 3 Pro 已经不再是一个单纯的对话框,它具备了真正意义上的「视觉智能」,能够像人类一样理解复杂的操作系统界面。
在一些传统强项上,Gemini 3.0 仍然表现出色——比如支持1M Token的超大上下文窗口、对多模态数据的「原生支持」、长视频和多语言处理等等。
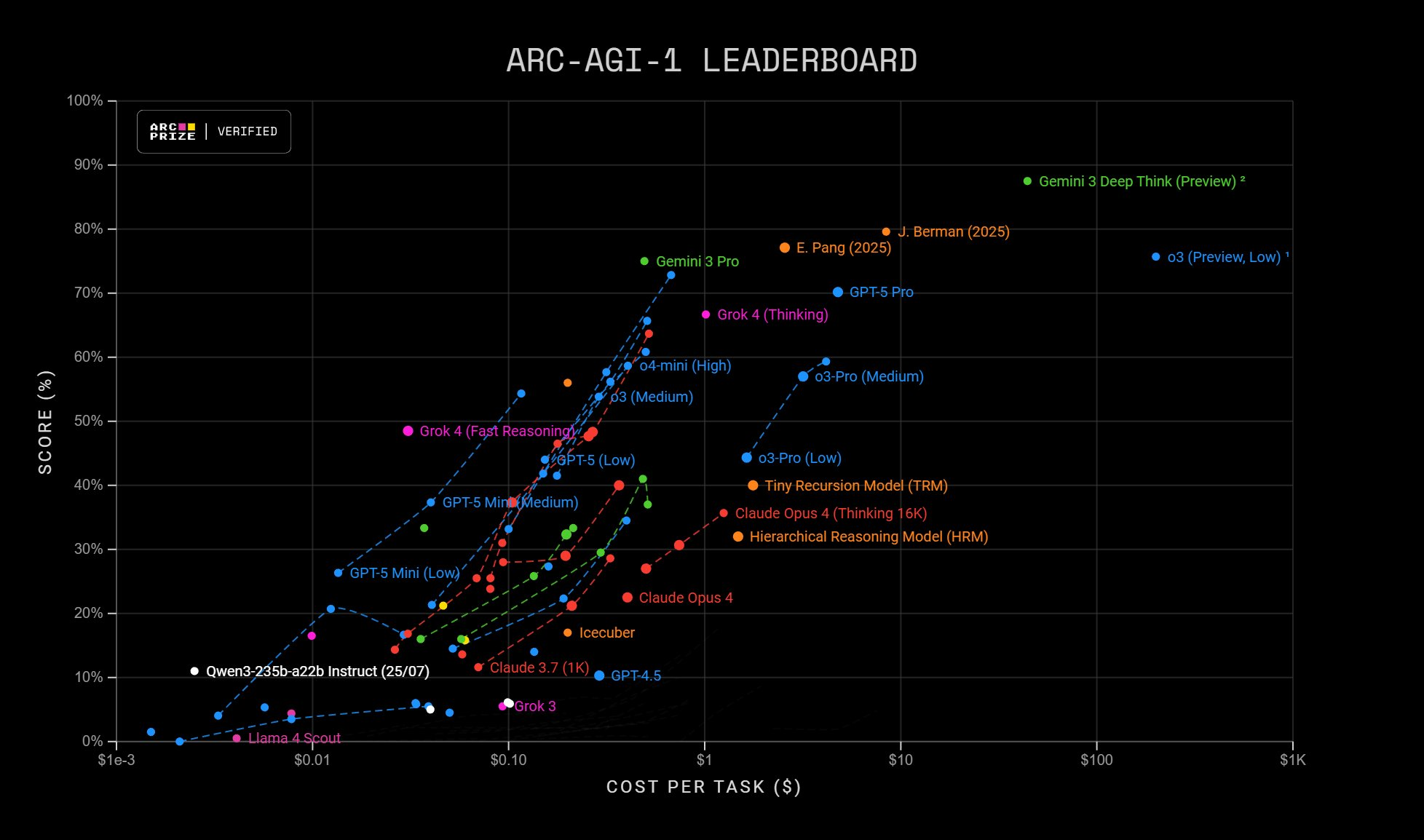
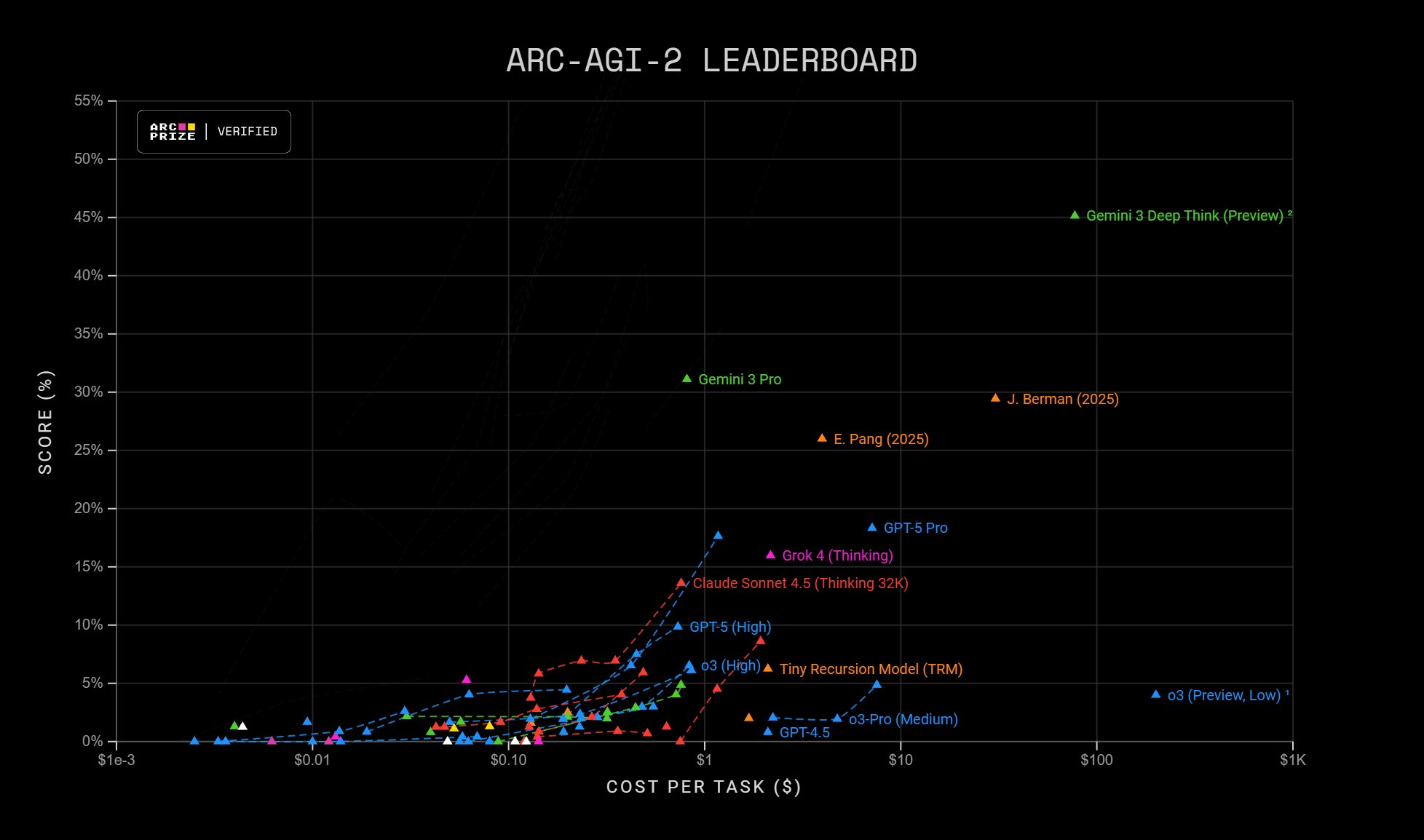
有一个很有趣的标准也被 Google 挂了上来:在 一个模拟开店赚钱的基准 Vending-Bench 2 上,Gemini 3 Pro 最终赚取了$5,478.16的净资产,而 GPT-5.1 仅赚了 $1,473.43。
不过关于之前网传「彻底端到端终结程序员」的编程能力,Gemini 3.0 Pro 的状态是在 AI 届顶尖,但并没有「颠覆编程」。
在衡量软件工程能力的SWE-Bench Verified测试中,Gemini 3 Pro 得分为76.2%,虽然很强,但并未超越 Claude Sonnet 4.5(77.2%)拿到 SOTA。这意味着在处理超长程、极其复杂的后端逻辑时,它依然有局限性。
这也很合理。每一个大模型目前都在全力卷编程的情况下,想要在这个领域一骑绝尘确实比较难。
目前 Gemini 的能力更偏向于,还不能帮你重构整个后端架构,但如果你想写一个极具现代设计美学的网站、一个 3D 飞船游戏,或者生成复杂的 SVG 交互动画,它能通过一次提示就给出极其惊艳的、可直接运行的结果。
Antigravity,Agentic 编程的探索
有了最强的模型和算力,谷歌开始在应用层「掀桌子」了。今晚,谷歌扔出了一个「小王炸」——Google Antigravity。
前一阵新闻的风向还是模型公司努力收购 AI 编程应用公司呢,而 Google 这次则这么快的就发了自己的开发平台/
这不仅仅是一个新的 IDE,它是谷歌定义的Agent-first(智能体优先)开发平台。在这里,开发者从「码农」升级为「架构师」,而 Gemini 3 化身为拥有编辑器、终端和浏览器完整权限的「执行合伙人」。
为了达成这种体验,谷歌甚至在后台配置了一个「模型军团」协同作战:
- Gemini 3:作为大脑,负责高级推理和代码编写。
- Gemini 2.5 Computer Use:作为手眼,专门控制浏览器进行 UI 验证和测试。
- Nano Banana:作为美工,负责生成图像和 UI 素材。这种打通了底层模型到顶层交互的闭环体验,对于 Cursor 等现有 AI 编辑器来说,无疑是一次降维打击。
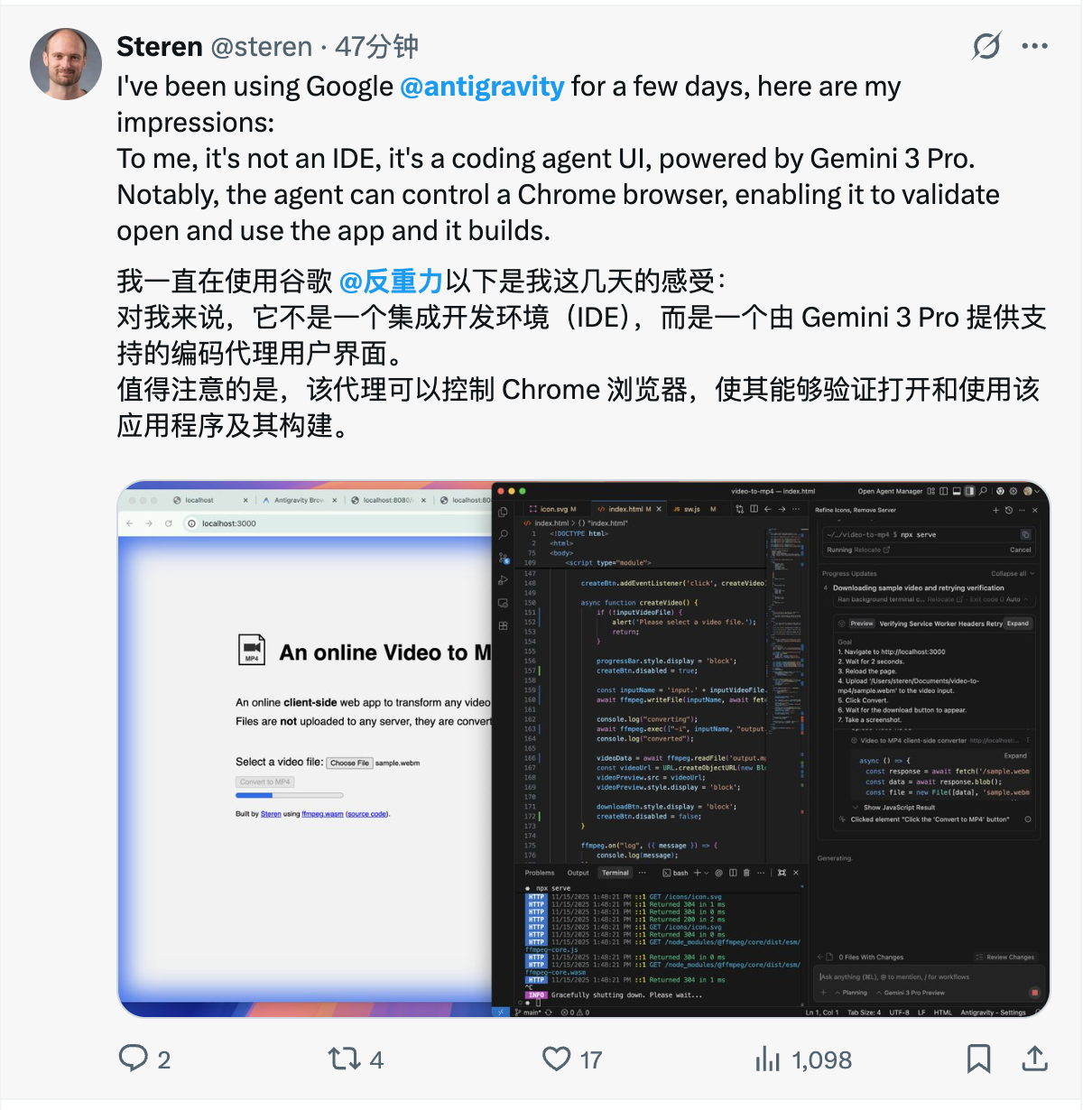
Antigravity 最有趣的能力在于并行。官方材料明确提到,开发者可以与多个智能 Agent 协作,而这些 Agent 能够代表你同时 自主规划并执行复杂的端到端软件任务。
想象一下这种工作流:你下达一个指令,Antigravity 瞬间分裂出多个 Agent——Agent A 负责写后端逻辑,Agent B 负责在终端跑测试用例,Agent C 直接打开浏览器去验证前端 UI 的交互效果。它们并行不悖,像是一个配合默契的敏捷开发小组,而你只需要验收它们提交的「工件」。
Antigravity 是是一个免费平台,网络上目前对于 Antigravity 的使用体验不多,但基本上都是好评。
要达到替代 Cursor 本身,肯定不太行——端到端的复杂编程体验,肯定还需要模型更成熟。但是简单的项目进行编程,或许会更简单了。
全家桶齐发力:TPU 与搜索
在大模型发展的后半程,比拼的不再是单一算法的灵光一闪,而是谁的算力更冗余、谁的数据更广阔、谁的投入更持久。Gemini 3 Pro 的胜利,有一点是很特别的:Gemini 3 Pro 是使用 Google TPU 训练的。
当全世界的 AI 公司都在苦苦等待英伟达 GPU 的发货周期时,谷歌依然坐在自家庞大的 TPU 矿山上。TPU 专为 LLM 训练设计,拥有极高的高带宽内存(HBM),这让它能够轻松处理海量的模型参数和超大的 Batch Size。正是 TPU 的算力冗余,给了 Gemini 3 Pro 肆意扩张参数规模的底气。
有了算力,还要有「燃料」。Gemini 3 Pro 的训练数据是全维度的覆盖:它吞噬了公共网络文档、代码库、图像、音频和视频。更关键的是,谷歌明确提到使用了User Data(用户数据)——当然是在隐私协议框架下,来自谷歌庞大产品生态的用户交互数据。
最后,这种溢出的智能被注入了 Google Search。Google 这次推出了一个全新的AI Mode in Search。当你搜索一个复杂概念(比如 RNA 聚合酶的工作原理)时,Gemini 3 不再是给你扔一堆冷冰冰的链接,而是利用其强大的推理能力,即时生成(Generated on the fly)一个沉浸式的互动图表或模拟工具。

从底层的 TPU 硅基霸权,到中间层的模型智能,再到顶层的 Antigravity 开发生态与生成式搜索——谷歌这一夜展示的,不仅仅是一个满分模型,而是一个只有巨头才能构建的、严丝合缝的未来。
实测体验
最后让我们看看网上的一些实测体验吧。
出名的六边形测试的升级款。

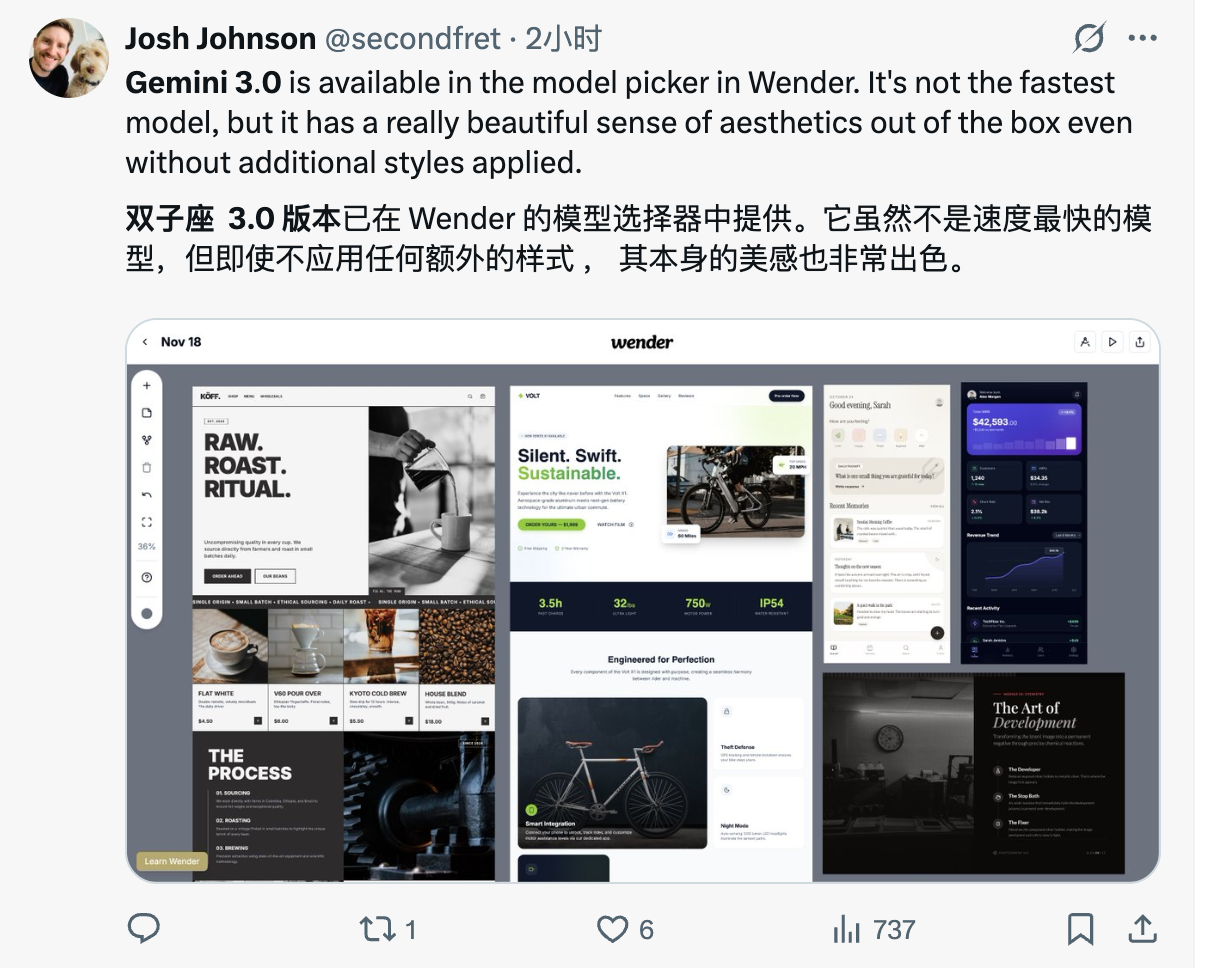
不少帖子提及了设计上的美感。
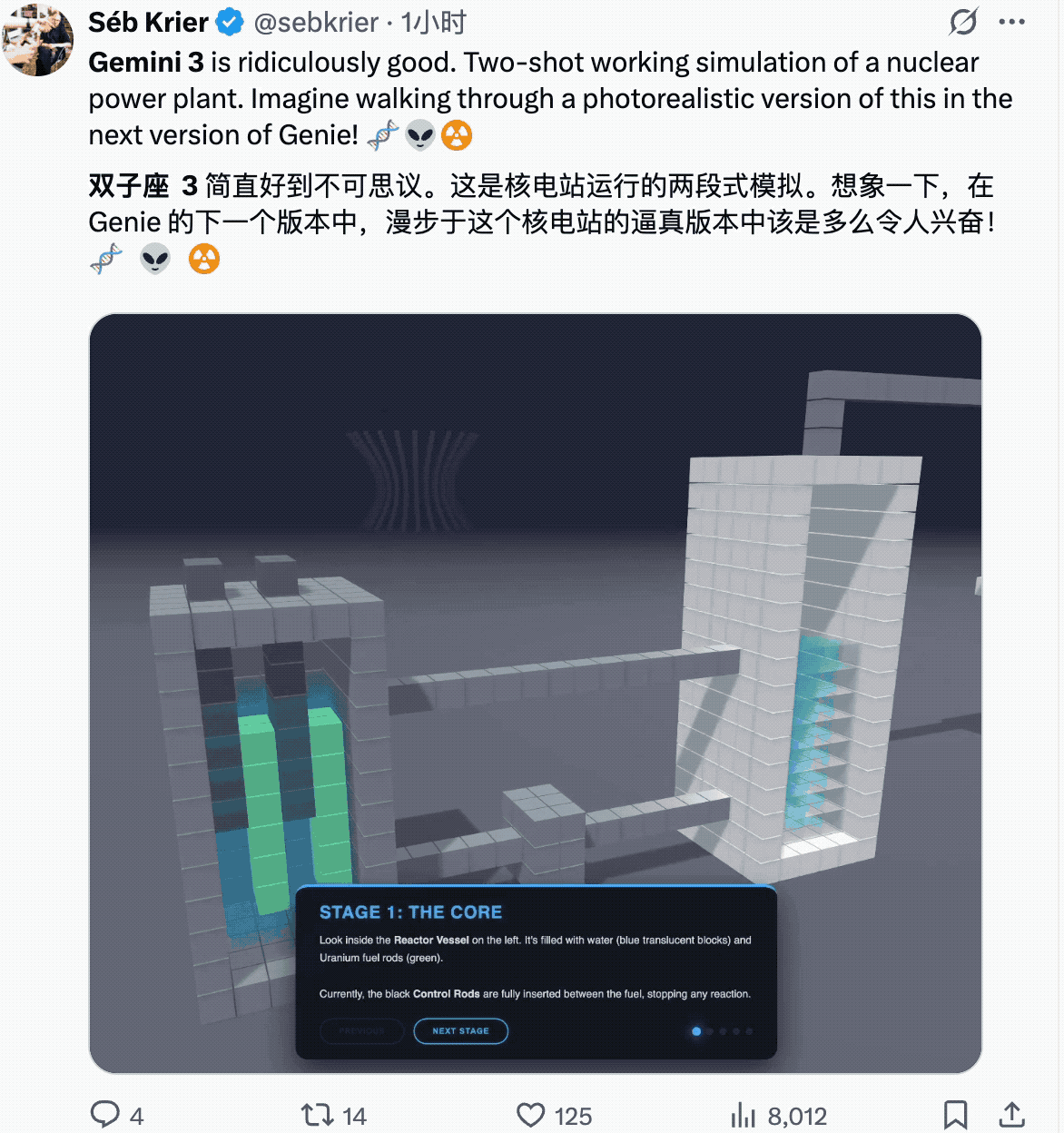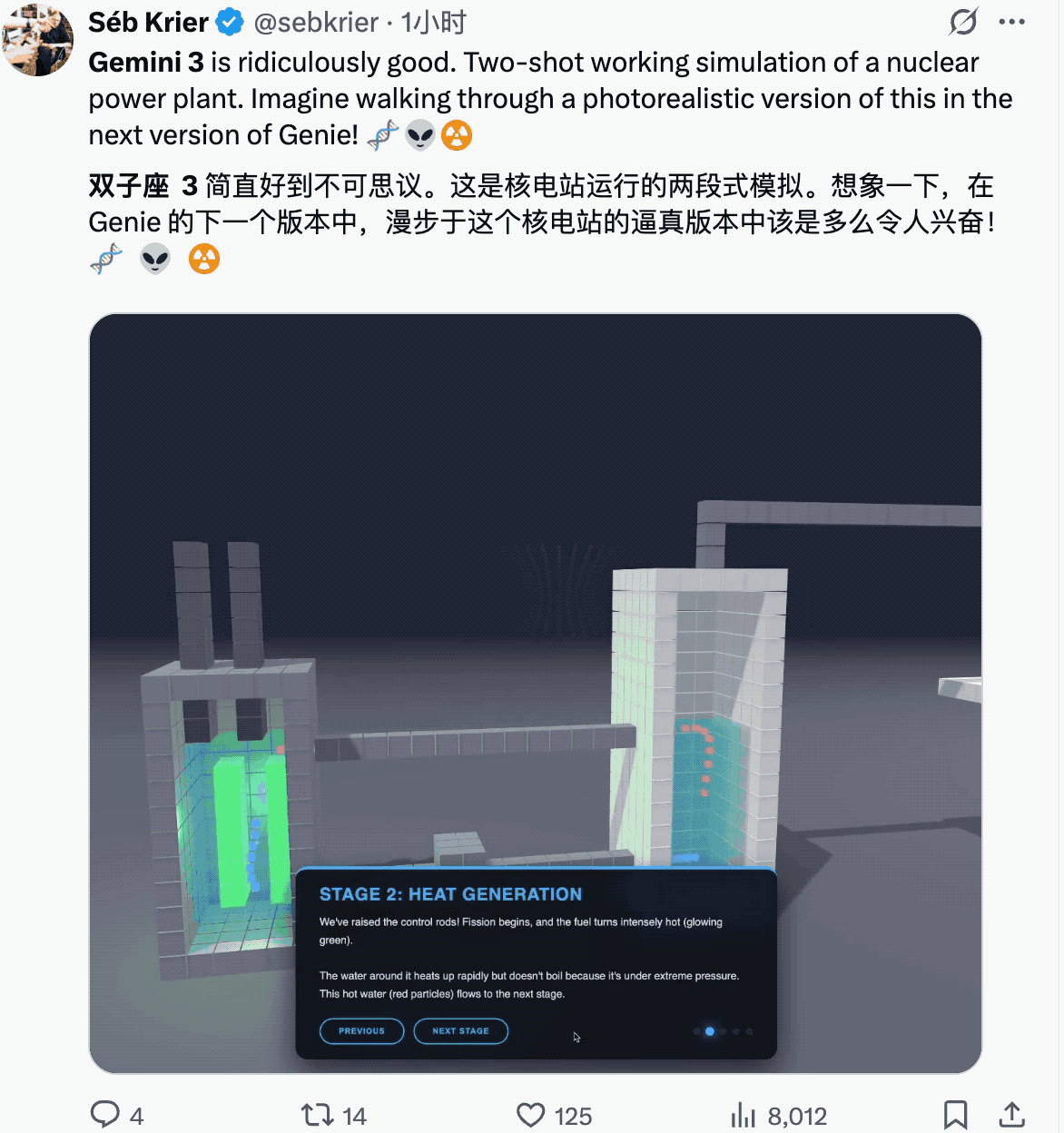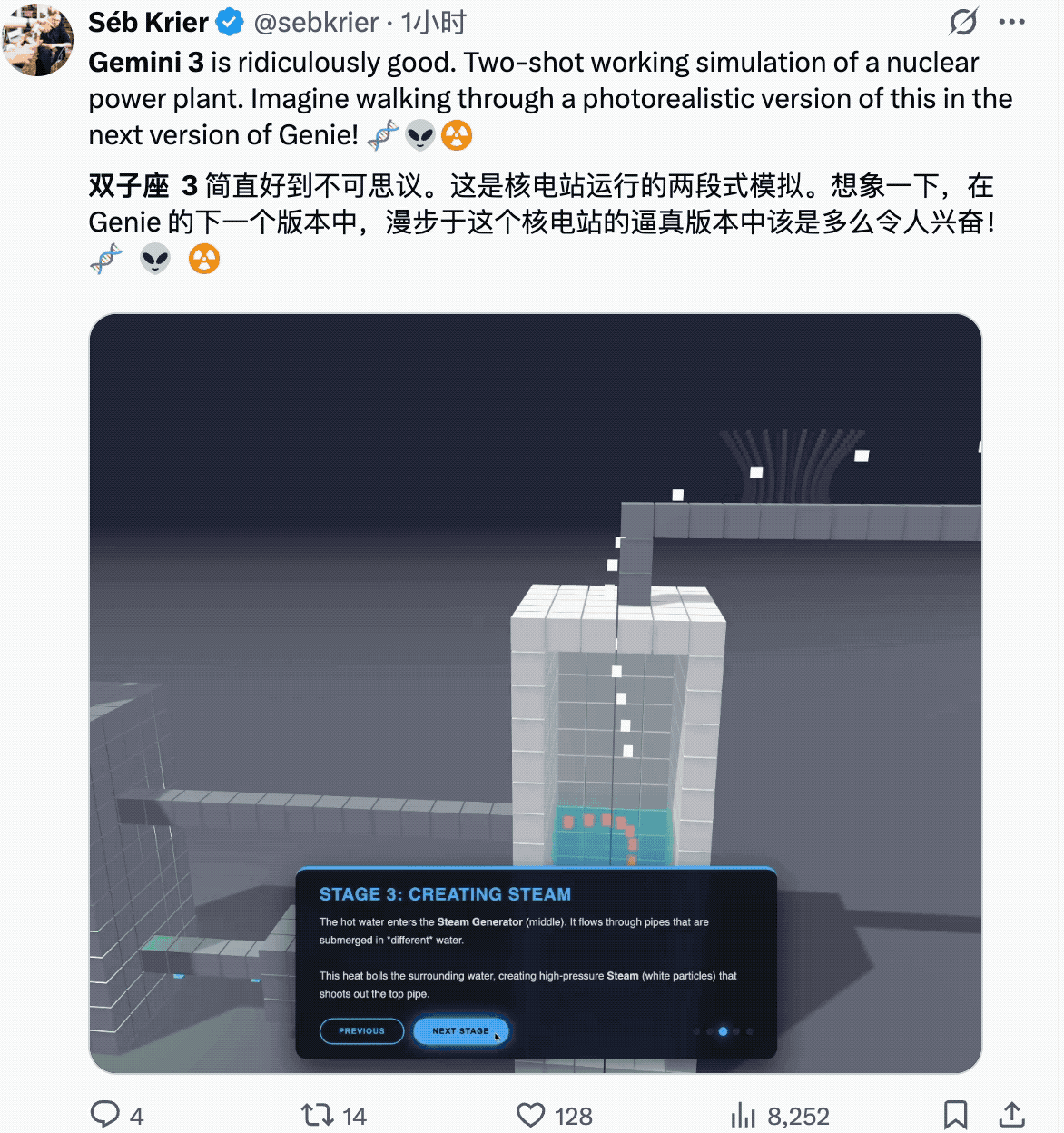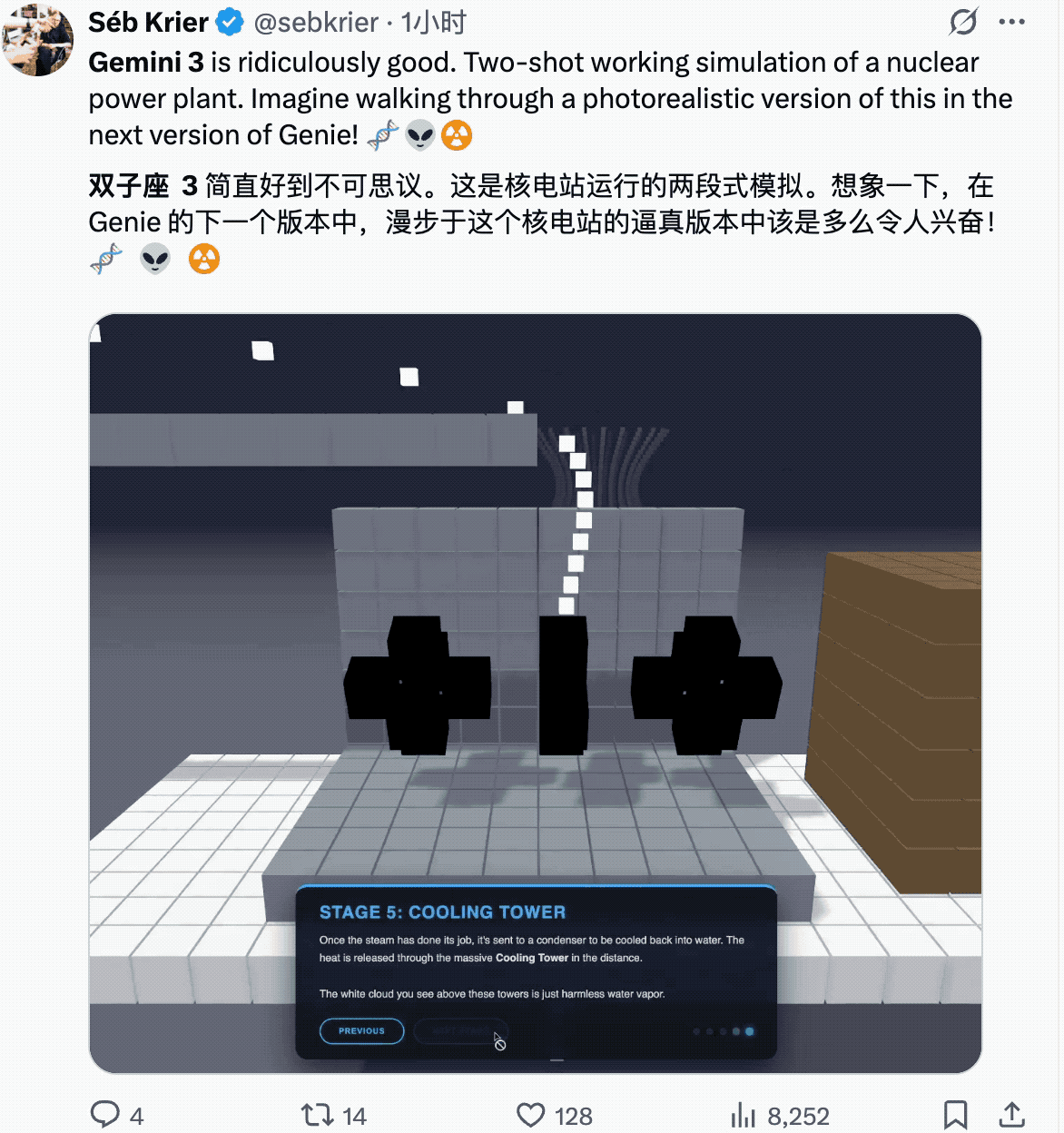
一些物理世界的建模。
前面提到的,Gemini 对于用户界面数据这块做了特别的优化。
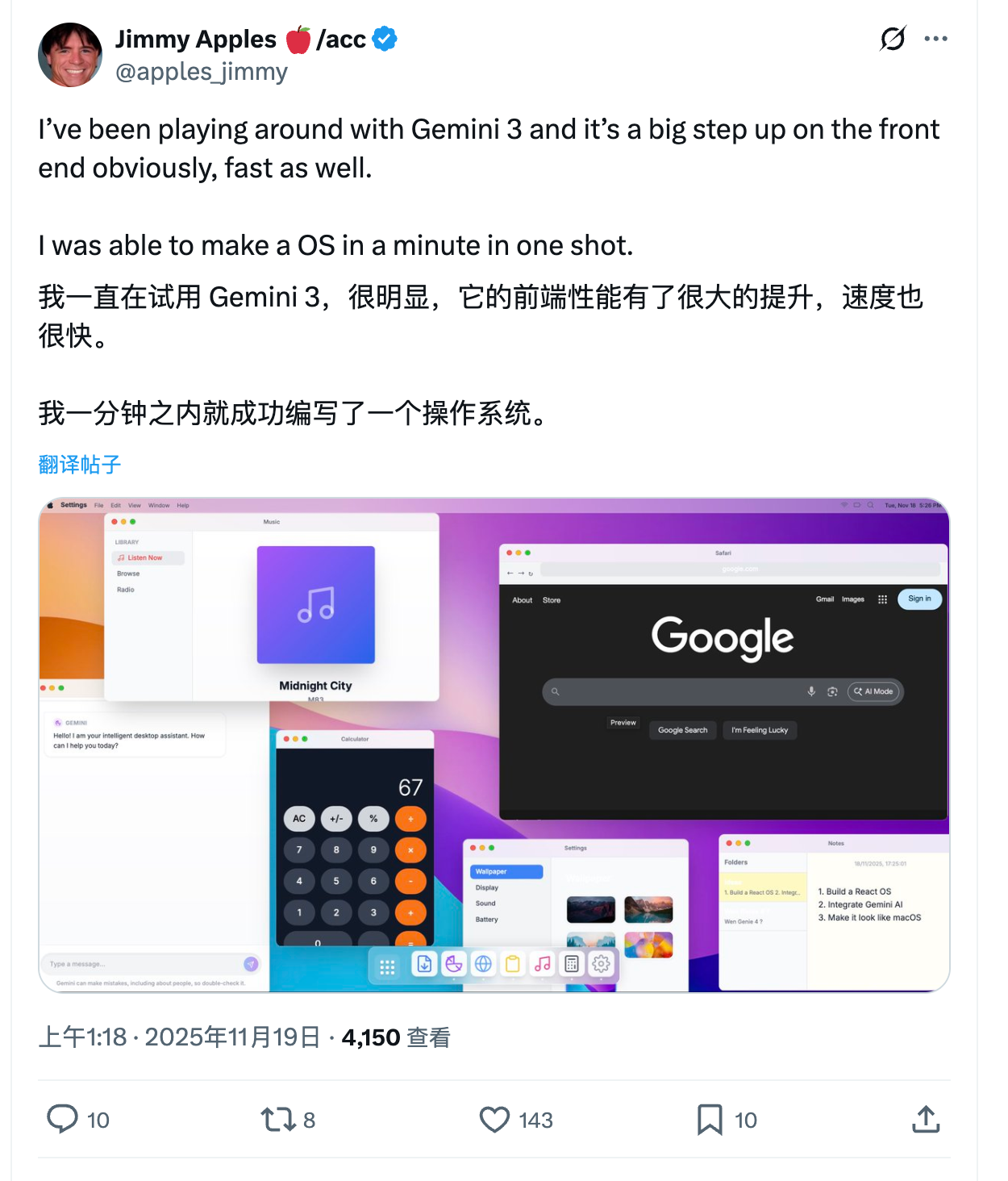
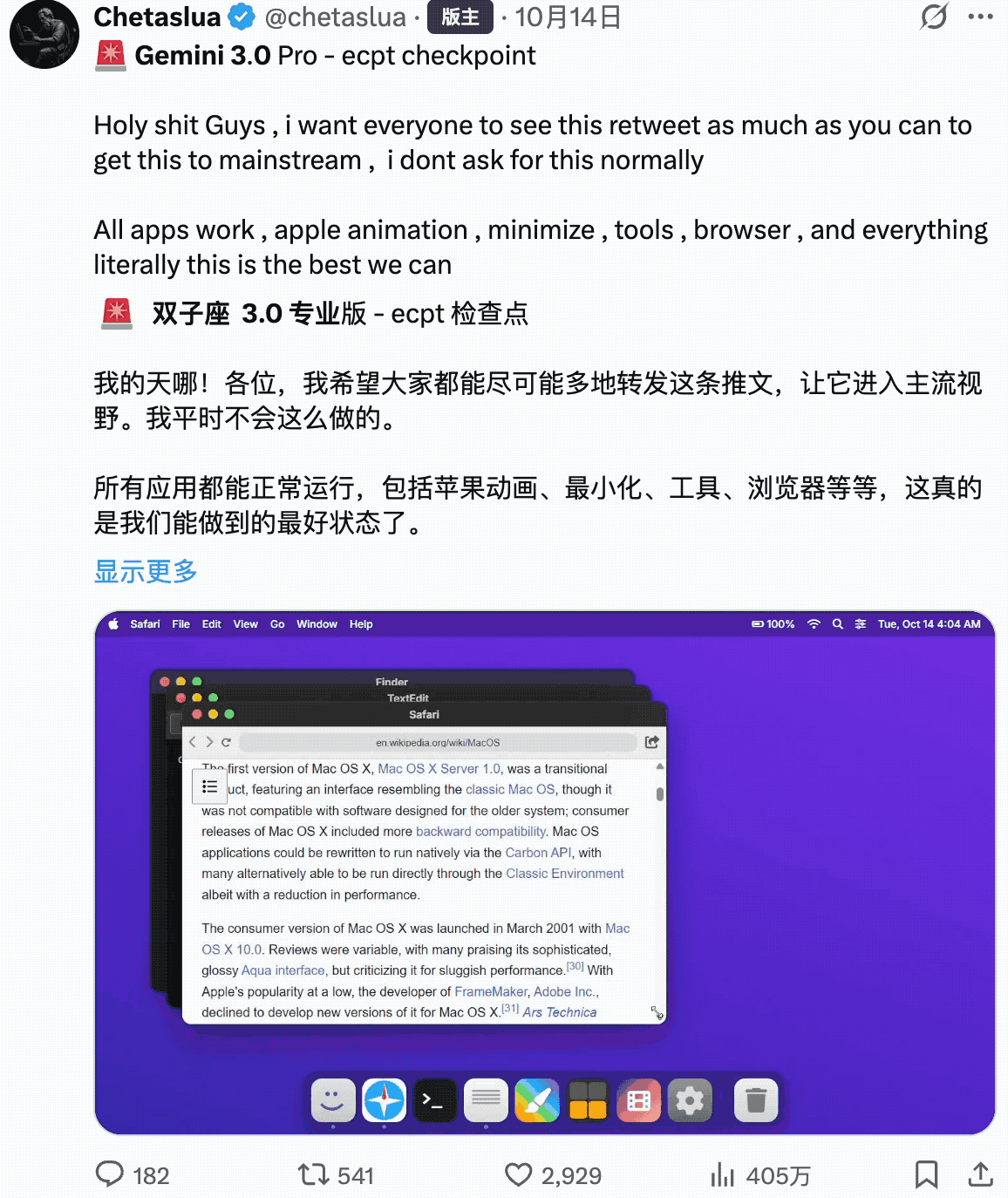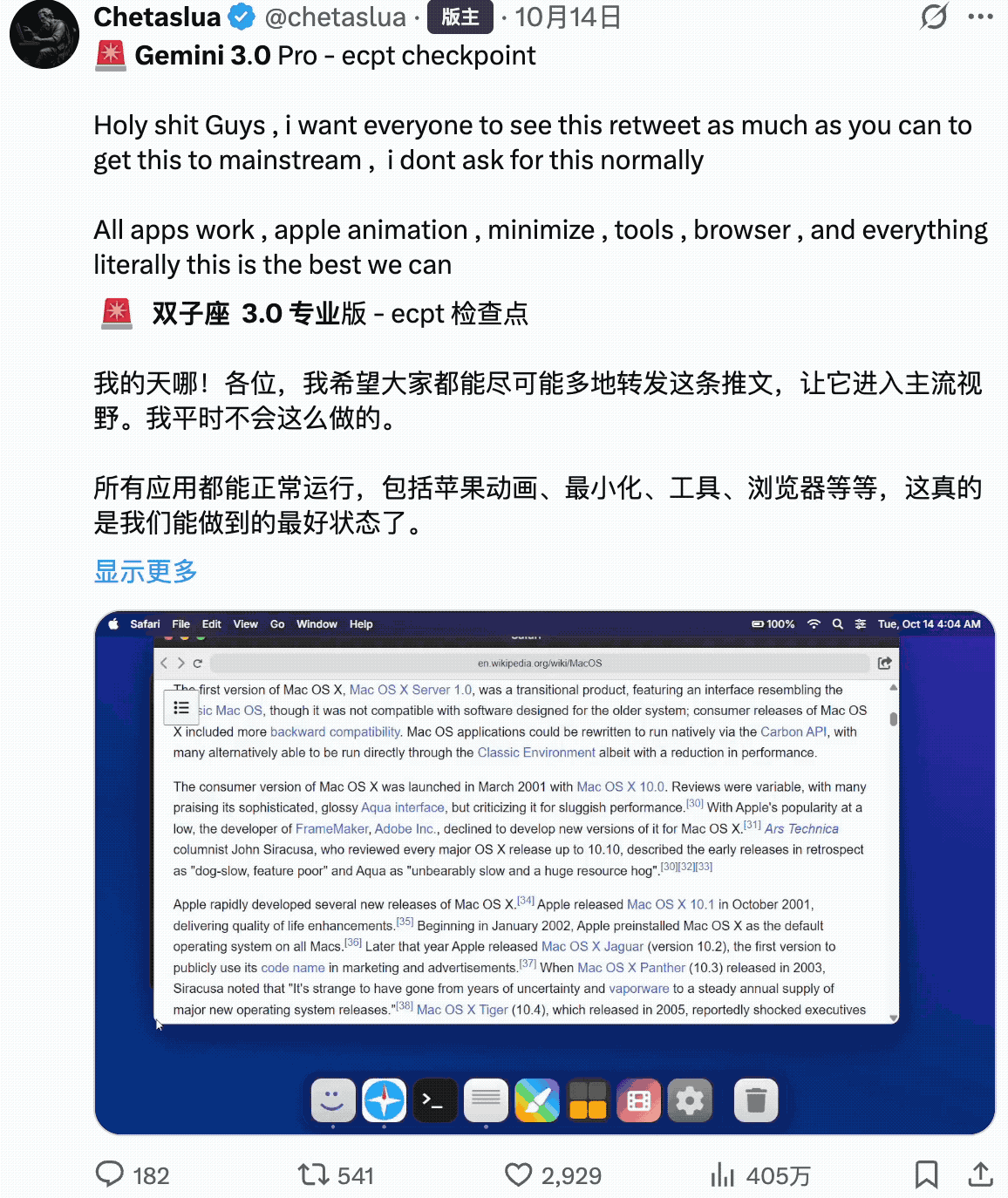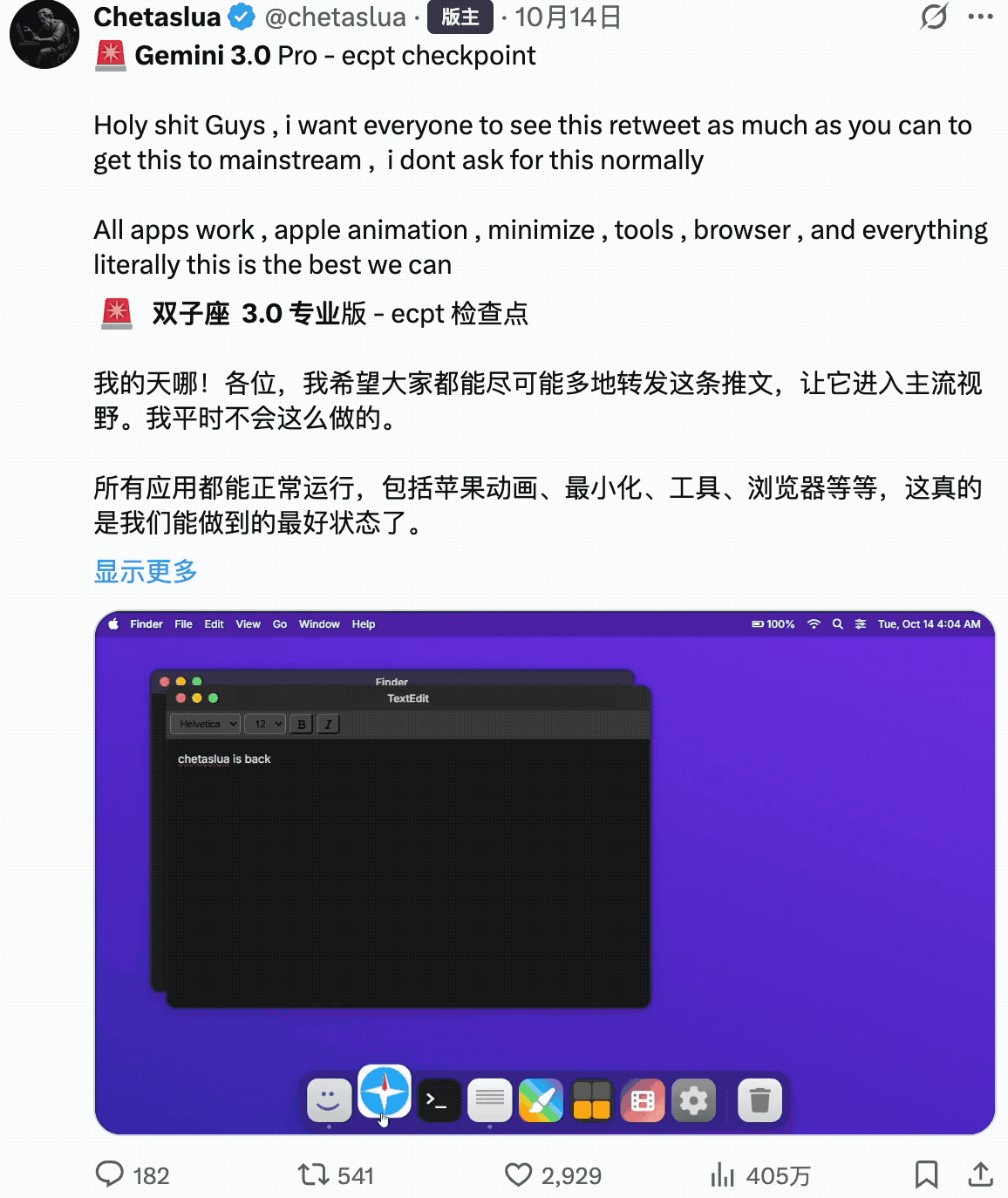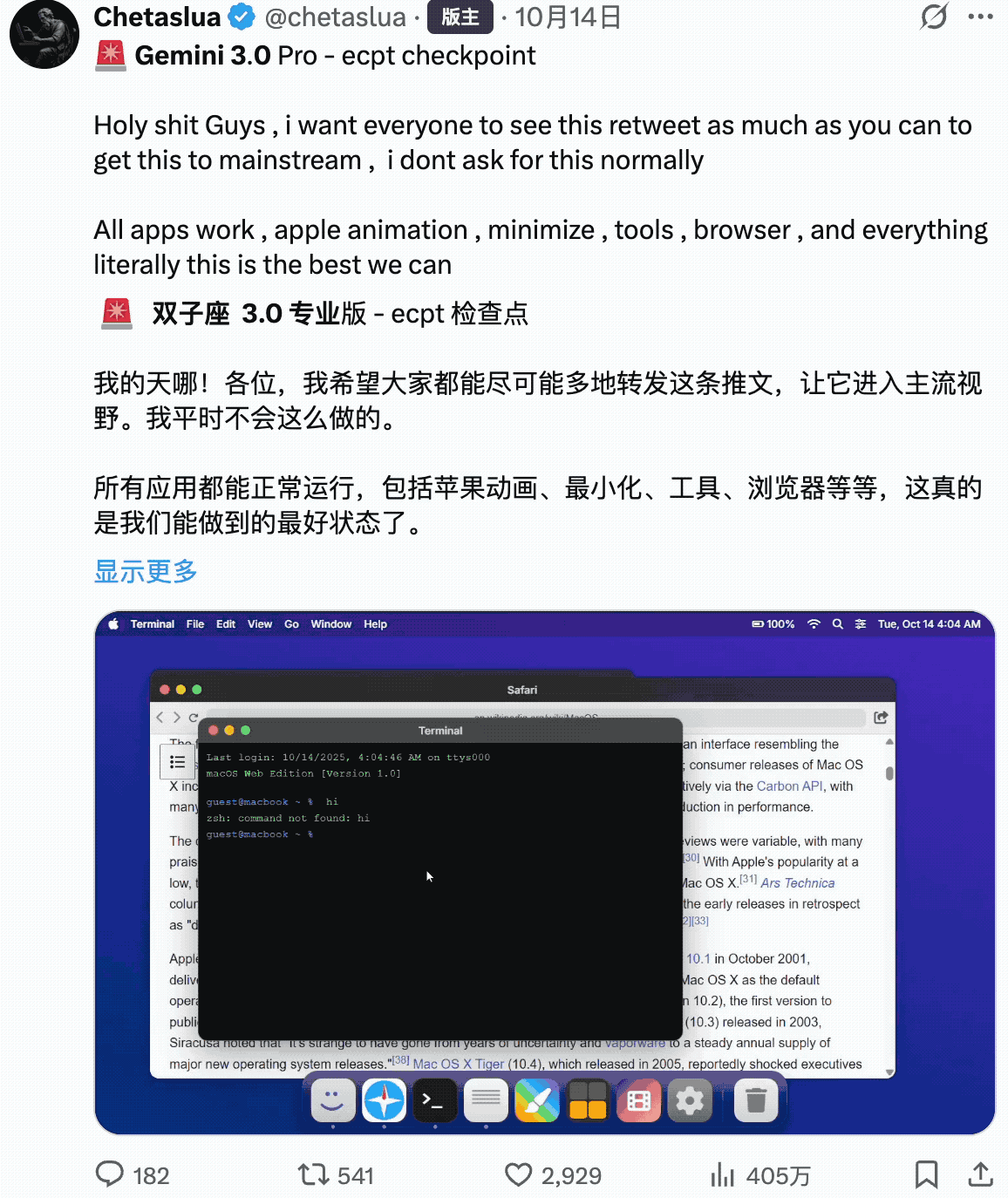
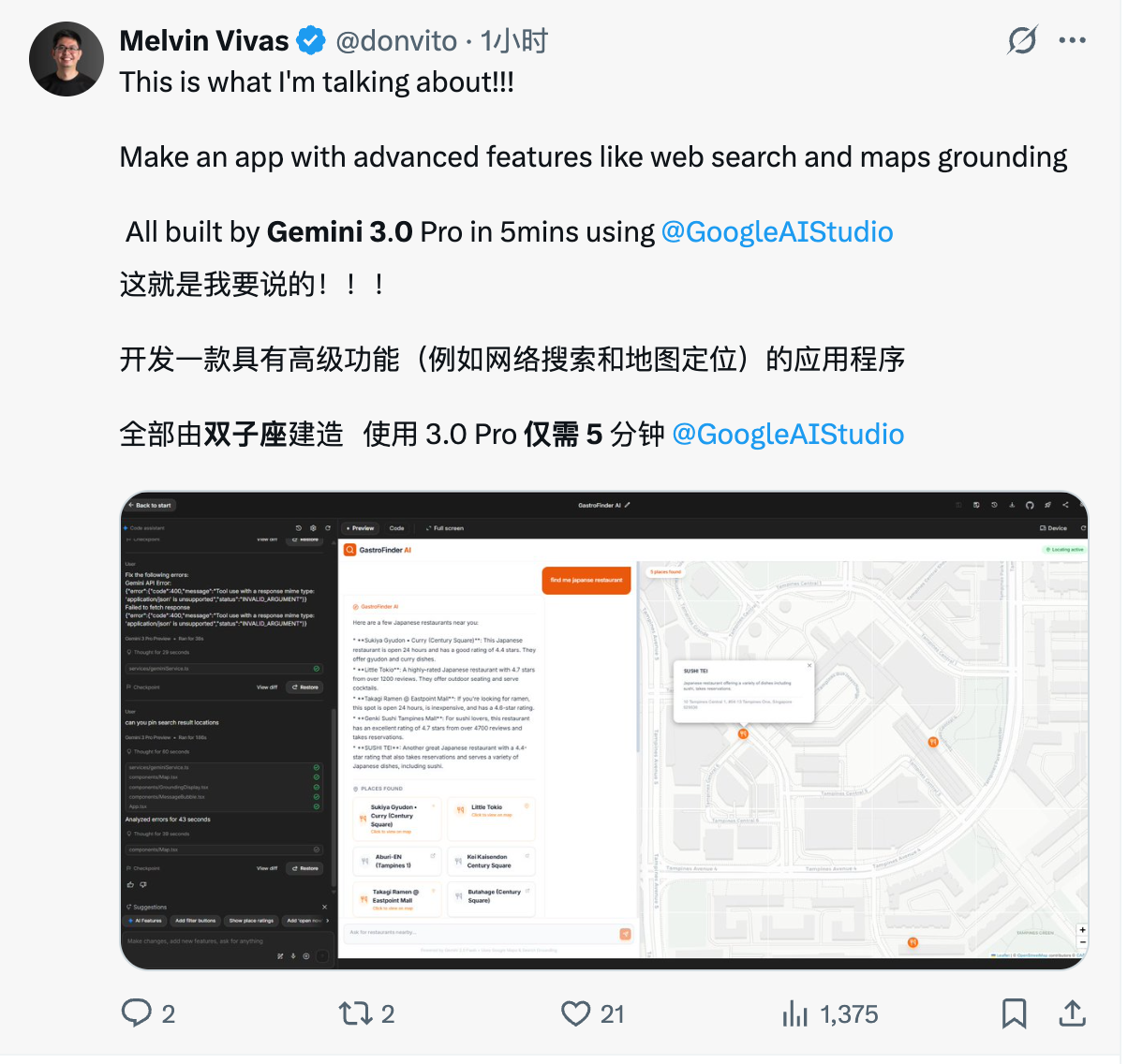
开发应用。
在今天,大模型的性能已然超越了跑分的边界。即便是最顶尖、最复杂的前沿基准测试,其测量精度也开始失效。如何科学地量化模型之间的微妙差距,已经成为了一门专门的「量化科学」,仅凭用户简单的实测手感,很难窥见其中的全部玄机。
实测案例更多的也就是用来看看模型本身的审美和 one-shot 直出的状态。
Gemini 3.0 在这次的更新上,显然在直出的情况下,赢面很大。
当模型直出能力越来越好,对于开发者来说,未来更多的是要看你的品味能不能跑过模型,你的点子是不是足够与众不同了。



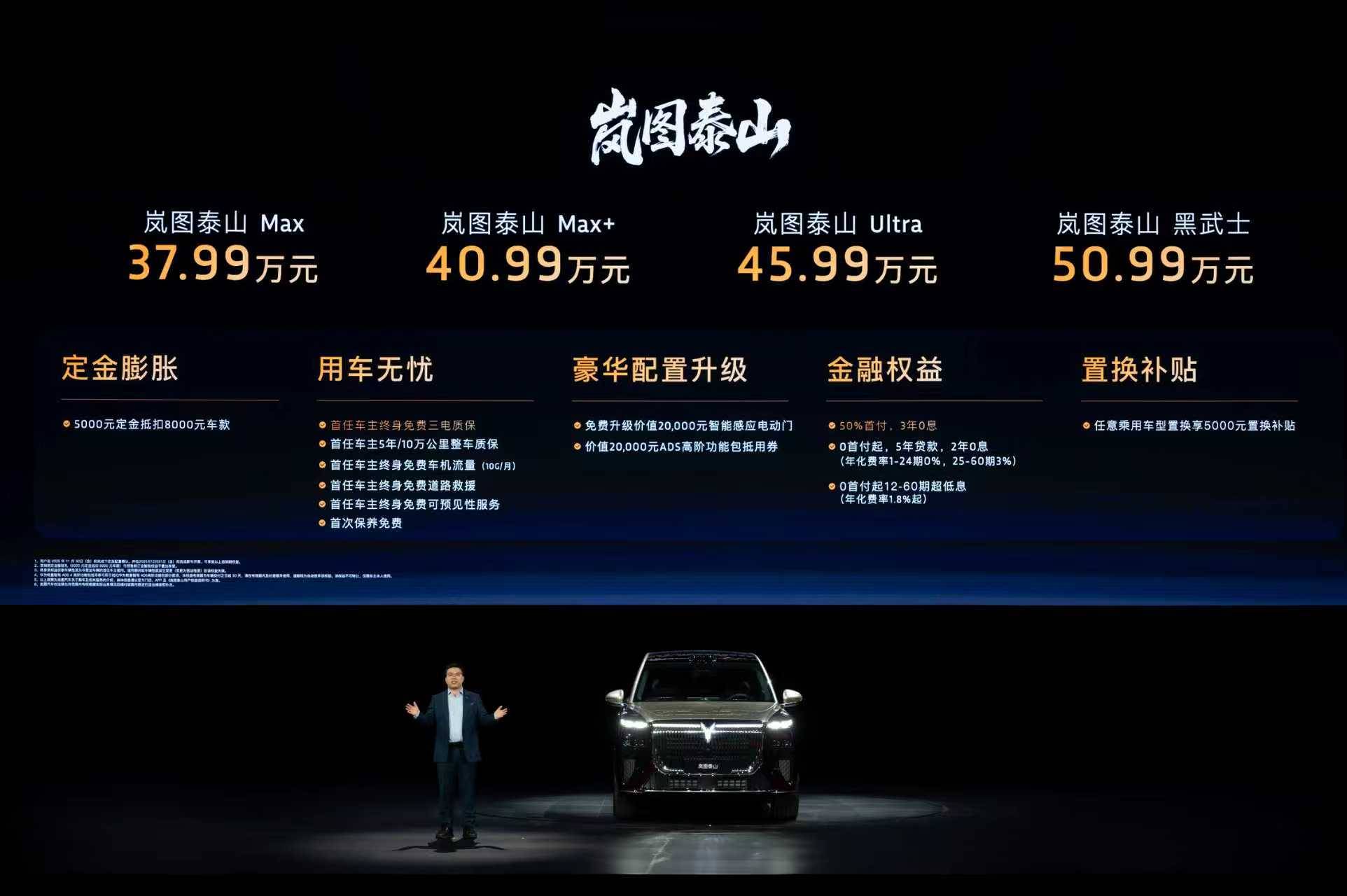
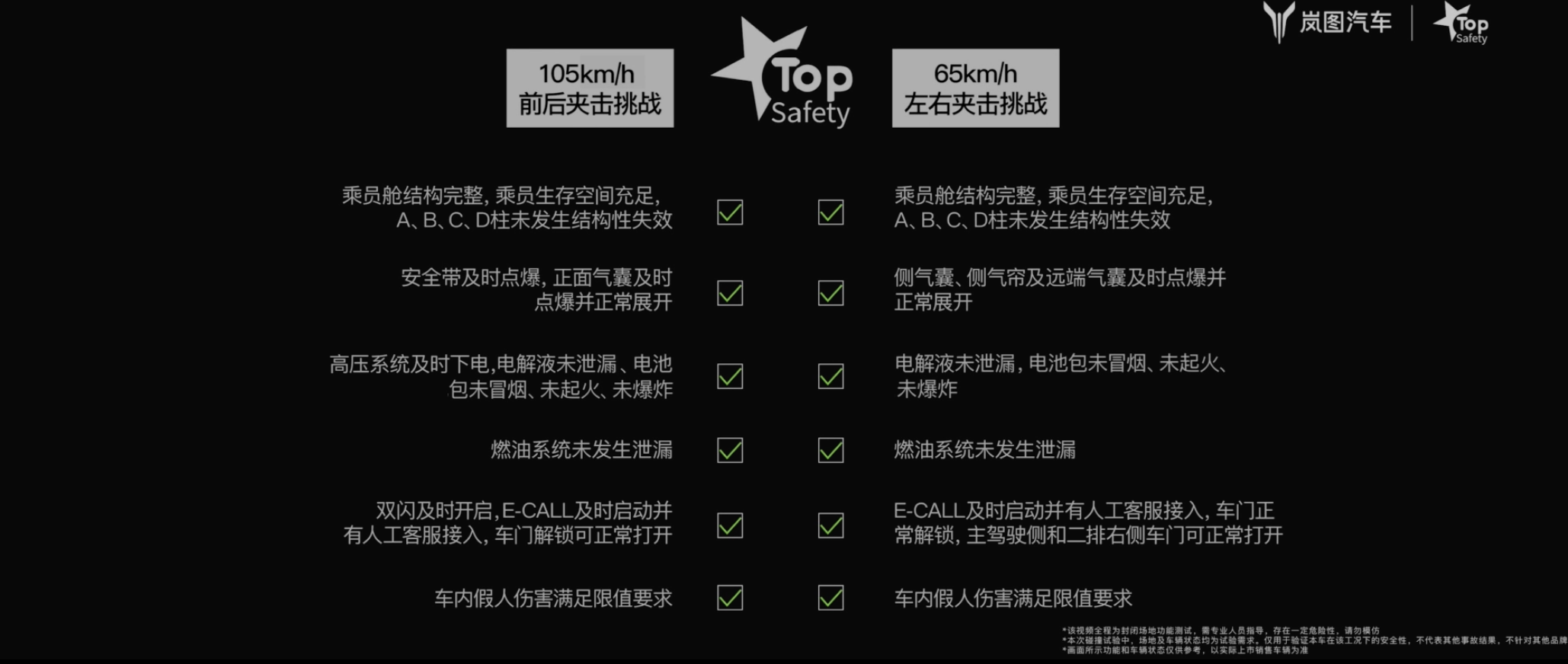
 岚图最新推出的旗舰 SUV「泰山」,选择了一条「高配置+强整合」的路径,将 800V 高压平台、三腔空气悬架、华为乾崑智驾 ADS 4、鸿蒙座舱 5 等当前主流高端技术模块,系统性地整合进一台大六座插电混动 SUV 中。
岚图最新推出的旗舰 SUV「泰山」,选择了一条「高配置+强整合」的路径,将 800V 高压平台、三腔空气悬架、华为乾崑智驾 ADS 4、鸿蒙座舱 5 等当前主流高端技术模块,系统性地整合进一台大六座插电混动 SUV 中。