65 岁图灵奖得主终于不用向 28 岁辍学生汇报了,小扎是怎么把他气走的

那个站在 LLM 风口上唱反调的倔老头,可能要离开 Meta 了。
硅谷大佬出走创业,三天两头就有一桩,但要出走的 Yann LeCun 不一样,他是能让扎克伯格亲自登门的重量级人物,是深度学习三巨头之一,图灵奖得主,Meta AI Research 的开山祖师。
更重要的是,他这些年一直在干一件特别拧巴的事:站在全世界最热闹的 LLM 路线门口,举着牌子说「这帮人走错路了」。

现在《金融时报》传出他要离职,说他在筹备自己的初创公司,已经开始接触投资人了。注意,目前只是风声,言之凿凿地说 LeCun 已经离职创业,这显然是不严谨的。
只是,截至发稿前,面对铺天盖地的报道,Yann LeCun 本人还没吭声,这沉默本身,就很说明问题。
从三顾茅庐到分道扬镳,这十二年到底发生了什么?
2013 年那场豪赌,扎克伯格赌对了吗?
Lecun 与 Meta 故事得从 2013 年说起。
那段时间,正是深度学习蓬勃兴起的阶段。2012 年,Geoffrey Hinton 与其学生 Alex Krizhevsky、Ilya Sutskever 提交的 AlexNet 在 ILSVRC-2012 一骑绝尘,top-5 错误率约 15.3%,这个突破让整个学术界和工业界都看到了神经网络的潜力。
然后就是科技巨头们的抢人大战——谷歌花大价钱收购了 Hinton 所在的创业公司 DNNresearch,顺带把老爷子本人也挖走了;微软研究院也在疯狂扩张 AI 团队。

扎克伯格坐不住了。
Facebook(现为 Meta)当时正在从 PC 互联网往移动互联网转型,新闻推送算法、照片识别、内容审核,哪哪儿都需要技术。
但问题是,Facebook 的 AI 能力跟谷歌、微软根本不在一个量级。扎克伯格需要一个能撑起门面的人物,最好是那种在学术界有足够分量、能吸引顶尖人才加盟的大牛。
他盯上了 Yann LeCun。
LeCun 当时在纽约大学当教授,已经干了十多年。那时的 Lecun 自然不是什么新人,早在 1989 年,他就在贝尔实验室搞出了卷积神经网络 (CNN),用来识别手写数字,这后来也成了计算机视觉的基石。

但那个年代深度学习不受待见,LeCun 就这么冷板凳坐了许久,眼睁睁看着自己的研究被边缘化。直到 2012 年,Hinton 用深度学习拿下 ImageNet 冠军,证明了神经网络这条路走得通。
LeCun 憋了的那口气,终于能吐出来了。
后续,扎克伯格亲自登门拜访。具体谈了什么外人不知道,但最后开出的条件足够诱人:
第一,给钱,主打一个资源自由;第二,给自由,LeCun 可以保留纽约大学的教授身份,继续教书搞研究;第三,给权,让他参与建立 Facebook AI 研究院,怎么招人、做什么方向,全由他说了算。
这对一个憋屈了多年的学者来说,简直是梦寐以求的机会。
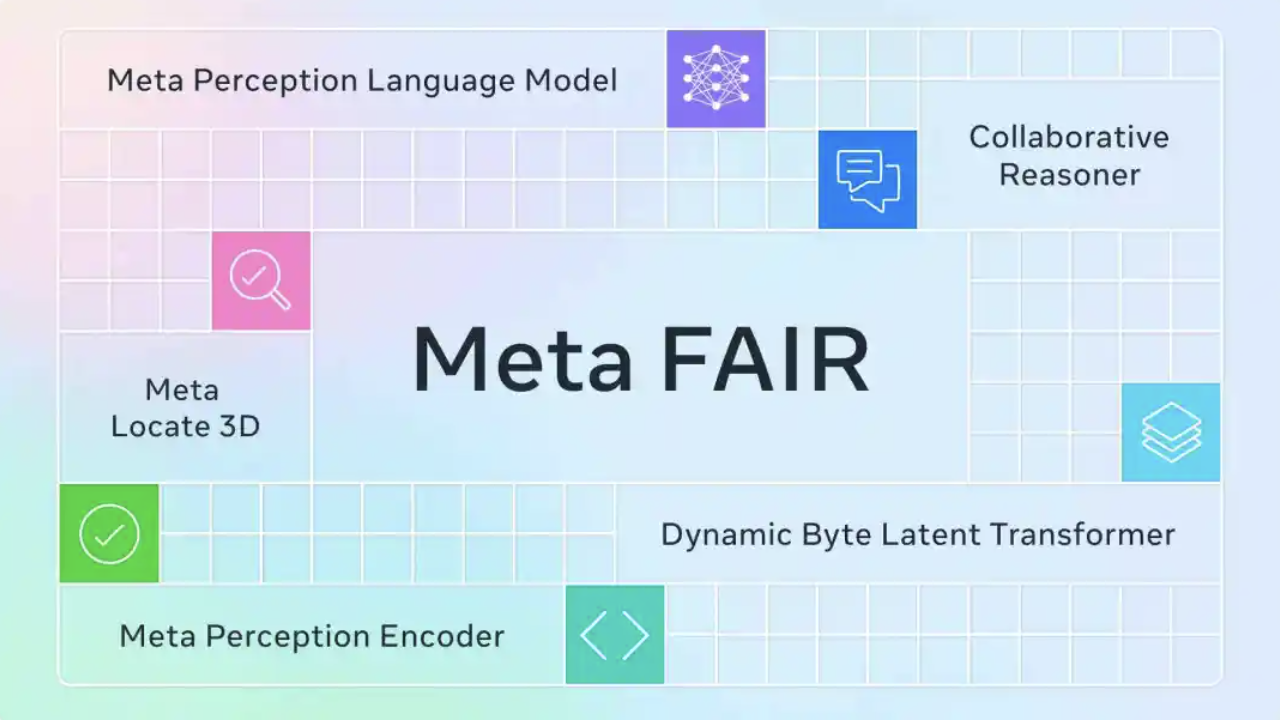
2013 年末,LeCun 正式加入 Facebook,出任新成立的 Facebook AI Research(FAIR) 实验室负责人。

他在纽约、门洛帕克和伦敦三地建起了 FAIR 实验室,自己常驻纽约办公室。
团队最初规模较小,但个个都是从顶尖高校和研究机构挖来的——LeCun 的号召力在这时候体现出来了,但凡是做深度学习的,没人不知道「卷积神经网络之父」这个名号。
扎克伯格给了资源,LeCun 也拿出了成果。
加入 Facebook 这些年,LeCun 干的事情可以分成三条线:一是把深度学习塞进 Facebook 的产品里,二是推动学术界的前沿研究,三是培养下一代 AI 人才。
产品线上,2014 年的 DeepFace 人脸识别系统达到 97.35% 准确率,深度学习优化的推送算法也提升了广告点击率。
与此同时,LeCun 自己继续在学术圈刷存在感:发论文、顶会 keynote、带学生办 workshop。直到和 Hinton、Bengio 一起拿图灵奖, 才算是熬出头了。

此外,在 LeCun 创建的 FAIR 实验室,Soumith Chintala 主导开发了 PyTorch 框架并于 2017 年开源,这也是 Meta 至今为数不多的形象招牌。
PyTorch 动态计算图、Python 原生接口, 调试方便, 学术圈迅速倒戈。这一招等于把全球 AI 研究者都拉进了 Facebook 生态。
不过,或许是冥冥中自有天意,Soumith 前几天也宣布离职 Meta,表示「不想一辈子做 PyTorch」。
而更重要的是人才培养。FAIR 有个规矩:研究员可以自由发表论文、跟学术界合作、指导外部学生。顶级资源加学术自由的组合,自然吸引了一批顶尖研究人员。
到 2020 年前后,FAIR 已是全球顶尖 AI 研究机构之一, 跟谷歌 DeepMind 并列第一梯队。扎克伯格的那场豪赌, 至少在前七八年就已经得到了不小的回报。
猫比 ChatGPT 聪明?这个图灵奖得主是认真的
在 ChatGPT 席卷世界初期,Yann Lecun 和扎克伯格也有过一段甜蜜期。
2023 年以来,Meta 陆续开源 LLaMA 系列模型,引发业界震动。
OpenAI、谷歌走的是封闭路线,靠 API 赚钱;Meta 却把模型权重直接扔出来,任人取用。这步棋背后的算盘其实挺清楚:与其让对手一家独大,不如用开源赢得开发者生态,让 LLaMA 成为 AI 界的 Android。
至少在明面上,身居 Meta 首席 AI 科学家一职的 LeCun,是这条路线最坚定的拥护者。
开源 LLaMA 让 Meta 在大模型竞赛中站稳了脚跟,也让 LeCun 的 AI 理想得到了一定程度的实现——尽管这个实现的方式,恰恰是通过他并不完全认同的 LLM 技术路线。

没错,LeCun 一直觉得 LLM 是条死胡同。这才是矛盾的核心。
LeCun 不止一次在公开场合炮轰 LLM 路线,在他看来,LLM 只会根据统计相关性预测下一个词,根本不理解世界。你问它常识问题,它能给你编出一本正经的瞎话——这叫「幻觉」(hallucination),说白了就是不懂装懂。
熟悉 LeCun 的人都知道,他最喜欢举的例子是猫和机器人:
「我们有了会考试聊天的语言模型,但家务机器人在哪里?哪怕像猫那样灵巧的机器人都没有出现。」
「你的猫肯定有一个比任何 AI 系统都更复杂的模型。动物拥有持久记忆的系统,这是目前的 LLM 所不具备的;能够规划复杂动作序列的系统,这在今天的 LLM 中是不可能的。」

他算过一笔账:一个 4 岁小孩通过视觉获取的信息量,几年下来就有 10 的 15 次方字节,远超 LLM 读遍互联网文本。但小孩已经掌握了基本的物理直觉和语言,LLM 耗费这么多数据,智能仍然很有限。
「光靠喂文本,不可能达到人类水平智能。这条路永远走不通。」他如此说道。
在当下最火的风口面前,这样唱反调的言论显然并不讨喜,有人批评他傲慢,有人说他故步自封。甚至 Meta 内部都有声音认为,正是 LeCun 对 LLM 路线的抵触,让公司在大模型竞赛中暂时落后。
但 LeCun 不在乎。
他有自己的路线图:世界模型 (World Model)、联合嵌入预测架构 (JEPA)等等。这些概念听起来学术味十足,核心思想其实很直观——
让 AI 通过观察世界来学习,而不是通过阅读文本来记忆。就像婴儿成长那样,先理解重力、因果关系这些物理常识,再逐步建立抽象认知。
他设想的 AI 架构是模块化的:感知模块、世界模型模块、记忆模块、行动模块,各司其职。不像 LLM 那样把所有知识和推理揉在一个巨型网络里,搞得像个什么都懂但其实什么都不懂的「书呆子」。

具体来说,世界模型就是让 AI 在内部学会一个对外部世界的预测模型。就像婴儿在成长过程中建立起对重力、物体恒存等常识那样,AI 应该通过观察世界,形成对物理规律、因果关系的理解。
有了世界模型,AI 就可以在脑海中模拟未来,从而具备计划行动的能力。
JEPA 则是实现这个世界模型的具体架构。
它采用自监督学习的方法,给 AI 两个相关的输入 (比如视频中相邻的两帧画面),模型将这两个输入分别编码到一个抽象的表示空间中,然后训练一个预测器,根据「上下文」表示去预测「目标」表示。
这种方式避免了直接生成所有细节,而是关注抽象的关键因素——更符合人类学习方式。LeCun 曾预言,如果团队的路线顺利推进,三到五年内就会有更好的范式出现,使得现在基于 LLM 的方法过时。
问题是,三到五年,Meta 等得起吗?
一场猝不及防的重组,FAIR 的黄金时代结束了
当初,LeCun 建立 FAIR 时的承诺是「做长期的、基础性的 AI 研究」,扎克伯格也同意了。
但这个「长期」到底有多长?「基础研究」到底能给公司带来多少直接收益?这些问题在早期不是问题,因为深度学习本身就是风口,FAIR 做什么都有望转化成产品优势。
可随着生成式 AI 开始爆发,竞争也日益激烈,形势开始发生了变化,尤其是 Llama 4 的失败也给了扎克伯格当头一棒。扎克伯格要的是现在就能用的技术,不是五年后可能有用的理念。
于是,一场猝不及防的重组出现了。
就在今年,Meta 搞了个大动作,成立「超级智能实验室」,把 FAIR、基础模型团队和各应用 AI 团队统统塞进一个筐里。表面上是整合资源,实际上是一场彻底的权力重组。

这场重组的核心逻辑很明确:让研究直接服务产品,让科学家为商业目标让路。
FAIR 团队原本「相对不受干扰地开展研究」,现在得跟着产品节奏走,研究方向要服务于个人 AI 助手。此外,Meta 对 FAIR 的研究发表制定了更严格的内部审核机制。
研究员在对外发布论文、开源代码之前,需要经过额外的内部交叉审阅和管理层审批,原因在于 Meta 担心自己砸钱搞出来的成果被竞争对手白嫖。
LeCun 对这些变化表现出强烈的抵触。
据多方报道,他在内部激烈反对新的论文审核制度,为维护研究自由据理力争。The Information 援引知情者的话称,LeCun 在今年 9 月一度「气到考虑辞职」以示抗议。

但或许更让他难以接受的是领导权的旁落。
扎克伯格在重组中做了一个大胆的人事任命:从外部挖来 Alexandr Wang,让他担任 Meta 的首席 AI 官,直接向 CEO 汇报。
Alexandr Wang 是谁?一个 28 岁的 MIT 辍学生,他创办的公司 Scale AI 专门做数据标注业务,给各大科技公司的 AI 模型提供训练数据。
扎克伯格看中的,恰恰是 Wang 的产品思维和商业嗅觉。在生成式 AI 的竞赛中,Meta 需要的不是象牙塔里的理想主义者,而是能快速把技术转化为产品的实干家。
这个任命的震撼在于:LeCun 这个图灵奖得主、深度学习三巨头之一、在 Meta 干了十二年的首席 AI 科学家,在新架构下的话语权被大幅削弱,甚至要向 Wang 汇报。
同时,今年 7 月,扎克伯格还任命了年轻有为的赵晟佳为超级智能实验室的首席 AI 科学家,负责制定新实验室的研究方向。

有趣的是,LeCun 当时发了个声明,说自己角色没变、使命没变,还期待跟新团队合作。这求生欲属实拉满。但他对于研究方向和领导层重组的分歧,显然是公开的秘密。
而真正可能成为压垮骆驼的最后一根稻草的,是最近的裁员。据报道,Meta 近期对 AI 团队进行了裁员,波及到 FAIR 研究部门以及与产品相关的 AI 团队,甚至华人大佬田渊栋也因此受到了波及。
裁员的信号很明确:Meta 不再愿意为「看不到短期回报」的基础研究买单了。那些不能直接转化为产品功能、不能立即提升用户增长或广告收入的研究方向,都成了被砍的对象。

FAIR 的黄金时代结束了。
种种因素之下,《金融时报》爆料他在筹备创业,倒也不算意外。
学术大佬出来单干,最近几年已经成了硅谷新常态。Hinton 退休后到处演讲呼吁 AI 监管,Bengio 也有自己的实验室和创业项目。LeCun 若是真出去创业,没准反而是好事。说到底,这事儿没有谁对谁错。

LeCun 能够在 Meta 之外继续他毕生的事业。
他带走了那个被 Meta「搁置」的愿景,可以放开手脚搞自己的世界模型,用自己的方式证明它是正确的,再也不用跟产品经理扯皮,不用向 28 岁的小老弟汇报。
成了,那就是「我早说过 LLM 是死路」;败了,顶多被人嘲笑几句「你看那个老顽固」。
而对于 Meta 来说,扎克伯格要给股东讲故事,要把最实用的生成式 AI 塞进旗下产品的各个角落,这确实是 CEO 该干的事。
只是,尽管少了 LeCun 也不会伤筋动骨,但可能会少点不一样的声音。等哪天大家发现 LLM 真的走到瓶颈了,回头看看当年那个举着反对牌子的倔老头说过什么,或许会觉得别有一番趣味。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。







































































 杨振宁逝世,享年 103 岁
杨振宁逝世,享年 103 岁
 苹果 CEO:Apple Intelligence 正努力入华
苹果 CEO:Apple Intelligence 正努力入华
 OpenAI 推「ChatGPT 登录」功能,打造个人 AI 订阅生态
OpenAI 推「ChatGPT 登录」功能,打造个人 AI 订阅生态
 https://www.theinformation.com/articles/openais-growing-ecosystem-play?rc=qmzset
https://www.theinformation.com/articles/openais-growing-ecosystem-play?rc=qmzset 我国生成式人工智能用户规模超 5 亿
我国生成式人工智能用户规模超 5 亿 维基百科警告:AI 导致人类访问量大幅下降
维基百科警告:AI 导致人类访问量大幅下降
 Gemini 3.0 或将于 12 月发布
Gemini 3.0 或将于 12 月发布 OpenAI 宣布自研 AI 芯片
OpenAI 宣布自研 AI 芯片
 英伟达开售全球最小 AI 超级计算机,黄仁勋给马斯克「送货上门」
英伟达开售全球最小 AI 超级计算机,黄仁勋给马斯克「送货上门」
 Windows 11 迎来重磅更新:Copilot 全面接管语音、屏幕与任务栏
Windows 11 迎来重磅更新:Copilot 全面接管语音、屏幕与任务栏
 Figma CEO 称 AI 不会取代工作,各部门持续招聘
Figma CEO 称 AI 不会取代工作,各部门持续招聘 前 OpenAI 科学家卡帕西:AGI 仍需十年,强化学习存在根本缺陷
前 OpenAI 科学家卡帕西:AGI 仍需十年,强化学习存在根本缺陷