PAG动效框架源码笔记 (五)渲染流程
转载请注明出处:http://www.olinone.com/
前言
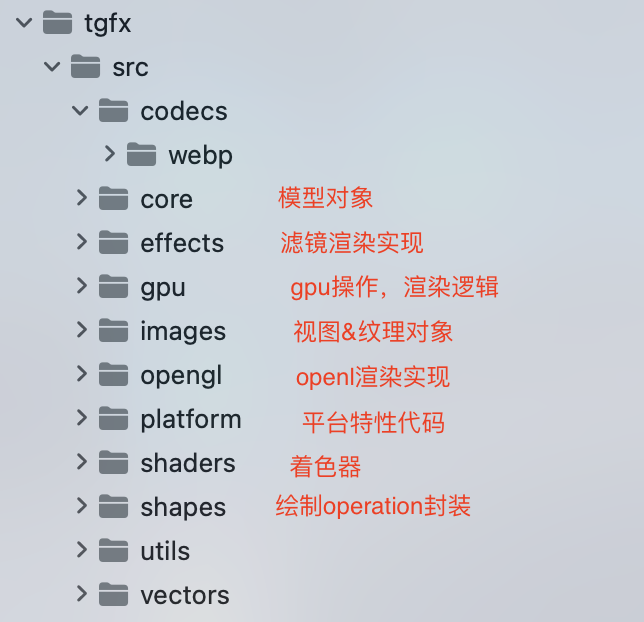
上一章介绍了TGFX渲染框架的大致结构,本章基于OpenGL介绍TGFX绘制Texture纹理详细的渲染流程
绘制Texture纹理,渲染引擎主要包括两个流程:GLSL着色器代码的装载及数据对象的绑定操作
着色器代码(GLSL)
渲染一个纹理,TGFX 需要构建顶点着色器(Vertex Shader)和片段着色器(Frament Shader)两个着色器,其代码分别如下
#version 100
precision mediump float;
uniform vec4 tgfx_RTAdjust; // 坐标系映射矩阵
uniform mat3 uCoordTransformMatrix_0_Stage0;
attribute vec2 aPosition;
attribute vec2 localCoord;
attribute vec4 inColor;
varying vec2 vTransformedCoords_0_Stage0;
varying vec4 vColor_Stage0;
void main() {
// Geometry Processor QuadPerEdgeAAGeometryProcessor
// 矩阵变化,比如缩放、偏移,更适合GPU并行计算
vTransformedCoords_0_Stage0 = (uCoordTransformMatrix_0_Stage0 * vec3(localCoord, 1)).xy;
vColor_Stage0 = inColor;
// 坐标系转化
gl_Position = vec4(aPosition.xy * tgfx_RTAdjust.xz + tgfx_RTAdjust.yw, 0, 1);
}
顶点着色器需要计算每个顶点在渲染坐标系中的坐标,同时将纹理数据输出给片段着色器
为了优化计算性能,TGFX没有在CPU阶段处理矩阵变化和坐标映射,而是交由GPU来处理( GPU更适合矩阵计算);同时,由GPU处理坐标系映射可以更灵活适配不同平台不同坐标系
#version 100
precision mediump float;
uniform mat3 uMat3ColorConversion_Stage1; // 颜色空间转化矩阵
uniform vec2 uAlphaStart_Stage1; // Alpha区域偏移量
uniform sampler2D uTextureSampler_0_Stage1;
uniform sampler2D uTextureSampler_1_Stage1;
varying highp vec2 vTransformedCoords_0_Stage0;
varying highp vec4 vColor_Stage0;
void main() {
vec4 outputColor_Stage0;
vec4 outputCoverage_Stage0;
{ // Stage 0 QuadPerEdgeAAGeometryProcessor
outputCoverage_Stage0 = vec4(1.0);
outputColor_Stage0 = vColor_Stage0;
}
vec4 output_Stage1;
{ // Stage 1 XfermodeFragmentProcessor - dst
vec4 child;
{
// Child Index 0 (mangle: _c0): YUVTextureEffect
// yuv取值,光栅化后每个点坐标都不一样
vec3 yuv;
yuv.x = texture2D(uTextureSampler_0_Stage1, vTransformedCoords_0_Stage0).rrra.r;
yuv.yz = texture2D(uTextureSampler_1_Stage1, vTransformedCoords_0_Stage0).rgrg.ra;
yuv.x -= (16.0 / 255.0);
yuv.yz -= vec2(0.5, 0.5);
// yuv数据转rgb
vec3 rgb = clamp(uMat3ColorConversion_Stage1 * yuv, 0.0, 1.0);
// 通过RGB颜色区域偏移计算Alpha区域,比如左rgb右alpha,整体+0.5
vec2 alphaVertexColor = vTransformedCoords_0_Stage0 + uAlphaStart_Stage1;
float yuv_a = texture2D(uTextureSampler_0_Stage1, alphaVertexColor).rrra.r;
// 为避免因压缩误差、精度等原因造成不透明变成部分透明(比如255变成254),
// 下面进行了减1.0/255.0的精度修正。
yuv_a = (yuv_a - 16.0/255.0) / (219.0/255.0 - 1.0/255.0);
yuv_a = clamp(yuv_a, 0.0, 1.0);
child = vec4(rgb * yuv_a, yuv_a) * vec4(1.0);
}
// Compose Xfer Mode: DstIn
output_Stage1 = child * outputColor_Stage0.a; // blend混合模式
}
{ // Xfer Processor EmptyXferProcessor
gl_FragColor = output_Stage1 * outputCoverage_Stage0;
}
}
片段着色器决定了光栅化后每个点像素的最终颜色,TGFX需要处理纹理RGBA计算、Mask蒙版遮罩以及多图层的blend混合计算等
渲染流程
1、任务创建
void Canvas::drawImage(std::shared_ptr<Image> image, const Paint* paint) {
// Mipmap纹理映射处理
auto mipMapMode = image->hasMipmaps() ? tgfx::MipMapMode::Linear : tgfx::MipMapMode::None;
tgfx::SamplingOptions sampling(tgfx::FilterMode::Linear, mipMapMode);
drawImage(std::move(image), sampling, paint);
}
void Canvas::drawImage(std::shared_ptr<Image> image, SamplingOptions sampling, const Paint* paint) {
...
// 记录Canvas当前状态
auto oldMatrix = getMatrix();
...
// 绘制image(包含解码后的texture纹理)
drawImage(std::move(image), sampling, paint);
// 还原Canvas上下文
setMatrix(oldMatrix);
}
void Canvas::drawImage(std::shared_ptr<Image> image, SamplingOptions sampling, const Paint& paint) {
...
// 纹理处理,序列帧左rgb右alpha数据
auto processor = image->asFragmentProcessor(getContext(), surface->options()->flags(), sampling);
...
// 创建画笔Paint
if (!PaintToGLPaintWithImage(getContext(), surface->options()->flags(), paint, state->alpha, std::move(processor), image->isAlphaOnly(), &glPaint)) {
return;
}
// 创建矩形填充绘制Operation
auto op = FillRectOp::Make(glPaint.color, localBounds, state->matrix);
// 绑定Paint到Op上,提交绘制Task
draw(std::move(op), std::move(glPaint), true);
}
// 创建Paint
static bool PaintToGLPaint(Context* context, uint32_t surfaceFlags, const Paint& paint, float alpha, std::unique_ptr<FragmentProcessor> shaderProcessor, GpuPaint* glPaint) {
...
// 绘制串行Pipeline
// 纹理
shaderFP = shader->asFragmentProcessor(args);
if (shaderFP) {
glPaint->colorFragmentProcessors.emplace_back(std::move(shaderFP));
}
// 滤镜
if (auto colorFilter = paint.getColorFilter()) {
if (auto processor = colorFilter->asFragmentProcessor()) {
glPaint->colorFragmentProcessors.emplace_back(std::move(processor));
}
}
// 蒙版遮罩
if (auto maskFilter = paint.getMaskFilter()) {
if (auto processor = maskFilter->asFragmentProcessor(args)) {
glPaint->coverageFragmentProcessors.emplace_back(std::move(processor));
}
}
return true;
}
// 绑定Paint到绘制Operation中,提交到绘制OperationQueue
void Canvas::draw(std::unique_ptr<DrawOp> op, GpuPaint paint, bool aa) {
...
// Canvas裁切
auto masks = std::move(paint.coverageFragmentProcessors);
Rect scissorRect = Rect::MakeEmpty();
auto clipMask = getClipMask(op->bounds(), &scissorRect);
if (clipMask) {
masks.push_back(std::move(clipMask));
}
op->setScissorRect(scissorRect);
BlendModeCoeff first;
BlendModeCoeff second;
// blend混合模式
if (BlendModeAsCoeff(state->blendMode, &first, &second)) {
op->setBlendFactors(std::make_pair(first, second));
} else {
op->setXferProcessor(PorterDuffXferProcessor::Make(state->blendMode));
op->setRequireDstTexture(!getContext()->caps()->frameBufferFetchSupport);
}
op->setAA(aaType);
// 纹理图层
op->setColors(std::move(paint.colorFragmentProcessors));
// 蒙版图层
op->setMasks(std::move(masks));
surface->aboutToDraw(false);
// 加入到绘制队列中
drawContext->addOp(std::move(op));
}
void SurfaceDrawContext::addOp(std::unique_ptr<Op> op) {
getOpsTask()->addOp(std::move(op));
}
2、Flush绘制
bool DrawingManager::flush(Semaphore* signalSemaphore) {
...
// 遍历执行
std::for_each(tasks.begin(), tasks.end(), [gpu](std::shared_ptr<RenderTask>& task) { task->execute(gpu); });
return context->caps()->semaphoreSupport && gpu->insertSemaphore(signalSemaphore);
}
bool OpsTask::execute(Gpu* gpu) {
// 先prepare
std::for_each(ops.begin(), ops.end(), [gpu](auto& op) { op->prepare(gpu); });
// 再execute
opsRenderPass->begin();
auto tempOps = std::move(ops);
for (auto& op : tempOps) {
op->execute(opsRenderPass);
}
opsRenderPass->end();
// 提交
gpu->submit(opsRenderPass);
return true;
}
3、绘制预处理
// 顶点着色器数据构造
void FillRectOp::onPrepare(Gpu* gpu) {
// 数据构造(CPU),包含画布、纹理以及RGB区域数据
auto data = vertices();
// 绑定数据到GPU
vertexBuffer = GpuBuffer::Make(gpu->context(), BufferType::Vertex, data.data(), data.size() * sizeof(float));
// 自定义绘制顺序index
if (aa == AAType::Coverage) {
indexBuffer = gpu->context()->resourceProvider()->aaQuadIndexBuffer();
} else {
indexBuffer = gpu->context()->resourceProvider()->nonAAQuadIndexBuffer();
}
}
std::shared_ptr<GpuBuffer> GpuBuffer::Make(Context* context, BufferType bufferType, const void* buffer, size_t size) {
...
auto glBuffer = std::static_pointer_cast<GLBuffer>(context->resourceCache()->findScratchResource(scratchKey));
...
// GPU数据绑定
gl->bindBuffer(target, glBuffer->_bufferID);
// GPU数据赋值
gl->bufferData(target, static_cast<GLsizeiptr>(size), buffer, GL_STATIC_DRAW);
return glBuffer;
}
4、绘制执行
void FillRectOp::onExecute(OpsRenderPass* opsRenderPass) {
// 着色器代码定义
auto info = createProgram(opsRenderPass, QuadPerEdgeAAGeometryProcessor::Make(opsRenderPass->renderTarget()->width(), opsRenderPass->renderTarget()->height(), aa, !colors.empty()));
// 着色器代码装载及数据绑定
opsRenderPass->bindPipelineAndScissorClip(info, scissorRect());
// 绑定顶点及自定义绘制顺序数据
opsRenderPass->bindBuffers(indexBuffer, vertexBuffer);
if (needsIndexBuffer()) {
// 自定义顺序绘制
opsRenderPass->drawIndexed(PrimitiveType::Triangles, 0, static_cast<int>(rects.size()) * numIndicesPerQuad);
} else {
// 默认顺序绘制
opsRenderPass->draw(PrimitiveType::TriangleStrip, 0, 4);
}
}
// 着色器代码生成,包括顶点和片段着色器代码
ProgramInfo DrawOp::createProgram(OpsRenderPass* opsRenderPass,
std::unique_ptr<GeometryProcessor> gp) {
auto numColorProcessors = _colors.size();
// 片段着色器函数代码Pipeline组装
std::vector<std::unique_ptr<FragmentProcessor>> fragmentProcessors = {};
fragmentProcessors.resize(numColorProcessors + _masks.size());
// 纹理
std::move(_colors.begin(), _colors.end(), fragmentProcessors.begin());
// 蒙版
std::move(_masks.begin(), _masks.end(),
fragmentProcessors.begin() + static_cast<int>(numColorProcessors));
...
ProgramInfo info;
// blend模式
info.blendFactors = _blendFactors;
info.pipeline = std::make_unique<Pipeline>(std::move(fragmentProcessors), numColorProcessors, std::move(_xferProcessor), dstTexture, dstTextureOffset, &swizzle);
info.pipeline->setRequiresBarrier(dstTexture != nullptr && dstTexture == opsRenderPass->renderTargetTexture());
// 顶点着色器函数代码
info.geometryProcessor = std::move(gp);
return info;
}
// 着色器代码装载,包括编译、链接及Uniform数据绑定
bool GLOpsRenderPass::onBindPipelineAndScissorClip(const ProgramInfo& info, const Rect& drawBounds) {
GLProgramCreator creator(info.geometryProcessor.get(), info.pipeline.get());
// Program函数创建,先缓存,没有再新建
_program = static_cast<GLProgram*>(_context->programCache()->getProgram(&creator));
auto glRT = static_cast<GLRenderTarget*>(_renderTarget.get());
auto* program = static_cast<GLProgram*>(_program);
// 绑定函数
gl->useProgram(program->programID());
gl->bindFramebuffer(GL_FRAMEBUFFER, glRT->getFrameBufferID());
gl->viewport(0, 0, glRT->width(), glRT->height());
// GL裁切
UpdateScissor(_context, drawBounds);
// GL混合模式
UpdateBlend(_context, info.blendFactors);
// 绑定数据,包括Uniform参数和纹理数据
program->updateUniformsAndTextureBindings(glRT, *info.geometryProcessor, *info.pipeline);
return true;
}
// 创建Program函数
std::unique_ptr<GLProgram> GLProgramBuilder::CreateProgram(Context* context, const GeometryProcessor* geometryProcessor, const Pipeline* pipeline) {
GLProgramBuilder builder(context, geometryProcessor, pipeline);
if (!builder.emitAndInstallProcessors()) {
return nullptr;
}
return builder.finalize();
}
bool ProgramBuilder::emitAndInstallProcessors() {
// 生成顶点着色器代码
emitAndInstallGeoProc(&inputColor, &inputCoverage);
// 生成片段着色器代码
emitAndInstallFragProcessors(&inputColor, &inputCoverage);
// 图层叠加混合代码
emitAndInstallXferProc(inputColor, inputCoverage);
emitFSOutputSwizzle();
return checkSamplerCounts();
}
std::unique_ptr<GLProgram> GLProgramBuilder::finalize() {
...
// Vertex Shader代码
auto vertex = vertexShaderBuilder()->shaderString();
// Frament Shader代码
auto fragment = fragmentShaderBuilder()->shaderString();
// 创建Program,编译、链接
auto programID = CreateGLProgram(context, vertex, fragment);
// GPU顶点着色器参数绑定
computeCountsAndStrides(programID);
// 获取Program Uniform位置
resolveProgramResourceLocations(programID);
return createProgram(programID);
}
std::unique_ptr<GLProgram> GLProgramBuilder::createProgram(unsigned programID) {
auto program = new GLProgram(context, uniformHandles, programID, _uniformHandler.uniforms, std::move(glGeometryProcessor), std::move(xferProcessor), std::move(fragmentProcessors), attributes, vertexStride);
// GPU Uniform参数绑定
program->setupSamplerUniforms(_uniformHandler.samplers);
return std::unique_ptr<GLProgram>(program);
}
// 提交绘制
void GLOpsRenderPass::draw(const std::function<void()>& func) {
// GPU顶点着色器参数赋值
gl->bindBuffer(GL_ARRAY_BUFFER, std::static_pointer_cast<GLBuffer>(_vertexBuffer)->bufferID());
auto* program = static_cast<GLProgram*>(_program);
for (const auto& attribute : program->vertexAttributes()) {
const AttribLayout& layout = GetAttribLayout(attribute.gpuType);
gl->vertexAttribPointer(static_cast<unsigned>(attribute.location), layout.count, layout.type, layout.normalized, program->vertexStride(), reinterpret_cast<void*>(attribute.offset));
gl->enableVertexAttribArray(static_cast<unsigned>(attribute.location));
}
// 绘制
func();
...
}
总结
为了支持多平台不同对象(纹理、图形等)绘制,TGFX抽象封装了一套完整的GLSL代码生成模版,各平台继承模版父类负责逻辑实现,后续可以针对iOS平台提供Metal绘制实现
class ProgramCreator {
public:
virtual ~ProgramCreator() = default;
virtual void computeUniqueKey(Context* context, BytesKey* uniqueKey) const = 0;
virtual std::unique_ptr<Program> createProgram(Context* context) const = 0;
};
class GLProgramCreator : public ProgramCreator {
public:
GLProgramCreator(const GeometryProcessor* geometryProcessor, const Pipeline* pipeline);
void computeUniqueKey(Context* context, BytesKey* uniqueKey) const override;
std::unique_ptr<Program> createProgram(Context* context) const override;
};
std::unique_ptr<Program> GLProgramCreator::createProgram(Context* context) const {
return GLProgramBuilder::CreateProgram(context, geometryProcessor, pipeline);
}
至此, PAG动效框架源码就全部讲解完成
框架中还有大量本文未提到的内容,比如滤镜、文本、图形绘制等等,有兴趣的同学建议阅读源码
相信未来行业内会有大量类似的解决方案,比如基于MP4方案的多图层绘制框架等