实测超火的 AI 浏览器 Dia,我看到了浏览器未来的 iPhone 时刻

30 年过去了,浏览器最大的变化可能是图标。
「互联网之父」蒂姆·伯纳斯-李 1990 年设计的基本交互模式——通过超链接(Hyperlink)实现网页之间的跳转,以及后面输入网址、等待加载、点击链接、回到上一页等逻辑,在今天岿然不动。
都 2025 年了,我们还在用同样的姿势,对着屏幕傻傻地等待页面加载。
过去十年,我们见证过许多号称「要颠覆浏览器市场」的浏览器,Arc 也是其中被誉为全村最有希望的种子选手,但却在拥有百万级用户,烧掉 1.5 亿美元后,母公司 The Browser Company 宣布停止更新,黯然退场。

去年,在完成 5000 万美元融资后,他们决定将重心转向开发一款名为 Dia 的原生 AI 浏览器。
创始人 Josh Miller 表示,Dia 要构建一种完全不同类型的浏览器——一个更加主动、更强大、更以 AI 为中心、更加符合最初愿景的浏览器,可以称它为网络浏览器的 iPhone,或者「互联网计算机」。
Arc 浏览器在其早期和公测阶段使用了邀请码制度,显然 The Browser Company 从中尝到了甜头。
最近,这款名为 Dia 的浏览器终于上线,采用邀请码制,开始小范围开放体验。体验设备有一定限制,目前适用于配备 Mac M1 芯片或更高版本的 macOS 14+。
在各家都在竞相将 AI 融入离用户最近的浏览器,Dia 的表现能否脱颖而出,AI 又该如何重塑浏览体验,这些都是我们想要探究的问题。
Google+Perplexity,Dia 想用 AI 改变浏览器?
Dia 的主页非常简洁,只有一个最为寻常不过的搜索框,甚至可以说清爽得有些不像样,但这也许正是浏览器最理想的样子:提问、获取答案、结束。而不是塞满热搜榜单,分散你的注意力。
输入问题后,Dia 会弹出一个候选窗口,提供 Google 和 Chat 两个选项。
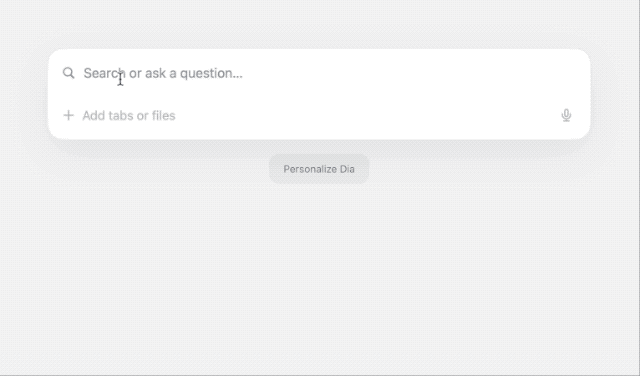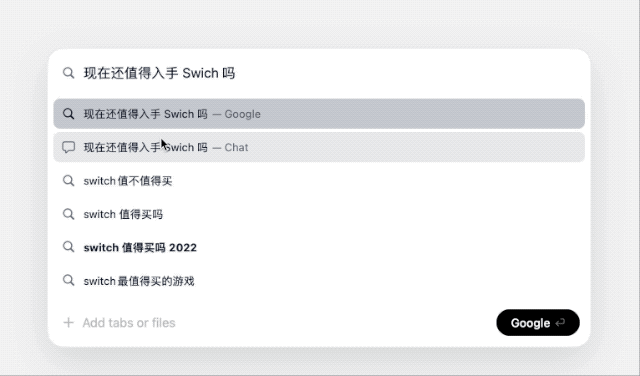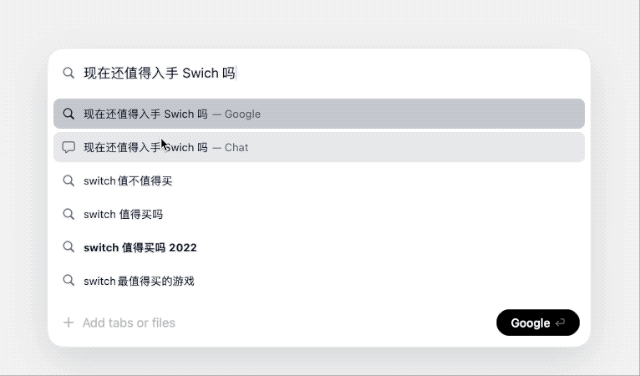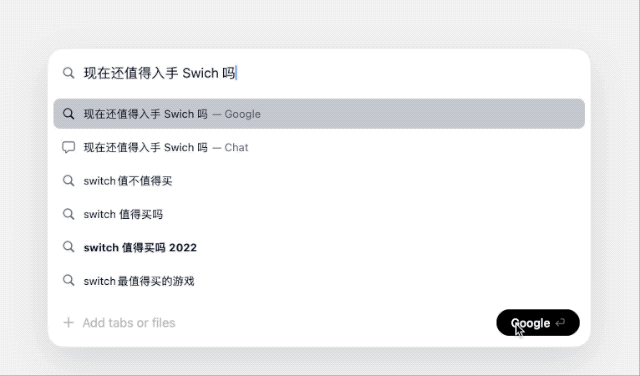
顾名思义,前者直接跳转到常规搜索引擎页面,后者则类似常见的 AI 聊天助手,调用 Dia 自带的大模型直接给出答案,并且拥有独自的历史聊天记录。当然,遇到复杂问题时,它也会联网搜索。 
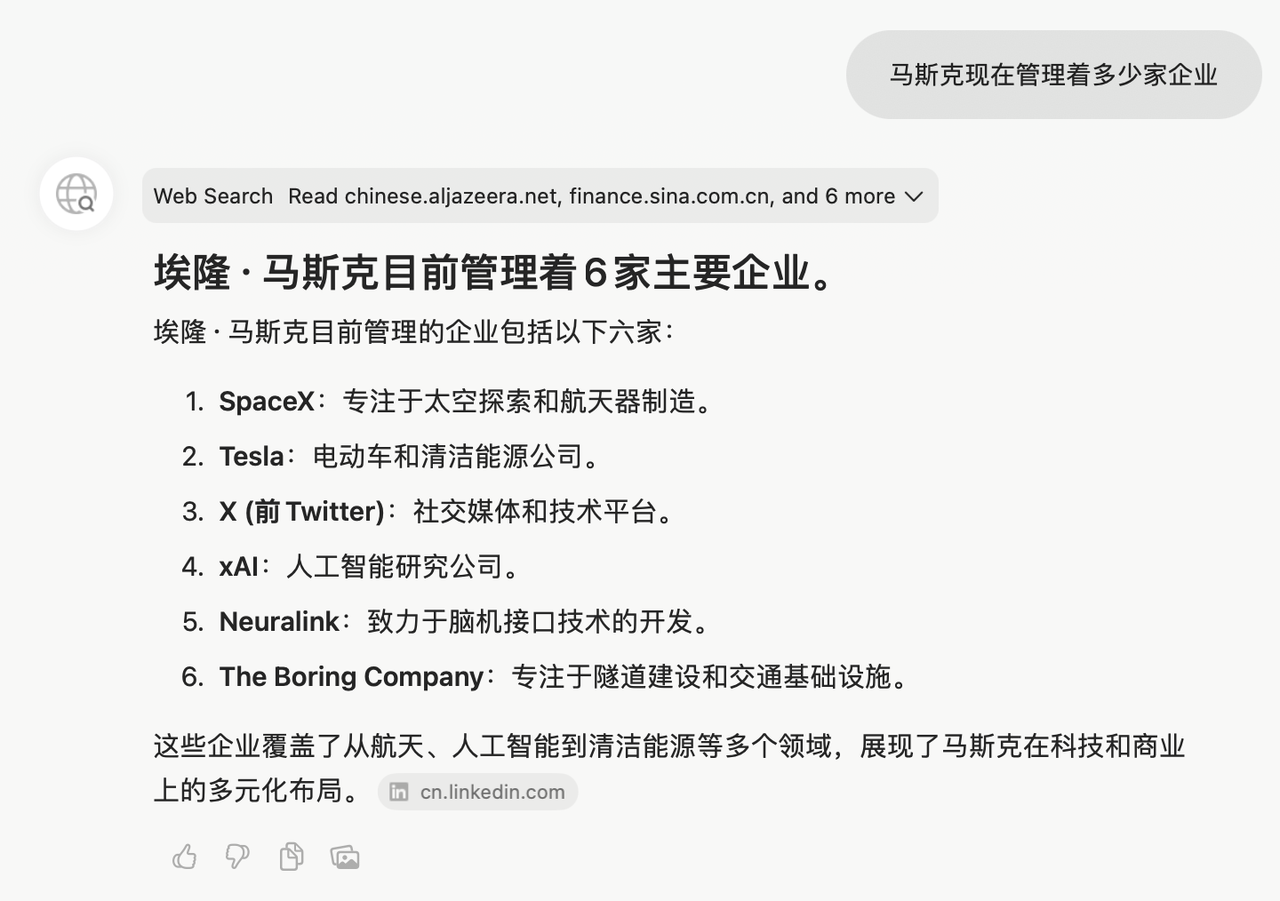
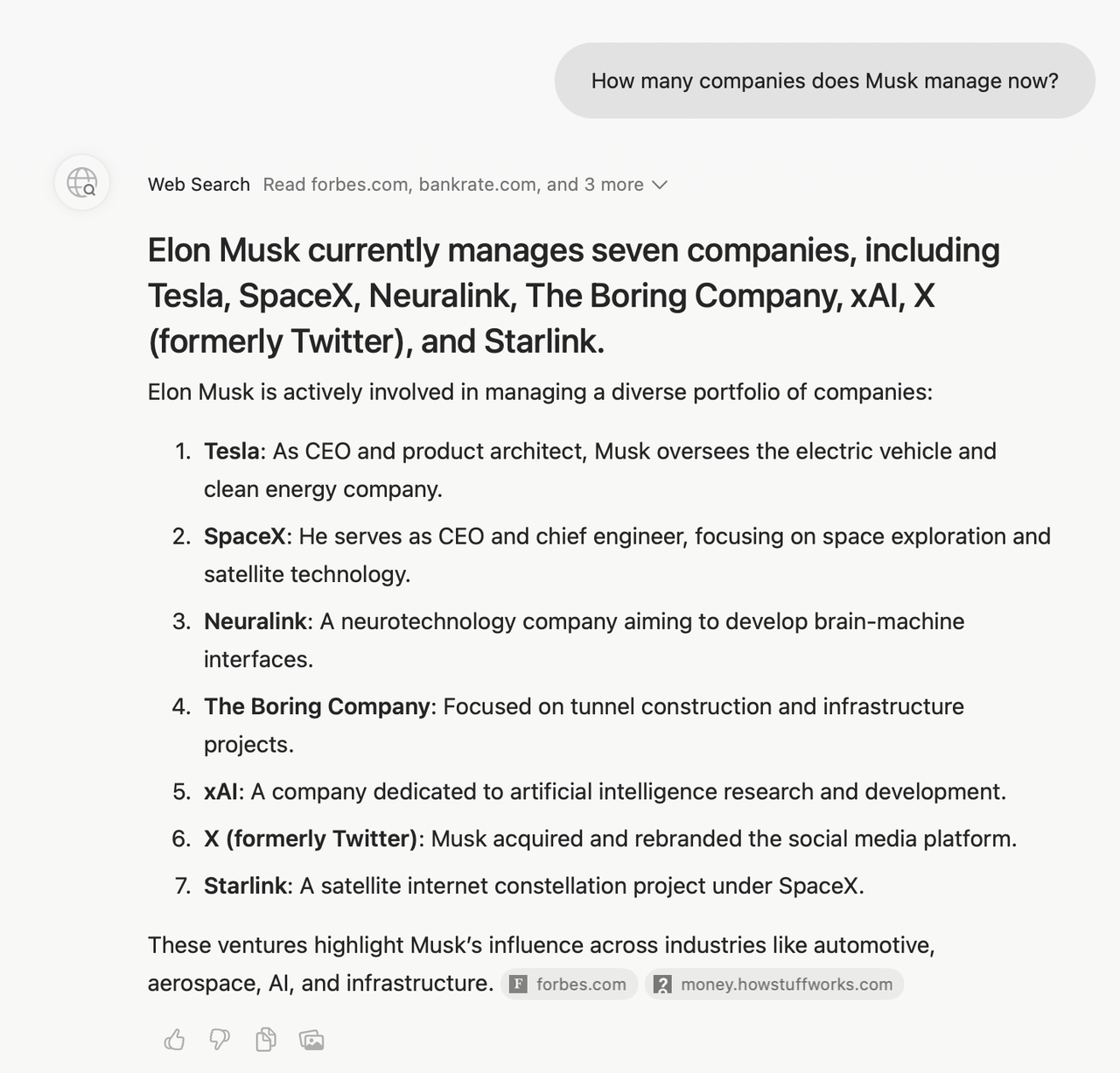
「现在的宠物能坐高铁了吗」「马斯克现在管理着多少家企业」,Dia 的回答质量也是属于不太稳定的那种,同一问题的几次回答,都在正确和出错之间反复横跳。


用英文提问,回答质量也不会显著提升,甚至它就把星链误认为独立公司。实测下来,Dia 偶尔会在回答中附上图片;用中文提问时,有时也会意外触发英文回答。
输入框底部,你还能看到「Personalize Dia」,设置崇拜对象、喜欢的学习方式,以及 Dia 的回答风格,可以帮助 Dia 快速了解自己,起到调教 AI 人设的作用。
随手上传一个互联网梗图,Dia 也能够轻松识别表情包的言外之意。文档总结很到位,10 万字被梳理得清晰明了,但值得注意的是,文档大小限制在 100M 内,且实测不支持上传 Doc 格式文档。
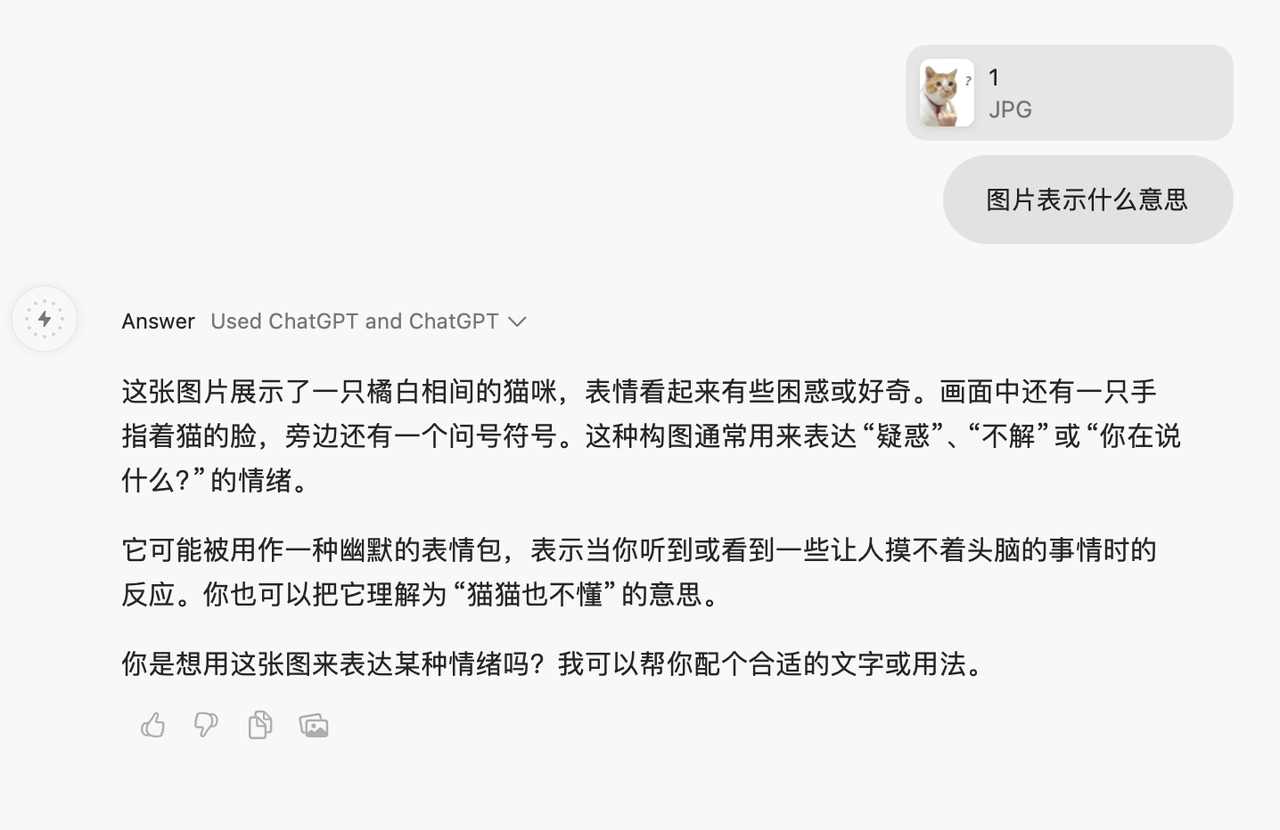
▲左上角会显示出现了两个 ChatGPT, 应该是 Bug
总结公众号文章,甩个链接即可。

值得注意的是,Dia 浏览器使用的是 Chromium 引擎的特定版本。Chromium 是一个开源项目,许多现代浏览器(包括 Chrome)都基于它构建。

交互是最大亮点,但 Dia 还是个半成品
Dia 的交互设计是一大亮点。传统 AI 插件主要以侧边栏、悬浮窗的形式呈现,涵盖 AI 聊天、翻译、网页总结等。右上角的 Chat 可以看作一个阉割版的 AI 插件,虽然功能稍显单薄,但在交互体验上却做得不错。
划词后,右侧就能直接提供查找或解释功能,整体操作流畅顺滑。
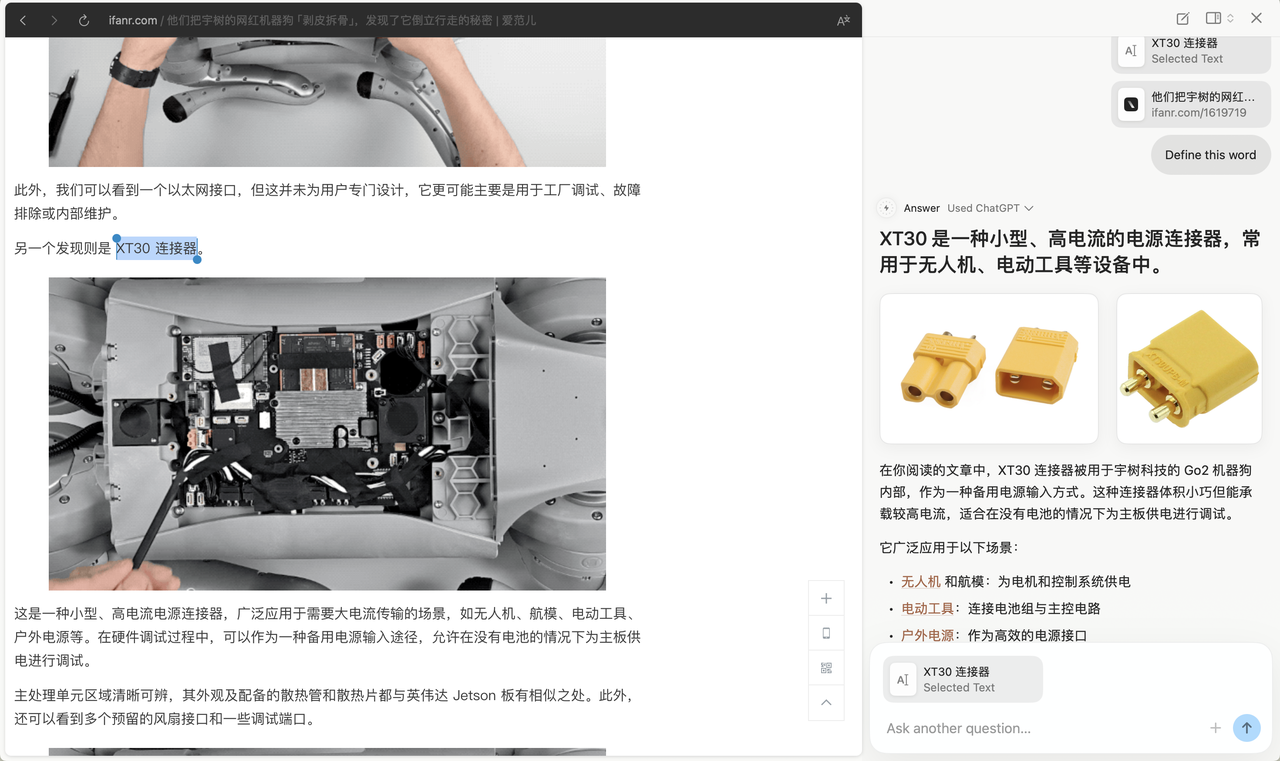
比如在知乎看到有人推荐线性代数书籍,我本来想评论一句「不明觉厉」,但写到一半卡住了,怎么办,这时候,放到光标处,光标就会变蓝变粗,点击会自动调出右侧 Chat 界面。
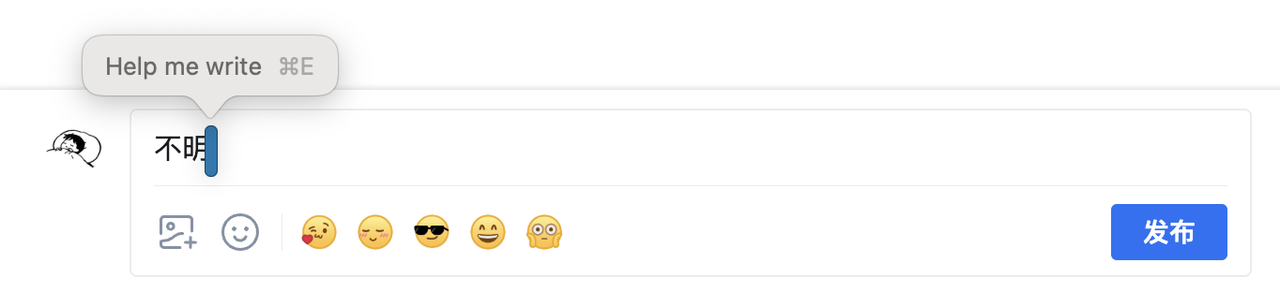
接着我简单描述了「看不懂,但我大受震撼」的想法,DIa 就会浏览完整个页面,并给出几个评论方案。
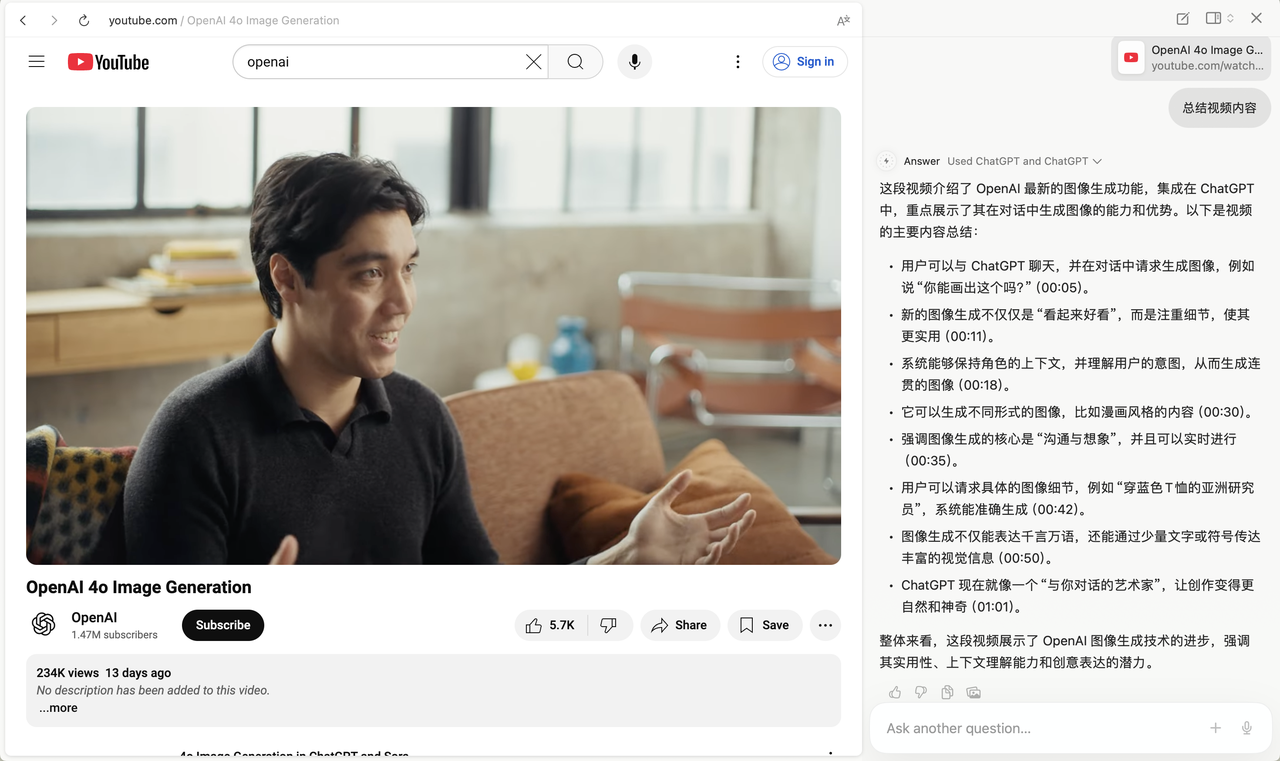
这些建议甚至模仿了知乎热评区的轻松语气,简洁直白又人性化。确认无误后,点击「Insert」就能自动插入扩写左侧评论。
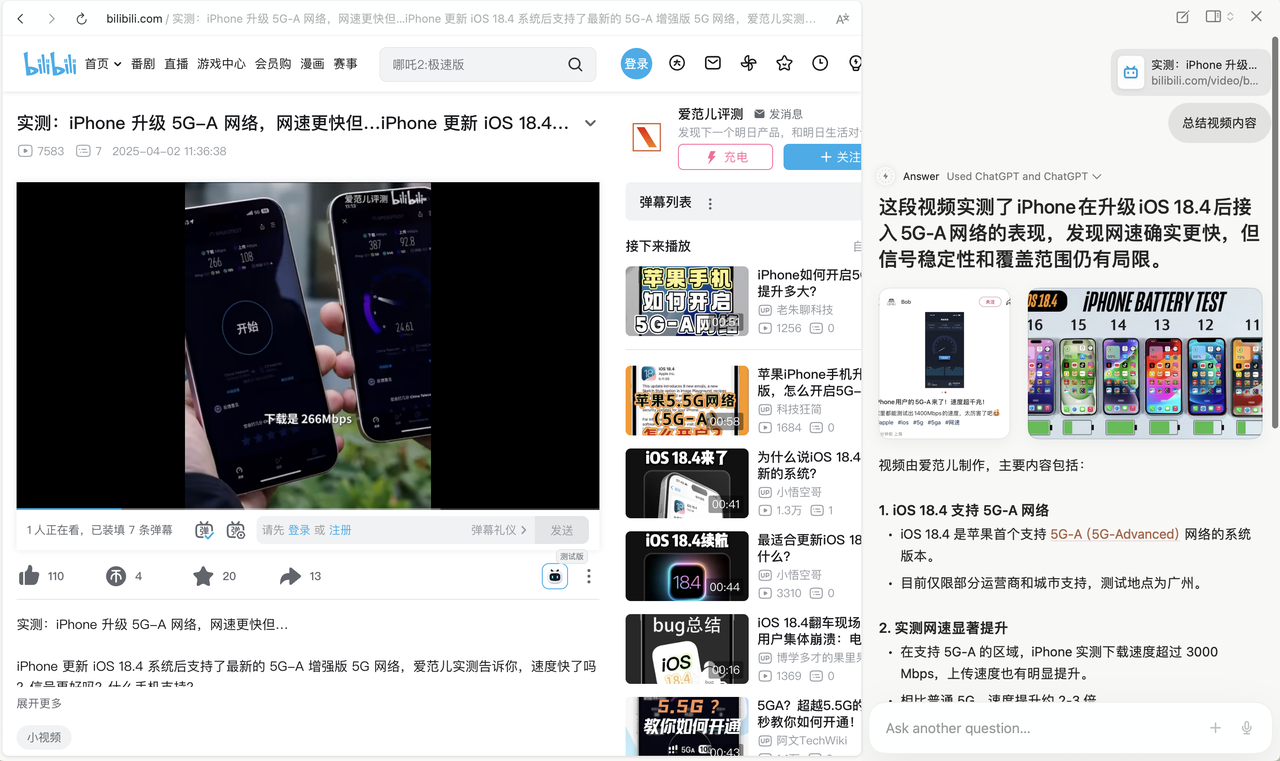
没时间看视频,总结视频内容也可以。这里有个小技巧,也能让它给出总结视频的字幕。不过,我让其生成 Word 或 PDF 文档后,却没有后续反馈。
另外,Dia 还能通过点击「View 菜单-Add Split View Pane,」在浏览器内实现快速「分屏」,最多可同时分出 4 块屏幕。不过,这个功能实用性有限:它仅显示搜索结果,点击具体网页仍会跳转到全屏模式,属实有点「中看不中用」。
此外,Arc 曾常被吐槽无法迁移 Chrome 书签,现在吸取教训的 Dia 提供了一键导入书签功能,支持无痛迁移。另一个是没有像 Arc 那样「剑走偏锋」,而是选择了更常规的横向标签页设计。你可以在输入框里添加各类网页标签,也能一口气将所有标签加入对话上下文,提升多标签页的信息联动能力。
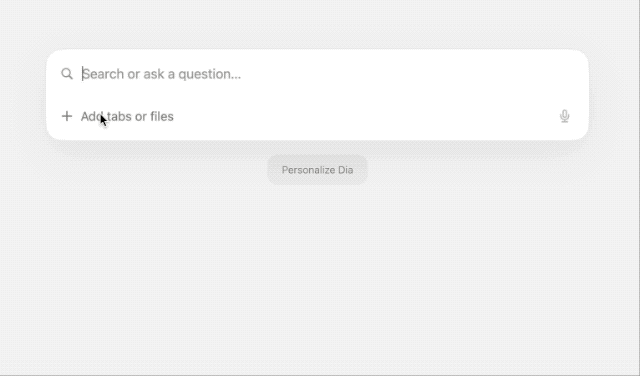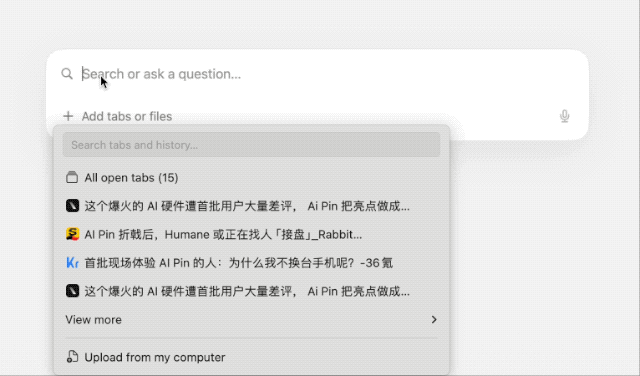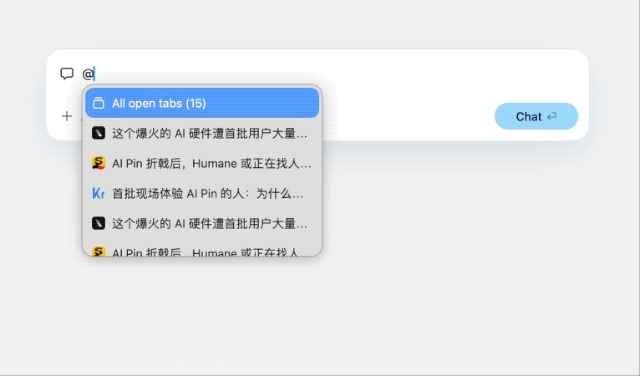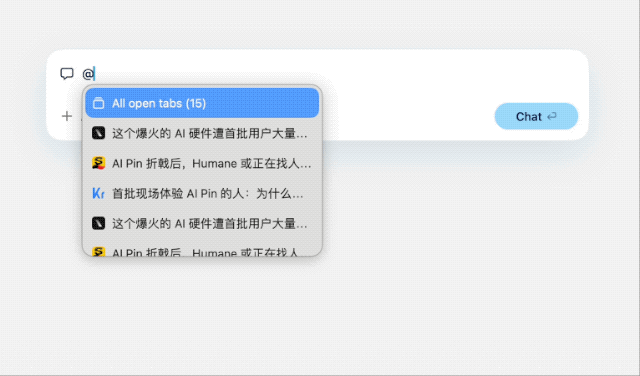
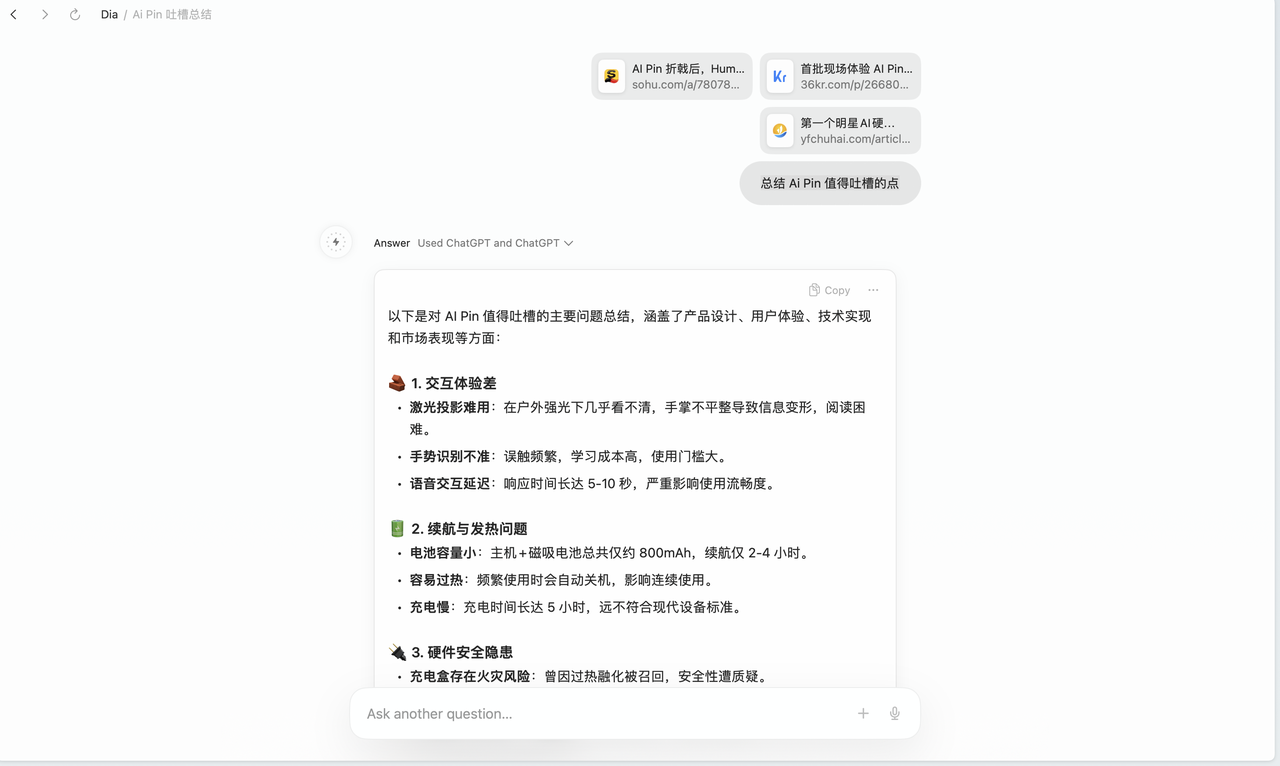
类似 ChatGPT 调用 GPTs 的方式,Dia 也支持通过 @ 调用各个网页标签。玩法很朴素,我挑选了过往几篇关于 Ai Pin 的文章,并让其总结 Ai Pin 值得吐槽的点,很快就得到了清晰的答案。
浏览器 2.0 时代已经开始,而 Web,远未走向死亡
2010 年,克里斯·安德森(Chris Anderson)与迈克尔·沃尔夫(Michael Wolff)在《连线》杂志共同撰写了《Web 已死,Internet 永生》一文。
文章犀利地指出,万维网(Web)在诞生二十年后正逐渐走向衰退,其原因在于传统的 Web 浏览模式逐渐被更简单、更流畅的服务所取代,尤其是应用程序(App)的崛起,更简洁、高效,能够直接满足他们的需求。
比如,打开一个新闻 App 就能立刻浏览头条,而无需在浏览器中输入网址、等待页面加载。这种「App 优先」的趋势在过去十年中几乎主导了互联网产品的开发逻辑。

然而,生成式 AI 的崛起重新将产品开发的焦点拉回到 Web 模式。
看似出人意料,却又合情合理。AI 交互本质上是以文本/对话为核心,Web 界面天然支持复杂的文本输入输出,且能便于分享结果和协作。
生成式 AI 模型计算需求大、迭代速度快。在不确定哪种 AI 应用场景最有价值的探索期,Web 平台能以最小成本覆盖所有设备用户,加速产品市场匹配验证。
并且,相比下载 App 的心理和实际成本,Web 版本让用户可以「即点即用」,这对于像 ChatGPT 这样天然陌生的产品尤为重要,减少了用户尝试的障碍。

浏览器的基本形态和功能已经维持了近三十年。1989 年,蒂姆·伯纳斯-李(Sir Tim Berners-Lee)在 CERN 工作时,创建了万维网(WWW),以满足科学家、大学和其他研究机构之间共享信息的需求。
网页浏览器应运而生,但它的设计初衷是围绕文档展开的,这一底层逻辑至今没翻篇。
到后来的 Netscape Navigator,再到如今的 Chrome、Safari、Firefox 和 Opera,浏览器的核心元素(标签页、地址栏、收藏夹)表面形态不能说毫无变化,但也变化不大。
过去,我们通过搜索引擎获取信息的方式是这样的:输入关键词,得到十几个甚至几十个结果页面,然后一个个点击,浏览,判断,筛选,最终从海量信息中找到自己需要的那一小部分。
这个过程就像在图书馆里翻阅一摞摞的书籍,耗时且低效。在那个年代,找到信息的能力本身就是一种技能,甚至催生了「高级搜索技巧」这样的教程和课程。

后来,搜索引擎变得更加智能,界面设计和性能有所优化,比如标签页从单一窗口变为多任务管理工具,地址栏也整合了搜索功能,可这些变化,说到底还是修修补补,算不上脱胎换骨。
在沉浸式、空间计算和对话式 AI 方兴未艾的当下,我们仍然被迫使用基于 30 多年前文档范式设计的浏览器。与其说这是界面问题,倒不如说是整个信息交互模式的不匹配。
AI 的狂飙突进,给浏览器体验的重塑撕开了一道口子。去年,AI 插件热潮席卷而来,Kimi、Monica 等玩家纷纷入局,带来了一些新玩法:不用离开页面,就能获取答案、完成任务,效率直线上升。
从目前体验上看,仍处于半成品的 Dia 在侧边栏交互、划词解释等细节上有些亮点,但说到底还是没跳出 AI 插件的范畴,更多是对现有功能的整合和打磨。
Josh Miller 曾表示,传统浏览器的界面需求已经不再那么迫切,其底层结构将决定我们的未来。「大多数人以为我们在造浏览器,」Miller 在一次对话中说,「其实我们造的是一个基于浏览器的系统。」
他的野心,是把浏览器从单纯的内容展示工具,变成一个类似操作系统的存在,管理个人偏好和行为,在系统层面实现跨设备的 AI 体验,而不用在每个应用里重复设定。
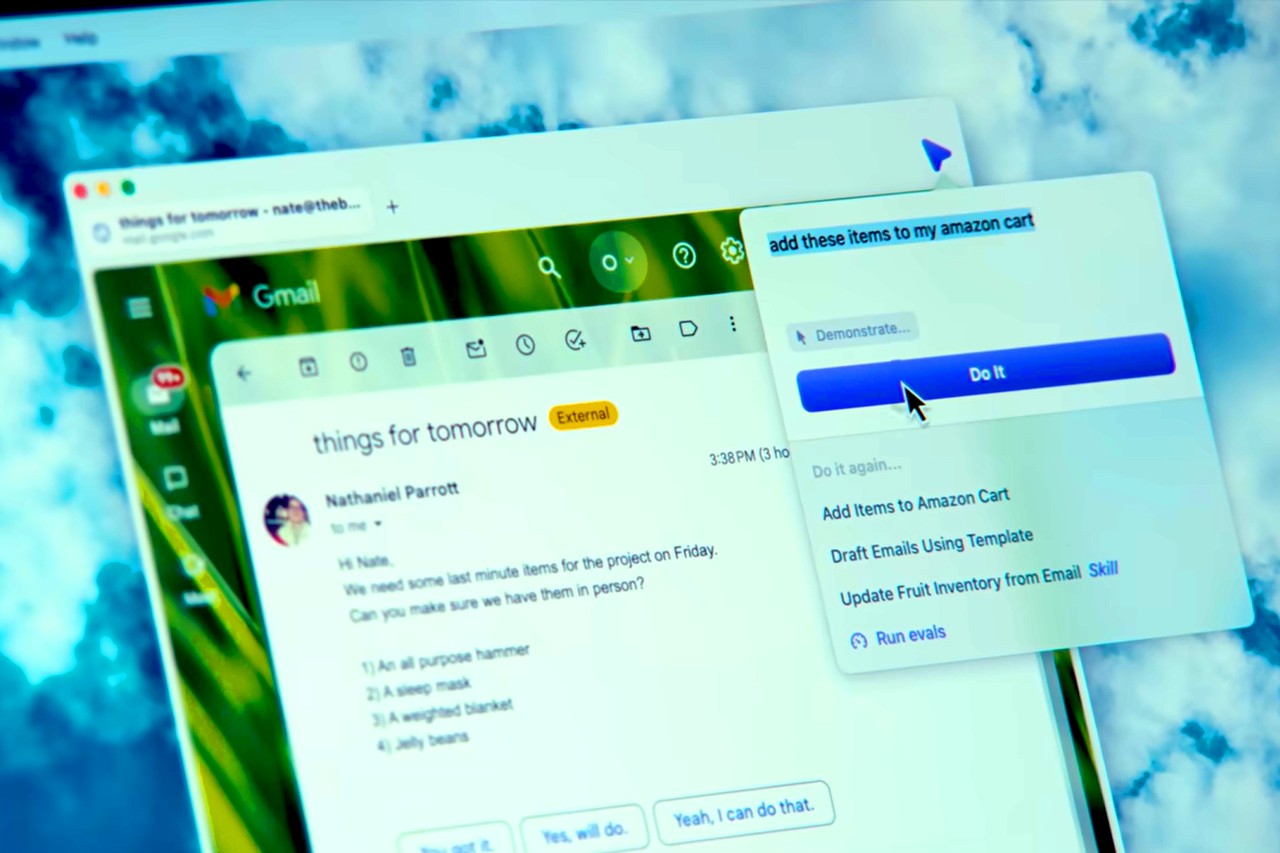
在早期演示中,Dia 就展示了浏览器如何代表人类执行任务。
例如,Dia 通过自己浏览亚马逊,找到这些物品并将它们添加到购物车中。这正是浏览器能做到的事——利用它对你所有 Web 应用和浏览数据的访问权限,替你完成任务。
尽管,如今的 Dia 距离这一目标尚有差距,但这种从被动响应到执行理念的转变,却与当下大火的 Agent 不谋而合。
在 OpenAI 推出的 Operator,以及智谱最新发布的「沉思」Agent 中,我们也看到浏览器开始代替用户采取行动,比如预订机票、比较产品价格、填写表单,甚至完成在线购物。
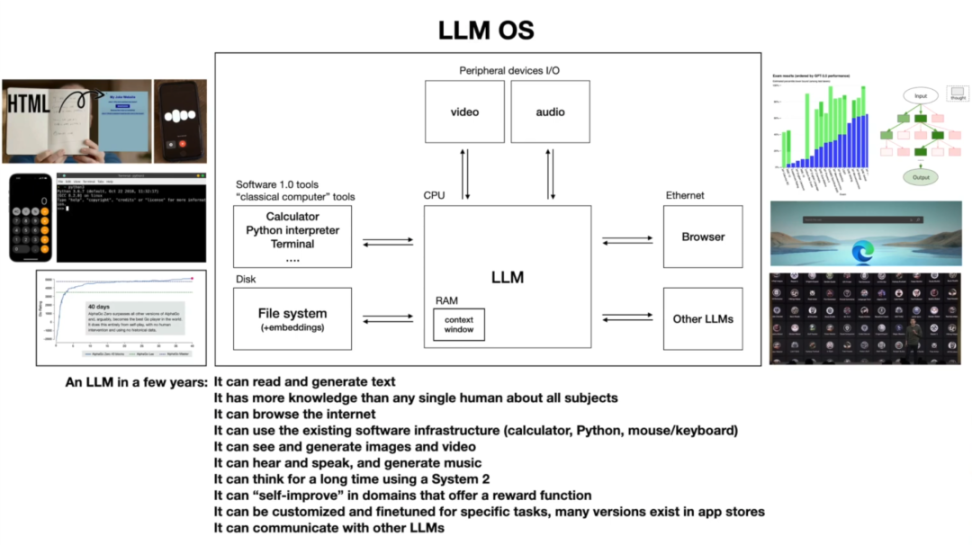
为了更好地了解这一趋势,不妨再来看看 OpenAI 前 AI 大神 Andrej Karpathy 提出的「LLM 操作系统」设想:
- LLM 作为内核:LLM 是整个系统的中心,类似于传统操作系统中的 CPU,负责处理核心任务和协调其他组件。
- 存储体系:包括上下文窗口(类似 RAM),用于存储当前正在处理的信息。
- 文件系统:用于长期存储数据,类似于传统计算机的硬盘。
- 向量数据库(embeddings/vector databases):用于存储和检索嵌入向量,是 LLM 进行语义理解和检索的重要基础。
- 浏览器:作为 I/O 外设之一,用于访问互联网资源,获取实时信息。
- 多模态工具:支持处理文本、图像、音频等多种数据类型。
- 其他工具:如代码解释器、计算器等,用于辅助 LLM 完成复杂任务。
从根源上讲,浏览器自诞生之初便紧密贴合人类需求,为人类而生的属性贯穿始终。传统浏览器依赖的 UI 自动化工具(如 Selenium)本质上是对人类操作的镜像模拟。
与图形化界面和手动操作有所不同,AI Agent 需要通过代码访问和解析数据与网页进行自动化交互,而动态加载的内容、复杂的页面结构,以及反爬机制(如验证码)的普遍应用,都是亟待解决的几道难关。
浏览器服务商 Browserbase 创始人 Paul Klein 也曾给出一些技术思路:
- 开发开源、高效的浏览器,减少浏览器启动时的等待时间和安装所需的资源量,提升运行速度和部署便利性。
- 利用 LLM 快速定位网页数据,VLM 基于截图识别元素,支持自然语言交互,无需复杂脚本,即使面对混淆或动态内容也能适应。
- 提供更可靠的 SDK 和 API 开发工具,简化开发流程,提高 AI Agent 使用体验。
更理想的状态是,AI Agent 与浏览器/网站则需要通过标准化协议直接通信,跳过视觉交互环节,基于数据接口(如 API、底层协议)实现自动化操作,完成从 「人→界面→数据」 到 「机器→协议→数据」的直连。
这段时间频繁出现在大众视野的 MCP,正是解决传统「人→界面→数据」模式瓶颈的一种方案。它通过客户端-服务器架构,将 AI Agent(主机/客户端)与外部资源(服务器)连接起来,用协议取代了界面操作。
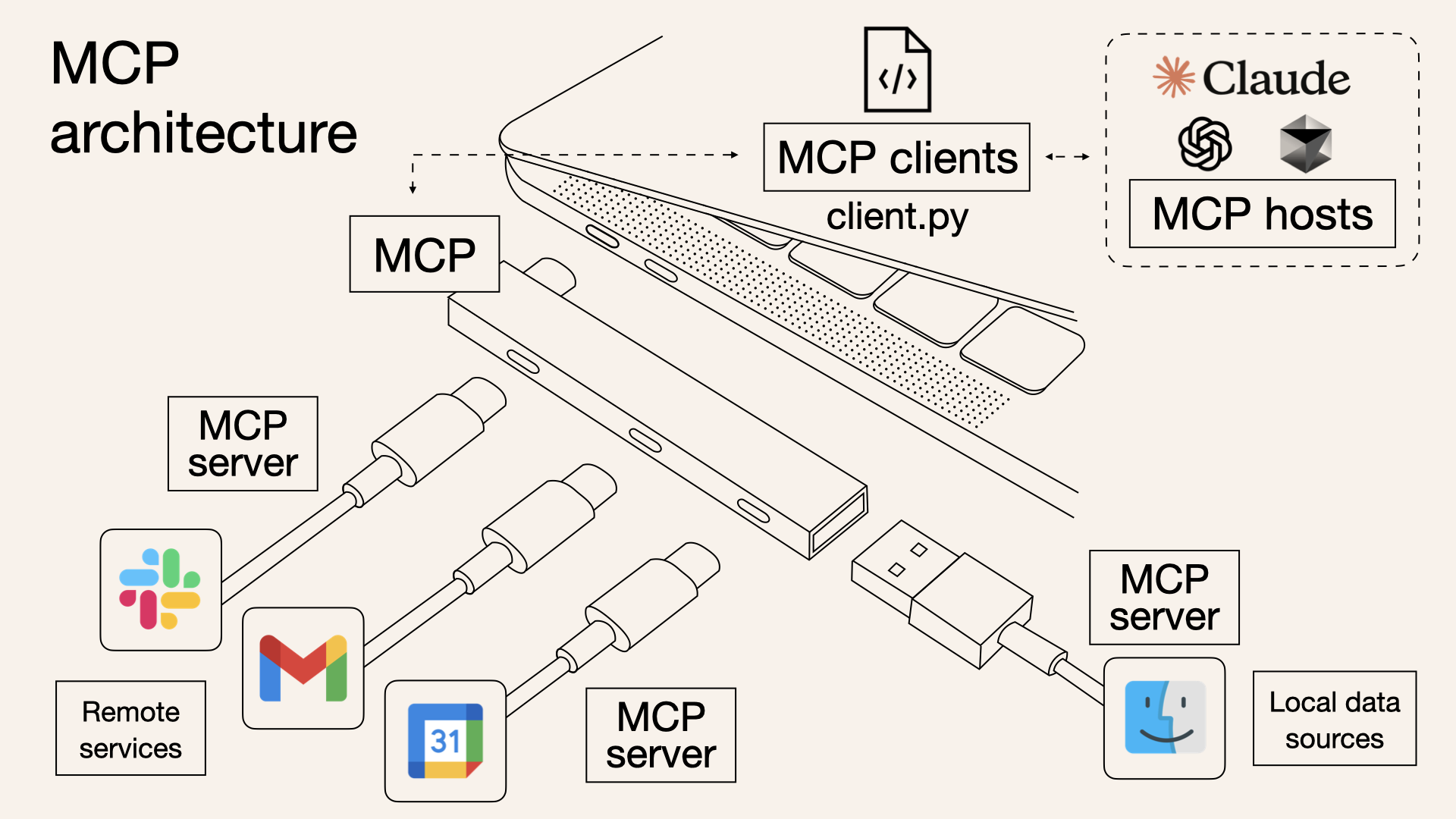
简单来说,你可以把 MCP 想象成一个「万能接口」,就像电脑上的 USB-C 接口一样。这个接口让 AI 模型能够轻松地连接到各种外部资源,比如文件、数据库、在线服务等。
通过 MCP,AI 助手不仅能获取数据,还能直接对数据进行操作,比如读取文件内容、更新数据库记录等。
浏览器会继续服务人类,但会越来越适配 AI 的需求。人类下达命令,Agent 高效执行的协作模式将成为未来的常态。
从早期的命令行界面(CLI),到图形用户界面(GUI),再到如今迈向人机纯自然语言交互以及机器与机器的协议层交互,技术在复杂化,但交互方式却在不断简化。
现在,浏览器 2.0 时代已经开始,而 Web,远未走向死亡。
「AI 不会以应用程序的形式存在,也不会是一个按钮。我们相信它将是一个全新的环境——建立在 Web 浏览器之上,」Dia 的官网如是说。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。