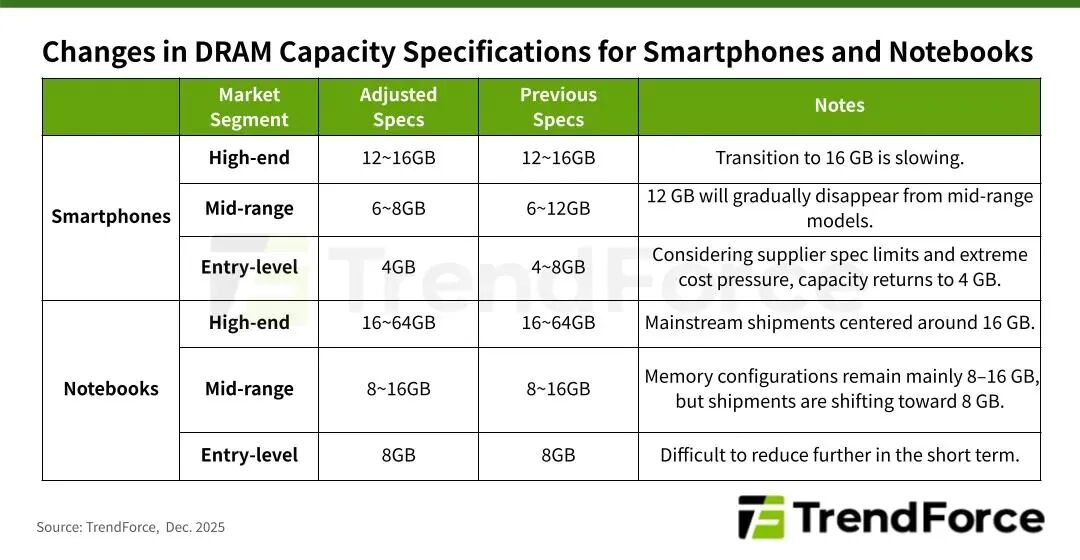
作者|汤一涛
编辑| 郑玄
智能汽车作为机器人的第一个大终端。在大模型技术快速发展的当下,源自智能汽车的算法、算力技术正在被加速复用,催生出从单一任务到通用智能、从交通工具到机器人的宏大图景,推动着一场从「车」到「人」的智能化跃迁。
然而,具身智能的发展还面临多重现实挑战。从数据采集到模型训练,从硬件本体到场景落地,产业链各环节都存在大量技术和工程问题。仅仅依靠单一机构难以全链条突破,必需要构建多方共建的产业协作生态。
地平线作为机器人时代的智能计算平台,既是这场进化的见证者,更是深度参与者与赋能者。当前,地平线已成为中国最大的消费类机器人计算平台,旗下地瓜机器人上市产品超过 100 款,连接着超 100 家上下游合作伙伴与 10 万余名开发者。
在 12 月 9 日举行的 2025 地平线技术生态大会上,极客公园创始人张鹏与本末科技创始人兼 CEO 张笛、极佳视界创始人兼 CEO 黄冠、优必选研究院 A1 大模型与交互部负责人石海林、香港大学数据科学研究院助理教授李弘扬、地瓜机器人 CEO 王丛等嘉宾,进行了一场「名」人不说暗话的硬核圆桌,全景呈现了从芯片、算法、开发平台到机器人本体的全产业链创新,深度探讨具身智能的技术发展、商业落地,聚焦技术跨域赋能的生态潜力。
在这场对话中,你既能看到具身智能当下直面的痛点与挑战,也能捕捉到切实可行的落地场景;既有对前沿技术路线与商业逻辑的深度剖析,也有这一赛道未来的无限可能。
以下为圆桌对话实录,由极客公园整理。

01
形态之争:类人形态 VS 功能形态
张鹏:在产品形态上,具身智能应当追求「类人形态」的极致拟人,还是「功能形态」的极致效率?
张笛 :首先是本末我们自己一方面有一个直驱型的机器人关节的特色技术平台,另外一块是以轮足为特色的具身智能的机器人技术平台。
我们选择这个方向出发点跟刚才张鹏老师讲到的,我们作为技术型的创业者,对乐观和悲观我们到底应该怎么看,怎么样去建模?因为我个人包括我们整个团队其实一直是对未来持有无限乐观,但是对中短期的界限,会尽可能保持悲观的状态。硬科技有一个特点,别到最后创业未半中道崩卒,还没等实现自己的技术愿景,反而最后导致自己的经营上出现问题,所以我们本质上建模可能会倾向于用这种方式,去做公司未来技术路线的选择。
在这个路线下面,我们去看人形机器人和轮足这样的形貌,其实核心的差异点是在于我们对移动和操作这两个大问题上,我们到底选择什么样的解题思路,一种解题思路是纯仿生,另外一种是不单纯的仿生,不只仿生,我们倾向于第二个。从人形的角度来看,当然可能有很多人会说人形会有很多落地的场景,我们也从来不排斥这样的观点和看法,但是我觉得今天的主题也比较好,名人不说暗话,还是虚火过剩的,我还是觉得这个行业是很强的。
张鹏 : 既然说是「虚火」,那一定是当下存在某些难以解决的问题。你觉得核心瓶颈主要卡在哪里?
张笛 :我觉得问题是现在其实大家对这个行业的关注是够的,这是非常好的一件事儿。因为任何一个行业都需要有一定的 show off 的能力,让大家有足够的传播点,但是问题在大家只关注到了其中的一方面,大家只关注机器人这个大品类当中类人形的一方面,这件事情是不够健康的。
其实机器人这个品类有非常多可以选择的余地,甚至说仿生、拟人都只是一个可以选择的方向,这个行业有无限的可能,这就是为什么我们说对未来无限乐观,但是对现在却保持相对审慎的态度,我们觉得机器人这个赛道可以走伴生的模式非常多,但是现在似乎有太多狭隘,把所有的精力和资源投在一个角度上,这就是我们倾向于未来在双足和轮足上面,我们会朝着非拟人、非仿生这个方向探索的一个主要原因。
张鹏 : 所以你认为超人的场景比拟人的场景会更多,或者说在有些场景超人是比拟人有更好的解法的,可以这么理解吗?
张笛 :可以这么理解,而且我觉得最主要的是,拟人作为一个大行业的入场券,没有任何的设计参照,开始想尽办法去开启一个行业,这个起始点非常好。
但是随着一个行业的向下发展,总会发现,其实垫脚石下一步踩在哪?英雄老路未必是最优解,我们有非常多的思路告诉你,机器人是新物种,可以完全设计一个新的产品,这个对整个行业来讲是最健康,最有诱惑力,对我们年轻的人来讲也是最有挑战的方向。
张鹏:优必选坚定走人形机器人方向,背后有怎样的判断和考量?在你们看来,哪些场景是只有人形才能满足的不可替代需求?
石海林 :这个问题,我们优必选作为人形机器人的先行者以及行业龙头,我们会很务实去看人形机器人,包括双足轮式,都是属于人形机器人,回到这个问题,我觉得可以从两方面去看。第一个我们追根溯源,去看人类为什么是人形的。从大自然还有生物进化千百年来看,人之所以成为人形,我们的四肢,我们的手有五个手指头,我们的五官在头上,我们大部分人的眼睛的距离平均在 6 厘米,为什么大家都是这样的,其实背后是因为适应了自然环境和我们人类社会环境的结果。
今天我们来看人形机器人,它去做到人形,其实更多的不是说我们一定要做到怎么样,而是说从自然最优化的结果拿到了一些结论,用在我们人形机器人的产品和形态上,这是第一点。
第二点,我觉得更多也是可以从产业的应用场景去看,就以优必选我们现在聚焦的工业场景(来说),人形机器人现在主要有三大应用场景,工业场景、商业场景以及家用陪伴场景。后两个商用场景和家用场景,因为还有一些交互和情感陪伴的需求,这些需求会更直接的去对人形外观、ID 设计甚至仿生人形有更高的要求,这些还是比较直接能得出的结论。从工业场景来看的话,为什么我们也要去看人形在这个场景里的优化,因为在工业场景,通过长期以来的应用,我们可以看到有大量的结构化任务,也有更大量的非结构化任务,这些非结构化的任务从需求出发,去要求产品和功能要具备更强的泛化能力。在我们在工厂看到,各类形形色色的机械臂各种捶打,但是只能做一些特定的死的任务,而且形态各异,动不动 4、5 米高,特别大。
但我们看到更多的任务,是比如说物流转运,里面包含了搬运、分拣的任务,还有上下料、精密装配,他们的场景很多是一些狭窄的通道,一些灵巧的柔性的操作,这些对机器人的操作更高,泛化能力也更强。比如这些操作、搬运、上下料,所以在这些场景需求的催生下,我们会往人形这个方向去看。

张鹏:还有一种观点认为,选择人形形态是因为它更利于数据迁移。例如,通过人类进行遥操作或动作捕捉来采集数据,能让算法在数据闭环中迭代得更高效。
你们在实际研发中,感知到了这种数据层面带来的效率优势了吗?
石海林 :对的,人形数据相对其他形态的数据更容易采集获取、标注清洗。以遥操作采集为例,如果设备与人形,比如手部、双臂,是同样的甚至同构的,那么操作员操作起来会更高效便捷,同时培训一个数量的操作员也更简单容易。
张鹏:目前有两种产品形态的发展路径,一种「通用底盘+功能模块」;另一种是直接开发一个全能一体化机器人。你们认为哪种技术路径更有可能实现大规模普及?
张笛 :其实本末科技在观察行业生态时有很多发现,因为我提到,我们公司是平台化的机器人供应商,我们是有关键技术去服务客户。在这个过程中我们发现整个具身智能大的方向可以分两类,按照张总讲的分类方法,但我们的叫法会叫成学院派和产业派,其实相差最主要的点,学院派是自上而下,以通用为大旗,去把所有的相关的技术去做推广和积累,但产业派就是循序渐进去做通用,本质上就是一个基座上面叠加模组。这两个一个是自下而上,一个是自上而下,但是我们从统计上来看,产业派的速度和市场化的速度确实没那么快,假如大家认可,以底层的通用化平台加各种各样的功能模组逐渐去做通用这件事,是一条通向具身智能的道路的话,现在从商业化的角度,还是产业化会推动得更快一点。

石海林 :我完全认同张笛总的观点,在产业派这一块,我们自下而上从场景任务出发,构建海量的数据,以及基于算力的一些资源和优势,去快速把学术界从上而下的基座模型应用在具体各类场景中。而且这个周期我们认为是一个绝对的加速化的过程,因为我们看到,比如十几年前我们说做智能化,那个时候是做感知智能,如果我们比如以 AlexNe t 作为标志物,作为开端,到 2022 年,比如说那会儿 ViT 作为一个成熟标志的话,从发展到成熟感知智能花了十年时间。但是在感知智能的下一阶段,交互智能如果我们以 17 年 transformer 出现为开端,到它成熟期,比如说正好三年前 ChatGPT 发布作为一个成熟标志的话,这个过程从十年加速到了五年。那我们今天来看具身智能这一块,如果我们以 ALOHA 为代表,他打通了 Neural Network 在具身智能这一块的技术方案。所以我们可以把 2023 年作为起始点的话,假设我们也是以最保守 5 年来估计,从 23 年到 28 年,今天来算的话可能就三年,或者 18 个月,就已经进入到成熟期,这个周期是大大加快。
02
技术路线之争:
「先验模型」(Model-based)
VS「数据规模」(Data-driven)
张鹏:极佳科技从自动驾驶世界模型切入具身智能,目前世界模型在具身智能领域已经解决了什么问题?还有什么问题有待解决?
黄冠 :觉得这个问题提得特别好,像「世界模型」「空间智能」这些概念都备受关注。大家探讨其在内容创作、自动驾驶以及具身智能等领域的应用时,我想先讲讲我个人对世界模型对具身智能领域价值的一些看法。
我认为世界模型是物理 AGI 最后的瓶颈,并且它不是要 5 年、10 年被攻克掉,实际上我们已经看到了它被解决的曙光,得益于整个生成式 AI 的发展,这是我对整个世界模型大的看法。
更具体,世界模型对具身智能的价值是全方位的。其实我们讲一个具身模型,无非就是讲数据来源、学习范式,以及模型架构。世界模型在这三方面都有非常高的价值,首先数据来源,如果具身智能仅仅依赖真实机器和传统仿真这两种方式,可能会存在比较大的瓶颈。真机要采集到足够的数据极其困难,基于规则构建的传统仿真上限也比较受限。而世界模型提供了一种非常高效生成世界的方式,虽然它目前并不完美,但已经展现出巨大的价值,它是一个数据引擎,能够为具身智能提供无限的所需的数据。
第二个是在学习范式上,模仿学习很有价值但是远远不够,强化学习如果只是依赖真实环境去做,也是很低效的,包括大家现在看到 Pi0.6 star,虽然已经进步很大了,但仍然高度依赖真实环境;而世界模型实际上为强化学习提供了一个非常好的闭环环境,它是能够被 action 驱动的,来预测未来环境变化的模型。
对,所以我们叫它是可以 Scale 的强化学习,这是它作为模拟器的第二点价值。第三点就是更本质了,叫做世界行动模型,可以替代 VLA,L 为什么会对 action 一定必须呢?我们过去做自动驾驶也没有语言,所以 VLA 依赖这个 L 问题是很大的,要真正实现智能,就得迈向世界行动模型,所以我认为这三个点的价值都会非常大。
目前行业进展上,在上面三个方面,无论是我们的一些工作,还是全球的包括像 Cosmos 很多一些工作,世界模型都已经开始大规模的产生价值了。这是我对世界模型和具身智能关系的理解。
张鹏:世界模型能够解决具身智能领域数据匮乏的问题,但世界模型也是模型,所需要的数据同样匮乏,极佳是如何解决这个死循环的?
黄冠 :这两个问题都问得非常好,我还是思考一下,我可能这样回答。我跟大家介绍一下,第一个是各个模型的关系,我们讲三个模型,语言模型、世界模型、行动模型。语言模型输出的是语言,世界模型输出的是对未来世界的预测,未来的世界可以用 video 去表示,可以用 3D 去表示,当然也可以把 physics 表示进去。第三个行动模型输出的是 action。所以这是三个非常不同的模型。
第二个,为什么语言模型跟世界模型其实可能相比行动模型会好解决呢?就是因为数据多,大家都知道,语言模型有互联网上的海量文字数据作为支撑。而世界模型所依赖的数据中,互联网的视频数据是最重要和基础的部分,这些视频数据看似没有直接呈现三维(3D)和 physics,但实际上 3D 和 physics 都隐含在视频的隐空间里了。大家看互联网上的视频,比如一个水杯被扔出去,这其中就蕴含了非常丰富的物理规律。所以视频数据其实是一个非常好的构建世界基础模型(world foundation model)的素材来源,虽然它并不完备,但是一个非常好的基础。而我们最不缺的就是互联网上记录的海量的视频数据。所以,语言模型和世界模型能够更高效地利用丰富的语言和视频数据,进而作为行动模型的基础。
第三点,我最近也思考很多,为什么智驾和具身可能不太一样,在智驾里面,大家之前没有所谓的 VLA,没有世界模型,但也干得还不错。包括中午体验的地平线的一段式端到端,真的非常丝滑,为什么?因为智驾有大量数据,只要数据足够多,可以不依赖语言模型和世界模型,只需要场景的端到端驾驶数据就好。当然,最后加上 VLA 和世界模型,会让系统的推理能力更强,迭代更高效。但是具身模型你会发现,如果从头做一个 VA 的端到端模型,是基本不可能的,核心是因为具身领域太缺数据了,这会导致驾驶模型和具身模型非常不一样的发展路径。

张鹏:具身智能领域的模型训练会遵循 Scaling Law 吗?跟大语言模型的 Scaling Law 会有什么不一样?
李弘扬 :这个我尝试回答一下这个问题,这个问题还是问得非常前沿的,首先有个结论,具身智能领域一定会有 Scaling Law,到目前为止真正能算得上,做过 Scaling Law 实验的,这个世界上只有一家公司,就是 Generalist AI,前一阵的 Gen-0。其余包括 Physical intelligence(Pi),都没有很大规模的用 Scaling Law 的实验,都还谈不上 Scaling Law。所以你问的下一个问题,如果真有规模法则 (Scaling Law),它会和大语言模型的规模法则呈现怎样的情况呢?
其实大概率还是沿着一种幂律分布的,或者说是线性的,无论是指数级还是线性的增长的趋势,这里面我想说一下,因为 Gen-0 这个工作一周积累 30 个小时,300 万条数据(有效的轨迹),我们大概也换算了一条,如果两班倒的话,采集这个不同的 manipulation task,一班 8 个小时,16 个小时,其实有效的转化率是 4、5 个小时,因为还要涉及到数据质检、熟悉的过程等。这样的话需要 Aloha 或者说主从臂这样的一套设备需要 500 套,很显然它不可能部署 500 套,所以肯定要走 UMI 等等这种低成本的路线。在具身领域大家都在谈论数据金字塔、真机数据等概念,我觉得从算法、数据、硬件以及法律这几个维度来看,如何构建一套高效的数据采集系统,在具身智能领域是非常关键,然后我们再来说 Scaling Law 这个事。
03
数据策略之争:
仿真/合成数据 VS 真机数据
张鹏:具身智能领域会有 ImageNet 时刻吗?什么时候收集真机数据的速度可以快速成长?
黄冠 :我觉得很可能不会有 ImageNet 时刻,因为图像分类任务很标准化,给一张图片给了一个标签就行;但是具身机器人,所有的传感器、执行器、环境、物体都不一样,本体也不一样,具身不是打造一个数据集的问题。所以我认为具身领域可能不会存在 ImageNet 的时刻,而是会直接到 chatgpt 时刻。
并且我们其实觉得没那么遥远,最近硅谷密集的出来一波公司,已经积累了 10 万小时以上的真机数据。所以可能明年很关键,明年全球可能会有 5-10 家公司,会把数据的量至少做到百万小时的级别(当然这里面大家数据来源的分布可能会不一样),可能会有公司接近 GPT-3 时刻。所以其实我们对 ChatGPT 时刻也不用那么悲观,就像凯哥开场的时候讲的,可能具身三五年时间就进入家庭场景了。我们其实更乐观,因为这个行业很卷,只要大家意识到可以做,只要资源投入到位,就没有那么大瓶颈,无论是数据获取、模型架构,还是具身本体研发,只需要时间,需要投入。明年可能会接近 GPT-3 的时刻,两三年之内有机会到 ChatGPT 时刻。
李弘扬 :我没有那么乐观,跟黄总差不多,所以还是要遵循这个数据金字塔或者说 pyramid 的这种形式。互联网数据,即 ego-centric data,加上 simulation,加上遥操等等这些,互为补充吧。

04
场景之争:工业场景 VS 家庭场景
张鹏:机器人触达 C 端用户的路径应该是怎样的,要让机器人真正走进千家万户需要突破哪些关键节点?
张笛 :刚才大家提到两个观点,一个是学院派,一个是产业派,一个是一口吃成个胖子,把通用实现,另外一个是循序渐进做通用。我们自己的观察,现在走进千家万户的具身机器人已经非常多了,甚至是在几百万到上千万以上这个数量级。
我们可以举一些例子,什么叫循序渐进的走向通用。当某一天我们在家里面看到自己的扫地机器人除了扫地以外,突然之间有了安防巡检的功能的时候,它就向通用迈出一步。当它有了安防巡检之后,又有一定的家居物品要维护的时候,它又向前走了一小步,但有一天总会有一个时刻,大家会忽然惊讶的发现,原来我家里的小机器人能干的事情竟然越来越多,竟然变成这个样子,竟然解决的问题已经不再是我当时一开始觉得它的这个样子了,这是一个产品系列,这是它在怎么样去逐渐走向通用的过程。
而且同时,我们家用的小型清洁机器人厂商,一开始瞄准的是室内的场景,后续就会逐渐的希望我的机器人从室内走出去,可以从室内走上电梯里,可以走向自己家的草坪,可以走向街区。对于企业而言,要实现产品这样循序渐进地走向通用化,究竟该如何推进呢?这两个力量都可以让一个行业从一开始对一个功能性的产品,从一个简单的功能性的产品的期待,到逐步转变为对能带来更优质体验产品的期待。这样的循序渐进过程我觉得已经正在发生,而且如火如荼,甚至正在加速发生。
张鹏 : 听起来你的思路是先聚焦于单一场景下的有效履约,就像扫地机器人也做出了千万台的市场一样。基于一次次成功的服务履约,逐步叠加任务能力、演进产品形态,最终实现通用化。而不是希望一下出现一个「iPhone 时刻」。
张笛 :也不完全是这样,一定是量变带来质变,在逐渐的履约的过程,现在的量变还不能引起质变,还没到那个关键节点,没到那个 turning point,就像传统的功能机时代,先有 BP 机,再有大哥大,最后能发短信,有彩铃,同时有 PDA,最后有一个大屏做整体的汇总,同时又能上网,又能听音乐。现在我们处在前夜的状态。
张鹏:C 端最有可能跑出来并且有商业价值的场景会是什么?
王丛 :如果我们现在说具身能做很多东西的肯定是在家庭用户场景,但问题是都做不出来。张笛哥说的我很认同,真的做消费电子的这帮人都很务实,都一定是价格成本对应 PMF(市场匹配度)的价值,一定是找到它的一个很匹配的点,这个东西才有可能在 C 端跑出来。C 端跑出来的东西绝对不是一个价格偏高,PMF(市场匹配度)没有的东西,所以 C 端消费电子产品的功能一定是一点点积累的,其实 Iphone 也是功能积累起来的。
iPhone 如果大家看乔布斯的发布会,其实就是通讯、MP3 加上一个电话,三个已有功能整合到了一个产品上,然后慢慢构建起一个生态系统,从而有了所谓的智能手机。但是其实在 Iphone 之前的诺基亚也有不同的软件,也叫智能机,其实我觉得消费电子一定还是回归到最本身的产品需求,一点点叠功能发展出来,所以包括我们国内很多客户,就像扫地机最初只是负责平面的清洁,这件事情它的价格空间就已经被定死了,因为它就是地面的清洁,就算把扫地机器人扫到 90 分、95 分、100 分,它的价格永远是那样,除非它变成一个空间清洁,但即便如此价格空间也有限,因为请个阿姨也就 40、50 块钱一小时,家庭清洁就三个小时家里都打扫一遍,其实它的价格也定死了,一定要找到那个关键增长点才能爆发。

张鹏:从情绪价值这个角度来看,具身智能有机会进入家庭吗?
王丛 :情绪机器人这个事情我是很看好,但是它并不是严格意义上的价值,因为每个人,男人、女人、小孩、老人,每个人定义陪伴、定义情绪的概念太非标了,所以你很难定义出来一个所谓的陪伴机器人。陪伴什么?我觉得这不是一个以场景定义产品的思路,真正好的产品定义,应该是当我想到某一个特定场景时,就能立刻联想到对应的产品;同时,当我看到某个产品时,也能马上明确它要解决的是哪个具体场景的问题。所以大家看很多产品不能推广,或者做的 idea 很好,但是卖不出去,虽然我觉得情绪机器人是个好东西,但是它一定要对应到不同细分的场景当中,大家才能进一步去谈这个问题。
05
生态模式之争:生态开放 VS 全栈自研
张鹏:目前的头部玩家很多都选择全栈自研,地瓜机器人为什么选择了「生态开放」路线?
王丛 :我觉得这个选择既有感性的一面,也有理性的一面。先说说感性的:任何一家公司做事情,创始人、CEO 都会有对未来的画面感——地瓜机器人的画面感是什么?或者说,什么事能让我们这帮人发自内心地开心?不是我们自己做出一个多智能、多厉害的机器人,而是看到各行各业的消费电子、智能硬件,都能通过我们的技术赋能实现智能化,这才是我幻想中的画面,也是能让我们真正开心的事——这是感性层面的原因。
我觉得机器人行业就算发展十年,也依然会是非标市场——各行各业的机器人本体形态,大概率都会不一样。哪怕几年以后人形机器人变得非常泛化、智能,我也无法理解「用几十万的人形机器人来扫地」这件事——大家看的科幻电影里,未来是各种各样的机器人各司其职,我觉得现实的未来也会是这样。机器人这件事情就是它很非标,它的场景很碎,它并不是一个寡头垄断的市场,那我觉得这个时代是需要有一家公司去把底层的一些东西给做好,才能真的加速这个时代的到来。虽然说这是我们的立场,但我觉得未来机器人公司有很多自研的,有很多会选择拥抱像地瓜这样的供应商,有很多公司会自研,这个太正常了。历史这么多年,每个行业都会有这样的分化:全栈自研的公司,比如苹果,是非常伟大的公司;拥抱生态开放的公司,比如英伟达,也是非常伟大的公司。所以世界是多元的,两种路线都对,只是我们感性上的追求,让我们选择了生态开放这一端。

张鹏:李老师前一阵联合智元开源了全球首个基于全域真实场景的百万真机数据集 AgiBot World,开源数据集会给行业带来哪些价值?
李弘扬 :感谢,首先要严谨说明,「全球首个」是智元的宣传表述,学术上还是要谨慎,毕竟说「the very first」很容易被人攻击。其实最开始 2023 年我就和姚卯青合计这个事,2024 年的时候智元还处在比较早期的阶段,但他能有这样的雄心壮志——在上海张江有 2000 平的数采场,而不是在大学实验室的简单的 pick-and-place,这一点才是最打动我的。后来才有了现在这样的体量,包括我前两天去那个数采厂,都已经需要访客门禁了,能看出来规模确实起来了。
这个百万真机数据集,至少现在回过头来看,可以用于预训练、世界模型的训练,能给那些没有海量数据的高校实验室提供一个很好的平台。但其实我们最近也在复盘,这样的模式能不能复制?毕竟像 agibot world 这样的数据集,买过来成本也不低,还需要一套完整的生态,上到云服务的支撑等等,都得配套。所以在这之后,开源开放的数据集其实挑战还是蛮多的,可能最后还是需要一个行业和众力共建的平台来牵引,搭建一个统一的真机测试场,而不是单纯靠一家的数据集独大,这样的生态会更合适一些。
06
人际关系之争:亲密共生 VS 警惕控制
张鹏:不同人群对人机亲密程度的需求差异显著,是否会催生功能型机器人与陪伴型机器人的细分赛道?「情绪价值」是否可以如何翻译成可落地的产品定义语言?
张笛 :其实我觉得我的综合判断跟王丛哥讲得比较类似,情绪价值这个事情怎么定义产品,其实是非常非常需要去仔细斟酌的一个方向,纯粹的情绪需求把它翻译成商业需求的语言,肯定是能够去做的。不管你是孤独也好,甚至孤独也可以分成若干种,解决不同的孤独,可能会有不同的产品形式可以去做,这个时候你发现情绪需求并不依赖于一个全能的机器人,只要针对那样专门的情绪需求定向去设计产品,这是我觉得最合理,也是最容易去取得一些市场进展的方式和方法。
这几年我们在观察整个市场,包括我们也服务了非常多的客户,这个过程当中我们也看到,确实还是有一些情绪需求,可以靠这些能移动的机器人,或者不能移动的对话终端,来去解决,进而形成一个比较稳定的市场,也能形成一个未来有机会逐渐走向通用的这样的 minimal available product(英),这些市场包括我们现在能看到方兴未艾的一些小型的、甚至不能移动的对话终端——如果我们把具身智能列一个九宫格,横轴看是否与物理世界产生接触,纵轴是它到底要不要使用非常非常 fancy 的机器人算法,那这类对话终端其实就属于「不接触物理世界、仅依赖 NLP 算法」的类别,它确实也已经在具身这个赛道下面,扎扎实实定义出了一个 minimal availbable product,这是一个方向。
另外,在能运动的机器人品类里面,我们也发现现在非常多小型的桌搭产品,开始逐渐叠加越来越多的新功能和新范式,而且这些桌搭产品里,情绪价值往往高过实用功能。那这样的桌搭产品,甚至是纯玩具类型的产品里面,其实也有机会跑出商业化路径。既然已经它是有 MVP 的这样的一个 minimal available 的这样的一个小市场了,那其实依然有机会在通用化的道路上越走越远。

张鹏:机器人越来越像人,是提升用户体验的必要设计,还是会模糊人机边界?如何定义「适度亲密」的交互阈值?
石海林 :其实在这个层面我们确实做过深入的思考,关于这个问题我们有一个比较适合的思考切入角度——从技术发展的速度来看,面向情感价值、情感陪护这个方向的机器人也好,具身智能产品也好,技术迭代真的非常快。从硬件上来说,不管是续航能力、结构复杂度,还是散热效果、运行噪音,甚至是外观设计,这些其实都还有很大的进步空间,但整体的发展速度非常快。从我们行业内的观察、实践以及整个产业的推进节奏来看,这些技术的收敛速度会高过我们以前对它的预期。
相对硬件来说,软件这两年其实是走在前面的,甚至如果我们今天把「情感陪伴」收窄到仅仅是「交互对话」这个范围的话,它其实已经是一个成熟的技术了。所以这个东西怎么说呢?软件相对来说是一个更成熟的板块,当然我们今天说的交互,可能不仅仅是语言上的交互——它给人提供情绪价值,可能是因为颜值足够讨喜;比如我今天回家很累了,我的机器人帮我打扫完房间、收拾好碗筷,这个过程本身也能给我提供情绪价值;再比如它能跟我顺畅互动、回应我的需求,同样能提供情绪价值。
我们回头看,面向情感陪伴的具身智能技术发展这么快,它势必会推动产品和功能的成熟化,也会推动整个市场化的成熟,这个趋势其实不太以人的意志为转移,它是一个技术驱动的必然结果。那我们今天来看,我本人属于那种技术狂热者,我会主动去买悟空机器人这种陪伴型产品。其实不只是我,陪伴型机器人的目标人群会从现在的技术狂热者,逐步渗透到普通大众接受者,这个过程同样不受人的意志为转移。
所以从今天的技术势头来看,我们更应该思考的是怎么拥抱它、去接受它,怎么样更好地使用它,而不是抗拒这个趋势。