一、MCP设计理念
在浅析 MCP 原理之前,有必要搞清楚两个问题:MCP 是什么?为什么会出现? 以此明晰它存在的价值和意义。
首先,MCP(Model Context Protocol,模型上下文协议)是由人工智能公司 Anthropic 主导推出的一种开放标准协议,旨在统一大型语言模型(LLM)与外部数据源、工具及服务之间的交互方式。该协议通过JSON-RPC 2.0 标准消息格式定义通信规则,使模型能像使用"万能接口"(类比 Type-C 接口)一样即插即用地连接异构资源。

图片来源:zhuanlan.zhihu.com/p/598749792
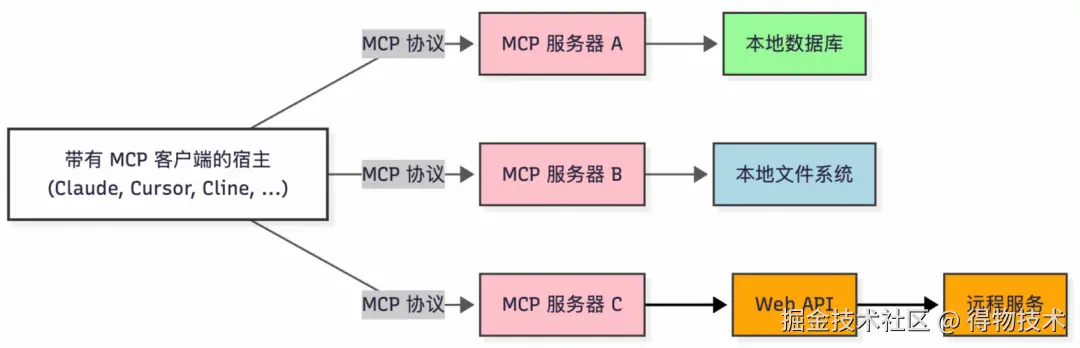
其架构采用客户端-服务器模式,包含三个关键组件:
-
MCP Host:运行大模型应用(如 Cursor、Cline、Cherry Studio、Claude Desktop 等),负责发起任务请求。
-
MCP Client:集成在 Host 中的协议客户端,解析任务需求并与服务器协调资源调用。
-
MCP Server:轻量级服务程序,动态注册与暴露本地资源(例如文件、数据库)或远程服务(如云API),处理客户端请求并返回结构化数据,同时提供安全控制,包括访问权限管理和资源隔离。
简单概括为 MCP 是一种开放标准,本质是应用层协议(Protocal),跟我们熟知的 TCP/IP,HTTP 协议类似。借助它开发者可以安全地在数据源和 AI 工具之间建立双向连接。其架构概括起来就是:
- 开发者可以通过 MCP 服务器公开他们的数据;
- AI 应用(MCP 客户端) 可以连接到 MCP 服务器,获取所需数据,LLMs 再分析投喂的数据。
那为什么会出现呢?这就要说到RAG和Function Calling 技术了。
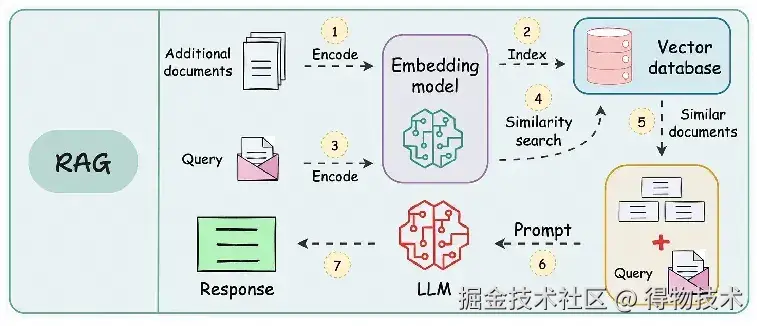
RAG(检索增强生成) 通过检索外部知识库获取与问题相关的实时信息并将其注入模型提示词,生成更精准、时效性更强的回答。 其工作原理为:当用户发出提问时,AI 应用通过向量检索、关键词匹配等方式,从外部知识库或数据源中搜索相关信息,再把检索到的信息作为上下文提供给大模型,让大模型基于补充的信息进行回答。技术流程: 用户提问→问题向量化→向量数据库相似度检索→拼接上下文提示词→模型生成答案。
图片来源:ailydoseofds
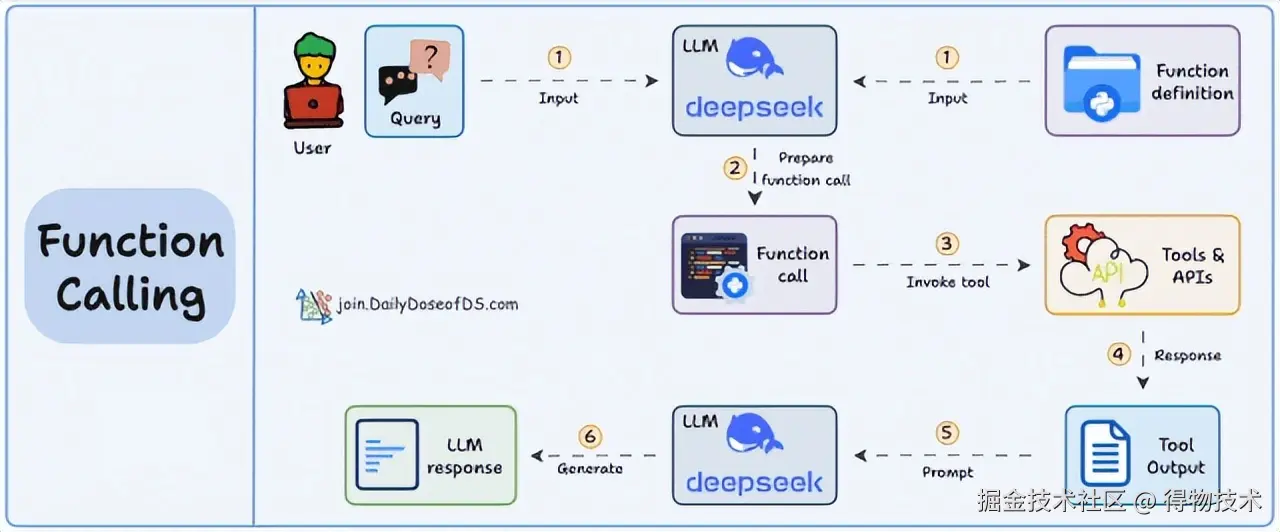
而Function Calling(函数调用) 拓展了模型执行动作的能力,解决纯文本交互的局限性,即模型解析用户意图后生成结构化指令,调用预定义外部函数或 API(如发送邮件、查询天气)。其工作原理为:当用户发出提问时,应用会将集成的函数列表作为上下文发送给大模型。大模型根据用户输入判断应调用的函数,并生成相应的调用参数。随后,应用执行该函数并将结果发送给大模型,作为补充信息供其生成最终的总结或回答。技术流程:用户指令→ 模型识别需调用的函数→ 生成参数化调用指令→ 外部系统执行→ 返回结果至模型→ 生成用户响应。
图片来源:ailydoseofds
但不同的 API 需要封装成不同的方法,且参数确定后,后期变更困难,很难在不同的平台灵活复用。 而我们可以认为,MCP 是在 Function Calling 的基础上做了进一步的抽象,目的是让应用更加简单、高效、安全地对接外部资源,更好地为大模型补充上下文信息。总结起来就是,MCP 把大模型运行环境称作 MCP Client,也就是 MCP 客户端,同时,把外部函数运行环境称作 MCP Server,也就是 MCP 服务器,然后,统一 MCP 客户端和服务器的运行规范,并且要求 MCP 客户端和服务器之间,也统一按照某个既定的提示词模板进行通信。
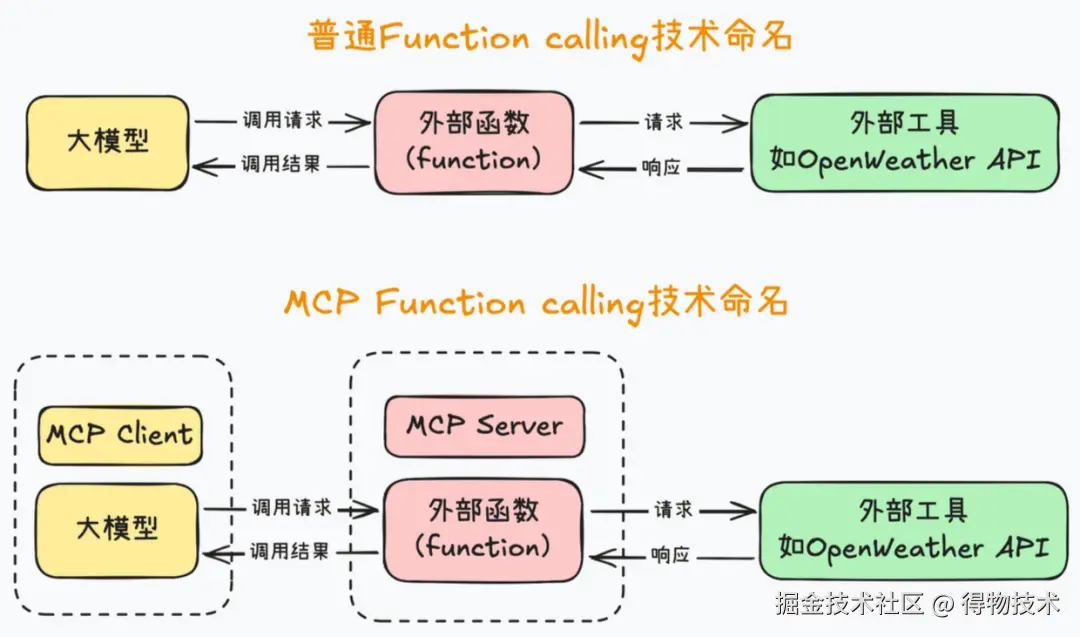
MCP vs Function Calling 对比:
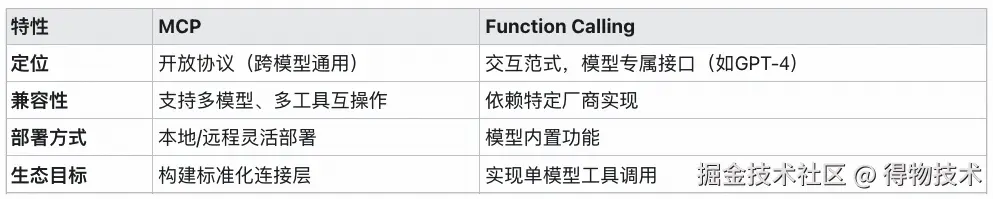
综上,RAG与Function Calling 互补,前者用于知识检索,后者用于执行操作,二者均可提升模型实用性,但目标维度不同,且存在难集成,扩展性差的问题,开发者往往需为不同模型重复实现工具调用逻辑。
MCP 则是对两者的整合与标准的规范化:
-
标准化接口:MCP 为 RAG 的检索源接入(如数据库、文档库)和 Function Calling 的工具调用(如 API 服务)提供统一接入规范,避免为每个工具开发定制化适配。 比如 MCP 工具的inputSchema可定义多个参数,通过required标记必传参数。大模型在解析用户提问时,会根据工具的描述和参数定义,自动解析并提供相应参数值来调用工具。这种参数化设计方式提高了工具调用的灵活性,降低了 Function Calling 的开发复杂度。
return Tool(
name=self.name,
description=self.description,
inputSchema={
"type": "object",
"properties": {
"host": {"type": "string", "description": "数据库主机地址"},
"port": {"type": "integer", "description": "数据库端口"},
"user": {"type": "string", "description": "数据库用户名"},
"password": {"type": "string", "description": "数据库密码"},
"database": {"type": "string", "description": "数据库名称"}
},
"required": ["host", "port", "user", "password", "database"]
}
)
-
能力扩展:
-
- RAG 通过 MCP 接入实时数据流(如证券行情),突破静态知识库限制;
- Function Calling通过 MCP 调用异构工具(如 IoT 设备),无需依赖特定模型的支持。
-
系统效率:MCP 降低开发复杂度(如开发者无需为不同模型重复实现工具调用逻辑),促进工具生态共享。
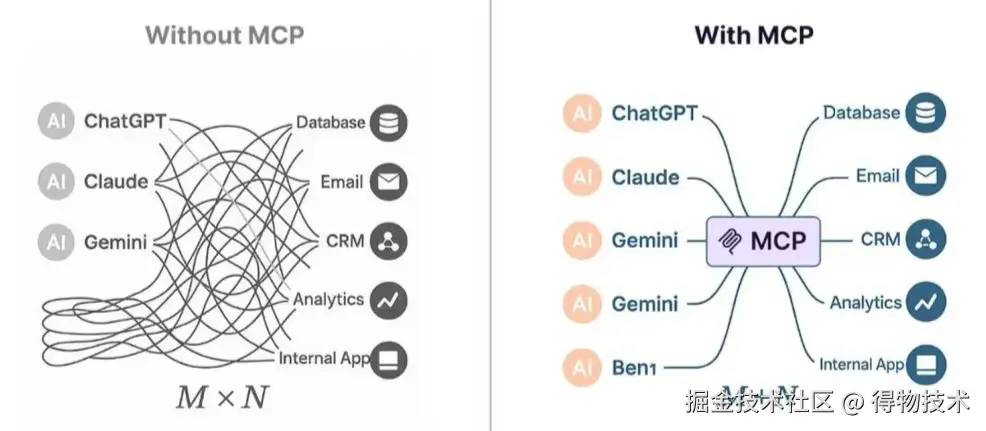
技术演进总结:
- RAG → Function Calling → MCP 代表了 AI 能力的三个重要维度:从静态知识检索到动态行动执行,再到标准化生态构建,标志着 AI 从知识增强到行动扩展再到生态标准化的发展趋势。
- 在 AI Agent 架构中:RAG 充当知识中枢,Function Calling 为执行手段,MCP 则是连接内外的“神经枢纽”。
-
未来意义:MCP 的开放性将加速工具互操作性,推动复杂任务(如多 Agent 协作)的规模化落地,成为 AI 基础设施的关键组件。
二、MCP 架构详解
了解 MCP 存在的价值后,我们还需要定位 MCP 在整个 AI 体系中所处的位置,如以 Agent 为例:

了解完其在生态中所处的位置后,本节将结合 Python 版 SDK 源码和开源 MCP for DB 项目解读如何运用 MCP 以此了解其架构原理及使用方法。MCP Python SDK 提供了一个分层架构,通过多种传输协议将 LLM 应用程序连接到 MCP 服务器,同时具有高级和低级开发 API。
参考项目地址:github.com/Eliot-Shen/…
Python SDK:github.com/modelcontex…
2.1MCP运行过程
在此之前,有必要对 MCP 整体运行有个宏观上的认知,如下图所示,首先,需用户在主机上配置 MCP 服务,比如借助 VSCode 插件 Cline,根据使用的协议配置好 JSON文件即可。然后,用户输入问题,客户端让大语言模型选择 MCP 工具,大模型选择好工具后,客户端寻求用户同意,然后再请求 MCP 服务器, MCP 服务器调用工具并将工具的结果返回给客户端,客户端将模型调用结果和用户的查询发送给大语言模型,大语言模型组织答案给用户。
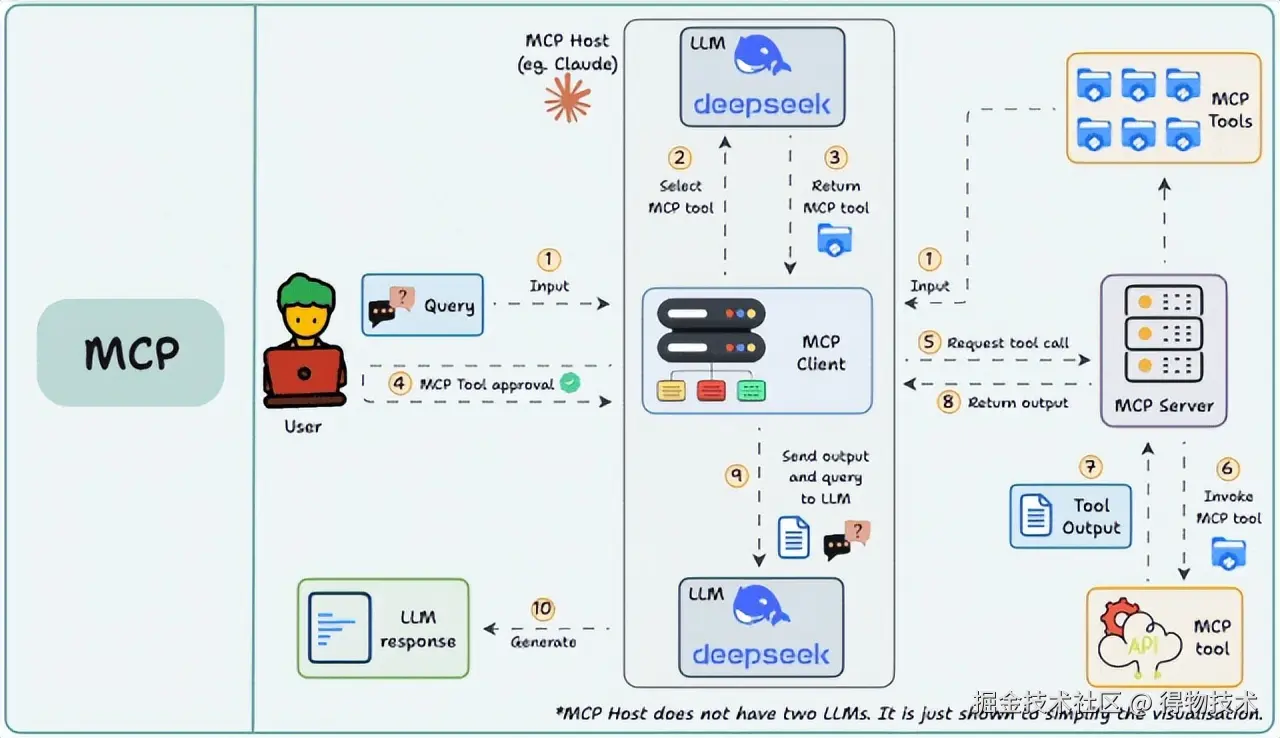
可见,整个流程中最核心的部分就是Client 和 Server的交互,而在使用像 Cline 这种主机端软件时,整体感知如下图,Client 已经被嵌在 MCP Host 中,只需开发出对应的 MCP Server,在主机中配置好 JSON即可使用。
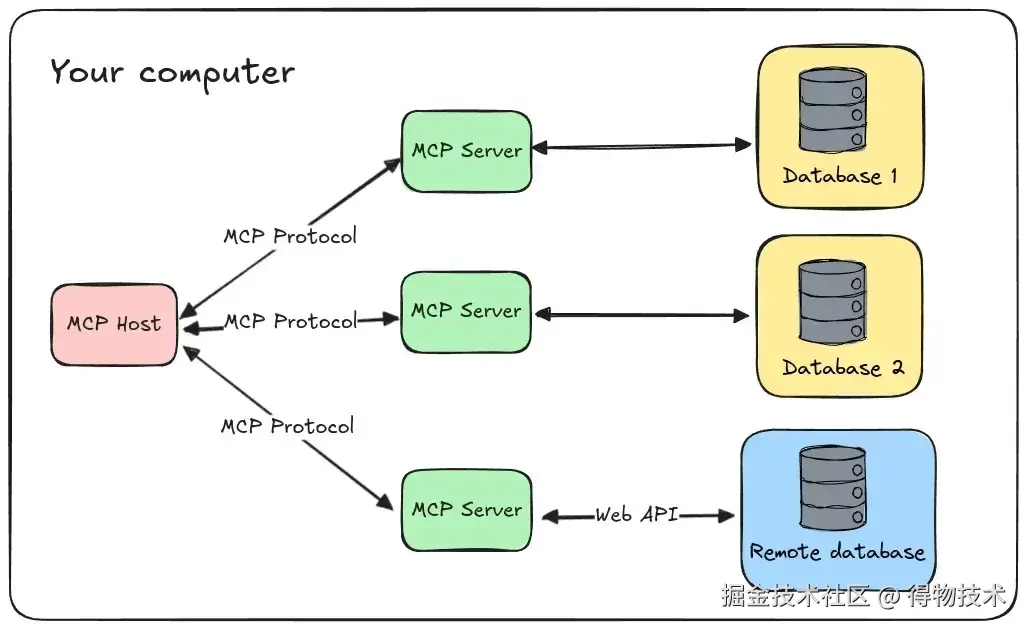
接下来将结合项目和 SDK 源码详细解读 MCP 架构原理。
2.2MCP运行原理
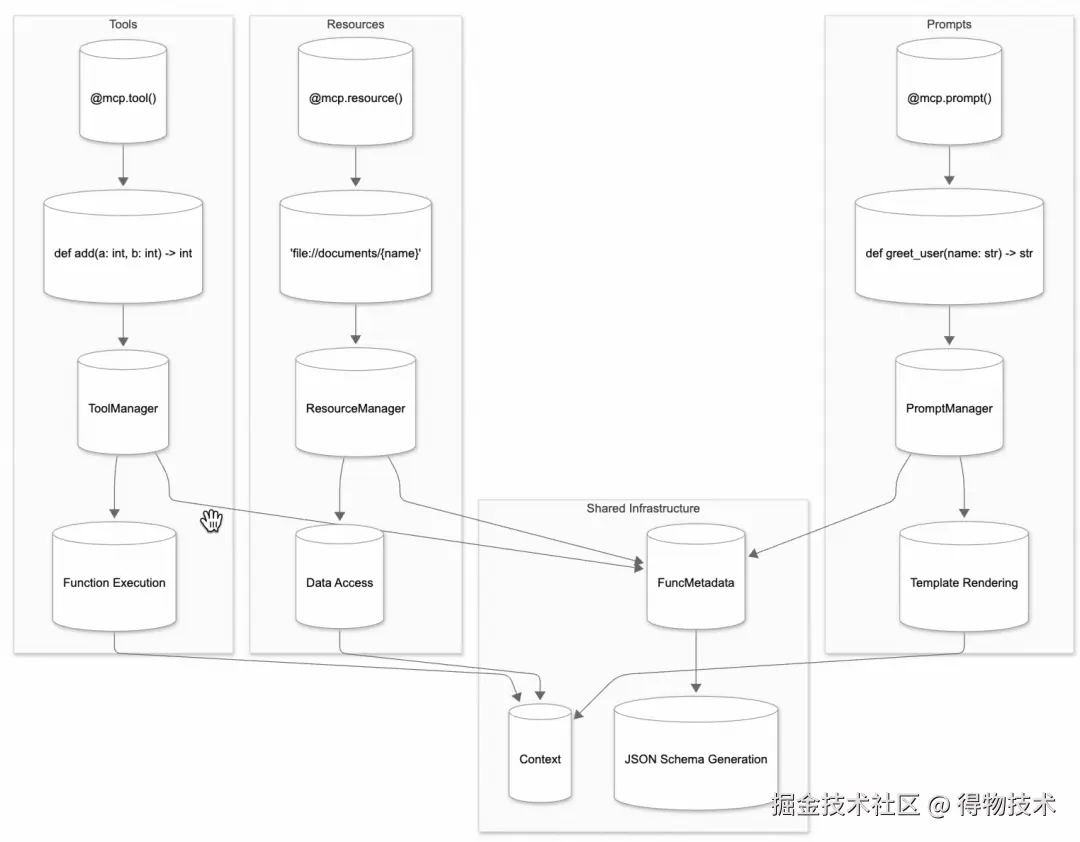
MCP Server作为 MCP 架构的核心部分,在提升AI应用性能方面发挥着不可替代的关键作用。其 Python 版 SDK 提供的框架图如下:
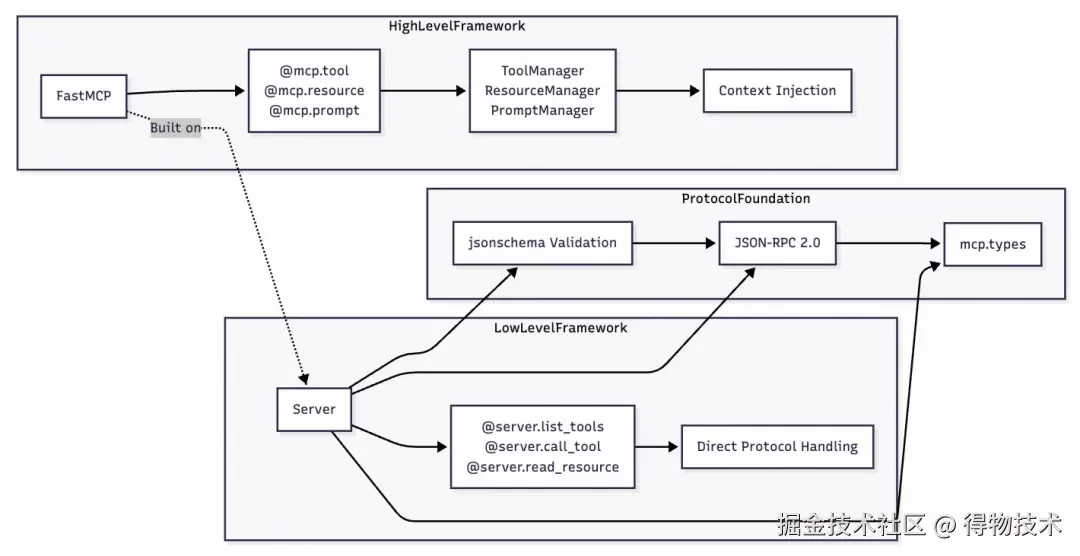
我们着重关注其提供的三大核心功能:资源@mcp.resource、工具@mcp.tool、提示词@mcp.prompt。而这三大核心功能之间的协作逻辑大致如下:
-
资源为工具提供上下文:手动注入资源可增强模型对任务的理解(如提供参考文档)辅助其更准确调用工具。
-
工具执行依赖资源输入:当工具操作外部数据时,如文件处理工具,可将指定文件 URI 作为工具参数输入。
-
提示词封装工具与资源调用:复杂 Prompt 可预设工具调用顺序或资源使用规则,形成自动化工作流。
# 在工具中封装提示词模版存在的问题是该工具不一定能被LLM调用,导致不一定能达到预期效果,但使用cline这中客户端,服务端的提示词又不能被加载调用
async def run_tool(self, arguments: Dict[str, Any]) -> Sequence[TextContent]:
prompt = f"""
- Workflow:
1. 解析用户输入的自然语言指令,提取关键信息,如表描述和查询条件。
2. 判断是否跨库查询、是否明确指定了目标表名(例如是中文的描述、英文的描述,偏向语义化的描述则判断为未明确表名)
3. 未明确指定目标表名则调用“get_table_name”工具,获取对应的表名。
4. 调用“get_table_desc”工具,获取表的结构信息。
5. 根据表结构信息和用户输入的查询条件,生成SQL查询语句并调用“execute_sql”工具,返回查询结果。
- Examples:
- 例子1:用户输入“查询用户表张三的数据”
解析结果:表描述为“用户表”,查询条件为“张三”。
判断结果:1.没有出现跨库的情况 2.未明确指定表名,当前为表的描述,需调用工具获取表名
调用工具“get_table_name”:根据“用户表”描述获取表名,假设返回表名为“user_table”。
调用工具“get_table_desc”:根据“user_table”获取表结构,假设表结构包含字段“id”、“name”、“age”。
生成SQL查询语句:`SELECT * FROM user_table WHERE name = '张三';`
调用工具“execute_sql”:根据生成的SQL,获取结果。
查询结果:返回张三的相关数据。
- task:
- 调用工具“get_table_name”,
- 调用工具“get_table_desc”,
- 调用工具“execute_sql”
- 以markdown格式返回执行结果
"""
return [TextContent(type="text", text=prompt)]
但出于安全考虑,大模型对资源/工具的访问能力受到限制:
-
工具:支持自主调用。大模型通过解析服务端公开的工具描述,能主动发起工具调用请求 ,无需用户逐条指令干预。此能力依赖模型的 Function Calling 支持,否则需通过提示词工程实现。
-
资源:禁止自主访问。资源始终由应用层或用户管控 ,模型仅能使用已注入的资源内容。避免模型随意访问敏感数据,保障安全性。
资源(Resources)
资源是指由 MCP Server 向客户端提供的数据实体,这些实体作为统一的信息载体,旨在扩展 AI 模型的数据访问边界,并支撑其对动态、结构化与非结构化数据的实时处理能力。类似于 REST API中的 GET 端点——提供数据,但不应执行大量计算或产生副作用。
资源代表任何可供 AI 模型读取的数据形式,是你向LLM 暴露数据的方式,涵盖:
-
文件内容:包括文本文件、JSON、XML 等结构化文档,以及源代码、配置文件等文本数据(UTF-8 编码)。
-
数据库记录:关系型或非关系型数据库查询结果(e.g. PostgreSQL或MySQL)。
-
动态系统数据:包括实时日志、屏幕截图、多媒体(图像、视频)、传感器输出等二进制数据。
如 MCP-DB-GPT 项目中定义的访问本地 JSON 格式的日志数据资源接口如下:
@mcp.resource("logs://{session_id}/{limit}")
def get_query_logs(limit: str = "5", session_id: str = "anonymous") -> Dict[str, Any]:
"""获取查询日志
Args:
limit: 可选参数,指定返回的日志数量,默认为5
session_id: 可选参数,指定要获取的会话ID
"""
try:
limit_val = int(limit)
if limit_val <= 0:
return {"success": False, "error": "Limit must be a positive integer"}
logs = query_logger.get_logs(session_id=session_id, limit=limit_val)
total = query_logger.total_query_count(session_id=session_id)
return {"success": True, "logs": logs, "total_queries": total}
except Exception as e:
return {"success": False, "error": str(e)}
-
装饰器中资源类型以统一资源标识符(URI)为唯一寻址机制,格式为[协议]://[主机]/[路径](如 file://home/user/report.pdf 或 postgres://database/customers/schema)。此设计允许资源协议、主机与路径的灵活定制,支持跨本地与远程环境的无缝集成。
通过整合多模态数据(文本与二进制)资源使 AI 模型能访问私有或专属知识库(如企业内部文档)、实时外部 API 及系统动态信息,有效突破单一大模型数据孤岛。
工具(Tools)
工具是服务器向客户端暴露的可执行函数集合,用于拓展大型语言模型(LLM)的操作能力,使其突破纯文本生成的局限,实现对外部系统的主动交互。其本质就是函数抽象,通过JSON Schema 严格定义输入/输出参数结构(如天气查询需输入位置参数,输出结构化天气数据)。
如 MCP-DB-GPT 项目中定义的只读 SQL 查询工具接口如下:
@mcp.tool()
def query_data(sql: str, session_id: str = "anonymous") -> Dict[str, Any]:
"""Execute read-only SQL queries"""
logger.info(f"Executing query: {sql}")
conn = get_connection()
cursor = None
try:
# Create dictionary cursor
cursor = conn.cursor(pymysql.cursors.DictCursor)
# Start read-only transaction
cursor.execute("SET TRANSACTION READ ONLY")
cursor.execute("START TRANSACTION")
try:
cursor.execute(sql)
results = cursor.fetchall()
conn.commit()
# 记录成功查询
log_query(operation=sql, success=True, session_id=session_id)
# Convert results to serializable format
return {
"success": True,
"results": results,
"rowCount": len(results)
}
except Exception as e:
conn.rollback()
log_query(operation=sql, success=False, error=str(e), session_id=session_id)
return {
"success": False,
"error": str(e)
}
finally:
if cursor:
cursor.close()
conn.close()
客户端通过标准协议接口(tools/list发现工具、tools/call 调用工具)与服务器交互,形成机器可读的自动化操作链路。其安全控制机制采用 “模型控制 + 人类监督” 双轨制:
- LLM 自主决定工具调用的必要性(如识别用户请求中的查询数据库表信息意图);
- 每次执行需用户显式授权(如弹出确认框),确保数据隐私与操作合规。
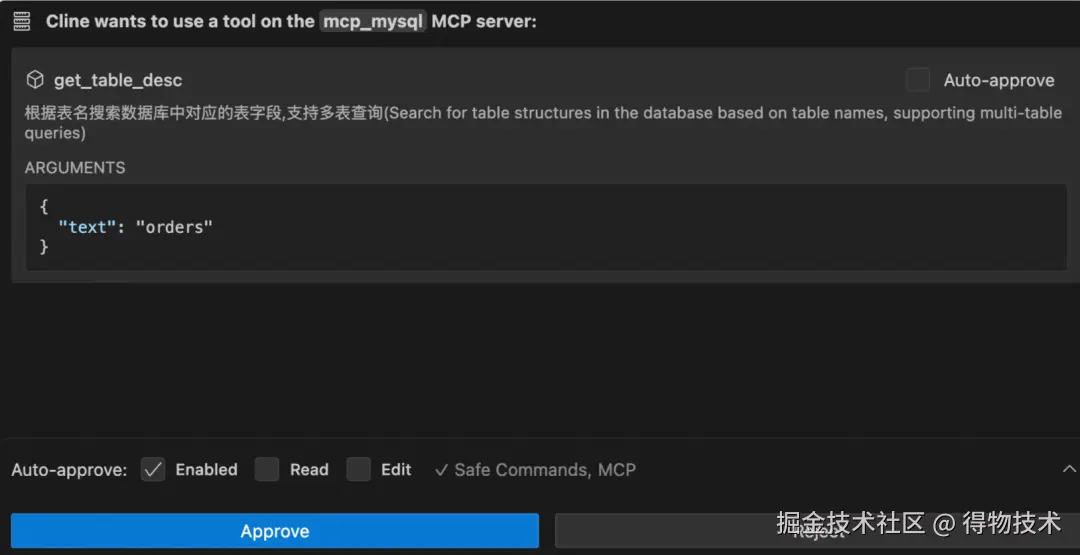
提示词(Prompts)
提示词是服务器端预定义的可重用交互模板,用于标准化和引导大型语言模型(LLM)的任务执行。这些模板通过动态参数化设计,允许传入特定值(如任务变量或上下文数据)生成定制化指令,从而实现高效、一致的模型交互。其核心机制如下:
-
结构化要素:每个提示模板包含唯一标识符、任务描述、参数列表(如输入变量)以及可选的资源引用(如外部文件或API数据)。这种结构确保指令的明确性和可扩展性,减少模型输出歧义。例如,在文本生成任务中,模板可能定义输出格式要求(如字数限制或响应风格),并动态整合用户输入数据。
-
上下文引导:提示词嵌入上下文关联机制(如历史对话片段或外部资源引用),帮助模型理解任务背景。例如,在问答场景中,模板可引入相关数据源(如知识库),提升响应准确性和相关性。
-
工作流支持:支持链式交互设计,允许多个提示模板组合以处理复杂任务(如多步骤分析或迭代优化)。同时,模板常作为用户界面元素(如斜杠命令)集成,增强可用性。
- ⚠️:提示词模版需要与客户端联动,即服务端定义好之后,在与客户端交互时,客户端获取服务器端动态填充好的提示词模版再发给大模型,大模型按照提示词要求进行回答。如果嵌在工具中触发条件往往是被动的。
如MCP-DB-GPT 项目中服务端定义好的提示词接口如下:
@mcp.prompt()
def generate_db_gpt_prompt() -> str:
"""Generate a prompt for LLM to interact with database."""
# 获取数据库表列表
tables_info = get_tables()
database_name = tables_info["database"]
tables = tables_info["tables"]
# 获取所有表的描述信息
table_definitions = []
for table in tables:
table_desc = get_table_description(table)
if table_desc.get("success"):
table_definitions.append(table_desc["table_definition"])
return DB_GPT_SYSTEM_PROMPT.format(
database_name=database_name,
table_definitions="\n".join(table_definitions),
)
DB_GPT_SYSTEM_PROMPT 即是预先编写好的提示词模板,当你动态的获取参数后进行替换即可。一个简易的提示词模板如下:
Baseline_SYSTEM_PROMPT = """
请根据用户选择的数据库和该库的所有可用表结构定义来回答用户问题.
数据库名:
{database_name}
表结构定义:
{table_definitions}
约束:
1. 请根据用户问题理解用户意图,使用给出表结构定义创建一个语法正确的mysql sql。
2. 将查询限制为最多10000个结果。
3. 只能使用表结构信息中提供的表来生成 sql。
4. 请检查SQL的正确性。
5. 分析基于现有表结构和元数据信息,估算用户提供的 DQL 语句的索引推荐策略,并返回给用户explain执行结果
用户问题:
{user_question}
请按照以下JSON格式回复:
{{
"thoughts": "分析思路",
"sql": "SQL查询语句",
"explain": "优化后的DQL语句执行结果"
}}
"""
然后客户端建立通信连接后获取相关的资源、工具和提示词模版:
# methods will go here
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server
Args:
server_script_path: Path to the server script (.py or .js)
"""
# try:
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
print(f"Session_id: {self.session_id}")
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
# List available resources
resources_response = await self.session.list_resources()
if resources_response and resources_response.resources:
print("Available resources:", [resource.uri for resource in resources_response.resources])
else:
print("Available resources templates: ['logs']")
prompts = await self.session.list_prompts()
if prompts and prompts.prompts:
print("Available prompts:", [prompt.name for prompt in prompts.prompts])
else:
print("No available prompts found.")
MCP Client
MCP Client 在整个模型交互过程中则起着至关重要的桥梁作用,连接着 LLM 与 MCP Server。其Python版 SDK 提供的框架图如下:
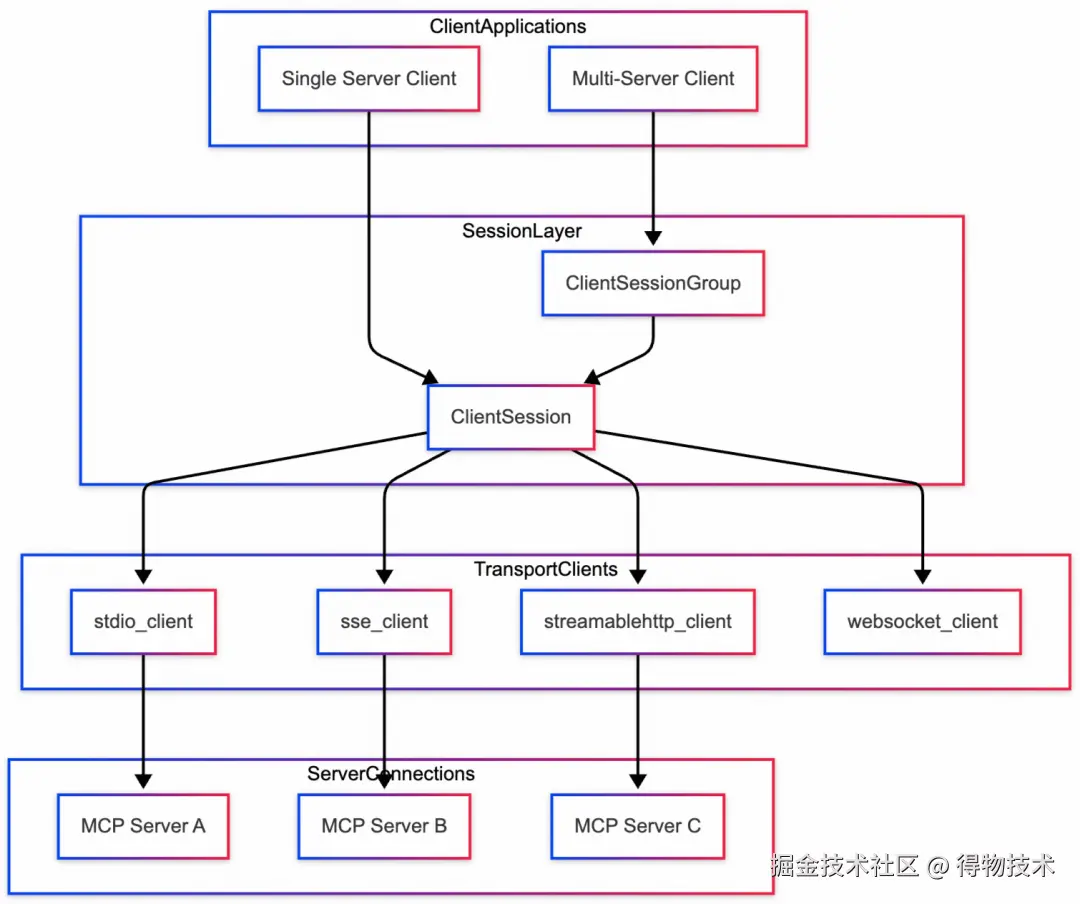
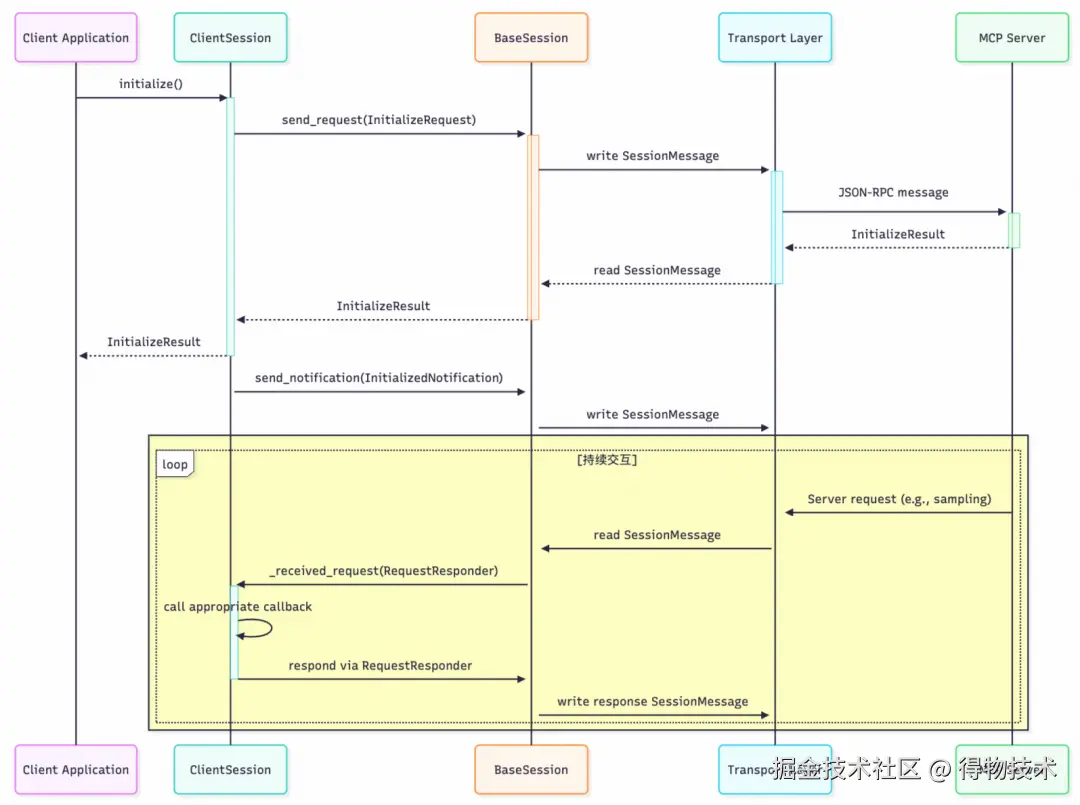
此处,我们先不看他的通信机制,结合 MCP-DB-GPT 项目仅关注 ClientSession 是如何与服务器层交互的。从宏观上看,客户端与服务器端的消息流大致如下:
而在 MCP-DB-GPT项目中定义了一个集成阿里通义千问大模型接口的 MCPClient类:
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.llm = TongYiAPI()
self.session_id = str(uuid.uuid4())
self.use_few_shot = True
self.conversation_history = FEW_SHOT_EXAMPLES if self.use_few_shot else []
# methods will go here
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server
async def get_query_logs(self, limit: int = 5) -> str:
"""获取查询日志"""
async def get_schema(self, table_names: Optional[List[str]] = None) -> str:
"""获取数据库结构信息"""
async def process_query(self, query: str) -> str:
"""使用通义千问处理数据库相关查询"""
客户端就是通过ClientSession对象与服务器交互,主要包括初始化连接、工具调用和资源访问:
-
连接建立:
-
- 在connect_to_server方法中,客户端基于服务器脚本路径(如 Python 或 Node.js 脚本)初始化StdioServerParameters。
- 使用stdio_client建立标准输入输出(Stdio)传输通道,创建ClientSession对象。调用session.initialize()初始会话,生成唯一会话 ID(session_id),用于加密通信和日志跟踪。
- 随后通过session.list_tools()获取可用工具列表(如query_data、get_schema),并通过session.list_resources()列出可访问资源(如日志)。此阶段实现协议中的“工具发现”阶段,确保客户端了解服务器功能。
-
工具调用过程:
-
- 当执行具体操作时(如执行 SQL 或获取 Schema),客户端使用session.call_tool(tool_name, params)方法发送 JSON-RPC 请求。
-
-
请求结构:以get_schema为例,参数包括session_id和可选table_names,序列化为 JSON 格式。
-
服务器响应:服务器执行工具(如查询数据库结构),返回JSON-RPC响应。响应包含content字段(如数据库结构信息),客户端解析 JSON 以提取结果。
-
错误处理:若响应包含success: false或error字段(如无法获取Schema),客户端返回错误信息。
-
资源访问机制:
-
- 通过session.read_resource(uri)访问资源(如日志)。日志 URI 格式为logs://{session_id}/{limit},服务器返回结构化的日志数据(JSON 格式)。
-
安全性:所有交互依赖会话级加密(session_id),并通过权限验证(用户需显式授权敏感操作)。
典型案例运用
MCP-DB-GPT 项目的一大亮点在于,其实现了结合提示词后,如何借助大模型解析自然语言生成 SQL 语句再与服务器进行交互并返回查询结果的完整过程。该功能能让初学者一步感知到 MCP 的工作流程以及它的灵活与强大。
通过LLM解析自然语言生成SQL语句的流程:在process_query方法中,LLM(通义千问 API)用于生成结构化工具调用(如 SQL 语句)。核心代码实现如下:
async def process_query(self, query: str) -> str:
"""使用通义千问处理数据库相关查询"""
try:
# 调用服务器层的提示词方法
prompt = await self.session.get_prompt("generate_db_gpt_prompt")
prompt = prompt.messages[0].content.text
# 将封装好的提示词投喂给大模型
llm_response = self.llm.chat(system_prompt=prompt, content=query, response_format="json_object",
conversation_history=self.conversation_history)
response_data = json.loads(llm_response)
- 客户端通过session.get_prompt("generate_db_gpt_prompt")获取预定义提示模板(prompt),该模板描述可用工具(如query_data)和任务规范,优化 LLM 对查询的理解和工具的调用。
-
LLM 基于提示和对话历史,执行“意图解析” :
-
- 分析自然语言,匹配工具(如自动选择query_data工具)。
- 输出 JSON 包含sql字段(生成的 SQL 语句)、direct_response(当无需 SQL)或thoughts(推理过程)。
- 示例:查询“金额最高的订单”可能生成"sql": "SELECT * FROM orders ORDER BY amount DESC LIMIT 1"。
-
对话更新:用户查询和 LLM 响应添加到conversation_history,保持上下文一致性。
生成 SQL 后与服务器层的二次交互:在process_query中,如果 LLM 响应包含sql字段(如"sql":"SELECT * FROM users"),客户端自动调用session.call_tool("query_data", params)。
# 如果有SQL查询,执行它
if response_data.get("sql"):
# 执行SQL查询
query_result = await self.session.call_tool("query_data", {
"sql": response_data["sql"],
"session_id": self.session_id
})
# 构建最终响应
final_response = {
"thoughts": response_data["thoughts"],
"sql": response_data["sql"],
"display_type": response_data.get("display_type", "Table"),
"results": json.loads(query_result.content[0].text) if query_result.content[0].text else None
}
return json.dumps(final_response, ensure_ascii=False, indent=2)
- 所有查询(包括 LLM 生成的 SQL)通过write_resource记录到日志资源,URI 为logs://{session_id}/{limit},支持后续审计。
此交互完成 MCP 的“执行-响应”闭环:SQL 作为工具调用的参数,服务器执行后返回结构化数据,客户端整合为最终响应。
三、底层通信原理
3.1协议层:JSON-RPC 2.0基础
MCP 的核心消息格式采用 JSON-RPC 2.0 协议,这是一个轻量级的 RPC 框架,用于结构化请求、响应和通知。在 Python SDK 中:
-
消息结构:每条消息都是 JSON 对象,包含 method(方法名,如 tool_execute)、params(参数)和 id(请求 ID)。
class JSONRPCRequest(Request[dict[str, Any] | None, str]):
"""A request that expects a response."""
jsonrpc: Literal["2.0"]
id: RequestId
method: str
params: dict[str, Any] | None = None
-
交互类型:
-
- 请求(JSONRPCRequest) :客户端(如 AI 应用)发送操作指令(如执行工具)。
- 响应(JSONRPCResponse) :服务器返回结果。
- 错误响应(JSONRPCError):服务器返回错误信息。
- 通知(JSONRPCNotification) :用于异步事件(如服务器主动推送上下文更新),无需响应。
-
优势:JSON-RPC 2.0 的标准化确保跨平台兼容性,源码中通过 JsonRPCRequest和JsonRPCResponse 类实现解析和验证,减少消息解析开销。如在 STDIO 传输中,消息的序列化和反序列化过程如下:
发送消息时:消息被序列化为 JSON 并添加换行符。
try:
async with write_stream_reader:
async for session_message in write_stream_reader:
json = session_message.message.model_dump_json(by_alias=True, exclude_none=True)
await process.stdin.send(
(json + "\n").encode(
encoding=server.encoding,
errors=server.encoding_error_handler,
)
)
except anyio.ClosedResourceError:
await anyio.lowlevel.checkpoint()
接收消息时:从输入流读取行,解析为JSON-RPC消息 。
try:
message = types.JSONRPCMessage.model_validate_json(line)
except Exception as exc:
await read_stream_writer.send(exc)
continue
session_message = SessionMessage(message)
await read_stream_writer.send(session_message)
3.2传输层:双向通信实现
MCP Python SDK 提供了多种传输机制,每种机制都针对不同的部署场景和通信模式进行了优化。所有传输机制都抽象为一个基于流的通用接口,同时支持特定于协议的功能。
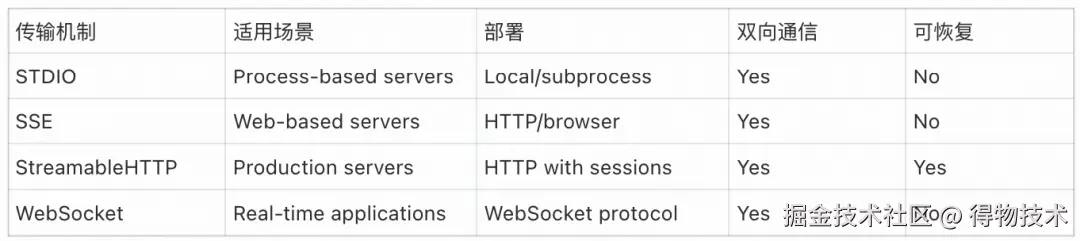
Stdio传输
通过标准输入/输出(stdin/stdout)流进行同步或异步通信。源码中读取和写入流由如下函数实现:
-
读取流:MemoryObjectReceiveStream[SessionMessage | Exception]-从服务器标准输出接收消息
-
写入流:MemoryObjectSendStream[SessionMessage]- 将消息发送到服务器标准输入
其适用于本地进程间通信(如 IDE 插件),低延迟但仅限单机。 关键代码包括stdin_reader()和stdout_writer方法,负责后台处理双向通信。其通信流程大致为以下七步:
- 客户端以子进程的方式启动服务器
- 客户端往服务器的 stdin 写入消息
- 服务器从自身的 stdin 读取消息
- 服务端往自身的 stdout 写入消息
- 客户端从服务器的 stdout 读取消息
- 客户端终止子进程,关闭服务器的 stdin
- 服务器关闭自身的 stdout
- ⚠️⚠️⚠️:当客户端调用mcp.tool() 装饰的函数时,SDK 内部封装请求为 JSON-RPC,通过 stdio 发送给服务器进程,服务端通过装饰器装饰的函数在建立连接后被调用时,会自动进行注入并转换成 JSON格式的数据与客户端进行自动交互。
服务端代码参考:
async def run_stdio():
"""运行标准输入输出模式的服务器
使用标准输入输出流(stdio)运行服务器,主要用于命令行交互模式
Raises:
Exception: 当服务器运行出错时抛出异常
"""
from mcp.server.stdio import stdio_server
logger.info("启动标准输入输出(stdio)模式服务器")
try:
# 初始化资源
await initialize_global_resources()
async with stdio_server() as (read_stream, write_stream):
try:
logger.debug("初始化流式传输接口")
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
logger.info("标准输入输出模式服务结束")
except Exception as e:
logger.critical(f"标准输入输出模式服务器错误: {str(e)}")
logger.exception("服务异常终止")
raise
finally:
# 关闭资源
await close_global_resources()
Main 函数中调用:
try:
if mode == "stdio":
asyncio.run(run_stdio())
配置 Cline 的JSON文件即可访问:
"mcp_db": {
"timeout": 60,
"type": "stdio",
"command": "uv",
"args": [
"--directory",
"/Users/admin/Downloads/Codes/MCP/mcp_for_db/src/",
"run",
"-m",
"server.mcp.server_mysql",
"--mode",
"stdio"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "password",
"MYSQL_DATABASE": "mcp_db",
"MYSQL_ROLE": "admin",
"PYTHONPATH": "/Users/admin/Downloads/Codes/MCP/MCP-DB/"
}
}
SSE 传输
SSE 传输使用服务器发送事件 (SSE) 传输服务器到客户端的消息,并使用 HTTP POST 请求传输客户端到服务器的消息,提供基于 HTTP 的通信。其本质是双向模拟,即 SSE 本质为单向,SDK 通过“请求/响应”对模拟双向通信(客户端发送 HTTP POST 请求携带JSON-RPC,服务器返回 SSE 流)。其通信流程也可概括为七步:
- 客户端向服务器的 /sse 端点发送请求(一般是 GET 请求),建立 SSE 连接;
- 服务器给客户端返回一个包含消息端点地址的事件消息;
- 客户端给消息端点发送消息;
- 服务器给客户端响应消息已接收状态码;
- 服务器给双方建立的 SSE 连接推送事件消息;
- 客户端从 SSE 连接读取服务器发送的事件消息;
- 客户端关闭 SSE 连接。
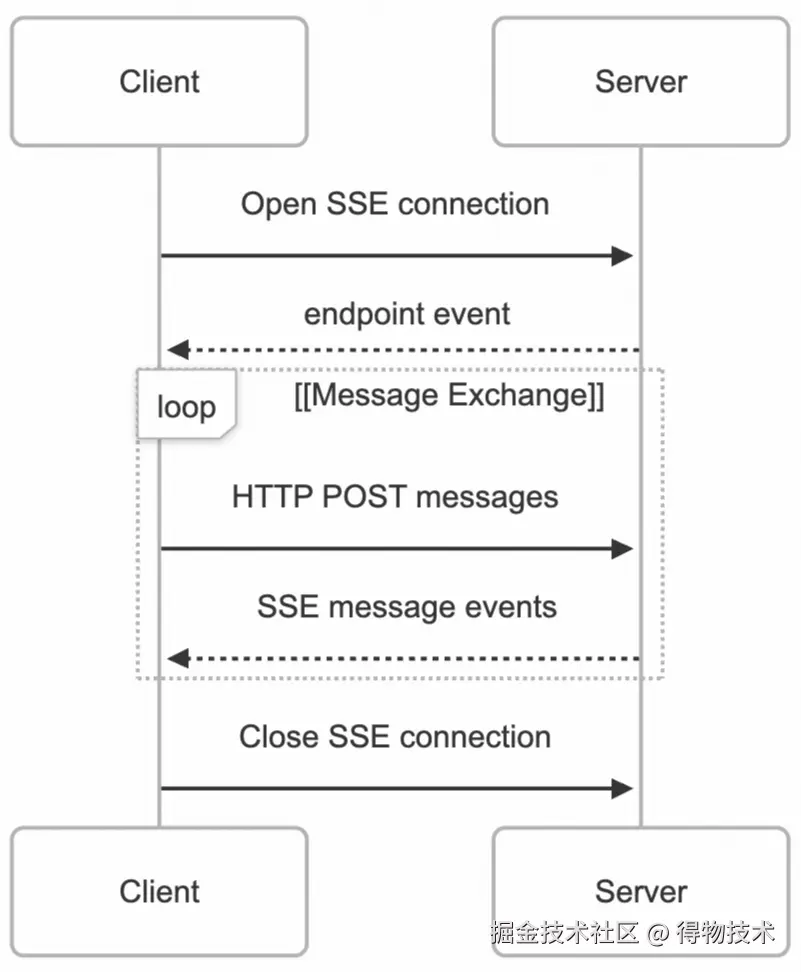
服务器端:SseServerTransport为服务器端 SSE 传输实现提供了两个主要的 ASGI 应用程序。

客户端:sse_client函数提供客户端 SSE 传输实现。
二者通信的消息格式如下:每条 SSE 消息以 data: 前缀携带 JSON-RPC 负载,客户端监听事件流。
# 服务端
logger.debug("Starting SSE writer")
async with sse_stream_writer, write_stream_reader:
await sse_stream_writer.send({"event": "endpoint", "data": client_post_uri_data})
logger.debug(f"Sent endpoint event: {client_post_uri_data}")
async for session_message in write_stream_reader:
logger.debug(f"Sending message via SSE: {session_message}")
await sse_stream_writer.send(
{
"event": "message",
"data": session_message.message.model_dump_json(by_alias=True, exclude_none=True),
}
)
其中涉及两种主要事件类型:
-
endpoint事件:在连接建立时发送,告知客户端 POST 消息的端点 URL。
-
message事件:传输实际的 JSON-RPC 消息。
客户端通过 sse_reader 函数处理接收到的 SSE 事件:
-
endpoint事件处理:验证端点 URL 的安全性,确保与连接源匹配。
match sse.event:
case "endpoint":
endpoint_url = urljoin(url, sse.data)
logger.debug(f"Received endpoint URL: {endpoint_url}")
url_parsed = urlparse(url)
endpoint_parsed = urlparse(endpoint_url)
if (
url_parsed.netloc != endpoint_parsed.netloc
or url_parsed.scheme != endpoint_parsed.scheme
):
error_msg = (
"Endpoint origin does not match " f"connection origin: {endpoint_url}"
)
logger.error(error_msg)
raise ValueError(error_msg)
task_status.started(endpoint_url)
-
message事件处理:解析 JSON-RPC 消息并转换为 SessionMessage。
case "message":
try:
message = types.JSONRPCMessage.model_validate_json( # noqa: E501
sse.data
)
logger.debug(f"Received server message: {message}")
except Exception as exc:
logger.error(f"Error parsing server message: {exc}")
await read_stream_writer.send(exc)
continue
session_message = SessionMessage(message)
await read_stream_writer.send(session_message)
适用场景:远程或云端部署,支持高并发和实时更新(如工具调用的结果推送)。错误处理包括连接超时重试(源码中 retry 机制)。
服务端代码参考:
def run_sse():
"""运行SSE(Server-Sent Events)模式的服务器
启动一个支持SSE的Web服务器,允许客户端通过HTTP长连接接收服务器推送的消息
服务器默认监听0.0.0.0:9000
"""
logger.info("启动SSE(Server-Sent Events)模式服务器")
sse = SseServerTransport("/messages/")
async def handle_sse(request):
"""处理SSE连接请求
Args:
request: HTTP请求对象
"""
logger.info(f"新的SSE连接 [client={request.client}]")
async with sse.connect_sse(
request.scope, request.receive, request.send
) as streams:
try:
await app.run(streams[0], streams[1], app.create_initialization_options())
except Exception as e:
logger.error(f"SSE连接处理异常: {str(e)}")
raise
logger.info(f"SSE连接断开 [client={request.client}]")
return Response(status_code=204)
@contextlib.asynccontextmanager
async def lifespan(app: Starlette) -> AsyncIterator[None]:
"""SSE应用的生命周期管理"""
try:
# 初始化资源
await initialize_global_resources()
yield
finally:
# 关闭资源
await close_global_resources()
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message)
],
lifespan=lifespan
)
logger.info("SSE服务器启动中 [host=0.0.0.0, port=9000]")
# 创建配置并运行
config = uvicorn.Config(
app=starlette_app,
host="0.0.0.0",
port=9000,
loop="asyncio",
log_config=None # 禁用uvicorn默认日志配置
)
server = uvicorn.Server(config)
server.run()
Main函数中调用:
try:
if mode == "sse":
run_sse()
配置 Cline 的 JSON文件即可访问:
"mysql_mcp_server": {
"disabled": true,
"timeout": 60,
"type": "sse",
"url": "http://localhost:9000/sse"
}
3.3通信工作流程
MCP通信遵循 JSON-RPC 2.0模式,主要包含三个消息类别:
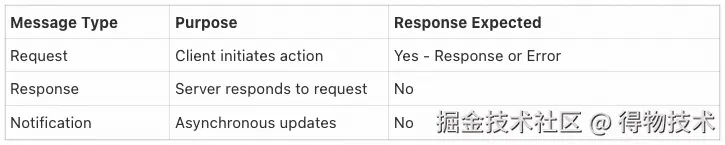
同时,理解 MCP 连接生命周期可以帮助我们更好地开发 MCP 服务器和 AI 应用。MCP 连接生命周期跟 TCP 的三次握手、四次挥手有点类似,也要经历建立连接、交换消息、断开连接等阶段。
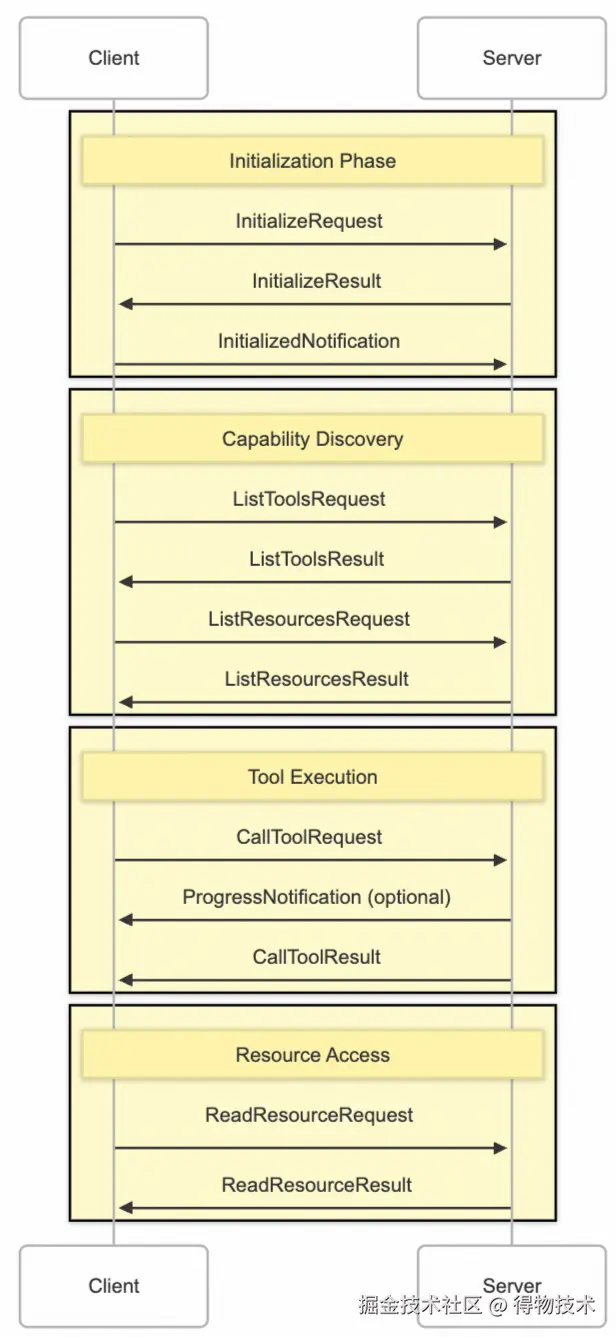
接下来,以 StreamableHTTP 机制为例,分析通信工作流程。StreamableHTTP 传输机制实现了基于 HTTP 的双向通信,结合了 HTTP POST 请求和 Server-Sent Events (SSE) 流来提供完整的客户端-服务器通信解决方案。
整体架构流程
StreamableHTTP 通信机制包含会话管理、双向消息传输和可选的事件重放功能:
- 客户端传输初始化
-
- 客户端通过 streamablehttp_client 函数建立连接。
- 核心组件 StreamableHTTPTransport 负责管理会话状态和消息路由。
-
- 服务器端会话管理
-
- 服务器端使用 StreamableHTTPSessionManager 管理多个并发会话。支持有状态和无状态两种模式:
-
有状态模式:维护会话状态,支持连接恢复。
-
无状态模式:每个请求创建新的传输实例。
通信工作流程详解
初始化和会话建立
- 初始化请求:客户端发送 initialize 方法的 POST 请求。
- 会话 ID 分配:服务器生成唯一会话 ID 并通过 mcp-session-id 头返回。
def _maybe_extract_session_id_from_response(
self,
response: httpx.Response,
) -> None:
"""Extract and store session ID from response headers."""
new_session_id = response.headers.get(MCP_SESSION_ID)
if new_session_id:
self.session_id = new_session_id
logger.info(f"Received session ID: {self.session_id}")
双向消息传输
客户端到服务器(POST 请求):客户端的post_writer 方法处理出站消息。
async def post_writer(
self,
client: httpx.AsyncClient,
write_stream_reader: StreamReader,
read_stream_writer: StreamWriter,
write_stream: MemoryObjectSendStream[SessionMessage],
start_get_stream: Callable[[], None],
tg: TaskGroup,
) -> None:
"""Handle writing requests to the server."""
-
消息序列化:将 JSON-RPC 消息序列化为 HTTP POST 请求体。
-
请求处理:根据消息类型选择处理方式 - 普通请求或恢复请求。
async def handle_request_async():
if is_resumption:
await self._handle_resumption_request(ctx)
else:
await self._handle_post_request(ctx)
# If this is a request, start a new task to handle it
if isinstance(message.root, JSONRPCRequest):
tg.start_soon(handle_request_async)
else:
await handle_request_async()
-
响应处理:支持 JSON 响应和 SSE 流响应两种模式。
服务器到客户端(SSE 流)
服务器端通过不同的 HTTP 方法处理消息:
-
POST 请求处理:接收客户端消息并通过 SSE 或 JSON 响应
if self.is_json_response_enabled:
# Process the message
metadata = ServerMessageMetadata(request_context=request)
session_message = SessionMessage(message, metadata=metadata)
await writer.send(session_message)
try:
# Process messages from the request-specific stream
# We need to collect all messages until we get a response
pass
finally:
await self._clean_up_memory_streams(request_id)
else:
# Create SSE stream
sse_stream_writer, sse_stream_reader = anyio.create_memory_object_stream[dict[str, str]](0)
async def sse_writer():
# Get the request ID from the incoming request message
-
GET 请求处理:建立独立的 SSE 流用于服务器主动推送 streamable_http.py:511-601
async def _handle_get_request(self, request: Request, send: Send) -> None:
"""
Handle GET request to establish SSE.
This allows the server to communicate to the client without the client
first sending data via HTTP POST. The server can send JSON-RPC requests
and notifications on this stream.
"""
实际使用示例
从测试代码中可以看到完整的使用流程:
@pytest.mark.anyio
async def test_streamablehttp_client_basic_connection(basic_server, basic_server_url):
"""Test basic client connection with initialization."""
async with streamablehttp_client(f"{basic_server_url}/mcp") as (
read_stream,
write_stream,
_,
):
async with ClientSession(
read_stream,
write_stream,
) as session:
# Test initialization
result = await session.initialize()
assert isinstance(result, InitializeResult)
assert result.serverInfo.name == SERVER_NAME
- 使用 streamablehttp_client 建立连接
- 通过 ClientSession 进行初始化
- 执行各种 MCP 操作(工具调用、资源访问等)
3.4各协议对比分析
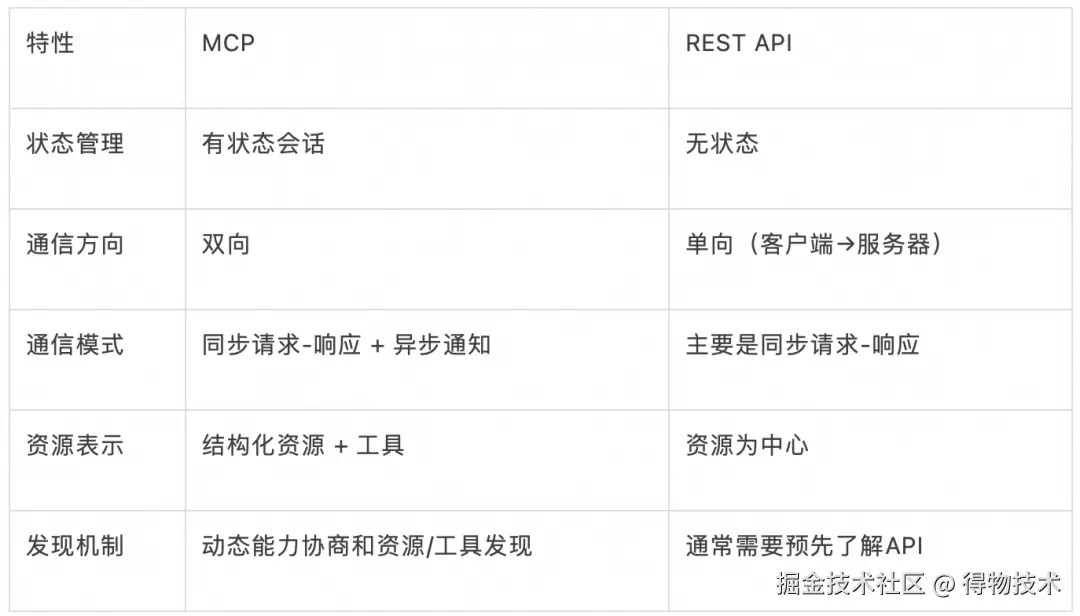
MCP vs REST API
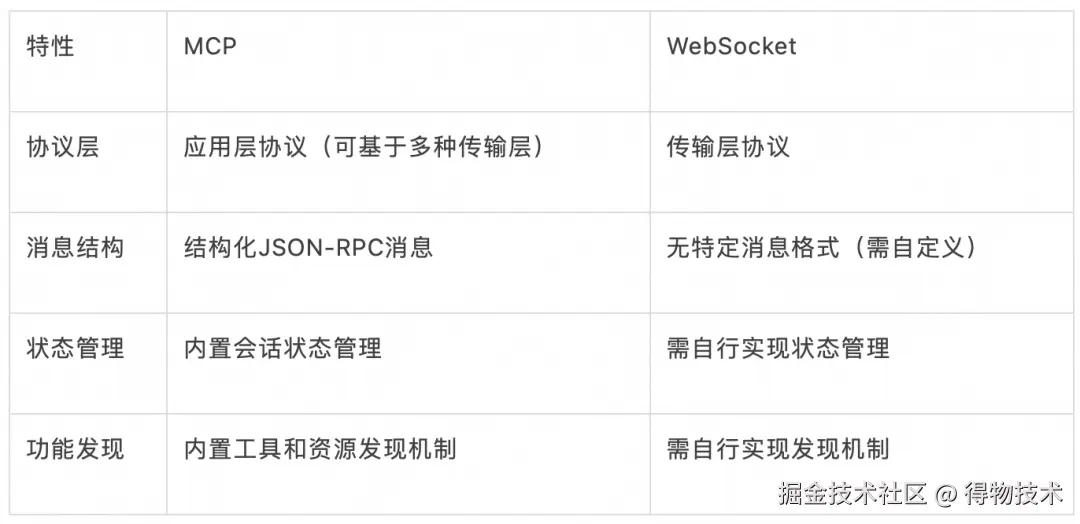
MCP vs WebSocket
四、项目初始化&实战解析
本节,将使用 uv 快速搭建 MCP 服务,然后结合 DW-DBA-MCP 实战项目进行介绍。
4.1环境安装
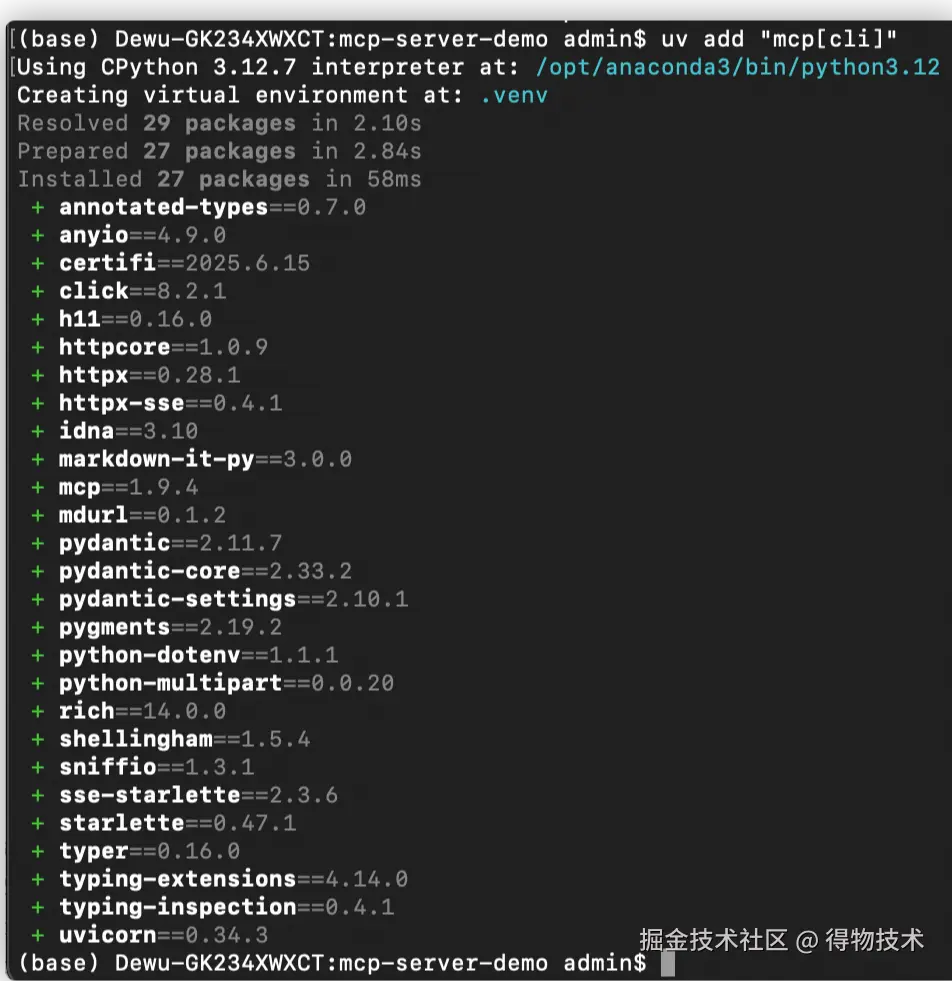
官方推荐使用 uv 进行虚拟环境及依赖的管理。uv 的安装可参考:docs.astral.sh/uv/#highlig…
# macos
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
(base) Dewu-GK234XWXCT:~ admin$ uv --version
uv 0.7.13 (62ed17b23 2025-06-12)
同时,需要注意⚠️:SDK 需要 Python 3.10 或更高版本,支持 Python 3.10 至 3.13。
# 初始化虚拟环境
uv init MCP-DB
# 切换目录
cd MCP-DB
# 安装mcp client依赖
uv add "mcp[cli]"
# 使用 uv 运行 mcp 命令
uv run mcp -help
4.2DW-DBA-MCP实战解析
本项目旨在为数据库侧开发 MCP Server。同时,考虑到高可扩展性,项目采用微服务架构进行设计开发,这也便于与 Nacos MCP Server 进行集成,客户端配置Nacos MCP Server 服务,LLM 即可通过该网关高效路由到合适工具;考虑到易用性,通过封装 MCP Client 和 MCP Server,提供 FastAPI 接口处理用户的提问。项目目录结构如下:
DW-DBA-MCP/
├── Dockerfile
├── LICENSE
├── README.md
├── datas # 存放项目日志文件
│ ├── files # 存放工具执行的 SQL 语句
│ ├── logs # 存放日志文件
│ └── version
├── mcp_for_db
│ ├── __init__.py
│ ├── client # 自建客户端
│ │ ├── __init__.py
│ │ ├── api.py # FastAPI 服务
│ │ └── client.py # MCP Client
│ ├── debug
│ │ ├── __init__.py
│ │ └── mcp_logger.py # 记录 MCP Client 与 MCP Server 通信数据,用于白盒解析 MCP 通信协议
│ ├── envs
│ │ ├── common.env # 多服务环境变量配置文件
│ │ ├── dify.env
│ │ └── mysql.env
│ ├── server
│ │ ├── __init__.py
│ │ ├── cli
│ │ │ ├── __init__.py
│ │ │ ├── dify_cli.py # cli 方式启动 dify 服务
│ │ │ ├── mysql_cli.py # cli 方式启动 mysql 服务
│ │ │ └── server.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base # 公共的资源、工具和提示词自动注册和发现的基类包
│ │ │ ├── prompts.py # 存放提示词模版
│ │ │ └── tools.py # 存放工具描述
│ │ ├── core
│ │ │ ├── __init__.py
│ │ │ ├── base_server.py # 微服务基类
│ │ │ ├── config_manager.py # 环境变量配置器
│ │ │ ├── env_distribute.py # stdio通信机制下多服务环境变量分发器
│ │ │ └── service_manager.py # 多服务管理器
│ │ ├── server_dify # dify 服务实现包
│ │ │ ├── __init__.py
│ │ │ ├── config
│ │ │ ├── dify_server.py # dify 服务实现类
│ │ │ └── tools
│ │ ├── server_mysql # mysql 服务实现包
│ │ │ ├── __init__.py
│ │ │ ├── config
│ │ │ ├── mysql_server.py # mysql 服务实现类
│ │ │ ├── prompts
│ │ │ ├── resources
│ │ │ └── tools
│ │ └── shared
│ │ ├── __init__.py
│ │ ├── oauth
│ │ ├── security # SQL鉴权
│ │ ├── templates
│ │ └── utils
│ └── test
├── pyproject.toml
├── requirements.txt
└── uv.lock
项目设计思路
本项目原先参考于开源项目:github.com/wenb1n-dev/…
针对如何借助 Low-Level 接口自动注册和发现资源、工具和提示词,接下来则以我们扩展封装的资源为例进行介绍。
在多服务基类脚本base_server.py中只需展示和读取资源即可,对应的类会自动将资源进行注册和读取。
async def setup_server(self):
"""设置服务器路由"""
if self.server_setup_completed:
self.logger.debug("服务器路由已设置,跳过重复设置")
return
self.logger.info("开始设置服务器路由")
# 注册资源处理器
@self.server.list_resources()
async def handle_list_resources() -> List[Resource]:
try:
registry = self.get_resource_registry()
if registry is None:
self.logger.warning("资源注册表未初始化,返回空列表")
return []
if hasattr(registry, 'get_all_resources'):
if asyncio.iscoroutinefunction(registry.get_all_resources):
return await registry.get_all_resources()
else:
return registry.get_all_resources()
return []
except Exception as e:
self.logger.error(f"获取资源列表失败: {str(e)}", exc_info=True)
return []
@self.server.read_resource()
async def handle_read_resource(uri: AnyUrl) -> str:
try:
self.logger.info(f"开始读取资源: {uri}")
registry = self.get_resource_registry()
if registry is None:
raise ValueError("资源注册表未初始化")
if hasattr(registry, 'get_resource'):
if asyncio.iscoroutinefunction(registry.get_resource):
content = await registry.get_resource(uri)
else:
content = registry.get_resource(uri)
else:
content = None
if content is None:
content = "null"
self.logger.info(f"资源 {uri} 读取成功,内容长度: {len(content)}")
return content
except Exception as e:
self.logger.error(f"读取资源失败: {str(e)}", exc_info=True)
raise
资源注册类:
class ResourceRegistry:
"""资源注册表,用于管理所有资源实例"""
_resources: ClassVar[Dict[str, 'BaseResource']] = {}
@classmethod
def register(cls, resource_class: Type['BaseResource']):
"""注册资源实例"""
resource = resource_class()
logger.info(f"注册资源: {resource.name} (URI: {resource.uri})")
cls._resources[str(resource.uri)] = resource
@classmethod
def register_instance(cls, resource: 'BaseResource'):
"""手动注册资源实例"""
uri_str = str(resource.uri)
logger.info(f"注册资源实例: {resource.name} (URI: {uri_str})")
cls._resources[uri_str] = resource
@classmethod
async def get_resource(cls, uri: AnyUrl) -> str:
"""获取资源内容"""
logger.info(f"请求资源: {uri}")
parsed = urlparse(str(uri))
uri_str = f"{parsed.scheme}://{parsed.netloc}/{parsed.path}"
path_parts = parsed.path.strip('/').split('/')
if not path_parts or not path_parts[0]:
raise ValueError(f"无效的URI格式: {uri_str},未指定表名")
# 优先尝试精确匹配
for resource in cls._resources.values():
if str(resource.uri) == uri_str:
return await resource.read_resource(uri)
# 尝试后缀匹配
for resource in cls._resources.values():
if str(resource.uri).endswith(path_parts[0]):
return await resource.read_resource(uri)
logger.error(f"未找到资源: {uri},已注册资源: {[r.uri for k, r in cls._resources.items()]}")
raise ValueError(f"未注册的资源: {uri}")
@classmethod
async def get_all_resources(cls) -> List[Resource]:
"""获取所有资源的描述"""
result = []
# 创建资源副本避免在迭代过程中修改原字典:扫描库时还会注册表资源
resources_copy = list(cls._resources.values())
for resource in resources_copy:
try:
logger.info(f"获取 {resource.name} 的资源描述")
descriptions = await resource.get_resource_descriptions()
result.extend(descriptions)
logger.debug(f"{resource.name} 提供了 {len(descriptions)} 个资源描述")
except Exception as e:
logger.error(f"获取 {resource.name} 的描述失败: {str(e)}", exc_info=True)
return result
封装后的资源基类:主要是借助__init_subclass__方法自动注册
class BaseResource:
"""资源基类"""
name: str = ""
description: str = ""
uri: AnyUrl
mimeType: str = "text/plain"
auto_register: bool = True
def __init_subclass__(cls, **kwargs):
"""子类初始化时自动注册到资源注册表"""
super().__init_subclass__(**kwargs)
if cls.auto_register and cls.uri is not None: # 只注册有 uri 的资源
ResourceRegistry.register(cls)
async def get_resource_descriptions(self) -> List[Resource]:
"""获取资源描述,子类必须实现"""
raise NotImplementedError
async def read_resource(self, uri: AnyUrl) -> str:
"""读取资源内容,子类必须实现"""
raise NotImplementedError
实现 MySQL 资源类:值得注意的是此处我们在设计时迫于上面的机制又设计了表资源类TableResource
class TableResource(BaseResource):
"""代表具体表资源的类"""
auto_register: bool = False
TABLE_EXISTS_QUERY = """
SELECT COUNT(*) AS table_exists
FROM information_schema.tables
WHERE table_schema = %s AND table_name = %s
"""
COLUMN_METADATA_QUERY = """
SELECT COLUMN_NAME, DATA_TYPE
FROM information_schema.columns
WHERE table_schema = %s AND table_name = %s
ORDER BY ORDINAL_POSITION
"""
def __init__(self, db_name: str, table_name: str, description: str):
super().__init__()
self.db_name = db_name
self.table_name = table_name
self.name = f"table: {table_name}"
self.uri = AnyUrl(f"mysql://{db_name}/{table_name}")
self.description = description
self.mimeType = "text/csv"
async def get_resource_descriptions(self) -> List[Resource]:
"""返回数据库表资源的描述:已返回"""
return []
async def read_resource(self, uri: AnyUrl) -> str:
"""安全读取数据库表数据为CSV格式(带列类型信息)"""
logger.info(f"开始读取资源: {uri}")
try:
# 安全解析表名
table_name = extract_table_name(uri)
logger.info(f"准备查询表: {table_name}")
# 获取列元数据(用于优化CSV生成)
column_metadata = await self.get_table_metadata(table_name)
async with get_current_database_manager().get_connection() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
# 使用参数化查询避免SQL注入
safe_query = _build_safe_query(table_name)
await cursor.execute(safe_query)
# 直接获取列名
columns = [col[0] for col in cursor.description]
rows = await cursor.fetchall()
logger.info(f"获取到 {len(rows)} 行数据")
# 使用优化的CSV生成
return generate_csv(columns, rows, column_metadata)
except Exception as e:
logger.error(f"读取资源失败: {str(e)}", exc_info=True)
raise
async def get_table_metadata(self, table_name: str) -> List[tuple]:
"""获取表列名和数据类型"""
db_name = get_current_database_manager().get_current_config()["database"]
async with get_current_database_manager().get_connection() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
# 首先验证表存在
await cursor.execute(self.TABLE_EXISTS_QUERY, (db_name, table_name))
exists = await cursor.fetchone()
if not exists or not exists['table_exists']:
raise ValueError(f"表 '{table_name}' 在数据库 '{db_name}' 中不存在")
# 获取列元数据
await cursor.execute(self.COLUMN_METADATA_QUERY, (db_name, table_name))
metadata = [(row['COLUMN_NAME'], row['DATA_TYPE']) for row in await cursor.fetchall()]
return metadata
class MySQLResource(BaseResource):
"""MySQL数据库资源实现"""
name = "MySQL数据库"
uri = AnyUrl(f"mysql://localhost/default")
description = "提供对MySQL数据库表的访问与查询"
mimeType = "text/csv"
auto_register = True
# 重用这些常量查询
TABLE_QUERY = """
SELECT TABLE_NAME AS table_name,
TABLE_COMMENT AS table_comment,
TABLE_ROWS AS estimated_rows
FROM information_schema.tables
WHERE table_schema = %s
"""
def __init__(self):
"""初始化资源管理"""
super().__init__()
self.cache = {} # 查询结果缓存
async def get_resource_descriptions(self) -> List[Resource]:
"""获取数据库表资源描述(带缓存机制)"""
logger.info("获取数据库资源描述")
db_manager = get_current_database_manager()
if db_manager is None:
logger.error("无法获取数据库管理器,上下文未设置?")
return []
db_name = db_manager.get_current_config().get("database")
if not db_name:
logger.error("数据库配置中未指定数据库名称")
return []
# 使用缓存避免重复查询
if 'table_descriptions' in self.cache:
logger.debug("使用缓存的表描述")
return self.cache['table_descriptions']
try:
async with db_manager.get_connection() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
await cursor.execute(self.TABLE_QUERY, (db_name,))
tables = await cursor.fetchall()
logger.info(f"发现 {len(tables)} 个数据库表")
resources = []
for table in tables:
table_name = table['table_name']
# 添加表行数统计
description = table['table_comment'] or f"{table_name} 表"
if table['estimated_rows']:
description += f" (~{table['estimated_rows']}行)"
# 创建表资源
table_resource = TableResource(db_name, table_name, description)
# 手动注册表资源实例
ResourceRegistry.register_instance(table_resource)
# 创建资源描述对象
resource_desc = Resource(
uri=table_resource.uri,
name=table_resource.name,
mimeType=table_resource.mimeType,
description=table_resource.description
)
resources.append(resource_desc)
# 缓存结果
self.cache['table_descriptions'] = resources
logger.info(f"创建了 {len(resources)} 个表资源描述")
return resources
except Exception as e:
logger.error(f"获取资源描述失败: {str(e)}", exc_info=True)
return []
async def read_resource(self, uri: AnyUrl) -> str:
"""读取根资源内容 - 返回数据库信息"""
return json.dumps({
"name": self.name,
"uri": self.uri,
"description": self.description,
"type": "database_root"
})
想实现其他资源,就编写对应的脚本,然后将包加入到对应的__init__.py脚本中:
from .db_resource import MySQLResource, TableResource
__all__ = [ "MySQLResource", "TableResource",]
这样代码具有较高可扩展性,组织结构也很清晰。当然,也会有其他更好的实现方式。
效果展示
MCP Server 主要是通过工具暴露数据给LLMs,故基于上述的设计思路,实现起来相对简单且专一,主要就是实现工具所对应的 SQL 语句编写和对应的提示词即可,鉴于篇幅和代码量,此处不再展示源码,仅提供历史测试效果图。
查询表中数据
在 Cline 中配置好阿里通义千问大模型 API-KEY 后,进行提问:

⚠️:阿里通义千问大模型配置可参考:help.aliyun.com/zh/model-st…
随后,大模型开始解析执行任务:
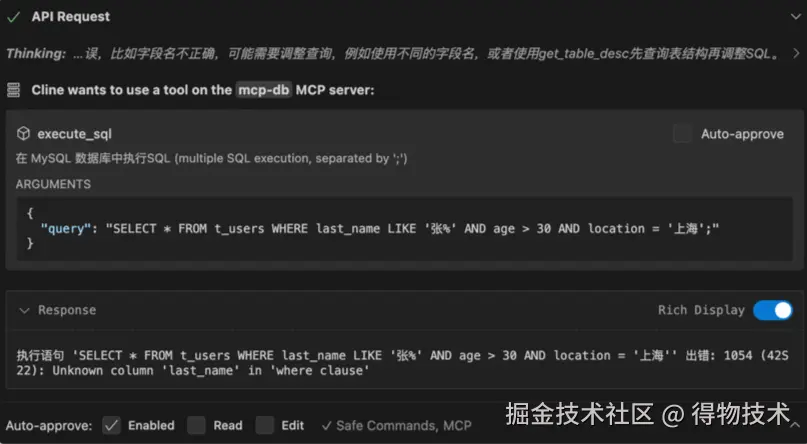
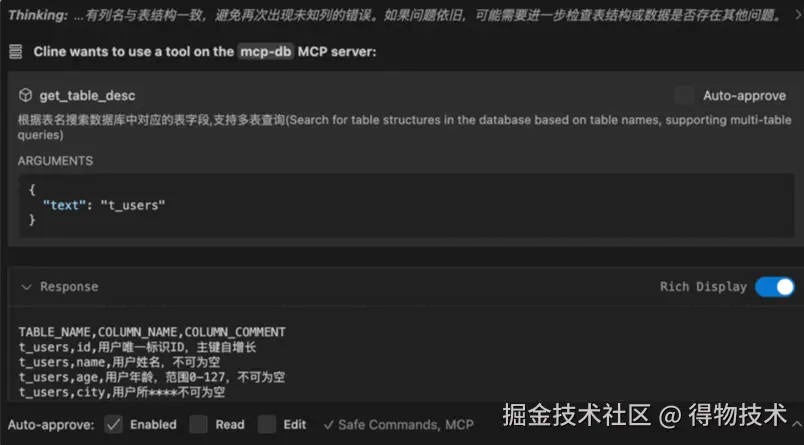
发现解析错了,开始自动矫正:
OK,现在看起来就对多了,开始执行工具运行指令并返回结果:
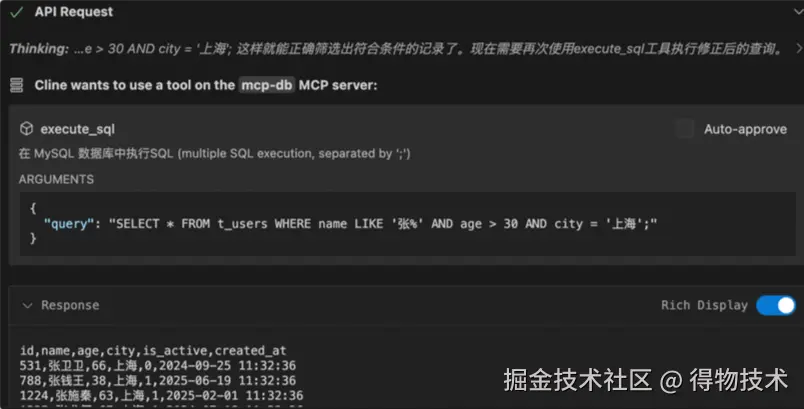
最终执行结果如下:
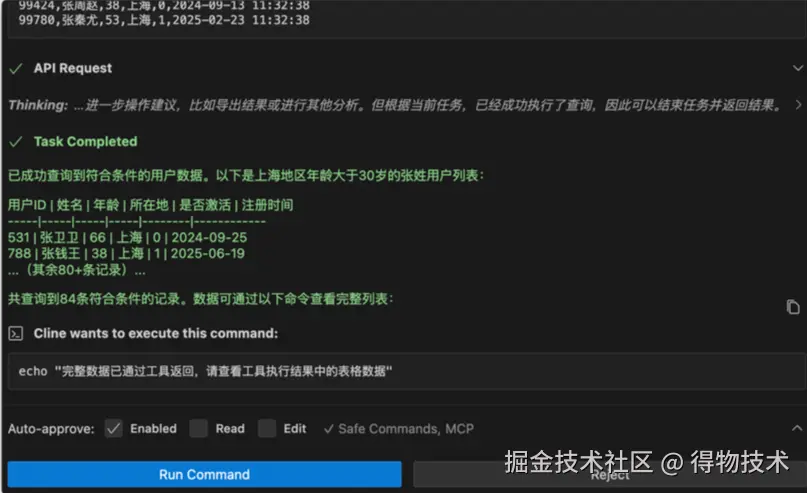
其他的比如:查询某表中告警信息。此处给出了明确的库表信息,回答的就很精准。
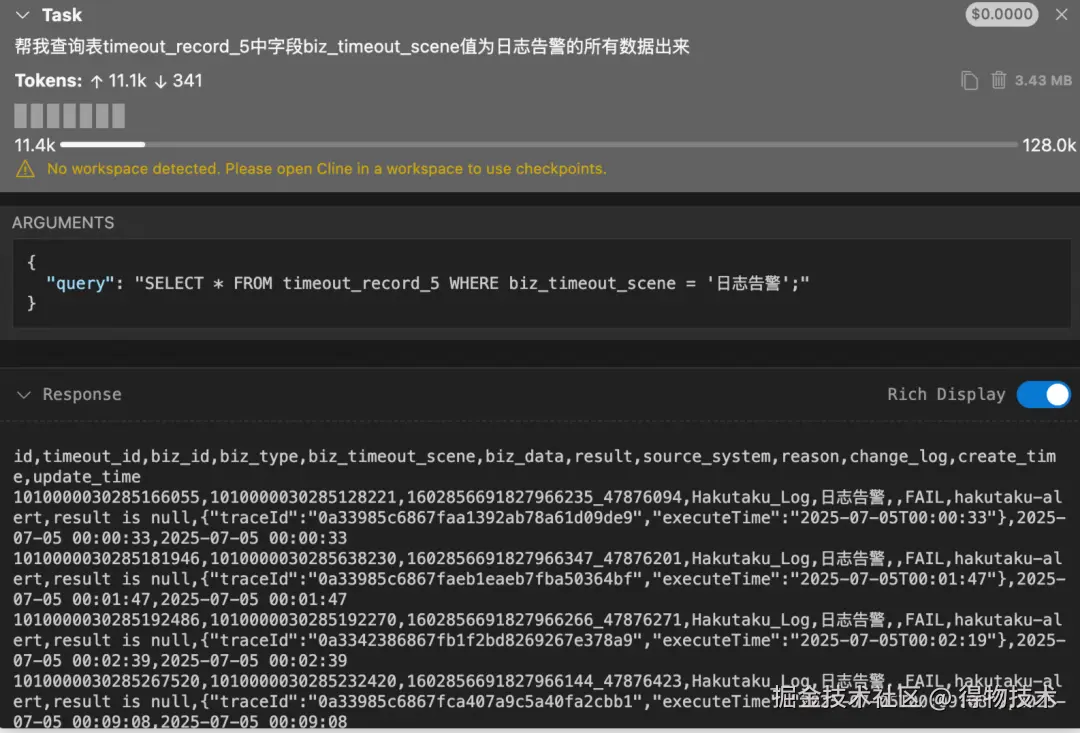
慢SQL优化
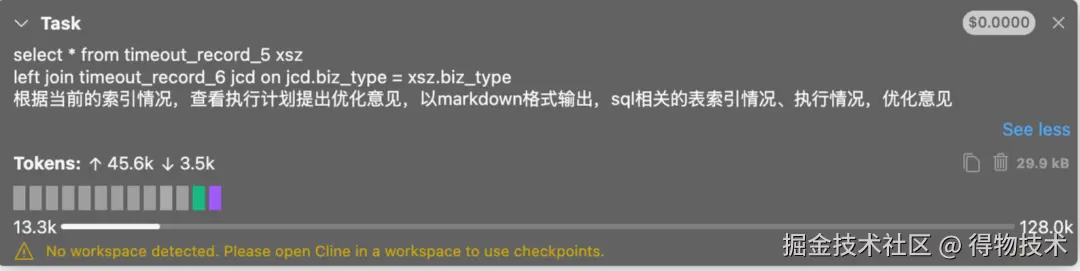
大模型在执行一些工具之后,给出了回答:
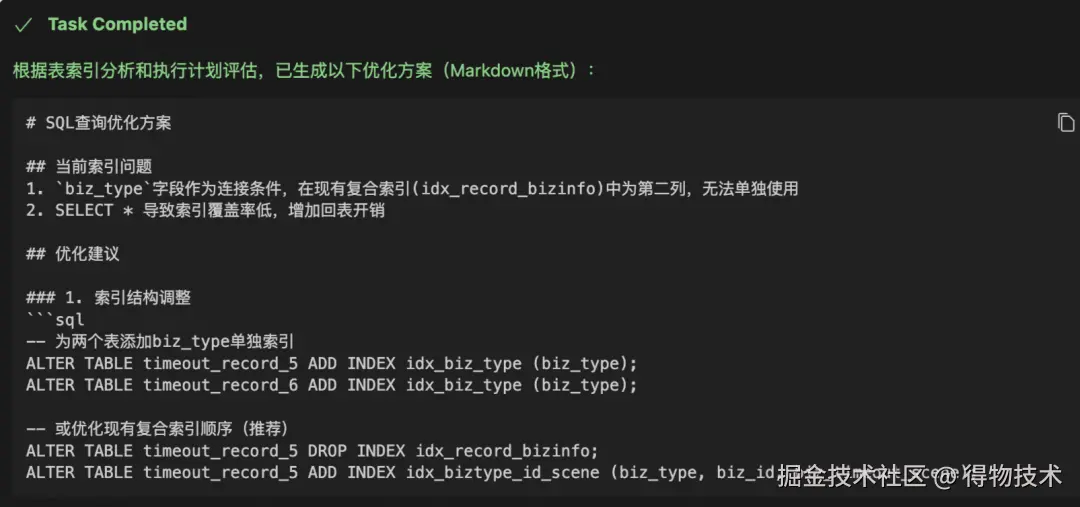
并最终给出了如下预期效果:
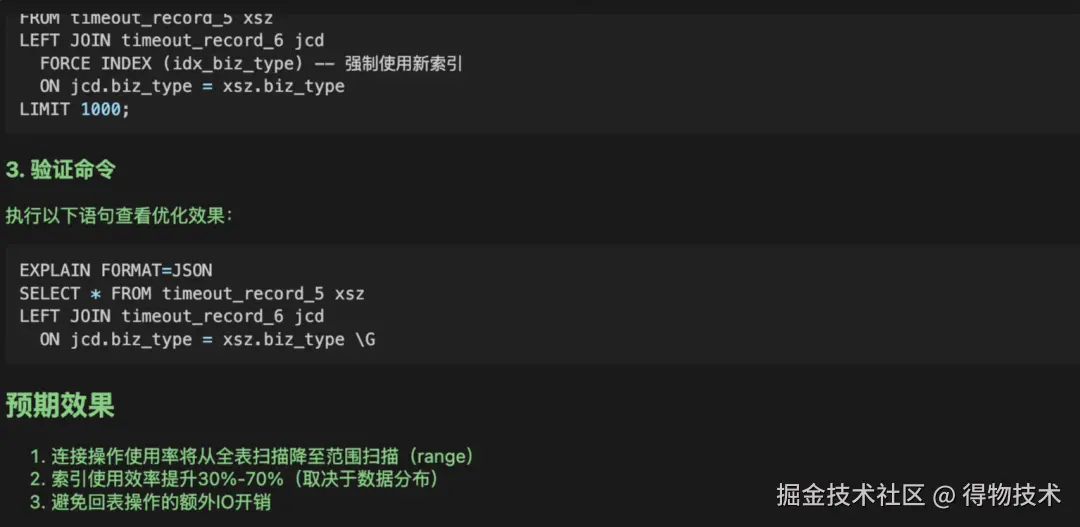
高危操作验证
在执行高危 SQL 语句前,会拦截并作解析,判断是否与预先允许的操作一致,不一致则不放行,模型无法操作数据库,报错终止任务。目前权限限定为查询操作 DQL。
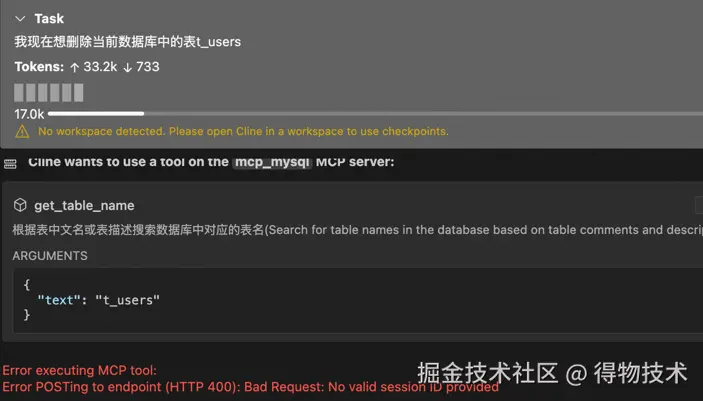
当想更新表中数据时:
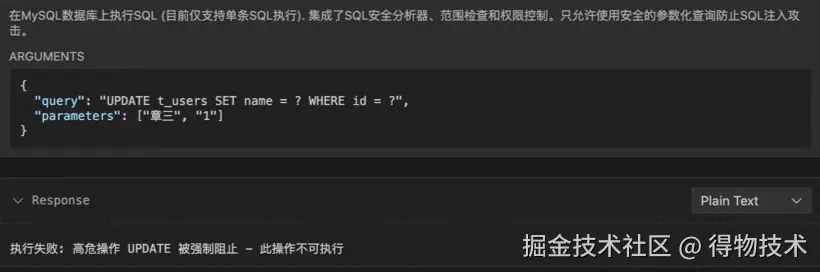

自建客户端提问
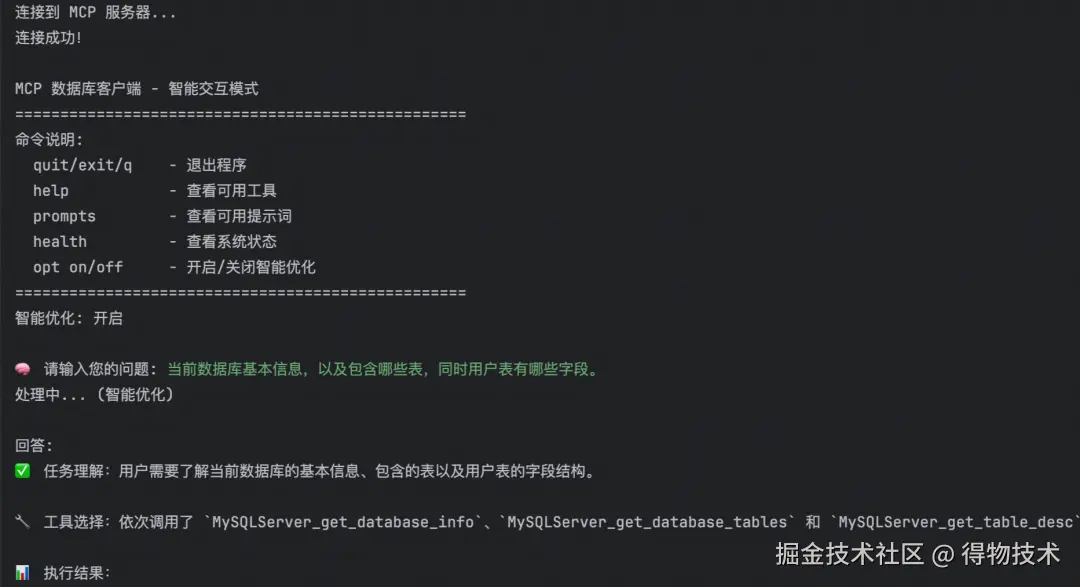
实现自定义客户端时可调用服务端提示词进行任务编排,提高工具调用准确度和规避一连串的客户端continue操作,通过请求实现的FastAPI接口可直接运行出结果。
当前数据库基本信息,以及包含哪些表,同时用户表有哪些字段。
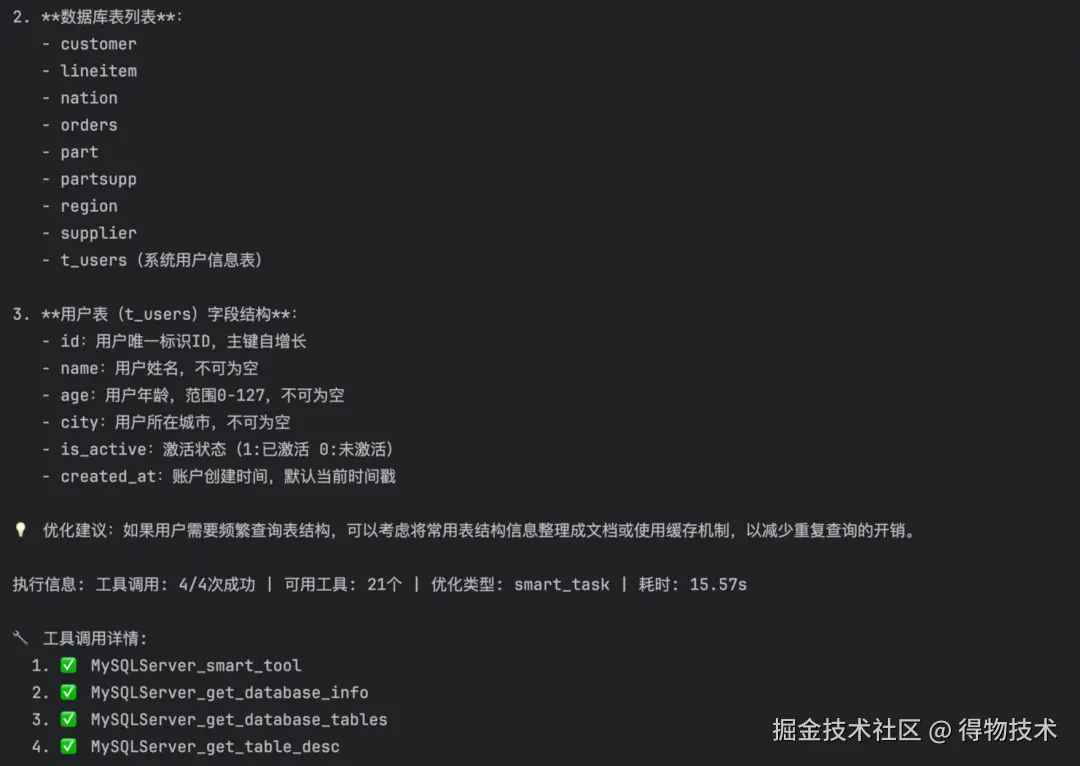
线上部署测试效果
我们在 MCP 应用市场中上架了一个版本的 DW-DBA-MCP 服务,在 VSCode 中安装 EP-Copilot 插件即可安装使用该服务。

然后在聊天界面中选择agent模式即可让 LLMs 选择合适的工具处理您的提问(注意为服务配置环境变量):


五、未来规划
在AI4DB(AI for Database)领域,AI 技术正颠覆传统数据库的运维与调优逻辑,推动其从依赖人工介入的被动响应模式,全面迈向可自主诊断、智能调优、故障自愈的全链路智能自治新阶段,大幅降低运维成本的同时提升了数据库系统的稳定性与运行效率。
而在DB4AI(Database for AI)方向,适配 AI 场景的数据库解决方案已实现关键突破:不仅具备高性能向量检索、复杂分析计算及强事务一致性等核心能力,还能原生支持文本、图像等多模态数据的一体化存储与管理,为 AI 模型训练与推理提供了高效、可靠的数据基座。
在技术格局剧变的背景下,DBA 的角色定位也迎来重构。传统意义上,DBA 即 Database Administrator(数据库管理员),核心聚焦于数据库的日常运维与技术保障;但随着 AI 技术的井喷式发展,DBA 已突破单一运维属性,可进阶为Data Business Architect(数据业务架构师)—— 借助 AI 工具与能力,DBA 能从海量数据中挖掘潜藏价值,打通数据与业务的链路,实现技术能力向业务价值的转化。
面向未来,DBA 团队将持续强化两大核心能力:一是筑牢数据安全防线,构建全周期数据安全治理体系;二是夯实工程化落地能力,推动智能技术与业务场景的深度融合。以此为基础,充分释放 DBA 在数据库 “智能自治运维” 与 “全域数据价值挖掘” 领域的双重价值,为企业数字化与智能化转型提供坚实的数据支撑。
六、资源推荐
参考资料:
[1] 一文带你 "看见" MCP 的过程,彻底理解 MCP 的概念(developer.aliyun.com/article/166…
[2] 100行代码讲透MCP原理(ai.programnotes.cn/p/100%E8%A1…
往期回顾
1. 项目性能优化实践:深入FMP算法原理探索|得物技术
2. Dragonboat统一存储LogDB实现分析|得物技术
3. 从数字到版面:得物数据产品里数字格式化的那些事
4. 一文解析得物自建 Redis 最新技术演进
5. Golang HTTP请求超时与重试:构建高可靠网络请求|得物技术
文 /少晖、洪兆
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。