-
背景
抖音长期存在renderD128内存占用过多导致的虚拟内存OOM,且多次出现renderD128内存激增导致OOM指标严重劣化甚至发版熔断。因受限于闭源的GPU驱动、现场有效信息极少、线上线下的Native内存检测工具均未能检测到相关内存分配等原因,多个团队都进行过分析,但一直未能定位到问题根因,问题反馈到厂商也一直没有结论。
以往发生renderD128内存激增时,解决办法往往都是通过二分法去定位导致问题MR进行回滚(MR代码写法并无问题,仅仅是正常调用系统Api),但是回滚业务代码会影响业务正常需求的合入,也无法从根本上解决该问题,而且每次都会消耗我们大量人力去分析排查,因此我们有必要投入更多时间和精力定位根因并彻底解决该问题。在历经数月的深入分析和排查后,我们最终定位了问题根因并彻底解决了该问题,也取得了显著的OOM收益,renderD128导致发版熔断的问题再也没有发生过。
接下来,将详细介绍下我们是如何一步步深入分析定位到问题根因,以及最终如何将这个问题给彻底解决的。
-
问题分析
-
问题特征
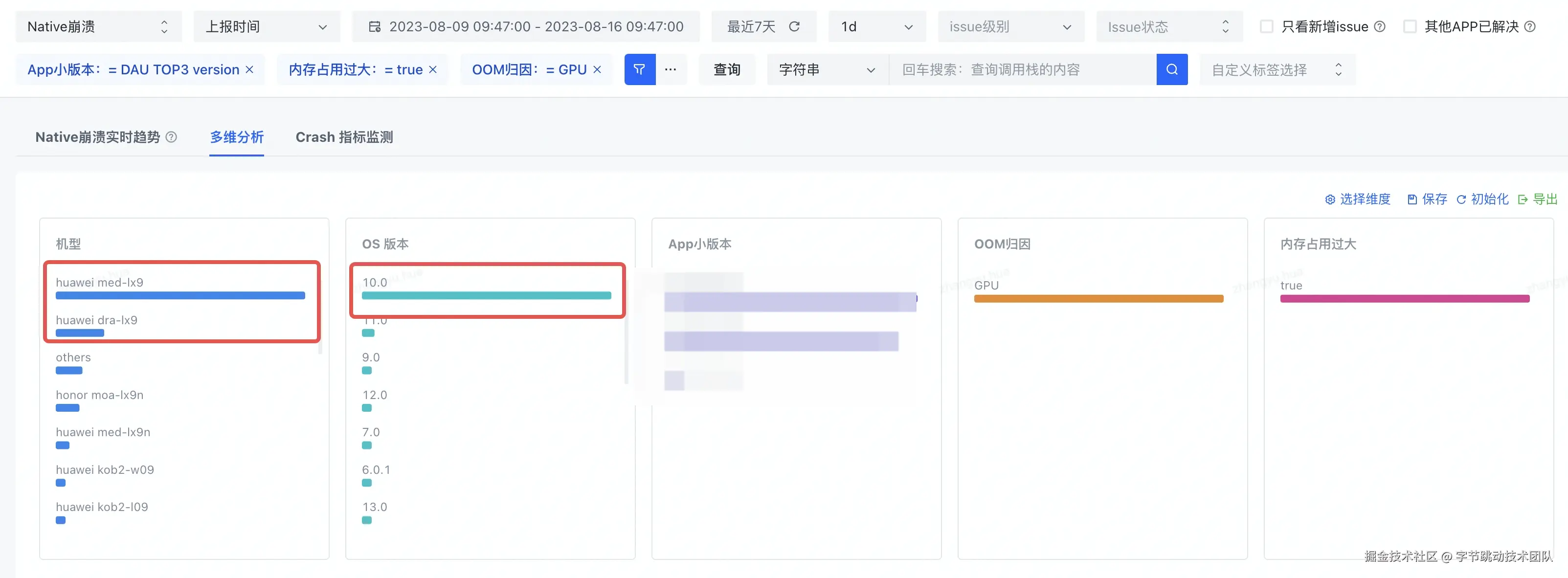
主要集中在华为Android10系统, 表现为renderD128内存占用过多。
机型特征: 联发科芯片、PowerVR GPU
如:华为y6p/华为畅享e
OS version: Android 10(主要),少量Android 8.1.0/9.0/11.0/12.0
abi: armeabi-v7a, armeabi
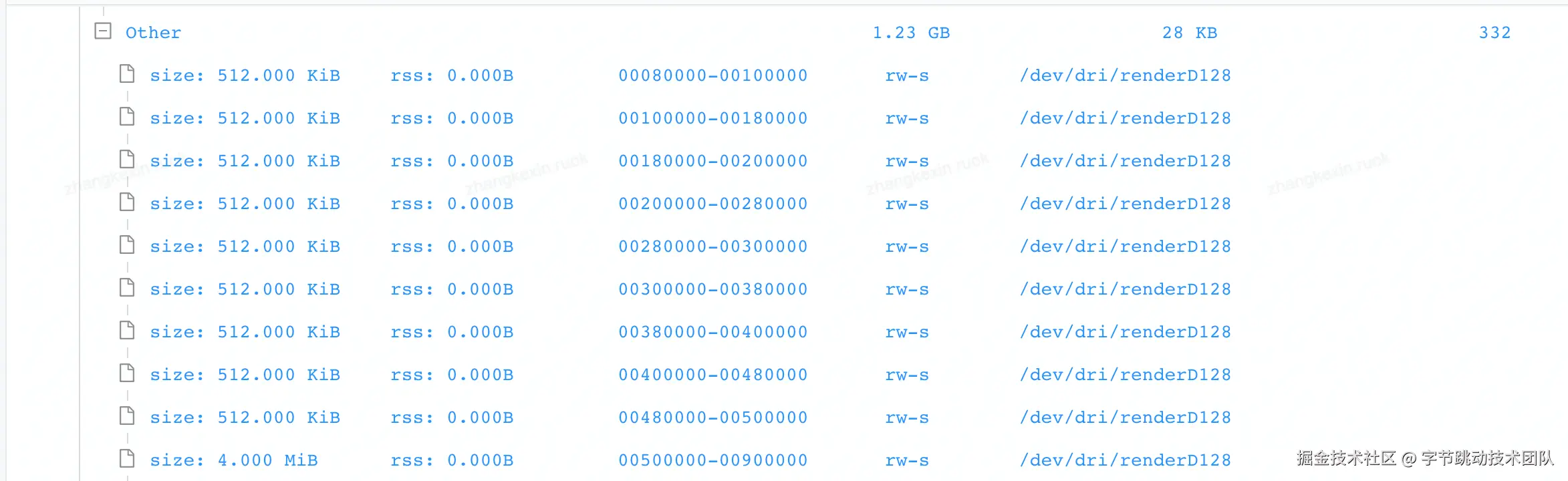
崩溃原因: 虚拟内存耗尽,主要由于/dev/dri/renderD128类型的内存占用过多(1G左右)
-
问题复现
我们根据抖音过往导致renderD128内存激增的MR,找到了一种能稳定复现该问题的办法“新增View,并调用View.setAlpha会引发renderD128内存上涨”。
复现机型:华为畅享10e(Android 10)
测试方式:
- 对照组:新增10个view,每个view设置背景色,不设置透明度,查看绘制前后内存变化
- 实验组:新增10个view,每个view设置背景色,并设置alpha为0.5,查看绘制10个view前后renderD128类内存变化
测试结果:
结论: 如果view被设置了透明度,绘制时会申请大量内存,且绘制完成不会释放
-
监控工具完善
我们在线上线下都开启了虚拟内存监控,但是均并未找到renderD128相关的内存监控信息(分配线程、堆栈等)
-
关键接口代理
以下是我们Hook相关接口开启虚拟内存监控的情况
| 接口 |
是否可以监控 |
备注 |
| mmap/mmap64/mremap/__mmap2 |
监控不到 |
|
| ioctl |
仅监控到一个命令,但该命令并没有映射内存操作 |
1. 命令调用前后renderD128相关内存并无变化 |
- 这个命令相关的ioctl调用频繁 |
| 上层接口 | 播放视频时没有监控到这些函数的调用(比较奇怪,讲道理应该是有调用的) |
 |
| open | 并未监控到设备文件打开的时机和路径 | |
|
| open | 并未监控到设备文件打开的时机和路径 | |
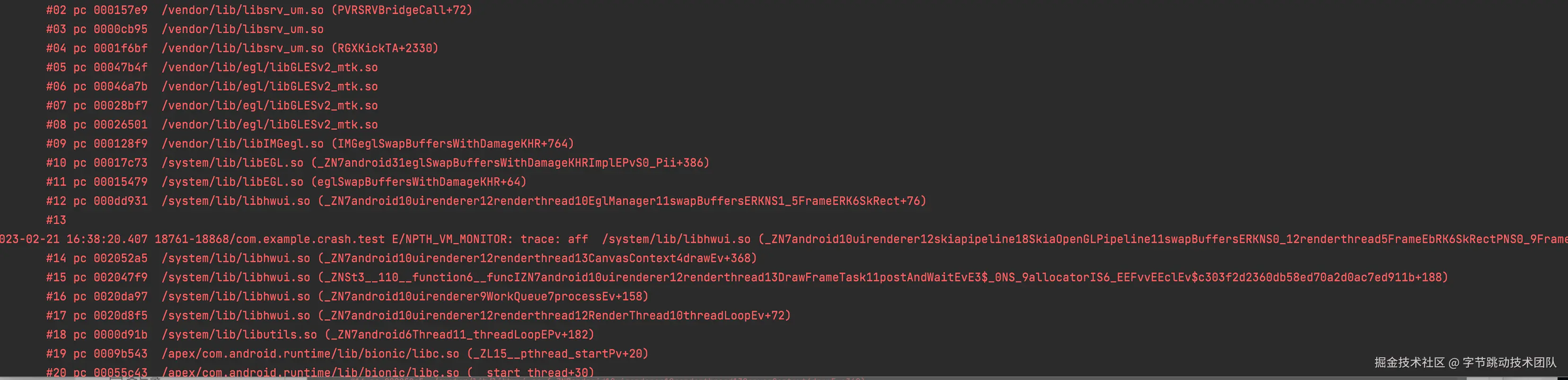
根据hook ioctl接口获取到的相关堆栈(虽然ioctl操作并没有影响内存,也可通过堆栈找到关键so库)
-
调查内存映射方式
-
从内核源码中寻找线索
由于关键接口代理均无法监控到renderD128相关的内存申请,此时猜想:可能是在内核中分配的内存?
于是找到了华为畅享e的内核源代码,阅读其中DRM驱动的相关代码
找到了唯一一个ioctl调用对应命令(0xc0206440)的定义和参数数据结构。
根据参数的数据结构,很容易理解驱动应该是根据传入的bridge_id和bridge_func_id来决定做何操作的。(根据堆栈其实也能大致推测每个id对应的操作,但此处暂时不对其进行研究)
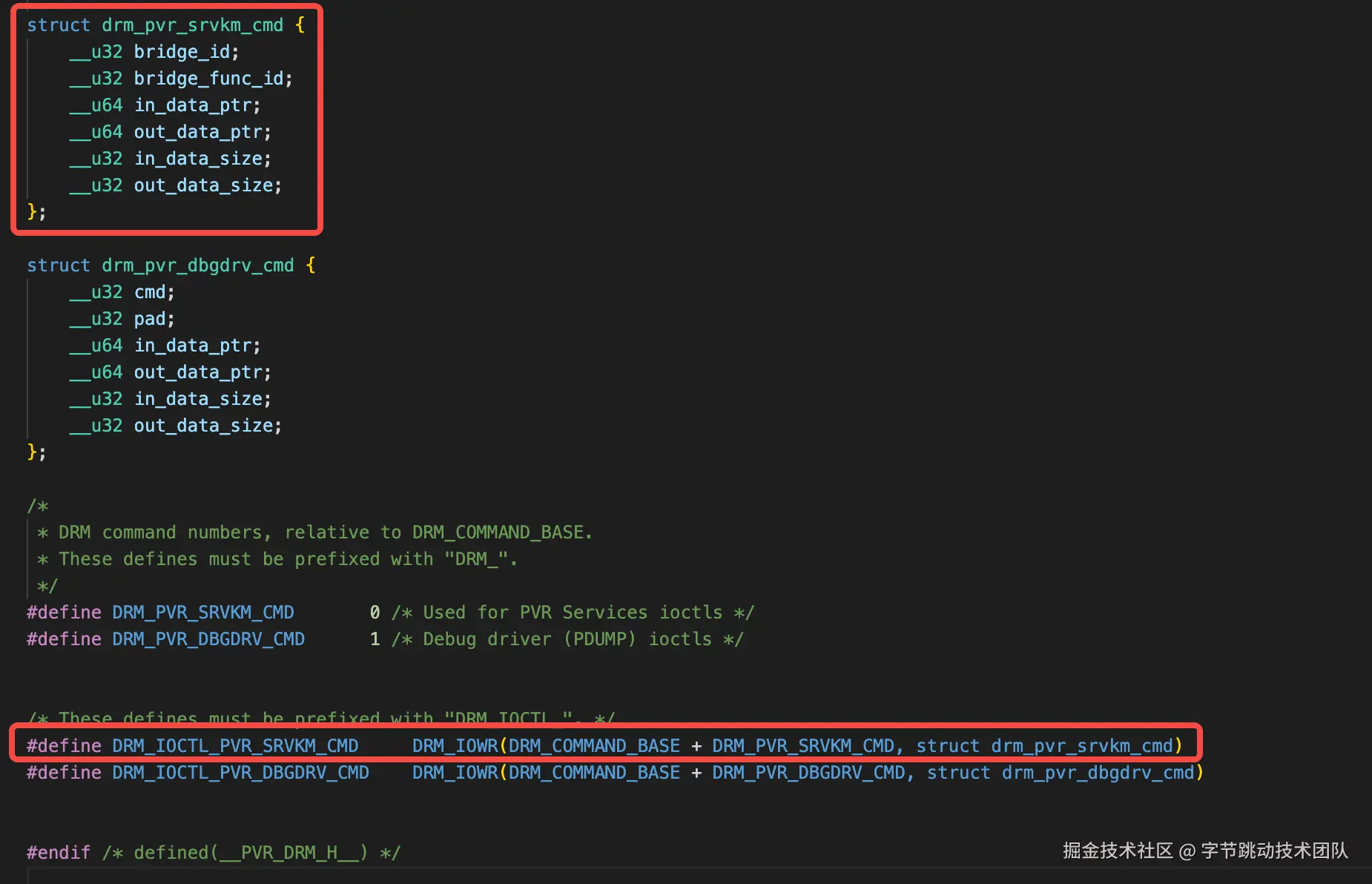
但除此之外,在内核代码中并没有找到“内存是在内核中分配的”证据,猜测应该还是用户空间申请的,比较有“嫌疑”的库是libdrm.so、libsrv_um.so和gralloc.mt6765.so
-
从驱动和关键so库中寻找线索
DRM
DRM是Linux内核层的显示驱动框架,它把显示功能封装成 open/close/ioctl 等标准接口,用户空间的程序调用这些接口,驱动设备,显示数据。libdrm库封装了DRM driver提供的这些接口。通过libdrm库,程序可以间接调用DRM Driver
但libdrm库中的drm_mmap是调用 mmap或__mmap2(都是监控中的接口)
#if defined(ANDROID) && !defined(__LP64__)
extern void *__mmap2(void *, size_t, int, int, int, size_t);
static inline void *drm_mmap(void *addr, size_t length, int prot, int flags,
int fd, loff_t offset)
{
/* offset must be aligned to 4096 (not necessarily the page size) */
if (offset & 4095) {
errno = EINVAL;
return MAP_FAILED;
}
return __mmap2(addr, length, prot, flags, fd, (size_t) (offset >> 12));
}
#else
/* assume large file support exists */
# define drm_mmap(addr, length, prot, flags, fd, offset) \
mmap(addr, length, prot, flags, fd, offset)
mesa3D
mesa3D中是通过调用libdrm库中的接口,间接调用DRM Driver的
gitlab.freedesktop.org/mesa/mesa
在mesa的源代码中找到了类似libsrv_um.so中PRVSRVBridgeCall的函数 pvr_srv_bridge_call
static int pvr_srv_bridge_call(int fd,
uint8_t bridge_id,
uint32_t function_id,
void *input,
uint32_t input_buffer_size,
void *output,
uint32_t output_buffer_size)
{
struct drm_srvkm_cmd cmd = {
.bridge_id = bridge_id,
.bridge_func_id = function_id,
.in_data_ptr = (uint64_t)(uintptr_t)input,
.out_data_ptr = (uint64_t)(uintptr_t)output,
.in_data_size = input_buffer_size,
.out_data_size = output_buffer_size,
};
int ret = drmIoctl(fd, DRM_IOCTL_SRVKM_CMD, &cmd);
if (unlikely(ret))
return ret;
VG(VALGRIND_MAKE_MEM_DEFINED(output, output_buffer_size));
return 0U;
}
同时发现了BridgeCall的相关id定义

通过提交的commit了解到这部分代码是为powerVR rogue GPU增加的驱动
commit链接:gitlab.freedesktop.org/mesa/mesa/-…

存在renderD128内存问题的机型使用的GPU也是PowerVR GPU,那么内存申请关键逻辑应该确实就在libsrv_um.so和gralloc.mt6765.so中
Huawei Y6p - Full phone specifications

- libsrv_um.so与gralloc.mt6765.so
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
奇怪的是,libsrv_um.so中只有munmap的符号,却没有mmap的符号(gralloc.mt6765.so同样没有)

这比较不符合常理,一般来说,mmap和munmap都是成对出现的,猜测有三种可能性:
-
在其他库中mmap
-
用其他方式实现mmap操作
-
使用dlsym拿到mmap等的符号,再调用 ❌
- 这种情况,使用inline hook是可以监控到的
-
调用ioctl实现mmap操作 ❌
- 并未监控到
-
直接使用系统调用 ✅
-
在libsrv_um.so中发现调用了syscall,系统调用号是0xC0(192),正是mmap的系统调用号!

-
gralloc.mt6765.so同libsrv_um.so,也是通过系统调用进行mmap的!
结论:hook syscall 应该可以监控到renderD128相关内存的调用!
-
验证监控方案
监控方式:
- 使用bytehook劫持了libsrv_um.so和gralloc.mt6765.so中对syscall的调用
- 记录renderD128内存的变化
测试: 播放视频
测试结果:
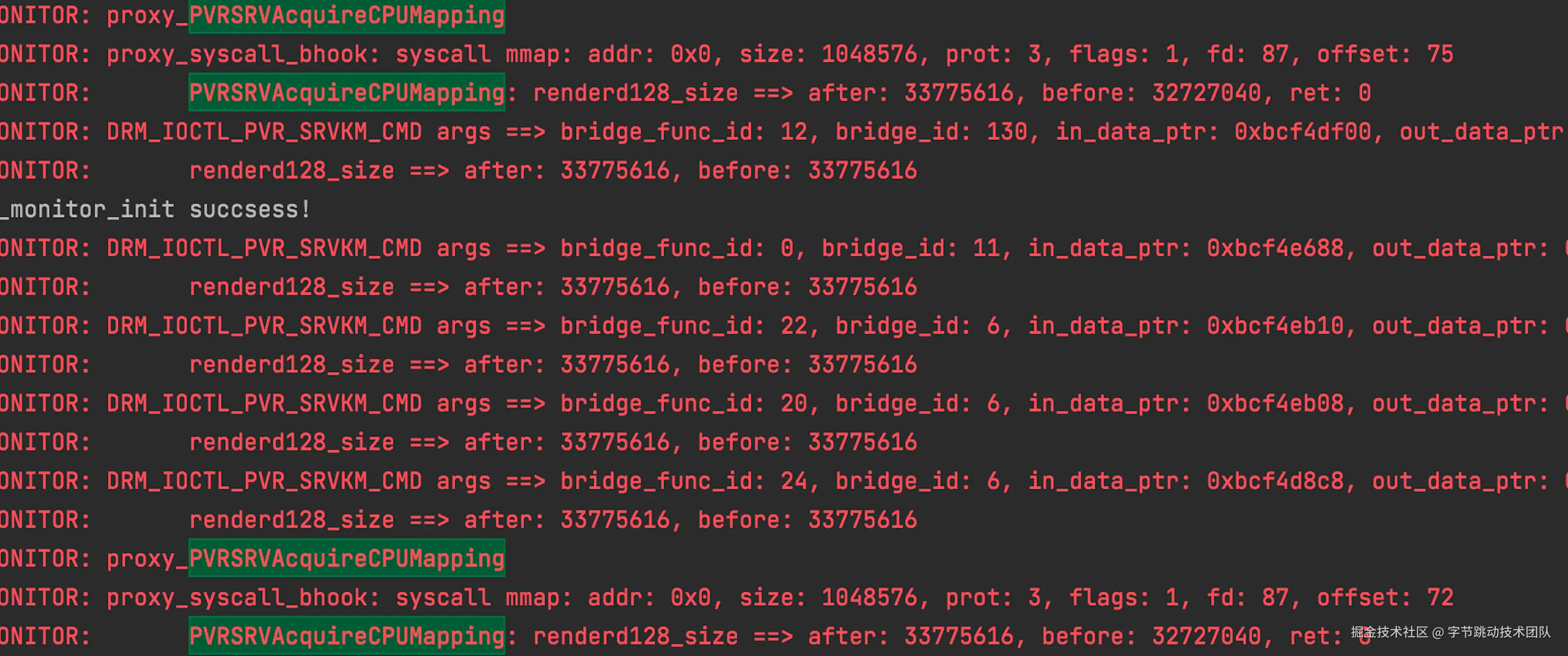
- 系统调用mmap可以监控到renderD128内存的分配
- 在播放视频期间renderD128内存增长大小符合通过系统调用mmap分配的大小
堆栈:
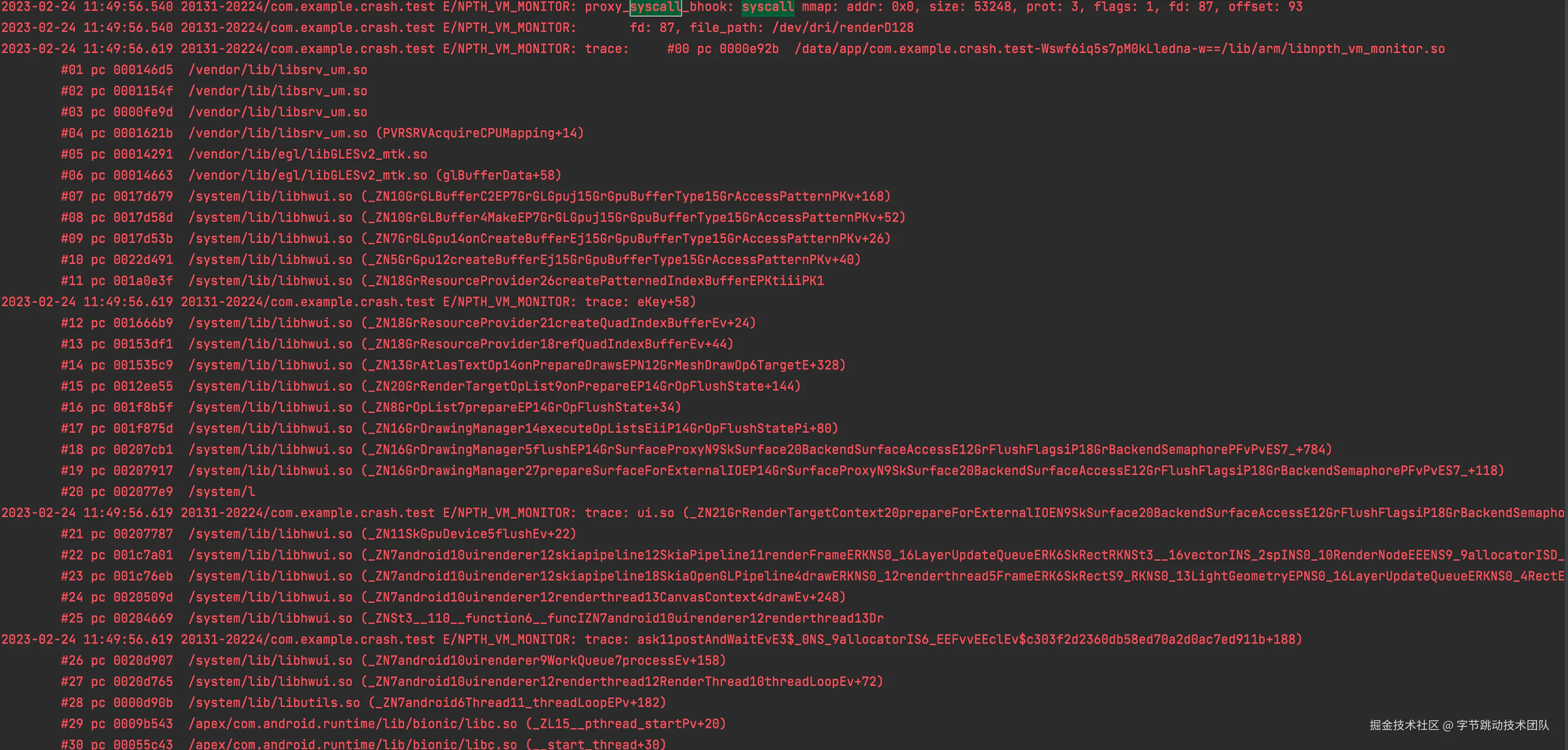
内存变化:
结论: 底层驱动可能考虑到架构适配或者效率问题,直接使用系统调用而非通用接口调用。在之前的监控中并未考虑到这种情况,所以会导致监控不全。
-
相关内存分配
内存监控工具完善之后,从线上我们收集到如下的堆栈信息:
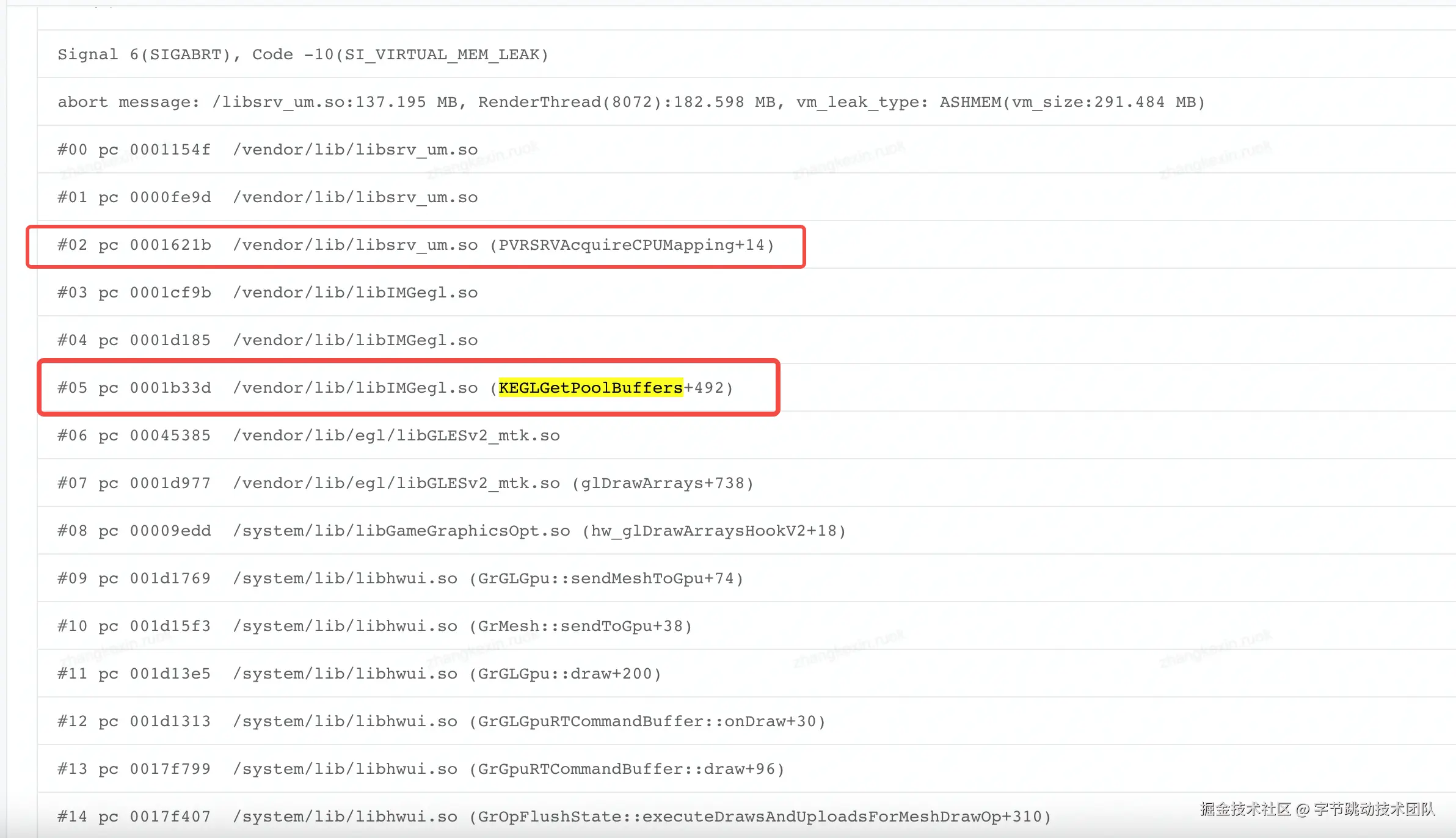
从堆栈上可以看到 libIMGegl.so有一个方法KEGLGetPoolBuffers,这个方法中会调用PVRSRVAcquireCPUMapping申请内存;
从“KEGLGetPoolBuffers”这个方法名可以推断:
-
有一个缓存池
-
可以调用KEGLGetPoolBuffers从缓存池中获取buffer
-
如果缓存池中有空闲buffer,会直接分配,无须从系统分配内存
-
如果缓存池中无空闲buffer,会调用PVRSRVAcquireCPUMapping从系统中申请内存
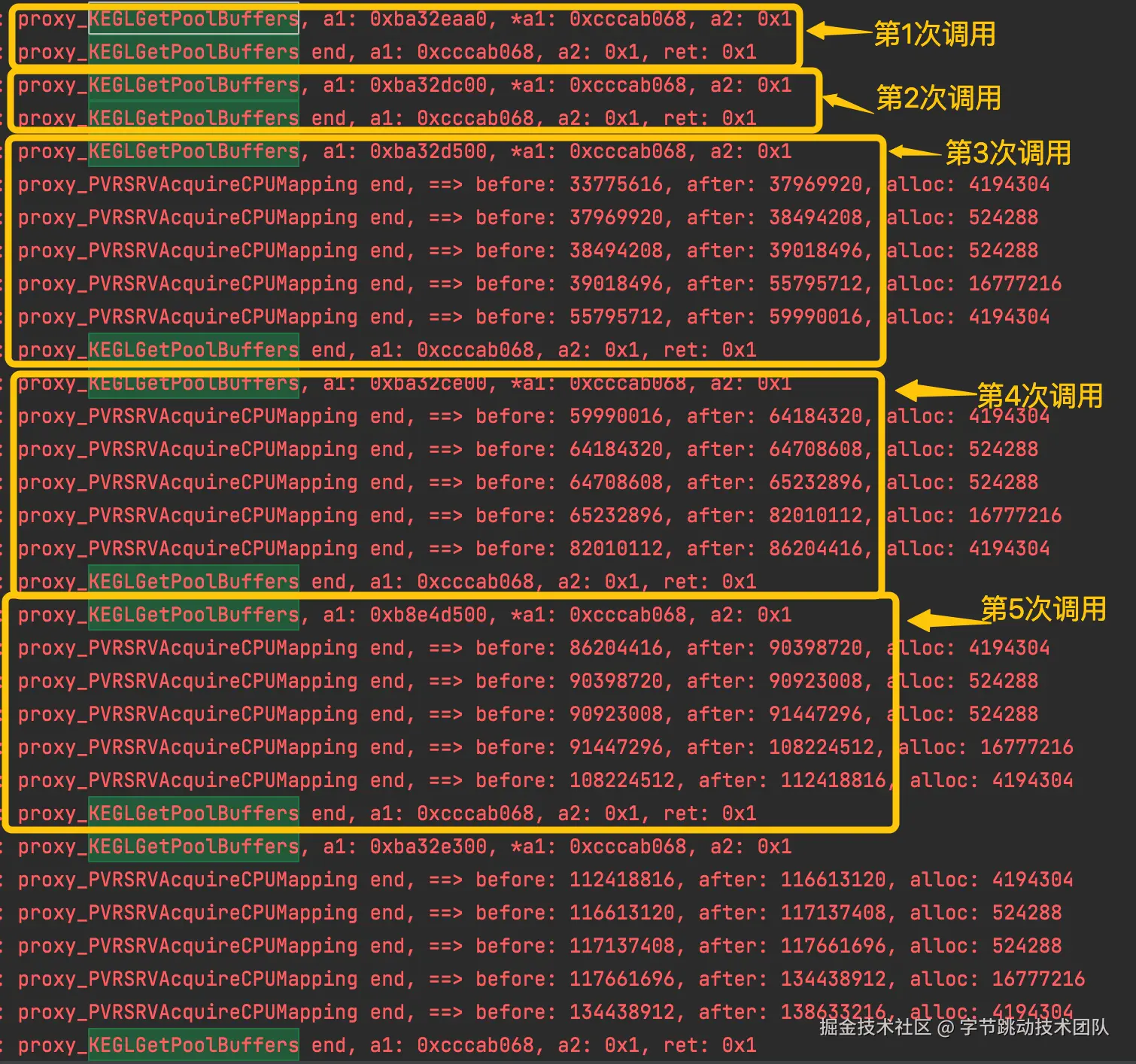
我们继续通过hook KEGLGetPoolBuffers 打印一些关键日志来确认猜想
日志中前两次调用KEGLGetPoolBuffers没有申请内存,符合“存在空闲buffer直接分配”的猜想。
后面的多次调用,每次都会连续调用5次 PVRSRVAcquireCPUMapping,分配5个大小不一的内存块(猜测应该是5类buffer),一共25M内存,和前面测试的结果刚好一致
-
相关内存释放
既然有内部分配,必然有其对应的内存释放,我们hook 泄漏线程RenderThread线程的munmap调用,抓到下面的堆栈,libsrv_um.so中相对偏移0xf060处(对应下面栈回溯#04栈帧,0xf061最后一位是1代表是thumb指令)的方法是DevmemReleaseCpuVirtAddr,但DevmemReleaseCpuVirtAddr这个方法并没有导出,glUnmapBuffer其实是调用了PVRSRVReleaseCPUMapping方法,在PVRSRVReleaseCPUMapping调用了DevmemReleaseCpuVirtAddr,进而最终调用到munmap方法释放内存的。
之所以在堆栈中没有PVRSRVReleaseCPUMapping这层栈帧,是因为PVRSRVReleaseCPUMapping跳转到DevmemReleaseCpuVirtAddr使用的是指令b(而非bl指令)
(glUnmapBuffer --> PVRSRVReleaseCPUMapping --> DevmemReleaseCpuVirtAddr --> ... --> munmap )
#01 pc 00009f41 /data/app/com.example.crash.test-bqPIslSQVErr7gyFpcHl_w==/lib/arm/libnpth_vm_monitor.so (proxy_munmap)
#02 pc 0001474b /vendor/lib/libsrv_um.so
#03 pc 000115d9 /vendor/lib/libsrv_um.so
#04 pc 0000f061 /vendor/lib/libsrv_um.so(DevmemReleaseCpuVirtAddr+44)
#05 pc 00015db1 /vendor/lib/egl/libGLESv2_mtk.so (glUnmapBuffer+536)
#06 pc 003b865d /system/lib/libhwui.so!libhwui.so (offset 0x244000) (GrGLBuffer::onUnmap()+54)
#07 pc 001a0eb3 /system/lib/libhwui.so (GrResourceProvider::createPatternedIndexBuffer(unsigned short const*, int, int, int, GrUniqueKey const*)+174)
#08 pc 001666b9 /system/lib/libhwui.so (GrResourceProvider::createQuadIndexBuffer()+24)
#09 pc 00153df1 /system/lib/libhwui.so (GrResourceProvider::refQuadIndexBuffer()+44)
#10 pc 001535c9 /system/lib/libhwui.so (GrAtlasTextOp::onPrepareDraws(GrMeshDrawOp::Target*)+328)
PVRSRVAcquireCPUMapping和PVRSRVReleaseCPUMapping是libsrv_um.so中进行内存分配和释放的一对方法
同理,KEGLGetPoolBuffers和KEGLReleasePoolBuffers是libIMGegl.so中分配和释放缓存buffer的一对方法
但在测试过程中,并没有看到在为buffer分配内存之后有调用PVRSRVReleaseCPUMapping释放内存,在绘制结束前,会调用KEGLReleasePoolBuffers释放buffer(但并未释放内存),查看KEGLReleasePoolBuffers的汇编发现方法内部只是对buffer标记可用,并不存在内存释放。
(左图KEGLGetPoolBuffers申请buffer,会申请内存;右图KEGLReleasePoolBuffers释放buffer,但不释放内存)
看来这个缓存池可能是统一释放内存的,由于libIMGegl.so中大部分方法都没有符号,从这层比较难推进,不妨再从上层场景分析一下,跟绘制相关的缓存池会什么时候释放呢?首先想到的可能是Activity销毁的时候,经过测试发现并没有……
但是在一次测试中发现 在Activity销毁之后,过了一段时间(1min左右)再启动一个新的Activity时突然释放了一堆renderD128相关的内存,抓到的是下面的堆栈。RenderThreaad中会执行销毁CanvasContext的任务,每次销毁CanvasContext时都会释放在一定时间范围内(30s)未使用的一些资源。销毁CanvasContext的时机是Activity Destroy时。(这里其实有些疑问,应该还有释放时机没有被发现)
#01 pc 0000edc1 /data/app/com.example.crash.test-o-BAwGot5UWCmlHJALMy2g==/lib/arm/libnpth_vm_monitor.so
#02 pc 0001d29b /vendor/lib/libIMGegl.so
#03 pc 0001af31 /vendor/lib/libIMGegl.so
#04 pc 000187c1 /vendor/lib/libIMGegl.so
#05 pc 0001948b /vendor/lib/libIMGegl.so
#06 pc 00018753 /vendor/lib/libIMGegl.so
#07 pc 0000b179 /vendor/lib/libIMGegl.so
#08 pc 0000f473 /vendor/lib/libIMGegl.so (IMGeglDestroySurface+462)
#09 pc 000171bd /system/lib/libEGL.so (android::eglDestroySurfaceImpl(void*, void*)+48)
#10 pc 0025d40b /system/lib/libhwui.so!libhwui.so (offset 0x245000) (android::uirenderer::renderthread::EglManager::destroySurface(void*)+30)
#11 pc 0025d2f7 /system/lib/libhwui.so!libhwui.so (offset 0x245000) (android::uirenderer::skiapipeline::SkiaOpenGLPipeline::setSurface(ANativeWindow*, android::uirenderer::renderthread::SwapBehavior, android::uirenderer::renderthrea
#12 pc 00244c03 /system/lib/libhwui.so!libhwui.so (offset 0x243000) (android::uirenderer::renderthread::CanvasContext::setSurface(android::sp<android::Surface>&&)+110)
#13 pc 00244af5 /system/lib/libhwui.so!libhwui.so (offset 0x243000) (android::uirenderer::renderthread::CanvasContext::destroy()+48)
#15 pc 0023015f /system/lib/libhwui.so!libhwui.so (offset 0x208000) (std::__1::packaged_task<void ()>::operator()()+50)
#16 pc 0020da97 /system/lib/libhwui.so!libhwui.so (offset 0x208000) (android::uirenderer::WorkQueue::process()+158)
#17 pc 0020d8f5 /system/lib/libhwui.so!libhwui.so (offset 0x208000) (android::uirenderer::renderthread::RenderThread::threadLoop()+72)
#18 pc 0000d91b /system/lib/libutils.so (android::Thread::_threadLoop(void*)+182)
#19 pc 0009b543 /apex/com.android.runtime/lib/bionic/libc.so!libc.so (offset 0x8d000) (__pthread_start(void*)+20)

-
总结
renderD128类内存导致的OOM问题,并非由于内存泄漏,而是大量内存长期不释放导致。在大型APP中,Activity存活的时间可能会很长,如果缓存池只能等到Activity销毁时才能释放,大量内存长期无法释放,就极易发生OOM。
-
优化方案
-
手动释放内存
-
方案一:释放空闲buffer
从相关内存的分配和释放章节的分析来看,get & release buffer的操作有点不对称,我们期望:
-
分配缓存:有可用buffer直接使用;无可用buffer则申请新的;
-
释放缓存:标记buffer空闲,空闲buffer达到某一阈值后则释放。
而现状是空闲buffer达到某一阈值后并不会释放,是否可以尝试手动释放呢?
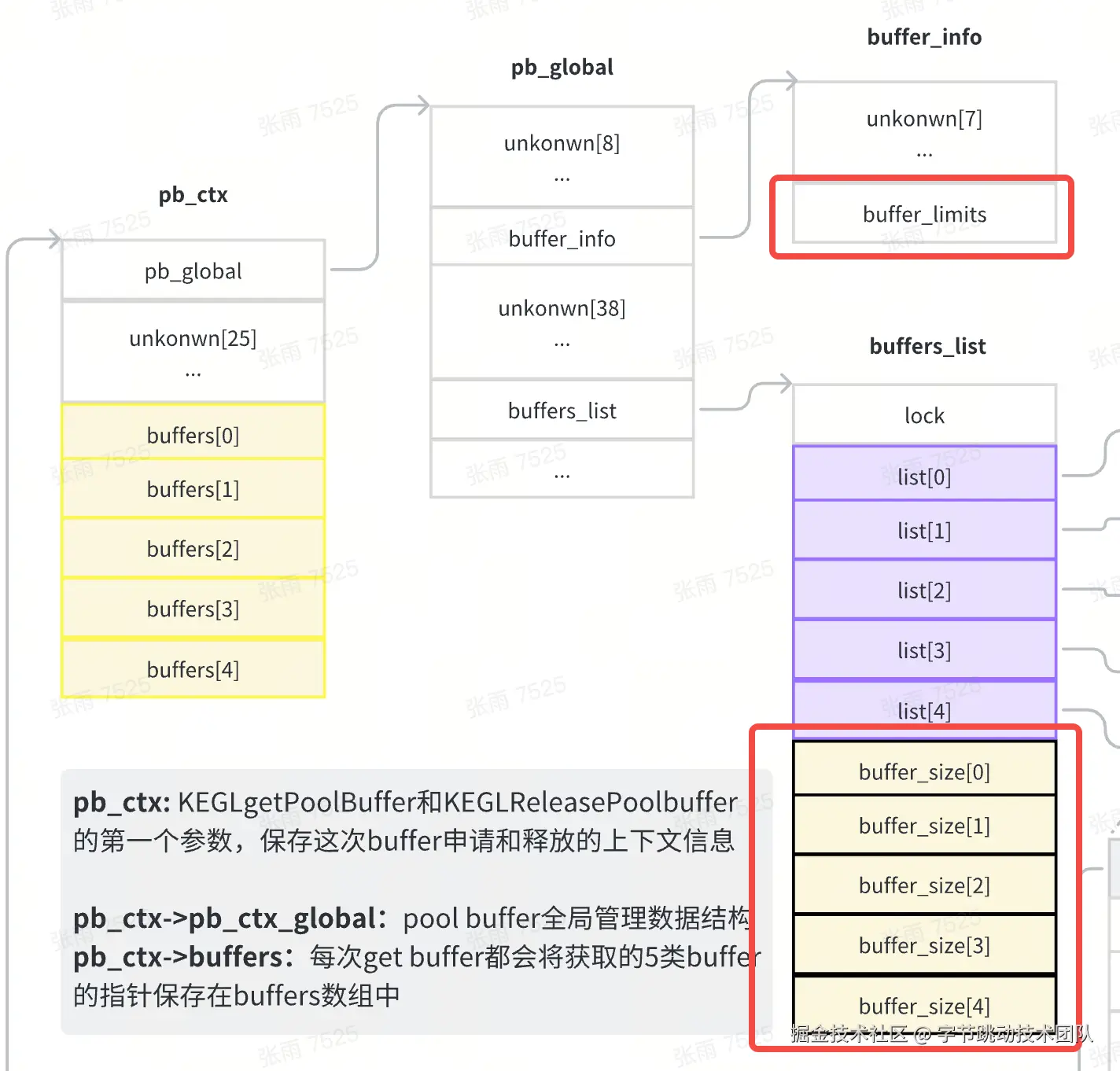
首先需要了解缓存池的结构
由于相关so代码闭源,我们通过反汇编推导出缓存池的结构,大致如下图所示,pb_global是缓存池的管理结构体,其中的buffers_list中分别保存了5类buffer的list,内存组织方式如下示意
KEGLReleasePoolBuffers中会标记每一个buffer->flag为0(空闲)
暂时无法在飞书文档外展示此内容
手动释放内存的方式
在KEGLReleasePoolBuffers标记buffer为空闲之后,检查当前空闲buffer个数是否超过阈值(或者检查当前render D128相关内存是否超过阈值),如果超过阈值则释放一批buffer,并将buffer从链表中取下。
(相关代码如下👇)
static void release_freed_buffer(pb_ctx_t* ctx) {
/** 一些检查和判空操作会省略 **/
...
/** 阈值检查 **/
if (!limit_check(ctx)) return;
// 拿到buffer_list
pb_buffer_list_t* buffers_list = ctx->pb_global->buffers_list;
pb_buffer_info_t *buffer_info, *prev_info;
for (int i = 0; i < 5; i++) {
buffer_info = buffer_info->buffers[i];
if (buffer_info == NULL) continue;
/** 第一个buffer不释放,简化逻辑 **/
while(buffer_info) {
prev_info = buffer_info;
buffer_info = buffer_info->next;
if (buffer_info && buffer_info->flag == 0) {
int ret = pvrsrvReleaseCPUMapping((void**)buffer_info->sparse_buffer->cpu_mapping_info->info);
LOGE("%s, release cpu mapping ret: %d", __FUNCTION__, ret);
if (ret == 0) {
buffer_info->flag = 1;
buffer_info->sparse_buffer->mmap_ptr = NULL;
prev_info->next = buffer_info->next;
buffers_list->buffer_size[i]--;
free(buffer_info);
buffer_info = prev_info;
}
}
}
}
}
方案效果
测试环境和方式与前面“问题复现”章节一致
| 内存释放时机 |
绘制结束后renderD128相关内存大小 |
结果比较 |
| 每次释放缓存 |
33M 左右
|
与不设置透明度的对照组结果接近 |
| renderD128内存> 100M |
86M 左右
|
100M以下,符合预期 |
| renderD128内存> 300M |
295M 左右
|
跟实验组一致,因为并没有超过300M的阈值。符合预期 |
| buffer总数 > 5 |
33M 左右
|
与不设置透明度的对照组结果接近,绘制结束时会释放完所有空闲buffer |
| buffer总数 > 10 |
|
|
| buffer总数 > 20 |
295M 左右
|
跟实验组一致,因为并没有超过20个buffer的阈值(10个view大概会用到10~15个buffer)。符合预期 |
| 空闲buffer > 5 |
138M 左右
|
空闲buffer个数不太可控,无法精确控制内存水位 |
| 空闲buffer > 10 |
33M 左右
|
|
方案结论:
这个方案虽然也可缓解问题,但是存在以下问题:
-
性能影响(理论,未测)
- 增加了内存申请和释放的概率,会有一定的性能影响
- 每次进行阈值判定,都需要统计当前buffer/内存的值,频繁调用接口时,也会影响性能
-
稳定性
- 硬编码缓存池相关的数据结构,如果有些机型数据结构不一致的话,就可能会崩溃
这个方案应该不是最优解,先做备用方案,再探索一下
-
方案二:上层及时释放资源
从前面“相关内存释放”章节的分析可知,缓存池的内存并不是不会释放,而是释放时机很晚,那么能否早点释放呢?
查看CanvasContext的释放路径,仅发现了一个可操作点(尝试了一些方式都会崩溃,会释放掉正在使用的资源),CacheManager::trimStaleResources方法中可以把释放30s内未使用的资源,改成释放1s(或10s)内未使用的资源

修改指令:MOVW R2, #30000 ==> MOVW R2,#1000
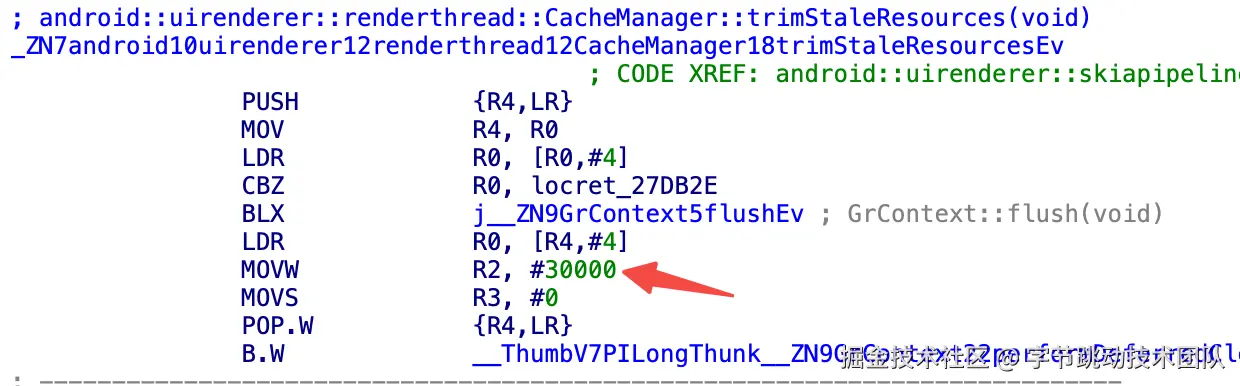
(相关代码如下👇)
#define ORIGIN_TIME_LIMIT_INST 0x5230f247 // 30s
#define NEW_TIME_LIMIT_INST 0x32e8f240 // 1s 提前构造好的指令编码
#define FUNC_SYM "_ZN7android10uirenderer12renderthread12CacheManager18trimStaleResourcesEv"
static void change_destroy_wait_time() {
/** 一些检查和判空操作会省略 **/
#ifdef __arm__
void* handle = dlopen("libhwui.so");
// 从trimStaleResources方法的起始地址开始搜索内存
void* sym_ptr = dlsym(handle, FUNC_SYM);
sym_ptr = (void*)((uint32_t)sym_ptr & 0xfffffffc);
uint32_t* inst_start = (uint32_t*)sym_ptr;
uint32_t* search_limit = inst_start + 12;
while(inst_start < search_limit) {
/* 找到并修改对应指令 */
if (*inst_start == ORIGIN_TIME_LIMIT_INST) {
if(mprotect((void*)((uint32_t)inst_start & (unsigned int) PAGE_MASK), PAGE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC)) {
return;
}
*inst_start = NEW_TIME_LIMIT_INST;
flash_page_cache(inst_start);
if(mprotect((void*)((uint32_t)inst_start & (unsigned int) PAGE_MASK), PAGE_SIZE, PROT_READ|PROT_WRITE|PROT_EXEC)) {
return;
}
break;
}
inst_start++;
}
#endif
}
方案结论: 该方案还是依赖于Activity销毁,只是销毁后能更快释放资源,所以缓解内存方面起到的作用很有限
-
控制缓存池增长
在尝试前面两个方案之后,这个问题逐渐让人崩溃,似乎已经没有什么好的解决办法了,已经准备就此放弃。
-
新的突破点
山重水复疑无路,柳岸花明又一村。在后续的一次压测中,我们发现了一个新的突破点“每次调用一次renderD128 内存会上涨25M,但是并不是无限上涨,上涨到1.3G左右就不再增长了”,且另外翻看线上相关OOM问题,renderD128内存占用最多的也在1.3G上下,由此我们大胆猜测renderD128 内存缓存池大小应该是有上限的,这个上限大概在1.3G上下,那么我们可以尝试从调小缓存池的阈值入手。

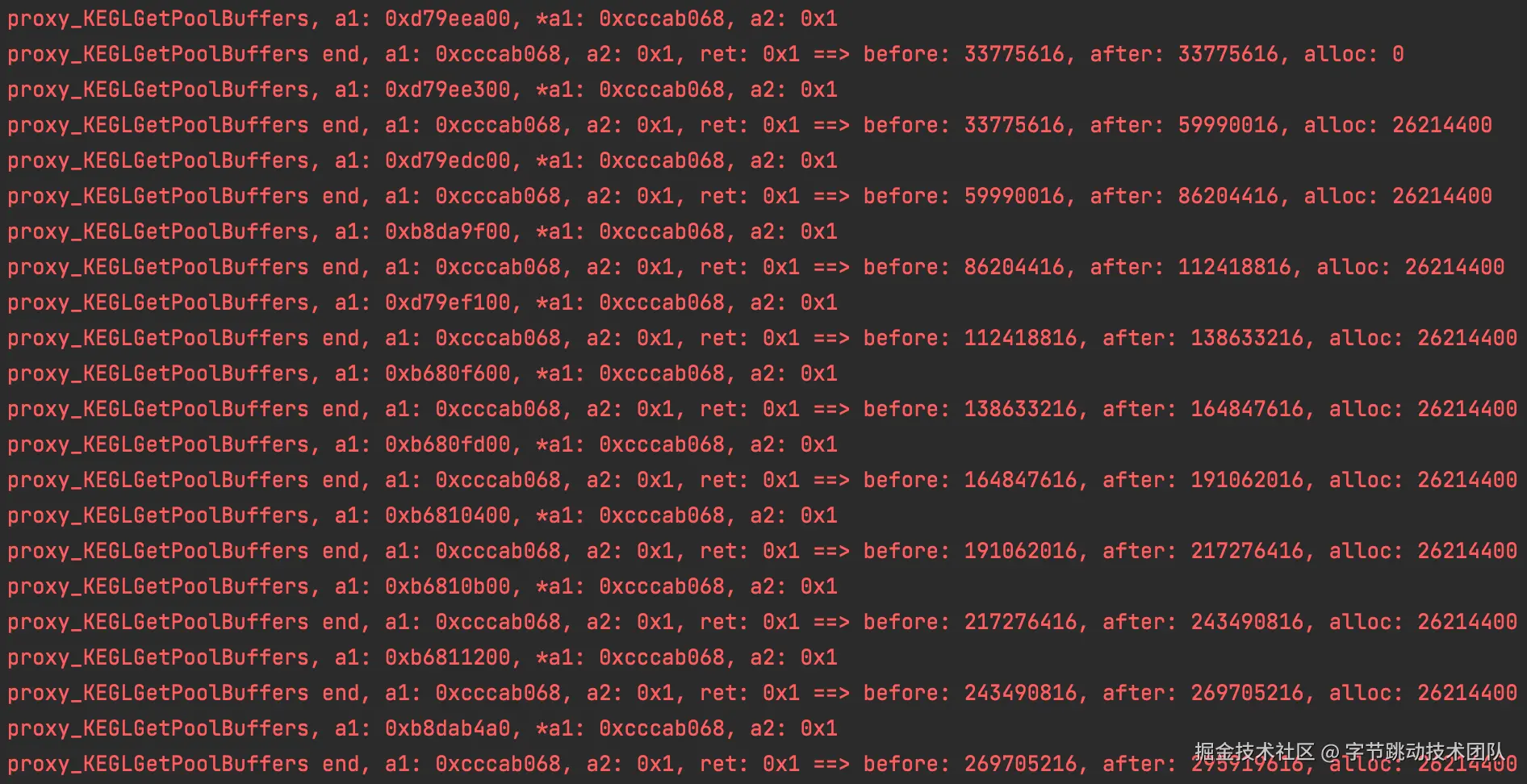
再次尝试:
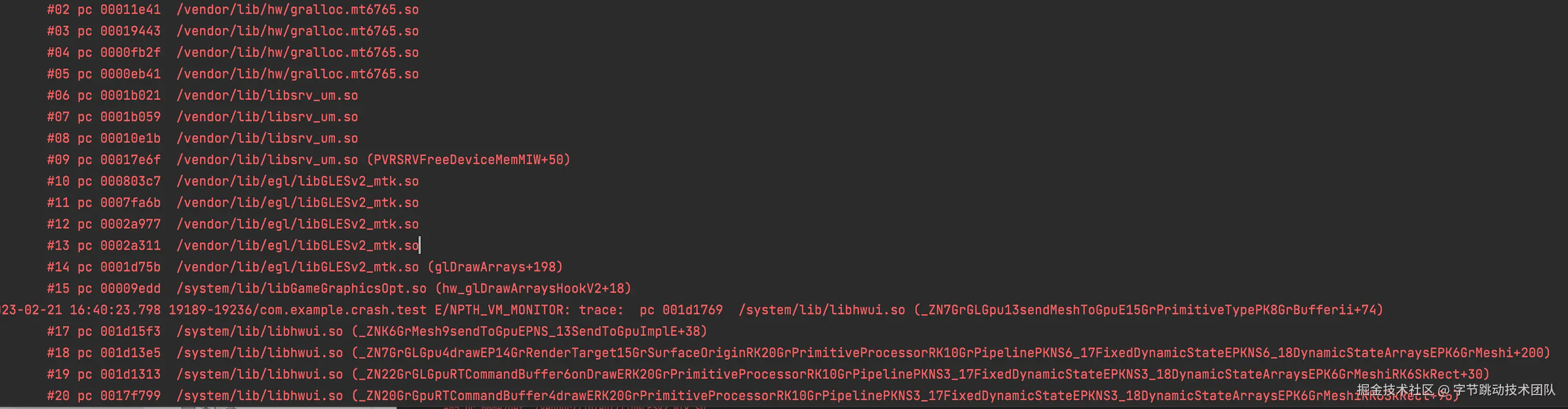
我们再次尝试复现该问题,并hook相关内存分配 ;从日志可以看到,在内存增长到1.3G后
- 下一次调用KEGLGetPoolBuffers获取buffer时,返回值是0(代表分配失败)
- 再下一次调用KEGLGetPoolBuffers,返回值是1(代表分配成功),但没有申请内存
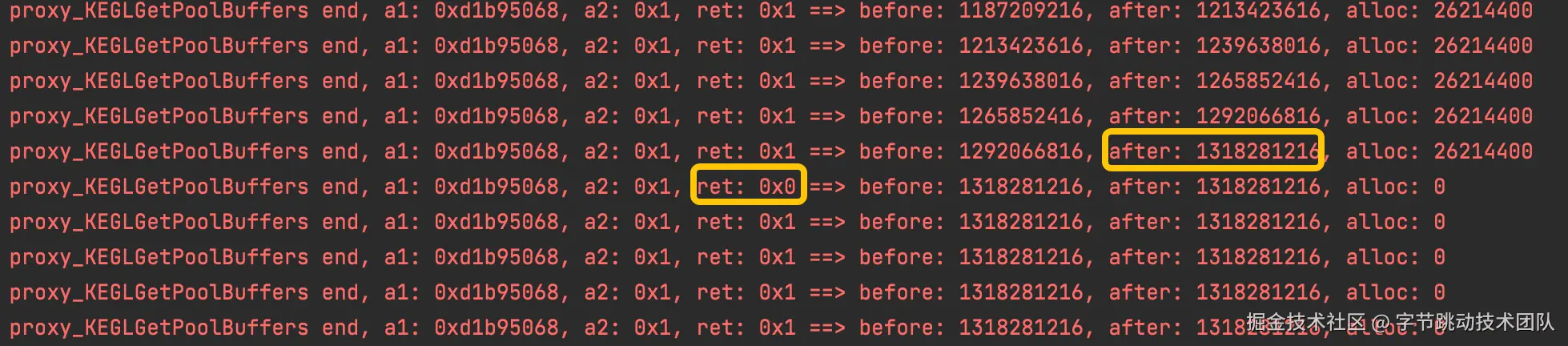
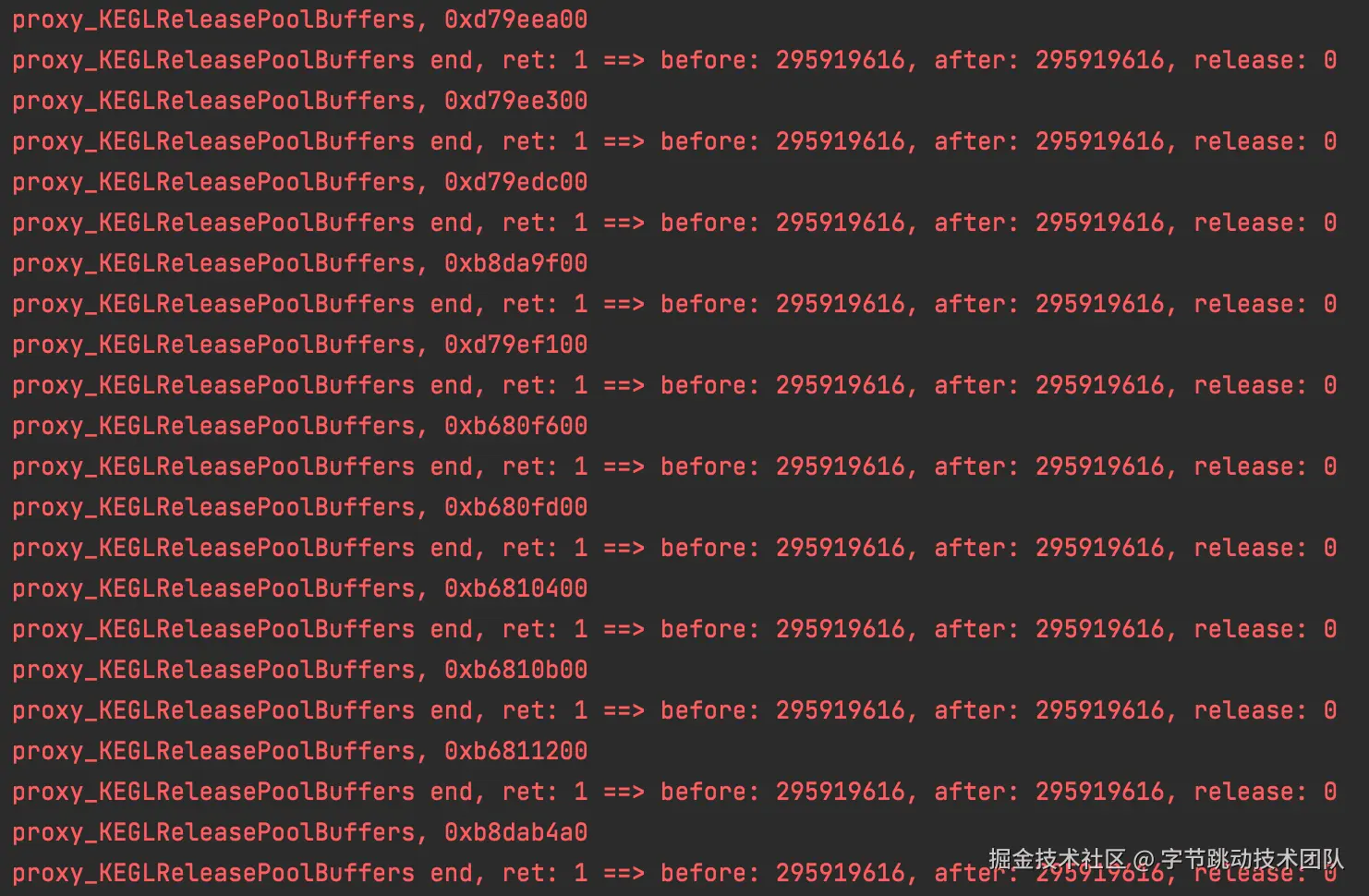
再增加多一点信息,发现当KEGLGetPoolBuffers获取buffer失败后,会有KEGLReleasePoolBuffers调用,释放了大量buffer,之后再重新调用KEGLGetPoolBuffers
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x1 ==> before: 1265852416, after: 1292066816, alloc: 26214400
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x1 ==> before: 1292066816, after: 1318281216, alloc: 26214400
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x0 ==> before: 1318281216, after: 1318281216, alloc: 0
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
...
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
KEGLReleasePoolBuffers end, ret: 1 ==> before: 1318281216, after: 1318281216, release: 0
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x1 ==> before: 1318281216, after: 1318281216, alloc: 0
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x1 ==> before: 1318281216, after: 1318281216, alloc: 0
KEGLGetPoolBuffers end, a1: 0xd1b95068, a2: 0x1, ret: 0x1 ==> before: 1318281216, after: 1318281216, alloc: 0
从堆栈看应该是提前flush了,所以就可以释放之前的buffer
#01 pc 0000ebf5 /data/app/com.example.crash.test-1hHKnp6FBSv-HjrVtXQo1Q==/lib/arm/libnpth_vm_monitor.so (proxy_KEGLReleasePoolBuffers)
#02 pc 00047c2d /vendor/lib/egl/libGLESv2_mtk.so
#03 pc 00046a7b /vendor/lib/egl/libGLESv2_mtk.so (ResetSurface)
#04 pc 00028bf7 /vendor/lib/egl/libGLESv2_mtk.so
#05 pc 000d2165 /vendor/lib/egl/libGLESv2_mtk.so (RM_FlushHWQueue)
#06 pc 00028c73 /vendor/lib/egl/libGLESv2_mtk.so
#07 pc 000453fd /vendor/lib/egl/libGLESv2_mtk.so (PrepareToDraw)
#08 pc 0001d977 /vendor/lib/egl/libGLESv2_mtk.so (glDrawArrays+738)
#09 pc 00009edd /system/lib/libGameGraphicsOpt.so (hw_glDrawArraysHookV2+18)
#10 pc 001d1769 /system/lib/libhwui.so (GrGLGpu::sendMeshToGpu(GrPrimitiveType, GrBuffer const*, int, int)+74)
#11 pc 001d15f3 /system/lib/libhwui.so (GrMesh::sendToGpu(GrMesh::SendToGpuImpl*) const+38)
#12 pc 001d13e5 /system/lib/libhwui.so (GrGLGpu::draw(GrRenderTarget*, GrSurfaceOrigin, GrPrimitiveProcessor const&, GrPipeline const
2. #### 方案三:KEGLGetPoolBuffers中限制buffer分配
根据上面的分析,发现可以尝试:
- Hook KEGLGetPoolBuffers函数,判断内存增长到一定阈值后,在KEGLGetPoolBuffers函数中就直接返回0,触发其内部的空闲buffer释放
- 空闲buffer释放之后,才允许分配buffer(如下流程)
暂时无法在飞书文档外展示此内容
方案结论: 该方案需要每次分配内存前读取maps获取renderD128占用内存大小,对性能不是很友好
-
方案四:修改缓存池阈值
从上面的分析,我们知道KEGLGetPoolBuffers函数返回0时分配失败,会开始释放buffer。我们继续反汇编KEGLGetPoolBuffers函数,根据KEGLGetPoolBuffers的返回值为0 可以回溯到汇编中进行阈值判断的逻辑
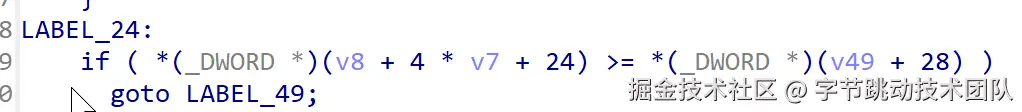
v8:buffers_list
v7:buffer类型(0~4)
v8+4*v7+24:v7这个buffer类型 的buffer数量(右图中的buffer_size[i]
v49:buffer_info
v49 + 28: buffer_limit 缓存池中每种类型的buffer 的阈值(右图中的buffer_limits)
简单来说,这里将buffer_limits与buffer_size[i]进行比较,如果buffer_size[i]大于等于阈值,就会返回0,分配失败
接下来的操作就很简单了,只需对buffer_limits进行修改就行,在测试设备上buffer_limits值是50(50*25M 大约是1.25G),我们将buffer_limits改小一点就可以将renderD128内存值控制在一个更小的阈值范围内,以此降低renderD128内存占用。
(相关代码如下👇)
int opt_mtk_buffer(int api_level, int new_buffer_size) {
...(无关代码省略)
if (check_buffer_size(new_buffer_size)) {
prefered_buffer_size = new_buffer_size;
}
KEGLGetPoolBuffers_stub = bytehook_hook_single(
"libGLESv2_mtk.so",
NULL,
"KEGLGetPoolBuffers",
(void*)proxy_KEGLGetPoolBuffers,
(bytehook_hooked_t)bytehook_hooked_mtk,
NULL);
...(无关代码省略)
return 0;
}
static void* proxy_KEGLGetPoolBuffers(void** a1, void* a2, int a3, int a4) {
//修改buffer_limits
modify_buffer_size((pb_ctx_t*)a1);
void* ret = BYTEHOOK_CALL_PREV(proxy_KEGLGetPoolBuffers, KEGLGetPoolBuffers_t, a1, a2, a3, a4);
BYTEHOOK_POP_STACK();
return ret;
}
static void modify_buffer_size(pb_ctx_t* ctx) {
if (__predict_false(ctx == NULL || ctx->node == NULL || ctx->node->buffer_inner == NULL)) {
return;
}
if (ctx->node->buffer_inner->num == ORIGIN_BUFFER_SIZE) {
ctx->node->buffer_inner->num = prefered_buffer_size;
}
}
Demo验证:
| 缓存值阈值 |
内存峰值 |
| 50 |
1.3G
|
| 20 |
530M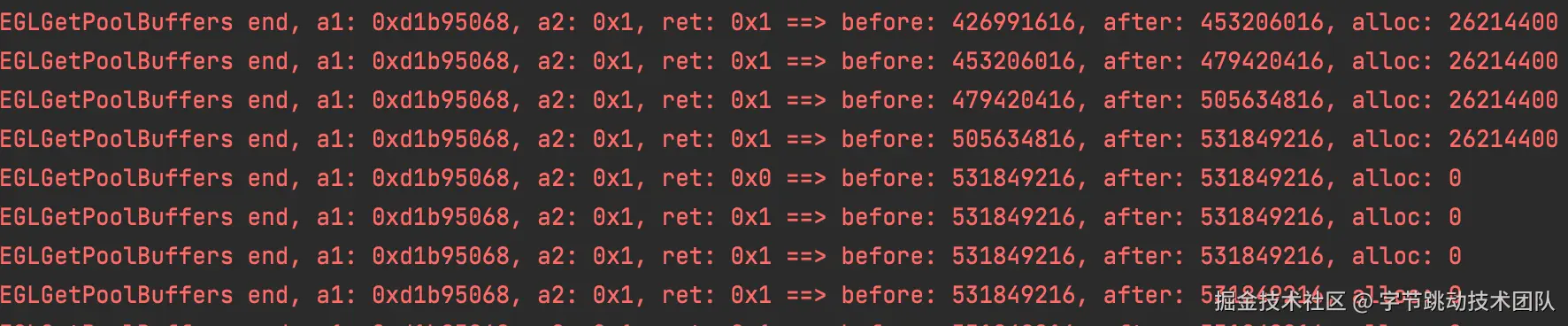
|
| 10 |
269M
|
方案结论: 该方案修改少,性能影响小,且稳定性可控
-
最终方案
通过的上面的分析,由于方案四“修改缓存池阈值”修改少,性能影响小,且稳定性可控 , 最终我们决定选用该方案。
-
修复效果
开启修复实验后相关机型OOM崩溃率显著下降近50% ,观察数周之后各项业务指标也均为正向,符合预期。全量上线后大盘renderD128相关OOM也大幅下降,另外renderD128导致发版熔断的情况从此再也没有发生过。
-
总结
在分析内存问题时,不论是系统申请的内存还是业务申请的内存,都需要明确申请逻辑和释放逻辑,才能确定是否发生泄漏还是长期不释放,再从内存申请和释放逻辑中寻找可优化点。
相关资料
- 华为畅享e内核源代码链接:consumer.huawei.com/en/opensour…
- mesa源代码链接:gitlab.freedesktop.org/mesa/mesa