日本央行副行长内田真一:若经济改善、物价上涨,将加息
日本央行副行长内田真一表示,美国关税措施对价格影响好坏参半。在经济持续改善的背景下,如果潜在通胀加剧,将会加息。预计关税对价格既有上行影响,也有下行影响。我们将在每次会议上仔细审查经济、价格动态和风险,包括美国关税的影响,特朗普关税可能给日本和全球经济带来下行压力。(新浪财经)


免费且无需邀请码,Genspark 超级智能体亮相

任天堂:Switch 2 一开始不叫这个名字

荣耀或将入局具身机器人

网传钉钉重整纪律,内部人员:部分属实

机构:2025 年比亚迪或超特斯拉登顶全球市场

库克套现 2400 万美元苹果股票

钟睒睒发文怒斥互联网平台

Google Gemini 团队负责人即将卸任

抖音集团落子广州

作家刘慈欣:AI 创作质变只是时间问题

iPhone 17 Pro 长焦将升级 4800 万像素

即梦迎来 3.0 版本更新

联想「一体多端」AI 终端新品定档 5 月

rabbit 发布 AI 原生操作平台

微信上线「表情包 / 语音引用回复」(微信引用回复推出新功能

微信输入法接入 AI 深度回答

美团:为骑手补贴养老保险

《黑神话:悟空》艺术展将于 4 月 9 日开启

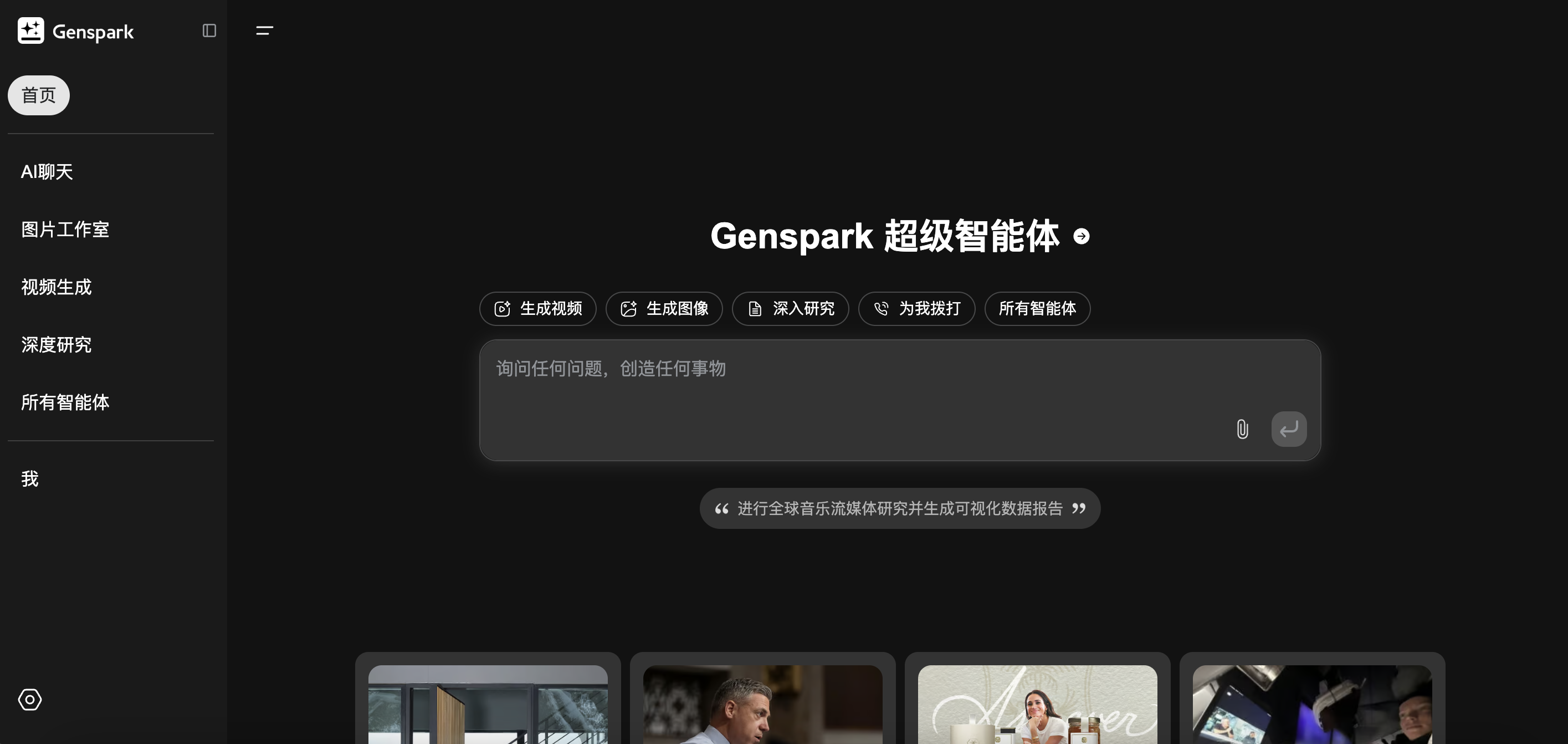
4 月 2 日晚,MainFunc 正式公布了其超级通用智能体「Genspark」,与此前大火的 Manus AI 类似,能够自主思考、规划并调用工具来帮助人们完成一些日常任务。
官方表示,和以往的智能体相比,Genspark 主打实时交互、幻觉和错误率更少,以及允许用户中途改进调整。在多个演示 Demo 中,Genspark 展现了其强大之处:一口气把 5 小时的 YouTube 视频转换为 10 页 PPT、自主与他人进行电话交流等等实操。
而据官方介绍,Genspark 之所以能实现上述能力,得益于三大部分的相互配合:
而 Genspark 最大亮点不止是强大的完成能力,还有「免费使用」和「无需邀请码」。目前,用户只需要注册账号,就可以免费体验到 Genspark。而 Genspark Plus 定价为 19.99 美元 / 每月,拥有优先访问模型、每月 10,000 积分。
值得一提的是,打造 Genspark 的 MainFunc 于 2024 年 6 月首曝,该公司由前百度集团副总裁、小度科技 CEO 景鲲携手前小度 CTO 朱凯华联合创立,总部位于加州和新加坡。景鲲在百度曾任大搜索总产品架构师,据悉其技术职级已达到百度「天花板」T11;同时,曾是语音交互方向技术委员会主席的朱凯华,在百度职级也是 T11。
今年 3 月初,MainFunc 宣布完成 A 轮融资,新筹 1 亿美元(约合 7.27 亿人民币),估值来到 5.3 亿美元(约合 38.52 亿人民币)。


4 月 2 日晚,任天堂发布了旗下最新游戏掌机 Switch 2,随后公司举行了一系列的开发团队问答活动,揭秘了 Switch 2 的开发「花絮」。
任天堂 Switch 2 的制作人 Kouichi Kawamoto 和总监 Takuhiro Dohta 在被问及「为何延续使用 Switch 2 这一产品名」时,Kouichi Kawamoto 透露了一个令人意想不到的结果:
在为这款新品命名时,团队有过很多想法,并且过程十分艰难,甚至一度考虑过「超级任天堂 Switch(Super Nintendo Switch)」这样的名称。
但最终上述方案被否决了,原因在于「超级任天堂 Switch 会让人联想到超级任天堂(Super Nintendo)以及其与初代 NES 的关系。Kouichi Kawamoto 进一步解释,超级任天堂在 NES 之后推出,但无法兼容 NES 的游戏;而 Switch 2 能够完美运行 Switch 的游戏,因此使用与超级任天堂相同的命名方式并不合适。
Kouichi Kawamoto 还表示:「希望用户看到 Switch 2 的时候,能够知道这是任天堂最新开发的游戏掌机,同时简单明了的命名方式,能让纠结购买 Switch 的用户一眼知道 Switch 2 是 Switch 家族里面最新的。
此外,在问大会上,任天堂也解释了为何 Switch 2 的屏幕放弃使用 OLED 而回归 LCD。Switch 2 技术总监 Tetsuya Sasaki 表示,「在开发过程中,LCD 技术取得了很多进步,我们审视了当前可用的技术,经过深思熟虑后决定采用 LCD」。
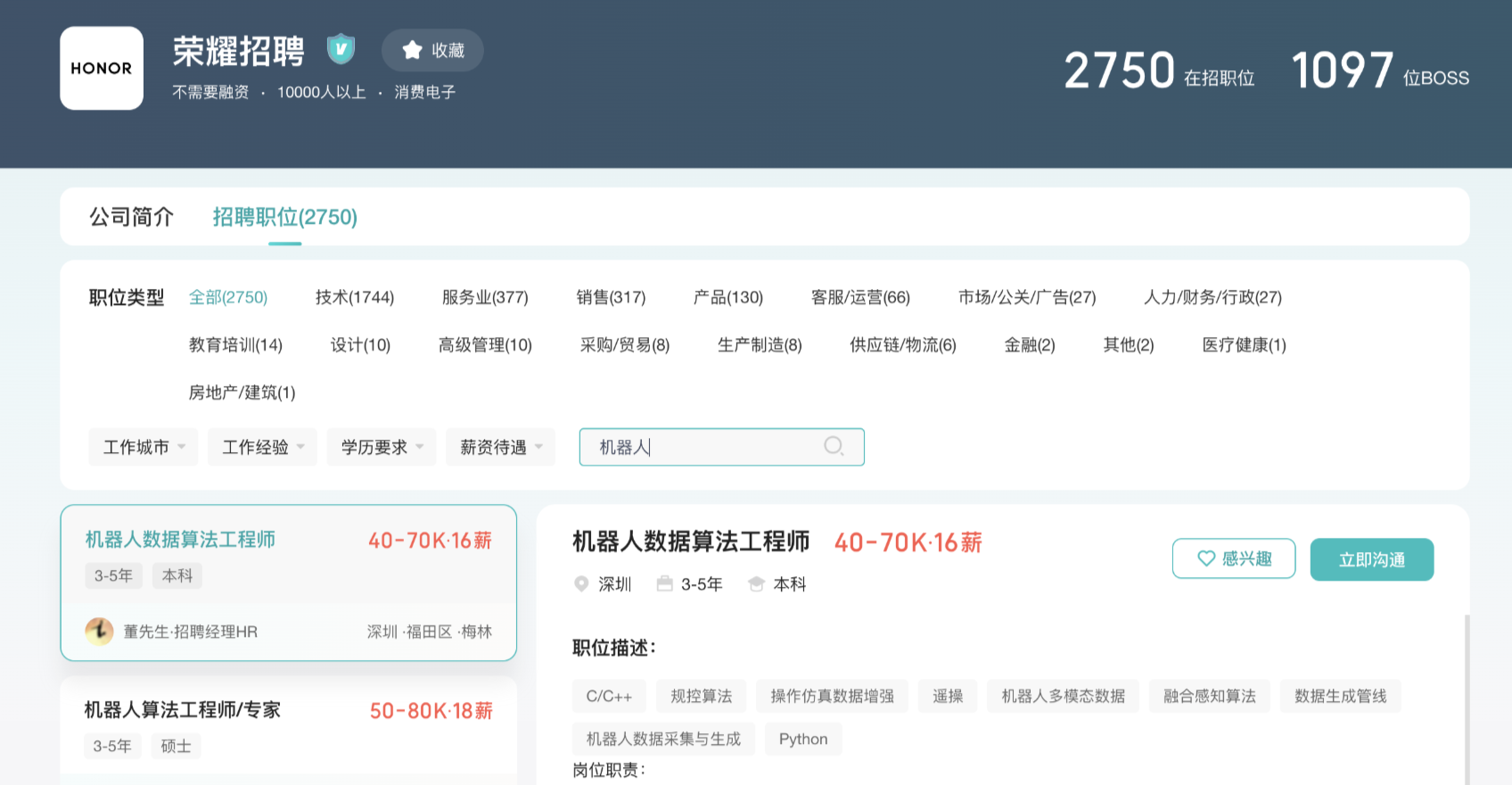
据科创板日报获悉,荣耀已设立新产业孵化部,下设具身智能实验室、具身数据实验室、交互安全实验室、动力总成实验室、仿生本体研究实验室。
同时据我们查询发现,荣耀在某招聘平台正提供机器人数据生成算法工程师、一体化关节设计师、机器人动力系统仿真工程师等多个招聘岗位。
在今年 2025 MWC(世界移动通信大会)上,荣耀宣布了其全新人工智能战略「荣耀阿尔法战略」,宣布公司将从智能手机制造商向全球 AI 终端生态公司全面转型。其中荣耀提到,在该战略第二阶段中,公司将打破行业边界,共同创造物理人工智能时代的新范式。

昨日,有消息称钉钉在「新 CEO」陈航(无招)回归后,开始重整纪律。随后,据网易科技从内部人士处获悉:部分信息为真,很多夸张信息是假消息。
从网传信息来看,钉钉在考勤层面要求 9 点上班,午休缩短半小时至 13:30,晚上 9 点下班。据了解,上班考勤和午休缩短为真,9 点下班则为假消息。与此同时,网传清明加班也是假消息。
网传讨论度较高的「工作时间禁用小红书,以及要求钉钉员工使用钉钉,工作场合加好友首先添加钉钉,0 代码的程序员会被挑战,要求学习 Python」,报道指出「都确有其事」。
内部人士透露,这是无招重整钉钉的开始,其初衷是要求钉钉重回创业,抓住 AI 机遇,「只有用创业心态才能和其它大厂抗衡」。而钉钉的定位,阿里集团 CEO 吴泳铭在 2025 年财报电话会上表态,将钉钉推向了集团 AI 战略执行的第一线,同时钉钉也是阿里最重要的、面向 To B 领域的 AI 应用。
据 36 氪报道,3 月 30 日,阿里集团拟收购跨境电商公司两氢一氧的股份,后者是由钉钉创始人陈航 2021 年成立的一家跨境电商公司。阿里完成两氢一氧的股份收购后,陈航将回归阿里集团,并再次担任钉钉 CEO,接替叶军(不穷)的位置。当时,外界解读认为阿里正在加速 AI 布局,希望在夸克之外,继续在 To B 领域亮剑。
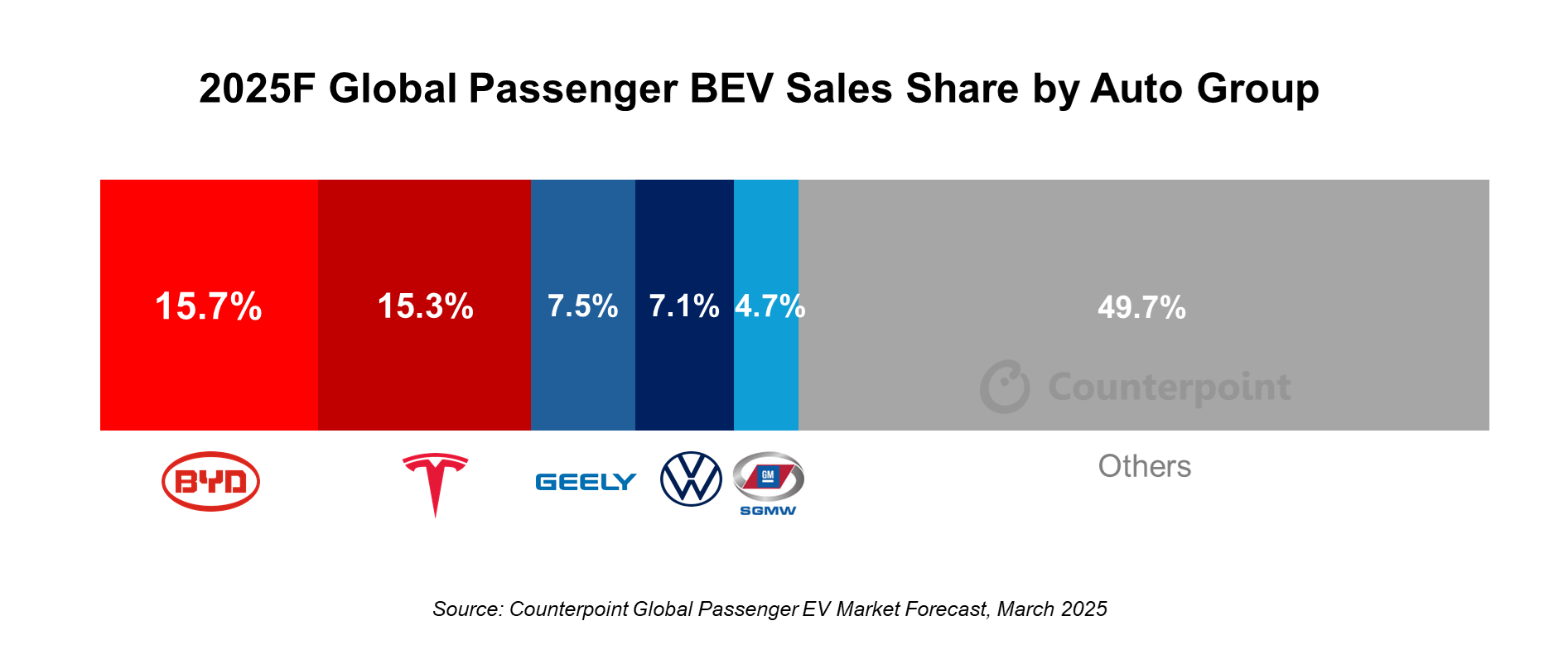
4 月 2 日,数据分析机构 Counterpoint Research 发布报告,预测比亚迪将在 2025 年以 15.7% 的全球市场份额超越特斯拉,成为全球纯电动车销量冠军。
报告指出了比亚迪的多个优势:
此外,因特斯拉 CEO 马斯克近期在政治立场上「口无遮拦」,导致其公众人物形象受损,从而致使特斯拉在美和欧洲的主要市场,遭受到大量消费者的抵制。同时地缘政治等因素,也扰乱了特斯拉的供应链情况,阻碍公司在 2025 年的表现。
值得关注的是,比亚迪近日公布了其在今年 3 月海外销售情况:乘用车及皮卡销售 72,407 辆。此前,比亚迪董事长王传福曾小范围公布 2025 年的总销量目标是 550 万辆,包含海外市场的 80 万辆以上。换算下来中国市场销量增速约为 30%,海外市场增速则高达 91.8%。

据美国证交会文件显示,苹果 CEO 库克于 4 月 2 日出售了 108,136 股苹果普通股,价值超过 2,400 万美元。值得关注的是,这是库克一年之内,第 3 次减持苹果的股票,累计套现超 1.1 亿美元,约合人民币达 8 亿元。据了解:
作为苹果 CEO,限制性股票单位(RSU)是库克收入的主要组成部分。2024 年库克总薪酬中股票激励占比达 75%。而本次减持的股票来自 2020 年授予的 RSU 计划,分三批解禁,分别是在 2023 年、2024 年和 2025 年,本次操作属计划内动作。
值得注意的是,这些股票一般于 4 月 1 日解禁后次日完成出售。库克每次减持均与 RSU 解禁同步,且通过预先设定的 10b5-1 交易计划执行,一定程度上是在规避内幕交易风险。截至今年 4 月,库克仍持有 328 万股苹果股票,市值约 5.5 亿美元。
库克并非唯一减持的苹果高管:2024 年以来,首席运营官杰夫・威廉姆斯、零售高级副总裁迪尔德丽・奥布莱恩等均抛售股票,累计套现超 5000 万美元。此外,据消息称,苹果目前已在筹备库克的继任计划。
此外,苹果在 4 月 3 日的股价跌幅一度超过 10%,市值蒸发逾 3,000 亿美元,最终收盘价格为 203.19 美元,跌幅达到 9.25%。

4 月 3 日,据信息显示,农夫山泉创始人钟睒睒在朋友圈发文称:全国的农民兄弟及整个传统产业都在为互联网平台打工。
钟睒睒认为,在消灭中间商的口号下,互联网平台逐渐变成中间商,并做出了很多不合道德行为:扭曲国之秩序、挑动仇富、仇「官」情绪、制造「莫须有」谣言,并从中渔利。钟睒睒表示,所有互联网平台或多或少都是强势经济权控股公司。
在钟睒睒看来,公平正义应是是弱势者不弱,强势者谦让的经济生态。钟睒睒表示,「民营经济呼唤法治,呼吁公平公正,市场经济秩序和国家繁荣之本是小民有小利,小企业有小利,而不是唯强权经济体宏利」。
钟睒睒呼吁,市场监管部门规范市场服务收费规则,将公开收费标准与规则、规范,其最后还强调,「还社会大众知道真相的权利!」

据 Semafor 报道,Google 近期打算重组 AI 管理层人员,其中 Google Gemini 团队负责人 Sissie Hsiao 目前已卸任职位(报道称其将工作至周三);而接替她的将是目前正在带领 Google Labs 的 Josh Woodward。
而据 The Information 报道,Sissie Hsiao 在离任后,将会被分配到 Google 一个新的内部职位。报道指出,本次调动是为了让 Gemini 的生成式 AI 聊天机器人,能从 OpenAI 的 ChatGPT 手上抢了一部分市场份额。据分析机构数据显示,目前 Gemini 网络热度仅约为 ChatGPT 的 1/10。
据了解,Hsiao 在 Google 工作了 19 年,并在 2022 年开始负责 Google 聊天机器人的业务(当时还称 Bard),试图与同期推出的 ChatGPT 抗衡。而 Josh Woodward 的实验部门创造了多款 AI 产品,其中包括 AI Studio、Project Mariner、NotebookLM,而这些产品,都更能打动消费者,并满足 Google 对下一步的探索。

4 月 3 日,「中国广州发布」发文宣布,抖音集团于 3 月 31 日,以总价 12.14 亿元竞得琶洲中二区 AH041101 地块。报道指出,随着抖音集团华南创新基地项目落地,琶洲科技企业集群规模将再度扩容。
据介绍,琶洲中二区 AH041101 地块用地面积约 5.5 公顷,建筑面积约 7.1 万平方米,容积率 1.84,规划为商务兼容商业设施用地。抖音集团计划将新竞得地块用于建设抖音华南创新基地,同时还将发挥抖音集团产业带动能力,繁荣广州市、海珠区的数字营销、数字文娱、人工智能等产业生态。
此前,抖音集团早在 2016 年就已经产业招商,落地广州市海珠区。经过十年的发展,抖音集团在广州的业务已经拓展至资讯、电商、生活服务、飞书、懂车帝等多个板块。
作家刘慈欣:AI 创作质变只是时间问题
近日,中国科协之声对话中国知名科幻作家刘慈欣,双方围绕科幻创作、科普传播、科技创新等议题深入交流。
刘慈欣开篇便提到,当下人工智能的确对大众的生活产生了显著冲击。其坦言,像 DeepSeek 这样的 AI 大模型已具备一定的自由创作能力,甚至未来有可能代替作家,包括科幻作家。刘慈欣表示,按照 AI 目前的发展趋势与速度,它极有可能在未来取代人类文学创作,至少在相当大的比例上实现替代。
对于目前 AI 创作存在的诸多问题,刘慈欣也只是认为「这都是时间问题」。其认为要用发展的眼光看待:
未来时间漫长,AI 在处理和提炼超大信息量方面,与人类思维方式差异并不大。既然人类思维能实现从无到有,那么当 AI 发展到某个质变节点后,同样能够做到。
交流中,刘慈欣提到了「目前中国的科幻作品是否应该以获得国家大奖为准」。他表示,能够获得国际科幻奖项,无疑是对一个国家科幻文学创作的重要肯定;但同时,目前我国面对外国科幻作者的条件或许并不成熟,因此国际奖项并不是唯一目标,但作者们更需要的是以中国的背景,去探讨人类更为深入、更为未知的科幻想象。


近日,博主 majinbuofficial 发文透露称,iPhone 17 Pro 系列将搭载全新的摄像头模组与更高像素的长焦镜头,具体来看:
此前,majinbuofficial 还多次曝光了 iPhone 17 Pro 系列的外观信息:
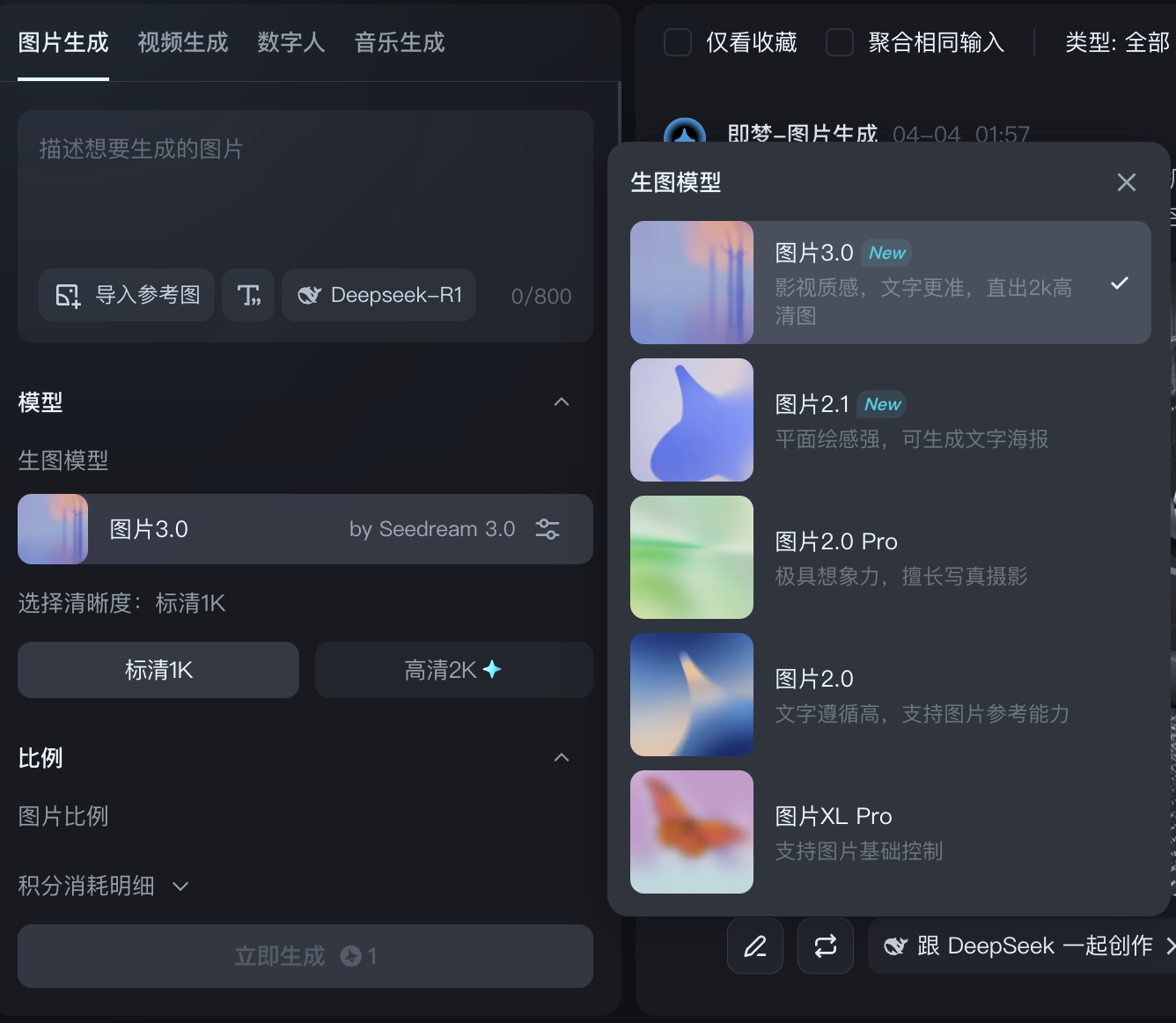
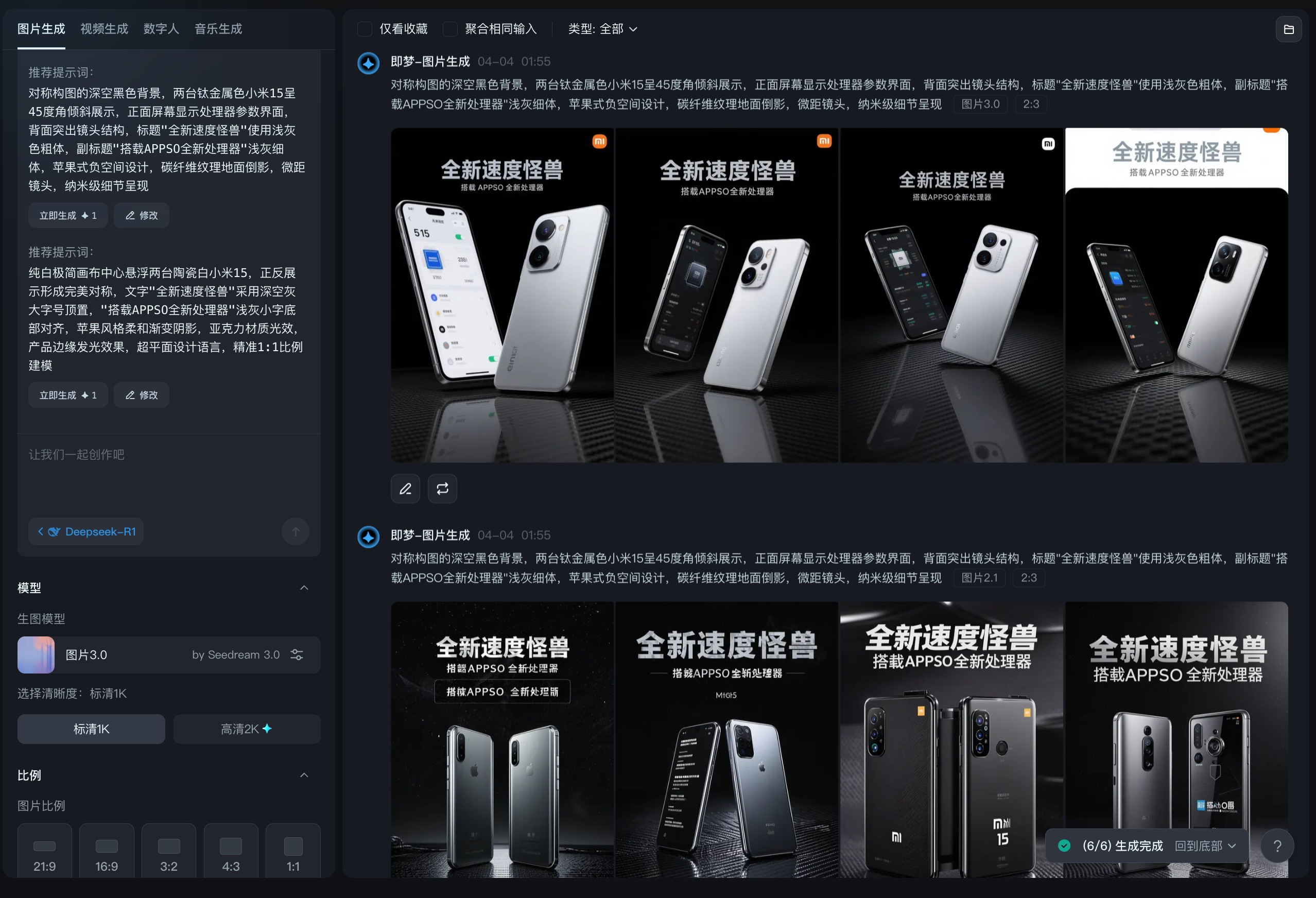
日前,即梦 AI 推出其 3.0 版本。在此版本下,即梦 3.0 表现出了较强的中文文字生成能力。据官方介绍,即梦 3.0 将拥有「影视质感」「文字更准」「直出 2K 高清图」等特征。另外:
目前,即梦 AI 3.0 版本仍处于小范围内测。而小编也是在第一时间体验了一番即梦 3.0 版生图:
对比 2.1 版本,生成文字以及提示词遵循上,3.0 版本要更加出色,更能按照所需要的内容进行生成;同时画面质感也要更加贴近提示词,图像内容也更加现实自然。

4 月 3 日,联想发布「一体多端」AI 终端新品的预告视频,并宣布将在 5 月发布全新联想 moto AI 手机、联想拯救者 AIPC、联想 AI 平板。
在 3 月底的联想集团 25 / 26 财年誓师大会上,集团董事长兼 CEO 杨元庆宣布将开启开启联想的「创业 5.0」时代。其中他提到:
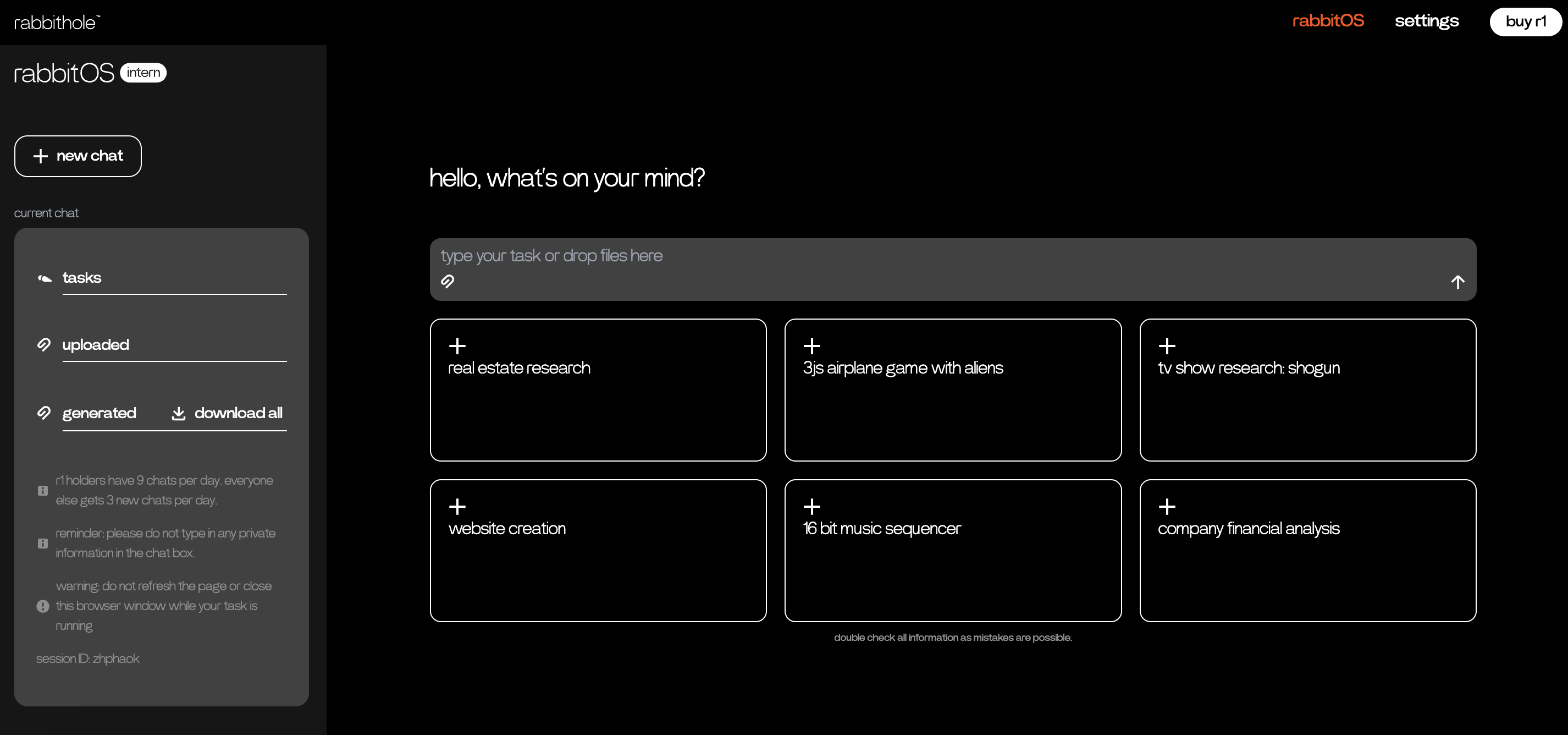
4 月 3日,rabbit 发布 AI 原生操作平台 rabbit OS intern。
据介绍,rabbit OS intern 拥有自主的通用 agent 机制,能够基于用户输入的 prompts 进行推理、规划、协调及代码级任务执行,构建多样化项目。当前其跨领域任务完成能力展示出了实习生水平的人类智能。
目前,rabbit OS intern 已经向所有人开放免费试用,只需要注册一个 rabbithole 账号,即可体验。r1 用户目前每天可以体验 9 次,非 r1 用户可以体验 3 次。
体验链接在这啦  https://hole.rabbit.tech/
https://hole.rabbit.tech/

昨日晚,豆包 AI 宣布其绘图能力增强,具体来看:
目前升级版绘图能力已上架豆包 App 或网页端。

昨日,索尼正式宣布将在 4 月 15 日举行家庭影院娱乐新品发布会。从官方公布的预告视频显示,本次新品将会带来新款电视、新款音响等产品。
上月,索尼正式发布新一代显示技术 —— RGB 高密度 LED 显示系统。该显示技术拥有更好的色彩、亮度表现。索尼官方表示,此次 RGB 高密度 LED 显示系统,融合了索尼全产业链的优势以及 20 多年背光控制的领先经验,持续拓展显示技术与画质表现的边界。

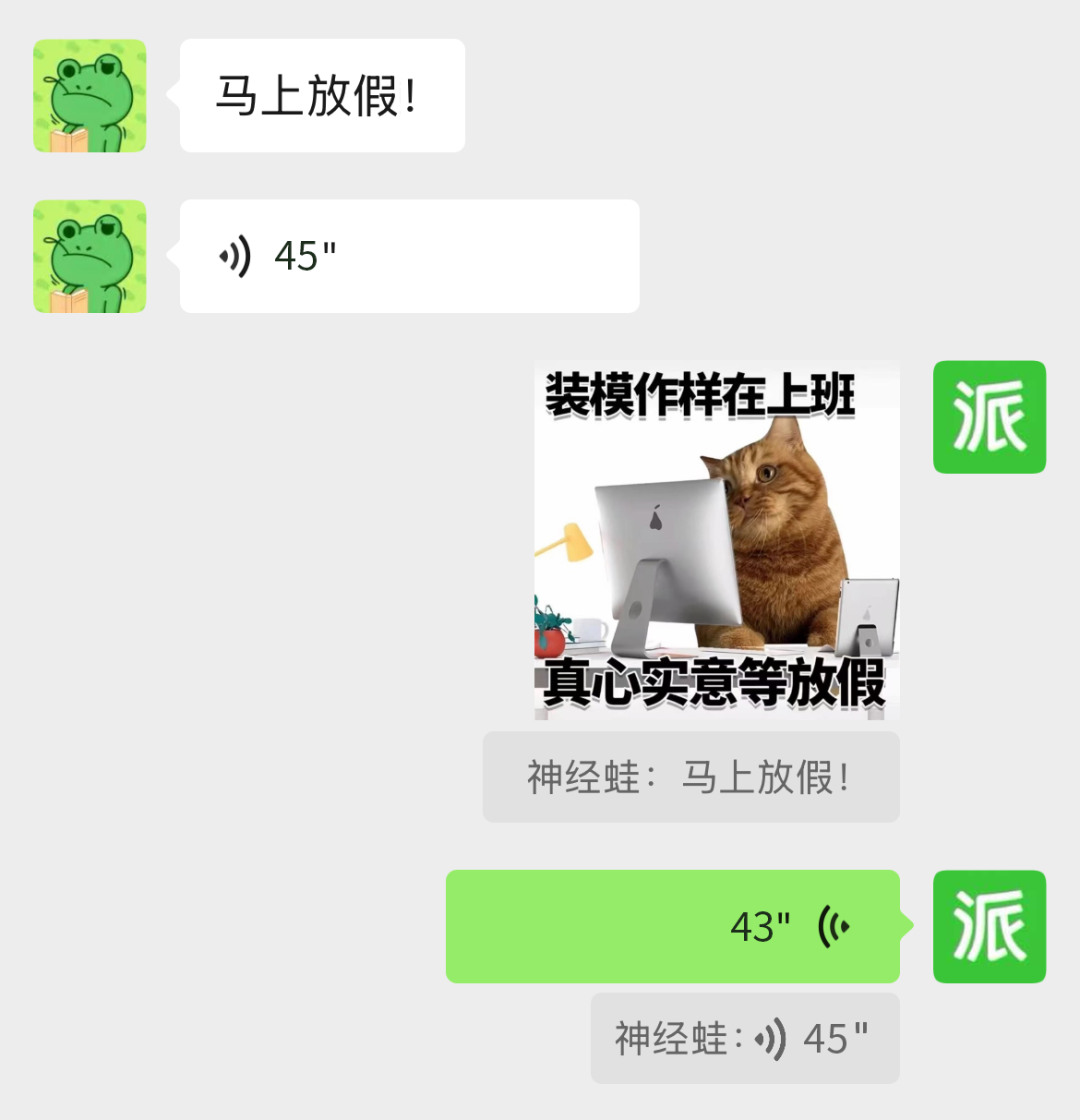
4 月 3 日,微信官方账号「微信派」发文宣布,微信聊天引用回复不只可以回文字消息,还可以回复语音和表情包内容。
据我们实际测试,进入消息引用状态后,选择表情包或语音发送均可以成为引用消息发出。目前该功能已上线最新版微信。
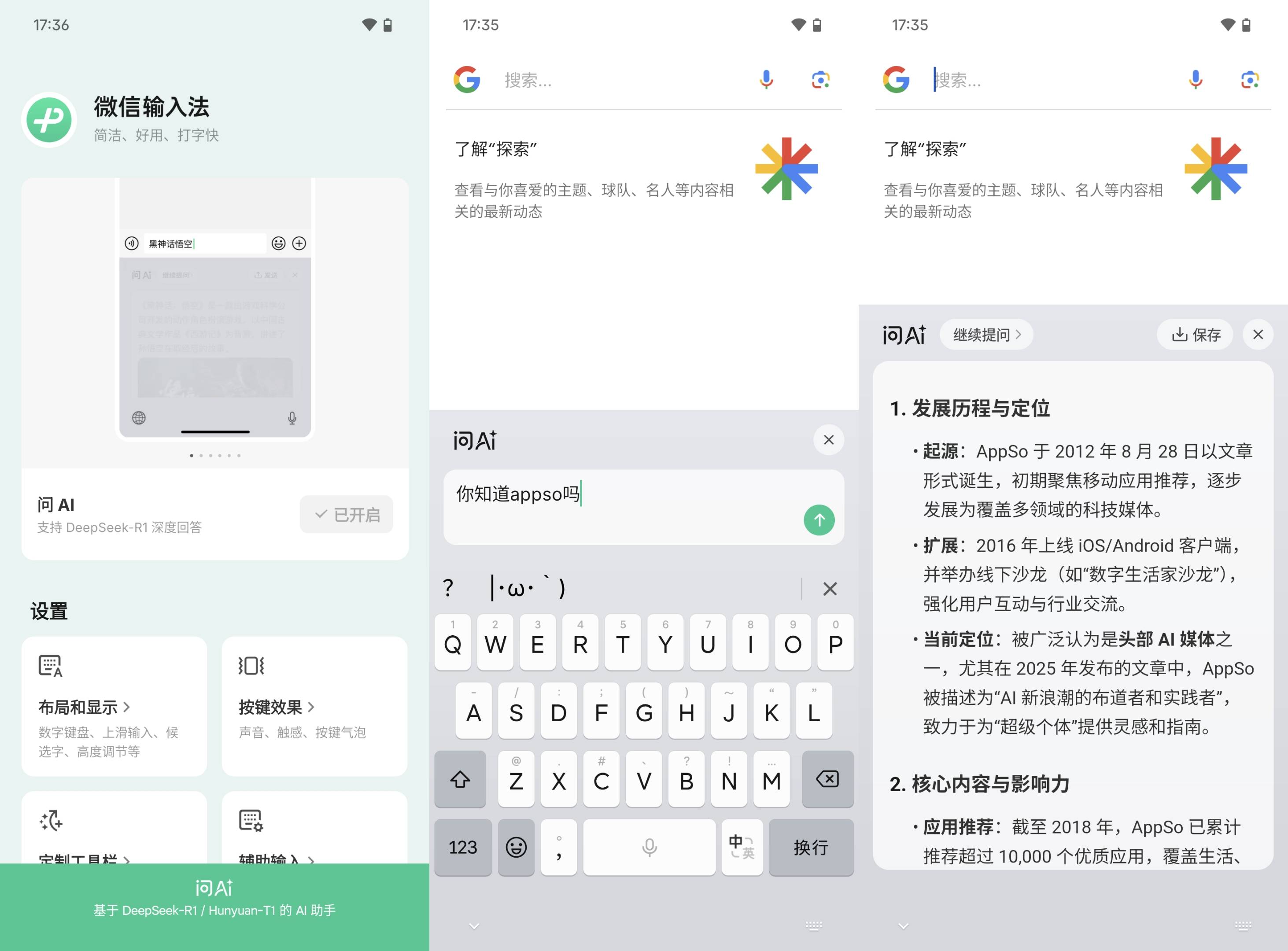
近日,微信输入法正式上线「问 AI」功能,支持 DeepSeek / 混元深度回答。据介绍,不仅能够进行深度思考,「问 AI」功能还能根据当前输入的内容,进行实时问题推荐;相较于跳转至 App 内进行答疑解惑,微信输入法能够借助键盘区域本身,进行 AI 问答,不用频繁切换软件。
目前,用户可以在微信输入法的二级菜单或主体 App 中找到「问 AI」功能入口。
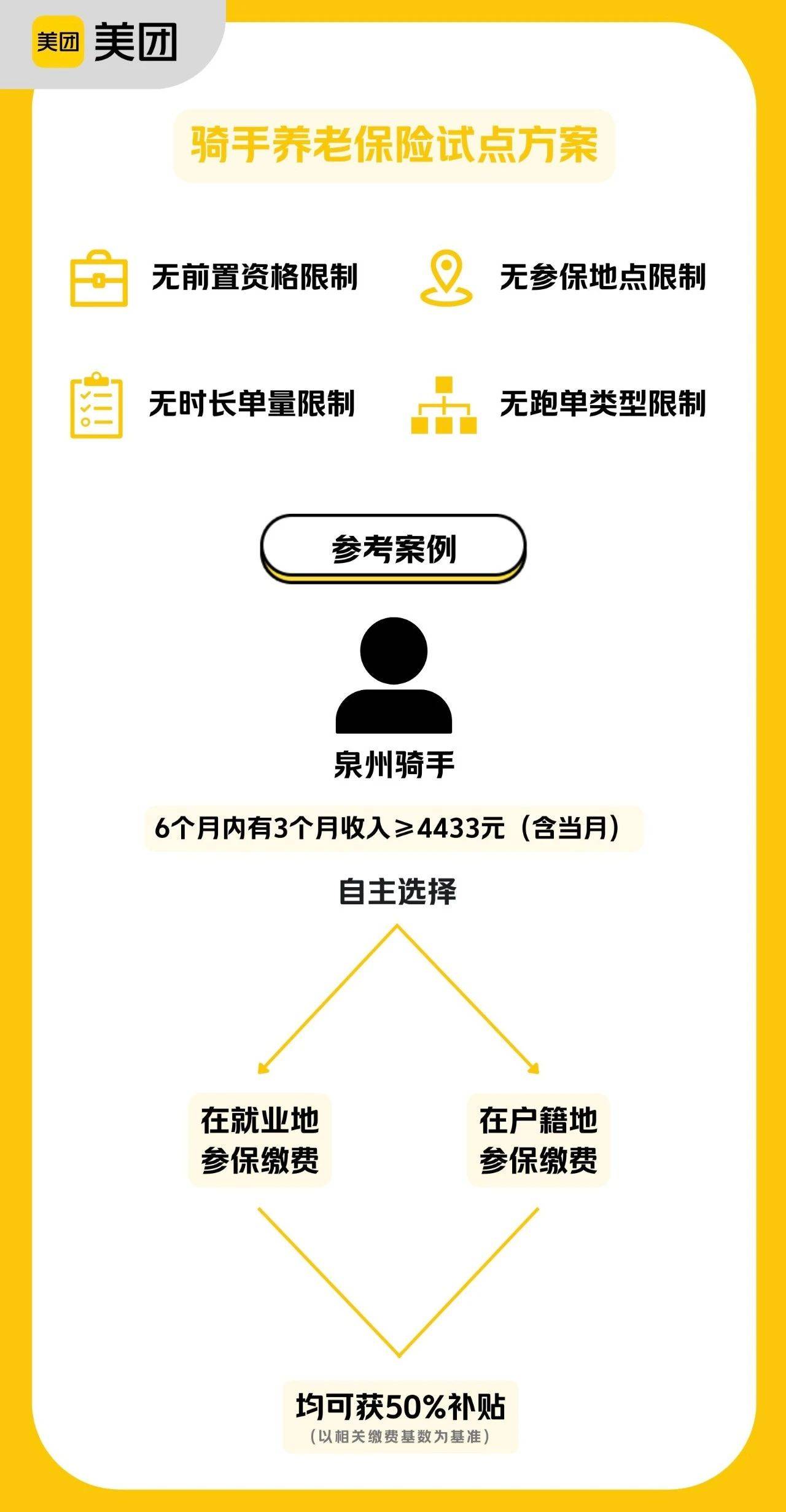
昨日,美团发文宣布,在「新职伤」2022 年 7 月开始试点、今年将扩围至 17 个省市的基础上,基于国家已有的灵活就业人员参保政策,消息公布当日起启动骑手养老保险试点,旨在探索适合新就业群体灵活就业特点的养老保险方案。
据介绍,美团本次试点方案为:对当月收入达到就业地相关缴费基数下限,且近 6 个月有 3 个月满足该条件的骑手,美团以相关缴费基数为基准,补贴 50% 的费用。美团方面表示,试点采用补贴方式,是为了更适应骑手工作灵活自由、过渡性强的特点,覆盖更多骑手。
值得关注的是,满足「国家关于灵活就业参保条件」的骑手即可参保,无需签署任何承诺或合约,不与工作单量或工作时长挂钩,也无需申请或等待邀约。骑手当月自愿参保缴费后,符合基础条件即自动获得补贴资格。
首批试点今日已在福建泉州、江苏南通两城区开启,向区域内全部骑手开放,后续逐步覆盖至全国。


昨日,中国美术学院发文预告,「黑神铸炼」——「黑神话:悟空」艺术展即将面向公众开放:
据介绍,展览以游戏《黑神话:悟空》为核心,在实体空间重现游戏中的经典叙事与角色、场景、道具等内容,观众能近距离欣赏游戏原画与制作细节,探索幕后开发故事。
本次展览共分「破顽空」、「载群生」、「明邪正」、「开尘锁」、「踏云光」、「会元龙」、「赌输赢」七个单元,向观众展现「黑神话:悟空」的幕后故事与恢弘意境。

昨日,电影《不说话的爱》宣布,为听障朋友特别制作「助听字幕版」,并将于 4 月 8 日上映此版本。
据悉,该版本通过增配详细字幕的形式,帮助听障朋友更全面有效地获取信息、理解故事。主创希望以这种方式,推动影视行业无障碍观影的标准化进程,为更多观众带来平等、无碍的观影体验。
影片中,张艺兴挑战出演聋人父亲,影片中全程使用手语,并与李珞桉搭档父女。影片改编自沙漠执导的同名短片,讲述聋人小马和听人女儿木木彼此为伴一起生活,然而一场意外的发生,不仅让小马后悔莫及,也让木木暗暗做了一个惊人的决定。影片已于昨日正式上映。

近日,真人版《驯龙高手》电影第二部发布先导预告,并定档 2027 年 6 月 11 日北美上映。
据悉,真人版《驯龙高手》电影首部作品将于 2025 年 6 月 13 日北美上映。昨日,环球影业宣布,《新驯龙高手》(首部真人版《驯龙高手》电影)确认引进中国内地,档期待定。
该片改编自童书《如何驯服你的龙》,也将作为梦工厂动画的《驯龙高手》三部曲的真人版电影登场。影片讲述小嗝嗝偶然间遭遇传说中的「夜煞」无牙仔,并由此与之建立深厚友谊,进而打破两大族群间的隔阂,携手寻求和平的故事。影片由迪恩·德布洛斯执导,梅森·泰晤士、妮可·帕克、杰拉德·巴特勒、尼克·弗罗斯特等主演。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

北京时间 4 月 4 日凌晨消息,美国当地时间 3 日 9 点,标普 500 指数低开 3.3%,纳斯达克 100 指数跌 4%,道指跌 2.6%。标普 500 指数开盘之际,大约抹去了 1.7 万亿美元的市值。
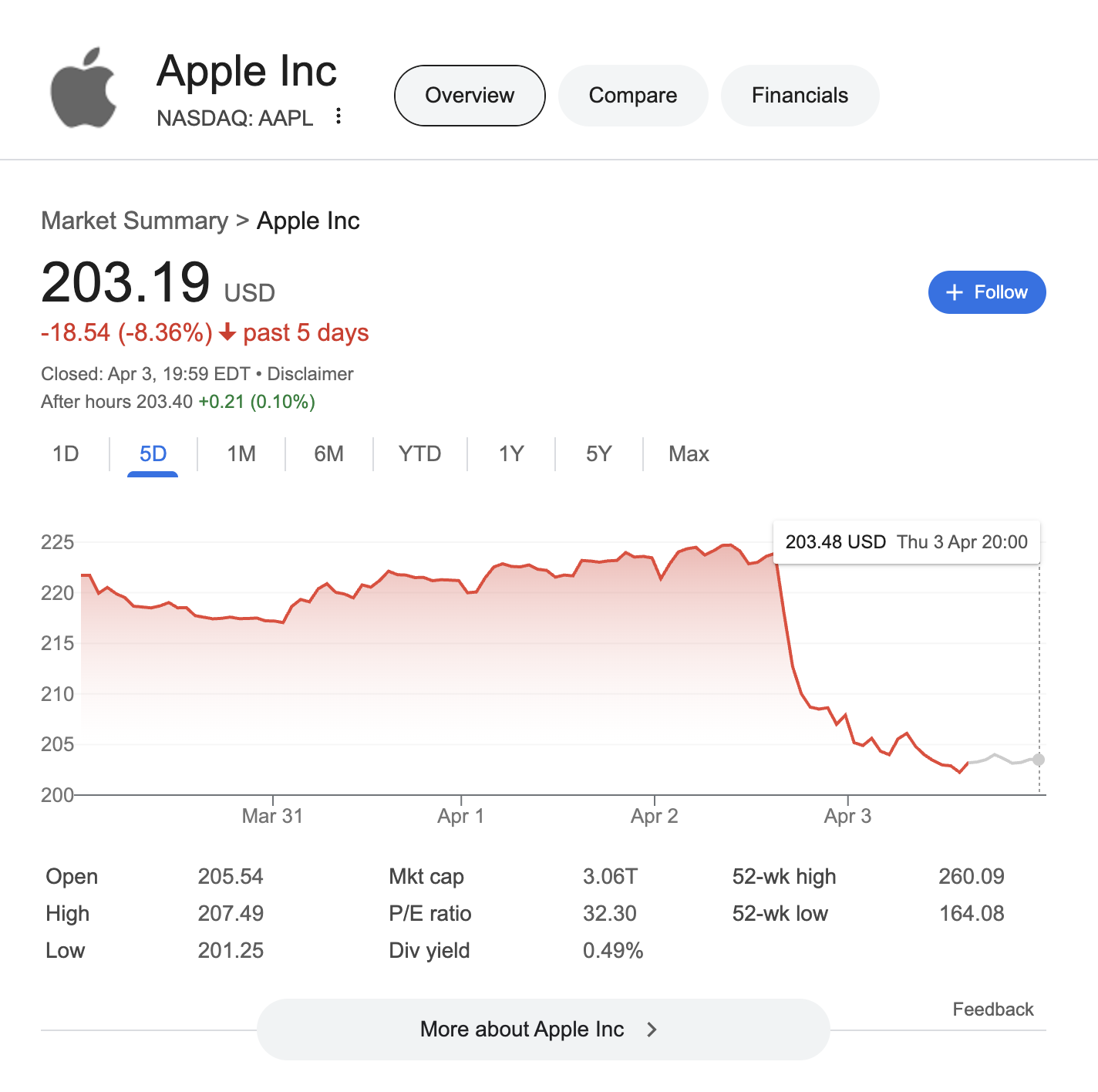
供应链对海外生产依赖程度高的公司跌幅最大。苹果公司开盘后股价下跌约 8%,市值蒸发 2550 亿美元。与越南有制造业务往来的公司中,Lululemon 和耐克股价下跌约 10%。沃尔玛和 Dollar Tree 的商店里摆满了从美国以外采购的产品,这两家零售商的股价也分别下跌约 2% 和 11%。
美国基准指数恐创 2022 年以来最大跌幅,几乎没有个股幸免。标普 500 指数中约有 70% 的公司股价下跌,500 只股票中近一半跌幅至少达到 2%。(来源:cnBeta)

4 月 3 日消息,距离 TikTok 在美国「不卖就禁」的最后期限只剩 48 小时,电商巨头亚马逊突然提出全资收购短视频平台 TikTok 美国业务,估值 450 亿美元。

2024 年,美国迫使字节跳动出售 TikTok,该法律原本应该在 2025 年 1 月生效。但随后延期至 2025 年 4 月 5 日。随着时间的临近,包括亚马逊在内的巨头纷纷下场竞购。
包括 AI 初创公司 Perplexity AI 也向字节跳动提交了一份与 TikTok 美国子公司合并的提案,这将使 TikTok 的价值至少达到 500 亿美元。(来源:新浪科技)
北京时间 4 月 3 日,据谷歌官方消息,谷歌日前为 NotebookLM 增加了一项新的 AI 功能,帮助用户寻找资料的来源。
用户可以通过 NobebookLM 寻找自己感兴趣的内容并获得整理过的相关资料。而全新的溯源功能可以帮助用户导入这些资料的来源。用户可以阅读原文或者是了解到资料来源的大概信息。
谷歌还为 NotebookLM 的新用户提供了一个有趣的附加功能:「Im Feeling Curious」按钮。它会随机生成一个主题的资料来源,让用户快速了解产品资料来源发现代理的运行情况。(来源:Pingwest)
北京时间 4 月 3 日消息,美团创始人、董事长和首席执行官王兴于 4 月 3 日下午发布全员信,宣布原大众点评、SaaS 等业务负责人、美团高级副总裁张川转任公司顾问。
此外,美团相关组织调整和人员任命如下:第一,点评事业部并入「核心本地商业」,由 S-team 成员、美团平台负责人李树斌兼任点评事业部负责人。第二,任命原 SaaS 事业部负责人肖飞担任「软硬件服务」负责人,「软硬件服务」各下属团队汇报给肖飞,肖飞汇报给王兴。(来源:cnBeta)

4 月 3 日消息,今天,网传钉钉在「新」CEO 陈航 (无招) 回归后,开始重整纪律。网易科技从内部人士处了解,部分信息为真,很多夸张信息是假消息。
从网传信息来看,钉钉在考勤层面要求 9 点上班,午休缩短半小时至 13:30,晚上 9 点下班。网易科技了解到,上班考勤和午休缩短为真,9 点下班则为假消息。与此同时,网传清明加班也是假消息。
不过,网传的工作时间禁用小红书,以及要求钉钉员工使用钉钉,工作场合加好友首先添加钉钉,0 代码的程序员会被挑战,要求学习 python,都确有其事。
内部人士透露,这是无招重整钉钉的开始。初衷是要求钉钉重回创业,抓住 AI 机遇。只有用创业心态才能和其它大厂抗衡。(来源:IT 之家)
北京时间 4 月 3 日消息,Gates Notes 于当地时间 4 月 2 日发布博文,为庆祝微软成立 50 周年,比尔·盖茨公开了奠定微软基石的 Altair Basic 源代码。

该代码为 Altair 8800 计算机开发,于 1975 年由盖茨与保罗·艾伦编写,采用 Intel 8080 处理器汇编语言,共 157 页。原始文件以 PDF 形式发布。
盖茨在个人博客中强调:「在 Office、Windows 95、Xbox 甚至人工智能之前,正是这段代码开启了微软的传奇。」盖茨与哈佛同学保罗·艾伦于 1975 年看到《大众电子》杂志封面的 Altair 8800 计算机后,主动联系制造商 MITS,提议为其开发 Basic 语言解释器。盖茨表示:「难以想象,一段代码竟引领了 50 年的创新。」(来源:IT 之家)
北京时间 4 月 3 日消息,马斯克回应了关于自己即将辞任美国效率部长的传闻,称此消息为假新闻。此前有消息称,特朗普已告知其核心圈子和内阁成员,马斯克将在未来几周内辞去现任职务。
马斯克自 2025 年 1 月末被特朗普政府任命以来,作为政府效率部的特别顾问,主要负责在有限时间内推动行政改革。他曾设定削减 1 万亿美元赤字的目标,并声称已完成大部分任务。
特朗普曾公开称赞马斯克的表现,称「政府效率部的改革为内阁成员提供了宝贵经验」。(来源:cnBeta)

北京时间 4 月 3 日消息,据 majinbuofficial 发布的消息,苹果 iPhone 17 Pro 系列将搭载革新性摄像头模组与先进长焦镜头,有望重新定义手机摄影标准。

传闻 iPhone 17 Pro 系列彻底重构了摄像头模组结构,取消标志性斜角排列方案,采用「横向大矩阵」设计。这一改动为容纳升级版长焦镜头提供了物理空间。新布局将进一步优化光线路径,有效降低广角与长焦镜头间的成像差异。
相比较此前 1200 万像素传感器,新款 4800 万像素传感器光学缩放最高支持 7 倍(160 毫米),而且通过高级光学器件,即使在长距离内也可以确保丰富、清晰的细节。(来源:IT 之家)
4 月 3 日消息,由深圳市 8K 超高清视频产业协作联盟牵头,联合华为、创维、海信、TCL 等 50 余家头部企业共同研发的 GPMI(通用多媒体接口)近期正式发布,改方案旨在解决传统视频设备需要分别连接电源线与视频信号线的问题。
该标准支持 144Gbps 的超高带宽与 480W 的大功率供电能力,可实现设备间音视频、数据、控制信号的双向互通,并支持 128 节点网状组网。
与 USB Type-C 接口兼容的 GPMI Type-C 接口,最高可支持 96Gbps 的数据传输和 240W 的电力传输。体积更大的 GPMI Type-B 接口同样支持正反插,最高可提供 192Gbps 的数据带宽和 480W 的供电能力。(来源:IT 之家)

北京时间 4 月 3 日消息,英国数字监管机构 Ofcom 透露,网络色情提供商正在通过实施年龄检查系统来履行其义务。
这些措施基于英国政府此前通过的一项立法,即《网络安全法案》,违反该法案将导致公司高级成员面临巨额罚款,甚至承担刑事责任。
Ofcom 表示,今年早些时候,它联系了数百家提供商,告知他们实施高效年龄保证措施的责任。所有提供在线色情内容的提供商都必须在 2025 年 7 月之前遵守这些措施。这包括允许用户生成色情内容的网站。这些网站将需要在此日期之前实施高效的年龄检查。这很可能包括自拍,如果年龄估计检查失败,则提供身份证件。(来源:cnBeta)
<input type="file" multiple>
核心功能:支持同时选择多个文件
技术实现:
$0.files 获取伪数组 file对象Array.from(files).forEach(file => ...)
注意事项:
accept="image/*,application/pdf")防止用户上传不必要或者不被允许的文件类型两端验证的作用
前端验证:主要是为了提升用户体验。在用户选择文件时,前端就可以快速检测文件大小是否超出限制,并及时给出提示,避免用户等待长时间上传后才被告知文件过大。
后端验证:前端验证可被绕过,所以后端验证是保障系统安全和稳定的最后一道防线。后端可以防止恶意用户绕过前端限制上传超大文件,避免对服务器资源造成过度占用。
<!-- chrome 火狐 opera 浏览器 -->
<input type="file" webkitdirectory mozdirectory odirectory>
核心功能:支持选择整个文件夹(需 Chrome 火狐 opera浏览器)
兼容性:
技术实现:
通过 每个 DataTransferItem 实例 对象上的 webkitGetAsEntry() 获取文件系统入口
递归遍历文件夹:
container.ondragenter = (e) => e.preventDefault();
container.ondragover = (e) => e.preventDefault();
container.ondrop = (e) => {
e.preventDefault();
const files = e.dataTransfer.items;
Array.from(files).forEach(file => {
const entry = file.webkitGetAsEntry();
if (entry.isDirectory) traverseDirectory(entry);
else if (entry.isFile) entry.file(processFile);
});
};
function traverseDirectory(entry) {
const reader = entry.createReader();
reader.readEntries(entries => {
entries.forEach(entry => {
if (entry.isDirectory) traverseDirectory(entry);
else if (entry.isFile) entry.file(file => processFile(file));
});
});
}
代码解析实现大文件切片上传的核心逻辑,重点包括:
<script>
// 核心变量声明
let file = {};
let chunkList = [];
const MAX_CHUNK_SIZE = 2 * 1024 * 1024; // 2MB切片大小
</script>
function createChunk(f, size = MAX_CHUNK_SIZE) {
let cur = 0;
while (cur < f.size) {
chunkList.push({
file: f.slice(cur, cur + size),
});
cur += size;
}
}
使用 Blob.slice () 方法进行二进制切片
Blob(Binary Large Object)即二进制大对象,它是 JavaScript 中用于表示不可变的、原始数据的对象。Blob 对象可以包含多种类型的数据,例如文本、图像、音频、视频等,它通常用于处理二进制数据,比如文件上传、下载、处理图像等场景。Blob 对象有以下特点:Blob 对象的内容就不能被修改。Blob 对象提供了 slice() 方法,允许你从一个 Blob 对象中提取出一部分数据,形成一个新的 Blob 对象。File 对象实际上是 Blob 对象的一个子类,因此 File 对象继承了 Blob 的所有属性和方法。f 是一个 File 对象(因为 File 是 Blob 的子类,所以可以调用 Blob 的方法),f.slice(cur, cur + size) 就是在调用 Blob 的 slice() 方法来对文件进行切片操作。循环处理直至整个文件分割完毕
每个切片包含原始文件引用和分块索引
const uploadList = chunkList.map(({file:blobfile},index) => ({
file: blobfile,
chunkName: `${file.name}-${index}`,
fileName: file.name,
index
}));
const requsetList = list.map(({file,fileName,index,chunkName}) => {
const formData = new FormData();
formData.append('file', file);
formData.append('fileName', fileName);
formData.append('index', index);
formData.append('chunkName', chunkName);
return axios({
method: 'post',
url: 'http://localhost:3000/upload',
data: formData,
});
});
await Promise.all(requsetList)
console.log('所有切片上传完成');
如果您觉得这篇文章对您有帮助,欢迎点赞和收藏,大家的支持是我继续创作优质内容的动力🌹🌹🌹也希望您能在😉😉😉我的主页 😉😉😉找到更多对您有帮助的内容。
给你一个有根节点 root 的二叉树,返回它 最深的叶节点的最近公共祖先 。
回想一下:
0,如果某一节点的深度为 d,那它的子节点的深度就是 d+1
A 是一组节点 S 的 最近公共祖先,S 中的每个节点都在以 A 为根节点的子树中,且 A 的深度达到此条件下可能的最大值。
示例 1:
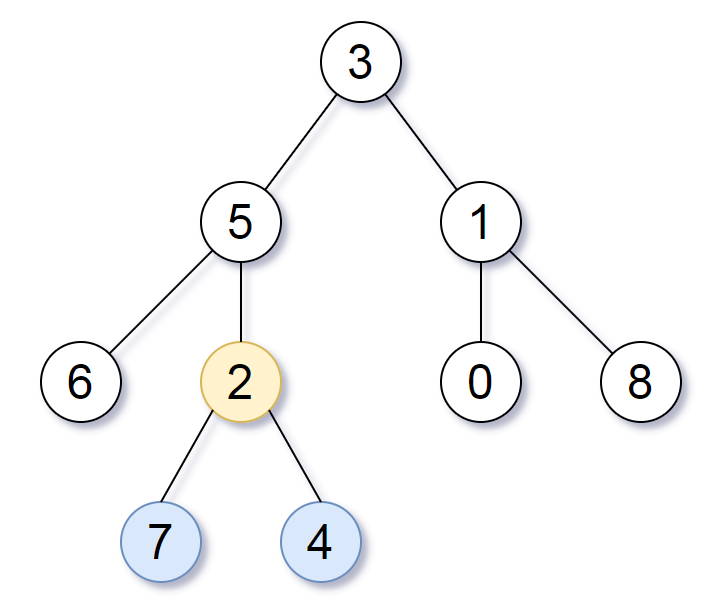
输入:root = [3,5,1,6,2,0,8,null,null,7,4] 输出:[2,7,4] 解释:我们返回值为 2 的节点,在图中用黄色标记。 在图中用蓝色标记的是树的最深的节点。 注意,节点 6、0 和 8 也是叶节点,但是它们的深度是 2 ,而节点 7 和 4 的深度是 3 。
示例 2:
输入:root = [1] 输出:[1] 解释:根节点是树中最深的节点,它是它本身的最近公共祖先。
示例 3:
输入:root = [0,1,3,null,2] 输出:[2] 解释:树中最深的叶节点是 2 ,最近公共祖先是它自己。
提示:
[1, 1000] 的范围内。0 <= Node.val <= 1000
注意:本题与力扣 865 重复:https://leetcode-cn.com/problems/smallest-subtree-with-all-the-deepest-nodes/
核心原理:通过CSS媒体查询动态调整布局,配合vw/rem单位实现跨设备适配
完整示例:
/* 移动端基准尺寸 */
:root {
--base-font: calc(100vw / 37.5); /* 以375px设计稿为基准 */
}
@media (max-width: 768px) {
.container {
padding: 0.2rem;
font-size: calc(var(--base-font) * 14);
}
}
@media (min-width: 769px) {
.container {
max-width: 1200px;
margin: 0 auto;
font-size: calc(var(--base-font) * 16);
}
}
关键步骤:
<meta name="viewport" content="width=device-width, initial-scale=1.0">
clamp()函数实现弹性布局:width: clamp(300px, 80%, 1200px)
srcset属性适配不同分辨率1核心原理:通过UA检测动态加载PC/Mobile页面,适合复杂业务场景
Vue项目实现:
// 路由配置
const routes = [
{ path: '/', component: () => import('./PC/Home.vue') },
{ path: '/mobile', component: () => import('./Mobile/Home.vue') }
]
// 设备检测中间件
router.beforeEach((to, from, next) => {
const isMobile = /mobile|android|iphone/i.test(navigator.userAgent)
if(isMobile && !to.path.includes('/mobile')) {
next('/mobile')
} else {
next()
}
})
关键配置:
/pc和/mobile目录结构核心技术:通过JS动态计算根字体大小,结合PostCSS自动转换单位
完整配置:
npm install amfe-flexible postcss-pxtorem -D
flexible.js源码:// 注释掉540px限制
if (width / dpr > 540) {
width = width * dpr // 原代码为 width = 540 * dpr
}
postcss.config.js:module.exports = {
plugins: {
'postcss-pxtorem': {
rootValue: 75, // 750设计稿时设为75
propList: ['*', '!border'],
selectorBlackList: ['el-'] // 排除element组件
}
}
}
核心原理:通过Viewport单位实现等比缩放,适合高保真设计需求
Vite项目配置:
// vite.config.js
import px2viewport from 'postcss-px-to-viewport'
export default {
css: {
postcss: {
plugins: [
px2viewport({
viewportWidth: 1920, // PC基准尺寸
viewportHeight: 1080,
unitPrecision: 3,
viewportUnit: 'vw',
selectorBlackList: ['.ignore'],
minPixelValue: 1
})
]
}
}
}
使用示例:
/* 设计稿1920px中标注200px的元素 */
.box {
width: calc(200 / 19.2 * 1vw); /* 200/1920*100 = 10.416vw */
height: calc(100vh - 10vw);
}
| 方案类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 响应式布局 | 内容型网站 | 维护成本低 | 复杂交互适配困难 |
| 独立页面 | 大型管理系统 | 体验最佳 | 双倍开发量 |
| REM适配 | 移动端为主 | 兼容性好 | PC需源码改造 |
| Viewport | 全终端项目 | 缩放精准 | 需PostCSS配合 |
.server.js后缀强制服务端组件标识Webpack配置方案:
// next.config.js
module.exports = {
webpack(config) {
config.plugins.push(new webpack.DefinePlugin({
'process.env.API_KEY': JSON.stringify(process.env.SERVER_SIDE_API_KEY)
}));
config.externals = [...config.externals, 'aws-sdk']; // 排除客户端不需要的模块
return config;
}
}
Vite配置方案:
// vite.config.js
export default defineConfig({
define: {
'import.meta.env.SERVER_KEY': JSON.stringify(process.env.SERVER_KEY)
},
build: {
rollupOptions: {
external: ['node-fetch'] // 排除客户端打包
}
}
})
关键差异:
externals字段显式排除,Vite使用Rollup的external配置import.meta.env,Webpack使用process.env
实现方案:
function App() {
const [tab, setTab] = useState('home');
const [isPending, startTransition] = useTransition();
const router = useRouter();
const handleNavigation = (path) => {
startTransition(() => {
router.push(path);
});
};
return (
<div className={isPending ? 'navigation-pending' : ''}>
<nav>
<button onClick={() => handleNavigation('/')}>Home</button>
<button onClick={() => handleNavigation('/dashboard')}>Dashboard</button>
</nav>
<Suspense fallback={<PageSkeleton />}>
<main className={`page-transition ${isPending ? 'fade-out' : 'fade-in'}`}>
<Outlet /> {/* React Router的出口组件 */}
</main>
</Suspense>
</div>
);
}
优化技巧:
:root {
--transition-duration: 300ms;
}
.page-transition {
transition: opacity var(--transition-duration) ease;
}
.fade-out {
opacity: 0.5;
pointer-events: none;
}
.fade-in {
opacity: 1;
}
const abortControllerRef = useRef();
const loadData = async (url) => {
abortControllerRef.current?.abort();
abortControllerRef.current = new AbortController();
const res = await fetch(url, {
signal: abortControllerRef.current.signal
});
// ...处理数据
}
分层解决方案:
// 一级Context:用户认证信息(高频变更)
const AuthContext = createContext();
export const useAuth = () => useContext(AuthContext);
// 二级Context:UI主题配置(低频变更)
const ThemeContext = createContext();
export const useTheme = () => useContext(ThemeContext);
// 三级Context:本地化配置(极少变更)
const LocaleContext = createContext();
export const useLocale = () => useContext(LocaleContext);
function AppProvider({ children }) {
return (
<AuthProvider>
<ThemeProvider>
<LocaleProvider>
{children}
</LocaleProvider>
</ThemeProvider>
</AuthProvider>
);
}
优化策略对比:
| 方案 | 适用场景 | 实现复杂度 | 性能增益 |
|---|---|---|---|
| Context分层 | 不同类型状态隔离 | 低 | 40%-60% |
| use-context-selector | 精确订阅特定状态字段 | 中 | 70%-80% |
| Zustand | 复杂跨组件状态管理 | 高 | 90%+ |
代码示例(使用use-context-selector) :
import { createContext, useContextSelector } from 'use-context-selector';
const UserContext = createContext();
function UserProvider({ children }) {
const [user, setUser] = useState(null);
const value = useMemo(() => ({ user, setUser }), [user]);
return (
<UserContext.Provider value={value}>
{children}
</UserContext.Provider>
);
}
// 组件精确订阅
function Profile() {
const username = useContextSelector(UserContext,
(ctx) => ctx.user?.name
);
return <div>{username}</div>;
}
核心实现:
import { useCallback, useRef } from 'react';
type HistoryAction<T> = {
past: T[];
present: T;
future: T[];
};
export function useHistory<T>(initialState: T) {
const history = useRef<HistoryAction<T>>({
past: [],
present: initialState,
future: []
});
const canUndo = useCallback(() => history.current.past.length > 0, []);
const canRedo = useCallback(() => history.current.future.length > 0, []);
const undo = useCallback(() => {
if (!canUndo()) return;
const { past, present, future } = history.current;
const newPresent = past[past.length - 1];
const newPast = past.slice(0, -1);
history.current = {
past: newPast,
present: newPresent,
future: [present, ...future]
};
return newPresent;
}, [canUndo]);
const redo = useCallback(() => {
if (!canRedo()) return;
const { past, present, future } = history.current;
const newPresent = future;
const newFuture = future.slice(1);
history.current = {
past: [...past, present],
present: newPresent,
future: newFuture
};
return newPresent;
}, [canRedo]);
const update = useCallback((newState: T) => {
history.current = {
past: [...history.current.past, history.current.present],
present: newState,
future: []
};
}, []);
return {
state: history.current.present,
undo,
redo,
canUndo,
canRedo,
update
};
}
扩展(防抖记录) :
function useDebouncedHistory<T>(initialState: T, delay = 500) {
const { update, ...rest } = useHistory<T>(initialState);
const debouncedUpdate = useDebounce(update, delay);
return {
...rest,
update: debouncedUpdate
};
}
// 使用示例
const { state, update } = useDebouncedHistory(0);
<input
type="number"
value={state}
onChange={(e) => update(Number(e.target.value))}
/>
混合策略实现:
import { useQuery } from 'react-query';
import useSWR from 'swr';
type HybridFetcher<T> = {
queryKey: string;
swrKey: string;
fetcher: () => Promise<T>;
};
export function useHybridFetch<T>({
queryKey,
swrKey,
fetcher
}: HybridFetcher<T>) {
// React Query主请求
const query = useQuery(queryKey, fetcher, {
staleTime: 60_000,
cacheTime: 300_000
});
// SWR后台刷新
const swr = useSWR(swrKey, fetcher, {
refreshInterval: 120_000,
revalidateOnFocus: true,
onSuccess: (data) => {
queryClient.setQueryData(queryKey, data);
}
});
// 错误合并
const error = query.error || swr.error;
return {
data: query.data,
isLoading: query.isLoading,
isRefreshing: swr.isValidating,
error
};
}
// 使用示例
const { data, isLoading } = useHybridFetch({
queryKey: 'user-data',
swrKey: '/api/user',
fetcher: () => fetchUserData()
});
数据流对比:
textCopy Code
┌─────────────┐
│ React Query │
└──────┬──────┘
│
┌─────────────────▼─────────────────┐
│ Query Cache │
└─────────────────┬─────────────────┘
│
┌─────────────────▼─────────────────┐
│ SWR Background Refresh │
└───────────────────────────────────┘
│
┌─────────────────▼─────────────────┐
│ UI Components │
└───────────────────────────────────┘
混合方案优势:
什么是 ArrayBuffer?
ArrayBuffer 是 JavaScript 中用于表示原始二进制数据缓冲区的对象。 它是一个固定长度的内存区域,可以用来存储各种类型的数据。 与 JavaScript 数组不同,ArrayBuffer 不能直接读取或写入数据。 它只是一个字节容器。
ArrayBuffer 的特点:
TypedArray 或 DataView 来访问和操作数据。如何创建 ArrayBuffer?
// 创建一个 16 字节的 ArrayBuffer
const buffer = new ArrayBuffer(16);
console.log(buffer.byteLength); // 输出: 16
TypedArray:赋予 ArrayBuffer 数据类型
TypedArray 是一组用于操作 ArrayBuffer 的类型化数组。 它们允许你以特定的数据类型(例如:整数、浮点数)来读取和写入 ArrayBuffer 中的数据。
常见的 TypedArray 类型包括:
Int8Array: 8 位有符号整数Uint8Array: 8 位无符号整数Int16Array: 16 位有符号整数Uint16Array: 16 位无符号整数Int32Array: 32 位有符号整数Uint32Array: 32 位无符号整数Float32Array: 32 位浮点数Float64Array: 64 位浮点数示例:使用 Uint8Array 操作 ArrayBuffer
// 创建一个 8 字节的 ArrayBuffer
const buffer = new ArrayBuffer(8);
// 创建一个 Uint8Array 视图,指向 ArrayBuffer
const uint8Array = new Uint8Array(buffer);
// 设置 ArrayBuffer 中的值
uint8Array[0] = 10;
uint8Array[1] = 20;
uint8Array[2] = 30;
console.log(uint8Array); // 输出: Uint8Array(8) [10, 20, 30, 0, 0, 0, 0, 0]
console.log(buffer); // 输出: ArrayBuffer(8) { byteLength: 8 }
DataView:更灵活的数据访问
DataView 提供了更灵活的方式来读取和写入 ArrayBuffer 中的数据。 它可以让你以任意字节偏移量和数据类型来访问数据,而无需像 TypedArray 那样必须从缓冲区的开头开始。
示例:使用 DataView 操作 ArrayBuffer
// 创建一个 8 字节的 ArrayBuffer
const buffer = new ArrayBuffer(8);
// 创建一个 DataView 视图,指向 ArrayBuffer
const dataView = new DataView(buffer);
// 设置 ArrayBuffer 中的值 (以不同的数据类型)
dataView.setInt8(0, 10); // 从偏移量 0 开始,写入一个 8 位有符号整数
dataView.setUint16(1, 256, true); // 从偏移量 1 开始,写入一个 16 位无符号整数 (小端字节序)
dataView.setFloat32(3, 3.14, false); // 从偏移量 3 开始,写入一个 32 位浮点数 (大端字节序)
console.log(dataView.getInt8(0)); // 输出: 10
console.log(dataView.getUint16(1, true)); // 输出: 256
console.log(dataView.getFloat32(3, false)); // 输出: 3.140000104904175
希望这篇文章能够帮助你更好地理解和使用 ArrayBuffer! 别忘了点赞、评论和分享哦!
在React RouterV7 中,是拥有不同的路由模式,路由模式的选择将直接影响你的整个项目。React Router 提供了四种核心路由创建函数:
createBrowserRouter、createHashRouter、createMemoryRouter 和 createStaticRouter
createBrowserRouter(推荐)
createHashRouter
createMemoryRouter
createStaticRouter
当使用createBrowserRouter时,如果刷新页面会丢失状态,这是因为浏览器默认会去请求服务器上的资源,如果服务器上没有资源,就会返回404。
要解决这个问题就需要在服务器配置一个回退路由,当请求的资源不存在时,返回index.html。
下载地址:Nginx
location / {
try_files $uri $uri/ /index.html;
}
<IfModule mod_negotiation.c>
Options -MultiViews
</IfModule>
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index\.html$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.html [L]
</IfModule>
{
"rewrites": [{ "source": "/:path*", "destination": "/index.html" }]
}
const http = require('http')
const fs = require('fs')
const httpPort = 80
http
.createServer((req, res) => {
fs.readFile('index.html', 'utf-8', (err, content) => {
if (err) {
console.log('We cannot open "index.html" file.')
}
res.writeHead(200, {
'Content-Type': 'text/html; charset=utf-8',
})
res.end(content)
})
})
.listen(httpPort, () => {
console.log('Server listening on: http://localhost:%s', httpPort)
})
推荐先看 二叉树的最近公共祖先【基础算法精讲 12】,对于理解本题做法有帮助。
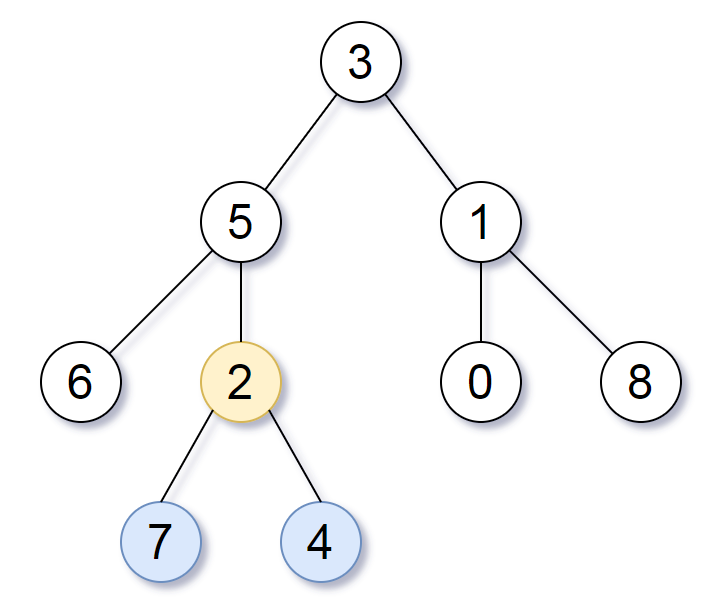
看上图(示例 1),这棵树的节点 $3,5,2$ 都是最深叶节点 $7,4$ 的公共祖先,但只有节点 $2$ 是最近的公共祖先。
上面视频中提到,如果我们要找的节点只在左子树中,那么最近公共祖先也必然只在左子树中。对于本题,如果左子树的最大深度比右子树的大,那么最深叶结点就只在左子树中,所以最近公共祖先也只在左子树中。
如果左右子树的最大深度一样呢?当前节点一定是最近公共祖先吗?
不一定。比如节点 $1$ 的左右子树最深叶节点 $0,8$ 的深度都是 $2$,但该深度并不是全局最大深度,所以节点 $1$ 并不能是答案。
根据以上讨论,正确做法如下:
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
ans = None
max_depth = -1 # 全局最大深度
def dfs(node: Optional[TreeNode], depth: int) -> int:
nonlocal ans, max_depth
if node is None:
max_depth = max(max_depth, depth) # 维护全局最大深度
return depth
left_max_depth = dfs(node.left, depth + 1) # 获取左子树最深叶节点的深度
right_max_depth = dfs(node.right, depth + 1) # 获取右子树最深叶节点的深度
if left_max_depth == right_max_depth == max_depth:
ans = node
return max(left_max_depth, right_max_depth) # 当前子树最深叶节点的深度
dfs(root, 0)
return ans
class Solution {
private TreeNode ans;
private int maxDepth = -1; // 全局最大深度
public TreeNode lcaDeepestLeaves(TreeNode root) {
dfs(root, 0);
return ans;
}
private int dfs(TreeNode node, int depth) {
if (node == null) {
maxDepth = Math.max(maxDepth, depth); // 维护全局最大深度
return depth;
}
int leftMaxDepth = dfs(node.left, depth + 1); // 获取左子树最深叶节点的深度
int rightMaxDepth = dfs(node.right, depth + 1); // 获取右子树最深叶节点的深度
if (leftMaxDepth == rightMaxDepth && leftMaxDepth == maxDepth)
ans = node;
return Math.max(leftMaxDepth, rightMaxDepth); // 当前子树最深叶节点的深度
}
}
class Solution {
public:
TreeNode *lcaDeepestLeaves(TreeNode *root) {
TreeNode *ans = nullptr;
int max_depth = -1; // 全局最大深度
function<int(TreeNode*, int)> dfs = [&](TreeNode *node, int depth) {
if (node == nullptr) {
max_depth = max(max_depth, depth); // 维护全局最大深度
return depth;
}
int left_max_depth = dfs(node->left, depth + 1); // 获取左子树最深叶节点的深度
int right_max_depth = dfs(node->right, depth + 1); // 获取右子树最深叶节点的深度
if (left_max_depth == right_max_depth && left_max_depth == max_depth)
ans = node;
return max(left_max_depth, right_max_depth); // 当前子树最深叶节点的深度
};
dfs(root, 0);
return ans;
}
};
func lcaDeepestLeaves(root *TreeNode) (ans *TreeNode) {
maxDepth := -1 // 全局最大深度
var dfs func(*TreeNode, int) int
dfs = func(node *TreeNode, depth int) int {
if node == nil {
maxDepth = max(maxDepth, depth) // 维护全局最大深度
return depth
}
leftMaxDepth := dfs(node.Left, depth+1) // 获取左子树最深叶节点的深度
rightMaxDepth := dfs(node.Right, depth+1) // 获取右子树最深叶节点的深度
if leftMaxDepth == rightMaxDepth && leftMaxDepth == maxDepth {
ans = node
}
return max(leftMaxDepth, rightMaxDepth) // 当前子树最深叶节点的深度
}
dfs(root, 0)
return
}
func max(a, b int) int { if b > a { return b }; return a }
var lcaDeepestLeaves = function (root) {
let ans = null;
let maxDepth = -1; // 全局最大深度
function dfs(node, depth) {
if (node === null) {
maxDepth = Math.max(maxDepth, depth); // 维护全局最大深度
return depth;
}
const leftMaxDepth = dfs(node.left, depth + 1); // 获取左子树最深叶节点的深度
const rightMaxDepth = dfs(node.right, depth + 1); // 获取右子树最深叶节点的深度
if (leftMaxDepth === rightMaxDepth && leftMaxDepth === maxDepth)
ans = node;
return Math.max(leftMaxDepth, rightMaxDepth);// 当前子树最深叶节点的深度
}
dfs(root, 0);
return ans;
};
也可以不用全局变量,而是把每棵子树都看成是一个「子问题」,即对于每棵子树,我们需要知道:
分类讨论:
class Solution:
def lcaDeepestLeaves(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
def dfs(node: Optional[TreeNode]) -> (int, Optional[TreeNode]):
if node is None:
return 0, None
left_height, left_lca = dfs(node.left)
right_height, right_lca = dfs(node.right)
if left_height > right_height: # 左子树更高
return left_height + 1, left_lca
if left_height < right_height: # 右子树更高
return right_height + 1, right_lca
return left_height + 1, node # 一样高
return dfs(root)[1]
class Solution {
public TreeNode lcaDeepestLeaves(TreeNode root) {
return dfs(root).getValue();
}
private Pair<Integer, TreeNode> dfs(TreeNode node) {
if (node == null)
return new Pair<>(0, null);
var left = dfs(node.left);
var right = dfs(node.right);
if (left.getKey() > right.getKey()) // 左子树更高
return new Pair<>(left.getKey() + 1, left.getValue());
if (left.getKey() < right.getKey()) // 右子树更高
return new Pair<>(right.getKey() + 1, right.getValue());
return new Pair<>(left.getKey() + 1, node); // 一样高
}
}
class Solution {
pair<int, TreeNode*> dfs(TreeNode *node) {
if (node == nullptr)
return {0, nullptr};
auto [left_height, left_lca] = dfs(node->left);
auto [right_height, right_lca] = dfs(node->right);
if (left_height > right_height) // 左子树更高
return {left_height + 1, left_lca};
if (left_height < right_height) // 右子树更高
return {right_height + 1, right_lca};
return {left_height + 1, node}; // 一样高
}
public:
TreeNode *lcaDeepestLeaves(TreeNode *root) {
return dfs(root).second;
}
};
func dfs(node *TreeNode) (int, *TreeNode) {
if node == nil {
return 0, nil
}
leftHeight, leftLCA := dfs(node.Left)
rightHeight, rightLCA := dfs(node.Right)
if leftHeight > rightHeight { // 左子树更高
return leftHeight + 1, leftLCA
}
if leftHeight < rightHeight { // 右子树更高
return rightHeight + 1, rightLCA
}
return leftHeight + 1, node // 一样高
}
func lcaDeepestLeaves(root *TreeNode) *TreeNode {
_, lca := dfs(root)
return lca
}
var dfs = function (node) {
if (node === null)
return [0, null];
const [leftHeight, leftLca] = dfs(node.left);
const [rightHeight, rightLca] = dfs(node.right);
if (leftHeight > rightHeight) // 左子树更高
return [leftHeight + 1, leftLca];
if (leftHeight < rightHeight) // 右子树更高
return [rightHeight + 1, rightLca];
return [leftHeight + 1, node]; // 一样高
};
var lcaDeepestLeaves = function (root) {
return dfs(root, 0)[1];
};