DeepSeek 发布多模态模型及技术报告;小红书官宣组织调整:柯南出任总裁;宇树发布双臂人形机器人,2.69万元起售

DeepSeek 发布多模态模型及技术报告

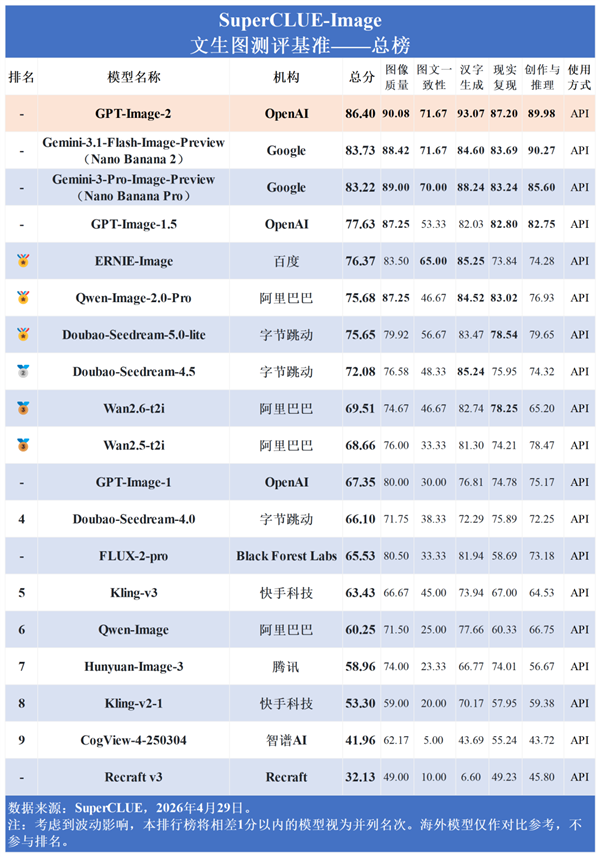
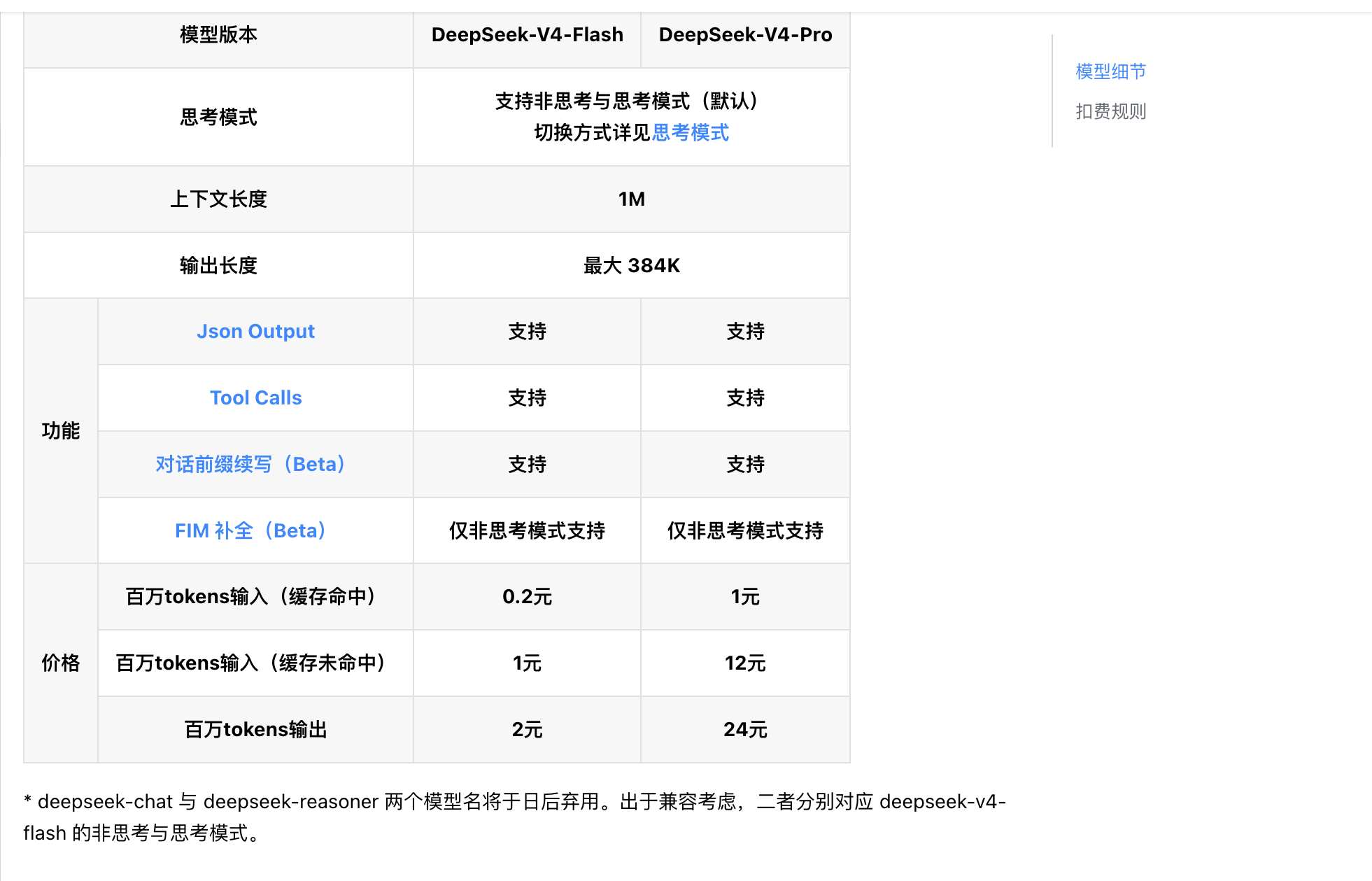
近日,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。
在技术报告中,DeepSeek 提到:尽管多模态大语言模型(MLLMs)取得了显著进展,但主流的思维链(CoT)范式仍主要局限于语言学领域。虽然近期研究重点通过高分辨率裁剪技术(例如基于图像的思考)来弥合感知鸿沟,却忽视了一个更根本的瓶颈:参照鸿沟。自然语言固有的模糊性往往无法为复杂的空间布局提供精确、明确的指引,导致需要严谨参照的任务出现逻辑崩溃。
而 DeepSeek 多模态技术报告提出基于视觉原语的思考——这一创新推理框架将点、边界框等空间标记提升为「思维的基本单元」。通过将这些视觉原语直接融入思考过程,DeepSeek 的模型在「推理」时能够「指代」,从而将其认知轨迹有效锚定在图像的物理坐标中。
值得注意的是,DeepSeek 技术报告提到,其框架基于高度优化的架构,具备极高的视觉标记效率。尽管模型规模紧凑且图像标记预算显著较低,DeepSeek 的多模态模型在具有挑战性的计数和空间推理基准测试上,能够与 GPT-5.4、Claude-Sonnet-4.6 和 Gemini-3-Flash 等前沿模型匹配。这为开发更高效、更具可扩展性的 System-2 类多模态智能指明了方向。(来源:每日经济新闻)

苹果发布季度财报:iPhone 17 系列表现强劲
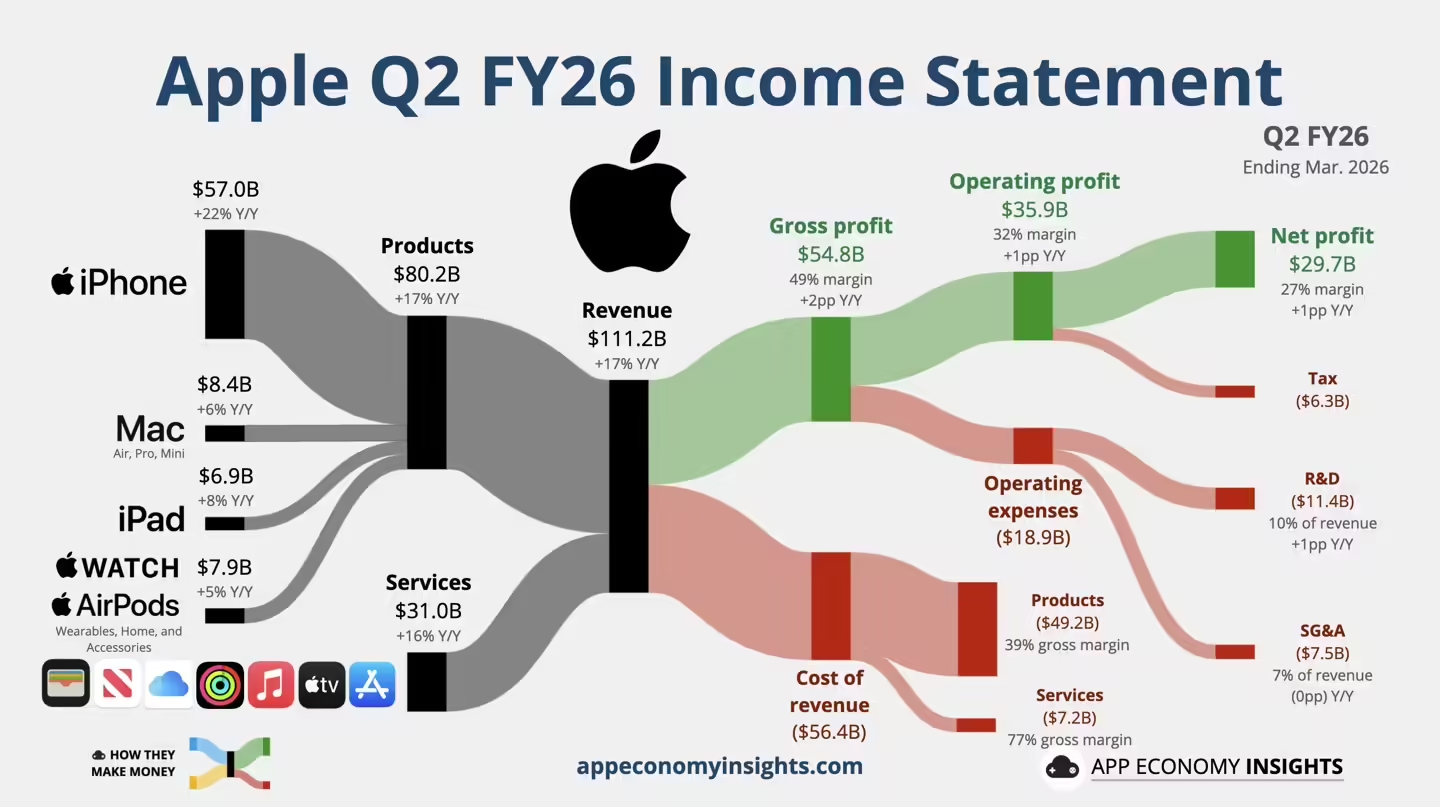
北京时间 5 月 1 日,苹果公布了 2026 财年第 2 财季(对应今年第 1 季度,截至 3 月 28 日)的财报数据,本季度公司营收 1111.84 亿美元,同比增长 16.6%;净利润为 296 亿美元,增长 19.4%;大中华区营收为 204.97 亿美元,同比增长 28.09%。
在 iPhone 17 系列驱动下,iPhone 业务表现强劲,营收达 570 亿美元,同比增长 22%。该产品在美国市场客户满意度达 99%,创下三月季度升级用户数新纪录。
服务业务收入攀升至 310 亿美元,同比增长 16%,再创历史新高,付费账户与交易账户数均达季度峰值。Mac 营收 84 亿美元,同比增长 6%,MacBook Neo 市场需求远超预期。
供应链方面,先进制程芯片产能成为主要瓶颈,导致 Mac mini、Mac Studio 及 MacBook Neo 等机型交付紧张。公司预计部分产品需数月才能实现供需平衡。毛利率环比提升 150 个基点至 49.3%,但内存成本上涨带来压力,下一季度影响将更为显著。(来源:IT之家)
Figure 机器人量产大幅提速,从每天一台到每小时一台
当地时间 4 月 29 日,人形机器人公司 Figure 创始人布雷特·阿德科克(Brett Adcock)在社交平台 X 发文称,过去 120 天里,Figure 的生产效率扩大了 24 倍——从每天 1 台机器人提升到每小时 1 台机器人。
阿德科克表示,仅在本周,Figure 就将生产 55 台机器人。
同日,Figure 公布了旗下第一代自动化生产线 BotQ 的最新进展:生产线末端的一次合格率已超过 80%,并且每周都在提升;电池生产线的一次合格率达到 99.3%,已交付超过 500 个电池组;已生产超过 9000 个执行器,涵盖 10 多个不同的 SKU。
值得注意的是,在 BotQ 工厂中,人形机器人本身也会参与搬运、组装新机器人。(来源:东方财富网)
小红书官宣组织调整:柯南出任总裁,成立 AI 一级部门
4 月 30 日,小红书通过全员内部信官宣新一轮组织升级。核心动作包括全面整合社区、电商、商业化与技术体系,加码 AI 战略布局并启动国际化攻坚。
本次人事调整中,柯南升任总裁,统管社区、电商、商业化三大核心业务及技术体系,直接向 CEO 星矢(毛文超)汇报。
内部信明确两大核心动作:一是成立 AI 一级部门 Dots,直接向柯南汇报,定位为构建从模型研发、基础设施、工程落地到产品应用的全链路技术体系,整合顶尖 AI 人才与资源,成为驱动业务增长的技术引擎;二是成立企业智能部,搭建适配 AI 时代的组织能力底座。
海豚社创始人李成东分析认为,将 AI 团队升格为一级部门,足见小红书对 AI 的重视程度,其核心意图是依托 AI 重构广告投放系统与电商供应链,通过提升广告精准度、优化智能选品、落地虚拟试妆等应用,最终实现变现效率的跨越式提升。(来源:科创板日报)
三星突破 4nm 制程芯片成熟工艺门槛
近日,三星晶圆代工 4nm FinFET 制程(SF4X)良率已正式突破 80% 门槛,终于迈入成熟生产阶段。
三星自 2021 年开始大规模生产 4nm 工艺,初期良率仅约 35%。此后经历长达六年的持续优化与良率爬坡,才终于撞线 80% 目标。
这是半导体制造领域公认的工艺成熟分水岭,此前一直被台积电牢牢占据。目前台积电 4nm 良率约在 85%-90% 区间。
良率跃升直接推动代工客户的密集涌入。由英伟达间接收购的 AI 芯片初创公司 Groq,已于今年 3 月将三星 4nm 晶圆订单从 9000 片追加至 15000 片。
除 Groq 外,三星 4nm 客户版图覆盖多家产业链玩家。据韩媒爆料,IBM、百度、以及一家加密货币公司均已采用三星 4nm 方案。(来源:快科技)

硅谷高管:现阶段 AI 成本高于人力,但高额 AI 账单仍是积极信号
近日,英伟达高管和 Uber 首席技术官指出,现阶段 AI 服务(如代码助手、自动化智能体)的运营成本高于人力成本。
这一观点挑战了「AI 必然降本增效」的普遍预期,揭示了当前阶段企业应用 AI 的一个现实:在追求技术革新的初期,投入成本可能不降反升,而管理层正试图将这种投入重新定义为战略投资。
英伟达应用深度学习副总裁 Bryan Catanzaro 表示:「对我的团队来说,计算成本远远超过了员工成本。」
真正的巨额开支源于基于 Token 的模式,尤其是 Claude Code 和 GitHub Copilot 等编程助手,以及执行复杂自动化任务的智能体。
尽管成本高昂,但企业界的反应出人意料。许多 CEO 并不将高额的 AI 账单视为负担,反而看作积极信号。他们认为,这证明员工正在深入使用 AI 工具,推动大规模自动化进程,从而驱动企业创新。(来源:IT之家)
马斯克旗下 Neuralink 打造手术机器人:缩短脑机芯片植入时间
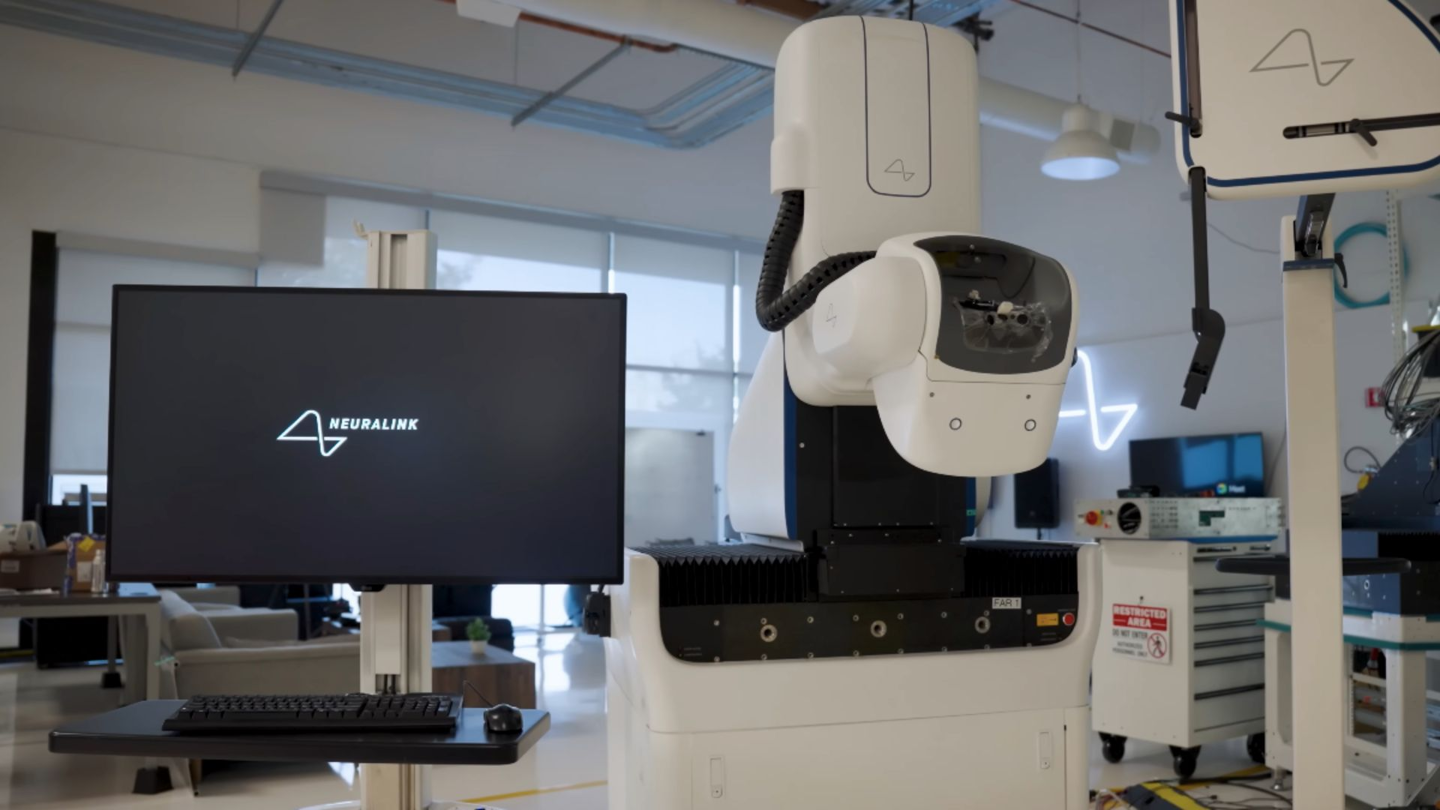
据外媒 Interesting Engineering 报道,近日马斯克旗下 Neuralink 推出了一款专用手术机器人,目标是让脑机接口植入过程实现更高程度的自动化。
这项新工具的重点,是提高植入手术的安全性和可靠性,并让未来大规模应用成为可能。
Neuralink 的植入线「细而柔软」,甚至比人的头发还细,传统手工手术很难精确处理。为此,Neuralink 开发了专用机器人,利用 8 个摄像头和 OCT 扫描仪,在手术过程中实时识别和避开脑组织。
目前,人类外科医生仍然不可或缺,机器人则开始承担高精度、重复性强的步骤。这类操作对稳定性要求极高,而机器人在一致性上更有优势。
这一看似很小的改动意义很大:手术时间会缩短,感染风险也会降低,未来甚至可能让植入流程变成一次快速完成的短住院手术。(来源:IT之家)
泡泡玛特首款 LABUBU 冰箱开售秒罄,二手溢价 4000 元

4 月 30 日晚,泡泡玛特 LABUBU 冰箱正式开售,商品上架后秒罄。
据悉,本次发售的泡泡玛特 THE MONSTERS 生活家系列冷藏箱分为 Home 款和 House of the Monsters 款两个版本,两个版本均为全球限量发售 999 台,每一台都拥有限定编号,售价为 5999 元。
值得一提的是,在抢购热潮下,原价 5999 元的泡泡玛特 LABUBU 冰箱,二手交易价格已达到 9999 元,溢价 4000 元。
从硬件配置来看,这款 LABUBU 小冰箱是一台入门级产品:总容积 121L,相当于普通迷你冰箱,且冷冻室极小(15L);ABS 食品级内胆和钢化玻璃隔板,符合安全标准的普通材质;温控、能效和噪音,也都是正常产品水准。
曾有报道称,这款小冰箱由某知名小家电代工巨头制造,双方主要采用 OEM(原始设备制造商)模式合作。门体布满 LABUBU 和 TYCOCO 的卡通角色形象,银色手柄上镶嵌着 LABUBU 立体头像,机身铭牌印着 THE MONSTERS 字样,强化了收藏级「手办」属性。(来源:快科技)

宇树发布双臂人形机器人,2.69万元起售

4月30日,宇树科技正式发布双臂人形机器人,定价2.69万元起。该机型主打上半身双臂操作,下半身可选固定底座或移动底盘。
本次发布的双臂人形机器人共推出四个版本,核心差异为手臂自由度与底座配置。四个版本均标配2kg手臂负载、±0.1mm末端夹爪精度,末端支持二指夹爪、三指灵巧手、五指灵巧手更换,语音与视觉协同配置保持一致。
整机支持15到31自由度,手臂自由度提供5x2和7x2两种方案,动作范围覆盖日常操作与工业辅助需求。
机身与头部均搭载8核CPU,头部模组算力达到10TOPS。配合视觉双目算力模组和语音交互系统,可实现多元人机交互。
机器人末端支持快速更换执行器,适配抓取、夹持、装配等任务,适用于轻工业、实验室及服务场景。(来源:快科技)
钉钉发布 DingTalk A1 Pro,支持为手机反向充电

4 月 30 日,钉钉正式发布 AI 硬件家族新成员 DingTalk A1 Pro,售价 1299 元。
这款产品在 AI 录音卡片的基础上集成了 2980mAh 大电池,支持为手机反向充电,已通过新国标 3C 认证。
硬件设计上,A1 Pro 整机厚度仅 6.4mm,机身自带磁吸设计,无需额外皮套即可吸附在手机背面,配备触摸屏可直接切换充电模式。
软件层面,A1 Pro 与钉钉 AI 听记能力深度整合,支持录音实时转写、AI 大模型总结分析和多语种实时翻译。内置 200 多种 AI 纪要模板,覆盖客户拜访、面试问答、法律咨询、跨国会议等典型场景,录音内容还可一键生成日程、待办和会议纪要,直接流转至钉钉工作台。(来源:快科技)
张雪机车 MX250 摩托车发布,2.98万起售

4 月 30 日,张雪机车发布首款场地越野车 ZXMOTO MX250,官方指导价 2.98 万元。
张雪机车 MX250 采用双喷油嘴发动机,最大功率 30kW@12500rpm,最大扭矩 27N·m@9500rpm。
张雪机车 MX250 采用了多项减重设计,整车重量 102kg,配有镁合金发动机左右边盖和顶盖、铝合金副车架、镁合金调压器、铝合金后摇臂、7050 铝合金轮圈等。
该车还配有 KYB 阻尼全可调前后减震,内置骨架手把胶、手把小屏。(来源:IT之家)

天文学家最新发现:2031 年,火星往返航线仅需 153 天
沿着地球与火星这颗邻近行星之间相对笔直的航线,单程火星之旅需要 7 至 10 个月左右。但一位天文学家借助小行星的早期轨道数据,或许找到了穿越太阳系的捷径。
在一项新研究中,来自里约热内卢州立大学北部分校的研究人员马塞洛,顺着小行星 2001 CA21 的预测运行轨迹,探寻通往火星的全新航线。这项研究成果发表在《Acta Astronautica》期刊上,研究确定了一条往返火星的航线,全程仅需约 153 天。
结合发射窗口期分析与该小行星的早期轨道预测,研究人员发现,2031 年是唯一一年地火天体几何排布与小行星轨道平面完美契合的年份。研究指出,在 2031 年发射窗口期内,有两套可行的火星往返任务方案,总时长分别约为 153 天和 226 天。
这项新研究旨在为星际航线规划提供一种全新思路,有望将星际航行时长缩短数百天。一直以来,科学家密切监测小行星主要是为防范其撞击地球的潜在威胁,而如今,这些太空岩石也有望成为人类穿越太阳系的天然航行路标。(来源:IT之家)