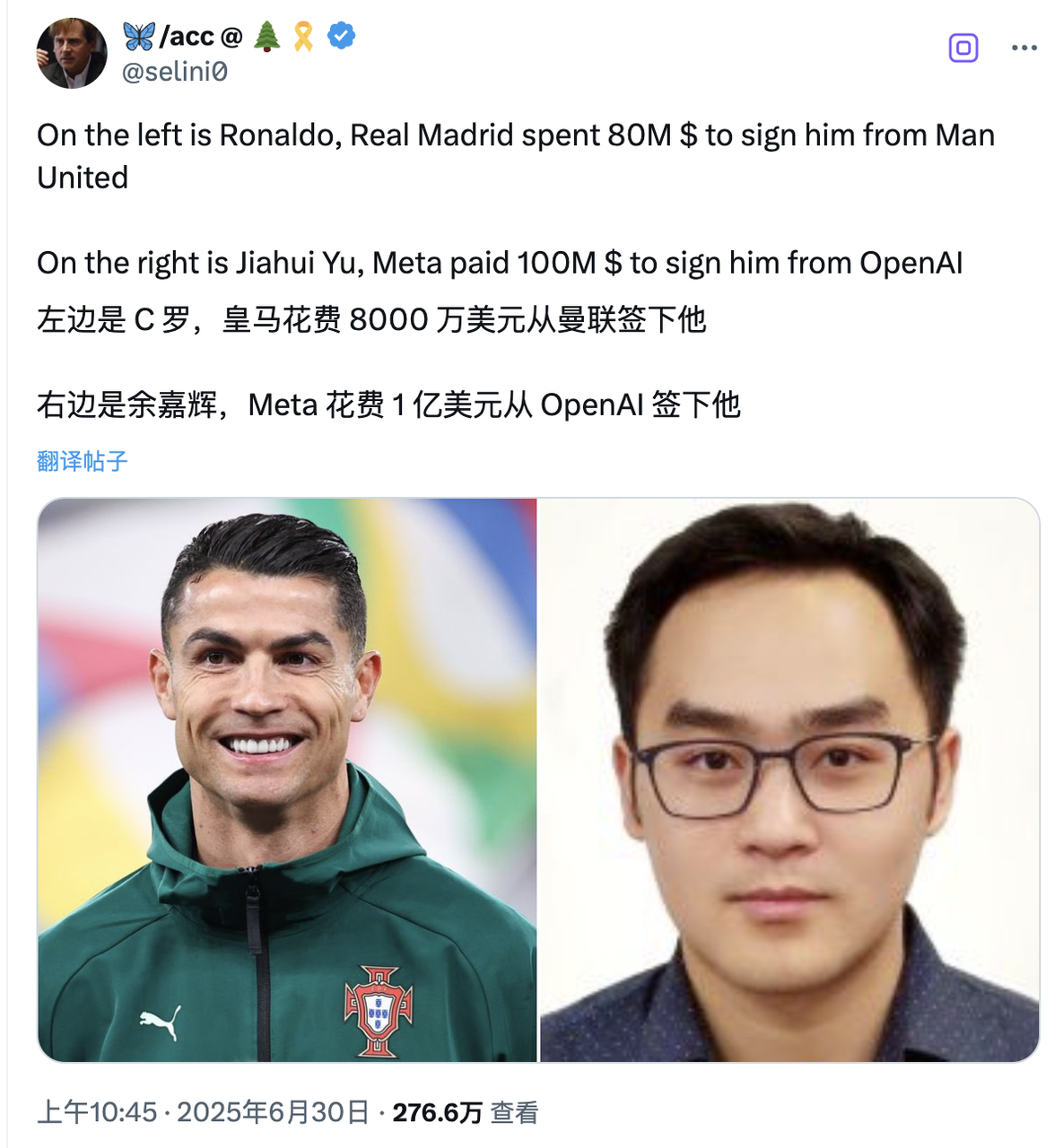
美国现在最贵的,是中国 AI 人才:清北中科大学霸正在「统治」硅谷 AI 圈

过去两周,AI 行业最出圈的不是哪个产品,而是人。经常一觉醒来,社交媒体的时间线都在刷新换汤不换药的新闻:又双叒叕有哪位 AI 大牛被挖走了。
顶级 AI 人才,正成为 AI 赛道上最稀缺、也最具品牌效应的资产。
在这轮人才流动的风暴中心中,我们发现一个格外显眼的细节:这群主导过 ChatGPT、Gemini、Claude 等大模型研发的核心成员中,华人科学家的比例出奇地高。
这个这个变化并不是突然出现的,这几年兴起的 AI 浪潮中,美国的顶级 AI 人才中华人占比不断升高。 根据 MacroPolo 发布的《全球人工智能人才追踪调查报告 2.0》,来自中国的顶尖 AI 研究人员占比在 2019 年到 2022 年间,从 29% 提升到了 47%。
而在智谱研究发布的《ChatGPT 团队背景研究报告》,更是发现在 ChatGPT 核心的 87人团队中,有 9 人都是华人,占比超过 10%。因此,我们也重新梳理了近期在硅谷头部公司中广受关注的华人 AI 研究员画像,并试图从中总结出一些特征:
1️⃣ 顶尖名校出身,学术能力极强
他们大多本科就读于清华、北大、中科大、浙大等顶尖高校,计算机或数学背景居多;研究生阶段普遍进入 MIT、斯坦福、伯克利、普林斯顿、UIUC 等名校深造,几乎每人都有顶会高引论文傍身(NeurIPS、ICLR、SIGGRAPH 等),
2️⃣ 年轻高产,爆发周期集中于 2020 年之后
年龄多在 30~35 岁;硕博阶段恰逢深度学习的全球爆发期,学术基础扎实,熟悉工程体系和团队协作。不少人职业的第一站就是接触大厂或服务大规模人群的 AI 产品或平台,起点更高、节奏更快。
3️⃣ 强多模态背景,攻坚模型后训练
他们的研究方向普遍着重于跨模态(文本、语音、图像、视频、动作)的统一推理系统,包括 RLHF、蒸馏、对齐、人类偏好建模、语音语调评估等具体细节。
4️⃣ 即便频繁流动,但基本不会脱离生态
Google、Meta、微软、英伟达,Anthropic、OpenAI……他们的流动范围横跨 AI 初创与巨头,但研究主题、技术积累往往保持连贯性,基本不换赛道。
OpenAI→Meta
Shuchao Bi
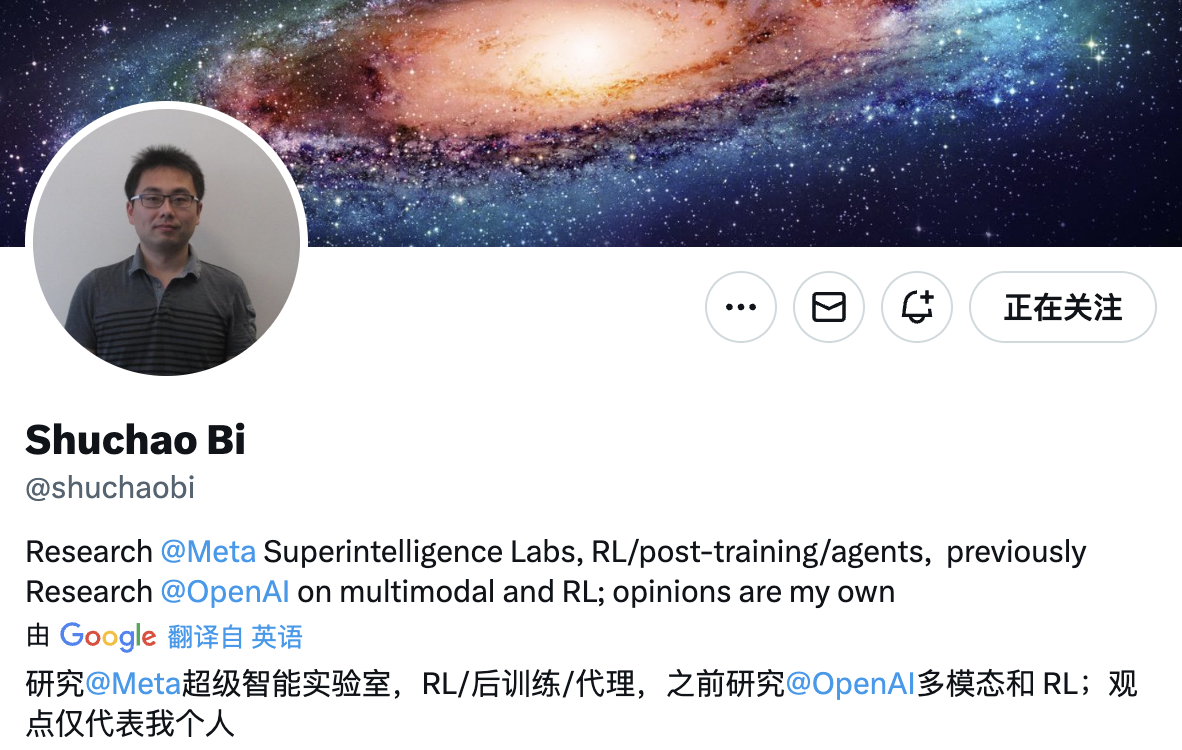
Shuchao Bi 本科毕业于浙江大学数学系,后赴加州大学伯克利分校深造,先后获得统计学硕士学位,并攻读数学博士。
2013 – 2019 年,他在 Google 担任技术负责人,主要贡献包括构建多阶段深度学习推荐系统,显著提升 Google 广告收益(数十亿美元级别)。
2019 – 2024 年,他担任 Shorts 探索负责人,期间,联合创建并主导 Shorts 视频推荐与发现系统,并 组建并扩展大规模机器学习团队,覆盖推荐系统、评分模型、互动发现、信任与安全等方向。
2024 年加入 OpenAI 后,他主要领导多模态后训练组织,是 GPT-4o 语音模式与o4-mini的联合创造者
期间,他主要推进 RLHF、图像/语音/视频/文本推理、多模态智能体、多模态语音到语音(VS2S)、视觉-语言-行动基础模型(VLA)、跨模态评估系统等,也涉及多模态链式推理、语音语调/自然度评分、多模态蒸馏与自监督优化,其核心目标是通过后训练构建更通用的多模态 AI Agent。
Huiwen Chang
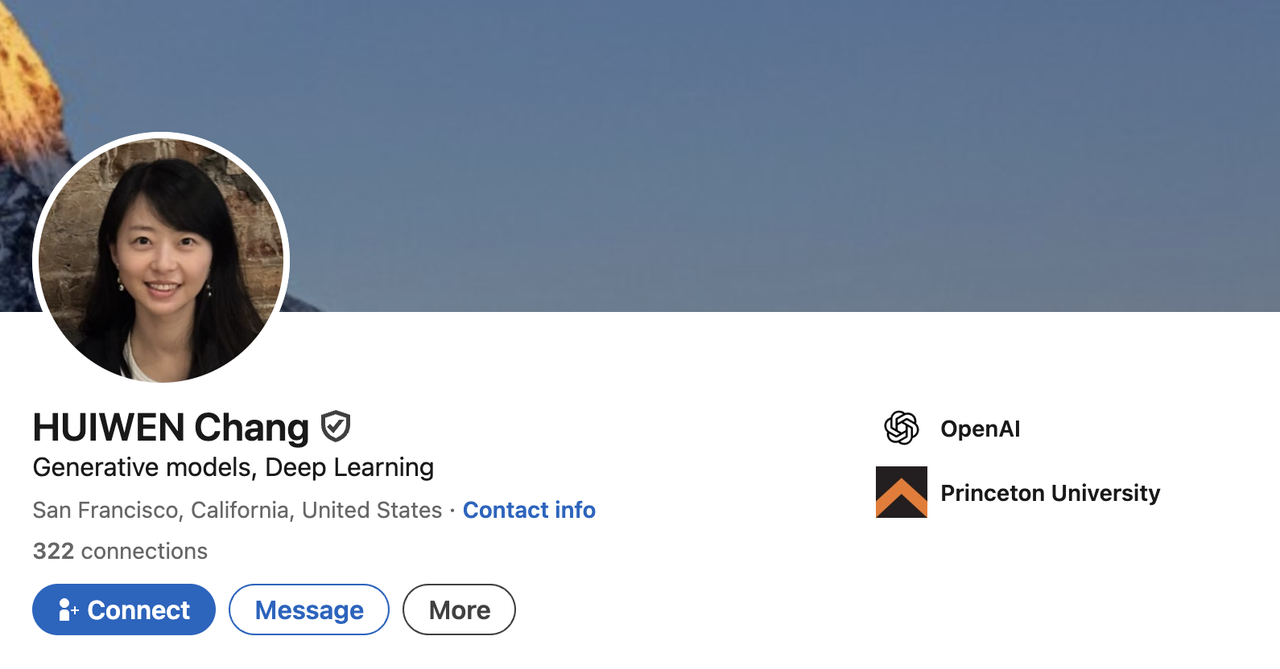
2013 年,Huiwen Chang 本科毕业于清华大学计算机系(姚班),后赴美国普林斯顿大学攻读计算机科学博士,研究方向聚焦于图像风格迁移、生成模型和图像处理,曾获微软研究院奖学金。
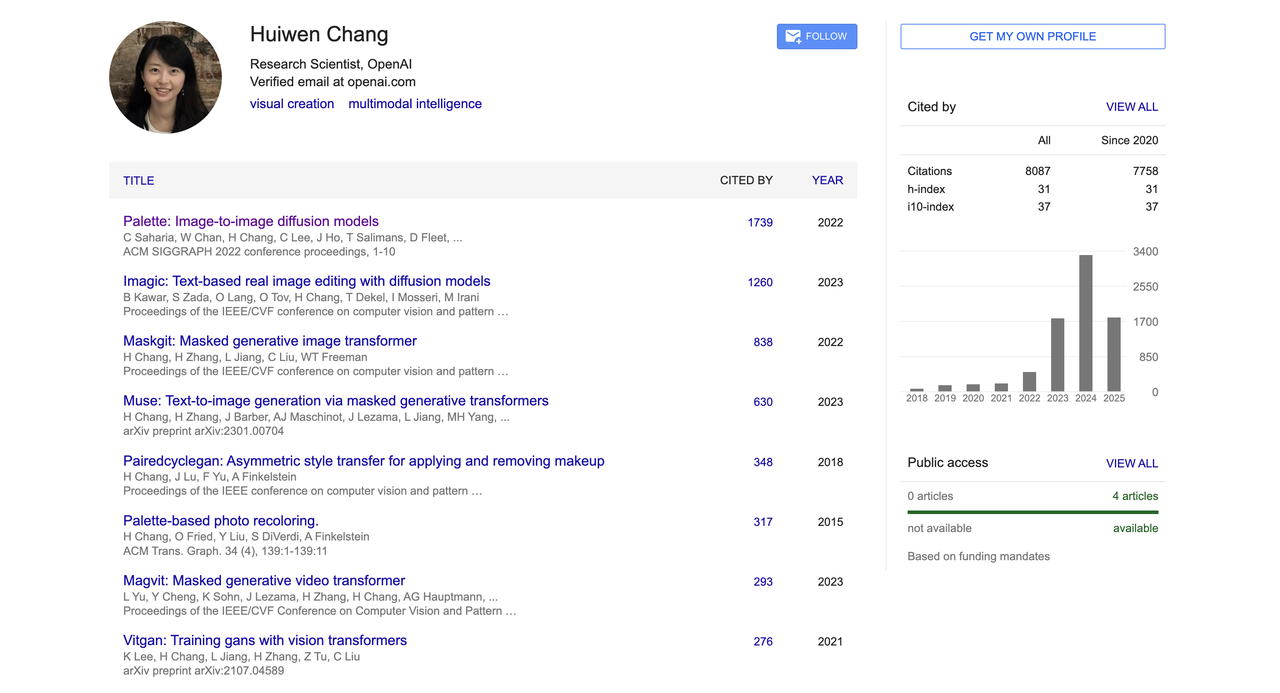
在加入 OpenAI 之前,她在 Google 担任高级研究科学家,累计工作超过六年,长期从事生成模型与计算机视觉研究,曾在 Google Research 发明 MaskGIT 和 Muse 文本生成图像架构。
早期的文本生成图像主要依赖扩散模型(如 DALL·E 2、Imagen),这些模型虽然生成质量高,但推理速度慢、训练开销大。而 MaskGIT 和 Muse 则采用了「离散化 + 并行生成」 的方式,大幅提升了效率。

MaskGIT 是非自回归图像生成的新起点,Muse 则是将这一方法推向文本图像生成的代表作。它们不像 Stable Diffusion 那样广为人知,但在学术与工程体系中,是非常重要的技术基石。
此外,她也是扩散模型顶级论文《Palette: Image-to-image diffusion models》的联合作者之一。
这篇论文发表于 SIGGRAPH 2022,提出了一种统一的图像到图像翻译框架,并在图像修复、着色、补全等多个任务上超过 GAN 和回归基线,至今已被引用超过 1700 次,成为该领域的代表性成果之一。
2023 年 6 月起,她加入 OpenAI 多模态团队,联合开发了 GPT-4o 图像生成功能,继续推动图像生成、多模态建模等前沿方向的研究与落地。

Ji Lin
Ji Lin 主要从事多模态学习、推理系统与合成数据方向的研究。他是多个核心模型的贡献者,包括 GPT-4o、GPT-4.1、GPT-4.5、o3/o4-mini、Operator、以及 4o 图像生成模型等。
他本科毕业于清华大学电子工程专业(2014–2018),从麻省理工学院获得电子工程与计算机科学博士学位,导师为知名学者 Prof. Song Han。
博士阶段,他的研究方向聚焦于模型压缩、量化、视觉语言模型、稀疏推理等关键方向。
在 2023 年加入 OpenAI 之前,他曾在英伟达、Adobe 和 Google 担任实习研究员,并在 MIT 长期从事神经网络压缩与推理加速相关研究,积累了深厚的理论基础与工程实践经验。
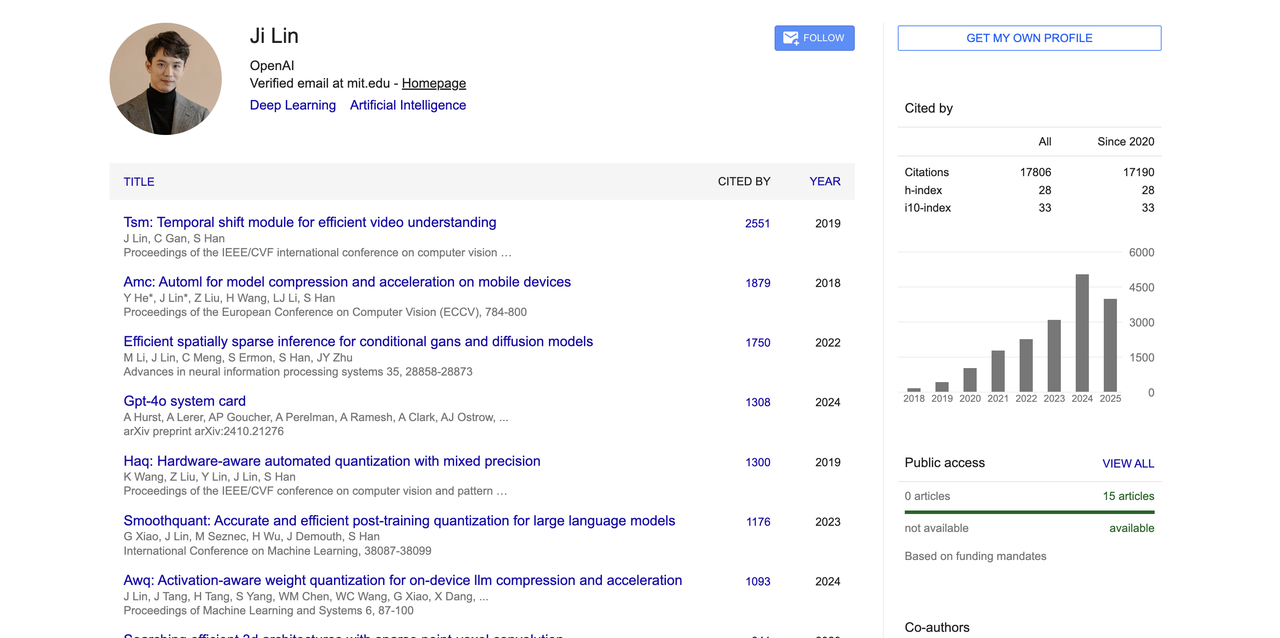
学术方面,他在模型压缩、量化和多模态预训练等方向有多篇高影响力论文,Google 学术总引用数超过 17800,代表成果包括视频理解模型 TSM、硬件感知量化方法 AWQ、SmoothQuant 以及视觉语言模型 VILA。
他也是 GPT-4o 系统技术文档的核心作者之一(比如 GPT-4o 系统卡),并凭借 AWQ 论文获得 MLSys 2024 最佳论文奖。
Hongyu Ren
Hongyu Ren 本科在北京大学获得计算机科学与技术学士(2014–2018)学位,随后在斯坦福大学获得计算机科学博士(2018–2023)学位。
他曾获得苹果、百度以及软银 Masason 基金会 PhD Fellowship 等多项奖学金,研究方向聚焦于大语言模型、知识图谱推理、多模态智能与基础模型评估。
在加入 OpenAI 之前,他曾在 Google、微软以及英伟达有过多段实习经历,比如 2021 年在苹果担任实习研究员期间,参与 Siri 问答系统的搭建。
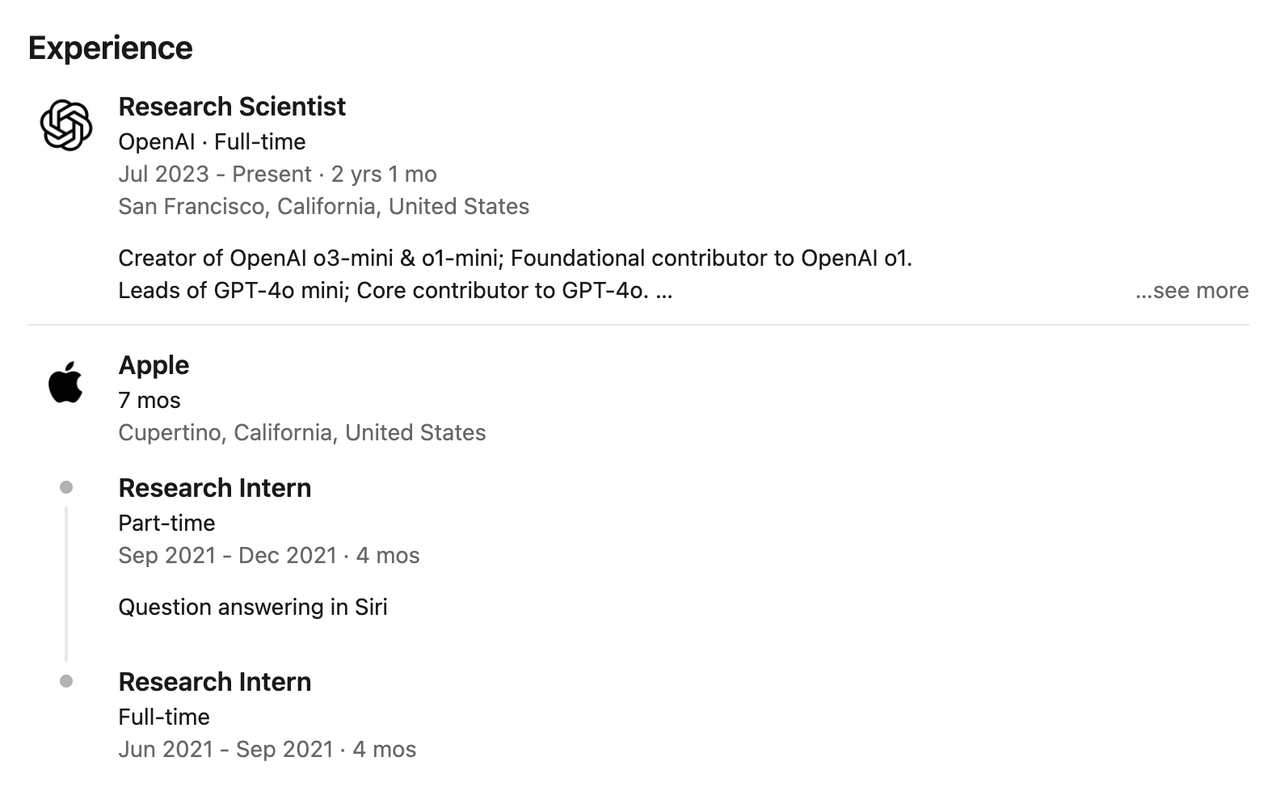
2023 年 7 月加入 OpenAI 后,Hongyu Ren 参与构建了 GPT-4o、4o-mini、o1-mini、o3-mini、o3 和 o4-mini 等多个核心模型,并领导后训练团队。
用他的话来说:「I teach models to think faster, harder and sharper.(我教模型更快、更努力、更敏锐地思考。)」
学术领域,他的 Google 学术总引用数超过 17742 次,高被引论文包括:《On the Opportunities and Risks of Foundation Models》(引用 6127 次);《Open Graph Benchmark》(OGB)数据集(引用 3524 次)等。
Jiahui Yu
Jiahui Yu 本科毕业于中国科学技术大学少年班,获得计算机科学学士学位,随后在伊利诺伊大学香槟分校(UIUC)获得计算机科学博士学位。
他的研究重点包括深度学习、图像生成、大模型架构、多模态推理和高性能计算。

在 OpenAI 任职期间,Jiahui Yu 担任感知团队负责人,主导开发 GPT-4o 图像生成模块、GPT-4.1、o3/o4-mini 等重要项目,提出并落地了「Thinking with Images」感知体系。
在此之前,他曾在 Google DeepMind 工作近四年,期间是 PaLM-2 架构与建模的核心贡献者之一,并共同领导了 Gemini 多模态模型的开发,是 Google 多模态战略中最重要的技术骨干之一。
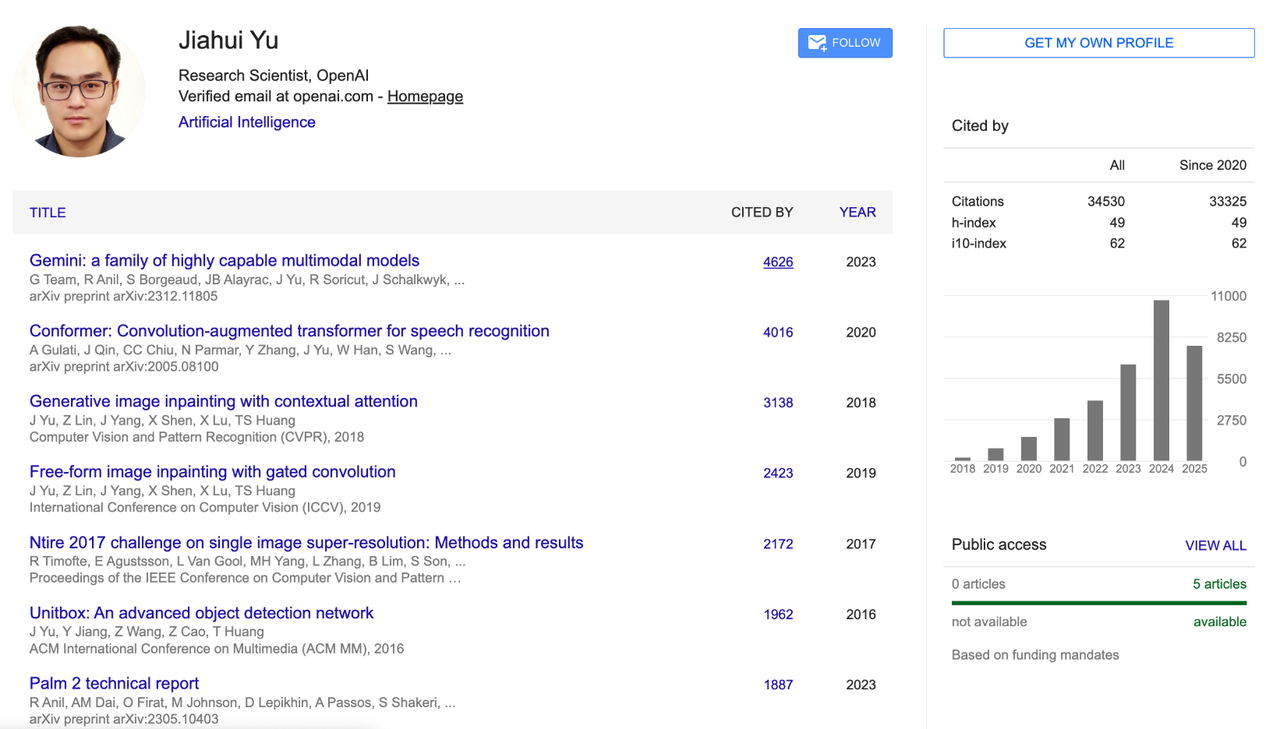
他还拥有在英伟达、Adobe、百度、Snap、旷视和微软亚洲研究院等多家机构的实习经历,研究内容涵盖 GAN、目标检测、自动驾驶、模型压缩、图像修复与大规模深度学习训练系统等多个方向。
Jiahui 在 Google 学术上总引用次数超过 34500 次,h 指数达 49,代表性研究成果包括图文对齐基础模型 CoCa、文本生成图像模型 Parti、神经网络可伸缩设计 BigNAS,以及广泛应用于 Adobe Photoshop 的图像修复技术 DeepFill v1 和 v2 等。
Shengjia Zhao
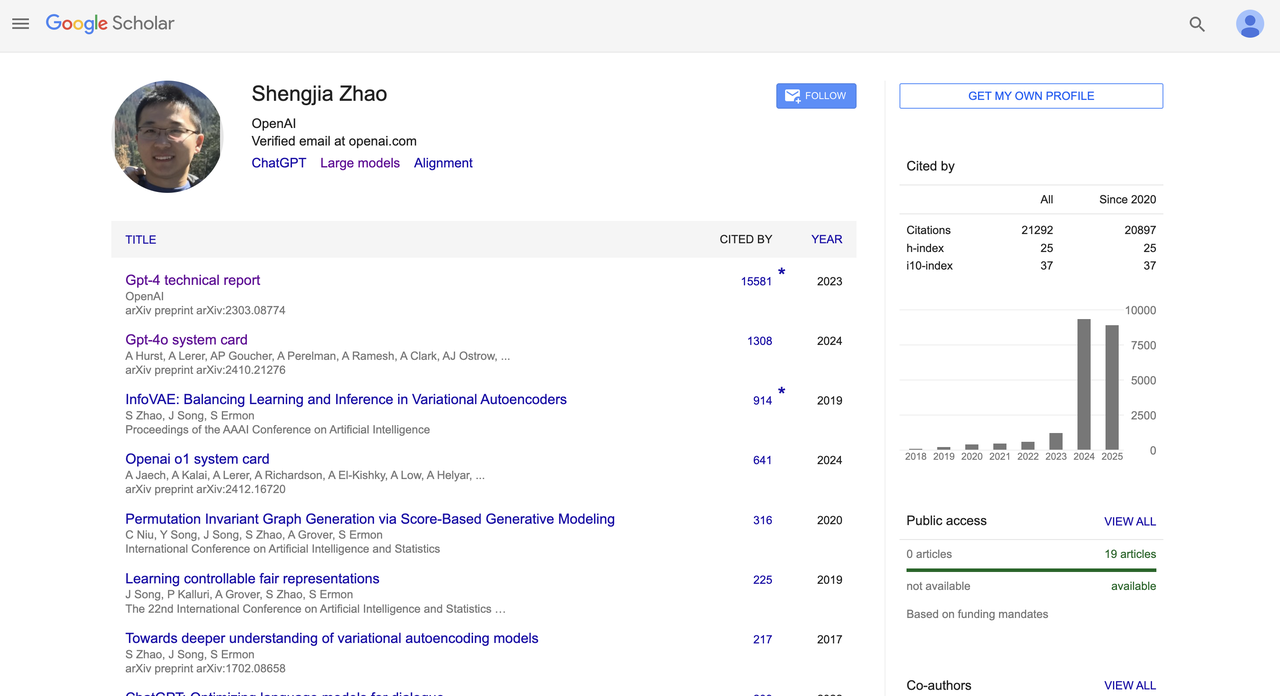
Shengjia Zhao 本科毕业于清华大学计算机系,曾在美国莱斯大学交换,后于斯坦福大学获得计算机科学博士学位,专注于大模型架构、多模态推理和对齐方向的研究。
2022 年,他加入 OpenAI,担任核心研发成员,深度参与 GPT-4 和 GPT-4o 的系统设计工作。曾主导 ChatGPT、GPT-4、所有 mini 模型、4.1 和 o3 的研发工作,还曾领导 OpenAI 合成数据团队。
他是《GPT-4 Technical Report》(被引超过 1.5 万次)和《GPT-4o System Card》(被引超过 1300 次)的联合作者,并参与了多个系统卡(如 OpenAI o1)的撰写,是推动 OpenAI 基础模型标准化与公开化的重要贡献者之一。
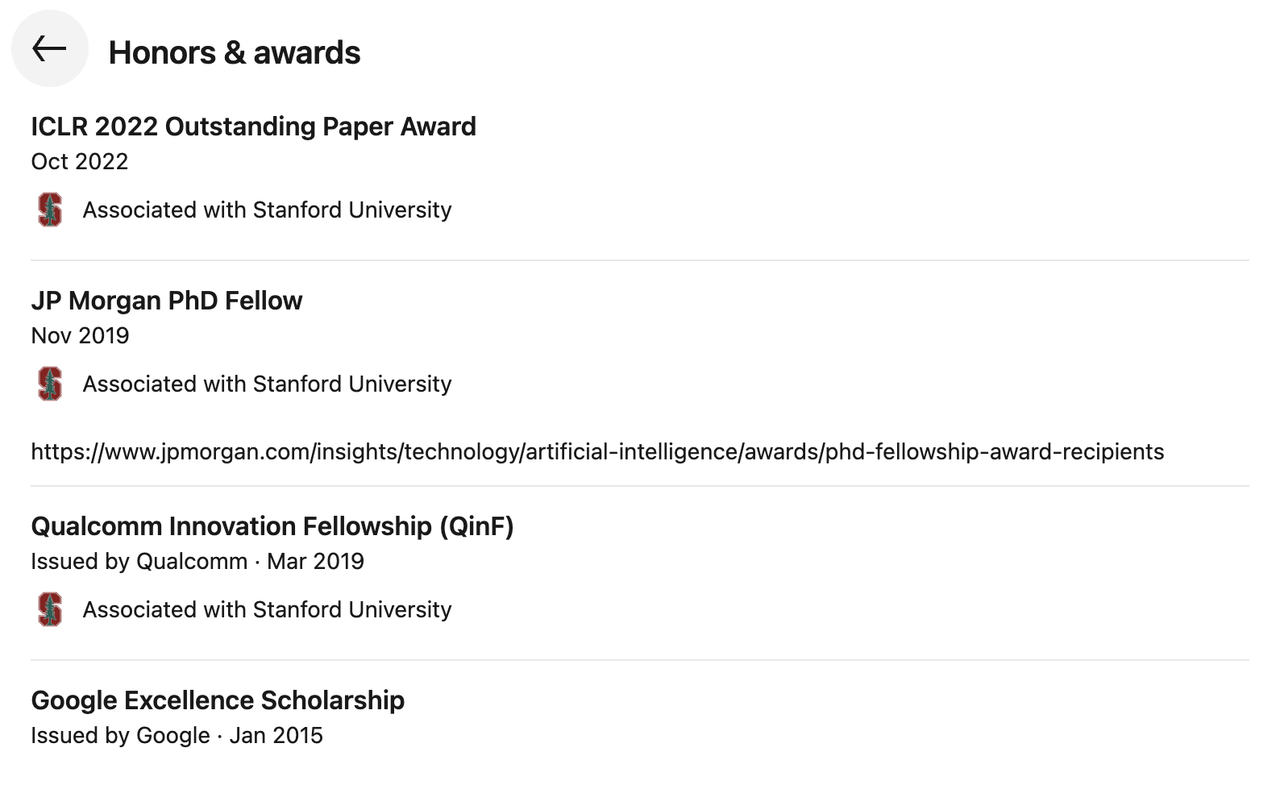
在学术表现上,他 Google 学术总引用数超过 21,000 次,h 指数为 25,曾获得过 ICLR 2022 Outstanding Paper Award、JP Morgan PhD Fellow、Qualcomm 创新奖学金(QinF)与 Google Excellence Scholarship 等多项奖项。
Google→Meta
Pei Sun
2009 年,Pei Sun在清华大学获得了学士学位,随后前往卡内基梅隆大学攻读硕士和博士学位,顺利完成硕士阶段学习,并在博士阶段选择退学。
他曾在 Google DeepMind 担任首席研究员,期间主攻 Gemini 模型的后训练、编程和推理工作,是 Gemini 系列模型(包括 Gemini 1、1.5、2 和 2.5)后训练、思维机制构建与代码实现的核心贡献者之一。
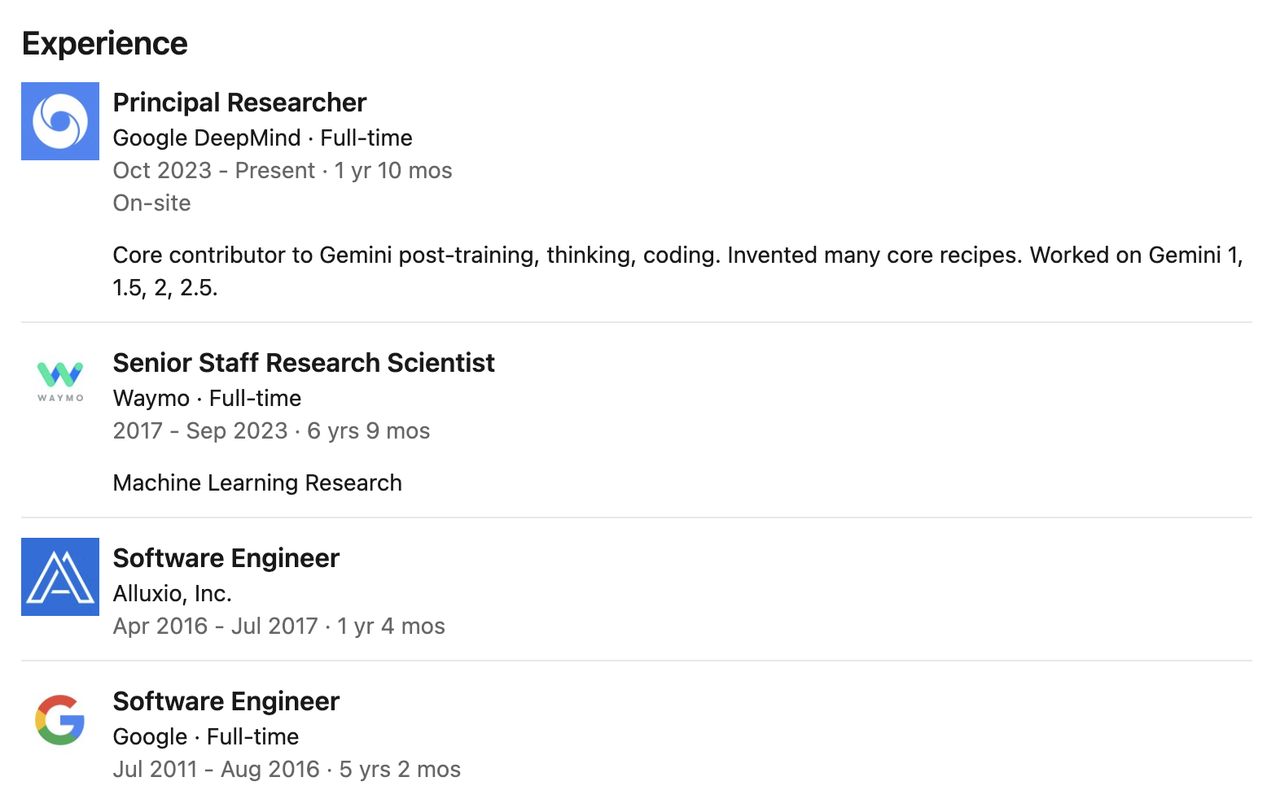
在加入 DeepMind 之前,Pei 曾在 Waymo 任职近七年,担任高级研究科学家,主导了 Waymo 两代核心感知模型的研发,是自动驾驶感知系统演进的中坚力量。
更早些时候,他曾在 Google 担任软件工程师五年多,后又加入分布式存储公司 Alluxio 任职工程师超过一年,参与系统架构研发。

Nexusflow→英伟达
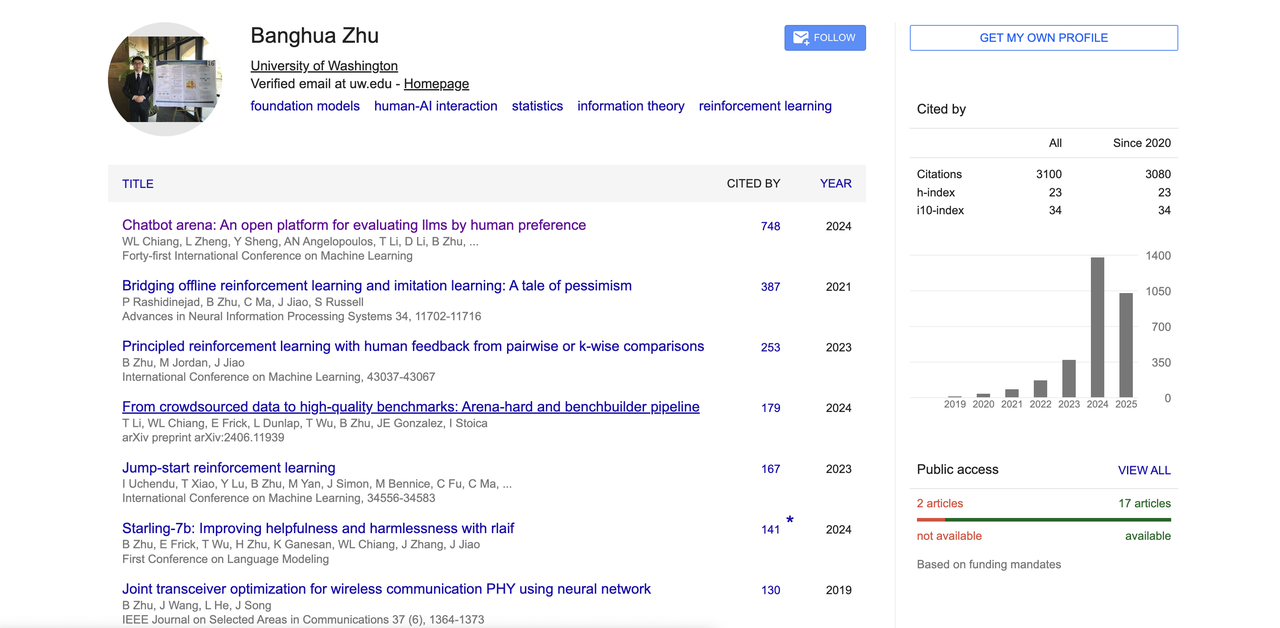
Banghua Zhu
Banghua Zhu 本科毕业于清华大学电子工程系,后赴美国加州大学伯克利分校攻读电气工程与计算机科学博士,师从著名学者 Michael I. Jordan 和 Jiantao Jiao。

他的研究聚焦于提高基础模型的效率与安全性,融合统计方法与机器学习理论,致力于构建开源数据集和可公开访问的工具。他的兴趣方向还包括博弈论、强化学习、人机交互以及机器学习系统设计。
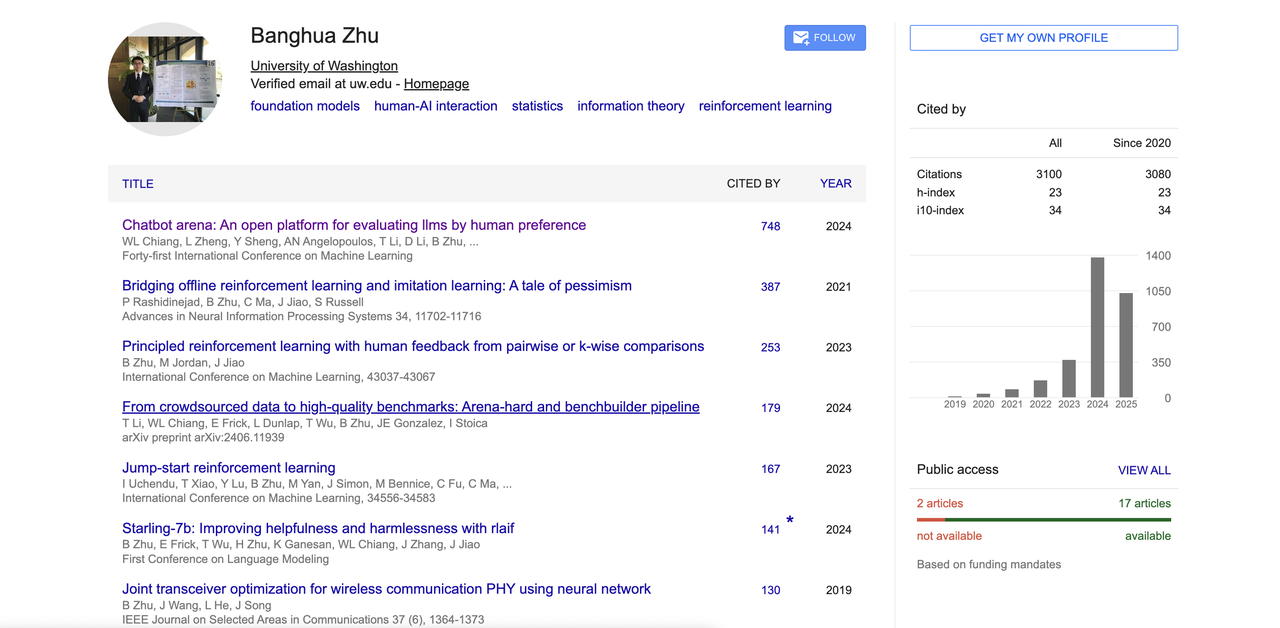
他代表性论文《Chatbot Arena》提出了人类偏好驱动的大模型评测平台,成为 LLM 领域的重要基准之一。
此外,他还在 RLHF、人类反馈对齐、开源对齐模型等方向有所贡献。其 Google 学术显示引用总数超过 3100,h 指数为 23,也是大模型竞技场「Chatbot Arena」、「Benchbuilder」、「Starling」等多个热门开源项目的核心作者之一。

他曾在 Microsoft 担任研究实习生,在 Google 担任学生研究员,曾联合创立 AI 初创公司 Nexusflow,今年 6 月,他宣布加入英伟达 Star Nemotron 团队担任首席研究科学家,此外将于今年秋季入职华盛顿大学的助理教授。
根据其发布内容,他将在英伟达参与模型后训练、评估、AI 基础设施和智能代理构建等项目,强调与开发者及学术界的深度协作,并计划将相关成果开源。
Jiantao Jiao
Jiantao Jiao 是加州大学伯克利分校电气工程与计算机科学系以及统计系的助理教授。
他于 2018 年获得斯坦福大学电气工程博士学位,目前是多个研究中心的联合负责人或成员,包括伯克利理论学习中心(CLIMB)、人工智能研究中心(BAIR Lab)、信息与系统科学实验室(BLISS)以及去中心化智能研究中心(RDI)。
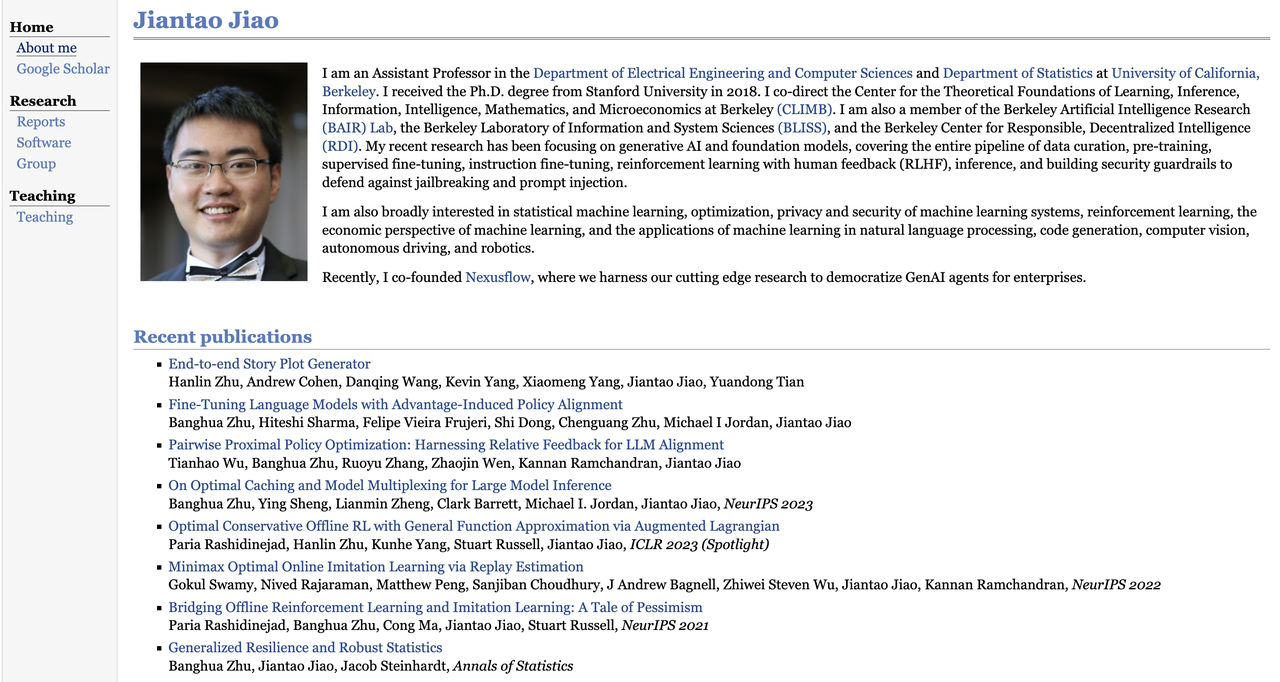
他的研究集中于生成式 AI 与基础模型,对统计机器学习、优化理论、强化学习系统的隐私与安全、经济机制设计以及自然语言处理、代码生成、计算机视觉、自动驾驶与机器人等方向也颇有兴趣。
和 Banghua Zhu 一样,他也是 Nexusflow 联合创始人之一,目前已经正式加入英伟达,担任研究总监兼杰出科学家。
Jiao 的总引用次数达 7259,h 指数为 34,代表性论文包括《Theoretically principled trade-off between robustness and accuracy》,以及与 Banghua Zhu 等人合作的《Bridging Offline Reinforcement Learning and Imitation Learning: A Tale of Pessimism》,均发表在 NeurIPS 等顶会。
Claude→Cursor
Catherine Wu
Catherine Wu 曾在 Anthropic 担任 Claude Code 的产品经理,专注于构建可靠、可解释、可操控的 AI 系统。据 The Information 报道,Catherine Wu 已被 AI 编程初创公司 Cursor 挖角,出任产品负责人一职。

在加入 Anthropic 之前,她曾是知名风投公司 Index Ventures 的合伙人,任职近三年,期间深度参与多家顶尖创业公司的早期投资与战略支持。
她的职业起点并不在投资圈,而是扎根于一线技术岗位。
她曾在 Dagster Labs 担任工程经理,主导公司首个商业化产品的研发,也曾在 Scale AI 担任早期产品工程师,参与多个关键产品的构建与运营扩张。
更早之前,她在摩根大通实习,并于普林斯顿大学获得计算机科学学士学位,在校期间还曾赴苏黎世联邦理工学院进行交换学习。
特斯拉 | Phil Duan
段鹏飞(Phil Duan)是特斯拉 AI 的首席软件工程师,现负责 Autopilot 下的 Fleet Learning 团队,致力于推动特斯拉自动驾驶系统(FSD)中「数据 + 感知」核心模块的建设。

他带领特斯拉团队开发高吞吐、快迭代的数据引擎,从数百万辆汽车中采集、处理并自动标注驾驶数据,强调数据质量、数量与多样性的协同优化。在感知方向,他主导构建多项关键神经网络,包括视觉基础模型、目标检测、行为预测、占据网络、交通控制和高精度泊车辅助系统等,是 Autopilot 感知系统的核心构建者之一。
他本科毕业于武汉理工大学,主修光信息科学与技术,随后攻读俄亥俄大学电气工程博士与硕士学位,研究方向为航空电子,并以博士论文荣获 2019 年 RTCA William E. Jackson Award,该奖项是美国航空电子与电信领域授予研究生的最高荣誉之一。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。