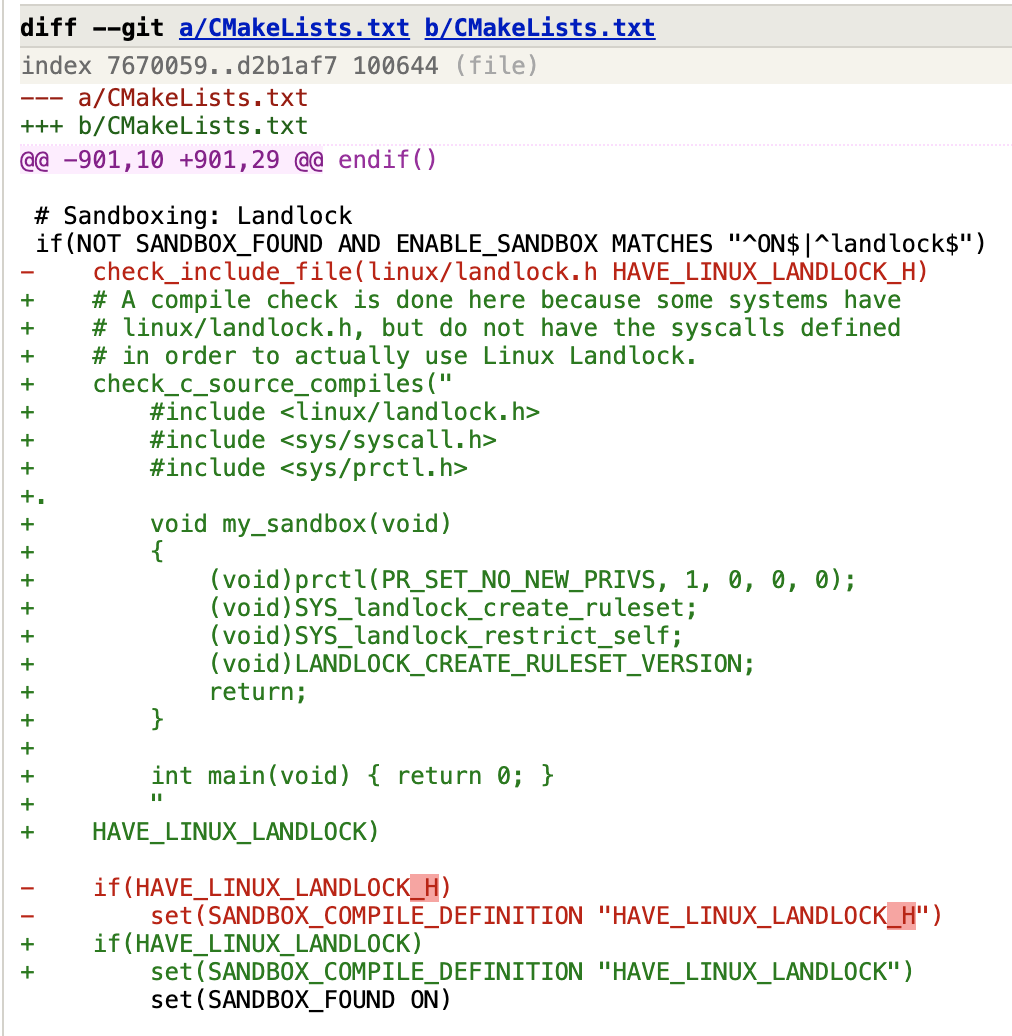
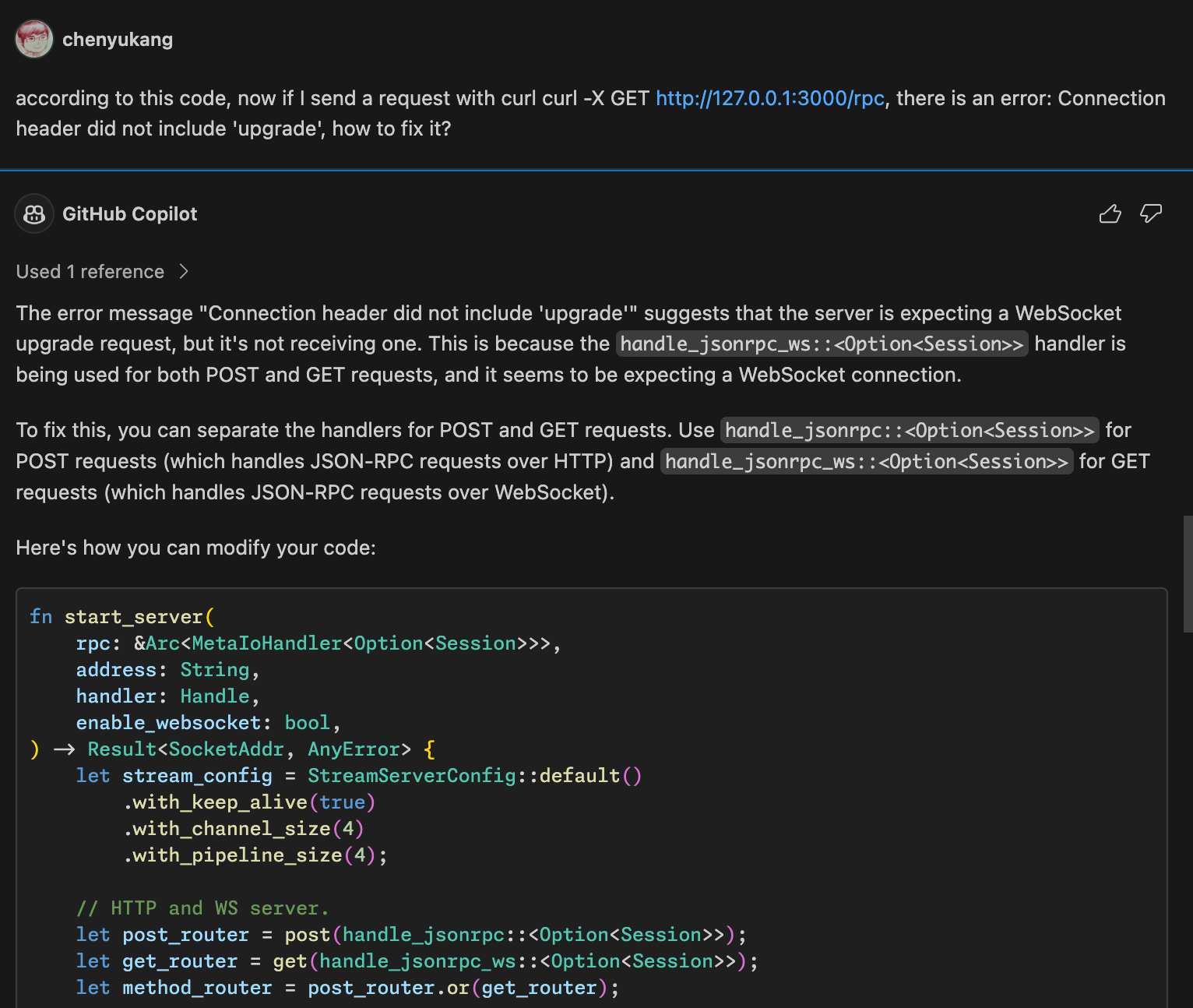
Rust Week 2025 杂记
5 月中旬我参加了在荷兰 Utrecht 举行的 Rust Week,想来可以写篇文章记录下所见所闻。
我年初和 Rust 基金会邮件确认参加,但直到 4 月 9 日才开始动手申请签证。在深圳办理荷兰签证流程简单,只需提交材料并录指纹,但我嫌麻烦找了中介帮忙。据说大概也就两周多就会有结果,但直到五一查询还是没结果,中介说可以加 600 元加急。看到官网解释近期审批延迟,我便花钱加急,第二周拿到了签证。不知道这其中是否有猫腻,但确实有华为的朋友同样卡在那个节点审批,结果没有如期下来。
从广州白云机场有直飞阿姆斯特丹的航班,只是起飞时间大概是凌晨 1 点多。飞机上座位空间狭小,难以入睡,趴着或躺着都不舒服,到了阿姆斯特丹是早晨 6 点多。通过海关后,我因不熟悉荷兰语而有些迷茫。由于未携带 Visa 卡,只能使用现金,幸好两位路人热心相助。我直接购买火车票前往 Utrecht,约于上午 10 点抵达酒店。因为时间还比较早没有空房,我把行李箱放在酒店自己去城里逛逛。
Utrecht 据说是荷兰第四大城市,交通方便。我查了一下,人口约为 30 万,这在中国估计只算是小镇了。我信步漫游,城市整洁如画,绿树成荫,空气清新怡人。由于是周六,商户大多已关门,街上行人多在跑步或散步,整体人口密度较低。5 月应该是荷兰最好的天气,不冷不热,只要不在太阳下就会感觉凉凉的。荷兰人身高马大,路上的自行车很多而汽车非常少,大多都是 A 级车,豪车基本没看到。很常见的场景是父母骑自行车,拉着个大篮筐里载着一两个小孩。
街头的人们神情轻松自在,仿佛时间在这里慢了下来。路旁一个年轻人倚着树,手捧书本读得入了神,旁边的金毛小狗却不耐烦地扯着牵绳,发出几声撒娇。草坪边,几个人懒洋洋地躺在长椅上晒着太阳,像是被微风哄睡了,手中未喝完的咖啡杯歪在一旁。运河边,一对白发苍苍的夫妇沐浴在阳光中,丈夫似乎想起什么趣事,侧身在妻子耳边低语几句,惹得她轻笑出声,随即两人轻轻接吻。这些场景对我这个匆匆旅客而言,宛如《楚门的世界》的开场,美好却略显不真实。

更实际的问题是吃饭,到了中午饭点,主城区我都快粗略走完了,但只有一两个餐厅开着。无奈,我去超市买了点面包和牛奶当作午饭,顺便看了一下日用品的物价,水果和蔬菜比较贵,牛奶之类的东西便宜点。回到酒店有了空房,前台给我办理了入住,稍微睡了一个来小时,起来后已经是下午三点多了,这时候我才后悔今天应该多在阿姆斯特丹逛逛,可玩的地方应该更多。我只能又往还没逛的城市另一边漫步,城市面貌都挺漂亮,不过总体而言房子大多是联排,空间不是很大,不像多年前第一次逛圣何塞那样户户大别墅带给我震撼。
晚上看到 zulip 里有消息,和我一样提前到达的人开始组局吃饭了。我们一行四人挑了个餐厅聊了两个小时左右,一个美国教授、一个德国年轻学生、还有一个马来西亚人,聊的都是技术趣闻和 Rust 相关的。但我这时候有点困了,所以主要在吃和听。没想到饭局结束后都晚上九点半了,天还微微暗,这时候 Utrecht 城市运河旁边的餐厅开着,游客熙熙攘攘,这大概是最热闹的时候了。
5.12 是周一,这天没有什么特别的活动,明天才是主会议的第一天,所以很多人还在路上。我上午去了会场注册领了参会牌,然后在会场逛了逛。我陆陆续续认出来了一些用真实照片做 Github 头像的人,期间和一个老哥聊了起来,他常年维护着 rustc-dev 这份开发文档,之前我提 PR 的时候帮我 Review 过。到了饭点就一起边聊边往市区走,我们想爬到教堂的楼顶参观,据说这里是城市的最高点,风景应该不错。去了之后发现一定要预约和请讲解员,而且一个下午才几十号人,便放弃了。走了 20 多分钟,都没找到什么看起来好吃的餐厅,碰到一个超市又买了点面包和牛奶,在附近的公园旁当作午餐。这老哥来自南非,比我大几岁,之前维护过 Debian 上的一些包。他给 Rust 做开源贡献快十年了,大多是一些文档类的工作。他现在全职远程在一个 Rust 相关的咨询公司工作,主要日常还是做些开源维护工作。
下午没什么特别的安排,我参加了一个 workshop。我们要做的是一个腐蚀的 Rust 实体 Logo,可以在背后用马克笔写上自己的名字,用磨砂纸摩擦一遍,然后用酒精还有各种化学染料涂在 Logo 的表面,等待一段时间就会形成腐蚀的效果和图案,我也跟着做了一个,是不是看起来很漂亮?但我第二天忘记去取了 :)

因为时差原因,我下午就开始犯困,在酒店睡了一下午后,看到群里又有人开始组饭局,这次是都是同住个酒店的人,我们在酒店大堂集合,总共大概有 10 个人左右。我看到了更多的熟悉面孔和 id,有几个维护 Rust 多年的成员,碰到了我第一次提 PR 帮我 review 的 estebank。
我们找了个店喝了点啤酒,然后服务员过来说后厨到点下班了,所以不提供晚餐。这对于中国人来说真是难以置信,哪有这么做生意的呢,这里果然是到点下班比挣钱更重要。后来我们坐火车去了主城区,接连询问了两家餐厅,均表示已快到打烊时间 (其实也就快晚上 9 点),最后终于找了一个运河边上的餐厅坐下。我点了个海鲜意面,味道非常不错,20 欧元也值了,但没想到这就是我这一周吃得最满意的一顿饭了。

一群程序员吃饭聊的还是技术话题,作为 Rust 程序员和维护者,吐槽 C++ 是不可避免的,有的聊得比较细节,比如如何提高链接速度之类的。总体来说气氛非常好,大概是很多人都远程工作,平时无法找到这么一群志同道合的人聊天,而且这些人平时在开源社区里合作交流,能见面聊聊自然是非常开心的。
有趣的事发生在我们用完餐之后,老板估计是犯懒,结账说不能分开支付,所以我们需要找个人先替大家把单买了,然后大家再转给他。一群程序员大眼对小眼,那气氛有点尴尬。后来是 eholk 站出来先买了单,然后一群人围着他看账单转钱给他,反正是异常耗时和麻烦,看来还是中国手机支付 AA 来得更方便。
5.13 是 Conference 的第一天,主题很多,而且分了三个分会场:主会场、生态、行业应用。这两天参会的人非常多,我估计得有 500 来人。公司展台比较少,右边有 Jetbrains、Zed、左边有一些硬件相关的和 Rust 培训咨询相关的公司,华为有个招聘展台。现场看到了其他几个中国人,聊了一下他们是在 Cargo 项目团队做开源贡献的。在会场我见到了更多熟悉的面孔,因为挂牌上有 Github 账号,所以基本盯着对方的名片看看就知道是否打过交道,可以说这是一个大型的网友见面会。我在社区里面断断续续也做了四年,有的人只是通过 review comments 交流,有的人通过 zulip 私聊过,能见面聊聊真是一种难得的体验。另外我和华为爱尔兰可信计算实验室的余教授聊了比较久。
这次会场居然选在了一个电影院,一楼是一个大的会展活动空间,整体非常宽敞。这是我第一次坐在电影院听技术演讲,座位宽敞、音效和视觉都棒极了,他们甚至做了一个类似电影的片头动画,看起来诙谐可爱。第一天最热的主题应该是 Alex Crichton 的 10 Years of Rust,我第一场也去听了这个演讲。推荐任何对 Rust 感兴趣的去看看这个视频。

Rust 在嵌入式领域取得了长足的进展,所以也是这次会议的热点,It’s Embedded Rust Time这个演讲谈到长远来看这个领域里的人希望 Rust 能得到更多应用,volvo 的人分享了他们使用 Rust 开发和发布第一个 ECU 的过程。来自南京大学的 Xiaolong 分享了一个异步任务编程框架 Dagrs。Refactoring in Rust 分享了些重构技巧,把一个典型场景的代码变得漂亮易维护。 We deserve helpful tools 介绍了编译器里的错误信息如何更友好,很多初学者喜欢 Rust 的一个原因是 rustc 的错误信息看起来人性化又有帮助,这是社区里很多人努力的结果。
午饭期间,有个比利时的工程师来拼桌,所以就聊了起来,他几年前去广州待过一个多月,所以有些共同话题。他业余时间喜欢折腾硬件和数学,组织了一个学习系统编程的小组。这个人非常健谈有趣,我们一起聊了聊各自的工作经历等,在 Linkedin 上加了个好友。
第一天会议结束后,我跟着 estebank 一行八个人出去就餐。这次我们选的是一家印度餐厅,因为已经有两三天没吃米饭了,我点了一个看起来有点辣的鱼加米饭,结果菜上来之后让我震惊,不管味道还是品相都达不到沙县小吃级别,但这饭饭菜居然也要 20 欧,这是我这周吃过的最差的一顿饭了吧。这周后面几天的晚上我都不想吃晚饭,一方面是白天在会场吃了很多零食,另一方面到了晚上七点左右我就非常困,这边晚上天黑的时间短,所以我通常回到酒店就睡觉。
5.14 第二天我首先去听了 Rust for Linux 这个演讲,这场非常火爆,看来大家都非常关注这个领域,无论是在贡献者数量还是提交到主线内核中的代码行数方面,增长都非常快。然后我去听了大部分 Rust Project track 相关的演讲,compiler-errors 没写 PPT,居然直接在 VsCode 里面讲解代码 。The Rust Vision Doc and You讲解了如何获取用户的意见和反馈,Rust 在全世界的整体采用情况,很高兴看到社区像是对待一个产品一样来发展一门编程语言。
所有两个天的 Conference 会议在油管上直播,也有录像,感兴趣的可以自己找来看看。
5.15 第三天的上午有各种 workshop,会场地址也变了另一个郊区的办公场所,这个会场在运河的旁边,河上经常有各种运货大船漂过,感觉像苏州的运河的场景。华为余教授帮我弄了个参加 workshop 的机会,我去体验了一下玩了会儿跨平台的 Rust GUI 框架 Makepad。然后我去了对面的 Rust all hands 的办公场所,这里都是 Rust 项目维护者和贡献者,大家以分组的方式进行讨论,有的人干脆找个角落写代码。这次组织者非常用心,说不提供单一的 t-shirt,但找了一个打印 Logo 的机器,大家可以自己选择在衣服、背包、帽子上打印 Rust 相关的图案,我把自己的上衣上印了一个黄色的螃蟹。有的人把自己平时收集的一些笔记本贴纸分享出来,我第一次看到这么多 Geek 贴纸,选了好多。

会场提供了很多酒水和小吃,我不停地喝橙汁。期间碰到了在华为俄罗斯工作的 petrochenkov,他穿着一件 Rust 1.0 发布的纪念 t-shirt,年龄和我相仿却已在开源社区工作十多年。他之前帮我 Review 过不少 PR,以前在中国华为办公室工作过,这次终于见面聊了聊。我们俩一起打乒乓球,虽然两个人水平都不太行,但玩得很来劲。
这天下午用来庆祝 Rust 1.0 发布 10 周年,有一个小型 Party,并且用实时发布 1.87 版本的方式进行庆祝。Niko 上台演讲了 Rust turns 10,余教授代表华为作为赞助商演讲了,华为应该是中国企业中对 Rust 投入最多的,不管是国内的华为还是海外分部都有投入,而且也在通过其他组织赞助社区的一些资深维护者。这会儿我才知道发行一个 Rust 新版本的脚本要运行一个多小时多,最后发布倒计时那会儿气氛达到高潮,拍下了这张照片,我大概在右边第三排的位置,但是身高不够被淹没了:

5.16 和 5.17 是两天的 Rust all hands meeting,可以自由选择参加分组讨论也可以自己找个地方工作一会儿。我选择性参与听了一些,比如 Rust society、Let’s talk about Burnout、Infra、Rust Foundation 的 office hours 等,感觉这两天讨论比较多的几个主题是和 C++ 的互操作性。期间也有很多时间留给大家自由讨论,有人安利 jj这个工具,我试用了一下还没理解好在哪里。我比较多时间和 Cargo 组的几个中国人待在一起,突然长时间处于全英文环境中,偶尔会感到表达上的疲惫。。
第二天下午和一个德国大学生聊了比较久,很多社区的贡献者都是业余时间在做开源,比如这个大二学生,他在学校学的是音乐,计算机只是自己的业余爱好。为什么 RustNL 比较活跃呢,大多是因为荷兰这个国家其实 Rust 爱好者还挺多的,加上德国这些周围国家,整个欧洲的 Rust 活跃度比我想象中高很多。在聊天的过程中,我问到一个问题:为什么很多贡献者来自德国?可能是因为德国人最喜欢 follow rules 并且个性严谨,这和 Rust 的特性非常符合。
另外,我发现很多人采用的是自己开个咨询公司的方式工作,这样可以同时和多个公司签短期劳动合同,按项目收费,当然这样收入也许并不稳定,但这种方式贵在灵活。我们也聊了一些生活类的话题,总体而言我觉得欧洲的国家大多税收比较重,但基础的生活保障方面的福利也挺好,总得来说人对挣钱的欲望没有那么强烈,人的选择和路径也比较多。
这期间张汉东过来找 jackh726,他们约了一个大约半小时的会谈,主要是聊聊 Rust 在中国的发展和使用情况,jack 让我临时做个翻译。这是我第一次做类似口译这事,几乎有一半时间我只是用英语概括了一下他的讲话。最后我自己也表达了些自己的想法,从全球 IT 产业规模看,Rust 在中国具有广阔发展前景,未来或将有更多中国开发者活跃于 Rust 社区,贡献力量。当然这里有很多因素在影响,一方面大部分国内的 IT 工程师都太忙,还有语言方面的障碍,也许未来情况会好一些,当然这也需要社区的支持。
访谈完后在茶水间,我偶然瞟了一眼对面人胸前的牌子,这个名字看起来眼熟,原来是世界上 crate 包被下载最多的作者,如果你是 Rust 程序员应该都能猜出来他的名字。我上前打了个招呼聊了起来,他前几天的会议都没参加,只是今天过来逛逛,了解到他现在 FB 工作,我说感觉 FB 的社区贡献不多,他反驳说 FB 也是 Rust Foundation 的铂金赞助者,内部还不少 Rust 相关的项目。我突然想起 GOSIM 要找人 9 月份在杭州演讲,开玩笑邀请他来中国参加技术分享,他说那段时间有事委婉拒绝了。
在这次 RustWeek 一周的时间里,我见到了各式各样的工程师,多数人看起来简单纯粹,比如《硅谷》里的 Gilfoyle 式的人物,我见到了一个从头到脚都非常类似的人,长发飘飘还赤脚走来走去,随便找个位置就能完全陷入了自己的编程世界。有次回宾馆的大巴上,nnethercote 坐在我旁边,他是 valgrind 的作者,可以说是一个世界级的基础软件工程师,感兴趣的可以读读这篇 Twenty years of Valgrind。我的第一份工作写 C/C++,特别依赖 valgrind 找内存问题,所以我一路都在问他问题,聊他的技术旅程。他说 Rust 从语言级的角度解决内存的安全性问题,已经成了另外一条路,valgrind 完全由其他人维护了。社区里的很多人他也是第一次见,随口说 all hands 的一大作用是以后大家在 Review PR 的时候能想起对方的面容,这表述得太正确了!
在会场乱逛我有时候会盯一下大家的开发环境,有的人真是非常极客,笔记本看起来巨大厚重,操作系统大多是 Linux。我发现一个编译器贡献排前三的大牛打字使用二指禅,有天早餐时他坐我对面,我问起为什么只用两个手指操作键盘,会不会效率不高。他说两个手指的速度已经够了,敲键盘能跟上我的思考速度就行。我那天早上刚好看到个视频,说是美国大学生使用 AI 写作业,把一个教授给逼得崩溃,我知道他在世界顶级大学 Eth 当教授,我问他如何看待学生使用 AI 完成作业或者写程序,他说他的作业 AI 基本无法解决,可能是因为程序语言类的很多作业都是证明,而 AI 通常只能完成简单的,稍微深入点的无法胜任,他还会和学生当面交流,如果依赖 AI 而脑子里没货是很容易被发现的。
这次没看到什么 AI 相关的主题,聊天时有人会偶尔吐槽一下 LLM。区块链更没有人聊了,每当有人问起我主业在干什么,我都有点不好意思说我在做这个行业,因为我知道社区里面很多人有些厌恶这个术方向,特别是一些投机者损坏了这行的口碑。我通常会解释说,从技术角度来说区块链就是一个抗拜占庭的分布式数据库,还是非常有趣和有挑战的,区块链这行也是 Rust 成为主流选择的第一个领域,推动了 Rust 的发展。仔细想想,做编程语言和编译器的,追求的就是确定性和速度,AI 有其不确定性,而区块链效率不高,所以这些人大多不喜欢相反特性的东西。从去年开始,有些人为了打造出来一个看似大有贡献的 Github 账号来获得某些加密货币的空投,于是用 AI 提出各种琐碎或者错误的 Pull Request,这些维护者看着这些毫无营养的 PR 浪费自己的时间,自然对这两个行业更加厌恶了。
虽然目前我还很喜欢自己在做的工作,但我顺带了解了些全职做 Rust 社区的工作机会,说不定以后会用到。通过和不同的人聊天,我发现主要有以下一些机构:
- 国内华为、爱尔兰华为,全职华为员工或者 Rust 相关工作的 contract
- 亚马逊,总体而言公司文化比较 push,我听到不少关于亚马逊工作环境的抱怨
- 微软,不一定是做社区的工作,而且微软最近也在裁员
- ferrous-systems 不确定是否还有职位,contract 或者全职
- futurewei 对员工很灵活,据说完全自己安排工作内容
- Rust Foundation,但主要偏 security 和 infra 相关的,社区里对 Rust 基金会直接雇人做语言方面的工作有顾及
如果是全职 Rust 开发的工作,欧洲应该是相对好找一些 (但需要签证),国内据我所知除了华为、还有字节、小米、汽车公司会用到 Rust。现在 AI 很火,AI 的 infra 也会用到些 Rust,我了解到社区里一个非常资深的维护者去了 OpenAI,这次也碰到一个 OpenAI 的人说公司内部有些 Rust 项目。但整体来说,整个世界的大环境不好,工作机会相比往年少很多。
十年无疑个具有纪念意义的里程碑,就像 Niko 在Rust turns 10所说的:
I just felt that was the most Rust of all problems: having great success but not being able to decide who should take credit. The reality is there is no perfect list – every single person who got named on that award richly deserves it, but so do a bunch of people who aren’t on the list. That’s why the list ends with _All Rust Contributors, Past and Present
Rust 目前的成功无法简单归功于个人和机构,无疑我们需要感谢项目发起人 Graydon Hoare 设置了宏大正确的愿景,而后 Rust 在开源社区自由生长,甚至完全不像是他所设想的编程语言了。现在几个 IT 巨头都有投入,但实际上也没有一个组织和个人能决定未来的发展,这既是社区的刻意设计,也是自然进化的结果。从我这种业余贡献者的角度来说,基金会虽然因为各种事饱受争议,但他们确实做了很好的幕后工作,比如这次参会的社区成员基本都能报销费用,甚至我的费用超过了计划申明的额度,基金会也直接说别担心,我们会如实报销所有费用。
总的来说,这次参会经历拓宽了我的视野。大家都因为对 Rust 和编程的激情和追求聚到了一起,交流起来非常有趣。十年前,我在 2015 年偶然发现了 Rust,当时并不知道它会塑造我的职业生涯,在我迷茫的时候重新捡起了 Rust,如今成为全职的 Rust 开发和社区贡献者。最近一年育儿和工作占据了我的大部分时间和精力,所以在 Rust 社区没那么活跃,我渴望通过编程和写作继续投入其中。
顺便一提,Rust Week 这一周我都没吃中餐,回家一称瘦了三四斤,算是意外达成健身目标!我应该是无法在欧洲长待的那类人。