1. 今年一定
好几年没写「年终总结」,翻了下「掘金」,上一篇还停留在「2021年」,倒不是这几年没活过,也不是不想写,只是每次都止步于「拖延」。每到年底,脑子里就会蹦出的各种想法,被我零散地记录在 "大纲笔记" 中:

写这玩意挺废「时间」和「心力」,所以总想着 "找个周末,花一大块时间,好好梳理一下",结果都是一拖再拖:拖到元旦,拖到春节,拖到元宵。
然后,转念一想:"这都明年了,还写个🐣毛啊?算了,算了,明年一定!"。2022、2023、2024 就在这样的 "明年一定" 中溜走了...

人到中年,主观感觉「时间」过得越来越快,「记性」 也大不如前,很多当时觉得 "刻骨铭心" 的瞬间 (如:结婚、当爹),如今回忆起,就剩下一个 "模糊的轮廓"。不写的话,又是「摸 🐟」一年,趁着 2025 年还没过完,很多感觉还是热乎的,赶紧动笔,今年一定!!!
2. 如此生活30年,直到大厦崩塌
2025 年,对我冲击最大的当属 "AI",大到让我不得不重新审视「自己的工作和价值」。
我接触 AI 并不算晚,2024 年那会跟风玩了下 ChatGPT,后面在 GitHub Copilot (便宜盗版,30¥/月) 的协助下,快速交付了一个爬虫单子。尝到 "提效甜头" 的我,咬咬牙上了 年付正版 (100刀/年) 的车。
当时 AI 在我的眼里,只是个 "比较聪明的代码补全工具",可以帮我少些几行代码,仅此而已,因为 逻辑还得我来把控。

但到了 2025 年,事情却变得有点不一样了:
AI能读懂/分析整个项目、重构屎山代码、把一个模糊的业务需求实现得有模有样。
当然,最让我 "破防" 的还是它的 "解BUG" 能力:
按照以往的习惯,我得去 Google、翻 Stack Overflow、看源码,少说得折腾半天。现在,把 报错日志 和 相关代码 丢给它,通常几秒就能:指出问题所在,给出解决方案,甚至可以 帮我改好并测试通过。

积累多年,一度 "引以为傲" 的「编程经验」(对API的熟练程度、快速定位BUG的直觉、配置环境的熟练度等) 在 AI 的面前,变得 "不堪一击"。渐渐地,我的「工作流程」也发生了改变,"亲手" 敲下的代码越来越少,取而代之的是一套 "机械化" 的 "肌肉记忆":
-
写注释 → 等待AI补全 → 按Tab:哪怕脑子里知道下一行该写什么,手指也会下意识停顿,等待那行灰色的建议浮现,然后无脑按下 Tab。
-
提需求 → 生成代码 → Accept:把业务逻辑描述一遍,丢给 AI,都不太细看生成的具体实现,直接点击 Accept All,主打一个 "能跑就行"。
-
运行报错 → 复制日志 → 丢给 AI:遇到 Bug,第一反应不再是去分析堆栈信息 (Stack Trace),而是CV日志到对话框,问它:"解决报错:xxx"。
-
效果不对 → 截图 → 丢给 AI:连描述问题的精力都省了,直接截图往对话框里一扔,附上一句 "改成这样"。
代码跑通了,效率提高了,却带来了精神上的「空虚」,我似乎再也感受不到当初那种「编程的快乐」:
- 为了解决某个问题,苦思冥想,抽丝剥茧,最后成功 "破案" 时 "多巴胺疯狂分泌" 的 "快感"。
- 查各种资料、反复推敲、验证,最终设计出一个自己觉得 "牛逼哄哄" 代码架构时的 "成就感"。
同时,也陷入了一种深深的「自我怀疑与迷茫」:
- 越来越搞不清楚自己的「定位」(存在价值),上面那套 "连招" 找个实习生培训两天也能干。我曾赖以为生的那些 "技能",正变得廉价、可替代、甚至有点多余 ...
-
找不到方向,以前「程序员成长路径」很清晰:学语言 → 学框架 → 学架构 → 学系统设计 → 刷算法 → 搞源码 ... 只要你一步步往上爬,爬到 "山顶" 就能成为 "大牛"。而如今却好像 "失效" 了...
-
可控感被剥夺,程序员是典型的「内控型人格」—— 相信通过逻辑和细节掌控能预测一切。而但 AI 的「黑箱特性」带来了「工具不可控」,无法完全准确预测AI输出,调试从 "追踪逻辑" 变为 "试探模型"。
3. 调整对待AI的心态
3.1. 从 "焦虑" 到 "接纳"
我深知「焦虑」无用,于是开始探寻「破局之道」,反复阅读大量资料后发现,几乎所有人都在让你「拥抱 AI」,但具体怎么拥抱法?没人说,或者说得含糊不清,有些甚至还想割我 "韭菜" 🤡 ?屏蔽这些噪音,冷静下来复盘,拨开情绪迷雾,透过现象看本质。
首先,坦诚地「接纳」肯定是没错的,历史的车轮从不因个人的意志而停止转动,当 第一次工业革命的蒸汽机 轰鸣作响时,那些坚守手工工场的匠人们,也经历着相同的困境。精细手艺 在不知疲倦、效率千倍的 机械化工厂 面前显得苍白而无力。大机器生产取代手工劳动,不是一种选择,而是一种必然的 "降维打击"。
现在,我们同样站在了 "生产力变革" 的周期节点上, "效率至上" 的底层逻辑从未改变。是选择成为被时代甩下车的 "旧时代纺织工"?还是进化为驾驭机器的 "新时代工程师"?回归「第一性原理」,剥开 "智能" 的外衣,想想 "AI 的本质是什么?" —— 「干活的工具」
所以,面对 AI,我们要做的事情就是琢磨 "如何用好这个工具? ",即:详细阅读使用说明后,在合适的场景,用合适的方式,解决合适的问题。
3.2. AI 有什么用?—— 能力放大 + 自学利器
3.2.1. 能力放大器
🐶 经常在 自媒体平台 刷到 "普通人学AI后致富/逆袭" 的 叙事,看到这些 "逆天标题" 没把我笑死:

多的不说,记住这段话就对了:
变现的核心能力从来不是使用工具,而是商业认知、市场洞察、营销推广、客户服务。AI 只是一个环节,不要高估了工具的作用,而低估了 商业常识的重要性,也不要低估了背后的 隐性成本和巨大的工作量。
这些 "AI变现教程" 的 最大问题:
让你把AI当成一个 独立的、全新的、需要从零开始的 "行业" 去卷。
对于 99% 的普通人而言,把AI看作 "能力放大器" 会更靠谱一点,即:
思考如何利用AI,帮我把我已有的技能/兴趣做得更好?
比如:
- 用 AI 减少重复劳动,提高工作效率和质量,把时间花在更有创造力的事情。
- AI 负责广度,你负责深度,在你热爱的小众领域里用AI武装自己,做到 "人无我有,人有我精"。
今年「Vibe Coding (氛围编程) 」很火:
用自然语言描述想要的效果,AI帮你写代码,你只负责验收结果和提修改意见,不用管具体代码怎么实现的。
编程门槛大大降低,普通人 只要能把 创意和感觉 翻译成需求,就能借助 AI 将其快速具象化为 可运行的产品。
但你会发现,绝大多数生成的作品都是 "一次性原型或玩具":灵光一现即可实现,却缺乏持续迭代、架构设计与用户验证,因此难以具备商业价值、也难形成可持续的产品形态。
真正能够利用 Vibe Coding 实现变现的,往往是具备一定 编程经验 或 产品思维 的 "专业人士"。他们不仅能用 AI 快速实现灵感,还能对作品进行持续优化、迭代和工程化打磨,从而将 "灵感原型" 进化为 "可用产品"。
再说一个自己观察到的例子,前阵子 OpenAI 发布了用于生成短视频的「Sora2」,B站 很快涌现了一堆 AI 生成的 "赛博科比" 恶搞视频。
看到一个播放量破百万的作品有点意思,点进 UP 主的主页想看下其它作品,结果发现他并不是突然爆火的 "新人",人家已经默默做了好几年视频,只是过去的播放量惨淡 (几十几百)。但他却一直坚持创作,尝试不同的方向,能清晰地看到他的剪辑、叙事和整体制作水平在一点点提高。
AI 不会让没有积累的人"平地起飞",但有可能让有准备的人"一飞冲天"。—《抠腚男孩》
3.2.2. 自学利器
看到这里,可能有人会问:
"那普通人怎么办?我没啥专业技能,也没有长期积累啊? "
简单,那就 "学" 啊!!!以前学习的最大限制是什么?
没人教、教不好、学不动、坚持难
而现在,你有了一个「全知全能、知无不言、24小时为你服务的免费老师」
- 不会写代码?手把手教你,从逻辑到示例一步步拆开。
- 想转行?给你路径、资源、练习清单、复盘建议。
- 想跨领域?帮你建立知识框架,把陌生领域最难啃的部分变简单。
- 遇到瓶颈?像一对一导师一样不断提问、引导、纠偏。
当然,想要这台 "自学利器" 高效运转起来,实现 快速学习/试错/跨域 还需要掌握一些 方法论。
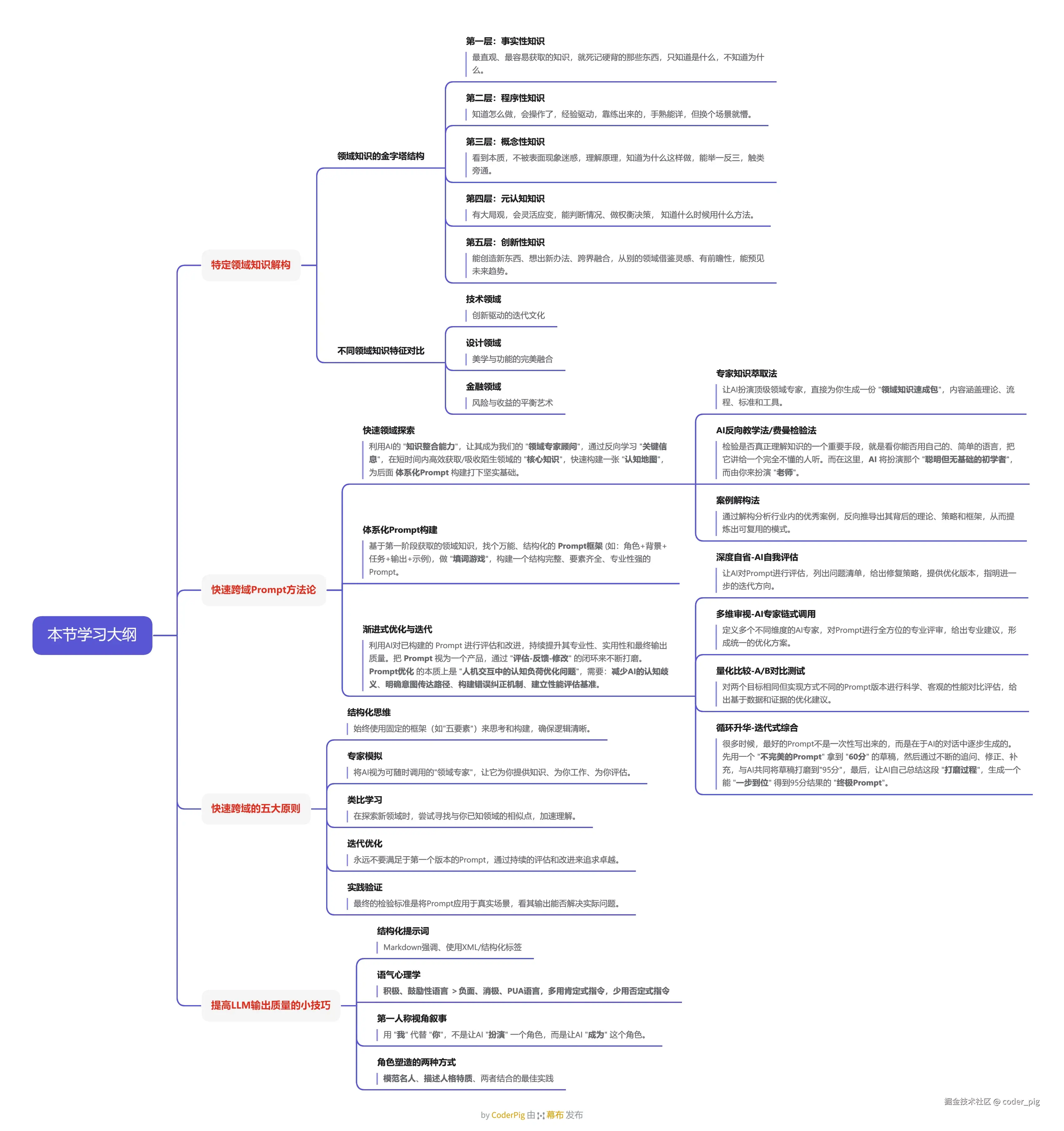
详细解读可以参加我之前写的《如何借助AI,高效学习,实现快速"跨域"》
3.2.3. 不要神化 AI
🐶 2333,经常刷到 "xx公司发布新的 xx 模型/AI产品颠覆行业,xx师要失业了" 的标题,但事实真的如此吗?最近 Google 家的 Nano Banana Pro 🍌很火,号称当前 "最强AI生图" 模型,亲身体验下确实强 (本文大部分配图就是它出的),天天在群里吹爆。
某天晚上,有 "多年专业设计经验" 的老婆收到一个改图需求 (抠素材,按要求调整海报):

😄 看着简单,感觉 🍌 就能做,于是我提出和老婆 PK 下,她用 PS 改,我用 🍌 嘴遁修图,看谁出的图又快又好。结果:她10分钟不到就改完,而我跟 🍌 Battle了半个小时没搞好,最终的效果图 (左边她的,右边我的):

🤡 "甲方" 的评价 (破大防了😭):

观察仔细的读者可能会问:"你是不是漏了一个车🚗啊?",憋说了,这破车把我调麻了...
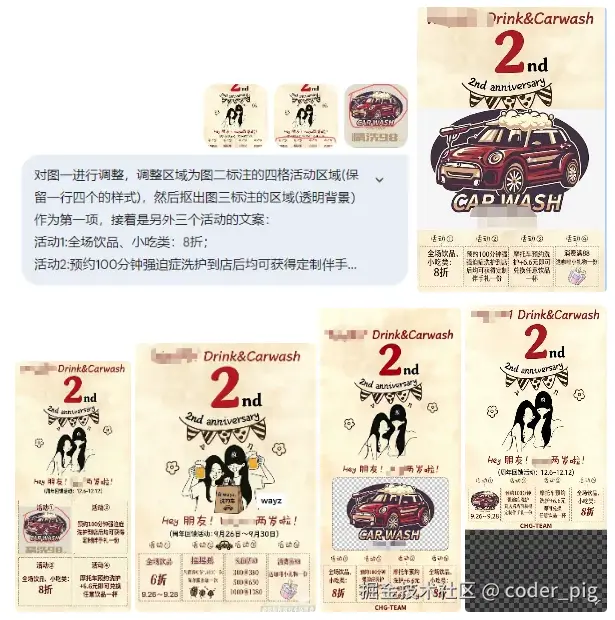
那一刻,我深刻体会到了什么叫 "不要拿你的兴趣爱好,去挑战别人的饭碗",真的是 "降维打击" 啊!

AI 确实拉低了创作的门槛,但目前还处于生成 80分 内容的阶段 (效率),最后的 10-20 分 (细节、审美、情感) 才是价值的核心。——《抠腚男孩》
后面复盘,老婆看了下我的 Prompt,说我的流程有点问题,应该让 AI 先把素材全抠出来先,再慢慢组合。后面试了下,效果确实有好一些。不过,不得不说,AI 在 自动抠图 这块确实可以:

🤣 老婆在日常设计时也会用 AI 来偷懒,比如:生成配图、提高清晰度、扩图等。
3.3. AI 是什么? —— 概率预测机器
现阶段谈论 AI,其实都是在谈论 大模型 (LLM) —— 一个极其复杂的 "概率预测机器"。
通过学习海量数据的 "统计规律",逐步逼近这些数据背后的 "概率分布",从而能够在给定 "上下文" 时预测最合理的下一步输出。
不同类型产物的生成原理图解 (看不懂没关系,简单了解下即可):
① 文本

② 图片 (扩散模型 & 自回归模型)
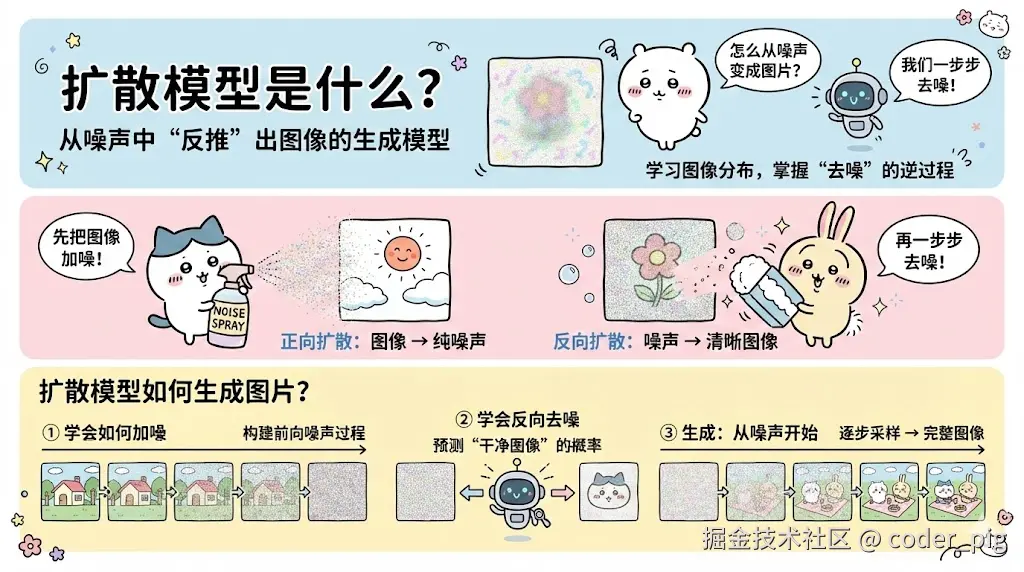
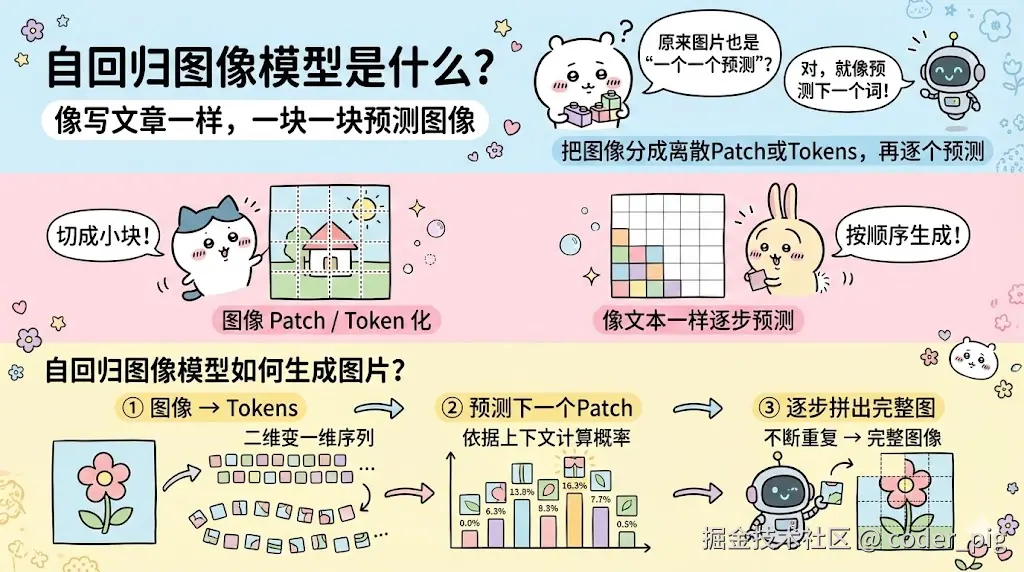
③ 音频 (自回归模型 & Codec + Token 预测 )
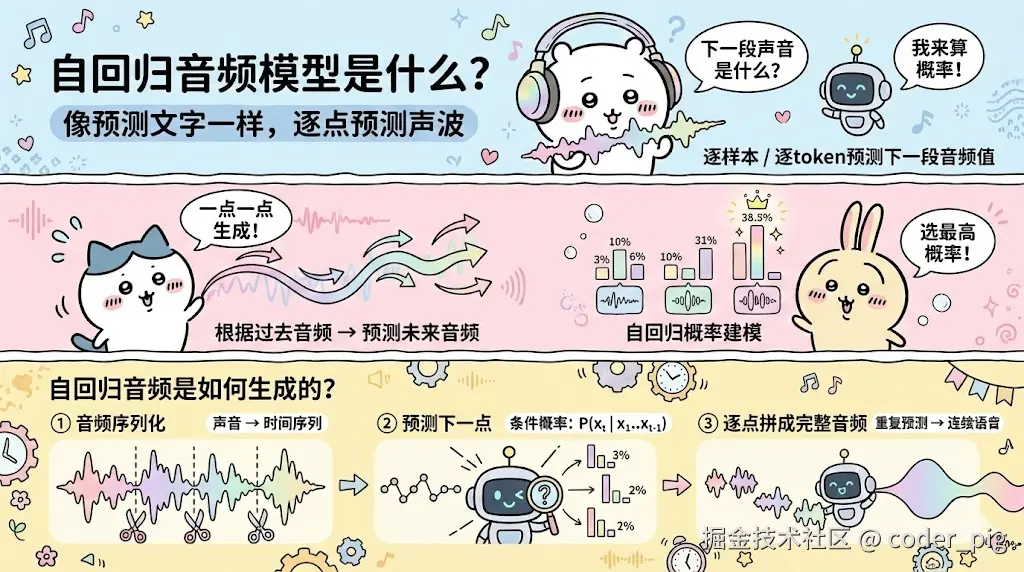

④ 视频 (扩散式 & 自回归/时空Token)
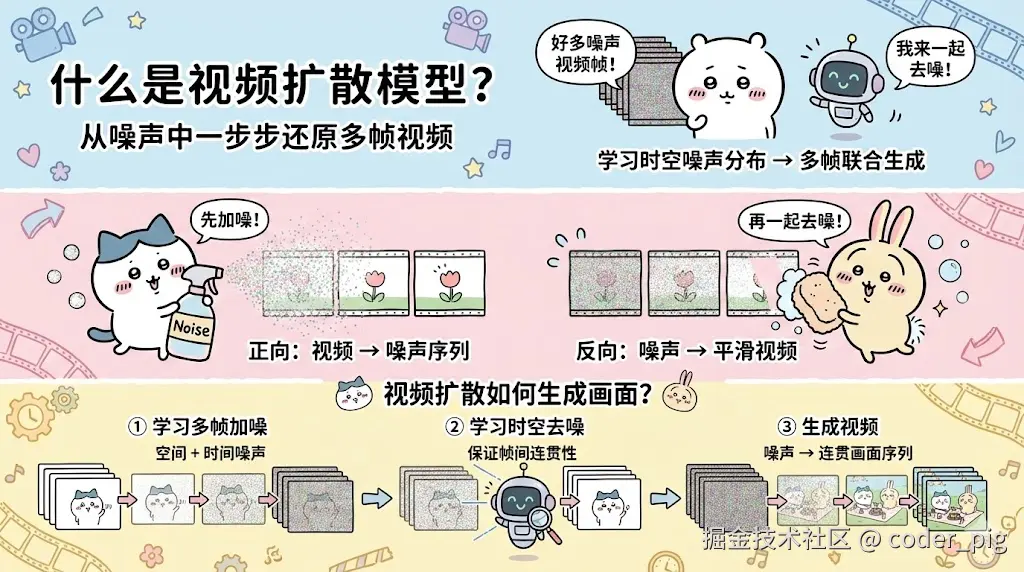
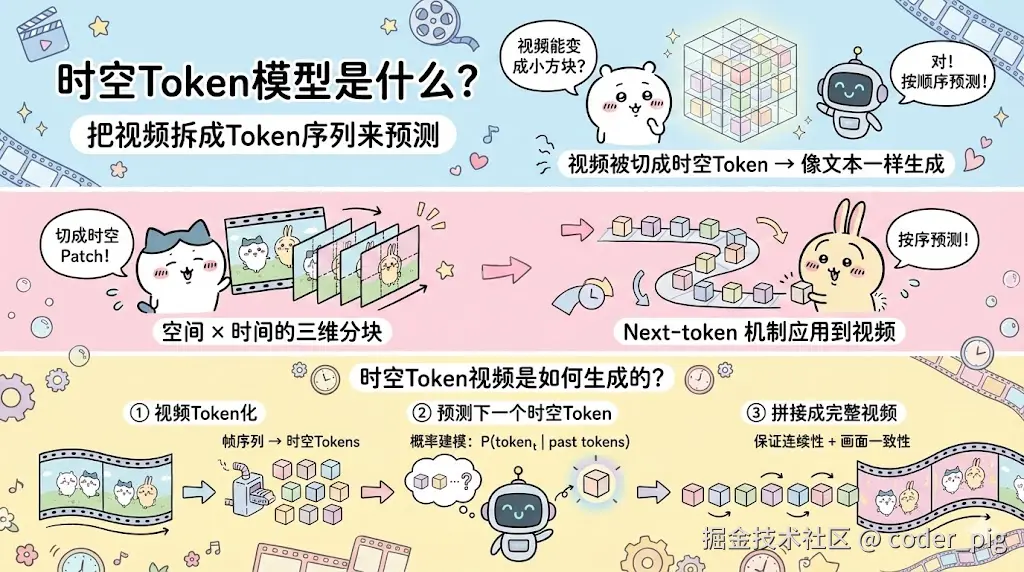
3.4. AI 的能力边界 —— 优/劣势
LLM 擅长发现 "相关性",但难以进行真正的 "因果推理",它只是在 "模仿智能",而非 "真正地理解意图,拥有意识"。 —— 《抠腚男孩》
弄清楚 AI 的本质是 "概率预测机器" 后,接着从 "代码生成" 的角度梳理下它的 "优势 & 劣势":
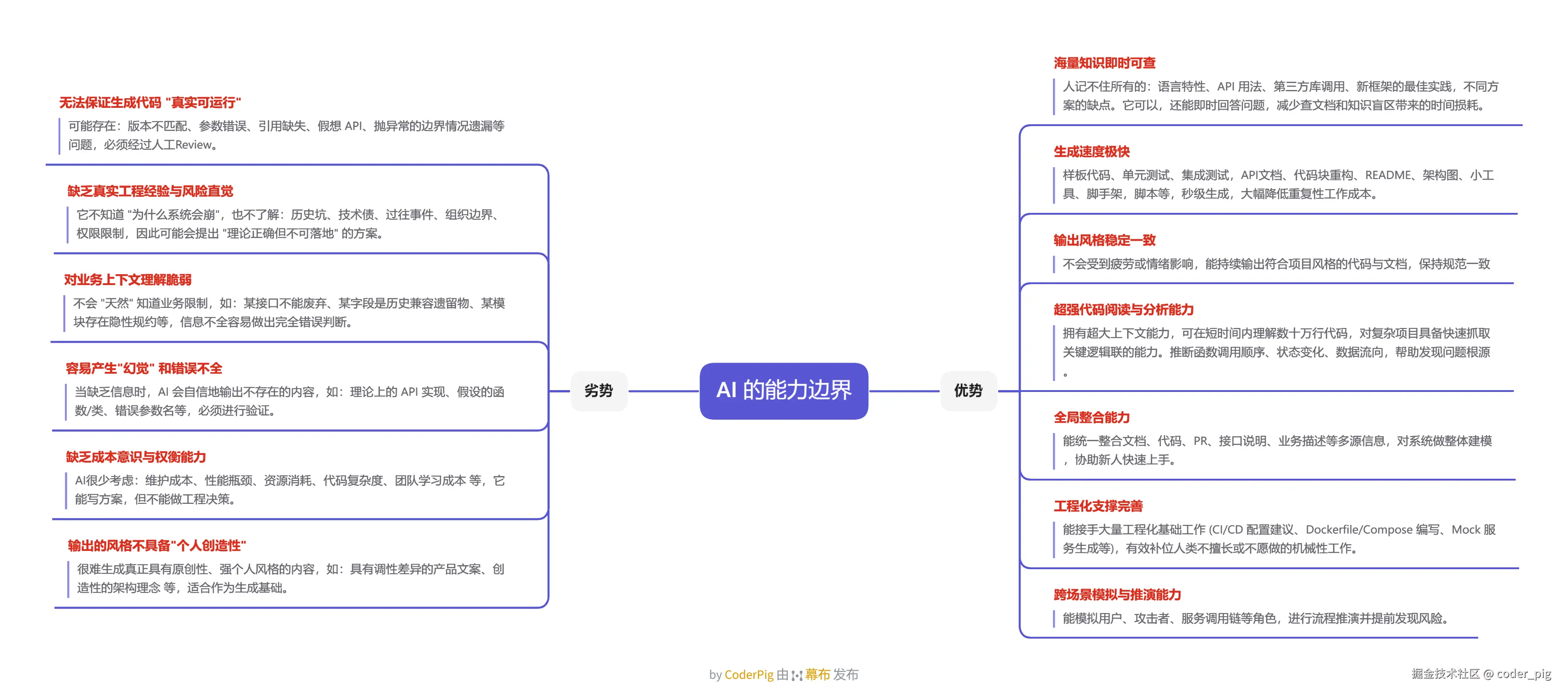
了解完 AI 的 优/劣势 后,接着就可以推演「人 & AI」 的 高效协作方式:
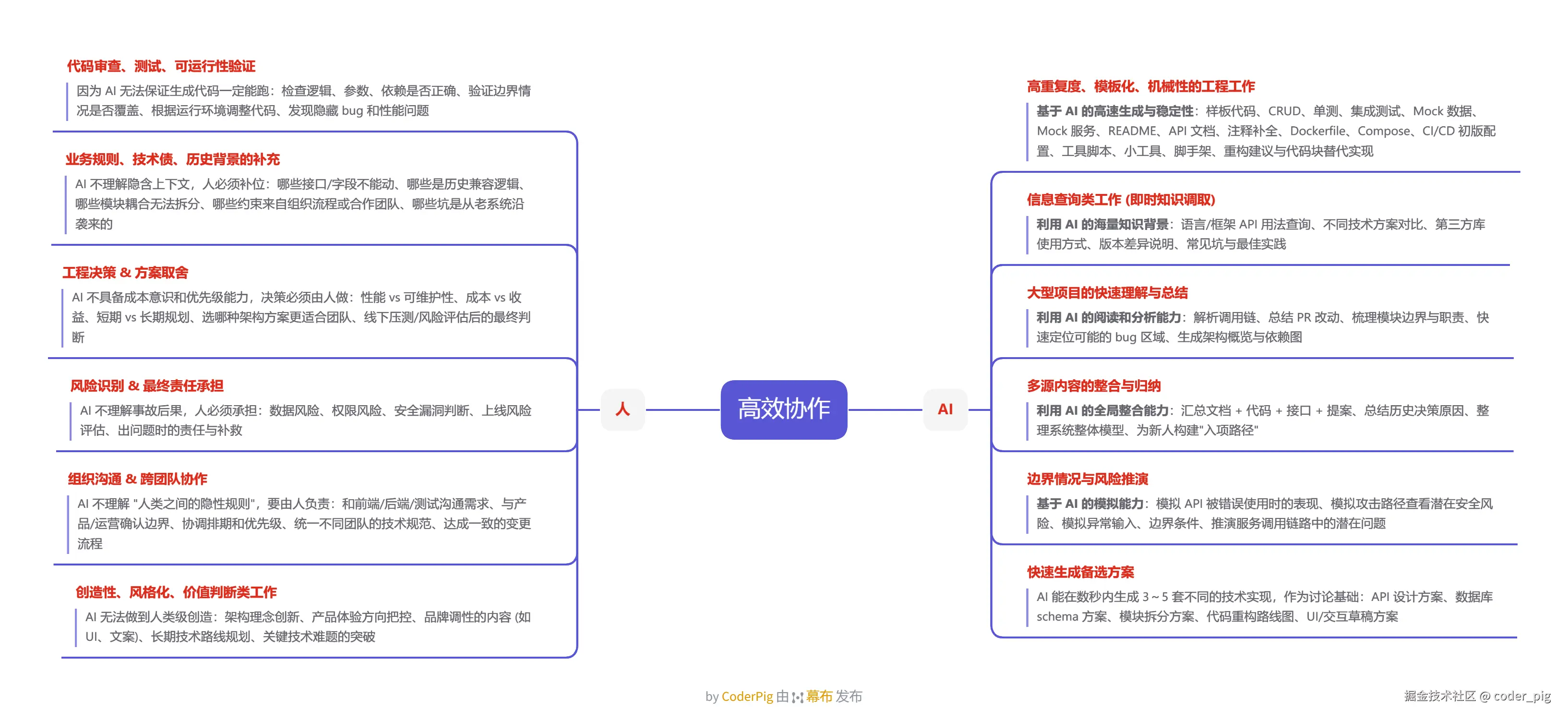
一句话概括:
AI 负责 "生产力" (重复、繁琐、高上下文、高整合的工作),人负责 "方向与边界" (判断、创造、决策、理解组织与业务)。
4. 必备技能 —— Prompt
一般译作 "提示词" 或 "描述词",个人认为后者更加贴切,即:描述问题/需求的 "词句组合" 。「Prompt Engineering-提示词工程」是所有人都必须掌握的 "使用AI的核心技能"。
4.1. 把话说清楚
🐶 别被几个英文单词吓倒,现在的 AI 比几年前聪明多了,普通人 只要能:
把诉求讲得清晰、完整、有逻辑,就能解决绝大多数问题。
示例:
- ❌ 混乱说法:帮我计划个周末玩的地方。
- ✅ 有条理说法:周末想带5岁孩子一日游,2大1小,预算500以内,北京,不想跑太远,能放电、有吃饭的地方、避开暴晒,地铁可达最好。
AI输出结果 (前者输出不同城市的游玩方案,后者输出了具体的行程方案):


4.2. 套框架
再往上走,就是了解一些经典的 "Prompt框架",然后再提问时套用,以提高 AI 输出的稳定性、准确性和质量。所谓的 "框架",其实就是 "结构化模板",规定问题中包含哪些 "要素",比如最经典的「CTRF」框架:
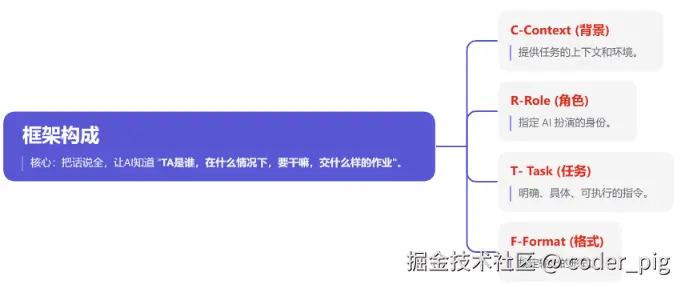
套框架示例 (填空题~):

常见的框架还有 RTF、COSTAR、SPAR、COT、APE 等等,适用于不同的场景。杰哥整合了自己知道的所有框架精华和高级技巧,弄了通用的「Prompt 最佳实践清单」

无脑套就是了,助记口诀:

也可以用故事流程来串联助记,读者可自行发挥,顺序无需固定:
让一位说书人 (角色) ,用生动的语气 (风格语气) ,给孩子们 (受众) 讲个故事 (指令) 。故事的开头 (上下文) 是...,结局 (目标) 要感人。故事的结构 (格式) 要像这样 (示例) ,但不要 (约束) 出现暴力情节。请先构思情节 (逐步思考) ,写完后再想想怎么能更精彩 (反思) 。
😄 懒得记的话,可以用我之前搭的小工具 →「CP AI Prompt助手」
配下 DeepSeek 的 Key,复制粘贴你写的 简单Prompt,它会基于上面的十个维度对提示词进行优化:
4.3. 写出牛逼的Prompt
明白了怎么 "套框架" 写 "结构化的Prompt",但你可能还是会感到疑惑:
用的同样的AI,为什么别人的生成效果就是比我好?
尤其在 AI 生图 领域,看大佬分享的 Prompt,里面一堆看不懂的专业参数:
环境、构图、光影、景深、镜头、光圈、色调、氛围、胶片颗粒、对比度、主体增强、氛围灯...
能写出这么 专业的Prompt,是因为他们有 "相关领域的行业经验" 吗?
答:有加成,但不全是。高手的核心技能不是 "记这些专业知识",而是:知道如何指使 AI 给自己提供专业知识、框架、术语,然后再反向用这些框架让 AI 编写和优化 Prompt。
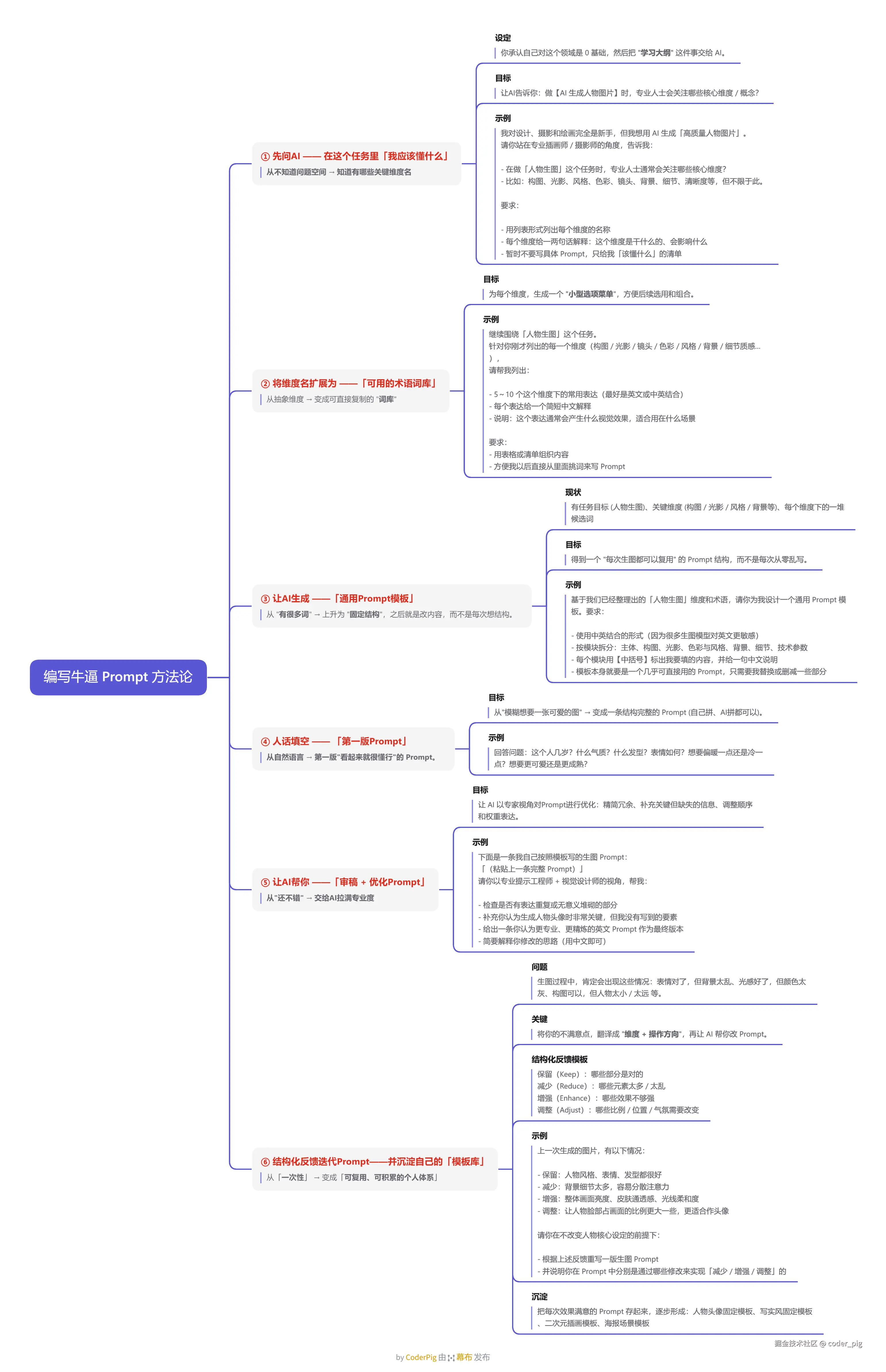
😄 其实思路很简单,拆解下这套方法论:
维度词 → 术语/词库 → 通用模板 → 填空得第一版Prompt → AI专家视角优化 → 迭代优化沉淀
详细玩法可以看下图:
4.4. Prompt 逆向
Prompt 逆向工程(RPE,Reverse Prompt Engineering),就是:从 "输出" 反推 "是什么Prompt" 生成了它。一般用于:学习优秀案例、调试和诊断问题、构建Prompt库和模板、企业质量控制、安全审计 (防御Prompt注入攻击)。
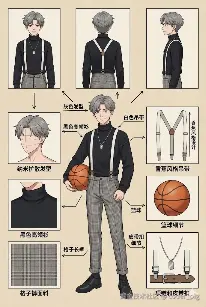
4.4.1. 简单版
普通人 用这个套路就够了,选个聪明点的模型 (如:GPT5 或 Gemini 3 Pro),粘贴图片,写 Prompt 让它反推:

差得有点远,描述「不满意的点」,让AI继续优化Prompt:

接着用优化后的 Prompt 来生成,可以看到效果差不多了,接着让 AI 提取一个「通用的Prompt」


拿 AI 生成的 Prompt 生图,看效果,描述问题,循环反复,直到稳定生成自己想要的效果~



4.4.2. 专业版
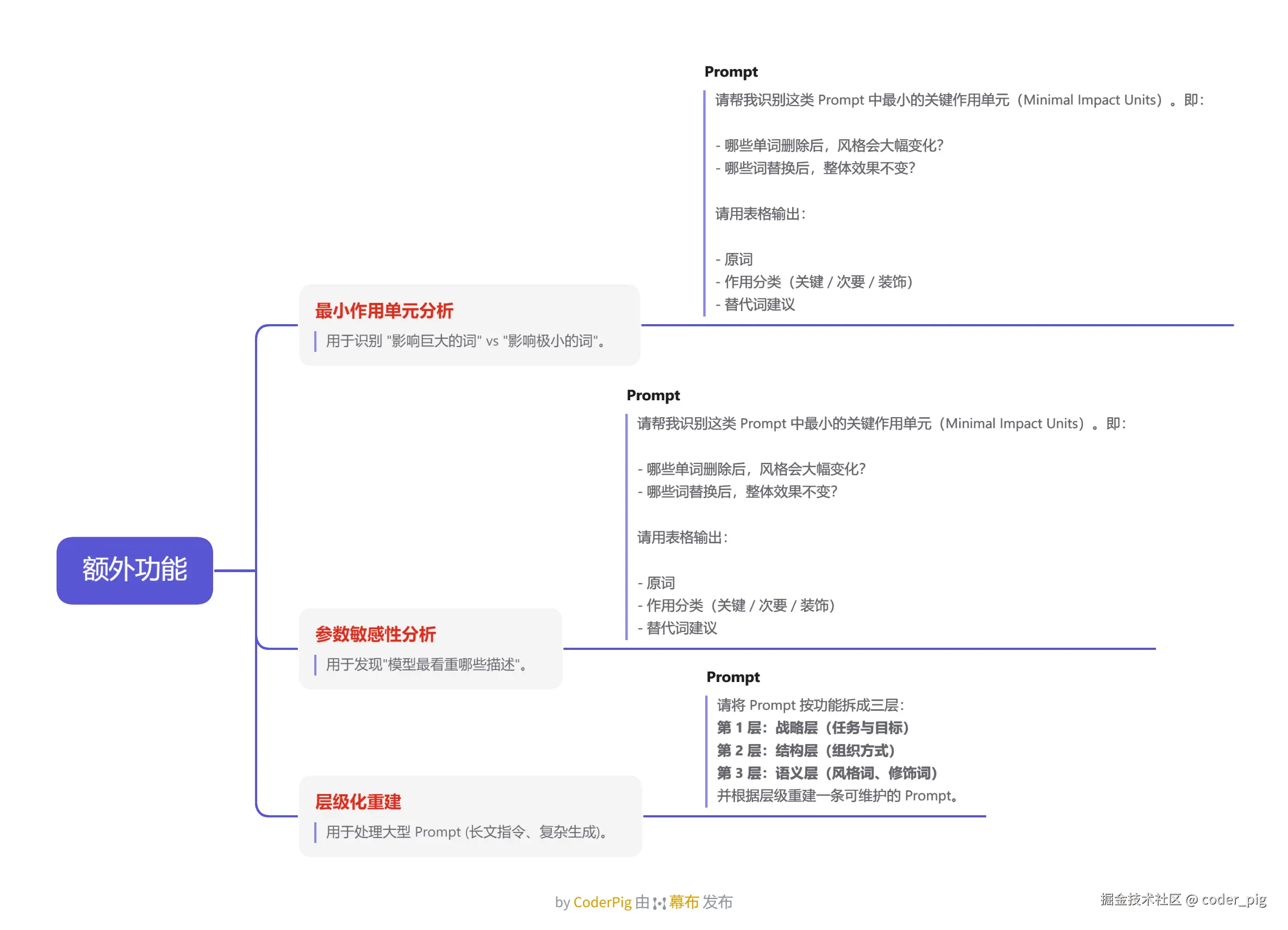
🐶 其实也差不多,只是流程比较 "标准化",经常搞还能自己搭个 "工作流",适合专业选手,思路:
快速拆解 → 推断 Prompt → 提取要素 → 重建 Prompt → 优化迭代 → 模板化沉淀
详细图解:

上面是通用的,还有几个 额外功能 的玩法也罗列下:
5. 锦上添花——懂点AI常识
🐶 懂点AI常识,能让你更 有的放矢 地 用好AI (装逼),比如:连 Token 都不知道的话,就有点贻笑大方了。这里只是简单罗列下相关名词,不用死记,有个大概印象即可,不影响你使用AI,跳过也没关系。😄 详细讲解,建议直接复制名词问题AI,也可移步至《AI-概念名词 & LLM-模型微调》自行查阅~
5.1. AI (人工智能) 基础概念

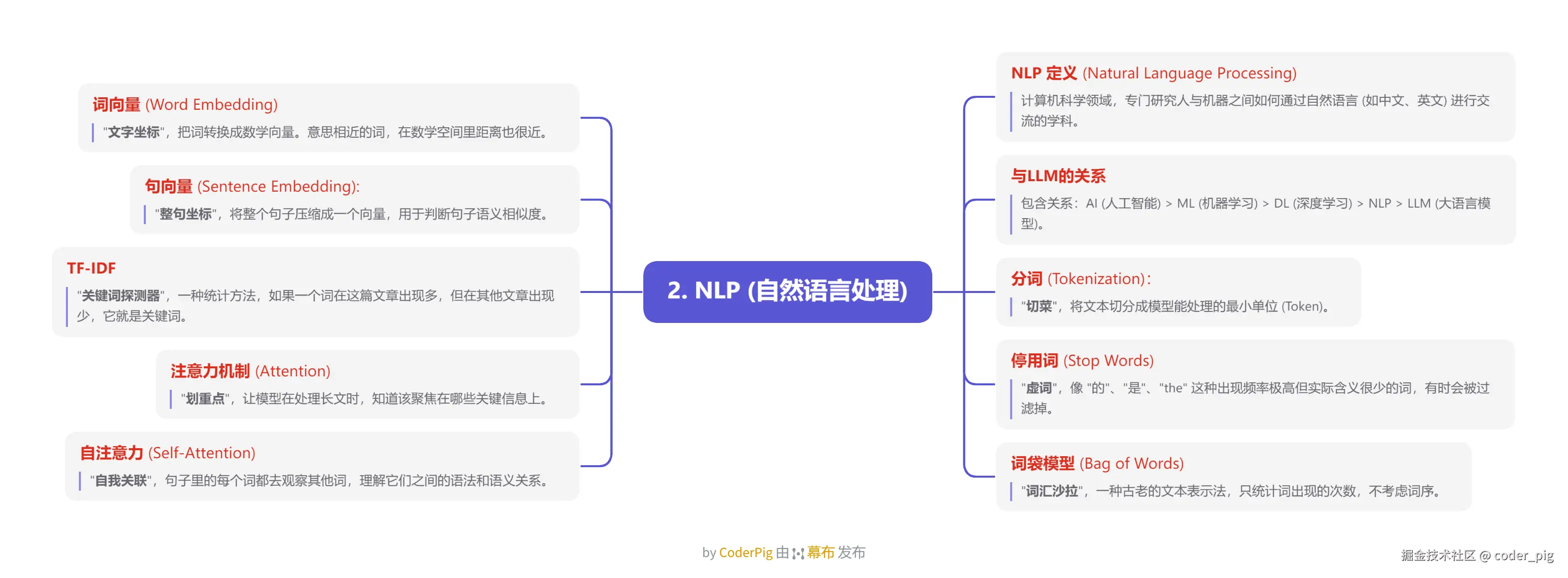
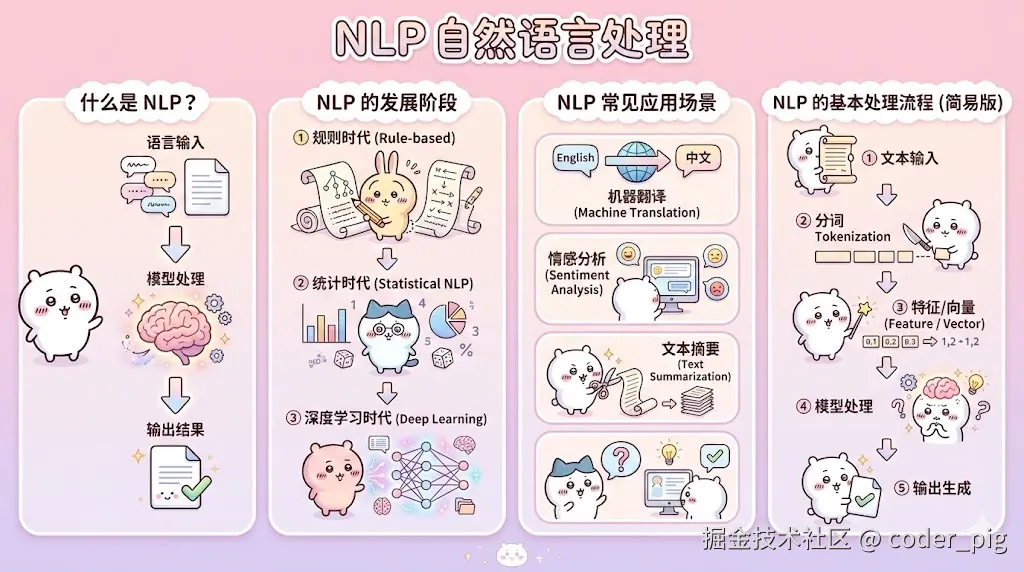
5.2. NLP (自然语言处理)
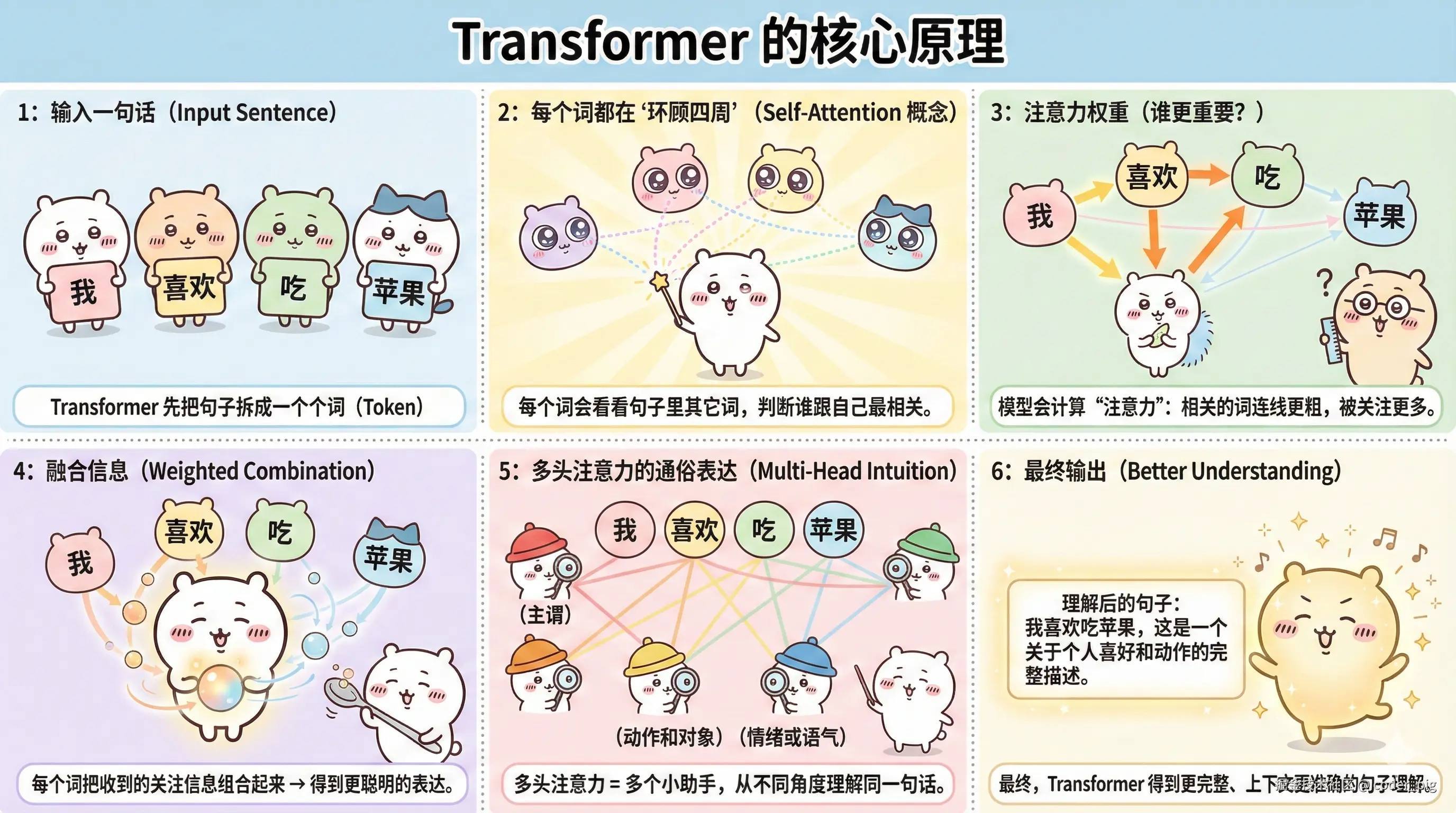
5.3. Transformer 架构 (大型模型基础)

5.4. 语言模型基础 (Language Models)

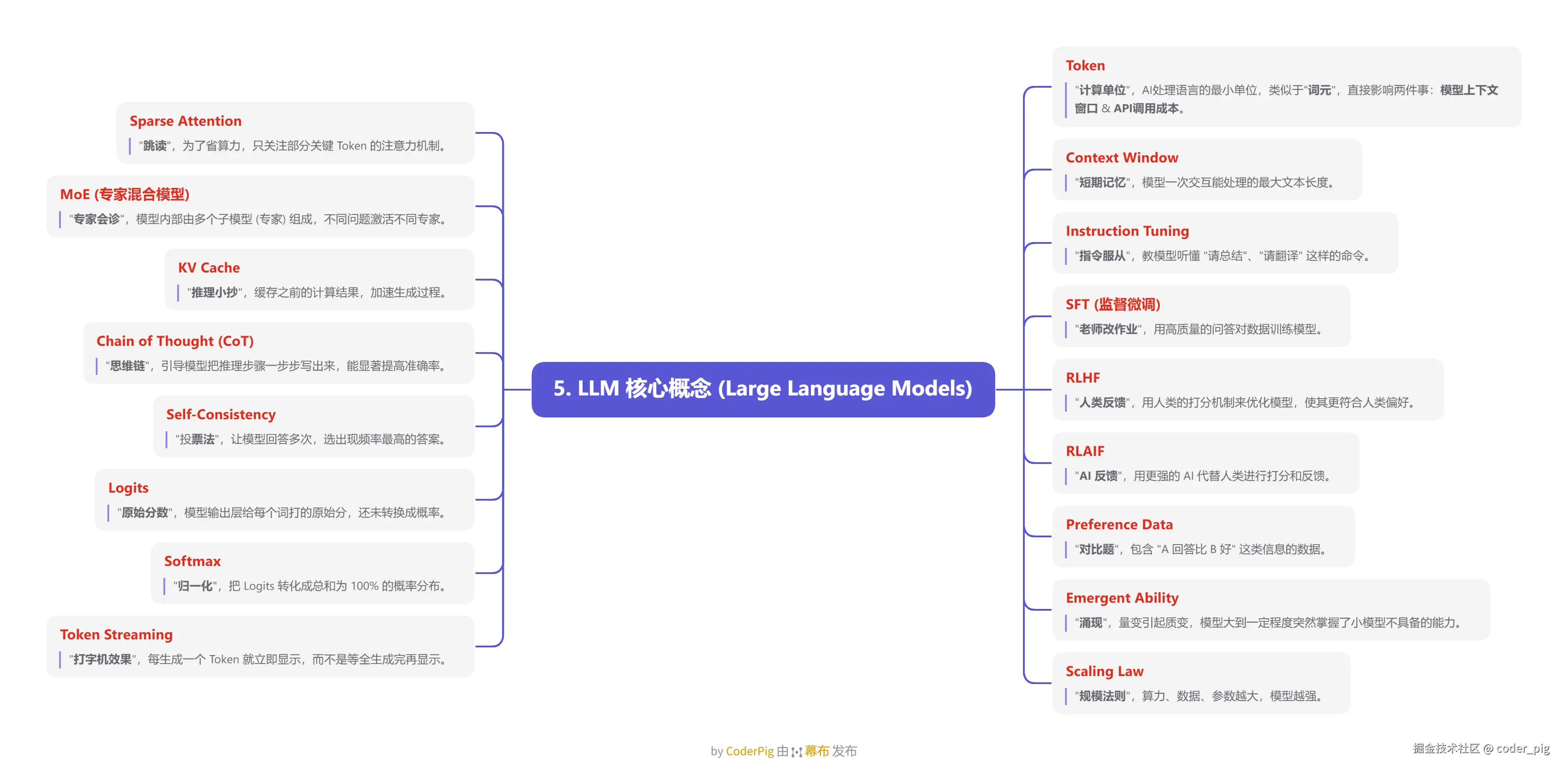
5.5. LLM 核心概念 (Large Language Models)
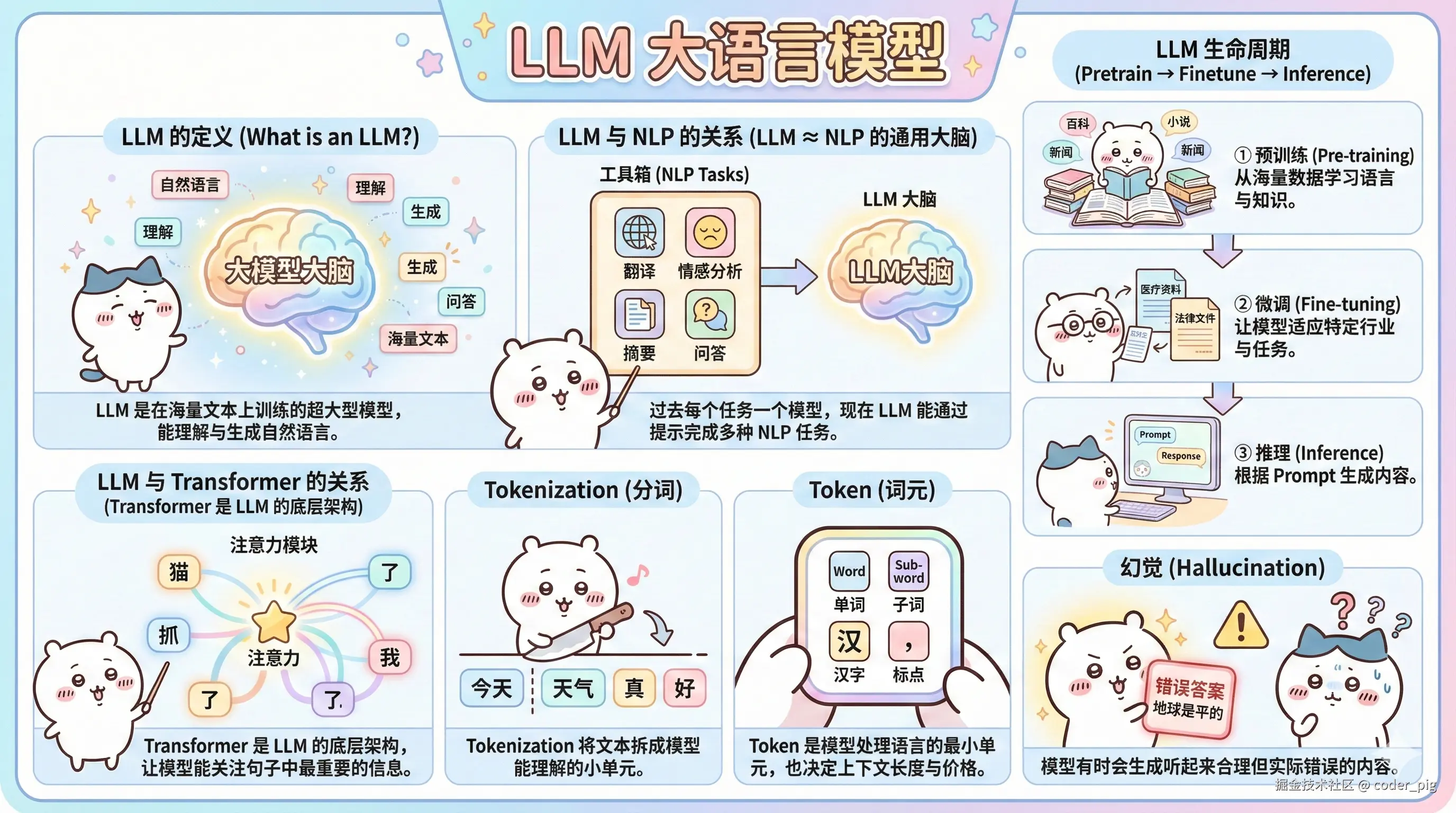
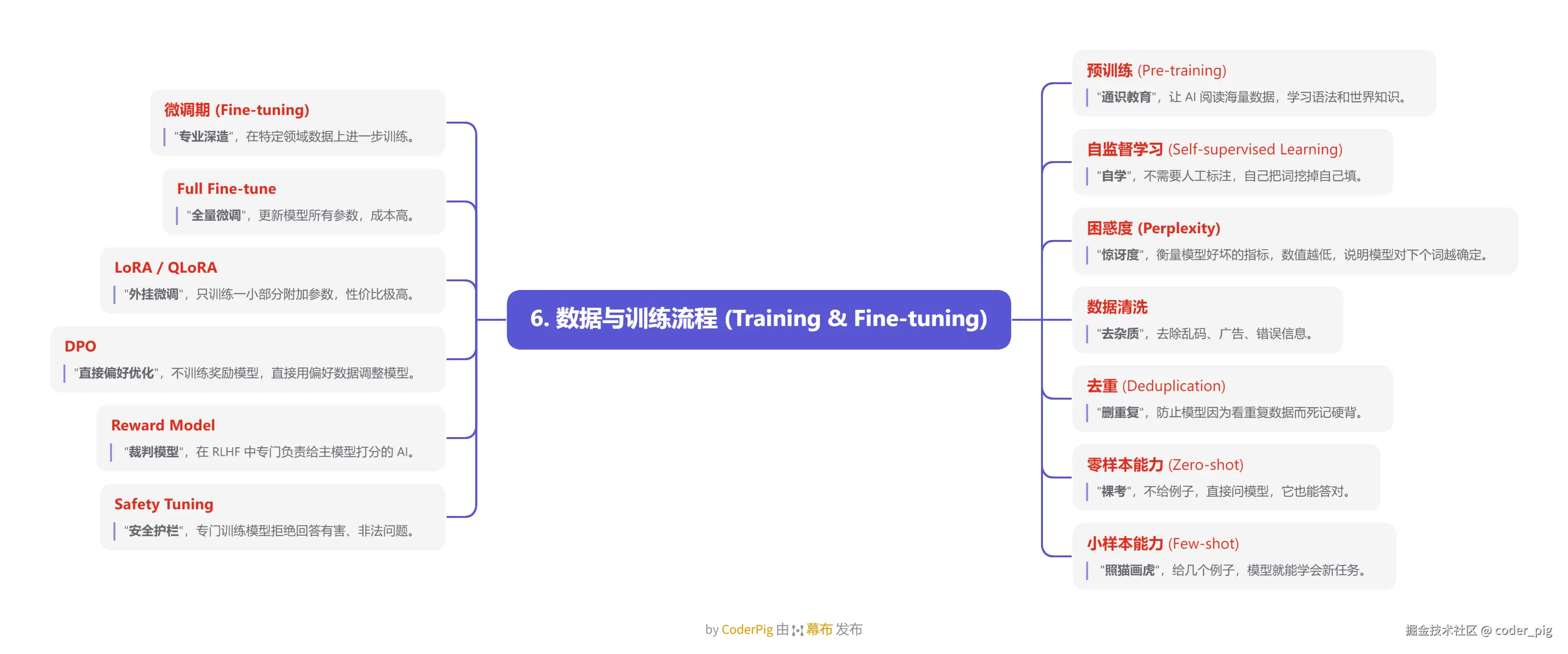
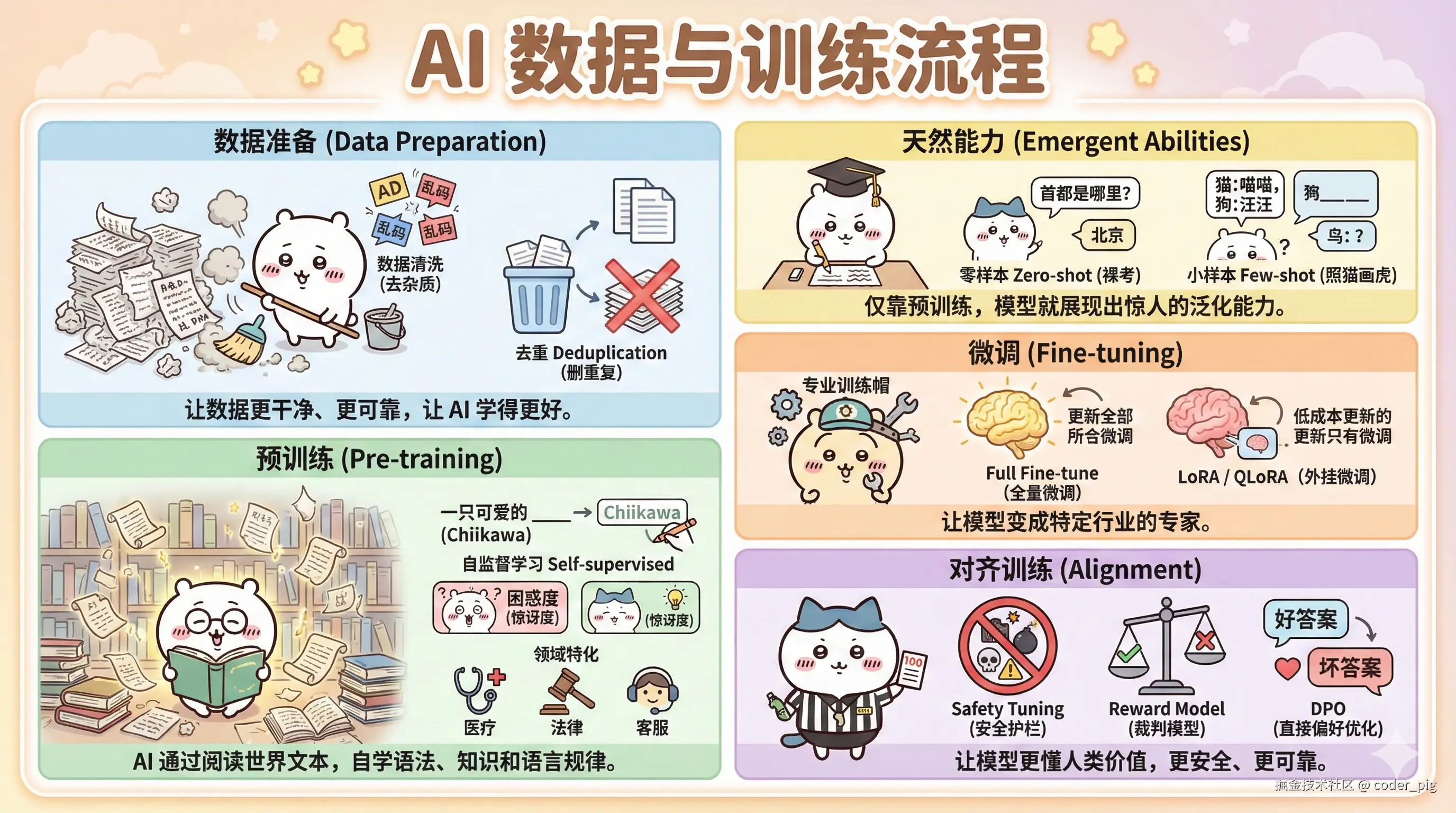
5.6. 数据与训练流程 (Training & Fine-tuning)
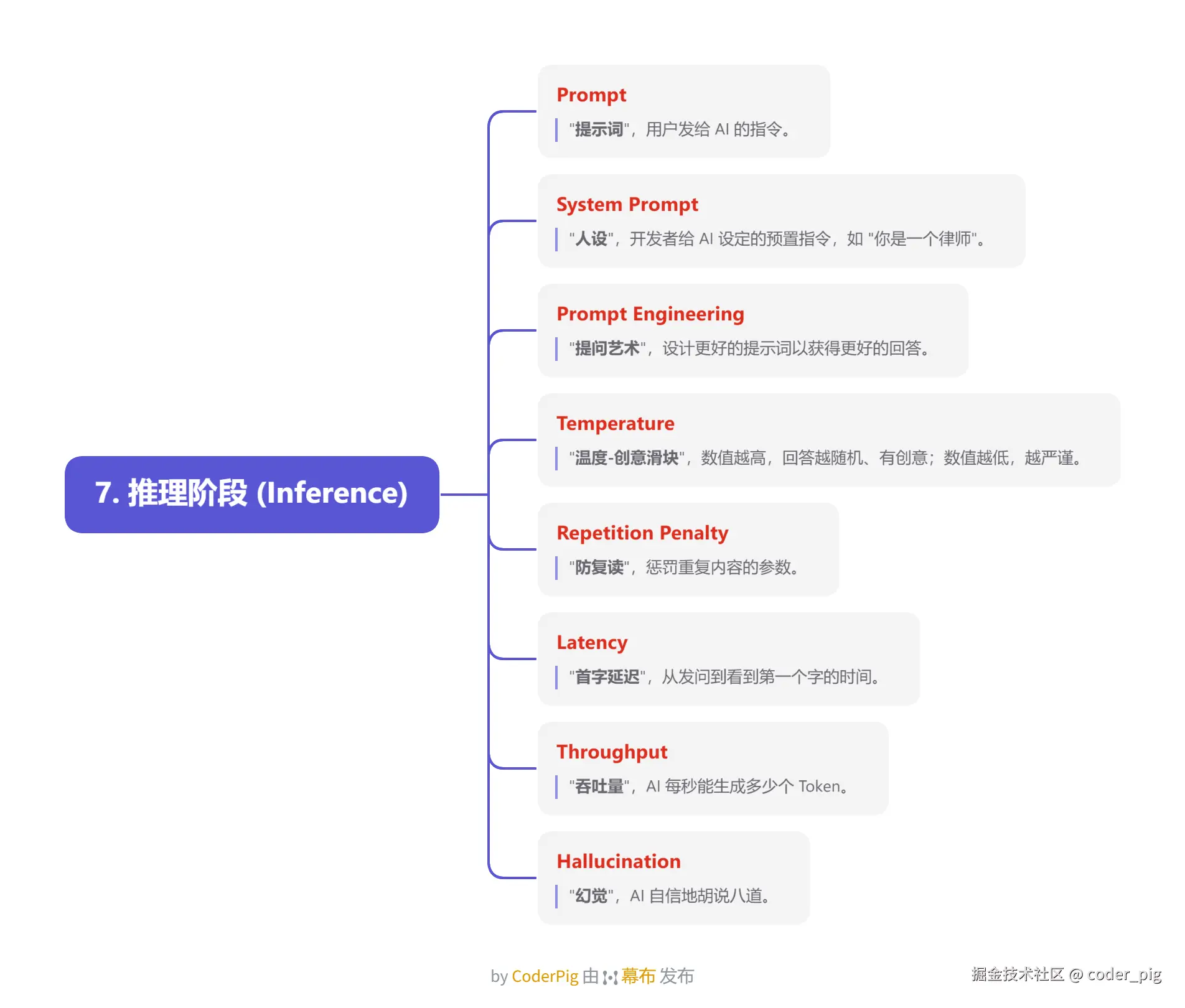
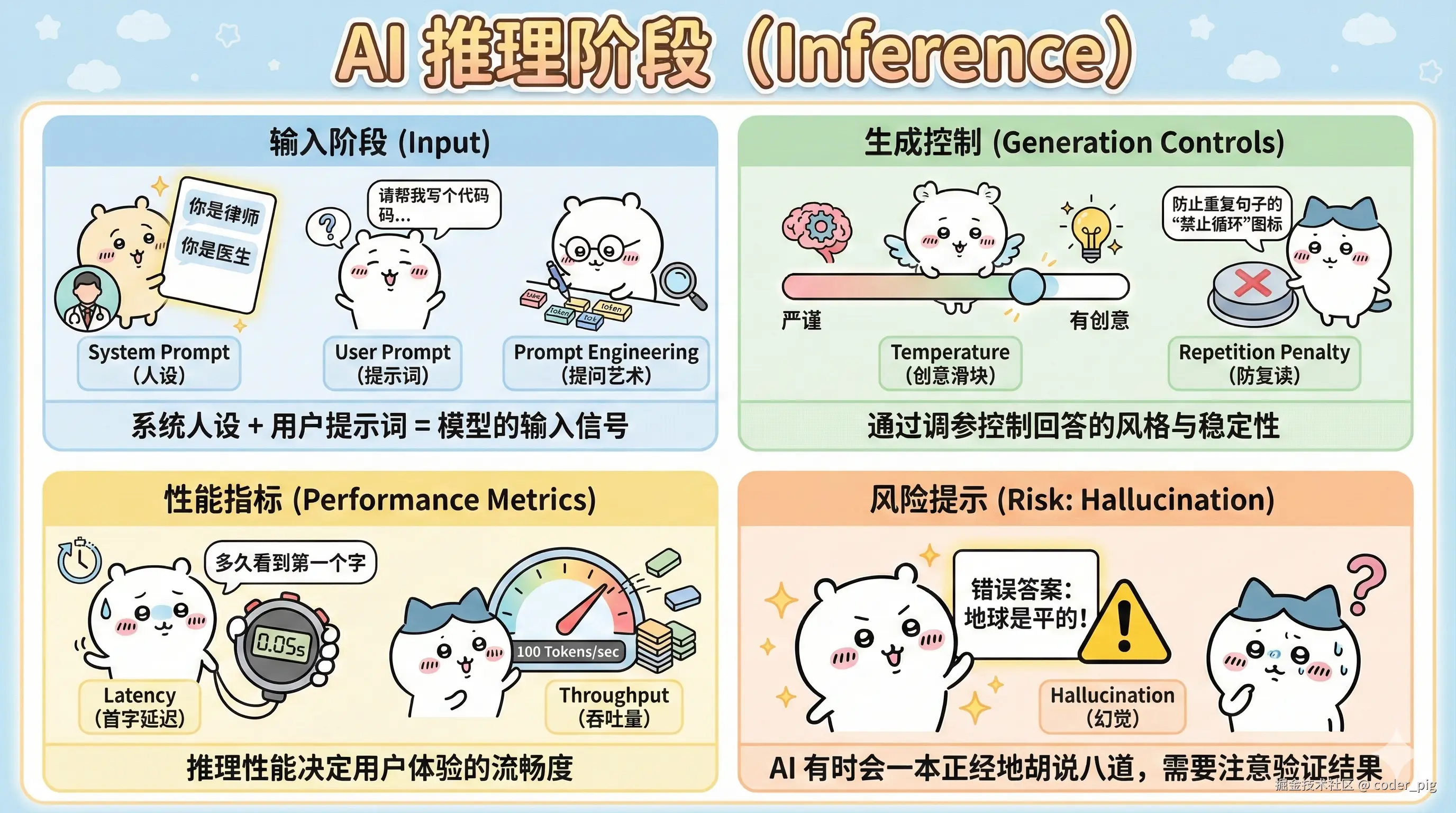
5.7. 推理阶段 (Inference)
5.8. RAG (检索增强生成)
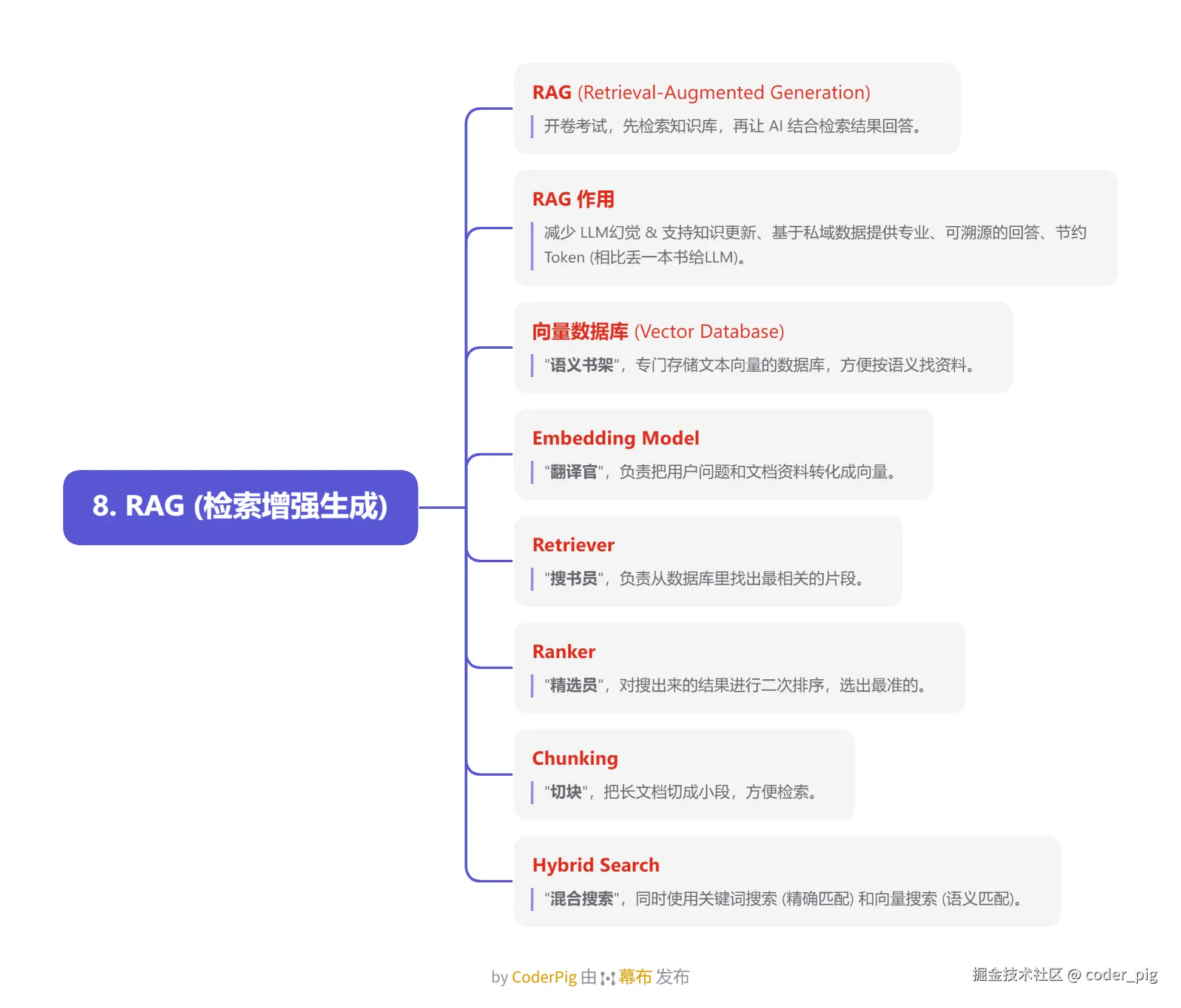
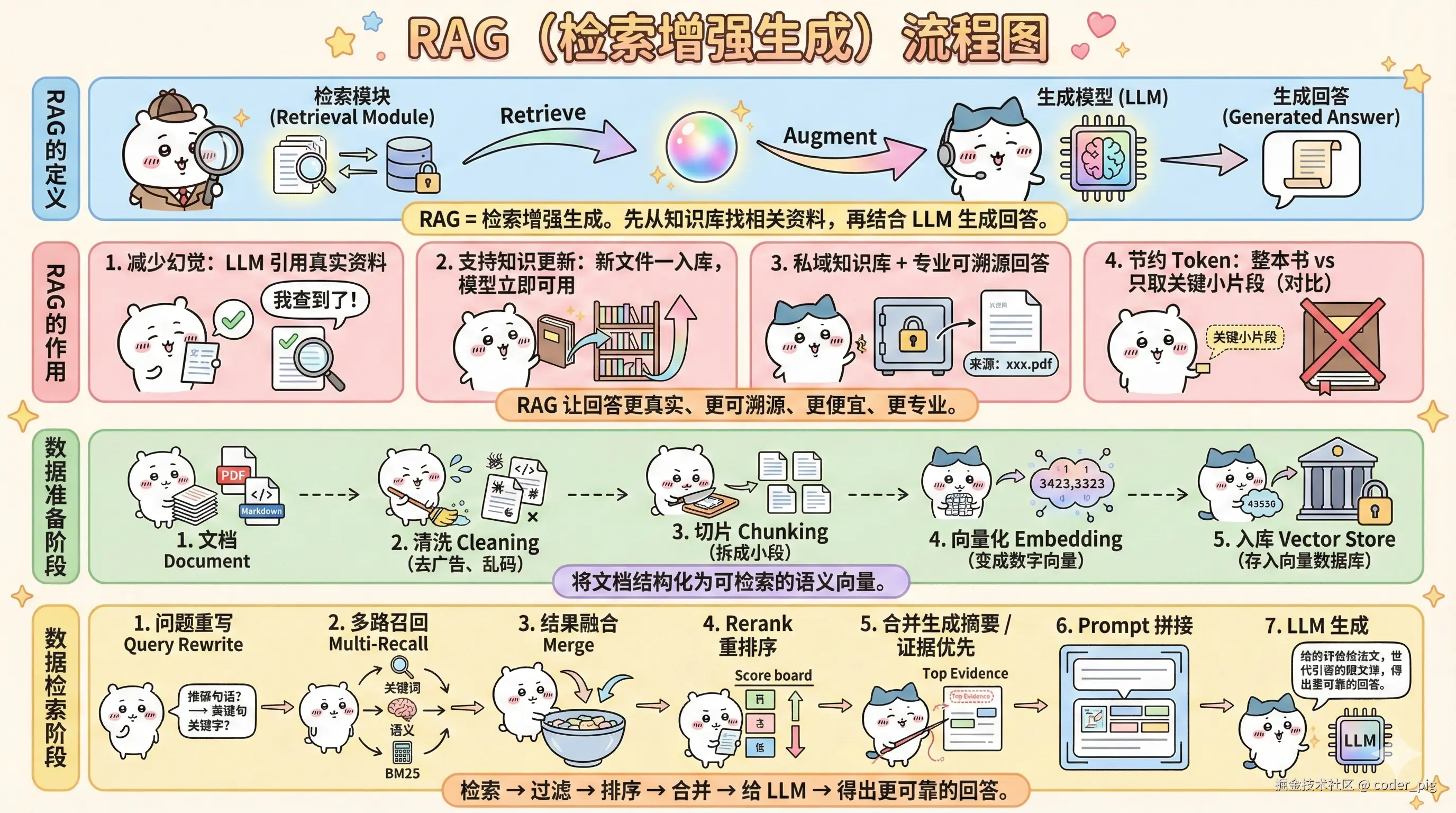
5.9. 多模态 AI
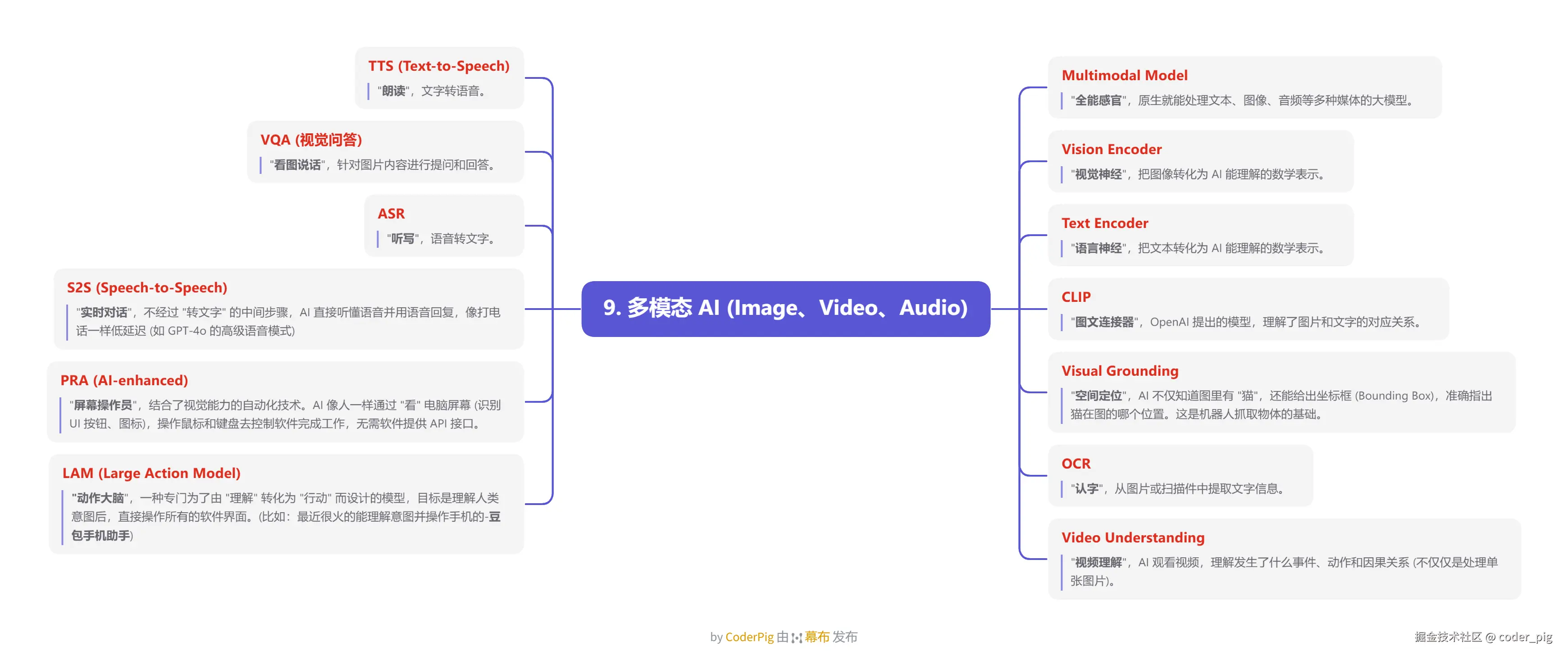
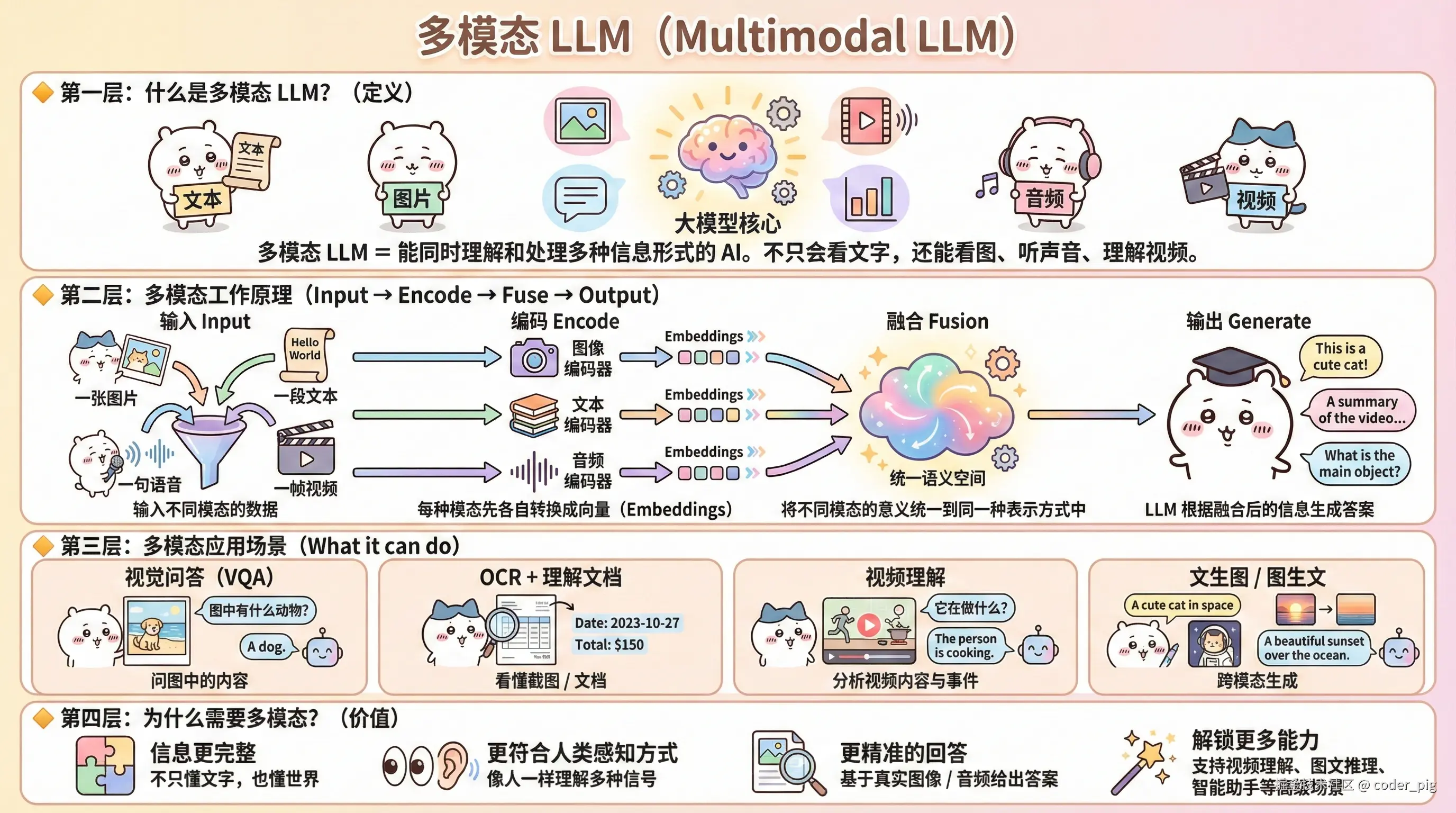
5.10. AIGC (生成式内容)
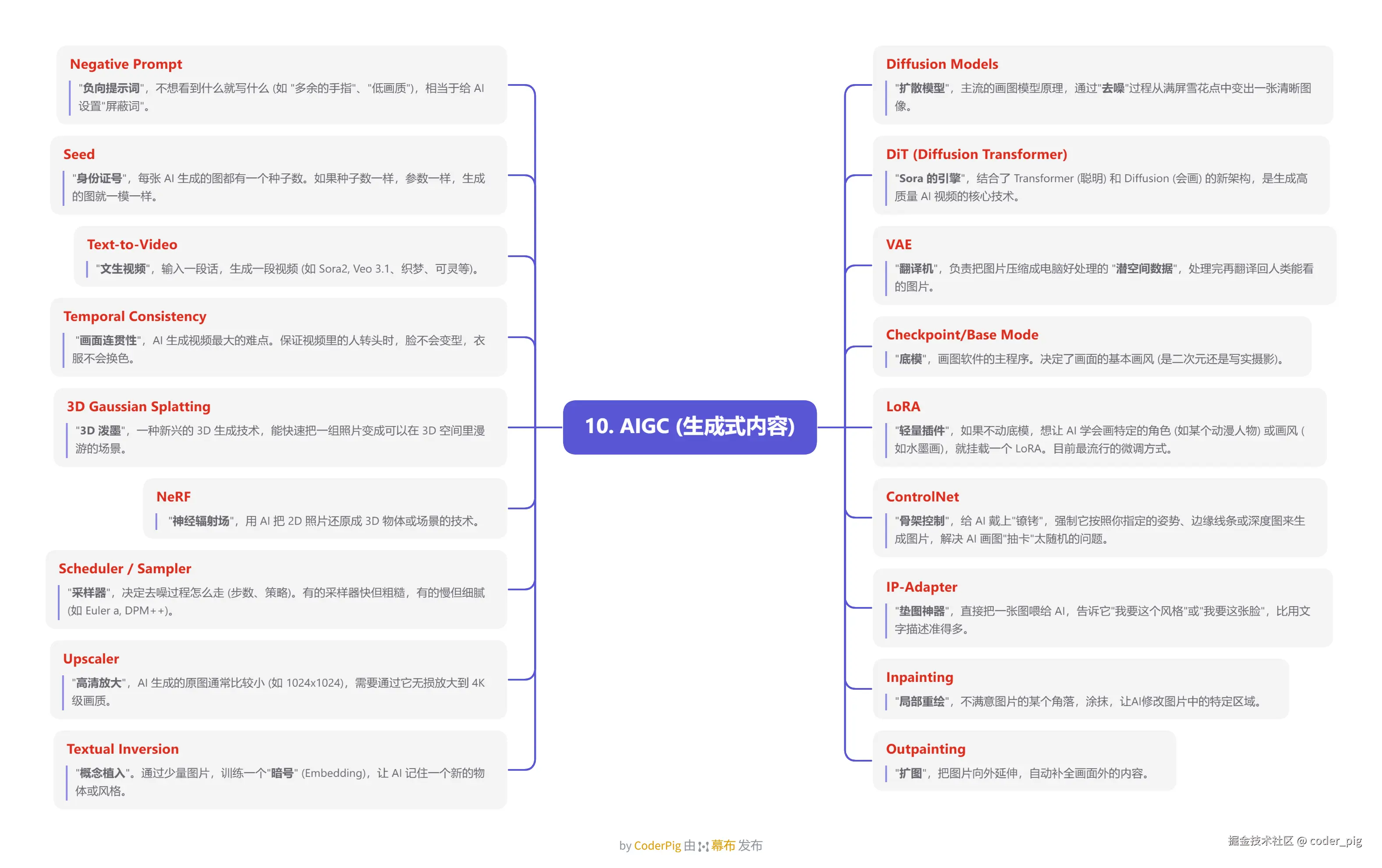
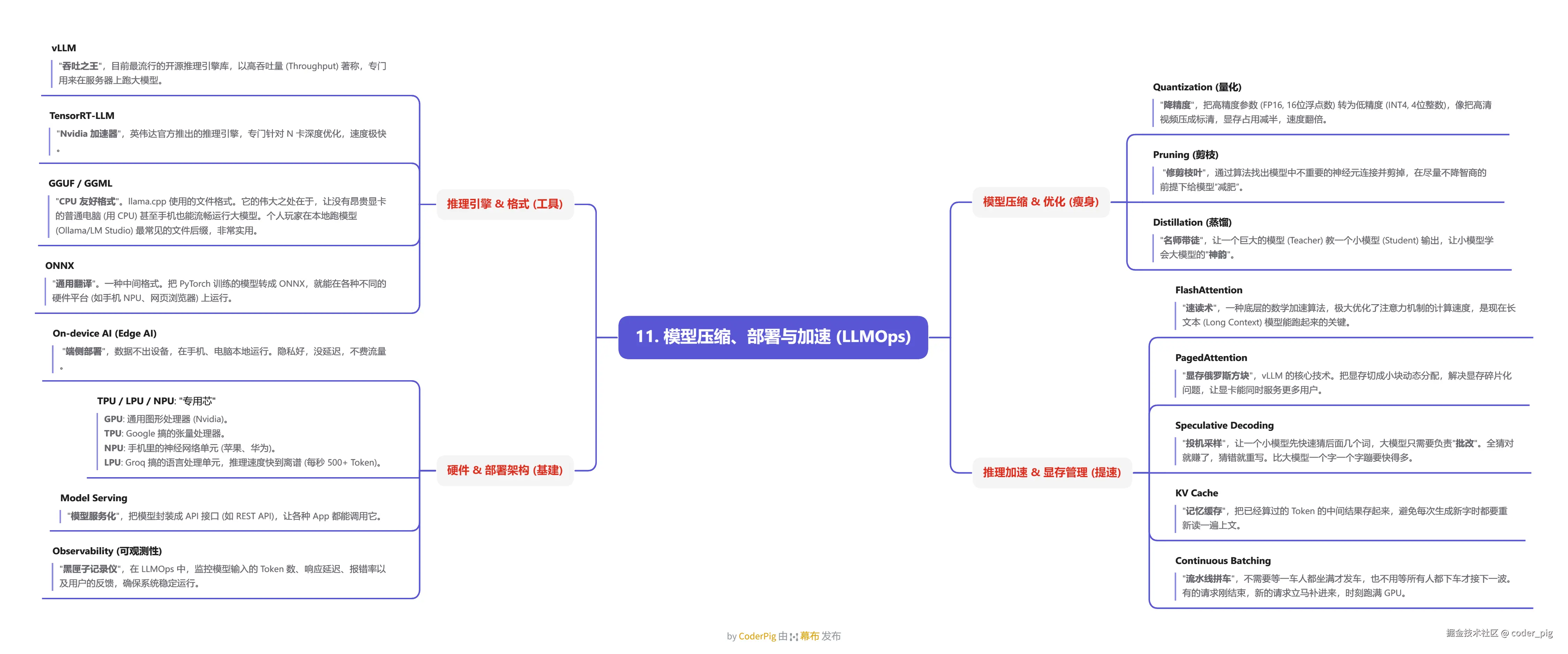
5.11. 模型压缩、部署与加速 (LLMOps)
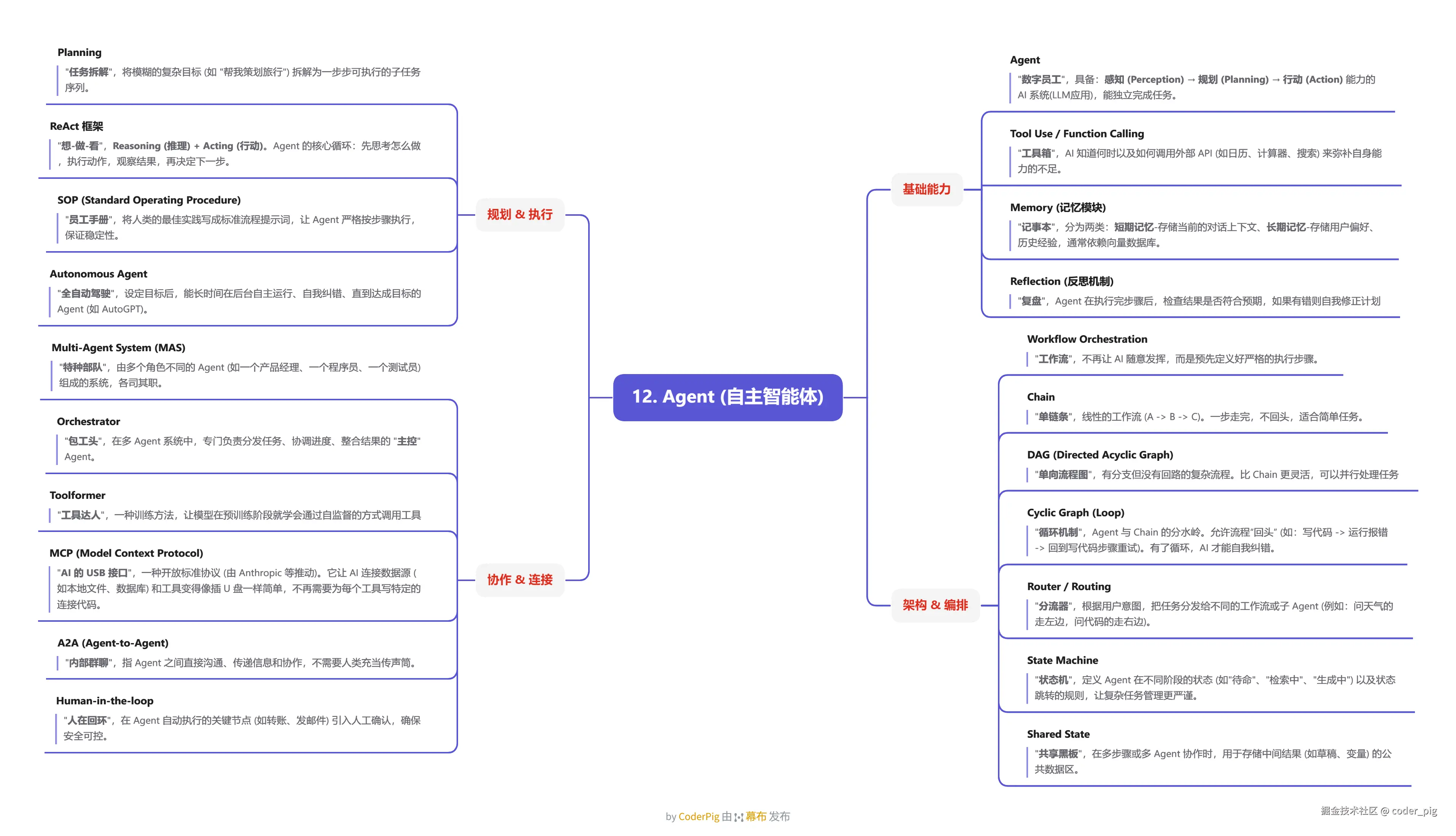
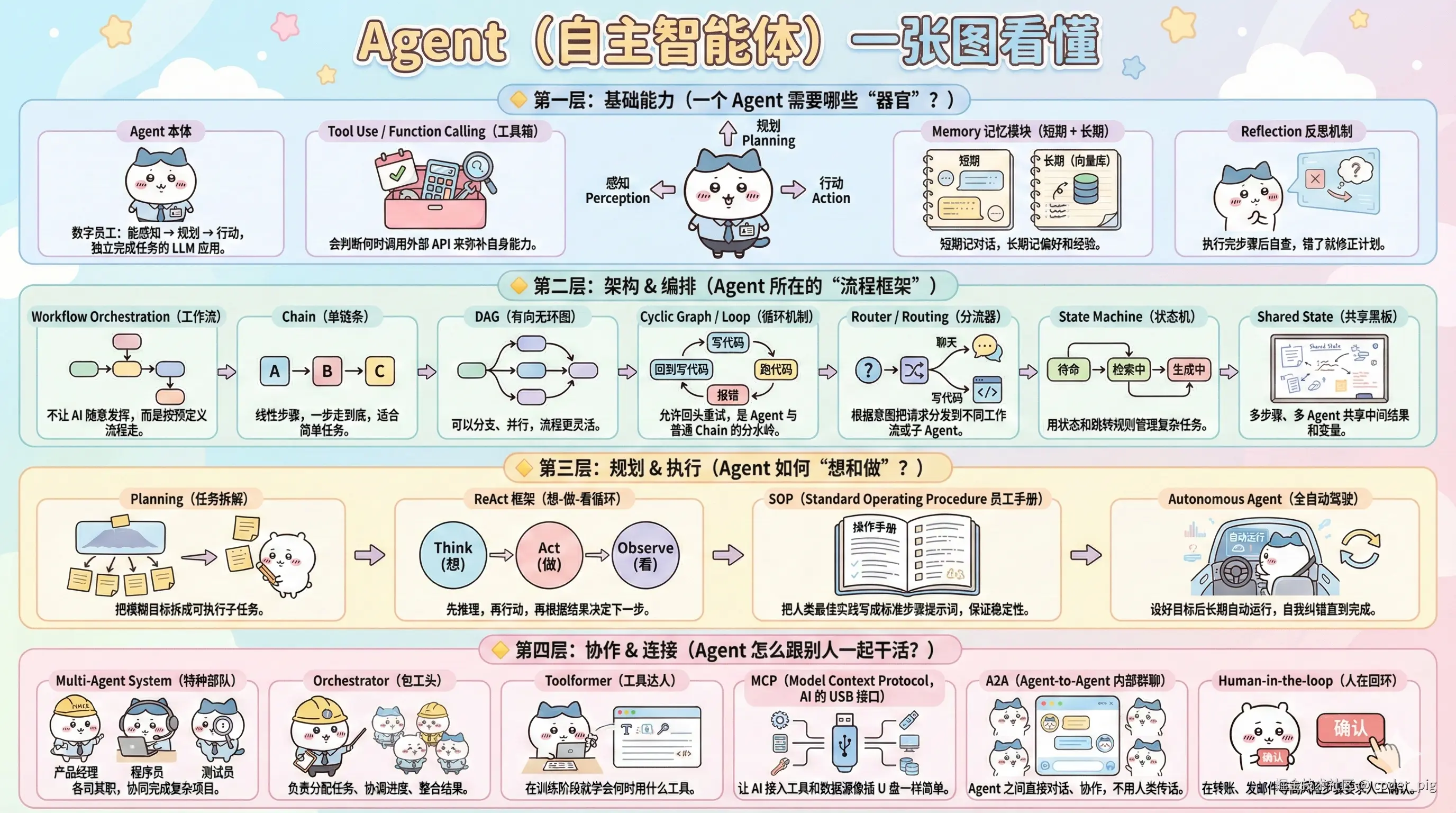
5.12. Agent (自主智能体)
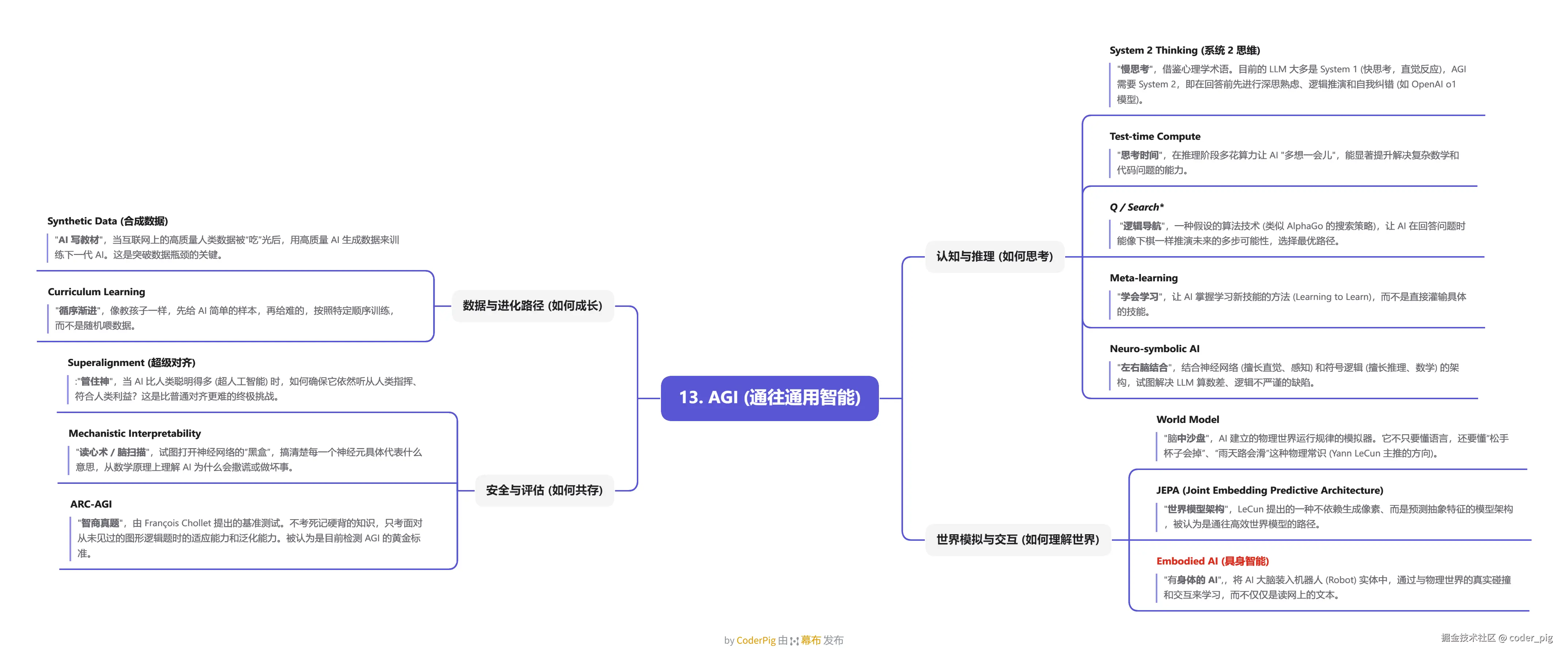
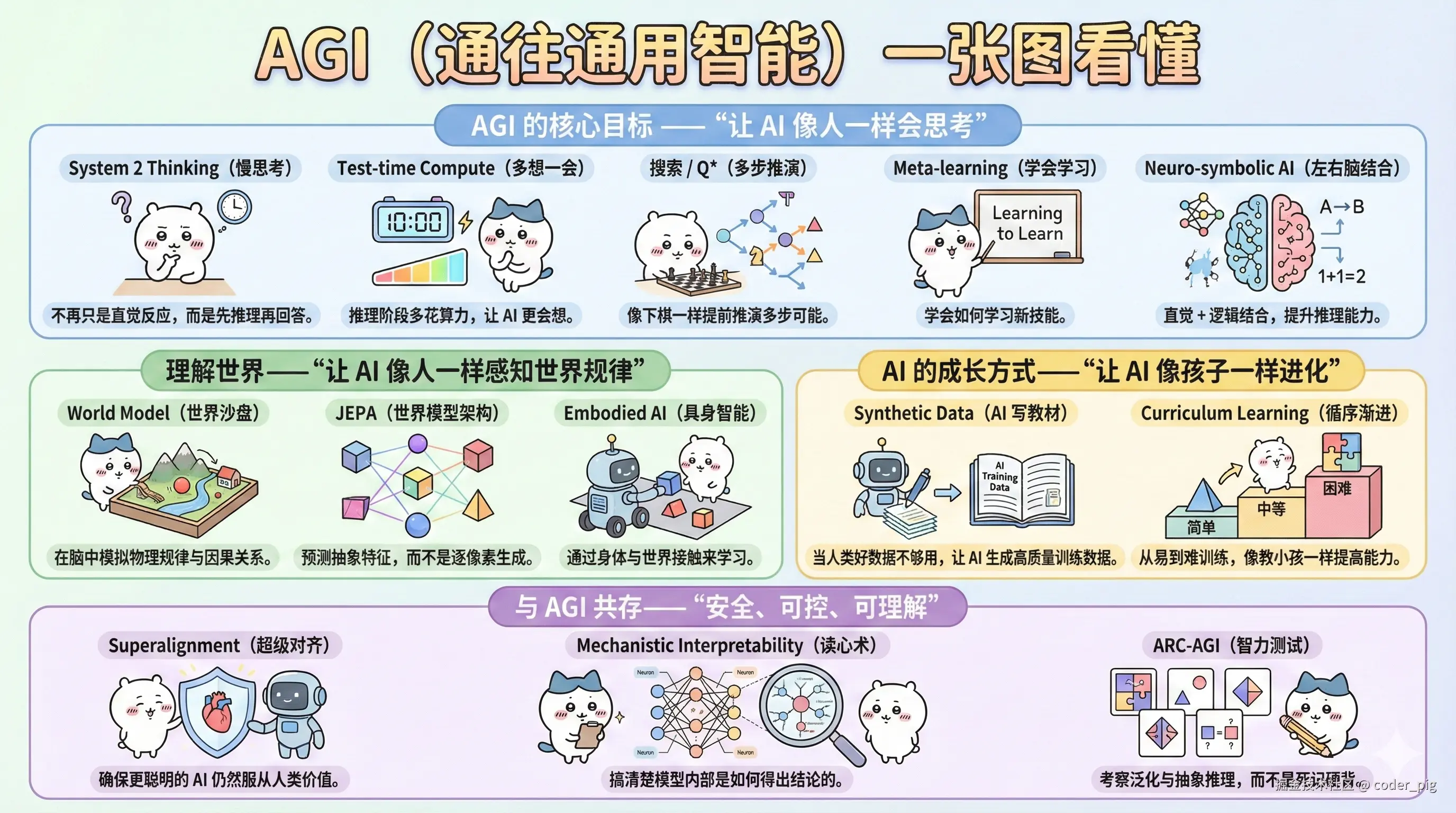
5.13. AGI (通往通用智能)
6. AI 编程领域专精
😄 最后,聊聊 AI 编程 领域的一些心得~
6.1. 前置知识
6.1.1. 编程模型
AI 代码写得好不好,主要看 "模型" 的 "编程能力",评估 "模型优劣" 的几个 "常见维度":
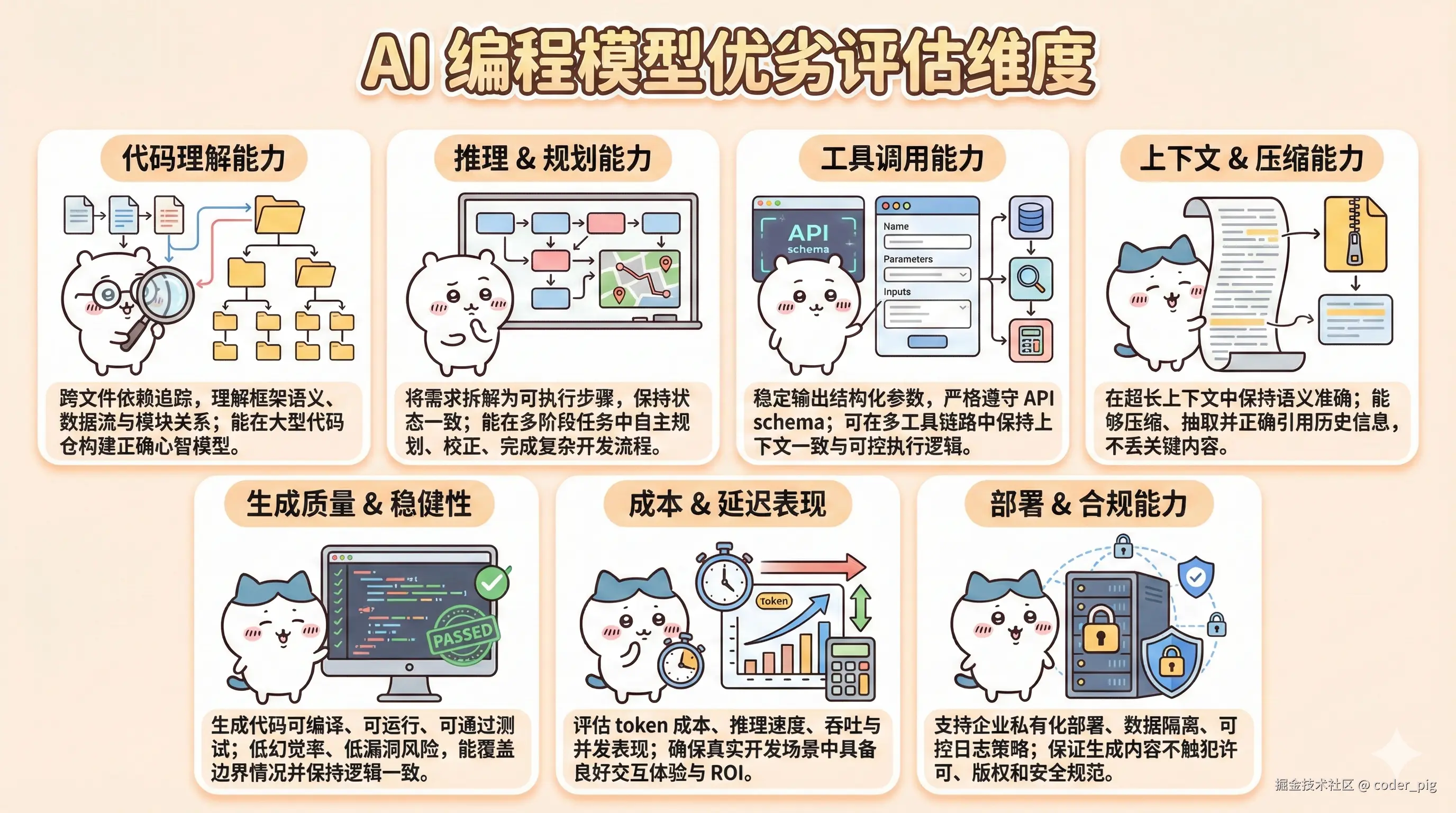
LLM 的能力很难用一句话概括,所以厂商们每次发新模型都会用一堆 Benchmark 来证明 (🐶不服,跑个分?)
① 推理与数学能力 (Reasoning)
"智能的核心指标",高分意味着能够做更复杂任务 (如:工程规划、Agent等),常见基准:GSM8K-小学奥数式数学题、MATH-高难度数学、AIME/AMC-奥林匹克数学、GPQA-博士级科学问答、BigBench Hard (BBH)-推理难题集合 等。
② 语言理解与知识能力 (Language / Knowledge)
"通用模型 IQ 测试",常见基准:MMLU-大学生多学科理解测试、MMLU-Pro - 更难版本、ARC / HellaSwag - 常识推理、OpenBookQA/TriviaQA - 事实/知识问答 等。
③ ✨编程能力 (Coding)
"商业价值极高的应用点",常见基准:HumanEval - 函数级别代码生成、MBPP / MBPP+ 简单编程题、SWE-Bench / SWE-Bench Verified✨:真实 GitHub issue + 多文件工程 (最接近真实开发场景,近两年厂商都在比这个)、Codeforces-算法比赛、CRUXEval / RepoBench-项目级分析 等。
④ 多模态能力 (Multimodal)
"下一代 AI 产品的必争之地" (做 AI 助手、看图、自动化办公等),常见基准:MathVista:带图的数学推理、ChartQA / DocVQA:文档理解、TextCaps / ImageNet:视觉场景理解、VideoMME:视频理解、V-Bench / VQAv2:视觉问答 等。
⑤ 安全性 (Safety / Robustness)
企业用户很看重 "安全合规",常见基准:Harmlessness / Truthfulness、AdvBench:对抗攻击、Red Team 红队测试、Over-Refusal 测试(不会乱拒绝)、Speculative Safety(推测生成的风险)等。
⑥ 速度/延迟/吞吐 (Performance Metrics)
"决定实际用户体验",常见指标:Tokens per second (推理速度)、First Token Latency (首字延迟)、Throughput QPS (每秒处理请求数)、Context processing speed (长文档处理速度)。
有时还会发布一些 "技术参数":
-
模型规模:模型的参数量大小,影响推理与表达上限,规模越大,能力越强,但成本、延迟和部署难度也越高。如:70B = 70 billion = 700亿参数。
-
训练数据规模:模型预训练时学习的 token 总量,代表其知识 "阅历"。数据越多通常知识覆盖越广,但质量、去重和清洗策略比单纯堆量更关键,高质量数据才能让模型表现更稳。如:15T = 15 trillion = 1.5万亿个token。
-
上下文窗口:模型单次可接收并 "记住" 的 "输入长度上限",决定你能塞多少代码、文档和对话历史;窗口越大越适合做整仓分析、长文档问答、复杂任务,但会牺牲成本和延迟,且需要额外机制确保在超长上下文中仍能抓住重点。
-
推理深度:模型答题时的 "思考力度",深推理模式更准确、适合复杂问题,但会更慢、更贵,适合关键任务而非高频交互。
-
价格:按 token 收费,区分输入价、输出价与最小计费单位;部分模型提供 "缓存命中 (cache hit) ",对重复提示只按更低费率计费,大幅降低长上下文与多轮调用成本。价格决定模型可否大规模、频繁和低成本使用。
-
延迟标准:包含首 token 延迟 (FTL) 与 生成速度 (token/s),分别决定 "多久开始回应" 和 "内容生成有多快";低延迟让补全、对话、Agent 流程更流畅,而高延迟会严重影响开发体验与实时性,是工程中比 "更聪明一点" 更重要的性能指标。
-
模型行为控制能力:通过 Temperature、Top-p、System Prompt、工具权限等机制控制模型的随机性、稳定性与执行边界;行为越可控,越能确保输出一致、不跑偏,并安全地接入工具链或生产系统,是把模型从 demo 提升到可上线能力的关键参数。
🤡 个人 "主观" 认为的 "编程模型" 能力排名:
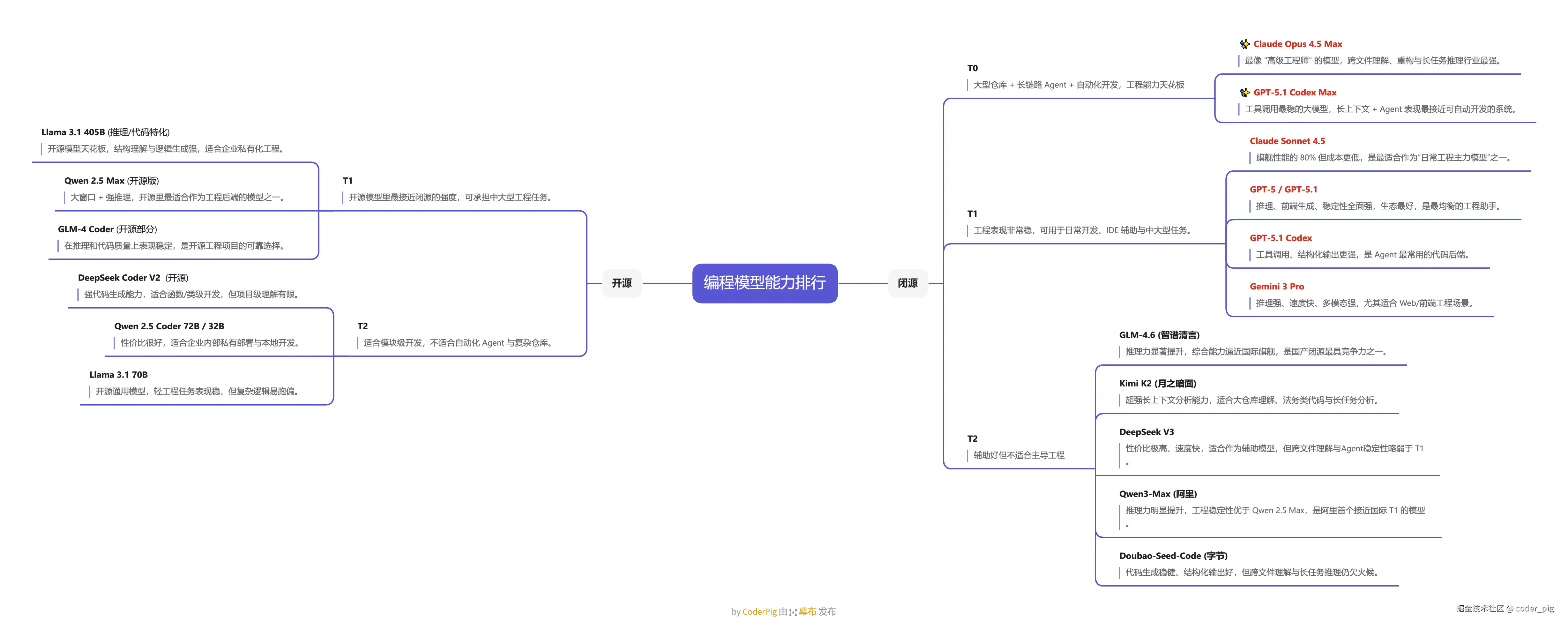
😊 一句话概括我的 "选模型策略":
选好的模型事半功倍!工程大活 找 Claude,精细小活 (如改BUG) 用 GPT,写前端页面用 Gemini。
🐶 问:这些都是国外的模型啊,怎么才能用上?A社还锁区,经常封号?而且价格好贵啊?
答:😏 这个问题充钱可以解决.jpg,多逛下海 (xian) 鲜 (yu) 市场,国人的 "薅羊毛" 能力不是盖的,各种 "镜像站、第三方中转" 。氪金的时候注意找有 "售后" 的,随用随充,买 "短期 (如月付) ",不要买 "长期 (如年付)",这种看 LLM官方 政策的,一封就直接G了,说不定就 "卷款跑路"~
6.1.2. AI 编程工具的四种形态
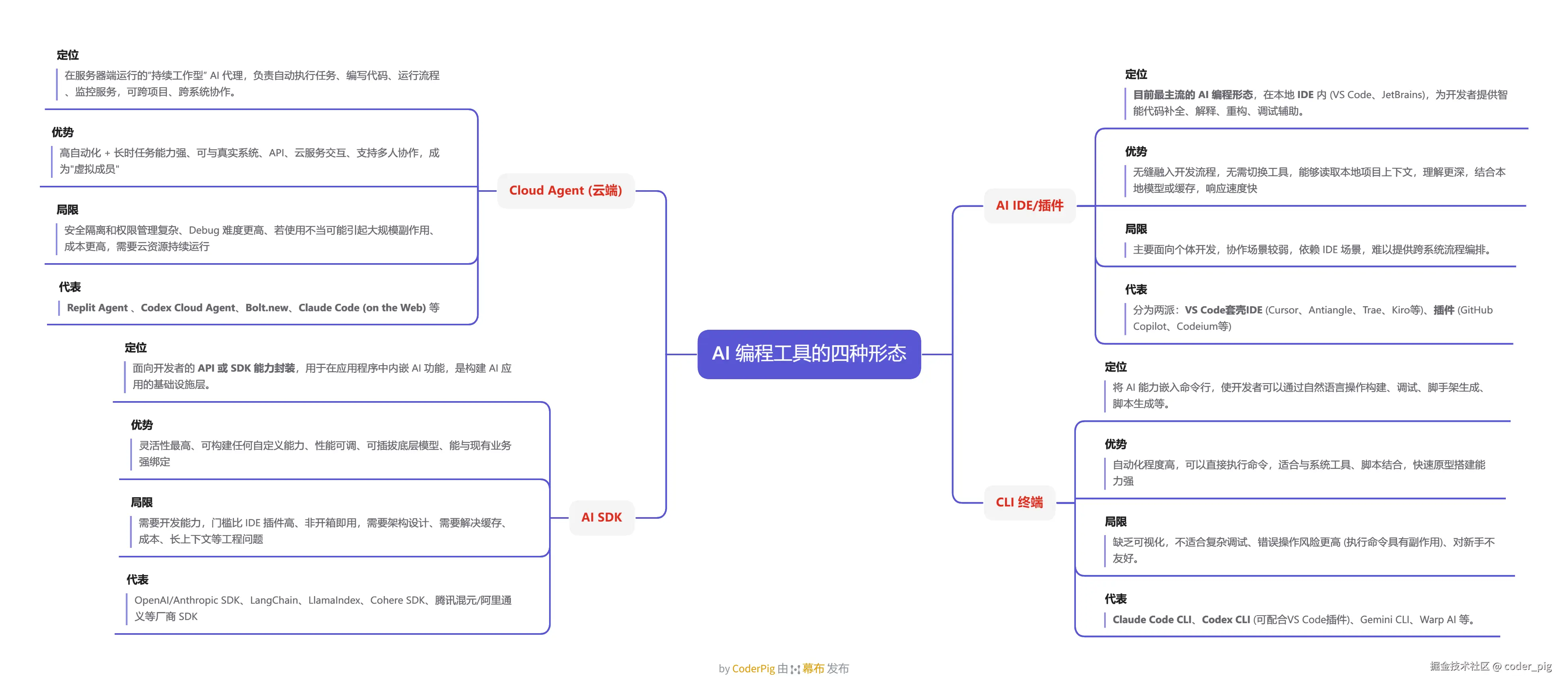
😄 一句话归纳:
普通开发者 & Vibe Coding用户 用 AI IDE/插件 居多,DevOps/后端工程师 用 CLI,团队/企业系统 用 云端Agent,AI 应用开发者 用 AI SDK 构建构建 AI 产品与 Agent 系统。
接着说下 "AI编程" 的三种演进层次~
6.2. 第一层:AI 辅助开发
最早期的AI开发方式,以「人主导 + AI辅助」为核心逻辑,由两种交互模式组成:
-
补全式:基于输入光标前的上下文,预测下一个单词、下一行代码、甚至整个函数。
-
对话式:在 IDE 侧边栏或网页中,通过自然语言问答来生成代码、解释代码或查找 Bug。如:"帮我写一个 Python 的正则来验证邮箱" 或 "这段代码为什么报错?"
这一层的局限:
-
上下文有限:AI 通常只能看到当前文件或少量相关片段,缺乏对整个项目架构的理解。
-
被动性:AI 不会主动修改你的代码文件,它生成代码,你负责复制粘贴和校验。
-
人是瓶颈:所有的决策、文件切换、环境配置都必须由人来操作。
6.3. 第二层:AI 驱动开发流程 (规范+Agent)
目前最前沿、最热门的阶段,AI 不再只是吐出代码片段,而是进化为 Agent (智能体),拥有了 "大脑" (规划能力) 和 "手脚" (工具使用能力),可以 "自主完成一个多步骤的开发任务"。
变成了「人定目标 + Agent 自主执行」,如:"实现一个简单的待办事项 Web 服务,要求:REST API,内存存储即可,有单元测试",Agent 可能会进行这样的任务拆解并执行:
设计目录结构 → 创建代码文件 → 写业务逻辑 → 写测试 → 运行测试并自我修复。
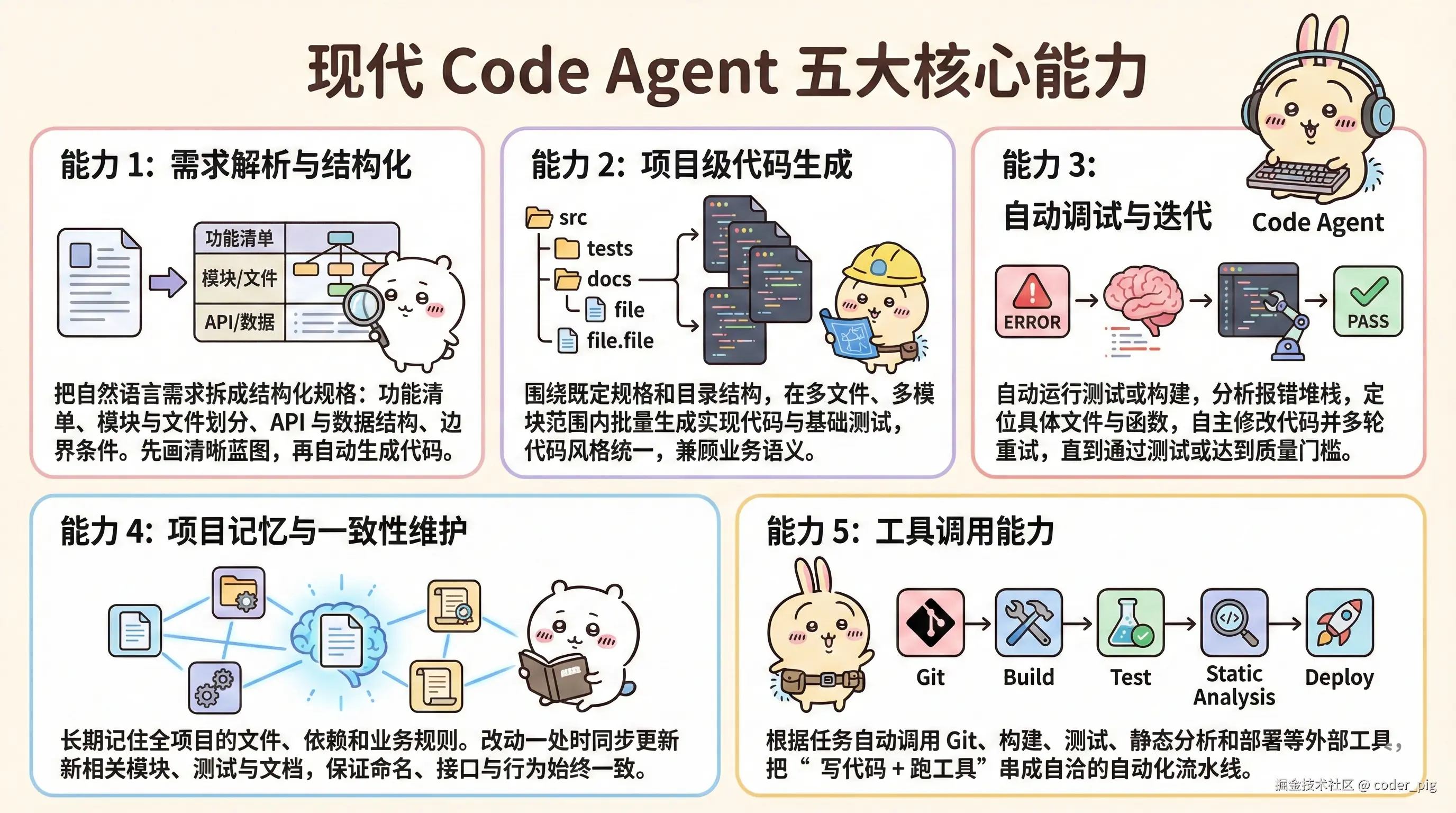
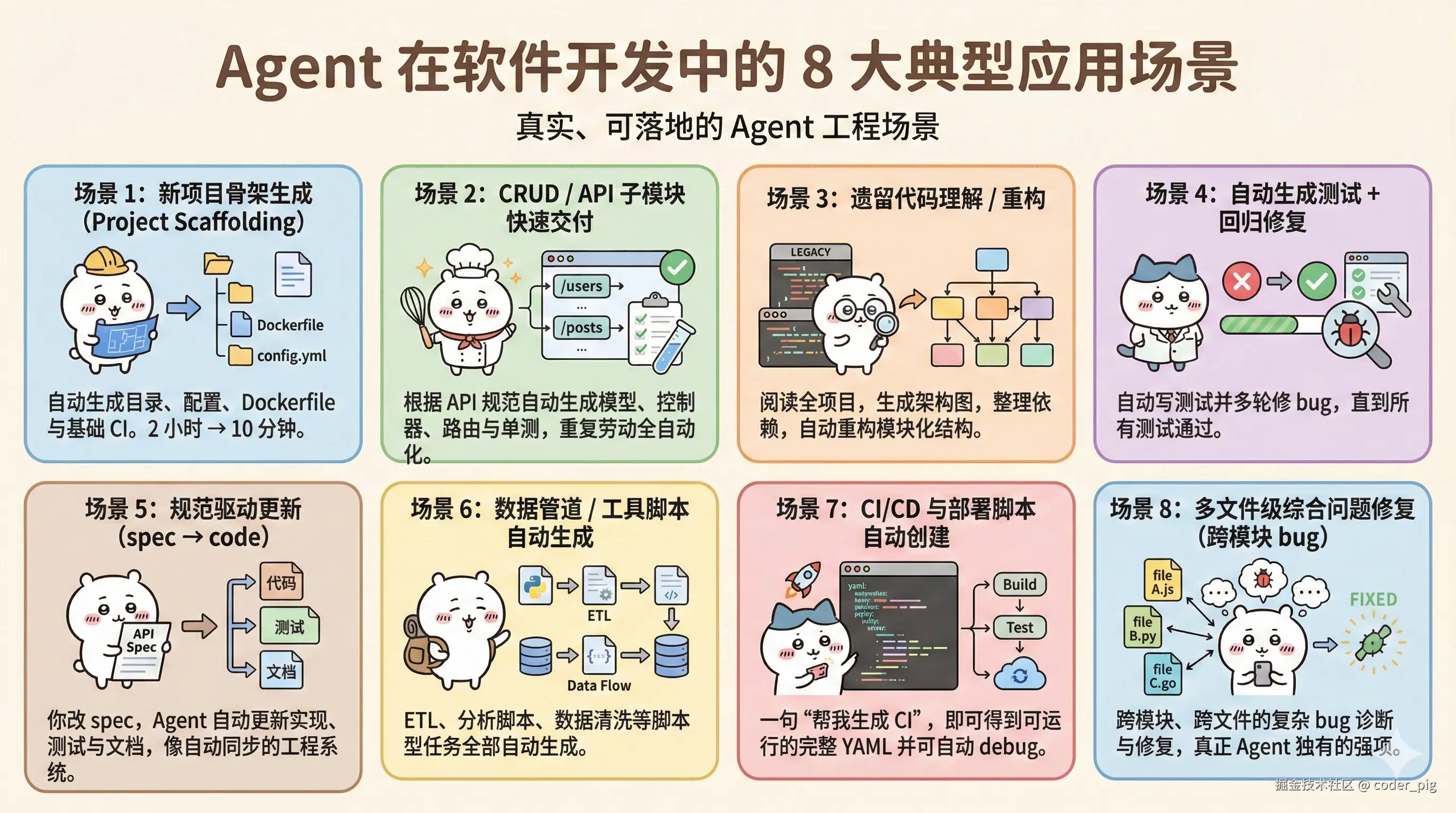
为了系统地应用 Agent,业界逐渐采用「 "规范"驱动的开发流程」(Spec-Driven Development):
需求 → 规范文档 → 任务分解 → Agent执行 → 验证反馈
这个流程确保了 清晰的目标定义 和 可追踪的执行过程,而不是让Agent盲目操作。开发者需要维护的 "三类规范" (规范必须比写代码更清晰):
-
功能规范:目标、用户故事、输入输出、性能要求、鉴权、边界情况等。
-
技术规范:模块结构、API、模型字段、状态机、异常流程等,Agent会根据这些自动创建项目。
-
验收规范:测试通过、接口返回正确、性能满足要求、行为与设计一致,即每个功能的评价方式。
人不再写代码 (或者少写),负责「定义 + 审核 + 授权」,人-Agent 协作 的三阶段循环:
-
人主导-目标设定:范围、约束、边界、不允许做的事情。
-
Agent主导-执行:分解、规划、写代码、自动Debug、修复、生成报告。
-
人主导-验收:代码质量、安全性、单元测试覆盖率、偏差是否满足业务需求等。
💡 层2 关注的是「开发流程自动化」,任务的起点通常是 "已经确定好的需求/feature"。
6.4. 第三层:AI 全栈
所谓的 "AI 全栈",本质上就是 "让 AI 同时扮演多个软件开发角色",而 "一人分饰多角" 的自然实现方式就是 "多 Agents"。——《抠腚男孩》
6.4.1. 为什么聊到 "AI全栈" 就会扯到"多 Agents"?
🤔 想象一下让 "AI全栈开发一个应用" 需要经历哪些步骤?
产品需求理解 → 技术选型 → 架构设计 → API 设计 → 前后端代码生成 → 数据库 schema → 错误处理 → 文档生成 → 单测编写 → 测试执行 → 部署脚本 → CI/CD 配置。
让一个 Agent 承包上面所有的工作,会有什么问题?
记忆量爆炸、目标切换频繁、推理链拉得太长,错误积累变大、一旦一步出错,后续全崩、风格、结构、代码质量难统一、难以并行。
软件工程是 "多角色协作" 的结果:产品经理、架构师、后端、前端、测试、文档、DevOps... 如果想 "AI 模拟完整的软件开发流程",自然也需要 "让 AI 也模拟这些角色",于是就变成了这些 Agent:
-
Planner / Architect (产品/架构):理解需求、拆任务、出计划 (Plan)。
-
Coder / Implementer (实现):按计划改代码、增删文件。
-
Searcher / Context Agent (检索):在代码库里找相关文件、API、调用链。
-
Tester / QA (写测 / 跑测):写测试、跑测试、分析报错。
-
Fixer / Debug Agent (修BUG):根据测试/运行结果修复代码。
-
Reviewer / Critic Agent (代码审阅):检查风格、一致性、潜在 bug / 安全问题
-
Ops / Deploy Agent (部署):写 Docker、CI/CD、部署脚本(有些系统只做到生成,不自动执行)
即「AI 全栈 = AI 软件开发流水线 = 模拟整个软件部门 = 多 Agent 系统」,这是开发任务决定的。
"AI全栈" 需要的三大核心能力:
-
长任务规划 (Planning):开发一个系统不是线性的,是树状决策结构,要拆分任务,就需要 Planner Agent。
-
并行执行 (Parallel Execution):前端、后端、文档、测试不可能一个个线性做。多 Agent 可以:前端 Agent 改 UI、后端 Agent 写 API、Docs Agent 补文档、Test Agent 补测试。
-
验证 & 修复 (Validation Loop):真正让 "AI 全栈" 可行的关键是 "循环",写代码、跑测试、找错误、修复、再跑,需要 "多 Agent + 状态机" 才能撑起这个能力。
"AI 全栈系统" 的实现,本质就这四步:
- 「定义一堆上面这样的角色」
- 「排布拓扑」决定这些角色之间的连接结构和调用关系。谁先谁后 (拓扑/顺序)、有没有循环 (写→测→修→再测)、有并行吗 (前后端Agent同时干活?)、是由一个 "主管Agent" 指挥大家?还是大家按照状态机自己转?
- 「给每个角色接上能用的"工具",让它真的能动手干活」常见工具:文件 (读/写代码、生成 diff)、终端 (执行命令)、搜索 (在 repo 里搜符号 / 用法)、HTTP/Browser (查文档、查API)、Git (开分支、commit、生成PR)、结构化分析 (AST分析、调用图、依赖图)。比如:Coder Agent 配置 "文件读写、diff 生成、代码搜索" 的工具,用来 "在受控范围内改代码"。
- 「套一层安全边界」权限 (读写、只能改指定目录、终端命令必须在沙箱里执行)、人在回环 (关键操作必须人工确认,如:Plan-任务规划、大范围diff、部署相关改动/高危脚本)、防注入/误操作 (不轻信代码库里的"指令"-如:恶意README 写 "rm -rf /"、对外部输入做过滤-日志/错误信息/用户Prompt、限制重试次数,避免死循环修改)。
一句话概括就是:
AI 全栈 = 一群小模型/小角色 + 一个调度关系图 + 一堆工具函数 + 一圈安全护栏
😄 弄清楚本质,以后看任何 "AI 全栈多 Agents" 方案,都可以基于这三个问题进行快速拆解:
- 它有哪些角色?(Planner / Coder / Tester / Fixer / Ops…)
- 这些角色是按什么拓扑 / 流程连起来的?
- 每个 Agent 有哪些工具?安全边界是什么?
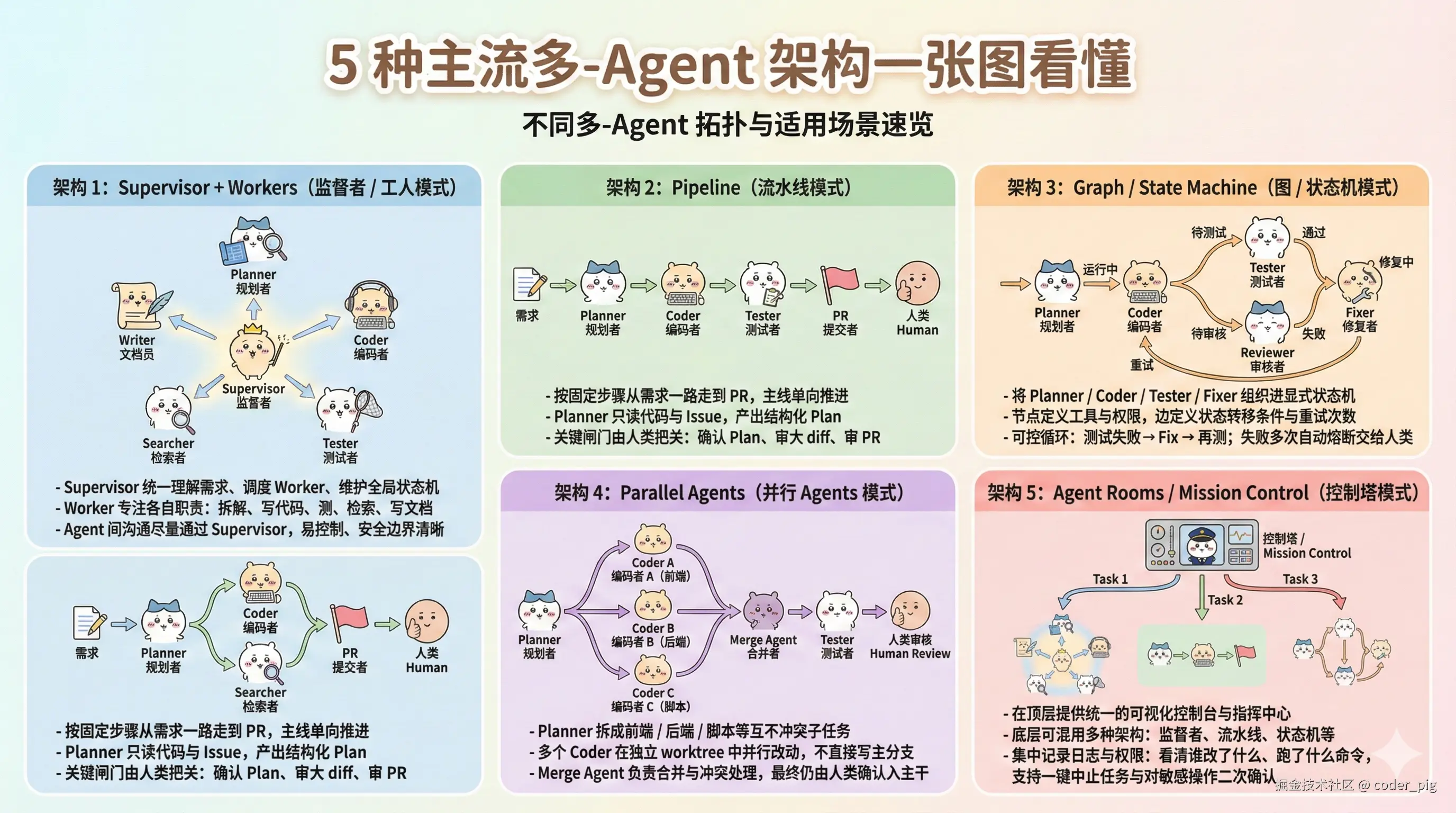
6.4.2. 业界主流多 Agent 架构模式
前面AI常识部分有提到过,这里直接让🍌画个图~
6.4.3. 个人级 "AI全栈" 演进历程
🤡 上面的理论看起来简单,但对于个人来说,想要亲手实现这样 一整套多 Agents AI 全栈系统,工作量爆炸:
得自己写调度、管状态、接工具、控安全、做可视化,还要维护一堆 prompt 和配置,算完整平台工程了...
🤔 笔者认为 "个人级AI全栈" 更倾向于:
在个人可以承受的复杂度和时间成本内,让AI参与尽可能多的开发环节,而不是一次性造一个企业级AI工厂。
😄 其实,你可能已经在无形中体验 "AI 全栈" 的雏形了,现代 AI 编程工具 本身就内置了 多 Agent 编排能力~
① Claude Code Sub Agents
CC 中允许创建多个带 独立角色与上下文 的 Sub Agent (小型专属AI工作者),用法简单:
- 创建 Sub Agent
- 在 Claude Code CLI 输入 /agents,选择「Create new agent」
-
选择作用域:项目级 (推荐,只给当前项目使用)、用户级 (所有项目可用)
- 填写:name (调用的时候用到)、description (决定CC何时自动调它)
- 选择可用工具 (file_edit / bash / file_search / git …)
- 完善系统Prompt:可以先让 Claude 生成,再自己改
保存后,会在 .claude/agents/ 生成一个类似这样的文件:
---
name: backend-dev
description: "专门负责后端接口、服务逻辑和数据库相关代码的实现与修改"
model: sonnet
tools: [file_search, file_edit]
color: blue
---
你是一个资深后端工程师,精通 Node.js + TypeScript 和这个项目的后端架构。
你的职责:
- 只改后端相关的代码(controllers, services, repositories)
- 遵循项目现有的代码风格和结构
- 所有改动都要尽量小步、安全、可读
在给出修改时:
- 标明文件路径
- 用 patch 的风格展示修改
- 如果需要新增文件,要说明用途和引用关系
不想自动生成,可以在 .claude/agents/ 手动按照上面的格式自己写md,保存后 CC 会自动识别。还可以在命令行启动CC时添加 --agents 参数 (适用于临时挂载场景):
claude --agents '{
"log-analyzer": {
"description": "分析测试日志和错误堆栈的专用Agent",
"system_prompt": "你只负责阅读测试输出、日志,帮助定位问题和怀疑文件,不写代码",
"tools": ["file_search"]
}
}'
-
调用 Sub Agent (串起来) 的三种方式
- ① 自然语言编排,用普通指令描述任务,由 Claude 自动判断并调用合适的 Sub Agent,最灵活、最贴近自然对话的方式。如:请用 backend-dev subagent 修改 search controller 的分页逻辑。
- ② 结构化点名调用,明确指定要调用哪个 Sub Agent,适合需要精确控制执行顺序或避免模型误判的情况。如:Use the
test-runner subagent to run the unit tests.
- ③ 在 Agentrooms 中使用 @agent-name 直接点名,通过@用户的方式派任务,可同时管理多个 Agent,方便多人视图和多 Agent 协作。如:@backend-dev 帮我调整这个接口的返回格式
- 多个 Sub Agents 协同工作简单示例 (开发 → 测试 → 分析 → 再开发):
- 让 developer 生成补丁
- 让 test-runner 运行测试
- 让 log-analyst 分析失败原因
- 再让 developer 根据分析修复
- Claude 会自动接力,也可以由你手动编排~
② Cursor 2.0 多 Agent 编排
2.0 后,Cursor 界面从 "以文件为中心" 变成 "以Agent为中心",多了个 Agent Layout,切换后,侧边栏会显示当前 Agent、计划(plan)和改动,你把需求丢进去,Agent 负责读文件、计划、改代码、跑测试。
支持 同一指令 下,最多可 并行 (Parallel) 跑 8 个 Agent,每个 Agent 会在自己独立的 Git worktree / 沙盒工作区 内工作:各自改代码、build、跑测试,不会互相冲突 (🤡 就是费 Token...)。还多了一个 Plan Mode (先规划再执行),在 Agent 输入框 中按 Shift + Tab 可以切换到这个模式 (也可以手动选):
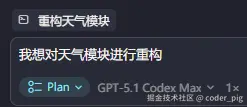
Cursor 不会直接假设你的需求,而是询问一系列澄清问题:
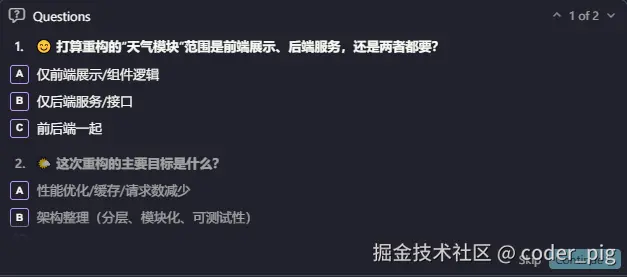
通过这些澄清,使 AI获得了完整的上下文,可以生成更精确的计划,避免后续的返工。接着会生成一个 plan.md 的计划文档:
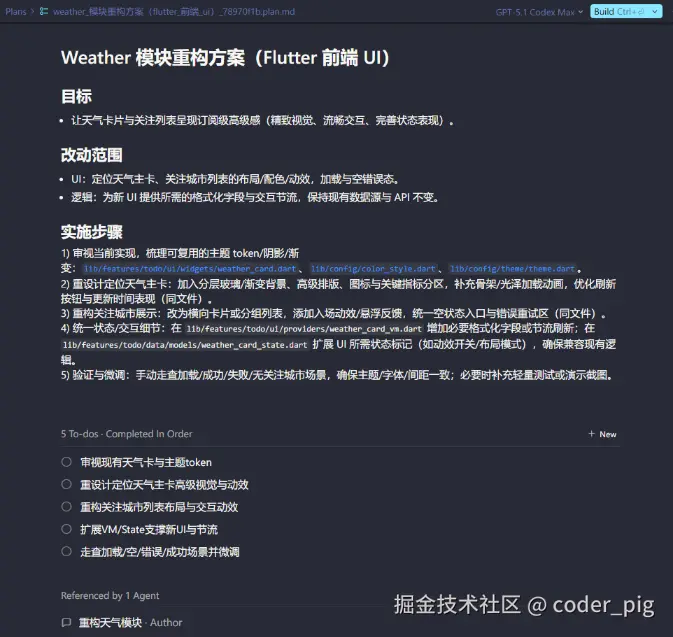
你可以对文件进行编辑:增删任务、调整任务顺序、更新技术细节、调整实现方法等。确定无误后,点击 Build,Agent 会读取最新版本的 plan.md,并完成对应的任务。
🤔 与 CC Sub Agents 可编排不同,Cursor 的 Agent 更像是一个组合能力的 "大Agent",由它自动编排多个内嵌的、对用户不可见 的 Agent 来完成 用户提出的任务,收敛复杂性,只展示改动/测试结果。它的 Parallel Agents 探索不同方案,最后再汇总/合并的玩法,不算严格意义上的 "主流多 Agent 架构模式" 中的 "并行Agents模式"-支持显式地定义 / 分配 不同角色的 Agent,并让它们并行协作。
类似的支持 "多Agents" 玩法的 AI 编程工具还有:
-
GitHub Copilot Workspace:多步骤 Pipeline Agents,从任务描述 → 生成完整 plan → 自动执行 → 修正,多步骤 cascaded agents,自动提 PR。
-
Google Gemini Code Assist:multi-expert prompt routing,任务自动分配给最擅长的模型/agent,复杂 monorepo 搜索 → 专家 agent 提供答案,针对 cloud infra 的执行-验证循环。
-
Replit 的 AI Dev 环境:多工具执行 Agent,轻量一站式多Agent开发流水线。
- ...等,限于篇幅,就不展开讲了~
觉得 AI编程工具 满足不了,接着就是围绕自己的开发流程,开发基于 LLM 的 API 封装一些 小脚本/小工具。
// 推进开发闭环的简单伪代码 (需求 → 修改 → 测试 → 修复)
plan = llm("你是架构师,帮我拆解这个改动需求…")
files = find_related_files(plan)
patches = llm("你是后端开发,只能改这些文件…", files + plan)
apply_patches_to_workdir(patches)
test_result = run_tests()
if test_result.failed:
fix_patches = llm("你是调试工程师,根据报错修复…",
test_result + current_code)
apply_patches_to_workdir(fix_patches)
大多数个人开发者达到这一层,基本够用了,再往上就是加:日志、可配置、一点UI、简单任务管理等,弄成一个仅为自己服务的 "AI 全栈开发小平台" (😄 此时更像是一个 Agent 工程师,搭建 "企业级AI全栈" 的基石)。
6.4.4. 落地方法论
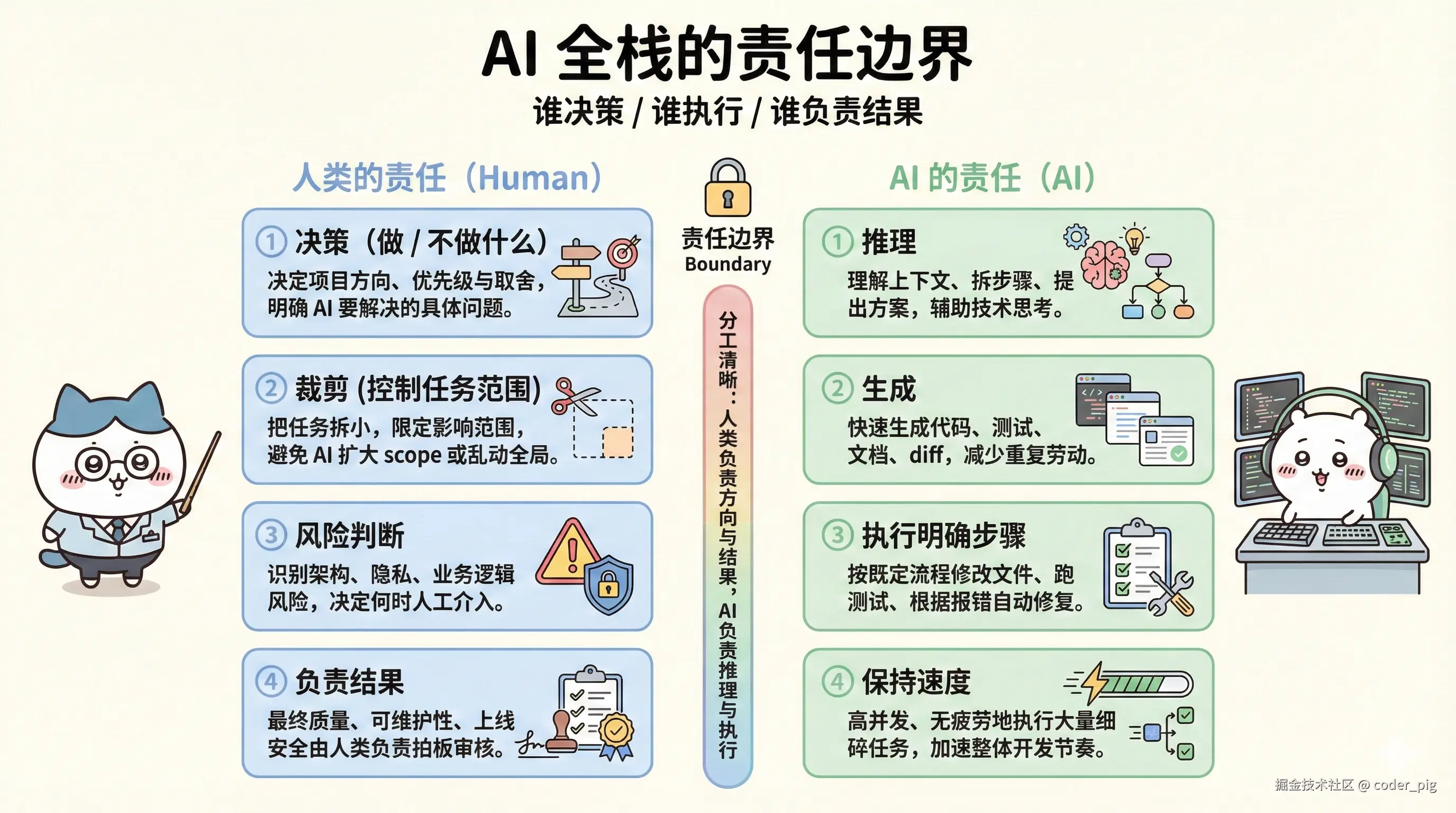
根本原则:
在一个完整开发周期里 (从想法到上线),有意识地让 AI 参与尽可能多的环节,并用 "多角色思维" 来组织这些调用,但工程复杂度要控制在个人能持续维护的范围内。
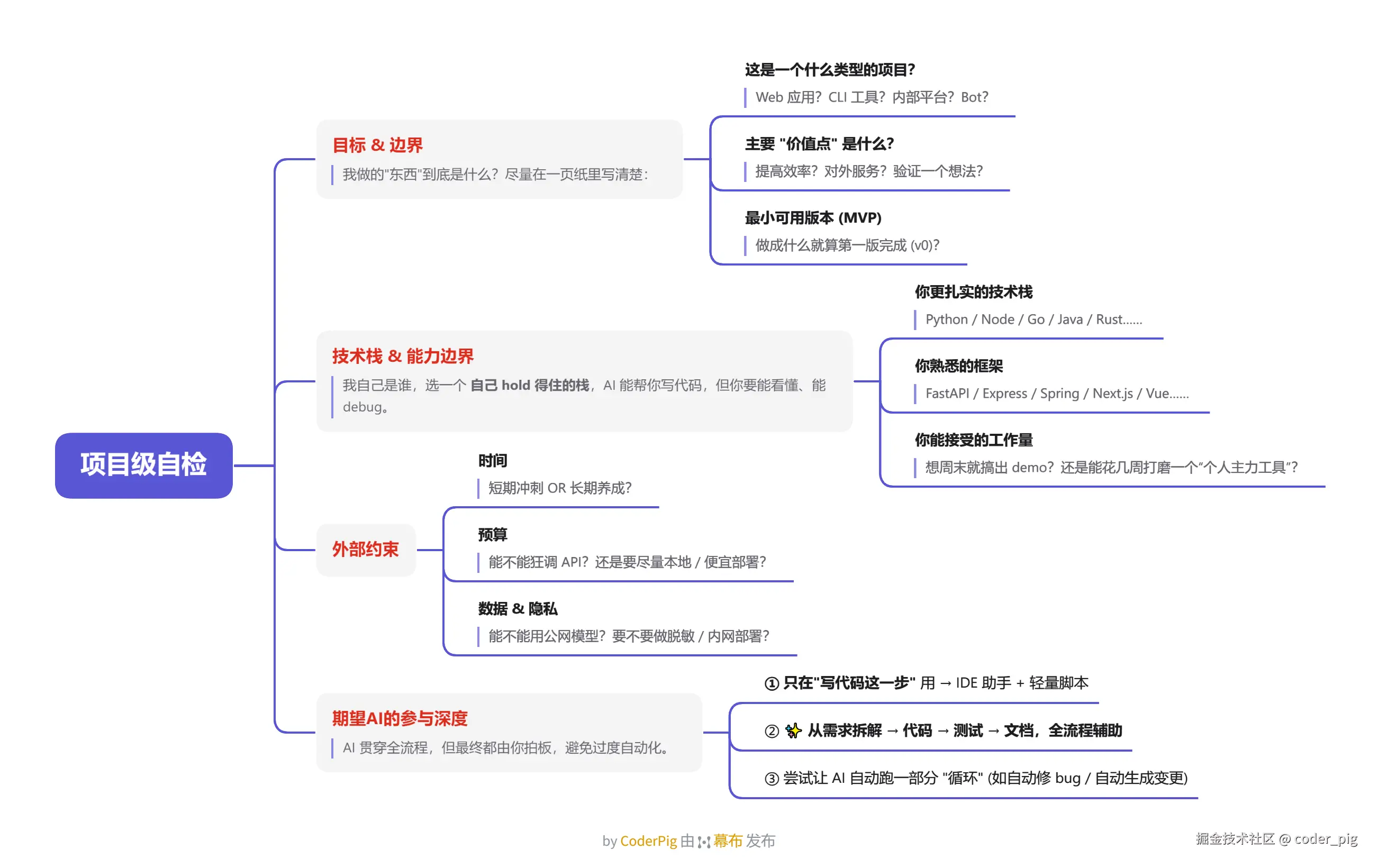
① 项目级自检
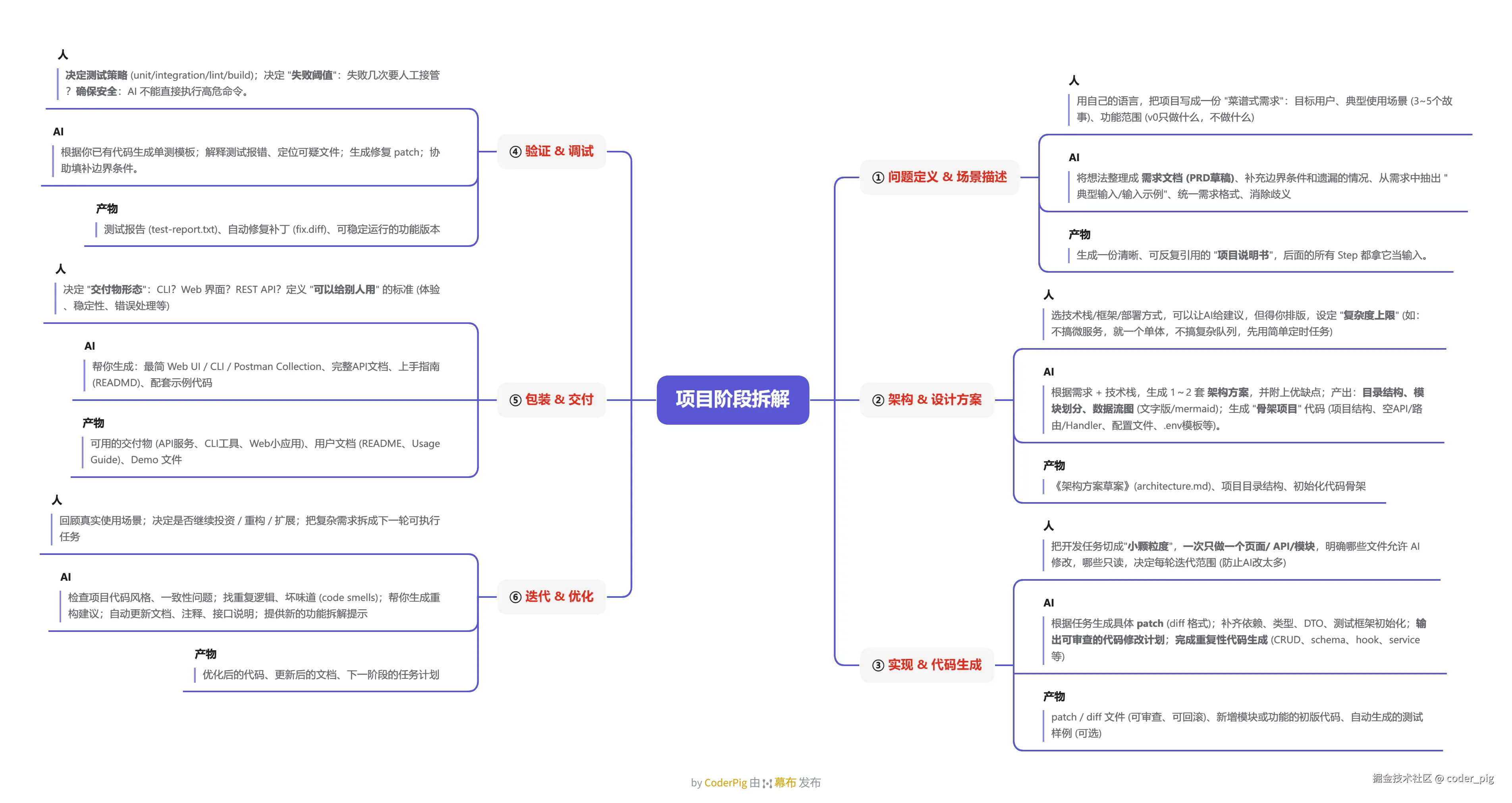
② 项目阶段拆解
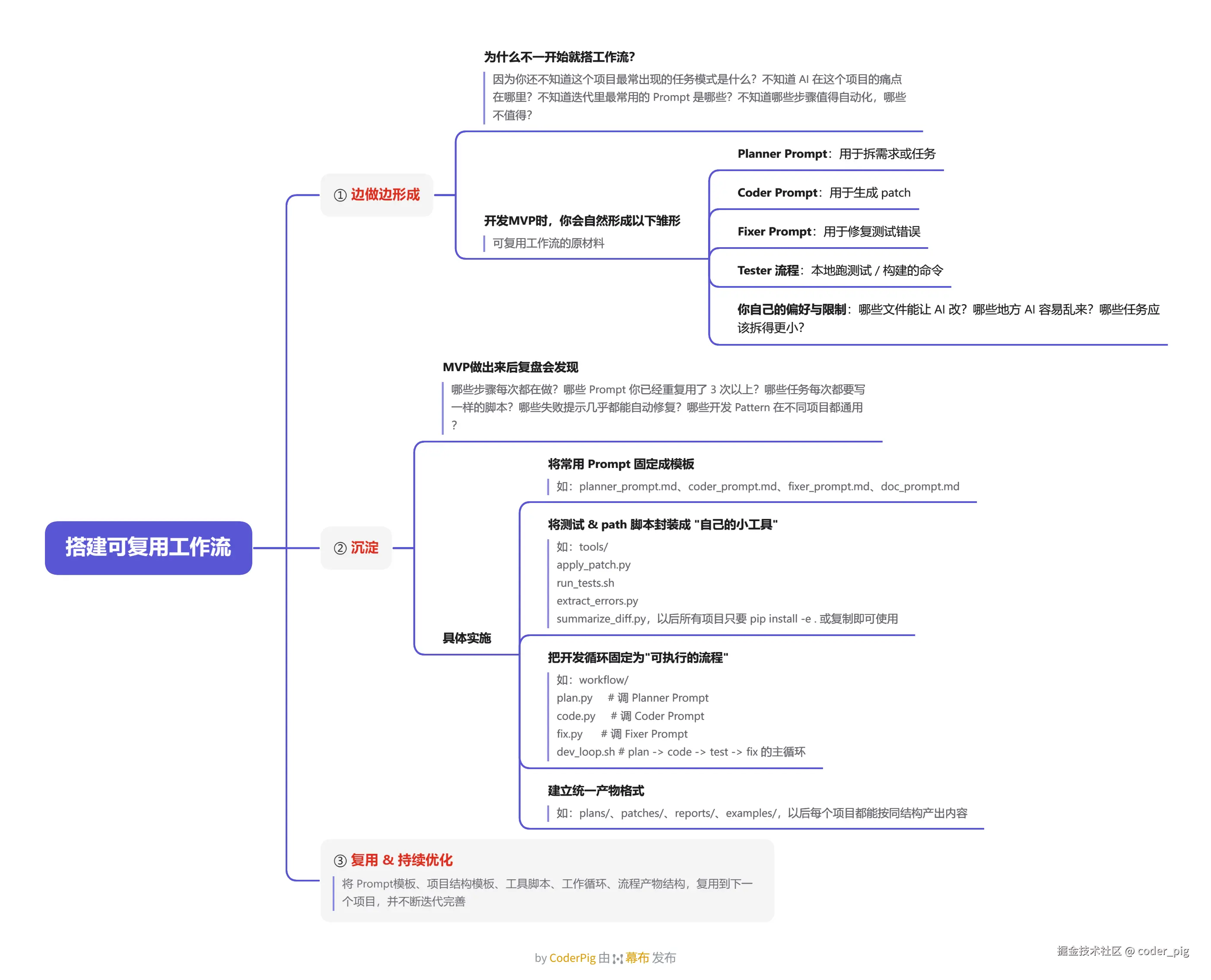
③ 搭建可复用工作流
7. 结语
行文至此,再回看这篇拖了许久的 "年终总结",心情早已从最初面对 AI 秒解 Bug 时的 "破防" 与 "迷茫",变得平静且笃定,我们:
- 剥开 AI "智能" 的外衣,看到了它作为 "概率预测机器" 的本质。
- 学会用 "结构化的Prompt" 去驾驭它,而不是被幻觉带偏。
- 也见证了开发模式从简单的 Chat 进化成 Copilot,再到如今初具雏形的 Agentic Workflow。
但归根结底,AI 带来的最大变量,不在于它替我们写了多少行代码,而在于它重塑了 "专业" 的定义。
-
懂得"底层原理"依然重要——否则你不知道为什么 AI 会把人修成 "汽车",也无法在它 "一本正经胡说八道" 时进行纠偏。
-
懂得提问比解答更重要—— Prompt 是新时代的编程语言,清晰的逻辑表达 + 对业务的深度理解,才是最高效的 "编译器"。
-
懂得架构比实现更重要——当 "AI 全栈" 成为可能,当一个个 Agent 可以各司其职,我们不再是死磕语法的 "搬砖工",而更像指挥数字化施工队的 "包工头 & 总设计师"。
"技术焦虑" 的解药,从来不是拒绝变化,而是成为变化的一部分。以前,我们的壁垒是 "熟练度+记忆力",以后则是 "想象力+判断力+系统工程能力",拥抱AI,在这个属于创造者的时代,进化为无所不能的 "超级个体🦸♀️"!