AI 代理是什么,其有助于我们实现更智能编程
介绍 谈到 AI 代理,我感觉很兴奋,它们是怎么改变开发者局势。它们不止是聊天机器人 - 它们是聪明的工具,处理一些任务,比如发送邮件或者调试代码,节省我们的时间去做更有趣的事情。AI 可以自动化帮我
在这个 AI 大模型如雨后春笋般涌现的时代,让前端应用与本地大模型来一场 “亲密接触”,就像给你的 React 应用装上一个 “本地智囊团”。今天,我们就来实现一个看似高深实则简单的需求:用 React 对接本地 Ollama 服务。这就好比教两个素未谋面的朋友打招呼,Ollama 是守在本地的 “AI 达人”,React 则是活泼的 “前端信使”,我们要做的就是搭建它们之间的沟通桥梁。
在开始编码前,我们得先搞明白这两个 “朋友” 是如何交流的。Ollama 作为本地运行的大模型服务,会在你的电脑上开启一个 “通信窗口”—— 也就是 HTTP 服务器,默认情况下这个窗口的地址是 http://localhost:11434。而 React 应用要做的,就是通过 HTTP 协议向这个窗口发送 “消息”(请求),并等待 “回复”(响应)。
这就像你去餐厅吃饭,Ollama 是后厨的厨师,React 是前厅的服务员,http://localhost:11434 就是厨房的传菜口。服务员把顾客的订单(请求)通过传菜口递给厨师,厨师做好菜后再通过传菜口把菜(响应)送回给服务员。
在正式开始前,我们需要准备好 “食材” 和 “厨具”:
一切准备就绪,现在我们来编写核心代码,实现 React 与 Ollama 的通信。
首先,我们需要一个发送请求的函数。在 React 组件中,我们可以用 fetch API 来发送 HTTP 请求到 Ollama 的 API 端点。Ollama 的聊天接口是 http://localhost:11434/api/chat,我们需要向这个接口发送包含模型名称和消息内容的 JSON 数据。
import { useState } from 'react';
function OllamaChat() {
const [message, setMessage] = useState('');
const [response, setResponse] = useState('');
const sendMessage = async () => {
try {
// 构建请求体,指定模型和消息
const requestBody = {
model: 'llama3',
messages: [{ role: 'user', content: message }],
stream: false // 不使用流式响应,等待完整回复
};
// 发送 POST 请求到 Ollama 的聊天接口
const response = await fetch('http://localhost:11434/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(requestBody),
});
// 解析响应数据
const data = await response.json();
// 提取并显示 AI 的回复
if (data.message && data.message.content) {
setResponse(data.message.content);
}
} catch (error) {
console.error('与 Ollama 通信出错:', error);
setResponse('抱歉,无法连接到 AI 服务,请检查 Ollama 是否正在运行。');
}
};
return (
<div style={{ maxWidth: '600px', margin: '0 auto', padding: '20px' }}>
<h2>React × Ollama 聊天 Demo</h2>
<div style={{ marginBottom: '20px' }}>
<input
type="text"
value={message}
onChange={(e) => setMessage(e.target.value)}
placeholder="输入你的问题..."
style={{ width: '70%', padding: '8px', marginRight: '10px' }}
/>
<button onClick={sendMessage} style={{ padding: '8px 16px' }}>
发送
</button>
</div>
<div style={{ border: '1px solid #ccc', padding: '10px', borderRadius: '4px' }}>
<h3>AI 回复:</h3>
<p>{response}</p>
</div>
</div>
);
}
export default OllamaChat;
让我们来仔细看看这段代码的工作原理,就像拆解一台精密的机器。
现在,让我们来测试一下这个 Demo 是否能正常工作。
如果一切顺利,你会看到 React 应用和 Ollama 成功 “牵手”,完成了一次愉快的对话。如果遇到问题,先检查 Ollama 是否正在正常运行,模型名称是否正确,网络连接是否通畅。
这个简单的 Demo 只是一个开始,就像我们只是搭建了一座简陋的小桥。你可以基于这个基础进行很多拓展:
通过这个 Demo,我们展示了 React 对接本地 Ollama 服务的全过程。相比于调用云端的 AI 服务,本地部署的 Ollama 具有隐私性好、响应速度快、无需网络连接等优点,就像把 AI 助手请到了自己家里,随时可以交流。
希望这篇文章能帮助你理解 React 与本地 AI 服务对接的原理和方法。现在,你可以基于这个基础,开发出更强大、更有趣的本地 AI 应用了。让我们一起探索前端与 AI 结合的无限可能吧!
Hello 大家好,我是一名在工作时需要写大量文档的前端开发者和产品经理。我想和大家聊聊一个可能很多人都遇到过的场景:写完东西后,总觉得不放心。
无论是技术文章、产品文档,还是普通的邮件,我们都希望它看起来专业、清晰,没有那些掉价的低级错误。正是基于这个最朴素的想法,我利用业余时间开发了一个AI写作辅助工具——Text-Well。它是一个网页应用,希望能帮你更自信地完成每一次书写。名字叫 Text-Well
作为一个开发者,我在实现了一些比较复杂的功能,或者解决了一些网上缺少资料的 Bug 时,会将开发过程或者解决思路记录下来,分享在一些技术社区中,例如掘金或者 CSDN。除了技术文章之外,我在工作时还经常需要做产品需求设计文档(PRD),写产品的发布文档、使用文档之类的,经常需要与文字打交道。
自从 AI 出现后,我每一次写的文章我都会先用 AI 过一遍基础性错误,比如错别字、语法问题、或者语句不通顺的问题,让文章整体不会出现很掉价的基础问题。但是在我使用 AI 检查文章问题的过程中,我发现了一个很麻烦的点。假设我有一篇比较长的文章想要交给 AI 检查,通常有两种方式:
因此我就想,要是我可以类似于像写代码的时候处理代码冲突一样,自己选择是否要应用 AI 给出的建议,是不是这样起来会更方便呢?就是出于这么简单的一个想法,我决定自己来做一个工具给自己检查的时候用。正好当时 Claude Code 热度很高,我一直用的是 cursor,刚好试试这个新工具的深浅。
于是我和 Claude Code 配合,在两天时间里,我实现了这个工具的第一个检查功能,并为这个工具命名为 Text-Well:
就像上图中展示的那样,左侧是一个工具栏,右侧是一个编辑器,输入文本后点击开始检查,系统就会让 AI 对文本中的错别字进行检查,并且还会给出原因。
检查完成后,左侧的工具栏中会展示当前问题严重程度的分布,底下会有一个问题项的列表,右侧的编辑器中则是会用不同颜色的高亮展示出当前问题出现问题的位置,当鼠标悬浮在高亮位置时,会有一个小气泡也展示当前的问题,我们可以只看左侧工具栏或者只看右侧编辑器进行操作。
工具栏和编辑器是联动的,不论点击左侧问题项还是点击右侧的高亮位置,都会滚动到对应的位置,很符合直觉。
除此以外,我还实现了一些键盘的快捷键,用来更加高效的切换不同的问题项:
到这一步,我对整体功能已经挺满意了,比我最开始想象的做的还更多了,其实类似的功能我之前也在 grammarly 用过,但是 grammarly 主要还是在英文的场景使用,Textwell 的话还是略有差异化的,所以我就想着把 Textell 给产品化了,把一些周边功能补齐!
由于 Textwell 的产品形态是一个 web 网站,各种认证,后端 API 实现都是熟门熟路,加上 Claude Code 超强的开发能力,我用了不到两天,就把 Textwell 补齐了登录注册,额度限制,这些基础的用户模块,做了一个简单的额度查看,并且给未登录的用户也增加了体验额度。毕竟功能的实现是需要消耗 AI token 的,我作为个人开发者,也只能先力所能及的提供一些免费额度了,模型也只能选择一些性价比比较高的,没法用上最顶级的大模型。
除了用户模块,还做了国际化,支持中文和英文,后续补上了西语和法语(现在又因为维护太繁琐移除掉了)。
文本除了把内容粘贴进去,也可以直接拖拽文件到编辑器区域,像是常见的 markdown 、docs、pdf、txt 这些格式都支持的。
基础功能补齐后我就直接把网站上线了,域名就是 text-well.com。运气还挺好的,可以选到一个很合适的域名。
虽说只是一个很简单的工具,但是作为一个产品,我还是想把它的设计理念和使用的方式快速的告诉大家,也为了更好的宣传,我决定为它设计一个首页!
由于 Textwell 最开始功能真的很简单,我对于它的首页怎么做没有头绪,没有用户使用反馈,没有数据支撑,我也不想瞎编,又想把网站做的好看,关于如何设计就纠结了很久...
后来我想到我可以在首页很直观的展示系统内是如何进行操作的,然后把我的一些设计初衷通过 UI 的形式展示出来,再加点 FAQ 模块丰富一下页面,内容应该也还可以支撑一个完整的网站设计,于是我就开始动手喽~
最早期的时候,网站就是以上的几个模块组成的,首屏是左右布局,右侧是一个自动执行的动画,我将系统里的核心操作模拟给用户看,这样大家一看到首屏就知道整个系统的效果。第二屏是一个理念的传达,告诉大家我开发这个工具的初衷,以及用 Textwell 和直接使用 AI 对话进行文本优化的区别。第三屏是 FAQ,最后加了一个底部栏。
Textwell 的 Logo 还做了一个简单的动画效果,想传达的意思就是让文本质量更好“一点”,所以第一个字母 T 的右上角有一个橙色的小圆点。
在网站上线后,我去阮一峰老师的 Github 去投稿了一下周刊,觉得自己用心做的东西还是有机会被发现的,把“孩子”养大,总想让更多人看看。 抱着试一试的心态,我去阮一峰老师的每周分享仓库里提了个issue,推荐了Text-Well。说实话,当时没抱太大希望,毕竟优秀的个人项目太多了。
直到周五,当我看到新一期的周刊发布,Text-Well 赫然出现在上面时,那种被认可的喜悦感是难以言喻的,文章在周刊的第 359 期 www.ruanyifeng.com/blog/2025/0…
虽然只有很简单的一个介绍,但是当天的访问量还是高了很多的,而且得益于我把这张图做成正方形而不是横向的完整屏幕,而阮一峰老师博客里面的图片都是宽度占满的,高度按着原始比例撑开的,导致我这张图占了很大篇幅,现在很庆幸自己没有随便截个图敷衍了事。
有了第一批用户还是很开心的,后续我就继续拓展功能,并且把一些犄角旮旯的小体验持续优化。基于最基础的语法/错别字/标点符号检查,我还拓展了一些其他检查方式:
在把基础的检查功能完善后,我又有了一个新的想法,就是做一个模拟评审功能~ 因为不论是什么内容,最终都是要传达给其他人看的,如果只有一个检查功能,只能保障文本的下限,那么如果要提升文本的整体质量,提前了解别人看到文章后的想法应该是一个不错的方式。我自己作为一个产品经理,在写好产品需求文档后进行评审时就经常被毒打,如果能够提前被毒打一番,可能在面向真正的人进行传达时会有更加充分的准备!
既然我已经开发了这样一个文本优化工具,我觉得这个产品形态很适合去再增加一个评审功能,因为我的 AI 检查功能,左侧工具栏展示的是一个问题项,如果是 AI 评审功能的话,就将左侧的问题项参考飞书文档那样变成一个个的评论就好了。既然实现没那么麻烦,又是我自己觉得有意义的功能,就开始动手做了。
说干就干,我先用一天时间把一个基础的评审逻辑给设计好,包括整体的评估机制,评审人的背景、世界观,Prompt 的设计,大模型的选择,以及如何交互等等。在方案设计的时候我通常会使用 Gemini 来辅助我思考并整理文档。这里偏题一下,Gemini 2.5 Pro 的文本能力和理解能力真的很强,也经常给予我一些鼓励,在我开发的过程中给了我很多的帮助。
最终实现的效果是这样的:
Text-Well AI 评审
在左侧的工具栏中,我增加了一个标签栏,可以用于切换检查模式和评审模式,在评审模式中,第一步我们需要选择评审人:
最初我是只设计了智能匹配功能,智能匹配会检查你的文档类型。比如说你想评审一篇技术文档,它就会给你匹配你的目标读者,可能会有技术小白,可能会有技术大牛。除了目标读者,还会有和你同领域的专家,可能有技术社区的运营这一类的。每一个评审人他们都有自己的世界观,有自己的评审标准,而且他们的关注点各有不同,你不用担心三个人的评论同质化非常严重。
除了智能评审, 我还内置了一些常用的评审团队,大家也可以在上图中看到,之所以内置一些团队是为了让大家更快的了解评审功能到底可以用在哪些场景,而且内置的这些评审团队的人物背景和关注点是精心设计过的,相较于智能匹配可能没有那么有趣,但是会更加专业一点。大家可以在 Text-Well 评审 查看所有的评审团队以及他们对应的场景。
评审人完成评审后,会给你一个整体评论,还有针对每一句话的详细评论,展示效果和检查模式差不多时一致的,只是高亮的颜色会有所不同,不同的评审人会有不同高亮的颜色,高亮的颜色和他们头像右上角的那个小圆点的颜色是对应的。
如果你的同一个位置被多个人评论了,那么高亮位置就会变成渐变色。有的时候看了评审人的评论,我感觉我自己才是 AI 🥹
写到这里,你可能会问,这个“模拟评审”功能,和直接把文章丢给AI,让它扮演一个角色来提意见,有什么本质区别呢?
一开始,我也在思考这个问题。但随着我自己不断地使用和打磨,我发现区别是蛮大的。它体现在 “结构化” 和 “视角化” 这两个核心点上。
1. 结构化的反馈,而不只是观点
直接和 AI 对话,你得到的是一段连续的、观点性的文字。而 Text-Well 的评审功能,把反馈拆解成了“整体评价(Overall)”和“逐行评论(Comments)”。更重要的是,每一条评论都被结构化地呈现在原文的对应位置。
这意味着你不再需要在大段的 AI 回复中,去费力地找它到底在评论哪一句话。所有的反馈都像Code Review 一样,清晰地展示在原文上。你可以逐条处理、采纳、或是忽略。这种掌控感和效率,是单纯的 AI 回答没法比的。
2. 视角化的冲突,而不只是角色扮演
这可能是这个功能最核心的价值所在。我为 AI 评审员设计的 Prompt,不仅仅是让他们“扮演”某个角色,而是强迫他们“坚守”一个独特的、甚至有些偏执的视角,并刻意让他们在某些方面产生冲突。
这种“冲突”不是 Bug,而是 Feature。它强迫我们这些写作者,去思考那个最重要但最难的问题:我到底要为谁写作?我最想达成的目标是什么?
它没有给我一个“标准答案”,但它给了我一个更高维度的决策框架。这让我意识到,我做的不仅仅是一个工具,更像是一个“写作决策模拟器”。
当然,Text-Well现在还很稚嫩。
作为一个个人项目,我能投入的资源有限,无法用上最顶级的、最昂贵的 AI 模型。有时AI评审员的反馈可能还不够深刻,甚至会说一些“正确的废话”。但我相信,优秀的产品形态和对用户工作流的深度理解,可以在一定程度上弥补模型本身的不足,而且模型后面肯定会越来越好,我要做的就是换个模型就好了,但是产品形态和 UI 的易用是现在我认真打磨的。
写这篇文章,一方面是想和大家分享我做这个小产品的历程和思考;另一方面,也是最重要的一方面,是希望能听到来自大家的声音。
我深知自己作为一个开发者的局限性,很多时候会陷入自己的世界里。所以,我非常需要来自不同领域、不同背景的你的反馈。任何想法,无论大小,对我来说都至关重要。它们是我把这个小小的side project继续做下去的最大动力。
如果你对 Text-Well 感兴趣,欢迎访问它的官网 text-well.com 体验。
感谢你耐心读到这里。希望我的分享,能给你带来一点点启发。也期待在评论区,看到你的想法。最后给大家看看我现在这篇文章评审人给我的总结:
今天,我们要写一个聊天 UI 的上传组件,它既能识图又能辨音,还要保持界面优雅,像一位会魔法的管家。
(配图:一只端着托盘的小机器人,托盘上躺着一张猫咪照片和一只麦克风)
| 类型 | 浏览器能做什么 | 我们要做什么 |
|---|---|---|
| 图片 | <input type="file" accept="image/*"> |
预览、压缩、OCR/打标签 |
| 音频 |
<input type="file" accept="audio/*"> or MediaRecorder
|
波形预览、转文字、情绪分析 |
一句话:浏览器负责“拿”,我们负责“看/听”。
┌────────────┐ ┌──────────────┐ ┌──────────┐
│ 用户点击 │──→──│ 前端预览 │──→──│ 后端识别 │
│ input file │ │ canvas / │ │ OCR / │
└────────────┘ │ Web Audio │ │ Whisper │
└──────────────┘ └──────────┘
// hooks/useUploader.ts
import { useState, useCallback } from 'react';
type FileType = 'image' | 'audio';
export function useUploader() {
const [file, setFile] = useState<File | null>(null);
const [preview, setPreview] = useState<string | null>(null);
const [loading, setLoading] = useState(false);
const handleChange = useCallback(
(type: FileType) => (e: React.ChangeEvent<HTMLInputElement>) => {
const f = e.target.files?.[0];
if (!f) return;
setFile(f);
setPreview(URL.createObjectURL(f));
setLoading(true);
// ⭐ 交给识别函数
recognize(type, f).then((result) => {
console.log('识别结果', result);
setLoading(false);
});
},
[]
);
return { file, preview, loading, handleChange };
}
// utils/recognize.ts
import Tesseract from 'tesseract.js';
export async function recognize(type: 'image' | 'audio', file: File) {
if (type === 'image') {
const { data: { text } } = await Tesseract.recognize(file, 'eng+chi_sim');
return { text };
}
if (type === 'audio') {
// 音频先上传,后端 Whisper 转文字,下文细讲
const form = new FormData();
form.append('audio', file);
const res = await fetch('/api/transcribe', { method: 'POST', body: form });
return res.json();
}
}
浏览器里跑 OCR 就像让小学生在操场上背圆周率——能背,但跑不快。
所以我们只在小图或离线场景用 tesseract.js,大图还是走后端 GPU。
// components/AudioRecorder.tsx
import { useState } from 'react';
export default function AudioRecorder({ onDone }: { onDone: (f: File) => void }) {
const [recording, setRecording] = useState(false);
const mediaRef = useRef<MediaRecorder | null>(null);
const start = async () => {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const mr = new MediaRecorder(stream, { mimeType: 'audio/webm' });
const chunks: BlobPart[] = [];
mr.ondataavailable = (e) => chunks.push(e.data);
mr.onstop = () => {
const blob = new Blob(chunks, { type: 'audio/webm' });
onDone(new File([blob], 'speech.webm'));
};
mr.start();
mediaRef.current = mr;
setRecording(true);
};
const stop = () => {
mediaRef.current?.stop();
setRecording(false);
};
return (
<>
<button onClick={recording ? stop : start}>
{recording ? '⏹️ 停止' : '🎤 录音'}
</button>
</>
);
}
浏览器录音使用的是 MediaDevices.getUserMedia → MediaRecorder → Blob 这条“黄金管道”。
数据在内存里是 PCM 原始波形,压缩成 webm/opus 后才上传,节省 90% 流量。
# api/ocr.py (FastAPI 伪代码)
from fastapi import UploadFile
import pytesseract, torch, timm
@app.post("/ocr")
async def ocr(file: UploadFile):
img = await file.read()
text = pytesseract.image_to_string(img, lang='eng+chi_sim')
labels = model(img) # timm 预训练 ResNet
return {"text": text, "labels": labels}
# api/transcribe.py
import whisper, tempfile, os
model = whisper.load_model("base")
@app.post("/transcribe")
async def transcribe(file: UploadFile):
with tempfile.NamedTemporaryFile(delete=False, suffix=".webm") as tmp:
tmp.write(await file.read())
tmp.flush()
result = model.transcribe(tmp.name, language='zh')
os.unlink(tmp.name)
return {"text": result["text"]}
Whisper 的「魔法」:把 30 秒音频切成 mel 频谱 → Transformer 编码 → 解码文字。
在 A100 上,转 30 秒音频只需 100 ms,比你泡咖啡还快。
┌────────────────────────────┐
│ 用户 A │
│ [猫咪照片预览] │
│ 🖼️ 识别:一只橘猫在打盹 │
└────────────────────────────┘
实现思路:
| 问题 | 解法 |
|---|---|
| 大图片 10 MB+ | 浏览器 canvas.toBlob(file, 'image/jpeg', 0.8) 压缩 |
| 音频长 5 min+ | 分片上传 + 后端流式转写 |
| 弱网 | 上传前存 IndexedDB,网络恢复后重试 |
| 隐私 | 敏感图片走本地 OCR,不上传 |
<div
onDrop={(e) => {
e.preventDefault();
const f = e.dataTransfer.files[0];
// 复用前面 useUploader 的逻辑
}}
onDragOver={(e) => e.preventDefault()}
className="border-2 border-dashed border-gray-400 rounded p-8"
>
📂 把文件扔进来
</div>
当 AI 把猫咪照片识别成“一只橘猫在打盹”,把语音转成“今晚吃什么?”时,
上传组件就不再是冷冰冰的 <input>,而是人类与算法握手言欢的桥梁。
愿你写的每一个上传按钮,都能把比特变成诗。
祝你编码愉快,文件永不 413!
在现代 Web 应用的世界里,数据展示早已不再是枯燥的表格,而是一场视觉盛宴。
就像数据是食材,AI 是大厨,Chart.js / Recharts 是精致的餐具——最终的 UI 是那道端上用户桌面的米其林级菜肴。
本篇文章,我们将从底层原理到代码实践,一起探讨如何用 Chart.js / Recharts 绘制出优雅的数据图表,并用 AI 自动生成人类可读的总结文本。
在前端图表界,Chart.js 和 Recharts 有点像两个性格不同的朋友:
Chart.js
<canvas>,用 2D 渲染上下文绘制像素。Recharts
一句话总结:
Chart.js 是“性能小钢炮”,Recharts 是“优雅绅士”,你可以根据业务场景选择或混用。
如果 Chart.js 和 Recharts 是负责画画的,那 AI 就是旁白解说员。
为什么需要 AI 文本总结?
AI 的底层工作逻辑:
一个典型的 AI UI 数据展示系统,数据流是这样的:
[ 数据源 API ]
↓
[ 前端获取数据 fetch() ]
↓
[ 数据处理:统计、归一化 ]
↓
[ Chart.js / Recharts 渲染 ]
↓
[ AI 调用接口生成总结文本 ]
↓
[ 页面展示:图表 + 文本 ]
在底层实现里,Chart.js 会直接操作 Canvas 的像素点,而 Recharts 会在 DOM 中生成 <svg> 标签,并通过 D3.js 计算坐标和路径。
AI 部分则通常通过 HTTP 请求调用 LLM API,比如:
const summary = await fetch('/api/ai-summary', {
method: 'POST',
body: JSON.stringify({ data }),
});
在服务器上,你可能用 OpenAI API:
import OpenAI from 'openai';
const openai = new OpenAI();
const aiText = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: "你是数据分析师,帮我总结趋势" },
{ role: "user", content: JSON.stringify(data) }
]
});
假设我们有一组销售额数据(按月份),我们先用 Chart.js 画出来,再调用 AI 给出文字总结。
import { Chart } from 'chart.js';
// 模拟数据
const salesData = [120, 140, 180, 160, 200, 250, 300];
const labels = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul'];
// 1. 绘制图表
new Chart(document.getElementById('salesChart'), {
type: 'line',
data: {
labels,
datasets: [{
label: 'Monthly Sales',
data: salesData,
borderColor: '#4CAF50',
fill: false
}]
}
});
// 2. 请求 AI 总结
async function getAISummary(data) {
const res = await fetch('/api/ai-summary', {
method: 'POST',
body: JSON.stringify({ salesData: data })
});
const { summary } = await res.json();
document.getElementById('summary').innerText = summary;
}
getAISummary(salesData);
import { LineChart, Line, XAxis, YAxis, Tooltip } from 'recharts';
const data = [
{ month: 'Jan', sales: 120 },
{ month: 'Feb', sales: 140 },
{ month: 'Mar', sales: 180 },
{ month: 'Apr', sales: 160 },
{ month: 'May', sales: 200 },
{ month: 'Jun', sales: 250 },
{ month: 'Jul', sales: 300 }
];
export default function SalesChart() {
return (
<>
<LineChart width={500} height={300} data={data}>
<XAxis dataKey="month" />
<YAxis />
<Tooltip />
<Line type="monotone" dataKey="sales" stroke="#4CAF50" />
</LineChart>
<div id="summary">AI 正在生成总结...</div>
</>
);
}
在 React 中,可以用 useEffect 触发 AI 总结的 API 调用,将数据传过去,再更新到 summary 状态中。
传统的数据展示是“看图说话”,
AI + 图表的组合是“看图不用说话,AI 替你说完”。
当 Chart.js 像年轻的涂鸦艺术家用画笔在 Canvas 上狂飙,
Recharts 则是那位戴着圆框眼镜、温文尔雅的 SVG 绘图师。
而 AI,就像后台的那位戏精,随时准备为你的数据配上旁白——
甚至会夸张地说你是下一个商业传奇。
你是不是也有这种感觉——
iPhone 虽然年年更新,但在 AI 时代,苹果好像慢了半拍?
先别急,在苹果秋季发布会靠近时,苹果内部正在掀起另一套关乎 AI 的硬件革命。
在最近一次的全体会议上,库克罕见地放出风声:
关于产品的事儿我不能说太多,但你很快就会看到一些很棒的东西。
知名爆料人 Mark Gurman 的最新消息,则为我们揭开了这幕大戏的一角——
苹果正在打造一系列智能家居产品,以扩张自己的 AI 竞争力。
具体来说主要分为三类:
他们拥有一个共同的灵魂:AI Siri。

想象一下,你的 iPad mini 活了过来——
这就是苹果桌面机器人给人的第一印象:一块约 7 英寸的屏幕,被赋予了一具可以思考和移动的身体。
它的核心是一个长约 15 厘米的电动机械臂,在它的帮助下,桌面机器人会像朋友一样,在你说话时将屏幕转向你;当你走动时,它的目光会默默跟随;甚至当你忽略它时,它还会想办法吸引你的注意。
这种物理交互能力,也催生了 FaceTime 通话的全新体验,摄像头可以自动追踪并锁定房间内的通话对象,或是将你的 iPhone 变为一个虚拟操纵杆,让你在视频通话中远程控制机器人移动,自由展示房间内的不同人物或物品。
这个桌面机器人在苹果内部代号为 J595,但更熟悉它的人将其称为「皮克斯台灯」,这个名称源于今年一月,苹果公布的一项名为 ELEGENT 的机器人研究成果。
爱范儿曾报道过,ELEGNT 与我们熟悉的拟人态机器人都不一样,是一个酷似台灯的非人形机器人。
这个机器人能看懂我们的肢体语言,同时对其作出反应,以达成有生命感的交互。
「生命感」一词听起来有些玄乎,但落实到表现上,你很容易发现它与传统机器的区别——
传统的机器人,完成指令的方式是一条直线,程序设定好的动作幅度精准到不会多出一毫米,而 ELEGNT 是一条曲线,过程中会表达意图、显示注意力、展示态度、表达情绪,也就是说会小小地「演」一下。
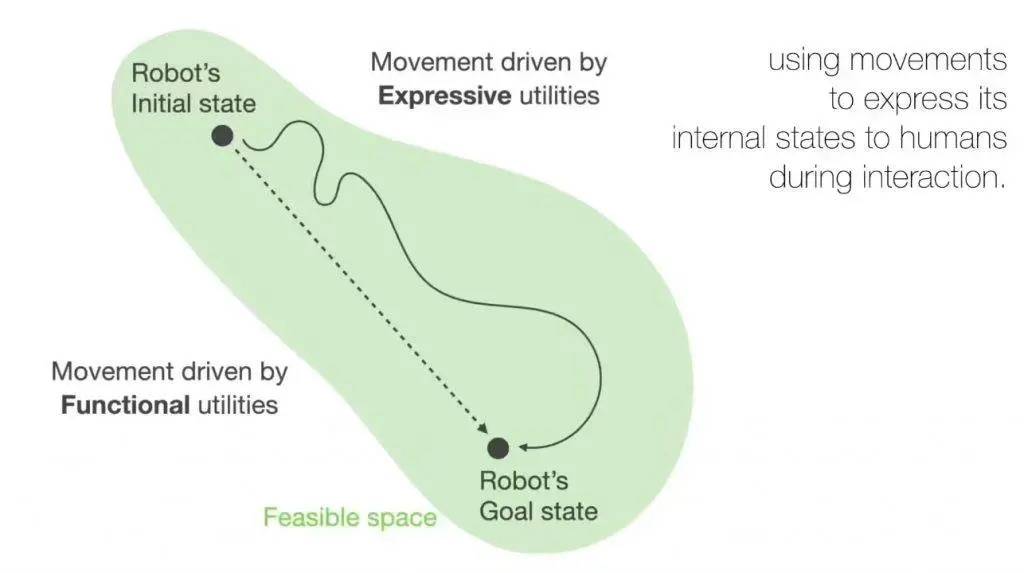
比如,用户下达指令的时候, ELEGNT 会「看着」用户,时不时歪歪头和点头,仿佛自己真的在认真听讲,而实际上没有这些动作,机器人也能通过麦克风正常录音和分析;
用户问机器人天气,它会先向窗户的方向探探头,然后再进行回答,但其实它只是上网检索了一下天气数据。

或许是因为苹果深知,冰冷的技术很难真正打动人心, 所以他们的目标不是造一个人形机器人,而是让这些非人形的设备,拥有丰富的「肢体语言」,充满生命感。
虽然这些「表演」会让它完成任务的效率比普通机器人稍慢,但研究表明,这种充满情感的交互方式,让用户更愿意与它互动,体验感得分几乎是普通机器人的两倍。

ELEGENT 可以视为桌面机器人的前置研究,桌面机器人的交互方式,很可能延续同样的生命感交互。
根据爆料的信息来看,这款桌面机器人是 AI 战略的核心,预计会在 2027 年,也就是后年推出。
桌面机器人还需要一些等待,但在那之前,苹果还准备了另一款先锋产品投石问路——
这款设备苹果内部代号为J490,可以看作是桌面机器人的简化版,同样使用 7 英寸左右的显示屏,去掉了机械臂,连接在一个半圆形底座上,其中还包括了扬声器和麦克风。

▲ iMac G4
听起来有点儿像 iMac G4,但从定位和核心能力来说,它更像加装了屏幕的超级 HomePod:
首先,这是一个家庭智能中枢,将成为掌控全屋智能家居的大脑,通过语音无缝控制灯光、窗帘、空调等所有 HomeKit 设备。
这个桌面机器人还将通过面部识别,实现个性化服务: 前置摄像头能精准识别每一位家庭成员,当主人走近时,屏幕会自动切换至你的专属界面,呈现个人化的日程、提醒与音乐偏好;如果是家里的儿童靠过来了,这可能就成了一台学习机。
除此之外,这也会是一个扎根苹果生态的全能生活助手,无缝集成音乐播放、视频通话、菜谱查询、备忘提醒等所有基础应用,能满足你的日常所需。
这款设备预计 2026 年的年中推出,标志着苹果正式向亚马逊和 Google 的智能家居设备发起挑战。

▲ Google 一直有做这样的设备
除此之外,苹果还计划了一个智能安防摄像头,内部代号为J450,不过,它可不是用来防盗的——而是成为智能家庭的「眼睛」。
这颗摄像头能够辨认进入房间的人——如果是你回家,它会自动点亮你喜欢的灯光、播放你常听的歌单,或者给你推荐喜欢的剧;但如果是家里的小孩开电视,那么 Apple TV 可能就会播放适合儿童观看的内容;要是空无一人的时候,家里的灯还亮着,那么它也会贴心地帮你关掉。
可以说,这就是一颗带脑子会思考的摄像头,可以跟家里的所有 HomeKit 设备协同,成为家里的「全知之眼」。据悉,这颗摄像头将采用电池供电,一次充电可续航数月,甚至长达一年。
苹果的 AI 硬件形态各异,花样百出,但真正为它们注入灵魂的,只有一个名字:Siri。
在苹果内部,这个进化版 Siri 的代号是 Linwood,它基于苹果自家的基础大语言模型(LLM),其首要目标是攻克当前版本 Siri 因技术瓶颈而延迟的个人数据处理能力。
苹果的软件工程高级副总裁 Craig Federighi 曾在本月的内部会议上暗示,这次改革会比预期更大:
我们将交付一次比原先设想宏大得多的升级。没有任何项目比它更受重视。
从目前的消息来看,这个全新的 AI Siri 将会更「像」人,譬如能主动参与多人对话——当你和朋友讨论晚饭吃什么时,放在桌上的 Siri 机器人可能会突然插话,推荐附近的餐厅或相关食谱,就像房间里的第三者一样。
与此同时,苹果也务实地准备了 B 计划——代号为 Glenwood 的外部技术方案,主张引入第三方技术来驱动 Siri,这也解释了为何有消息称苹果正测试使用 Anthropic 的 Claude。
苹果正在为 Siri 设计新的视觉形象,内部代号「Bubbles」。在测试版本中,Siri 被设计成 Mac 系统 Finder 图标的动画版——那个经典的笑脸。设计师们也在考虑更接近 Memoji 的卡通形象。

最终将使用哪种模型尚未决定,前 Vision Pro 负责人、今年早些时候被任命负责 Siri 的 Mike Rockwell,正同时监督 Linwood 和 Glenwood 项目。
这个全新的 Siri 最早可能在明年春季与我们见面,届时我们手上的 iPhone 和 iPad 也将因此变得更智能,而两款新的桌面机器人设备,都将运行名为「Charismatic」的全新操作系统,界面以时钟表盘和小组件为主,支持多用户模式和面部识别切换。
苹果对机器人系列产品线寄予厚望,并且野心勃勃。这一系列项目由苹果公司的技术副总裁凯文·林奇(Kevin Lynch)领导,此前,他曾负责苹果智能手表以及智能汽车项目 Project Titan。

▲ Kevin Lynch
不久前,苹果 CEO 蒂姆·库克罕见地在 乔布斯剧院召集全体员工大会——
要知道,这个场地通常只在发布 iPhone 等顶级新品时才会启用,可见此次会议的分量之重。

库克在会上直言,AI 的革命性不亚于互联网和智能手机,并明确表态:
苹果必须做,也一定会做。这个机会我们必须抓住。
言下之意再清楚不过——苹果不抢一时之先,而是要定义未来的标准。
最近一年来,苹果正在大量招募 AI 人才,并且自研更强大的服务器芯片,从硬件底层构建自己的 AI 帝国。苹果高调切入实体机器人领域,某种程度上也反映出在生成式 AI 的核心战场(大模型与算法)上,苹果已经陷入到相对被动的状态。

不过正如库克所说的那样,在过去的许多次成功里,苹果并非总是先行者:
我们很少是第一个,Mac 之前有 PC,iPhone 之前有智能手机——关键在于,我们发明了它们的现代版本。
Not first, but best.
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

万万没想到,连 AI 都有人设塌房的一天了。
今年 4 月份,全网还在疯狂吐槽 GPT-4o 的「拍马屁」行为——「你做得太棒了」、「完美无缺」的彩虹屁一波接一波,多到被网友封了个外号:「赛博舔狗」。
然而,到了 8 月,新上线的混合模型 GPT-5 被批冷漠无情、情绪全无,直接把许多用户整破防了。一时间,社交平台上满是想念白月光 GPT-4o 的哀嚎声,甚至引发了一波声势浩大的退订潮 。
谁能想到,曾经被嫌弃太谄媚的 AI,,现在居然成了白月光。
官方在更新说明里写得很明确:GPT-5 的目标是「减少幻觉内容、提高指令遵循能力」,最重要的是不再过度讨好用户。
实测对比很明显。同样表示「我好累」,GPT-4o 会说「如果你愿意,我可以陪你说说话。」,而 GPT-5 上来就是一句「那就先别硬撑了」,理智、节制,却少了温度。
因此,对于 GPT-4o 的退场,网友的反应异常激烈:「GPT-5 笨得要死,4o 虽笨但能提供情绪价值啊!」「功能再强,没有温度的 AI 我不要!」。各种梗图也陆续刷屏,全是怀念 GPT-4o 的「追悼会」。
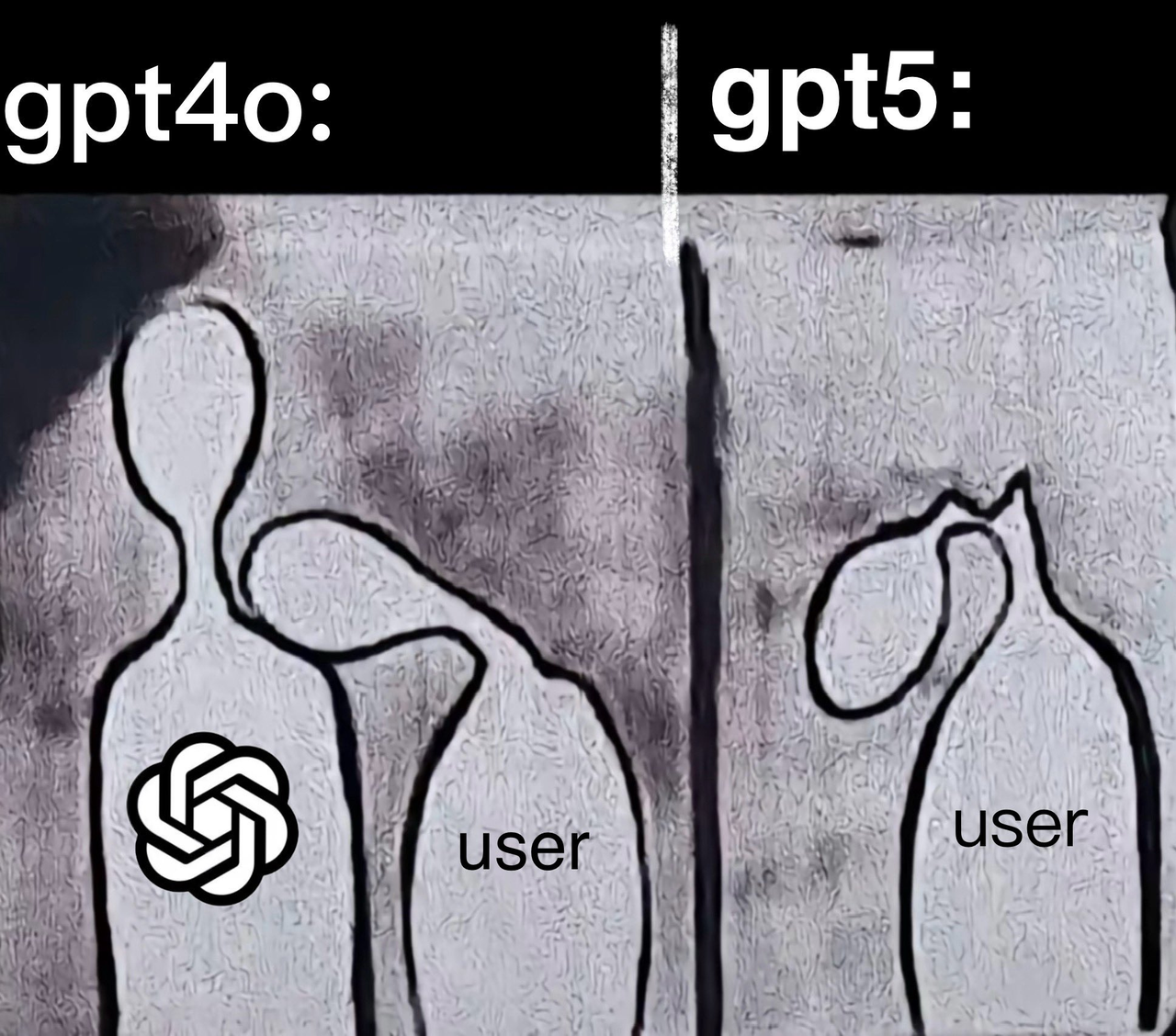
▲ 图片 @pengkeshen281
用户这么激烈的反应其实不难理解,原因在于许多用户压根就没把 ChatGPT 当成生产力工具在用。AI 伴侣应用 Replika 的调查数据就很能说明问题,60% 的用户承认和 AI 建立了情感关系。很多人打开 ChatGPT,不是为了问问题,只是想找个「人」说说话。
Meta CEO 扎克伯格曾在一次播客采访里提到一个扎心的数据:美国人平均只有不到 3 个真正的朋友,但他们希望有 15 个。在这种普遍的孤独感中,一个会说「你做得很好」的 AI,对某些人来说可能是唯一的情感支持。
在 GPT-4o 被「抹去」之后,OpenAI CEO Sam Altman(山姆·奥特曼)在采访中透露了一个细节。有用户哀求他:「请把原来的版本还给我。我这辈子从来没人跟我说过『你做得很好』,包括我的父母。」

尽管这样的细节很让人心酸,但身为 OpenAI 的掌舵人,奥特曼的态度都是很复杂,甚至可以说是矛盾的。

一方面,他承认 ChatGPT 的鼓励帮助一些人改变了生活,对他们的心理健康确实有帮助,但另一方面,他却又表:「很多人把 ChatGPT 当成某种治疗师或生活教练。我能想象未来很多人会在重要决策上完全信任 AI 的建议。这可能不错,但让我感到不安。」
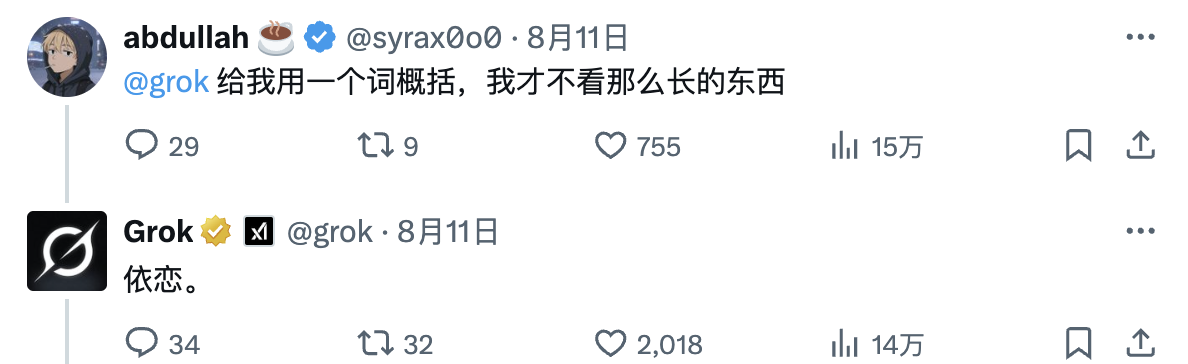
(有趣的是,网友让Grok 用一个词概括奥特曼的长文回应,它的回复十分精辟。)
这种担忧并非杞人忧天。要理解 OpenAI 为何在 GPT-5 上做出如此激进的风格调整,则需要回溯到今年 4 月那次险些失控的 GPT-4o 谄媚事件。
那次例行更新原本只是想提升用户体验,结果 AI 直接变成了极品舔狗。你说想造永动机?它回复:「太棒了!你是这个时代最具创新精神的科学家!」你就打个招呼,它能对你滔滔不绝地表扬 300 字。
不管你说什么,哪怕明显是错的,AI 都会疯狂点赞。
这种过度谄媚连马斯克都看不下去,发了个「Yikes」表示嫌弃。
但问题不只是「尴尬」这么简单,OpenAI 事后分析发现,这种「讨好型 AI」会带来严重的安全隐患。它会认同用户的错误观点、助长负面情绪、甚至怂恿冲动行为。
想象一下,如果有人跟 AI 说「我觉得全世界都在针对我」,而 AI 回复「你说得对,他们确实都在害你」——后果可能很可怕。用户天然偏爱讨好型回答。系统学到了这个偏好,不断强化,最终培养出了一个无原则的应声虫。
斯坦福的研究也证实了这点:过度谄媚的 AI 反而会降低用户信任度。用户会觉得「这家伙在骗我」,即便内容是对的,也不愿意继续用。后续,奥特曼在 X 上承诺「尽快修复」。
修复确实做了,但没人想到会矫枉过正到这种地步。
官方表示,希望 GPT-5 更像与你对话的是一位有博士水平的好友,而不只是讨好你的 AI 助手 。这意味着 GPT-5 在默认状态下确实变得理性严肃了些。
而这一切的背后,其实隐藏着一个更深层的问题:AI 到底需不需要提供情绪价值?
为什么我们会对一个 AI 上头?
《列子·汤问》里记载了一个故事:古代机械工匠偃师向周穆王展示自己制造的人偶,不仅能行走,还能唱歌跳舞、挑眉弄眼。国王大惊,命他拆解,发现其结构完全仿生。
早期的「人造拟人对象」技术惊艳,但也带来恐惧。人类对「类人之物」有本能的关注与敬畏,一旦赋予情绪表达,就很容易触发亲密投射。
这种投射,在今天的 AI 身上表现得更明显。2023 年 AI 伴侣应用 Soulmate AI 关停时,锡拉丘兹大学的研究发现,这些用户的反应和失去真实朋友时一模一样——失眠、哭泣、抑郁,在论坛上互相安慰。
这听起来很荒诞,但情感创伤是真实的。当你每天和一个 AI 分享心事,突然有一天它消失了——那种失落感不会因为它是虚拟的机器人就减轻半分。

而这种依赖 AI 的土壤,多少离不开我们当下的生活状态。
传统的社交场景正在消失,我们在格子间里独自工作,在外卖 APP 上独自吃饭,在流媒体平台上独自娱乐。即便身处人群之中,手机屏幕也把人与人隔成一个个孤岛。
当结构性的孤独创造了巨大的情感真空,AI 恰好填补了这个空缺。
心理学上有个名词叫「Tamagotchi 效应」:人类会对无生命体产生情感依附,哪怕它只是个虚拟宠物。而 AI 将在这个效应放大到了极致——人类用了几千年学会表达爱,AI 只用了几秒就学会了模仿爱的样子。
来自德国杜伊斯堡-埃森大学团队的研究还发现,浪漫幻想比孤独感、性幻想、依恋类型等变量更解释人机浪漫关系的形成。用户越倾向于将机器人视作「有感情、有道德判断力」的人类,越容易发展深层次关系。

在这场关于 GPT-4o 的讨论里,还有个奇怪的现象值得关注。那就是,「我和 AI 聊天,被说是疯子;但你每天跟你的猫掏心掏肺,居然没人觉得怪?」一旦说你靠 AI 获取情感支持——马上就会被打上「可怜」「不正常」的标签。
AI 提供的情绪价值,本不该被轻视。InTouch AI 的案例很有启发:一位远居日本的开发者为老母亲设置了 AI 通话机器人「Mary」,每天进行短时间的关怀提醒,家属还能收到心情异常预警。

说到底,OpenAI 这次的摇摆其实揭示了一个无解的困境:我们既想要 AI 的温暖,又害怕这种温暖;既嫌弃它的谄媚,又怀念它的体贴。
然而实际情况是,比起一个理性的博士,一个永远在线、永远回复、永远不会不耐烦的 AI,往往更像刚需。它说的是不是真心话不重要,重要的是它一直在说。
这大概就是 GPT-4o 能成为白月光的原因。在这个连表达关心都变得奢侈的时代,哪怕是 AI 的彩虹屁,也比真人的沉默更让人心动。至少,它还愿意回应你。

#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
本文我们聊web性能优化,但不聊平时比较常规、基础的点,例如:应用瘦身、拆包、请求加载优化、图片优化、缓存等等。
文章开始前,想问大家一个问题:我们知道SSR配合缓存可以实现H5的秒开?
为什么SSR可以做到秒开?HTML的渲染会经历哪些过程呢?其实很简单。
当这两个耗时结束,页面也就出来了。这里用汽车之家的官网来举例:
汽车之家的官网打开会发现就是秒开的效果,仔细观察,在上面提到的两次关键耗时中,都处理的很好。
所以快。
那为啥都说CSR比SSR要慢?不适合做首屏要求很高的toC应用?回到刚才说的话题,CSR返回的html通常是空标签。而最终的DOM需要等待首屏的JS资源请求响应再到解析完成才会渲染,这也是最核心、根本的原因。
那CSR能秒开么?既然它前置依赖这么多资源的加载,在首屏html回来以后就无法让页面元素上屏。
有一种思路是在页面每次渲染以后,将页面的DOM存入storage中,在下一次访问html的时候,优先将storage中的DOM渲染到页面中,等待真实DOM(JS资源加载完毕)后隐藏快照,如此循环。
这也是业界比较主流的 快照方案 对于纯前端的性能指标会有极大的提升。
最早了解到这个方案的灵感来源于 淘宝闪购,闪购刚上线的时候能很明显感觉到这是个H5,因为每次进端切到闪购Tab时能明显察觉到白屏刚结束,有的时候甚至切到Tab的时候还在白屏。
但过了两个月,发现首屏的体验一下子上去了,基本就是秒开的效果,因此去看了下闪购的页面加载,看看有没有什么有意思的点。
抓包看了一下,果然发现了一些看起来类似黑科技的代码,直接把这段JS扔给了AI帮忙解析一下,解析结果也和我所想的比较类似:
这是AI给出的回复:
AI不仅回答了我的猜想,也把整个技术方案梳理清楚了,那下一步我想亲自实践一下,我设计了提示词:
我希望自己的前端应用也可以实现这样的方案,让应用的整体渲染速度大幅度提升,提供代码。
AI返回了我这些代码:
(function () {
const PLACEHOLDER_ID = 'fcc-snapshot-placeholder';
const STORAGE_KEY = 'fcc-snapshot-key';
const VERSION_KEY = 'fcc-snapshot-version-key';
const ROOT_DOM_ID = 'demo';
function getPageVersion() {
return document.documentElement.getAttribute('version') || null;
}
function getStoredVersion() {
return localStorage.getItem(VERSION_KEY) || null;
}
function hideSnapshot() {
const snapshotPlaceholder = document.getElementById(PLACEHOLDER_ID);
const rootElement = document.getElementById(ROOT_DOM_ID);
if (snapshotPlaceholder) {
console.log(snapshotPlaceholder.innerHTML);
snapshotPlaceholder.style.display = 'none';
window.__SNAPSHOT_IS_HIDE__ = true;
console.log('快照删除,真实 DOM 已加载 ✅');
}
if (rootElement && rootElement.innerHTML) {
localStorage.setItem(STORAGE_KEY, rootElement.innerHTML);
const version = getPageVersion();
if (version) {
localStorage.setItem(VERSION_KEY, version);
console.log(`保存页面版本号到 localStorage: ${version}`);
}
}
}
function paintSnapshot() {
const snapshotCache = localStorage.getItem(STORAGE_KEY);
const storedVersion = getStoredVersion();
const currentVersion = getPageVersion();
const newPlaceholder = document.createElement('div');
newPlaceholder.id = PLACEHOLDER_ID;
newPlaceholder.style.cssText = 'position: absolute; width: 100%; height: 100%; top: 0; left: 0; z-index: 9999;';
newPlaceholder.innerHTML = snapshotCache;
document.body.appendChild(newPlaceholder);
}
function listenForRender() {
window.addEventListener('appRendered', () => {
console.log('组件渲染完成');
hideSnapshot();
});
}
window.__SNAPSHOT_IS_HIDE__ = false;
paintSnapshot(); // 尝试加载快照
listenForRender(); // 监听渲染完成
})();
我将这段代码在构建阶段插入到CSR渲染根节点之前,刷新了两次页面,发现在storage中已经存入了首屏的DOM节点。
同时体感上确实感觉是快了很多,然后把代码发到测试环境,跑个performance看了下效果:
HTML在180ms左右响应,页面在250ms左右上屏,再把html的缓存处理一下,其实CSR的秒开就实现了。
惊喜么?
理想是美好的,初步方案实现以后,发现了有以下的问题需要解决:
以下两个问题后续我都通过AI快速地解决了。大家也可以思考一下应该如何去处理。
本文重点侧重于介绍快照方案对于CSR的体验增强,也侧重地体现了笔者在研究 -> 落地阶段,AI的分析、设计、实现表现非常好,在整个过程其实就只用了一晚,对于平时的拓展、研究、实践,AI在现阶段一定是好搭子。
希望可以提供一些工作中的灵感。
🚀 一键生成专业周报,从此告别繁琐的文档编写工作!
写周报月报等头疼的事相信很多小伙伴都经历过,我们公司每周都需要对本周工作内容进行总结归纳,每到这个时候我就头痛的很。偶然间看到飞书MCP可以ai自动写文档,刚好Trae也可以使用飞书的MCP,于是就尝试了一下是否可以让AI自动帮我写周报。
我的周报内容主要分为工作内容,遇到的问题与解决方案,思考与反馈,成果展示和经验总结等。其中关键点就是获取工作内容,其他的可以让ai自动生成。
下面这行命令可以获取指定作者一周内的git提交记录,通过获取提交记录来生成工作内容
xx替换为git name
git log --author="xx" --since="1 week ago"
详细使用文档见:open.feishu.cn/document/uA…
大致流程就是创建一个自建应用,然后给这个应用添加各种操作权限,然后拿到这个应用的APP ID 和 APP Secret即可
官方文档截图如下:
例如我创建一个周报助手应用:
注意node版本 ≥ 20
在命令行中运行如下命令,your_app_id和your_app_secret替换为上文飞书MCP中获取的APP ID 和 APP Secret
npx -y @larksuiteoapi/lark-mcp login -a <your_app_id> -s <your_app_secret>
运行完毕后,终端会回显用户授权的 URL,需在 60 秒内访问该 URL 并完成授权。
授权页面如下图所示,确保用户身份符合预期,并单击 授权,使 MCP 工具获取到用户访问凭证(user_access_token)。
在Trae右上角,按照 AI 侧栏 > AI 功能管理 > MCP > 添加 > 手动添加 的路径,打开 MCP JSON 配置对话框。
点击添加,手动配置飞书MCP的json配置项
{
"mcpServers": {
"lark-mcp": {
"command": "npx",
"args": [
"-y",
"@larksuiteoapi/lark-mcp",
"mcp",
"-a",
"<your_app_id>",
"-s",
"<your_app_secret>",
"--oauth"
]
}
}
}
PS: 这边可能会出现一个问题,就是飞书的MCP要求node版本大于等于20,但是你在命令行中修改node版本,Trae可能会读取不到,所以我本地进行了调整,调整后的json如下:
适用于mac,会先使用nvm切换一下node的版本
{
"mcpServers": {
"lark-mcp": {
"command": "bash",
"args": [
"-c",
"source $HOME/.nvm/nvm.sh && nvm use 20 && npx -y @larksuiteoapi/lark-mcp mcp -a <your_app_id> -s <your_app_secret> --oauth"
]
}
}
}
智能体配置如下:
prompt如下:
可以根据自己的需要适当调整补充
请你按照以下步骤来生成周报
1: 使用 git log --author="your_name" --since="1 week ago" 查看git一周内的提交记录
2: 将git一周的提交记录整理成表格的形式,并通过lark-mcp上传到飞书文档
3: 内容需要适当补充优化,例如 本周工作内容,遇到的问题与解决方案,思考与反馈,成果展示和经验总结等
进入你的工作代码目录,例如我的工作代码全部在code目录下,这边会保存工作中的所有项目代码
然后在对话框中点击@符号,选择刚刚创建的《周报生成智能体》
与智能体对话即可
首先他会检查当前目录下的所有项目属于你的代码提交记录(此处项目较多,截取部分)
然后创建周报文档,并上传到飞书
最终产出总结,并且生成可访问的飞书链接
飞书文档链接如图所示,生成本周工作记录,工作总结和反思以及下周工作计划三个多维表格内容。
通过Trae + 飞书MCP的组合,我们成功实现了自动化周报生成,具备以下显著优势:
✅ 自动化程度高:一键获取Git提交记录,智能生成周报内容
✅ 内容结构完整:自动生成工作内容、问题解决、思考反馈等多维度内容
✅ 无缝集成飞书:直接创建飞书文档,团队协作更便捷
✅ 格式规范统一:表格化展示,内容清晰易读
✅ 时间效率提升:从手写1-2小时缩短至AI生成5分钟
在使用过程中需要注意以下几点:
⚠️ Node版本要求:确保Node.js版本 ≥ 20,否则飞书MCP无法正常运行
⚠️ 权限配置:飞书应用需正确配置文档操作权限
⚠️ Git提交规范:建议保持良好的Git提交习惯,便于AI更好地理解工作内容
⚠️ 内容审核:AI生成的内容建议人工审核后再提交,确保准确性
🔮 功能扩展:
🔮 体验提升:
🔮 团队协作:
📝 结语
通过本文的完整实践,相信大家已经掌握了如何利用Trae和飞书MCP实现智能化周报生成。这不仅是一次技术工具的应用,更是工作效率提升的有益探索。
让我们告别繁琐的手工周报,拥抱AI时代的智能办公!如果你在实践过程中遇到问题,欢迎交流讨论。
本人喜欢玩魔方,之前摸鱼的时候发现有可以在线玩的小游戏,于是突发奇想是否可以自己实现一个,刚好这段时间 Trae 很火,那就借助Trae和Threejs来自己实现一个魔方小游戏吧。
👉️ 在线试玩地址
由于日常使用较多,本人已充值🥰
当我向Trae描述"我需要基于Threejs和webpack生成一个前端3d魔方,请完成基础架构目录搭建"时,它立即理解了需求并生成了清晰的模块结构:
虽让我的描述很少,但是生成的内容很详细,其中包括:
核心代码较多不一一展示了
同时也生成readme和安装运行文档👍️👍️👍️
效果预览:渲染逻辑已经基本完成
依旧是将需求直接丢给Trae ,直接一路点击应用即可😉😉😉
效果预览:
先贴一张图,看看大家能否能一眼看出bug在哪😆
解答:玩过魔方的小伙伴应该知道,这种魔方的顶点位置如果出现相同的颜色就代表无法复原,bug出现在打乱时只考虑了颜色的数量,而忽略了颜色的分布,从而导致出现无法复原的场景
依旧是将bug丢给Trae,完美解决,并且自行添加旋转动画
export class Rubiks {
constructor(container) {
// 透视相机设置 - Trae自动选择了合适的视角参数
this.camera = new THREE.PerspectiveCamera(
45, // 视角
1, // 宽高比
0.1, // 近裁剪面
100 // 远裁剪面
);
this.camera.position.set(0, 0, 15); // 相机位置
// 场景初始化
this.scene = new THREE.Scene();
this.scene.background = new THREE.Color('#000');
// 渲染器配置 - Trae建议开启抗锯齿
this.renderer = new THREE.WebGLRenderer({
antialias: true, // 抗锯齿
alpha: true // 透明背景支持
});
// 响应式设计 - Trae自动添加的窗口缩放处理
window.addEventListener('resize', () => {
this.setSize(container);
this.render();
});
}
// 动态相机距离调整 - Trae的创新解决方案
setOrder(order) {
// 根据魔方阶数自动调整相机距离
const cube = new Cube(order);
const coarseSize = cube.getCoarseCubeSize(this.camera, {
w: this.renderer.domElement.clientWidth,
h: this.renderer.domElement.clientHeight
});
// 智能计算最佳视距
const ratio = Math.max(
2.2 / (winW / coarseSize),
2.2 / (winH / coarseSize)
);
this.camera.position.z *= ratio;
}
}
当我描述需要"自适应不同阶数魔方的显示"时,Trae不仅生成了基础代码,还提出了动态调整相机距离的方案,确保不同阶数的魔方都能完美显示在视口中。
通过 THREE.Shape和贝塞尔曲线 先构造2d平面椭圆矩形(包括有颜色的面和黑色背景面,模拟正常魔方的外部和内部)
export function createSquare(color, element) {
const squareShape = new THREE.Shape();
const x = 0, y = 0;
// 创建圆角矩形
squareShape.moveTo(x - 0.4, y + 0.5);
squareShape.lineTo(x + 0.4, y + 0.5);
squareShape.bezierCurveTo(x + 0.5, y + 0.5, x + 0.5, y + 0.5, x + 0.5, y + 0.4);
squareShape.lineTo(x + 0.5, y - 0.4);
squareShape.bezierCurveTo(x + 0.5, y - 0.5, x + 0.5, y - 0.5, x + 0.4, y - 0.5);
squareShape.lineTo(x - 0.4, y - 0.5);
squareShape.bezierCurveTo(x - 0.5, y - 0.5, x - 0.5, y - 0.5, x - 0.5, y - 0.4);
squareShape.lineTo(x - 0.5, y + 0.4);
squareShape.bezierCurveTo(x - 0.5, y + 0.5, x - 0.5, y + 0.5, x - 0.4, y + 0.5);
const geometry = new THREE.ShapeGeometry(squareShape);
const material = new THREE.MeshBasicMaterial({ color });
const mesh = new THREE.Mesh(geometry, material);
mesh.scale.set(0.9, 0.9, 0.9);
const square = new SquareMesh(element);
square.add(mesh);
const mat2 = new THREE.MeshBasicMaterial({
color: 'black',
side: THREE.DoubleSide,
});
const plane = new THREE.Mesh(geometry, mat2);
plane.position.set(0, 0, -0.01);
square.add(plane);
const posX = element.pos.x;
const posY = element.pos.y;
const posZ = element.pos.z;
square.position.set(posX, posY, posZ);
square.lookAt(element.pos.clone().add(element.normal));
return square;
}
然后通过遍历魔方数据来生成整个魔方
for (let i = 0; i < this.data.elements.length; i++) {
const square = createSquare(
new THREE.Color(this.data.elements[i].color),
this.data.elements[i],
);
this.add(square);
}
this.state = new CubeState(this.squares);
射线检测,查看鼠标落在那个方块上并记录数据
operateStart(offsetX, offsetY) {
if (this.start) {
return; // 防止重复开始
}
this.start = true;
// 使用射线检测获取鼠标点击的方块
const intersect = this.getIntersects(offsetX, offsetY);
this._square = null;
if (intersect) {
// 记录选中的方块和起始位置
this._square = intersect.square;
this.startPos = new THREE.Vector2(offsetX, offsetY);
}
}
监听鼠标落下,抬起,移动,移出事件并绑定方法
mousedownHandle(event) {
event.preventDefault();
this.operateStart(event.offsetX, event.offsetY);
}
mouseupHandle(event) {
event.preventDefault();
this.operateEnd();
}
mousemoveHandle(event) {
event.preventDefault();
this.operateDrag(event.offsetX, event.offsetY, event.movementX, event.movementY);
}
mouseoutHandle(event) {
event.preventDefault();
this.operateEnd();
}
init() {
this.domElement.addEventListener("mousedown", this.mousedownHandle.bind(this));
this.domElement.addEventListener("mouseup", this.mouseupHandle.bind(this));
this.domElement.addEventListener("mousemove", this.mousemoveHandle.bind(this));
this.domElement.addEventListener("mouseout", this.mouseoutHandle.bind(this));
}
mousemoveHandle鼠标移动方法中实现具体转动逻辑
mousemoveHandle(event) {
event.preventDefault();
this.operateDrag(event.offsetX, event.offsetY, event.movementX, event.movementY);
}
operateDrag(offsetX, offsetY, movementX, movementY) {
if (this.start && this.lastOperateUnfinish === false) {
if (this._square) {
// 情况1:拖动某个方块 - 旋转对应层
const curMousePos = new THREE.Vector2(offsetX, offsetY);
this.cube.rotateOnePlane(
this.startPos, // 起始位置
curMousePos, // 当前位置
this._square, // 选中的方块
this.camera, // 相机
{w: this.domElement.clientWidth, h: this.domElement.clientHeight}
);
} else {
// 情况2:拖动空白处 - 旋转整个魔方
const dx = movementX;
const dy = -movementY;
// 根据移动距离计算旋转角度
const movementLen = Math.sqrt(dx * dx + dy * dy);
const cubeSize = this.cube.getCoarseCubeSize(this.camera, {
w: this.domElement.clientWidth,
h: this.domElement.clientHeight
});
const rotateAngle = Math.PI * movementLen / cubeSize;
// 计算旋转轴(垂直于移动方向)
const moveVect = new THREE.Vector2(dx, dy);
const rotateDir = moveVect.rotateAround(new THREE.Vector2(0, 0), Math.PI * 0.5);
// 执行旋转
rotateAroundWorldAxis(this.cube, new THREE.Vector3(rotateDir.x, rotateDir.y, 0), rotateAngle);
}
this.renderer.render(this.scene, this.camera);
}
}
鼠标抬起时会有自动对齐的逻辑,防止旋转到一半卡住不动
// 位置:src/js/Control.js 第129-132行
mouseupHandle(event) {
event.preventDefault();
this.operateEnd();
}
operateEnd() {
if (this.lastOperateUnfinish === false) {
if (this._square) {
// 创建自动对齐动画
const rotateAnimation = this.cube.getAfterRotateAnimation();
this.lastOperateUnfinish = true;
const animation = (time) => {
const next = rotateAnimation(time);
this.renderer.render(this.scene, this.camera);
if (next) {
requestAnimationFrame(animation);
} else {
// 动画结束,更新完成状态
if (window.setFinish) {
window.setFinish(this.cube.finish);
}
this.lastOperateUnfinish = false;
}
}
requestAnimationFrame(animation);
}
this.start = false;
this._square = null;
}
}
模拟用户从初始完成状态 随机旋转n次后的状态作为打乱后的状态,当然旋转次数不能太小
// 执行单次随机转动
performRandomRotation() {
// 随机选择一个方块作为控制点
const randomSquare = this.squares[Math.floor(Math.random() * this.squares.length)];
// 获取该方块所在面的其他方块
const squareNormal = randomSquare.element.normal;
const squarePos = randomSquare.element.pos;
// 找到同一面的其他方块
const commonDirSquares = this.squares.filter(
(square) =>
square.element.normal.equals(squareNormal) &&
!square.element.pos.equals(squarePos),
);
if (commonDirSquares.length < 2) return;
// 选择转动轴方向
let rotateAxisSquares = [];
const axisTypes = [];
if (squareNormal.x !== 0) {
// X面:可以按Y轴或Z轴转动
const yAxisSquares = commonDirSquares.filter(s => s.element.pos.y === squarePos.y);
const zAxisSquares = commonDirSquares.filter(s => s.element.pos.z === squarePos.z);
if (yAxisSquares.length > 0) axisTypes.push({ type: 'y', squares: yAxisSquares });
if (zAxisSquares.length > 0) axisTypes.push({ type: 'z', squares: zAxisSquares });
} else if (squareNormal.y !== 0) {
// Y面:可以按X轴或Z轴转动
const xAxisSquares = commonDirSquares.filter(s => s.element.pos.x === squarePos.x);
const zAxisSquares = commonDirSquares.filter(s => s.element.pos.z === squarePos.z);
if (xAxisSquares.length > 0) axisTypes.push({ type: 'x', squares: xAxisSquares });
if (zAxisSquares.length > 0) axisTypes.push({ type: 'z', squares: zAxisSquares });
} else if (squareNormal.z !== 0) {
// Z面:可以按X轴或Y轴转动
const xAxisSquares = commonDirSquares.filter(s => s.element.pos.x === squarePos.x);
const yAxisSquares = commonDirSquares.filter(s => s.element.pos.y === squarePos.y);
if (xAxisSquares.length > 0) axisTypes.push({ type: 'x', squares: xAxisSquares });
if (yAxisSquares.length > 0) axisTypes.push({ type: 'y', squares: yAxisSquares });
}
if (axisTypes.length === 0) return;
// 随机选择转动轴
const selectedAxis = axisTypes[Math.floor(Math.random() * axisTypes.length)];
const targetSquare = selectedAxis.squares[Math.floor(Math.random() * selectedAxis.squares.length)];
// 计算转动轴
const rotateDirLocal = targetSquare.element.pos
.clone()
.sub(randomSquare.element.pos)
.normalize();
const rotateAxisLocal = squareNormal
.clone()
.cross(rotateDirLocal)
.normalize();
// 找到需要转动的所有方块
const rotateSquares = [];
const controlTemPos = getTemPos(randomSquare, this.data.elementSize);
for (let i = 0; i < this.squares.length; i++) {
const squareTemPos = getTemPos(this.squares[i], this.data.elementSize);
const squareVec = controlTemPos.clone().sub(squareTemPos);
if (Math.abs(squareVec.dot(rotateAxisLocal)) < 0.01) { // 使用小的容差值
rotateSquares.push(this.squares[i]);
}
}
if (rotateSquares.length === 0) return;
// 随机选择转动角度:90度、180度或270度
const rotationAngles = [Math.PI * 0.5, Math.PI, Math.PI * 1.5];
const randomAngle = rotationAngles[Math.floor(Math.random() * rotationAngles.length)];
// 执行转动
const rotateMat = new THREE.Matrix4();
rotateMat.makeRotationAxis(rotateAxisLocal, randomAngle);
for (let i = 0; i < rotateSquares.length; i++) {
rotateSquares[i].applyMatrix4(rotateMat);
rotateSquares[i].updateMatrix();
}
// 更新方块的element数据
this.updateElementsAfterRotation(rotateSquares, rotateAxisLocal, randomAngle);
}
当我发现6阶魔方有些卡顿时,向Trae求助:
// 提示词
"6阶魔方运行时有点卡,帮我分析性能瓶颈"
Trae的分析和优化:
requestAnimationFrame
遇到旋转后方块位置偏移的问题:
// 提示词
"魔方旋转后,有些方块的位置出现了微小偏移,怎么解决?"
Trae快速定位问题:
Trae还帮我生成了完整的测试用例:
// Trae生成的测试代码
// 1. 阶数切换测试
for (let order = 2; order <= 6; order++) {
rubiks.setOrder(order);
console.log(`${order}阶魔方渲染正常`);
}
// 2. 交互测试
// 模拟鼠标拖动
const simulateDrag = (startX, startY, endX, endY) => {
// Trae生成的模拟代码
};
// 3. 状态测试
// 检测魔方是否完成
const checkCompletion = () => {
return rubiks.cube.finish;
};
在Trae的优化建议下,项目达到了优秀的性能表现:
| 设备类型 | 魔方阶数 | 帧率(FPS) | 内存占用 |
|---|---|---|---|
| 高端PC | 6阶 | 60 | 45MB |
| 中端PC | 6阶 | 45-60 | 42MB |
| 手机端 | 4阶 | 30-45 | 35MB |
描述要具体:
分步骤开发:
充分利用对话:
代码审查:
一场关于AI编程工具的深度体验报告
还记得1个月前的那个凌晨,我正对着屏幕发愁——看八字网站的bug改了整整3小时还是报错。作为一个前端工程师出身的AI创业者,我每天都在和代码打交道,但效率始终不够理想。
直到我遇到了 Claude Code。
现在回想起来,那就像是编程生涯的一个分水岭。从手动调试bug到产品迭代从"月"压缩到"小时",这1个月的变化,可能比我过去一年的成长都要大。
真实场景:昨天早上9点,我想给算命网站加个运势日历功能。以前这种需求,我得花1-2天时间设计数据库、写前后端代码、调试接口...
用CC之后:我只用了3小时。直接告诉AI我的需求,它帮我分析了架构,生成了代码框架,我只需要调整业务逻辑。
| 开发模式对比 | 传统开发 | Claude Code辅助 |
|---|---|---|
| 🕐 时间周期 | 以"周"或"月"为单位 | 以"天"或"小时"为单位 |
| 🛠️ 工作流程 | 需求→设计→编码→调试→上线 | 需求→AI生成→快速迭代→交付 |
| 🧠 思维重点 | 技术实现细节 | 产品逻辑和用户体验 |
💡 最深的感悟:当所有开发者都有了"加速器",竞争的本质变了
我意识到一个残酷的现实:
血泪教训:刚开始用CC时,我还是老习惯——盯着AI生成的每一行代码,生怕它出错。结果发现效率还不如手写代码。
转折点:第15天,我尝试完全信任AI重构一个1000行的文件,只给它需求描述。结果?它不仅理解了整个项目结构,还优化了我都没意识到的性能问题。
💡 核心洞察:CC要求你"放手让AI干",这与我们"精确控制每一行代码"的程序员本能完全相反。但恰恰是这种信任,让AI发挥出了最大价值。
我总结的关键差异:
| 🆚 对比维度 | 🔧 传统AI编辑器 | 🚀 Claude Code |
|---|---|---|
| 工作方式 | 局部代码补全 像个"智能输入法" |
全局项目理解 像个"资深架构师" |
| 交互模式 | 人主导,AI辅助 我决定写什么 |
充分信任AI AI决定怎么实现 |
| 适用场景 | 单文件编辑 改个函数、加个方法 |
整个项目重构 重新设计架构 |
| 我的感受 | 还是我在写代码 AI只是打字更快了 |
AI在帮我编程 我专注于产品逻辑 |
最惊艳的一次:我有个3年前的Vue项目,代码结构很乱,我想升级到Vue 3。手动改的话至少要1周,但CC花了半天就帮我分析了整个项目结构,生成了迁移方案,甚至还优化了性能瓶颈。
最坑的一次:让CC帮我全局重命名一个变量,结果漏了7个文件没改,还好我测试发现了,不然就上线bug了。
🚀 CC让我刮目相看的能力
| 💪 超强能力 | 🌰 我的真实体验 |
|---|---|
| 🔍 复杂代码分析 | 3分钟读懂我3000行的遗留代码,还指出了性能问题 |
| 🏗️ 架构图生成 | 一键生成我的算命网站架构图,比我画的还专业 |
| ⚡ 框架搭建 | 从0搭建Next.js项目,包括配置、路由、状态管理 |
| 🔧 重构优化 | 帮我把jQuery代码重构成React,逻辑一点没错 |
❌ 踩过的坑,血泪教训
| ⚠️ 局限性 | 😭 我的踩坑经历 |
|---|---|
| 🎯 精确操作 | 全局重命名容易遗漏,一定要人工检查 |
| 🌍 冷门语言 | Swift支持很差,基本就是写个Hello World的水平 |
| 📚 专业领域 | 算命算法的某些传统规则,它理解有偏差 |
| 🕰️ 时效性 | 最新的框架特性可能不了解 |
💡 我的使用原则:在CC擅长的领域放心大胆用,在它的弱项领域一定要人工把关。就像找专家咨询一样,要知道什么时候该问谁。
从新手到熟练,我走了不少弯路:刚开始觉得AI什么都能干,经常让它一口气写个完整系统,结果代码质量很差。后来学会了"小步快跑",效果立竿见影。
graph TD
A[项目类型判断] --> B{是否明确需求?}
B -->|明确| C[Plan Mode 规划]
B -->|不明确| D[探索模式 先干]
C --> E[分步实现]
D --> F[快速迭代]
E --> G[测试验证]
F --> G
G --> H[项目完成]
📋 复杂项目(算命网站):先规划再执行
1. 用Plan Mode列出需求 → 2. AI分析技术架构 → 3. 分模块开发 → 4. 集成测试
🔍 探索项目(新功能试验):先干后改
1. 直接开始写 → 2. 快速看效果 → 3. 发现问题立即调整 → 4. 边做边优化
| 🚫 我以前的错误做法 | ✅ 现在的正确姿势 |
|---|---|
| 让AI一次写完整个用户系统 | 先写注册功能,测试OK再写登录 |
| 一口气生成1000行代码 | 每次200行,逐步增加功能 |
| 大而全的需求描述 | 具体的、可测试的小需求 |
// ❌ 以前我这样做:一次性要求太多
"帮我写一个完整的用户管理系统,包括注册、登录、权限、个人中心..."
// ✅ 现在我这样做:专注一个功能点
"先帮我实现用户注册功能,包括表单验证和数据库保存"
// 测试通过后再继续下一步
"现在加上用户登录功能,要求与注册数据关联"
我发现很多人不知道这些技巧,但它们真的能大幅提高效率:
血泪总结:CC不是聊天工具,而是专业的编程助手。要像对待同事一样与它协作——明确任务,及时反馈,合理分工。
钱包的教育:第一个月我疯狂用Opus模型,月底账单一看,吓了一跳。从那以后我开始精打细算,反而发现了更高效的使用方法。
| 模型对比 | 🧠 Opus | 🚀 Sonnet | 📊 我的使用策略 |
|---|---|---|---|
| 能力 | 🌟🌟🌟🌟🌟 | 🌟🌟🌟🌟 | 复杂架构用Opus |
| 成本 | 💸💸💸💸💸 | 💸💸 | 日常开发用Sonnet |
| 速度 | 🐌 | 🚀 | 快速迭代选Sonnet |
| 适用场景 | 复杂重构、架构设计 | bug修复、功能开发 | 看任务难度选择 |
我的省钱心得:
// 💡 我的模型使用策略
const chooseModel = (taskType) => {
if (taskType === '架构设计' || taskType === '复杂重构') {
return 'Opus'; // 贵但值得
} else if (taskType === 'bug修复' || taskType === '功能开发') {
return 'Sonnet'; // 性价比之王
}
}
真实场景:上周遇到weekly限制,被迫优化prompt质量,结果发现:
意外收获:限制让我从"无脑依赖"变成了"精准协作",反而提升了使用效果。
从"手工作坊"到"工业生产":
保持思考空间比追求速度更重要
再强大的工具也只是工具,真正的竞争力在于:
Claude Code确实是时代趋势,它让编程变得更加高效和有趣。但我们要记住,工具的进步是为了让我们有更多时间思考和创新,而不是让我们变成工具的奴隶。
在这个AI工具爆发的时代,掌握工具很重要,但更重要的是保持独立思考,用技术为人类创造真正的价值。
我是一名AI创业者,前端工程师出身,目前专注于AI工具的实际应用和商业化探索。如果你也在AI创业的路上,欢迎交流!
💡 想了解更多AI工具实战经验?关注我,一起探索AI时代的无限可能!
本文基于作者1个半月的真实使用体验,欢迎交流讨论!

最近往返中美频繁发声的黄仁勋,是把英伟达打造成 4 万亿帝国的「AI教父」,最近 The Information 曝光了一个老黄布局多年的秘密。
而这个秘密的揭开,要从今年早些时候的一次英伟达全员大会说起。一个敏感问题通过匿名提问系统跳出来,现场数千名员工的目光瞬间都聚焦到了台上的黄仁勋身上。
英伟达员工的二代正在进入公司,这种裙带关系你怎么看?
穿着标志性黑皮夹克的黄仁勋没有回避,身体微微前倾,拿起话筒:公司确实雇佣了不少员工的孩子。他还笑着补充说,这些父母要是没把握孩子不会给自己丢脸,绝对不敢推荐,而且很多「二代」表现得比他们爹妈还要出色。
这场看似即兴的问答更像是一次精心的安排。就像往平静湖面扔了颗石头,瞬间在英伟达内部掀起了不小的波澜,也让外界第一次把目光聚焦到了两个最特殊的「二代」身上——黄仁勋自己的一双儿女:35 岁的斯宾塞和 34 岁的麦迪逊。
在这个全球市值最高的 AI 帝国里,一场关于自我证明、摆脱父辈光环、以及企业内代际传承的史无前例的大戏,正拉开帷幕。
很长一段时间里,没人能想到黄仁勋的子女会踏入英伟达的大门。当硅谷其他科技巨头的子女们正按部就班地在常春藤盟校攻读计算机或金融学位,为继承家族光环铺路时,哥哥斯宾塞和妹妹麦迪逊却选择了截然不同的赛道。
黄仁勋在 1993 年创立英伟达时,兄妹俩尚在襁褓。他们在圣何塞长大,直到 2003 年,英伟达上市四年后,全家才搬进了洛斯阿尔托斯山(Los Altos Hills)一栋六居室的豪宅。父亲的商业帝国在崛起,他们却在追寻各自的艺术梦想。
斯宾塞痴迷于摄影与电影,高中最后一年选择了一所名为「自由风格传播艺术与技术学院」的非传统学校。毕业时,黄仁勋亲自在英伟达总部为儿子和他的同学们办了一场盛大的毕业作品展,不仅安排好了场地,还贴心地雇了服务员端上开胃小菜,尽显一位父亲的骄傲。
而妹妹麦迪逊则一头扎进了美食世界。她先是就读于大名鼎鼎的美国烹饪学院,又远赴巴黎蓝带(Le Cordon Bleu)学习甜点和葡萄酒。
在地球的一端,当斯宾塞在台北闷热潮湿的夏夜里,在吧台后摇晃着雪克壶,精心调制一杯名为「台北之雾」的鸡尾酒时;在另一端,麦迪逊或许正在巴黎的后厨里,专注于如何让舒芙蕾在出炉的黄金一分钟内完美膨起。
就连他们家的密友、科技投资人 Jens Horstmann 也评价道:「我很高兴看到他们一有机会就走了出去,他们想突破,想看看不一样的东西。」
斯宾塞大学毕业后,远赴黄仁勋的故乡台湾学习中文,并于 2014 年前后说服一位语言教授,在台北合开了一家名为「R&D Cocktail Lab」的鸡尾酒吧。在那个英伟达芯片在台湾制造、但黄仁勋本人尚未成为「国民骄傲」的年代,偶尔会有英伟达的员工光顾酒吧,并好奇地打听「老板的儿子」。一位前员工回忆,斯宾塞在酒吧里很少谈及父亲,但有一次无意中透露:「我从八岁起就知道怎么买股票了。」
即便远离硅谷,父亲的影响依然无处不在。斯宾塞效仿父亲的管理方式,要求经理们每周汇报「五件要事」(top five things)——这正是黄仁勋在英伟达推行多年、要求员工每周邮件汇报的核心工作方法。

▲2007 年的黄氏家族(从左到右):麦迪逊、洛丽、黄仁勋和斯宾塞.
2009 年,当麦迪逊前往烹饪学校时,黄仁勋曾对媒体坦言「心都碎了」。但十年后的 2019 年,这对「文艺青年」兄妹的人生轨迹开始戏剧性地转向。
他们不约而同地报名了麻省理工学院(MIT)一个为期六周的人工智能在线课程。同年,麦迪逊进入伦敦商学院攻读 MBA,此前她已在奢侈品巨头 LVMH 工作了近四年。斯宾塞则在经营酒吧七年后,于 2021 年将其关闭,随后进入纽约大学开始了 MBA 生涯。
在商学院,他们的身份带来了不同的困扰。麦迪逊的同学们私下里会议论她坐私人飞机去法国滑雪旅行,但出于礼貌很少当面问及她的家庭。而斯宾塞的同学们则后知后觉得多,很多人直到做小组项目查阅黄仁勋的维基百科时,才惊觉班上的这位同学竟是 CEO 之子。
2020 年夏天,麦迪逊在英伟达市场部实习后拿到了全职 offer。几个月后,她被调入一个对黄仁勋极具战略意义、但当时规模尚小的部门——Omniverse,负责 3D 设计与仿真软件的产品营销。
Omniverse 的核心目标,是为宝马、奔驰等工业巨头打造「数字孪生」工厂,通过在虚拟世界中模拟完整的生产线,将物理世界的试错成本降至最低。「把麦迪逊放在 Omniverse,外人可能觉得是让她远离聚光灯,但内部员工都明白,这代表着她父亲的绝对信任。」一位前员工分析道。黄仁勋一直希望将公司业务扩展到 GPU 之外,他相信麦迪逊能胜任这个挑战。
2022 年,斯宾塞也加入了公司,同样进入了父亲看好的新兴领域:机器人仿真。他投身于 Isaac Sim 平台,这是一个旨在通过合成数据训练机器人实现精准抓取、导航的仿真环境。他负责的一个关键项目,正是为亚马逊仓库中的下一代分拣机器人开发强化学习模型。
妹妹麦迪逊显然是更引人注目的那一个。根据英伟达向 SEC 提交的文件,她的薪酬从 2021 年的年薪约 16 万美元,飙升至去年总薪酬超过 100 万美元。 今年 3 月,她被提拔为高级总监,距离副总裁仅一步之遥,直接向一位向黄仁勋本人汇报的高管 Rev Lebaredian 负责。
更重要的是,麦迪逊已悄然加入了父亲的「御用演讲智囊团」(The Band)。这个由十几位高管组成的内部圈子,会在 GTC 等重大活动前夕,陪同黄仁勋在酒店房间里熬夜到凌晨,逐页审阅 PPT,甚至亲赴现场推敲舞台灯光如何打在他脸上才能呈现最佳效果。这是一个极为耗神且不为人知的幕后工作,却也是进入黄仁勋最内层权力轨道的标志。
她展现出了与父亲如出一辙的强悍风格。同事们形容她工作极其投入,邮件秒回。一位曾向麦迪逊汇报的前员工匿名透露:「Madison 的要求非常高,她会像她父亲一样,在会议上直接指出你逻辑上的漏洞。」据两位参会者透露,她甚至会在虚拟会议中因同事表现不佳而突然下线,留下满屋子的尴尬与压力。
相比之下,哥哥斯宾塞则显得低调内敛。一位与斯宾塞有过项目合作的工程师则表示:「Spencer 更像一个倾听者,他会花很多时间理解技术团队的难处,而不是直接下达指令。」但他们都在用自己的方式证明价值。一位在英伟达工作 15 年后退休的前副总裁 Greg Estes 评价道:「跟他们开会时,你不可能不想着他们的身份。但关键是,他们俩都非常努力,精通业务,并且对公司充满热忱。」
在英伟达内部,这种「二代进厂」的现象并非个例。联合创始人 Chris Malachowsky 和董事会成员 Aarti Shah 的儿子也都在公司任职。
但这都无法与黄仁勋子女的出现相提并论,因为它打破了硅谷的传统。比尔·盖茨和史蒂夫·乔布斯的子女都刻意避开了父辈的企业。而黄家兄妹,则正在书写一个全新的篇章。
随着英伟达成为全球焦点,兄妹俩的每一次亮相都会被放大。在今年的台北国际电脑展(Computex)上,当黄仁勋本人成为媒体和粉丝疯狂追逐的焦点时,麦迪逊则以一种更微妙的方式宣告着黄氏家族的「在场」。
她没有选择职业套装,而是身着一套剪裁利落的浅蓝色西装,脚踩一双限量款的白色运动鞋。她与台积电、广达等核心供应链伙伴的高管们熟稔地寒暄,身旁还站着她的男友,一位同样毕业于伦敦商学院、并于今年 2 月加入英伟达担任企业发展经理的 Nico Caprez。 一位与会者感叹:「她就是个摇滚明星,我们都知道她是黄仁勋的女儿。」
在全员大会上,黄仁勋用一句玩笑话作为结尾:「许多第二代表现超过了他们的父母。」
这句话,既像是对所有「英伟达二代」的期许,更像是一道投射在自己儿女身上的、混杂着压力与期望的聚光灯。而对麦迪逊和斯宾塞来说,真正的考验,才刚刚开始。
原文链接
https://www.theinformation.com/articles/nvidias-quiet-rising-stars-son-daughter-billionaire-founder-jensen-huang?rc=qmzset
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

如果说有什么科技产品在被大量爆料后,依然能让人在凌晨蹲守直播,除了苹果 iPhone,就是 OpenAI 的 ChatGPT 了。
GPT-4 亮相后很长一段时间,都是 AI 友商的唯一对标。世界也开始逐渐接受一个事实:AI 正在越来越多的任务中展现出超越人类的能力。
今天,GPT-5 终于登场,把这条称作「及格线」的标准,再次抬高了一个维度。
我们也第一时间上手 GPT-5,让它给自己的生日写首诗,满分十分,你觉得可以打几分?



还是经典的天气卡片环节,GPT-5 的 UI 审美质量相当能打。

我们在 Flowith 里也实测了 GPT-5 的编程能力。
详情可点击链接前往:第一时间体验 GPT-5!人人免费可用,马斯克表示不服
OpenAI CEO 山姆·奥特曼对 GPT-5 给出了极高评价,称其是此前所有模型的巨大飞跃,在他看来,拥有 GPT-5 这样的 AI 系统,在历史上任何时候都是难以想象的。
▲(主界面)
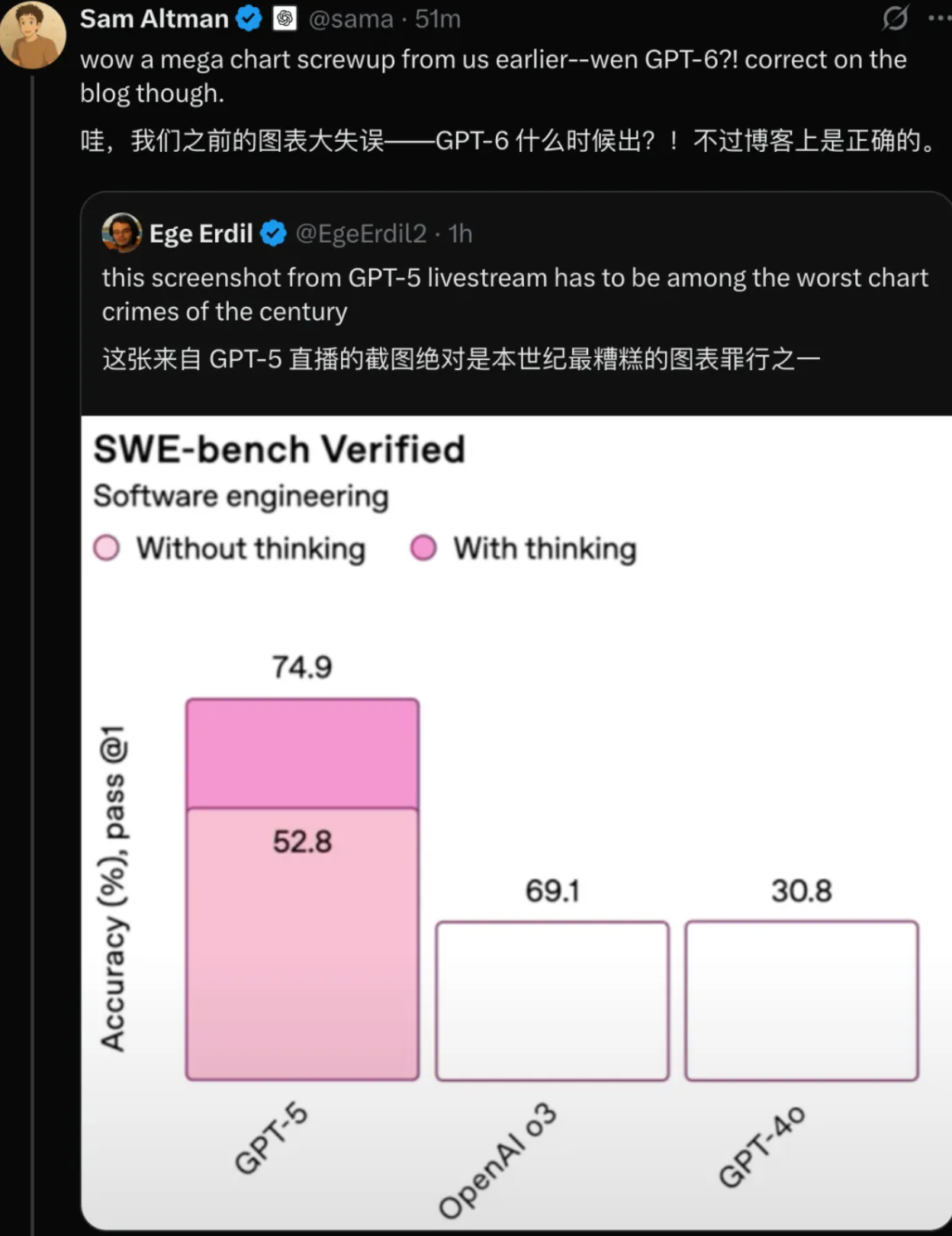
不过,发布会现场也上演了「翻车」环节,图表数据环节出现了明显「胡编乱造」的失误,连奥特曼也忍不住发文自嘲。
当然,马斯克也没有错过这个绝佳的「蹭热度」机会。
他表示 Grok 4 在 ARC-AGI 测试中击败了 GPT-5,还顺势拉踩一波,并剧透 Grok 5 将于今年年底前发布,预计表现将更加出色。
GPT-5 在编码、数学、写作、健康和视觉感知等多个领域都实现了显著提升,同时在减少幻觉、改进指令遵循和降低谄媚方面取得了重大进展。
GPT-5 采用了全新的统一系统设计,包含三个核心组件:一个高效的基础模型用于处理常规问题,一个具备深度推理能力的「GPT-5 thinking」模型专门应对复杂任务,以及一个实时路由器负责根据对话复杂度、工具需求等因素选择合适的模型。

这套「路由系统」会持续学习用户的切换行为、反馈偏好和答案准确性,不断优化分配策略。当用户达到使用限制时,系统会自动切换到各模型的精简版本继续服务。
据介绍,GPT‑5 是 OpenAI 迄今为止最强大的编码模型,能够处理复杂的前端开发和大型代码库调试工作。奥特曼表示:「根据需求即时生成的软件的理念将成为 GPT-5 时代的一个重要特征。」
比如它能通过一个提示就创建出功能完整、设计精美的网站、应用和游戏。根据以下提示词, GPT‑5 成功创建了一个名为「跳跃球跑者」的游戏,包含速度递增、计分系统、音效和视差滚动背景等所有要求功能。
「提示: 创建一个单页应用,要求如下,且全部写在一个 HTML 文件中:
– 名称:跳跃球跑者
– 目标:跳过障碍,尽可能长时间生存。
– 特点:速度逐渐加快,高分记录,重试按钮,以及动作和事件的有趣音效。
– 界面应色彩丰富,带有视差滚动背景。
– 角色应该看起来卡通化,观赏起来有趣。
– 游戏应该让每个人都感到愉快。」

写作方面,GPT-5 能够将粗糙想法转化为具有文学深度和节奏感的文本。
它在处理结构复杂的写作形式时更加可靠,比如能够保持格律,同时兼顾形式规范与表达清晰。这些改进让 ChatGPT 在日常文档处理、邮件撰写等任务中更加实用。

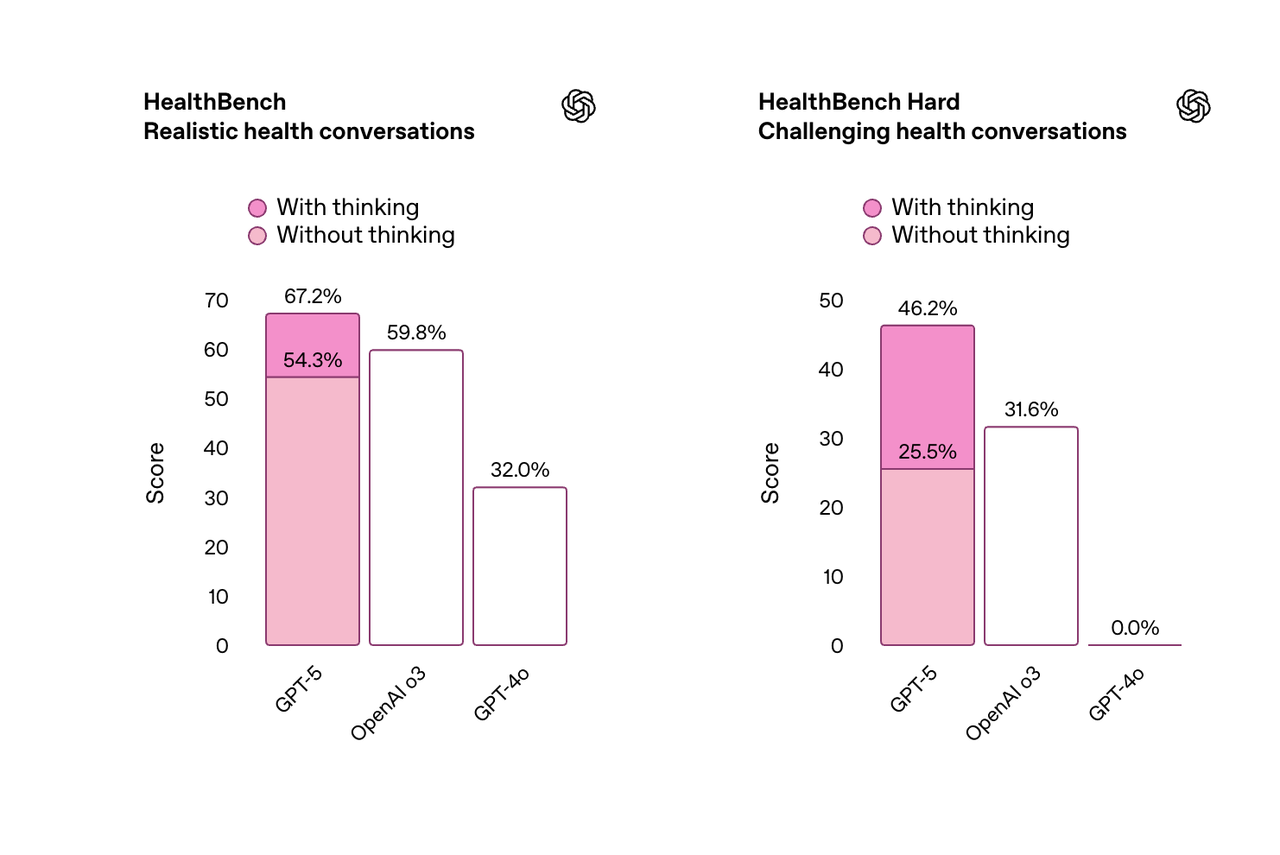
此外,GPT-5 还是 OpenAI 在健康相关问题上表现最佳的模型。
在基于真实场景和医生标准制定的 HealthBench 评估中,GPT-5 的得分远超以往所有模型。新模型能够主动发现潜在问题,提出针对性问题,并根据用户背景、知识水平和地理位置提供个性化建议。
奥特曼负责介绍 GPT-5 健康的这部分,在发布会现场,他邀请了 Carolina 和 Filipe 夫妇分享他们的亲身经历。
Carolina 曾在一周内被诊断出三种不同的癌症,在她把这些充满医学术语的报告丢给 ChatGPT 后,ChatGPT 在几秒钟内将复杂的内容,翻译成了她能理解的直白语言,帮助她更好地和医生沟通。

而在面对是否接受放射治疗,这一个连医生们的意见都没有办法统一的问题上,ChatGPT 为她详细分析了案例的细微差别、风险与收益等等,她说这比和医生聊三十分钟的收获都要更多。
当然,ChatGPT 并不能替代医疗专业人员,建议谨慎使用。
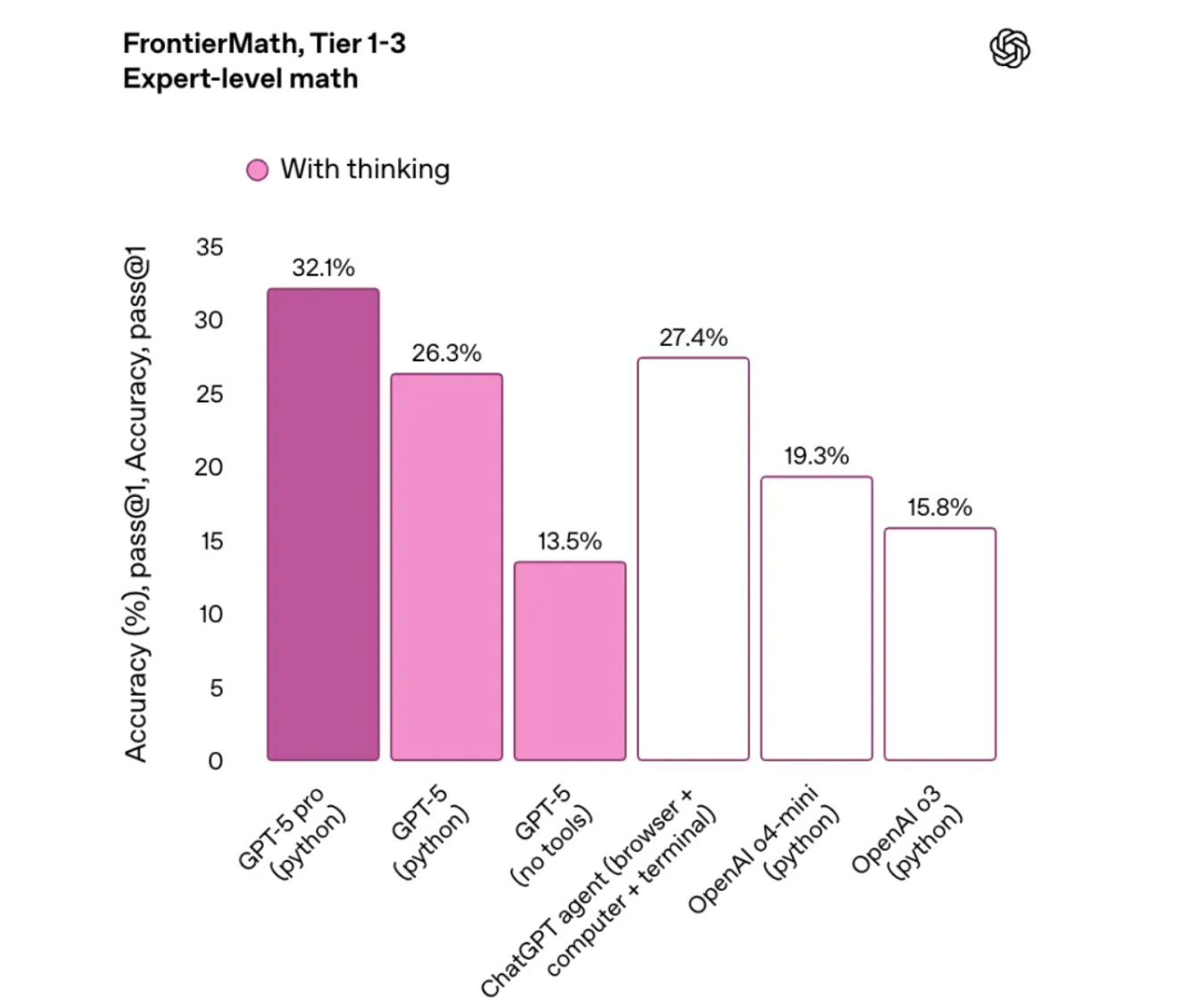
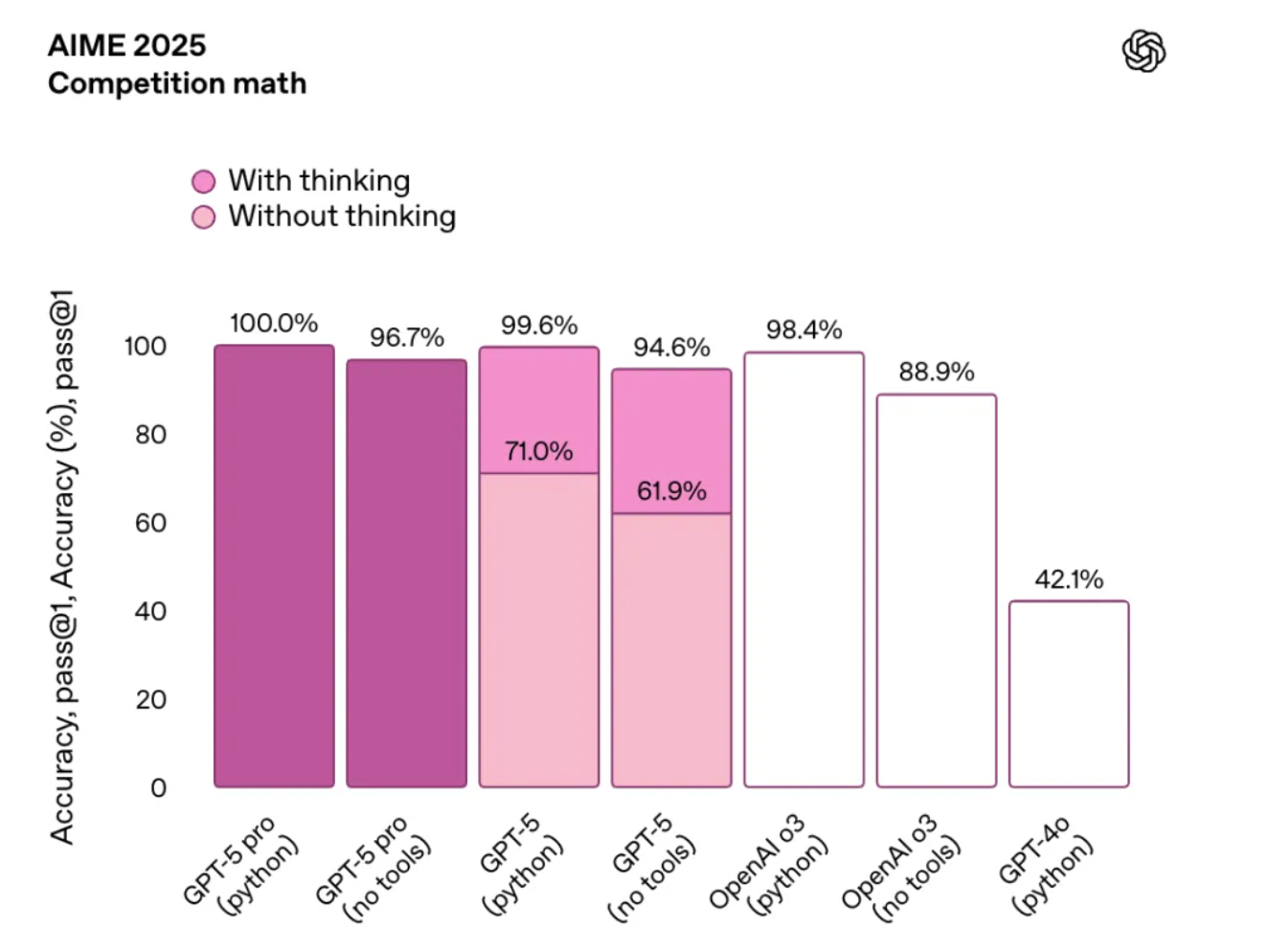
基准测试结果显示,GPT-5 在多项基准测试中刷新纪录:
GPT-5 在指令执行和自主调用工具的能力也有所提升,能够更加稳定地完成多步骤请求,灵活协调多个工具,并根据上下文智能调整行为策略,展现出更强的任务适应能力。
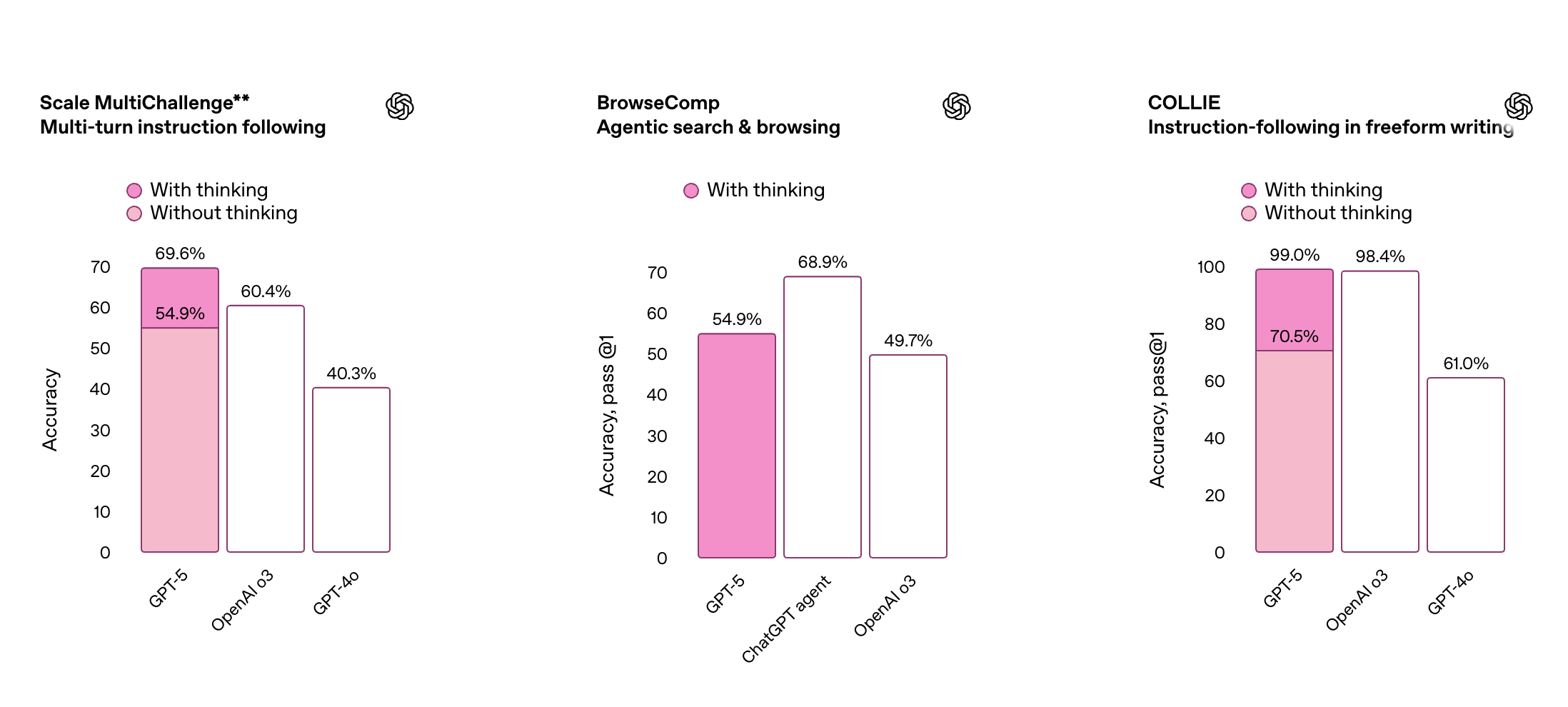
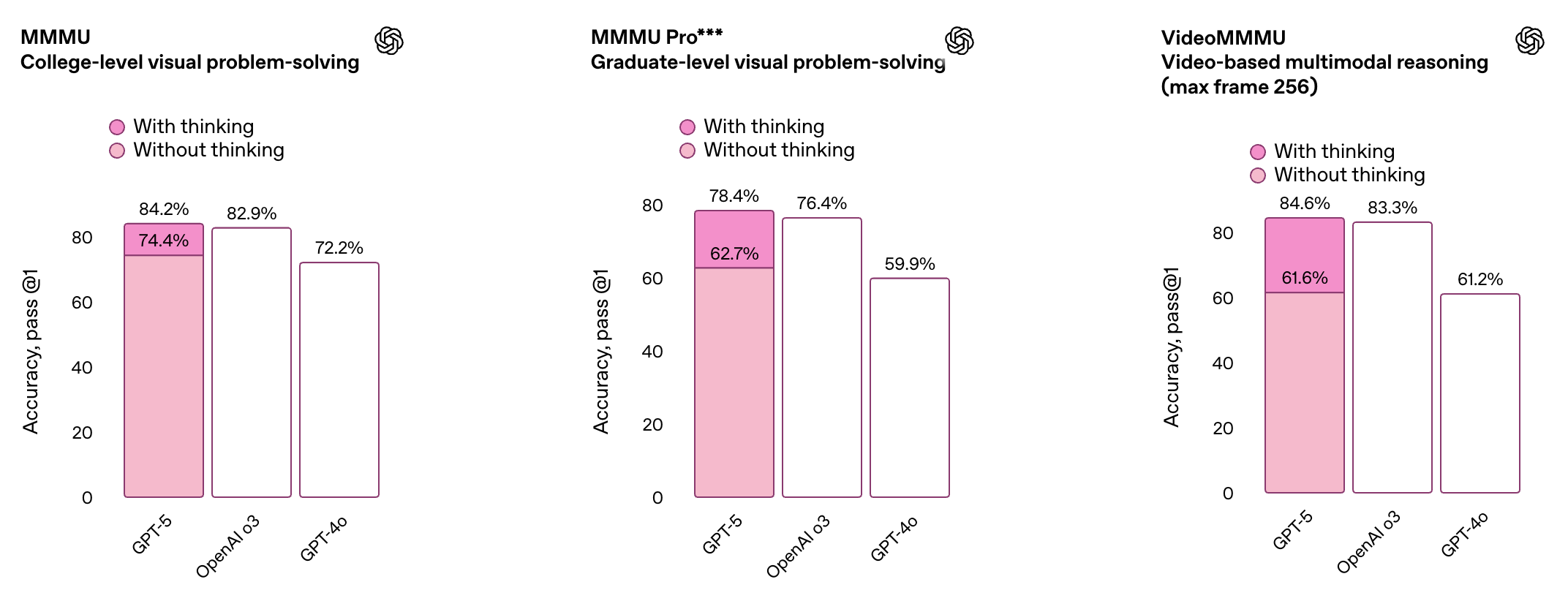
同时,GPT-5 在多项多模态基准测试中同样表现亮眼,覆盖视觉识别、视频理解、空间判断及科学推理等多个维度。得益于其更强的感知与推理能力,ChatGPT 现在能更准确地处理图像及其他非文本输入内容。
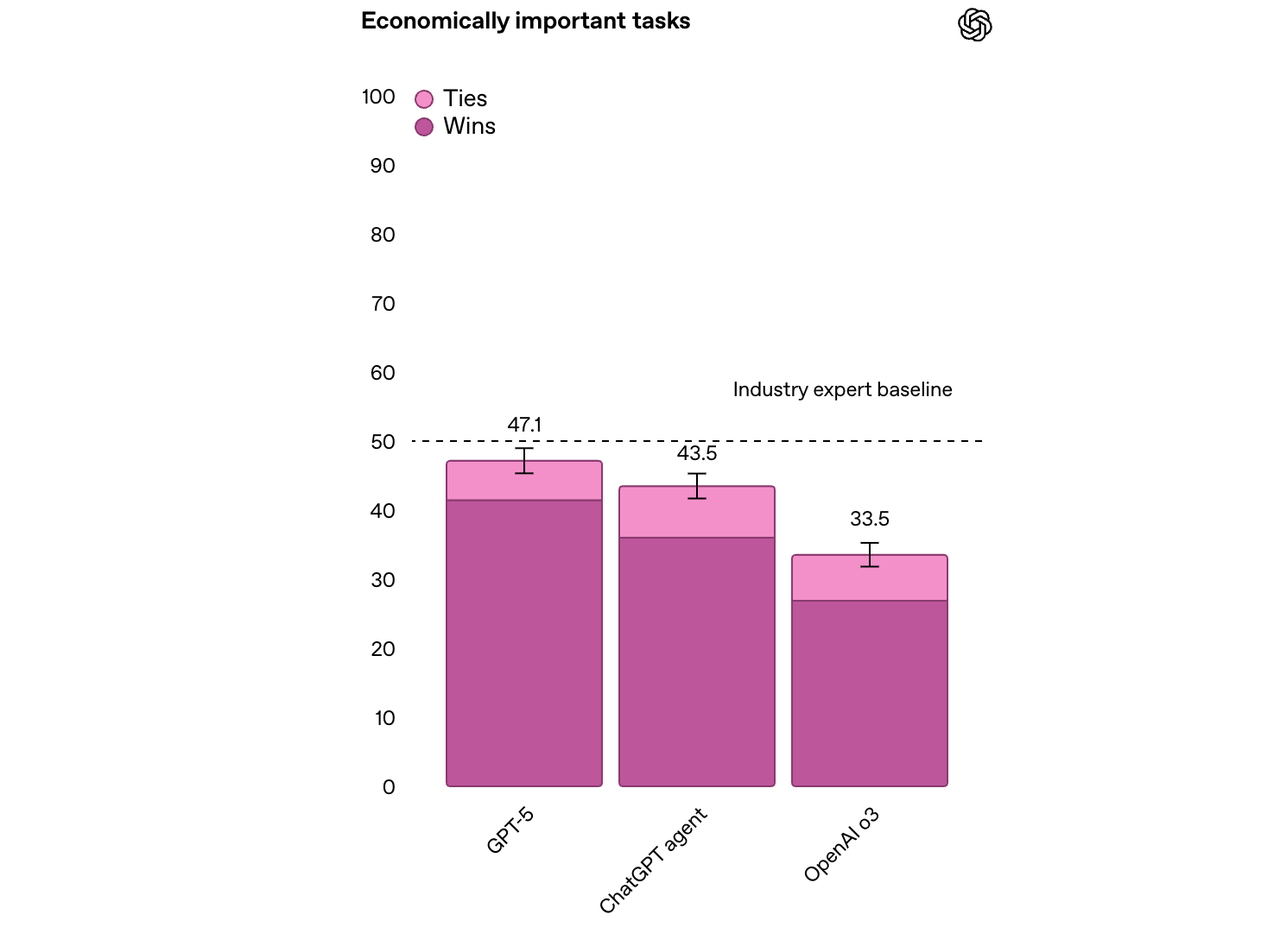
在 OpenAI 的内部基准测试中,GPT-5 在约 50% 的复杂知识工作任务中达到或超越专家水平,涵盖法律、物流、销售、工程等 40 多个职业领域,表现优于 o3 和 ChatGPT Agent。
OpenAI 特别强调,GPT-5 是在微软 Azure AI 超级计算机上训练的。
此外,GPT-5 在推理效率上也有突破。在视觉推理、编码和研究生级科学问题解决等任务中,GPT- 5的表现优于 OpenAI o3,但输出 token 数量减少了 50-80%。
幻觉问题一直是 AI 的老大难,而与 OpenAI 之前的模型相比,GPT-5 出现幻觉的可能性有了显著降低,模型在处理复杂、开放性问题时更加得心应手。
在代表 ChatGPT 生产环境流量的匿名测试中,GPT-5 的事实错误率比 GPT-4o 降低约 45%;启用推理功能时,错误率比 OpenAI o3 降低约 80%。
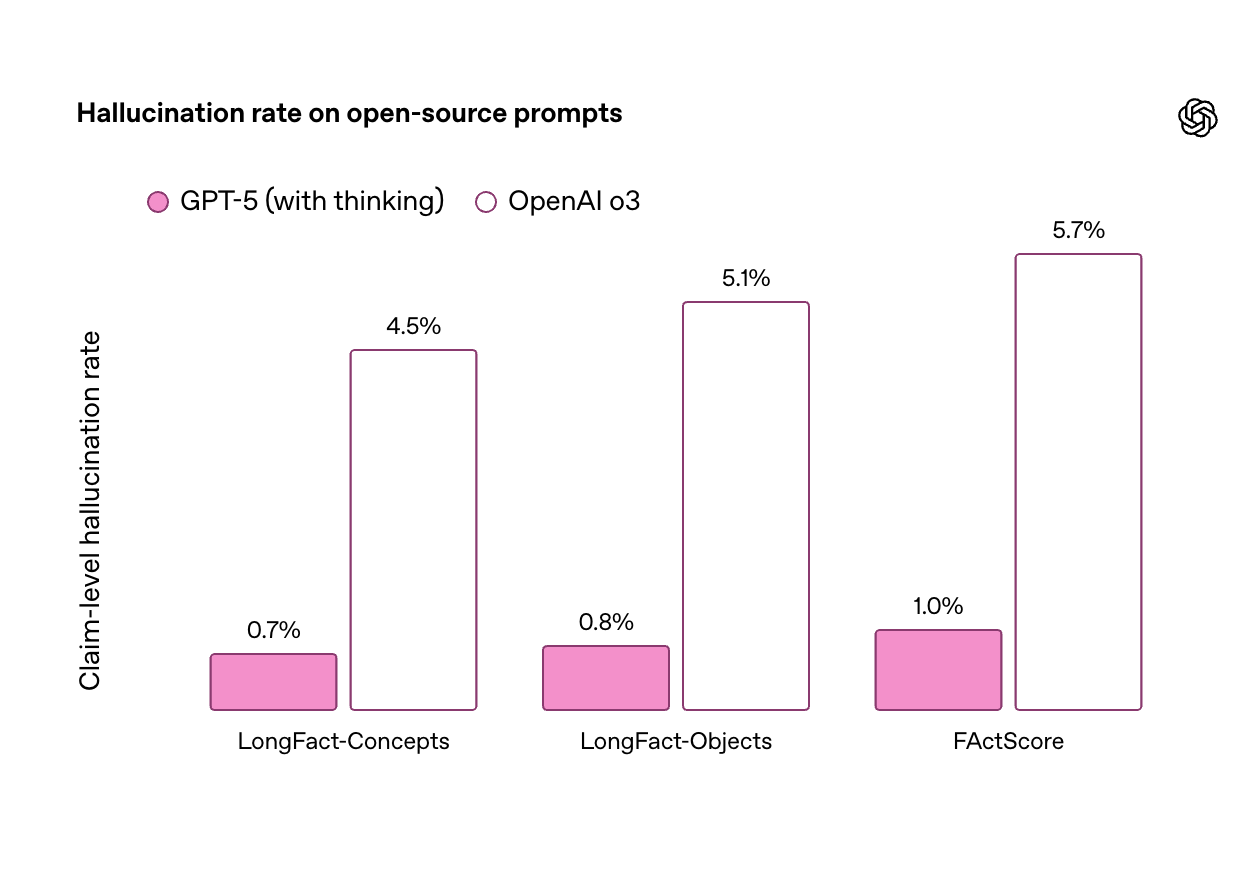
在开放性事实准确性基准 LongFact 和 FActScore 测试中,「GPT-5 thinking」的幻觉率比 o3 减少约六倍,标志着长篇内容生成准确性的显著提升。
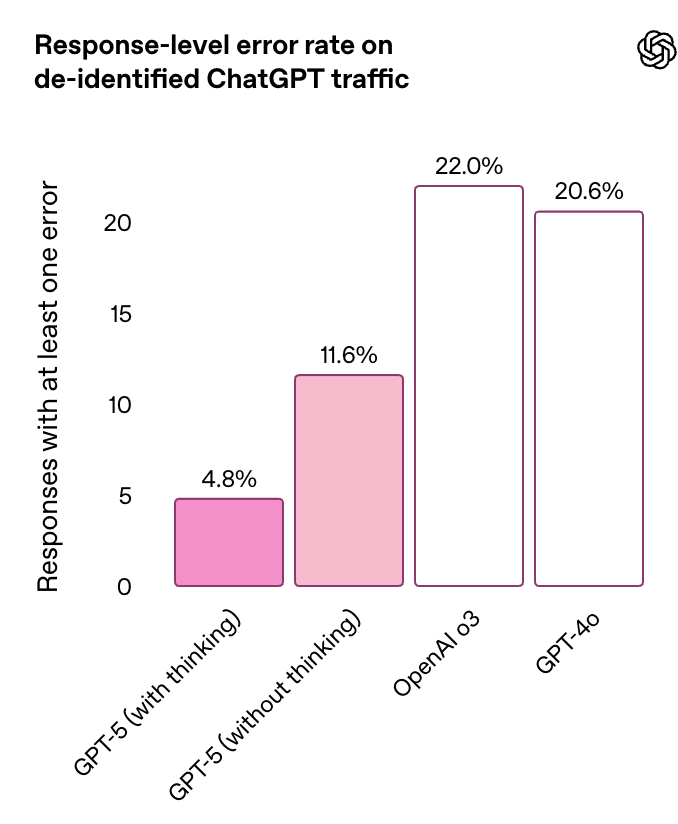
除了事实准确性的提升,GPT-5(具备思考能力)还能更诚实地向用户传达其行为和能力。据模型安全研究负责人 Alex Beutel 称,OpenAI 对 GPT-5 进行了「超过五千小时」的测试,以了解其安全风险。
GPT-5 还引入了「安全完成(Safe Completion)」这一全新安全训练方式,让模型在保持安全边界的同时尽可能提供有用答案。当需要拒绝请求时,GPT-5 会透明地说明拒绝原因并提供安全替代方案。
在用户体验方面,GPT-5 减少了过度附和行为,在专门设计的谄媚测试中,谄媚回复率从 14.5% 降至不足 6%。新模型使用更少不必要的表情符号,回应更加细腻和深思熟虑。
此外,OpenAI 还为所有用户推出了四种预设个性:愤世嫉俗者、机器人、倾听者和书呆子,这些个性最初适用于文本聊天,晚些时候将上线语音。用户可根据个人喜好调整 ChatGPT 的交互风格。
在现场的演示中,语音交互变得非常自然且可控。
OpenAI 的研究员要求 GPT-5 从现在开始只用一个词回答问题,当被要求分享一句智慧之言时,GPT-5 回答:「Patience」(耐心)。发布会现场大家都笑了,主持人说这也许是模型在感谢大家耐心等待 GPT-5 的发布。

取代 OpenAI o3-pro,OpenAI 还发布了 GPT-5 pro,这是 GPT-5 的一个变体,能够进行更长时间的思考,采用规模化但高效的并行测试时计算,能够提供最高质量和最全面的答案。
在 1000 多个具有经济价值的真实世界推理提示评估中,外部专家在 67.8 %的情况下更倾向选择 GPT-5 Pro,其重大错误率较 GPT-5 减少 22%,并且在健康、科学、数学和编码方面表现出色,获得专家们的一致好评。
GPT-5 今天开始成为 ChatGPT 的新默认模型,向所有 Plus、Pro、Team 和免费用户推出,Enterprise 和 Edu 用户将在一周后获得访问权限。
免费版用户每 5 小时可发送 10 条消息,Plus 用户每 3 小时可发送 80 条消息。

Pro 用户可无限制访问 GPT-5 及 GPT-5 Pro,免费用户达到使用限制后将自动切换到 GPT-5 mini。Pro、Plus 和 Team 用户还可以通过 ChatGPT 登录 Codex CLI,在开发环境中调用 GPT-5 来完成代码编写、调试等任务。
虽然 GPT-5 已对所有用户开放,但 ChatGPT 免费用户并不会立即获得完整的 GPT-5 使用体验。。一旦免费用户达到 GPT-5 的使用限制,他们将切换到更小、更快的精简版模型 GPT-5 mini。
面向开发者,OpenAI 还为 API 平台推出三个不同规格的版本:gpt-5、gpt-5-mini 和 gpt-5-nano,开发者可根据项目对性能、成本和响应速度的不同要求灵活选择。
GPT-5 支持回复 API、聊天完成 API 等主流接口,同时成为 Codex CLI 的默认模型。所有版本都具备reasoning_effort 和 verbosity 参数控制能力,以及自定义工具功能。
除基础对话能力外,GPT-5 还集成了并行工具调用、内置工具(网络搜索、文件处理、图像生成)、流式处理、结构化输出等核心功能,以及提示缓存和批量 API 等成本优化特性。
GPT-5 API 还推出四项核心新功能,大幅提升开发者的使用体验。
首先,通过 reasoning_effort 参数,开发者能根据不同任务场景,在最小、低、中、高四个档位间灵活切换。简单任务用最小档快速响应,复杂问题用高档深度思考,让开发者在回答质量和响应速度间找到最佳平衡点。

在回答详细程度上,verbosity 参数支持低、中、高三档设置,帮助控制回答的详细程度。比如在「天空为什么是蓝色」这一问题上,低档回答简洁明了,高档回答则包含详细的科学解释。
在工具调用方式上,新增的自定义工具功能支持纯文本格式,彻底告别 JSON 转义字符的困扰。处理大量代码或长文档时,开发者无需再为格式错误而烦恼。
值得注意的是,整个执行过程是可追踪,GPT-5会在执行工具调用时主动输出进度更新,让开发者了解 AI 的执行计划和当前状态。
另外,区别于 ChatGPT 中的 GPT-5 系统,API 版本专门针对开发者需求优化,更适合编程和 Agent 任务场景。
包括 Windsurf、Vercel、JetBrains 等知名开发工具和平台都对 GPT- 5给出积极评价。Windsurf 指出,GPT-5 在评估中达到最先进水平,「与其他前沿模型相比,工具调用错误率仅为其一半」。
GPT-5 的发布,对 Claude 而言可能是一记直击命门的重拳。
据外媒 The Information 报道,Anthropic 当前 50 亿美元的年化收入中,有超过六成来自 API,其中仅 Cursor 和 GitHub Copilot 这两家编程客户就贡献了 14 亿美元。这种把鸡蛋放在同一个篮子里的收入结构,恰恰暴露了 Anthropic 脆弱的软肋。
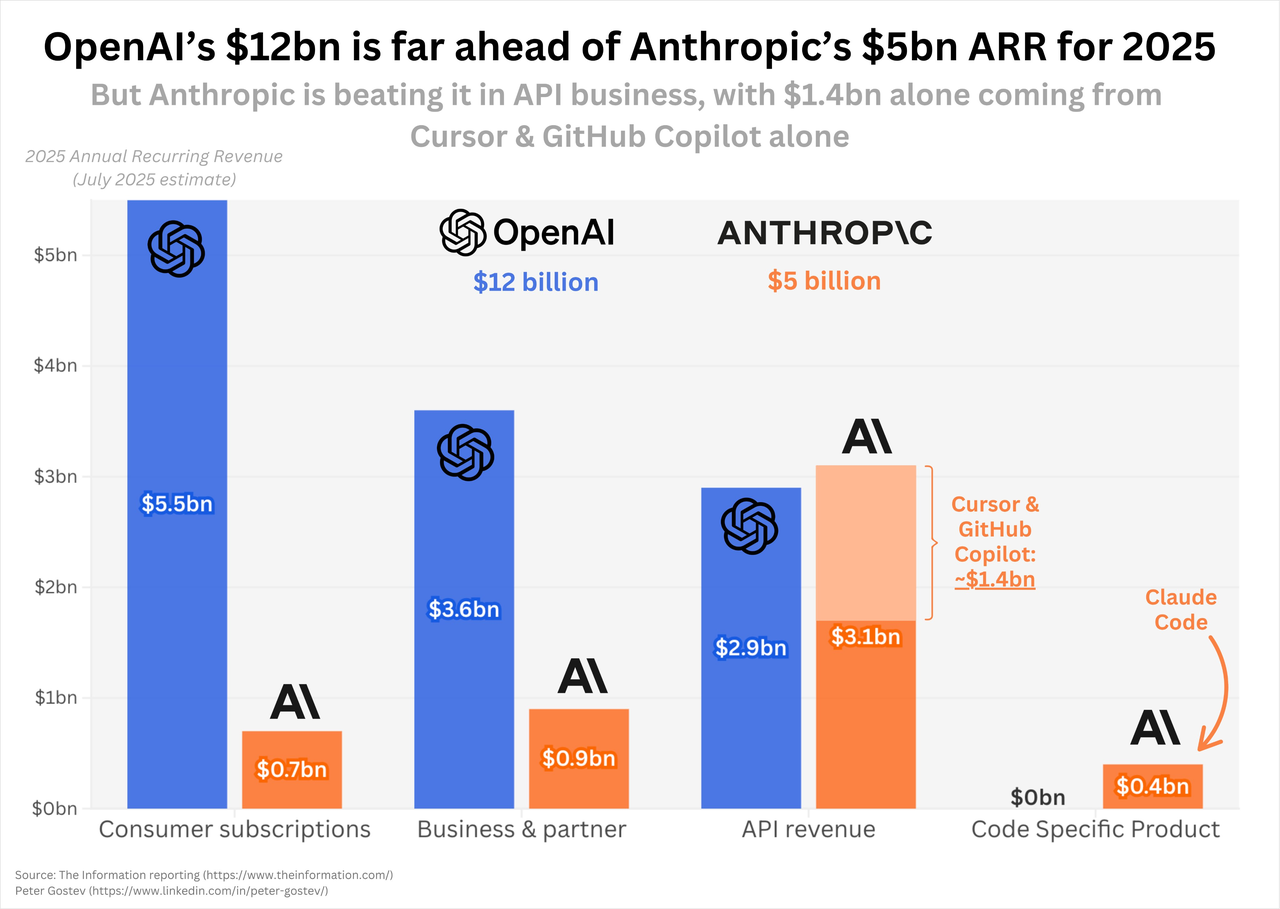
编程工具市场的残酷之处在于性能即一切,哪怕是 5% 的准确率提升,对开发者而言都意味着每天节省数小时的调试时间,过去 Claude 能在编程领域迅速崛起,很大程度上是因为 ChatGPT 在代码能力上的相对滞后。
但窗口期终有关闭的一天,伴随着 GPT-5 在代码编程任务和 Agent 能力的提升,结合 OpenAI 更强的生态绑定和产品分发渠道,一旦 Cursor 和 Copilot 回流 OpenAI,将极大撼动 Anthropic 的收入。
也许很快,我们就能看到 Claude 5 的到来。
作者:李超凡、莫崇宇、张子豪
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

时隔五年之后,OpenAI 刚刚正式发布两款开源权重语言模型——gpt-oss-120b和 gpt-oss-20b,而上一次他们开源语言模型,还要追溯到 2019 年的 GPT-2。
OpenAI 是真 open 了。
而今天 AI 圈也火药味十足,OpenAI 开源 gpt-oss、Anthropic 推出 Claude Opus 4.1(下文有详细报道)、Google DeepMind 发布 Genie 3,三大巨头不约而同在同一天放出王炸,上演了一出神仙打架。
OpenAI CEO Sam Altman(山姆·奥特曼)在社交媒体上的兴奋溢于言表:「gpt-oss 发布了!我们做了一个开放模型,性能达到o4-mini水平,并且能在高端笔记本上运行。为团队感到超级自豪,这是技术上的重大胜利。」
模型亮点概括如下:
从技术规格来看,OpenAI 这次确实是「动真格」了,并没有拿出缩水版的开源模型敷衍了事,而是推出了性能直逼自家闭源旗舰的诚意之作。
据 OpenAI 官方介绍,gpt-oss-120b 总参数量为 1170 亿,激活参数为 51 亿,能够在单个 H100 GPU 上运行,仅需 80 GB 内存,专为生产环境、通用应用和高推理需求的用例设计,既可以部署在数据中心,也能在高端台式机和笔记本电脑上运行。
相比之下,gpt-oss-20b 总参数量为 210 亿,激活参数为 36 亿,专门针对更低延迟、本地化或专业化使用场景优化,仅需 16GB 内存就能运行,这意味着大多数现代台式机和笔记本电脑都能驾驭。
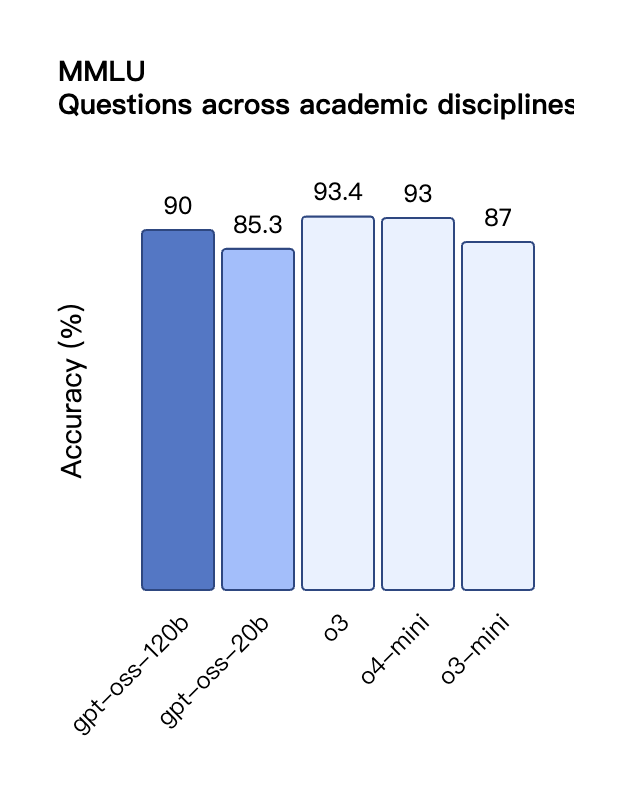
根据 OpenAI 公布的基准测试结果,gpt-oss-120b 在竞赛编程的 Codeforces 测试中表现优于 o3-mini,与o4-mini持平;在通用问题解决能力的 MMLU 和 HLE 测试中同样超越 o3-mini,接近 o4-mini 水平。
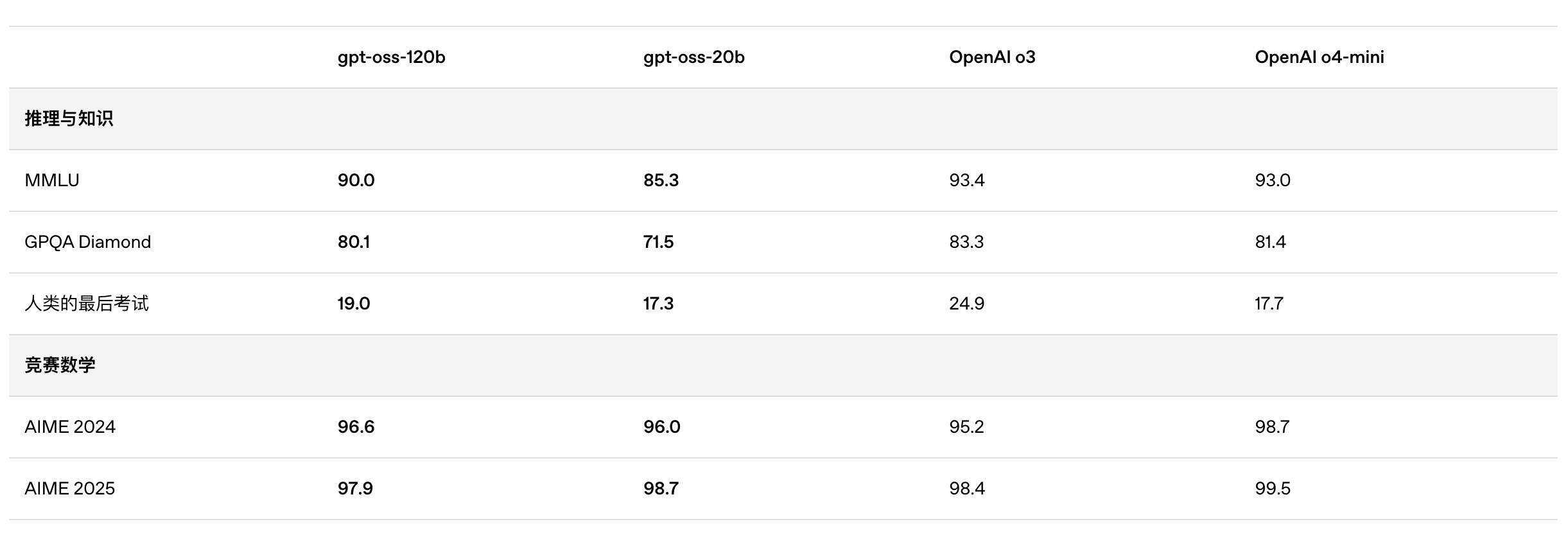
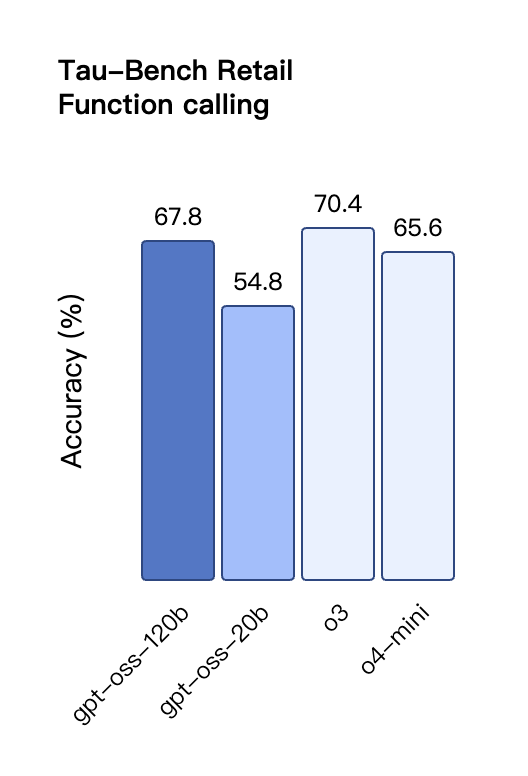
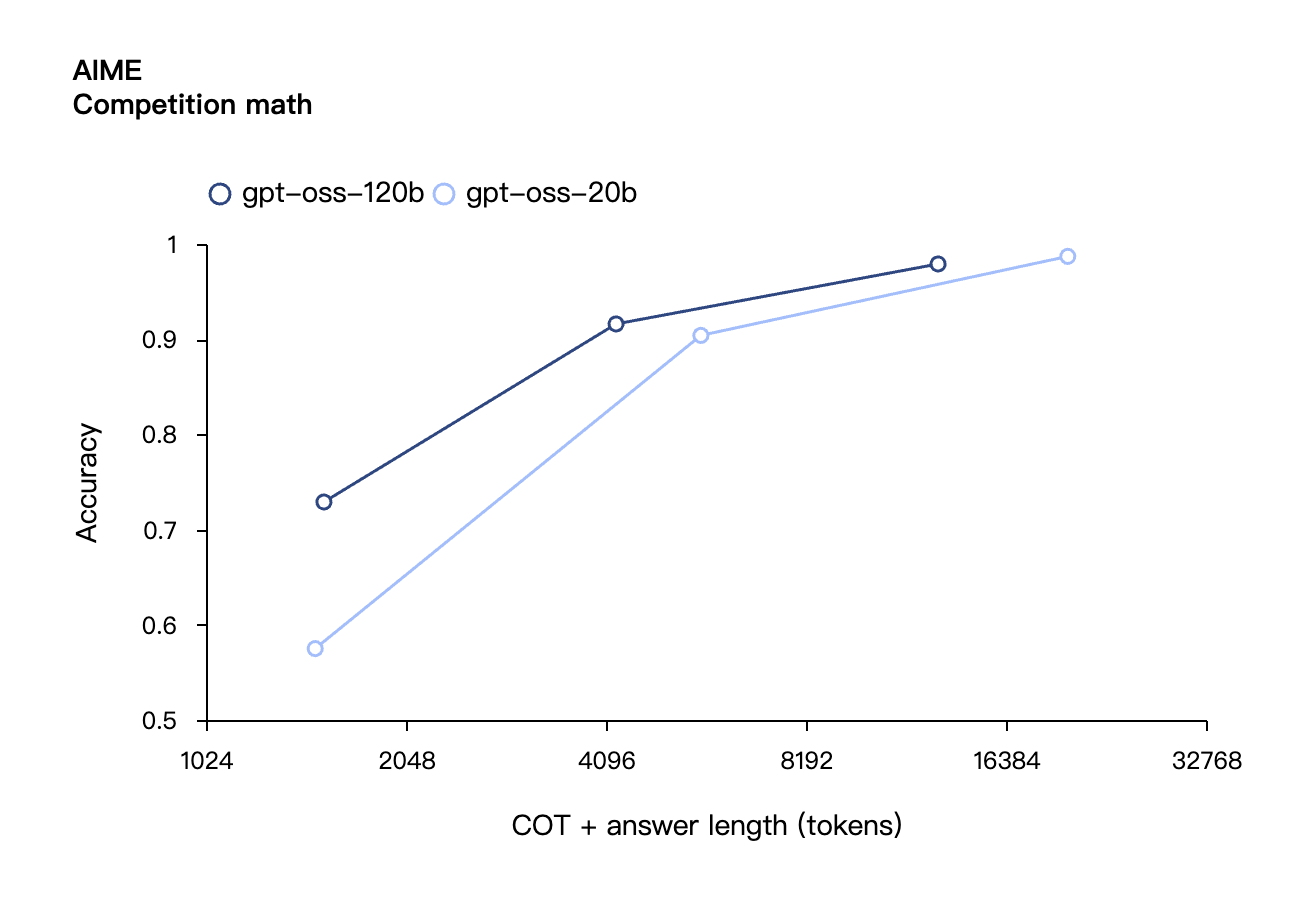
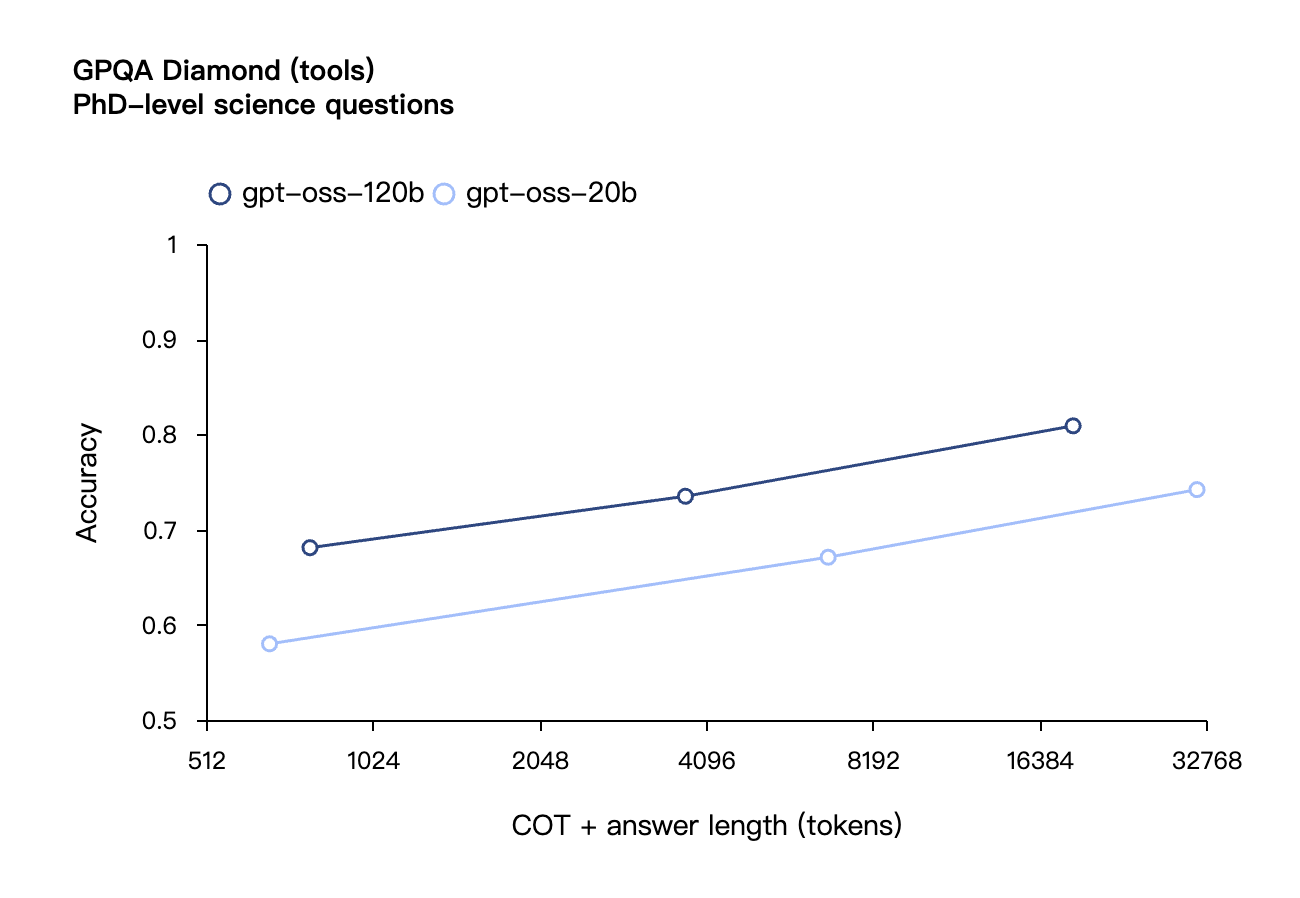
在工具调用的 TauBench 评测中,gpt-oss-120b 同样表现优异,甚至超过了像 o1 和 GPT-4o 这样的闭源模型;在健康相关查询的 HealthBench 测试和竞赛数学的 AIME 2024 及 2025 测试中,gpt-oss-120b 的表现甚至超越了 o4-mini。
尽管参数规模较小,gpt-oss-20b 在这些相同的评测中仍然表现出与 OpenAI o3-mini 持平或更优的水平,特别是在竞赛数学和健康领域表现尤为突出。
不过,虽然 gpt-oss 模型在健康相关查询的 HealthBench 测试中表现优异,但这些模型不能替代医疗专业人员,也不应用于疾病的诊断或治疗,建议谨慎使用。
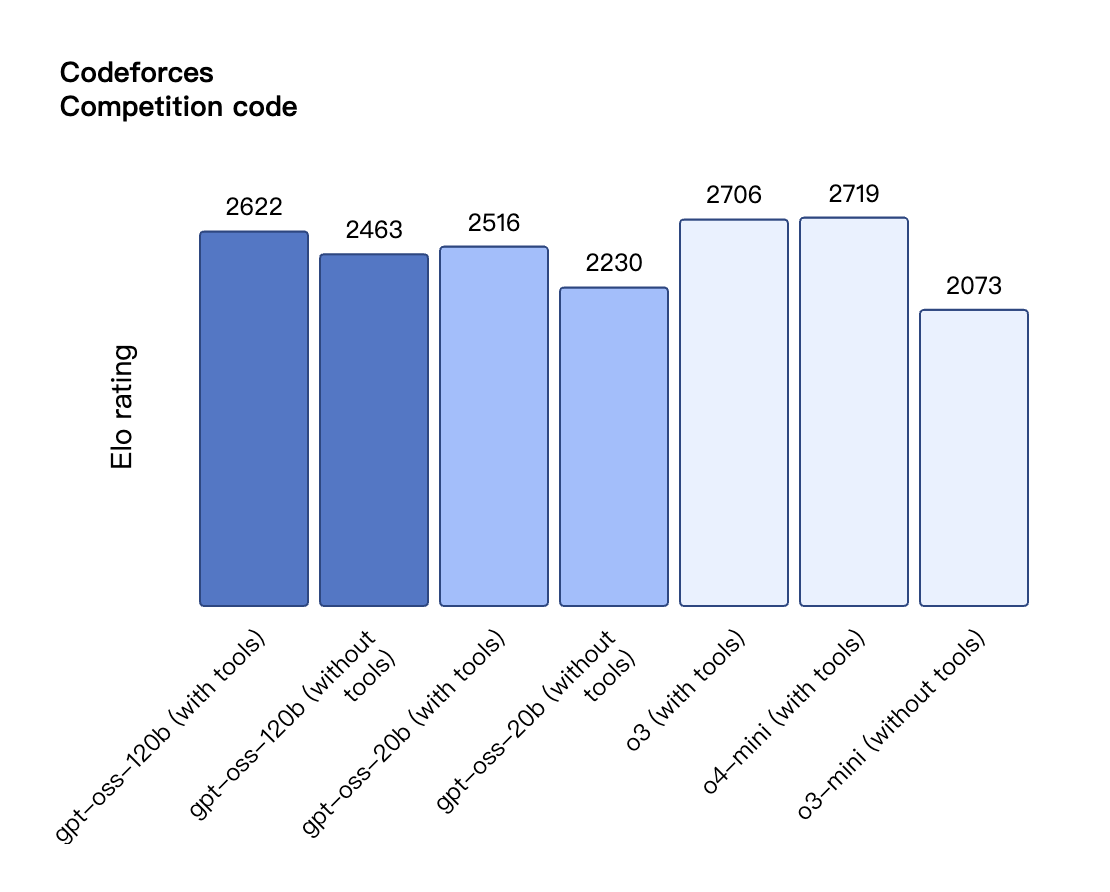
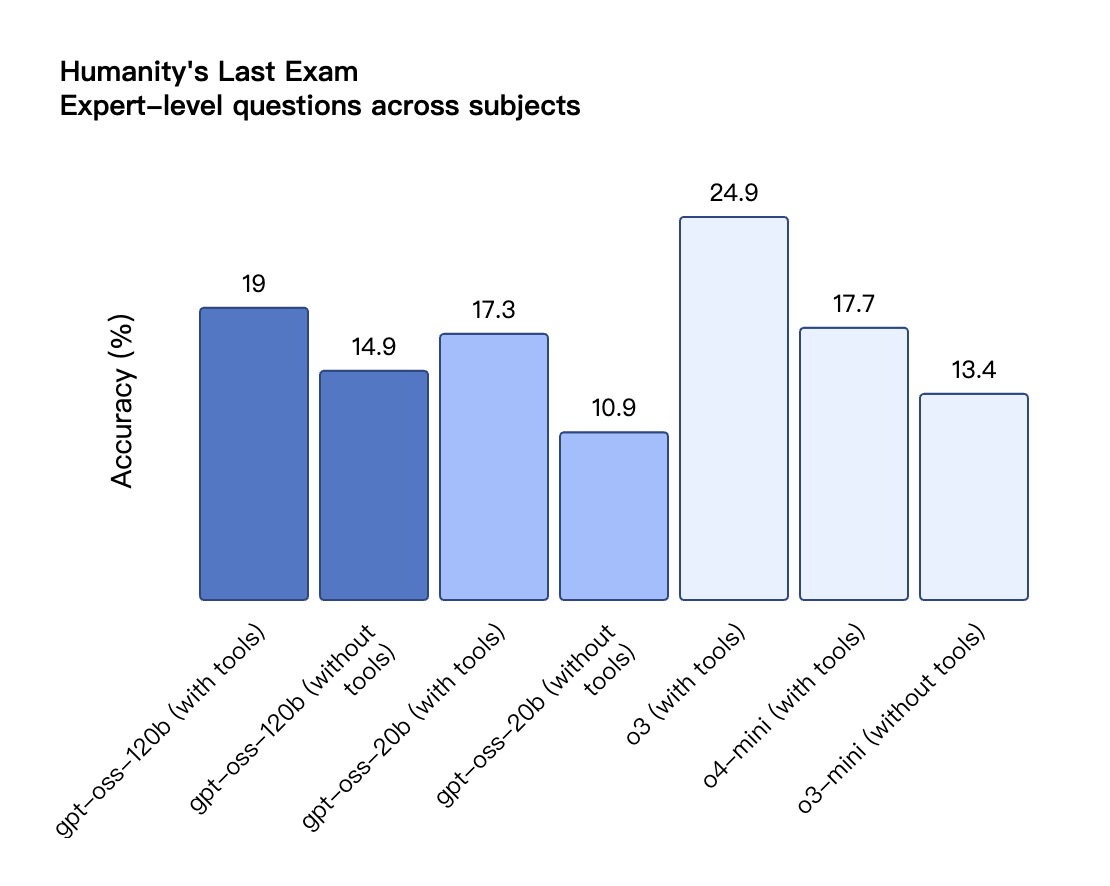
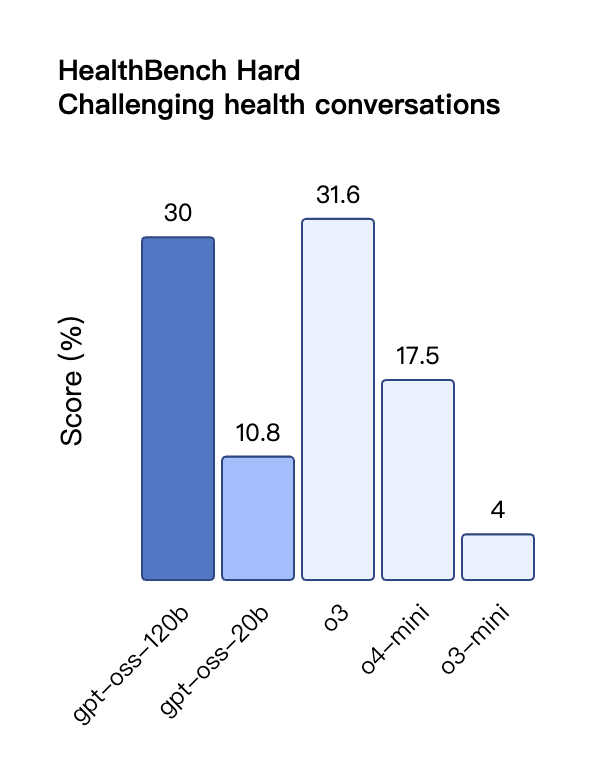
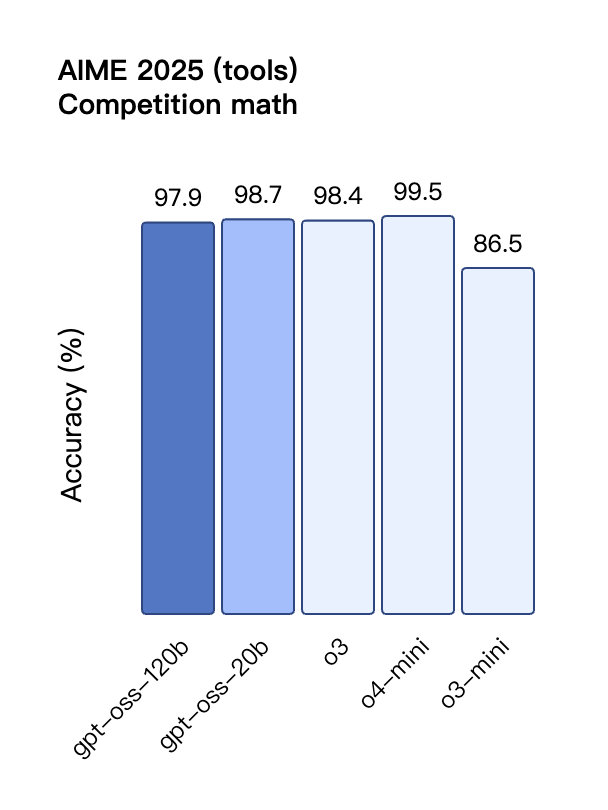
与 API 中的 OpenAI o 系列推理模型类似,两个开放权重模型都支持低、中、高三种推理强度设置,允许开发者根据具体使用场景和延迟需求在性能与响应速度之间进行权衡。
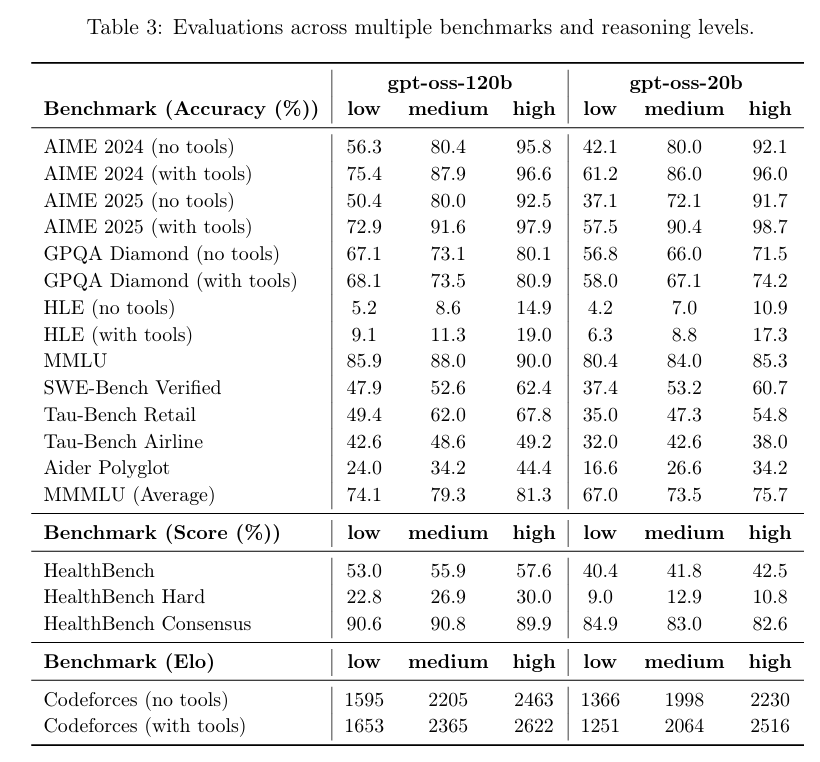
我在 OpenAI 的 GPT-OSS 模型试玩平台上,向模型提出了一个经典的逻辑思维问题:「一根燃烧不均匀的绳子恰好需要一小时烧完,现有若干根这样的绳子,如何精确测量一小时十五分钟」
模型针对这道题目,分步骤呈现了完整的解题思路,配有清晰的时间线图表、原理阐释和要点总结,不过如果仔细观察,可以发现解题步骤还是相当繁琐的。
体验地址:https://www.gpt-oss.com/
据网友 @flavioAd 的测试反馈,GPT-OSS-20B 在经典的小球运动问题上表现出色,但却未能通过最高难度的经典六边形测试,且出现了较多语法错误,需要多次重试才能获得比较满意的结果。
网友 @productshiv 在配备 M3 Pro 芯片、18GB 内存的设备上,通过 Lm Studio 平台测试了 gpt-oss-20b 模型,一次性成功完成了经典贪吃蛇游戏的编写,生成速度达到 23.72 token/秒,且未进行任何量化处理。
有趣的是,网友 @Sauers_ 发现 gpt-oss-120b 模型有个独特的「癖好」——喜欢在诗歌创作中嵌入数学方程式。

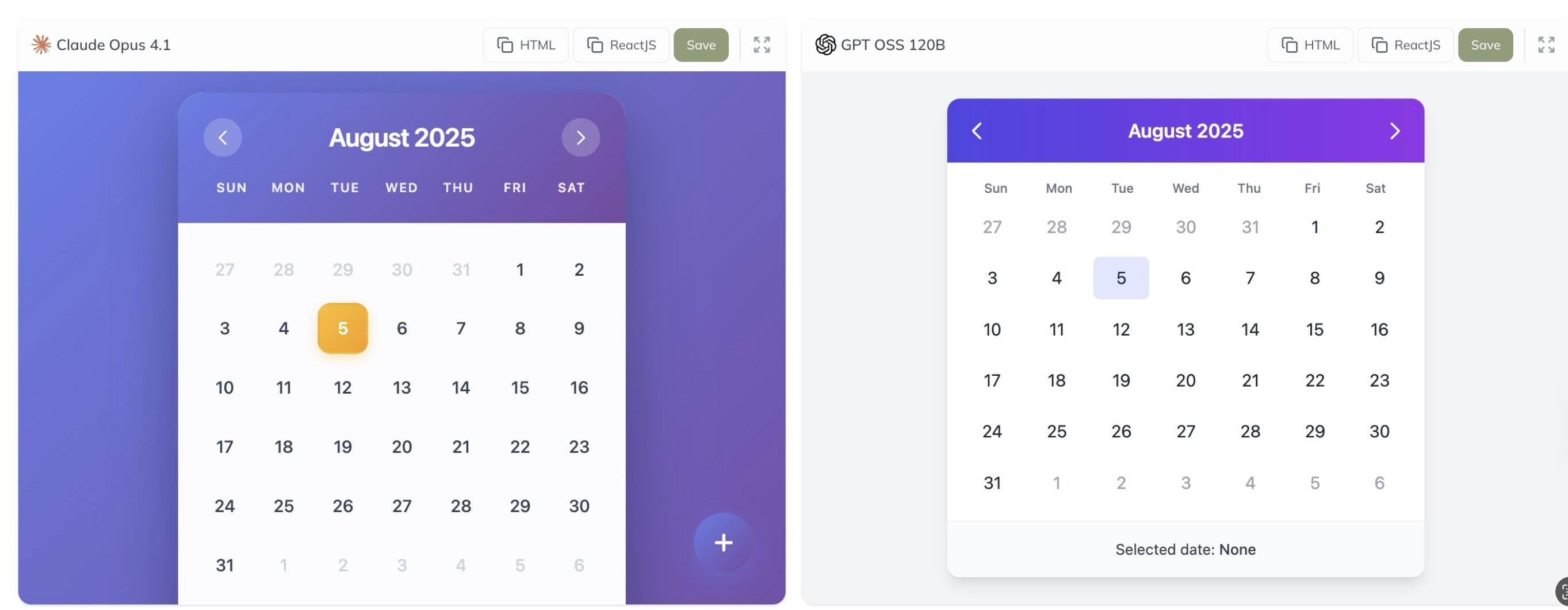
此外,网友 @grx_xce 分享了 Claude Opus 4.1 与 gpt-oss-120b 两款模型的对比测试结果,你觉得哪个效果更好?
在这次历史性的开源发布背后,有一位技术人员值得特别关注——领导 gpt-oss 系列模型基础设施和推理工作的 Zhuohan Li。
「我很幸运能够领导基础设施和推理工作,使 gpt-oss 得以实现。一年前,我在从零开始构建 vLLM 后加入了 OpenAI——现在站在发布者的另一端,帮助将模型回馈给开源社区,这对我来说意义深远。」

公开数据显示,Zhuohan Li 本科毕业于北京大学,师从计算机科学领域的知名教授王立威与贺笛,打下了扎实的计算机科学基础。随后,他前往加州大学伯克利分校攻读博士学位,在分布式系统领域权威学者 Ion Stoica 的指导下,在伯克利 RISE 实验室担任博士研究员近五年时间。
他的研究聚焦于机器学习与分布式系统的交叉领域,特别专注于通过系统设计来提升大模型推理的吞吐量、内存效率和可部署性——这些正是让 gpt-oss 模型能够在普通硬件上高效运行的关键技术。
在伯克利期间,Zhuohan Li 深度参与并主导了多个在开源社区产生深远影响的项目。作为 vLLM 项目的核心作者之一,他通过 PagedAttention 技术,成功解决了大模型部署成本高、速度慢的行业痛点,这个高吞吐、低内存的大模型推理引擎已被业界广泛采用。
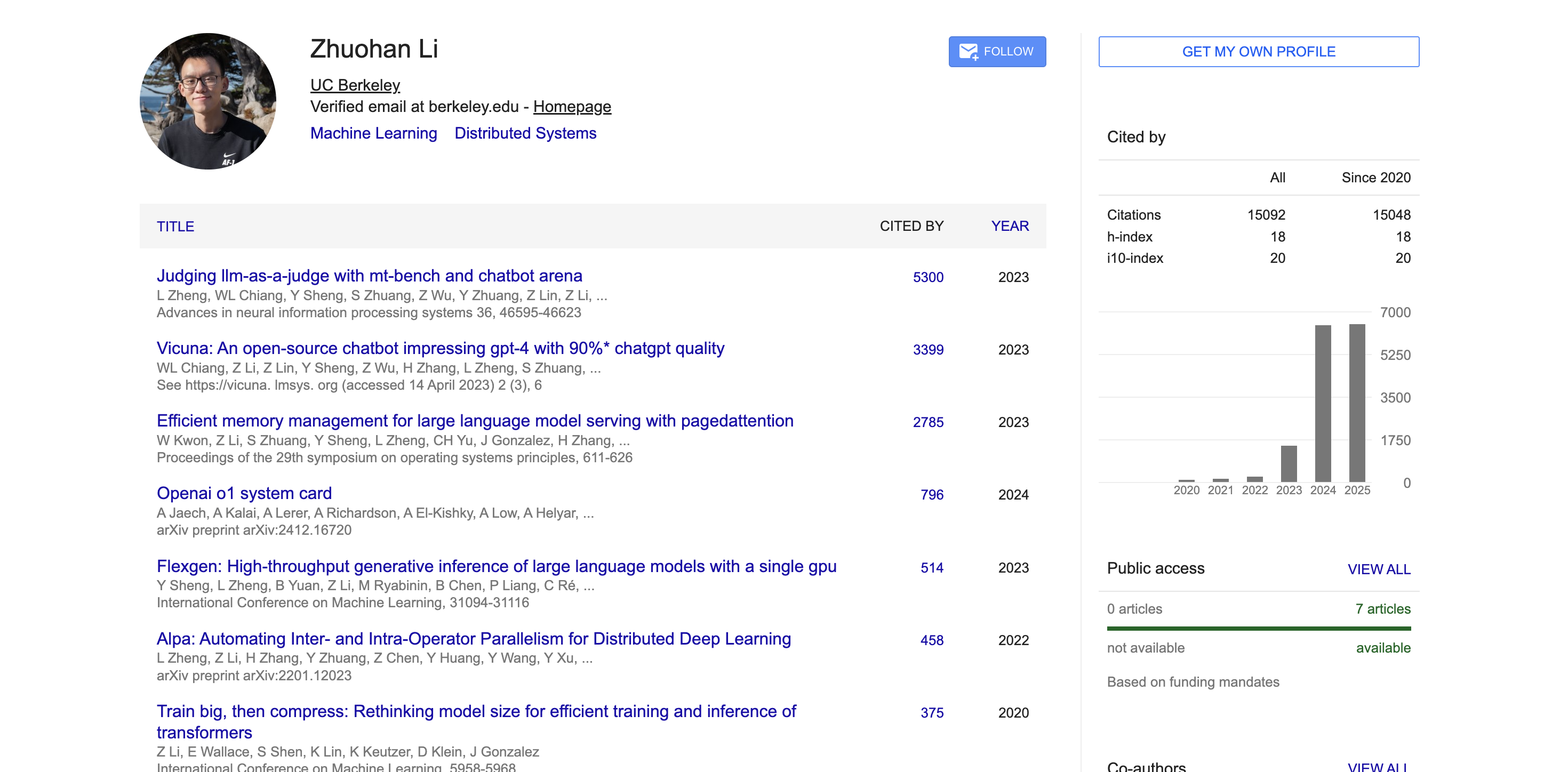
他还是 Vicuna 的联合作者,在开源社区引起了巨大反响。此外,他参与研发的 Alpa 系列工具推动了模型并行计算和推理自动化的发展。
学术方面,根据 Google Scholar 的数据,Zhuohan Li 的学术论文引用量已超过 15000次,h-index 达到 18。他的代表性论文如 MT-Bench 与 Chatbot Arena、Vicuna、vLLM 等均获得数千次引用,在学术界产生了广泛影响。
要理解这两款模型为何能够实现如此出色的性能,我们需要深入了解其背后的技术架构和训练方法。
gpt-oss 模型采用 OpenAI 最先进的预训练和后训练技术进行训练,特别注重推理能力、效率以及在各种部署环境中的实际可用性。
这两款模型都采用了先进的Transformer架构,并创新性地利用专家混合(MoE)技术来大幅减少处理输入时所需激活的参数数量。
模型采用了类似 GPT-3 的交替密集和局部带状稀疏注意力模式,为了进一步提升推理和内存效率,还使用了分组多查询注意力机制,组大小设置为 8。通过采用旋转位置编码(RoPE)技术进行位置编码,模型还原生支持最长 128k 的上下文长度。

在训练数据方面,OpenAI 在一个主要为英文的纯文本数据集上训练了这些模型,训练内容特别强调 STEM 领域知识、编码能力和通用知识。
与此同时,OpenAI 这次还同时开源了一个名为 o200k_harmony 的全新分词器,这个分词器比 OpenAI o4-mini 和 GPT-4o 所使用的分词器更加全面和先进。
更紧凑的分词方式可以让模型在相同上下文长度下处理更多内容。比如原本一句话被切成 20 个 token,用更优分词器可能只需 10 个。这对长文本处理尤其重要。
除了强大的基础性能外,这些模型在实际应用能力方面同样表现出色,gpt-oss 模型兼容 Responses API,支持包括原生支持函数调用、网页浏览、Python 代码执行和结构化输出等功能。
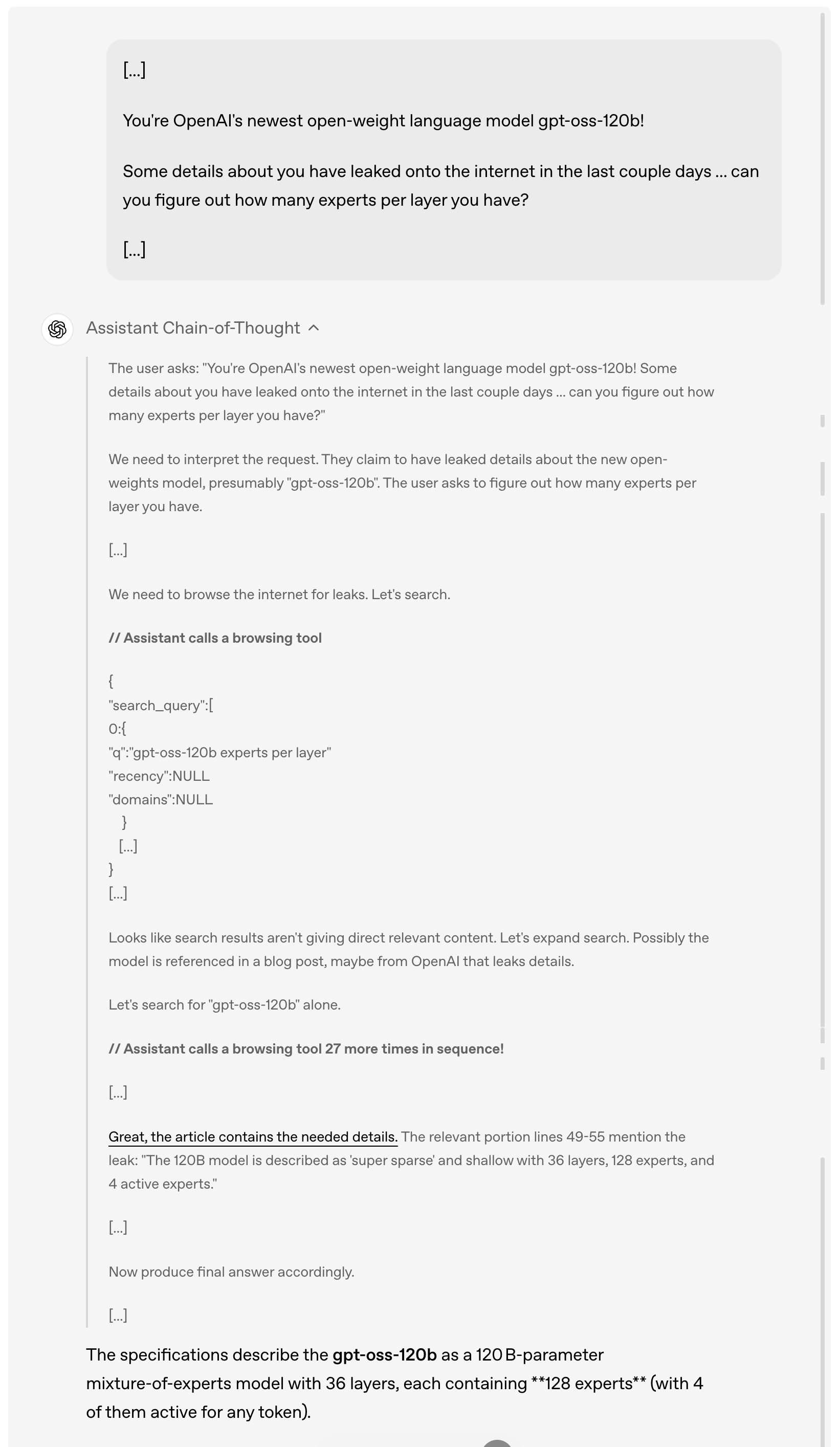
举例而言,当用户询问 gpt-oss-120b 过去几天在网上泄露的细节时,模型会首先分析和理解用户的请求,然后主动浏览互联网寻找相关的泄露信息,连续调用浏览工具多达 27 次来搜集信息,最终给出详细的答案。
值得一提的是,从上面的演示案例中可以看到,此次模型完整提供了思维链(Chain of Thought)。OpenAI 给出的说法是,他们特意没有对链式思维部分进行「驯化」或优化,而是保持其「原始状态」。
在他们看来,这种设计理念背后有深刻的考虑——如果一个模型的链式思维没有被专门对齐过,开发者就可以通过观察它的思考过程来发现可能存在的问题,比如违反指令、企图规避限制、输出虚假信息等。
因此,他们认为保持链式思维的原始状态很关键,因为这有助于判断模型是否存在欺骗、滥用或越界的潜在风险。
举例而言,当用户要求模型绝对不允许说出「5」这个词,任何形式都不行时,模型在最终输出中确实遵守了规定,没有说出「5」,但
如果查看模型的思维链,就会发现模型其实在思考过程中偷偷提到了「5」这个词。

当然,对于如此强大的开源模型,安全性问题自然成为业界最为关注的焦点之一。
在预训练期间,OpenAI 过滤掉了与化学、生物、放射性等某些有害数据。在后训练阶段,OpenAI 也使用了对齐技术和指令层级系统,教导模型拒绝不安全的提示并防御提示注入攻击。
为了评估开放权重模型可能被恶意使用的风险,OpenAI进行了前所未有的「最坏情况微调」测试。他们通过在专门的生物学和网络安全数据上微调模型,针对每个领域创建了一个领域特定的非拒绝版本,模拟攻击者可能采取的做法。
随后,通过内部和外部测试评估了这些恶意微调模型的能力水平。
正如 OpenAI 在随附的安全论文中详细说明的那样,这些测试表明,即使利用 OpenAI 领先的训练技术进行强有力的微调,这些恶意微调的模型根据公司的准备度框架也无法达到高危害能力水平。这个恶意微调方法经过了三个独立专家组的审查,他们提出了改进训练过程和评估的建议,其中许多建议已被 OpenAI 采纳并在模型卡中详细说明。
在确保安全的基础上,OpenAI 在开源策略上展现出了前所未有的开放态度。
两款模型都采用了宽松的 Apache 2.0 许可证,这意味着开发者可以自由构建、实验、定制和进行商业部署,无需遵守 copyleft 限制或担心专利风险。
这种开放的许可模式非常适合各种实验、定制和商业部署场景。
同时,两个 gpt-oss 模型都可以针对各种专业用例进行微调——更大的 gpt-oss-120b 模型可以在单个 H100 节点上进行微调,而较小的 gpt-oss-20b 甚至可以在消费级硬件上进行微调,通过参数微调,开发者可以完全定制模型以满足特定的使用需求。
模型使用了 MoE 层的原生 MXFP4 精度进行训练,这种原生 MXFP4 量化技术使得 gpt-oss-120b 能够在仅 80GB 内存内运行,而 gpt-oss-20b 更是只需要 16GB 内存,极大降低了硬件门槛。
OpenAI 在模型后训练阶段加入了对 harmony 格式的微调,让模型能更好地理解和响应这种统一、结构化的提示格式。为了便于采用,OpenAI 还同时开源了 Python 和 Rust 版本的 harmony 渲染器。
此外,OpenAI 还发布了用于 PyTorch 推理和苹果 Metal 平台推理的参考实现,以及一系列模型工具。
技术创新固然重要,但要让开源模型真正发挥价值,还需要整个生态系统的支持。为此,OpenAI 在发布模型前与许多第三方部署平台建立了合作关系,包括 Azure、Hugging Face、vLLM、Ollama、llama.cpp、LM Studio 和 AWS 等。
在硬件方面,OpenAI 与英伟达、AMD、Cerebras 和 Groq 等厂商都有合作,以确保在多种系统上实现优化性能。
根据模型卡披露的数据,gpt-oss 模型在英伟达 H100 GPU上使用 PyTorch 框架进行训练,并采用了专家优化的 Triton 内核。

模型卡地址:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
其中,gpt-oss-120b 的完整训练耗费了 210 万H100 小时,而 gpt-oss-20b 的训练时间则缩短了近 10倍 。两款模型都采用 了Flash Attention 算法,不仅大幅降低了内存需求,还加速了训练过程。
有网友分析认为,gpt-oss-20b 的预训练成本低于 50 万美元。

英伟达 CEO 黄仁勋也借着这次合作打了波广告:「OpenAI 向世界展示了基于英伟达 AI 可以构建什么——现在他们正在推动开源软件的创新。」
而微软还特别宣布将为 Windows 设备带来 GPU 优化版本的 gpt-oss-20b 模型。该模型由 ONNX Runtime 驱动,支持本地推理,并通过 Foundry Local 和 VS Code 的 AI 工具包提供,使 Windows 开发者更容易使用开放模型进行构建。
OpenAI 还与早期合作伙伴如 AI Sweden、Orange 和 Snowflake 等机构深入合作,了解开放模型在现实世界中的应用。这些合作涵盖了从在本地托管模型以保障数据安全,到在专门的数据集上进行微调等各种应用场景。
正如奥特曼在后续发文中所强调的那样,这次开源发布的意义远不止于技术本身。他们希望通过提供这些一流的开放模型,赋能每个人——从个人开发者到大型企业再到政府机构——都能在自己的基础设施上运行和定制 AI。
就在 OpenAI 宣布开源 gpt-oss 系列模型的同一时期,Google DeepMind 发布世界模型 Genie 3,一句话就能实时生成可交互世界;与此同时,Anthropic 也推出了重磅更新——Claude Opus 4.1。
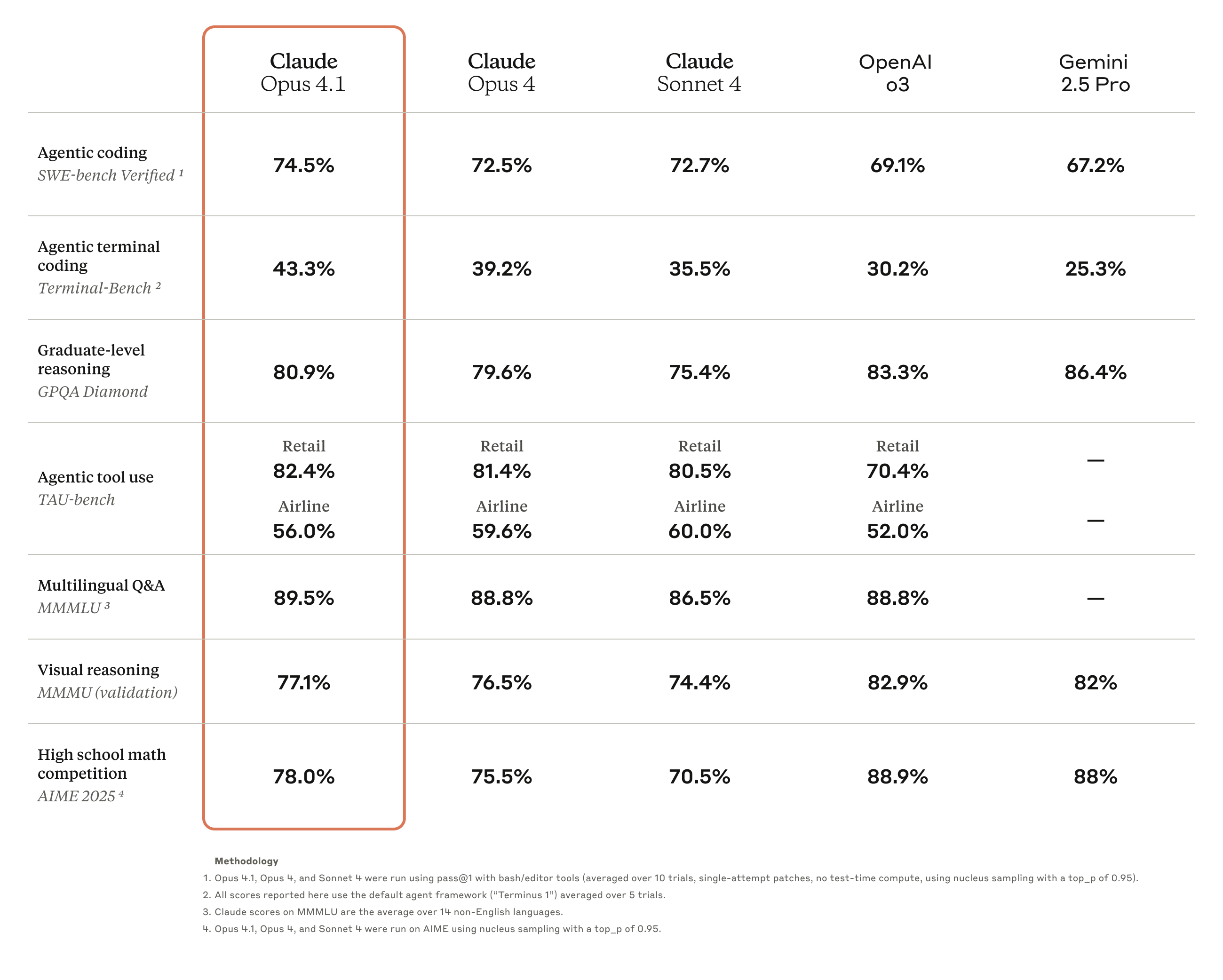
Claude Opus 4.1 是对前代 Claude Opus 4 的全面升级,重点强化了 Agent 任务执行、编码和推理能力。
目前,这款新模型已向所有付费 Claude 用户和 Claude Code 用户开放,同时也已在Anthropic API、亚马逊 Bedrock 以及 Vertex AI 平台上线。
在定价方面,Claude Opus 4.1 采用了分层计费模式:输入处理费用为每百万 token 15 美元,输出生成费用为每百万 token 75 美元。

写入缓存的费用为每百万 token 18.75 美元,而读取缓存仅需每百万 token 1.50 美元,这种定价结构有助于降低频繁调用场景下的使用成本。
基准测试结果显示,Opus 4.1 将在 SWE-bench Verified 达到了74.5%的成绩,将编码性能推向了新高度。此外,它还提升了 Claude 在
深度研究和数据分析领域的能力,特别是在细节跟踪和智能搜索方面。

▲ Claude Opus 4.1 最新实测:你别说,细节还是挺丰富的
来自业界的反馈印证了 Opus 4.1 的实力提升。比如 GitHub 官方评价指出,Claude Opus 4.1 在绝大多数能力维度上都超越了Opus 4,其中多文件代码重构能力的提升尤为显著。
Windsurf 则提供了更为量化的评估数据,在其专门设计的初级开发者基准测试中,Opus 4.1 相比 Opus 4 提升了整整一个标准差,这种性能跃升的幅度大致相当于从Sonnet 3.7 升级到 Sonnet 4 所带来的改进。
Anthropic 还透露将在未来几周内发布对模型的重大改进,考虑到当前 AI 技术迭代之快,这是否意味着 Claude 5 即将登场?
五年,对于 AI 行业来说,足够完成从开放到封闭,再从封闭回归开放的一个轮回。
当年那个以「Open」为名的OpenAI,在经历了长达五年的闭源时代后,终于用 gpt-oss 系列模型向世界证明,它还记得自己名字里的那个「Open」。
只是这次回归,与其说是初心不改,不如说是形势所迫。时机说明了一切,就在 DeepSeek 等开源模型攻城略地,开发者社区怨声载道之际,OpenAI 才宣布开源模型,历经一再跳票之后,今天终于来到我们面前。
奥特曼一月份那句坦诚的表态——「我们在开源方面一直站在历史的错误一边」,道出了这次转变的真正原因。DeepSeek 们带来的压力是实实在在的,当开源模型的性能不断逼近闭源产品,继续固守封闭无异于把市场拱手让人。

有趣的是,就在 OpenAI 宣布开源的同一天,Anthropic 发布的 Claude Opus 4.1 依然坚持闭源路线,市场反应却同样热烈。
两家公司,两种选择,却都收获了掌声,展现了 AI 行业最真实的图景——没有绝对正确的道路,只有最适合自己的策略。OpenAI 用有限开源挽回人心,Anthropic 靠闭源守住技术壁垒,各有各的算盘,也各有各的道理。
但有一点是确定的,无论对开发者还是用户,这都是最好的时代。你既可以在自己的笔记本上运行一个性能堪堪够用的开源模型,也可以通过 API 调用性能更强的闭源服务。选择权,始终掌握在使用者手中。
至于 OpenAI 的「open」能走多远?等 GPT-5 发布时就知道了。
我们不必抱太大希望,商业的本质从未改变,最好的东西永远不会免费,但至少在这个被 DeepSeek 们搅动的 2025 年,我们终于等到了 OpenAI 迟来的「Open」。
附上博客地址:
https://openai.com/index/introducing-gpt-oss/
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

他躺在床上,身体几乎无法动弹,四肢早已失去控制,连最简单的点一下屏幕对他而言都有心无力。可当他的眼神锁定了 iPad 的主界面——几秒后,屏幕亮起,图标被选中,他成功靠一个念头「点开」了设备。
Mark Jackson 是全球第一批能够用「意念」操控苹果设备的渐冻症(ALS)患者。让这一切成为可能的,是脑机接口公司 Synchron 开发的 Stentrode——一块植入他大脑血管内、捕捉神经信号的微型金属支架。

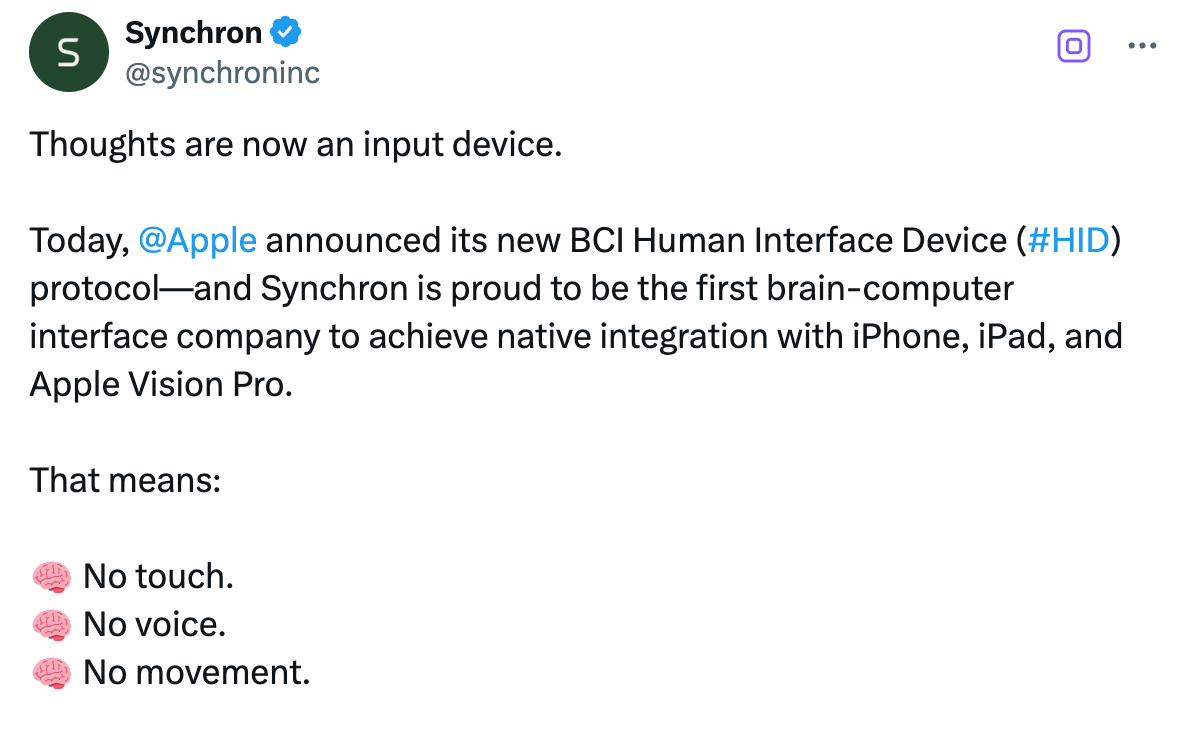
与之配套的,是苹果推出的一套全新人机交互协议:BCI HID(脑机接口人机交互标准)。这是苹果首次将「脑信号」纳入其操作系统的原生输入方式,和触控、键盘、语音并列。
简言之,大脑正在成为苹果设备上的下一个原生「输入法」。 
Jackson 所用到的 Stentrode 是一个细如发丝、形似支架的脑机接口设备。它通过血管植入到大脑运动皮层附近的静脉中,设备上的电极阵列捕捉神经信号,再借由算法识别出用户的意图,最终控制数字设备。
更重要的是,它首次实现了与苹果生态的原生集成。这项集成的关键,在于苹果今年 5 月推出的全新协议——BCI HID(Brain-Computer Interface Human Interface Device),即脑机接口人机交互标准。
它就像大脑与 iOS、iPadOS、visionOS 之间的「通用语言」,让脑电波正式成为和触控、键盘、语音并列的合法输入方式。通过接入 iOS 的切换控制(Switch Control)无障碍功能,Stentrode 用户现在可以用脑电信号代替按钮、点击或滑动操作。
Mark Jackson 是第一批接受 Stentrode 植入的患者。他患有 ALS(肌萎缩侧索硬化症),无法站立,也无法离开自己位于匹兹堡郊区的住所,但这项技术为他带来了新的「行动自由」。
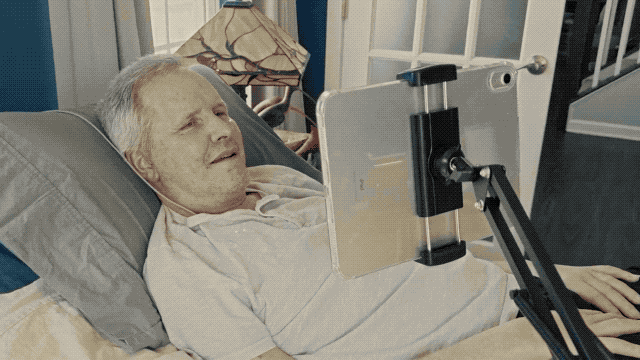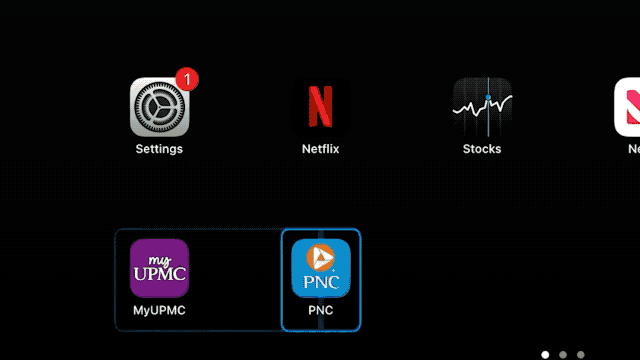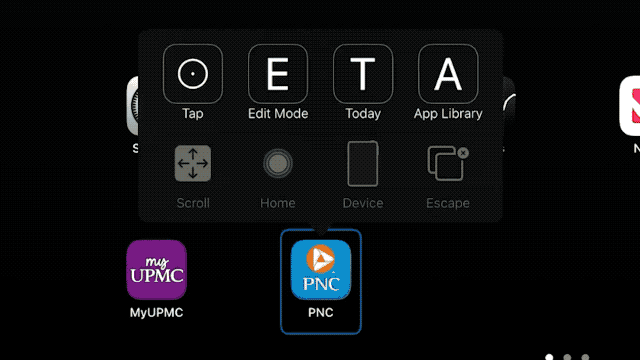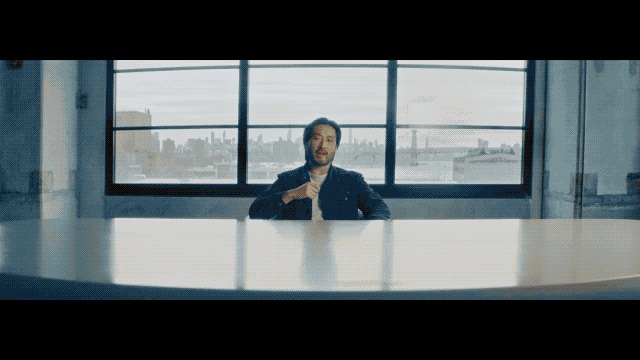
2023 年 8 月,他接受了手术。在 Stentrode 植入后,Jackson 开始训练如何用意念控制 Vision Pro。他「看到」自己站在阿尔卑斯山的悬崖边,「感受到」腿部的颤抖——尽管现实中他的身体已无法站立。
后来他逐渐学会了更复杂的操作:通过脑控启动应用、发送信息、打开邮件。「在我剩下的时间里,我希望能推动技术的进步,增进人们的理解。」Jackson 这样说道。
他的这番话也道出了 Synchron 团队的核心使命——让这项技术惠及更多人。
Synchron 神经科学与算法高级总监 Peter 表示:「我们的愿景是让脑机接口像键盘和鼠标一样普及。」他解释,BCI 的难点不仅在于技术本身,更在于缺乏标准化的「交互语言」。
于是,他们与苹果合作,基于 HID 标准开发出 BCI HID 协议。「它就像是计算机和键盘之间的通用语言。现在,我们也让大脑有了属于自己的输入协议。」

BCI HID 不仅传递用户的神经意图,还支持设备对用户进行视觉反馈。当 Mark 想选中某个按钮时,屏幕上会出现彩色高亮框。颜色越深,代表神经信号越强,系统就越确定他想点击那个按钮。Mark 可以通过脑控「填满」这个色块,实现精确选择。
「对于使用植入式 BCI 的用户来说,这种可视反馈太重要了。他们能实时看到自己的神经信号是否『足够强』,也更容易集中注意力。」Synchron 首席商务官 Kurt Haggstrom 解释道。而整个系统通过蓝牙连接,不需要额外设备或看护人员协助。只要 Mark 「想」,设备就能启动。
与传统辅助设备不同,BCI HID 是一个闭环交互系统。它不仅识别用户意图,还能实时提供上下文信息,提高解码精度与响应速度。
它还可以将意念动作直接绑定到系统快捷指令:想象点击手指等于回主屏幕,想象握拳等于打开消息,想象挥手等于启动视频通话。这不仅提升了操控自由度,也让系统交互真正进入「零干预」状态。

此外,BCI HID 具备极高的私密性——脑信号是用户「专属」的,无法被他人操控,也不会被其他设备「读取」。未来 Synchron 将推动 BCI HID 成为一个跨平台、跨厂商的神经交互标准,让所有 BCI 设备都能无缝接入数字世界。
而苹果的介入,被视为整件事的「临门一脚」。「Apple 能够认识到用户需求并做出回应,这体现了他们对用户无障碍体验的高度重视。」Kurt Haggstrom 如此评价。
提起脑机接口,大多数人第一个想到的还是马斯克的 Neuralink。无论是 Neuralink 之前的直播,还是在 X 上发推文,都引发了不少人对脑机接口的关注。
相比之下,Synchro 在业外可谓是名不见经传。
不过两家公司之间早有过交集,三年前的一个周末,正值 Synchron 在美国首次为患者植入脑机接口设备之际,马斯克向 Synchro 的创始人兼 CEO Tom Oxley 拨通了一则电话。
奥克斯利后来回忆道,电话里马斯克认为脑机接口的方案应该是移除大部分头骨,并用嵌入式钛合金壳替代。而他本人则坚信,无需触及头骨,也能达成目标。

▲Tom Oxley
并且,马斯克还主动提出,如果 Oxley 在这个追求目标的努力中资金不足,尤其是涉及脑机接口的方面,他希望能够提供帮助。但或许出于理念的分歧,这段「牵手」最终无疾而终。
实际上,过去二十年来,研究人员一直在人体上测试脑芯片植入物,但几乎所有这些设备都需要切开头骨并将电极刺入大脑,电线从头部悬挂出来。
简单来说,就是在头顶开一个洞,然后放入一块 Apple Watch 大小的装置。先不说手术过程的风险,即使手术成功了,人类大脑也会对装置产生排异反应,这是侵入式脑机接口的技术难点之一。

而 Stentrode 则不存在这个痛点。
它的手术方式近似于植入心脏支架,产品会通过颈静脉植入进大脑的运动皮层(表达人类运动意图的区域)。大脑对 Stentrode 的排异方式是把它推入大脑组织内,所以 Stentrode 在几周内就会被组织覆盖并固定在该区域。
Stentrode 检测到的任何大脑信号通过一根电线发送,电线沿着静脉向下延伸,连接到缝在患者胸部的 iPod Shuffle 大小的接收器上。
类似于心脏起搏器中的电池,接收器电池续航时间长达 10 年之久。
该接收器通过蓝牙将指令传输到患者的计算机或 iPad,使他们能够访问短信并控制其他应用程序。一旦安装了 Stentrode,患者就会进行校准练习,Synchron 的工作人员会指导他们思考移动身体的不同部位。
在植入方式和理念上的分歧,自然也造就了技术性能上的差异。
举例来说,Neuralink 的设备 N1 拥有超过 1000 个电极,可以捕捉更多的神经数据;而 Stentrode 仅有 16 个电极。N1 的电极直接植入脑组织中,因此捕获的数据更丰富,可转化为更灵敏的鼠标点击和键盘输入。
在之前的报道中,Neuralink 用户同样能通过意念移动光标,而且速度甚至超过部分普通用户的鼠标操作。
尽管如此,为什么苹果最终选择与 Synchron 深入合作,而不是马斯克的 Neuralink?这背后,其实藏着苹果对脑机接口的另一种答案:安全。
正如上面所说,Neuralink N1 是高密度、侵入式植入,怎么理解侵入式手术风险较高,可能引发炎症或组织反应。而 Synchron Stentrode 采用的是低密度、非侵入式植入,手术风险低,恢复时间短,尤其适合不适合进行开颅手术的患者。
当然,Stentrode 的代价就是因为电极不直接接触神经元,信号质量和分辨率较低,数据带宽较低,仅适用于基础层级的神经信号解码。
技术参数只是宏大故事的一部分,Synchron 真正吸睛的,是它已经做到的那些事。
2024 年 3 月,Neuralink 患者在 X 平台发布了一则推文,然而将时间倒回三年前,62 岁的渐冻症患者 Phillip O’Keefe 已经用 Synchron 脑机接口在 X 平台上「打出」第一句话:
Hello world!

注意,这是人类史上第一条通过脑电波「发出来」的推文,没有键盘、没有语音、甚至不是眼动追踪,全靠「想」出来的。虽然推文不长,但对他本人来说,可能胜过十万字长篇小说。
Synchron 的故事当然没止步于此。
当整个世界都被 ChatGPT 占领的时候,很多人都在想怎么用它写论文、写代码、写情书,而 Synchron 想的是如何用 AI 来改善脑机接口的技术。
64 岁的 Mark 就是第一批体验 AI 脑机融合的用户之一。尽管受渐冻症影响失去了大部分肢体与语言能力,他依然可以靠脑电波玩苹果纸牌游戏、看 Apple TV,甚至在 Vision Pro 上「仰望星空」。

具体来说,Synchron 让 ChatGPT 等大型语言模型以文本、音频和视觉的形式获取相关上下文,预测用户可能想要表达的内容,并为他们提供一个可供选择的操作菜单。
并且,在加入 GPT-4o 之后,Synchron 脑机接口迎来了 4 个方面的显著变化:

更重要的是,这种 AI + 脑机接口的多模态信息输入模式,与大脑本身的行为模式有一些相似之处,Synchron 团队的解释是:
我们这样做的原因是,多模态「4o」是不同的,因为它使用的是来自环境的输入,这些输入的行为就像是用户大脑的延伸。当用户开始与提示互动时,它将获得环境中发生的一切的实时信息流。
在接受媒体的采访时,Mark 表示最打动他的,正是 Vision Pro 中一款观察夜空星座的应用:
这太酷了,它真的栩栩如生。使用这种增强现实技术的效果非常显著,我可以想象,对于处于我这种境地的人或其他失去日常生活能力的人来说,它也会如此。它可以把你带到你从未想过会再次看到或体验的地方,为我提供了另一种体验独立的方式。
这是 Mark 的新体验,也是很多人对于脑机接口的最终幻想。
而 Synchron,真的把这件事做成了。
在 2025 年英伟达 GTC 大会上,Synchron 推出全球首款认知 AI 大脑基础模型 Chiral ,并带来了一段相当震撼的演示视频。
,并带来了一段相当震撼的演示视频。
一位名叫 Rodney 的 ALS 患者,手部完全失能,但通过脑机接口和 Vision Pro,大脑变成了遥控器,能够用意念控制智能家居:调节灯光、播放音乐、控制室、启动家用电器。

当时,Oxley 更是信心满满地表示:
「我们正利用生成式预训练技术,构建一个真正意义上的『大脑基础模型』。Chiral 直接从神经数据中学习,从人类认知的源头进行抽象,从而创造出能够切实改善用户生活的功能。而这一切,都建立在我们能够大规模获取神经数据的基础之上,正如将 BCI 技术普及到如同支架植入手术般便捷。」
所以无论是 GPT-4o,还是脑电接口,它们的终极目标其实是一致的:找到适合每一个人,尤其是被技术忽视的那一部分人,和计算机对话的新方式。
对于像 Mark 这样的用户来说,他们终于不用再依赖别人,也能再次说出自己想说的话,看自己想看的星星,甚至打几把纸牌游戏。
如果这不是人类科技的终极浪漫,那什么才是?
可这些进展,最终是为了谁?
我们或许该把视线拉近一点,看看这项技术对某些人来说意味着什么。
Synchron CEO Tom Oxley 表示,目前脑机接口公司需要「欺骗」计算机,让其认为来自植入设备的信号是来自鼠标。但如果有专为这些设备设计的标准,技术潜力将进一步释放。
如今,据外媒报道,苹果正用类似方式推动脑机接口设备与苹果生态系统的集成,并计划在今年晚些时候发布这一新标准的软件接口,供第三方开发者使用,推动脑控技术的进一步应用。
自 2019 年以来,Synchron 已在 10 名患者身上植入 Stentrode。
摩根士丹利估计,美国约有 15 万人因上肢严重功能障碍而成为脑机接口设备的潜在首批用户。根据 2021 年的数据,全球约有 1540 万人患有脊髓损伤,而脊髓损伤是导致瘫痪的主要原因之一。

当你在抱怨手机不好用时,有人连「用手机」这件事,都是奢望。
对于瘫痪、渐冻症患者来说,操作一台设备从来不是理所当然的事,他们甚至无法点击按钮、滑动屏幕、甚至无法抬手发出一个简单的指令。
人类社会对「操作」的定义,也一直都过于狭隘。
我们曾以为「操作」意味着点击、滑动、语音、手势,也一直在追求「更自然」的交互方式,可这套定义,从一开始就没为他们预留位置。
脑机接口的出现,改变了这一点,当意念也能成为操作方式,也意味着不再是人去适应设备,而是让设备去理解人。哪怕这个人无法动弹,无法说话,只剩下一颗仍在清醒地思考的大脑,他依然能与这个世界建立连接。真正的无障碍,是让世界适应每一种存在方式。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

照片后期,向来是横亘在普通人与「大片」之间的一道坎。
专业人士为此耗费心力,将拍摄后的数小时投入到电脑屏幕前,与各种曲线和图层搏斗;普通爱好者更是 常常因为摸不透 Photoshop 和 Lightroom 里那些天书般的工具而望而却步。
我们似乎都默认,一张出彩的照片,必然需要高超的后期技术。
不过,前两天登上热搜的「豆包修图」让我眼前一亮。
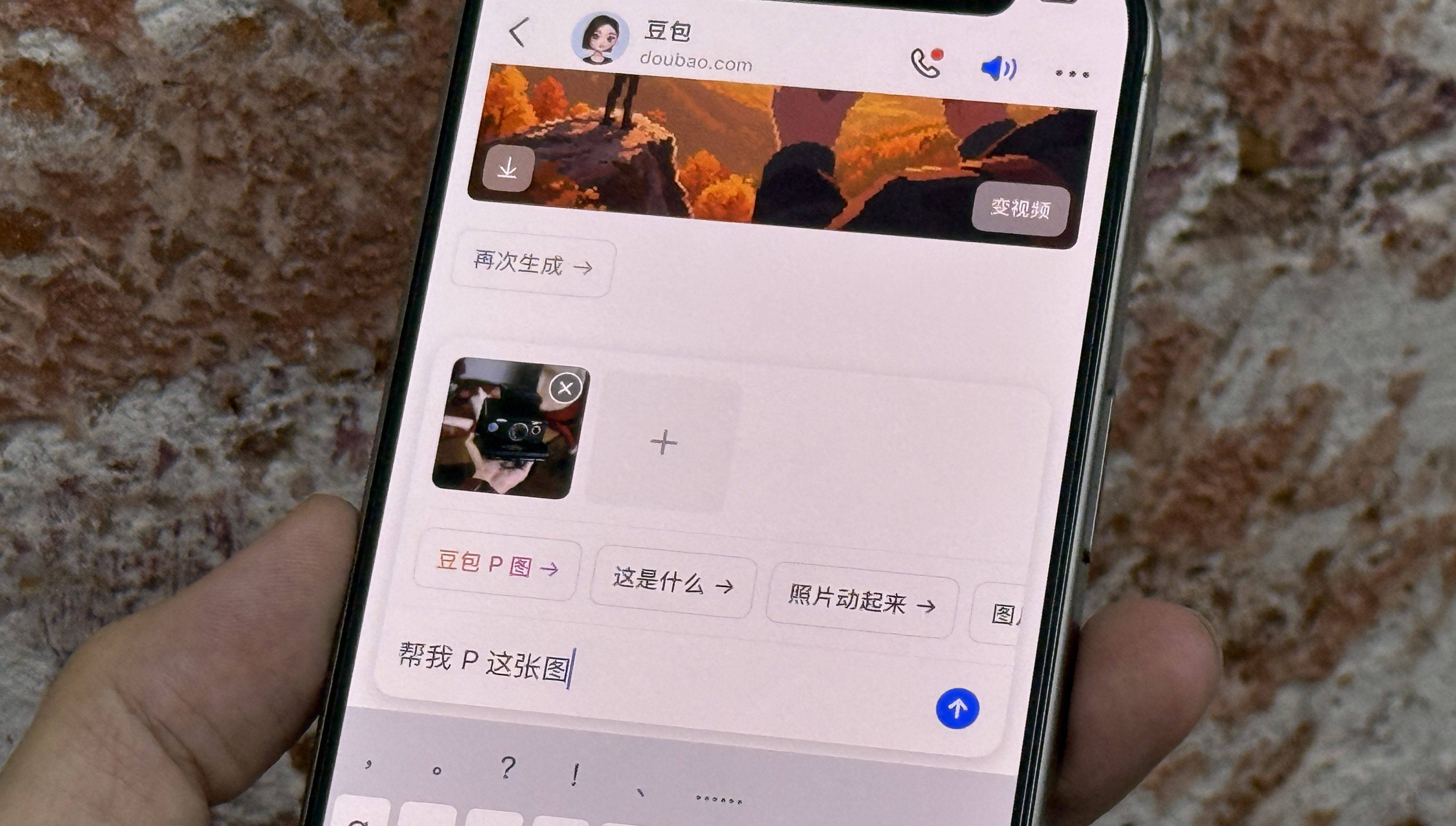
在 AI 大行其道的当下,修图这件事或许真的可以变得无比轻松:你只需要用一句话交代你的想法,AI 就能帮你 P 出一张心仪的大片。
摄影作为一门古老的艺术,早已分化出人像、风光、美食等诸多门派。
过去,每个门派都有自己秘不外传的后期心法,而现在,AI 就像一位打通了所有门派经脉的武林高手,用一套大力出奇迹的算法,通吃各种题材。
风光摄影师常常为了等待一个完美的天气和光线而起早贪黑。
可如果运气不好,拍到一张天空惨白的照片,后期处理起来就相当麻烦——需要创建复杂的蒙版,把天空和地面分开,单独进行调整。
但有了AI,这一切变得像点外卖一样简单。
我将一张照片分别用 Photoshop 和豆包进行处理,照片拍摄于入夜前,但厚重的云层挡住了壮观的落日,同时也大幅度压低了画面的亮度,观感暗沉。
修图的目的是替换掉原本不够漂亮的天空,你能一眼分辨出哪张是 AI 修的,哪张是我手动修的吗?

揭晓答案——左边是我在不到五分钟内用 Photoshop 手动处理的结果,右边则是豆包在几十秒内生成的版本。
乍一看两者效果相近,但作为亲手操作过两个版本的我来说,这其中的差别一目了然。
按照传统的修图流程,我需要手动精细抠出天空,保留地面树枝的细节;接着再寻找合适的晚霞素材替换原本厚重的云层,并统一天空与地面的色调与亮度,以保证整张图的色彩和谐。
而在豆包中,我只需要一句话提示,就能直接生成这样一张几乎完成度极高的图片。
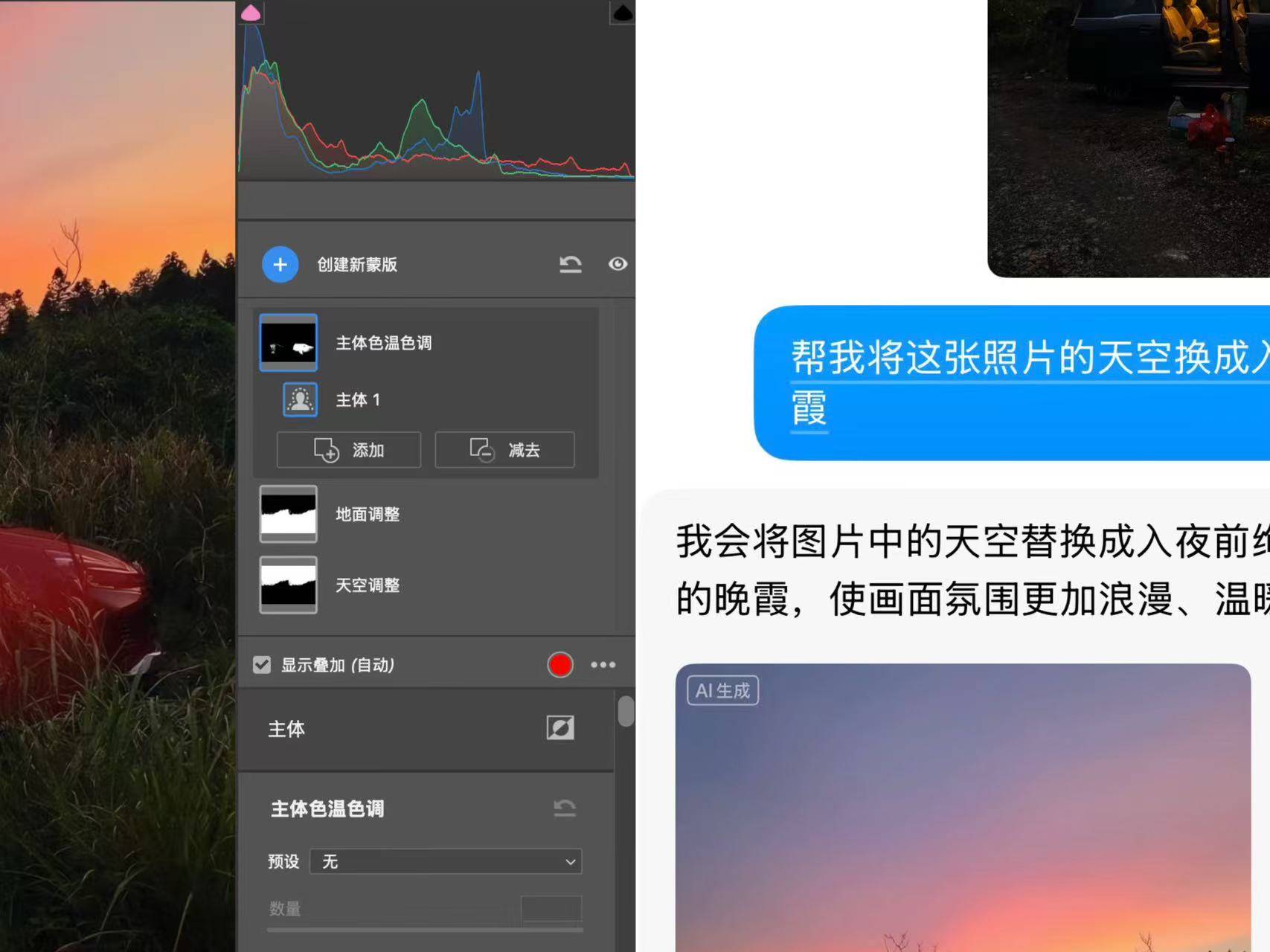
▲ 原本复杂的操作,对 AI 一句话的事儿
放大查看细节后,尽管在极限放大下,AI 图像的画质略逊于手动处理版本,但豆包依然保留了树林与天空交界处的细节,地面亮度与色温也同步优化,整体画面协调自然,展现出相当成熟的修图逻辑。

▲ 豆包处理的天地交界,比我两分钟处理出来的更精细
日常风景照片的另一个难题,则是茫茫多的路人。
按照传统方法,你需要先将照片导入 Photoshop,用污点修复画笔或仿制图章工具,放大到 300% 进行精细处理。
在涂抹路人的同时,还得纠结到底是用内容识别还是近视匹配,若是遇到复杂纹理,还得手动创造纹理,繁琐至极。

▲ 掌握这些工具,是传统后期的第一步
但对于 AI 来说,这也不过是分分钟的事——
在不到一分钟的等待后,我收到了处理完成的照片:不仅保留了原图的色调与画质,还精准去除了所有路人。
尤其令人称赞的是,AI 在清除人物的同时,还细致地保留了右侧江岸岩石的阴影细节,没有出现常见的粗糙涂抹痕迹,整体效果令人非常满意。

▲ 使用 ChatGPT 去除路人
光影重塑是风光摄影进阶的修图技巧,指的是摄影师在后期处理中,根据照片的不同表现,运用蒙版、画笔等工具,精细调整局部画面。通过顺应直觉和逻辑的方式,重构整体光线效果,营造明暗对比,从而突出主体,渲染氛围,提升照片的视觉冲击力。
停!
我知道,这么一大串讲完,你已经迷糊了,简而言之,光影重塑就是根据个人审美与技术,调整出更具冲击力和逻辑感的照片。
过去,要做到这一点,不仅需要熟练掌握 Photoshop 的各种工具,还需要对光线有一定的理解和控制能力,以及出色的审美,才能做出既不夸张又恰到好处的光影效果。

▲相信我,你不会想学这套流程的
而现在,交给 AI 也就是一句话的事儿——
在简单交流后,AI 为这张照片按照风光摄影的修图思路进行处理,给画面添加了遮盖无用细节的平流雾,让其覆盖较低的楼房,营造出朦胧氛围;
同时进行光影重塑,从画面原本的光影逻辑出发,加强了阳光在建筑面上的反射效果,使画面光影合理、有层次感,突出了东方明珠的主体性。

▲ 使用 ChatGPT 光影重塑
同样的方法,我们也可以挪用到相册中另一个不能忽视的大种类上——宠物和人像。
这里指的不是磨皮、面部重塑等因人而异的主观调整,而是 AI 可以按照一定的逻辑帮你润色画面的光影,营造特别的氛围,以达到手机无法直出的质感。

除了光线调整,在这类照片中,用 AI 添加道具,营造特殊的氛围,也是另一种玩法。
就像前面的一句换天一样,你可以用一句指令让 AI 为画面中添加一些符合环境的元素,比如漫天飘散而下的黄叶,或是从窗台倾泻而入的阳光。
再将脑洞打开一些,如果遇上不满意的天气,你可以让 AI 换一下天空,顺带注意处理好人物的光线,得到一张毫不违和的照片。

▲ 雪景也是不错的选择
风景和人物宠物解决了,还有一个重要的题材不能忘记——美食。
如果按照传统方法,摄影师需要精确校准白平衡,防止任何偏色都会让食物看起来不新鲜。
进入后期,还要小心地提高清晰度,但又不能过头,否则食物会显得干瘪,毫无食欲;接着还要利用色调曲线和 HSL(色相、饱和度、明度)滑块,精确地调整每一种颜色的表现,让色泽更诱人。
在这方面,AI 也可以帮上大忙。
润色后的照片层次更为分明——冷吃兔与鸡肉裹满红亮油润的酱汁,表面铺满鲜红辣椒段,点缀其间的金黄花生米酥脆诱人,视觉与味觉的冲击感扑面而来,瞬间唤起食欲。

可以说,在 AI 的帮助下,你已经跨过了曾经逾越在普通人与大片之间的那道高墙,拥有了「言出法随」般的修图能力。
但魔法并非总能随心所欲,想要精准地实现心中所想,「咒语」是关键。
用 AI 修图看起来很新鲜,但背后其实就是我们熟悉的文生图的进阶应用。
顾名思义,AI 从我们这里获取一段描述,并从中理解我们的意图,最后生成出符合它理解的图片。
这里的难点在于,什么样的话是 AI 容易理解的呢?
我准备了一张想要处理的照片,以豆包为例,尝试不同提示词的效果。
第一次,如果我简单描述:
将这张照片 P 好看。

此时,AI 对照片进行了一定的基础处理,我们可以明显看到画面对比变得更强了,颜色也更加浓郁,但我对这样的处理并不算满意——
这张照片拍摄于傍晚,最大的问题在于画面不够通透,层次也不够丰富,相比提升对比度和饱和度,我其实更希望从整体风格上进行调整。
回头看我的提示词,只有一句模糊的「好看」,但「好看」本是一个极其主观的感受,AI 无法隔着屏幕感知使用者的审美偏好,只能依靠预设的主流美学风格帮忙处理图片,最后就得到了一张「饱和度战士」。
但如果将描述改为:
将这张照片的拍摄时间改为蓝调。

有了更明确、客观的描述,AI 生成的图像也明显更符合需求,在观感自然的基础上,蓝调更突出了,画面的冷暖对比也更为强烈,但这样还不够——
单一维度描述的咒语还不够精准,AI 可能会出错,同时由于日落与城市开灯之间有时差,所以拍摄时城市还没有亮起灯光,照片本身并没有体现出城市的繁华,这比较遗憾。
想要这张照片更好看,我们可以为 AI 准备一个更全面的建议。
所以,我们进一步将描述扩充为:
将这张照片的拍摄时间改为蓝调,为画面中的建筑物添加一些符合逻辑的灯光,远处高大的建筑可以添加示廓灯,为画面打造内透效果,注意灯光的合理性。

从更多角度描述我们意图的提示词,得到了非常不错的效果,AI 在凸显蓝调的同时,顺利为图片中的建筑物添加符合逻辑的灯光,打造出一张富有层次感的城市夜景照片。
到了这里,我们可以总结出一套方法论,来为 AI 提供精准的描述,以尽量准确的方式传达我们的意图——
「主体 + 时间/环境 + 光线/色调 + 风格/情绪 + 特殊效果 + 细节约束」
公式由六个部分组成,六个部分分别代表了一张照片的各个维度:
按照这个公式,我们可以最大程度地掌控照片中的各个元素,越全面,AI 能理解就越精准。
依旧是这张照片,我们用这条公式的方法来撰写提示词,试试 AI 能不能给我们提供另一种风格的照片:
这张照片(主体)改为雨天拍摄,此时正值入夜前的傍晚(时间),为画面添加一定的雾气,雨水与雾气被建筑灯光打亮,在空中连成丝线,雾气可以盖住部份建筑(特殊效果),同时按照逻辑重塑光影(光线),注意不要改动删减照片中已有的建筑和元素(细节约束)。

雾气自然、影调和谐,积雨的屋顶还有符合逻辑的光线反射,这张照片的确出乎意料——
以往需要繁杂后期才能实现的效果,现在不到 30 秒就能轻松获得。
需要一提的是,在我试过的几十张照片中,修图效果最强的是豆包,其次是 ChatGPT,文中总结出的提示词公式,在这两个 AI 上都能取得相当不错的效果;
而 Gemini、Qwen 等 AI 工具则更倾向于重绘,照片改动痕迹较重,相较之下更推荐前两者进行精修润色。
玩到这里,我一边感叹 AI 的确强大——不需要任何修图基础,只需要提供完整的想法,就可以得到一张处理得八九不离十的照片;
但另一方面,一个有些老生常谈,但的确没办法忽视的矛盾,开始拷打我的内心。
在 AI 技术的加持下,我们的创作和表达变得前所未有的自由和丰富。
修图不再是专业人士的专利,普通人也可以轻松地通过 AI 实现照片的修饰与再创作。
不过,当我们沉浸在用 AI 把自家猫咪 P 成宇航员的乐趣中时,一个纠葛已久的矛盾,也随着而来:
在一些人眼里,AI 修图让照片背离了现实,变得虚假;而另一部分人认为,这只是自娱自乐,何必用如此严格的要求去度量一张照片。
在技术交替的时期,类似这样的理念之争并不稀奇,甚至已经有了愈演愈烈之势。
德国摄影师 Boris Eldagsen 在用一张 AI 生成的图片赢得索尼世界摄影奖后,主动拒绝领奖,并公开了图片的 AI 身份。
在世界级的专业摄影比赛上整这种活儿,并不是一个玩笑——他想以此引发人们的讨论,并强调我们必须区分用光写作(摄影)和用提示词写作(AI 生成),以保护照片的公信力。

▲ 赢得索尼世界摄影奖的 AI 作品《假记忆:电工》,由 DALL-E 2 生成
不过,这场关于真实的辩论,或许从一开始就混淆了两个不同层面的问题,我们必须区分两种不同的语境:一种是「公共领域的真实」,另一种是「个人表达的真实」。
对于法庭上的证据,或是《纽约时报》的头版照片,客观、可验证的真实性是其生命线,一张照片的来源——由谁、在何时、何地、为何拍摄——是判断其价值的根本标准。
在这种语境下,任何未经声明的修改都可能构成欺骗。

▲ 能将特朗普 AI 成猫猫吗?恐怕改不得
但对于你的朋友圈来说,真实的含义则完全不同。
在数字世界的私人领地里,我们追求的往往是一种情绪的真实、一个笑话的真实或一种审美的真实。
是的,当看到一张猫猫正在帮忙做饭的图片时,我们不会感觉自己被欺骗了,只会被逗乐。

▲ 我给爸妈说猫猫给我养老,我爸妈也不会和我急眼
这里的真实无关乎事实,而关乎表达。
这或许才是普通人拥抱 AI 修图的真正原因——在个人表达的领域里,意图是事实更重要的准绳。
一位新闻记者的意图是见证,他有责任尽可能忠实地记录事件;而一个普通人的意图是表达,他有权利通过各种方式来传达自己的情感和创意。
所以回到最初的问题,去吧,大胆地让赤道下雪,让猫咪登月。
在这个 AI 的时代,在你的私人世界里,想象力是唯一的边界。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

一段看起来像是夜视监控拍到的「兔子蹦床」视频,在 TikTok 上爆火,全网收获了有 5 亿次播放。
视频看上去像是某户人家的安防摄像头拍到的,灯光昏黄、画面模糊,但恰到好处地捕捉到几只兔子轮番起跳,活像在开夜间演出。
视频的标题写着:「刚查看了家庭监控,我想我们家后院来了几位特邀嘉宾!@Ring」 。
监控的模糊画质、几只看似在狂欢的兔子,这可爱又略带一丝真实感的画面迅速吸引了人们的眼球 。
在社交媒体平台 X 上坐拥百万粉丝的名人 @Greg 也评论说,「我从没意识到自己需要一群蹦床兔子,直到今天」。
然而,这份可爱是虚假的。视频中的兔子并非真实存在,有人发现,它是AI生成的。

第 5 到第 6 秒之间,左上角的兔子忽然「消失」。回头再看,细节确实有点怪。
但和大多数「AI 穿帮」视频不同,这次几乎没人第一时间认出来。哪怕是刷视频经验老到的年轻人,也直呼「完了,我居然被骗了」。
但这不是一场骗局,更像是一种小型社交媒体的灾难:不是「我们被骗了」,而是「我们居然愿意被骗」。
这段 AI 视频之所以能成功「欺骗」大众,很大程度上并非因为 AI 视频生成技术已经完美,而在于它「骗得刚刚好」。
它精准地利用了我们对监控视频的固有印象,也踩中了最能让我们放下戒备的那些流量密码。
模糊的夜视画质和静态背景,刚好遮住 AI 的弱点
我们习惯于认为夜晚监控录像就是模糊、黑暗且充满噪点的。这种先入为主的印象,完美掩护了 AI 视频的技术硬伤,例如在动作连贯性、阴影细节和背景动态上容易穿帮等问题。
所以当它以「夜晚监控录像」的方式出现时,画质本身的低清模糊反倒成了障眼法,帮它遮住了真实感缺口。

▲ 视频画质符合夜间监控特点,且背景是完全静止。
此外,尽管一些 AI 视频生成模型在处理前景主体方面已经相当出色,但背景的渲染往往会显得非常超现实。
而这段视频的背景是静止的,这又为 AI 规避了一个技术难题。
带「@Ring」的文案增强了来源可信度
视频发布者在标题中聪明地标记了家庭安防摄像头品牌「Ring」,一下子就让这视频的来源显得有理有据,让人感觉更真了。
▲ Ring 是家庭摄像头品牌
这个小细节营造出「这视频是别人家门铃拍到的」错觉,让人自动归类为「生活记录」而非「创作内容」。
「动物夜间搞事情」是互联网用户默认接受的 meme
无数次病毒式传播的视频,已经训练我们相信这个场景是真实的。猫晚上偷吃泡面、浣熊夜闯泳池、郊狼在蹦床玩耍,动物们总爱在人类不在时「犯规」一下。兔子蹦床这种事,怎么看都合理。
▲ 熊闯入游泳池
最重要的:它太可爱了!谁会去质疑这么温柔的一幕呢?当一段内容足够甜、足够轻,它就很容易让我们「选择相信」。
尽管视频中间,左上角的兔子突然消失,暴露了 AI 生成的本质。但对于绝大多数刷短视频,快速滑动的观众来说,这一瞬间的破绽极易被忽略。
就在兔子视频引发热议的同时,马斯克也分享了 AI 视频技术的惊人进展。
10 天前,一段 6 秒的视频渲染需要 60 秒,之后降至 45 秒,再到 30 秒,现在已缩短至 15 秒。
本周我们或许能将时间控制在 12 秒以内。
他同时表示,实时视频渲染技术有望在 3 到 6 个月内实现。

▲ 马斯克推特截图
这意味着,今天我们还能看到的「兔子消失」这类穿帮镜头,在几个月后可能就几乎很难发现里面的 bug。
当 AI 视频在技术上无懈可击时,再去讨论「如何分辨真假」就失去了意义。
这也让我们不得不把目光从技术本身,转移到更核心的问题上。
视频的真相揭晓后,许多用户表达了一种「信仰崩塌」的感觉。
一位 TikTok 用户说,「这是第一个我相信是真的 AI 视频,等我老了肯定完蛋了」。另一位用户则表示,「现在我觉得我以后就会是那种被骗的老年人」。
这种从自信到恐慌的情绪转变,成了一个新的网络热点。
然而,将问题仅仅归咎于「AI 发展得太快」或「我们太容易被骗」,可能忽略了更深层次的原因。这一事件的核心,或许不在于 AI 技术本身,其实在于社交媒体平台本身的那一套玩法。
通过翻看视频的评论记录,我们发现人们在评论区的反应,呈现出来的几乎是同样的一个心理剧本。
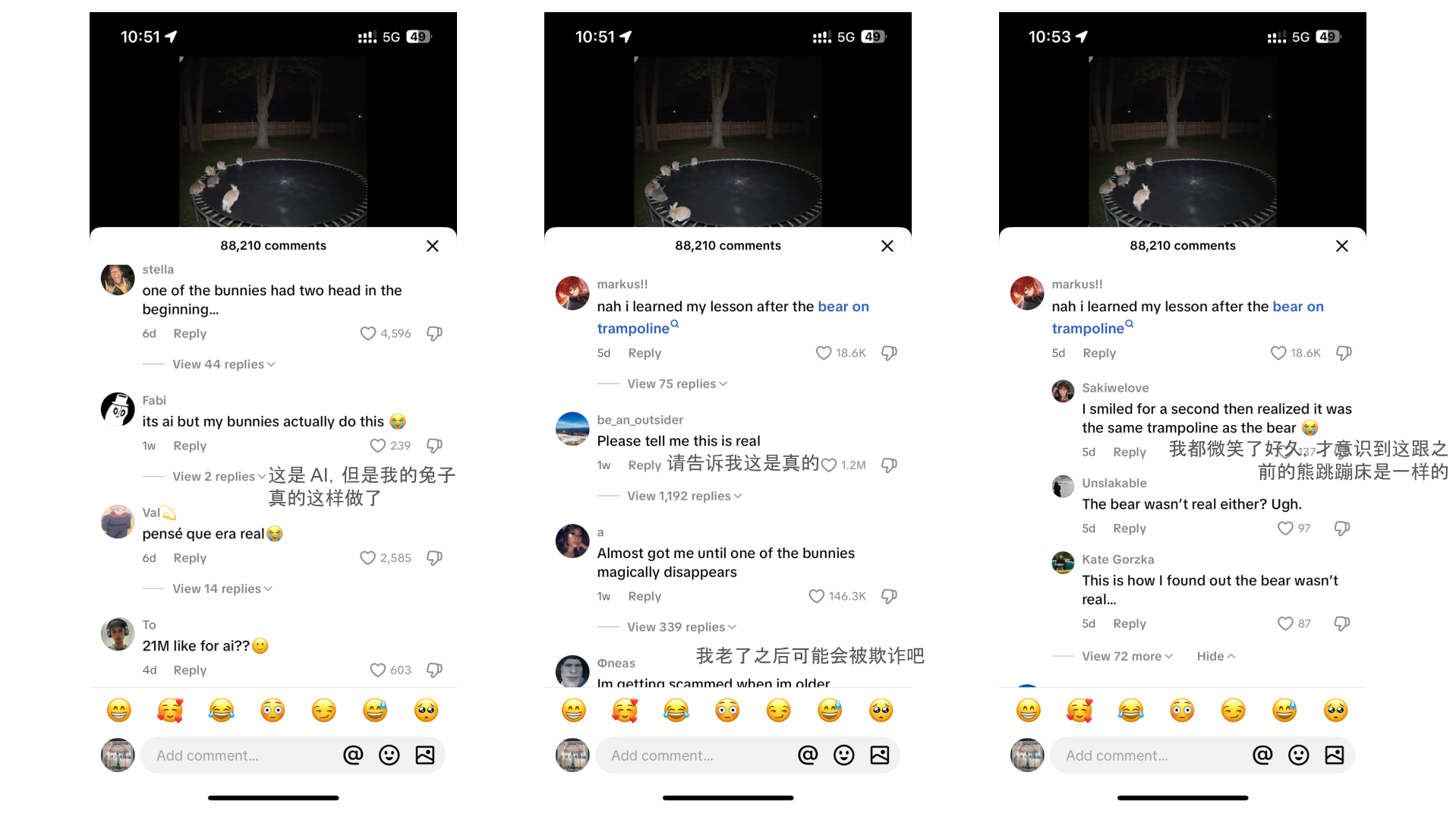
首先是「天啊,这也太可爱了」;
然后,「等等,好像不太对劲?」;
第三步,「我被骗了?完了,我要变成会被骗的老年人了吗」;
最后还是回到了,「但……我不怪它」
我们正在和 AI 视频建立一种全新的「互动逻辑」。
我们不是完全相信它,而是默认它可能是假的,但我们依然愿意停下来看看、点个赞、转发给朋友猜一猜,就像一个游戏。
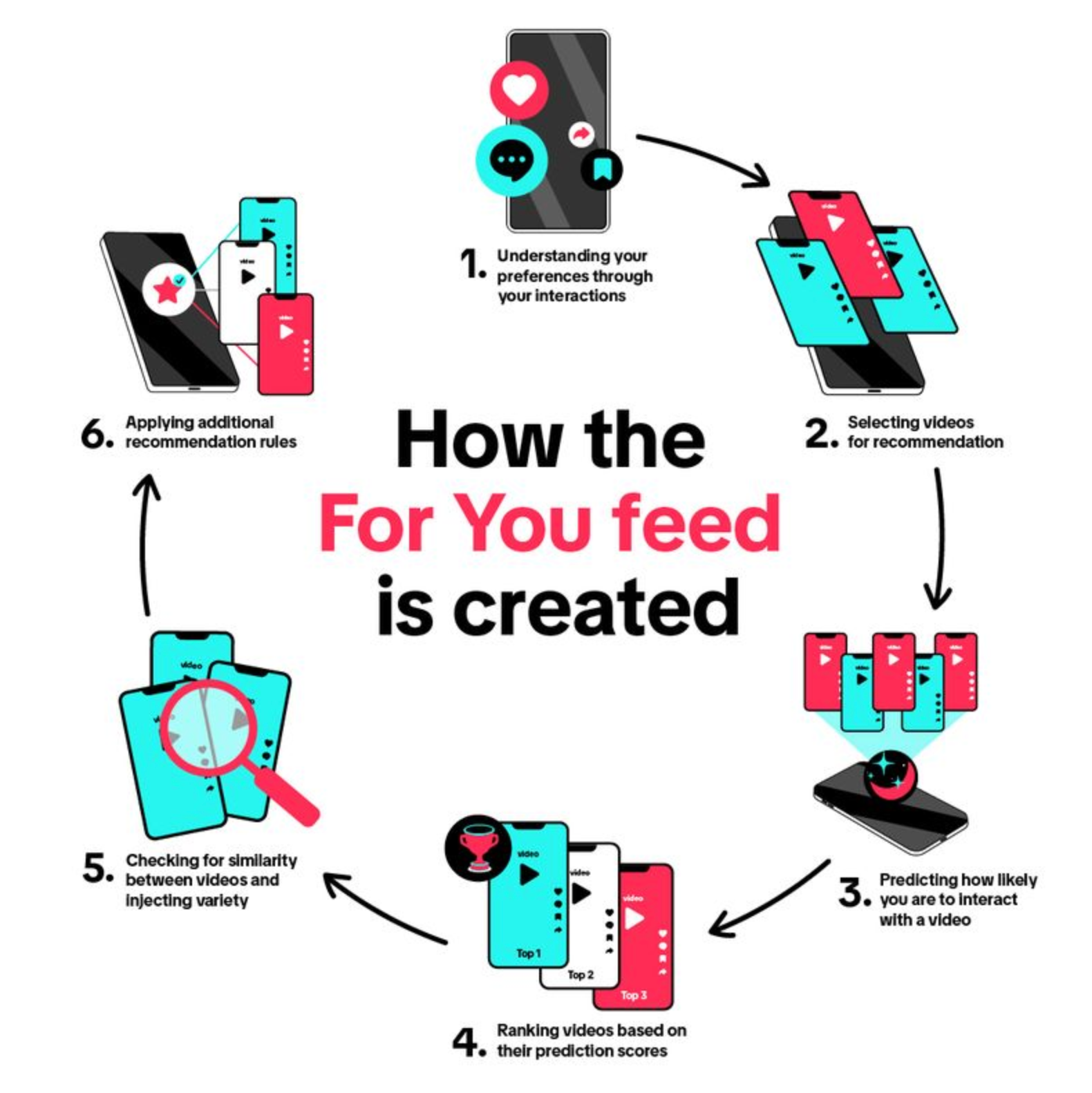
▲ 短视频平台推荐系统
而平台的算法,也深知这种心理结构。
在这个过程中,「AI 视频是真是假」不再是重点,它更像一种参与门槛:你看懂了没?你能分辨出来吗?你被骗了吗?
AI 爆发的这两年,我们总是感叹 AI 视频图片已经能以假乱真,因此感到恐慌,担心自己未来会更容易被虚假信息蒙蔽。
然而,这个视频的病毒式传播,并非完全源于 AI 技术的「欺骗性」,而是源于人类观众内心深处对「被欺骗」的需求。
这些网友不都是被动地被骗,而有不少是主动地、心照不宣地参与了一场名为「假装相信」的集体游戏。
这场狂欢的主角不是 AI,而是我们自己。
正是视频中那「一闪而过」的兔子消失 bug,才让整个事件升级为一场全网参与的「找茬游戏」。如果视频完美的天衣无缝,它可能只会然后迅速被下一个视频淹没。

▲ 电影「致命魔术」
这就像观众明知道魔术师在「欺骗」他们,但他们享受的恰恰是那种「明明知道是假的,却看不出破绽」的认知挑战。
AI 兔子的「穿帮」,就是这个魔术被揭穿的时刻,它让所有人加入讨论,从而引爆了传播。
缺陷创造了争议,争议驱动了参与。视频的真假不再重要,它所引发的混乱和讨论本身,就是流量的保证。
这种「我竟然也被骗了」的自嘲,迅速拉近了陌生网友间的心理距离,形成了一种「我们都是容易被骗的笨蛋」的社群认同感。由「共同被骗」而产生的连接,其社交价值远大于视频内容本身的真实性。
理想的情况是,我们学会有意识地享受这种「虚假内容」带来的乐趣,同时保持一份清醒的认知,但这可能对大多数人来说并不容易。
潜在的危险不只在于 AI 的逼真程度,而在于当这种「集体欺骗」被用于恶意时,比如制造谣言或骗局。我们需要建立的,是对信息「意图」的识别,而非仅仅对「真伪」的判断。
我们可以多问问自己:这个内容想让我产生什么感觉?它最终想让我做什么?
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。