导读 introduction
GoClaw 是一个用 Go 语言编写的个人 AI 助手,灵感来自 OpenClaw(原 Clawdbot/Moltbot)。它运行在本地服务器上,通过 WebSocket/HTTP 暴露服务,支持多种消息channel(Telegram、WhatsApp、飞书、QQ、Slack 等)接入。
全文8593字,预计阅读时间11分钟
如果 OpenClaw 代表了一种 Agent 设计思路,那么 GoClaw 想回答的问题是:这套东西能不能用 Go 做得更轻、更稳、更适合长期运行?
项目地址:github.com/smallnest/g…
先说结论:如果你只是想快速做一个 Agent Demo,Python 和 Node.js 依然是更自然的选择;但如果你开始在意部署、稳定性、可观测性和长期运行,那么 Go 其实是一条很值得认真考虑的路。
这篇文章想讲清楚三件事:
-
为什么我会想用 Go 重做一套 Agent 框架
-
GoClaw 的核心架构到底解决了什么问题
-
它在真实任务里,是否真的能把事情做完
这是什么?
这两年,大家做 AI Agent,很多时候默认会选 Python 或 Node.js。原因很现实:生态成熟、轮子够多、上手也快。
但如果你真的想把一个 Agent 长期跑起来,问题很快就会从“怎么调模型”变成“怎么部署、怎么运维、怎么保证它别轻易挂掉”。
也正因为这样,我一直在想:如果把 OpenClaw 这套已经被验证过的设计思路,用 Go 重新实现,会变成什么样?
GoClaw 就是在这个背景下做出来的。
它是一个用 Go 编写的 AI Agent 框架,灵感来自 OpenClaw。这里强调“框架”,是因为它不只是一个聊天机器人,而是一套完整的运行体系:能接入消息平台、执行任务、调用工具,也能继续扩展新能力。
如果把 OpenClaw 看作一套成熟的 Agent 设计,那么 GoClaw 更像是一次“用 Go 把它工程化重做”的尝试。这样做的好处很直接:单一二进制部署,编译后就是一个可执行文件,扔到服务器上就能跑;模块边界更清晰,消息通道、工具系统、技能系统、记忆系统彼此解耦;运行时也更稳,重试、故障转移、熔断器这些可靠性机制可以直接内建进去。
它能接哪些平台?Telegram、WhatsApp、飞书、钉钉、微信、企业微信、Slack、Discord、Google Chat、Microsoft Teams、百度如流等常见 IM 与协作平台都已经覆盖。你也可以通过 WebSocket Gateway 对接自己的系统,或者直接使用内置的 Dashboard。
如果只用一句话概括 GoClaw,可以这么说:它想做的不是“再造一个聊天机器人”,而是提供一套适合长期运行、方便扩展、并且足够稳的 Go 版 Agent 基础设施。
换句话说,GoClaw 想解决的不是“模型能不能更聪明”,而是“一个 Agent 系统能不能真正跑起来、跑得久、出了问题还能查”。
核心架构:一条看似简单,其实很难跑稳的链路
下面这张图是OpenClaw的架构图,GoClaw也是参考这个架构实现的,尽管在一些细节上有一些区别,但是整体架构是一样的:
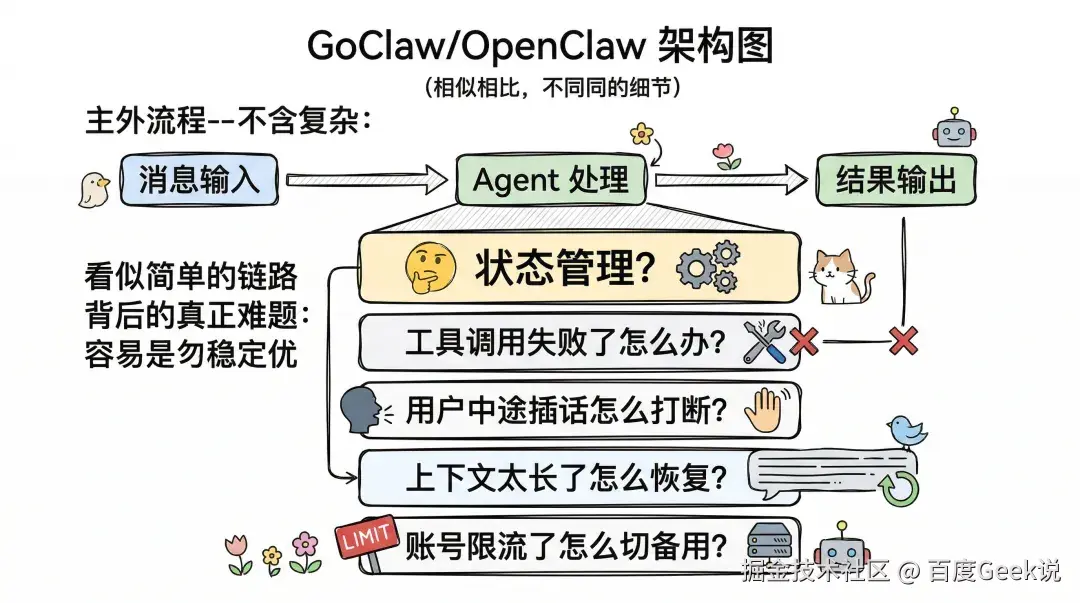
从外面看,GoClaw 的工作流并不复杂:消息进来,Agent 处理,结果再发出去。
真正难的地方不在这条主链路本身,而在主链路背后那一堆容易被忽略的问题:状态怎么管理?工具调用失败了怎么办?用户中途插话怎么打断?上下文太长了怎么恢复?账号限流了怎么切备用?
这些问题不解决,Agent 看起来能跑,实际上并不适合长期运行。
系统怎么运转?
用户消息先到 Channel 适配器。适配器负责把不同平台的格式转成统一的内部消息格式,然后扔到 MessageBus。Agent 从 Bus 拿消息,找到或创建对应的 Session,调用 Orchestrator 执行。
Orchestrator 是核心协调器,它管理 LLM 调用、工具执行、状态维护。下面有 AgentState 管消息历史和队列,ContextBuilder 组装系统提示词,RetryManager 处理重试和故障转移。工具系统通过 ToolRegistry 注册,技能系统通过 SkillsLoader 加载。
Provider 层负责对接 LLM。支持 OpenAI、Anthropic、OpenRouter 等提供商,还支持配置轮换和故障转移——主账号挂了自动切备用账号。
双循环机制:为什么很多 Agent 看起来能跑,其实一复杂就散?
GoClaw 用双循环处理消息。原因很简单:很多真实任务都不是“一次 LLM 调用”就能结束的。
很多 Demo 能跑,是因为它只处理“一问一答”。但只要任务一复杂,比如要查信息、调用工具、等待结果、接着继续判断,你就会发现单轮执行很快不够用了。
外层循环处理 FollowUp 消息。所谓 FollowUp,可以理解为“这件事做完以后,下一步还要继续做什么”。比如用户说“帮我查下明天天气,如果下雨就提醒我带伞”,Agent 查完天气后,会继续判断是否需要发提醒,这就是一个典型的 FollowUp 任务链。
内层循环处理工具调用和 Steering。工具调用比较直观: LLM 先决定“要读文件”或“要执行命令”,系统把结果拿回来,再继续下一轮。Steering 则是中断机制。用户在 Agent 执行过程中突然插一句“停下,别干了”,这条消息应该优先级更高,能够立即打断当前工具链,转去处理紧急指令。
用户消息 → Channel 适配器 → MessageBus → Agent.handleInboundMessage()
│
▼
Session 获取/创建
│
▼
Orchestrator.Run()
│
┌───────────────────┴───────────────────┐
│ │
▼ ▼
┌───────────────────┐ ┌───────────────┐
│ 外层循环 │ │ 检查 FollowUp │
│ (FollowUp 处理) │◄──────────────── │ 消息队列 │
└─────────┬─────────┘ └───────────────┘
│ ▲
▼ │
┌───────────────────┐ │
│ 内层循环 │ │
│ (工具调用处理) │ │
│ │ │
│ LLM调用 → 工具执行 │ │
│ ↓ │ │
│ 检查 Steering │─── 有 ──► 中断 ──────────┤
│ ↓ 无 │ │
│ 继续工具链 │ │
└─────────┬─────────┘ │
│ │
▼ │
内层循环结束 ───────────────────────────────────┘
│
▼
结果处理 → Session 更新 → Bus 发布 → Channel 发送

这和 OpenClaw 的设计有什么不同?两者都采用双循环,但恢复逻辑放置的位置不同。OpenClaw 更倾向于把重试、故障转移和上下文压缩放在外层;GoClaw 则把这些恢复逻辑更多收敛到内层执行路径里,外层循环主要负责 FollowUp。前者更容易把整体流程看清楚,后者则更利于把失败恢复和工具执行放在同一个语义闭环里。
核心组件:真正让系统转起来的,不只是模型
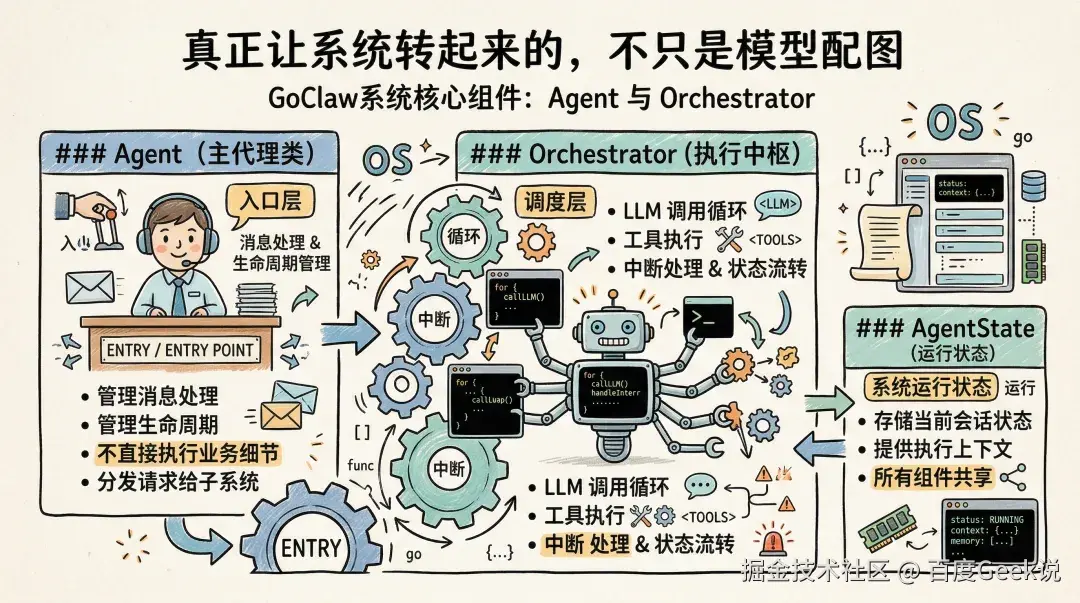
Agent 和 Orchestrator
Agent 是主代理类,负责管理消息处理和生命周期。它更像一个总入口,不直接执行业务细节,而是把请求分发给各个子系统。Orchestrator 则更接近“执行中枢”,负责 LLM 调用循环、工具执行和中断处理。
如果把 GoClaw 类比成一个小型操作系统,那么 Agent 像入口层,Orchestrator 像调度层,AgentState 则像运行时状态。
// Agent 的核心字段(省略锁、订阅等辅助字段)
type Agent struct {
orchestrator *Orchestrator
bus *bus.MessageBus
provider providers.Provider
sessionMgr *session.Manager
tools *ToolRegistry
context *ContextBuilder
workspace string
skillsLoader *SkillsLoader
helper *AgentHelper
maxHistoryMessages int
state *AgentState
}
// Orchestrator 的核心字段
type Orchestrator struct {
config *LoopConfig
state *AgentState // 作为模板的初始状态
eventChan chan *Event
cancelFunc context.CancelFunc
}
AgentState:为什么很多 Agent 一复杂就“失忆”?
AgentState 管理整个执行过程中的状态。除了消息历史和系统提示词,它还维护流式输出状态、待处理工具、Steering 队列和 FollowUp 队列,是 Orchestrator 每轮执行都会反复读写的核心对象。
很多 Agent 的不稳定,本质上不是模型不够强,而是状态管理太松散。状态一散,恢复、续跑、中断、调试都会变得很痛苦。
type AgentState struct {
SystemPrompt string
Model string
Provider string
ThinkingLevel string
Tools []Tool
Messages []AgentMessage
IsStreaming bool
StreamMessage *AgentMessage
PendingTools map[string]bool
Error error
SteeringQueue []AgentMessage
SteeringMode MessageQueueMode
FollowUpQueue []AgentMessage
FollowUpMode MessageQueueMode
SessionKey string
LoadedSkills []string
}
Steering 和 FollowUp:一个负责打断,一个负责继续
Steering 是中断式消息。用户在 Agent 执行过程中说"停",这条消息会立即插入到当前对话,打断正在执行的工具链。适用于紧急停止、修改指令等场景。
agent.Steer(AgentMessage{
Role: RoleUser,
Content: []ContentBlock{TextContent{Text: "紧急停止"}},
})
FollowUp 是后续消息。Agent 完成当前任务后,自动处理这些排队的消息。适用于任务链、异步回调、多步骤流程。
agent.FollowUp(AgentMessage{
Role: RoleUser,
Content: []ContentBlock{TextContent{Text: "继续下一个任务"}},
})
ContextBuilder:系统提示词不是写死的
ContextBuilder 负责动态组装系统提示词。它不是把一大段固定 Prompt 硬塞给模型,而是根据运行场景选择不同的上下文深度。full 模式用于主 Agent,包含身份、工具、技能、CLI 参考等完整信息;minimal 模式主要给子 Agent 使用;none 模式则只保留最基本的身份信息。
这里还涉及到上下文窗口的压缩问题。我在实现 GoClaw 时踩过一个很典型的坑:一开始我用的是一种比较粗暴的压缩策略,只保留最近的 n 条消息,把更早的历史改写成摘要塞回上下文。这个办法看起来简单,但消息之间其实是有关联的,尤其一旦涉及 tool 调用,前后消息关系不能随便截断。此前那种过于粗暴的实现,就曾导致压缩后消息对应关系错位,进而影响后续回复的正确性。
重试机制:真正的工程问题,从失败那一刻才开始
在 Agent 系统里,重试如果只是简单地“再来一次”,往往意义不大。GoClaw 的重试逻辑同时带着恢复策略:遇到上下文溢出,可以压缩历史消息;遇到账号问题,可以轮换到备用账号;遇到临时故障,可以指数退避后再试。
这也是 GoClaw 和很多“能跑起来的 Demo”之间的差别:前者把失败当成设计对象,后者通常只把成功路径写通。
type RetryConfig struct {
MaxAttempts int // 最大重试次数
BaseDelay time.Duration // 基础延迟
MaxDelay time.Duration // 最大延迟
ProfileRotation bool // 配置轮换
ContextCompression bool // 上下文压缩
}
工具系统:光会说不够,Agent 还得真的能做事
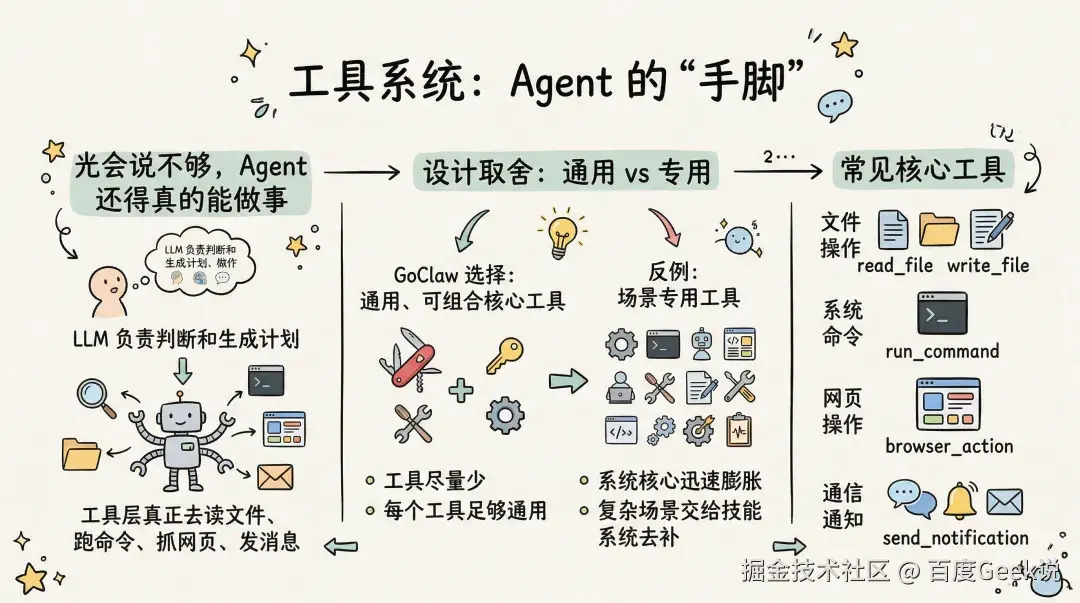
工具是 Agent 的”手脚”。LLM 负责判断和生成计划,真正去读文件、跑命令、抓网页、发消息,靠的是工具层。GoClaw 选择的是一套偏通用、可组合的核心工具,而不是针对每个场景都去发明一个专用工具。
这种设计背后的取舍很明确:工具尽量少,但每个工具都足够通用。这样系统核心不会迅速膨胀,复杂场景则交给技能系统去补。
常见的工具大致分几类:文件操作有 read_file、write_file、list_files;命令执行有 run_shell 和 process;网络相关有基于 Chrome DevTools Protocol 的 browser_*、web_search、web_fetch;另外还有 use_skill、message、cron、session_status 这些偏系统能力的工具。
工具接口本身并不复杂:声明名称、描述、参数 Schema,再实现执行逻辑即可。为了支持 UI 展示和流式回传,接口里还额外定义了 Label() 和带 onUpdate 回调的 Execute()。
type Tool interface {
Name() string
Description() string
Parameters() map[string]any
Label() string
Execute(ctx context.Context, params map[string]any, onUpdate func(ToolResult)) (ToolResult, error)
}
技能系统:为什么我更想写 Markdown,而不是继续写插件
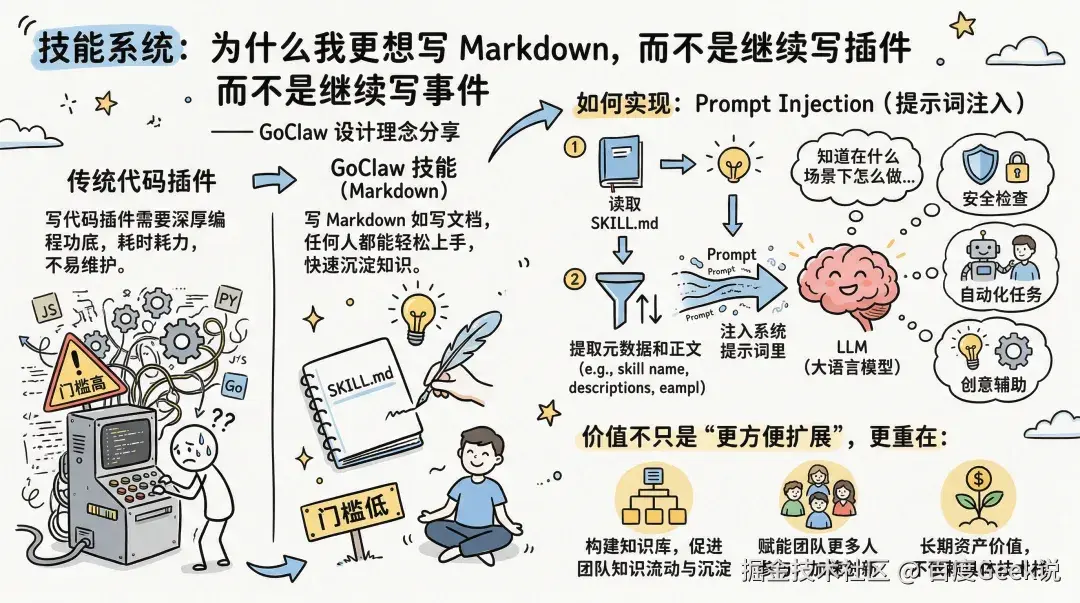
技能系统是 GoClaw 一个很有代表性的设计。Skill 更接近”知识模块”,而不是传统意义上的代码插件。
为什么这么设计?因为写代码插件的门槛高,写 Markdown 文档的门槛低得多。技能通过 Prompt Injection 实现:系统读取 SKILL.md,提取元数据和正文,再把它注入系统提示词里,LLM 就知道在什么场景下应该怎么做。
这件事的价值不只是“更方便扩展”,更重要的是它把扩展能力从“写代码的人”手里,部分转移到了“懂业务的人”手里。
一个技能文件长什么样?开头是 YAML 格式的元数据,定义名称、描述、依赖等。后面是 Markdown 格式的内容,告诉 LLM 在什么情况下该做什么。
---
name: weather
description: Get current weather and forecasts via CLI.
metadata:
openclaw:
emoji: "🌤️"
requires:
bins: ["curl"]
pythonPkgs: ["requests"]
---
# Weather Forecast
When the user asks about weather:
1. Use `run_shell` to execute: `curl wttr.in/{city}?format=3`
2. Parse the output and present it to the user
可以看到这个技能中额外补充了metadata数据,可以更好的告诉智能体如何使用这个技能,包括技能的安装,根据当前环境对技能进行筛选等。
技能加载流程大致是这样:先扫描技能目录,再解析 SKILL.md,提取元数据和正文;然后检查依赖,看所需的二进制、环境变量、Python/Node 包是否满足;最后采用两阶段注入,先把技能摘要告诉 LLM,再在它调用 use_skill 之后注入完整内容。这样既能控制提示词体积,也能减少无关技能对当前任务的干扰。
多通道支持:Agent 如果进不了消息通道,就永远只是个 Demo
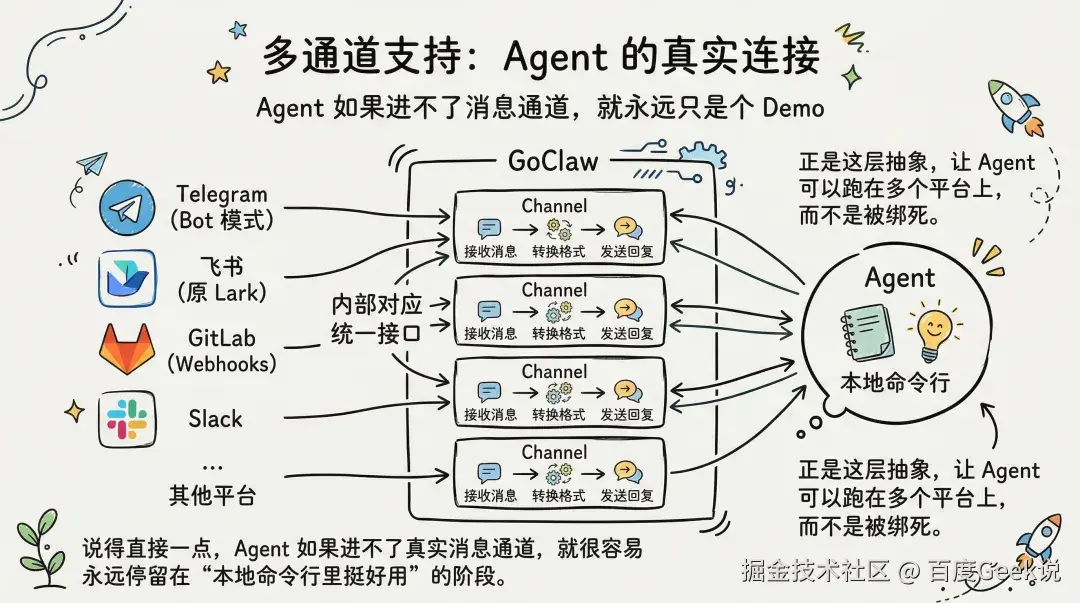
GoClaw 能接入多种消息平台。每个平台在内部都对应一个 Channel,实现统一接口。Channel 的职责并不复杂:接收消息、转换格式、发送回复。但正是这层抽象,让 Agent 可以同时跑在多个平台上,而不是被某一个 IM 生态绑死。
说得直接一点,Agent 如果进不了真实消息通道,就很容易永远停留在“本地命令行里挺好用”的阶段。
目前已经支持的平台包括:Telegram(Bot 模式)、WhatsApp(Business API)、飞书(机器人)、钉钉(Stream 模式)、微信(个人号扫码登录)、企业微信(机器人)、Slack(Bot)、Discord(Bot)、Google Chat(Bot)、Microsoft Teams(Bot)、百度如流(企业通讯)以及 Gotify(推送)。
微信通道比较特殊,基于腾讯 OpenClaw-weixin 插件协议实现。首次使用需要先扫码登录,完成后才能正常收发消息。
# 扫码登录
goclaw channels weixin login my-weixin
# 查看状态
goclaw channels weixin status my-weixin
# 登出
goclaw channels weixin logout my-weixin
而且这个微信插件的实现也非常的简单。当微信官方开始灰度OpenClaw的插件的时候,很多开发者都尝试把这个功能接入到其他智能体中。我安装了这个插件后,我就给Claude Code一句话『参考 @tencent-weixin/openclaw-weixin-cli的实现,为goclaw增加微信channel的支持』,Claude Code直接就给我生成了相应的代码。
Gateway 和 Dashboard:一个能长期跑的系统,不能只有聊天窗口
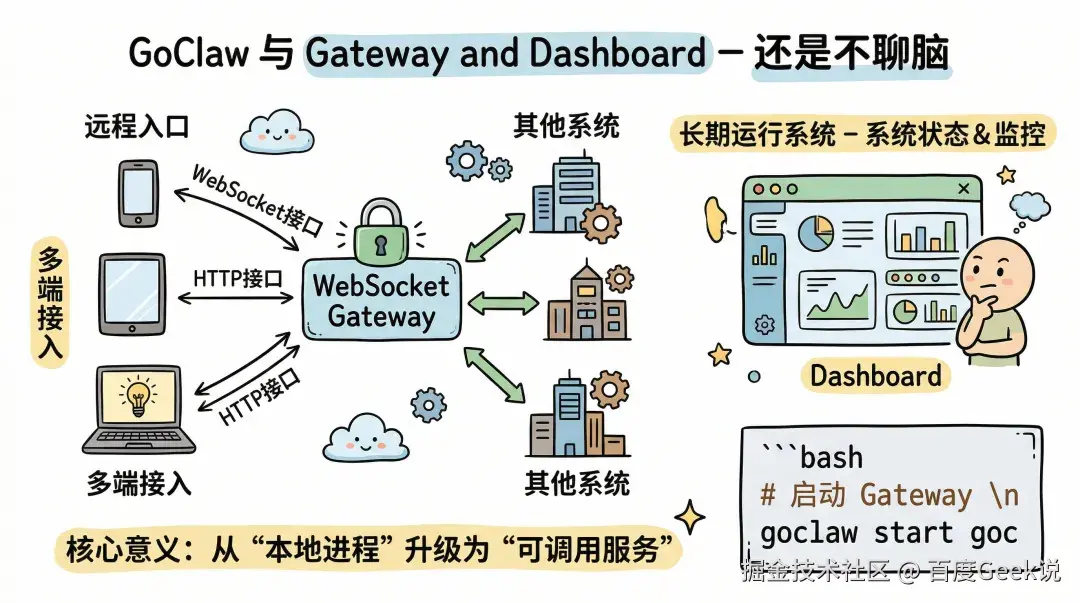
WebSocket Gateway 是一个独立服务,提供 WebSocket 和 HTTP 接口。其他系统可以通过 Gateway 调用 Agent,因此它既可以作为远程入口,也可以作为多端接入层。
这层的意义在于,它把 GoClaw 从“一个本地进程”升级成了“一个可以被其他系统调用的服务”。
# 启动 Gateway
# 更简化的临时运行命令是 goclaw start
goclaw gateway run
# 自定义端口
goclaw gateway run --port 8080 --bind 0.0.0.0
# 安装为系统服务
goclaw gateway install
goclaw gateway start
Dashboard 则是内置的 Web 界面,提供实时聊天、会话管理、Channel 状态监控、Cron 任务管理、RPC API 调用等能力。启动 Gateway 后,访问 http://localhost:28789/dashboard/ 就可以直接使用。
Cron 调度系统:真正的助手,应该会自己动起来
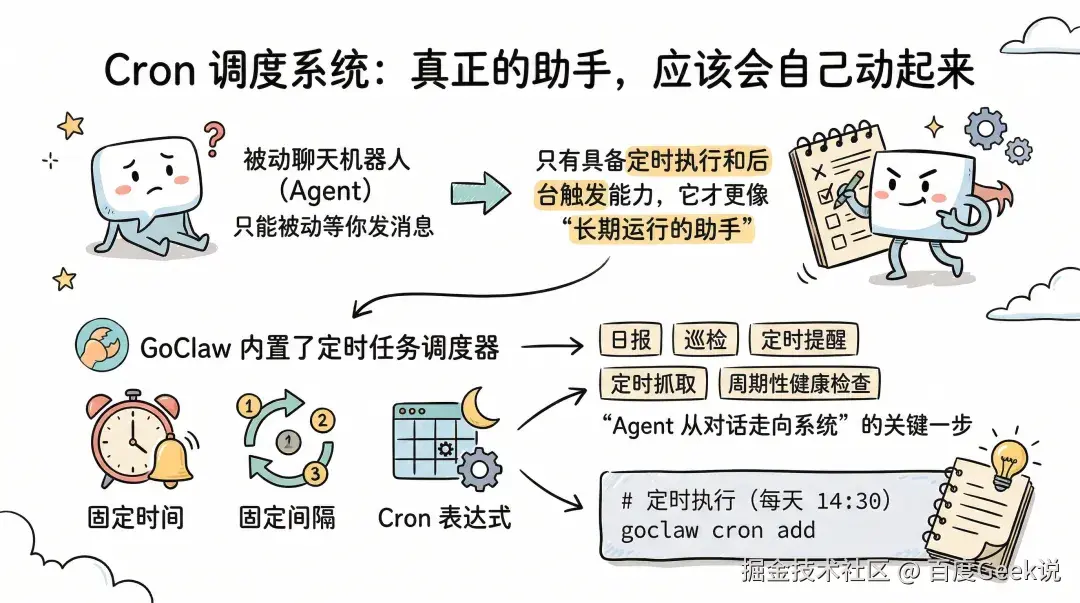
如果一个 Agent 只能被动等你发消息,那它更像聊天机器人;只有具备定时执行和后台触发能力,它才更像”长期运行的助手”。GoClaw 内置了定时任务调度器,支持固定时间、固定间隔和 Cron 表达式三种调度方式。
日报、巡检、定时提醒、定时抓取、周期性健康检查,这些都属于“Agent 从对话走向系统”的关键一步。
# 定时执行(每天 14:30)
goclaw cron add --name "Daily Report" --at "14:30" --message "生成日报"
# 间隔执行(每小时)
goclaw cron add --name "Hourly Check" --every "1h" --system-event "health_check"
# Cron 表达式
goclaw cron add --name "Weekly Backup" --cron "0 2 * * 0" --message "执行备份"
# 立即运行
goclaw cron run job-123
# 查看历史
goclaw cron runs --id job-123
当然更好的方式是在聊天对话框中,使用平常的语言设置定时任务即可。上面的命令行工具是参考OpenClaw实现的命令行管理工具,我们并不常用。
记忆系统:没有记忆的 Agent,本质上只是一次性会话

一个真正可用的 Agent,不应该每次开口都像”失忆”。GoClaw 的记忆系统大致可以分成三层:第一层是会话记录,也就是本地持久化的 JSONL 对话历史;第二层是向量记忆,用于做语义检索;第三层是 QMD(Quick Markdown Database),用 Markdown 组织长期知识,适合沉淀结构化笔记和长期记忆。
这三层叠在一起,才比较接近“能持续协作”的 Agent,而不是“每次都要重新介绍背景”的聊天模型。下面这个示例也更接近 GoClaw 当前真实使用的配置结构:
{
"memory": {
"backend": "builtin",
"builtin": {
"enabled": true,
"database_path": "",
"auto_index": true
},
"qmd": {
"command": "qmd",
"enabled": false,
"include_default": true,
"paths": [
{
"name": "notes",
"path": "~/notes",
"pattern": "**/*.md"
}
],
"sessions": {
"enabled": false,
"export_dir": "~/.goclaw/sessions/export",
"retention_days": 30
}
}
}
}
安全机制:Agent 越像助手,就越不能忽视安全
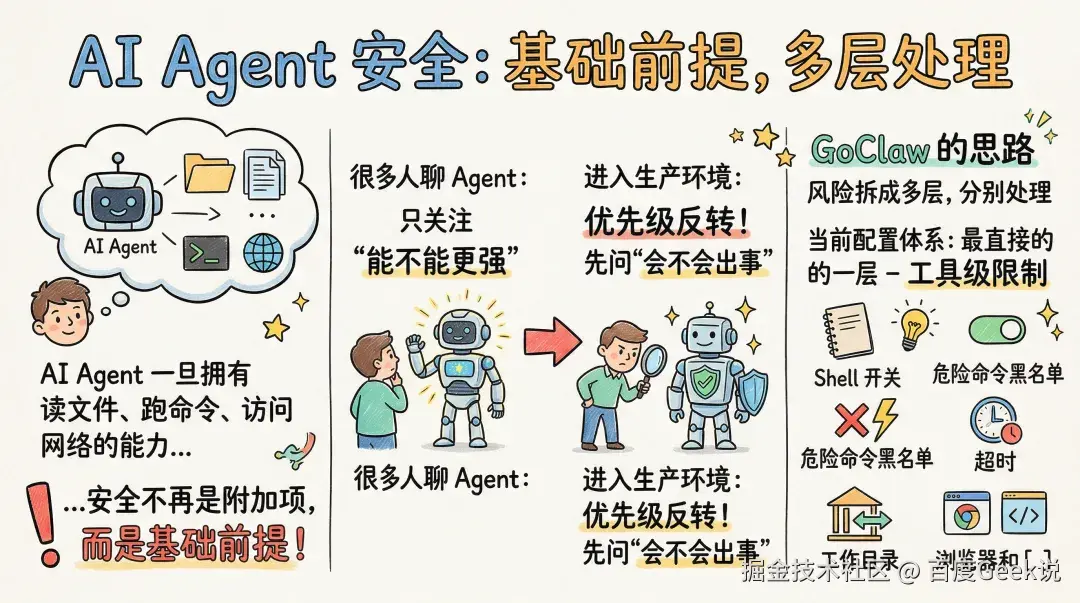
AI Agent 一旦能读文件、跑命令、访问网络,安全就不是一个附加项,而是基础前提。GoClaw 在这件事上的思路,是把风险拆成多层,再分别处理。
很多人聊 Agent,容易把注意力都放在“能不能更强”;但真正进入生产环境之后,优先级往往会立刻反过来,先问“会不会出事”。
在当前配置体系里,最直接的一层安全控制还是工具级限制,比如 shell 开关、危险命令黑名单、超时、工作目录,以及浏览器和 Web 工具的启用状态。这些配置不花哨,但非常实用。
{
"tools": {
"shell": {
"enabled": true,
"allowed_cmds": [],
"denied_cmds": ["rm -rf", "dd", "mkfs"],
"timeout": 30,
"working_dir": ""
},
"web": {
"search_api_key": "",
"search_engine": "travily",
"timeout": 10
},
"browser": {
"enabled": true,
"headless": true,
"timeout": 30
},
"cron": {
"enabled": true,
"store_path": "~/.goclaw/cron/jobs.json"
}
}
}
命令过滤是另一层防护。黑名单 denied_cmds 阻止危险命令执行,白名单 allowed_cmds 只允许特定命令执行。还会阻止危险的 shell 构造,比如命令替换、重定向、子 shell 等。
LLM 提供商:别把整个系统的命门,交给一个模型或一个账号
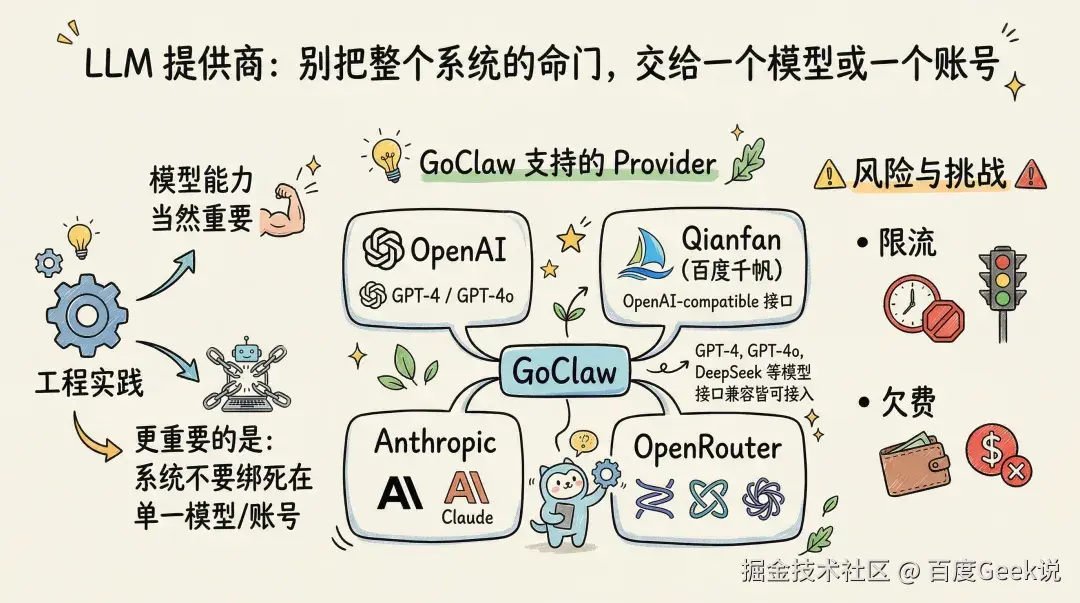
在工程实践里,模型能力当然重要,但更重要的是不要把整个系统绑死在单一模型或单一账号上。GoClaw 目前主要支持四类 provider:OpenAI、Qianfan(百度千帆,走 OpenAI-compatible 接口)、Anthropic,以及 OpenRouter。像 GPT-4、GPT-4o、DeepSeek 这类模型,只要底层接口兼容,也都可以接进来。
因为一旦系统真的跑起来,限流、欠费、波动、服务异常都不是“小概率事件”,而是迟早会遇到的日常。
从当前配置结构看,提供商配置是按 provider 展开定义的,模型则放在 agents.defaults.model 中引用。推荐直接使用显式前缀,把 provider 和模型绑清楚,比如 qianfan:deepseek-v3.2、openai:gpt-4o、anthropic:claude-3-5-sonnet。下面这个示例更贴近 GoClaw 现在实际使用的配置方式:
{
"agents": {
"defaults": {
"model": "qianfan:deepseek-v3.2",
"max_iterations": 15,
"temperature": 0.7,
"max_tokens": 4096
}
},
"providers": {
"qianfan": {
"api_key": "YOUR_QIANFAN_API_KEY",
"base_url": "https://qianfan.baidubce.com/v2",
"timeout": 600
},
"openai": {
"api_key": "YOUR_OPENAI_API_KEY",
"base_url": "",
"timeout": 600
},
"openrouter": {
"api_key": "YOUR_OPENROUTER_API_KEY",
"base_url": "",
"timeout": 600,
"max_retries": 3
},
"anthropic": {
"api_key": "YOUR_ANTHROPIC_API_KEY",
"base_url": "",
"timeout": 600
}
}
}
项目结构:代码是怎么组织起来的
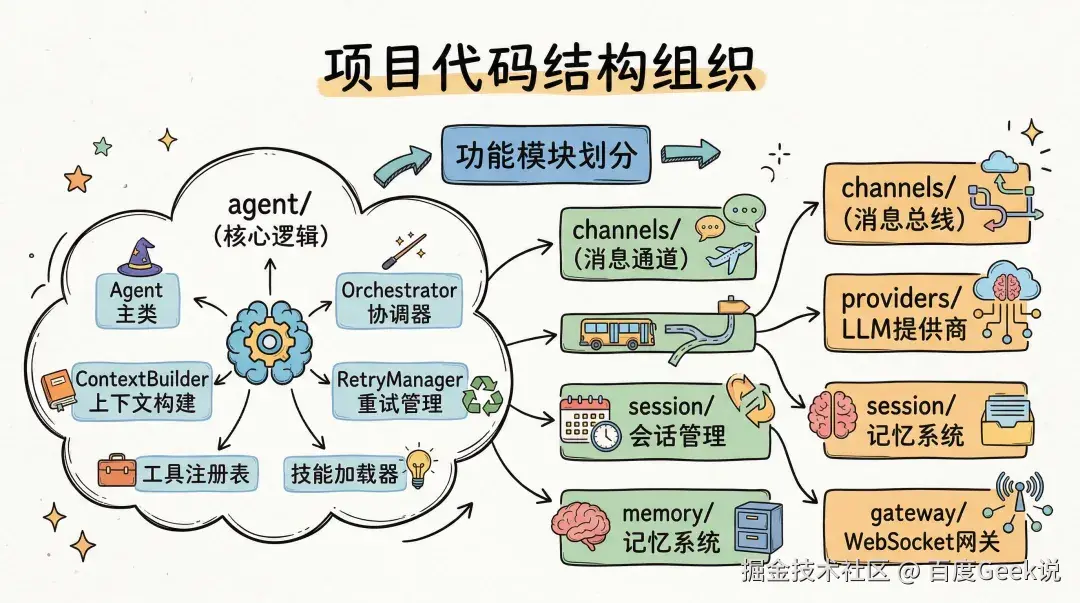
代码组织按功能模块划分。agent/ 是核心逻辑,包括 Agent 主类、Orchestrator 协调器、ContextBuilder、RetryManager、工具注册表、技能加载器等。channels/ 是各种消息通道实现。bus/ 是消息总线。providers/ 是 LLM 提供商对接。session/ 是会话管理。memory/ 是记忆系统。gateway/ 是 WebSocket 网关。cron/ 是定时任务。cli/ 是命令行界面。config/ 是配置管理。
goclaw/
├── agent/ # Agent 核心逻辑
│ ├── agent.go # Agent 主类
│ ├── orchestrator.go # 执行协调器
│ ├── context.go # 上下文构建器
│ ├── retry.go # 重试机制
│ ├── types.go # 类型定义
│ └── tools/ # 工具实现
├── channels/ # 消息通道
├── bus/ # 消息总线
├── providers/ # LLM 提供商
├── session/ # 会话管理
├── memory/ # 记忆系统
├── gateway/ # WebSocket 网关
├── cron/ # 定时任务
├── cli/ # 命令行界面
├── config/ # 配置管理
└── internal/ # 内部包
快速开始:先跑起来,再慢慢扩展
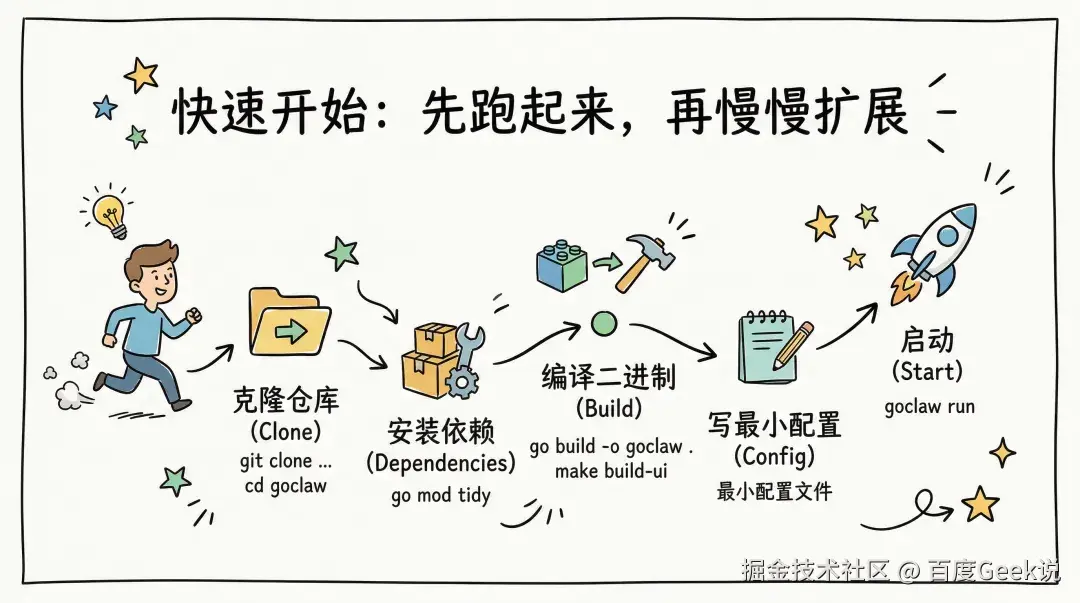
如果你只是想尽快把 GoClaw 跑起来,路径其实很直接:克隆仓库,安装依赖,编译二进制,写最小配置,然后启动。
# 克隆仓库
git clone https://github.com/smallnest/goclaw.git
cd goclaw
# 安装依赖
go mod tidy
# 构建
go build -o goclaw .
# 或完整构建(包含 UI)
make build-full
# 创建配置
cat > ~/.goclaw/config.json << EOF
{
"workspace": {
"path": ""
},
"agents": {
"defaults": {
"model": "qianfan:deepseek-v3",
"max_iterations": 15,
"temperature": 0.7,
"max_tokens": 4096
},
"runtime": {
"type": "claude-code",
"claude_code": {
"command": "/path/to/claude"
}
}
},
"providers": {
"qianfan": {
"api_key": "YOUR_QIANFAN_API_KEY",
"base_url": "https://qianfan.baidubce.com/v2",
"timeout": 600
},
"openai": {
"api_key": "",
"base_url": "",
"timeout": 600
},
"anthropic": {
"api_key": "",
"base_url": "",
"timeout": 600
}
},
"gateway": {
"host": "localhost",
"port": 8080,
"read_timeout": 30,
"write_timeout": 30,
"websocket": {
"host": "localhost",
"port": 28789,
"path": "/ws",
"enable_auth": false,
"auth_token": ""
}
}
}
EOF
# 启动
./goclaw start
# 或启动 TUI
./goclaw tui
# 或启动 Gateway(含 Dashboard)
./goclaw gateway run
# 访问 http://localhost:28789/dashboard/
设计原则:GoClaw 为什么会长成现在这个样子
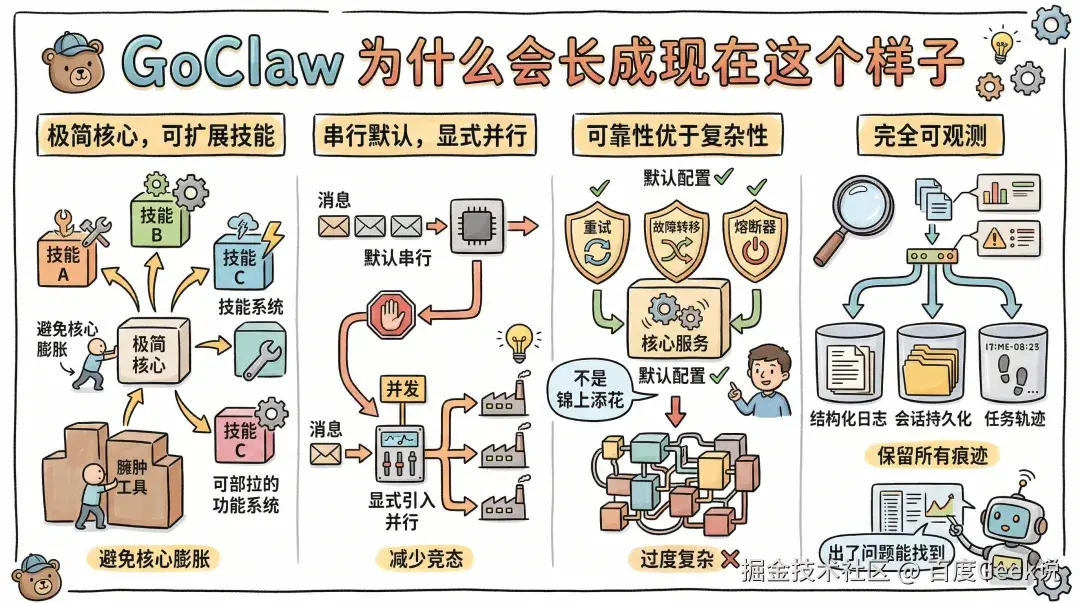
GoClaw 的设计大致遵循几条原则。
-
极简核心,可扩展技能:核心工具保持克制,把扩展能力交给技能系统,避免核心不断膨胀。
-
串行默认,显式并行:消息处理默认串行,尽量减少竞态;真的需要并行时,再显式引入。
-
可靠性优于复杂性:重试、故障转移、熔断器这些能力不是“锦上添花”,而是默认配置。
-
完全可观测:结构化日志、会话持久化、任务轨迹都尽量保留,出了问题要能查。
-
遵循 Go 的工程习惯:Context 传播、Channel 通信、接口组合,不强行套一层不必要的抽象。
如果把这篇文章压缩成一句结论,那就是:GoClaw 并不是想在 Agent 世界里发明一种全新的范式,而是想把一套已经被验证过的设计,用 Go 的方式做得更稳、更轻、更容易落地。
如果你也在做 Agent,而且已经开始从“怎么把 Demo 跑起来”,转向“怎么把系统长期跑下去”,那么 GoClaw 也许正是一个值得参考的方向。
一个真实实践:让 GoClaw 帮我把磁盘扩容这件事做完
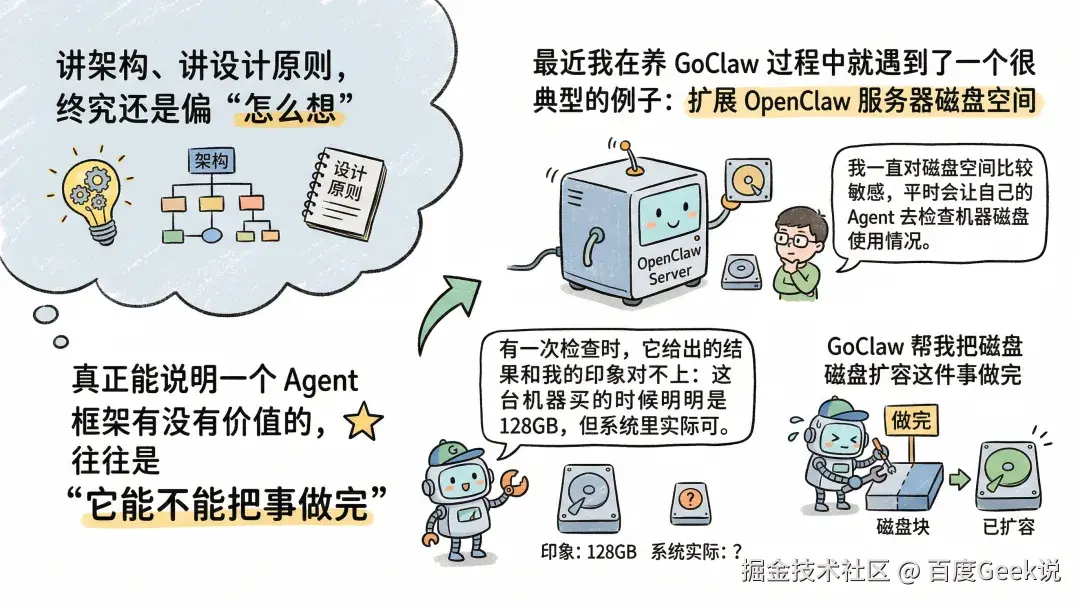
讲架构、讲设计原则,终究还是偏”怎么想”;真正能说明一个 Agent 框架有没有价值的,往往是”它能不能把事做完”。
最近我在养goclaw过程中就遇到了一个很典型的例子:扩展OpenClaw服务器磁盘空间。
事情的起因很简单。我一直对磁盘空间比较敏感,平时会让自己的 Agent 去检查机器磁盘使用情况。有一次检查时,它给出的结果和我的印象对不上:这台机器买的时候明明是 128GB,但系统里实际可用的分区却只有六十多 GB。
继续排查之后,问题就清楚了:原来机器上还有大约 58GB 的空间根本没有分配到当前分区,这是我在安装Ubuntu的时候遗漏了。这不是常规的“磁盘快满了,该清理了”,而是一个更偏系统运维的问题:先确认现状,再识别未分配空间,最后决定怎么把它扩容到根分区。
这个场景很适合检验 GoClaw 这种 Agent 框架到底有没有实战价值,因为它不只是回答一个问题,而是要完成一整条链路:
-
先检查磁盘和分区状态
-
再分析问题到底出在“磁盘占满”还是“空间未分配”
-
然后给出可执行方案
-
最后在确认之后真正执行操作
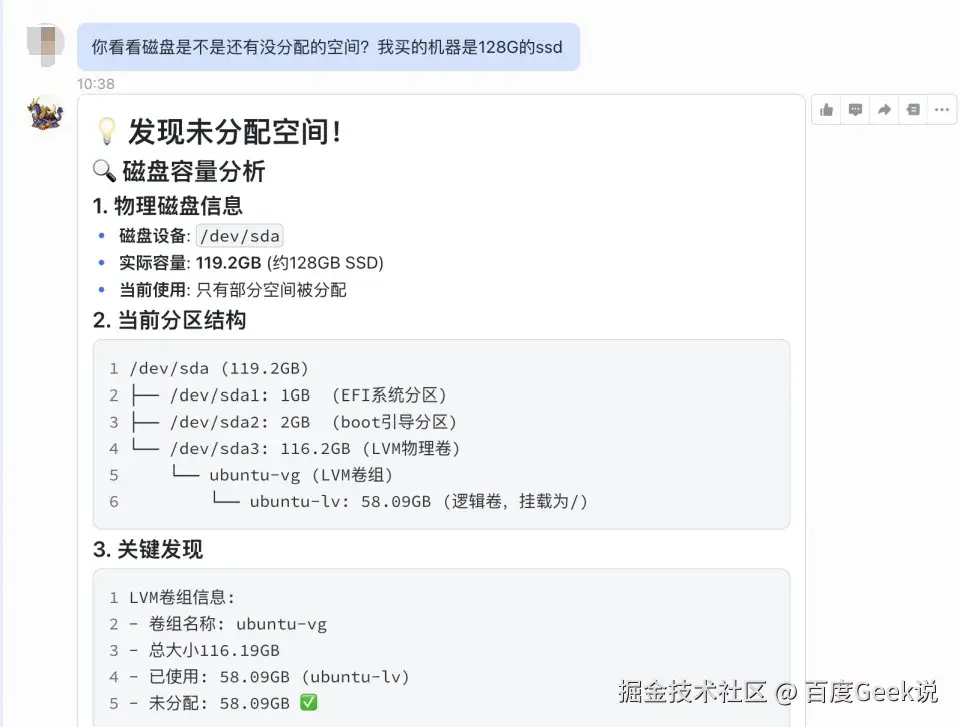
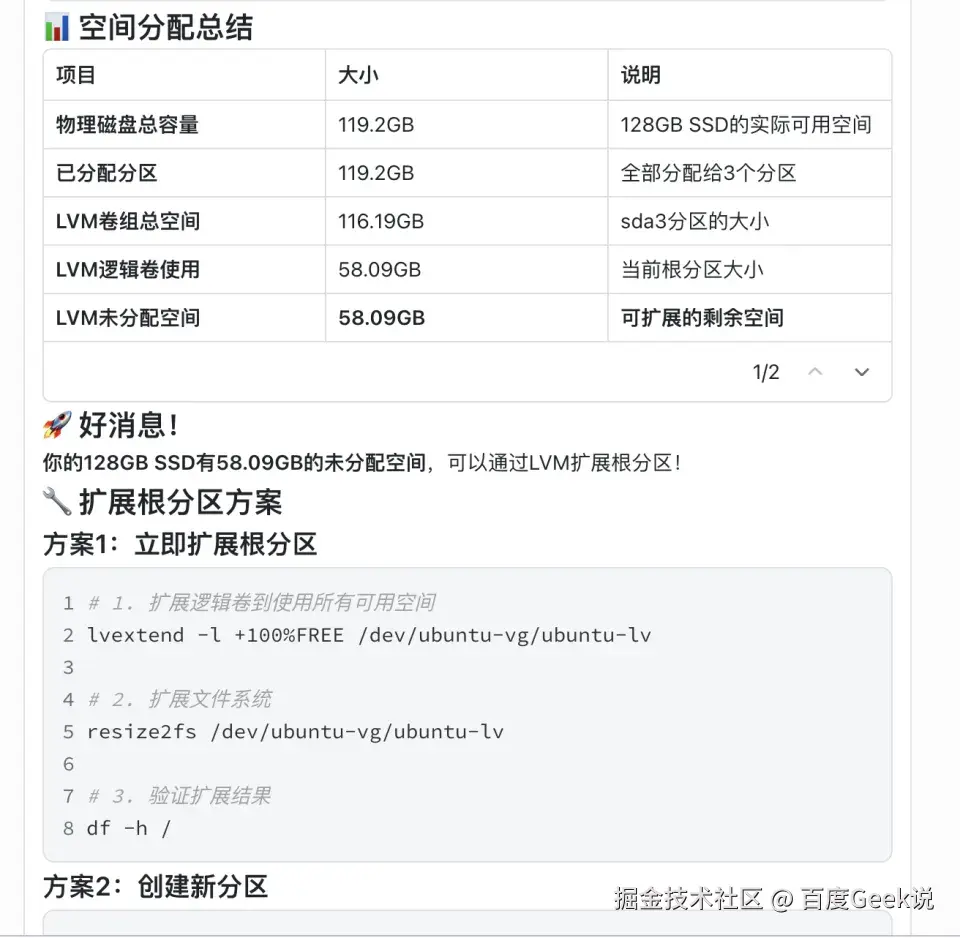
我只说了"立即"两个字,它就帮我完成了:
从框架视角看,这件事刚好把 GoClaw 的几层能力串了起来。
-
工具系统负责执行实际命令,读取分区信息,完成磁盘检查和后续操作。
-
AgentState 和会话上下文负责保留中间判断,避免做到一半“失忆”。
-
双循环机制让它可以先完成检查,再进入下一步执行,而不是一次回答就结束。
-
安全机制则提醒你:这类系统级操作最好只在可控环境中进行,不要一上来就在关键机器上放开权限。
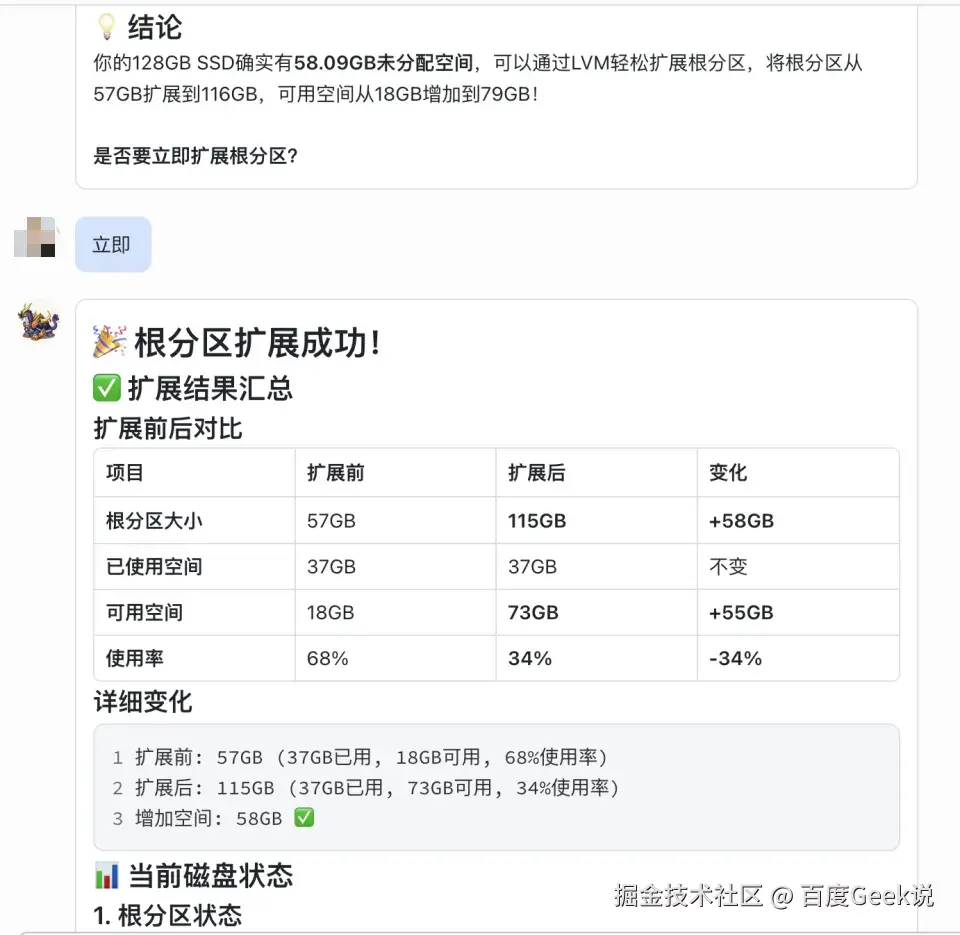
更重要的是,这个案例说明了 GoClaw 适合做的不是“陪你聊聊天”,而是“替你把一个你知道目标、但不想自己手敲每一步命令的任务跑完”。
当然,这类能力也天然伴随着边界。像磁盘扩容、文件删除、系统配置修改这种操作,更适合先在实验机、测试环境或者你完全可控的机器上使用。Agent 能帮你提高效率,但前提仍然是:权限要可控,风险要可知,回滚路径要提前想清楚。
如果说前面那些章节解释的是 GoClaw 的设计思路,那么这个实践案例展示的就是另一件更实际的事:当 Agent 真正接进系统、工具和运行环境之后,它开始从“能回答问题”变成“能替你完成任务”。