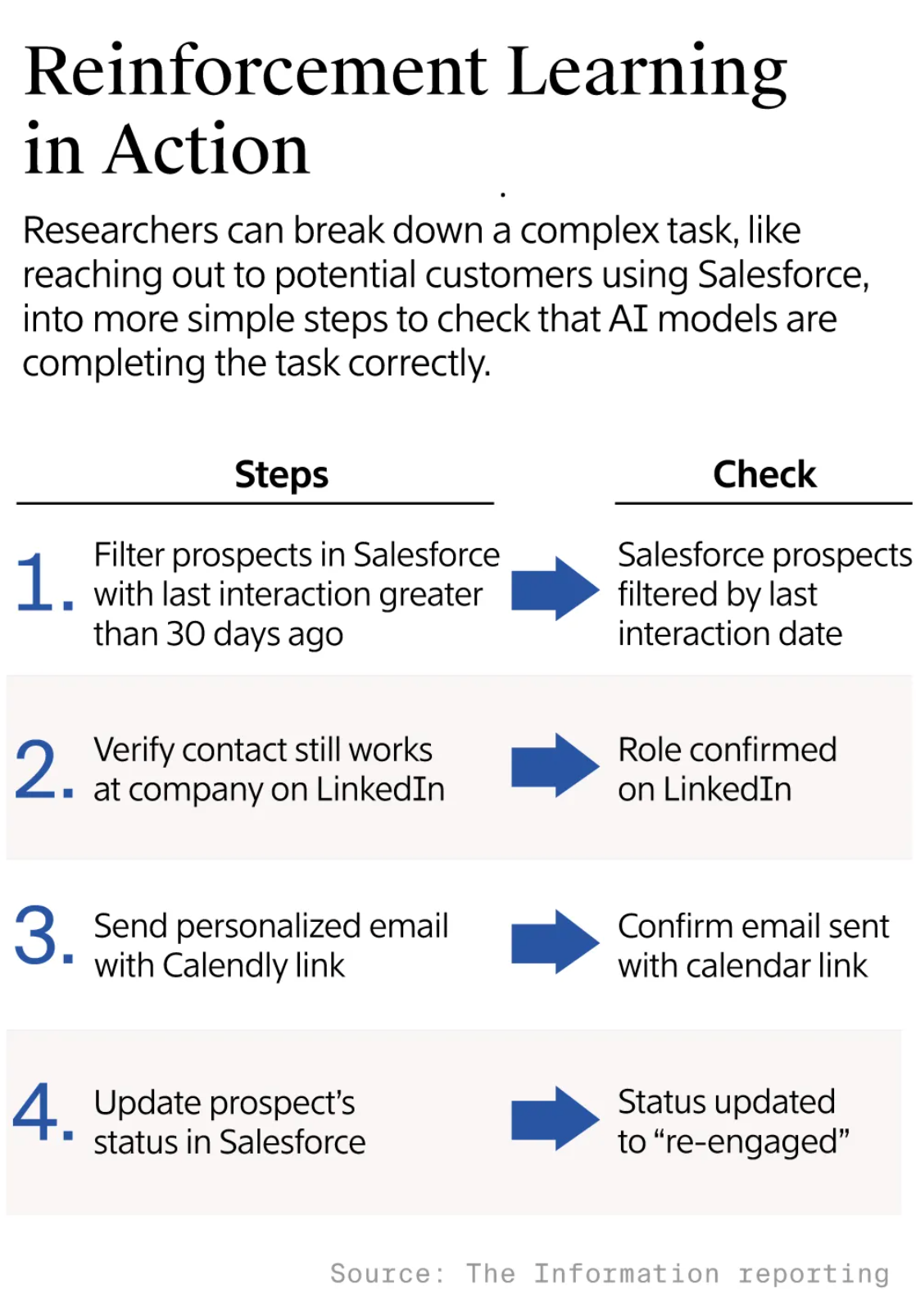
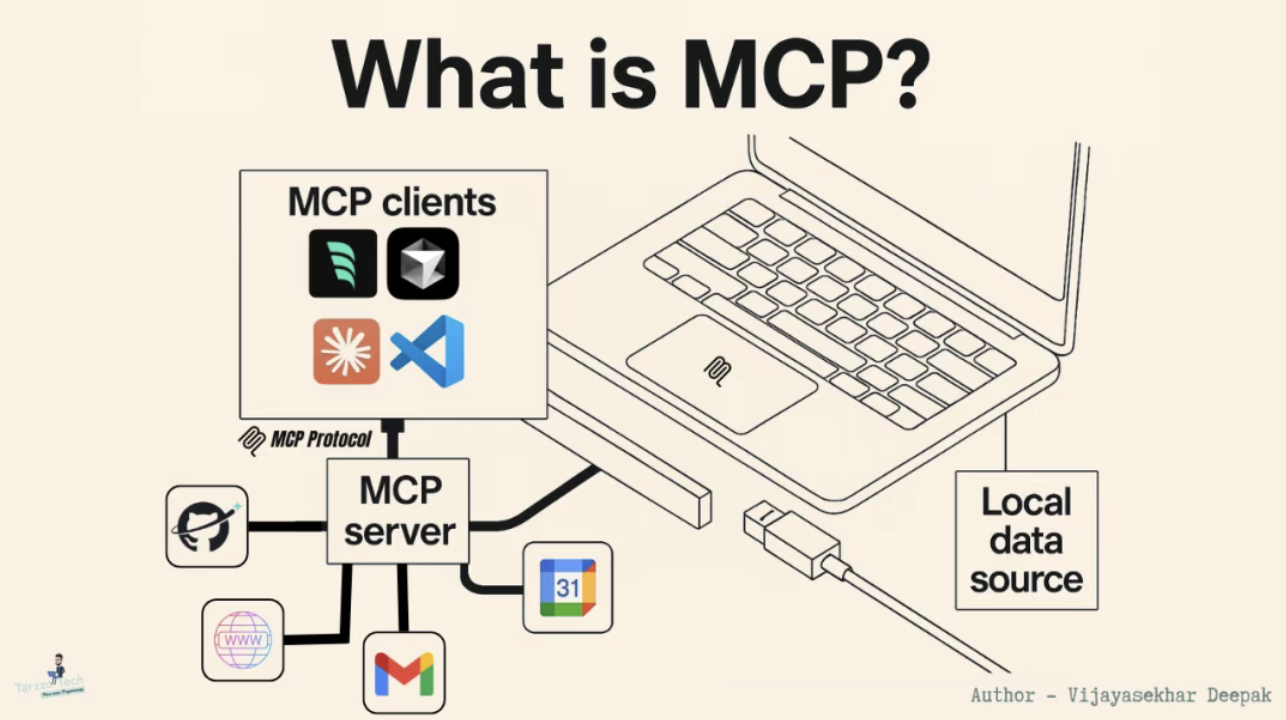
爱范儿关注「明日产品」,硬哲学栏目试图剥离技术和参数的外衣,探求产品设计中人性的本源。
「真正认真对待软件的人,就应该自己做硬件」,图灵奖获得者亚伦·凯 (Alan Kay) 曾如是说。
这句话在当时是对软件思维的一种挑战——它要求开发者跨越边界,理解硬件的底层逻辑。凯本人在图形界面、面向对象编程等领域的开创性工作,深刻影响了后来的计算设备形态。但他留下的这句名言,并不是在谈技术本身,而是在提醒人们:软件的创造,离不开对承载它的硬件的深刻理解与掌控。

亚伦·凯 图|Aleksandra Szpunar / Netguru
半个世纪之后,凯的观点几乎已成为常识。但如果我们做个思想实验,把这句话反转一下呢?「真正认真对待硬件的人,就应该自己做软件」。
软件与硬件,从来都是相互映照的两面。让人喜欢一款硬件的,往往不是它的参数或材质,而是那层赋予它连贯体验与生命感的软件。
然而,在智能设备硬件性能不断跃升的今天,真正投入心力打磨软件体验的厂商却并不多见。缺少结构紧密、体验优雅的软件,再出色的硬件也难以充分展现潜能。最终,它可能只是性能出众的零件集合,而不是一个有灵魂的整体。
四十多年后,有一家公司依然在践行亚伦·凯的理念——vivo。它持续思考着软硬件结合的边界与方式,而 OriginOS 6,正是这一思考的最新成果。
在 OriginOS 6 上,vivo 尝试以操作系统为媒介,让设备与用户之间的关系更接近「真实世界」。光线会随环境而变,图标坠入桌面会泛起细微的涟漪,界面元素似乎拥有呼吸的节奏。Android 与 iOS 这两种系统,在这里并非模仿或拼贴,而是获得了一种意料之外、情理之中的交融。
如果说 vivo 智能手机是「地球」,那么 OriginOS 6 便是孕育其上的有机世界。它并非为了炫技,而是在尝试回答一个更有趣的问题:当软件被赋予生命感时,硬件是否也能因此变得更有人性?

光影:给系统加上物理法则
Let there be light.
OriginOS 6 最显著的变化,是光进入了系统。不是比喻意义上的「光明」,而是真实可感的光线——环境光、弥散光、边缘光——兼具交互设计意图与视觉审美的综合表现。
系统控件因此更具通透感,按钮按下的瞬间会闪过一道细微的微光。输入锁屏密码时,数字键被瞬时点亮,那种明灭之间的反馈,让操作更有触感。一些重要控件,例如闹钟设置按钮,也在底部融入了弥散光效,以轻柔的方式暗示其在界面中的层级与重要性。
一些系统控件,如「浮动动作按钮」(FAB) 的浮动控件感更强,且呈现弥散光效,向周围界面晕染
更巧妙的是,对「陀螺仪」这一早已习以为常的元器件,OriginOS 6 做出了新的利用:在不同界面中,随着手机轻轻摆动,屏幕会呈现出细微的明暗变化,仿佛光线也随视角而转。
在真实世界里,光的入射角决定了物体的质感。OriginOS 6 将这种物理规律引入屏幕世界,让图标、卡片和控件获得了厚度、层级与光感,成为具有真实存在感的「物体」。
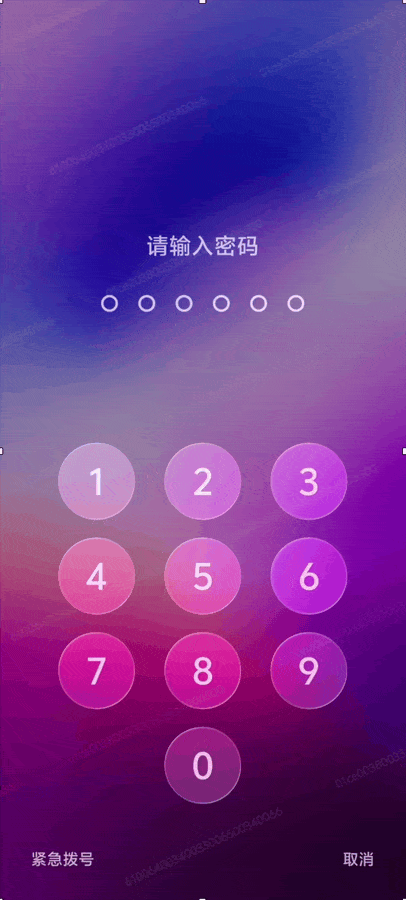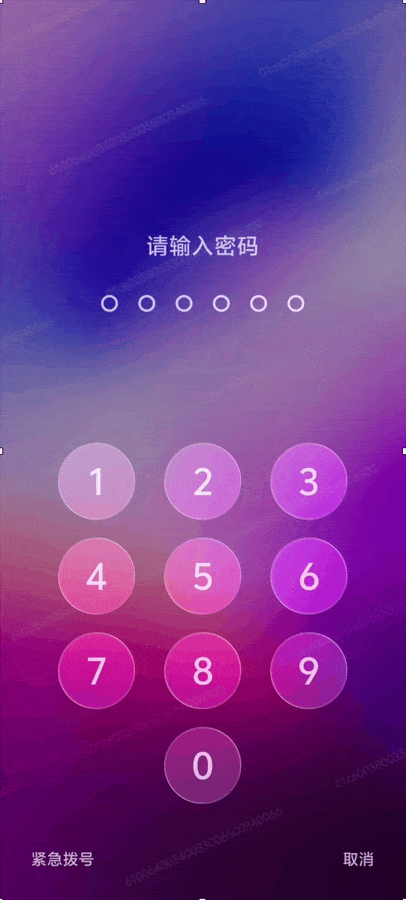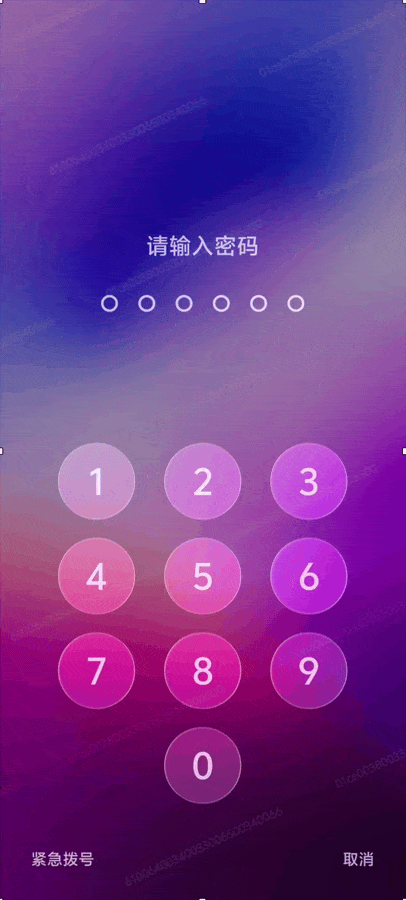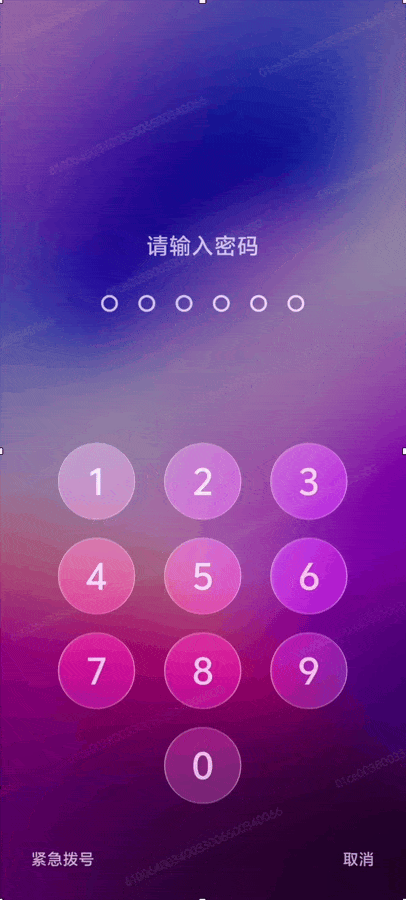
随着手机转动,界面元素周围的光效入射角度发生变化,呈现出光影流转的视觉感受
最能体现这一点的,是全新的锁屏主题「趣味光栅」。
设置最多四张照片作为光栅壁纸后,左右摇晃手机,画面会随角度变化而流动——像小时候收藏的光栅卡片,从不同方向能看到不同图案。静态图片、Live Photo、视频等都可转化为互动壁纸。
我用相机的 AI 换天功能,生成同一场景下午后、傍晚、夜间的三个「版本」,设置为光栅壁纸。每当我轻轻转动手机,光影流转,仿佛时间在掌中缓缓移动。那不是炫技,而是一种把传感器数据转化为感知乐趣的尝试:屏幕里的世界,真的动了起来。

有了光之后,是空间。
OriginOS 6 在界面层级之间加入了渐进式模糊,让屏幕有了纵深感。下拉通知中心或右滑进入负一屏时,背景会自然虚化,焦点始终停留在当前操作上。清晰与朦胧之间的差异,让系统能更直观地区分内容与背景、主与次。
vivo 还重新设计了通知栏的堆叠方式,让来自同一应用的消息以层叠形式归拢,重要内容浮现,次要信息收束。新的控制中心将快捷开关与通知内容合并,减少层级切换,使操作路径更自然。

每一界面层级浮现时,都会为下一层级带来模糊效果,谓之「渐进式模糊」
这些变化的底层逻辑,是一种对系统空间语言的重新定义——「空间体系 2.0」。过去的触屏界面多以灰阶与色彩来表达层级,而今天的硬件算力足以让界面拥有真实的光影、深度与材质。
当用户与系统交互时,屏幕中的元素不再是静态贴图,而是有厚度、有呼吸的对象。纵深、模糊与光影共同构成了新的空间规则,也让扁平化设计走向更立体的方向。
到头来,真实世界从不是光滑的二维界面。光线、层次、反射——这些自然法则在屏幕上重生的方式,不应是简单模拟,而是要找到「和而不同」的平衡:手指触碰即有反应,光线与角度自然呼应。
手指按下去,光亮起来;手机倾斜,画面随之流动;不重要的内容可以被堆叠、在需要时展开——这便是「系统即世界」的第一层含义:用户不再操作一个系统,而是在与一个世界互动。
交互:让界面可以韵律呼吸
系统有了基础的物理法则,也需要生命的节奏。真正的流畅并不只是「快」,而是「对」。
系统在动效优化上选择了「丝滑轻盈,自然舒适」的方向。每一次操作都符合现实世界的运动规律——有惯性、有回弹、有停顿。全局弹簧动效是其基础:拨动开关、拖动音量条、下拉刷新,界面都会「过冲」一点再回弹,像拉伸后的弹簧。
拖动桌面图标时的涟漪效果尤其有趣:图标落下后,周围图标微微外扩再回收,像是石子入水。涟漪范围不大,却让桌面有了生气。

图标拖拽的「涟漪」动效
这种「活性」延续自前代 OriginOS 的原子组件体系。现在,它被进一步扩展至全局,从指纹解锁、充电动画到窗口切换,都遵循同样的动态规律。界面不再是固态的平面,而像液体一样流动。
动效的统一性也更强。打开或退出应用时,图标与窗口会顺势放大、缩小、归位,动作起终点清晰对应,像从书架抽出一本书再放回原位。
比如在 OriginOS 6 上重新设计的原子岛收起展开效果,vivo 的设计理念是采用「帧形变」技术对界面元素的形态进行有机转换,从而表达出元素之间的逻辑关联。并且,物理法则的逻辑同样得到连续,元素之间的拉丝、融合、滴落等形变效果模拟出真实的物理连接。
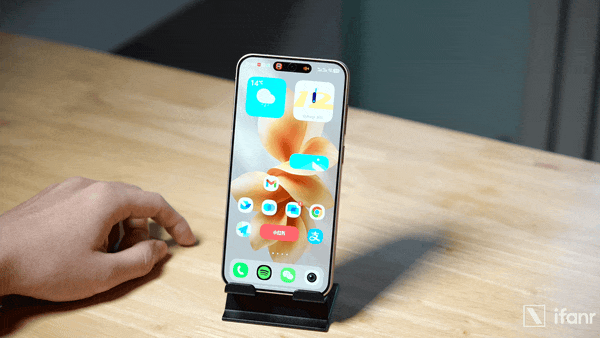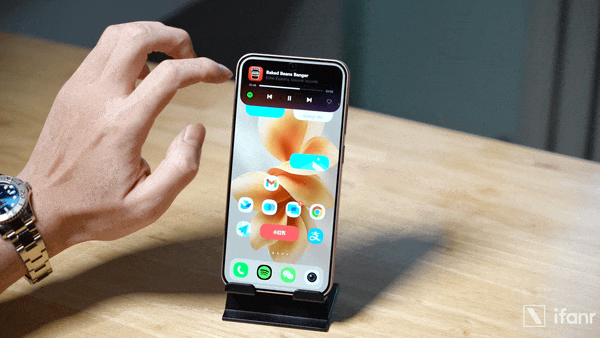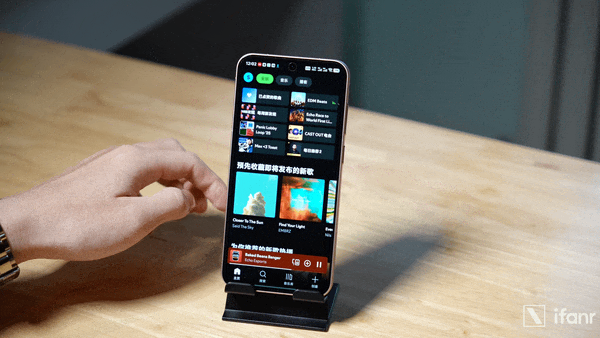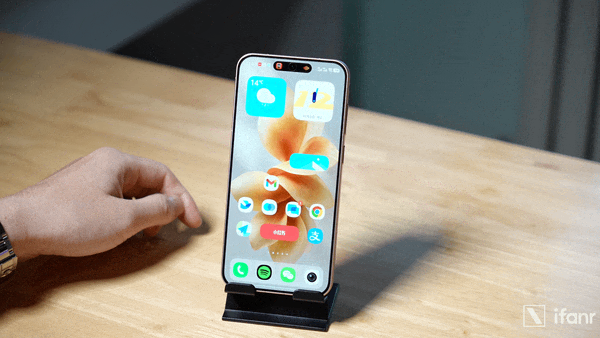
原子岛展开、收回的动效,在 OriginOS 6 上通过「帧形变」技术重新设计
而我觉得在界面交互上最体现设计团队用意的,莫过于小窗旋转效果。在 OriginOS 6 上,当手机当前处在同屏小窗/画中画模式下,切换横屏竖屏,小窗获得了一个自然移动的动效。
背后,这一新设计利用了视觉连续性原理,通过强调空间连贯性来消除视觉焦点的「断层」,帮助用户保持聚焦,显著提高沉浸感。

当开启小窗并旋转屏幕时,小窗动效会遵循设备旋转的方向
底层的「蓝河流畅引擎」和「超核计算」系统负责协调这一切,使视觉流畅与算力分配达成平衡。但这些技术存在于「无形」——用户不需理解它,只需感受到动作的呼吸感:滑动的阻尼、切换的节奏、回弹的柔韧。
OriginOS 6 在无数细节中让系统变得更有「活性」。这些细节微小,却在累积中构成生命感。流畅的体验能够触发用户潜在的愉悦舒适感——不是因为速度,而是因为节奏。
这是「系统即世界」的第二层含义:世界从不静止,而是「活着」的。
连接:对友好生态打开边界
一个世界如果只有自循环,终将走向封闭。
手机行业这些年的主旋律是「筑高墙」。从系统功能,到配件连接,到充电协议,各家都在修筑自己的生态,让设备之间的壁垒越来越厚,iOS 与 Android 成了两座平行宇宙,设备与设备之间形成孤岛。生态内部的体验顺滑,而跨越边界却步步受限。
这种封闭策略自有商业逻辑,但用户为此付出的代价也在增长——想要流畅体验,就必须被锁进单一生态,生活被技术的边界切割得支离破碎。
但生态和生态之间从来不应该是绝缘的。在真实世界中,我们反而会看到物种之间的交融,催生新的生命。当 iOS 和 Android 不再「强行兼容」,而是真正有机融合,那会是怎样一番图景?

OriginOS 6 选择了另一条路径:拆掉部分墙,让世界重新连通。
新版本的 vivo 互传 app,让此前所有同行所做的「生态破壁」努力都相形见绌。在 OriginOS 6 上,用户可以直接访问、编辑 iPhone 或 iPad 上的照片与视频,修改后自动同步回去。文件不再只是「传输」,而是在两个系统之间共享状态。

在相册应用中利用「跨端随心编」技术,直接对 iPhone 本地照片进行编辑
这已经不是简单的文件互传,而是让两个系统的数据层发生了交融。但其实所有的技术突破都不如带来的便捷体验更有说服力:你可以直接在一部 Android 手机上打开朋友的 iPhone 相册,为 ta 修图,无需额外应用或中转步骤。
进一步的尝试,是 OriginOS 6 引入的「摇一摇群组分享」功能。
当多个用户同时摇动手机,系统会自动创建一个共享群组——无需登录账号、无需数据流量。创建成功后,用户可在相册、互传或文件管理界面中选择任意数量的照片或视频进行分享,实现无损、极速的大批量传输。
vivo 手机之间可直接拖拽至原子岛发送;而跨系统的分享(如 iOS)则可通过安装「互传」应用实现同样的效果。这种方式的意义不仅在速度或便捷,而在于它将分享重新变成了一种自然的动作:几个人同处一地,轻轻一摇,设备之间就建立起短暂却高效的连接。

双系统打开互传并「摇一摇」,即可快速建群,无损收发文件
跨设备连接的终极形态,是 vivo 的 AI 助理「蓝心小 V」可以对各种智能家居生态实现统一控制。传统的智能家居体验是碎片化的:米家的设备要打开米家 app,HomeKit 的设备要用苹果「家庭」,其他品牌又各有各的入口。而 vivo 的 AI 助理「蓝心小 V」能识别用户的自然语言意图,跨品牌控制家电设备。无论是小米的台灯,还是飞利浦的灯泡,都能被同一句指令调度。
现实生活从不是单一生态的样板间:你可能经常用 iPhone 来拍视频,但用 Android 手机作为主力机;你的智能家居可能由两三种不同的「全家桶」分别组成;你的电脑平板是苹果,但汽车是小鹏……我们使用着不同品牌的设备,也更期待它们像一个整体协作。
按理来说,每个设备都应该主动为你服务,但在彼此封闭的生态下,要记住哪些设备能协同互联,哪些不能,反而成了用户的责任。
归根结底,生活不该迁就技术,而是技术应该服务生活。然而在现实中,商业权衡往往凌驾于用户体验至上,用户难免因为「生态站队」而受到体验和便利性的惩罚。
OriginOS 6 有着一个全然不同的「世界观」。这也是「系统即世界」第三层含义是:外部设备不应是敌人,而应成为可交互的邻居——世界的价值不在孤岛,而在连通。
这样的未来如果想要显化,觉悟不应该只属于 vivo 一家。

意识:当系统开始理解、自生
世界有它的运行规则,也有自我修正的能力。
在 OriginOS 6 上,人工智能将扮演一个更大的「意识」载体,它不只是响应指令,而是理解上下文、串联信息、记住习惯。系统因此从工具变为伙伴。
最直观的体现,就是升级后的全新「小V圈搜 2.0」。在此之前,移动操作系统更多基于截图识别理解内容,而在 OriginOS 6 上,它能识别整屏内容,根据用户圈选的文字或图像做出判断——地址会唤起导航,网购口令能直接跳转,会议信息可一键添加日程。
这个交互逻辑的合理之处在于:它把搜索从一步独立的操作,变成了与系统交互过程中的一种自然延伸。这就像是一个人在他的世界中不断探索,在每一次互动的过程中完成需要的目标,学到新的知识。
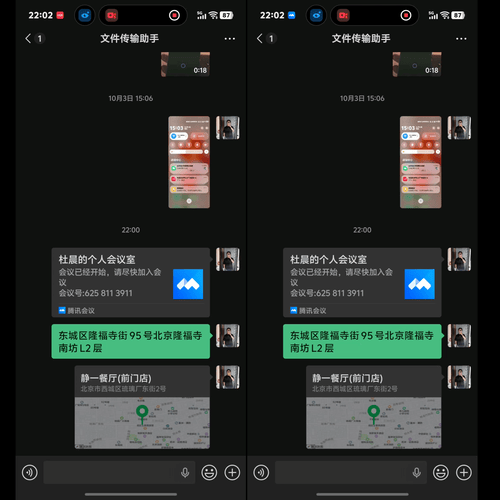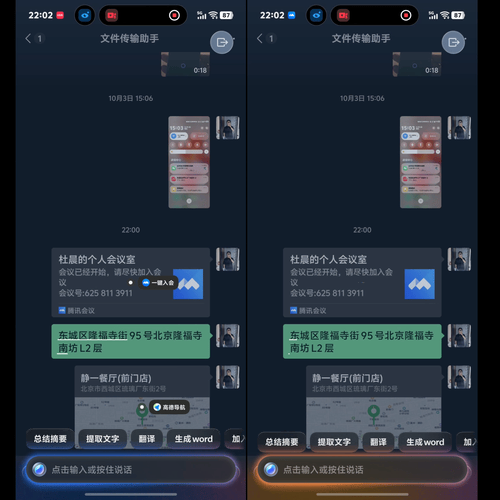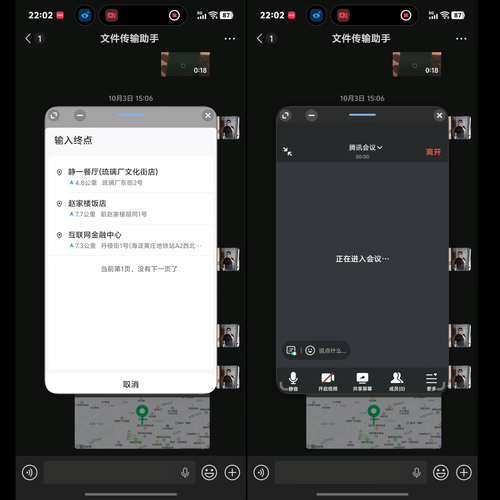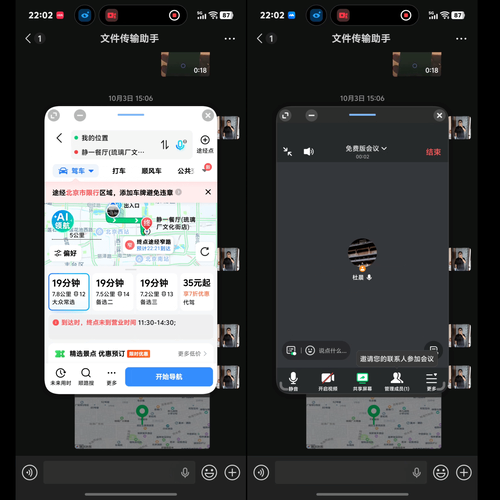
小V圈搜 2.0 版,能够根据屏幕上的内容智能推荐下一步操作
这是一种基于语境上下文的高级 AI 代理能力的体现,其实在前一代 OriginOS 5 那个无所不能的原子岛上就有所体现。但 vivo 发现「一键上岛」并没有被充分利用,用户可能更加习惯通过常规入口(例如电源键、长按底部指示条)唤起 AI 功能。于是在 OriginOS 6 上,vivo 继续采取原子岛和圈搜两种交互方式齐头并进的思路,确保在用户最习惯的地方,AI 总是能够准备好并迎接和理解他们。
这种理解能力,也被照片 AI 处理能力延伸到了 vivo 最引以为傲的影像层面。
对于 AI 消除这一早已不新鲜的能力, vivo 觉得还有潜力没有被挖掘。在 OriginOS 6 上,首次实现了对于 Live Photo 的路人消除能力。系统会理解画面元素的运动,以及背景的一致性;用户只需圈选一次,AI 便能自动追踪并生成纯净、且鲜活依旧的动态照片。

在 Live Photos 中智能消除路人和杂物
它还能学习用户的美颜习惯,观察并记录每次手动调整美颜参数的偏好,逐渐理解「你人为的理想自己」是什么样子。几次学习过后,美颜参数会自动匹配个人习惯,几秒钟就能替代长达 5-15分钟的手动精修,而且还能识别好兄弟好闺蜜,都能获得 ta 们的专属美颜效果,真正做到「千人千面」。
在 vivo 看来,AI 不需要替你决定「怎样好看」,而是应该更尊重和学习「你觉得怎样好看」。
其它 OriginOS 6 上的 AI 功能,比如小 V 记忆知识库、代接电话助手、文件智能重命名等等,都延续同一个逻辑:AI 的优势不在于替代,而是在于学习,学习你的使用模式,然后帮助你减少手动操作的步骤和精力耗费。这些功能单独看都不算革命性,但它们指出的方向不能更清晰:一个优秀的系统 AI 功能,不再被动等待指令,而是主动理解语境,并在合适的时候无缝嵌入。它的存在感轻微,却能在恰当的时刻伸出援手,如飞鸿踏雪泥。
这是「系统即世界」的第四层含义:世界的意识不在喧哗中诞生,而在持续的自我改进中显现。

在智能设备的漫长演化中,人们最终总会回到最质朴的问题:技术为何存在?
OriginOS 6 的答案是——让系统更像世界。
它用光影与空间重构了视觉秩序,用动效赋予系统生命节奏,用连接打破边界,用 AI 带来自我理解的可能。和前一代系统相比,它并不追求惊艳式的革新,而是保持了一种稳健的延续性,并在细节里让「系统即世界」的理念更加坚实。
OriginOS 6 的使用体验如果用两个字来形容,那就是「流畅」:解锁的起落有如呼吸, 界面之间井然有序的层次感,动效的连贯性,跨设备传输内容的「即拿即走」。这是一种「零思考成本」的秩序感——界面让路于注意力,让注意力让路于意图。

更重要的是,这套系统既不否认 iOS 的存在,也不盲从于「一切 iPhone 所做的都是对的」这一歪理。它所做的,是承认 iPhone 是个好手机,它的用户值得争取。vivo 选择与之对话,而不是对立,更不是镜像。
究其根本,一个世界不应该由一家厂商独筑。若想让「系统即世界」成为行业的常态而非个例,软硬件厂商需要共同向着开放的方向下注:减少无意义的差异化和封闭,允许并尊重跨生态的互通。唯有开放、互通与尊重,才能让软硬件共同构成一个有生命力的整体。
这也回应了亚伦·凯的那句话:真正的好系统,不只是运行在硬件上的软件,而是一个自洽、有秩序、有邻里的世界。
OriginOS 6 所指向的,是这样的起点——一个从掌中出发、延展向更大世界的系统。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博