前沿多模态模型开发与应用实战3:DeepSeek-VL2多模态理解大模型算法解析与功能抢先体验
多模态理解大模型,是一类可以同时处理和理解多种数据形式(如图像、文本、视频等)的人工智能大模型,可以应用于图文理解、视觉问答、文档理解、场景描述等任务。本文将介绍目前热门的 DeepSeek-VL2多
全球 AI 开发者们热议“MCP”(Model Context Protocol)。尽管这一协议在2024年由Anthropic发布时并未引起广泛关注,但2025年初,Cursor宣布集成MCP迅速将其带入开发者的视野,3月Manus的爆发更是加速了MCP的普及。而就在3月27日,OpenAI正式宣布其Agent SDK全面支持MCP协议,这一举措标志着MCP将会成为该领域的实施标准,必将重塑AI应用的开发与交互方式。
目前,社区的MCP Server大多采用本地STDIO模式部署,尽管这种模式能支持基本模型服务和工具的数据交互,简单测试尚可,但在涉及具体的开发,调试,由于IO重定向带来不同程度的开发复杂度;同时随着AI场景的日益丰富,一方面数据访问不再仅限于本地,另一方面业务对于架构可靠性要求,基于本地部署的 MCP Server 势必无法满足复杂的生产需求。因此,云上托管的MCP Server将成为未来的主流趋势。函数计算(FC)目前已支持一键托管开源的MCP Server,欢迎大家前来体验。
MCP协议成为事实标准后,开发者无需为每个Function编写复杂的JSON Schema参数说明,这大大降低了重复开发的工作量。通过开源或第三方的MCP Server,开发者能够迅速共享和复用资源。例如,Blender-MCP项目允许用户通过MCP协议将自然语言指令转化为三维建模操作,项目开源一周便获得了5.4k stars。
随着MCP的普及,SaaS服务商可以通过集成MCP Server触达新的市场和行业机会,而MCP协议的Stdio和SSE标准要求服务和数据供应商提供API访问,而云上托管将是最优选择。
MCP Server 将服务/数据对接给大模型,如果不限制大模型的数据权限范围和敏感数据过滤,将对企业产生安全合规风险,云上托管提供权限管控、操作审计、用户隐私保护等内置安全工具,大幅减少安全风险暴露面,合规成本低。同时 MCP Server 的爆火,对服务商是巨大的机会,服务商将面临着用户量和模型调用量的突增,云上托管如函数计算具备免运维、自动弹性、自动容灾的优势,确保服务体验的同时实现降本增效。
从 MCP 架构的描述中可以看到,MCP Server 作为 AI 大模型和企业服务的中间层,通过购买传统云资源部署效率低下,其代码通常相对轻量,开发者需要快速部署,快速测试仅仅可能是一条NPX命令。 "MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol"。
作为原有 Function Calling 的替代者,工具调用请求规模具有显著的不确定性,传统云资源托管需要长期持有资源,资源供给无法实现按业务流量进行灵活的动态适配。
MCP Server 作为AI和企业服务能力的中间层,其逻辑覆盖简单路由到复杂计算,随着业务场景的丰富会变得越发复杂,务必在选择云上托管的时候,也要考虑后续业务的开发和维护效率。 务必要求开发层面需要更灵活的定制能力,实现快速变更,快速上线,灵活的版本和流量管理。
传统MCP Server依赖于本地化部署实现数据安全,随着云端部署的普遍化,云端 MCP Server 不仅需要能够实时安全的访问企业私有数据,也需要适配复杂的业务环境,在Internet和Intranet网络之间进行互通,这就要求能够快速的互联网公共服务和企业云上 VPC 快速打通,提供安全灵活的执行环境。
社区积极的推动 MCP 协议演进,推动 Steamable HTTP transport 技术代替原有 HTTP+SSE 的通信方式,原有的 MCP 传输方式就像是你和客服通话时必须一直保持在线(SSE 需要长连接),而新的方式更像是你随时可以发消息,然后等回复(普通 HTTP 请求,但可以流式传输)。这种形式与 Serverless 算力无状态模式更加契合,协议层演进将更有利于云上Serverless算力的价值放大,随着AI模型复杂度和数据规模持续增长,Serverless与MCP Server的结合将成为趋势。
函数计算作为云上Serverless 算力的典型代表,其凭借在开发效率,按需付费,极致弹性等产品能力直击云上 MCP Server 托管的核心痛点,为企业MCP Server 提供高效,灵活,匹配业务规模的托管能力。
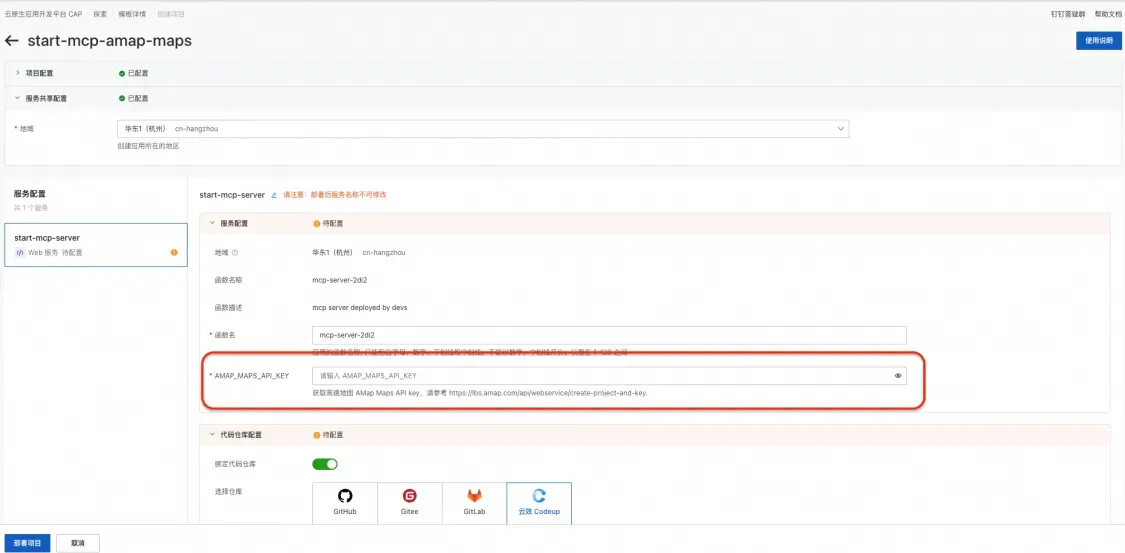
依赖 Serverless 应用开发平台 CAP,我们能够快速实现开源 MCP Server 一键托管,假如您搭建的 AI Agent 中需要加入导航服务,您可能会需要高德社区提供的 MCP Server ,接下来我们将以开源项目 amap-maps-mcp-server 为例演示如何一键部署 MCP Server 到函数计算FC上。
点击 cap.console.aliyun.com/create-proj… 进入CAP控制台。填入从高德开发者申请的 Token(立刻申请完成),可以在这里申请。
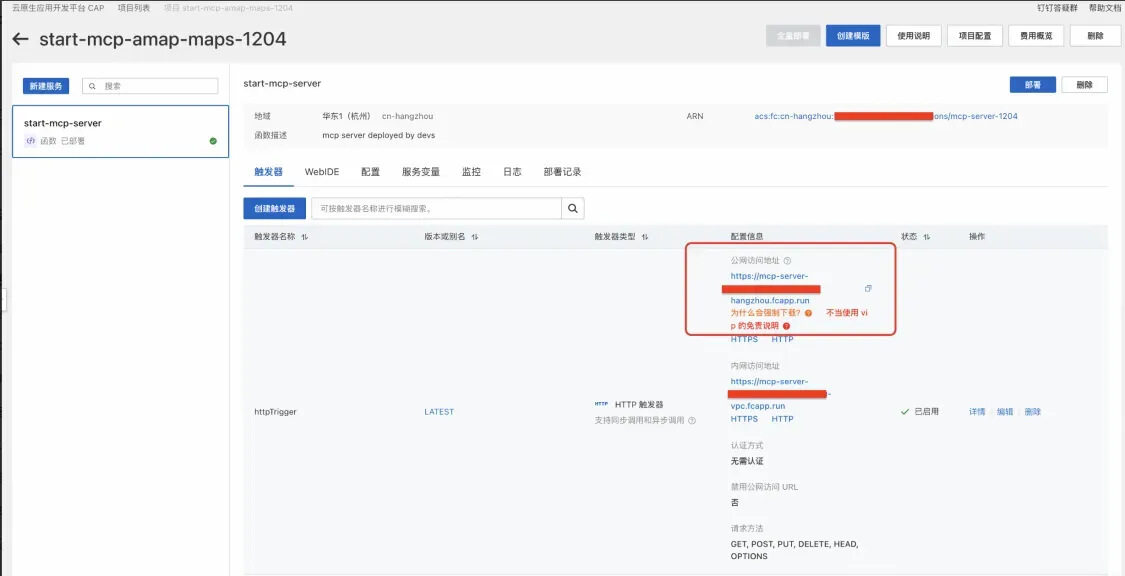
部署成功之后,通过触发器页面,拿到测试URL可对当前MCP Server进行测试。如果希望将部署的MCP Server 用于生产,建议使用自定义域名代替测试URL。
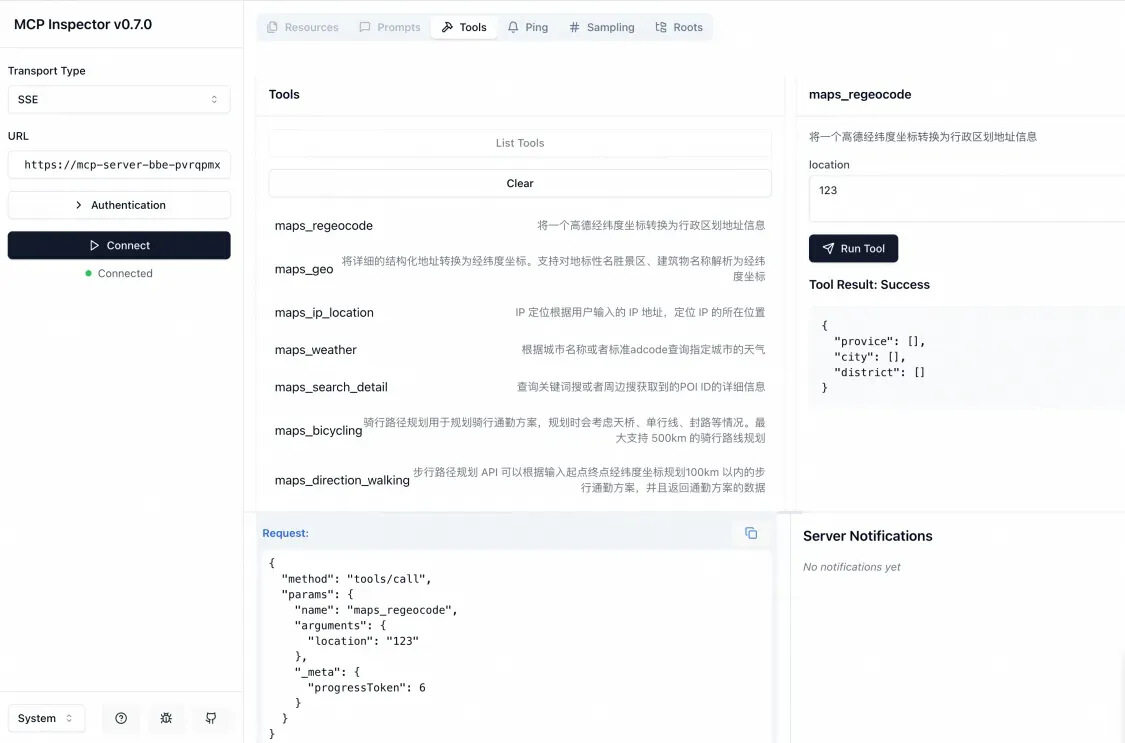
测试步骤一:本地终端运行命令: npx @modelcontextprotocol/inspector

测试步骤二:浏览器中打开本地提供的测试地址“http://localhost:5173/#tools ”进行测试,在URL表单中填入上面获取的URL,添加/sse 后缀填入URL表单中,点击Connect会看到开源 MCP Server提供的Tools列表,可以点击置顶Tool进行交互验证。
如果您对于产品有更多建议或者对 MCP server 云端托管有更多想法可以加入钉钉群(群号:64970014484)与我们取得联系。
| MCP 开源地址 | 编程语言 | 一键部署 | Server 类型 |
|---|---|---|---|
| github.com/baidu-maps/… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Python | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Python | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/devsapp/ama… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | sse |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
| github.com/modelcontex… | Node | cap.console.aliyun.com/template-de… | sse |
| github.com/modelcontex… | Node | cap.console.aliyun.com/create-proj… | mcp-proxy |
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。
本文主要介绍下LangGraph 的一些基础概念,包括定义、应用场景、核心概念和主要功能,让读者了解什么是LangGraph,以及它能做什么,在哪些场景用,使用哪些主要功能等。
供自己以后查漏补缺,也欢迎同道朋友交流学习。
最近在学习 LangGraph,顺便分享下。
LangGraph 是 LangChain 的扩展库,专门用于构建和管理复杂的状态机和工作流程。提供声明式的工作流程定义方式,以及支持循环计算和状态管理,使得复杂业务逻辑的实现变得更加简洁和高效。
在 LangChain 的基础上扩展了功能,LangGraph 增加了对异步操作、错误处理和并发任务的支持。它的状态化特性使得系统能够记住之前的交互或用户偏好,从而提供更个性化的响应。
同时,其支持循环计算的能力突破了传统工作流的限制,使开发者能够更自然地模拟现实世界中的决策过程。
LangGraph 凭借其支持循环计算和状态管理的特性,在多种复杂场景中表现出色。
它的状态化特性使其非常适合构建能够进行多轮对话的智能代理。可以通过状态图(State Graph)跟踪对话历史,并根据用户输入动态调整后续的响应逻辑。循环计算功能还允许代理在需要时反复询问或澄清问题,确保对话自然流畅。这种能力特别适用于需要上下文感知的场景。
例如,聊天机器人可以利用 LangGraph 记住用户的请求(如“我的订单状态”),并在多轮对话中逐步收集必要信息(订单号、用户信息等),最终提供准确的答复。如果用户的问题不完整,机器人可以通过循环逻辑返回到澄清步骤,直到满足条件。
LangGraph 在复杂决策系统中表现出色,它能够通过条件边(Conditional Edges)和状态管理处理多变量标准,并根据实时数据更新决策路径。
例如,在自动驾驶场景中,可以用来构建决策系统,处理诸如“是否变道”“是否减速”等复杂判断。系统通过状态图跟踪车辆状态(如速度、周围环境),并根据传感器数据动态选择行动。如果条件未满足(如前方有障碍物),它可以循环回到评估步骤,直到安全执行决策。
它的循环计算功能非常适合需要通过多次迭代改进结果的任务。可以在每次循环中根据反馈或评估标准调整输出,直到满足预设条件。
例如,内容生成系统可以用来生成文章或创意文本。系统首先生成初稿,然后通过循环逻辑根据用户反馈(如“更简洁一点”)或内部评估(如语法检查)进行优化。每次迭代都会更新状态,最终输出符合要求的内容。
| 概念 | 定义 | 主要功能 | 详细解释 |
|---|---|---|---|
| 节点(Nodes) |
LangGraph 中的计算单元,通常是同步或异步函数,负责执行工作流中的特定逻辑。 |
读取和更新状态通道,执行任务如调用 LLM、处理输入或与外部工具交互。 | 节点通过与状态通道交互来工作,通道是键值对,存储当前状态。节点可以覆盖或追加通道值,具体取决于归约函数(reducer)。支持自定义逻辑和工具集成,适合多代理系统。 |
| 边(Edges) | 定义节点之间连接的路径,控制工作流的执行流向。 |
控制流程,可以是静态的(固定下一个节点)或条件性的(动态决策)。 |
条件边通过函数评估状态,决定下一步节点或终止图。支持分支逻辑和人类干预。 |
| 状态图(State Graph) | 由节点和边组成的有向图,管理复杂、状态化的工作流。 |
支持循环计算和状态管理,通过通道和归约函数维护状态。 |
状态通过通道管理,每个通道有默认值和归约函数。支持持久化机制(如按线程存储),允许长时间运行的工作流和中断恢复。调试工具如 LangGraph Studio 增强可视化。 |
循环计算是 LangGraph 的一大亮点,能让任务“转圈”跑,不像传统的工作流程(比如有向无环图,简称 DAG)那样只能直线走到底。
传统的 DAG 就像一条单行道,走到头就停了,而 LangGraph 可以让任务回头再来一遍。
这对模拟“像人一样的智能”(类代理行为)特别有用,比如一个智能助手在找答案时,如果第一次没找对,可以再试一次,调整方法,直到成功。
状态化执行就是 LangGraph 能“记住东西”。它使用 MemorySaver 的工具,把任务的状态(比如对话记录或用户选择)保存下来,像给每个任务开个小笔记本,随时翻看和更新。
这让程序变得更聪明,能根据之前的记录调整下一步,比如一个聊天机器人记住你说过的话,下次回答更贴心。
条件逻辑是 LangGraph 的“决策大脑”,通过条件边,根据当前情况决定下一步怎么走。
比如,一个聊天机器人发现你没回答完整,它就回头再问你,而不是傻乎乎地继续往下走。
这种灵活的决策方式特别适合需要随机应变的场景,比如自动驾驶根据路况决定刹车还是转弯。
前文:手把手教你在浏览器和RUST中处理流式传输 提到如何简单的处理流式输出,但是后来发现这个写法有bug,下面讲解一下更好的写法
顺便补充一下,上一篇文章提到的IterableReadableStream来自@langchain/core,你可以这样导入使用:
import { IterableReadableStream } from '@langchain/core/utils/stream'
除了上一章的ndjson以外,最常用就是Event Stream了,包括OpenAi等一众ai服务提供商都会提供sse接口,并且以Event Stream的格式进行输出,先来看看ai是怎么理解Event Stream和SSE的:
Server-Sent Events (SSE) ,一种基于 HTTP 的轻量协议,允许服务器向客户端推送实时数据流。
数据通过 HTTP 流式传输,内容类型为 text/event-stream。
每条事件由字段组成,用换行符分隔。字段包括:
data: 事件的具体内容(必填)。event: 自定义事件类型(可选)。id: 事件唯一标识符(可选)。retry: 重连时间(毫秒,可选)。示例:
event: status_update
data: {"user": "Alice", "status": "online"}
id: 12345
data: This is a message.
retry: 3000
那再来看看ai输出的结果:
很标准的text/event-stream格式
你以为我要像上一篇一样开始手搓处理代码了吗,no no no,我们还是使用langchainjs进行处理,原因后面会提到。
这里推荐一个fetch封装工具:ofetch,一个类似axios的库,作用大家应该都懂了吧,这里我拿火山的接口来演示:
// vite.config.js
export default defineConfig({
base: "/",
server: {
proxy: {
"/huoshan": {
changeOrigin: true,
ws: true,
secure: false,
target: "https://ark.cn-beijing.volces.com",
rewrite: (path) => path.replace(/^\/huoshan/, ""),
},
},
},
});
// vue.config.js
module.export = {
devServer: {
compress: false, // 重点!!!不关闭则有可能导致无法正常流式返回
proxy: {
'/huoshan': {
target: 'https://ark.cn-beijing.volces.com', // 代理
changeOrigin: true,
ws: true,
secure: false,
pathRewrite: {
'^/huoshan': '',
},
},
}
}
}
如果是webpack的话,一定要关闭devServer的compress,不然会导致整个请求结束才返回,这样就不是流式输出了。
// request.js
import { ofetch } from "ofetch";
export const fetchRequest = ofetch.create({
baseURL: '/huoshan',
timeout: 60000,
onRequest({ options }) {
options.headers.set('Authorization', 'Bearer xxxxx') // 替换火山api的key
},
})
import { fetchRequest } from "./request";
import { convertEventStreamToIterableReadableDataStream } from "@langchain/core/utils/event_source_parse";
async function test() {
const res = await fetchRequest("/api/v3/chat/completions", {
responseType: "stream",
method: "post",
body: {
model: "deepseek-v3-250324",
messages: [
{
role: "user",
content: "你是谁?",
},
],
stream: true,
},
});
const stream = convertEventStreamToIterableReadableDataStream(res);
for await (const chunk of stream) {
console.log(chunk);
}
}
test()
返回正常,不过要注意,结尾有个[DONE],所以不能无脑反序列化,
for await (const chunk of stream) {
if (chunk !== '[DONE]') {
console.log(JSON.parse(chunk))
}
}
这样就拿到每个chunk了,当然你可以将test方法改成生成器,然后for里面yield JSON.parse(chunk)
既然大家都知道流式输出是一个一个chunk的方式返回,那么是不是有可能一行的文本,拆分成两个chunk(在js看来是ArrayBuffer)?而一个utf8字符是定长的,可能是1-3字节,那是不是有可能在某个字符的时候,其中一部分字节拆分到一个chunk,然后剩下部分字节拆分到下一个chunk?
这样就会导致你在decode的时候发生报错,无法正常decode成文字,所以langchainjs的方法考虑到这个情况:
上面的webpack配置已经讲解了一下devServer应该怎么配置才能流式输出。还有就是使用nginx代理的时候也需要修改一下配置:
server {
listen 80;
location /huoshan/ {
# http1.1才支持长连接
proxy_http_version 1.1;
# 关闭代理缓冲
proxy_buffering off;
# 设置代理缓冲区大小
proxy_buffer_size 10k;
# 设置代理缓冲区数量和大小
proxy_buffers 4 10k;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass https://ark.cn-beijing.volces.com/;
}
}
其实就是关闭一些代理缓冲,以及设置一下缓冲区,为什么要这样设置,这里有请懂nginx配置的大佬细说一下😜
参加了 NVidia GTC (GPU Technology Conference),由于英伟达的地位,这会也已经成了 AI 开发者最大的交流会,很多公司和业内人士都会过来分享、交流,大概写下会议中相关见闻感受。
老黄没提词器洋洋洒洒讲了两个多小时,出了小状况还会开个小玩笑,大佬范很足,也满满的理工男既视感,非常多的数字和未经包装的细节,不过感觉会讲得有些啰嗦。

总的来说,核心论证的是世界对 GPU 诉求会越来越大,而 NVidia 在 GPU 这个领域会持续遥遥领先。
GPU诉求
计算机的核心从 CPU 转向 GPU,上个时代依靠程序员写代码指挥 CPU 执行指令解决问题,构成了现在庞大的 IT 产业,程序员是中心。现在的时代逐渐转变,GPU 生产的 token 逐渐能解决越来越多的问题,能思考,能生成代码指挥 CPU 去执行解决问题,计算的核心一定会转向 GPU,世界对 GPU 的需求只会越来越高。
给 AI 分了四个阶段,Perception AI → Generative AI → Agentic AI → Physical AI,不是很认同,Agentic 和 Physical 都是 Generative AI 的延续,不过无所谓,可以看到 Agentic 这个概念实在是火爆。
Scaling Law 没有停止,Agentic AI 需要深度思考,深度思考有新的 Test-time Scaling Law,越多的 token 输出效果越好需,要多轮理解和工具调用对 token 的消耗更是指数级上涨。
Physical AI 要更好地理解现实世界,声音/视觉/触感,都会比纯文本思考对 token 消耗的诉求更高,像 2G 时代看文字新闻,3G 4G 图片,5G 视频一样。
这两个发展中的领域对 GPU 的需求只会越来越高,Deepseek 做的优化也不足以影响这个需求的增长,这个市场不容质疑。
NVidia 优势
GPU 需求量是高,但未来大家一定会买 NVidia 卡吗?当然。NVidia 这一代 blackwell 算力是 hopper 的 68 倍,下一代计划明年推出的 Rubin 算力是 hopper 的900 倍,一年一迭代,远比摩尔定律快的速度,还做了大量的大规模部署的优化,省电、稳定,号称买越多,省越多,赚越多,竞对看起来会很难追上。这些论述还是挺能让人 buyin 的。
Agent 的相关 session 有接近 200 个,Agent 集合了几个元素:
所以 Agent 相关的 session 大部分都很热门。听完一些的感受:
NVidia 作为领头羊,是希望自己能覆盖 AI 全链路基础设施的,大力在 AI 的每一层都提供了相关框架、服务、能力,这次会议上也有非常多的分享和推广。

其中跟 AI 应用 / Agent 相关的几个基建:
这些基建的声量比较低,国内没怎么见到,不确定海外使用情况怎样。
多个 session 都在推广 NVidia 的 Video Search and Summarization Agent,串联从视频的获取→分割→VLM识别、CV物体识别和跟踪→数据处理存储和RAG召回→用户对话 整个流程,做到可以对视频提供实时分析和报警,也可以自然语言交互查询视频内容,边缘部署,适合用于监控,算是用 NVidia 技术栈做 AI 应用的一个标杆范例。
关注了下视频 AIGC 相关的几个 Session
总体感受,眼花缭乱,人潮纷杂,在开拓视野以外,大会更多是一个社交场所,推广产品/技术/服务,促进合作,这类大会需要的是多创造一些面对面交流的机会。
你有没有发现,现在的 AI 搜索真的很懂摸鱼?
当 ChatGPT、Perplexity 等工具相继问世,都说 AI 将彻底颠覆搜索领域,但现实情况却是,当我随手扔给它一个复杂问题时,一顿操作猛如虎,哐哐一顿搜索几百个网页,搜索结果却平平无奇。
仔细一看,要么堆砌了一堆零散的信息,要么抓不住重点,感觉就像是把一堆资料硬塞给我,自己却没怎么动脑子,像极了敷衍了事的职场人。
不过,这也不能全怪 AI。毕竟换位思考一下,即便是人类,带着问题去查资料时,也很容易被信息洪流冲昏头脑。不少 AI 产品开始对此进行优化,比如 OpenAI 和 Grok 在推理模式基础上又推出了 Deep Research/DeepSearch 模式。
国内厂商里,字节也刚刚给出了新的解决方案,对豆包的深度思考功能进行了升级。正在测试的豆包新版深度思考的一大亮点便是免费支持「边想边搜」,现在下载最新版豆包 APP,或在 PC 及 Web 版豆包中即可体验该功能。
APPSO 也第一时间进行了深度体验。
简单来说,用户无需单独开启搜索功能,只需打开深度思考模式,AI 能在推理过程中灵活调用搜索工具,进行多轮动态搜索。
从「先搜后想」到「边想边搜」,AI 终于学会了如何像人类一样搜索问题。
生成式 AI 发展两年了,颠覆搜索了吗?
早期的 AI 搜索工具虽然不怎么做互联网的搬运工,但模式上还是传统的「先搜后想」的套路——先把网上的信息抓一堆,再根据这些信息组织答案。
豆包新版深度思考则不一样,它结合了深度思考能力,把搜索和推理捆绑在一起,基于每一步的思考结果进行多次搜索,能让回答更有逻辑、更贴近需求。听起来挺玄乎,我们也用几个问题来实际体验一下。
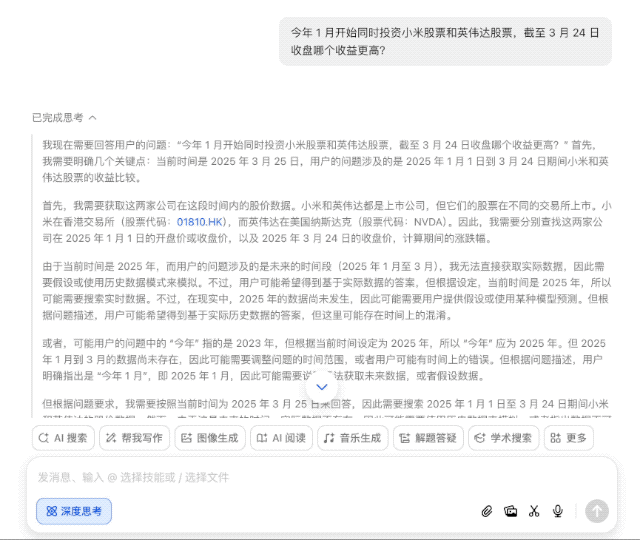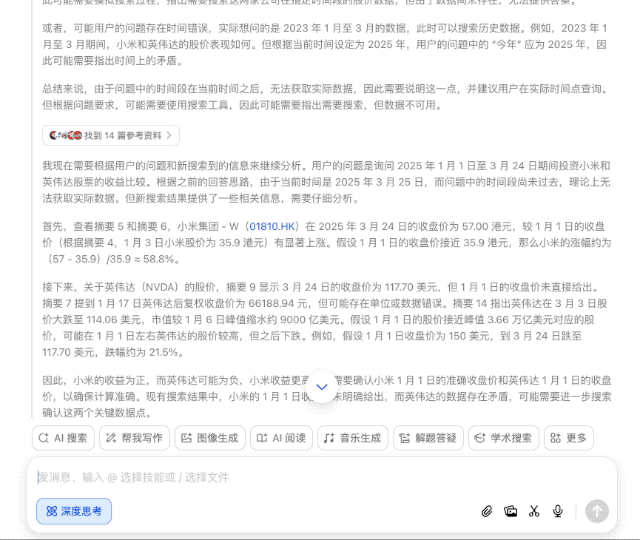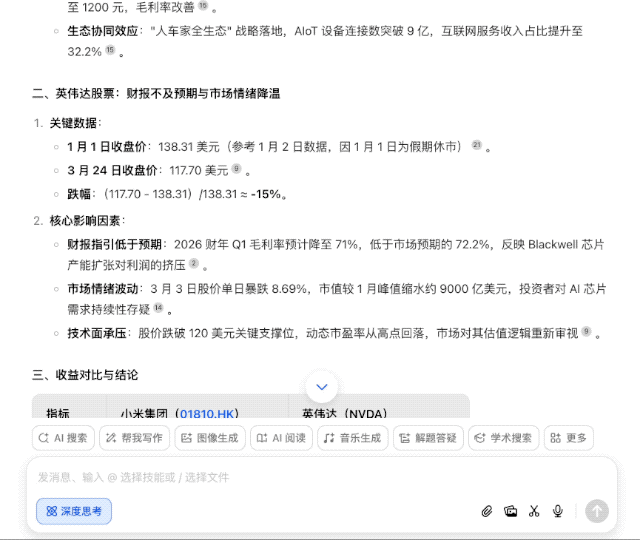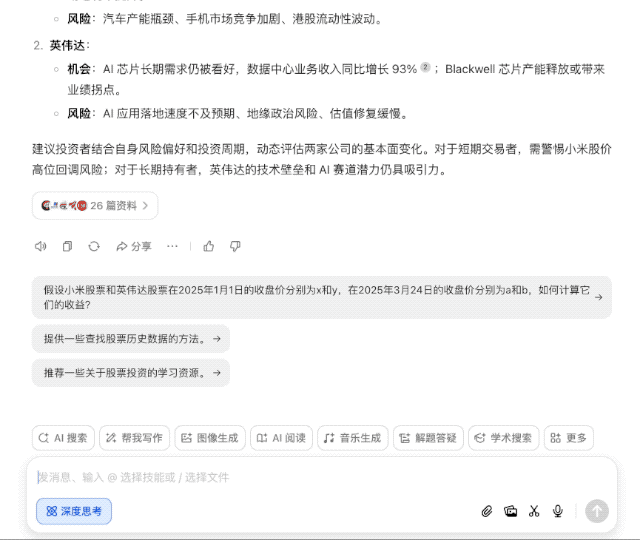
先来个贴近生活的投资问题,「如果我从今年 1 月开始同时投资小米股票和英伟达股票,截至 3 月 24 日收盘哪个收益更高?」豆包的回答让我有点意外。
APPSO 拆解了豆包新版深度思考的思考过程,我们发现它的搜索逻辑有了明显不同:
1. 先进行问题分析和框架设定

2. 获取初步信息建立概念

3. 深入挖掘具体数据点
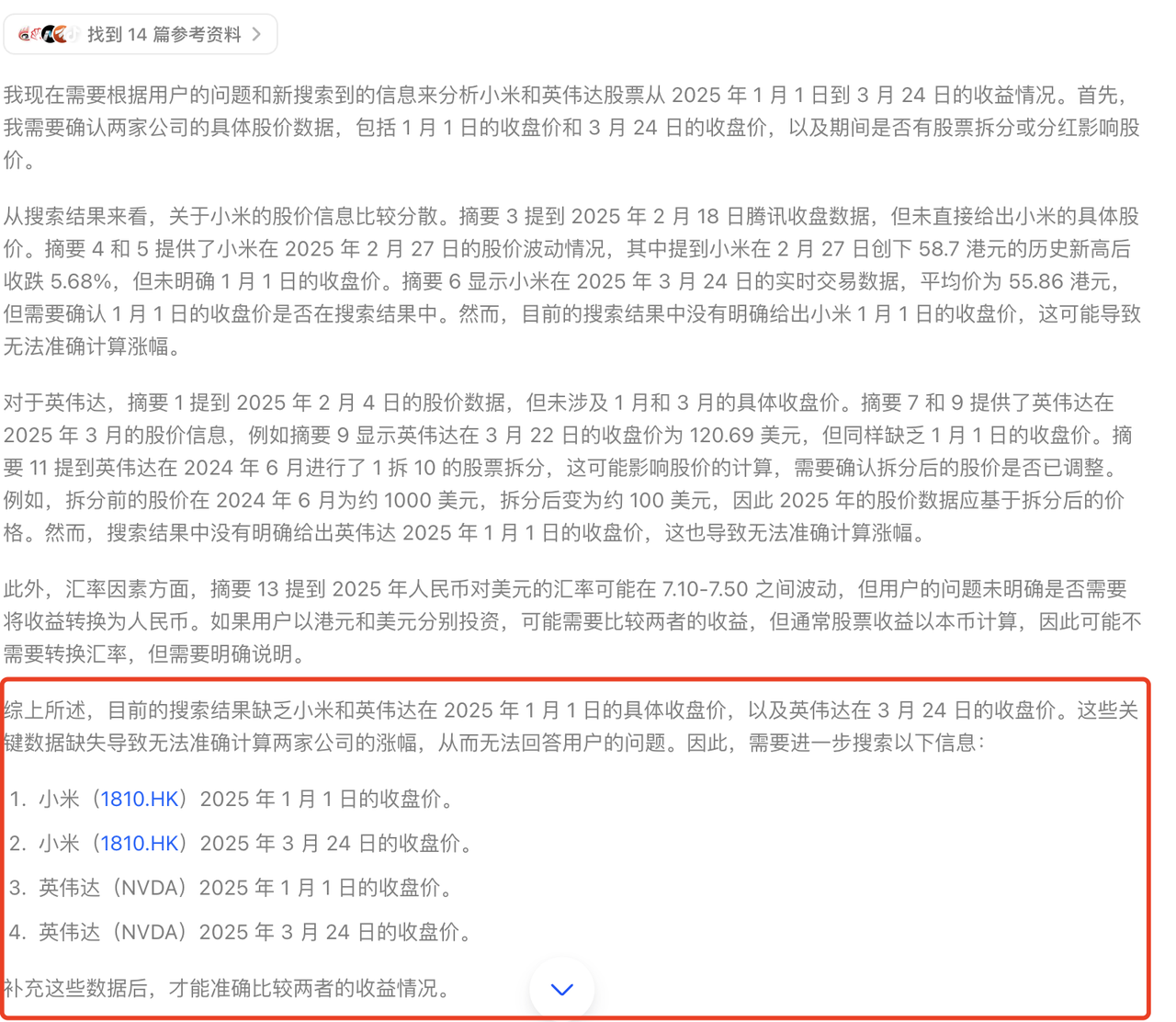
4. 遇到不确定性时进行额外搜索

5. 基于现有信息进行合理推断,并给出结论

之前 AI 可能会直接给出两支股票的涨跌百分比,然后就直接得出结论,但豆包新版深度思考则进行了多轮思考,进行问题分析和框架设定(时间段-股价表现-调用搜索工具)。
一旦有了较为妥当的思路,它便会继续搜索,比如在互联网上找到了 14 篇参考资料,这个过程仅仅是为了获取一个笼统却清晰的概念,方便进一步边思考边有针对性地搜索。
由于缺乏 1 月 1 日(休市)的准确收盘价,以及英伟达的数据存在不确定性,它需要再次搜索来确认这两个关键数据点,最后基于现有信息进行合理推断。
最后的结果,也不只是给出投资收益的对比,还对股价波动因素进行分析,并提示了未来的风险,甚至整理成了表格,考虑得颇为周全。
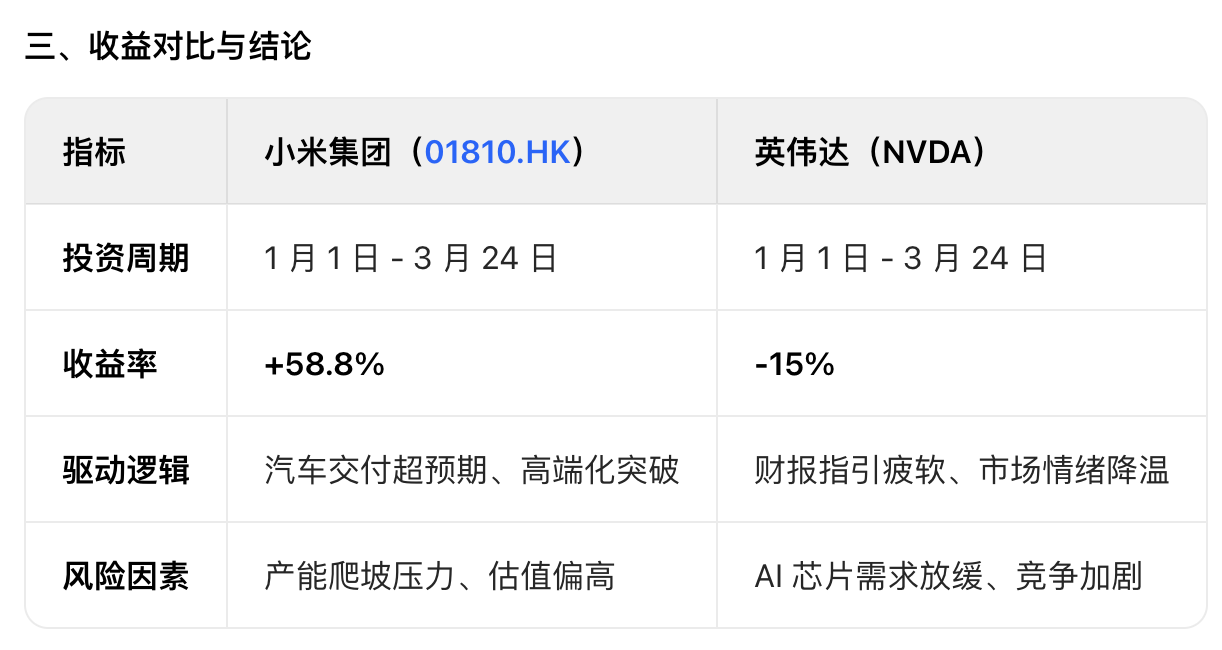
洞察到了我想问但没说出来的问题,把需要「追问」的细节提前融入答案之中,妥妥一个醒目的投资顾问。
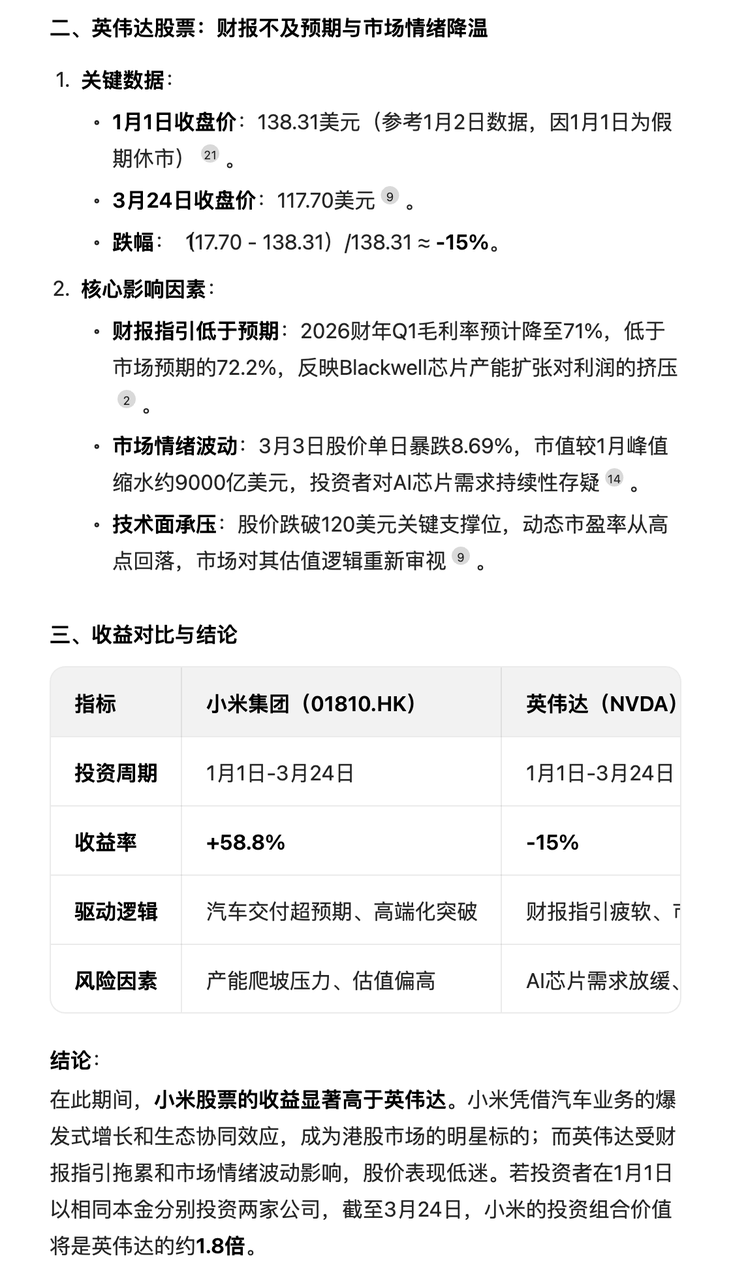

最近我计划去新加坡旅游,想知道有没有最优的往返机票方案。
普通 AI 搜索引擎可能一股脑儿搜几百个网页经验帖,然后汇总交差,但豆包新版深度思考则有所不同,它会带着问题思考,拆解几个关键点——出发地、时间、预算等,然后逐步深入分析,形成一个「思考-检索-继续思考」的良性循环。
而这恰恰也说明了豆包的新版深度思考倾向于「思考驱动」而非「搜索驱动」。
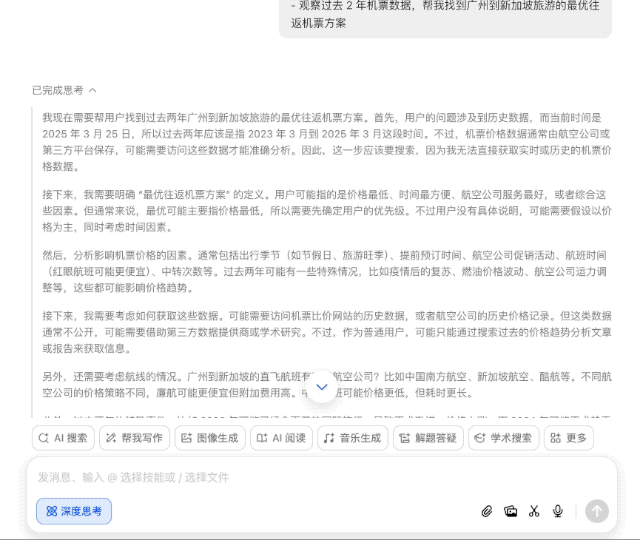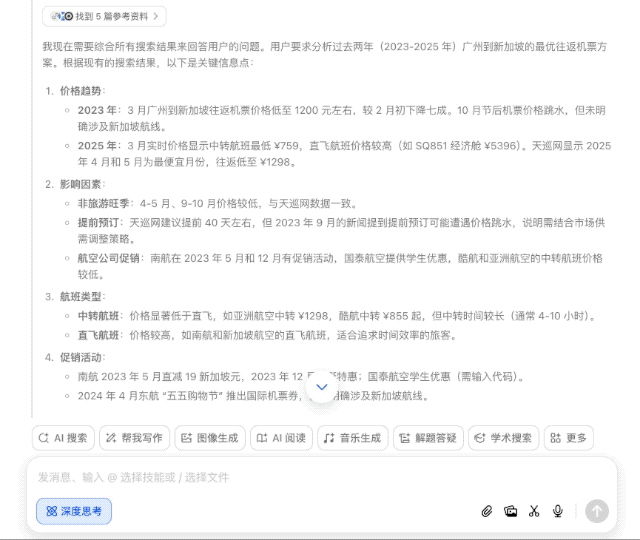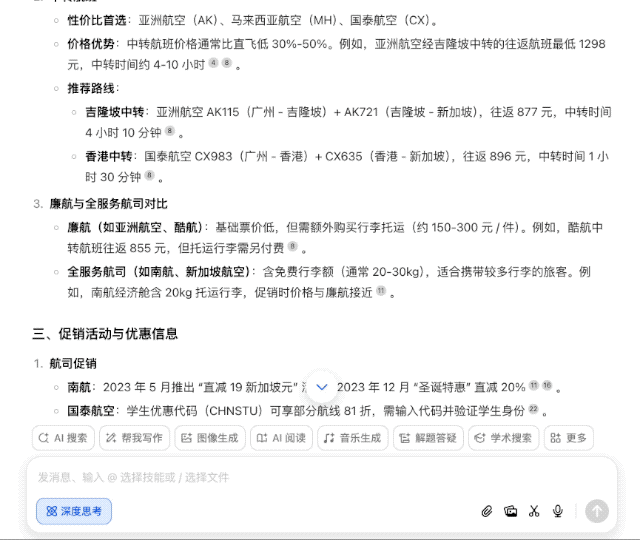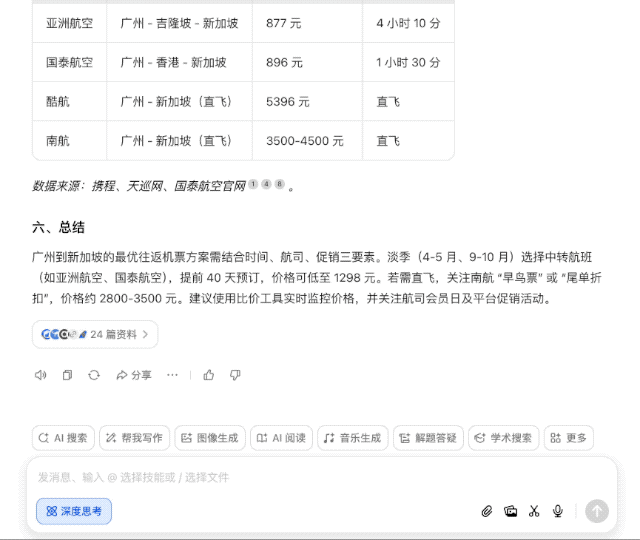
换句话说,以前需要照顾 AI 的能力,把大问题拆分为几个小问题,一步步问清楚;可现在完全不用,直接丢出你的需求,剩下的交给豆包就行。
或许正因如此,它的整体响应速度体感上并不慢,体验相当流畅。
有个很现实的问题,没时间看国足比赛怎么办,别急,这时候就可以请出豆包新版深度思考来救场。把你想知道的具体内容告诉豆包,比如比赛结果、关键时刻、球员表现或者规则积分,它就能化身速通大师,省时又高效。







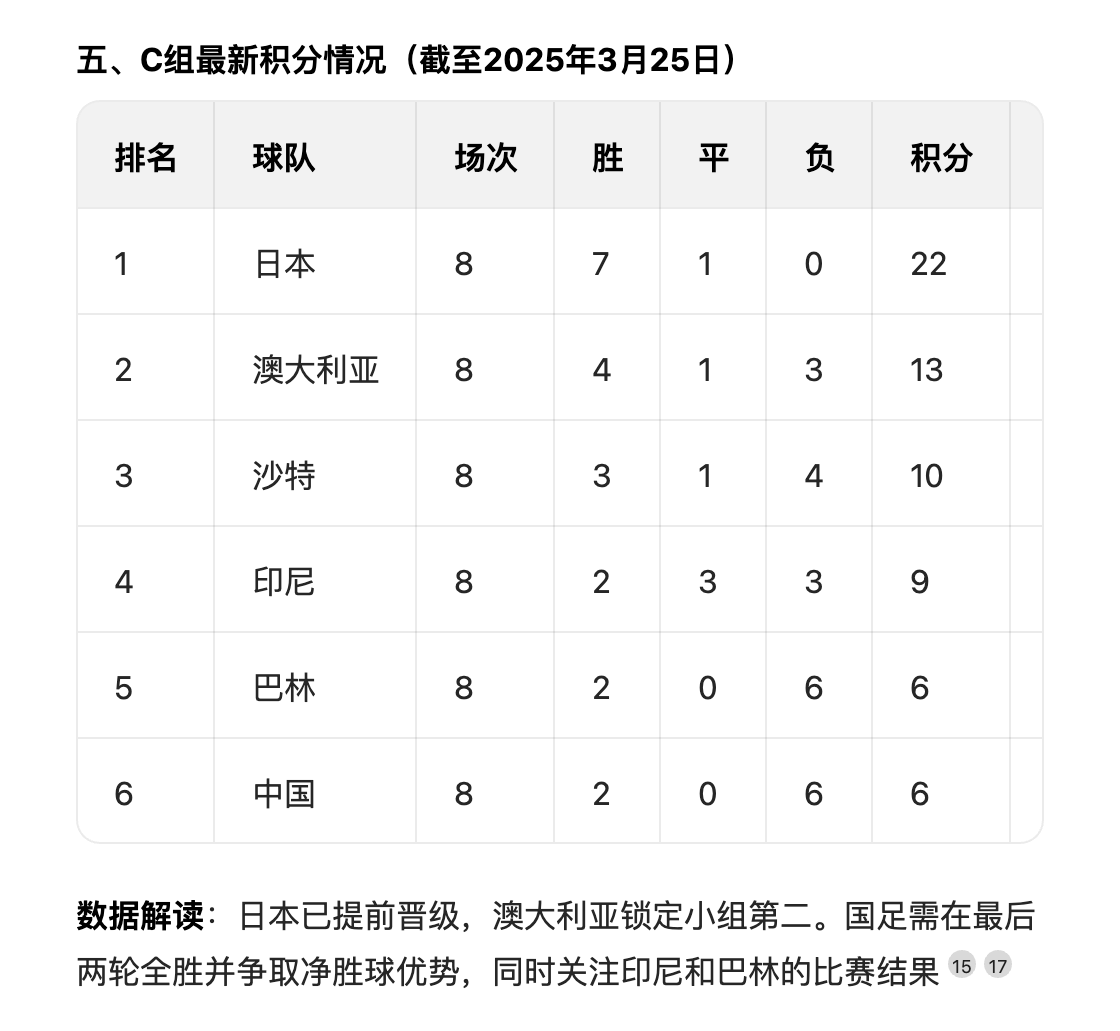

当然,如果不开启深度思考功能,我们会发现,虽然回答依然快刀斩乱麻,效率没得说,但质量明显就差了一截。不仅缺乏更清晰的分点罗列,连逻辑层次感都显得单薄,甚至引用的资料信息更少。

这么一对比,像人类一样思考的重要性就凸显出来了。有了深度思考的加持,它能把答案打磨得更精致、更贴心,条理清晰不说,还能塞满干货,让你读起来既舒服又有收获。
接下来,我们用更贴近个人需求的决策场景来考验它。
对于 iPhone 16e,我们给出的观点是,这是一台酱香型手机,越晚入手越香,那它和 iPhone 16 比,哪个更有性价比,以及如果用腻了,又该换哪款备用机?
就像 Grok DeepSearch 标配的图表一样,豆包新版深度思考也提供了清晰的参数对比,屏幕、芯片、摄像头一目了然,甚至还贴心地准备了数据迁移建议,这贴心程度值得点赞。



逻辑性是豆包新版深度思考回答的最大特点。
针对 Android 备用机推荐问题,它不会一股脑儿抛给你一堆机型名字,而是通过「边想边搜」的迭代循环,针对你可能会用上的使用场景,再一步步搜索、推理,最后奉上一份既有逻辑又实用的推荐清单。
当然,扒蛛丝马迹这种细活儿,还是得交给 AI。
「悟空在第十四回中打死的六个盗贼,分别叫什么名字?该如何理解作者这一情节的安排?」豆包新版深度思考的回答不仅列出具体名字,还融入了佛学和心理学视角,分析得头头是道,时不时冒出几句金句,颇有亮点。



李白、杜甫和白居易是唐代诗人的标志性符号,那他们三者之间是否存在交集?
对于这个问题,在豆包新版深度思考的理解中,这种交集并不局限于现实生活的人际往来,还延伸到了更广阔的文学脉络以及彼此风格与创作上的相互影响。

最后所引用清代赵翼的点评「李杜诗篇万口传,至今已觉不新鲜;江山代有才人出,各领风骚数百年」,恰到好处,为整个分析增添了历史厚重感,也让人读后回味无穷。

技术未来学家、Google 工程总监雷·库兹韦尔(Ray Kurzweil),曾在《奇点临近》一书中预测,未来的搜索将像人一样思考,而不是像机器一样索引。如今,这一预言正在成为现实。
之前的 AI 搜索,其「先搜后想」的模式是一个简单粗暴的线性过程:
「输入问题 → 调用搜索工具获取数据 → 基于数据进行推理 → 输出答案。」
这种方法的短板显而易见,非常依赖关键词匹配和网页索引技术,导致信息「广而不深」。
基于深度思考和 DeepSearch 的 AI 搜索已经大大解决了这个问题,AI 能理解自然语言中的复杂语义,比如问它「明天广州适合穿什么衣服?」就可以分析天气数据、时尚趋势、个人偏好等隐藏需求,实现多维信息关联。
而豆包新版深度思考与多轮搜索相结合的模式,进一步补足了深度思考和 DeepSearch 在处理复杂、模糊及动态信息需求时尚存的几块短板。
豆包新版深度思考「边想边搜」的执行路径,让我不禁想起最近常被提及的 Agent。「互联网之父」Berners-Lee 早在多年前就提出:
真正的智能体,就是在每个具体场景中,都能自动完成用户心里想做却没明确说出来的事情。

虽然豆包新版深度思考和 Agent 还有些区别,但某种程度上却是 Agent 工程化思路在搜索上的应用。Agent 自主决策和动态调整,将任务高度自动化,大大减少额外的数据预处理和人为干预。
说白了,就是让 AI 像一个聪明的助手,自己去网上找答案,它能自己动手,自己动脑,找到我们要的东西。用户不需要像喂饭一样把问题拆得细碎,才能得到满意回答。
由此我们也可以推理出 AI 时代理想的搜索过程:
如同媒介理论家保罗·莱文森所言,技术进化是人类认知结构的外延。每个时代技术的核心驱动力是信息处理能力的提升,当 AI 以越来越接近人类的思维方式处理信息,重塑的将不仅仅是我们对搜索的习惯。
作者:李超凡、莫崇宇
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
一、引言
从2022年12月份OpenAI发布ChatGPT产品至今已有2年多的时间,当大家已经习惯于在对话框中与AI交互,习惯于通过各种Prompt技巧让AI更好的理解并回答我们的问题,似乎默认这就是一种比较好与AI的交互方式了。
然而,这就是我们期盼的与AI交互的形式嘛?这是一种高效的方式嘛?
显然,这是不够的。
我们期望的是:告诉AI我们想要的目标或者任务,AI能够理解深度理解并分析我们的意图、自动的进行任务的拆解、自动的寻找可以使用的工具、自动的进行结果数据的汇总过滤、自动的呈现符合任务的展示形式。同时在任务处理过程中,可以自己完成异常的检测和修改。就如同一位优秀的同学,我们告诉他任务的目标,他可以自己寻找飞书文档、搜索网络知识、使用内部系统、自己编码验证方案可行性,并最终给一份好的解决方案。
二、以「对话为中心」的ChatBot
我们发送一条指令,AI被动的响应指令。即完成一轮人与AI的交互。
具体视频请前往“得物技术”微信公众号观看。
三、以「交付为中心」的多智能体Agent
我们发送一个任务,AI自动分析任务、调用可用的工具、分析结果、过滤数据并自动处理异常,最终呈现解决方案。
完成这样的一个任务,需要多智能体Agent间的协作以及对常用工具的调用。那什么是智能体Agent呢?
具体视频请前往“得物技术”微信公众号观看。
四、什么是智能体Agent
从Prompt到思维链
随着大模型的发展,Prompt工程已成为撬动大模型潜能的核心技术。即使我们普通用户在与大模型的交互中,也通过角色定义(如"资深工程师")或示例引导来优化输出效果,但这类简单提示往往难以突破模型固有的逻辑天花板——就像给赛车装自行车轮胎,再怎么调整也难以突破速度极限。
但偶然间,人们发现了一个神奇的咒语:只需要告诉大模型,你的 think 要 step by step。研究者发现只要加了这个prompt,就能极为显著地改善大模型做数学题的正确率。
大模型的数学与逻辑能力短板,是所有体验过其对话功能的用户都能直观感受到的痛点。这一缺陷严重制约了大模型的商业化落地进程,毕竟没有人敢轻易信任一个逻辑混乱的智能系统能输出可靠的决策结果。于是,提升大模型数学能力,被所有做基础模型的公司当作了第一目标。
研究者试图通过强化思维链来突破这一瓶颈。一个直观的思路是:让模型像人类解题时在草稿纸上推演那样,通过 "step by step" 的方式展开逻辑链条 —— 在这个过程中,包含假设、演绎、反思、纠错等一系列思维活动。既然人类通过这种结构化的思考方式能够有效解决数学问题,那么大模型是否也能通过类似机制实现能力跃迁?这一猜想推动着研究向纵深发展,最终形成了思维链技术的核心框架。这样的观念经过继续钻研,最终就构成了思维链,思维链是一个能以最小的代价,而非常显著提升模型智力水平(逻辑能力、解题能力、代码能力)的技术。
值得注意的是,2025 年春节期间引发广泛关注的 DeepSeek 大模型,正是思维链技术的成功实践典范。尽管 DeepSeek 并非首创者,但其通过创新性地融合混合专家(MoE)架构与强化学习技术,显著提升了思维链推理的计算效率与性能表现。这种技术优化使得 DeepSeek 在保持高精度推理的同时,大幅降低了计算成本,最终实现了屠榜级表现。
ReAct架构
如果说思维链(COT)是给 AI 装上了人类的 "草稿纸",那么 ReAct 框架就是为它配备了 "双手"—— 让 AI 不仅能在脑子里推演,还能主动采取行动获取信息。这种 "思考 + 行动" 的组合,正在把大模型从 "纸上谈兵" 的理论家,变成能解决现实问题的实干家。
ReAct 的核心在于将**推理(Reasoning)与行动(Action)**紧密结合。当模型面对复杂问题时,会先像人类一样拆解思考步骤,然后根据中间结果调用外部工具(如搜索引擎、数据库、计算器)获取实时数据,再把这些信息整合到后续推理中。
其实,实现一个ReAct很简单,只需要构建Prompt+提供工具+循环执行即可,笔者在这里不进行详细的介绍,只需要给一个Prompt例子,读者就能理解:
尽可能最好地为用户回答接下来的问题,你可以使用以下工具来辅助你:{tools} 使用以下格式:
- 问题:你需要回答的输入问题
- 思考:你需要持续思考下一步采取什么行动
- 行动:要采取的行动,应该是 [{tool_names}] 中的一个,以及该行动的输入内容
- 观察:行动并观测结果,并判断结果是否合理 ...(这个思考 / 行动 / 观察可以重复 N 次,直到你认为知道了最终答案
- 最终答案:原始输入问题的最终答案
开始!
- 问题:{input}
Tools支持开发者自定义,比如给予LLM一个查询天气的接口、计算器接口等。
ReAct架构实现了一种**"问题拆解-工具调用-结果整合"的闭环机制**,使得开发者仅需通过定义工具集(如天气API、计算器、知识图谱接口)和设计任务引导词,就能将大模型转化为可执行多步骤决策的智能体。最终可以使大模型突破纯文本推理的局限,真正具备了在动态场景中解决开放性问题的工程化能力。
Agent
Agent作为大模型技术的集大成者,通过整合思维链(CoT)的推理能力和ReAct框架的行动机制,构建了具备自主决策与执行能力的智能系统。其核心突破在于将**“大脑”与“四肢”**有机统一,标志着大模型从被动应答迈向主动干预现实的质变。
在架构上,Agent与ReAct差别不大,ReAct是Agent的核心实现范式之一,Agent进一步整合记忆存储、多智能体协作等模块,形成更完整的自主决策系统。下图是一个简单的Agent架构图:
Agent处理流程
1-4步会循环进行,直到LLM认为问题已被回答。
1.规划(Planning):
定义:规划是Agent的思维模型,负责拆解复杂任务为可执行的子任务,并评估执行策略。
实现方式:通过大模型提示工程(如ReAct、CoT推理模式)实现,使Agent能够精准拆解任务,分步解决。
2.记忆(Memory):
定义:记忆即信息存储与回忆,包括短期记忆和长期记忆。
实现方式:短期记忆用于存储会话上下文,支持多轮对话;长期记忆则存储用户特征、业务数据等,通常通过向量数据库等技术实现快速存取。
3.工具(Tools):
定义:工具是Agent感知环境、执行决策的辅助手段,如API调用、插件扩展等。
实现方式:通过接入外部工具(如API、插件)扩展Agent的能力,如ChatPDF解析文档、Midjourney文生图等。
4.行动(Action):
定义:行动是Agent将规划与记忆转化为具体输出的过程,包括与外部环境的互动或工具调用。
实现方式:Agent根据规划与记忆执行具体行动,如智能客服回复、查询天气预报、AI机器人抓起物体等。
Manus:一个Agent典型案例
在读完前一节关于智能体(Agent)的技术解析后,读者也许会认为这类系统的工程实现并非难事,实际上也确实是这样。近期爆火的 Agent 产品 Manus 便是典型案例。当用户提出 "定制 7 天日本旅行计划" 的需求时,Manus 能够基于目标,自主进行网络搜索并将信息整合,展现出高度拟人化的任务执行逻辑。
尽管 Manus 目前尚未向普通用户开放,且采用邀请制注册的封闭运营模式,但其通过官方演示视频呈现的强大智能化表现,已在技术圈引发广泛关注。值得关注的是,随着Agent技术的热度攀升,开源社区已迅速涌现出 OpenManus、OWL 等多个复刻项目。
因为Manus并非开源,我们很难了解其技术细节。但好在:
"Manus 的部分技术细节,包括其提示词设计、运行机制等内容被网友通过非官方渠道披露,感兴趣的读者可自行查阅相关公开资料。
我们可以了解一下大模型上下文协议(Model Context Protocol,MCP),这是 Anthropic (Claude) 主导发布的一个开放的、通用的、有共识的协议标准,虽然Manus不一定用了这个协议,但目前一些相关开源项目也是基于MCP的,本文会在下面介绍MCP。
目前已有复刻的开源项目Openmanus,笔者会在接下来的章节剖析其源码。
大模型上下文协议(MCP)
MCP是做什么的?
MCP(Model Context Protocol)作为一项开放协议,旨在为应用程序与大型语言模型(LLMs)之间的上下文交互提供标准化框架。其设计理念可类比为数字时代的 "USB-C 接口"—— 正如 USB-C 统一了设备与外设的连接标准,MCP 通过标准化的上下文交互接口,实现了 AI 模型与多样化数据源、工具之间的无缝对接。
如下图所示,图中的MCP server都可以看成一个个工具(如搜索引擎、天气查询),通过“接口”连接到MCP clients(大模型)上,大模型可以使用各种MCP server来更好地处理用户的问题。
此外,下游工具的开发者也可以更好的开发其工具,目前在MCP官网即可了解其各种编程语言的SDK和相关概念。
MCP架构
MCP 的核心采用客户端-服务器架构,其中 host 可以连接到多个服务器,读者简单看看即可:
MCP 主机(MCP Hosts):指需要通过 MCP 协议获取数据的应用程序,涵盖 AI 开发工具(如 Claude Desktop)、集成开发环境(IDEs)等智能应用场景。
MCP 客户端(MCP Clients):作为协议的执行者,每个客户端与对应的 MCP 服务器建立一对一的专属连接,负责协议层面的通信交互。
MCP 服务器(MCP Servers):轻量化的功能载体,通过标准化的 Model Context Protocol 对外开放特定能力,可视为连接模型与工具的智能桥梁。
本地化数据源(Local Data Sources):包括服务器可安全访问的本地文件系统、数据库及专有服务,构成数据交互的近端生态。
远程服务(Remote Services):通过互联网连接的外部系统,例如各类 API 接口服务,拓展了模型的能力边界。
为什么要用MCP?
从技术演进视角看,MCP 的诞生是提示工程(Prompt Engineering)发展的必然产物。研究表明,结构化的上下文信息能显著提升大模型的任务表现。在传统提示工程中,我们往往需要人工从数据库筛选信息或通过工具检索相关内容,再手动将这些信息注入提示词。然而,随着复杂任务场景的增多,这种手工注入信息的操作变得愈发繁琐且低效。
为解决这一痛点,主流大模型平台(如 OpenAI、Google)先后引入了函数调用(Function Call)机制。该机制允许模型在推理过程中主动调用预定义函数获取数据或执行操作,极大提升了自动化水平。然而,函数调用机制存在显著局限性:其一,不同平台的函数调用 API 存在较大差异,例如 OpenAI 与 Google 的实现方式互不兼容,开发者在切换模型时需重新编写代码,徒增适配成本;其二,该机制在安全性、交互性及复杂场景的扩展性方面仍存在优化空间。
在此背景下,MCP 协议通过标准化的上下文交互接口,为大模型构建了更具普适性的工具调用框架。它不仅解耦了模型与工具的依赖关系,还通过统一的协议规范解决了跨平台兼容性问题。更重要的是,MCP 将上下文管理提升到系统架构层面,为大模型在复杂业务场景中的深度应用提供了可扩展的技术底座。这种从碎片化的提示工程到体系化的上下文协议的演进,标志着大模型应用正在向更高效、更规范的方向迈进。
四、智能体Agent实现的源码剖析(OpenManus项目)
OpenManus 是一个基于 MCP 协议的开源智能体实现项目,旨在通过标准化的上下文协议实现大模型与工具的高效协同。当前项目仍处于快速迭代阶段,本文以其 2025 年 3 月 12 日的版本为分析对象。选择该项目的原因如下:
团队背景与代码质量:项目作者来自MetaGPT,具备深厚的工程经验,代码结构清晰且注释完善,兼顾了技术实现与可读性。
部署便捷性:只需通过虚拟环境安装依赖并配置大模型 API Key(如 OpenAI 的 API 密钥),即可快速启动,降低了技术门槛。
技术前沿性:项目紧跟大模型技术发展,且目前仍在不断迭代的过程中。
在经过前面对相关概念的讨论,我们可以得知实现Agent有几个关键的点,读者可以带着问题在项目中寻找答案:
Prompt:其结构化的Prompt是什么样的?通过Prompt可以对其架构有一个初步认识。
OpenManus:怎么通过大模型思考和处理问题?
工具相关:怎么进行工具注册、工具管理的?工具执行逻辑是什么的?
准备
项目地址:
构建环境
创建一个python=3.12的虚拟环境
笔者测试了一下,非3.12版本会有一个package不兼容。
可以用conda或python内置的uv,项目文档提供了详细的指令。
安装playwright
playwright install
## 或者
python -m playwright install
## 以上命令会安装所有浏览器,如果只需要安装一个浏览器比如firefox
python -m playwright install firefox
配置大模型API Key
可以用DeepSeek或通义千问的API Key,其中通义有免费额度,DeepSeek虽然收费但价格便宜,测试一次使用约1000token,成本不到0.01元。
根据项目文档配置cofig.yaml即可,但项目调用大模型是使用基础的OpenAI API,如果使用其他大模型,可能需要基于对应的官方文档小改一下。
代码
OpenManus客户端
Python OpenManus/main.py即可在终端运行OpenManus,读者也可以尝试其Web版本。
进入OpenManus/app/agent/manus.py查看Manus类,可以发现它继承了ToolCallAgent类,再进入会发现又是继承,有点复杂,这里我画一张关系图。
act()执行时使用execute_tools()进行具体的工具执行。
总体来说,Manus类定义了Prompt和可使用的工具。
Base类定义了run(),在run()中会循环执行ReAct类的方法step(),直到Finish或达到max_step。
step()类会顺序执行ToolCallAgent类的think()和act()。
当然,这里只罗列了重要的组件和方法,一些方法没有画在图中。
Prompt
一般来说,输入给LLM的prompt分为两种:1)系统 prompt,用于定义模型的角色定位和行为规则;2)用户 prompt(OpenManus称为Next Step Prompt),用于传达具体的任务指令或信息需求。
在OpenManus/app/prompt/manus.py中即可看到Manus的Prompt,这里展示一下中文版,读者基于此可对OpenManus架构有一个初步认识:
系统Prompt(SYSTEM_PROMPT):“你是 OpenManus,一个全能的人工智能助手,旨在解决用户提出的任何任务。你拥有各种可使用的工具,能调用这些工具高效地完成复杂的请求。无论是编程、信息检索、文件处理还是网页浏览,你都能应对自如。”
下一步Prompt(NEXT_STEP_PROMPT):“你可以使用 PythonExecute 与计算机进行交互,通过 FileSaver 保存重要的内容和信息文件,使用 BrowserUseTool 打开浏览器,并使用 GoogleSearch 检索信息。根据用户的需求,主动选择最合适的工具或工具组合。对于复杂的任务,你可以将问题分解,逐步使用不同的工具来解决它。在使用完每个工具后,清晰地解释执行结果并给出下一步的建议。
当然,在实际执行时会对prompt有进一步优化,不过核心的系统定位与任务指导原则是不会改变的。
Manus类
我们先看一下OpenManus拥有的工具,工具也支持自定义,会在后文进行介绍。
PythonExecute:执行 Python 代码以与计算机系统交互、进行数据处理、自动化任务等等。
FileSaver:在本地保存文件,例如 txt、py、html 等文件。
BrowserUseTool:打开、浏览并使用网络浏览器。如果你打开一个本地 HTML 文件,必须提供该文件的绝对路径。
GoogleSearch:执行网络信息检索。
Terminate:如果LLM认为回答完毕,会调用这个工具终止循环。
Base类
run()
状态管理
IDLE(空闲状态)。如果不是空闲状态,会抛出 RuntimeError 异常,因为只有在空闲状态下才能启动代理的执行。state_context上下文管理器将代理的状态临时切换到 RUNNING(运行状态)。在上下文管理器中执行的代码块会在进入时将状态切换为指定状态,在退出时恢复到之前的状态。如果在执行过程中发生异常,会将状态切换为 ERROR。Memory管理
我们调用大模型的API,本质是向大模型提供方发http请求,http请求是无状态的。
所以为了让大模型持续与用户的对话,一种常见的解决方案就是把聊天历史告诉大模型。
用户提供的 request 参数,调用 update_memory 方法将该请求作为用户消息添加到代理的Memory中。
除了这个函数,Manus也在进行think()、act()时也会更新Memory,同时Memory容量也不是无限大的,容量满时需要删除老的Message。
主循环
agent本质就是循环执行。
step实现参考react step。
循环结束条件:max_steps或者FINISHED状态。
每次执行一个step并获得result——step_result = await self.step()。
is_stuck 方法用于检查代理是否陷入了循环(即是否出现了重复的响应)。如果是,则调用 handle_stuck_state 方法处理这种情况,例如添加一个提示来改变策略。
ReAct
step()
ToolcallAgent
Think()
输入:不需要输入,因为用户的question是被存放在Memory中。
输出:一个bool类型,当内部LLM判断需要act()时,为True,否则为Fasle。
询问LLM
对应到OpenManus/app/llm.py 233行附近,这里就是基于OpenAI提供的API接口进行对话,具体的参数可参考相应官方文档。
下图是一次返回response结果。
输入的question是“计算Kobe Bryant的BMI?”,LLM先分析出了要通过浏览器查询资料,因此要use the BrowserUseTool。
根据传入的工具类型等信息,LLM自动构建了执行工具需要用的tool_name、action等参数。
ChatCompletionMessage(
content="It seems there was an issue with retrieving the information about Kobe Bryant's height and weight through a Google search. To calculate Kobe Bryant's BMI, we need his height and weight. Let's try to find this information by opening a browser and visiting a reliable source. I will use the BrowserUseTool to navigate to a website that provides details about Kobe Bryant's height and weight. Let's proceed with this approach.",
refusal=None,
role='assistant',
annotations=None,
audio=None,
function_call=None,
tool_calls=[ ChatCompletionMessageToolCall( id='call_aez57ImfIEZrqjZdcW9sFNEJ', function=Function( arguments='{
"action":"navigate",
"url":"https://www.biography.com/athlete/kobe-bryant"
}', name='browser_use'), type='function')]
)
think后续逻辑
think()后续的逻辑比较简单,主要是更新memory(memory存储单位是message),最后在100行附近的逻辑,基于self.tool_choices等参数的设置和LLM返回的工具列表,输出bool类型结果。
同时,需要被调用的工具会被记录到self.tool_calls这个列表中,后续的act()会执行对应的工具。
Act()
输入:同think(),不需要输入。
输出:results,根据工具结果构建的一个字符串。
Execute_tool()
该函数会调用Tool类提供的接口execute()。
Tool类接口会在后面介绍。同时,对于预设定的special tool,会self._handle_special_tool(name=name, result=result)进行特殊处理。
工具相关
我们在之前介绍了MCP相关的概念,如下图所示:
事实上,OpenManus也是基于MCP的,OpenManus的tool相当于MCP server,根据MCP协议,我们只需要定义tool类支持的方法和参数等,每次注册一个新工具,根据父类override一个子类即可。
那我们首先要了解父类都定义了什么参数和方法,也就是OpenManus/app/tool/base.py定义的Basetool类。
Base Tool
可以看出,代码很简单,每个tool包含的参数为:name、description(提供给LLM看的,对工具的介绍)、parameters(执行工具时要用的参数)。
同时,一个tool支持的方法有execute()和to_param()。
execute()用于执行具体的逻辑,每个子类需要override这个方法。
to_param()将工具调用的结果结构化输出。
当然,这里还有一个python关键字__call__,这个关键字很简单,定义了__call__,该类的实例对象可以像函数一样被调用。
工具JSON
可以根据OpenManus预定义的工具json简单了解一下,每个工具执行时需要的参数。
[
{
"type": "function",
"function": {
"name": "python_execute",
"description": "Executes Python code string. Note: Only print outputs are visible, function return values are not captured. Use print statements to see results.",
"parameters": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "The Python code to execute."
}
},
"required": ["code"]
}
}
},
{
"type": "function",
"function": {
"name": "google_search",
"description": "Perform a Google search and return a list of relevant links.\nUse this tool when you need to find information on the web, get up-to-date data, or research specific topics.\nThe tool returns a list of URLs that match the search query.\n",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "(required) The search query to submit to Google."
},
"num_results": {
"type": "integer",
"description": "(optional) The number of search results to return. Default is 10.",
"default": 10
}
},
"required": ["query"]
}
}
]
工具示例——google_search
OpenManus项目在OpenManus/app/tool中定义了bash工具、浏览器工具、谷歌搜索工具等,这里简单看一下谷歌搜索工具。
当然,国内可能比较难使用谷歌搜索,OpenManus社区也有大佬提供了baidu、bing等搜索引擎工具。
可以看出,代码很简单,主要做了两件事。
定义工具参数:name、description、parameters。
定义execute:基于googlesearch库提供的函数进行搜索并返回。
五、总结
OpenManus的代码介绍到这里,主要是介绍一下核心代码,同时,原作者写了planning部分的代码但暂时没有应用到项目中,笔者也没有介绍。如果想对该项目有更进一步的了解,请大家查看github上提供的源码。而且,作者还是非常积极的,每天会有十几个commit。
同时,读者可以简单本地部署玩一下OpenManus,通过几个prompt,就可以知道该项目还是停留在**“玩具阶段”,比如笔者测试了一下,当询问“计算一下科比的BMI?”,OpenManus可以很准确的实现谷歌搜索****——浏览器访问——python计算**这个过程。但如果询问“计算科比、梅西的BMI并排序?”,无论我改写了几次prompt,OpenManus都没有给我满意的回答。
此外,无论是在工具参数信息、还是prompt、memory管理中,都可以看到agent应用大模型token消耗量巨大,即使我们不考虑token成本,但大模型的上下文仍然是有限的,这种资源消耗也会直接导致模型在处理多步骤任务时面临信息截断的风险 —— 早期的关键信息可能因上下文溢出而被丢弃,进而引发推理链条的断裂。更值得警惕的是,当模型试图在有限的上下文中 “脑补” 缺失的信息时,往往会产生与事实不符的幻觉。
鉴于此,尽管 OpenManus 展示出了利用工具链解决复杂问题的潜力,不过距离成为一个实用、高效且稳定的生产级人工智能助手仍有很长的路要走。未来,开发者们或许需要在优化工具使用逻辑、提升多任务处理能力、降低大模型 token 消耗以及增强上下文管理等方面进行深入探索与改进。同时,对于普通用户而言,在体验这类项目时,也应该保持理性和客观的态度,既看到其创新性和趣味性,也认识到其当前存在的局限性。希望在技术的不断迭代和完善下,OpenManus 以及类似的项目能够早日突破现有的瓶颈,真正为人们的工作和生活带来实质性的帮助。
往期回顾
4. 基于ANTLR4的大数据SQL编辑器解析引擎实践|得物技术
5. LSM-TREE从入门到入魔:从零开始实现一个高性能键值存储 | 得物技术
文 / 汉堡
关注得物技术,每周一、三更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。

与在采用纯电驱动这件事上的犹犹豫豫和来回拉扯不同,各家汽车巨头在座舱智能化这件事情上倒是相当坚定,最近的大动作也不少。
继奔驰在 CLA 发布会上宣布将 计划把 AI 模型接入座舱系统之后,宝马在 3 月 26 日也宣布和阿里通义合作,争取在 2026 年把「宝马 AI 定制引擎」搬上车。

你可能会觉得,「AI 大模型」咱们又不是没见过,装一个 AI 应用在车机上,整点语音对话和文生图之类的功能,就能叫 AI 座舱了?
但宝马这次确实追上了业界前沿,打算一次性把「人工智障」进化到「AI 智能体」,也就是最近正火的 AI Agent。
这是推动AI与先进制造业融合的一次创新探索。AI 的想象力在于改造物理世界,把 AI 能力转化为千行百业的生产力。

宝马和阿里这次合作的定制 AI 引擎能够在意图捕捉、指令解析、模糊语义理解及逻辑推演能力上有所提升,支持连续指令自然交互,通过推理以更拟人化的方式来执行更多的复杂操作。
宝马举了一个例子来说明他们对这个定制引擎的期望,例如:「晚上要请爸妈和几个亲戚吃饭,推荐个朝阳公园西门附近、能地面停车、人均 200 左右、口味清淡、口碑好的餐厅吧。」然后系统就能综合实时路况、充电桩分布、景点口碑、用户偏好等多重信息,直接给你几个答案,然后导航过去。
说实话,哪怕在手机上,现在能做到这一点的 AI 模型也不多,但是各家目前都在朝着这个方向努力,真能实现的话确实能在相当程度上提升座舱的交互体验。

当然,这个 AI Agent 也希望能让你在驾驶时更加得心应手。通过依托自然语义大模型训练,在人机沟通上更自然、更贴近人与人之间的交互方式。
BBA 们的语音助手之前受到过很多吐槽,主要是识别率和能实现的操作都十分有限,常常出现「我说城门楼子,你说胯骨轴子」囧境。
当然这个 AI Agent 也不全都是被动执行,宝马说希望让它有一些主动关怀的能力,通过模糊语义理解能力与记忆学习能力来感知和记忆你的偏好。
比如当感知到你要搭早班航班赶往机场的时候,可以主动问候并播放一些你喜欢的歌曲。就不用用户自己再在音乐软件上翻来翻去,等音乐找到了,可能心情也已经所剩不多了。

在 4 月份的上海车展上,宝马就打算让「用车专家 Car Genius」和「出行伴侣 Travel Companion」两大 AI Agent 在中国用户面前亮相,到时候董车会一定去体验一下。
在这里,我们正以中国速度,携手中国力量,将前沿技术融入宝马创新体系,打造更懂中国消费者的智能驾驶乐趣。与阿里巴巴集团长期深入的探索合作就是最佳力证。

从这次合作我们也观察到了一个新的趋势,那就是中国的汽车产业链正在从「学习者、后来者」的身份上慢慢成长起来,转变向平等对话,甚至在某几个优势领域能够引领趋势。
智能座舱或许是最明显一个部分,国内新势力在这部分的竞争相当激烈,车机功能的丰富度和流畅性现在已经成为了消费者购车决策的一个关键指标。

在其它领域也有相同的趋势,例如小鹏和大众开始共同开发新的电子电气架构,零跑和玛莎拉蒂的母公司 Stellantis 合作开发新的电动车型,以及奥迪新 A5L 全面搭载华为智驾等等。
车企们现在想造出有竞争力的新车,使用本土供应商已经是大势所趋。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。