专访联想智能设备业务集团总裁 Luca Rossi:最好的 AI 应用,还没被发明出来

过去一年,大模型技术几乎以季度为单位向前跃进,从文生图到多模态,再到 AI Agent,功能越卷越细,参数越堆越大。然而,技术上扬的速度越快,终端硬件的滞后感就越发强烈。尤其是在 PC 领域——一个曾被视作技术基础设施的产品线,如今却面临重塑定义的压力。
AI PC 如今成了行业热词,也成了一道新难题。对用户来说,它听起来像是下一代生产力工具的代名词;但对厂商来说,它则意味着系统架构的再设计、算力瓶颈的重构,以及一场几乎从芯片层开始的转身。
在 IFA 展会期间,联想集团执行副总裁、智能设备业务集团总裁 Luca Rossi 接受了爱范儿等媒体的专访。比起「AI 能做什么」,他更关心的是,「PC 该成为什么」。
AIPC 是一剂「及时但不唯一」的药方
「去年我们预测 PC 市场将在 2024 年恢复增长,现在看来,这一判断基本应验。」采访刚开始,Luca Rossi 便选择以数据回应曾经的预期。
过去几个季度,PC 市场整体回到正增长轨道,同比涨幅在 4% 到 7% 之间波动,联想自身则稳定高出市场 4 到 5 个百分点。这个势头在最新季度表现得尤为明显:联想的出货增幅超过了 10%。
「这波增长当然得益于 AIPC 的投入,但它不是唯一的驱动因素。」Luca 坦承。在他看来,Windows 10 向 Windows 11 的升级周期,同样释放了大量替换需求——微软将在 2025 年 10 月彻底停止对 Windows 10 的支持,目前企业侧的升级刚刚过半。也就是说,接下来的两个到三个季度,这一替换潮还将持续推高需求。
在联想自身的新一代设备中,约 30% 已具备 AIPC 特征,这一比例仍在持续提升。Luca 认为,目前 AIPC 的硬件层已趋于成熟,接下来的看点将在软件和应用生态:「真正的爆发会在明年。」

「理解」 AI 也许没那么重要
对于 C 端市场,Luca 有着非常清醒的判断:今天绝大多数消费者,未必真的了解 AIPC 能带来什么价值,但并不妨碍他们购买。
他说,真正因为 AI 功能而明确购买 AIPC 的人,依然是少数中的专业用户;而更多消费者的决策动因,往往是更浅层的因素——轻薄设计、长续航、未来可拓展性。
「我们的 AIPC 产品,不带 AI 也很有吸引力。续航 12 小时、本身就很轻薄好看。」他说,正是因为基础体验足够优秀,AI 的价值才能在使用中逐步浮现,而不是靠一场说明会讲明白。

他将 AIPC 的价值链划分为三个阶段:一是基础体验(硬件)已具备,二是早期 AI 场景正在落地,三是生态应用的井喷仍在前方。
「目前全球 AIPC 占比在 20-25%,我们已达到 30%。一年半内能到 50%,三年内 70-80%。四五年后,几乎所有 PC 都会是 AIPC。」

混合 AI:不是概念,而是未来计算的基本面
AIPC 的核心争议不在硬件,而在价值认知。一个旷日持久的质疑是:本地 AI 是否真的有意义?
面对这个问题,Luca 没有回避:「我们坚信,未来是一个混合 AI 的世界。」
Luca 将未来的 AI 计算分为三个层次:云端、边缘与设备端,每一层都有其存在的价值与必要性。
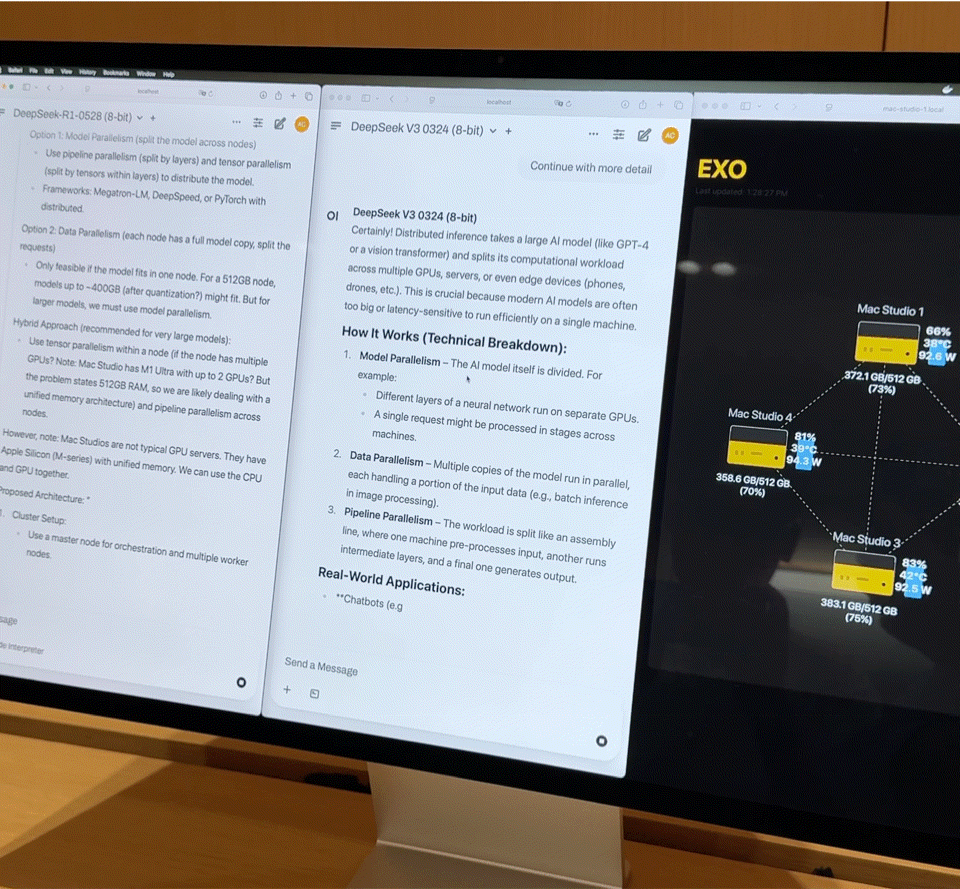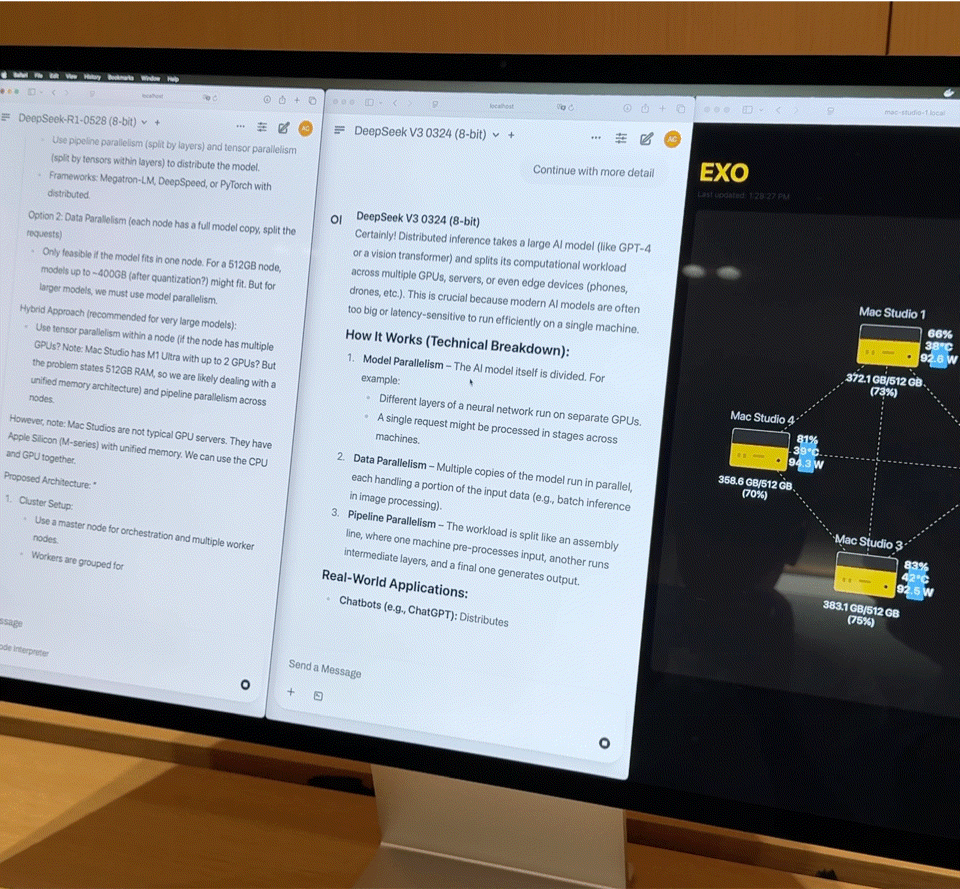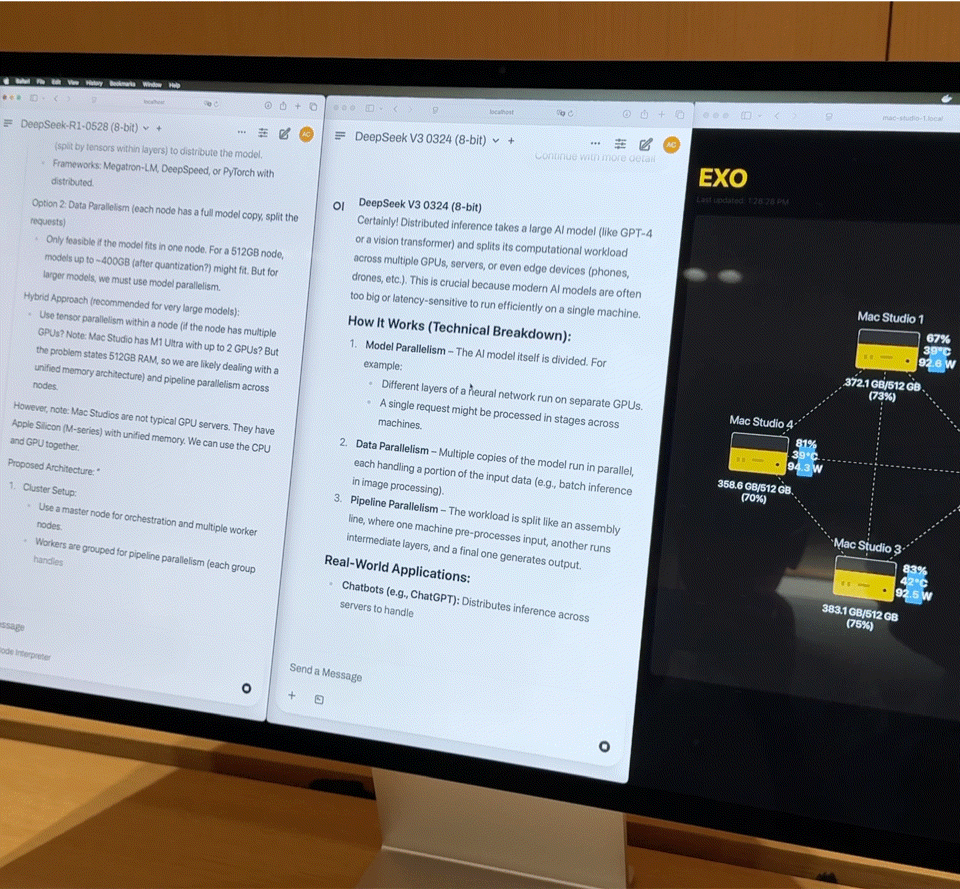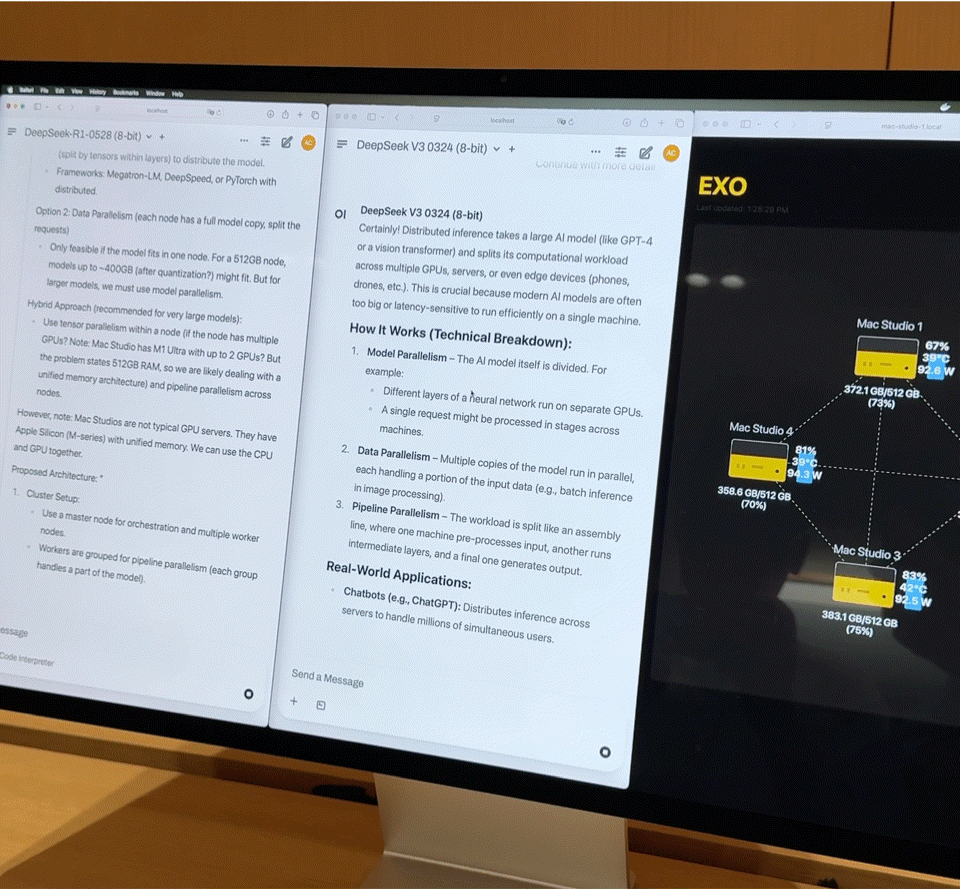
「目前全球约有 80 到 100 家 ISV 正在将他们的核心应用,迁移到 CPU 的 NPU 上运行。」他指出,这种迁移并非为炫技,而是为了解决具体问题——降低延迟、保障隐私、减少云端算力成本。
这也是联想选择 All-in 的根本原因:AI 应用并不必然等于云端推理,尤其在生成式模型与用户上下文深度绑定的场景下,本地运行反而可能是更优解。Luca 进一步举例:
「我们在中国的 ‘小天’,最近已升级为超级智能体。接下来你会在笔记本、手机、平板、甚至手表(虽然手表会稍晚一点)中看到它的身影。」
超级智能体(Super Agent)不仅是联想对 AI 交互范式的探索,更是其混合 AI 架构落地的一环。Luca 强调,设备之间的上下文共享将成为未来体验的基础能力,而这一点,云端无法单独完成。

形态革新:AI 是动因,但不该是噱头
聊到 AIPC,自然无法绕开设备形态是否将随之变化的问题。对此,Luca 给出的回答意外地乐观:「不是障碍,是机会。」
他强调,今天我们所使用的笔记本,其外观和交互方式,在过去二十年中几乎没有发生根本变化。但正是 AI,尤其是自然语言处理、大模型和多模态推理的发展,提供了打破固有形态的可能性。

▲ 联想在 IFA2025 上展示的灵动 AI 底座
「没有键盘、纯语音交互的设备不是幻想。但这不会在下个季度发生,也不会是明年。」他说,这是一个需要时间和可靠性的转型。自然语言交互的瓶颈从来都不是可行性,而是稳定性。AI 的提升,让这种过渡首次变得现实可期。
在这点上,联想并非纸上谈兵。过去几年,它在几乎每一场技术发布会上都展示了形态实验:可折叠屏、模块化 PC、移动游戏设备 Legion Go……即便没有每款产品都能商业化,但在 Luca 看来,这些试验不是副产品,而是主路径。

▲ 左:联想 ThinkBook VertiFlex 概念机
「失败的实验也会为成功的实验铺路。我们曾在 2017 年展示第一款折叠屏 PC,后来,这项技术落地在 Moto Razr 上,成为我们最畅销的产品之一。」
AI 不只是重写体验,也可能催生新硬件物种
谈及 AI 是否会催生全新的硬件形态,Luca Rossi 给出了肯定回答。他认为,在未来五年内,笔记本、平板、手机等设备都可能因 AI 的应用方式而出现新的变化,而联想将持续测试各种可能性。

▲ 联想 Yoga Tab,具备混合 AI 能力
在众多设想中,眼镜被他单独提及。他指出:「我个人认为,眼镜是未来有前景的平台之一,在未来 2 到 5 年的时间范围内会有不同程度的成功。」
他之所以看好这个方向,并非因为技术突破已至,而是用户习惯的存在。「要让几百万人习惯一种全新的设备形态,本身就是巨大的挑战。而眼镜是人们已经熟悉的。」
他也坦率指出,当前仍有三大技术难题需要攻克:计算能力、电池续航与镜片设计。这些问题并非不可解,但仍需时间。
对于目前市面上已有的产品,Luca 点名提到了 Meta 与 Ray-Ban 联合推出的智能眼镜,并评价道:「它们已经证明是成功的。不是大获成功,但至少比我所知的其他例子都更成功。」
这也是他支持持续探索的原因。「更多的竞争和创新是积极的,它能打开市场。」至于联想是否将加入这个市场,他只留下一句意味深长的回答:「我们会在时机合适时参与竞争。」

最好的 AI 应用,还没被发明出来,但路径已清晰
采访的尾声,我们再次回到那个问题:AIPC 的 killer app 究竟在哪?
Luca 没有直接给出答案,他只说:「最好的应用,还没有被发明出来。」
他相信,在商用市场,效率提升将成为 AI 的确定性价值;而在消费端,超级智能体将有机会成为那个定义新交互、创造新价值的关键点。
正如 App Store 用了数年才建立起应用生态,AIPC 也才刚刚起步。NPU 作为一项硬件能力,两年前全球还没有一个开发者了解它;今天,已经有上百家 ISV 投入进来。

▲ 联想展示的 Legion 拯救者产品组合
「我们从不认为 AIPC 能替代云端的 ChatGPT。但我们相信,它能在不同的用户上下文中,成为体验更轻盈、更私密、更即时的智能入口。」
这是 Luca Rossi 对 PC 行业的再定义,不是作为曾经生产力工具的延续,而是作为 AI 时代的前哨站。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。