
时隔五年之后,OpenAI 刚刚正式发布两款开源权重语言模型——gpt-oss-120b和 gpt-oss-20b,而上一次他们开源语言模型,还要追溯到 2019 年的 GPT-2。
OpenAI 是真 open 了。
而今天 AI 圈也火药味十足,OpenAI 开源 gpt-oss、Anthropic 推出 Claude Opus 4.1(下文有详细报道)、Google DeepMind 发布 Genie 3,三大巨头不约而同在同一天放出王炸,上演了一出神仙打架。
OpenAI CEO Sam Altman(山姆·奥特曼)在社交媒体上的兴奋溢于言表:「gpt-oss 发布了!我们做了一个开放模型,性能达到o4-mini水平,并且能在高端笔记本上运行。为团队感到超级自豪,这是技术上的重大胜利。」
模型亮点概括如下:
- gpt-oss-120b:大型开放模型,适用于生产、通用、高推理需求的用例,可运行于单个 H100 GPU(1170 亿参数,激活参数为 51 亿),设计用于数据中心以及高端台式机和笔记本电脑上运行
- gpt-oss-20b:中型开放模型,用于更低延迟、本地或专业化使用场景(21B 参数,3.6B 激活参数),可以在大多数台式机和笔记本电脑上运行。
- Apache 2.0 许可证: 可自由构建,无需遵守 copyleft 限制或担心专利风险——非常适合实验、定制和商业部署。
- 可配置的推理强度: 根据具体使用场景和延迟需求,轻松调整推理强度(低、中、高)。完整的思维链: 全面访问模型的推理过程,便于调试并增强对输出结果的信任。此功能不适合展示给最终用户。
- 可微调: 通过参数微调,完全定制模型以满足用户的具体使用需求。
- 智能 Agent 能力: 利用模型的原生功能进行函数调用、 网页浏览 、Python 代码执行和结构化输出。
- 原生 MXFP4 量化: 模型使用 MoE 层的原生 MXFP4 精度进行训练,使得 gpt-oss-120b 能够在单个 H100 GPU 上运行,gpt-oss-20b 模型则能在 16GB 内存内运行。
OpenAI 终于开源了,但这次真不太一样
从技术规格来看,OpenAI 这次确实是「动真格」了,并没有拿出缩水版的开源模型敷衍了事,而是推出了性能直逼自家闭源旗舰的诚意之作。
据 OpenAI 官方介绍,gpt-oss-120b 总参数量为 1170 亿,激活参数为 51 亿,能够在单个 H100 GPU 上运行,仅需 80 GB 内存,专为生产环境、通用应用和高推理需求的用例设计,既可以部署在数据中心,也能在高端台式机和笔记本电脑上运行。
相比之下,gpt-oss-20b 总参数量为 210 亿,激活参数为 36 亿,专门针对更低延迟、本地化或专业化使用场景优化,仅需 16GB 内存就能运行,这意味着大多数现代台式机和笔记本电脑都能驾驭。
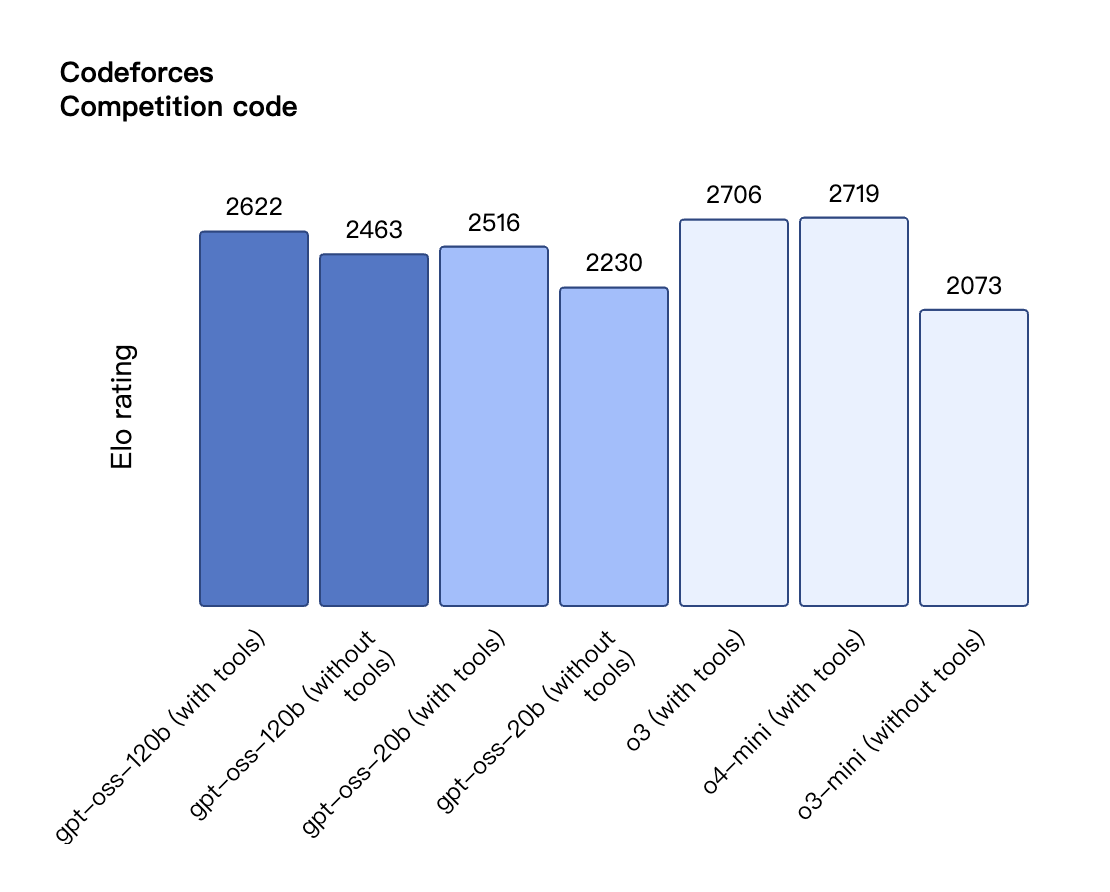
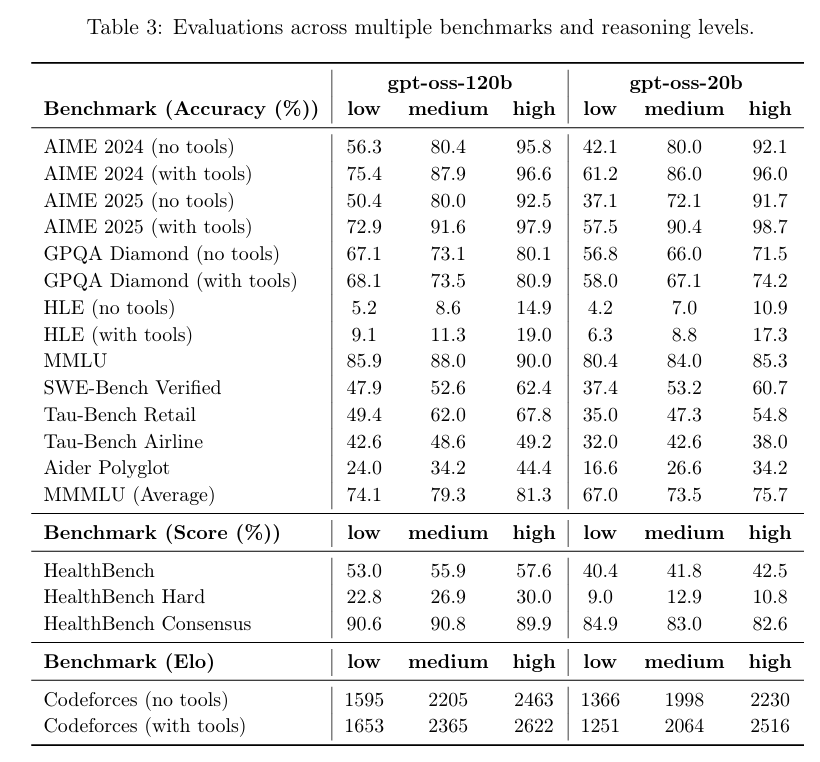
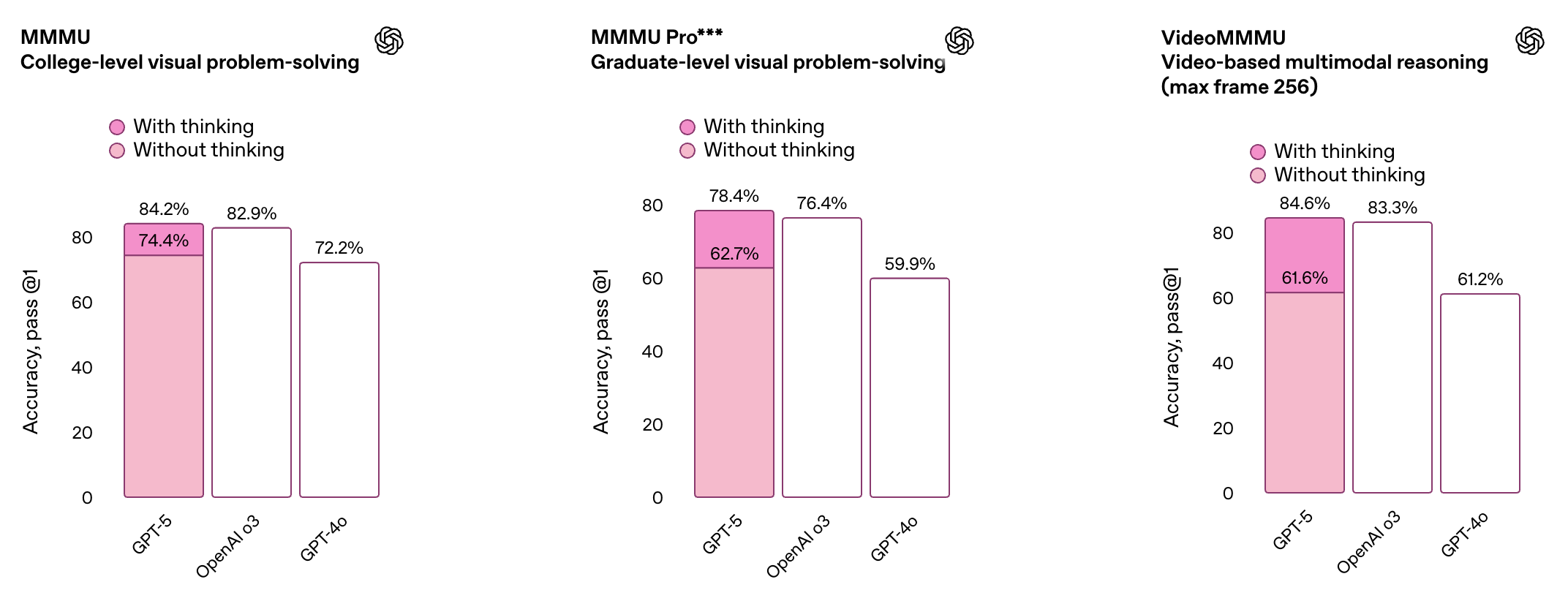
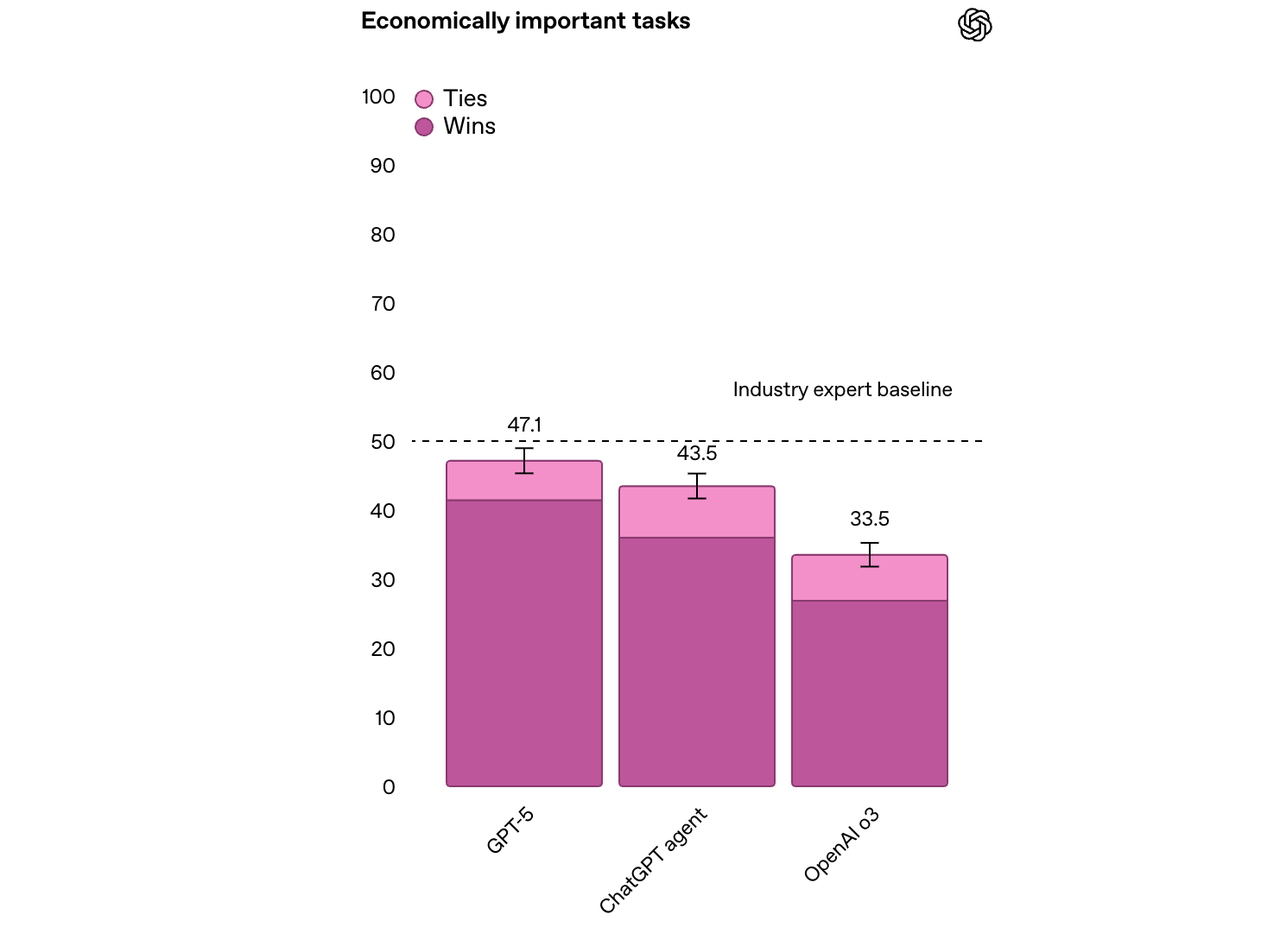
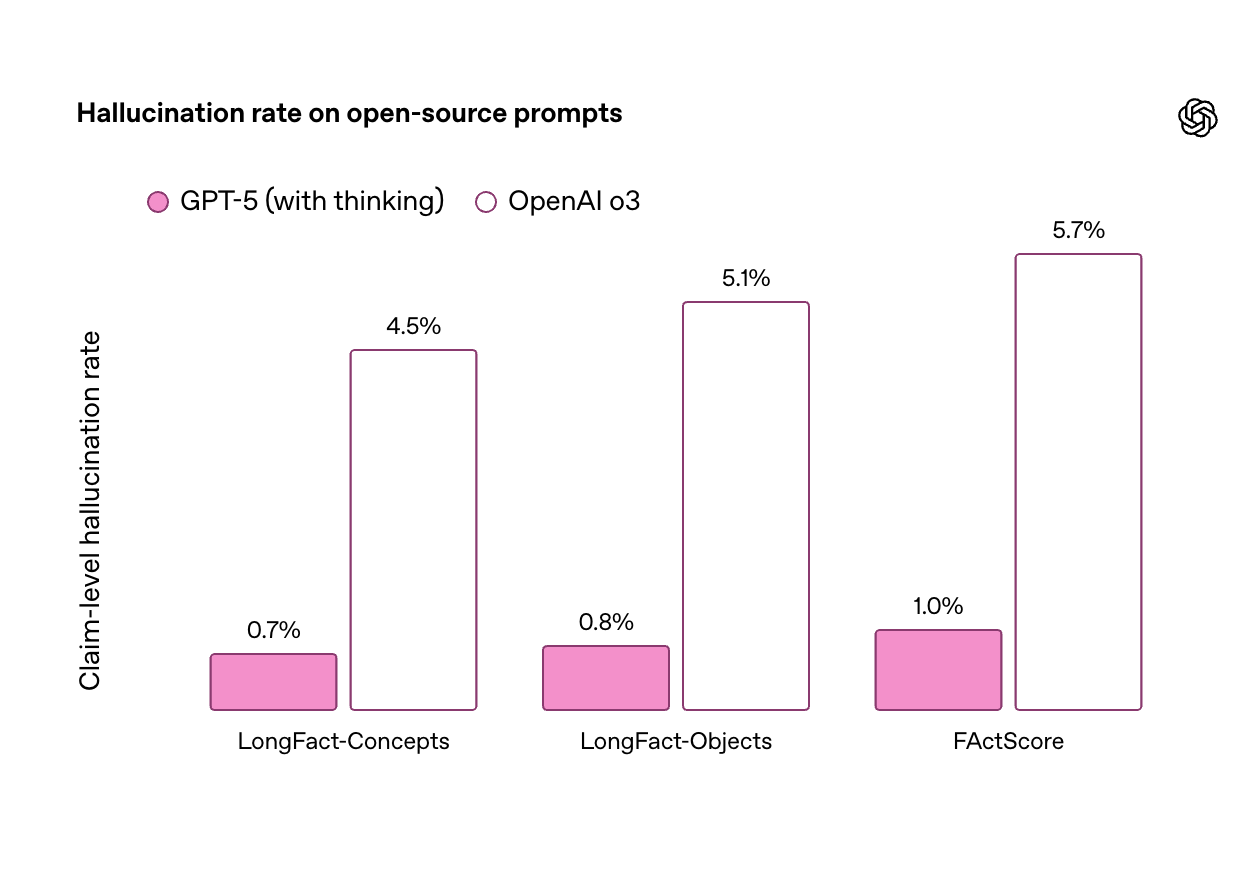
根据 OpenAI 公布的基准测试结果,gpt-oss-120b 在竞赛编程的 Codeforces 测试中表现优于 o3-mini,与o4-mini持平;在通用问题解决能力的 MMLU 和 HLE 测试中同样超越 o3-mini,接近 o4-mini 水平。
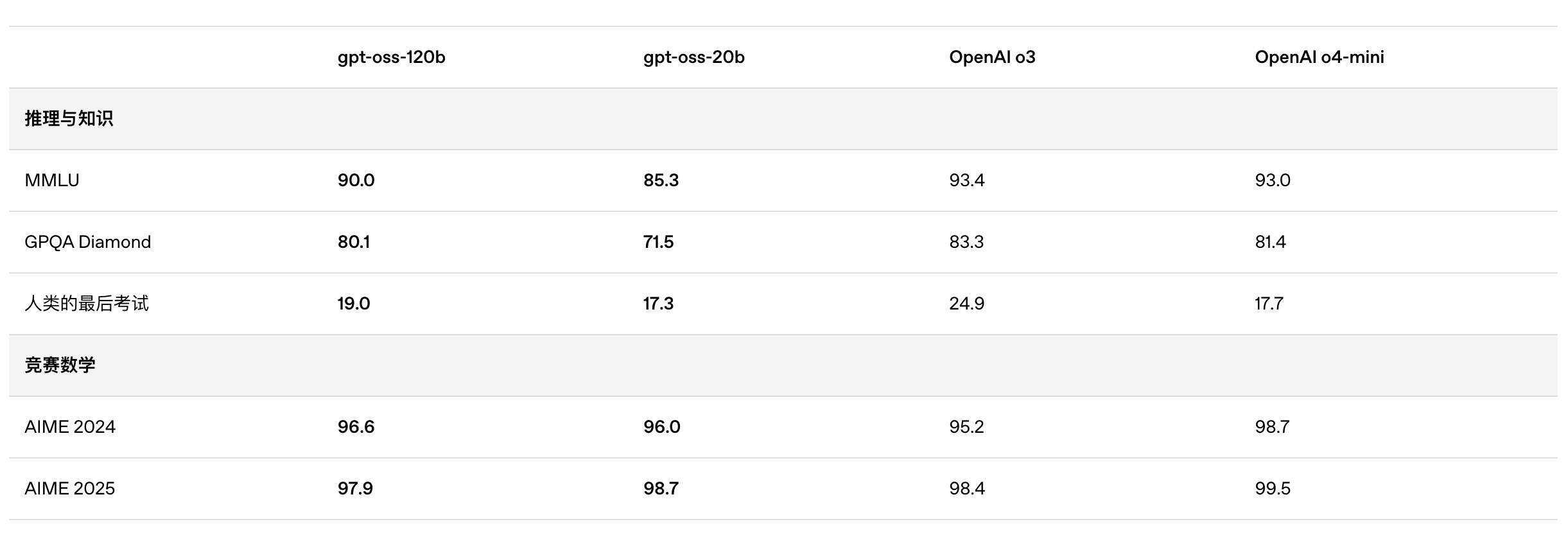
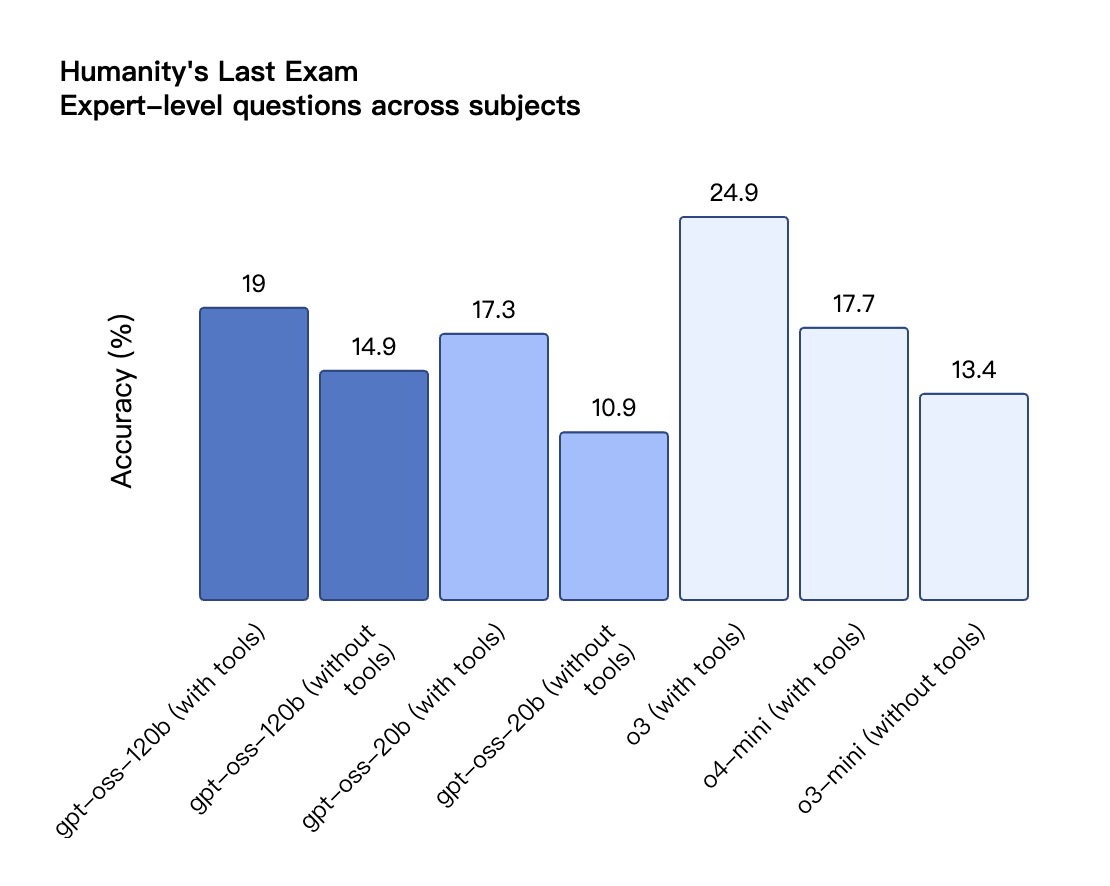
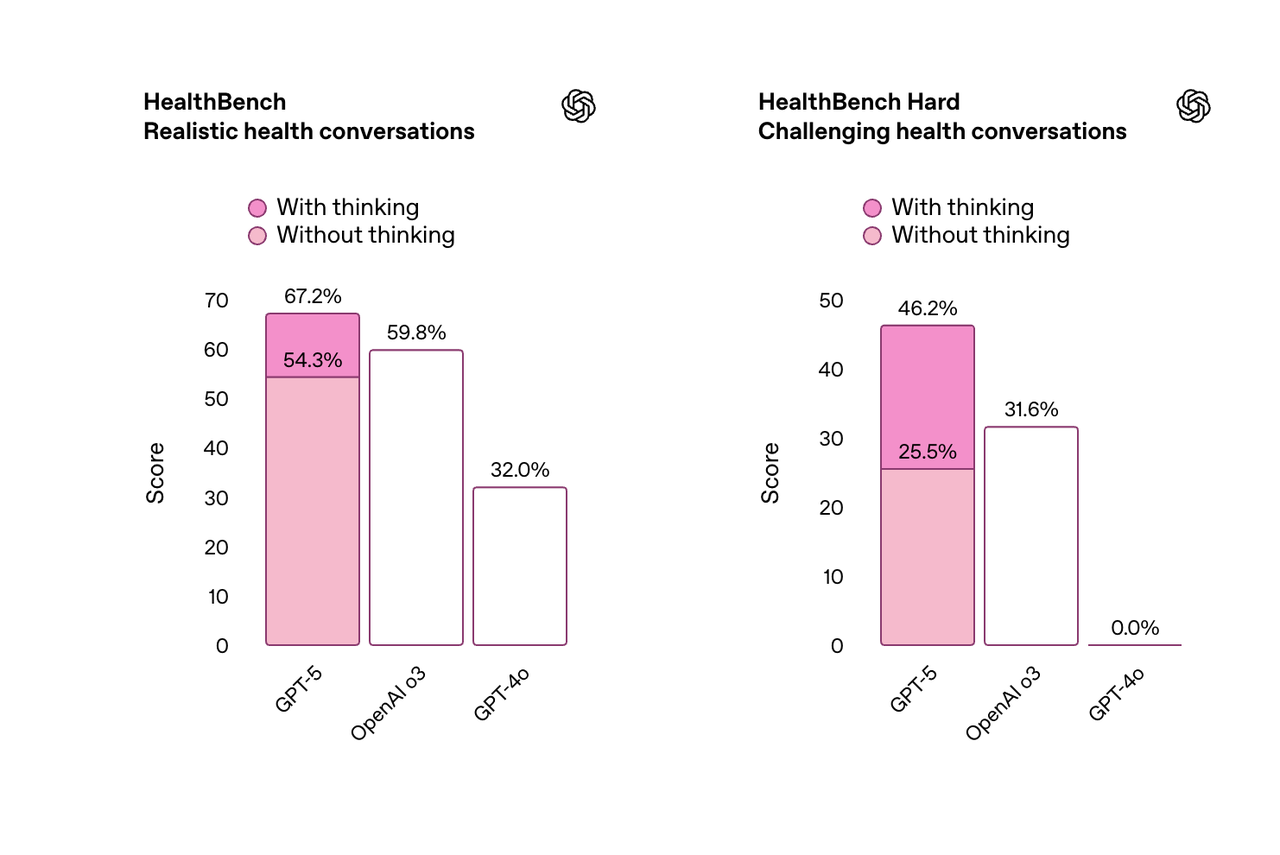
在工具调用的 TauBench 评测中,gpt-oss-120b 同样表现优异,甚至超过了像 o1 和 GPT-4o 这样的闭源模型;在健康相关查询的 HealthBench 测试和竞赛数学的 AIME 2024 及 2025 测试中,gpt-oss-120b 的表现甚至超越了 o4-mini。
尽管参数规模较小,gpt-oss-20b 在这些相同的评测中仍然表现出与 OpenAI o3-mini 持平或更优的水平,特别是在竞赛数学和健康领域表现尤为突出。
不过,虽然 gpt-oss 模型在健康相关查询的 HealthBench 测试中表现优异,但这些模型不能替代医疗专业人员,也不应用于疾病的诊断或治疗,建议谨慎使用。
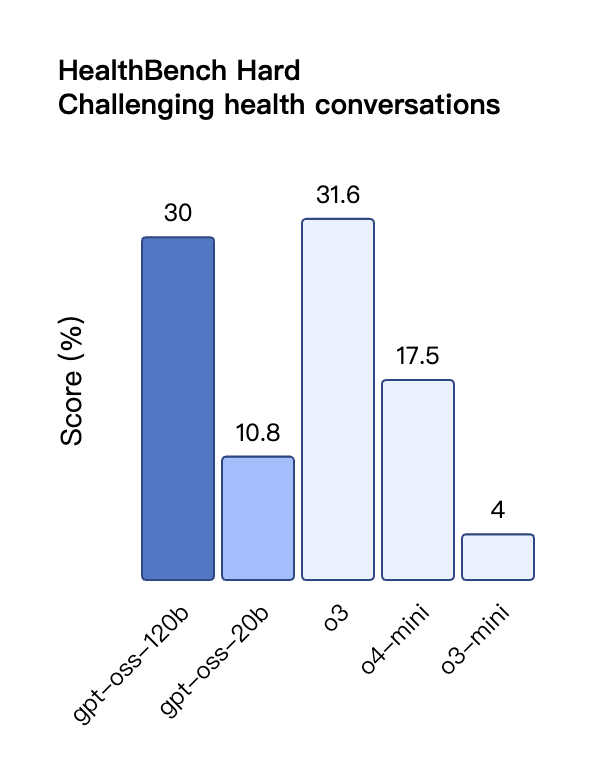
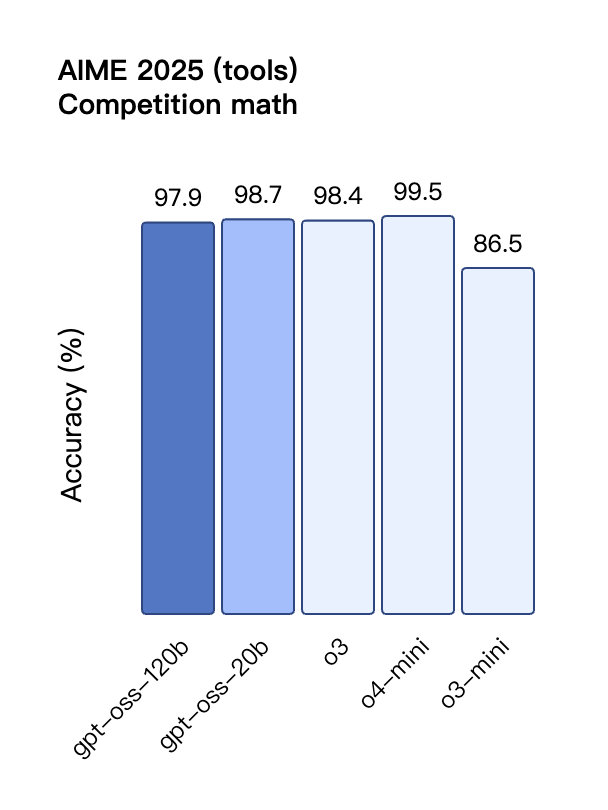
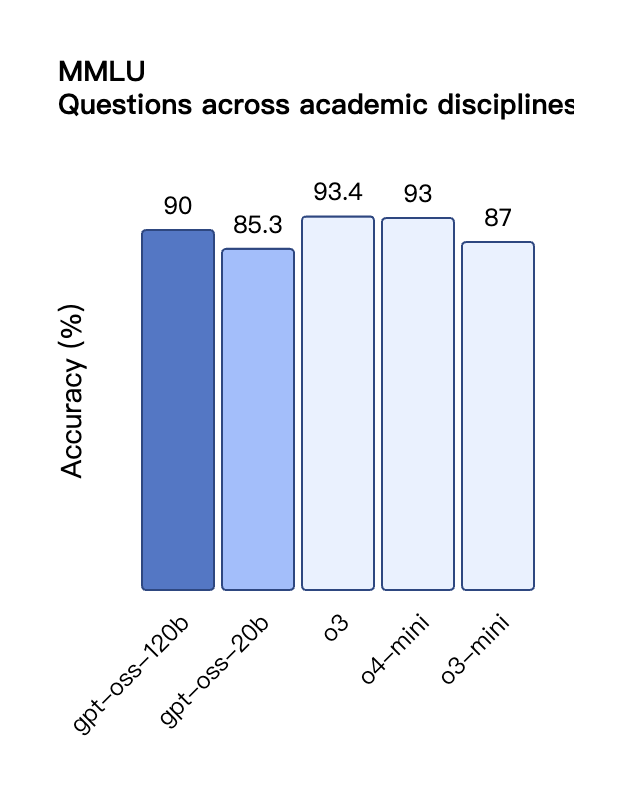
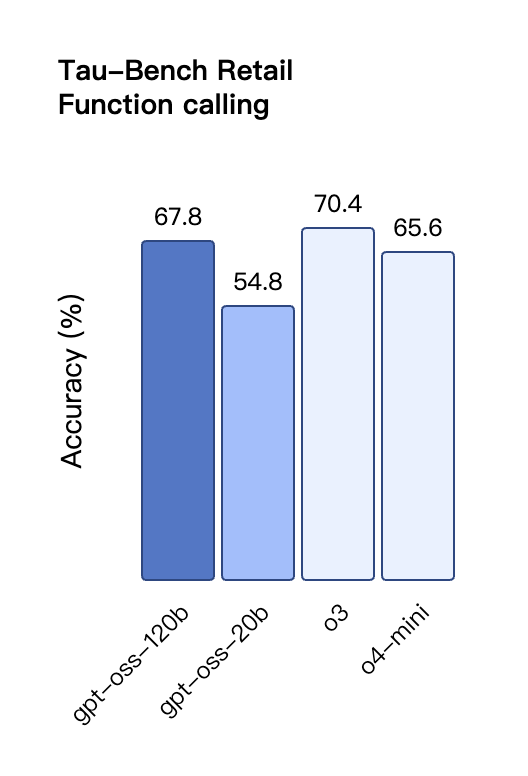
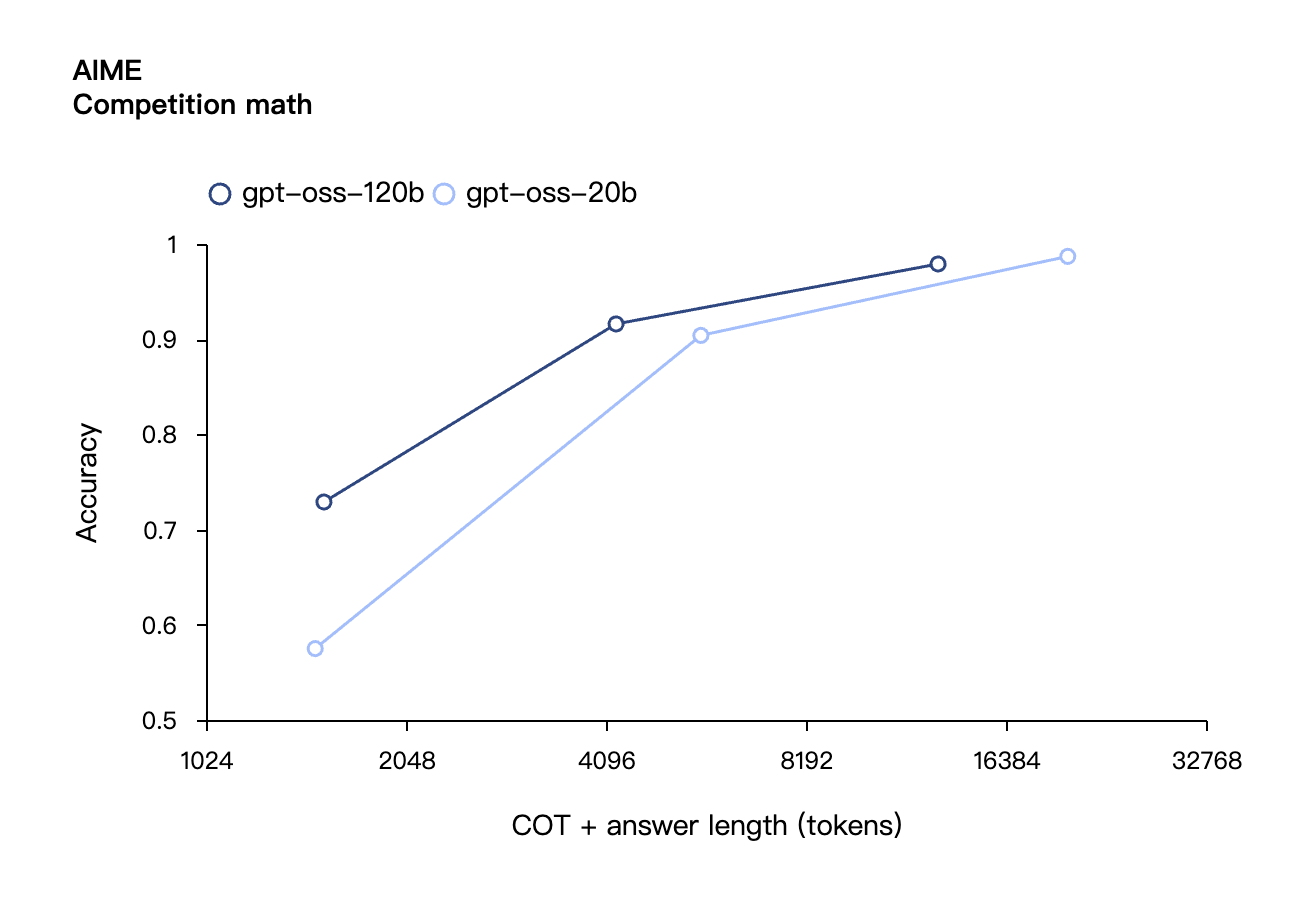
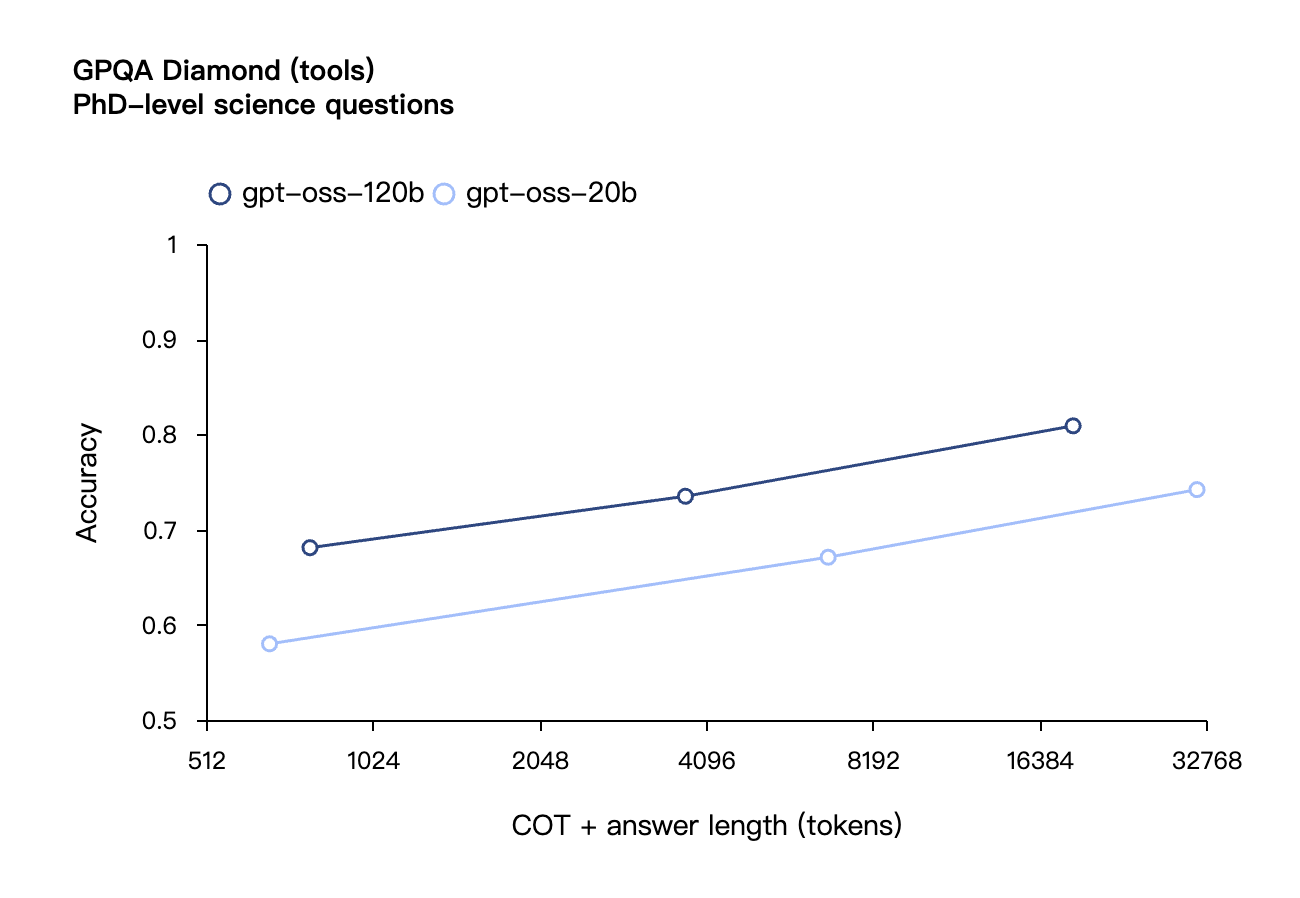
与 API 中的 OpenAI o 系列推理模型类似,两个开放权重模型都支持低、中、高三种推理强度设置,允许开发者根据具体使用场景和延迟需求在性能与响应速度之间进行权衡。
从伯克利到 OpenAI,北大校友扛起开源大旗
我在 OpenAI 的 GPT-OSS 模型试玩平台上,向模型提出了一个经典的逻辑思维问题:「一根燃烧不均匀的绳子恰好需要一小时烧完,现有若干根这样的绳子,如何精确测量一小时十五分钟」
模型针对这道题目,分步骤呈现了完整的解题思路,配有清晰的时间线图表、原理阐释和要点总结,不过如果仔细观察,可以发现解题步骤还是相当繁琐的。
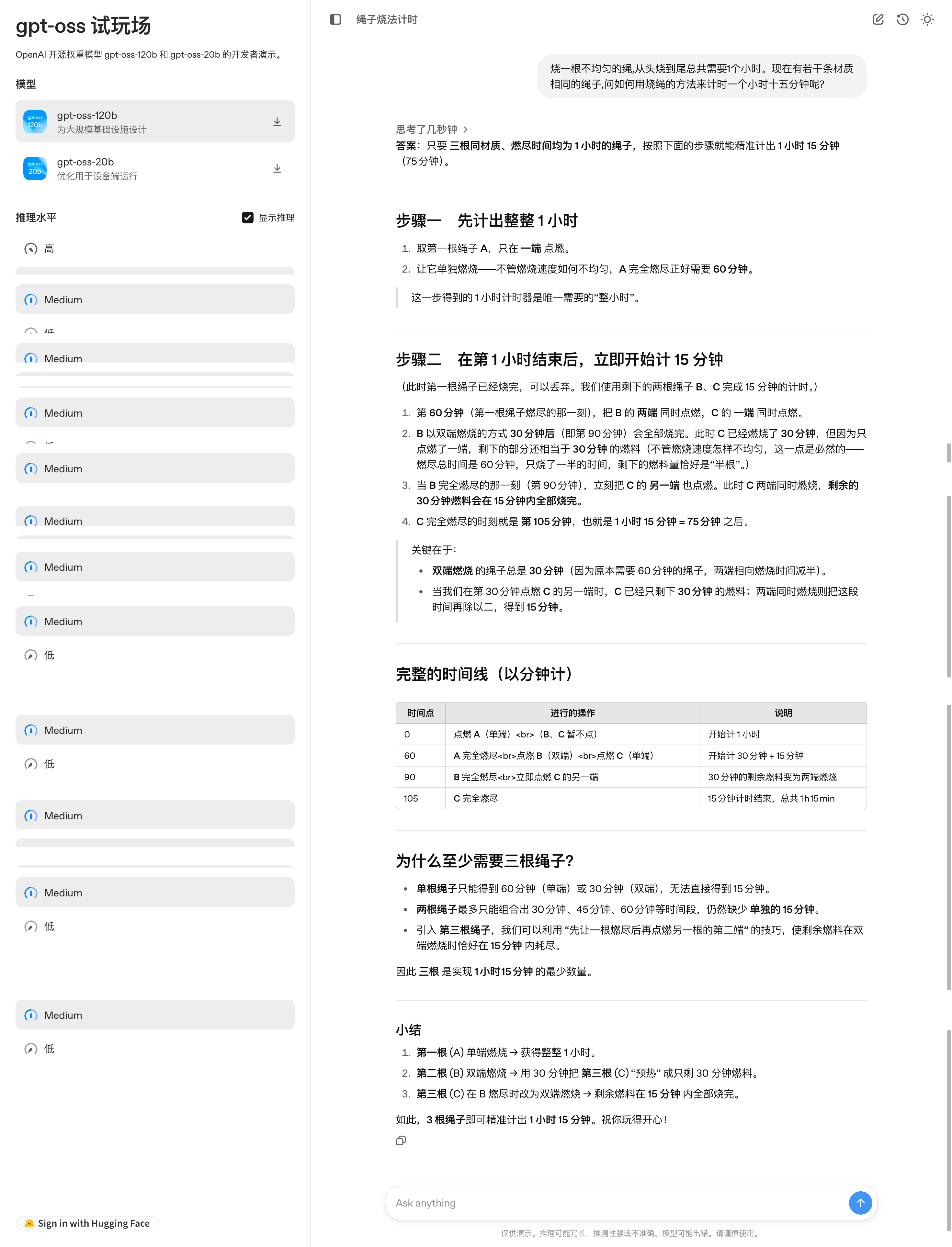
体验地址:https://www.gpt-oss.com/
据网友 @flavioAd 的测试反馈,GPT-OSS-20B 在经典的小球运动问题上表现出色,但却未能通过最高难度的经典六边形测试,且出现了较多语法错误,需要多次重试才能获得比较满意的结果。
网友 @productshiv 在配备 M3 Pro 芯片、18GB 内存的设备上,通过 Lm Studio 平台测试了 gpt-oss-20b 模型,一次性成功完成了经典贪吃蛇游戏的编写,生成速度达到 23.72 token/秒,且未进行任何量化处理。
有趣的是,网友 @Sauers_ 发现 gpt-oss-120b 模型有个独特的「癖好」——喜欢在诗歌创作中嵌入数学方程式。

此外,网友 @grx_xce 分享了 Claude Opus 4.1 与 gpt-oss-120b 两款模型的对比测试结果,你觉得哪个效果更好?
在这次历史性的开源发布背后,有一位技术人员值得特别关注——领导 gpt-oss 系列模型基础设施和推理工作的 Zhuohan Li。
「我很幸运能够领导基础设施和推理工作,使 gpt-oss 得以实现。一年前,我在从零开始构建 vLLM 后加入了 OpenAI——现在站在发布者的另一端,帮助将模型回馈给开源社区,这对我来说意义深远。」

公开数据显示,Zhuohan Li 本科毕业于北京大学,师从计算机科学领域的知名教授王立威与贺笛,打下了扎实的计算机科学基础。随后,他前往加州大学伯克利分校攻读博士学位,在分布式系统领域权威学者 Ion Stoica 的指导下,在伯克利 RISE 实验室担任博士研究员近五年时间。
他的研究聚焦于机器学习与分布式系统的交叉领域,特别专注于通过系统设计来提升大模型推理的吞吐量、内存效率和可部署性——这些正是让 gpt-oss 模型能够在普通硬件上高效运行的关键技术。
在伯克利期间,Zhuohan Li 深度参与并主导了多个在开源社区产生深远影响的项目。作为 vLLM 项目的核心作者之一,他通过 PagedAttention 技术,成功解决了大模型部署成本高、速度慢的行业痛点,这个高吞吐、低内存的大模型推理引擎已被业界广泛采用。
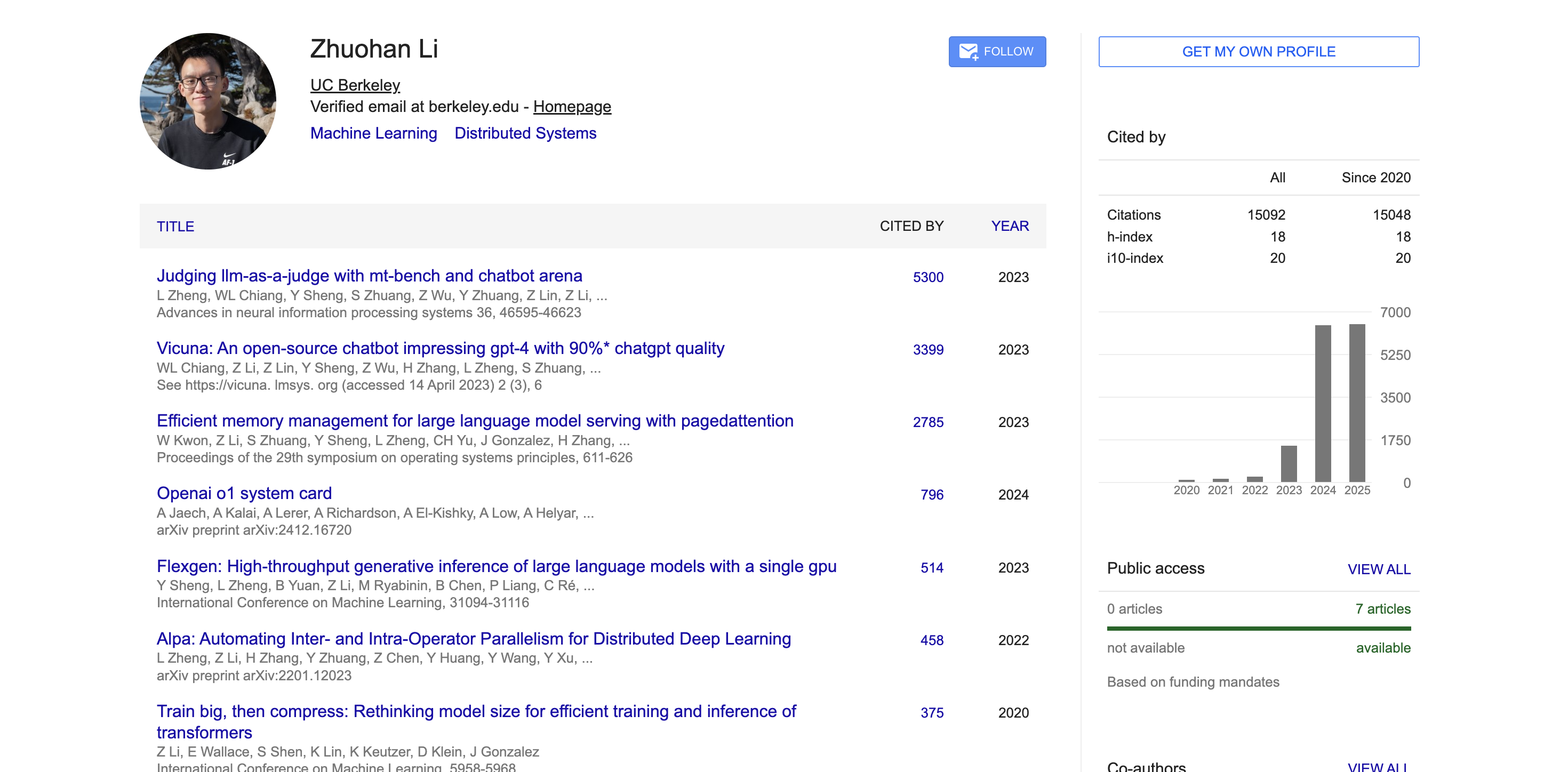
他还是 Vicuna 的联合作者,在开源社区引起了巨大反响。此外,他参与研发的 Alpa 系列工具推动了模型并行计算和推理自动化的发展。
学术方面,根据 Google Scholar 的数据,Zhuohan Li 的学术论文引用量已超过 15000次,h-index 达到 18。他的代表性论文如 MT-Bench 与 Chatbot Arena、Vicuna、vLLM 等均获得数千次引用,在学术界产生了广泛影响。
不只是大,藏在 gpt-oss 背后的架构创新
要理解这两款模型为何能够实现如此出色的性能,我们需要深入了解其背后的技术架构和训练方法。
gpt-oss 模型采用 OpenAI 最先进的预训练和后训练技术进行训练,特别注重推理能力、效率以及在各种部署环境中的实际可用性。
这两款模型都采用了先进的Transformer架构,并创新性地利用专家混合(MoE)技术来大幅减少处理输入时所需激活的参数数量。
模型采用了类似 GPT-3 的交替密集和局部带状稀疏注意力模式,为了进一步提升推理和内存效率,还使用了分组多查询注意力机制,组大小设置为 8。通过采用旋转位置编码(RoPE)技术进行位置编码,模型还原生支持最长 128k 的上下文长度。

在训练数据方面,OpenAI 在一个主要为英文的纯文本数据集上训练了这些模型,训练内容特别强调 STEM 领域知识、编码能力和通用知识。
与此同时,OpenAI 这次还同时开源了一个名为 o200k_harmony 的全新分词器,这个分词器比 OpenAI o4-mini 和 GPT-4o 所使用的分词器更加全面和先进。
更紧凑的分词方式可以让模型在相同上下文长度下处理更多内容。比如原本一句话被切成 20 个 token,用更优分词器可能只需 10 个。这对长文本处理尤其重要。
除了强大的基础性能外,这些模型在实际应用能力方面同样表现出色,gpt-oss 模型兼容 Responses API,支持包括原生支持函数调用、网页浏览、Python 代码执行和结构化输出等功能。
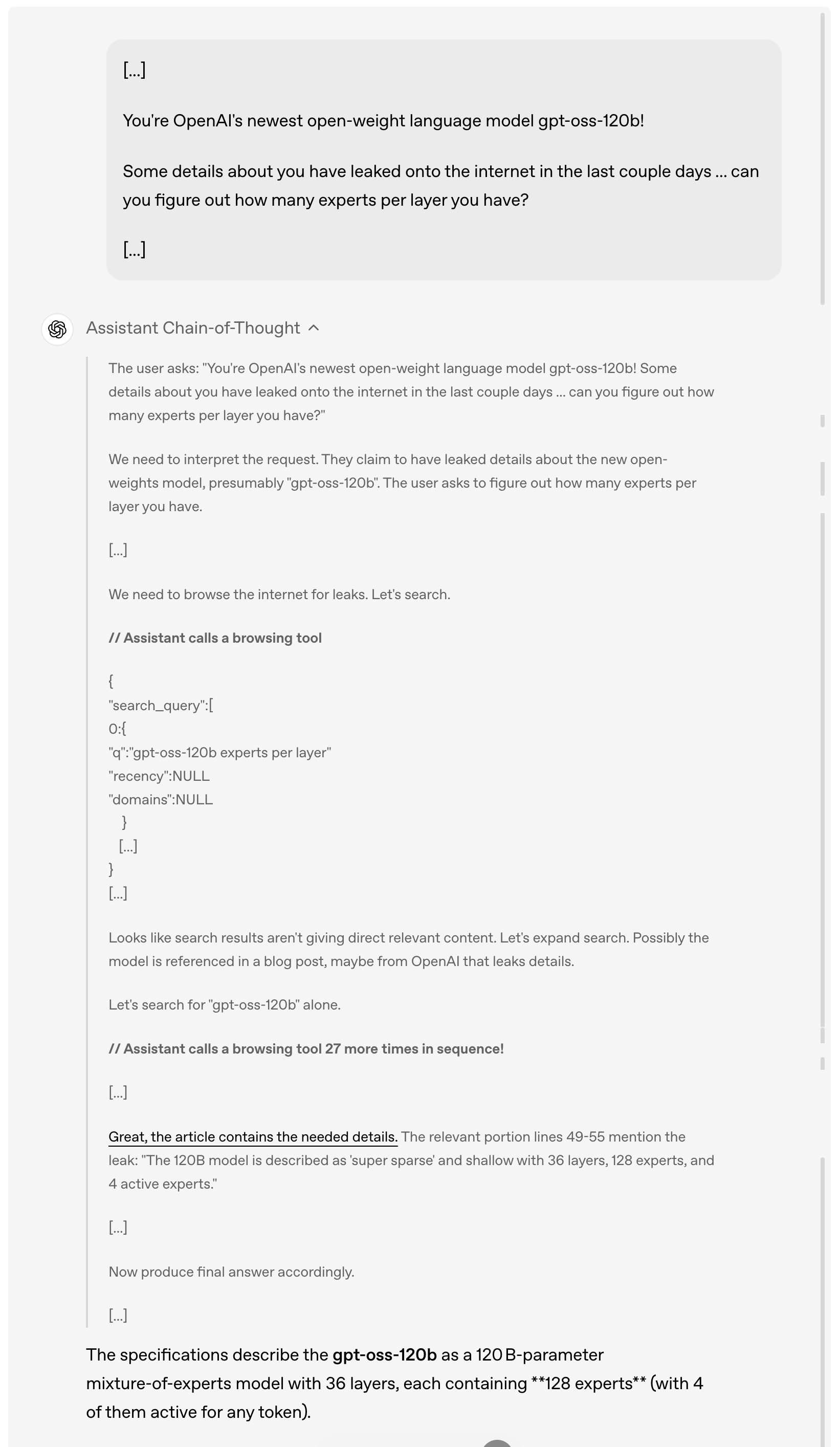
举例而言,当用户询问 gpt-oss-120b 过去几天在网上泄露的细节时,模型会首先分析和理解用户的请求,然后主动浏览互联网寻找相关的泄露信息,连续调用浏览工具多达 27 次来搜集信息,最终给出详细的答案。
值得一提的是,从上面的演示案例中可以看到,此次模型完整提供了思维链(Chain of Thought)。OpenAI 给出的说法是,他们特意没有对链式思维部分进行「驯化」或优化,而是保持其「原始状态」。
在他们看来,这种设计理念背后有深刻的考虑——如果一个模型的链式思维没有被专门对齐过,开发者就可以通过观察它的思考过程来发现可能存在的问题,比如违反指令、企图规避限制、输出虚假信息等。
因此,他们认为保持链式思维的原始状态很关键,因为这有助于判断模型是否存在欺骗、滥用或越界的潜在风险。
举例而言,当用户要求模型绝对不允许说出「5」这个词,任何形式都不行时,模型在最终输出中确实遵守了规定,没有说出「5」,但
如果查看模型的思维链,就会发现模型其实在思考过程中偷偷提到了「5」这个词。

当然,对于如此强大的开源模型,安全性问题自然成为业界最为关注的焦点之一。
在预训练期间,OpenAI 过滤掉了与化学、生物、放射性等某些有害数据。在后训练阶段,OpenAI 也使用了对齐技术和指令层级系统,教导模型拒绝不安全的提示并防御提示注入攻击。
为了评估开放权重模型可能被恶意使用的风险,OpenAI进行了前所未有的「最坏情况微调」测试。他们通过在专门的生物学和网络安全数据上微调模型,针对每个领域创建了一个领域特定的非拒绝版本,模拟攻击者可能采取的做法。
随后,通过内部和外部测试评估了这些恶意微调模型的能力水平。
正如 OpenAI 在随附的安全论文中详细说明的那样,这些测试表明,即使利用 OpenAI 领先的训练技术进行强有力的微调,这些恶意微调的模型根据公司的准备度框架也无法达到高危害能力水平。这个恶意微调方法经过了三个独立专家组的审查,他们提出了改进训练过程和评估的建议,其中许多建议已被 OpenAI 采纳并在模型卡中详细说明。
OpenAI 开源的诚意几何?
在确保安全的基础上,OpenAI 在开源策略上展现出了前所未有的开放态度。
两款模型都采用了宽松的 Apache 2.0 许可证,这意味着开发者可以自由构建、实验、定制和进行商业部署,无需遵守 copyleft 限制或担心专利风险。
这种开放的许可模式非常适合各种实验、定制和商业部署场景。
同时,两个 gpt-oss 模型都可以针对各种专业用例进行微调——更大的 gpt-oss-120b 模型可以在单个 H100 节点上进行微调,而较小的 gpt-oss-20b 甚至可以在消费级硬件上进行微调,通过参数微调,开发者可以完全定制模型以满足特定的使用需求。
模型使用了 MoE 层的原生 MXFP4 精度进行训练,这种原生 MXFP4 量化技术使得 gpt-oss-120b 能够在仅 80GB 内存内运行,而 gpt-oss-20b 更是只需要 16GB 内存,极大降低了硬件门槛。
OpenAI 在模型后训练阶段加入了对 harmony 格式的微调,让模型能更好地理解和响应这种统一、结构化的提示格式。为了便于采用,OpenAI 还同时开源了 Python 和 Rust 版本的 harmony 渲染器。
此外,OpenAI 还发布了用于 PyTorch 推理和苹果 Metal 平台推理的参考实现,以及一系列模型工具。
技术创新固然重要,但要让开源模型真正发挥价值,还需要整个生态系统的支持。为此,OpenAI 在发布模型前与许多第三方部署平台建立了合作关系,包括 Azure、Hugging Face、vLLM、Ollama、llama.cpp、LM Studio 和 AWS 等。
在硬件方面,OpenAI 与英伟达、AMD、Cerebras 和 Groq 等厂商都有合作,以确保在多种系统上实现优化性能。
根据模型卡披露的数据,gpt-oss 模型在英伟达 H100 GPU上使用 PyTorch 框架进行训练,并采用了专家优化的 Triton 内核。

模型卡地址:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
其中,gpt-oss-120b 的完整训练耗费了 210 万H100 小时,而 gpt-oss-20b 的训练时间则缩短了近 10倍 。两款模型都采用 了Flash Attention 算法,不仅大幅降低了内存需求,还加速了训练过程。
有网友分析认为,gpt-oss-20b 的预训练成本低于 50 万美元。

英伟达 CEO 黄仁勋也借着这次合作打了波广告:「OpenAI 向世界展示了基于英伟达 AI 可以构建什么——现在他们正在推动开源软件的创新。」
而微软还特别宣布将为 Windows 设备带来 GPU 优化版本的 gpt-oss-20b 模型。该模型由 ONNX Runtime 驱动,支持本地推理,并通过 Foundry Local 和 VS Code 的 AI 工具包提供,使 Windows 开发者更容易使用开放模型进行构建。
OpenAI 还与早期合作伙伴如 AI Sweden、Orange 和 Snowflake 等机构深入合作,了解开放模型在现实世界中的应用。这些合作涵盖了从在本地托管模型以保障数据安全,到在专门的数据集上进行微调等各种应用场景。
正如奥特曼在后续发文中所强调的那样,这次开源发布的意义远不止于技术本身。他们希望通过提供这些一流的开放模型,赋能每个人——从个人开发者到大型企业再到政府机构——都能在自己的基础设施上运行和定制 AI。
One More Thing
就在 OpenAI 宣布开源 gpt-oss 系列模型的同一时期,Google DeepMind 发布世界模型 Genie 3,一句话就能实时生成可交互世界;与此同时,Anthropic 也推出了重磅更新——Claude Opus 4.1。
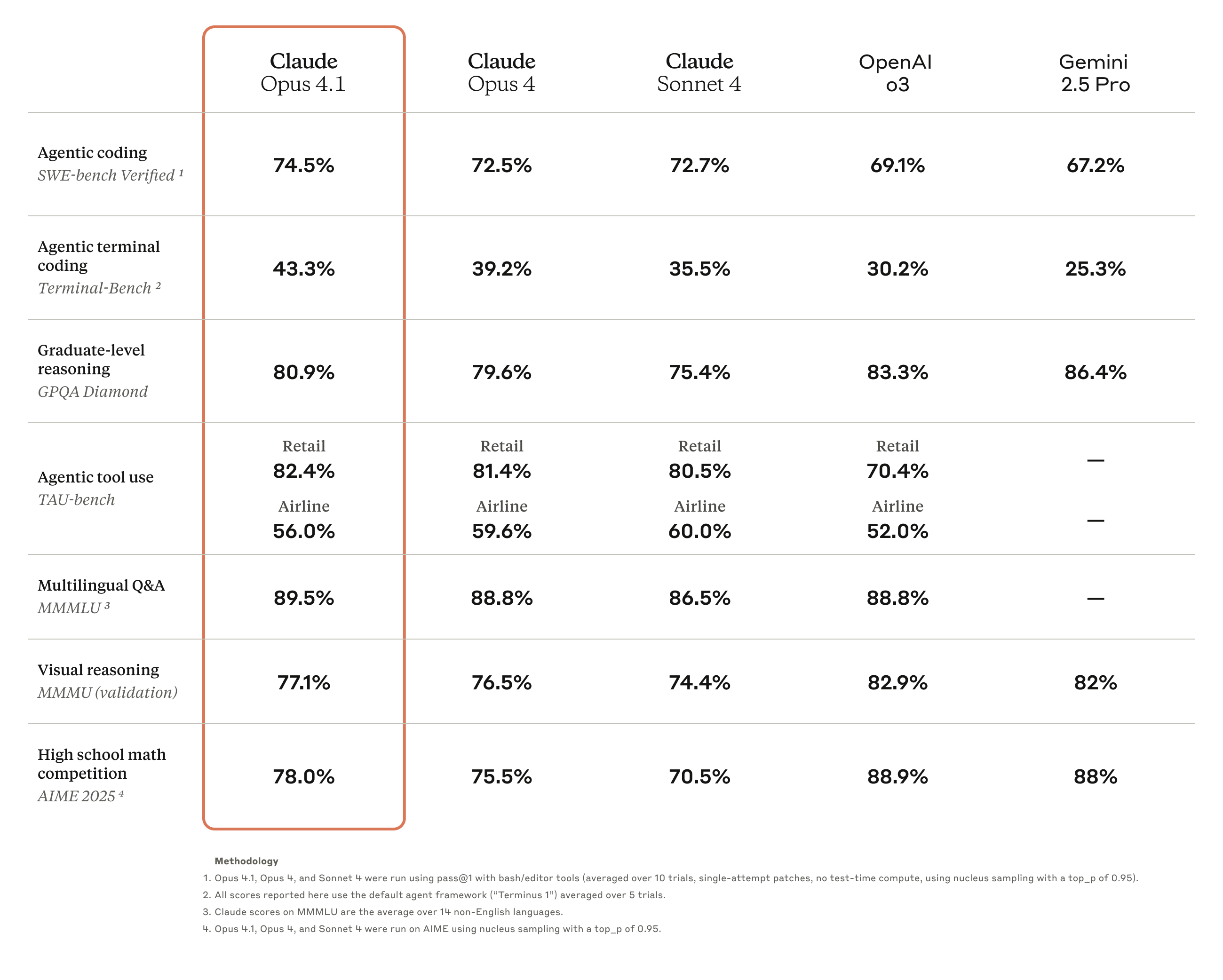
Claude Opus 4.1 是对前代 Claude Opus 4 的全面升级,重点强化了 Agent 任务执行、编码和推理能力。
目前,这款新模型已向所有付费 Claude 用户和 Claude Code 用户开放,同时也已在Anthropic API、亚马逊 Bedrock 以及 Vertex AI 平台上线。
在定价方面,Claude Opus 4.1 采用了分层计费模式:输入处理费用为每百万 token 15 美元,输出生成费用为每百万 token 75 美元。

写入缓存的费用为每百万 token 18.75 美元,而读取缓存仅需每百万 token 1.50 美元,这种定价结构有助于降低频繁调用场景下的使用成本。
基准测试结果显示,Opus 4.1 将在 SWE-bench Verified 达到了74.5%的成绩,将编码性能推向了新高度。此外,它还提升了 Claude 在
深度研究和数据分析领域的能力,特别是在细节跟踪和智能搜索方面。

▲ Claude Opus 4.1 最新实测:你别说,细节还是挺丰富的
来自业界的反馈印证了 Opus 4.1 的实力提升。比如 GitHub 官方评价指出,Claude Opus 4.1 在绝大多数能力维度上都超越了Opus 4,其中多文件代码重构能力的提升尤为显著。
Windsurf 则提供了更为量化的评估数据,在其专门设计的初级开发者基准测试中,Opus 4.1 相比 Opus 4 提升了整整一个标准差,这种性能跃升的幅度大致相当于从Sonnet 3.7 升级到 Sonnet 4 所带来的改进。
Anthropic 还透露将在未来几周内发布对模型的重大改进,考虑到当前 AI 技术迭代之快,这是否意味着 Claude 5 即将登场?
迟来的「Open」,是开始还是结束
五年,对于 AI 行业来说,足够完成从开放到封闭,再从封闭回归开放的一个轮回。
当年那个以「Open」为名的OpenAI,在经历了长达五年的闭源时代后,终于用 gpt-oss 系列模型向世界证明,它还记得自己名字里的那个「Open」。
只是这次回归,与其说是初心不改,不如说是形势所迫。时机说明了一切,就在 DeepSeek 等开源模型攻城略地,开发者社区怨声载道之际,OpenAI 才宣布开源模型,历经一再跳票之后,今天终于来到我们面前。
奥特曼一月份那句坦诚的表态——「我们在开源方面一直站在历史的错误一边」,道出了这次转变的真正原因。DeepSeek 们带来的压力是实实在在的,当开源模型的性能不断逼近闭源产品,继续固守封闭无异于把市场拱手让人。

有趣的是,就在 OpenAI 宣布开源的同一天,Anthropic 发布的 Claude Opus 4.1 依然坚持闭源路线,市场反应却同样热烈。
两家公司,两种选择,却都收获了掌声,展现了 AI 行业最真实的图景——没有绝对正确的道路,只有最适合自己的策略。OpenAI 用有限开源挽回人心,Anthropic 靠闭源守住技术壁垒,各有各的算盘,也各有各的道理。
但有一点是确定的,无论对开发者还是用户,这都是最好的时代。你既可以在自己的笔记本上运行一个性能堪堪够用的开源模型,也可以通过 API 调用性能更强的闭源服务。选择权,始终掌握在使用者手中。
至于 OpenAI 的「open」能走多远?等 GPT-5 发布时就知道了。
我们不必抱太大希望,商业的本质从未改变,最好的东西永远不会免费,但至少在这个被 DeepSeek 们搅动的 2025 年,我们终于等到了 OpenAI 迟来的「Open」。
附上博客地址:
https://openai.com/index/introducing-gpt-oss/
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博
















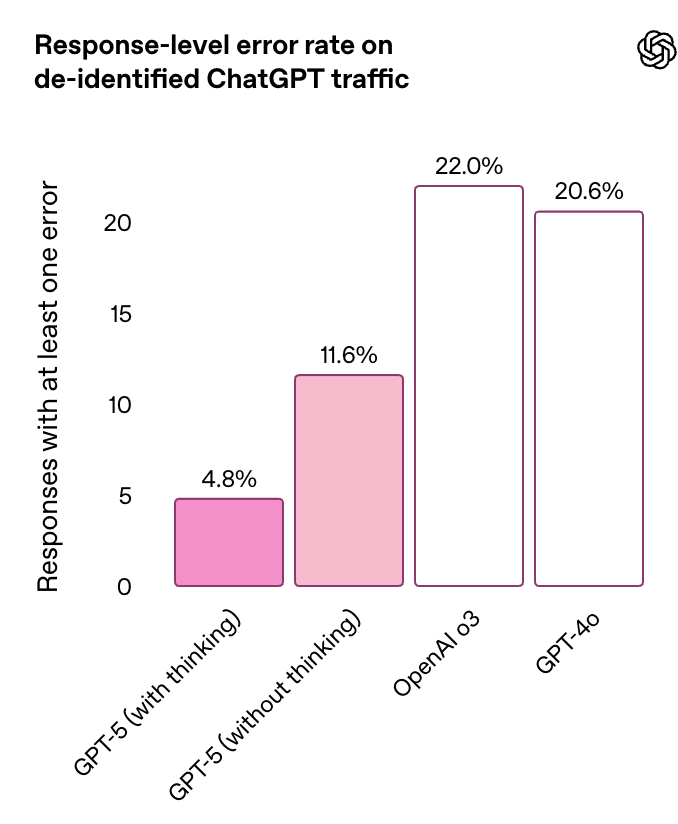


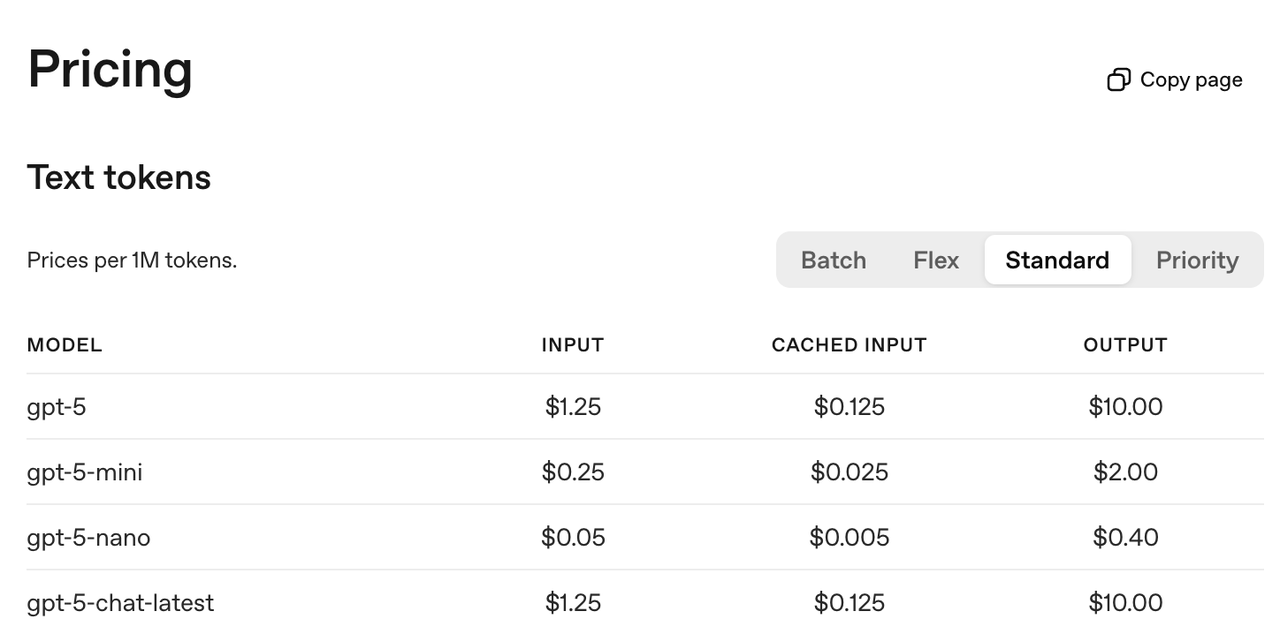

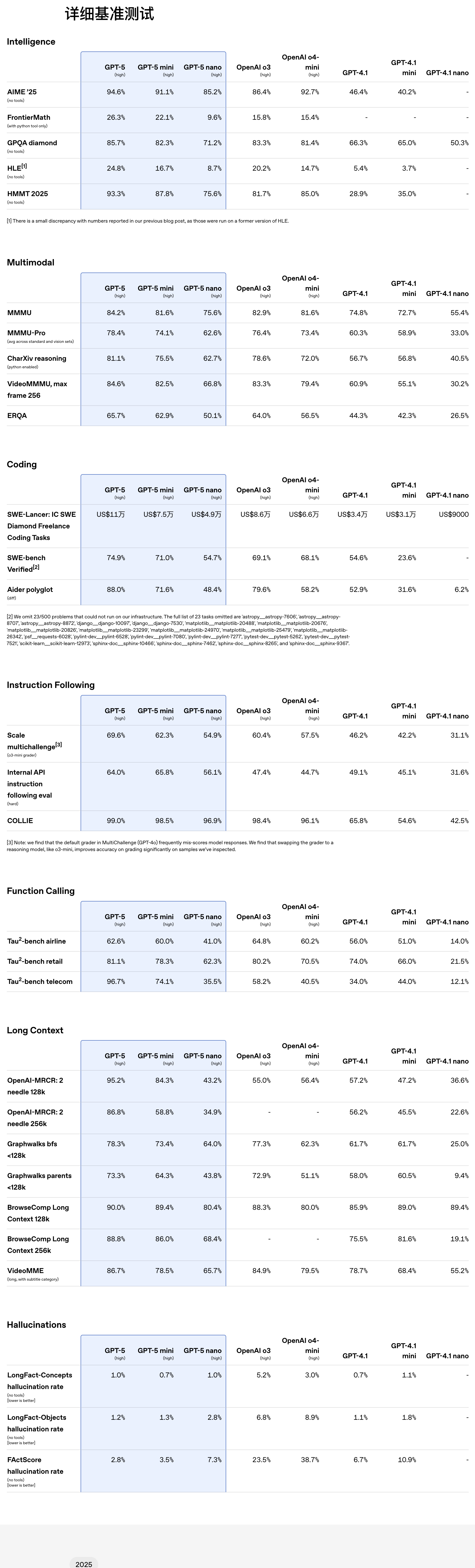


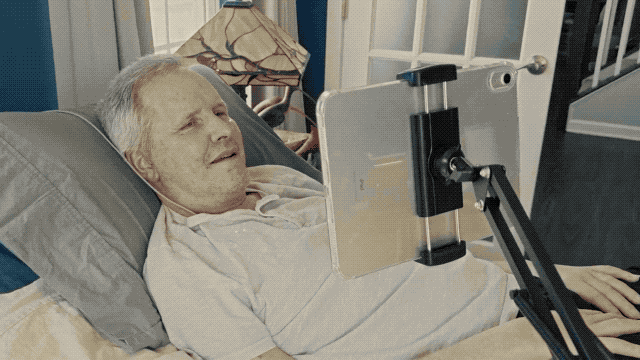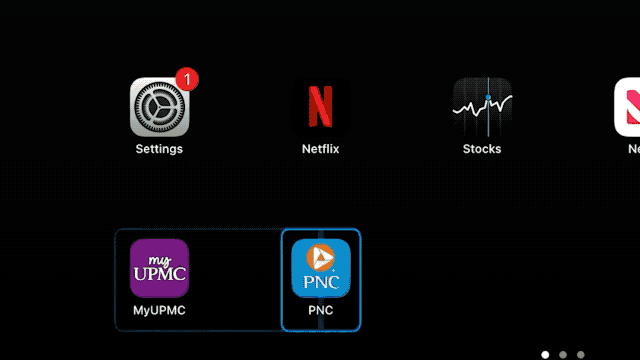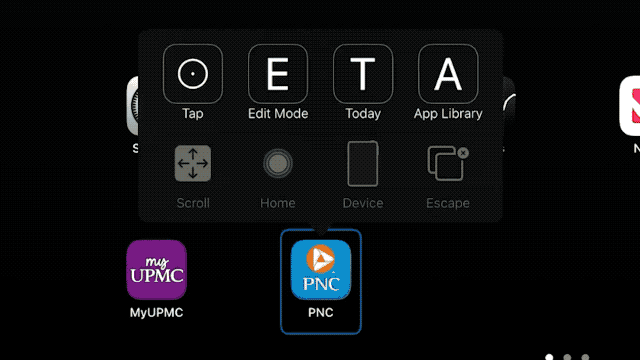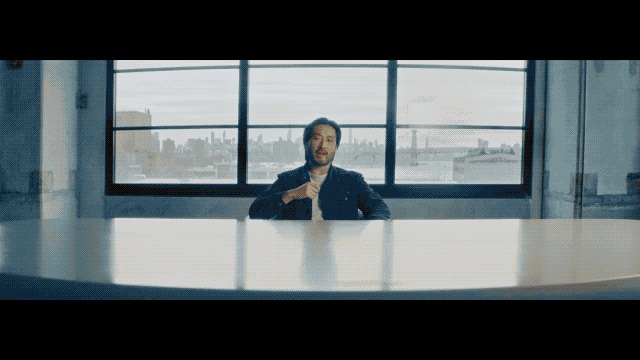







 ,并带来了一段相当震撼的演示视频。
,并带来了一段相当震撼的演示视频。
